
Abstract
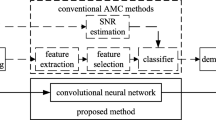
Deep learning method has been gradually applied to Automatic Modulation Classification (AMC) because of its excellent performance. In this paper, a lightweight one-dimensional convolutional neural network module (OnedimCNN) is proposed. We explore the recognition effects of this module and other different neural networks on IQ features and AP features. We conclude that the two features are complementary under high and low SNR. Therefore, we use this module and probabilistic principal component analysis (PPCA) to fuse the two features, and propose a one-dimensional convolution feature fusion network (FF-Onedimcnn). Simulation results show that the overall recognition rate of this model is improved by about 10%, and compared with other automatic modulation classification (AMC) network models, our model has the lowest complexity and the highest accuracy.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Automatic modulation classification has broad application value in both commercial and military applications. On the business side, The number of connected devices has been growing exponentially over the past decade. Cisco [1] predicts that machine-to-machine (M2M) connections will account for half of the connected devices in the world by 2023, and the massive number of devices will put great pressure on the spectrum resources, signaling overhead and energy consumption of base stations [2, 3]. To address these challenges, software defined radio (SDR), cognitive radio (CR) and adaptive regulation systems have been extensively studied. In the military aspect, especially in the process of unmanned aerial vehicle system signal reconnaissance, how to accurately and quickly judge the modulation type of the received signal under the condition of non-cooperative communication is very important for the real-time processing of the subsequent signal.
Deep learning (DL) can automatically learn advanced features. It has received much attention for its excellent performance in complex and deep architecture identification tasks. O‘Shea [4] first proposed the use of CNNs to classify the modulation of raw signal samples generated using GNU radio, and their later publication [5] introduced a richer radio (OTA) data set that included a wider range of modulation types in real-world environments. To cope with a more complex realistic environment and reduce the influence of channels on transmitted signals, an improved CNN method is proposed in [6] to correct signal distortion that may occur in wireless channels. In [7], a channel estimator based on neural network is designed to find the inverse channel response and improve the accuracy of the network by reducing the influence of channel fading [8]. Based on the theoretical knowledge of signal parameter estimation, a parameter estimator is introduced to extract information related to phase offset and transform phase parameters. In terms of lightweight network design, [9] proposed a lightweight end-to-end AMC model lightweight deep neural network (LDNN) through a new group-level sparsity induced norm. [10] proposed convolutional neural network (CNN) and convolutional Long and short Term Deep neural Network (CLDNN),Reduce the parameters in the network while maintaining reasonable accuracy. One-dimensional convolutional neural network is utilized in [11], and one-dimensional convolutional neural network achieves good performance only through original I/Q samples.In terms of feature fusion, [12] proposed two ideas of feature fusion. Firstly, the received radar signal is fused with the image fusion algorithm of non-multi-scale decomposition, The image of a single signal is combined with different time-frequency (T-F) methods. Using the convolutional neural network (CNN) based on transfer learning and stacked autoencoder (SAE) based on self-training, the sufficient information of fusion image is extracted [13]. Combining the advantages of convolutional neural network (CNN) and long and short term memory (LSTM), features are extracted from the I/Q stream and A/P stream to improve performance.
The contributions of this paper are summarized as follows:
-
A lightweight one-dimensional convolutional neural network module is proposed. The one-dimensional convolutional neural network can better extract the features of data flow. Experiments show that this single module can achieve recognition accuracy comparable to other network models, but with the most minor parameters.
-
The performance of different neural network models on I/Q time series and A/P time series is explored. Two conclusions can be drawn from the experimental results. First, it verifies that the proposed network module performs best in two input features. Second, the input features of the I/Q time series and the A/P time series can complement each other at low SNR and high SNR.
-
According to the proposed one-dimensional convolutional neural network module and the method of probabilistic principal component analysis (PPCA) to fuse the two features, we designed a one-dimensional convolutional feature fusion network model (FF-OnedimCNN). Experimental results show that this model has more advantages in both accuracy and complexity.
2 Signal Model and Preprocessing
2.1 Signal Model
After the signal passes through the channel and is sampled discretely, the equivalent baseband signal can be expressed as follows:
where \(s(u)\) is the transmitting symbol sequence, \(h(nT)\) is the channel response function, \(T\) is the symbol interval, \(\varepsilon\) represents synchronization error, \(f_{0}\) represents frequency offset, \(\theta_{n}\) represents phase jitter, \(g(n)\) represents noise, and \(\sum\limits_{u}^{L - 1} {s(u)h(nT - } uT)\) represents symbol interference.
2.2 Signal Preprocessing
In this paper, the I/Q format of the original complex sample is mainly converted to A/P format; in other words, the original sample is converted from I/Q coordinates to polar coordinates [7]. In literature [15], the author directly mapped the received complex symbols to the constellation map on the complex plane as features and achieved good performance. Although this method is practical and straightforward, learning features from images on the I-Q plane loses the domain knowledge and available features of the communication system. Obviously, the constellation of QPSK can be regarded as a subgraph of 8PSK, as shown in Fig. 1(a) and (b), which will lead to their wrong classification. Therefore, preprocessing the original sample can improve the recognition accuracy. We define \(r\) as a signal segment, and the receiving and sampling period T is described in the previous section. The I/Q symbol sequence can be regarded as a sampling sequence with time step, \(n = 1,...,N\), which can be expressed as:
The instantaneous amplitude of the signal is defined as:
The instantaneous phase of the signal is defined as:
Although the I/Q components have been normalized, it is still necessary to normalize them after the amplitude and phase data are obtained from the I/Q components through the standard formula; otherwise the model will perform poorly. The I/Q component of the original sample is transformed into an A/P component, as shown in Fig. 1(c) and (d).

(a) QPSK constellation diagram; (b) 8PSK constellation diagram; (c) 16QAM I/Q sequence waveform at SNR 12; (d) 16QAM A/P sequence waveform at SNR 12
3 The Proposed Modulation Classification Method
3.1 The Proposed One-Dimensional Convolutional Neural Network Module
The one-dimensional convolutional neural network module proposed is shown in Fig. 2. We train eight kinds of modulation signals on the RadioML data set. After the original data is preprocessed, we get two characteristic data sets, namely the I/Q sequence data set and the A/P sequence data set. For the I/Q sequence dataset, each data sample is an I/Q sampling sequence with 128-time steps, represented by a 2 × 128 matrix. The specific process of each layer is as follows:
-
Input layer: The input layer of the network needs to transform the original 2 × 128 matrix into a 128 × 2 matrix, so as to input it into the one-dimensional convolution layer.
-
The first 1D CNN layer: the first layer defines a filter (also called feature detector) of height 4 (also called convolution kernel size). We defined eight filters. So we have eight different features trained in the first layer of the network. The output of the first neural network layer is a 128 × 8 matrix. Each column of the output matrix contains the weight of a filter. When defining the kernel size and considering the length of the input matrix, each filter will contain 72 weight values.
-
Second 1D CNN layer: The output of the first CNN will be input into the second CNN layer. We will define 16 different filters again on this network layer for training. Following the same logic as the first layer, the output matrix is 128 × 16 in size. Each filter will contain 528 weight values.
-
Third and fourth 1D CNN layers: To learn higher-level features, two additional 1D CNN layers are used here. The output matrix after these two layers is a 128 × 64 matrix.
-
Global average pooling layer: After passing four 1D CNN layers, we add a GlobalAveragePooling1D layer to prevent over-fitting. The difference between GlobalAveragePooling and our average pooling is thatGlobalAveragePooling averages each feature map internally.
-
Dropout layer: The Dropout layer randomly assigns zero weights to neurons in the network. If we choose a ratio of 0.5, 50% of the neurons will be weighted to zero. By doing this, the network is sensitive to small changes in data.
-
The full connection layer is activated by Softmax: finally, after two full connection layers, the number of filters is 256 and 8, respectively. After the global average pooling layer, a vector with a length of 64 is obtained. After the full connection layer, the probability of occurrence of each type in 8 modulation types is obtained.

Module structure of one-dimensional convolutional neural network
3.2 Datesets and Implementation Process
The three RF radioML datasets are available here: https://www.deepsig.ai/datasets. 2016.04C and 2016.10A data sets contain 11 types of modulation schemes with SNR ranging from −20 dB to 18 dB. Each data sample is an I/Q time series with 128-time steps, and the modulation signal is stored as a 2 × 128 I/Q vector. Data sets are simulated in real channel defects (generated by GNU radio), and the detailed process of data set generation can be found in O‘Shea et al.‘s paper [16]. There are eight digital modulation classes (BPSK, QPSK, 8PSK, PAM4, QAM16, QAM64, GFSK, CPFSK) and three analog modulation classes (WBFM, AM-DSB, AM-SSB).After a detailed exploration of three data sets. We found defects in 2016.04C and 2018.01A data sets. 2016.04C data sets were not normalized correctly. QAM16 and QAM64 occupied A larger range in value than other modulation types, while 2016.10A data were within ±0.02 on both axes.2018.01A contains 24 modulation types, but some of them are incorrectly marked. In addition, the analog modulation of the three data sets is almost impossible to distinguish between the analog modulation because the voice recording is paused. Therefore, digital modulation in 2016.10A dataset was selected for training and testing.
We divide the digital modulation data set in 2016.10A data set into training set (67%), verification set (13%) and test set (20%). Due to the limitation of memory, the batch size of time series data input is 512 and the training period is 200. In this paper, Adam optimizer is used to optimize the network, and the initial learning rate is set to 0.001. GPU environment of all programs is NVIDIA Quadro P4000.Other deep learning models include CNN [4], Resnet [5] and CLDNN [17]. Table 1 compares the performance and complexity of several indicators, including the number of parameters, training time, overall classification accuracy and classification accuracy under different signal-to-noise ratios.
As shown in Table 1, compared with other benchmark models, the one-dimensional convolutional network module is superior to other network models in all aspects of indicators. Among the benchmark models, CLDNN performs best, with a classification accuracy of 93% at a high SNR. Compared with CLDNN, the proposed one-dimensional convolutional network module has more obvious advantages, The classification accuracy of the model is slightly 3% higher than that of CLDNN, but the parameters of the model are only 1/5 of that of CLDNN. The classification accuracy within the whole SNR range is shown in Fig. 3. As can be seen from Fig. 3, among all the models, the classification accuracy of the A/P feature at high SNR is about 7.25% higher than that of the I/Q feature, and I/Q data is more resistant than the A/P feature at low SNR. As seen from the confusion matrix of OnedimCNN-IQ and OnedimCNN-AP, as shown in Fig. 4, the A/P feature is better than the I/Q feature to help the model distinguish between QAMs and PSKs. OnedimCNN-AP can completely distinguish 8PSK from QPSK, while QAM still confuses. This shows that amplitude-phase time series are more prominent features of modulation classification, but they are more susceptible to noise conditions.

Classification accuracy of the time series model within the overall SNR range

(a) OnedimCNN-IQ and (b) OnedimCNN-AP confusion matrices in the SNR range of 6db to 18db
3.3 Feature Fusion
Feature fusion is divided into two steps. Firstly, we apply probabilistic principal component analysis to reduce the dimension of high-dimensional features extracted by one-dimensional convolution module. Then, we use the method of sequence fusion for feature fusion. Our one-dimensional convolution feature fusion network model (FF-Onedimcnn) is shown in Fig. 5 features are extracted from the two feature fusion networks through two convolution modules. The input size of both components is 128 × 2, and ReLu is selected as the activation function. In the one-dimensional convolutional feature fusion network structure, after the features are extracted through Block1, the main parts of the two segments are screened by combining the method of probabilistic principal component analysis. Then the features are fused by sequence splicing. In addition, A/P data after normalization increases the risk of overlap with the I/Q data. In order to prevent network model fitting, we have two kinds of feature extraction of regularization is introduced after the operation, L2 regularization to make the network more tend to use all the input characteristics, rather than rely heavily on the input features in some small part. L2 penalizes smaller, more diffuse weight vectors, which encourages classifiers to eventually use features from all dimensions, rather than relying heavily on a few of them. We introduce L2 regularization in the fully connected layer to improve the generalization ability of the model and reduce the risk of overfitting.

Model structure of one-dimensional convolution feature fusion network
4 Experimental Results and Discussion
This section illustrates the effectiveness of the one-dimensional convolution feature fusion network model through some comparative experiments. We still conduct training and testing on the previous datasets, and first verify whether the feature fusion method can inherit the advantages of the two features. Secondly, we compared this model with the latest automatic modulation classification algorithms based on deep learning, including CNN-1 [4], CNN-2 [10], CLDNN-1 [10], CLDNN-2 [13], MCLDNN [18], and PET-CGDNN [8]. The evaluation is also carried out from four aspects: the number of parameters, training time, overall classification accuracy and classification accuracy under different SNR, as shown in Table 2. Among the classification models mentioned above, CLDNN-2 and MCLDNN both involve the idea of feature fusion. The model proposed by us is comparable to the two models in accuracy, but our model is superior in model complexity.
4.1 Classification Accuracy
As can be seen from Fig. 6, after the fusion of the two features, the classification accuracy of the one-dimensional convolution module proposed by us is consistent with that of A single module on I/Q features at low SNR, and roughly the same as that of A single module on A/P features at high SNR. We verify that the advantages of both can be inherited by the method of feature fusion. In addition, the overall recognition rate is 10% better than Resnet's A/P feature recognition rate, 5% better than the I/Q feature recognition rate of individual modules, and 3% better than the A/P feature recognition rate. Meanwhile, as shown in Fig. 6, the recognition rate of the FF-OnedimCNN model proposed is significantly higher than that of other network models starting from -4dB. When the SNR reaches 2 dB, the recognition rate of the model tends to be stable. The average recognition accuracy from 6 dB to 18 dB reaches 94.95%, which is almost equal to the recognition rate of the A/P feature of A single module. It can also be seen from Table 2 that, compared with other network models, the FF-OnedimCNN model proposed by us has the highest classification accuracy in terms of both overall classification accuracy and high SNR classification accuracy. Figure 7 shows the confusion matrices of the FF-OnedimCNN model under different SNR. For the confusion matrices, each row represents the real modulation type, and each column represents the predicted modulation type. From the confusion matrices from −20 dB to 18 dB, the confusion mainly focuses on the classification of 8PSK and QPSK, 16QAM and 64QAM. From the second section, we know that there are two reasons for the significant classification error. The first one is influenced by the channel. To simulate the real scene, the channel has interfered with frequency offset, center frequency offset, selective fading and Gaussian white noise. Second, they have overlapping constellation points, which leads to the decline of recognition rate. However, according to the confusion matrix from 6 dB to 18 dB, the FF-OnedimCNN model proposed can completely distinguish 8PSK from QPSK, and 16QAM and 64QAM are also greatly improved.
4.2 Computational Complexity
In order to better deploy the model to edge devices, we should consider not only the accuracy of the model, but also the complexity of the model. The most intuitive evaluation criteria for model complexity are the training parameters and training time of the model, as shown in Table 2. The training parameters of CNN-2 and PET-CGDNN are similar to those of the FF-OnedimCNN model, among which PET-CGDNN has the least training parameters. However, from the perspective of training time, The training time of FF-OnedimCNN model was only 1/3 of that of PET-CGDNN. The sum of model parameters of CNN-2 is almost equal to that of the FF-OnedimCNN model, from the perspective of accuracy, the FF-OnedimCNN model proposed by us has a higher classification accuracy. In addition, both CLDNN-2 and MCLDNN adopt the idea of feature fusion. Both combine two network models of convolutional neural network (CNN) and long and short-term memory (LSTM) for classification. In terms of classification accuracy, the two models both reach more than 92% at high SNR, indicating that multi-feature fusion is better than single-feature fusion. However, from the perspective of training parameters, the training parameters of the two models increased more than seven times than that of the FF-OnedimCNN model. At the same time, we also found that the LSTM network would increase the training time of the network. In summary, we can conclude that the FF-OnedimCNN model proposed has more significant advantages in both accuracy and complexity, and has more potential in future model deployment.

Comparison between the proposed method and deep learning based method under different SNR

Confusion matrices for the proposed method at different SNRs. (a) SNR range of −20 db to 18 db; (b) SNR range of −10 db to 5 db; (c) SNR range of 6 db to 18 db
5 Conclusions
In this article, we first proposed a lightweight one-dimensional convolutional neural network module. We compared the modules and other network model in the I/Q performance features and A/P, we found that the A/P characteristics under high signal to noise ratio of classification accuracy are about 7.25% higher than the I/Q characteristics, I/Q data under low SNR more resistance than A/P characteristics, We conclude that the I/Q feature and A/P feature can complement each other at high and low SNR. Therefore, a one-dimensional convolution feature fusion network structure (FF-OnedimCNN) is proposed by using one-dimensional convolution neural module combined with probabilistic principal component analysis (PPCA) to fuse the two features. We discuss the validity of the proposed model from two aspects of classification accuracy and complexity. Experimental results show that compared with the newly proposed network model for automatic modulation classification, our model has obvious advantages in both classification accuracy and complexity.
References
Cisco Annual Internet Report (2018–2023) White Paper. https://www.cisco.com/c/en/us/solutions/collateral/executiveperspectives/annual-internet-report/white-paper-c11-741490.html
Qualcomm Inc.: mMTC KPI evaluation assumptions .3GPP R1-162195, April 2016
Evans, D.: The Internet of Things: How the next evolution of the internet is changing everything. In: Proceedings of Cisco White Pap, pp. 1–11 (2011)
O’Shea, T.J., Corgan, J., Clancy, T.C.: Convolutional radio modulation recognition networks. In: International Conference on Engineering Applications of Neural Networks, pp. 213–226. Springer, Heidelberg (2016)
O’Shea, T.J., Roy, T., Clancy, T.C.: Over-the-air deep learning based radio signal classifification. IEEE J. Sel. Top. Signal Process. 12, 168–179 (2018)
Yashashwi, K., Sethi, A., Chaporkar, P.: A learnable distortion correction module for modulation recognition. J. IEEE Wirel. Commun. Lett. 8, 77–80 (2018)
Teng, C.F., Chou, C.Y., Chen, C.H., et al.: Accumulated polar feature-based deep learning for efficient and lightweight automatic modulation classification with channel compensation mechanism. J. IEEE Trans. Vehicular Technol. 69, 15472–15485 (2020)
Zhang, F., Luo, C., Xu, J., Luo, Y.: An efficient deep learning model for automatic modulation recognition based on parameter estimation and transformation. J. IEEE Commun. Lett. 25, 3287–3290 (2021)
Liu, X., Wang, Q., Wang, H.: A two-fold group lasso based lightweight deep neural network for automatic modulation classification. In: 2020 IEEE International Conference on Communications Workshops (ICC Workshops), pp. 1–6. ICCE, Ireland (2020)
Pijackova, K., Gotthans, T.: Radio modulation classification using deep learning architectures. In: 2021 31st International Conference Radioelektronika (RADIOELEKTRONIKA), pp. 1–5 (2021)
Wang, Y., Liu, M., Yang, J., Gui, G.: Data-driven deep learning for automatic modulation recognition in cognitive radios. J. IEEE Trans. Veh. Technol. 68, 4074–4077 (2019)
Gao, L., Zhang, X., Gao, J., You, S.: Fusion image based radar signal feature extraction and modulation recognition. J. IEEE Access. 7, 13135–13148 (2019)
Zhang, Z., Luo, H., Wang, C., Gan, C., Xiang, Y.: Automatic modulation classification using CNN-LSTM based dual-stream structure. J. IEEE Trans. Veh. Technol. 69, 13521–13531 (2020)
Meng, F., Chen, P., Wu, L., et al.: Automatic modulation classification: a deep learning enabled approach. IEEE Trans. Veh. Technol. 67(11), 10760–10772 (2018)
Peng, S., Jiang,H. ,Wang, H., Alwageed, H., Yao,Y.D.: Modulation classifification using convolutional neural network based deep learning model. In: 26th Wireless Optical Communication Conference, Newark, NJ, USA, pp. 1–5 (2017)
O’Shea,T., West, N.: Radio machine learning dataset generation with gnu radio. In: Proceedings of the GNU Radio Conference 1 (2016)
West, N.E., O’Shea, T.J.: Deep architectures for modulation recognition. CoRR, vol.abs/1703.09197 (2017)
Xu, J., Luo, C., Parr.G., Luo,Y.: A spatiotemporal multi-channel learning framework for automatic modulation recognition. IEEE Wirel. Commun. Lett. 9, 1629–1632 (2020)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Ma, R., Wu, D., Hu, T., Yi, D., Zhang, Y., Chen, J. (2022). Automatic Modulation Classification Based on One-Dimensional Convolution Feature Fusion Network. In: Qian, Z., Jabbar, M., Li, X. (eds) Proceeding of 2021 International Conference on Wireless Communications, Networking and Applications. WCNA 2021. Lecture Notes in Electrical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-19-2456-9_90
Download citation
DOI: https://doi.org/10.1007/978-981-19-2456-9_90
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-2455-2
Online ISBN: 978-981-19-2456-9
eBook Packages: EngineeringEngineering (R0)