
Abstract
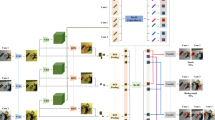
In this paper we introduce a new problem which we call object co-detection. Given a set of images with objects observed from two or multiple images, the goal of co-detection is to detect the objects, establish the identity of individual object instance, as well as estimate the viewpoint transformation of corresponding object instances. In designing a co-detector, we follow the intuition that an object has consistent appearance when observed from the same or different viewpoints. By modeling an object using state-of-the-art part-based representations such as [1,2], we measure appearance consistency between objects by comparing part appearance and geometry across images. This allows to effectively account for object self-occlusions and viewpoint transformations. Extensive experimental evaluation indicates that our co-detector obtains more accurate detection results than if objects were to be detected from each image individually. Moreover, we demonstrate the relevance of our co-detection scheme to other recognition problems such as single instance object recognition, wide-baseline matching, and image query.
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Felzenszwalb, P.F., Girshick, R.B., McAllester, D., Ramanan, D.: Object detection with discriminatively trained part-based models. TPAMI (2010)
Xiang, Y., Savarese, S.: Estimating the aspect layout of object categories. In: CVPR (2012)
Dalal, N., Triggs, B.: Histograms of oriented gradients for human detection. In: CVPR (2005)
Bao, S.Y., Savarese, S.: Semantic structure from motion. In: CVPR (2011)
Ess, A., Leibe, B., Gool, L.V.: Depth and appearance for mobile scene analysis. In: ICCV (2007)
Savarese, S., Fei-Fei, L.: 3d generic object categorization, localization and pose estimation. In: ICCV (2007)
Leibe, B., Leonardis, A., Schiele, B.: Combined object categorization and segmentation with an implicit shape model. In: Workshop on Statistical Learning in Computer Vision, ECCV (2004)
Su, H., Sun, M., Fei-Fei, L., Savarese, S.: Learning a dense multi-view representation for detection, viewpoint classification and synthesis of object categories. In: ICCV (2009)
Gu, C., Ren, X.: Discriminative Mixture-of-Templates for Viewpoint Classification. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010, Part V. LNCS, vol. 6315, pp. 408–421. Springer, Heidelberg (2010)
Lowe, D.G.: Object recognition from local scale-invariant features. In: ICCV (1999)
Ferrari, V., Tuytelaars, T., Gool, L.V.: Simultaneous object recognition and segmentation from single or multiple model views. IJCV (2006)
Rothganger, F., Lazebnik, S., Schmid, C., Ponce, J.: 3d object modeling and recognition using local affine-invariant image descriptors and multi-view spatial constraints. IJCV (2006)
Hsiao, E., Collet, A., Hebert, M.: Making specific features less discriminative to improve point-based 3d object recognition. In: CVPR (2010)
Rother, C., Kolmogorov, V., Minka, T., Blake, A.: Cosegmentation of image pairs by histogram matching. In: CVPR (2006)
Batra, D., Kowdle, A., Parikh, D., Luo, J., Chen, T.: icoseg: Interactive co-segmentation with intelligent scribble guidance. In: CVPR (2010)
Hochbaum, D., Singh, V.: An efficient algorithm for co-segmentation. In: ICCV (2009)
Wu, B., Nevatia, R.: Detection and tracking of multiple, partially occluded humans by bayesian combination of edgelet based part detectors. IJCV (2007)
Ess, A., Leibe, B., Schindler, K., van Gool, L.: A mobile vision system for robust multi-person tracking. In: CVPR (2008)
Choi, W., Savarese, S.: Multiple Target Tracking in World Coordinate with Single, Minimally Calibrated Camera. In: Daniilidis, K., Maragos, P., Paragios, N. (eds.) ECCV 2010, Part IV. LNCS, vol. 6314, pp. 553–567. Springer, Heidelberg (2010)
Bao, S.Y., Bagra, M., Chao, Y.-W., Savarese, S.: Semantic structure from motion with points, regions, and objects. In: CVPR (2012)
Zia, M.Z., Stark, M., Schiele, B., Schindler, K.: Revisiting 3d geometric models for accurate object shape and pose. In: ICCV Workshop on 3D Representation and Recognition (3dRR 2011) (2011)
Nister, D., Stewenius, H.: Scalable recognition with a vocabulary tree. In: CVPR (2006)
Berg, A., Berg, T., Malik, J.: Shape matching and object recognition using low distortion correspondences. In: CVPR (2005)
David, G.: Distinctive image features from scale-invariant keypoints. IJCV (2004)
Matas, J., Chum, O., Urban, M., Pajdla, T.: Robust wide-baseline stereo from maximally stable extremal regions. Image and Vision Computing (2004)
Toshev, A., Shi, J., Daniilidis, K.: Image matching via saliency region correspondences. In: CVPR (2007)
Lazebnik, S., Schmid, C., Ponce, J.: Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In: CVPR (2006)
Fei-Fei, L., Fergus, R., Torralba, A.: Recognizing and learning object categories. CVPR Short Course (2007)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2012 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Bao, S.Y., Xiang, Y., Savarese, S. (2012). Object Co-detection. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds) Computer Vision – ECCV 2012. ECCV 2012. Lecture Notes in Computer Science, vol 7572. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-33718-5_7
Download citation
DOI: https://doi.org/10.1007/978-3-642-33718-5_7
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-33717-8
Online ISBN: 978-3-642-33718-5
eBook Packages: Computer ScienceComputer Science (R0)