
Abstract.
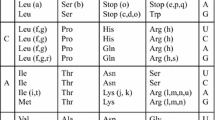
Distances between amino acids were derived from the polar requirement measure of amino acid polarity and Benner and co-workers' (1994) 74-100 PAM matrix. These distances were used to examine the average effects of amino acid substitutions due to single-base errors in the standard genetic code and equally degenerate randomized variants of the standard code. Second-position transitions conserved all distances on average, an order of magnitude more than did second-position transversions. In contrast, first-position transitions and transversions were about equally conservative. In comparison with randomized codes, second-position transitions in the standard code significantly conserved mean square differences in polar requirement and mean Benner matrix-based distances, but mean absolute value differences in polar requirement were not significantly conserved. The discrepancy suggests that these commonly used distance measures may be insufficient for strict hypothesis testing without more information. The translational consequences of single-base errors were then examined in different codon contexts, and similarities between these contexts explored with a hierarchical cluster analysis. In one cluster of codon contexts corresponding to the RNY and GNR codons, second-position transversions between C and G and transitions between C and U were most conservative of both polar requirement and the matrix-based distance. In another cluster of codon contexts, second-position transitions between A and G were most conservative. Despite the claims of previous authors to the contrary, it is shown theoretically that the standard code may have been shaped by position-invariant forces such as mutation and base content. These forces may have left heterogeneous signatures in the code because of differences in translational fidelity by codon position.
A scenario for the origin of the code is presented wherein selection for error minimization could have occurred multiple times in disjoint parts of the code through a phyletic process of competition between lineages. This process permits error minimization without the disruption of previously useful messages, and does not predict that the code is optimally error-minimizing with respect to modern error. Instead, the code may be a record of genetic process and patterns of mutation before the radiation of modern organisms and organelles.
Similar content being viewed by others

Author information
Authors and Affiliations
Additional information
Received: 28 July 1997 / Accepted: 23 January 1998
Rights and permissions
About this article
Cite this article
Ardell, D. On Error Minimization in a Sequential Origin of the Standard Genetic Code. J Mol Evol 47, 1–13 (1998). https://doi.org/10.1007/PL00006356
Issue Date:
DOI: https://doi.org/10.1007/PL00006356