
Abstract
Deep learning has achieved significant success in various applications due to its powerful feature representations of complex data. Financial time series forecasting is no exception. In this work we leverage Generative Adversarial Nets (GAN), which has been extensively studied recently, for the end-to-end multi-classification of financial time series. An improved generative model based on Convolutional Long Short-Term Memory (ConvLSTM) and Multi-Layer Perceptron (MLP) is proposed to effectively capture temporal features and mine the data distribution of volatility trends (short, neutral, and long) from given financial time series data. We empirically compare the proposed approach with state-of-the-art multi-classification methods on real-world stock dataset. The results show that the proposed GAN-based method outperforms its competitors in precision and F1 score.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In the past two decades, people have become more and more interested in the classification of time series, and more and more scholars at home and abroad have joined the research. Moreover, with the advent of the 5G era, big data is closely related to our lives. Time series data is everywhere, especially in the medical industry, industrial industry, and meteorology [1,2,3].
Time series classification is a critical issue in the research of time series data mining. Time series classification (TSC) accurately classifies a series of unknown time series according to the known “category” labels in the time series, and TSC can be regarded as a “supervised” learning mode. TSC has always been regarded as one of the most challenging problems in data mining, and it is more challenging than traditional classification methods [4]. First of all, time series classification needs to consider the numerical relationship between different attributes and the order relationship of all time series points. In addition, the financial time series has complex, highly noisy, dynamic, non-linear, non-parameters and chaos characteristics, so how the model can learn the characteristics of the sequence to have a better performance in classification performance will be very challenging. Since 2015, hundreds of TSC algorithms have been proposed [5]. Traditional time series classification methods based on sequence distance have proven to achieve the best classification performance in most fields. In addition, there are feature-based classification methods that have excellent classification performance based on existing good features. However, it is challenging to design good features when faced with financial time series to capture some inherent properties. Although the methods based on distance or feature are used in many research works, these two methods have caused too much calculation for many practical applications [6]. As many researchers apply deep learning methods to TSC, more and more TSC methods are proposed, especially with new deep structures such as residual neural networks and convolutional neural networks. These methods are applied in image, text, and audio areas to process time series data and related analysis. Such as Fazle et al. proposed a multivariate LSTM-FCNs for time series classification, which further improved the model’s classification accuracy by improving the structure of the full convolution block [7].
Inspired by the classification application of deep learning in the image field, such as GAN, which has achieved remarkable success in generating high-quality images in computer vision, we explore a deep learning framework for multivariate financial time series classification. The model uses ConvLSTM as the generator to learn the distribution characteristics of the data and MLP as the discriminator to discriminate whether the output data of the generator is true or false. We evaluated the performance of our model on publicly available stock datasets and selected several classic comparison methods. The experimental results show that the classification performance of the GAN on the MSFT is significantly improved compared to other models and less pre-processing. We summarize our contributions as follows:
-
We propose an effective GAN-based volatility trends multi-classification model for multivariate financial time series based on stock data with multiple technical indicators.
-
We improved the generator of GAN by adopting ConvLSTM to capture temporal dependencies and classify various volatility trends efficiently.
The organizational structure of this paper is as follows: Sect. 2 reviews relevant research work. Section 3 introduces the proposed improved model. The Sect. 4 presents the experiments done. Finally, we draw our conclusions in Sect. 5.
2 Related Work
In the classification research of time series, many deep learning methods have been applied. For example, Michael [8] and others took the lead in applying recurrent neural networks (RNN) to time series classification. Recently, Yi et al. [9] have proposed multi-channels deep convolutional neural networks (MC-DCNN) by improving convolutional neural networks (CNN). This model automatically learns the features of a single variable time series in each channel [10] has achieved great success in computer vision, especially in graphic recognition tasks, such as GAN has been achieved remarkable success in computer vision high-quality image generation. The application scenarios of GAN have been rapidly developed, covering images, texts, time series. With the continuous investment of researchers, GAN has been researching more and more in data generation, anomaly detection, time series prediction, classification. Ian Goodfellow and others first proposed the GAN to generate high-quality pictures [11]. Later, Xu, Zhan, and others [12] used improved GAN and LSTM to predict satellite images, thereby obtaining important resources for weather forecasting. In recent years, there have been more and more researches using generative confrontation networks on financial time series, and the research on the price trend fluctuation prediction is of great practical value. Zhang et al. [13] applied GAN to stock price prediction, tried to use GAN to capture the distribution of actual stock data, and achieved good results compared with existing deep learning methods. Feng [14] and others proposed a method based on adversarial training to improve the generalization of neural network prediction models. The results show that their model performs better than the existing methods. According to the characteristics of financial time series, we know that the challenge of this research is how to let GAN learn the price data trend distribution of the original data to have a better performance in the end-to-end classification. Meanwhile, the three-classification research on the financial time series price trend is more challenging than binary classification. However, it has an outstanding good reference value for stock trading.
3 Methodology
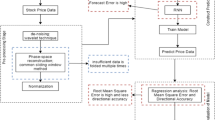
We propose a new GAN architecture for end-to-end three-classification of stock closing price trends based on this principle. Based on the improvement on GAN. We will show the detailed structure description in Fig. 1. It shows that the model’s input is \({\text{X}} = {\text{\{ x}}_{1} \,{\text{,x}}_{2} {,} \cdots {\text{,x}}_{\text{t}} {\text{\} }}\) composed of daily stock data for t days. Both \(X_{fake}\) and \(X_{real}\)are a probability matrix with one row and three columns of the discriminator’s output. In the GAN, both the generator and the discriminator try to optimize a value function, and eventually, they reach an equilibrium point called Nash equilibrium. Therefore, we can define our value function \(V(G,D)\)as:
When calculating the error of the probability matrix one-hot encoding, we usually use the cross- entropy loss function. Given two probability distributions p and q, the cross-entropy of p expressed by q is defined as follows:
where p represents the actual label and q represents the predicted label. We get the probability matrix \(\hat{C}_{t + 1}\) and calculate the cross-entropy loss with the actual probability matrix \(C_{t + 1}\) at that moment.

The architecture of our GAN.
The eleven technical indicators are: ‘Close’, ’High’, ‘Low’, ‘Open’, ‘RSI’, ‘ADX’, ‘CCI’, ‘FASTD’, ‘SLOWD’, ‘WILLER’, ‘SMA’ [15]. Each input X is a vector composed of the above eleven features. Based on the generator, we extract the output of ConvLSTM and put it into a fully connected layer to generate three types of probability matrices of short, neutral, and long through the softmax activation function, which is defined as follows:
The goal is to let \(\hat{C}_{t + 1}\) approach \(C_{t + 1}\), and we can get \(\hat{x}_{t + 1,C}\) from \(\hat{x}_{t + 1}\) so that we can get the probability matrices. The output of generator \(G(X)\) defined as follows.
Where \(g( \cdot )\) denotes the output of ConvLSTM and \(h_t\) is the output of the ConvLSTM with \({\text{X}} = {\text{\{ x}}_{1}\, {\text{,x}}_{2} {,} \cdots {\text{,x}}_{\text{t}} {\text{\} }}\) as the input \(\delta\) stands for the softmax activate function.\(W_h\) and \(b_h\) denote the weight and bias in the fully connected layer. We also use dropout as a regularization method to avoid overfitting. In addition, we can use the idea of a sliding window to predict \(\hat{C}_{t + 2}\) by \(\hat{C}_{t + 1}\) and \(X\).
4 Experiments
4.1 Dataset Descriptions
We selected actual stock trading data from the Yahoo Finance website (https://finance.yahoo.com/) to evaluate our model and selected several classic deep learning methods as baseline methods. These stock data is Microsoft Corporation (MSFT). We construct our label data through the closing price (Close) and define \(x_{Close,i} { - }x_{Close,i + 1} > \mu\) as short, \(x_{Close,i + 1} { - }x_{Close,i} < \theta\) as long, and \(x_{Close,i + 1} { - }x_{Close,i} = \lambda\) as neutral \((0 < i < n)\), where \(\mu ,\theta > 0,\lambda = 0\) is the parameter we set according to the corresponding stock. We first normalize the data with Z-score to eliminate the influence of dimensions between different variables. Our goal is to predict the trend of the stock’s closing price on the next day and get the trend of the closing price on the t + 1 day through the input \(X_t\) of the past t days. Through repeated experiments, we set t to be 30. Our data is divided into three parts: training, validation and testing. We select the first 85%–90% of the data on each stock as the training set and the rest (10%–15%) part as the validation and test set. We will give the trend chart in Fig. 2.

The trend image of MSFT.
From Fig. 2, we can intuitively see that the MSFT data’s price trends fluctuate from the beginning. When it rose to 2000, it began to decline in an oscillating trend and then remained in a long-term turbulence “stable” until it began to rise in 2012. As a result, it can be seen that MSFT can better test the robustness of different models. The MSFT data set started from 1999/1/4 to 2018/12/31, the length is 5031, the training set length is 5031, the validation set length is 252, and the test set length is 503.
4.2 Experiment Setting
In our model, the ConvLSTM’s filters in the convolutional layer set to 256, 128, the size of the convolution kernel is 2. After the convolutional layer, we add a pooling layer of size 2, followed by the convolutional layer is connected to the LSTM layer, the number of cells is 100, 100. Then a fully connected layer is output with the softmax activation function. We also use the generator parameter settings in the ConvLSTM benchmark method. The cells in the four layers of the discriminator set to 256, 128, 100, 3, and the softmax activation function is used in the last fully connected layer. The training epochs are usually kept at 1000, and we set the initial batch size to 60. We add a dropout layer with a value of 0.2 after the CNN and LSTM layers to prevent overfitting. The learning rate of the generator is 1e−3, the final learning rate is 1e–4. Every 50 epoch, if the recall index on the validation set does not improve, the learning rate will decrease by 2e–5 until the final learning rate reaches. All model training is performed with the Keras version 2.3.1 library of TensorFlow version 2.0 background. The experimental operating system is Ubuntu 16.04 and using NVIDIA GeForce GTX 1080Ti GPU. Some third-party libraries, such as the use of Talib to calculate technical indicators.
4.3 Experiment Results
We conducted a detailed experimental analysis on the MSFT based on several different comparison methods. First, we selected Macro and Weighted based on the multi-classification indicators. Among them, the macro and weighted include the corresponding precision, recall, and f1-score indicators. For ease of description, the bold font in our table represents the best value in the comparison method, and the underlined data indicates the secondary. At the same time, the Macro-f1-score and Weighted-f1-score indicators of different methods on the MSFT are shown in Fig. 3.

The experiment results
From experimental results, we can see that the proposed method performed better than the contrasted deep learning methods on four indicators, primarily the Weighted-precision indicator reached 0.3732. Compared with the highest 0.3690 in the comparison method, it is improved by 0.0042. As shown in Fig. 3, compared to others, the proposed method has slightly improved in average Macro. It should be noted that we select the best performance among other methods to compare with our method. Moreover, it can be seen that ConvLSTM is added as a generator to the generative confrontation network, and the classification performance is improved compared to the end-to-end ConvLSTM on the indicators.
5 Conclusion
In the research on the movement trend classification of financial time series prices, an improved generative model based on ConvLSTM and MLP is proposed to capture temporal features effectively and mine the data distribution of volatility trends from given financial time series data. The experimental results show that the proposed method has been further optimized under the above circumstances. Our model improves the overall classification performance and guides actual transactions. Moreover, our model outperforms the baseline methods on the datasets with complicated distribution characteristics. However, the limitation of the experiments is that the eleven technical indicators we selected in this experiment may not be the best. Different indicator combinations may have different effects on the performance of the model. Therefore, detailed experimental comparisons of the impact of different indicator selections on model performance are also follow-up work arrangements.
References
Maleki, M., et al.: Time series modelling to forecast the confirmed and recovered cases of COVID-19. Travel Med. Infect. Dis. 37, 101742 (2020)
Sezer, O.B., Gudelek, M.U., Ozbayoglu, A.M.: Financial time series forecasting with deep learning: a systematic literature review: 2005–2019. Appl. Soft Comput. 90, 106181 (2020)
Gao, Z.-K., Small, M., Kurths, J.: Complex network analysis of time series. EPL (Europhys. Lett.) 116(5), 50001 (2017)
Yang, Q., Xindong, W.: 10 challenging problems in data mining research. Int. J. Inf. Technol. Decis. Mak. 5(04), 597–604 (2006)
Bagnall, A., et al.: The great time series classification bake off: a review and experimental evaluation of recent algorithmic advances. Data Min. Knowl. Discov. 31(3), 606–660 (2017)
Xiaopeng, X., et al.: Fast time series classification using numerosity reduction. In: Proceedings of the 23rd International Conference on Machine Learning (2006)
Karim, F., et al.: LSTM fully convolutional networks for time series classification. IEEE Access 6, 1662–1669 (2017)
Hüsken, M., Stagge, P.: Recurrent neural networks for time series classification. Neurocomputing 50, 223–235 (2003)
Zheng, Y., Liu, Q., Chen, E., Ge, Y., Zhao, J.L.: Time series classification using multi-channels deep convolutional neural networks. In: Li, F., Li, G., Hwang, Sw., Yao, B., Zhang, Z. (eds.) Web-Age Information Management. WAIM 2014. LNCS, vol. 8485. Springer, Cham. https://doi.org/10.1007/978-3-319-08010-9_33
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. Adv. Neural. Inf. Process. Syst. 25, 1097–1105 (2012)
Goodfellow, I., et al.: Generative adversarial nets. Adv. Neural Inf. Process. Syst. 27 (2014)
Xu, Z., et al.: Satellite image prediction relying on GAN and LSTM neural networks. In: ICC 2019–2019 IEEE International Conference on Communications (ICC). IEEE (2019)
Zhang, K., et al.: Stock market prediction based on generative adversarial network. Procedia Comput. Sci. 147, 400–406 (2019)
Feng, F., et al.: Enhancing stock movement prediction with adversarial training. arXiv preprint arXiv:1810.09936 (2018)
Patel, J., et al.: Predicting stock and stock price index movement using trend deterministic data preparation and machine learning techniques. Expert Syst. Appl. 42(1), 259–268 (2015)
Acknowledgement
This work is partially supported by China Scholarship Council, Science and Technology Program of Sichuan Province under Grant 2020JDRC0067 and 2020YFG0326, and Talent Program of Xihua University under Grant Z202047.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Liu, L., Pei, Z., Chen, P., Gao, Z., Gan, Z., Feng, K. (2022). An Effective GAN-Based Multi-classification Approach for Financial Time Series. In: Qian, Z., Jabbar, M., Li, X. (eds) Proceeding of 2021 International Conference on Wireless Communications, Networking and Applications. WCNA 2021. Lecture Notes in Electrical Engineering. Springer, Singapore. https://doi.org/10.1007/978-981-19-2456-9_110
Download citation
DOI: https://doi.org/10.1007/978-981-19-2456-9_110
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-2455-2
Online ISBN: 978-981-19-2456-9
eBook Packages: EngineeringEngineering (R0)