
Abstract
A cloud quantum computer is similar to a random number generator in that its physical mechanism is inaccessible to its users. In this respect, a cloud quantum computer is a black box. In both devices, its users decide the device condition from the output. A framework to achieve this exists in the field of random number generation in the form of statistical tests for random number generators. In the present study, we generated random numbers on a 20-qubit cloud quantum computer and evaluated the condition and stability of its qubits using statistical tests for random number generators. As a result, we observed that some qubits were more biased than others. Statistical tests for random number generators may provide a simple indicator of qubit condition and stability, enabling users to decide for themselves which qubits inside a cloud quantum computer to use.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Given a coin with an unknown probability distribution, there are two approaches to decide whether the coin is fair (Tamura and Shikano 2019). The first approach is to examine the coin itself; one expects an evenly shaped coin to yield fair results. The second approach is to actually toss the coin a number of times to see if the output is sound. In this approach, the coin is treated as a black box. A random number generator is similar to a coin in that it is expected to produce unbiased and independent 0s and 1s. Unlike a coin, however, the physical mechanism of a random number generator is often inaccessible to its users. Therefore, users rely on statistical tests to decide the fairness of the device from its output.
Random number generators play an important role in cryptography, particularly in the context of key generation. For example, the security of the RSA cryptosystem is based on keys that are determined by random choices of two large prime numbers (Boneh 1999). If the choices of prime numbers are not random, an adversary could predict future keys and hence compromise the security of the system. Randomness in cryptography derives from what is called the seed. The seed is provided by physical random number generators (Schindler and Killmann 2003; Ugajin et al. 2017). It is required that the physical mechanism of a physical random number generator remains a black box for the seed to be unpredictable. Given that the measurement outcomes are theoretically unpredictable in quantum mechanics, random number generators based on quantum phenomena are a promising source of unpredictability (Pironio et al. 2010; Ma et al. 2016; Herrero-Collantes and Garcia-Escartin 2017).
Cloud quantum computers are quantum computers that are accessed online (Srivastava et al. 2016; Gibney 2017; Castelvecchi 2017; Xin et al. 2018; Yamamoto et al. 2019; National Academies of Sciences, Engineering, and Medicine 2019). In order to use a cloud quantum computer, users are required to send programs specifying the quantum circuit to be executed and the number of times the circuit should be run (LaRose 2019). When a user’s turn arrives, the quantum computer executes the program and returns the results (Preskill 2018). A similarity between random number generators and cloud quantum computers is that its users do not have direct access to the physical mechanism of the device. So, as far as the users are concerned, both random number generators and cloud quantum computers are black boxes. In the field of random number generation, much research has been done on how to characterize the device from its output. This leads to the creation of statistical tests for random number generators. The present study aims to introduce the idea of statistical tests for random number generators to the field of cloud quantum computing. This aim is supported by three points. Firstly, the cloud quantum computer is a black box to its users, which is also the case with random number generators. Secondly, quantum computers become random number generators when given certain programs. Finally, the cloud quantum computer lacks a simple benchmark that would enable its users to decide the condition of the device.
The rest of this article is organized as follows. In Sect. 2, statistical tests for random number generators are generally explained. In Sect. 3, a group of statistical tests called the NIST SP 800-22 is reviewed. In Sect. 4, we present the results of the statistical analysis of random number samples obtained from the cloud quantum computer, IBM 20Q Poughkeepsie, and the test results of the eight statistical tests from the NIST SP 800-22. Finally, Sect. 5 is devoted to the conclusion. In the appendix, a measure of uniformity often employed in the field of cryptography, the min-entropy, is explained.
2 Statistical Tests for Random Number Generators
Statistical tests for random number generators are necessary to confirm that a random number generator is suitable for use in encryption processes (Demirhan and Bitirim 2016). Random number generators used in this context are required to have unpredictability. This means that given any subset of a sequence produced by the device, no adversary can predict the rest of the sequence, including the output from the past. Statistical tests aim to detect random number generators that produce sequences with a significant bias and/or correlation.
When subjected to statistical tests, a random number generator is considered a black box. This means that the only information available is its output. Under the null hypothesis that the generator is unbiased and independent, one expects its output to have certain characteristics. The characteristics of the output are quantified by the test statistic, whose probability distribution is known. From the test statistic, the probability that a true random number generator produces an output with a worse test statistic value is calculated. This probability is called the p-value. If the p-value is below the level of significance \(\alpha \), the generator fails the test, and the null hypothesis that the generator is unbiased and independent is rejected. Since statistical tests for random number generators merely rule out significantly biased and/or correlated generators, these tests do not verify that a device is the ideal random number generator. Nevertheless, a generator that passes the tests is more reliable than a generator that doesn’t. This is why statistical tests are usually organized in the form of test suites, so as to be comprehensive. Some well known test suites are the NIST SP 800-22 (Bassham 2010), TestU01 (L’ecuyer and Simard 2007), and the Dieharder test.
Because statistical tests are designed to check for statistical anomalies under the hypothesis that the generator is unbiased, a biased random number generator would naturally fail the tests. This can be a problem when testing quantum random number generators, as they can be biased and unpredictable at the same time. Given that statistically faulty generators can still be unpredictable, the framework of statistical tests fails to capture the essence of randomness: unpredictability. There have been attempts to assure the presence of unpredictability by exploiting quantum inequalities, but they have not reached the point of replacing statistical tests altogether.
3 NIST SP 800-22
The NIST SP 800-22 is a series of statistical tests for cryptographic random number generators provided by the National Institute of Standards and Technology (Bassham 2010). Random number generators for cryptographic purposes are required to have unpredictability, which is not strictly necessary in other applications such as simulation and modeling, but is a crucial element of randomness. The test suite contains 16 tests, each test with a different test statistic to characterize deviations of binary sequences from randomness. The entire testing procedure of the NIST SP 800-22 is divided into three steps. The first step is to subject all samples to the 16 tests. For each sample, each test returns the probability that the sample is obtained from an unbiased and independent RNG. This probability, which is called the p-value, is then compared to the level of significance \(\alpha = 0.01\). If the p-value is under the level of significance, the sample fails the test. The second step involves the proportion of passed samples for each test. Under the level of significance \(\alpha = 0.01\), 1% of samples obtained from an unbiased and independent RNG is expected to fail each test. If the proportion of passed samples is too high or too low, the RNG fails the test. Finally, p-value uniformity is checked for each test. Suppose one tested 100 binary samples. This yields 100 p-values per test. If the samples are independent, the p-values should be uniformly distributed for all tests. The distribution of p-values is checked via the chi-squared test.
In the following sections, eight tests from the NIST SP 800-22 are explained (Table 1). The input sequence will be denoted by \(\varepsilon {=} \varepsilon _1 \varepsilon _2 \cdots \varepsilon _n\), and the ith element by \(\varepsilon _i\).
3.1 Frequency Test
The frequency test aims to test whether a sequence contains a reasonable proportion of 0s and 1s. If the probability of obtaining the sequence from an independent and unbiased random number generator is lower than 1%, it follows that the random number generator is not “independent and unbiased”. The minimum sample length required for this test is 100.
Test Description
-
1.
Convert the sequence into \(\pm {1}\) using the formula: \(X_i = 2\varepsilon _i-1\).
-
2.
Add the elements of X together to obtain \(S_n\).
-
3.
Compute test statistic: \(s_{{\mathrm {obs}}} = |S_n|/\sqrt{n}\).
-
4.
Compute p-value \(={\mathrm {erfc}}(s_{{\mathrm {obs}}} / \sqrt{2})\) using complementary error function shown as
$$\begin{aligned} {\mathrm {erfc}}(z) = \frac{2}{\sqrt{\pi }}\int _z^\infty e^{-u^2}du. \end{aligned}$$(1) -
5.
Compare p-value to 0.01. If p-value \(\ge \) 0.01, then the sequence passes the test. Otherwise, the sequence fails.
Example: \(\varepsilon = 1001100010\), length \(n = 10\).
-
1.
\(1,0,0,1,1,0,0,0,1,0 \rightarrow +1,-1,-1,+1,+1,-1,-1,-1,+1,-1\).
-
2.
\(S_{10} = 1-1-1+1+1-1-1-1+1-1 = -2\).
-
3.
\(s_{{\mathrm {obs}}} = |-2|/\sqrt{10} \approx 0.632455\).
-
4.
P-value \(={\mathrm {erfc}}(s_{\mathrm {obs}} / \sqrt{2}) \approx 0.527089\).
-
5.
P-value \(=0.527089 > 0.01 \rightarrow \) the sequence passes the test.
This test is equivalent to testing the histogram for bias. Because the test only considers the proportion of 1s, sequences such as 0000011111 or 0101010101 would pass the test. Failing this test means that the sample is overall biased.
3.2 Frequency Test Within a Block
Firstly, the sequence is divided into N blocks of size M. The frequency test is then applied to the respective blocks. As a result, one obtains N p-values. The second part of this test aims to check whether the variance of the p-values is by chance or not. This is called the chi-squared (\(\chi ^2\)) test. For meaningful results, a sample with a length of at least 100 is required. The following is the test description.
Test Description
-
1.
Divide the sequence into \(N = \lfloor \frac{n}{M} \rfloor \) non-overlapping blocks of size M.
-
2.
Determine the proportion of 1s in each block using
$$\begin{aligned} \pi _i = \frac{\sum _{j=1}^M \varepsilon _{(i-1)M+j}}{M}. \end{aligned}$$(2) -
3.
Compute \(\chi ^2\) statistic \(\chi ^2_{{\mathrm {obs}}} = 4M\sum _{i=1}^N \left( \pi _i-\frac{1}{2} \right) ^2\).
-
4.
Compute p-value \(= 1 - {\mathrm {igamc}}\left( \frac{N}{2}, \frac{\chi ^2_{{\mathrm {obs}}}}{2} \right) \). Note that \({\mathrm {igamc}}\) stands for the incomplete gamma function.
$$\begin{aligned} \Gamma (z)&= \int _0^\infty t^{z-1} e^{-t}\end{aligned}$$(3)$$\begin{aligned} {\mathrm {igamc}}(a,x)&\equiv \frac{1}{\Gamma (a)}\int _0^x e^{-t} t^{(a-1)}dt \end{aligned}$$(4) -
5.
Compare p-value to 0.01. If p-value \(\ge \) 0.01, then the sequence passes the test. Otherwise, the sequence fails.
Example: \(\varepsilon = 1001100010\), length: \(n = 10\).
-
1.
If \(M=3\), then \(N=3\) and the blocks are 100, 110, 001. The final 0 is discarded.
-
2.
\(\pi _1 = 1/3\), \(\pi _2 = 2/3\), \(\pi _3 = 1/3\).
-
3.
\(\chi ^2_{{\mathrm {obs}}} = 4M\sum _{i=1}^N(\pi _i-\frac{1}{2})^2\).
-
4.
\(\chi ^2_{{\mathrm {obs}}} = 4\times 3 \times \left\{ (\frac{1}{3}-\frac{1}{2})^2+ (\frac{2}{3}-\frac{1}{2})^2+ (\frac{1}{3}-\frac{1}{2})^2 \right\} = 1\).
-
5.
P-value \(=1 - {\mathrm {igamc}}(\frac{3}{2}, \frac{1}{2})=0.801252\).
-
6.
P-value \(=0.801252 > 0.01 \rightarrow \) the sequence passes the test.
This test divides the sequence into blocks and checks each block for bias. Depending on the block size, samples such as 001100110011 or 101010101010 could pass the test. Failing this test means that certain sections of the sequence are biased.
3.3 Runs Test
The proportion of 0s and 1s does not suffice to identify a random sequence. A run, which is an uninterrupted sequence of identical bits, is also a factor to be taken into account. The runs test determines whether the lengths and oscillation of runs in a sequence are as expected from a random sequence. A minimum sample length of 100 is required for this test. The following is the test description.
Test Description
-
1.
Compute proportion of ones \(\pi = \left( \sum _j \varepsilon _j \right) / n\).
-
2.
If the sequence passes frequency test, proceed to next step. Otherwise, the p-value of this test is 0.
-
3.
Compute test statistic \(V_n({\mathrm {obs}}) = \sum _{k=1}^{n-1}(\varepsilon _k\oplus \varepsilon _{k+1})+1\), where \(\oplus \) stands for the XOR operation.
-
4.
Compute p-value \(= {\mathrm {erfc}}\left( \frac{|V_n({\mathrm {obs}})-2n\pi (1-\pi )|}{2\sqrt{2n}\pi (1-\pi )} \right) \).
-
5.
Compare p-value to 0.01. If p-value \(\ge \) 0.01, then the sequence passes the test. Otherwise, the sequence fails.
Example: \(\varepsilon = 1010110001\), length \(n = 10\).
-
1.
\(\pi = \frac{5}{10} = 0.5\).
-
2.
\(|\pi - 0.5| = 0 < \frac{2}{\sqrt{n}} = \frac{2}{\sqrt{10}} = 0.63\rightarrow \) test is applicable.
-
3.
\(V_{10}({\mathrm {obs}}) = (1 + 1 + 1 + 1 + 0 + 1 + 0 + 0+ 1) + 1 = 7\).
-
4.
P-value \(= {\mathrm {erfc}}\left( \frac{|7-2\times 10\times 0.5\times (1-0.5)|}{2\times \sqrt{2\times 10}\times 0.5 \times (1-0.5)} \right) = 0.21\).
-
5.
P-value \(= 0.21\ge 0.01\), so sequence passes the test.
3.4 The Longest Run of Ones Within a Block Test
This test determines whether the longest runs of ones \(111\cdots \) within blocks of size M is consistent with what would be expected in a random sequence. The possible values of M for this test are limited to three values, namely, 8, 128, and 10,000, depending on the length of the sequence to be tested.
Test Description
-
1.
Divide the sequence into blocks of size M. The choices of M and N are determined in regard to the length of the sequence. N denotes the number of blocks, and the elements exceeding the number of blocks are discarded. The possible choices of n and M provided by NIST are shown in Table 2.
-
2.
Classify each block into the following categories regarding M and the length of the longest run in each block. See Table 3.
-
3.
Compute \(\chi ^2({\mathrm {obs}}) = \sum _{i = 0}^{K}\frac{(v_i - N\pi _i)^2}{N\pi _i}\). Note that K, N, and \(\pi _i\) are determined by M. See Tables 4 and 5.
-
4.
Compute p-value \(= 1 - {\mathrm {igamc}}\left( \frac{K}{2},\frac{\chi ^2({\mathrm {obs}})}{2}\right) \).
-
5.
Compare p-value to 0.01. If p-value \(\ge \) 0.01, then the sequence passes the test. Otherwise, the sequence fails.
Example: \(n = 10000\)
-
1.
\(M = 128\) and \(N = 49\). The remaining 3728 elements are discarded.
-
2.
The counts for the longest run of ones are \(v_0 = 6\), \(v_1 = 10\), \(v_2 = 10\), \(v_3 = 7\), \(v_4 = 7\), and \(v_5 = 9\).
-
3.
$$\begin{aligned} \chi ^2({\mathrm {obs}})&= \frac{(6 - 49\times 0.1174)^2}{49\times 0.1174} + \frac{(10 - 49\times 0.2430)^2}{49\times 0.2430} \\&+ \frac{(10 - 49\times 0.2493)^2}{49\times 0.2493} + \frac{(7 - 49\times 0.1752)^2}{49\times 0.1752}\\ {}&+ \frac{(7 - 49\times 0.1027)^2}{49\times 0.1027} + \frac{(9 - 49\times 0.1124)^2}{49\times 0.1124}\\&= 3.994459. \end{aligned}$$
-
4.
P-value \(= 1 - {\mathrm {igamc}}\left( \frac{5}{2},\frac{3.994459}{2}\right) = 0.550214\).
-
5.
P-value \(= 0.550214 \ge 0.01\), so the sequence passes the test.
3.5 Discrete Fourier Transform Test
This test checks for periodic patterns in the sequence by performing a discrete Fourier transform (DFT). The minimum sample length required for this test is 1000. The following is the test description.
Test Description
-
1.
Convert the sequence \(\varepsilon \) of 0s and 1s into a sequence X of \(-1\)s and \(+1\)s.
-
2.
Apply a DFT on X: \(S = DFT(X)\). This should yield a sequence of complex variables representing the periodic components of the sequence of bits at different frequencies.
-
3.
Compute \(M = {\mathrm {modulus}}(S') \equiv |S'|\), where \(S'\) is the first \(\frac{n}{2}\) element of S. This produces a sequence of peak heights.
-
4.
Compute \(T = \sqrt{\left( \log _e\frac{1}{0.05}\right) }\). This is the 95 % peak height threshold value. 95 % of the values obtained by the test should not exceed T for a random sequence.
-
5.
Compute \(N({{\mathrm {ideal}}}) = \frac{0.95n}{2}\), which is the expected theoretical number of peaks that are less than T.
-
6.
Compute \(N({\mathrm {obs}})\), which is the actual number of peaks in M that are less than T.
-
7.
Compute \(d = \frac{N({{\mathrm {ideal}}})-N({\mathrm {obs}})}{\sqrt{n\cdot 0.95\cdot 0.05\cdot \frac{1}{4}}}\).
-
8.
Compute p-value \(= {\mathrm {erfc}}\left( \frac{|d|}{\sqrt{2}}\right) \).
-
9.
Compare p-value to 0.01. If p-value \(\ge \) 0.01, then the sequence passes the test. Otherwise, the sequence fails.
This test checks for periodic features. Samples with periodic features may look like 0110011001100110 or 010010100101001 among various other possibilities. Failing this test suggests that the sample has periodic patterns. It is noted that the probability distribution of the test statistic d should be rectified as it does not converge to the standard normal distribution (Hamano 2005).
Example: \(\varepsilon = 1001010011\), length \(n = 10\).
-
1.
\(X = 2\varepsilon _1 - 1, 2\varepsilon _2 - 1, \ldots , 2\varepsilon _n - 1= 1,-1,-1,1,-1,1,-1,-1,1,1\).
-
2.
\(N({{\mathrm {ideal}}}) = 4.75\).
-
3.
\(N({\mathrm {obs}}) = 4\).
-
4.
\(d = \frac{(4.75-4)}{\sqrt{10\cdot 0.95\cdot 0.05\cdot \frac{1}{4}}} = 2.147410\).
-
5.
P-value \(= {\mathrm {erfc}}\left( \frac{|2.147410|}{\sqrt{2}}\right) = 0.031761\).
-
6.
P-value \(= 0.031761 \ge 0.01\), so the sequence passes the test.
3.6 Approximate Entropy Test
The approximate entropy test compares the frequency of m-bit overlapping patterns with that of \((m+1)\)-bit patterns in the sequence. It checks whether the relation of two frequencies is what is expected from an unbiased and independent RNG. The level of significance is \(\alpha = 0.01\). This test can be applied to samples with lengths equal to or larger than 64. The test description is below.
Test Description
-
1.
Append the first \(m-1\) bits of the sequence to the end of the sequence.
-
2.
Divide the sequence into overlapping blocks with a length of m.
-
3.
There are \(2^m\) possible m-bit blocks. Count how many of each possible m-bit block there are in the sequence.
-
4.
Compute \(\frac{\mathrm {count}}{n}\log _e(\frac{\mathrm {count}}{n})\) for each count.
-
5.
Compute the sum of all counts \(\varphi _m\).
-
6.
Replace m with \(m+1\) and repeat steps 1 through 5 to obtain \(\varphi _{m+1}\).
-
7.
Calculate test statistic \(\mathrm {obs} = 2n(\log _e(n) - (\varphi _m - \varphi _{m+1}))\).
-
8.
Derive p-value \(= 1 - {\mathrm {igamc}}(2^{(m-1)}, \mathrm {obs}/2)\).
-
9.
Compare p-value with level of significance \(\alpha = 0.01\). If p-value \(\ge 0.01\), the result is pass. Otherwise, the sequence fails the test.
Example: \(\varepsilon = 1011010010\), length \(n = 10\), \(m = 3\).
-
1.
\(\varepsilon = {10}11010010\) \(\rightarrow \) 101101001010.
-
2.
101101001010 \(\rightarrow \) 101, 011, 110, 101, 010, 100, 001, 010, 101, 010.
-
3.
“000” : 0, “001” : 1,
“010” : 3, “011” : 1, “100” : 1, “101” : 3, “110” : 1, “111” : 0.
-
4.
“000” : 0, “001” : 0.1\(\log _e (0.1)\), “010” : 0.3 \(\log _e(0.3)\),
“011” : 0.1\(\log _e(0.1)\), “100” : 0.1\(\log _e(0.1)\), “101” : 0.3\(\log _e(0.3)\),
“110” : 0.1\(\log _e(0.1)\), “111” : 0.
-
5.
\(\varphi _3 = -1.643418\)
-
6.
\(\varphi _{3+1} = -2.025326\).
-
7.
\(\mathrm {obs} = 2\times 10\times (\log _e(10) - (-1.643418 - (-2.025326))) = 6.224774\).
-
8.
P-value \(= 1 - {\mathrm {igamc}}(2^{(3-1)}, \mathrm {6.224774}/2) = 0.622069\).
-
9.
P-value \(= 0.622069 \ge 0.01\). The sequence passes the test.
The approximate entropy test checks for correlation between the number of m-bit patterns and \((m+1)\)-bit patterns in the sequence. The difference between the number of possible m-bit patterns and the number of possible \((m+1)\)-bit patterns in the sequence is computed, and if this difference is too small or too large, the two patterns are correlated.
3.7 Cumulative Sums Test
The cumulative sums test is basically a random walk test. It checks how far from 0 the sum of the sequence in terms of \(\pm 1\) reaches. For a sequence that contains uniform and independent 0s and 1s, the sum should be close to 0. This test requires a minimum sample length of 100.
Test Description
-
1.
Convert 0 to −1 and 1 to \(+\)1.
-
2.
In forward mode, compute the sum of the first i elements of X. In backward mode, compute the sum of the last i elements of X.
-
3.
Find the maximum value z of the sums.
-
4.
Compute the following p-value. \(\Phi \) is the cumulative distribution function for the standard normal distribution.
 (5)
(5) -
5.
Compare p-value to \(\alpha = 0.01\). If p-value \(\ge 0.01\), the result is pass. Otherwise, the sequence fails the test.

Example: \(\varepsilon = 1011010010\), length \(n = 10\).
-
1.
\(\varepsilon = 1011010010\) \(\rightarrow \) \(X = 1, -1, 1, 1, -1, 1, -1, -1, 1, -1\).
-
2.
Forward mode: \(S_1 = 1\), \(S_2 = 1 + (-1) = 0\), \(S_3 = 1 + (-1) + 1 = 2\), \(S_4 = 1 + (-1) + 1 + 1\), \(S_5 = 1 + (-1) + 1 + 1 + (-1) = 1\), \(S_6 = 1 + (-1) + 1 + 1 + (-1) + 1 = 2\), \(S_7 = 1 + (-1) + 1 + 1 + (-1) + 1 + (-1) = 1\), \(S_8 = 1 + (-1) + 1 + 1 + (-1) + 1 + (-1) + 1 = 2\), \(S_9 = 1 + (-1) + 1 + 1 + (-1) + 1 + (-1) + 1 + (-1) = 1\).
-
3.
In forward mode, the maximum value is \(z = 2\).
-
4.
P-value \(= 0.941740\) for both forward and backward.
-
5.
P-value \(= 0.941740 \ge 0.01\). The sequence passes the test.
Once the p-value has been calculated for all tests and samples, the proportion of samples that passed the test is computed for each test. Let us consider a case where 1000 samples were subjected to each of the 15 tests. This results in 1000 p-values per test. For example, if 950 out of 1000 samples passed the frequency test, the proportion of passed samples is 0.95. If the proportion of passed samples falls within the following range for all 15 tests, the samples pass the second step of the NIST SP 800-22. The acceptable range of proportion is calculated with
where \(\alpha \) stands for the level of significance and m the sample size. It is noted that it is controversial whether the coefficient should be 3. A suggestion that the coefficient should be 2.6 exists (Marek et al. 2015). In the case of the current example, Eq. (6) can be calculated using \(\alpha = 0.01\) and \(m = 1000\) as
From the fact that 0.95 is not within the acceptable range, it follows that the samples fail the frequency test. The same process is done with all 16 tests, and unless the samples pass all tests, the result is that the hypothesis that the RNG is unbiased and independent is rejected.
The final step of the NIST SP 800-22 is to evaluate the p-value uniformity of each test. In order to perform the chi-squared (\(\chi ^2\)) test, the p-value is divided into 10 regions: \([k,k+0.1)\) for \(k = 0, 1, \ldots , 9\). The test statistic is given by
When the number of samples in each region is 2, 8, 10, 13, 17, 17, 13, 10, 8, 2, the test statistic (8) is calculated as \(\chi ^2 = 25.200000\). From \(\chi ^2\), the p-value is

Therefore, in the current example where \(\chi ^2 = 25.200000\), the p-value is 0.002758. The level of significance for the p-value uniformity is \(\alpha = 0.0001\). So when the p-value is 0.002758, it follows that the p-value distribution is uniform. The p-value uniformity test requires at least 55 samples. As mentioned before, it is remarked that passing the NIST SP 800-22 does not ensure a sequence to be truly random (Kim et al. 2020; Fan et al. 2014; Haramoto and Matsumoto 2019).
4 Quantum Random Number Generation on the Cloud Quantum Computer
According to quantum mechanics, the measurement outcomes of the superposition state \((|0\rangle +{|1\rangle })/\sqrt{2}\) along the computational basis ideally form random number sequences. This means that the resulting sequences are expected to pass the statistical tests for RNGs explained previously. Here, the computational basis, \(|0\rangle \) and \({|1\rangle }\), spans the two-dimensional Hilbert space. In a quantum computer, the desired state \((|0\rangle +{|1\rangle })/\sqrt{2}\) is generated from the initial state \(|0\rangle \) by applying the Hadamard gate to a single quantum bit (qubit). Note that in this process, the initial state is always the same. Unlike classical random number generators and pseudorandom number generators that require random seeds to produce independent sequences, quantum random number generators are capable of producing independent sequences with the same seed. This reduces the risk of the output of a random number generator being predicted from the seed, because all possible outputs come from the same seed.
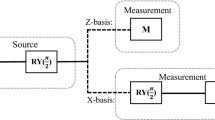
In the present study, the cloud superconducting quantum computer, IBM 20Q Poughkeepsie, was used. The device was given the circuit in Fig. 1a and was repeatedly instructed to execute the circuit 8192 times without interruption from 2019/05/09 11:24:27 GMT. Because the quantum computer has multiple users across the globe, interruption between jobs occur (Aleksandrowicz et al. 2019). 8192 is the maximum number of uninterrupted executions (shots) available. Running the circuit with 8192 shots yields a binary sequence with a length of 8192 per qubit. This process was automatically repeated across calibrations. The device goes through calibration once in a day as seen in Table 6.
As a result, 579 samples were obtained from the IBM 20Q Poughkeepsie device. Note that each qubit produced 579 samples, each with a length of 8192. The samples were subjected to the eight tests from the NIST SP 800-22, which are: the frequency test, frequency within a block test, runs test, longest runs within a block test, DFT test, approximate entropy test, and the cumulative sums test (forward, backward). The p-value of each test corresponding to the respective samples was computed. For each test, the proportion of passed samples was checked. The acceptable range of the proportion of passed samples for 579 samples under the level of significance \(\alpha = 0.01\) is \({>} 0.977595\).

a: QRNG quantum circuit using the Hadamard gate. b: Device topology of IBM 20Q Poughkeepsie provided by Qiskit

Min-entropy transition of qubit [0]\(\sim \) [19]. The blue plots are the experimental results and the red plots the noisy simulation results. The figure has been rotated \(90^\circ \). The horizontal axis ranges from 2019/05/09 11:24 GMT to 2019/05/14 07:54 GMT
By constantly running the IBM 20Q Poughkeepsie device for five days, we obtained 579 samples for each of the 20 qubits. In theory, these samples should qualify as the output of an ideal random number generator. In random number generation, the output sequences are checked for two properties: bias and patterns. When the sequences show signs of bias or patterns, the device is not in ideal condition. The same logic applies to the cloud quantum computer. We also simulated the same quantum circuit on the simulator with the obtained noise parameters such as the T1 and T2 time, the coherent error, the single-qubit error, and the readout error, all of which are updated. The simulator is referred to as the noisy simulator in the following. The noisy simulator program was also provided by IBM (Aleksandrowicz et al. 2019).
In the present section, the random number output of each qubit inside the IBM 20Q Poughkeepsie device is analyzed. The qubits that are connected by arrows in Fig. 1b represent the pairs of qubits on which the controlled NOT gate can operate. The controlled NOT gate is a two-qubit gate.
The min-entropy, whose definition and properties are seen in the Appendix, was computed for each qubit from the 579 samples. This resulted in 579 min-entropy transition plots for 20 qubits. Figure 2 is organized to form the topology of the IBM 20Q Poughkeepsie. The min-entropy takes values from 0 to 1 depending on the highest probability of the probability distribution. When the probability distribution is uniform, the min-entropy is 1. Figure 2 shows how each qubit has a unique tendency for min-entropy. Qubit [17], for example, shows a sudden drop in min-entropy at around 60 h. This does not occur in simulation. A sudden drop in min-entropy suggests that the measurement results can vary depending on when the cloud quantum computer executes a circuit. Overall, the noisy simulator tends to have a higher min-entropy compared to the actual device. According to Aleksandrowicz et al. (2019), the readout error that IBM provides does not reflect the asymmetry between the error output 1 on the state \(|0\rangle \) and the error output 0 on the state \({|1\rangle }\). The discrepancy between the min-entropy of the actual device and the simulator suggests that readout asymmetry exists.
Next, the samples were checked for bias. Each qubit produced 579 samples with a length of 8192, which form 4,743,168-bit sequences when chronologically connected. Figure 2 demonstrates the proportion of 1s in the entire sequence output by each qubit. Under the level of significance \(\alpha = 0.01\), the proportion of 1s of a 4,743,168-bit sequence should fall between the red lines. The result is that none of the qubits produced acceptable proportions of 1s as seen in Fig. 3. Furthermore, Fig. 4 shows that the actual device failed to pass the eight statistical tests, which indicates that the current quantum computing device does not have the statistical properties of a uniform random number generator.
The problem with histograms as seen in Fig. 3 is that they fail to detect certain anomalies. For example, a sequence consisting of all 0s for the former half and all 1s for the latter half yields a perfect histogram. However, such a sequence is clearly not random. To compensate for this flaw, we focused on the transition of the number of 1s in the sequence. Ideally, the number of 1s in a random number sequence should always be roughly half of the sequence length. The difference between the ideal number of 1s and the observed number of 1s for the 4,743,168-bit sequence of each qubit is examined in Fig. 5. Note that here, too, the figures are aligned topologically. Figure 5 shows the stability of each qubit in terms of the proportion of 1s in its output; a linear plot suggests that the qubit is being stably operated. While qubit[7] is more biased than qubit[17] overall, the line representing qubit[7] shows more stability than that of qubit[17]. Furthermore, the noisy simulator does not capture the trend of the qubits. Therefore, the discrepancy between the output of the actual device and the noisy simulator may not only be a result of readout asymmetry, but also time-varying parameters.

The proportion of 1s of qubit[0]\(\sim \)[19]. The acceptable range under the level of significance \(\alpha = 0.01\) is between the two dotted lines. The blue bars are the experimental results and the red plots the noisy simulation results

The proportion of passed samples for each test. The test names corresponding to the test numbers can be found in Table 1. The acceptable range provided by the NIST is above the red line marking the proportion 0.977595. The blue plots are the experimental results and the red plots the noisy simulation results. The figure has been rotated \(90^\circ \)

The difference between the ideal and observed increase in the number of 1s of qubit [0]\(\sim \) [19]. The blue plots are the experimental results and the red plots the noisy simulation results. The figure has been rotated \(90^\circ \)
5 Conclusion
We characterized the qubits in a cloud quantum computer by using statistical tests for random number generators to provide a potential indicator of the device’s condition. The IBM 20Q Poughkeepsie device was repeatedly run for a period of five days, and 579 samples with a length of 8192 were obtained for each of the 20 qubits. For comparison, the noise parameters obtained in the experiment were used to run the noisy simulator. Samples from both the actual device and the simulator were statistically analyzed for bias and patterns. To evaluate the uniformity of each sample, the min-entropy was computed. The transition of min-entropy showed that the qubits have unique characteristics. We identified a sudden drop of min-entropy in qubit [17]. The histogram of the proportion of 1s in the 4,743,168-bit sequences produced by each qubit revealed that, overall, none of the qubits produced acceptable proportions of 1s. However, we evaluated each qubit’s stability from the time-series data of the proportion of 1s and found that qubits [0] and [12] were relatively stable. Finally, eight tests from the NIST SP 800-22 were applied to the 529 samples of the 20 qubits. None of the qubits cleared the standards of the test suite. However, the test results showed that qubits [0] and [12] were the closest to the ideal in terms of the proportion of passed samples for each test.

Relation between Shannon’s entropy and min-entropy
As is the case with random number generators, a cloud quantum computer is a black box to its users. Therefore, users are required to decide for themselves when to use a cloud quantum computer and which qubits to choose. Statistical tests for random number generators are a potential candidate for a simple indicator of qubit condition and stability inside a cloud quantum computer (Shikano et al. 2020).
References
G. Aleksandrowicz et al., version: 0.10.1 (2019). https://doi.org/10.5281/zenodo.2562110
L.E. Bassham et al., NIST Special Publication 800-22rev1a (2010)
D. Boneh, Notices Amer. Math. Soc. 46, 203 (1999)
D. Castelvecchi, Nature 543, 159 (2017)
H. Demirhan, N. Bitirim, J. Statisticians, Stat. Actuar. Sci. 9, 1 (2016)
L. Fan, H. Chen, S. Gao, in Information Security Applications, WISA 2013, Lecture Notes in Computer Science, vol. 8267 ed. by Y. Kim, H. Lee, A. Perrig (Springer, Cham, 2014), p. 52
E. Gibney, Nature 541, 447 (2017)
K. Hamano, IEICE Trans. Fundam. 88, 67 (2005)
H. Haramoto, M. Matsumoto, Math. Comput. Simul. 161, 66 (2019)
M. Herrero-Collantes, J.C. Garcia-Escartin, Rev. Mod. Phys. 89, 015004 (2017)
S.-J. Kim, K. Umeno, A. Hasegawa (2020), arXiv:nlin/0401040
R. LaRose, Quantum 3, 130 (2019)
P. L’ecuyer, R. Simard, ACM Trans. Math. Softw. (TOMS) 33, 22 (2007)
X. Ma, X. Yuan, Z. Cao, B. Qi, Z. Zhang, npj Quantum Inf. 2, 16021 (2016)
S. Marek, R. Zdenĕk, M. Vashek, M. Kinga, S. Alin, Rom. J. Inf. Sci. Tech. 18, 1 (2015)
National Academies of Sciences, Engineering, and Medicine, Quantum Computing: Progress and Prospects (The National Academies Press, Washington DC, 2019)
S. Pironio et al., Nature 464, 1021 (2010)
J. Preskill, Quantum 2, 79 (2018)
W. Schindler, W. Killmann, in Cryptographic Hardware and Embedded Systems - CHES 2002, Lecture Notes in Computer Science, vol. 2523, ed. by B.S. Kaliski, K. Koç, C. Paar (Springer, Berlin, 2003), p. 431
R. Srivastava, I. Choi, T. Cook, The Commercial Prospects for Quantum Computing (Networked Quantum Information Technologies, 2016)
K. Tamura, Y. Shikano, in Proceedings of Workshop on Quantum Computing and Quantum Information, ed. by M. Hirvensalo, A. Yakaryilmaz, TUCS Lecture Notes, vol. 30 (2019), http://urn.fi/URN:ISBN:978-952-12-3840-6
K. Ugajin et al., Opt. Exp. 25, 6511 (2017)
T. Xin et al., Sci. Bull. 63, 17 (2018)
Y. Yamamoto, M. Sasaki, H. Takesue, Quant. Sci. Tech. 4, 020502 (2019)
X. Zhang, Y. Nie, H. Liang, J. Zhang, in IEEE-NPSS Real Time Conference (RT), Padua, vol. 1 (2016)
Y. Shikano, K. Tamura, R. Raymond, EPTCS 315, 18-25 (2020)
Acknowledgements
The authors thank Hidetoshi Okutomi, Atsushi Iwasaki, Shumpei Uno, and Rudy Raymond for valuable discussions. This work is partially supported by JSPS KAKENHI (Grant Nos. 17K05082 and 19H05156) and 2019 IMI Joint Use Research Program Short-term Joint Research “Mathematics for quantum walks as quantum simulators”. The results presented in this paper were obtained in part using an IBM Q quantum computing system as part of the IBM Q Network. The views expressed are those of the authors and do not reflect the official policy or position of IBM or the IBM Q team.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Min-entropy
Appendix: Min-entropy
Among various entropy measures for uniformity, the min-entropy is often used in the context of cryptography. The min-entropy for a random variable X is defined as follows:
On the other hand, Shannon’s entropy, which is also a measure for uniformity, is defined as follows:
Both measures (10) and (11) take values ranging from 0 to 1 for a random variable on \(\{0, 1\}\). The reason why the min-entropy is more appropriate in the context of cryptography is that it is more sensitive than Shannon’s entropy. This is apparent from Fig. 6. Figure 6 compares the min-entropy and Shannon’s entropy corresponding to the probability of X yielding 1. The min-entropy provides a clearer distinction of probability distributions close to uniform than Shannon’s entropy.
The min-entropy also indicates the probability that an adversary with knowledge of the probability distribution of X predicts the outcome of X correctly (Zhang et al. 2016). Here, the adversary predicts the value that appears with the highest probability. For this reason, the min-entropy considers the maximum probability of X.
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this paper

Cite this paper
Tamura, K., Shikano, Y. (2021). Quantum Random Numbers Generated by a Cloud Superconducting Quantum Computer. In: Takagi, T., Wakayama, M., Tanaka, K., Kunihiro, N., Kimoto, K., Ikematsu, Y. (eds) International Symposium on Mathematics, Quantum Theory, and Cryptography. Mathematics for Industry, vol 33. Springer, Singapore. https://doi.org/10.1007/978-981-15-5191-8_6
Download citation
DOI: https://doi.org/10.1007/978-981-15-5191-8_6
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-5190-1
Online ISBN: 978-981-15-5191-8
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)