
Abstract
Convolutional neural network (CNN) depth is of crucial importance for image super-resolution (SR). However, we observe that deeper networks for image SR are more difficult to train. The low-resolution inputs and features contain abundant low-frequency information, which is treated equally across channels, hence hindering the representational ability of CNNs. To solve these problems, we propose the very deep residual channel attention networks (RCAN). Specifically, we propose a residual in residual (RIR) structure to form very deep network, which consists of several residual groups with long skip connections. Each residual group contains some residual blocks with short skip connections. Meanwhile, RIR allows abundant low-frequency information to be bypassed through multiple skip connections, making the main network focus on learning high-frequency information. Furthermore, we propose a channel attention mechanism to adaptively rescale channel-wise features by considering interdependencies among channels. Extensive experiments show that our RCAN achieves better accuracy and visual improvements against state-of-the-art methods.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
We address the problem of reconstructing an accurate high-resolution (HR) image given its low-resolution (LR) counterpart, usually referred as single image super-resolution (SR) [8]. Image SR is used in various computer vision applications, ranging from security and surveillance imaging [45], medical imaging [33] to object recognition [31]. However, image SR is an ill-posed problem, since there exists multiple solutions for any LR input. To tackle such an inverse problem, numerous learning based methods have been proposed to learn mappings between LR and HR image pairs.

Recently, deep convolutional neural network (CNN) based methods [5, 6, 10, 16, 19, 20, 23, 31, 34, 35, 39, 42,43,44] have achieved significant improvements over conventional SR methods. Among them, Dong et al. [4] proposed SRCNN by firstly introducing a three-layer CNN for image SR. Kim et al. increased the network depth to 20 in VDSR [16] and DRCN [17], achieving notable improvements over SRCNN. Network depth was demonstrated to be of central importance for many visual recognition tasks, especially when He at al. [11] proposed residual net (ResNet). Such effective residual learning strategy was then introduced in many other CNN-based image SR methods [21, 23, 31, 34, 35]. Lim et al. [23] built a very wide network EDSR and a very deep one MDSR by using simplified residual blocks. The great improvements on performance of EDSR and MDSR indicate that the depth of representation is of crucial importance for image SR. However, to the best of our knowledge, simply stacking residual blocks to construct deeper networks can hardly obtain better improvements. Whether deeper networks can further contribute to image SR and how to construct very deep trainable networks remains to be explored.
On the other hand, most recent CNN-based methods [5, 6, 16, 19, 20, 23, 31, 34, 35, 39, 43] treat channel-wise features equally, which lacks flexibility in dealing with different types of information. Image SR can be viewed as a process, where we try to recover as more high-frequency information as possible. The LR images contain most low-frequency information, which can directly forwarded to the final HR outputs. While, the leading CNN-based methods would treat each channel-wise feature equally, lacking discriminative learning ability across feature channels, and hindering the representational power of deep networks.
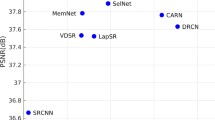
To practically resolve these problems, we propose a residual channel attention network (RCAN) to obtain very deep trainable network and adaptively learn more useful channel-wise features simultaneously. To ease the training of very deep networks (e.g., over 400 layers), we propose residual in residual (RIR) structure, where the residual group (RG) serves as the basic module and long skip connection (LSC) allows residual learning in a coarse level. In each RG module, we stack several simplified residual block [23] with short skip connection (SSC). The long and short skip connection as well as the short-cut in residual block allow abundant low-frequency information to be bypassed through these identity-based skip connections, which can ease the flow of information. To make a further step, we propose channel attention (CA) mechanism to adaptively rescale each channel-wise feature by modeling the interdependencies across feature channels. Such CA mechanism allows our proposed network to concentrate on more useful channels and enhance discriminative learning ability. As shown in Fig. 1, our RCAN achieves better visual SR result compared with state-of-the-art methods.
Overall, our contributions are three-fold: (1) We propose the very deep residual channel attention networks (RCAN) for highly accurate image SR. (2) We propose residual in residual (RIR) structure to construct very deep trainable networks. (3) We propose channel attention (CA) mechanism to adaptively rescale features by considering interdependencies among feature channels.
2 Related Work
Numerous image SR methods have been studied in the computer vision community [5, 6, 13, 16, 19, 20, 23, 31, 34, 35, 39, 43]. Attention mechanism is popular in high-level vision tasks, but is seldom investigated in low-level vision applications [12]. Due to space limitation, here we focus on works related to CNN-based methods and attention mechanism.
Deep CNN for SR. The pioneer work was done by Dong et al. [4], who proposed SRCNN for image SR and achieved superior performance against previous works. SRCNN was further improved in VDSR [16] and DRCN [17]. These methods firstly interpolate the LR inputs to the desired size, which inevitably loses some details and increases computation greatly. Extracting features from the original LR inputs and upscaling spatial resolution at the network tail then became the main choice for deep architecture. A faster network structure FSRCNN [6] was proposed to accelerate the training and testing of SRCNN. Ledig et al. [21] introduced ResNet [11] to construct a deeper network with perceptual losses [15] and generative adversarial network (GAN) [9] for photo-realistic SR. However, most of these methods have limited network depth, which has demonstrated to be very important in visual recognition tasks [11]. Furthermore, most of these methods treat the channel-wise features equally, hindering better discriminative ability for different features.
Attention Mechanism. Generally, attention can be viewed as a guidance to bias the allocation of available processing resources towards the most informative components of an input [12]. Recently, tentative works have been proposed to apply attention into deep neural networks [12, 22, 38], ranging from localization and understanding in images [3, 14] to sequence-based networks [2, 26]. It’s usually combined with a gating function (e.g., sigmoid) to rescale the feature maps. Wang et al. [38] proposed residual attention network for image classification with a trunk-and-mask attention mechanism. Hu et al. [12] proposed squeeze-and-excitation (SE) block to model channel-wise relationships to obtain significant performance improvement for image classification. However, few works have been proposed to investigate the effect of attention for low-level vision tasks (e.g., image SR).

Network architecture of our residual channel attention network (RCAN)
3 Residual Channel Attention Network (RCAN)
3.1 Network Architecture
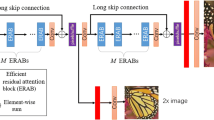
As shown in Fig. 2, our RCAN mainly consists four parts: shallow feature extraction, residual in residual (RIR) deep feature extraction, upscale module, and reconstruction part. Let’s denote \(I_{LR}\) and \(I_{SR}\) as the input and output of RCAN. As investigated in [21, 23], we use only one convolutional layer (Conv) to extract the shallow feature \(F_{0}\) from the LR input
where \(H_{SF}\left( \cdot \right) \) denotes convolution operation. \(F_{0}\) is then used for deep feature extraction with RIR module. So we can further have
where \(H_{RIR}\left( \cdot \right) \) denotes our proposed very deep residual in residual structure, which contains G residual groups (RG). To the best of our knowledge, our proposed RIR achieves the largest depth so far and provides very large receptive field size. So we treat its output as deep feature, which is then upscaled via a upscale module
where \(H_{UP}\left( \cdot \right) \) and \(F_{UP}\) denote a upscale module and upscaled feature respectively.
There’re several choices to serve as upscale modules, such as deconvolution layer (also known as transposed convolution) [6], nearest-neighbor upsampling + convolution [7], and ESPCN [32]. Such post-upscaling strategy has been demonstrated to be more efficient for both computation complexity and achieve higher performance than pre-upscaling SR methods (e.g., DRRN [34] and MemNet [35]). The upscaled feature is then reconstructed via one Conv layer
where \(H_{REC}\left( \cdot \right) \) and \(H_{RCAN}\left( \cdot \right) \) denote the reconstruction layer and the function of our RCAN respectively.
Then RCAN is optimized with loss function. Several loss functions have been investigated, such as \(L_{2}\) [5, 6, 10, 16, 31, 34, 35, 39, 43], \(L_{1}\) [19, 20, 23, 44], perceptual and adversarial losses [21, 31]. To show the effectiveness of our RCAN, we choose to optimize same loss function as previous works (e.g., \(L_{1}\) loss function). Given a training set \(\left\{ I_{LR}^{i}, I_{HR}^{i}\right\} _{i=1}^{N}\), which contains N LR inputs and their HR counterparts. The goal of training RCAN is to minimize the \(L_1\) loss function
where \(\Theta \) denotes the parameter set of our network. The loss function is optimized by using stochastic gradient descent. More details of training would be shown in Sect. 4.1. As we choose the shallow feature extraction \(H_{SF}\left( \cdot \right) \), upscaling module \(H_{UP}\left( \cdot \right) \), and reconstruction part \(H_{UP}\left( \cdot \right) \) as similar as previous works (e.g., EDSR [23] and RDN [44]), we pay more attention to our proposed RIR, CA, and the basic module RCAB.
3.2 Residual in Residual (RIR)
We now give more details about our proposed RIR structure (see Fig. 2), which contains G residual groups (RG) and long skip connection (LSC). Each RG further contains B residual channel attention blocks (RCAB) with short skip connection (SSC). Such residual in residual structure allows to train very deep CNN (over 400 layers) for image SR with high performance.
It has been demonstrated that stacked residual blocks and LSC can be used to construct deep CNN in [23]. In visual recognition, residual blocks [11] can be stacked to achieve more than 1,000-layer trainable networks. However, in image SR, very deep network built in such way would suffer from training difficulty and can hardly achieve more performance gain. Inspired by previous works in SRRestNet [21] and EDSR [23], we proposed residual group (RG) as the basic module for deeper networks. A RG in the g-th group is formulated as
where \(H_{g}\) denotes the function of g-th RG. \(F_{g-1}\) and \(F_{g}\) are the input and output for g-th RG. We observe that simply stacking many RGs would fail to achieve better performance. To solve the problem, the long skip connection (LSC) is further introduced in RIR to stabilize the training of very deep network. LSC also makes better performance possible with residual learning via
where \(W_{LSC}\) is the weight set to the Conv layer at the tail of RIR. The bias term is omitted for simplicity. LSC can not only ease the flow of information across RGs, but only make it possible for RIR to learning residual information in a coarse level.
As discussed in Sect. 1, there are lots of abundant information in the LR inputs and features and the goal of SR network is to recover more useful information. The abundant low-frequency information can be bypassed through identity-based skip connection. To make a further step towards residual learning, we stack B residual channel attention blocks in each RG. The b-th residual channel attention block (RCAB) in g-th RG can be formulated as
where \(F_{g,b-1}\) and \(F_{g,b}\) are the input and output of the b-th RCAB in g-th RG. The corresponding function is denoted with \(H_{g,b}\). To make the main network pay more attention to more informative features, a short skip connection (SSC) is introduced to obtain the block output via
where \(W_{g}\) is the weight set to the Conv layer at the tail of g-th RG. The SSC further allows the main parts of network to learn residual information. With LSC and SSC, more abundant low-frequency information is easier bypassed in the training process. To make a further step towards more discriminative learning, we pay more attention to channel-wise feature rescaling with channel attention.

Channel attention (CA). \(\otimes \) denotes element-wise product
3.3 Channel Attention (CA)
Previous CNN-based SR methods treat LR channel-wise features equally, which is not flexible for the real cases. In order to make the network focus on more informative features, we exploit the interdependencies among feature channels, resulting in a channel attention (CA) mechanism (see Fig. 3).
How to generate different attention for each channel-wise feature is a key step. Here we mainly have two concerns: First, information in the LR space has abundant low-frequency and valuable high-frequency components. The low-frequency parts seem to be more complanate. The high-frequency components would usually be regions, being full of edges, texture, and other details. On the other hand, each filter in Conv layer operates with a local receptive field. Consequently, the output after convolution is unable to exploit contextual information outside of the local region.
Based on these analyses, we take the channel-wise global spatial information into a channel descriptor by using global average pooling. As shown in Fig. 3, let \(X=\left[ x_1,\cdots , x_c,\cdots ,x_C \right] \) be an input, which has C feature maps with size of \(H\times W\). The channel-wise statistic \(z\in \mathbb {R}^{C}\) can be obtained by shrinking X through spatial dimensions \(H\times W\). Then the c-th element of z is determined by
where \(x_{c}\left( i,j \right) \) is the value at position \(\left( i,j \right) \) of c-th feature \(x_c\). \(H_{GP}\left( \cdot \right) \) denotes the global pooling function. Such channel statistic can be viewed as a collection of the local descriptors, whose statistics contribute to express the whole image [12]. Except for global average pooling, more sophisticated aggregation techniques could also be introduced here.
To fully capture channel-wise dependencies from the aggregated information by global average pooling, we introduce a gating mechanism. As discussed in [12], the gating mechanism should meet two criteria: First, it must be able to learn nonlinear interactions between channels. Second, as multiple channel-wise features can be emphasized opposed to one-hot activation, it must learn a non-mututually-exclusive relationship. Here, we opt to exploit simple gating mechanism with sigmoid function
where \(f\left( \cdot \right) \) and \(\delta \left( \cdot \right) \) denote the sigmoid gating and ReLU [27] function, respectively. \(W_{D}\) is the weight set of a Conv layer, which acts as channel-downscaling with reduction ratio r. After being activated by ReLU, the low-dimension signal is then increased with ratio r by a channel-upscaling layer, whose weight set is \(W_{U}\). Then we obtain the final channel statistics s, which is used to rescale the input \(x_{c}\)
where \(s_{c}\) and \(x_{c}\) are the scaling factor and feature map in the c-th channel. With channel attention, the residual component in the RCAB is adaptively rescaled.

Residual channel attention block (RCAB)
3.4 Residual Channel Attention Block (RCAB)
As discussed above, residual groups and long skip connection allow the main parts of network to focus on more informative components of the LR features. Channel attention extracts the channel statistic among channels to further enhance the discriminative ability of the network.
At the same time, inspired by the success of residual blocks (RB) in [23], we integrate CA into RB and propose residual channel attention block (RCAB) (see Fig. 4). For the b-th RB in g-th RG, we have
where \(R_{g,b}\) denotes the function of channel attention. \(F_{g,b}\) and \(F_{g,b-1}\) are the input and output of RCAB, which learns the residual \(X_{g,b}\) from the input. The residual component is mainly obtained by two stacked Conv layers
where \(W_{g,b}^{1}\) and \(W_{g,b}^{2}\) are weight sets the two stacked Conv layers in RCAB.
We further show the relationships between our proposed RCAB and residual block (RB) in [23]. We find that the RBs used in MDSR and EDSR [23] can be viewed as special cases of our RCAB. For RB in MDSR, there is no rescaling operation. It is the same as RCAB, where we set \(R_{g,b}\left( \cdot \right) \) as constant 1. For RB with constant rescaling (e.g., 0.1) in EDSR, it is the same as RCAB with \(R_{g,b}\left( \cdot \right) \) set to be 0.1. Although the channel-wise feature rescaling is introduced to train a very wide network, the interdependencies among channels are not considered in EDSR. In these cases, the CA is not considered.
Based on residual channel attention block (RCAB) and RIR structure, we construct a very deep RCAN for highly accurate image SR and achieve notable performance improvements over previous leading methods. More discussions about the effects of each proposed component are shown in Sect. 4.2.
4 Experiments
4.1 Settings
Following [23, 36, 43, 44], we use 800 training images from DIV2K dataset [36] as training set. For testing, we use five standard benchmark datasets: Set5 [1], Set14 [41], B100 [24], Urban100 [13], and Manga109 [25]. We conduct experiments with Bicubic (BI) and blur-downscale (BD) degradation models [42,43,44]. The SR results are evaluated with PSNR and SSIM [40] on Y channel (i.e., luminance) of transformed YCbCr space. Data augmentation is performed on the 800 training images, which are randomly rotated by 90\(^{\circ }\), 180\(^{\circ }\), 270\(^{\circ }\) and flipped horizontally. In each training batch, 16 LR color patches with the size of \(48\times 48\) are extracted as inputs. Our model is trained by ADAM optimizor [18] with \(\beta _{1}=0.9\), \(\beta _{2}=0.999\), and \(\epsilon =10^{-8}\). The initial leaning rate is set to \(10^{-4}\) and then decreases to half every \(2\times 10^{5}\) iterations of back-propagation. We use PyTorch [28] to implement our models with a Titan Xp GPU.Footnote 1
We set RG number as G=10 in the RIR structure. In each RG, we set RCAB number as 20. We set 3 \(\times \) 3 as the size of all Conv layers except for that in the channel-downscaling and channel-upscaling, whose kernel size is 1 \(\times \) 1. Conv layers in shallow feature extraction and RIR structure have C=64 filters, except for that in the channel-downscaling. Conv layer in channel-downscaling has \(\frac{C}{r}\)=4 filters, where the reduction ratio r is set as 16. For upscaling module \(H_{UP}\left( \cdot \right) \), we use ESPCNN [32] to upscale the coarse resolution features to fine ones.
4.2 Effects of RIR and CA
We study the effects of residual in residual (RIR) and channel attention (CA).
Residual in Residual (RIR). To demonstrate the effect of our proposed residual in residual structure, we remove long skip connection (LSC) or/and short skip connection (SSC) from very deep networks. Specifically, we set the number of residual block as 200. In Table 1, when both LSC and SSC are removed, the PSNR value on Set5 (\(\times 2\)) is relatively low, no matter channel attention (CA) is used or not. This indicates that simply stacking residual blocks is not applicable to achieve very deep and powerful networks for image SR. These comparisons show that LSC and SSC are essential for very deep networks. They also demonstrate the effectiveness of our proposed residual in residual (RIR) structure for very deep networks.
Channel Attention (CA). We further show the effect of channel attention (CA) based on the observations and discussions above. When we compare the results of first 4 columns and last 4 columns, we find that networks with CA would perform better than those without CA. Benefitting from very large network depth, the very deep trainable networks can achieve a very high performance. It’s hard to obtain further improvements from such deep networks, but we obtain improvements with CA. Even without RIR, CA can improve the performance from 37.45 dB to 37.52 dB. These comparisons firmly demonstrate the effectiveness of CA and indicate adaptive attentions to channel-wise features really improves the performance.

Visual comparison for \(4\times \) SR with BI model on Urban100 and Manga109 datasets. The best results are highlighted
4.3 Results with Bicubic (BI) Degradation Model
We compare our method with 11 state-of-the-art methods: SRCNN [5], FSRCNN [6], SCN [39], VDSR [16], LapSRN [19], MemNet [35], EDSR [23], SRMDNF [43], D-DBPN [10], and RDN [44]. Similar to [23, 37, 44], we also introduce self-ensemble strategy to further improve our RCAN and denote the self-ensembled one as RCAN+. More comparisons are provided in supplementary material.
Quantitative results by PSNR/SSIM. Table 2 shows quantitative comparisons for \(\times \)2, \(\times \)3, \(\times \)4, and \(\times \)8 SR. The results of D-DBPN [10] are cited from their paper. When compared with all previous methods, our RCAN+ performs the best on all the datasets with all scaling factors. Even without self-ensemble, our RCAN also outperforms other compared methods. On the other hand, when the scaling factor become larger (e.g., 8), the gains of our RCAN over EDSR also becomes larger. EDSR has much larger number of parameters (43 M) than ours (16 M), but our RCAN obtains much better performance. CA allows our network to further focus on more informative features. This observation indicates that very large network depth and CA improve the performance.

Visual comparison for \(8\times \) SR with BI model on Urban100 and Manga109 datasets. The best results are highlighted
Visual results. In Fig. 5, we show visual comparisons on scale \(\times \)4. For image “img_004”, we observe that most of the compared methods cannot recover the lattices and would suffer from blurring artifacts. In contrast, our RCAN can alleviate the blurring artifacts better and recover more details. Similar observations are shown in images “img_073” and“YumeiroCooking”. Such obvious comparisons demonstrate that networks with more powerful representational ability can extract more sophisticated features from the LR space. To further illustrate the analyses above, we show visual comparisons for 8\(\times \) SR in Fig. 6. For image “img_040”, due to very large scaling factor, the result by Bicubic would lose the structures and produce different structures. This wrong pre-scaling result would also lead some state-of-the-art methods (e.g., SRCNN, VDSR, and MemNet) to generate totally wrong structures. Even starting from the original LR input, other methods cannot recover the right structure either. While, our RCAN can recover them correctly. Similar observations are shown in image “TaiyouNiSmash”. Our proposed RCAN makes the main network learn residual information and enhance the representational ability.

Visual comparison for \(3\times \) SR with BD model on Urban100 dataset. The best results are highlighted
4.4 Results with Blur-Downscale (BD) Degradation Model
We further apply our method to super-resolve images with blur-down (BD) degradation model, which is also commonly used recently [42,43,44].
Quantitative results by PSNR/SSIM. Here, we compare 3\(\times \) SR results with 7 state-of-the-art methods: SPMSR [29], SRCNN [5], FSRCNN [6], VDSR [16], IRCNN [42], SRMDNF [43], and RDN [44]. As shown in Table 3, RDN has achieved very high performance on each dataset. While, our RCAN can obtain notable gains over RDN. Using self-ensemble, RCAN+ achieves even better results. Compared with fully using hierarchical features in RDN, a much deeper network with channel attention in RCAN achieves better performance. This comparison also indicates that there has promising potential to investigate much deeper networks for image SR.
Visual Results. We also show visual comparisons in Fig. 7. For challenging details in images “img_062" and“img_078", most methods suffer from heavy blurring artifacts. RDN alleviates it to some degree and can recover more details. In contrast, our RCAN obtains much better results by recovering more informative components. These comparisons indicate that very deep channel attention guided network would alleviate the blurring artifacts. It also demonstrates the strong ability of RCAN for BD degradation model.

Performance and number of parameters. Results are evaluated on Set5
4.5 Object Recognition Performance
Image SR also serves as pre-processing step for high-level visual tasks (e.g., object recognition). We evaluate the object recognition performance to further demonstrate the effectiveness of our RCAN. Here we use the same settings as ENet [31]. We use ResNet-50 [11] as the evaluation model and use the first 1,000 images from ImageNet CLS-LOC validation dataset for evaluation. The original cropped 224 \(\times \) 224 images are used for baseline and downscaled to 56 \(\times \) 56 for SR methods. We use 4 stat-of-the-art methods (e.g., DRCN [17], FSRCNN [6], PSyCo [30], and ENet-E [31]) to upscale the LR images and then calculate their accuracies. As shown in Table 4, our RCAN achieves the lowest top-1 and top-5 errors. These comparisons further demonstrate the highly powerful representational ability of our RCAN.
4.6 Model Size Analyses
We show comparisons about model size and performance in Fig. 8. Although our RCAN is the deepest network, it has less parameter number than that of EDSR and RDN. Our RCAN and RCAN+ achieve higher performance, having a better tradeoff between model size and performance. It also indicates that deeper networks may be easier to achieve better performance than wider networks.
5 Conclusions
We propose very deep residual channel attention networks (RCAN) for highly accurate image SR. Specifically, the residual in residual (RIR) structure allows RCAN to reach very large depth with LSC and SSC. Meanwhile, RIR allows abundant low-frequency information to be bypassed through multiple skip connections, making the main network focus on learning high-frequency information. Furthermore, to improve ability of the network, we propose channel attention (CA) mechanism to adaptively rescale channel-wise features by considering interdependencies among channels. Extensive experiments on SR with BI and BD models demonstrate the effectiveness of our proposed RCAN. RCAN also shows promising results for object recognition.
Notes
- 1.
The RCAN source code is available at https://github.com/yulunzhang/RCAN.
References
Bevilacqua, M., Roumy, A., Guillemot, C., Alberi-Morel, M.L.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: BMVC (2012)
Bluche, T.: Joint line segmentation and transcription for end-to-end handwritten paragraph recognition. In: NIPS (2016)
Cao, C., et al.: Look and think twice: capturing top-down visual attention with feedback convolutional neural networks. In: ICCV (2015)
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8692, pp. 184–199. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10593-2_13
Dong, C., Loy, C.C., He, K., Tang, X.: Image super-resolution using deep convolutional networks. TPAMI 38(2), 295–307 (2016)
Dong, C., Loy, C.C., Tang, X.: Accelerating the super-resolution convolutional neural network. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 391–407. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_25
Dumoulin, V., Shlens, J., Kudlur, M.: A learned representation for artistic style. In: ICLR (2017)
Freeman, W.T., Pasztor, E.C., Carmichael, O.T.: Learning low-level vision. IJCV 40(1), 25–47 (2000)
Goodfellow, I., et al.: Generative adversarial nets. In: NIPS (2014)
Haris, M., Shakhnarovich, G., Ukita, N.: Deep back-projection networks for super-resolution. In: CVPR (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507 (2017)
Huang, J.B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: CVPR (2015)
Jaderberg, M., Simonyan, K., Zisserman, A., Kavukcuoglu, K.: Spatial transformer networks. In: NIPS (2015)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 694–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_43
Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks. In: CVPR (2016)
Kim, J., Kwon Lee, J., Mu Lee, K.: Deeply-recursive convolutional network for image super-resolution. In: CVPR (2016)
Kingma, D., Ba, J.: Adam: A method for stochastic optimization. In: ICLR (2014)
Lai, W.S., Huang, J.B., Ahuja, N., Yang, M.H.: Deep laplacian pyramid networks for fast and accurate super-resolution. In: CVPR (2017)
Lai, W.S., Huang, J.B., Ahuja, N., Yang, M.H.: Fast and accurate image super-resolution with deep laplacian pyramid networks. arXiv:1710.01992 (2017)
Ledig, C., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR (2017)
Li, K., Wu, Z., Peng, K.C., Ernst, J., Fu, Y.: Tell me where to look: Guided attention inference network. In: CVPR (2018)
Lim, B., Son, S., Kim, H., Nah, S., Lee, K.M.: Enhanced deep residual networks for single image super-resolution. In: CVPRW (2017)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: ICCV (2001)
Matsui, Y., Ito, K., Aramaki, Y., Fujimoto, A., Ogawa, T., Yamasaki, T., Aizawa, K.: Sketch-based manga retrieval using manga109 dataset. Multimedia Tools Appl. 76(20), 21811–21838 (2017)
Miech, A., Laptev, I., Sivic, J.: Learnable pooling with context gating for video classification. arXiv preprint arXiv:1706.06905 (2017)
Nair, V., Hinton, G.E.: Rectified linear units improve restricted Boltzmann machines. In: ICML (2010)
Paszke, A., et al.: Automatic differentiation in pytorch (2017)
Peleg, T., Elad, M.: A statistical prediction model based on sparse representations for single image super-resolution. TIP 23(6), 2569–2582 (2014)
Pérez-Pellitero, E., Salvador, J., Ruiz-Hidalgo, J., Rosenhahn, B.: PSyCo: manifold span reduction for super resolution. In: CVPR (2016)
Sajjadi, M.S., Schölkopf, B., Hirsch, M.: EnhanceNet: single image super-resolution through automated texture synthesis. In: ICCV (2017)
Shi, W., et al.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR (2016)
Shi, W., et al.: Cardiac image super-resolution with global correspondence using multi-atlas patchmatch. In: Mori, K., Sakuma, I., Sato, Y., Barillot, C., Navab, N. (eds.) MICCAI 2013. LNCS, vol. 8151, pp. 9–16. Springer, Heidelberg (2013). https://doi.org/10.1007/978-3-642-40760-4_2
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: CVPR (2017)
Tai, Y., Yang, J., Liu, X., Xu, C.: MemNet: a persistent memory network for image restoration. In: ICCV (2017)
Timofte, R., et al.: Ntire 2017 challenge on single image super-resolution: Methods and results. In: CVPRW (2017)
Timofte, R., Rothe, R., Van Gool, L.: Seven ways to improve example-based single image super resolution. In: CVPR (2016)
Wang, F., et al.: Residual attention network for image classification. In: CVPR (2017)
Wang, Z., Liu, D., Yang, J., Han, W., Huang, T.: Deep networks for image super-resolution with sparse prior. In: ICCV (2015)
Wang, Z., Bovik, A.C., Sheikh, H.R., Simoncelli, E.P.: Image quality assessment: from error visibility to structural similarity. TIP 13(4), 600–612 (2004)
Zeyde, R., Elad, M., Protter, M.: On single image scale-up using sparse-representations. In: Proceedings of 7th International Conference Curves Surfaces (2010)
Zhang, K., Zuo, W., Gu, S., Zhang, L.: Learning deep CNN denoiser prior for image restoration. In: CVPR (2017)
Zhang, K., Zuo, W., Zhang, L.: Learning a single convolutional super-resolution network for multiple degradations. In: CVPR (2018)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: CVPR (2018)
Zou, W.W., Yuen, P.C.: Very low resolution face recognition problem. TIP 21(1), 327–340 (2012)
Acknowledgements
This research is supported in part by the NSF IIS award 1651902, ONR Young Investigator Award N00014-14-1-0484, and U.S. Army Research Office Award W911NF-17-1-0367.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y. (2018). Image Super-Resolution Using Very Deep Residual Channel Attention Networks. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11211. Springer, Cham. https://doi.org/10.1007/978-3-030-01234-2_18
Download citation
DOI: https://doi.org/10.1007/978-3-030-01234-2_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01233-5
Online ISBN: 978-3-030-01234-2
eBook Packages: Computer ScienceComputer Science (R0)