
Abstract
Purpose
With recent advances in artificial intelligence (AI), it has become crucial to thoroughly evaluate its applicability in healthcare. This study aimed to assess the accuracy of ChatGPT in diagnosing ear, nose, and throat (ENT) pathology, and comparing its performance to that of medical experts.
Methods
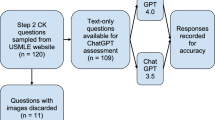
We conducted a cross-sectional comparative study where 32 ENT cases were presented to ChatGPT 3.5, ENT physicians, ENT residents, family medicine (FM) specialists, second-year medical students (Med2), and third-year medical students (Med3). Each participant provided three differential diagnoses. The study analyzed diagnostic accuracy rates and inter-rater agreement within and between participant groups and ChatGPT.
Results
The accuracy rate of ChatGPT was 70.8%, being not significantly different from ENT physicians or ENT residents. However, a significant difference in correctness rate existed between ChatGPT and FM specialists (49.8%, p < 0.001), and between ChatGPT and medical students (Med2 47.5%, p < 0.001; Med3 47%, p < 0.001). Inter-rater agreement for the differential diagnosis between ChatGPT and each participant group was either poor or fair. In 68.75% of cases, ChatGPT failed to mention the most critical diagnosis.
Conclusions
ChatGPT demonstrated accuracy comparable to that of ENT physicians and ENT residents in diagnosing ENT pathology, outperforming FM specialists, Med2 and Med3. However, it showed limitations in identifying the most critical diagnosis.

Similar content being viewed by others


Availability of data and materials
The data that support the findings of this study are available on request from the corresponding author.
Code availability
Not applicable.
Abbreviations
- AI:
-
Artificial intelligence
- ChatGPT:
-
Chat-based generative pre-trained transformer
- ENT:
-
Ear, nose, and throat
- FM:
-
Family medicine
- Med2:
-
Second-year medical students
- Med3:
-
Third-year medical students
References
Rao A, Pang M, Kim J, Kamineni M, Lie W, Prasad AK et al (2023) Assessing the utility of ChatGPT throughout the entire clinical workflow. Health Inform. https://doi.org/10.1101/2023.02.21.23285886
Liu J, Wang C, Liu S (2023) Utility of ChatGPT in clinical practice. J Med Internet Res 28(25):e48568
Duarte F (2023) Number of ChatGPT Users
Barat M, Soyer P, Dohan A (2023) Appropriateness of recommendations provided by ChatGPT to interventional radiologists. Can Assoc Radiol J 13:084653712311701
Strong E, DiGiammarino A, Weng Y, Basaviah P, Hosamani P, Kumar A et al (2023) Performance of ChatGPT on free-response, clinical reasoning exams. Med Educ. https://doi.org/10.1101/2023.03.24.23287731
AlGhamdi KM, Moussa NA (2012) Internet use by the public to search for health-related information. Int J Med Inf 81(6):363–373
Tonsaker T, Bartlett G, Trpkov C (2014) Health information on the Internet: gold mine or minefield? Can Fam Physician Med Fam Can 60(5):407–408
Emerick KS, Deschler DG (2006) Common ENT disorders. South Med J 99(10):1090–1099
Lechien JR, Georgescu BM, Hans S, Chiesa-Estomba CM (2023) ChatGPT performance in laryngology and head and neck surgery: a clinical case-series. Eur Arch Otorhinolaryngol. https://doi.org/10.1007/s00405-023-08282-5
Hoch CC, Wollenberg B, Lüers JC, Knoedler S, Knoedler L, Frank K et al (2023) ChatGPT’s quiz skills in different otolaryngology subspecialties: an analysis of 2576 single-choice and multiple-choice board certification preparation questions. Eur Arch Otorhinolaryngol 280(9):4271–4278
Hirosawa T, Harada Y, Yokose M, Sakamoto T, Kawamura R, Shimizu T (2023) Diagnostic Accuracy of differential-diagnosis lists generated by generative pretrained transformer 3 chatbot for clinical vignettes with common chief complaints: a pilot study. Int J Environ Res Public Health 20(4):3378
Qu RW, Qureshi U, Petersen G, Lee SC (2023) Diagnostic and management applications of ChatGPT in structured otolaryngology clinical scenarios. OTO Open 7(3):e67
Ravipati A, Pradeep T, Elman SA (2023) The role of artificial intelligence in dermatology: the promising but limited accuracy of ChatGPT in diagnosing clinical scenarios. Int J Dermatol. https://doi.org/10.1111/ijd.16746
Cao JJ, Kwon DH, Ghaziani TT, Kwo P, Tse G, Kesselman A et al (2023) Accuracy of information provided by ChatGPT regarding liver cancer surveillance and diagnosis. Am J Roentgenol 221(4):556–559
Massey PA, Montgomery C, Zhang AS (2023) Comparison of ChatGPT–35, ChatGPT-4, and orthopaedic resident performance on orthopaedic assessment examinations. J Am Acad Orthop Surg 31(23):1173–1179
Acknowledgements
No acknowledgements
Funding
This manuscript is not supported by any grant.
Author information
Authors and Affiliations
Contributions
All authors contributed to the study conception and design. Material preparation, data collection and analysis were performed by MM, AM, PEK, CEH, and NM. The first draft of the manuscript was written by MM and all authors commented on previous versions of the manuscript. All authors read and approved the final manuscript. MM and AM revised the manuscript after reviewer comments.
Corresponding author
Ethics declarations
Conflict of interest
All authors have no conflicts of interest to disclose.
Ethics approval
This study received approval from the Hotel Dieu de France Ethical Committee (CEHDF 2219).
Informed consent
Written informed consent was obtained from each participant.
Consent to participate
Not applicable.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Makhoul, M., Melkane, A.E., Khoury, P.E. et al. A cross-sectional comparative study: ChatGPT 3.5 versus diverse levels of medical experts in the diagnosis of ENT diseases. Eur Arch Otorhinolaryngol 281, 2717–2721 (2024). https://doi.org/10.1007/s00405-024-08509-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00405-024-08509-z