
Abstract
In this paper, we propose a novel Person Re-identification model that combines physical biometric information and traditional appearance features. After manually obtaining a target human ROI from human detection results, the skeleton points of target person will be automatically extracted by OpenPose algorithm. Combining the skeleton points with the biometric information (height, shoulder width.) calculated by the vision-based geometric estimation, the further physical biometric information (stride length, swinging arm.) of target person could be estimated. In order to improve the person re-identification performance, an improved triplet loss function has been applied in the framework of [1] where both the human appearance feature and the calculated human biometric information are utilized by a full connection layer (FCL). Through the experiments carried out on public datasets and the real school surveillance video, the effectiveness and efficiency of proposed algorithm have been confirmed.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
How to identify a person through long distance, where the facial features of target will be blurred due to the low resolution of face region, has been an important task in many fields such as surveillance, security and recommendation system. Since the outbreak of COVID-19, it has drawn more and more attention from numerous researchers because the performance of conventional face recognition algorithms will degrade greatly due to the request of wearing mask, therefore, people need other methods to identify the target person regardless of their facial masks. On the other hand, close contacts are often found in busy areas (shopping streets, malls, restaurants, etc.), the appearance of people tends to change significantly. Compared with the physical biometric information, appearance is more sensitive to clothing and lighting changes. On the contrary, people’s physical information is less affected by external factors.
The methods of Person Re-identification (Re-ID) can roughly be divided into part-based Re-ID, mask-based Re-ID, pose-guided Re-ID, attention-model Re-ID, GAN Re-ID and Gait Re-ID [7].
Part-based Re-ID: global features and local features of target are extracted and calculated to achieve Person Re-ID. McLaughlin [2] using color and optical flow information in order to capture appearance and motion information for Person Re-ID. Under different cameras, Cheng [3] present a multi-channel parts-based convolutional neural network (CNN) model. To effectively use features from a sequence of tracked human areas, Yan [4] built a Long Short-Term Memory (LSTM) network. To establish the correspondence between images of a person taken by different cameras at different times, Chung [5] proposed a weighted two stream training objective function. Inspired by the above studies, Zheng [6] proposed AlignedReID that extracts a global feature and first surpass human-level performance. These methods are fast, but performance will be affected when facing background clutter, illumination variations or obstacle blocking.
Mask-base Re-ID: masks and semantic information is used to alleviate the problem of Part-based Re-ID. Song [8] first designed a mask-guided contrastive attention model (MGCAM) to learn features from the body and background to improve robust during background clutter. Kalayeh, M [9] proposed an adopt human semantic parsing model (SPReID) to further improve the algorithm. To reduce the impact of the appearance variations, Qi [10] added multi-layer fusion scheme and proposed a ranking loss. The accuracy of mask-base Re-ID is improved compared with part-based Re-ID, but it usually suffers from its expensive computational cost and its segmentation result lacks of more accurate information for Person Re-Id proposes.
Pose-guided Re-ID: When extracting features from person, part-based Re-ID and mask-base Re-ID usually simply divide the body into several parts. In Pose-guided Re-ID, after prediction the human pose, the same parts of the human body features are extracted for Re-ID. Su [11] proposed a Pose-driven Deep Convolutional (PDC) model to match the features from global human body and local body parts. To capture human pose variations, Liu [12] proposed a pose-transferrable person Re-ID framework. Suh [13] found human body parts are frequently misaligned between the detected human boxes and proposed a network that learns a part-aligned representation for person re-identification. Considering of people wearing black clothes or be captured by surveillance systems in low light illumination, Xu [15] proposed head-shoulder adaptive attention network (HAA) that is effective in dealing with person Re-ID in black clothing. Pose-guided Re-ID has a good balance between speed and accuracy. But the performance is influenced by skeleton points detection algorithm, especially when pedestrians are blocking each other.
Attention-model Re-ID: using attention model to determine attention by globally considering the interrelationships between features for Person Re-ID. The LSTM/RNN model with the traditional encoder-decoder structure suffers from a problem: it encodes the input into a fixed-length vector representation regardless of its length, which makes the model cannot performing well for long input sequences. Unfortunately, Person Re-ID always working in long input sequences. Many researches chosen to use attention-based model and reached the state-of-the-art. Xu [16] proposed a spatiotemporal attention model for Person Re-ID. The model is assumed the availability of well-aligned person bounding box images, W. Li [17] and S. Li [18] proposed two different spatiotemporal attention to complementary information of different levels of visual attention re-id discriminative learning constraints. In study, researchers found the methods based on a single feature vector are not sufficient enough to overcome visual ambiguity [19] and proposed Dual Attention Matching networks [20]. Compared with above methods, attention-model re-ID method has better performance in accuracy, but it is computationally intensive.
GAN Re-ID: using generative adversarial network (GAN) to generate more training data only from the training set and reduce the interference of lighting changes. A challenge of Person Re-ID is the lacking of datasets, especially in the complex scenes and view changes. To obtain more training data only from the training set and improve performance during different datasets, semi-supervised models using generative adversarial network (GAN) such as LSRO [21], PTGA [22] and DG-Net [23] was proposed. GAN Re-ID works well in different environments, but there are still some problems in stability of training.
Gait Re-ID: using skeleton points of human to extract gait features for person Re-ID. This type of method does not focus on the appearance of a person, but requires a continuous sequence of frames to identify a person by the changes in appearance caused by motion. Gait Re-ID method exploit either two-dimensional (2D) or 3D information depending on the image acquisition methods.
For 3D methods, depth-based person re-identification was proposed [24, 25], which works on Kinect or other RGBD cameras to obtain human pose information. This method is fast and show better robustness to a variety of factors such as clothing change or carrying goods. However, not many surveillances use RGBD cameras in real-life and this method can only maintain accuracy at close distance (usually less than 4 0 or 5 m).
For 2D methods, Carley, C [26] proposed an autocorrelation-based network. Rao [27] proposed a self-supervised method CAGEs to obtain better gait representations. This method provides a solution of “Appearance constancy hypothesis” in appearance-based method, but it is more computationally expensive and require higher-quality data.
In this paper, we propose a person Re-ID algorithm with the combination of physical biometric information and appearance features. To get appearance features, we modified the ResNet-50 proposed by framework of [1] and design a new triplet loss function, trained it on Market1501 and DUKEMTMC. On the other hand, Re-ID is often used in surveillance video, where the camera’s view is often fixed. By calibrating the camera and measuring the camera’s position information, combined with human skeletal point, we can calculate physical biometric information such as human height, shoulder width and stride length, which is useful for the person Re-ID. In the end, we calculate the Euclidean distance between target person and others, reranking the results. In order to improve the person re-identification performance, both the human appearance feature and the calculated human biometric information are utilized by a full connection layer (FCL).
Since most of the conventional Person Re-ID datasets do not contain physical biometric information and the intrinsic matrix of cameras, we built our dataset by using real surveillance video in school and evaluate our combine method.
2 Algorithm Description
2.1 System Overview
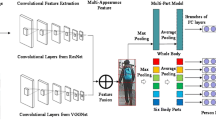
The framework of proposed algorithm is shown in Fig. 1. To reduce calculation errors, the camera needs to be calibrated and positioned before running the person Re-ID. Our algorithm works on video streams, we need to mark the target ROI manually for query sets. The algorithm will use object detection algorithm to predict human ROI for gallery set. The method consists of two parts named global appearance features part and physical biometric information part. The first part extracts the global feature from the person image and distance from each target. The other part is designed to predict physical biometric information by using human skeleton points and calculate triple loss. The losses of these two parts are sent to a fully connected layer classified and re-ranking to match the target person. More details of this work will be described in the following sections.

System overview
2.2 Query Sets and Gallery Sets Data Collection
To simplify the operation, we need to select the target ROI manually. In this part, we mark the target in multiple video frames. Marking multiple angles of the same target can improve the accuracy of the subsequent algorithm.
To collect the gallery data, we use object detection to predict human ROI for next part. In comparison experiments, we found out that using the larger model can hardly improve the accuracy of prediction, but would greatly increase the computational cost. Consider the balance between speed and accuracy, we choose YOLOV5S, the smallest and fastest model of YOLOV5, as our detector.
After collecting Data of Query Sets and Gallery Sets, these images will be sent into the Global Appearance Part and Physical Biometric Information Part to extract features for person re-identification.
2.3 Global Appearance Part
In this research we using a modified model of framework in [1] to extract global appearance. The backbone of this model is ResNet-50 with the span of the last spatial down-sampling set to 2. After extracting features by the backbone, the model uses a GAP layer to obtain the global feature. During prediction, the model will calculate the Euclidean distance of global feature between Gallery sets and Query sets. During training, the framework will calculate triplet loss based on the distance between positive pair and negative pair of global features. To improve the performance of the model, we use RKM (reliability-based k-means clustering algorithm) [33] modified the loss function. After applied the new triplet loss function (1) in the framework, we retraining and evaluated our model on Market1501 [34] and DukeMTMC [35]. The experimental results will be described in the EXPERIMENT section.
Our triplet loss (\({\text{F}}_{\text{t}}\)) is computed as:
where dp and dn are feature distances of positive pair and negative pair. α is the margin of triplet loss. In this paper we set α as 0.2. R represents the reliability to classify a gallery sample into the query or other clusters. Detailed information about how to compute R could be found in [33].
2.4 Physical Biometric Information Part
The physical biometric information calculated by this part is shown in Fig. 1. To calculate the physical biometric information, the position information, intrinsic matrix of the camera and the skeleton points of target are needed. For getting human skeleton points we using OpenPose [29], a bottom-up algorithm, which first detect 25 human skeleton points of the human body in the whole image and then correspond these points to different individual people. The human skeleton points predicted by OpenPose are shown in the Fig. 2 By using human ROI that we get by object detection, the computation required by OpenPose decreases significantly.

Physical biometric information

OpenPose predict result
In this paper, every result predicted by OpenPose will be stored in an array of 25 lengths skeleton points. The human physical biometric information is calculated by dividing ROI on human body pictures. When the whole human body is in the camera, we use the y-point coordinate at the top of the target detection frame as the top coordinate y1. The lowest point coordinates of the target ankle, max (skeleton points [24] [1], skeleton points [21] [1]), is used as the bottom coordinate y2. In order to calculate shoulder breadth, we use the skeleton points of human shoulder x coordinates, skeleton points [2] [0] and skeleton points [5] [0], as X-axis coordinates x1 and x2. By using x1, y1, x2, y2 into the Formula (2), the distance between human head, heel, left shoulder and right shoulder in the realistic reference system can be calculated, as further calculate the information of human height and shoulder width.
When the camera is on the side of the person, we can calculate the stride length and arm swing length of the person from the skeleton points of the arms and toes in consecutive video frames.In this part, we still use the (y1, y2) coordinates calculated in the height. The difference is that we take the maximum and minimum values of the left toes and right feet toes in a sequence as the x-coordinate (x3, x4). By substituting (y1, y2, x3, x4) into the Formula (2), we can obtain the stride length. Similarly, using the coordinates of the target’s left elbow and right elbow we can calculate the swing arm. We use 0 fill the physical information when we can’t calculate physical information because of the orientation of person or the obstruction.
This part is based on single-view metrology algorithm by obtaining the distance of object between two parallel planes. With distortion compensation processing, the images can be used to measure human physical biometric information. We use the traditional pinhole model to transform camera reference frame to world reference frame, and this model is defined as (2):
where xb, yb is a point on the image, Cx, Cy is the centric point of the image plane coordinates, fk is the distance from the center of projection to the image plane, R is the extrinsic matrix of the camera, XW, YW, ZW is a point in the world reference frame, and X0, Y0, Z0 is the centric point in the world reference frame.
In the experimental, we found that when human body moved, the posture changes would lead to data fluctuation, which affected the stability of calculation body height. Therefore, we used a simplified Kalman filter to solve the problem. The simplified Kalman filter formula is given by the following:
where P is the predicted matrix, X is the estimate matrix, K is the Kalman gain matrix, P is covariance matrix, Z is measurement result, Q is process noise matrix, R is measurement error covariance matrix, t, t−1 is current time and previous time. E is identity matrix. H is measurement matrix.
Human height and shoulder width are numerically independent, we simplify the control matrix and use the \(\left[\begin{array}{cc}{\text{h}}& {0}\\ {0}& {\text{w}}\end{array}\right]\) as the input of Kalman filter, where the h is height of target and w is the shoulder width of target. Kalman filter takes a weighted average (5) of the predicted result of the current state (t) and the previous state (t−1) with the measurement result. The weighted mean named Kalman gain is defined by the covariance matrix of the previous state, the measurement noise covariance and the system process covariance (4). In this work (Q, R) are hyperparameters, which Q was set to 0.0001 and R was set to 1. The covariance matrix is determined by the previous moment’s covariance, the process noise matrix Q and Kalman gain (3) (6). The effect of Kalman filtering for height measurement will be shown in Fig. 3. Kalman Filter Comparison Chart, where the ‘truth’ line refers the real height of the person, the ‘original’ line refers each predicted result, the ‘filtered’ line refers the result after Kalman filtering. As shown in the Fig. 3, after Kalman filtering, the max error predicted by our method is reduced from ± 10 cm to ± 4 cm.

Kalman Filter comparison chart
In the end, the features calculated by global appearance part and physical biometric information part will be sent into a network to classification and re-ranking to find the target person.
2.5 Classification and Re-ranking
In this part, we designed a network (Fig. 4) to utilize physical biometric information and human appearance features for person re-identification. In order to ensure the independent robustness, we first use relatively independent networks and loss functions to process the two features separately and score the results obtained from each in a consistent manner. We use a fully connected network with two hidden layers to jointly compute the triplet loss and SoftMax loss, at the same time, optimizing the ratio of both. We introduce Dropout into the fully connected layer to prevent overfitting. After processing the physical biometric feature information by the fully connection network, the output dimension will be consistent with the appearance features. Finally, we add two feature losses to calculate the ID loss. For comprehensive consideration, we introduce a sigmoid function and trainable parameters λ to give appropriate activation intensity, to control the weight of the two kinds of features.
During prediction, we obtain the feature vectors of query sets and gallery sets respectively to calculate the Euclidean distance between them, re-ranking the data of gallery through the distance difference, and select the top five IDs as the final result.

Fully connection network
3 Experiment
3.1 Evaluation of Human Height Prediction
In this part, we requested 3 persons with different heights to walk in same trajectory for evaluating the accuracy of our human height prediction method. Each person was requested to walk in the circle, where the range between the camera and human varied between 5 to 10 m. Before the experiment, the true heights of each target person were manually recorded. Then we recorded a ten-minute video of each person. Table 1 shows the accuracy and max error of our prediction algorithm, where ‘Truth’ refers to the truth height of the person, ‘Average’ refers the average height of predicted person, ‘Max Error’ refers to the maximum error between ‘truth’ and predicted human height.
3.2 Evaluation on Public Dataset
In this section, we trained our modified models on Market1501 [34] and DukeMTMC [35] datasets. Market1501 [34] dataset collected 32,668 images of 1,501 identities using 6 video cameras at different perspectives distances. Due to the openness of the environment, images of each identity were captured by at least of two cameras. In this dataset, 751 of these individuals were classified as the training set, which contains 12,936 images. The remaining 750 individuals were classified as the test set, which contains 19,732 images. DukeMTMC [35] dataset is recorded by 8 calibrated and synchronized static outdoor cameras, it has over 2700 identities, with 1404 individuals appearing on more than two cameras and 408 individuals appearing on one camera. This dataset randomly sampled 702 individuals containing 17,661 images as the training set and 702 individuals containing 17,661 images as the test set.
Since most of the Person Re-ID datasets do not contain human physical information or camera location information, we evaluated our global appearance part on public dataset. The results of the evaluation are shown in Table 2. The Rank1 accuracy and mean Average Precision (mAP) are reported as evaluation metrics.
3.3 Evaluation on Surveillance Dataset
To train and evaluate our method, we build our dataset by using real surveillance video in school. We took several videos of 30 people walking at different angles by using 3 calibrated cameras. Before recording, we calibrated and measured position of the camera. The cameras were placed horizontally and measured by a laser rangefinder to get the height and pitch angle for composition extrinsic matrix. Then, we use a checkerboard calibration plate to calibrate the camera and get intrinsic matrix. The information will be used to calculate human physiological information and reduce calculation errors.
We randomly intercept 100 consecutive frames for each video and use object detection algorithm to obtain the bounding box of each person, then manually label each target as our dataset. For getting human physical biometric information, we measured each person’s height, shoulder width, stride length and swing arm manually. Totally, we labeled 9000 images and the dataset was divided equally according to identity as our test and training set. Because of privacy problem, we put part of people images in Fig. 5 and blur them (Fig. 6).

Some examples of surveillance dataset
In this part we conducted comparative experiments on the surveillance dataset, the appearance feature method (without Physical Biometric part) and the combining method (with Physical Biometric part) respectively, bold number denote the better performance (Table 3).
4 Conclusion
In this research, we propose a person re-identification algorithm that combines physical biometric information and human appearance features. We calculate human physiological parameters by human skeletal point prediction algorithm combined with camera single-view metrology algorithm. The human appearance features are extracted by a modified ResNet50. To combine appearance features and physiological biometric information, we introduce a feature-weighted fusion model to learn both feature information. By evaluating on a public dataset, we demonstrate the effectiveness of the new loss function. Since it is not feasible to conduct comparative experiments of combining methods on public datasets, we produced our own dataset to train and evaluate our improved global appearance method and combination method, confirmed the effectiveness of the combining method.
5 Future Work
In our experiments, we found that when using the object detector to predict the human body, the ROI changes also lead to incorrect prediction of human height. This situation seriously reduces the accuracy of the algorithm. We will try to use mask-based methods to predict persons and calculate biometric information in future work. On the other hand, our physical biometric part relies heavily on camera position information, which makes our method not so compatible, we will try to solve these problems in our future work.
References
Hao, L., et al.: Bag of tricks and a strong baseline for deep person re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (2019)
McLaughlin, N., Del Rincon, J.M., Miller, P.: Recurrent convolutional network for video-based person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2016)
Cheng, D., Gong, Y., Zhou, S., Wang, J., Zheng, N.: Person re-identification by multi-channel parts-based cnn with improved triplet loss function. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1335–1344 (2016)
Yan, Y., et al.: Person re-identification via recurrent feature aggregation. In: European Conference on Computer Vision. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_42
Chung, D., Tahboub, K., Delp, E.J.: A two stream Siamese convolutional neural network for person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision (2017)
Zheng, L., Zhang, H., Sun, S., Chandraker, M., Tian, Q.: Person re-identification in the wild. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 1367–1376 (2017)
Ye, M., et al.: Deep learning for person re-identification: a survey and outlook. IEEE Transactions on Pattern Analysis and Machine Intelligence (2021)
Song, C., Huang, Y., Ouyang, W., Wang, L.: Mask-guided contrastive attention model for person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1179–1188 (2018)
Kalayeh, M.M., Basaran, E., Gökmen, M., Kamasak, M.E., Shah, M.: Human semantic parsing for person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1062–1071 (2018)
Qi, L., Huo, J., Wang, L., Shi, Y., Gao, Y.: Maskreid: a mask based deep ranking neural network for person re-identification. arXiv preprint arXiv:1804.03864 (2018)
Su, C., Li, J., Zhang, S., Xing, J., Gao, W., Tian, Q.: Pose-driven deep convolutional model for person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3960–3969 (2017)
Liu, J., Ni, B., Yan, Y., Zhou, P., Cheng, S., Hu, J.: Pose transferrable person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4099–4108 (2018)
Suh, Y., Wang, J., Tang, S., Mei, T., Lee, K.M.: Part-aligned bilinear representations for person re-identification. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 402–419 (2018)
Qian, X., et al.: Pose-normalized image generation for person re-identification. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11213, pp. 661–678. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01240-3_40
Xu, B., et al.: Black re-id: a head-shoulder descriptor for the challenging problem of person re-identification. In: Proceedings of the 28th ACM International Conference on Multimedia (2020)
Xu, S., Cheng, Y., Gu, K., Yang, Y., Chang, S., Zhou, P.: Jointly attentive spatial-temporal pooling networks for video-based person re-identification. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 4733–4742 (2017)
Li, S., et al.: Diversity regularized spatiotemporal attention for video-based person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2018)
Li, W., Zhu, X., Gong, S.: Harmonious attention network for person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2285–2294 (2018)
Si, J., et al.: Dual attention matching network for context-aware feature sequence-based person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5363–5372 (2018)
Qi, G., et al.: EXAM: a framework of learning extreme and moderate embeddings for person re-ID. J. Imaging 7(1), 6 (2021)
Zheng, Z., Zheng, L., Yang, Y.: Unlabeled samples generated by gan improve the person re-identification baseline in vitro. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 3754–3762 (2017)
Wei, L., Zhang, S., Gao, W., Tian, Q.: Person transfer gan to bridge domain gap for person re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 79–88 (2018)
Zheng, Z., Yang, X., Yu, Z., Zheng, L., Yang, Y., Kautz, J.: Joint discriminative and generative learning for person re-identification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 2138–2147 (2019)
Karianakis, N., Liu, Z., Chen, Y., Soatto, S.: Reinforced temporal attention and split-rate transfer for depth-based person re-identification. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11209, pp. 737–756. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01228-1_44
Nambiar, A.M., Bernardino, A., Nascimento, J.C., Fred, A.L.: Towards view-point invariant person re-identification via fusion of anthropometric and gait features from kinect measurements. In: VISIGRAPP (5: VISAPP), pp. 108–119, February 2017
Carley, C., Ristani, E., Tomasi, C.: Person re-identification from gait using an autocorrelation network. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (p. 0) (2019)
Rao, H., et al.: A self-supervised gait encoding approach with locality-awareness for 3D skeleton-based person re-identification. IEEE Trans. Patt. Anal. Mach. Intell. (2021)
Jocher, G.: ultralytics. “YOLOV5”. https://github.com/ultralytics/yolov5
Cao, Z., et al.: “OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields. IEEE Trans. Patt. Anal. Mach. Intell. 43(1), 172–186 (2019)
Zheng, Z., Zheng, L., Yang, Y.: A discriminatively learned cnn embedding for person reidentification. ACM Trans. Multim. Comput. Commun. Appl. (TOMM) 14(1), 1–20 (2017)
Hermans, A., Beyer, L., Leibe, B.: In Defense of the Triplet Loss for Person Re-Identification (2017)
Ristani, E., Tomasi, C.: Features for multi-target multi-camera tracking and re-identification. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6036–6046 (2018)
Hua, C., Chen, Q., Wu, H., Wada, T.: RK-means clustering: K-means with reliability. IEICE Trans. Inf. Syst. 91(1), 96–104 (2008)
Zheng, L., Shen, L., Tian, L., Wang, S., Wang, J., Tian, Q.: Scalable person re-identification: a benchmark. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1116–1124 (2015)
Ristani, E., Solera, F., Zou, R., Cucchiara, R., Tomasi, C.: Performance measures and a data set for multi-target, multi-camera tracking. In: European Conference on Computer Vision, pp. 17–35. Springer, Cham, October 2016. https://doi.org/10.1007/978-3-319-48881-3_2
Lin, Y., et al.: Improving person re-identification by attribute and identity learning. Patt. Recogn. 95, 151–161 (2019)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Hua, C., Zhao, X., Meng, W., Pan, Y. (2022). Deep Person Re-identification with the Combination of Physical Biometric Information and Appearance Features. In: Qian, Z., Jabbar, M., Li, X. (eds) Proceeding of 2021 International Conference on Wireless Communications, Networking and Applications. WCNA 2021. Lecture Notes in Electrical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-19-2456-9_89
Download citation
DOI: https://doi.org/10.1007/978-981-19-2456-9_89
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-2455-2
Online ISBN: 978-981-19-2456-9
eBook Packages: EngineeringEngineering (R0)