
Abstract
Lipids are natural substances found in all living organisms and involved in many biological functions. Imbalances in the lipid metabolism are linked to various diseases such as obesity, diabetes, or cardiovascular disease. Lipids comprise thousands of chemically distinct species making them a challenge to analyze because of their great structural diversity.
Thanks to the technological improvements in the fields of chromatography, high-resolution mass spectrometry, and bioinformatics over the last years, it is now possible to perform global lipidomics analyses, allowing the concomitant detection, identification, and relative quantification of hundreds of lipid species. This review shall provide an insight into a general lipidomics workflow and its application in metabolic biomarker research.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
Metabolic diseases can present long before becoming clinically apparent. Early predictors of metabolic disease are of particular importance since a delay or prevention of morbidity is possible via pharmacological and behavioral interventions. Thus, biomarkers are essential tools to select patients for appropriate treatment schemes, optimally providing the right treatment to the right patient at the right time.
Cardiovascular diseases (CVDs) and associated mortality have a high prevalence in western societies. For coronary artery disease (CAD), the average annual mortality ranges between 1 and 3% (for fatal and non-fatal myocardial infarctions) and remains a clinical challenge (Morrow 2010). In patients who survived an acute event of a coronary syndrome (ACS), the rate of myocardial infarction and death is markedly increased (Hamm et al. 2012). However, at the individual patient level, the risk may vary considerably and therefore risk estimation tools are needed to better manage such patients. A better risk stratification would also help to identify individuals at risk who require interventions that are more intensive. Conversely, it is equally important to identify patients with a good prognosis, to avoid unnecessary procedures or aggressive drug treatments with associated side effects. Concentrations of cholesterol in total plasma (TC), low density lipoproteins (LDL-C), and high density lipoproteins (HDL-C) as well as triglycerides (TG) have been used for risk prediction. LDL-C has become the main therapeutic target in the management of patients with CAD. However, a number of studies have failed to show any association between LDL-C and outcomes in large series of CAD patients (Puri et al. 2013). There is a clinical need for additional risk markers in CVD as well as a better understanding on how lipids relate with established metabolic risk factors to evaluate their potential as clinical biomarkers.
2 Biochemistry of Lipids
Biological systems are comprised of thousands of chemically distinct lipids. The structural diversity of lipids confers a broad spectrum of functionality. For most lipids, their functions depend on their molecular structure and can be very different for the different lipid classes as well as for different lipid species within the same lipid class (Stahlman et al. 2012). Lipids are found in all living organisms. They are involved in many critical cellular functions such as energy storage, structural plasma membrane integrity, and cell signaling. Imbalances of lipid metabolism are linked to the pathology of various diseases such as diabetes, Alzheimer’s, obesity, cancer, and atherosclerosis (Cavojsky et al. 2016; Jung and Choi 2014; Steinberg 2006; Tan et al. 2017; Watson 2006; Wenk 2005). While routine plasma lipid analysis precedes prescription of lipid-lowering drugs (Quehenberger et al. 2010), the abundance of particular lipid species may be indicative of a specific disease (Quehenberger and Dennis 2011). Abnormal concentrations of lipids are observed in various metabolic disorders.
Moreover, many inborn errors of metabolism are related to alterations in the metabolism of lipids, and particularly that of sphingolipids. Sphingolipidoses are monogenic inherited diseases caused by defects in the sphingolipid degradation pathways (Kolter and Sandhoff 2006; Sandhoff and Harzer 2013), leading to a massive storage of undegraded sphingolipid species in the lysosomes, causing neuroinflammation and neurodegeneration. Sphingolipids also emerged over the last years as significant factors in the pathogenesis of cardiometabolic diseases (Cowart 2009; Summers 2006; Deevska and Nikolova-Karakashian 2011).
Lipids show a large structural diversity that is comprised in the term “lipidome.” According to the comprehensive classification system proposed by the LIPID MAPS consortium (http://www.lipidmaps.org), lipids can be classified into eight different classes (Fig. 1): glycerophospholipids (GP), sphingolipids (SL), glycerolipids, sterol lipids, free fatty acids, prenol lipids, saccharolipids, and polyketides (Fahy et al. 2005; Fahy et al. 2009).

Structures of the most abundant lipid families
GP constitute the largest lipid class and are derived from sn-glycero-3-phosphoric acid. Nearly 200 GP species were identified in human plasma (Fig. 2). Among them glycerophosphocholines and glycerophosphoethanolamines are most abundant and glycerophosphoserines least abundant (Quehenberger et al. 2010; Quehenberger and Dennis 2011). Lyso-GPs only bear one fatty acid that is esterified to a hydroxyl group either at sn-1 or sn-2 position.

Distribution of the individual lipid classes in human plasma (reproduced from Quehenberger et al. (2010))
Human plasma contains more than 200 different SL species. The largest SL fraction in human plasma is sphingomyelin, while ceramides are least abundant.
Among sterols cholesterol is most abundant in plasma followed by lathosterol and desmosterol. The largest part of cholesterol in plasma is esterified (Fig. 2). Among the cholesteryl esters (CE) of human plasma, CE(18:2) and CE(20:4) contribute the major fraction (Quehenberger et al. 2010).
Prenol lipids are built from five carbon isoprene units. The two main prenol lipids in plasma are dolichol and ubiquinone (Shiota et al. 2008).
3 Lipidomics
Lipidomics is a relatively young field of science, which aims to identify and quantify all individual lipid species and their functions within a biological system (Han and Gross 2003). Lipidomics technologies are increasingly applied to biomarker discovery. They offer great promise for new-generation biomarkers in common and complex phenotypes such as dyslipidemia and cardiovascular diseases (CVDs).
3.1 Mass Spectrometry and Chromatography
A lipidomics analysis provides an overall picture of the lipids in a sample, thanks to the combined use of analytical chemistry and data mining tools. However, the comprehensive characterization of a lipidome in biological samples is still challenging. The huge structural diversity of lipids that primarily arises from the combination of various fatty acids and functional head groups makes a complete molecular profiling of the lipidome difficult. In particular, the presence of multiple isobaric lipid species increases the complexity. Also the detection of quantitatively minor lipid species remains a challenge.
The development of mass spectrometry (MS) based technologies over the last decade has rapidly expanded research in the field of lipidomics. In lipidomics, the mass spectrometer can be used without prior separation (“shot-gun lipidomics”) or connected to chromatographic systems in order to provide an additional dimension of separation.
In the shot-gun strategy, the crude lipid extract is directly introduced into the MS system (Han and Gross 1994), which is a fast and simple method to obtain a quantitative lipid profile from biological matrices. However, as the trade-off, the technology suffers from a limited dynamic range and the risk of ion suppression, making the detection of isobaric and low concentrated lipid species difficult. Therefore, recent methodologies are often based on the progress in high-resolution (HR) MS, such as Orbitrap (Ejsing et al. 2009; Schwudke et al. 2011) or Q-TOF detectors (Guo et al. 2012; Li et al. 2013). Using HR-MS, individual lipid species are identified and quantified according to their exact chemical mass. Nevertheless, the major limitation of shot-gun MS is the lack of discrimination between isobaric species. Because of the building block-like nature of many lipid families, isobaric species are frequently found in the lipidome. This is in particular the case for certain glycero- and sphingolipids, which have a very similar accurate mass (Schwudke et al. 2011).
Thin layer chromatography (TLC) was one of the earliest chromatographic methods applied in lipid analysis. However, it is time-consuming and lacks resolution power and reproducibility. Nevertheless, TLC is still widely used, because of its simplicity and low cost. Also, with gas chromatography (GC), it is possible to obtain information on individual lipid species. Volatile lipid classes, in particular triacylglycerols, can be separated directly and without any chemical modification, whereas the analysis of more polar compounds such as fatty acids, phospholipids, and sphingolipids requires initial derivatization or hydrolysis. Also capillary electrophoresis has been applied for the separation of phospholipids at high data acquisition speed (Jang et al. 2011). However, (ultra) high-performance liquid chromatography ((U)HPLC) is the most versatile method and the majority of lipid classes including glycerophospholipids, glycerolipids, sphingolipids, sterols, and fatty acids can be separated directly by (U)HPLC (Wenk 2005).
In lipidomics studies, either normal-phase (NPLC) or reversed-phase (RPLC) liquid chromatography is used. In NPLC, lipid species are primarily separated by the polarity of their head groups, while RPLC separates the lipids based on their lipophilicity which is primarily determined by the acyl chain length, the number of double bonds, and hydroxylations (Merrill Jr. et al. 2005). In RPLC, lipids with shorter acyl chains and/or a higher degree of unsaturation elute earlier. Furthermore, RPLC can separate isomeric species based on the type of double bond (cis or trans) or whether a fatty acid is in sn-1 or sn-2 position (Bird et al. 2012). Other HPLC based separation techniques have been developed recently and show a great potential for lipidomics. In particular, supercritical fluid chromatography-mass spectrometry (SFC-MS) has been used for the separation of lipids over a wide range of polarities depending on the choice of the chromatographic columns (Bamba et al. 2012). In lipidomics, MS instruments are mostly combined with LC systems. This strategy drastically decreases ion suppression and improved the separation of isobaric and low-abundance species (Taguchi and Ishikawa 2010). In addition, ion mobility (IM) separation offers an additional dimension for the separation of isobaric lipid species which can even be combined with LC based separation methods (Kliman et al. 2011). Also, HR-MS is often combined with high- or ultra-performance liquid chromatography (Bird et al. 2011a, b) or ion mobility spectroscopy (Kliman et al. 2011).
In addition to chromatography, technological advancements in MS, particularly in the field of ionization methods, have played a critical role in advancing the lipid analysis from complex matrices. Electrospray ionization (ESI) and atmospheric pressure ion (API) sources, including atmospheric pressure chemical ionization (APCI) and atmospheric pressure photoionization (APPI) are most widely used. Other methods such as matrix-assisted laser desorption ionization (MALDI) are also applied but are not the most established methods for lipid profiling. In contrast to ESI or atmospheric pressure ion sources, MALDI cannot be easily coupled to chromatographic systems. However, MALDI-MS is used in mass spectrometry imaging (MSI) (Aichler and Walch 2015) to analyze individual lipid species directly in tissue sections. Also, the combination of MALDI-MS with TLC provides direct information about the molecular species and the molecular weight (Guittard et al. 1999) as by TLC, lipids are normally separated according to their classes.
The first analysis of a complex lipid mixture using an ESI source was reported by Han and Gross (Han and Gross 1994). Today, ESI is the most widely used method for lipidomic studies, although some important classes, such as cholesteryl esters and glycerolipids (mono-, di- and tri-acylglycerols) are not well ionized with ESI and therefore require the addition of ammonium, lithium, or copper ions to increase signal strength (Murphy and Axelsen 2011; Murphy and Gaskell 2011).
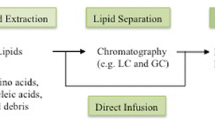
With the advent of high-resolution MS and the capability to perform simultaneous HR-MS and MS/MS analysis, the major challenge for LC-MS based lipidomics is to deal with the vast amount of information generated during data acquisitions. Therefore, bioinformatics tools (Table 1) have been developed to handle, process, and interpret large amounts of data generated during lipidomics analysis. Typically, a lipidomics workflow includes four steps.
I. Sample preparation, II. LC-MS/MS analysis, III. Automatic data processing for peak detection and alignment based on commercial or freely available software algorithms, and IV. Feature identification using public or proprietary databases (Fig. 3).

Typical workflow for lipid biomarker identification
3.2 Pre-analytical Considerations
A key factor for the quality of a lipid profiling study is the integrity of the samples (Ellervik and Vaught 2015). Errors during the pre-analytical phase including sample collection, processing, and storage may severely affect subsequent downstream analyses and resulting data (Ellervik and Vaught 2015). Anticoagulants are commonly used in plasma preparation and the most common anticoagulants such as EDTA and heparin plasma as well as serum are compatible with lipidomics studies. Nonetheless, the peak responses of a number of lipid species can be influenced by the material (Hammad et al. 2010). Therefore, the same anticoagulant should be used throughout a study. In addition, the correct storage of the samples is of importance. Particularly in large clinical cohorts, batches of samples may be stored for a long period of time. Samples are commonly stored at −80 °C or lower before they undergo a lipidomics profiling. However, certain lipids such as sphingomyelins were lost from plasma samples over 5 years of storage (Haid et al. 2018). Plasma concentrations of cholesterol and triglycerides were shown to decrease in serum samples stored over 7 and 5 years, respectively (Shih et al. 2000) even at −80 °C. This should be considered as the time-dependent degradation of certain lipids may lead to biased results. Consequently, the time between sampling and analysis should be kept as short as possible.
3.3 Lipid Extraction
Usually, lipids are extracted from biological sources using liquid–liquid extractions. Lipid extraction is a crucial step in obtaining global coverage of the lipidome. The two most commonly applied methods are using either a 2/1 mixture of chloroform and methanol according to Folch (Folch et al. 1957) or a 1/1 mixture of chloroform and methanol according to Bligh and Dyer (Bligh and Dyer 1959). Based on these traditional protocols, new methods have been developed, although most of them are adaptations of either the one or the other. Chloroform and methanol can be replaced by either dichloromethane (Hu et al. 2008), methyl tert-butyl ether (MTBE) or by heptane and ethyl acetate (Lofgren et al. 2012). Comparing the yeast lipidome prepared by three extraction methods (chloroform/methanol 17/1 (v/v), chloroform/methanol 2/1 (v/v), or chloroform/methanol/H2O 1/1/0.9 (v/v/v) showed a large heterogeneity in the extraction yield which was also dependent on the respective lipid classes (Ejsing et al. 2009). Therefore, the appropriate extraction protocol depends on the underlying analytical question and the lipid class of interest (Danne-Rasche et al. 2018).
3.4 Targeted vs. Untargeted Lipidomics
LC-MS is typically applied in two distinct operational modes – targeted or untargeted. A targeted approach is normally chosen for a limited, predefined number of lipid species. It is typically more sensitive and specific than untargeted approaches. In a targeted approach, often low-resolution MS systems are used, such as triple quadrupole or quadrupole linear ion trap instruments, because of their speed, sensitivity, and quantification capabilities (Bielawski et al. 2009). However, the development of HR-MS instruments such as Orbitrap and quadrupole time-of-flight MS also allows untargeted lipidomic approaches, which is independent of a predefined compound list (Junot et al. 2014). HR-MS enables the concomitant analysis of multiple lipid families without the need for extensive fragmentation. Improvements in the duty cycle allow the combination of high-resolution MS and higher energy collisional dissociation (HCD) scans, which provides further information about the accurate mass of precursor and fragment ions of the detected lipids (Bird et al. 2013, 2015). Depending on the model and MS manufacturer, also combined approaches of HR-MS together with ion fragmentation are possible. Many instrument manufacturers offer the possibility to generate HR-MS fragment data using either a data dependent (DDA) or data independent (DIA) acquisition mode.
3.5 Annotation
Lipid species detected by MS-based approaches are typically annotated with the help of dedicated databases. Numerous lipid databases have been developed in the field of lipidomics (see Table 1). The LIPID MAPS consortium has developed the structure database LIPID MAPS (Schmelzer et al. 2007), wherein lipid species are classified by families, class, and subclasses according to their accurate mass and structure. This database is openly available and can be downloaded allowing an automatic annotation. This database consists of compiled databases such as LipidBank, LIPIDAT, or LipidBlast (Cajka and Fiehn 2017). Also databases commonly used in the field of metabolomics, such as HMDB, METLIN, and KEGG, contain data on lipid species as well as other sources such as Cyberlipids and Lipid Library.
However, before the individual lipid species can be annotated, the raw data obtained from an MS analyzer must be pre-processed. Typically, raw MS data are first converted into either a proprietary data format of the respective MS manufacturer or an open data container such as NetCDF, mzXML, or mzData (i.e., XCMS or MZmine). In parallel with advances in instrumentation technology (particularly for high-resolution mass spectrometers), manufacturers have developed commercial software packages for direct interpretation of the raw data obtained. In contrast to manufacturer specific data formats, which normally can only be read in combination with branded software packages, open data formats are commonly used in freely available software programs such as MZmine (Katajamaa et al. 2006) or XCMS (Smith et al. 2006) (Table 1). Data processing in MZmine is based on algorithms for spectral filtering, alignments according to the retention time, peak picking detection, normalization, and visualization. XCMS in contrast uses non-linear retention time peak alignment, matching by a filter process and peak matching.
Many of these data processing tools allow to perform univariate or multi-variate statistical analysis to identify discriminant variables (potential biomarker lipid species, for example). However, in case of unclear structural definitions, often further MS/MS experiments are needed to identify the lipid metabolite of interest unambiguously.
3.6 Biostatistics
Finally, advanced biostatistical tools are needed to process, analyze, and interpret high-dimensional lipidomics data in the context of clinical information. Based on the typically large and comprehensive dataset, supervised and unsupervised statistical methods are applied. This includes but is not limited to partial least squares discriminant analysis (PLS-DA), orthogonal projection-potential structure analysis (OPLS-DA), principal component analysis (PCA), clustering analysis, linear discriminant analysis, or other stoichiometric methods (Liland et al. 2010). Tools such as MetaboAnalyst can help to identify relevant markers and lipid signatures (Xia and Wishart 2016).
4 Application of Lipidomics in Clinical and Epidemiological Studies
In plasma, lipids are mostly transported and distributed by lipoproteins (e.g., HDL, LDL, VLDL). Several studies have examined the lipid components of lipoproteins among healthy participants (Quehenberger et al. 2010; Christinat and Masoodi 2017; Kontush et al. 2013). However, the lipid composition of lipoproteins varies (Cardner et al. 2020). Triacylglycerols (TAGs) are the predominant core lipid in VLDL, while CEs predominate in the core of LDL and HDL. Compared to LDL, HDL contains a higher amount of phospholipids, particularly PC and LPC. The fatty acid composition of phospholipids, TAGs, and CE is similar in HDL, LDL, and VLDL.
CVD is mostly associated with increased blood levels for one or more lipid classes. These hyperlipidemias (HL) can be linked to familial or non-familial reasons. Familial HL are caused by genetic alterations in lipoprotein metabolism but the penetrance can vary considerably depending on the condition (De Castro-Oros et al. 2010). Non-familial HL occur due to adverse lifestyle behavior such as physical inactivity, intake of lipid-rich diet, smoking, and alcohol consumption or due to underlying diseases such as obesity, liver diseases, and diabetes. Urban diets, stress, and unhealthy eating pattern have made non-familial HL highly prevalent and a focal topic in health prevention. HL affects a large proportion of the human lipidome, resulting in changes in plasma levels of saturated diacylglycerols (DAGs), TAGs, SM, and phospholipids in obese individuals (Graessler et al. 2009; Hanamatsu et al. 2014; Kim et al. 2010). Plasma levels of PC, phosphatidylethanolamine, ether-linked lipids, phosphatidylinositol (PI), LPC, and CE (Barber et al. 2012; Donovan et al. 2013; Eisinger et al. 2014; Graessler et al. 2009; Hanamatsu et al. 2014; Kim et al. 2010; Samad et al. 2006) were also altered while LPCs showed a mixed behavior. At present, hyperlipidemic conditions are monitored routinely by the measurement of cholesterol and TAG in total plasma, LDL, and HDL. However, lipidomics demonstrated that besides cholesterol also other lipid classes and lipid species of the plasma lipidome are associated with the risk for CVD (Razquin et al. 2018). In particular plasma levels of ceramides show a positive association with the risk of CVD (Laaksonen et al. 2016). Ceramides are primarily present in LDL and may influence the function and atherogenicity of LDL. In fact, LDL extracted from human atherosclerosis lesions are highly enriched in ceramides (Schissel et al. 1996), and animal studies showed a decrease in atherosclerotic lesion size when ceramide synthesis was inhibited (Hojjati et al. 2005).
Relatively few studies have compared the lipidomics profile of lipoproteins in relation to CVD outcomes. Higher TAGs, lower PUFAs, lower phospholipids, and lower sphingomyelin (SM) in HDL may be associated with higher risks of CVD and type 2 diabetes (T2D), although it is currently unknown whether these associations are confounded by HDL-C. In two studies, a low HDL-C has been associated with higher TAGs, lower PUFAs, lower LPC, and lower SM levels (Kontush et al. 2013). Another study found that, compared to participants without CVD or at early stages of CVD, participants with severe CVD had higher levels of short chain FAs in both HDL and non-HDL particles. PC and SM levels were lower in HDL, and PUFAs reduced in non-HDL particles. Additionally, two studies showed that lower levels of PC-plasmalogens were associated with a higher risk of CVD, particularly pf acute CVD (Meikle et al. 2019; Sutter et al. 2015).
Obesity also leads to increased lipolysis in adipose tissues and thus increases plasma level of FFAs (Haus et al. 2009). There is a direct relationship between increased intake of saturated fatty acids (e.g., lauric, myristic, or palmitic acid) and an increase in TAGs (Fernandez and West 2005; Steinberg 2005). Increased FFAs and MAGs in plasma can be attributed to an increased lipolysis of TAGs obtained from high fat diet (Ho and Storch 2001). Dietary saturated fatty acids have a tendency to increase TAG while polyunsaturated fatty acids have the ability to lower TAG and LDL-C (Siri-Tarino et al. 2010; Williams and Salter 2016). On the other hand, diets rich in SM were shown to specifically increase HDL-C without affecting other lipids (Ramprasath et al. 2013).
Mouse models of diet-induced obesity showed elevation in plasma ceramide level and alterations in PCs, LPCs, and SMs (Barber et al. 2012; Samad et al. 2006). Perturbation in lipid levels is also associated with both type 1 (T1D) (Fox et al. 2011; Sorensen et al. 2010) and type 2 diabetes (T2D) (Graessler et al. 2009; Barber et al. 2012; Samad et al. 2006). In diabetes, plasma levels of most LPC decrease, while PCs showed a mixed behavior. An important hallmark of T2D is an increase in plasma concentration of FFA (Barber et al. 2012; Samad et al. 2006), ceramides (Samad et al. 2006; Haus et al. 2009; Kang et al. 2013), and TAGs enriched with short chain saturated fatty acids (Rhee et al. 2011). Moreover, atypical 1-deoxy-Spingolipids (1-deoxySL) were found to be elevated in T2DM and showed a similar or even closer association with T2DM or metabolic syndrome than established markers such as waist circumference, glucose, triglycerides, HDL cholesterol, and blood pressure (Bertea et al. 2010; Othman et al. 2012; Othman et al. 2015a). Further studies showed that elevated plasma 1-deoxySL levels are strong and independent risk predictors of future T2DM, especially for non-obese individuals in the general population (Mwinyi et al. 2017). Plasma C20-Sphingolipids were also shown to indicate cardiovascular events independently from conventional cardiovascular risk factors in patients undergoing coronary angiography (Othman et al. 2015b).
High-throughput lipidomics analyses were recently applied to plasma samples of 10,339 participants from the Australian Diabetes, Obesity and Lifestyle Study (AusDiab) (Huynh et al. 2019; Beyene and Olshansky 2020). The data were validated in a second cohort with 4,207 participants (the Busselton Health Study) (Beyene and Olshansky 2020). The studies showed differences in the plasma lipidome related to metabolic disease and gender. A class of specific ether-phospholipids and lysophospholipids were inversely associated with age in men. The comparison of post- and premenopausal women showed higher TAG and lower lysoPC species in the postmenopausal group. Lysophospholipids were negatively associated with BMI in both sexes (with a larger effect size in men). Based on specific lipid ratios the authors identified the lipid metabolizing enzymes stearoyl CoA desaturase (SCD-1), fatty acid desaturase 3 (FADS3), and plasmanylethanolamine Δ1-desaturase, as well as the sphingolipid metabolic pathway as relevant factors associated with cardiometabolic phenotypes.
In conclusion, MS-based lipid analysis combined with bioinformatics tools have revolutionized the field of lipidomics. Thanks to commercial and freely available software packages that allow automatic peak detection, alignment, and feature annotation using public or proprietary databases to study large cohorts of patients and identify novel biomarkers which are getting increasingly important particularly in the growing field of precision and personalized medicine.
References
Aichler M, Walch A (2015) MALDI imaging mass spectrometry: current frontiers and perspectives in pathology research and practice. Lab Investig 95:422–431
Bamba T, Lee JW, Matsubara A, Fukusaki E (2012) Metabolic profiling of lipids by supercritical fluid chromatography/mass spectrometry. J Chromatogr A 1250:212–219
Barber MN, Risis S, Yang C, Meikle PJ, Staples M, Febbraio MA, Bruce CR (2012) Plasma lysophosphatidylcholine levels are reduced in obesity and type 2 diabetes. PLoS One 7:e41456
Bertea M, Rutti MF, Othman A, Marti-Jaun J, Hersberger M, von Eckardstein A, Hornemann T (2010) Deoxysphingoid bases as plasma markers in diabetes mellitus. Lipids Health Dis 9:84
Beyene HB, Olshansky G, Adam Alexander TS, Giles C, Huynh K, Cinel M, Mellett NA, Cadby G, Hung J, Hui J et al (2020) High-coverage plasma lipidomics reveals novel sex-specific lipidomic fingerprints of age and BMI: evidence from two large population cohort studies. PLoS Biol 18:e3000870
Bielawski J, Pierce JS, Snider J, Rembiesa B, Szulc ZM, Bielawska A (2009) Comprehensive quantitative analysis of bioactive sphingolipids by high-performance liquid chromatography-tandem mass spectrometry. Methods Mol Biol 579:443–467
Bird SS, Marur VR, Sniatynski MJ, Greenberg HK, Kristal BS (2011a) Serum lipidomics profiling using LC-MS and high-energy collisional dissociation fragmentation: focus on triglyceride detection and characterization. Anal Chem 83:6648–6657
Bird SS, Marur VR, Sniatynski MJ, Greenberg HK, Kristal BS (2011b) Lipidomics profiling by high-resolution LC-MS and high-energy collisional dissociation fragmentation: focus on characterization of mitochondrial cardiolipins and monolysocardiolipins. Anal Chem 83:940–949
Bird SS, Marur VR, Stavrovskaya IG, Kristal BS (2012) Separation of cis-trans phospholipid isomers using reversed phase LC with high resolution MS detection. Anal Chem 84:5509–5517
Bird SS, Marur VR, Stavrovskaya IG, Kristal BS (2013) Qualitative characterization of the rat liver mitochondrial lipidome using LC-MS profiling and high energy collisional dissociation (HCD) all ion fragmentation. Metabolomics 9:67–83
Bird SS, Stavrovskaya IG, Gathungu RM, Tousi F, Kristal BS (2015) Qualitative characterization of the rat liver mitochondrial lipidome using all ion fragmentation on an Exactive benchtop Orbitrap MS. Methods Mol Biol 1264:441–452
Bligh EG, Dyer WJ (1959) A rapid method of total lipid extraction and purification. Can J Biochem Physiol 37:911–917
Cajka T, Fiehn O (2017) LC-MS-based lipidomics and automated identification of lipids using the LipidBlast in-silico MS/MS library. Methods Mol Biol 1609:149–170
Cardner M, Yalcinkaya M, Goetze S, Luca E, Balaz M, Hunjadi M, Hartung J, Shemet A, Krankel N, Radosavljevic S et al (2020) Structure-function relationships of HDL in diabetes and coronary heart disease. JCI Insight 5:e131491
Cavojsky T, Bilka F, Paulikova I (2016) The relationship of lipid imbalance and chronic inflammation mediated by PPAR. Ceska Slov Farm 65:3–9
Christinat N, Masoodi M (2017) Comprehensive lipoprotein characterization using lipidomics analysis of human plasma. J Proteome Res 16:2947–2953
Cowart LA (2009) Sphingolipids: players in the pathology of metabolic disease. Trends Endocrinol Metab 20:34–42
Danne-Rasche N, Coman C, Ahrends R (2018) Nano-LC/NSI MS refines lipidomics by enhancing lipid coverage, measurement sensitivity, and linear dynamic range. Anal Chem 90:8093–8101
De Castro-Oros I, Pocovi M, Civeira F (2010) The genetic basis of familial hypercholesterolemia: inheritance, linkage, and mutations. Appl Clin Genet 3:53–64
Deevska GM, Nikolova-Karakashian MN (2011) The twists and turns of sphingolipid pathway in glucose regulation. Biochimie 93(1):32–38
Donovan EL, Pettine SM, Hickey MS, Hamilton KL, Miller BF (2013) Lipidomic analysis of human plasma reveals ether-linked lipids that are elevated in morbidly obese humans compared to lean. Diabetol Metab Syndr 5:24
Eisinger K, Liebisch G, Schmitz G, Aslanidis C, Krautbauer S, Buechler C (2014) Lipidomic analysis of serum from high fat diet induced obese mice. Int J Mol Sci 15:2991–3002
Ejsing CS, Sampaio JL, Surendranath V, Duchoslav E, Ekroos K, Klemm RW, Simons K, Shevchenko A (2009) Global analysis of the yeast lipidome by quantitative shotgun mass spectrometry. Proc Natl Acad Sci U S A 106:2136–2141
Ellervik C, Vaught J (2015) Preanalytical variables affecting the integrity of human biospecimens in biobanking. Clin Chem 61:914–934
Fahy E, Subramaniam S, Brown HA, Glass CK, Merrill AH Jr, Murphy RC, Raetz CR, Russell DW, Seyama Y, Shaw W et al (2005) A comprehensive classification system for lipids. J Lipid Res 46:839–861
Fahy E, Subramaniam S, Murphy RC, Nishijima M, Raetz CR, Shimizu T, Spener F, van Meer G, Wakelam MJ, Dennis EA (2009) Update of the LIPID MAPS comprehensive classification system for lipids. J Lipid Res 50(Suppl):S9–S14
Fernandez ML, West KL (2005) Mechanisms by which dietary fatty acids modulate plasma lipids. J Nutr 135:2075–2078
Folch J, Lees M, Sloane Stanley GH (1957) A simple method for the isolation and purification of total lipides from animal tissues. J Biol Chem 226:497–509
Fox TE, Bewley MC, Unrath KA, Pedersen MM, Anderson RE, Jung DY, Jefferson LS, Kim JK, Bronson SK, Flanagan JM, Kester M (2011) Circulating sphingolipid biomarkers in models of type 1 diabetes. J Lipid Res 52:509–517
Graessler J, Schwudke D, Schwarz PE, Herzog R, Shevchenko A, Bornstein SR (2009) Top-down lipidomics reveals ether lipid deficiency in blood plasma of hypertensive patients. PLoS One 4:e6261
Guittard J, Hronowski XL, Costello CE (1999) Direct matrix-assisted laser desorption/ionization mass spectrometric analysis of glycosphingolipids on thin layer chromatographic plates and transfer membranes. Rapid Commun Mass Spectrom 13:1838–1849
Guo Y, Wang X, Qiu L, Qin X, Liu H, Wang Y, Li F, Wang X, Chen G, Song G et al (2012) Probing gender-specific lipid metabolites and diagnostic biomarkers for lung cancer using Fourier transform ion cyclotron resonance mass spectrometry. Clin Chim Acta 414:135–141
Haid M, Muschet C, Wahl S, Romisch-Margl W, Prehn C, Moller G, Adamski J (2018) Long-term stability of human plasma metabolites during storage at −80 degrees C. J Proteome Res 17:203–211
Hamm CW, Bassand JP, Agewall S, Bax J, Boersma E, Bueno H, Caso P, Dudek D, Gielen S, Huber K et al (2012) ESC guidelines for the management of acute coronary syndromes in patients presenting without persistent ST-segment elevation. The task force for the management of acute coronary syndromes (ACS) in patients presenting without persistent ST-segment elevation of the European Society of Cardiology (ESC). G Ital Cardiol (Rome) 13:171–228
Hammad SM, Pierce JS, Soodavar F, Smith KJ, Al Gadban MM, Rembiesa B, Klein RL, Hannun YA, Bielawski J, Bielawska A (2010) Blood sphingolipidomics in healthy humans: impact of sample collection methodology. J Lipid Res 51:3074–3087
Han X, Gross RW (1994) Electrospray ionization mass spectroscopic analysis of human erythrocyte plasma membrane phospholipids. Proc Natl Acad Sci U S A 91:10635–10639
Han X, Gross RW (2003) Global analyses of cellular lipidomes directly from crude extracts of biological samples by ESI mass spectrometry: a bridge to lipidomics. J Lipid Res 44:1071–1079
Hanamatsu H, Ohnishi S, Sakai S, Yuyama K, Mitsutake S, Takeda H, Hashino S, Igarashi Y (2014) Altered levels of serum sphingomyelin and ceramide containing distinct acyl chains in young obese adults. Nutr Diabetes 4:e141
Haus JM, Kashyap SR, Kasumov T, Zhang R, Kelly KR, Defronzo RA, Kirwan JP (2009) Plasma ceramides are elevated in obese subjects with type 2 diabetes and correlate with the severity of insulin resistance. Diabetes 58:337–343
Ho SY, Storch J (2001) Common mechanisms of monoacylglycerol and fatty acid uptake by human intestinal Caco-2 cells. Am J Physiol Cell Physiol 281:C1106–C1117
Hojjati MR, Li Z, Zhou H, Tang S, Huan C, Ooi E, Lu S, Jiang XC (2005) Effect of myriocin on plasma sphingolipid metabolism and atherosclerosis in apoE-deficient mice. J Biol Chem 280:10284–10289
Hu C, van Dommelen J, van der Heijden R, Spijksma G, Reijmers TH, Wang M, Slee E, Lu X, Xu G, van der Greef J, Hankemeier T (2008) RPLC-ion-trap-FTMS method for lipid profiling of plasma: method validation and application to p53 mutant mouse model. J Proteome Res 7:4982–4991
Huynh K, Barlow CK, Jayawardana KS, Weir JM, Mellett NA, Cinel M, Magliano DJ, Shaw JE, Drew BG, Meikle PJ (2019) High-throughput plasma lipidomics: detailed mapping of the associations with cardiometabolic risk factors. Cell Chem Biol 26:71–84.e74
Jang R, Kim KH, Zaidi SA, Cheong WJ, Moon MH (2011) Analysis of phospholipids using an open-tubular capillary column with a monolithic layer of molecularly imprinted polymer in capillary electrochromatography-electrospray ionization-tandem mass spectrometry. Electrophoresis 32:2167–2173
Jung UJ, Choi MS (2014) Obesity and its metabolic complications: the role of adipokines and the relationship between obesity, inflammation, insulin resistance, dyslipidemia and nonalcoholic fatty liver disease. Int J Mol Sci 15:6184–6223
Junot C, Fenaille F, Colsch B, Becher F (2014) High resolution mass spectrometry based techniques at the crossroads of metabolic pathways. Mass Spectrom Rev 33:471–500
Kang SC, Kim BR, Lee SY, Park TS (2013) Sphingolipid metabolism and obesity-induced inflammation. Front Endocrinol (Lausanne) 4:67
Katajamaa M, Miettinen J, Oresic M (2006) MZmine: toolbox for processing and visualization of mass spectrometry based molecular profile data. Bioinformatics 22:634–636
Kim JY, Park JY, Kim OY, Ham BM, Kim HJ, Kwon DY, Jang Y, Lee JH (2010) Metabolic profiling of plasma in overweight/obese and lean men using ultra performance liquid chromatography and Q-TOF mass spectrometry (UPLC-Q-TOF MS). J Proteome Res 9:4368–4375
Kliman M, May JC, McLean JA (2011) Lipid analysis and lipidomics by structurally selective ion mobility-mass spectrometry. Biochim Biophys Acta 1811:935–945
Kolter T, Sandhoff K (2006) Sphingolipid metabolism diseases. Biochim Biophys Acta 1758:2057–2079
Kontush A, Lhomme M, Chapman MJ (2013) Unraveling the complexities of the HDL lipidome. J Lipid Res 54:2950–2963
Laaksonen R, Ekroos K, Sysi-Aho M, Hilvo M, Vihervaara T, Kauhanen D, Suoniemi M, Hurme R, Marz W, Scharnagl H et al (2016) Plasma ceramides predict cardiovascular death in patients with stable coronary artery disease and acute coronary syndromes beyond LDL-cholesterol. Eur Heart J 37:1967–1976
Li F, Qin X, Chen H, Qiu L, Guo Y, Liu H, Chen G, Song G, Wang X, Li F et al (2013) Lipid profiling for early diagnosis and progression of colorectal cancer using direct-infusion electrospray ionization Fourier transform ion cyclotron resonance mass spectrometry. Rapid Commun Mass Spectrom 27:24–34
Liland KH, Almoy T, Mevik BH (2010) Optimal choice of baseline correction for multivariate calibration of spectra. Appl Spectrosc 64:1007–1016
Lofgren L, Stahlman M, Forsberg GB, Saarinen S, Nilsson R, Hansson GI (2012) The BUME method: a novel automated chloroform-free 96-well total lipid extraction method for blood plasma. J Lipid Res 53:1690–1700
Meikle PJ, Formosa MF, Mellett NA, Jayawardana KS, Giles C, Bertovic DA, Jennings GL, Childs W, Reddy M, Carey AL et al (2019) HDL phospholipids, but not cholesterol distinguish acute coronary syndrome from stable coronary artery disease. J Am Heart Assoc 8:e011792
Merrill AH Jr, Sullards MC, Allegood JC, Kelly S, Wang E (2005) Sphingolipidomics: high-throughput, structure-specific, and quantitative analysis of sphingolipids by liquid chromatography tandem mass spectrometry. Methods 36:207–224
Morrow DA (2010) Cardiovascular risk prediction in patients with stable and unstable coronary heart disease. Circulation 121:2681–2691
Murphy RC, Axelsen PH (2011) Mass spectrometric analysis of long-chain lipids. Mass Spectrom Rev 30:579–599
Murphy RC, Gaskell SJ (2011) New applications of mass spectrometry in lipid analysis. J Biol Chem 286:25427–25433
Mwinyi J, Bostrom A, Fehrer I, Othman A, Waeber G, Marti-Soler H, Vollenweider P, Marques-Vidal P, Schioth HB, von Eckardstein A, Hornemann T (2017) Plasma 1-deoxysphingolipids are early predictors of incident type 2 diabetes mellitus. PLoS One 12:e0175776
Othman A, Rutti MF, Ernst D, Saely CH, Rein P, Drexel H, Porretta-Serapiglia C, Lauria G, Bianchi R, von Eckardstein A, Hornemann T (2012) Plasma deoxysphingolipids: a novel class of biomarkers for the metabolic syndrome? Diabetologia 55:421–431
Othman A, Saely CH, Muendlein A, Vonbank A, Drexel H, von Eckardstein A, Hornemann T (2015a) Plasma 1-deoxysphingolipids are predictive biomarkers for type 2 diabetes mellitus. BMJ Open Diabetes Res Care 3:e000073
Othman A, Saely CH, Muendlein A, Vonbank A, Drexel H, von Eckardstein A, Hornemann T (2015b) Plasma C20-sphingolipids predict cardiovascular events independently from conventional cardiovascular risk factors in patients undergoing coronary angiography. Atherosclerosis 240:216–221
Puri R, Nissen SE, Libby P, Shao M, Ballantyne CM, Barter PJ, Chapman MJ, Erbel R, Raichlen JS, Uno K et al (2013) C-reactive protein, but not low-density lipoprotein cholesterol levels, associate with coronary atheroma regression and cardiovascular events after maximally intensive statin therapy. Circulation 128:2395–2403
Quehenberger O, Dennis EA (2011) The human plasma lipidome. N Engl J Med 365:1812–1823
Quehenberger O, Armando AM, Brown AH, Milne SB, Myers DS, Merrill AH, Bandyopadhyay S, Jones KN, Kelly S, Shaner RL et al (2010) Lipidomics reveals a remarkable diversity of lipids in human plasma. J Lipid Res 51:3299–3305
Ramprasath VR, Jones PJ, Buckley DD, Woollett LA, Heubi JE (2013) Effect of dietary sphingomyelin on absorption and fractional synthetic rate of cholesterol and serum lipid profile in humans. Lipids Health Dis 12:125
Razquin C, Liang L, Toledo E, Clish CB, Ruiz-Canela M, Zheng Y, Wang DD, Corella D, Castaner O, Ros E et al (2018) Plasma lipidome patterns associated with cardiovascular risk in the PREDIMED trial: a case-cohort study. Int J Cardiol 253:126–132
Rhee EP, Cheng S, Larson MG, Walford GA, Lewis GD, McCabe E, Yang E, Farrell L, Fox CS, O'Donnell CJ et al (2011) Lipid profiling identifies a triacylglycerol signature of insulin resistance and improves diabetes prediction in humans. J Clin Invest 121:1402–1411
Samad F, Hester KD, Yang G, Hannun YA, Bielawski J (2006) Altered adipose and plasma sphingolipid metabolism in obesity: a potential mechanism for cardiovascular and metabolic risk. Diabetes 55:2579–2587
Sandhoff K, Harzer K (2013) Gangliosides and gangliosidoses: principles of molecular and metabolic pathogenesis. J Neurosci 33:10195–10208
Schissel SL, Tweedie-Hardman J, Rapp JH, Graham G, Williams KJ, Tabas I (1996) Rabbit aorta and human atherosclerotic lesions hydrolyze the sphingomyelin of retained low-density lipoprotein. Proposed role for arterial-wall sphingomyelinase in subendothelial retention and aggregation of atherogenic lipoproteins. J Clin Invest 98:1455–1464
Schmelzer K, Fahy E, Subramaniam S, Dennis EA (2007) The lipid maps initiative in lipidomics. Methods Enzymol 432:171–183
Schwudke D, Schuhmann K, Herzog R, Bornstein SR, Shevchenko A (2011) Shotgun lipidomics on high resolution mass spectrometers. Cold Spring Harb Perspect Biol 3:a004614
Shih WJ, Bachorik PS, Haga JA, Myers GL, Stein EA (2000) Estimating the long-term effects of storage at −70 degrees C on cholesterol, triglyceride, and HDL-cholesterol measurements in stored sera. Clin Chem 46:351–364
Shiota Y, Kiyota K, Kobayashi T, Kano S, Kawamura M, Matsushima T, Miyazaki S, Uchino K, Hashimoto F, Hayashi H (2008) Distribution of dolichol in the serum and relationships between serum dolichol levels and various laboratory test values. Biol Pharm Bull 31:340–347
Siri-Tarino PW, Sun Q, Hu FB, Krauss RM (2010) Saturated fatty acids and risk of coronary heart disease: modulation by replacement nutrients. Curr Atheroscler Rep 12:384–390
Smith CA, Want EJ, O'Maille G, Abagyan R, Siuzdak G (2006) XCMS: processing mass spectrometry data for metabolite profiling using nonlinear peak alignment, matching, and identification. Anal Chem 78:779–787
Sorensen CM, Ding J, Zhang Q, Alquier T, Zhao R, Mueller PW, Smith RD, Metz TO (2010) Perturbations in the lipid profile of individuals with newly diagnosed type 1 diabetes mellitus: lipidomics analysis of a diabetes antibody standardization program sample subset. Clin Biochem 43:948–956
Stahlman M, Boren L, Ekross K (2012) High-throughput molecular lipidomics. In: Ekross K (ed) Lipidomics. Wiley-VCH Verlag GmbH & Co. KGaA, Weinheim, pp 35–51
Steinberg D (2005) Thematic review series: the pathogenesis of atherosclerosis. An interpretive history of the cholesterol controversy: part II: the early evidence linking hypercholesterolemia to coronary disease in humans. J Lipid Res 46:179–190
Steinberg D (2006) Thematic review series: the pathogenesis of atherosclerosis. An interpretive history of the cholesterol controversy, part V: the discovery of the statins and the end of the controversy. J Lipid Res 47:1339–1351
Summers SA (2006) Ceramides in insulin resistance and lipotoxicity. Prog Lipid Res 45:42–72
Sutter I, Velagapudi S, Othman A, Riwanto M, Manz J, Rohrer L, Rentsch K, Hornemann T, Landmesser U, von Eckardstein A (2015) Plasmalogens of high-density lipoproteins (HDL) are associated with coronary artery disease and anti-apoptotic activity of HDL. Atherosclerosis 241:539–546
Taguchi R, Ishikawa M (2010) Precise and global identification of phospholipid molecular species by an Orbitrap mass spectrometer and automated search engine lipid search. J Chromatogr A 1217:4229–4239
Tan L, Xing A, Zhao DL, Sun FR, Tan MS, Wan Y, Tan CC, Zhang W, Miao D, Yu JT, Tan L (2017) Strong association of lipid metabolism related microRNA binding sites polymorphisms with the risk of late onset Alzheimer’s disease. Curr Neurovasc Res 14:3–10
Watson AD (2006) Thematic review series: systems biology approaches to metabolic and cardiovascular disorders. Lipidomics: a global approach to lipid analysis in biological systems. J Lipid Res 47:2101–2111
Wenk MR (2005) The emerging field of lipidomics. Nat Rev Drug Discov 4:594–610
Williams CM, Salter A (2016) Saturated fatty acids and coronary heart disease risk: the debate goes on. Curr Opin Clin Nutr Metab Care 19:97–102
Xia J, Wishart DS (2016) Using MetaboAnalyst 3.0 for comprehensive metabolomics data analysis. Curr Protoc Bioinformatics 55:14 10 11–14 10 91
Acknowledgments
This work was supported by the Swiss Science Foundation (#31003A), the Herzog-Egli Stiftung, and the Swiss Life foundation. I also would like to thank Dr. A. Hülsmeier for his corrections and comments on this manuscript.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2021 The Author(s)
About this chapter

Cite this chapter
Hornemann, T. (2021). Lipidomics in Biomarker Research. In: von Eckardstein, A., Binder, C.J. (eds) Prevention and Treatment of Atherosclerosis . Handbook of Experimental Pharmacology, vol 270. Springer, Cham. https://doi.org/10.1007/164_2021_517
Download citation
DOI: https://doi.org/10.1007/164_2021_517
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-86075-2
Online ISBN: 978-3-030-86076-9
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)