
Abstract
Relative position encoding (RPE) is important for transformer based pretrained language model to capture sequence ordering of input tokens. Transformer based model can detect entity pairs along with their relation for joint extraction of entities and relations. However, prior works suffer from the redundant entity pairs, or ignore the important inner structure in the process of extracting entities and relations. To address these limitations, in this paper, we first use BERT with complex relative position encoding (cRPE) to encode the input text information, then decompose the joint extraction task into two interrelated subtasks, namely head entity extraction and tail entity relation extraction. Owing to the excellent feature representation and reasonable decomposition strategy, our model can fully capture the semantic interdependence between different steps, as well as reduce noise from irrelevant entity pairs. Experimental results show that the F1 score of our method outperforms previous baseline work, achieving a better result on NYT-multi dataset with F1 score of 0.935.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Transformer recently has drawn great attention in natural language processing because of its superior capability in capturing long-range dependencies [1]. Extracting entity pairs with relations from unstructured text is an essential step in the construction of automatic knowledge database. Joint extraction of entities and all the possible relations between them at once, which considers the potential interaction between the two subtasks and eliminates the error propagation issue in traditional pipeline method [2, 3]. A typical joint extraction scheme is ETL-Span [4], which transforms information extraction into a sequence labelling problem with multi-part labels. It also proposed a novel decomposition strategy to decompose the task into simpler modules, that is, to decompose the task into several sequence label problems hierarchically. The key point is to distinguish all candidate head entities that may be related to the target relation starting from the beginning of the sentence, and then mark the corresponding tail entity and relation for each extracted head entity. This method achieves excellent performance in overlapping entity extraction.
Despite the efficiency of this framework, it is weak for the limited feature representation comparing with other complex models, especially transformer-based encoder BERT [5]. Using BERT to encode sentence extraction features could share feature representation with advanced semantic information. However, the Transformer [6] based network structure is a superposition of self-attention mechanism, which is inherently unable to learn the sequential relations of sentences. The position and order of words in the text are very important features, which will affect the accuracy of information extraction task in which the target is determined by the boundary.
To address the aforementioned limitations, we present our cRPE-Span model, which makes the following contributions:
-
1.
The shared embedding module is improved through BERT, and the complex field relative position encoding is added to represent the relative position information between entities, so that the extractor can consider the semantic and position information of the given entity when marking the tail entity and relation.
-
2.
The hierarchical boundary marker only marks the entity start and end position in a cascade structure and ignores the entity category, which could reduce the task difficulty for one step prediction process, and then alleviate the accumulated error.
-
3.
Our method achieves consistently better performances on three benchmark datasets of entity and relation joint extraction, obtaining a better result on NYT-multi dataset with F1 score of 0.935.
2 Related Works
The entity-relation extraction task has always been widely concerned for its crucial role in information extraction. For most traditional methods ignore the interaction between entity recognition and relationship extraction, researchers have proposed a variety of joint learning methods with end-to-end neural architectures [4, 7,8,9]. Unfortunately, due to the shared encoder limitation, these methods cannot fully exploit the inter-dependency between entities and relations.
Introducing powerful transformer-based BERT to encode the input information could enhance the capability of modeling the relationship of tokens in a sequence. The core of transformer is self-attention, however, the self-attention has an inherent deficiency that it does not contain sequential order information of input tokens, so that it needs to add positional representations to encode information explicitly. The approaches for positional representations of transformer-based network can fall into two categories. The first one is the absolute position encoding, which inject the positional information to the model by encoding the positions of input tokens from 1 to maximum sequence length. Typically, sinusoidal position encoding in Transformer and learned position encoding in BERT, GPT [10]. However, such absolute positions cannot model the interaction information between any two input tokens explicitly. Therefore, the second relative position encoding (RPE) extends the self-attention mechanism to consider the relative positions or distances between sequential elements. Such as the model NEZHA [11], Transformer-XL [1], T5 [12] and DeBERTa [13]. As such information is not necessary for non-entity tokens, and may introduce noise on the contrary. Different from the relative positions mentioned above, we introduce complex relative position encoding (cPRE) into BERT for entity and relation joint extraction.
3 Method
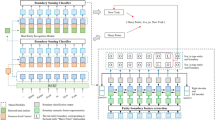
cRPE-Span joint extraction structure is an end-to-end neural architecture, which jointly extracts entities and overlapping relations. We first add the cRPE to the powerful transformer-based BERT, and then use it to encode the input information for more accurate representation of the relative position information between entities. In the joint extraction structure, we use span-based tagging scheme as well as the reasonable decomposition strategy. In essence, the framework reduces the influence of redundant entity pairs, and captures the correlation between the head entity and the tail entity, thus obtaining better joint extraction performance. Figure 1 shows the framework diagram of our cRPE-Span extraction system.

Framework diagram of our cRPE-Span extraction system
3.1 Shared Feature Representation Module
Intuitively, the distance between entities and other context tokens provides important evidence for entity and relation extraction. So we inject location information for this network structure by adding position encodings to the input token embedding. In Transformer, absolute positional encoding in the form of sine and cosine function is generally used, which can ensure that each position vector is not repeated and there is a relationship between different positions. However, Yan et al. [14] found that the location information of trigonometric function, which is commonly used in Transformer, will lose its relative relationship in the process of forward propagation. Similarly, the embedding vectors of different positions have no obvious constraint relationship in transformer-based BERT. Because the embedding vectors of each position are independently trained in BERT, so they can only model absolute position information, and not model the relative relationship between different positions (such as adjacency and precursor relationship).
In order to make the model capture more accurate relative position relationship, we add the cRPE to the input of BERT except its origin learned position embedding. The continuous function of complex field is adopted to encode the representation of words in different positions. In this paper, the input embedding vector of BERT is the superposition of four embedding features, namely piece-wise word embedding, segmentation embedding, learned position embedding and complex field position embedding.
Relative Position Embedding in Complex Field.
Typically, the method to encode the relative position between the token \({{\varvec{x}}}_{i}\) and \({{\varvec{x}}}_{j}\) into vectors \({{\varvec{p}}}_{ij}^{V}\), \({{\varvec{p}}}_{ij}^{Q}\), \({{\varvec{p}}}_{ij}^{K}\in {\mathbb{R}}^{{d}_{z}}\) is encoding the positional vectors into the self-attention module, which reformulates the self-attention module as
each weight coefficient \({\alpha }_{ij}\) is computed using a softmax:
where \({e}_{ij}\) is calculated using a scaled dot-product attention:
Instead of simply adding the word vector and the position vector, we use a function to add the position information modeling the relative position of words. This function is continuously changing with the position. Like complex relative position representations proposed by Wang et al. [15], we first define a function to describe the word in the text with position pos and index j as:
g is a vector-valued function, which satisfies the following two properties:
1. There exists a function \(\mathrm{T}: {\mathbb{C}}\times {\mathbb{R}}\to {\mathbb{R}}\) such that for all \(pos \ge 0, n\ge 0\), \({{\varvec{g}}}_{i}(\text{pos + n) = T(n,}{ {\varvec{g}}}_{i}(\text{pos))}\). Namely, if we know the word vector representation of a word at a certain position, we can calculate the word vector representation of it at any position. That is to say, linear transformation has nothing to do with position, but only with relative position.
2. There exists \({\delta \in {\mathbb{R}}}_{+}\) such that for all position pos, \({{\varvec{g}}}_{i}(\text{pos) }<=\delta \). That is, the norm of the word vector is bounded.
If \(\mathrm{T}\) is a linear function, then \({{\varvec{g}}}_{i}(\text{pos)}\) admits only one solution in vector:
it can also be written in the form of components as:
In this way, we hope to get the word order modeling in this smooth way. Where \({{\varvec{r}}}_{j}\) is the amplitude, \({{\varvec{\theta}}}_{j}\) is the initial phase, \({{\varvec{w}}}_{i}\) is the angular frequency. Amplitude is only related to the index of words in the sentence, which represents the meaning of words and corresponds to ordinary word vectors. Phase \({{\varvec{w}}}_{j}pos + {{\varvec{\theta}}}_{j}\) is not only related to the word itself, but also related to the position of the word in the text. It corresponds to the position of a word in the text. When the angular frequency is small, the word vectors of the same word in different positions are almost constant. In this case, the word vector in complex field is not sensitive to position, which is similar to the ordinary word vector without considering position information. When the angular frequency is very large, the complex-valued word vector is very sensitive to the position and will change dramatically with the change of position.
3.2 Joint Extraction of Entities and Relations
The joint entity and relation extraction task is transformed into a sequential pointer marking problem. Firstly, the hierarchical boundary marker is used to mark the start and end positions in a cascade structure, and then the multi span decoding algorithm is used to jointly decode the head entity and tail entity based on the range marker, and the index of the start and end positions is predicted to identify the entity boundary.
Joint Extractor.
The extractor consists of a head entity extractor (HE) and a tail entity and relationship extractor (TER). For entity extraction, the HE and TER are decomposed into two sequential marking subtasks. The subtasks are to identify the entity starting and end position by using pointer network [16]. The difference HE and TER is that the TER would predict the relations at the same time. It is worth to note that the entity category information does not involve in this sequential marking process, that is, the model is no need to predict the entity category first, and then predict the relationship according to the category, and only need to predict the relationship according to the entity location information. Therefore, the task difficulty is reduced for the only one step prediction process, as well as the accumulated error is alleviated.
The purpose of HE extractor is to distinguish candidate entities and exclude irrelevant entities. Firstly, the triple library is constructed by training set, and after that the embedding vector sequence \({{\varvec{h}}}_{i}\) is obtained by embedding module. Then, the training data is searched remotely to obtain the prior information representation vector \({\varvec{p}}\). Finally, the feature vector \({{\varvec{x}}}_{i}=[{{\varvec{h}}}_{i};{\varvec{p}}]\) is obtained by connecting the feature coding vector sequence with the prior information representation vector. \({{\varvec{h}}}_{HE} ({{\varvec{h}}}_{HE}=\{{{\varvec{x}}}_{1}, \dots ,\) \({{\varvec{x}}}_{n}\)}) is used to represent the vector representation of all the words used for HE extraction. Inputting \({{\varvec{h}}}_{HE}\) into HE to extract the head entity, which includes all the head entities in the sentence and the corresponding entity location labels.
Similar to HE extractor, TER also uses basic representation \({{\varvec{h}}}_{i}\) and prior information vector \({\varvec{p}}\) as input feature. However, the combination of \({{\varvec{h}}}_{i}\) and \({\varvec{p}}\) is insufficient to detect tail entities and relationships with specific head entities. The key information needed for TER extraction includes: (1) words in tail entities (2) dependent header entities (3) context representing relationships. In a comprehensive way, we combine the head entity and context-related feature representation. That is, given a header entity \(h\), \({{\varvec{x}}}_{i}\) is defined as follows:
Here, \({{\varvec{h}}}^{h}=[{{\varvec{h}}}_{sh};{{\varvec{h}}}_{eh}]\). \({{\varvec{h}}}_{sh}\) and \({{\varvec{h}}}_{eh}\) are the index of the beginning and end position of the head entity \(h\), respectively. [\({\varvec{p}};{{\varvec{h}}}^{h}]\) is the auxiliary feature vector of tail entity and relation extraction. We will take \({{{\varvec{h}}}_{THE}\boldsymbol{ }({\varvec{h}}}_{THE}=\{{{\varvec{x}}}_{1}, \dots ,\) \({{\varvec{x}}}_{n}\)}) as the input of hierarchical boundary annotation, and the output is obtained as \(\{(h, {rel}_{o}, {t}_{o})\}\), which contains all triples in sentence \(s\) given header entity \(h\).
In general, for a sentence with m entities, the whole joint decoding task includes two sequence annotation tasks for HE tags and 2 m for TER tags.
Loss Function.
In the training process, we aim to share the input sequence among tasks and carry out joint training. So for each training instance, we do not input sentences repeatedly in order to use all the triple information in the sentences, but randomly select a head entity from the labeled head entities as the input of TER extractor. At the same time, two loss functions are used to train the model, one is \({L}_{HE}\) for HE extraction, and the other is \({L}_{TER}\) for TER extraction.
This optimization function can make the extraction of head entity, tail entity and relationship interact with each other, so that the element in each triplet can be constrained by another element. \({L}_{HE}\) and \({L}_{TER}\) can be defined as the sum of negative logarithm probability of real start tag and end tag:
Here, \({\widehat{y}}_{i}^{sta}\) and \({\widehat{y}}_{i}^{end}\) are real tags that represent the beginning and end positions of the i-th word, respectively. \(n\) is the length of the sentence. \({P}_{i}^{sta}\) and \({P}_{i}^{end}\) represent the prediction probabilities of the starting and ending positions of the i-th word as the target entity respectively.
Here, \(\chi \) is an indicator function such that \({\chi }_{A}=1\) if and only if \(A\) is true.
4 Experiments
4.1 Datasets
We have conducted experiments on three datasets: (1) CoNLL04 was published by Dan et al. [17], we used segmented dataset with 5 relation types defined by Gupta and Adel et al. [18, 19], which contains 910 training data, 243 evaluation data and 288 test data. (2) NYT-multi was published by Zeng et al. [20]. In order to test the overlapping relation extraction in 24 relation types, they selected 5000 sentences from NYT-single as the test set, 5000 sentences as the verification set, and the remaining 56195 sentences as the training set. (3) WebNLG was released by Claire et al. [21] and used for natural language generation task. We used the WebNLG data preprocessed by Zeng et al. [20], including 5019 training data, 500 evaluation data,703 test data and 246 relation types.
4.2 Experimental Evaluation
We follow the evaluation metric in previous work [4, 22]. If and only if the relation type and two corresponding entities of a triple are correct, the triple is labeled as correct. If the head and tail position boundaries are correct, the entity is considered to be correct. We used standard Micro Precision, Recall and F1 scores to evaluate the results.
4.3 Experimental Parameters
We use the mini-batch mechanism to train our model, the batch size is 8, using the weighted moving average Adam to optimize the parameters. The learning rate is set to be 1e−5 and the stacked bidirectional transformer has 12 layers and 768 dimensions of hidden state. We used pretrained BERT base model [Uncased-BERT-Base]. The maximum length of the input sentence in our model is set to be 128. We did not adjust the threshold of the joint extractor, and set the threshold to 0.5 by default. All super parameters are adjusted on the validation set. In each experiment, we use an early stop mechanism to prevent the model from over fitting, and then report the test results of the optimal model on the test set. All our training and test results were performed on 32 GB Tesla V100 GPU.
5 Results and Analyses
5.1 Comparison Models
We mainly compare our model with the following baseline models: (1) Multi-Head [22] and (2) ETL-Span [4]. We reimplement these models on CoNLL04, NYT-multi and WebNLG datasets, marked with * in Table 1 and Table 2.
Table 1 reports the results of our models against other baseline methods on CoNLL04 dataset. Our model achieved a comparable result with F1 score of 67.6%, and with the recall of 68.7%. We found that the result of our model is better than the method based on sequence-by-sequence encoding, such as Biaffine-attention and Multi-Head. This is probably due to the inherent limitation for RNN expansion to generate triples.
In Table 2, It can be seen that our proposed joint extraction based on complex position embedding method, cRPE-Span, significantly outperforms all other methods, especially on NYT-multi dataset with precision, recall and F1 score of 94.6%, 92.5% and 93.6%, respectively.
Compared with ETL-Span, a joint extraction method based on span scheme, the F1 scores of cRPE-Span on NYT-multi and WebNLG datasets have increased by 17.9% and 2.9%, respectively. In comparison with Multi-Head, the F1 scores of cRPE-Span on NYT-multi and WebNLG datasets increased by 14.6% and 5.2%, respectively. We consider that it is because (1) we decompose the difficult joint extraction task into several more manageable subtasks and handle them in a mutually enhancing way, this suggests that our HE extractor and TER extractor actually work in a mutually enhancing manner; (2) our shared feature extractor based on BERT with cRPE effectively captures the semantic and position information of the dependence of the first entity, while ETL-Span uses LSTM to shared encoding, and it needs to predict the category of entity, and then predict the relationship based on the category, that may cause error propagation issues. Overall, these results demonstrate that our extraction paradigm first extracts the head entity, and then marks the corresponding tail entity, and can better capture the relationship information in the sentence.
5.2 Ablation Study
To demonstrate the effectiveness of each component, we conducted ablation experiments by removing one particular component at a time to understand its impact on the performance. We study the influence of cRPE (complex relative positional encoding) and RSS (remote supervised search) on the WebNLG dataset, as shown in Table 3.
In the table we can find that: (1) when we delete the cRPE, the F1 score drops by 1.4%. This shows that relative position encoding plays a vital role in information extraction, allowing the tail entity extractor to know the position information of a given head entity, so as to filter out irrelevant entities through implicit distance constraints. Secondly, by predicting the entities in the HE extractor, we can explicitly integrate the entity location information into the entity representation, which is also very helpful for subsequent TER mark; (2) after removing the remote supervised search strategy, the F1 score dropped by 0.2%. The above comparison tests once again confirm the effectiveness and rationality of our cRPE and RSS strategy.
5.3 Model Convergence Analysis
In order to analyze the convergence of our model, we conducted further experiments on three test datasets and selected our baseline model RSS-Span for comparison. The RSS-Span model is with the remote supervised search strategy, but without the complex relative positional encoding. To differentiate the test results of baseline and cRPE-Span model, the baseline results are drawn with black hollow circles, and the cRPE-Span results are drawn with blue solid circles, as shown in Fig. 2. The dash lines in the table are benchmark scores which are relatively smaller scores value in the best F1 scores. For the NYT-multi dataset, we select 92.8% of the F1 score between cRPE-Span and the baseline model, which is the smaller of 93.6% and 92.8%. Similarly, for the CoNLL04 and WebNLG datasets, the selected F1 benchmark scores are 66.1% and 85.7%, respectively. That is to say, we analyze the number of training epochs at this time when the benchmark score is reached.

Comparison results of model convergence
From Fig. 2, we observe that the convergence of cRPE-Span is slightly inferior to that of RSS-Span. After training for about 100 epochs, RSS-Span reaches the F1 benchmark score, while cRPE-Span needs to be iterated to about 1000 epochs. This is because the cRPE-Span position embedding layer is a continuous function in the complex domain to encode the representation of words at different positions, which involves to be learned new parameters including amplitude, angle frequency and the initial phase. The parameters will increase the parameter amount of the embedding vector, and furthermore, it takes longer to train iteratively. In addition, we also observe that the performance stability is better than RSS-Span. The possible reason is that the increase in the number of parameters makes the model have better generalization ability, which further proves the superiority of our embedding method based on the relative position of complex domain.
6 Conclusion
In this paper, we improve a joint extraction method of entities and relationships based on an end-to-end sequence labeling framework with complex relative position encoding. The framework is based on a shared encoding of a pre-trained language model and a novel decomposition strategy. The experimental results show that the functional decomposition of the original task simplifies the learning process and brings a better overall learning effect. Compared with the baseline model, it reaches a better level on the three public datasets. Further analysis proves the ability of our model to handle multi-entity and multi-relation extraction. In the future, we hope to explore similar decomposition strategies in other information extraction tasks, such as event extraction and concept extraction.
References
Dai, Z., Yang, Z., Yang, Y., et al.: Transformer-XL: attentive language models beyond a fixed-length context. In: ACL, pp. 2978–2988 (2019)
Lin, Y., Shen, S., Liu, Z., Luan, H., Sun, M.: Neural relation extraction with selective attention over instances. In: ACL, pp. 2124–2133 (2016)
Miwa, M., Sætre, R., Miyao, Y., Tsujii, J.: A rich feature vector for protein-protein interaction extraction from multiple corpora. In: EMNLP, pp. 121–130 (2009)
Yu, B., Zhan, Z., Shu, X., Liu, T., Wang, Y., et al.: Joint extraction of entities and relations based on a novel decomposition strategy. In: ECAI, pp. 2282–2289 (2019)
Devlin, J., Chang, M., Lee, K., Toutanova, K.: BERT: pre-training of deep bidirectional transformers for language understanding. In: NAACL, pp. 4171–4186 (2019)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., et al.: Attention is all you need. In: NIPS, pp. 6000–6010 (2017)
Sun, C., Wu, Y., Lan, M., Sun, S., Wang, W., et al.: Extracting entities and relations with joint minimum risk training. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp. 2256–2265 (2018)
Tan, Z., Zhao, X., Wang, W., Xiao, W.: Jointly extracting multiple triplets with multi-layer translation constraints. In: Proceedings of the AAAI Conference on Artificial Intelligence (2019)
Dai, D., Xiao, X., Lyu, Y., et al.: Joint extraction of entities and overlapping relations using position-attentive sequence labeling. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 6300–6308 (2019)
Radford, A., Narasimhan, K., Salimans, T., Sutskever, I.: Improving language understanding by generative pre-training (2018)
Wei, J., Ren, X., Li, X., et al.: NEZHA: neural contextualized representation for Chinese language understanding. arXiv preprint arXiv:1909.00204 (2019)
Raffel, C., Shazeer, N., Roberts, A., et al.: Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 1–67 (2020)
He, P., Liu, X., Gao, J., Chen, W.: DeBERTa: decoding-enhanced BERT with disentangled attention. In: Proceedings of ICLR (2021)
Yan, H., Deng, B., Li, X., Qiu, X.: TENER: adapting trans-former encoder for named entity recognition. arXiv preprint arXiv:1911.04474 (2019)
Wang, B., Zhao, D., Lioma, C., Li, Q., Zhang, P., Simonsen, J.G.: Encoding word order in complex embeddings. In: ICLR ( 2020)
Li, X., Feng, J., Meng, Y., et al.: A unified MRC framework for named entity recognition. In: ACL, pp. 5849–5859 (2020)
Roth, D., Yih, W.: A linear programming formulation for global inference in natural language tasks. In: Proccedings of CoNLL (2004)
Gupta, P., Schütze, H., Andrassy, B.: Table filling multi-task recurrent neural network for joint entity and relation extraction. In: COLING, pp. 2537–2547 (2016)
Adel, H., Schütze, H.: Global normalization of convolutional neural networks for joint entity and relation classification. In: EMNLP, pp. 1723–1729 (2017)
Zeng, X., Zeng, D., He, S., Liu, K., Zhao, J.: Extracting relational facts by an end-to-end neural model with copy mechanism. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, vol. 1, pp. 506–514 (2018)
Gardent, C., Shimorina, A., Narayan, S., Perez-Beltrachini, L.: Creating training corpora for NLG micro-planning. In: 55th Annual Meeting of the Association for Computational Linguistics, pp. 179–188 (2017)
Bekoulis, G., Deleu, J., Demeester, T., Develder, C.: Joint entity recognition and relation extraction as a multi-head selection problem. Expert Syst. Appl. 114, 34–45 (2018)
Nguyen, D.Q., Verspoor, K.: End-to-end neural relation extraction using deep biaffine attention. In: Azzopardi, L., Stein, B., Fuhr, N., Mayr, P., Hauff, C., Hiemstra, D. (eds.) ECIR 2019. LNCS, vol. 11437, pp. 729–738. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-15712-8_47
Tran, T., Kavuluru, R.: Neural metric learning for fast end-to-end relation extraction. arXiv preprint arXiv:1905.07458 (2019)
Wang, Y., Yu, B., Zhang, Y., Liu, T., Zhu, H., Sun, L.: TPLinker: single-stage joint extraction of entities and relations through token pair linking. In: COLING, pp. 1572–1582 (2020)
Sui, D., Chen, Y., Liu, K., Zhao, J., Zeng, X., Liu, S.: Joint entity and relation extraction with set prediction networks. arXiv preprint arXiv:2011.01675 (2020)
Acknowledgement
The work presented in this paper is supported by the International Science and Technology Cooperation Foundation of Shanghai (grant No. 18510732000).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Cai, H., Xu, Q., Shen, W. (2022). Complex Relative Position Encoding for Improving Joint Extraction of Entities and Relations. In: Qian, Z., Jabbar, M., Li, X. (eds) Proceeding of 2021 International Conference on Wireless Communications, Networking and Applications. WCNA 2021. Lecture Notes in Electrical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-19-2456-9_66
Download citation
DOI: https://doi.org/10.1007/978-981-19-2456-9_66
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-2455-2
Online ISBN: 978-981-19-2456-9
eBook Packages: EngineeringEngineering (R0)