
Abstract
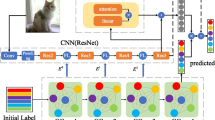
Vision Transformer (ViT) has achieved promising single-label image classification results compared to conventional neural network-based models. Nevertheless, few ViT related studies have explored the label dependencies in the multi-label image recognition field. To this end, we propose STMG that combines transformer and graph convolution network (GCN) to extract the image features and learn the label dependencies for multi-label image recognition. STMG consists of an image representation learning module and a label co-occurrence embedding module. Firstly, in the image representation learning module, to avoid computing the similarity between each two patches, we adopt Swin transformer instead of ViT to generate the image feature for each input image. Secondly, in the label co-occurrence embedding module, we design a two-layer GCN to adaptively capture the label dependencies to output the label co-occurrence embeddings. At last, STMG fuses the image feature and label co-occurrence embeddings to produce the image classification results with the commonly-used multi-label classification loss function and a L2-norm loss function. We conduct extensive experiments on two multi-label image datasets including MS-COCO and FLICKR25K. Experimental results demonstrate STMG can achieve better performance including the convergence efficiency and classification results compared to the state-of-the-art multi-label image recognition methods. Our code is open-sourced and publicly available on GitHub: https://github.com/lzHZWZ/STMG.








Similar content being viewed by others


References
Ba LJ, Kiros JR, Hinton GE (2016) Layer normalization. CoRR abs/1607.06450
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. In: Vedaldi A, Bischof H, Brox T, Frahm J (eds) Computer vision - ECCV 2020 - 16th European conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part I. Lecture Notes in Computer Science, vol 12346, Springer, pp. 213–229
Chen S, Chen Y, Yeh C, Wang YF (2018) Order-free RNN with visual attention for multi-label classification. In: McIlraith SA, Weinberger KQ (eds) Proceedings of the thirty-second AAAI conference on artificial intelligence, (AAAI-18), the 30th innovative Applications of Artificial Intelligence (IAAI-18), and the 8th aaai symposium on educational advances in artificial intelligence (EAAI-18), New Orleans, Louisiana, USA, February 2–7, 2018. AAAI Press, pp 6714–6721
Chen T, Xu M, Hui X, Wu H, Lin L (2019) Learning semantic-specific graph representation for multi-label image recognition. In: 2019 IEEE/CVF international conference on computer vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019. IEEE, pp 522–531
Chen Z, Wei X, Wang P, Guo Y (2019) Multi-label image recognition with graph convolutional networks. In: ieee conference on computer vision and pattern recognition, CVPR 2019, Long Beach, CA, USA, June 16–20, 2019. Computer Vision Foundation/IEEE, pp 5177–5186
Defferrard M, Bresson X, Vandergheynst P (2016) Convolutional neural networks on graphs with fast localized spectral filtering. In: D.D. Lee, M. Sugiyama, U. von Luxburg, I. Guyon, R. Garnett (eds.) Advances in Neural Information Processing Systems 29: Annual Conference on Neural Information Processing Systems 2016, December 5-10, 2016, Barcelona, Spain, pp. 3837–3845
Deng J, Dong W, Socher R, Li L, Li K, Li F (2009) Imagenet: a large-scale hierarchical image database. In: 2009 IEEE computer society conference on computer vision and pattern recognition (CVPR 2009), 20–25 June 2009, Miami, Florida, USA. IEEE Computer Society, pp 248–255
Devlin J, Chang M, Lee K, Toutanova K (2018) BERT: pre-training of deep bidirectional transformers for language understanding. CoRR abs/1810.04805
Devlin J, Chang M, Lee K, Toutanova K (2019) BERT: pre-training of deep bidirectional transformers for language understanding. In: Burstein J, Doran C, Solorio T (eds) Proceedings of the 2019 conference of the north american chapter of the association for computational linguistics: human language technologies, NAACL-HLT 2019, Minneapolis, MN, USA, June 2–7, 2019, vol 1 (Long and Short Papers). pp 4171–4186. Association for Computational Linguistics
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N (2020) An image is worth 16x16 words: transformers for image recognition at scale. CoRR abs/2010.11929
Ge W, Yang S, Yu Y (2018) Multi-evidence filtering and fusion for multi-label classification, object detection and semantic segmentation based on weakly supervised learning. In: 2018 IEEE conference on computer vision and pattern recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018. IEEE Computer Society, pp 1277–1286
Girdhar R, Carreira J, Doersch C, Zisserman A (2019) Video action transformer network. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16–20, 2019. Computer Vision Foundation/IEEE, pp 244–253
Guo H, Zheng K, Fan X, Yu H, Wang S (2019) Visual attention consistency under image transforms for multi-label image classification. In: IEEE conference on computer vision and pattern recognition, CVPR 2019, Long Beach, CA, USA, June 16–20, 2019. Computer Vision Foundation/IEEE, pp 729–739
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016, Las Vegas, NV, USA, June 27–30, 2016. IEEE Computer Society, pp 770–778
He T, Jin X (2019) Image emotion distribution learning with graph convolutional networks. In: El-Saddik A, Bimbo, AD, Zhang Z, Hauptmann AG, Candan KS, Bertini M, Xie L, Wei X (eds) Proceedings of the 2019 on international conference on multimedia retrieval, ICMR 2019, Ottawa, ON, Canada, June 10–13, 2019. ACM, pp 382–390
Huiskes MJ, Lew MS (2008) The MIR flickr retrieval evaluation. In: Lew MS, Bimbo AD, Bakker EM (eds) Proceedings of the 1st ACM SIGMM international conference on multimedia information retrieval, MIR 2008, Vancouver, British Columbia, Canada, October 30–31, 2008. ACM, pp 39–43
Kipf TN, Welling M (2017) Semi-supervised classification with graph convolutional networks. In: 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24–26, 2017, Conference Track Proceedings. OpenReview.net
Lee C, Fang W, Yeh C, Wang YF (2018) Multi-label zero-shot learning with structured knowledge graphs. In: 2018 IEEE conference on computer vision and pattern recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018. IEEE Computer Society, pp 1576–1585
Li Q, Peng X, Qiao Y, Peng Q (2020) Learning label correlations for multi-label image recognition with graph networks. Pattern Recognit Lett 138:378–384
Lin T. Maire M, Belongie SJ, Hays J, Perona P, Ramanan D, Dollár P, Zitnick CL: Microsoft COCO: common objects in context. In: Fleet DJ, Pajdla T, Schiele B, Tuytelaars T (eds) Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6–12, 2014, Proceedings, Part V. Lecture Notes in Computer Science, vol 8693. Springer, pp 740–755 (2014)
Liu Z, Lin Y, Cao Y, Hu H, Wei Y, Zhang Z, Lin S, Guo B (2021) Swin transformer: hierarchical vision transformer using shifted windows. CoRR abs/2103.14030
Mikolov T, Chen K, Corrado G, Dean J (2013) Efficient estimation of word representations in vector space. In: Bengio Y, LeCun Y (eds) 1st International Conference on Learning Representations, ICLR 2013, Scottsdale, Arizona, USA, May 2–4, 2013, Workshop Track Proceedings
Neimark D, Bar O, Zohar M, Asselmann D (2021) Video transformer network. CoRR abs/2102.00719
Pennington J, Socher R, Manning CD (2014) Glove: Global vectors for word representation. In: Moschitti A, Pang B, Daelemans W (eds) Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, October 25--29, 2014, Doha, Qatar, A meeting of SIGDAT, a Special Interest Group of the ACL. ACL, pp 1532–1543
Sun C, Shrivastava A, Singh S, Gupta A (2017) Revisiting unreasonable effectiveness of data in deep learning era. In: IEEE international conference on computer vision, ICCV 2017, Venice, Italy, October 22–-29, 2017. IEEE Computer Society, pp 843–852
Szegedy C, Vanhoucke V, Ioffe S, Shlens J, Wojna Z (2016) Rethinking the inception architecture for computer vision. In: 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016, Las Vegas, NV, USA, June 27–30, 2016, IEEE Computer Society, pp 2818–2826
Tan H, Bansal M (2019) LXMERT: learning cross-modality encoder representations from transformers. In: Inui K, Jiang J, Ng V, Wan X (eds) Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing, EMNLP-IJCNLP 2019, Hong Kong, China, November 3–7, 2019. Association for Computational Linguistics, pp. 5099–5110
Touvron H, Cord M, Douze M, Massa F, Sablayrolles A, Jégou H (2020) Training data-efficient image transformers and distillation through attention. CoRR abs/2012.12877
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser L, Polosukhin I (2017) Attention is all you need. In: Guyon I, von Luxburg U, Bengio S, Wallach HM, Fergus R, Vishwanathan SVN, Garnett R (eds) Advances in neural information processing systems 30: annual conference on neural information processing systems 2017, December 4–9, 2017, Long Beach, CA, USA. pp 5998–6008
Wang J, Yang Y, Mao J, Huang Z, Huang C, Xu W (2016) CNN-RNN: A unified framework for multi-label image classification. In: 2016 IEEE conference on computer vision and pattern recognition, CVPR 2016, Las Vegas, NV, USA, June 27–30, 2016. IEEE Computer Society, pp 2285–2294
Wang X, Ye Y, Gupta A (2018) Zero-shot recognition via semantic embeddings and knowledge graphs. In: 2018 IEEE conference on computer vision and pattern recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018. IEEE Computer Society, pp 6857–6866
Wang Y, Song J, Zhou K, Liu Y (2021) Unsupervised deep hashing with node representation for image retrieval. Pattern Recognit 112:107785
Wang Y, Xie Y, Liu Y, Zhou K, Li X (2020) Fast graph convolution network-based multi-label image recognition via cross-modal fusion. In: d’Aquin M, Dietze S, Hauff C, Curry E, Cudré-Mauroux P (eds) CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, Ireland, October 19–23, 2020. ACM, pp 1575–1584
Wang Z, Chen T, Li G, Xu R, Lin L (2017) Multi-label image recognition by recurrently discovering attentional regions. In: IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22–29, 2017. IEEE Computer Society, pp. 464–472
Ye J, He J, Peng X, Wu W, Qiao Y (2020) Attention-driven dynamic graph convolutional network for multi-label image recognition. In: Vedaldi A, Bischof H, Brox T, Frahm J (eds) Computer vision - ECCV 2020 - 16th European cnference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXI. Lecture Notes in Computer Science, vol 12366. Springer, pp 649–665
Zheng S, Lu J, Zhao H, Zhu X, Luo Z, Wang Y, Fu Y, Feng J, Xiang T, Torr PHS, Zhang L (2020) Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers. CoRR abs/2012.15840
Zhu F, Li H, Ouyang W, Yu N, Wang X (2017) Learning spatial regularization with image-level supervisions for multi-label image classification. In: 2017 IEEE conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21–26, 2017. IEEE Computer Society, pp. 2027–2036
Acknowledgements
Thanks for the support of the National Natural Science Foundation of China No.61871139 and the International Science and Technology Cooperation Projects of Guangdong Province No.2020A0505100060.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, Y., Xie, Y., Fan, L. et al. STMG: Swin transformer for multi-label image recognition with graph convolution network. Neural Comput & Applic 34, 10051–10063 (2022). https://doi.org/10.1007/s00521-022-06990-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00521-022-06990-3