
Abstract
The seminal result that every language having an interactive proof also has a zero-knowledge interactive proof assumes the existence of one-way functions. Ostrovsky and Wigderson [33] proved that this assumption is necessary: if one-way functions do not exist, then only languages in BPP have zero-knowledge interactive proofs.
Ben-Or et al. [9] proved that, nevertheless, every language having a multi-prover interactive proof also has a zero-knowledge multi-prover interactive proof, unconditionally. Their work led to, among many other things, a line of work studying zero knowledge without intractability assumptions. In this line of work, Kilian, Petrank, and Tardos [28] defined and constructed zero-knowledge probabilistically checkable proofs (PCPs).
While PCPs with quasilinear-size proof length, but without zero knowledge, are known, no such result is known for zero knowledge PCPs. In this work, we show how to construct “2-round” PCPs that are zero knowledge and of length \(\tilde{O}(K)\) where K is the number of queries made by a malicious polynomial time verifier. Previous solutions required PCPs of length at least \(K^6\) to maintain zero knowledge. In this model, which we call duplex PCP (DPCP), the verifier first receives an oracle string from the prover, then replies with a message, and then receives another oracle string from the prover; a malicious verifier can make up to K queries in total to both oracles.
Deviating from previous works, our constructions do not invoke the PCP Theorem as a blackbox but instead rely on certain algebraic properties of a specific family of PCPs. We show that if the PCP has a certain linear algebraic structure — which many central constructions can be shown to possess, including [2, 4, 15] — we can add the zero knowledge property at virtually no cost (up to additive lower order terms) while introducing only minor modifications in the algorithms of the prover and verifier. We believe that our linear-algebraic characterization of PCPs may be of independent interest, as it gives a simplified way to view previous well-studied PCP constructions.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
- Probabilistically Checkable Proofs (PCP)
- Zero Knowledge
- Oracle String
- Multi-prover Interactive Proofs (MIP)
- Proof Length
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
We continue the study of proof systems that provide soundness and zero knowledge, simultaneously and unconditionally (i.e., no intractability assumptions are needed to achieve the two), as we now explain.
Interactive Proofs. An interactive proof [6, 20] for a language \(\mathscr {L}\) is a pair of interactive algorithms \((P,V)\), where \(P\) is known as the prover and \(V\) as the verifier, that satisfies the following: (i) (completeness) for every instance  in \(\mathscr {L}\),
in \(\mathscr {L}\),  can make
can make  accept with probability 1; (ii) (soundness) for every instance
accept with probability 1; (ii) (soundness) for every instance  not in \(\mathscr {L}\), every prover \(\tilde{P}\) can make
not in \(\mathscr {L}\), every prover \(\tilde{P}\) can make  accept with at most a small probability \(\epsilon \). Shamir [35] showed the expressive power of interactive proofs by proving that \(\mathbf {IP}=\mathbf {PSPACE}\), i.e., all and only languages in \(\mathbf {PSPACE}\) have interactive proofs.
accept with at most a small probability \(\epsilon \). Shamir [35] showed the expressive power of interactive proofs by proving that \(\mathbf {IP}=\mathbf {PSPACE}\), i.e., all and only languages in \(\mathbf {PSPACE}\) have interactive proofs.
Zero Knowledge. An interactive proof is zero knowledge [20] if the verifier, even if malicious, cannot learn any information about an instance  in \(\mathscr {L}\), by interacting with the prover, besides the fact
in \(\mathscr {L}\), by interacting with the prover, besides the fact  is in \(\mathscr {L}\): for any efficient verifier \(\tilde{V}\) there exists an efficient simulator \(S\) such that
is in \(\mathscr {L}\): for any efficient verifier \(\tilde{V}\) there exists an efficient simulator \(S\) such that  is “indistinguishable” from the view of \(\tilde{V}\) while interacting with
is “indistinguishable” from the view of \(\tilde{V}\) while interacting with  . Depending on the choice of definition for indistinguishability, one gets different flavors of zero knowledge.
. Depending on the choice of definition for indistinguishability, one gets different flavors of zero knowledge.
If indistinguishability is required to hold for efficient deciders only, then one gets computational zero knowledge; \(\mathbf {CZK}\) denotes the corresponding complexity class. A seminal result in cryptography says that if one-way functions exist then \(\mathbf {CZK}=\mathbf {IP}\), i.e., every language having an interactive proof also has a computational zero-knowledge interactive proof [8, 20, 23]. If indistinguishability is required to hold for all deciders, then one gets statistical zero knowledge; if instead the simulator’s output and the verifier’s view are the same distribution (and not merely close to each other), then one gets perfect zero knowledge. These stronger notions determine the corresponding complexity classes \(\mathbf {SZK}\) and \(\mathbf {PZK}\), both of which are contained in \(\mathbf {AM}\cap \mathbf {coAM}\); of course, \(\mathbf {PZK}\subseteq \mathbf {SZK}\subseteq \mathbf {CZK}\).
Unfortunately, zero knowledge cannot be achieved unconditionally for non-trivial languages: Ostrovsky and Wigderson [33] proved that if one-way functions do not exist then \(\mathbf {CZK}\) equals an average-case variant of \(\mathbf {BPP}\).
Other Types of Proof Systems. Due to the limitations of interactive proofs with respect to zero knowledge that holds unconditionally, researchers have explored other types of proof systems, as an alternative to interactive proofs.
-
MIP. Ben-Or et al. [9] first studied statistical zero knowledge, and proved that it can be achieved in a new model, multi-prover interactive proof (MIPs), where the verifier interacts with multiple provers that are not allowed to communicate while interacting with the verifier (though they may share a random string before such an interaction begins). More precisely, Ben-Or et al. prove that every language having a multi-prover interactive proof also has a perfect zero-knowledge multi-prover interactive proof (again, without relying on intractability assumptions). The result of [9] was subsequently improved in a number of papers [5, 19, 29].
-
PCP. Kilian et al. [28] study statistical zero knowledge in the model of probabilistically checkable proofs (PCPs) [2–4], where the verifier has oracle access to a string. Essentially, the oracle string can be thought of as a stateless prover: the answer to a query depends only on the query itself, but not any other queries that were previously made. Building on results implicit in [19], Kilian et al. showed two main theorems. First, every language in \(\mathbf {NEXP}\) has a PCP that is statistical zero knowledge against verifiers that make at most any polynomial number of queries to the PCP. Second, every language in \(\mathbf {NP}\) has, for every constant \(c > 0\), a PCP that is statistically zero knowledge against verifiers that make at most \(\mathsf {k}(n) :=n^c\) queries to the PCP.
Subsequent works [24–26, 31] provided simplifications (giving alternative constructions or simplifying that of [28]) and limitations (showing that for languages in \(\mathbf {NP}\) one cannot efficiently sample the oracle if one seeks statistical zero knowledge against verifiers that make at most a polynomial number of queries).
-
IPCP. Goyal et al. [21] study statistical zero knowledge in the model of interactive PCPs (IPCPs) [27], where the verifier interacts with two provers of which one is restricted to be an oracle. Goyal et al. prove that every language in \(\mathbf {NP}\) has a constant-round interactive PCP that is statistical zero knowledge against verifiers that make at most any polynomial number of queries to the PCP, and where both provers’ strategies can be implemented efficiently as a function of the instance and the witness.
A Limitation of Prior Work. PCPs with quasilinear-size proof length, but without zero knowledge, are known: for every language \(\mathscr {L}\) in \(\mathbf {NTIME}(T(n))\), there is a PCP with proof length \(\tilde{O}(T(n))\) and query complexity O(1) [14, 15, 17, 32]. On the other hand, no such result for statistical zero knowledge PCPs is known: even when applied to PCPs of length \(\tilde{O}(T(n))\), [28]’s result and followup improvements yields a proof length that is polynomial in \(T(n) \cdot \mathsf {k}(n)\), where \(\mathsf {k}(n)\), known as the knowledge bound, is a bound on the number of queries by any verifier (see Sect. 4.1 for further discussion). We thus ask the following question: are there statistical zero knowledge PCPs with proof length quasilinear in \(T(n) + \mathsf {k}(n)\)?
1.1 Our Contributions
We do not answer the above question in the PCP model, but we give a positive answer in a closely related model that can be thought of as a “2-round PCP”, which we call duplex PCP (DPCP). At a high level, a DPCP works as follows: the prover first sends an oracle string \(\pi _{0}\) to the verifier, just as in a PCP; then, the verifier sends a message \(\rho \) to the prover; finally, the prover answers with a second oracle string \(\pi _{1}\); the verifier may query both oracles, and then accept or reject. In other words, a DPCP is merely a 2-round interactive proof in which the prover sends oracle strings rather than messages. We prove the following theorem:
Theorem 1
(see Theorem 4 for formal statement). For every language \(\mathscr {L}\) in \(\mathbf {NTIME}(T)\cap \mathbf {NP}\) and polynomially-bounded knowledge bound \(\mathsf {k}\) there exists a DPCP system satisfying the following:
-
the proof length (in fact, also the prover running time) is quasilinear in \(n+ T(n) + \mathsf {k}(n)\);
-
the query complexity is polynomial in \(\log (T(n) + \mathsf {k}(n))\);
-
the verifier running time is polynomial in \(n+ \log (T(n) + \mathsf {k}(n))\);
-
perfect zero knowledge holds against any verifier that makes at most \(\mathsf {k}(n)\) adaptive queries (in total to both oracles);
-
the soundness error is 1 / 2 (and can be reduced by repetition to \(2^{-\lambda }\) while preserving perfect zero knowledge, provided that the number of queries does not exceed \(\mathsf {k}(n)\)).
Moreover, similarly to the PCPs of [28], the DPCP system that we construct is in fact not only sound but is also a proof of knowledge [7]; however, in contrast to [28], the DPCP verifier is non-adaptive, in the sense that the query locations depend only on the verifier’s random tape.
Perhaps the main difference between our construction and prior work is the techniques that we use. While previous works use the PCP Theorem as a black box, compiling a PCP into a zero knowledge PCP by using locking schemes [28], we use certain algebraic properties of a specific family of PCPs to guarantee zero knowledge. In comparison to the generic approach, we are more specific, but the addition of zero knowledge essentially comes “for free” when compared to the corresponding constructions without zero knowledge. (In contrast, [28] achieves a proof length of \(\varOmega (\mathsf {k}(n)^6 \cdot \mathsf {l}(n)^c)\), for some large enough c, when starting from a PCP with proof length \(\mathsf {l}(n)\).)
DPCP vs IPCP. Duplex PCPs are an alternative to interactive PCPs that combine PCPs and interaction. In a DPCP, the verifier gets an oracle string from the prover, replies with a message, and then gets another oracle string from the prover; in an IPCP, the verifier gets an oracle string from the prover, and then engages in an interactive proof with him.
Both [21] and our work are similar in that both address aspects that we do not know how to address in the PCP model, and resort to studying alternative models, i.e., IPCP and DPCP respectively. The two works however give different flavors of results: [21] obtain IPCPs that are zero knowledge against verifiers that ask at most any polynomial number of queries \(\mathsf {k}(n)\) but their oracle is of polynomial size in \(\mathsf {k}(n)\) (actually, of exponential size but with a polynomial-size circuit describing it); on the other hand, our work obtains DPCPs that are zero knowledge against verifiers that ask at most a fixed polynomial number of queries \(\mathsf {k}(n)\) and our oracles are of quasilinear size in \(\mathsf {k}(n)\).
Finally, we note that our construction can be also cast as an IPCP, because the knowledge bound \(\mathsf {k}(n)\) holds only for the first oracle, i.e., perfect zero knowledge is preserved even if the verifier reads the second oracle in full. This provides a result on a 2-round IPCP incomparable to [21]’s 4-round IPCP.
On the Minimal Computational Gap Between Prover and Verifier Needed for Zero Knowledge. IP and MIP systems assume a computational gap between prover and verifier. The prover is allowed (and often assumed) to be computationally unbounded and the verifier is polynomially bounded. An intriguing corollary of our theorem is that the computational gap between prover and verifier can be drastically reduced, to a mere polylogarithmic one. Namely, suppose that we wish to create zero-knowledge systems in which the verifier runs in time \(\mathsf {tv}(n)\); in the model above, as long as \(\mathsf {tp}(n)> \mathsf {tv}(n)\cdot (\log \mathsf {tv}(n))^{c}\) for an absolute constant \(c\), then perfect zero knowledge with a small soundness error can be obtained under no intractability assumptions. (See Corollary 1 for a formal statement.)
2 Preliminaries
Functions and Distributions. We use \(f :D\rightarrow R\) to denote a function with domain \(D\) and range \(R\); given a subset \(\tilde{D}\) of \(D\), we use \(f|_{\tilde{D}}\) to denote the restriction of f to \(\tilde{D}\). Given a distribution \(\mathcal {D}\), we write \(x \leftarrow \mathcal {D}\) to denote that x is sampled according to \(\mathcal {D}\).
Distances. A distance measure is a function \(\varDelta :\varSigma ^{n} \times \varSigma ^{n} \rightarrow [0,1]\) such that for all \(x,y,z \in \varSigma ^{n}\): (i) \(\varDelta (x,x) = 0\), (ii) \(\varDelta (x,y) = \varDelta (y,x)\), and (iii) \(\varDelta (x,y) \le \varDelta (x,z) + \varDelta (z,y)\). For example, the relative Hamming distance over alphabet \(\varSigma \) is a distance measure: \(\varDelta ^{\mathrm {Ham}}_{\varSigma }(x,y) :=|\{i \,|\, x_{i} \ne y_{i}\}|/n\). We extend \(\varDelta \) to distances of strings to sets: given \(x \in \varSigma ^{n}\) and \(S \subseteq \varSigma ^{n}\), we define \(\varDelta (x,S) :=\min _{y \in S} \varDelta (x,y)\) (or 1 if S is empty). We say that a string x is \(\epsilon \)-close to another string y if \(\varDelta (x,y) \le \epsilon \), and \(\epsilon \)-far from y if \(\varDelta (x,y) > \epsilon \); similar terminology applies for a string x and a set S.
Fields and Polynomials. We denote by \(\mathbb {F}\) a finite field, by \(\mathbb {F}_{q}\) the field of size \(q\), and by \(\mathscr {F}\) the set of all finite fields. We denote by \(\mathbb {F}[X_{1},\dots ,X_{m}]\) the ring of polynomials in m variables over \(\mathbb {F}\); given a polynomial P in \(\mathbb {F}[X_{1},\dots ,X_{m}]\), \({\mathrm {deg}_{{X_{i}}}(P)}\) is the degree of P in the variable \(X_{i}\); the total degree of P is the sum of all of these individual degrees.
Linear Spaces. Given \(n \in \mathbb {N}\), a subset \(S\) of \(\mathbb {F}^{n}\) is an \(\mathbb {F}\)-linear space if \(\alpha x + \beta y \in S\) for all \(\alpha ,\beta \in \mathbb {F}\) and \(x,y \in S\).
Languages and Relations. We denote by \(\mathscr {R}\) a relation consisting of pairs  , where
, where  is the instance and
is the instance and  is the witness. We denote by \(\mathrm {Lan}(\mathscr {R})\) the language corresponding to \(\mathscr {R}\), and by
is the witness. We denote by \(\mathrm {Lan}(\mathscr {R})\) the language corresponding to \(\mathscr {R}\), and by  the set of witnesses in \(\mathscr {R}\) for
the set of witnesses in \(\mathscr {R}\) for  .
.
Complexity Classes. We write complexity classes in bold capital letters: \(\mathbf {NP}\), \(\mathbf {PSPACE}\), \(\mathbf {NEXP}\), and so on. We take a “relation-centric” point of view: we view \(\mathbf {NTIME}\) as a class of relations rather than as the class of the corresponding languages; we thus may write things like “let \(\mathscr {R}\) be in \(\mathbf {NP}\)”. If \(\mathscr {R}\) is in \(\mathbf {NTIME}(T)\), we fix an arbitrary machine \(M_{\mathscr {R}}\) that decides \(\mathscr {R}\) in time \(T(n)\), i.e.,  always halts after
always halts after  steps and
steps and  if and only if
if and only if  ; we then say that \(M_{\mathscr {R}}\) decides \(\mathscr {R}\) (or \(\mathrm {Lan}(\mathscr {R})\)). Throughout, we assume that \(T(n) \ge n\).
; we then say that \(M_{\mathscr {R}}\) decides \(\mathscr {R}\) (or \(\mathrm {Lan}(\mathscr {R})\)). Throughout, we assume that \(T(n) \ge n\).
Codes. An error correcting code \(C\) is a set of functions \(w:H\rightarrow \varSigma \), where \(H,\varSigma \) are finite sets. The message length of \(C\) is \(n:=\log _{|\varSigma |} |C|\), its block length is \(\ell :=|H|\), its rate is \(\rho :=n/\ell \), its (minimum) distance is \(d:=\min \{ \varDelta (w,z) \,|\, w,z\in C,\, w\ne z\}\) when \(\varDelta \) is the (absolute) Hamming distance, and its (minimum) relative distance is \(\delta :=d/\ell \). Given a code family \(\mathscr {C}\), we denote by \(\mathrm {Rel}(\mathscr {C})\) the relation that naturally corresponds to \(\mathscr {C}\), i.e., \(\{(C,w) \mid C\in \mathscr {C},\, w\in C\}\). A code \(C\) is linear if \(\varSigma \) is a finite field and \(C\) is a \(\varSigma \)-linear space in \(\varSigma ^{\ell }\); we denote by \(\mathrm {dim}(C)\) the dimension of \(C\) when viewed as a linear space. A code \(C\) is \(t\)-wise independent if, for every subset \(I\) of \([\ell ]\) with cardinality \(t\), the distribution of \(w|_{I}\) (viewed as a string) for a random \(w\in C\) equals the uniform distribution on \(\varSigma ^{t}\).
Random Shifts. We later use the following folklore claim about distance preservation for random shifts in linear spaces; for completeness, we include its short proof.
Claim
Let n be in \(\mathbb {N}\), \(\mathbb {F}\) a finite field, \(S\) an \(\mathbb {F}\)-linear space in \(\mathbb {F}^{n}\), and \(x,y \in \mathbb {F}^{n}\). If x is \(\epsilon \)-far from \(S\), then \(\alpha x+y\) is \(\epsilon /2\)-far from \(S\), with probability \(1-|\mathbb {F}|^{-1}\) over a random \(\alpha \in \mathbb {F}\). (Distances are relative Hamming distances.)
Proof
Suppose, by way of contradiction, that there exist \(\alpha _{1}, \alpha _{2} \in \mathbb {F}\) and \(y_{1},y_{2} \in S\) with \(\alpha _{1} \ne \alpha _{2}\) such that, for every \(i \in \{1,2\}\), \(\alpha _{i} x+y\) is \(\epsilon /2\) close to \(y_{i}\). Then, by the triangle inequality, \(z :=y_{1} - y_{2}\) is \(\epsilon \)-close to \((\alpha _{1} x+y) -(\alpha _{2} x+y) = (\alpha _{1}-\alpha _{2}) x\). We conclude that x is \(\epsilon \)-close to \(\frac{1}{\alpha _{1}-\alpha _2} z\in S\), a contradiction.
2.1 Probabilistically Checkable Proofs
A PCP system [2–4] for a relation \(\mathscr {R}\) is a tuple \(\mathsf {PCP}=(P ,V)\) that works as follows.
-
The prover \(P\) is a probabilistic algorithm that, given as input an instance-witness pair
 with
with  , outputs a proof \(\pi :D(n) \rightarrow \varSigma (n)\), where both \(D(n)\) and \(\varSigma (n)\) are finite sets.
, outputs a proof \(\pi :D(n) \rightarrow \varSigma (n)\), where both \(D(n)\) and \(\varSigma (n)\) are finite sets. -
The verifier \(V\) is a probabilistic oracle algorithm that, given as input an instance
 with
with  and with oracle access to a proof \(\pi :D(n) \rightarrow \varSigma (n)\), queries \(\pi \) at a few locations and then outputs a bit.
and with oracle access to a proof \(\pi :D(n) \rightarrow \varSigma (n)\), queries \(\pi \) at a few locations and then outputs a bit.
 with
with  , outputs a proof
, outputs a proof  with
with  and with oracle access to a proof
and with oracle access to a proof The system \(\mathsf {PCP}\) has (perfect) completeness and soundness error \(\mathsf {e}(n)\) if the following two conditions hold. (Below, we explicitly denote the prover’s and verifier’s randomness as \(r_{P}\) and \(r_{V}\).)
- Completeness: :
-
For every instance-witness pair
 in the relation \(\mathscr {R}\),
in the relation \(\mathscr {R}\), 
- Soundness: :
-
For every instance
 not in the language \(\mathrm {Lan}(\mathscr {R})\) and proof \(\pi :D(n) \rightarrow \varSigma (n)\),
not in the language \(\mathrm {Lan}(\mathscr {R})\) and proof \(\pi :D(n) \rightarrow \varSigma (n)\), 
 in the relation
in the relation 
 not in the language
not in the language 
A relation \(\mathscr {R}\) belongs to the complexity class \(\mathbf {PCP}[\mathsf {a},\mathsf {l},\mathsf {q},\mathsf {e},\mathsf {tp},\mathsf {tv}]\) if there is a PCP system for \(\mathscr {R}\) in which:
-
the answer alphabet (i.e., \(\varSigma (n)\)) is \(\mathsf {a}(n)\),
-
the proof length over that alphabet (i.e., \(|D(n)|\)) is at most \(\mathsf {l}(n)\),
-
the verifier queries the proof in at most \(\mathsf {q}(n)\) locations,
-
the soundness error is \(\mathsf {e}(n)\),
-
the prover runs in time \(\mathsf {tp}(n)\), and
-
the verifier runs in time \(\mathsf {tv}(n)\).
Finally, we add the symbol \(\mathrm {na}\) in the square brackets (i.e., we write \(\mathbf {PCP}[\dots ,\mathrm {na}]\)) if the queries to the proof are non-adaptive (i.e., the queried locations only depend on the verifier’s inputs).
2.2 Probabilistically Checkable Proofs of Proximity
A PCPP system [12, 18] for a relation \(\mathscr {R}\) is a tuple \(\mathsf {PCPP}= (P,V)\) that works as follows.
-
The prover \(P\) is a probabilistic algorithm that, given as input an instance-witness pair
 with
with 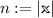 , outputs a proof \(\pi :D(n) \rightarrow \varSigma (n)\), where both \(D(n)\) and \(\varSigma (n)\) are finite sets.
, outputs a proof \(\pi :D(n) \rightarrow \varSigma (n)\), where both \(D(n)\) and \(\varSigma (n)\) are finite sets. -
The verifier \(V\) is a probabilistic oracle algorithm that, given as input an instance
 with
with  and with oracle access to a witness
and with oracle access to a witness  and proof \(\pi :D(n) \rightarrow \varSigma (n)\), queries
and proof \(\pi :D(n) \rightarrow \varSigma (n)\), queries  and \(\pi \) at a few locations and then outputs a bit.
and \(\pi \) at a few locations and then outputs a bit.
 with
with 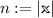 , outputs a proof
, outputs a proof  with
with  and with oracle access to a witness
and with oracle access to a witness  and proof
and proof  and
and The system \(\mathsf {PCPP}\) has (perfect) completeness, soundness error \(\mathsf {e}\), distance measure \(\varDelta \), and proximity parameter \(\mathsf {d}\) if the following two conditions hold. (Below, we explicitly denote the prover’s and verifier’s randomness as \(r_{P}\) and \(r_{V}\).)
- Completeness: :
-
For every instance-witness pair
 in the relation \(\mathscr {R}\),
in the relation \(\mathscr {R}\), 
- Soundness: :
-
For every instance-witness pair
 , perhaps not in the language, such that
, perhaps not in the language, such that  and proof \(\pi :D(n) \rightarrow \varSigma (n)\),
and proof \(\pi :D(n) \rightarrow \varSigma (n)\), 
 in the relation
in the relation 
 , perhaps not in the language, such that
, perhaps not in the language, such that  and proof
and proof 
A relation \(\mathscr {R}\) belongs to the complexity class \(\mathbf {PCPP}[\mathsf {a},\mathsf {l},\mathsf {q},\varDelta ,\mathsf {d},\mathsf {e},\mathsf {tp},\mathsf {tv}]\) if there is a PCPP system for \(\mathscr {R}\) in which:
-
the answer alphabet (i.e., \(\varSigma (n)\)) is \(\mathsf {a}(n)\),
-
the proof length over that alphabet (i.e., \(|D(n)|\)) is at most \(\mathsf {l}(n)\),
-
the verifier queries the two oracles (codeword and proof) in at most \(\mathsf {q}(n)\) locations (in total),
-
the distance measure is \(\varDelta \),
-
the proximity parameter is \(\mathsf {d}(n)\),
-
the soundness error is \(\mathsf {e}(n)\),
-
the prover runs in time \(\mathsf {tp}(n)\), and
-
the verifier runs in time \(\mathsf {tv}(n)\).
Finally, we add the symbol \(\mathrm {na}\) in the square brackets (i.e., we write \(\mathbf {PCPP}[\dots ,\mathrm {na}]\)) if the queries to the oracles are non-adaptive (i.e., the queried locations only depend on the verifier’s inputs).
2.3 Zero Knowledge PCPs
The notion of zero knowledge for PCPs was first considered in [19, 28]. A PCP system \(\mathsf {PCP}=(P ,V)\) for a relation \(\mathscr {R}\) has perfect zero knowledge with knowledge bound \(\mathsf {k}\) if there exists an expected-polynomial-time probabilistic algorithm \(S\) such that, for every \(\mathsf {k}\)-query polynomial-time probabilistic oracle algorithm \(\tilde{V}\), the following two distribution families are identical:

where  is the view of \(\tilde{V}\) in its execution when given input
is the view of \(\tilde{V}\) in its execution when given input  and oracle access to
and oracle access to  . The definition of statistical and computational zero knowledge (with knowledge bound \(\mathsf {k}\)) are similar: rather than identical, the two distribution families are required to be statistically and computationally close (as
. The definition of statistical and computational zero knowledge (with knowledge bound \(\mathsf {k}\)) are similar: rather than identical, the two distribution families are required to be statistically and computationally close (as  grows), respectively.
grows), respectively.
A relation \(\mathscr {R}\) belongs to the complexity class \(\mathbf {PCP}_{\mathrm {pzk}}[\mathsf {a},\mathsf {l},\mathsf {q},\mathsf {e},\mathsf {tp},\mathsf {tv},\mathsf {k}]\) if there exists a PCP system for \(\mathscr {R}\) that (i) puts \(\mathscr {R}\) in \(\mathbf {PCP}[\mathsf {a},\mathsf {l},\mathsf {q},\mathsf {e},\mathsf {tp},\mathsf {tv}]\), and (ii) has perfect zero knowledge with knowledge bound \(\mathsf {k}\); as for \(\mathbf {PCP}\), we add the symbol \(\mathrm {na}\) in the square brackets of \(\mathbf {PCP}_{\mathrm {pzk}}\) if the queries to the proof are non-adaptive. The complexity classes \(\mathbf {PCP}_{\mathrm {szk}}\) and \(\mathbf {PCP}_{\mathrm {czk}}\) are similarly defined for statistical and computational zero knowledge.
The KPT Result. Kilian, Petrank, and Tardos proved the following theorem:
Theorem 2
[28]. For every polynomial time function \(T:\mathbb {N}\rightarrow \mathbb {N}\), polynomial security function \(\lambda :\mathbb {N}\rightarrow \mathbb {N}\), and polynomial knowledge bound function \(\mathsf {k}:\mathbb {N}\rightarrow \mathbb {N}\),
Remark 1
We make two remarks: (i) the symbol \(\mathrm {na}\) does not appear above because [28]’s construction relies on adaptively querying the proof; (ii) inspection of [28]’s construction reveals that \(\mathsf {l}(n) \ge \mathrm {poly}(T(n) ) \cdot \mathsf {k}(n)^{6}\).
2.4 Reed–Muller and Reed–Solomon Codes
We define Reed–Muller and Reed–Solomon codes, as well as their “vanishing” variants [15]; all of these are linear codes. We then state a theorem about PCPPs for certain families of RS codes.
RM Codes. Let \(\mathbb {F}\) be a finite field, \(H,V\) subsets of \(\mathbb {F}\), \(m\) a positive integer, and \(\varrho \) a constant in (0, 1]; \(\varrho \) is called the fractional degree. The Reed–Muller code with parameters \(\mathbb {F},H,m,\varrho \) is \( \mathsf {RM}[\mathbb {F},H,m,\varrho ] :=\{w:H^{m} \rightarrow \mathbb {F} \mid \max _{i \in [m]} {\mathrm {deg}_{X_{i}}(w)} < \varrho |H|\} \); its message length is \(n= ( \varrho |H| )^{m}\), block length is \(\ell = |H|^{m}\), rate is \(\rho = \varrho ^{m}\), and relative distance is \(\delta = 1-\varrho \). The vanishing Reed–Muller code with parameters \(\mathbb {F},H,m,\varrho ,V\) is \( \mathsf {VRM}[\mathbb {F},H,m,\varrho ,V] :=\{w\in \mathsf {RM}[\mathbb {F},H,m,\varrho ] \mid w(V^{m})=\{0\}\} \); it is a subcode of \(\mathsf {RM}[\mathbb {F},H,m,\varrho ]\).
RS Codes. Let \(\mathbb {F}\) be a finite field, \(H,V\) subsets of \(\mathbb {F}\), and \(\varrho \) a constant in (0, 1]. The Reed–Solomon code with parameters \(\mathbb {F},H,\varrho \) is \( \mathsf {RS}[\mathbb {F},H,\varrho ] :=\mathsf {RM}[\mathbb {F},H,1,\varrho ] \). The vanishing Reed–Solomon code with parameters \(\mathbb {F},H,\varrho ,V\) is \( \mathsf {VRS}[\mathbb {F},H,\varrho ,V] :=\{w\in \mathsf {RS}[\mathbb {F},H,\varrho ] \mid w(V)=\{0\}\} \).
Two RS Code Families and Their PCPPs. Given \(\varrho \in (0,1]\), we denote by: (i) \(\mathcal {RS}^{*}_{\varrho }\) the set of Reed–Solomon codes \(\mathsf {RS}[\mathbb {F},H,\varrho ]\) for which \(\mathbb {F}\) has characteristic 2 and \(H\) is an \(\mathbb {F}_{2}\)-affine space; and (ii) \(\mathcal {VRS}^{*}_{\varrho }\) the set of vanishing Reed–Solomon codes \(\mathsf {VRS}[\mathbb {F},H,\varrho ,V]\) for which \(\mathbb {F}\) has characteristic 2 and \(H\) is an \(\mathbb {F}_{2}\)-affine space. The following theorem is from [10, 15] (the prover running time is shown in [10] and the other parameters in [15]).
Theorem 3
For every security function \(\lambda :\mathbb {N}\rightarrow \mathbb {N}\), \(\varrho \in (0,1)\), and \(s > 0\),
We will also require the following folklore claim, whose correctness can be proved by induction on \(m\):
Claim
Let \(\mathbb {F}\) be a finite field, \(H,V\) subsets of \(\mathbb {F}\) with \(H\cap V= \emptyset \), \(m\) a positive integer, and \(t\) a positive integer not exceeding \(|H|-|V|\). Then \(\mathsf {VRM}[\mathbb {F},H,m,\frac{|V|+t}{|H|},V]\) is \(t\)-wise independent.
3 Duplex PCPs
We define duplex PCPs, and then define notions of zero knowledge for this model. Our main theorem is the construction of a duplex PCP with certain parameters; see Sect. 4. The difference between a PCP and a duplex PCP is that all provers (both honest and malicious) produce two proof oracles rather than one: the prover produces a proof \(\pi _{0}\); then the verifier sends a message \(\rho \) to the prover; then the prover produces another proof \(\pi _{1}\); finally the verifier queries both \(\pi _{0}\) and \(\pi _{1}\) and either accepts or rejects. (Thus, a PCP is a special case of a duplex PCP, but not vice versa.) More precisely, a duplex PCP system for a relation \(\mathscr {R}\) is a tuple \(\mathsf {DPCP}=(P ,V)\) that works as follows.
-
The prover \(P\) is a pair \((P_{0},P_{1})\) of probabilistic algorithms, with shared randomness, where: (a) given as input an instance-witness pair
 with
with  , \(P_{0}\) outputs a proof \(\pi _{0} :D_{0}(n) \rightarrow \varSigma (n)\); (b) given as input
, \(P_{0}\) outputs a proof \(\pi _{0} :D_{0}(n) \rightarrow \varSigma (n)\); (b) given as input  and the verifier’s message \(\rho \) (see below), \(P_{1}\) outputs a proof \(\pi _{1} :D_{1}(n) \rightarrow \varSigma (n)\). Here \(D_{0}(n),D_{1}(n),\varSigma (n)\) are finite sets.
and the verifier’s message \(\rho \) (see below), \(P_{1}\) outputs a proof \(\pi _{1} :D_{1}(n) \rightarrow \varSigma (n)\). Here \(D_{0}(n),D_{1}(n),\varSigma (n)\) are finite sets. -
The verifier \(V\) is a pair \((V_{0},V_{1})\) of probabilistic algorithms, with shared randomness, where: (a) given as input an instance
 with
with  , \(V_{0}\) outputs a message \(\rho \); (b) given as input
, \(V_{0}\) outputs a message \(\rho \); (b) given as input  and with oracle access to proofs \(\pi _{0} :D_{0}(n) \rightarrow \varSigma (n)\) and \(\pi _{1} :D_{1}(n) \rightarrow \varSigma (n)\), \(V_{1}\) queries \(\pi _{0}\) and \(\pi _{1}\) at a few locations and then outputs a bit.
and with oracle access to proofs \(\pi _{0} :D_{0}(n) \rightarrow \varSigma (n)\) and \(\pi _{1} :D_{1}(n) \rightarrow \varSigma (n)\), \(V_{1}\) queries \(\pi _{0}\) and \(\pi _{1}\) at a few locations and then outputs a bit.
 with
with  ,
,  and the verifier’s message
and the verifier’s message  with
with  ,
,  and with oracle access to proofs
and with oracle access to proofs The system \(\mathsf {DPCP}\) has (perfect) completeness and soundness error \(\mathsf {e}(n)\) if the following two conditions hold. (Below, we explicitly denote the prover’s and verifier’s randomness as \(r_{P}\) and \(r_{V}\).)
- Completeness: :
-
For every instance-witness pair
 in the relation \(\mathscr {R}\),
in the relation \(\mathscr {R}\), 
- Soundness: :
-
For every instance
 not in the language \(\mathrm {Lan}(\mathscr {R})\) and pair of algorithms \(\tilde{P} = (\tilde{P}_{0},\tilde{P}_{1})\),
not in the language \(\mathrm {Lan}(\mathscr {R})\) and pair of algorithms \(\tilde{P} = (\tilde{P}_{0},\tilde{P}_{1})\), 
 in the relation
in the relation 
 not in the language
not in the language 
A relation \(\mathscr {R}\) belongs to the complexity class \(\mathbf {DPCP}[\mathsf {a},\mathsf {l},\mathsf {q},\mathsf {e},\mathsf {tp},\mathsf {tv}]\) if there is a DPCP system for \(\mathscr {R}\) in which:
-
the answer alphabet (i.e., \(\varSigma (n)\)) is \(\mathsf {a}(n)\),
-
the proof length over that alphabet (i.e., \((|D_{0}(n)| + |D_{1}(n)|)\)) is at most \(\mathsf {l}(n)\),
-
the verifier queries the two proofs in at most \(\mathsf {q}(n)\) locations (in total),
-
the soundness error is \(\mathsf {e}(n)\),
-
the prover runs in time \(\mathsf {tp}(n)\), and
-
the verifier runs in time \(\mathsf {tv}(n)\).
Finally, we add the symbol \(\mathrm {na}\) in the square brackets (i.e., we write \(\mathbf {DPCP}[\dots ,\mathrm {na}]\)) if the queries to the proof are non-adaptive (i.e., the queried locations only depend on the verifier’s inputs).
Zero Knowledge. A DPCP system \(\mathsf {DPCP}=(P ,V)\) for a relation \(\mathscr {R}\) has perfect zero knowledge with knowledge bound \(\mathsf {k}\) if there exists an expected-polynomial-time probabilistic algorithm \(S\) such that for every pair of polynomial-time probabilistic oracle algorithms \(\tilde{V} :=(\tilde{V}_{0},\tilde{V}_{1})\) the following two distribution families are identical:

where  is the view of \(\tilde{V}_{1}\) in its execution when given input
is the view of \(\tilde{V}_{1}\) in its execution when given input  and when allowed to make a total of \(\mathsf {k}(n)\) adaptive queries to \(\pi _{0},\pi _{1}\), where
and when allowed to make a total of \(\mathsf {k}(n)\) adaptive queries to \(\pi _{0},\pi _{1}\), where  and
and  . (As above, \(P_{0},P_{1}\) share the same randomness \(r_{P}\); ditto for \(\tilde{V}_{0},\tilde{V}_{1}\).) The definition of statistical and computational zero knowledge (with knowledge bound \(\mathsf {k}\)) are similar: rather than identical, the two distribution families are required to be statistically and computationally close (as
. (As above, \(P_{0},P_{1}\) share the same randomness \(r_{P}\); ditto for \(\tilde{V}_{0},\tilde{V}_{1}\).) The definition of statistical and computational zero knowledge (with knowledge bound \(\mathsf {k}\)) are similar: rather than identical, the two distribution families are required to be statistically and computationally close (as  grows), respectively.
grows), respectively.
4 Main Theorem
The main result of this paper is the following.
Theorem 4
For every polynomial time function \(T:\mathbb {N}\rightarrow \mathbb {N}\), polynomial knowledge bound function \(\mathsf {k}:\mathbb {N}\rightarrow \mathbb {N}\),
A Corollary. The theorem above implies that, fixing \(T\), the prover running time is merely quasilinear in the knowledge bound \(\mathsf {k}\), while the verifier running time increases only polylogarithmically in \(\mathsf {k}\). This leads to an intriguing corollary: a poly-logarithmic computational overhead of the prover over the verifier is all that is needed to maintain perfect zero knowledge in the duplex PCP model. We state this formally next.
Corollary 1
For every polynomial time function \(T:\mathbb {N}\rightarrow \mathbb {N}\) and relation \(\mathscr {R}\in \mathbf {NTIME}(T)\), there is a constant \(c\) such that, for every function \(\mathsf {tv}:\mathbb {N}\rightarrow \mathbb {N}\) with \(\mathsf {tv}(n) \ge n\cdot (\log T(n))^{c}\), there is a DPCP system with:
-
completeness 1 and soundness \(2^{-\mathsf {tv}(n)/\mathrm {polylog}(T(n))}\);
-
perfect zero knowledge;
-
the verifier running time is \(\mathsf {tv}(n)\) and prover running time is \( \mathsf {tp}(n) :=\max \{ T(n) \cdot (\log T(n))^{c}, \mathsf {tv}(n) \cdot (\log \mathsf {tv}(n))^{c} \} \).
The verifier has no limitations other than a bound on its running time (its query complexity can be as large as \(\mathsf {tv}(n)\)).
4.1 Proof Sketch
Let \(\mathscr {R}\) be a relation in \(\mathbf {NP}\), and let  be an instance-witness pair in \(\mathscr {R}\). The prover and verifier both know
be an instance-witness pair in \(\mathscr {R}\). The prover and verifier both know  , while the prover also knows
, while the prover also knows  . The prover wishes to convince the verifier that he knows a witness
. The prover wishes to convince the verifier that he knows a witness  for
for  , in such a way that the verifier does not learn anything about
, in such a way that the verifier does not learn anything about  (beyond what can be inferred from the prover’s claim).
(beyond what can be inferred from the prover’s claim).
The KPT Approach. We introduce our ideas by contrasting them with those of [28]. Suppose that the prover wishes to convince the verifier by sending him a PCP proof  such that any \(\mathsf {k}\) values in \(\pi \) do not reveal anything about
such that any \(\mathsf {k}\) values in \(\pi \) do not reveal anything about  . Loosely speaking, [28] (building on [19]) provide a probabilistic transformation that maps the PCP proof \(\pi \) to a new proof \(\pi '\), in which each bit of \(\pi \) is “hidden” amongst many bits of \(\pi '\). The main tool employed in the transformation is a locking scheme, and its use imposes certain limitations: (i) the new proof \(\pi '\) is \(\mathrm {poly}(\mathsf {k})\) larger than the original one (\(\mathsf {k}^{6}\) by inspection of [19, 28]); (ii) zero knowledge holds only statistically, but not perfectly, because a malicious verifier can be “lucky” and obtain information on the bit of \(\pi \) being locked with fewer queries to \(\pi '\) than expected.
. Loosely speaking, [28] (building on [19]) provide a probabilistic transformation that maps the PCP proof \(\pi \) to a new proof \(\pi '\), in which each bit of \(\pi \) is “hidden” amongst many bits of \(\pi '\). The main tool employed in the transformation is a locking scheme, and its use imposes certain limitations: (i) the new proof \(\pi '\) is \(\mathrm {poly}(\mathsf {k})\) larger than the original one (\(\mathsf {k}^{6}\) by inspection of [19, 28]); (ii) zero knowledge holds only statistically, but not perfectly, because a malicious verifier can be “lucky” and obtain information on the bit of \(\pi \) being locked with fewer queries to \(\pi '\) than expected.
Our Approach (Ideally). We take a different approach: apply a “local” PCP to a “random” witness, as we now explain. Suppose that  is \((t,\mathsf {k})\)
-local, i.e., any \(\mathsf {k}\) positions of the PCP proof \(\pi \) jointly depend on at most \(t\) positions of the witness
is \((t,\mathsf {k})\)
-local, i.e., any \(\mathsf {k}\) positions of the PCP proof \(\pi \) jointly depend on at most \(t\) positions of the witness  . Note that, even if \(\pi \) is \((t,\mathsf {k})\)-local, a single bit of \(\pi \) can still leak information about
. Note that, even if \(\pi \) is \((t,\mathsf {k})\)-local, a single bit of \(\pi \) can still leak information about  . So suppose further that the relation \(\mathscr {R}\) is \(t\)
-randomizable: given
. So suppose further that the relation \(\mathscr {R}\) is \(t\)
-randomizable: given  , one can efficiently sample a witness
, one can efficiently sample a witness  from a \(t\)-wise independent subset of the set of witnesses for
from a \(t\)-wise independent subset of the set of witnesses for  . In such a case, the prover can produce a zero-knowledge PCP as follows: (1) sample a witness
. In such a case, the prover can produce a zero-knowledge PCP as follows: (1) sample a witness  from the \(t\)-wise independent subset; then (2) send to the verifier the PCP proof
from the \(t\)-wise independent subset; then (2) send to the verifier the PCP proof  . Indeed, the locality of \(\pi \) ensures that seeing any \(\mathsf {k}\) indices of \(\pi \) reveals nothing about
. Indeed, the locality of \(\pi \) ensures that seeing any \(\mathsf {k}\) indices of \(\pi \) reveals nothing about  , because these \(\mathsf {k}\) indices are a function of \(t\) random bits. In sum, if we had a \((t,\mathsf {k})\)-local PCP for a \(t\)-randomizable relation \(\mathscr {R}\), then we could obtain a PCP for \(\mathscr {R}\) that is zero knowledge against verifiers that ask at most \(\mathsf {k}\) queries.
, because these \(\mathsf {k}\) indices are a function of \(t\) random bits. In sum, if we had a \((t,\mathsf {k})\)-local PCP for a \(t\)-randomizable relation \(\mathscr {R}\), then we could obtain a PCP for \(\mathscr {R}\) that is zero knowledge against verifiers that ask at most \(\mathsf {k}\) queries.
Our Approach (in Reality). Unfortunately, we do not know how to obtain local PCPs for randomizable relations. However, we are able to obtain “partially local” duplex PCPs for certain randomizable relations, and also show that \(\mathbf {NTIME}\) can be efficiently reduced to these randomizable relations, as we now explain.
Our starting point are algebraic PCPs: certain PCPs that prove satisfiability of algebraic problems (APs) [34]. Numerous known PCP constructions can be viewed as algebraic PCPs. Informally, in this work we make two basic observations: (i) algebraic PCPs exist for certain randomizable relations; and (ii) an algebraic PCP proof can be split in two parts, one part is local, while the other part is not local but enjoys convenient linear algebraic properties that, nevertheless, enable us to hide information about the witness, in the duplex PCP model. (Recall that, in the duplex PCP model, the prover produces a proof \(\pi _{0}\); then the verifier sends a message \(\rho \) to the prover; then the prover produces another proof \(\pi _{1}\); finally the verifier queries both \(\pi _{0}\) and \(\pi _{1}\) and either accepts or rejects.)
In more detail, from a technical viewpoint, we proceed as follows. First, we introduce a family of constraint satisfaction problems (CSPs) called linear algebraic CSPs, and show that \(\mathbf {NTIME}\) is efficiently reducible to randomizable linear algebraic CSPs. The reduction consists of two parts: we go through an intermediary that we call group preserving algebraic problems (GAPs), a special case of APs that we believe to be of independent interest for the study of algebraic PCPs. Second, we construct a duplex PCP system for randomizable linear algebraic CSPs that is zero knowledge against verifiers that ask at most a certain number of queries.
A Technical Piece: Zero-Knowledge Duplex PCPP for Low-Degreeness. Later sections address all of the above steps (see Sect. 4.2 for a roadmap of these), and for now we only sketch one of these steps. Above we mention that an algebraic PCP proof has two parts: a local part, and a non-local part. This latter part of the proof arises from a central component of many PCP proofs: a PCP of proximity (PCPP) [13, 18] that facilitates low-degree testing. Informally, given a function \(f :H\rightarrow \mathbb {F}\) and an integer d, a PCPP for degree d is a proof \(\pi (f)\) that f is \(\epsilon \)-close to an evaluation of a polynomial degree at most degree d. We explain how to transform a PCPP for low-degreeness into a duplex PCPP for low-degreeness that is zero knowledge against verifiers that make at most \(t\) queries.
The set \(C\) of functions \(f :H\rightarrow \mathbb {F}\) that are evaluations of a polynomial of degree at most d is a subspace of \(\mathbb {F}^{|H|}\). The basic idea is that, in order for the prover to convince the verifier that a function f is close to \(C\), it suffices for the prover to convince the verifier that a random offset of f is close to \(C\): one can verify that, for any \(u:H\rightarrow \mathbb {F}\), if f is \(\epsilon \)-far from \(C\), then \(\alpha f+u\) is \(\epsilon /2\)-far from \(C\), with probability \(1-|\mathbb {F}|^{-1}\) over a random \(\alpha \in \mathbb {F}\). Hence, we can let the duplex PCP work as follows: (i) the prover samples a witness  from the \(t\)-wise independent subset, chooses a random \(u\in C\), and sends
from the \(t\)-wise independent subset, chooses a random \(u\in C\), and sends  to the verifier; (ii) the verifier sends to the prover a random \(\alpha \in \mathbb {F}\); (iii) the prover sends \(\pi _{1}=(v, \pi (v))\) to the verifier, where
to the verifier; (ii) the verifier sends to the prover a random \(\alpha \in \mathbb {F}\); (iii) the prover sends \(\pi _{1}=(v, \pi (v))\) to the verifier, where  is a PCPP for low-degreeness of \(v\); (iv) the verifier runs the PCPP verifier on \((v, \pi )\) to check that \(v\) is close to \(C\), and then checks that
is a PCPP for low-degreeness of \(v\); (iv) the verifier runs the PCPP verifier on \((v, \pi )\) to check that \(v\) is close to \(C\), and then checks that  for a few random indices i in \(\{1,\dots ,|H|\}\).
for a few random indices i in \(\{1,\dots ,|H|\}\).
Let us discuss the various properties of the duplex PCPP.
-
Completeness: If
 , then
, then  ; therefore, the prover convinces the verifier.
; therefore, the prover convinces the verifier. -
Zero-knowledge: If the verifier asks at most \(t\) queries, then he learns nothing about
 because:
because:  contains
contains  sampled from a \(t\)-wise independent subset and \(u\) random in \(C\); \(\pi _{1} = (v, \pi (v))\) is running the PCPP on a vector \(v\) that is random in \(C\).
sampled from a \(t\)-wise independent subset and \(u\) random in \(C\); \(\pi _{1} = (v, \pi (v))\) is running the PCPP on a vector \(v\) that is random in \(C\). -
Soundness: If \(v\) does equal
 , then the verifier rejects with high probability because \(v\) is far from \(C\) (and the PCPP verifier rejects \(\pi \) with high probability). If instead \(v\) does not equal
, then the verifier rejects with high probability because \(v\) is far from \(C\) (and the PCPP verifier rejects \(\pi \) with high probability). If instead \(v\) does not equal  , then the fact that \(v\) is close to \(C\) does not prove anything about whether
, then the fact that \(v\) is close to \(C\) does not prove anything about whether  is also close. So, in this case, we need to reason about the success probability of the verifier’s linearity tests: if these pass with enough probability, then with high probability \(v\) is close to
is also close. So, in this case, we need to reason about the success probability of the verifier’s linearity tests: if these pass with enough probability, then with high probability \(v\) is close to  , which again suffices for our purpose. Overall, soundness holds.
, which again suffices for our purpose. Overall, soundness holds.
 , then
, then  ; therefore, the prover convinces the verifier.
; therefore, the prover convinces the verifier. because:
because:  contains
contains  sampled from a
sampled from a  , then the verifier rejects with high probability because
, then the verifier rejects with high probability because  , then the fact that
, then the fact that  is also close. So, in this case, we need to reason about the success probability of the verifier’s linearity tests: if these pass with enough probability, then with high probability
is also close. So, in this case, we need to reason about the success probability of the verifier’s linearity tests: if these pass with enough probability, then with high probability  , which again suffices for our purpose. Overall, soundness holds.
, which again suffices for our purpose. Overall, soundness holds.Next, we discuss how the technical sections are organized, and how they come together to yield our main theorem.
4.2 Roadmap of the Rest of the Paper
The rest of the paper is dedicated to turn the above intuition into a more formal proof. To do so, we introduce various intermediate steps, as follows.
-
In Sect. 5, we introduce linear algebraic CSPs (a family of constraint satisfaction problems), and then describe how to obtain a canonical PCP for any linear algebraic CSP.
-
In Sect. 6, we introduce randomizable linear algebraic CSPs, a subfamily of linear algebraic CSPs; then we show that, for every randomizable linear algebraic CSP, we can convert the CSP’s canonical PCP into a corresponding zero-knowledge duplex PCP, incurring only little overheads.
-
In Sect. 7, we show an efficient reduction from \(\mathbf {NTIME}\) to randomizable linear algebraic CSPs; along the way, we introduce a family of algebraic problems, having special symmetry properties, that we believe to be of independent interest (e.g., for studying other questions about PCPs).
Combining (i) the efficient reduction from \(\mathbf {NTIME}\) to randomizable linear algebraic CSPs together with (ii) the zero-knowledge duplex PCP for such problems yields Theorem 4. In Sect. 8 we provide details about how these components are combined.
5 Linear Algebraic CSPs and Their Canonical PCPs
We introduce linear algebraic CSPs, a family of constraint satisfaction problems; then we describe how to obtain a canonical PCP for any linear algebraic CSP.
5.1 Linear Algebraic Constraint Satisfaction Problems
A constraint satisfaction problem asks whether, for a given “local” function \(g\), there exists an input \(\alpha \) such that \(g(\alpha )\) is an “accepting” output. For example, in the case of 3-SAT with \(n\) variables and \(m\) clauses, the function \(g\) maps \(\{0,1\}^{n}\) to \(\{0,1\}^{m}\), and \(g(\alpha )\) indicates which clauses are satisfied by \(\alpha \in \{0,1\}^{n}\); hence \(\alpha \) yields an accepting output if (and only if) \(g(\alpha )=1^{m}\). Below we introduce a family of constraint satisfaction problems whose domain and range are linear-algebraic objects, namely, linear error correcting codes.
We begin by providing the notion of locality that we use for \(g\); we also provide two other notions, one for the efficiency of computing a single coordinate of \(g\)’s output, and another for measuring \(g\)’s “pseudorandomness”.
Definition 1
Let \(g:\varSigma ^{n} \rightarrow \varSigma ^{m}\) be a function. We say that \(g\) is:
-
\(q\) -local if for every \(j\in [m]\) there exists \(I_{j} \subseteq [n]\) with \(|I_{j}| \le q\) such that \(g(\alpha )[j]\) (the j-th coordinate of \(g(\alpha )\)) depends only on \(\alpha |_{I_{j}}\) (the restriction of \(\alpha \) to \(I_{j}\));
-
\(c\) -efficient if there is a time \(c\) algorithm that, given j and \(\alpha |_{I_{j}}\), computes the set \(I_{j}\) and value \(g(\alpha )[j]\);
-
\((\gamma ,\epsilon )\) -sampling if \(\Pr [\,I_{j} \cap I\ne \emptyset \,|\, j \leftarrow [m]\,] \le \gamma \) for every \(I\subseteq [n]\) with \(|I|/n\le \epsilon \).
Next we introduce \(\mathscr {R}_{\mathsf {LA}}\), the relation of linear algebraic CSPs:
Definition 2
( \(\mathscr {R}_{\mathsf {LA}}\) ). Given functions \(f:\mathbb {N}\rightarrow \mathscr {F}\), \(\ell ,q,c:\mathbb {N}\rightarrow \mathbb {N}\), and \(\rho ,\delta ,\gamma ,\epsilon :\mathbb {N}\rightarrow (0,1]\), the relation
consists of instance-witness pairs  satisfying the following.
satisfying the following.
-
The instance
 is a tuple \((1^{n}, C_{\circ }, C_{\bullet },g)\) where:
is a tuple \((1^{n}, C_{\circ }, C_{\bullet },g)\) where:-
\(C_{\circ }, C_{\bullet }\) are linear error correcting codes with block lengths \(\ell _{\circ }(n),\ell _{\bullet }(n)\) at most \(\ell (n)\), each with rate at most \(\rho (n)\) and relative distance at least \(\delta (n)\) over the same field \(f(n)\);
-
\(g:f(n)^{\ell _{\circ }(n)}\rightarrow f(n)^{\ell _{\bullet }(n)}\) is a \(q(n)\)-local, \(c(n)\)-efficient, \((\gamma (n),\epsilon (n))\)-sampling function;
-
\(C_{\bullet } \cup g(C_{\circ })\) has relative distance at least \(\delta (n)\) (though may not be a linear space).
-
-
The witness
 is a tuple \((\alpha _{\circ },\alpha _{\bullet })\) where \(\alpha _{\circ } \in f(n)^{\ell _{\circ }(n)}\) and \(\alpha _{\bullet } \in f(n)^{\ell _{\bullet }(n)}\).
is a tuple \((\alpha _{\circ },\alpha _{\bullet })\) where \(\alpha _{\circ } \in f(n)^{\ell _{\circ }(n)}\) and \(\alpha _{\bullet } \in f(n)^{\ell _{\bullet }(n)}\). -
The instance
 and witness
and witness  jointly satisfy the following: \(\alpha _{\circ } \in C_{\circ }\), \(\alpha _{\bullet } \in C_{\bullet }\), and \(g(\alpha _{\circ }) = \alpha _{\bullet }\).
jointly satisfy the following: \(\alpha _{\circ } \in C_{\circ }\), \(\alpha _{\bullet } \in C_{\bullet }\), and \(g(\alpha _{\circ }) = \alpha _{\bullet }\).
 is a tuple
is a tuple  is a tuple
is a tuple  and witness
and witness  jointly satisfy the following:
jointly satisfy the following: We prove a simple claim about instances not in the language \(\mathrm {Lan}(\mathscr {R}_{\mathsf {LA}})\), which we use several times later on.
Claim
For every instance  not in the language \(\mathrm {Lan}(\mathscr {R}_{\mathsf {LA}})\) and (candidate) witness
not in the language \(\mathrm {Lan}(\mathscr {R}_{\mathsf {LA}})\) and (candidate) witness  at least one of the following holds:
at least one of the following holds:
-
at least one of \(\tilde{\alpha }_{\circ }\) and \(\tilde{\alpha }_{\bullet }\) is \(\epsilon \)-far in relative Hamming distance from \(C_{\circ }\) or \(C_{\bullet }\), respectively; or
-
there exist \(\alpha _{\circ } \in C_{\circ }\) and \(\alpha _{\bullet } \in C_{\bullet }\) such that \(\tilde{\alpha }_{\circ }\) and \(\tilde{\alpha }_{\bullet }\) are \(\epsilon \)-close to \(\alpha _{\circ }\) and \(\alpha _{\bullet }\), respectively, but \(g(\alpha _{\circ }) \ne \alpha _{\bullet }\).
Proof
If neither of the two cases hold, then there exist \(\alpha _{\circ } \in C_{\circ }\) and \(\alpha _{\bullet } \in C_{\bullet }\) such that \(g(\alpha _{\circ }) = \alpha _{\bullet }\). But then \((\alpha _{\circ }, \alpha _{\bullet })\) is a satisfying assignment for  , contradicting our assumption that
, contradicting our assumption that  is not in the language \(\mathrm {Lan}(\mathscr {R}_{\mathsf {LA}})\).
is not in the language \(\mathrm {Lan}(\mathscr {R}_{\mathsf {LA}})\).
Finally we need notation for referring to codes appearing in instances of \(\mathscr {R}_{\mathsf {LA}}\):
Definition 3
Given \(\mathscr {R}\subseteq \mathscr {R}_{\mathsf {LA}}\), we denote by
-
\(\mathscr {C}_{\mathscr {R},\circ }\) the set of codes \(C\) for which there is an instance
 in the relation \(\mathscr {R}\) with \(C=C_{\circ }\);
in the relation \(\mathscr {R}\) with \(C=C_{\circ }\); -
\(\mathscr {C}_{\mathscr {R},\bullet }\) the set of codes \(C\) for which there is an instance
 in the relation \(\mathscr {R}\) with \(C=C_{\bullet }\).
in the relation \(\mathscr {R}\) with \(C=C_{\bullet }\).
 in the relation
in the relation  in the relation
in the relation 5.2 A Canonical PCP for Linear Algebraic CSPs
We show how to construct a “canonical” PCP system for instances in \(\mathscr {R}_{\mathsf {LA}}\) (the relation of linear algebraic CSPs). At a high level, a canonical PCP proof for a \(\mathscr {R}_{\mathsf {LA}}\)-instance  consists of a witness
consists of a witness  concatenated with two PCPP proofs \(\pi _{\circ },\pi _{\bullet }\), showing that \(\alpha _{\circ },\alpha _{\bullet }\) are close to \(C_{\circ },C_{\bullet }\) respectively. The canonical PCP verifier first checks the two PCPP proofs and then checks that \(g(\alpha _{\circ })[j]=\alpha _{\bullet }[j]\) for a uniformly random \(j\in [\ell _{\bullet }]\).
concatenated with two PCPP proofs \(\pi _{\circ },\pi _{\bullet }\), showing that \(\alpha _{\circ },\alpha _{\bullet }\) are close to \(C_{\circ },C_{\bullet }\) respectively. The canonical PCP verifier first checks the two PCPP proofs and then checks that \(g(\alpha _{\circ })[j]=\alpha _{\bullet }[j]\) for a uniformly random \(j\in [\ell _{\bullet }]\).
Definition 4
Given (i) a relation \(\mathscr {R}\subseteq \mathscr {R}_{\mathsf {LA}}\), (ii) a PCPP system \(\mathsf {PCPP}_{\circ }=(P_{\circ },V_{\circ })\) for \(\mathrm {Rel}(\mathscr {C}_{\mathscr {R},\circ })\), and (iii) a PCPP system \(\mathsf {PCPP}_{\bullet }=(P_{\bullet },V_{\bullet })\) for \(\mathrm {Rel}(\mathscr {C}_{\mathscr {R},\bullet })\), the canonical PCP system for the triple \((\mathscr {R},\mathsf {PCPP}_{\circ },\mathsf {PCPP}_{\bullet })\) is the PCP system \(\mathsf {PCP}=(P,V)\) constructed as follows.
-
Prover. Given
 , the PCP prover \(P\) outputs
, the PCP prover \(P\) outputs  where \(\pi _{\circ } :=P_{\circ }(C_{\circ },\alpha _{\circ })\) and \(\pi _{\bullet } :=P_{\bullet }(C_{\bullet },\alpha _{\bullet })\). In other words, the PCP prover outputs a PCP proof that is the concatenation of the witness
where \(\pi _{\circ } :=P_{\circ }(C_{\circ },\alpha _{\circ })\) and \(\pi _{\bullet } :=P_{\bullet }(C_{\bullet },\alpha _{\bullet })\). In other words, the PCP prover outputs a PCP proof that is the concatenation of the witness  and a pair of PCPP proofs, the first proving that \(\alpha _{\circ } \in C_{\circ }\) and the second proving that \(\alpha _{\bullet } \in C_{\bullet }\).
and a pair of PCPP proofs, the first proving that \(\alpha _{\circ } \in C_{\circ }\) and the second proving that \(\alpha _{\bullet } \in C_{\bullet }\). -
Verifier. Given
 and oracle access to a PCP proof
and oracle access to a PCP proof  , the PCP verifier \(V\) works as follows:
, the PCP verifier \(V\) works as follows:-
(proximity) check that \(V_{\circ }^{(\alpha _{\circ },\pi _{\circ })}(C_{\circ })\) and \(V_{\bullet }^{(\alpha _{\bullet },\pi _{\bullet })}(C_{\bullet })\) both accept;
-
(consistency) check that \(g(\alpha _{\circ })[j] = \alpha _{\bullet }[j]\) for a uniformly random \(j \in [\ell _{\bullet }]\).
-
 , the PCP prover
, the PCP prover  where
where  and a pair of PCPP proofs, the first proving that
and a pair of PCPP proofs, the first proving that  and oracle access to a PCP proof
and oracle access to a PCP proof  , the PCP verifier
, the PCP verifier The next lemma says that the above construction is a PCP system when \(\mathscr {R}_{\mathsf {LA}}\)’s parameters are sufficiently “good”.
Lemma 1
( \(\mathscr {R}_{\mathsf {LA}}\rightarrow \mathbf {PCP}\) ). Suppose that \(\mathscr {R}\) is a relation that satisfies the following conditions:
-
(i)
\(\mathscr {R}\subseteq \mathscr {R}_{\mathsf {LA}}[f_{1},\ell _{1},\rho _{1},\delta _{1},q_{1},c_{1},\gamma _{1},\epsilon _{1}]\) with \(\epsilon _{1} < \min \{\frac{\delta _{1}}{2},\delta _{1}-\gamma _{1}\}\);
-
(ii)
\(\mathrm {Rel}(\mathscr {C}_{\mathscr {R},\circ }),\mathrm {Rel}(\mathscr {C}_{\mathscr {R},\bullet }) \in \mathbf {PCPP}[\mathsf {a}_{2},\mathsf {l}_{2},\mathsf {q}_{2},\varDelta ^{\mathrm {Ham}}_{\mathsf {a}_{2}},\mathsf {d}_{2},\mathsf {e}_{2},\mathsf {tp}_{2},\mathsf {tv}_{2},\mathrm {na}?]\) with \(\mathsf {a}_{2} = f_{1}\) and \(\mathsf {d}_{2} \le \epsilon _{1}\).
Then there is a canonical PCP system for a triple \((\mathscr {R},\mathsf {PCPP}_{\circ },\mathsf {PCPP}_{\bullet })\) that yields

Above, \(\mathrm {na}?\) denotes the fact that if the PCPP systems are non-adaptive so is the canonical PCP system.
Proof
(Proof of Lemma 1 ). First, we show that the canonical PCP system satisfies completeness and soundness; afterwards, we discuss the efficiency parameters achieved by it.
Completeness. Consider an instance-witness pair  in the relation \(\mathscr {R}\). Parse the instance
in the relation \(\mathscr {R}\). Parse the instance  as \((1^{n}, C_{\circ }, C_{\bullet },g)\) and the witness
as \((1^{n}, C_{\circ }, C_{\bullet },g)\) and the witness  as \((\alpha _{\circ },\alpha _{\bullet })\). Since
as \((\alpha _{\circ },\alpha _{\bullet })\). Since  , we have that \(\alpha _{\circ } \in C_{\circ }\), \(\alpha _{\bullet } \in C_{\bullet }\), and \(g(\alpha _{\circ }) = \alpha _{\bullet }\). Therefore, the PCP proof
, we have that \(\alpha _{\circ } \in C_{\circ }\), \(\alpha _{\bullet } \in C_{\bullet }\), and \(g(\alpha _{\circ }) = \alpha _{\bullet }\). Therefore, the PCP proof  generated by the PCP prover is accepted by the PCP verifier with probability 1: the PCPP verifiers \(V_{\circ }^{(\alpha _{\circ },\pi _{\circ })}(C_{\circ })\) and \(V_{\bullet }^{(\alpha _{\bullet },\pi _{\bullet })}(C_{\bullet })\) always accept and \(g(\alpha _{\circ })[j] = \alpha _{\bullet }[j]\) for every \(j \in [\ell _{\bullet }]\).
generated by the PCP prover is accepted by the PCP verifier with probability 1: the PCPP verifiers \(V_{\circ }^{(\alpha _{\circ },\pi _{\circ })}(C_{\circ })\) and \(V_{\bullet }^{(\alpha _{\bullet },\pi _{\bullet })}(C_{\bullet })\) always accept and \(g(\alpha _{\circ })[j] = \alpha _{\bullet }[j]\) for every \(j \in [\ell _{\bullet }]\).
Soundness. Consider an instance  not in the language \(\mathrm {Lan}(\mathscr {R})\) and a PCP proof
not in the language \(\mathrm {Lan}(\mathscr {R})\) and a PCP proof  . Parse the instance
. Parse the instance  as \((1^{n}, C_{\circ }, C_{\bullet },g)\) and the wintess
as \((1^{n}, C_{\circ }, C_{\bullet },g)\) and the wintess  , inside \(\tilde{\pi }\), as \((\tilde{\alpha }_{\circ },\tilde{\alpha }_{\bullet })\). We use Claim in Sect. 5.1 to prove that \(V\) accepts \(\tilde{\pi }\) with probability at most \(\max \{1-\delta _{1}+\gamma +\epsilon _{1}, \mathsf {e}_{2}\}\), by considering the following three cases.
, inside \(\tilde{\pi }\), as \((\tilde{\alpha }_{\circ },\tilde{\alpha }_{\bullet })\). We use Claim in Sect. 5.1 to prove that \(V\) accepts \(\tilde{\pi }\) with probability at most \(\max \{1-\delta _{1}+\gamma +\epsilon _{1}, \mathsf {e}_{2}\}\), by considering the following three cases.
-
Case 1: \(\tilde{\alpha }_{\circ }\) is \(\epsilon _{1}\)-far in relative Hamming distance from \(C_{\circ }\) . The canonical PCP verifier’s proximity test fails, because \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\tilde{\alpha }_{\circ },C_{\circ }) \ge \epsilon _{1} \ge \mathsf {d}_{2}\), and so the PCPP verifier \(V_{\circ }^{(\alpha _{\circ },\tilde{\pi }_{\circ })}(C_{\circ })\) accepts with probability at most \(\mathsf {e}_{2}\).
-
Case 2: \(\tilde{\alpha }_{\bullet }\) is \(\epsilon _{1}\) -far in relative Hamming distance from \(C_{\bullet }\) . This case is analogous to the previous one.
-
Case 3: there exist \(\alpha _{\circ } \in C_{\circ }\) and \(\alpha _{\bullet } \in C_{\bullet }\) with \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\alpha _{\circ }, \tilde{\alpha }_{\circ }) \le \epsilon _{1}\) and \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\alpha _{\bullet }, \tilde{\alpha }_{\bullet }) \le \epsilon _{1}\) .
First, since \(\epsilon _{1}\) is less than \(\delta _{1}/2\) (the unique decoding radius of \(C_{\circ }\) and \(C_{\bullet }\)), the codewords \(\alpha _{\circ }\) and \(\alpha _{\bullet }\) are unique.
Next, we claim that \(\alpha '_{\bullet } := g(\alpha _{\circ })\) and \(g(\tilde{\alpha }_{\circ })\) are \(\gamma _{1}\)-close. Indeed, since \(g\) is \((\gamma _{1},\epsilon _{1})\)-sampling, \(\alpha _{\circ }\) and \(\tilde{\alpha }_{\circ }\) differ in at most \(\epsilon _{1} \cdot \ell _{\circ }(n)\) positions, and so at most \(\gamma _{1} \cdot \ell _{\bullet }(n)\) positions of \(g(\tilde{\alpha }_{\circ })\) depend on an index where \(\alpha _{\circ }\) and \(\tilde{\alpha }_{\circ }\) differ.
Next, we claim that \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\alpha _{\bullet }, \alpha '_{\bullet }) \ge \delta _{1}\). Indeed, we have that \(\alpha _{\bullet } \ne \alpha '_{\bullet }\) because otherwise \((\alpha _{\circ }, \alpha _{\bullet })\) would be a satisfying assignment for
 (contradicting the assumption that
(contradicting the assumption that  ); moreover, we also have that \(C_{\bullet } \cup g(C_{\circ })\) has relative distance at least \(\delta _{1}\).
); moreover, we also have that \(C_{\bullet } \cup g(C_{\circ })\) has relative distance at least \(\delta _{1}\).We now use the triangle inequality, along with the above observations, to obtain that
$$\begin{aligned} \delta _{1} \varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\alpha _{\bullet }, \alpha '_{\bullet })&\le \varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\alpha _{\bullet }, \tilde{\alpha }_{\bullet }) + \varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\tilde{\alpha }_{\bullet }, g(\tilde{\alpha }_{\circ })) + \varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(g(\tilde{\alpha }_{\circ }), \alpha '_{\bullet }) \\&\le \epsilon _{1} + \varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\tilde{\alpha }_{\bullet }, g(\tilde{\alpha }_{\circ })) + \gamma _{1} . \end{aligned}$$Thus, \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\tilde{\alpha }_{\bullet }, g(\tilde{\alpha }_{\circ })) \ge \delta _{1} - (\gamma _{1} + \epsilon _{1})\), and so the canonical PCP verifier’s consistency check passes with probability at most \(1-\delta _{1}+\gamma _{1}+\epsilon _{1}\).
 (contradicting the assumption that
(contradicting the assumption that  ); moreover, we also have that
); moreover, we also have that We conclude that \(V\) accepts \(\tilde{\pi }\) with probability at most \(\max \{1-\delta _{1}+\gamma _{1}+\epsilon _{1}, \mathsf {e}_{2}\}\).
Other Parameters. The remaining parameters are straightforward to establish. The canonical PCP does not change the alphabet, so \(\mathsf {a}= f_{1}\) (which also equals \(\mathsf {a}_{2}\)). The proof length, and the running times of the prover and verifier are the sum of the same measures of the canonical PCP’s components: the PCP proof has \(\mathsf {l}= 2 \mathsf {l}_{2}(\ell _{1}) + 2 \ell _{1}\) symbols, is produced in time \(\mathsf {tp}= 2 \mathsf {tp}_{2}(\ell _{1})\), and is verified in time \(\mathsf {tv}= 2 \mathsf {tv}_{2}(\ell _{1})+ c_{1} + O(1)\). The canonical PCP verifier makes \(q_{1} + 1\) queries on top of those made by the PCPP verifiers, so its query complexity is \(\mathsf {q}= 2\mathsf {q}_{2}(\ell _{1}) + q_{1} + 1\). The \(q_{1} + 1\) additional queries are non-adaptive; so if the PCPP verifiers are non-adaptive, so is the canonical PCP verifier.
6 Zero-Knowledge Duplex PCPs from Randomizable Linear Algebraic CSPs
We introduce randomizable linear algebraic CSPs, a subfamily of linear algebraic CSPs. Then we show that, for every randomizable linear algebraic CSP, we can convert the CSP’s canonical PCP into a corresponding zero-knowledge duplex PCP, incurring only little overheads.
6.1 Randomizable Linear Algebraic CSPs
The definition below specifies the notion of randomizability for linear algebraic CSPs.
Definition 5
(
\(\mathscr {R}_{\mathsf {RLA}}\)
). The relation \(\mathscr {R}_{\mathsf {RLA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ,t,r]\) is the sub-relation of \(\mathscr {R}_{\mathsf {LA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ]\) obtained by restricting it to instances that are \(t\)-randomizable in time \(r\). An instance  is \(t(n)\)
-randomizable in time
\(r(n)\) if: (i) there exists a \(t(n)\)-wise independent subcode \(C'\subseteq C_{\circ }\) such that if \((w_{\circ }, g(w_{\circ }))\) satisfies
is \(t(n)\)
-randomizable in time
\(r(n)\) if: (i) there exists a \(t(n)\)-wise independent subcode \(C'\subseteq C_{\circ }\) such that if \((w_{\circ }, g(w_{\circ }))\) satisfies  , then, for every \(w'_{\circ }\) in \(C'+ w_{\circ } :=\{w'+ w_{\circ } \mid w'\in C'\}\), the witness \((w'_{\circ }, g(w'_{\circ }))\) satisfies
, then, for every \(w'_{\circ }\) in \(C'+ w_{\circ } :=\{w'+ w_{\circ } \mid w'\in C'\}\), the witness \((w'_{\circ }, g(w'_{\circ }))\) satisfies  ; and (ii) one can sample, in time \(r(n)\), three uniformly random elements in \(C'\), \(C_{\circ }\) and \(C_{\bullet }\) respectively.
; and (ii) one can sample, in time \(r(n)\), three uniformly random elements in \(C'\), \(C_{\circ }\) and \(C_{\bullet }\) respectively.
6.2 Construction of Zero-Knowledge Duplex PCPs
We construct a zero-knowledge duplex PCP system for randomizable linear algebraic CSPs. The duplex PCP system does little more than invoking, as a subroutine, the canonical PCP system for the linear algebraic CSP; hence, the efficiency of the duplex PCP and of the canonical PCP system are closely related. The construction demonstrates that “adding zero knowledge to an algebraic PCP” is cheap, provided that one moves from the PCP model to the (more general) duplex PCP model. More precisely, we prove the following theorem.
Theorem 5
( \(\mathscr {R}_{\mathsf {RLA}}\rightarrow \mathbf {DPCP}_{\mathrm {pzk}}\) ). Suppose that \(\mathscr {R}\) is a relation that satisfies the following conditions:
-
(i)
\(\mathscr {R}\subseteq \mathscr {R}_{\mathsf {RLA}}[f_{1},\ell _{1},\rho _{1},\delta _{1},q_{1},c_{1},\gamma _{1},\epsilon _{1},t_{1},r_{1}]\) with \(\epsilon _{1} < \min \{\frac{\delta _{1}}{2},\delta _{1}-\gamma _{1}\}\) and \(r_{1}\) polynomially bounded;
-
(ii)
\(\mathrm {Rel}(\mathscr {C}_{\mathscr {R},\circ }),\mathrm {Rel}(\mathscr {C}_{\mathscr {R},\bullet }) \in \mathbf {PCPP}[\mathsf {a}_{2},\mathsf {l}_{2},\mathsf {q}_{2},\varDelta ^{\mathrm {Ham}}_{\mathsf {a}_{2}},\mathsf {d}_{2},\mathsf {e}_{2},\mathsf {tp}_{2},\mathsf {tv}_{2},\mathrm {na}?]\) with \(\mathsf {a}_{2}=f_{1}\) and \(\mathsf {d}_{2} \le \epsilon _{1}/4\).
Then there is a duplex PCP system for \(\mathscr {R}\) that yields

Above, \(\mathrm {na}?\) denotes the fact that if the PCPP systems are non-adaptive so is the duplex PCP system.
Proof
We prove the claim by constructing a suitable duplex PCP system \(\mathsf {DPCP}= (P,V)\) for the relation \(\mathscr {R}\). Recall that: the prover \(P\) is a pair of algorithms \((P_{0},P_{1})\), and the verifier \(V\) is also a pair of algorithms \((V_{0},V_{1})\); moreover, an instance  of \(\mathscr {R}\) is of the form \((1^{n},C_{\circ },C_{\bullet },g)\), while a witness
of \(\mathscr {R}\) is of the form \((1^{n},C_{\circ },C_{\bullet },g)\), while a witness  of \(\mathscr {R}\) is of the form \((\alpha _{\circ },\alpha _{\bullet })\); finally, randomizability implies that there is a \(t(n)\)-wise independent subcode \(C'\subseteq C_{\circ }\) such that if \((w_{\circ }, g(w_{\circ }))\) satisfies
of \(\mathscr {R}\) is of the form \((\alpha _{\circ },\alpha _{\bullet })\); finally, randomizability implies that there is a \(t(n)\)-wise independent subcode \(C'\subseteq C_{\circ }\) such that if \((w_{\circ }, g(w_{\circ }))\) satisfies  then so does the witness \((w'_{\circ }, g(w'_{\circ }))\), for every \(w'_{\circ }\) in \(C'+ w_{\circ }\).
then so does the witness \((w'_{\circ }, g(w'_{\circ }))\), for every \(w'_{\circ }\) in \(C'+ w_{\circ }\).
We now describe the construction of the duplex PCP system \(\mathsf {DPCP}= (P,V)\):
-

Sample uniformly random \(v_{\circ } \in C_{\circ }, v_{\bullet } \in C_{\bullet }, u'\in C'\); compute \(w_{\circ } :=u'+ \alpha _{\circ }\), \(w_{\bullet } :=g(w_{\circ })\) and output \(\pi _{0} :=(w_{\circ } \Vert v_{\circ } \Vert w_{\bullet } \Vert v_{\bullet })\).
-

Sample uniformly random \(\rho _{\circ },\rho _{\bullet } \in f_{1}\), and output \(\rho :=(\rho _{\circ },\rho _{\bullet })\).
-

Compute \(z_{\circ } :=\rho _{\circ } w_{\circ } + v_{\circ }\) and \(z_{\bullet } :=\rho _{\bullet } w_{\bullet } + v_{\bullet }\); compute \(\pi _{\circ } :=P_{\circ }(C_{\circ },z_{\circ })\) and \(\pi _{\bullet } = P_{\bullet }(C_{\bullet },z_{\bullet })\); and output \(\pi _{1} :=(z_{\circ } \Vert z_{\bullet } \Vert \pi _{\circ } \Vert \pi _{\bullet })\). (Essentially, this step corresponds to running the canonical PCP prover with respect to a uniformly random pair \((z_{\circ },z_{\bullet })\) in \((C_{\circ },C_{\bullet })\).)
-

Conduct the following tests (and reject if any of them fails):
-
(proximity) check that \(V_{\circ }^{(z_{\circ },\pi _{\circ })}(C_{\circ })\) and \(V_{\bullet }^{(z_{\bullet },\pi _{\bullet })}(C_{\bullet })\) both accept;
-
(consistency) check that \(g(w_{\circ })[j] = w_{\bullet }[j]\) for a random \(j \in [\ell _{\bullet }]\);
-
(linearity) check that \(z_{\circ }[i] = \rho _{\circ } w_{\circ }[i] + v_{\circ }[i]\) and \(z_{\bullet }[k] = \rho _{\bullet } w_{\bullet }[k] + v_{\bullet }[k]\) for random \(i\in [\ell _{\circ }(n)]\) and \(k \in [\ell _{\bullet }(n)]\).
(Essentially the first two steps correspond to running the canonical PCP verifier on modified inputs, while the third step consists of two linearity tests.)
-




Having described the duplex PCP system, we now show that it satisfies completeness, soundness and zero-knowledge; afterwards, we discuss the efficiency parameters achieved by it.
Completeness. Consider an instance-witness pair  in the relation \(\mathscr {R}\). Since
in the relation \(\mathscr {R}\). Since  , we have that \(\alpha _{\circ } \in C_{\circ }\), \(\alpha _{\bullet } \in C_{\bullet }\), and \(g(\alpha _{\circ }) = \alpha _{\bullet }\). Since \(w_{\circ } \in C'+ \alpha _{\circ }\) and \(\mathscr {R}\) is randomizable, we have that \((w_{\circ }, w_{\bullet }) :=(w_{\circ }, g(w_{\circ }))\) satisfies
, we have that \(\alpha _{\circ } \in C_{\circ }\), \(\alpha _{\bullet } \in C_{\bullet }\), and \(g(\alpha _{\circ }) = \alpha _{\bullet }\). Since \(w_{\circ } \in C'+ \alpha _{\circ }\) and \(\mathscr {R}\) is randomizable, we have that \((w_{\circ }, w_{\bullet }) :=(w_{\circ }, g(w_{\circ }))\) satisfies  ; thus \(V_{1}\)’s consistency check passes with probability 1. Since the codes \(C_{\circ }\) and \(C_{\bullet }\) are linear and \(w_{\circ }, v_{\circ } \in C_{\circ }\), \(w_{\bullet }, v_{\bullet } \in C_{\bullet }\), we have that \(z_{\circ } :=\rho _{\circ } w_{\circ } + v_{\circ } \in C_{\circ }\) and \(z_{\bullet } :=\rho _{\bullet } w_{\bullet } + v_{\bullet } \in C_{\bullet }\); thus the PCPP verifiers \(V_{\circ }^{(z_{\circ },\pi _{\circ })}(C_{\circ })\) and \(V_{\bullet }^{(z_{\bullet },\pi _{\bullet })}(C_{\bullet })\) accept with probability 1. Finally, by construction of \(z_{\circ }\) and \(z_{\bullet }\), \(V_{1}\)’s linearity tests also accept with probability 1. We conclude that the duplex PCP system described above has perfect completeness.
; thus \(V_{1}\)’s consistency check passes with probability 1. Since the codes \(C_{\circ }\) and \(C_{\bullet }\) are linear and \(w_{\circ }, v_{\circ } \in C_{\circ }\), \(w_{\bullet }, v_{\bullet } \in C_{\bullet }\), we have that \(z_{\circ } :=\rho _{\circ } w_{\circ } + v_{\circ } \in C_{\circ }\) and \(z_{\bullet } :=\rho _{\bullet } w_{\bullet } + v_{\bullet } \in C_{\bullet }\); thus the PCPP verifiers \(V_{\circ }^{(z_{\circ },\pi _{\circ })}(C_{\circ })\) and \(V_{\bullet }^{(z_{\bullet },\pi _{\bullet })}(C_{\bullet })\) accept with probability 1. Finally, by construction of \(z_{\circ }\) and \(z_{\bullet }\), \(V_{1}\)’s linearity tests also accept with probability 1. We conclude that the duplex PCP system described above has perfect completeness.
Soundness. Consider an instance  not in the language \(\mathrm {Lan}(\mathscr {R})\). Fix an arbitrary proof string \(\tilde{\pi }_{0} = (\tilde{w}_{\circ } \Vert \tilde{v}_{\circ } \Vert \tilde{w}_{\bullet } \Vert \tilde{v}_{\bullet })\), and let the proof string \(\tilde{\pi }_{1} = (\tilde{z}_{\circ } \Vert \tilde{z}_{\bullet } \Vert \tilde{\pi }_{\circ } \Vert \tilde{\pi }_{\bullet })\) depend arbitrarily on the verifier message \(\rho = (\rho _{\circ },\rho _{\bullet })\). We use Claim in Sect. 5.1 with respect to the instance
not in the language \(\mathrm {Lan}(\mathscr {R})\). Fix an arbitrary proof string \(\tilde{\pi }_{0} = (\tilde{w}_{\circ } \Vert \tilde{v}_{\circ } \Vert \tilde{w}_{\bullet } \Vert \tilde{v}_{\bullet })\), and let the proof string \(\tilde{\pi }_{1} = (\tilde{z}_{\circ } \Vert \tilde{z}_{\bullet } \Vert \tilde{\pi }_{\circ } \Vert \tilde{\pi }_{\bullet })\) depend arbitrarily on the verifier message \(\rho = (\rho _{\circ },\rho _{\bullet })\). We use Claim in Sect. 5.1 with respect to the instance  and witness \((\tilde{w}_{\circ },\tilde{w}_{\bullet })\) and distinguish between three cases below.
and witness \((\tilde{w}_{\circ },\tilde{w}_{\bullet })\) and distinguish between three cases below.
-
Case 1: \(\tilde{w}_{\circ }\) is \(\epsilon _{1}\) -far in relative Hamming distance from \(C_{\circ }\) .
Claim in Sect. 2 implies that \(z'_{\circ } :=\rho _{\circ } \tilde{w}_{\circ } + \tilde{v}_{\circ }\) is \(\epsilon _{1}/2\)-far from \(C_{\circ }\), with probability \(1-|f_{1}|^{-1}\) over a random choice of \(\rho _{\circ }\). Let \(\theta :=\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(z'_{\circ }, \tilde{z}_{\circ })\) and \(\eta :=\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\tilde{z}_{\circ }, C_{\circ })\). By the triangle inequality, \(\theta + \eta \ge \varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(z'_{\circ },C_{\circ }) \ge \epsilon _{1}/2\); hence, at least one of the inequalities \(\theta \ge \epsilon _{1}/4\) and \(\eta \ge \epsilon _{1}/4\) holds. In the former case, \(V_{1}\)’s first linearity test accepts with probability at most \(1 - \epsilon _{1}/4\); in the latter case, the PCPP verifier \(V_{\circ }^{(\tilde{z}_{\circ },\tilde{\pi }_{\circ })}(C_{\circ })\) for \(V_{1}\)’s first proximity test accepts with probability at most \(\mathsf {e}_{2}\), as \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(\tilde{z}_{\circ },C_{\circ }) \ge \epsilon _{1}/4 \ge \mathsf {d}_{2}\).
-
Case 2: \(\tilde{w}_{\bullet }\) is \(\epsilon _{1}\) -far in relative Hamming distance from \(C_{\bullet }\) .
This case is analogous to the previous one.
-
Case 3: there exist \(w_{\circ } \in C_{\circ }\) and \(w_{\bullet } \in C_{\bullet }\) with \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(w_{\circ }, \tilde{w}_{\circ }) \le \epsilon _{1}\) and \(\varDelta ^{\mathrm {Ham}}_{\mathsf {a}}(w_{\bullet }, \tilde{w}_{\bullet }) \le \epsilon _{1}\) .
In this case we follow the very end of the soundness analysis in Lemma 1’s proof, replacing \(\tilde{\alpha }_{\circ },\tilde{\alpha }_{\bullet }\) there with \(\tilde{w}_{\circ },\tilde{w}_{\bullet }\), and conclude that the verifier accepts with probability at most \(1-\delta _{1}+\gamma _{1}+\epsilon _{1}\).
Summing up, in the first case the verifier’s acceptance probability is at most \((1-|f_{1}|^{-1}) \cdot \max \{\mathsf {e}_{2}, \epsilon _{1}/4\} + |f_{1}|^{-1}\); similarly for the second case. In the third case the rejection probability is \(1-\delta _{1}+\gamma _{1}+\epsilon _{1}\), that of the canonical PCP consistency verifier. This completes the soundness analysis.
Zero Knowledge. We construct a simulator \(S\) that yields perfect zero knowledge with knowledge bound \(\mathsf {k}\). Consider an instance-witness pair  in the relation \(\mathscr {R}\), and a malicious verifier \(\tilde{V} = (\tilde{V}_{0},\tilde{V}_{1})\) making at most \(\mathsf {k}\) adaptive queries.
in the relation \(\mathscr {R}\), and a malicious verifier \(\tilde{V} = (\tilde{V}_{0},\tilde{V}_{1})\) making at most \(\mathsf {k}\) adaptive queries.  , the output of the simulator \(S\), when given as input \(\tilde{V}\) and
, the output of the simulator \(S\), when given as input \(\tilde{V}\) and  , has to be identically distributed to
, has to be identically distributed to  , which is the view of \(\tilde{V}_{1}\) in its execution when given input
, which is the view of \(\tilde{V}_{1}\) in its execution when given input  and when allowed to make a total of \(\mathsf {k}(n)\) adaptive queries to \(\pi _{0},\pi _{1}\), where
and when allowed to make a total of \(\mathsf {k}(n)\) adaptive queries to \(\pi _{0},\pi _{1}\), where  and
and  . In fact, we will prove a stronger statement: the output of the simulator continues to exactly match the view of the verifier, interacting with the honest prover, even if the verifier is allowed unbounded access to \(\pi _{1}\), provided that \(\tilde{V}\) makes at most \(\mathsf {k}\) queries to \(\pi _{0}\).
. In fact, we will prove a stronger statement: the output of the simulator continues to exactly match the view of the verifier, interacting with the honest prover, even if the verifier is allowed unbounded access to \(\pi _{1}\), provided that \(\tilde{V}\) makes at most \(\mathsf {k}\) queries to \(\pi _{0}\).
We now discuss how \(S\) works. At a high level, \(S\) treats \(\tilde{V}\) as a black box, running it once without rewinding; along the way, \(S\) samples suitable answers for each query (as discussed below); when \(\tilde{V}\) halts, \(S\) outputs all the answers and \(\tilde{V}\)’s randomness (which together form the view of the verifier). The simulator \(S\) runs in strict polynomial time, without ever aborting. We now describe how \(S\) answers each query.
The simulator \(S\) maintains a proof string \({\pi }^{S}\) that is initially unspecified at all locations; we write \({\pi }^{S}[i]=*\) if the i-th location of this proof string is unspecified. During the simulation, \(S\) adaptively specifies locations in \({\pi }^{S}\) as a result of answering \(\tilde{V}\)’s queries; this specification process is definitive, in the sense that queries to locations that have been previously specified are answered consistently with the previously-specified value. We now discuss how \(S\) adaptively specifies locations in \({\pi }^{S}\). We distinguish between two parts of the simulation: before the point when \(\tilde{V}\) sends his message \(\rho \), and only queries to \(\pi _{0}\) are possible; and afterwards, when queries to both \(\pi _{0}\) and \(\pi _{1}\) are possible.
-
Simulating answers to \(\pi _{0} = (w_{\circ } \Vert v_{\circ } \Vert w_{\bullet } \Vert v_{\bullet })\) , before \(\tilde{V}\) outputs \(\tilde{\rho } = (\tilde{\rho }_{\circ },\tilde{\rho }_{\bullet })\) .
-
1.
For a query \(j\in [\ell _{\circ }]\) to \(w_{\circ }[j]\): if unspecified, answer with a random field element. That is, if \({w}^{S}_{\circ }[j]=*\), then sample a random \(\beta \in f_{1}\) and set \({w}^{S}_{\circ } :=\beta \).
-
2.
For a query \(j\in [\ell _{\circ }]\) to \(v_{\circ }[j]\): if unspecified, answer with a random field element. That is, if \({v}^{S}_{\circ }[j]=*\), then sample a random \(\gamma \in f_{1}\) and set \({v}^{S}_{\circ }[j] = \gamma \). Then check if there are any unspecified locations of \({v}^{S}_{\circ }\) that are determined by the linear constraint “\({v}^{S}_{\circ } \in C_{\circ }\)” and the currently specified locations of \({v}^{S}_{\circ }\); if there are, set these accordingly.
-
3.
For a query \(j \in [\ell _{\bullet }]\) to \(w_{\bullet }[j]\): if unspecified, (i) compute the set \(I_{j} \subseteq [\ell _{\circ }]\) of locations on which \(g({w}^{S}_{\circ })[j]\) depends (see Definition 2); (ii) deduce \({w}^{S}_{\circ }|_{I_{j}}\) by querying each \(i \in I_{j}\) according to Step 1; and (iii) set \({w}^{S}_{\bullet }[j] :=g({w}^{S}_{\circ }|_{I_{j}})\).
-
4.
For a query \(j \in [\ell _{\bullet }]\) to \(v_{\bullet }[j]\): answer in an analogous way to the case of a query \(j\in [\ell _{\circ }]\) to \(v_{\circ }\).
-
1.
-
Simulating answers to \(\pi _{0} = (w_{\circ } \Vert v_{\circ } \Vert w_{\bullet } \Vert v_{\bullet })\) and \(\pi _{1} = (z_{\circ } \Vert z_{\bullet } \Vert \pi _{\circ } \Vert \pi _{\bullet })\) , after \(\tilde{V}\) outputs \(\tilde{\rho } = (\tilde{\rho }_{\circ },\tilde{\rho }_{\bullet })\) .
-
5.
After receiving \(\tilde{\rho } = (\tilde{\rho }_{\circ },\tilde{\rho }_{\bullet })\), immediately do the following:
-
(a)
sample a random \({z}^{S}_{\circ } \in C_{\circ }\) under the constraint “\({z}^{S}_{\circ }[i] = \tilde{\rho }_{\circ } {w}^{S}_{\circ }[i] + {v}^{S}_{\circ }[i]\) for all i s.t. \({w}^{S}_{\circ }[i] \ne *\,\wedge \,{v}^{S}_{\circ }[i] \ne *\)”;
-
(b)
sample a random \({z}^{S}_{\bullet } \in C_{\bullet }\) under the analogous constraint;
-
(c)
compute \({\pi }^{S}_{\circ } :=P_{\circ }(C_{\circ },{z}^{S}_{\circ })\);
-
(d)
compute \({\pi }^{S}_{\bullet } :=P_{\bullet }(C_{\bullet },{z}^{S}_{\bullet })\).
-
(a)
-
6.
All queries to \(z_{\circ },z_{\bullet },\pi _{\circ },\pi _{\bullet }\) are answered according to the values specified in Step 5.
-
7.
For a query \(j\in [\ell _{\circ }]\) to \(w_{\circ }[j]\) or \(v_{\circ }[j]\): if both are unspecified, answer with a random field element; otherwise, the one that is unspecified is determined according to the constraint \({z}^{S}_{\circ }[i] = \tilde{\rho }_{\circ } {w}^{S}_{\circ }[i] + {v}^{S}_{\circ }[i]\) (except that, if \(\tilde{\rho }_{\circ } = 0\), then answer according to the constraint \({z}^{S}_{\circ }[i] = {v}^{S}_{\circ }[i]\) by setting \({w}^{S}[i]\) to be a random field element).
-
8.
For a query \(j \in [\ell _{\bullet }]\) to \(w_{\bullet }[j]\): answer analogously to Step 3, except that subqueries to \(w_{\circ }[j]\) follow Step 7.
-
9.
For a query \(j \in [\ell _{\bullet }]\) to \(v_{\bullet }[j]\): compute \({w}^{S}_{\bullet }[j]\) as in Step 8 and set \({v}^{S}_{\bullet }[j] :=\tilde{\rho }_{\bullet } {w}^{S}_{\bullet }[j] - {z}^{S}_{\bullet }[j]\).
-
5.
We claim that the above simulation achieves perfect zero-knowledge, that is,  is identically distributed to
is identically distributed to  . We show that the distribution of answers provided by the simulation to \(\tilde{V}\) is the same as the distribution of answers obtained by \(\tilde{V}\) from the oracles provided by the honest prover. First, we discuss the answers to queries asked before \(\tilde{V}\) sends \(\tilde{\rho } = (\tilde{\rho }_{\circ },\tilde{\rho }_{\bullet })\), which can only be to the oracle \(\pi _{0} = (w_{\circ } \Vert v_{\circ } \Vert w_{\bullet } \Vert v_{\bullet })\):
. We show that the distribution of answers provided by the simulation to \(\tilde{V}\) is the same as the distribution of answers obtained by \(\tilde{V}\) from the oracles provided by the honest prover. First, we discuss the answers to queries asked before \(\tilde{V}\) sends \(\tilde{\rho } = (\tilde{\rho }_{\circ },\tilde{\rho }_{\bullet })\), which can only be to the oracle \(\pi _{0} = (w_{\circ } \Vert v_{\circ } \Vert w_{\bullet } \Vert v_{\bullet })\):
-
(i)
In an honest proof, \(v_{\circ }\) and \(v_{\bullet }\) are random in \(C_{\circ }\) and \(C_{\bullet }\), respectively. The simulator answers a query to either of these by selecting a random field element and then propagating to other locations the linear constraints imposed by belonging to the linear code.
-
(ii)
In an honest proof, \(w_{\circ }\) is computed as \(w_{\circ } :=u'+ \alpha _{\circ }\), where \(u'\) is random in \(C'\). Any \(t\) values from a random codeword in \(C'\) are distributed identically to \(t\) random field elements, because \(C'\) is \(t\)-wise independent. The queries of \(\tilde{V}\) determine at most \(\mathsf {k}\cdot q= t\) locations of \(w_{\circ }\). Hence, in an honest proof, \(\tilde{V}\) gets uniformly random answers for its queries to \(w_{\circ }\); this matches the simulated view where \(S\) answers \(\tilde{V}\)’s queries to \(w_{\circ }\) with random fields elements.
-
(iii)
In an honest proof, \(w_{\bullet }\) is a deterministic function of \(w_{\circ }\): \(w_{\bullet } :=g(w_{\circ })\). As described above, the \(\le t\) positions of \(w_{\circ }\) determined by the verifier’s questions are uniformly random in the honest proof, as well as in the simulated proof. Therefore the honest and the simulated views of \(w_{\bullet }\) are identically distributed, as deterministic functions of identically distributed random variables.
Next, we discuss the answers to queries asked after \(\tilde{V}\) sends \(\tilde{\rho } = (\tilde{\rho }_{\circ },\tilde{\rho }_{\bullet })\); now \(\tilde{V}\) can query both \(\pi _{0} = (w_{\circ } \Vert v_{\circ } \Vert w_{\bullet } \Vert v_{\bullet })\) and \(\pi _{1} = (z_{\circ } \Vert z_{\bullet } \Vert \pi _{\circ } \Vert \pi _{\bullet })\).
In an honest proof, answers to verifiers queries after sending \(\tilde{\rho }\) are from an uniform distribution of \(v_{\circ } \in C_{\circ }, v_{\bullet } \in C_{\bullet }, u'\in C'\) (and deterministic functions of those and \(\alpha _{\circ }\)), that is further conditioned on the answers given before sending \(\tilde{\rho }\).
We conclude the discussion of the simulator by examining the time complexity of the simulation. Most steps of the simulation require (a) sampling a random field element and, possibly, (b) solving a linear system with a polynomial number of equations. The only expensive part of the simulation is Step 5, because it requires sampling random codewords in \(C_{\circ }\) and \(C_{\bullet }\), as well as computing PCPP proofs for these two codewords. Provided that \(r_{1}\) is polynomially bounded, the entire simulation also runs in polynomial time in the instance size \(n\). (The definition of zero knowledge in Sect. 3 prescribes, as typically done, a simulator that runs in expected probabilistic polynomial time; our simulator runs in strict probabilistic polynomial time.)
7 From NTIME to Randomizable Linear Algebraic CSPs
-
\( \underline{\mathscr {R}_{\mathsf {AP}}\, \& \,\mathscr {R}_{\mathsf {GAP}}.}\) In Sect. 7.1, we define algebraic problems, implicit in several influential works on PCPs and IP [2, 4, 5, 30] and explicitly defined in [22, 34, 37]. Afterward, we define group-preserving algebraic problems, a new “symmetric” variant of algebraic problems that not only are powerful enough to efficiently capture \(\mathbf {NTIME}\) but are also naturally “randomizable”, as discussed below.
-
\(\underline{\mathscr {R}_{\mathsf {AP}}\rightarrow \mathscr {R}_{\mathsf {LA}}.}\) In Sect. 7.2 (see Lemma 2), we show that algebraic problems are a sublanguage of linear algebraic CSPs. This observation shows that the techniques of this paper could potentially be applied to many PCP systems (e.g., those in [2, 4, 5, 11, 13–16, 22, 30, 37] to name a few) and also provides a “warm up” for the next item.
-
\(\underline{\mathscr {R}_{\mathsf {GAP}}\rightarrow \mathscr {R}_{\mathsf {RLA}}.}\) In Sect. 7.3 (see Lemma 3), we show an efficient reduction from group-preserving algebraic problems to randomizable linear algebraic CSPs. In other words, the property of group preservation allows the corresponding linear algebraic CSPs to be randomizable.
-
\(\underline{\mathbf {NTIME}\rightarrow \mathscr {R}_{\mathsf {GAP}}.}\) In Sect. 7.4 (see Lemma 4), we show an efficient reduction from \(\mathbf {NTIME}\) to group-preserving algebraic problems.
-
\(\underline{\mathbf {NTIME}\rightarrow \mathscr {R}_{\mathsf {RLA}}.}\) In Sect. 7.5 (see Theorem 6), we explain how to combine the above to obtain the efficient reduction from \(\mathbf {NTIME}\) to randomizable linear algebraic CSPs.
7.1 Algebraic Problems and Group Preservation
The definition below of algebraic problems is essentially due to [34] (though the term “algebraic problem” is from [22]); variants of it appear in later works such as [10, 14–16, 22, 36, 37].
Definition 6
( \(\mathscr {R}_{\mathsf {AP}}\) ). Given functions \(F:\mathbb {N}\rightarrow \mathscr {F}\), and \(h,m,\eta ,d,\sigma :\mathbb {N}\rightarrow \mathbb {N}\), the relation
consists of instance-witness pairs  satisfying the following.
satisfying the following.
-
The instance
 is a tuple \((1^{n},H,Q,\mathbf {N})\) where:
is a tuple \((1^{n},H,Q,\mathbf {N})\) where:-
\(H\) is a subset of \(F(n)\) with cardinality \(h(n)\);
-
\(Q\) is a polynomial in \(F(n)[X_{1},\dots ,X_{m(n)},Y_{1},\dots ,Y_{\eta (n)}]\) such that (i) it has degree less than \(h(n)\) in each variable \(X_{i}\), (ii) it has total degree at most \(d(n)\) when viewed as a polynomial in the variables \(Y_{1},\dots ,Y_{\eta (n)}\) with coefficients in \(F(n)[X_{1},\dots ,X_{m(n)}]\), (iii) it can be evaluated by an arithmetic circuit of size \(\sigma (n)\);
-
\(\mathbf {N}= (N_{1},\dots ,N_{\eta (n)})\) and each \(N_{i} :F(n)^{m(n)} \rightarrow F(n)^{m(n)}\) is an invertible affine function.
-
-
The witness
 is a polynomial \(A\) in \(F(n)[X_{1},\dots ,X_{m(n)}]\).
is a polynomial \(A\) in \(F(n)[X_{1},\dots ,X_{m(n)}]\). -
The instance
 and witness
and witness  jointly satisfy the following: $$\begin{aligned} \text {for every } \alpha \in H^{m(n)}, (Q\circ A\circ \mathbf {N})(\alpha )=0 \end{aligned}$$(1)
jointly satisfy the following: $$\begin{aligned} \text {for every } \alpha \in H^{m(n)}, (Q\circ A\circ \mathbf {N})(\alpha )=0 \end{aligned}$$(1)where
$$\begin{aligned} (Q\circ A\circ \mathbf {N})(X) :=Q( X_{1},\dots ,X_{m(n)}, A(N_{1}(X_{1},\dots ,X_{m(n)})), \dots , A(N_{\eta (n)}(X_{1},\dots ,X_{m(n)})) ). \end{aligned}$$(2)
 is a tuple
is a tuple  is a polynomial
is a polynomial  and witness
and witness  jointly satisfy the following:
jointly satisfy the following: Next, we define group-preserving algebraic problems, a family of algebraic problems in which the set \(H\) is a subgroup of \(F(n)\) and the neighbor functions act on the product group \(H^{m(n)}\). The additional symmetry enables a reduction to randomizable linear algebraic CSPs, which give rise to zero knowledge duplex PCPs. We believe that group-preserving algebraic problems may find applications in the study of PCPs beyond their use in this paper.
Definition 7
(
\(\mathscr {R}_{\mathsf {GAP}}\)
). The relation \(\mathscr {R}_{\mathsf {GAP}}[F,h,m,\eta ,d,\sigma ]\) is the sub-relation of \(\mathscr {R}_{\mathsf {AP}}[F,h,m,\eta ,d,\sigma ]\) obtained via restriction to instances that are group preserving. An instance  is group preserving if: (i) \(H\) is an additive or a multiplicative subgroup of \(F(n)\); (ii) each \(N_{i} :F(n)^{m(n)} \rightarrow F(n)^{m(n)}\) in \(\mathbf {N}\) can be identified with an element \(\chi _{i}\) in \(H^{m(n)}\) such that \(N_{i}(x)= \chi _{i} \odot x\), where \(\odot \) denotes the group operation of the product group \(H^{m(n)}\).
is group preserving if: (i) \(H\) is an additive or a multiplicative subgroup of \(F(n)\); (ii) each \(N_{i} :F(n)^{m(n)} \rightarrow F(n)^{m(n)}\) in \(\mathbf {N}\) can be identified with an element \(\chi _{i}\) in \(H^{m(n)}\) such that \(N_{i}(x)= \chi _{i} \odot x\), where \(\odot \) denotes the group operation of the product group \(H^{m(n)}\).
We also write \(\mathscr {R}_{\mathsf {GAP}}[F,h,m,\eta ,d,\sigma ,+]\) to denote the further restriction to instances that are additively group preserving (i.e., \(H\) is an additive subgroup); similarly, we write \(\mathscr {R}_{\mathsf {GAP}}[F,h,m,\eta ,d,\sigma ,\times ]\) to denote the restriction to instances that are multiplicatively group preserving.
-
The degree of
 , denoted
, denoted  , is \(\deg _{Y_{1},\dots ,Y_{\eta (n)}}(Q)\), i.e., the total degree of \(Q\) viewed as a polynomial in the variables \(Y_{1},\dots ,Y_{\eta (n)}\) with coefficients in the ring \(\mathbb {F}[X_{1},\dots ,X_{m(n)}]\).
, is \(\deg _{Y_{1},\dots ,Y_{\eta (n)}}(Q)\), i.e., the total degree of \(Q\) viewed as a polynomial in the variables \(Y_{1},\dots ,Y_{\eta (n)}\) with coefficients in the ring \(\mathbb {F}[X_{1},\dots ,X_{m(n)}]\). -
The circuit size of
 , denoted
, denoted  , is the circuit size of \(Q\).
, is the circuit size of \(Q\).
 , denoted
, denoted  , is
, is  , denoted
, denoted  , is the circuit size of
, is the circuit size of 7.2 Algebraic Problems Naturally Reduce to Linear Algebraic CSPs
Lemma 2
( \(\mathscr {R}_{\mathsf {AP}}\rightarrow \mathscr {R}_{\mathsf {LA}}\) ). For every \(F:\mathbb {N}\rightarrow \mathscr {F}\), \(h,m,\eta ,d,\sigma :\mathbb {N}\rightarrow \mathbb {N}\), \(\epsilon :\mathbb {N}\rightarrow (0,1)\), and \(\mathscr {R}\subseteq \mathscr {R}_{\mathsf {AP}}[F,h,m,\eta ,d,\sigma ]\) there exist a relation \(\mathscr {R}'\) and algorithms \(\mathsf {inst},\mathsf {wit}_{1},\mathsf {wit}_{2}\) satisfying the following conditions:
-
Efficient reduction. For every instance
 , letting
, letting  :
:-
for every witness
 , if
, if  then
then  ;
; -
for every witness
 , if
, if  then
then  .
.
Moreover, \(\mathsf {inst}\) runs in time
 , \(\mathsf {wit}_{1}\) in time
, \(\mathsf {wit}_{1}\) in time  , and \(\mathsf {wit}_{2}\) in time
, and \(\mathsf {wit}_{2}\) in time 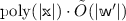 .
. -
-
Linear algebraic CSP. The relation \(\mathscr {R}'\) is a subset of
$$\begin{aligned} \mathscr {R}_{\mathsf {LA}}\left[ \begin{array}{lll} f&{}=&{} F\\ \ell &{}=&{} |F|^{m} \\ \rho &{}=&{} (\frac{hd}{|F|})^{m} \\ \delta &{}=&{} 1-\frac{hd}{|F|} \\ q&{}=&{} \eta \\ c&{}=&{} \sigma + \eta \\ \gamma &{}=&{} \eta \epsilon \\ \epsilon &{} &{} \end{array} \right] . \end{aligned}$$ -
RM codes. If
 then
then  with
with-
\(C_{\circ } = \mathsf {RM}\left[ F(n), F(n), m(n), \frac{h(n)}{|F(n)|} \right] \);
-
\(C_{\bullet } = \mathsf {VRM}\left[ F(n), F(n), m(n), \frac{h(n) d(n)}{|F(n)|}, H\right] \);
-
\(g\) is the function that maps \(F(n)[X_{1},\dots ,X_{m(n)}]\) to \(F(n)^{F(n)^{m(n)}}\) as follows: given \(A\) in \(F(n)[X_{1},\dots ,X_{m(n)}]\) and \(\omega \in F(n)^{m(n)}\), the \(\omega \)-th coordinate of \(g(A)\) equals to \((Q\circ A\circ \mathbf {N})(\omega )\).
-
 , letting
, letting  :
: , if
, if  then
then  ;
; , if
, if  then
then  .
. ,
,  , and
, and 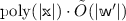 .
. then
then  with
withProof
(Proof of Lemma 2
). Let  be an instance of \(\mathscr {R}_{\mathsf {AP}}[F,h,m,\eta ,d,\sigma ]\), and construct
be an instance of \(\mathscr {R}_{\mathsf {AP}}[F,h,m,\eta ,d,\sigma ]\), and construct  as above. We first argue that
as above. We first argue that  is an instance of \(\mathscr {R}_{\mathsf {LA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ]\).
is an instance of \(\mathscr {R}_{\mathsf {LA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ]\).
First, \(C_{\circ }\) and \(C_{\bullet }\) are linear error correcting codes with block length at most \(\ell :=|F|^{m}\), rate at most \(\rho :=\max \{(\frac{h}{|F|})^{m},(\frac{hd}{|F|})^{m}\}\), and relative distance at least \(\delta :=\min \{1-\frac{h}{|F|},1-\frac{hd}{|F|}\}\) over the same field \(F\). (See Sect. 2.4.)
By construction, the function \(g\) is \(q\)-local with \(q:=\eta \) and \(c\)-efficient with \(c:=\sigma +\eta \); moreover, \(g\) is \((\gamma ,\epsilon )\)-sampling with \(\gamma :=\eta \epsilon \), as we now explain. (See Definition 1 for definitions of these properties.) For every \(\omega \in F^{m}\), \(I_{\omega }\) denotes the set of indices in \(F^{m}\) that \(g(\cdot )[\omega ]\) depends on; for the \(g\) above, \(I_{\omega }\) equals \(\{N_{1}(\omega ), \dots , N_{\eta }(\omega )\}\). For every \(\omega '\in F^{m}\) and \(\omega \in F^{m}\), if \(\omega '\in I_{\omega }\) then \(\omega \in \{N^{-1}_{1}(\omega '), \dots , N^{-1}_{\eta }(\omega ')\}\). Hence, the number of \(\omega \)’s with \(\omega '\in I_{\omega }\) is at most \(\eta \), because each \(N_{i}\) is invertible. We deduce that \(\Pr [\,I_{\omega } \cap I\ne \emptyset \,|\, \omega \leftarrow F^{m}\,] \le \left( \eta \cdot |I| \right) / |F|^{m} \le \eta \epsilon \).
Finally, \(C_{\bullet } \cup g(C_{\circ })\) has relative distance at least \(\delta \) because it is a subset of \(\mathsf {RM}[F,F,m,\frac{hd}{|F|}]\). This claim is immediate for \(C_{\bullet }\); for \(g(C_{\circ })\), it follows from the fact that \(Q\circ A\circ \mathbf {N}\) has, in each variable, a degree that is at most a multiplicative factor of \(d\) larger than the degree of \(A\).
We conclude the proof by explaining how one obtains the two witness maps \(\mathsf {wit}_{1},\mathsf {wit}_{2}\). For \(\mathsf {wit}_{1}\), suppose that  is a witness for
is a witness for  ; then one can verify that
; then one can verify that  , where \(\alpha _{\circ } :=A\) and \(\alpha _{\bullet } :=Q\circ A\circ \mathbf {N}\), is a witness for
, where \(\alpha _{\circ } :=A\) and \(\alpha _{\bullet } :=Q\circ A\circ \mathbf {N}\), is a witness for  ; \(\alpha _{\bullet }\) can be efficiently obtained by first computing the evaluation of \(A\) on \(F^{m}\) (via an FFT), then computing the evaluation of \(Q\circ A\circ \mathbf {N}\) on \(F^{m}\) (via point-to-point computation), and finally interpolating (via an inverse FFT). Conversely, for \(\mathsf {wit}_{2}\), suppose that
; \(\alpha _{\bullet }\) can be efficiently obtained by first computing the evaluation of \(A\) on \(F^{m}\) (via an FFT), then computing the evaluation of \(Q\circ A\circ \mathbf {N}\) on \(F^{m}\) (via point-to-point computation), and finally interpolating (via an inverse FFT). Conversely, for \(\mathsf {wit}_{2}\), suppose that  is a witness for
is a witness for  ; then one can verify that
; then one can verify that  is a witness for
is a witness for  .
.
7.3 From Group-Preserving Algebraic Problems to Randomizable Linear Algebraic CSPs
Lemma 3
( \(\mathscr {R}_{\mathsf {GAP}}\rightarrow \mathscr {R}_{\mathsf {RLA}}\) ). For every \(F:\mathbb {N}\rightarrow \mathscr {F}\), \(h,m,\eta ,d,\sigma ,t:\mathbb {N}\rightarrow \mathbb {N}\), \(\delta ,\epsilon :\mathbb {N}\rightarrow (0,1)\) with \(|F| \ge \hat{h}\), where \(\hat{h}\) denotes the smallest integral multiple of \(h\) that is greater than \(\frac{(h+t)d}{1-\delta }\), and for any \(\mathscr {R}\subseteq \mathscr {R}_{\mathsf {GAP}}[F,h,m,\eta ,d,\sigma ]\) there exist a relation \(\mathscr {R}'\) and algorithms \(\mathsf {inst},\mathsf {wit}_{1},\mathsf {wit}_{2}\) satisfying the following conditions:
-
Efficient reduction. For every instance
 , letting
, letting  :
:-
for every witness
 , if
, if  then
then  ;
; -
for every witness
 , if
, if  then
then  .
.
Moreover, \(\mathsf {inst}\) runs in time
 , \(\mathsf {wit}_{1}\) in time
, \(\mathsf {wit}_{1}\) in time  , and \(\mathsf {wit}_{2}\) in time
, and \(\mathsf {wit}_{2}\) in time  .
. -
-
Randomizable linear algebraic CSP. The relation \(\mathscr {R}'\) is a subset of
$$\begin{aligned} \mathscr {R}_{\mathsf {RLA}}\left[ \begin{array}{lll} f&{}=&{} F\\ \ell &{}=&{} \hat{h}^{m} \\ \rho &{}=&{} (\frac{(h+t)d}{\hat{h}})^{m} \\ \delta &{}=&{} 1-(\frac{(h+t)d}{\hat{h}}) \\ q&{}=&{} \eta \\ c&{}=&{} \sigma + \eta \\ \gamma &{}=&{} \eta \epsilon \\ \epsilon &{} &{} \\ t&{} &{} \\ r&{}=&{} \tilde{O}(\hat{h}^{m}) \end{array} \right] . \end{aligned}$$
 , letting
, letting  :
: , if
, if  then
then  ;
; , if
, if  then
then  .
. ,
,  , and
, and  .
.Proof
(Proof of Lemma 3
). Let  be an instance of \(\mathscr {R}_{\mathsf {GAP}}[F,h,m,\eta ,d,\sigma ]\). We construct an instance
be an instance of \(\mathscr {R}_{\mathsf {GAP}}[F,h,m,\eta ,d,\sigma ]\). We construct an instance  of \(\mathscr {R}_{\mathsf {RLA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ,t,r]\) as follows.
of \(\mathscr {R}_{\mathsf {RLA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ,t,r]\) as follows.
Let \(\hat{H}\) be a subset of \(F\) that is a union of cosets of \(H\) with \(|\hat{H}| = \hat{h}\) and \(\hat{H}\cap H= \emptyset \). (This can be done as follows: let S be a subset of the quotient group \(F^{\odot }/H\) with cardinality \(|S| = \hat{h}/h\) that does not include \(1_{\odot }\), where \(F^{\odot }\) denotes the additive or multiplicative group of \(F\), depending on whether \(H\) is additive or multiplicative, and \(1_{\odot }\) is the identity in \(H\); then set \(\hat{H}:=\{x \odot y \,|\, x \in S, y \in H\}\).) Analogously to the proof of Lemma 2, we define:
-
\(C_{\circ } :=\mathsf {RM}\left[ F(n),\hat{H},m(n),\frac{h(n)+t(n)}{\hat{h}(n)}\right] \);
-
\(C_{\bullet } :=\mathsf {VRM}\left[ F(n),\hat{H},m(n),\frac{(h(n)+t(n))d(n)}{\hat{h}(n)},H\right] \);
-
\(g\) to be the function that maps \(F(n)[X_{1},\dots ,X_{m(n)}]\) to \(F(n)^{\hat{H}^{m(n)}}\) as follows: given \(A\) in \(F(n)[X_{1},\dots ,X_{m(n)}]\) and \(\omega \in \hat{H}^{m(n)}\), the \(\omega \)-th coordinate of \(g(A)\) equals to \((Q\circ A\circ \mathbf {N})(\omega )\). Note that \(g\) is well-defined, i.e., \(g(A)\) is a function from \(\hat{H}^{m(n)}\) to \(F(n)\); this follows from the group preservation property of
 (see Definition 7): for every \(\omega \in \hat{H}^m\) and \(i \in [\eta ]\), it holds that \(N_{i}(\omega ) \subseteq \hat{H}^m\) because \(\hat{H}\) is a union of cosets of \(H\) and \(N_{i}\) multiplies every coordinate of \(\omega \) by an element of \(H\).
(see Definition 7): for every \(\omega \in \hat{H}^m\) and \(i \in [\eta ]\), it holds that \(N_{i}(\omega ) \subseteq \hat{H}^m\) because \(\hat{H}\) is a union of cosets of \(H\) and \(N_{i}\) multiplies every coordinate of \(\omega \) by an element of \(H\).
 (see Definition
(see Definition We first argue that  constructed above is an instance of \(\mathscr {R}_{\mathsf {RLA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ,t,r]\).
constructed above is an instance of \(\mathscr {R}_{\mathsf {RLA}}[f,\ell ,\rho ,\delta ,q,c,\gamma ,\epsilon ,t,r]\).
First, analogously to the proof of Lemma 2, we note that \(C_{\circ }\) and \(C_{\bullet }\) are linear error correcting codes with block length at most \(\ell :=\hat{h}^{m}\), rate at most \(\rho :=\max \{(\frac{h+t}{\hat{h}})^{m},(\frac{(h+t)d}{\hat{h}})^{m}\}\), and relative distance at least \(\delta :=\min \{1-\frac{h+t}{\hat{h}},1-\frac{(h+t)d}{\hat{h}}\}\) over the same field \(F\); also, we deduce that \(g\) is \(q\)-local with \(q:=\eta \), \(c\)-efficient with \(c:=\sigma +\eta \), and \((\gamma , \epsilon )\)-sampling with \(\gamma :=\eta \epsilon \).
Next, recalling Definition 5,  is \(t\)-randomizable in time \(r:=\tilde{O}(\hat{h}^{m})\) because: (i) \(C':=\mathsf {VRM}[F(n),\hat{H},m, \frac{h+t}{\hat{h}},H]\) is a subcode of \(C_{\circ }\) and it is \(t\)-wise independent due to Claim in Sect. 2.4 (\(C'\) satisfies the hypotheses because \(H\cap \hat{H}= \emptyset \) and \(\hat{h}-h\ge \frac{(h+t)d}{1-\delta } -h\ge t\)); and (ii) one can sample random elements from \(C'\), \(C_{\circ }\) and \(C_{\bullet }\) in time \(\tilde{O}(\hat{h}^{m})\) by using the quasilinear FFT algorithms for multipoint evaluation and interpolation (sampling the random polynomial in necessary basis is easy for \(C_{\circ }\); for vanishing Reed–Muller codes we rely on Alon’s Combinatorial Nullstelensatz [1] as per Lemma 4.11 of [15]).
is \(t\)-randomizable in time \(r:=\tilde{O}(\hat{h}^{m})\) because: (i) \(C':=\mathsf {VRM}[F(n),\hat{H},m, \frac{h+t}{\hat{h}},H]\) is a subcode of \(C_{\circ }\) and it is \(t\)-wise independent due to Claim in Sect. 2.4 (\(C'\) satisfies the hypotheses because \(H\cap \hat{H}= \emptyset \) and \(\hat{h}-h\ge \frac{(h+t)d}{1-\delta } -h\ge t\)); and (ii) one can sample random elements from \(C'\), \(C_{\circ }\) and \(C_{\bullet }\) in time \(\tilde{O}(\hat{h}^{m})\) by using the quasilinear FFT algorithms for multipoint evaluation and interpolation (sampling the random polynomial in necessary basis is easy for \(C_{\circ }\); for vanishing Reed–Muller codes we rely on Alon’s Combinatorial Nullstelensatz [1] as per Lemma 4.11 of [15]).
We conclude the proof by observing that necessary witness maps \(\mathsf {wit}_{1},\mathsf {wit}_{2}\) exist. Just as in Lemma 2, if  is a witness for
is a witness for  then
then  outputs
outputs  , which is a witness for
, which is a witness for  ; conversely, if
; conversely, if  is a witness for
is a witness for  then
then  outputs
outputs  , which is a witness for
, which is a witness for  .
.
7.4 An Efficient Reduction from \(\mathbf {NTIME}\) to Group-Preserving Algebraic Problems
The following lemma gives an efficient reduction from \(\mathbf {NTIME}\) to group-preserving algebraic problems in which instances are over fields of characteristic 2 and preserve additive groups.
Lemma 4
( \(\mathbf {NTIME}\rightarrow \mathscr {R}_{\mathsf {GAP}}\) ). For every \(h,m,T:\mathbb {N}\rightarrow \mathbb {N}\) with \(h(n)^{m(n)} = \varOmega (T(n) \log T(n))\) and \(\mathscr {R}\in \mathbf {NTIME}(T)\) there exist a relation \(\mathscr {R}'\) and algorithms \(\mathsf {inst},\mathsf {wit}_{1},\mathsf {wit}_{2}\) satisfying the following conditions:
-
Efficient reduction. For every instance
 , letting
, letting  :
:-
for every witness
 , if
, if  then
then  ;
; -
for every witness
 then
then  .
.
Moreover, \(\mathsf {inst}\) runs in time \(\mathrm {poly}(n+ \log h(n) + m(n))\) and \(\mathsf {wit}_{1},\mathsf {wit}_{2}\) run in time \(\tilde{O}(T(n))\).
-
-
Group preserving algebraic problem. The relation \(\mathscr {R}'\) is a subset of
$$\begin{aligned} \mathscr {R}_{\mathsf {GAP}}\left[ \begin{array}{lll} F&{}=&{} \mathbb {F}_{2^{\log T+ O(\log \log T)}} \\ h&{} &{} \\ m&{} &{} \\ \eta &{}=&{} \mathrm {polylog}(T) \\ d&{}=&{} O(1) \\ \sigma &{}=&{} \mathrm {poly}(n+ \log T) \\ + \end{array} \right] . \end{aligned}$$
 , letting
, letting  :
: , if
, if  then
then  ;
; then
then  .
.The proof appears in the full version.
7.5 Combining the Two Reductions
By combining Lemmas 3 and 4, we obtain the following theorem, which gives the reduction claimed at the beginning of this section.
Theorem 6
( \(\mathbf {NTIME}\rightarrow \mathscr {R}_{\mathsf {RLA}}\) ). For every \(T,t:\mathbb {N}\rightarrow \mathbb {N}\), \(\delta ,\epsilon :\mathbb {N}\rightarrow (0,1)\), and \(\mathscr {R}\in \mathbf {NTIME}(T)\) there exist a relation \(\mathscr {R}'\) and algorithms \(\mathsf {inst},\mathsf {wit}_{1},\mathsf {wit}_{2}\) satisfying the following conditions:
-
Efficient reduction. For every instance
 , letting
, letting  :
:-
for every witness
 , if
, if  then
then  ;
; -
for every witness
 , if
, if  then
then  .
.
Moreover, \(\mathsf {inst}\) runs in time \(\mathrm {poly}(n+ \log (\frac{T(n)+t(n)}{1-\delta (n)}))\) and \(\mathsf {wit}_{1},\mathsf {wit}_{2}\) run in time \(\mathrm {poly}(n) \cdot \tilde{O}(\frac{T(n)+t(n)}{1-\delta (n)})\).
-
-
Randomizable linear algebraic CSP. The relation \(\mathscr {R}'\) is a subset of
$$\begin{aligned} \mathscr {R}_{\mathsf {RLA}}\left[ \begin{array}{lll} f&{}=&{} \mathbb {F}_{2^{\log (T+t)+O(\log \log (T+t))}} \\ \ell &{}=&{} \tilde{O}(\frac{T+t}{1-\delta }) \\ \rho &{}=&{} 1-\delta \\ \delta &{} &{} \\ q&{}=&{} \mathrm {polylog}(T) \\ c&{}=&{} \mathrm {poly}(n+ \log T) \\ \gamma &{}=&{} \mathrm {polylog}(T) \cdot \epsilon \\ \epsilon &{} &{} \\ t&{} &{} \\ r&{}=&{} \tilde{O}(\frac{T+t}{1-\delta }) \\ \end{array} \right] . \end{aligned}$$ -
Affine RS codes over characteristic 2. Both \(\mathscr {C}_{\mathscr {R}',\circ }\) and \(\mathscr {C}_{\mathscr {R}',\bullet }\) are subsets of \(\mathcal {RS}^{*}_{\rho } \cup \mathcal {VRS}^{*}_{\rho }\) (see Sect. 2.4).
 , letting
, letting  :
: , if
, if  then
then  ;
; , if
, if  then
then  .
.Proof
(Proof of Theorem 6
). First, we invoke Lemma 4 with \(h,m,T\) such that \(m(n)=1\) and \(h(n) = O(T(n) \log T(n))\); this yields a relation \(\mathscr {R}^{(1)}\) and algorithms \(\mathsf {inst}^{(1)},\mathsf {wit}_{1}^{(1)},\mathsf {wit}_{2}^{(1)}\) such that: (i) \(\mathsf {inst}^{(1)},\mathsf {wit}_{1}^{(1)},\mathsf {wit}_{2}^{(1)}\) provide a reduction from \(\mathscr {R}\in \mathbf {NTIME}(T)\) to \(\mathscr {R}^{(1)}\), with  running in time \(\mathrm {poly}(n+ \log h(n) + m(n))\) and
running in time \(\mathrm {poly}(n+ \log h(n) + m(n))\) and  in time \(\tilde{O}(T(n))\); and (ii) \(\mathscr {R}^{(1)}\) is a subset of
in time \(\tilde{O}(T(n))\); and (ii) \(\mathscr {R}^{(1)}\) is a subset of
Next, we invoke Lemma 3 on \(\mathscr {R}^{(1)}\), using \(\delta ,\epsilon ,t\) from the theorem statement. Note that the conditions of the theorem are satisfied as \(|F| \ge \frac{(h+t)d}{1-\delta } + h\ge \hat{h}\). Therefore this yields a relation \(\mathscr {R}^{(2)}\) and algorithms \(\mathsf {inst}^{(2)},\mathsf {wit}_{1}^{(2)},\mathsf {wit}_{2}^{(2)}\) such that: (i) \(\mathsf {inst}^{(2)},\mathsf {wit}_{1}^{(2)},\mathsf {wit}_{2}^{(2)}\) provide a reduction from \(\mathscr {R}^{(1)}\) to \(\mathscr {R}^{(2)}\), with  running in time
running in time  ,
,  in time
in time  and
and  in time
in time  ; and (ii) \(\mathscr {R}^{(2)}\) is a subset of
; and (ii) \(\mathscr {R}^{(2)}\) is a subset of
One can check that \(\mathscr {R}^{(2)}\) achieves the parameters specified in the theorem statement.
The desired reduction from \(\mathscr {R}\) to \(\mathscr {R}^{(2)}\) is given by the algorithms  ,
,  , and
, and  . One can verify that \(\mathsf {inst}\) runs in time \(\mathrm {poly}(n+ \log (\frac{T(n)+t(n)}{1-\delta (n)}))\) and \(\mathsf {wit}_{1},\mathsf {wit}_{2}\) run in time \(\mathrm {poly}(n) \cdot \tilde{O}(\frac{T(n)+t(n)}{1-\delta (n)})\).
. One can verify that \(\mathsf {inst}\) runs in time \(\mathrm {poly}(n+ \log (\frac{T(n)+t(n)}{1-\delta (n)}))\) and \(\mathsf {wit}_{1},\mathsf {wit}_{2}\) run in time \(\mathrm {poly}(n) \cdot \tilde{O}(\frac{T(n)+t(n)}{1-\delta (n)})\).
8 Proof of Theorem 4
Proof
(Proof of Theorem 4 ). We explain how to combine Theorem 6 and Lemma 5 (and Theorem 3) so to obtain Theorem 4.
Let \(\mathscr {R}\) be a relation in \(\mathbf {NTIME}(T)\); we need to construct a duplex PCP system for \(\mathscr {R}\) with the claimed parameters. For now we focus on achieving soundness of \(\frac{1}{2}\), and discuss the general case at the end of the proof.
We first reduce \(\mathbf {NTIME}\) to randomizable linear algebraic CSPs: invoke Theorem 6 on \(\mathscr {R}\) to obtain a relation \(\mathscr {R}'\) and algorithms \(\mathsf {inst},\mathsf {wit}_{1},\mathsf {wit}_{2}\) such that: (i) \(\mathsf {inst},\mathsf {wit}_{1},\mathsf {wit}_{2}\) provide a reduction from \(\mathscr {R}\) to \(\mathscr {R}'\), with \(\mathsf {inst}\) running in time \(\mathrm {poly}(n+ \log (T(n)+t_{1}(n)))\) and \(\mathsf {wit}_{1},\mathsf {wit}_{2}\) in time \(\tilde{O}(T(n)+t_{1}(n))\); and (ii) \(\mathscr {R}'\) is a subset of
Above, as parameters of Theorem 6, we chose \(\epsilon _{1}\), \(\delta _{1}\) and \(t_{1}\) as follows: \(\epsilon _{1}\) such that \(\gamma _{1} = \mathrm {polylog}(T) \cdot \epsilon _{1} \le \frac{2}{9}\), then \(\delta _{1} :=1 - \epsilon _{1}/4\), and \(t_{1} :=\mathsf {k}\cdot q_{1} = \mathsf {k}\cdot \mathrm {polylog}(T)\).
Next we obtain PCPP systems for the relations corresponding to codes appearing in instances of \(\mathscr {R}'\). Theorem 6 guarantees that both \(\mathscr {C}_{\mathscr {R}',\circ }\) and \(\mathscr {C}_{\mathscr {R}',\bullet }\) are subsets of \(\mathcal {RS}^{*}_{\rho }\cup \mathcal {VRS}^{*}_{\rho }\). We now invoke Theorem 3, choosing \(\lambda =2\) and s such that fields \(f_{1}\) for \(\mathscr {R}'\) and \(\mathsf {a}_{2}\) for the PCPPs match. That is, we chose \(s = \tilde{O}(\log \log (T+t_{1}))\) and obtain:
Finally we invoke Theorem 5 for \(\mathscr {R}'\) to obtain a duplex PCP system for \(\mathscr {R}'\), supplying the PCPPs we just obtained from Theorem 3. Note that our choices satisfy the hypothesis of Theorem 5 is satisfied, as the two fields match, \(r_{1}\) is polynomially bounded, and as we chose \(\gamma _{1}, \epsilon _{1} \le \frac{2}{9}\), \(\delta _{1} \ge \frac{17}{18}\), we also have \(\epsilon _{1} < \min \{\frac{\delta _{1}}{2},\delta _{1}-\gamma _{1}\}\) and \(\mathsf {d}_{2} \le \epsilon _{1}/4\). This establishes our claim that:
The precise expression for soundness error is \(\mathsf {e}:=\max \{1-\delta _{1}+\gamma _{1}+\epsilon _{1} \,,\,(1-|f_{1}|^{-1}) \cdot \max \{\mathsf {e}_{2}, \epsilon _{1}/4\} + |f_{1}|^{-1}\}\), but it is upper bounded by \(\frac{1}{2}\), as for us \(1-\delta _{1}+\gamma _{1}+\epsilon _{1} \le \frac{1}{2}\), \(\max \{\mathsf {e}_{2}, \epsilon _{1}/4\} = \frac{1}{4}\) and \(|f_{1}| \ge 4\).
References
Alon, N.: Combinatorial Nullstellensatz. Comb. Probab. Comput. 8, 7–29 (1999)
Arora, S., Lund, C., Motwani, R., Sudan, M., Szegedy, M.: Proof verification and the hardness of approximation problems. JACM 45, 501–555 (1998)
Arora, S., Safra, S.: Probabilistic checking of proofs: a new characterization of NP. JACM 45, 70–122 (1998)
Babai, L., Fortnow, L., Levin, L.A., Szegedy, M.: Checking computations in polylogarithmic time. In: STOC 1991 (1991)
Babai, L., Fortnow, L., Lund, C.: Non-deterministic exponential time has two-prover interactive protocols. Comput. Complex. 1, 3–40 (1991)
Babai, L., Moran, S.: Arthur-Merlin games: a randomized proof system, and a hierarchy of complexity class. J. Comput. Syst. Sci. 36, 254–276 (1988)
Bellare, M., Goldreich, O.: On defining proofs of knowledge. In: Brickell, E.F. (ed.) CRYPTO 1992. LNCS, vol. 740, pp. 390–420. Springer, Heidelberg (1993)
Ben-Or, M., Goldreich, O., Goldwasser, S., Håstad, J., Kilian, J., Micali, S., Rogaway, P.: Everything provable is provable in zero-knowledge. In: Goldwasser, S. (ed.) CRYPTO 1988. LNCS, vol. 403, pp. 37–56. Springer, Heidelberg (1990)
Ben-Or, M., Goldwasser, S., Kilian, J., Wigderson, A.: Multi-prover interactive proofs: how to remove intractability assumptions. In: STOC 1988 (1988)
Ben-Sasson, E., Chiesa, A., Genkin, D., Tromer, E.: Fast reductions from RAMs to delegatable succinct constraint satisfaction problems. In: ITCS 2013 (2013)
Ben-Sasson, E., Chiesa, A., Genkin, D., Tromer, E.: On the concrete efficiency of probabilistically-checkable proofs. In: STOC 2013 (2013)
Ben-Sasson, E., Goldreich, O., Harsha, P., Sudan, M., Vadhan, S.: Robust PCPs of proximity, shorter PCPs and applications to coding. In: STOC 2004 (2004)
Ben-Sasson, E., Goldreich, O., Harsha, P., Sudan, M., Vadhan, S.: Short PCPs verifiable in polylogarithmic time. In: CCC 2005 (2005)
Ben-Sasson, E., Goldreich, O., Harsha, P., Sudan, M., Vadhan, S.: Robust PCPs of proximity, shorter PCPs, and applications to coding. SIAM J. Comput. 36, 889–974 (2006)
Ben-Sasson, E., Sudan, M.: Short PCPs with polylog query complexity. SIAM J. Comput. 38, 551–607 (2008)
Ben-Sasson, E., Viola, E.: Short PCPs with projection queries. In: Esparza, J., Fraigniaud, P., Husfeldt, T., Koutsoupias, E. (eds.) ICALP 2014. LNCS, vol. 8572, pp. 163–173. Springer, Heidelberg (2014)
Dinur, I.: The PCP theorem by gap amplification. JACM 54, 12:1–12:44 (2007)
Dinur, I., Reingold, O.: Assignment testers: towards a combinatorial proof of the PCP theorem. In: FOCS 2004 (2004)
Dwork, C., Feige, U., Kilian, J., Naor, M., Safra, M.: Low communication 2-prover zero-knowledge proofs for NP. In: Brickell, E.F. (ed.) CRYPTO 1992. LNCS, vol. 740, pp. 215–227. Springer, Heidelberg (1993)
Goldwasser, S., Micali, S., Rackoff, C.: The knowledge complexity of interactive proof-systems. In: STOC 1985 (1985)
Goyal, V., Ishai, Y., Mahmoody, M., Sahai, A.: Interactive locking, zero-knowledge PCPs, and unconditional cryptography. In: Rabin, T. (ed.) CRYPTO 2010. LNCS, vol. 6223, pp. 173–190. Springer, Heidelberg (2010)
Harsha, P., Sudan, M.: Small PCPs with low query complexity. Comput. Complex. 9, 157–201 (2000)
Impagliazzo, R., Yung, M.: Direct minimum knowledge computations. In: Pomerance, C. (ed.) CRYPTO 1987. LNCS, vol. 293, pp. 40–51. Springer, Heidelberg (1988)
Ishai, Y., Kushilevitz, E., Ostrovsky, R., Sahai, A.: Zero-knowledge proofs from secure multiparty computation. SIAM J. Comput. 39, 1121–1152 (2009)
Ishai, Y., Mahmoody, M., Sahai, A.: On efficient zero-knowledge PCPs. In: Cramer, R. (ed.) TCC 2012. LNCS, vol. 7194, pp. 151–168. Springer, Heidelberg (2012)
Ishai, Y., Mahmoody, M., Sahai, A., Xiao, D.: On zero-knowledge PCPs: limitations, simplifications, and applications (2015). http://www.cs.virginia.edu/mohammad/files/papers/ZKPCPs-Full.pdf
Kalai, Y.T., Raz, R.: Interactive PCP. In: Aceto, L., Damgård, I., Goldberg, L.A., Halldórsson, M.M., Ingólfsdóttir, A., Walukiewicz, I. (eds.) ICALP 2008, Part II. LNCS, vol. 5126, pp. 536–547. Springer, Heidelberg (2008)
Kilian, J., Petrank, E., Tardos, G.: Probabilistically checkable proofs with zero knowledge. In: STOC 1997 (1997)
Lapidot, D., Shamir, A.: A one-round, two-prover, zero-knowledge protocol for NP. Combinatorica 15, 204–214 (1995)
Lund, C., Fortnow, L., Karloff, H., Noam, N.: Algebraic methods for interactive proof systems. JACM 39, 859–868 (1992)
Mahmoody, M., Xiao, D.: Languages with efficient zero-knowledge PCPs are in SZK. In: Sahai, A. (ed.) TCC 2013. LNCS, vol. 7785, pp. 297–314. Springer, Heidelberg (2013)
Mie, T.: Polylogarithmic two-round argument systems. J. Math. Cryptol. 2, 343–363 (2008)
Ostrovsky, R., Wigderson, A.: One-way functions are essential for non-trivial zero-knowledge. In: ISTCS 1993 (1993)
Polishchuk, A., Spielman, D.A.: Nearly-linear size holographic proofs. In: STOC 1994 (1994)
Shamir, A.: IP = PSPACE. JACM 39, 869–877 (1992)
Spielman, D.: Computationally efficient error-correcting codes and holographic proofs. Ph.D. thesis, Massachusetts Institute of Technology (1995)
Szegedy, M.: Many-valued logics and holographic proofs. In: Wiedermann, J., Van Emde Boas, P., Nielsen, M. (eds.) ICALP 1999. LNCS, vol. 1644, pp. 676–686. Springer, Heidelberg (1999)
Acknowledgments
We thank Yuval Ishai and Mor Weiss for helpful discussions. The research leading to these results has received funding from: the European Community’s Seventh Framework Programme (FP7/2007–2013) under grant agreement number 240258; the Israeli Science Foundation (grant 1501/14); and the Center for Science of Information (CSoI), an NSF Science and Technology Center, under grant agreement CCF-0939370.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 International Association for Cryptologic Research
About this paper
Cite this paper
Ben-Sasson, E., Chiesa, A., Gabizon, A., Virza, M. (2016). Quasi-Linear Size Zero Knowledge from Linear-Algebraic PCPs. In: Kushilevitz, E., Malkin, T. (eds) Theory of Cryptography. TCC 2016. Lecture Notes in Computer Science(), vol 9563. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-662-49099-0_2
Download citation
DOI: https://doi.org/10.1007/978-3-662-49099-0_2
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-662-49098-3
Online ISBN: 978-3-662-49099-0
eBook Packages: Computer ScienceComputer Science (R0)
