
Zusammenfassung
In diesem Kapitel wird die Planung, Durchführung und Auswertung der qualitativen Forschung beschrieben. Hierbei geht es nicht nur darum, Informationen zur Weiterentwicklung der hier beschriebenen Interventionsmaßnahme zu sammeln, sondern vor allem darum, grundsätzliche Erkenntnisse zu Problemlöseprozessen von Studienanfängern zu gewinnen.
You have full access to this open access chapter, Download chapter PDF
In diesem Kapitel wird die Planung, Durchführung und Auswertung der qualitativen Forschung beschrieben. Hierbei geht es nicht nur darum, Informationen zur Weiterentwicklung der hier beschriebenen Interventionsmaßnahme zu sammeln, sondern vor allem darum, grundsätzliche Erkenntnisse zu Problemlöseprozessen von Studienanfängern zu gewinnen.
Wie in Abschnitt 2.1 beschrieben, gibt es hierzu noch recht wenig Studien. Erwähnenswert sind in diesem Zusammenhang neben den Klassikern von Lucas (1974) und Schoenfeld (1985) eine Studie von Zazkis et al. (2015), bei der Problembearbeitungsprozesse von erfolgreichen Studierenden höherer Semester untersucht werden, und die Dissertation von Kirsten (im Druck), die die in Abschnitt 5.3.1 beschriebene Einteilung von Problemlöseprozessen in Episoden nach Schoenfeld (1985) an Beweisprozesse anpasst.
Abschnitt 5.1 beschreibt den grundsätzlichen Ablauf der qualitativen Forschung. Hierbei handelt es sich um eine Prozessanalyse von Problembearbeitungen der Probanden. In Abschnitt 5.2 wird eine kurze stoffdidaktische Analyse der verwendeten Aufgaben durchgeführt.
In diesem Kapitel soll eingegangen werden auf die
- Forschungsfrage 2: :
-
Wie laufen Problembearbeitungsprozesse bei Studienanfängern der Mathematik an authentischen Übungsaufgaben ab und welchen Einfluss hat dabei die Teilnahme an der Fördermaßnahme?
In Abschnitt 5.3 werden die Methoden beschrieben, die zur Auswertung der videographierten Prozesse und damit der Beantwortung der Forschungsfrage 2 verwendet wurden. Diese ist bewusst recht allgemein gestellt, da eine Präzisierung die Gefahr birgt, dass der Suchraum eingeschränkt wird. Da es, wie eben beschrieben, im betrachteten Kontext bisher wenig Studien gibt, es sich hier also um Grundlagenforschung handelt, soll ein holistischer Blick auf die Prozesse gerichtet werden. Aus demselben Grund ist es auch nicht sinnvoll, die Untersuchung auf ausgewählte, quantitativ messbare Aspekte zu beschränken. Die Wahl fiel also auf eine qualitative Untersuchung. Um eine gewisse Objektivität sicherzustellen, wurden vorher festgelegte Aspekte, denen aufgrund der theoretischen Überlegungen und der oben genannten Studien eine gewisse Bedeutung unterstellt werden kann, unabhängig von zwei Personen kodiert. Hierbei handelt es sich um Schoenfeld-Episoden (Abschnitt 5.3.1), das Nutzen externer Hilfsmittel, wie dem Skript oder dem Internet (Abschnitt 5.3.2), Heurismeneinsatz (Abschnitt 5.3.4), metakognitive Aktivitäten (Abschnitt 5.3.5), das Auftreten neuer Ideen und Lösungsansätze, den Einfluss von Fachwissen (Abschnitt 5.3.6) sowie die Kodierung von Fehlern.
In Abschnitt 5.4 wird erläutert, wie die Kodierer geschult wurden, um eine möglichst objektive Kodierung zu erreichen. In Abschnitt 5.5 werden schließlich die Ergebnisse präsentiert, bevor diese in Abschnitt 5.6 zusammengefasst werden. Um einen guten Überblick über die betrachteten Teilaspekte zu bekommen, werden in Abschnitt 5.5 Teilfragen gestellt, die sich, um den holistischen Blick nicht im Vorfeld einzuschränken, erst im Prozess der Auswertung als sinnvoll herauskristallisiert haben.
5.1 Forschungsdesign
In diesem Abschnitt werden die Gegebenheiten der qualitativen Datenerhebung beschrieben. Bei den Probanden handelt es sich um Freiwillige aus jedem Zyklus der Maßnahme, die etwa zu gleichen Teilen aus Interventionsgruppe und Kontrollgruppe stammen (für eine Übersicht vgl. Tabelle 5.1). Von den meisten dieser Freiwilligen liegen aufgabenbasierte Interviews (s. u.) von zwei Messzeitpunkten – zu Beginn und am Ende des Semesters – vor. Manche haben nur am ersten Interview teilgenommen, in der Regel, weil sie ihr Mathematikstudium abgebrochen haben, in wenigen Fällen auch ohne Angabe von Gründen oder aus Zeitmangel. Von Einzelnen liegt auch noch Material eines dritten Messzeitpunktes in der Mitte des Semesters vor. In der vorliegenden Arbeit wurden allerdings von jedem Teilnehmer maximal zwei Prozesse ausgewertet. Das Forschungsvorhaben und der geplante Ablauf der Interviews wurde zu Beginn des Semesters in allen Übungsgruppen kurz durch den Autor vorgestellt, um dort die Freiwilligen zu rekrutieren. Es ist gut denkbar, dass es sich bei der Stichprobe um eine Positivauswahl handelt, falls sich etwa Studierende erst dann freiwillig melden, wenn sie sich die Bearbeitung der Aufgaben zutrauen. Insgesamt wurde nach Möglichkeit darauf geachtet, dass sich die Probanden gleichmäßig auf die Übungsgruppen aufteilen, um Verzerrungen, die sich durch die Persönlichkeit des jeweiligen Tutors ergeben, möglichst auszugleichen. Da in manchen Zyklen die Übungen erst in der zweiten Vorlesungswoche begannen, wurden die ersten Interviews teilweise erst in der dritten oder vierten Woche geführt. Die letzten Interviews hingegen sollten noch im Semester stattfinden, damit die Probanden, auch im Hinblick auf die für die bevorstehenden Klausuren dringend benötigte Vorbereitungszeit, nicht eigens dafür anreisen mussten. Daher lagen in machen Fällen zwischen dem ersten und dem letzten Interview nur acht Übungsstunden (Feiertage nicht mitberechnet). Hauptkriterium dafür, ob ein Prozess ausgewertet wurde, war dass der Proband ausreichend gesprochen hat. Bei einigen Prozessen hat dies nicht gut funktioniert. Außerdem wurde darauf geachtet, zumindest von der Interventionsgruppe genügend Teilnehmer zu zwei Messzeitpunkten betrachten zu können. Aus der Kontrollgruppe gibt es leider nur einen Probanden, von dem zwei Bearbeitungen untersucht wurden. Es ist nicht klar, warum die Studierenden aus dieser Gruppe beim zweiten Messzeitpunkt ausblieben. Eine höhere Abbruchquote oder geringere Nähe zum Interviewer sind nur zwei mögliche Gründe. Insgesamt wurden 13 Prozesse von 9 verschiedenen Probanden analysiert (vgl. Tabelle 5.1).
Bei aufgabenbasierten Interviews (vgl. Goldin, 2000) wird den Teilnehmenden eine Aufgabe (in dem Fall ein Problem) vorgelegt, das sie lösen sollen. Im Mittelpunkt steht weniger die Interaktion mit dem Interviewer als die Interaktion mit der Aufgabe. Ziel ist es, die ablaufenden Prozesse besser zu verstehen. Hilfestellungen und Zwischenfragen gelten als Teil der Lernumgebung. Hierbei ist von minimalen Interventionen (z. B. durch die Aufforderung zum lauten Denken) über metakognitive Fragen bis hin zu heuristischen Hilfestellungen (in vorher festgelegten Situationen) alles möglich. In diesem Fall wurde versucht, den Problembearbeitungsprozess möglichst wenig zu stören, weswegen sich der Interviewer weitestgehend zurückgezogen hat (auch räumlich – er hat sich einige Meter entfernt außerhalb der natürlichen Blickrichtung des Probanden hingesetzt).
Die Auswahl der zu bearbeitenden Probleme durchläuft, wie das Design der Intervention, einen Entwicklungsprozess. Nachdem vorher verschiedene Möglichkeiten getestet wurden, wurden in den letzten vier Zyklen ausschließlich authentische Übungsaufgaben ausgewählt, die in vorherigen Durchläufen der Veranstaltung (Analysis I bzw. Lineare Algebra I) als Übungsaufgaben verwendet wurden. Durch die thematische Anbindung an die Vorlesung waren die Aufgaben zeitlich nicht austauschbar. Dadurch ist es schwieriger, die Entwicklung der Problemlösekompetenz der Probanden nachzuvollziehen, denn die Beschaffenheit der Aufgaben kann einen großen Einfluss auf Prozess und Erfolg des Problemlösens haben. Der große Vorteil ist allerdings, dass diese Aufgaben die Realität des universitären Übungsbetriebs widerspiegeln, also Problemlösen im authentischen Kontext betrachtet werden konnte. Es wurden bewusst Aufgaben mit einem hohen Problemgehalt ausgewählt. Das heißt, dass die Aufgaben von keinem der Probanden routinemäßig gelöst werden konnten.
Da große Teile des zur Bearbeitung der Aufgaben benötigten Vorwissens erst kurz zuvor in der Vorlesung behandelt wurden, war davon auszugehen, dass die Probanden dieses Wissen noch nicht hinreichend abgespeichert hatten. Aus diesem Grund wurde entschieden, das jeweils aktuelle Kapitel des Vorlesungsskriptes zu Verfügung zu stellen. So konnten die Studierenden ohne künstliche Hürden auf aktuelle Begriffe und Zusammenhänge zurückgreifen. Zusätzlich wurde auch betont, dass sämtliche selbst mitgebrachten Materialien, inklusive des Zugangs zum Internet, verwendet werden durften. Auch dadurch sollte eine möglichst authentische Problembearbeitung nachgestellt werden. Aus demselben Grund wurde auch keine Zeitbeschränkung vorgegeben, wobei die Prozesse in der Regel nach spätestens einer Stunde von den Probanden abgebrochen wurden. Der längste Lösungsversuch dauerte etwa 90 Minuten. Insofern weichen die beobachteten Problembearbeitungen von dem wöchentlichen Bearbeiten eines Übungsblattes ab. Es gibt keine Möglichkeit eines Entfernens von der Aufgabe, um auf eine Illumination im Sinne Hadamards (1959) zu wartenFootnote 1.
5.2 Stoffdidaktische Analyse ausgewählter Aufgaben
Vor der Durchführung der Interviews wurden die verwendeten Aufgaben einer stoffdidaktischen Analyse unterzogen. Exemplarisch sollen an dieser Stelle Überlegungen zu drei Aufgaben wiedergegeben werden. Kurzfassungen solcher Überlegungen zu den anderen Aufgaben finden sich in Anhang D. Hierbei soll ein typischer Lösungsprozess skizziert werden. An Stelle eines lückenlosen Beweises sollen aber nur die wesentlichen Eckpunkte skizziert werden. Stärker werden aber Überlegungen zur Vorgehensweise und möglichen Heurismen in Betracht gezogen. Metakognitive Elemente lassen sich hierbei nicht so leicht einbeziehen, da diese zu großen Teilen der Korrektur von ungünstigen Entscheidungen dienen. Dennoch werden alternative Vorgehensweisen benannt, wenn es sich anbietet. Darüber hinaus wird analysiert, welches deklarative und prozedurale Fachwissen zur erfolgreichen Bearbeitung der Aufgabe notwendig oder hilfreich ist. Grundsätzlich ist es natürlich immer möglich, einen notwendigen Zusammenhang, der etwa in der Vorlesung bereits bewiesen wurden, während des Problembearbeitungsprozesses selbstständig herzuleiten, wenngleich dieses Vorgehen sehr aufwändig und daher eher unwahrscheinlich ist. Auch mögliche Fehlerquellen sollen antizipiert werden.
5.2.1 Aufgabe 1: Quetschlemma
- Aufgabe 1: :
-
(Quetschlemma)
Seien \(a_n\), \(b_n\) und \(c_n\) Folgen mit \(a_n \le b_n \le c_n\) für alle \(n \in \mathrm{{I\!N}}\).
Zeigen Sie: Wenn \(a_n\) und \(c_n\) gegen den gemeinsamen Grenzwert c konvergieren, dann konvergiert auch \(b_n\) gegen c.
Zunächst sollte man sich die Konvergenz entweder als formale Definition
(und entsprechend für \(c_n\) und das zu zeigende \(b_n\)) oder in Form einer Skizze darstellen (siehe Abbildung 5.1). Ab einem gewissen \(N \in \mathrm{{I\!N}}\) liegen alle Glieder von \(a_n\) bzw. \(c_n\) innerhalb des Intervalls. Hierbei kann sich N für \(a_n\) und \(c_n\) unterscheiden. Zu zeigen ist, dass ab einem (möglicherweise wieder anderen) N auch alle \(b_n\) in dieser Umgebung liegen.

\(\varepsilon \)-Umgebung um den Punkt c
Die Informationen aus der Definition und der Skizze weichen leicht von einander ab. Übersetzt man die Skizze in eine Formel, ergibt sich „für große n“:
(und entsprechend für \(c_n\)). Alternativ lässt sich auch die Ungleichung aus der Definition durch Äquivalenzumformungen schnell in diese Form bringen. Verknüpft man diese Formeln mit der Voraussetzung, dass \(a_n \le b_n \le c_n\) ist, so erhält man direkt
Eine genauere Betrachtung, für welche n diese Gleichung gilt (in Kurzform: \(\forall n \ge \max (N_a,N_c)\), schließt die Aufgabe ab.
Didaktische Kommentare
Um diese Aufgabe lösen zu können ist die Kenntnis des Grenzwertbegriffes notwendig. Außerdem sollte der Betragsbegriff beherrscht werden, entweder durch sicheren rechnerischen Umgang oder durch die Abstandsvorstellung. Auf heuristischer Ebene kann, wenngleich nicht zwingend notwendig, das Erstellen einer Skizze (s. o.) sehr hilfreich sein. Alternativ kann auch ein zweidimensionaler Graph der Folgen dargestellt werden. Hat man weiterhin Schwierigkeiten, kann eine Zerlegung in Teilaufgaben hilfreich sein: Zum einen ist \(c-\varepsilon <b_n\) bzw. \(c-b_n<\varepsilon \) zu beweisen, was mit Hilfe von \(a_n \le b_n\) gelingt, zum anderen \(b_n<c+\varepsilon \) bzw. \(b_n-c<\varepsilon \) mit Hilfe von \(b_n \le c_n\). Fügt man beide Ergebnisse wieder zusammen, ergibt sich das gesuchte \(|b_n-c|<\varepsilon \).
5.2.2 Aufgabe 2: Konstante Funktion
- Aufgabe 2: :
-
(Konstante Funktion)
Gegeben sei eine stetige Funktion \(f:\mathrm {I\!R} \rightarrow \mathrm {I\!R}\). Es gelte außerdem für alle \(x \in \mathrm{{I\!R}}\) die Gleichung
$$\begin{aligned} f(x)=f(x^2) \qquad . \end{aligned}$$Zeigen Sie, dass dann f konstant sein muss.
Betrachtet man die vorgegebene Gleichung, kommt man noch vergleichsweise schnell darauf, dass man diese fortsetzen kann:
Eine Möglichkeit hier weiterzukommen ist, Werte für \(x \in (0,1)\) zu betrachten. Dann geht \(x^{2^n}\) gegen Null, egal wie das \(x \in (0,1)\) gewählt wird. An dieser Stelle kommt das Konzept der Folgenstetigkeit ins Spiel, denn es gilt:
Also ist die Funktion zumindest für alle Werte zwischen 0 und 1 konstant. Um dieses Prinzip auch für Werte außerhalb dieses Intervalls nutzen zu können, muss man auf die Idee kommen, die Folge umzukehren. Wenn \(f(x)=f(x^2)\) ist, gilt auch:
Mit dem (in einer vorherigen Übung hergeleiteten) Wissen, dass die n-te Wurzel einer Konstanten gegen 1 konvergiert, ergibt sich für alle \(x \in \mathrm{{I\!R}}\):
Damit ist die Konstanz der Funktion bewiesen.
Didaktische Kommentare
Diese Aufgabe hat sich als besonders schwierig erwiesen und wurde von keinem der Probanden gelöst. Um sie bearbeiten zu können, muss man mit dem Stetigkeitsbegriff vertraut sein, insbesondere muss man mit der Folgenstetigkeit als äquivalenter Eigenschaft zur \(\varepsilon \)-\(\delta \)-Stetigkeit vertraut sein. Zwar lässt sich die Behauptung grundsätzlich auch ohne Folgenstetigkeit beweisen, allerdings wird die Aufgabe dann deutlich aufwändiger. Hier besteht die Gefahr, sich zu sehr in aussichtslosen Versuchen zu verlieren, weswegen eine gute metakognitive Kontrolle notwendig sein kann. Darüber hinaus muss bekannt sein, dass \(\lim \limits _{n \rightarrow \infty } \root n \of {k}=1\) ist für jede Konstante k. Das Betrachten von Beispielwerten (Spezialfällen) für x und das Anfertigen einer Skizze können hilfreiche Heurismen beim Verstehen der Aufgabe sein. Insbesondere der oben erwähnte Spezialfall, dass x zunächst zwischen 0 und 1 liegt, kann einen auf den richtigen Weg bringen und ist deswegen, wenngleich für die eigentliche Lösung nicht notwendig, hier mit aufgeführt. Eine Musterlösung würde mit der Umkehrung der Voraussetzung zur Wurzel beginnen. Grundsätzlich ist auch das Ausnutzen des Symmetrieprinzips denkbar (\(f(-x)=f(x^2)=f(x)\)), letztlich erspart es aber keine Arbeit.
5.2.3 Aufgabe 3: Grenzwert von Quotient und Wurzel
- Aufgabe 3: :
-
(Grenzwert von Quotient und Wurzel)
Sei \(a_n\) eine Folge mit \(a_n>0\) für alle \(n \in \mathrm{{I\!N}}\) und
$$\begin{aligned} \lim _{n \rightarrow \infty } \frac{a_{n+1}}{a_n}=L \quad . \end{aligned}$$Beweisen Sie, dass dann gilt:
$$\begin{aligned} \lim _{n \rightarrow \infty } \root n \of {a_n}=L \quad . \end{aligned}$$
Zu dieser Aufgabe soll keine vollständige Lösung gegeben werden, sondern ein mögliches heuristisches Vorgehen, da es sich hierbei um ein spezielles handelt. Didaktische Kommentare werden daher auch nicht am Ende gesondert gegeben, sondern direkt in den Text eingebaut. Nachdem man sich Beispiele für Folgen \(a_n\) angeschaut hat, die die erste Gleichung erfüllen, erkennt man, dass das L eine Art Wachstumsfaktor darstellt. Ein Spezialfall wäre die Konvergenz von \(a_n\), bei der \(L=1\) wäre. Hier liegt auch eine mögliche Fehlerquelle, denn die Grenzwertsätze (in dem Fall: der Grenzwert des Quotienten ist der Quotient der Grenzwerte) lassen sich eben nur anwenden, wenn \(a_n\) konvergent ist. Eine falsche Anwendung könnte aber zu der Vermutung führen, dass L immer gleich Eins sein muss. Ein sehr geschicktes heuristisches Vorgehen wäre, sich zunächst ein einfacheres ähnliches Problem anzuschauen, indem man die Voraussetzung zu
verstärkt. Dadurch hat man viele Details (Was passiert mit kleinen n? Wie gehe ich mit dem \(\varepsilon \) um, um das sich auch bei großen n der Quotient von L unterscheidet?) zunächst ausgeblendet und kann sich auf den Kern der Aufgabe konzentrieren. Es ergibt sich für alle n:
Auch das Detail, dass möglicherweise die Folge erst ab \(a_1\) definiert ist, soll zunächst vernachlässigt werden. Es folgt direkt:
Für \(n \rightarrow \infty \) ergibt sich der Grenzwert L. Zwar sind noch viele Details zu klären, die zum Teil schon erwähnt wurden, allerdings wurde schonmal eine Beweisidee entwickelt. Eine andere Möglichkeit, sich der Aufgabe zu nähern, ist, sich den oben erwähnten Spezialfall anzuschauen, dass \(a_n\) gegen einen Wert (ungleich 0) konvergiert. Dann ist \(L=1\) und der Beweis, dass \(\root n \of {a_n}\) dagegen konvergiert, ist schnell geführt.
5.3 Auswertungsmethoden
Da zunächst unvoreingenommen ein holistischer Blick auf die Problembearbeitungsprozesse geworfen werden sollte, wurden möglichst viele Aspekte in der Breite in Augenschein genommen. Die einzelnen Betrachtungen können daher auch nicht in die Tiefe gehen, die eine Konzentration auf wenige Aspekte ermöglicht hätte. In Abschnitt 5.3.1 wird eine Episodenkodierung in Anlehnung an Schoenfeld (1985) beschrieben, die mit einer Kodierung des Umgangs mit externen Ressourcen (Abschnitt 5.3.2) kombiniert wurde. Anschließend wird in Abschnitt 5.3.3 die Beschreibung der Lösungsqualität der Bearbeitungen dargestellt. In den Abschnitten 5.3.4 und 5.3.5 wird die Kodierung von Heurismen bzw. Metakognition erläutert. Außerdem wurden benötigtes Fachwissen und begangene Fehler sowie neue Lösungsansätze und Ideen (Abschnitt 5.3.6) festgehalten. Zu guter Letzt wurde mit Hilfe der vorherigen detaillierten Analysen wieder ein ganzheitlicher Blick auf die Prozesse geworfen, der durch die in Abschnitt 5.3.7 beschriebenen Leitfragen gelenkt wurde.
5.3.1 Episodenkodierung nach Schoenfeld
Um verschiedene Problemlöseprozesse auf einen Blick miteinander vergleichen zu können hat Schoenfeld (1985) in Anlehnung an das Phasenmodell (vgl. Abschnitt ) von Pólya (1945) Problemlöseprozesse in verschiedene Episoden eingeteiltFootnote 2. Hierbei handelt es sich grob gesagtFootnote 3 um Zeitintervalle, in denen die Problemlöser zusammengehörige Handlungen ausführen. Man spricht in diesem Zusammenhang vom Event-Sampling-Verfahren. Im Gegensatz zum Time-Sampling wird der Prozess also nicht in Zeitintervalle gleicher Länge, denen dann eine Kategorie (bzw. ein Episodentyp) zugeordnet wird, sondern in inhaltlich zusammengehörige Abschnitte zerlegt, deren Länge variieren kann (vgl. Reusser, Pauli & Waldis, 2010). Die Einteilung der Schoenfeld-Episoden ist (bei Hinzunahme der Transition) lückenlos, das heißt jeder Zeitpunkt ist einer bestimmten Episode zugeordnet. Die verschiedenen Episodentypen sind: Reading (hierzu gibt es keine Entsprechung bei Pólya), Analysis (angelehnt an die Pólya-Phase Understanding the Problem), Exploration, Planning (diese beiden Phasen teilen die Pólya-Phase Devising a Plan weiter auf), Implementation (entspricht Carrying out the Plan) und Verification (Looking Back). Sie werden weiter unten ausführlich beschrieben. Zusätzlich dazu gibt es noch eine Episode (die Transition), die den Übergang von einer offensichtlich abgeschlossenen Episode zu einer anderen, die noch nicht begonnen hat, markiert. Während der Transition finden häufig metakognitive Aktivitäten statt, z. B. die Entscheidung, die Aktivitäten der vorherigen Episode abzubrechen oder zu verändern oder Überlegungen, welcher Ansatz im Folgenden aufgegriffen werden soll. Übergänge von einer Episode zur nächsten können auch ohne zeitliche Ausdehnung und ohne von außen erkennbare Kontrollentscheidungen vonstatten gehen. Trotzdem ist ein Episodenwechsel ein Hinweis auf metakognitive Aktivitäten, da hier die Richtung des Vorgehens geändert wird. Grundsätzlich ist es auch möglich, dass zwei Episoden desselben Typs aufeinander folgen. Solche Episodenwechsel wurden in der vorliegenden Arbeit nicht markiert, da es hierdurch zu größeren Abweichungen zwischen verschiedenen Kodierern gekommen ist (s. u.). Stattdessen wurden neue Ansätze im Prozess markiert (vgl. Abschnitt 5.3.6). Rott (2013) hat zusätzlich zu den Schoenfeld’schen Episoden noch weitere, nicht-inhaltliche Episodentypen (Abschweifung, Organisation und Schreiben) eingeführt, die er bei der Beobachtung von Problemlöseprozessen von Fünftklässlern identifiziert hat. Da solche Aktivitäten bei den in der vorliegenden Arbeit betrachteten Prozessen selten isoliert aufgetreten sind (d. h. sie waren nur von sehr kurzer Dauer oder sind zeitgleich mit den Episoden nach Schoenfeld aufgetreten), wurde hier auf diese Kategorien verzichtetFootnote 4. Es wurde allerdings (wie bei Rott) eine Kategorie Sonstiges eingeführt, um die selten auftretenden nicht-inhaltlichen AktivitätenFootnote 5 erfassen zu können.
Zum besseren Verständnis der einzelnen Episodentypen wird an dieser Stelle das in der vorliegenden Arbeit verwendete Kodiermanual zitiertFootnote 6, welches in Anlehnung an das von (Rott, 2013) entstanden und basierend auf den gemachten Erfahrungen erster Probe-Kodierungen angepasst worden ist. Die Bezeichnungen der Episodentypen wurden im englischen Original belassen:
- Reading: :
-
Hierbei handelt es sich um das Lesen der Aufgabenstellung. Ob das laut oder leise geschieht, spielt keine Rolle. Auch das Abschreiben der Aufgabe gehört dazu, sofern wörtlich abgeschrieben, also keine Paraphrasierung vorgenommen wird. Die Kodierung beginnt, sobald der Blick für längere Zeit auf das Aufgabenblatt gerichtet wird. Rückfragen an den Interviewer, die sich nicht auf den Aufgabentext (sondern beispielsweise auf organisatorische Dinge) beziehen und vor dem eigentlichen Lesen stattfinden, werden somit ausgeschlossen und nicht kodiert. Der Prozess beginnt also in der Regel mit dem Lesen des Aufgabentextes. Während des Prozesses wird diese Episode nur kodiert, wenn für einen längeren Zeitraum gelesen wird. Kurzes Nachschauen einzelner Aspekte wird nicht als Reading kodiert. Geht das Notieren der Aufgabenstellung über reines Abschreiben hinaus, z. B. durch Umformulieren oder Ändern der Reihenfolge, wird dies nicht als Reading, sondern als Analysis kodiert.
- Analysis: :
-
Aktivitäten, die dazu dienen, die Aufgabe an sich zu verstehen oder besser zu verstehen. Hierzu zählen vor allem Umformulierungen und Darstellungswechsel der Voraussetzung oder der Behauptung (Klären von Definitionen, Äquivalente Formulierungen, Skizzen, Aufstellen von Gleichungen etc.), aber auch bereits das Paraphrasieren der Aufgabenstellung. Analysis wird nur dann mitten im Prozess kodiert, wenn es wirklich um das Verstehen der Aufgabenstellung geht und beispielsweise bisher nicht genau verstanden wurde, was zu machen ist. Aussagen wie „Ich versuche noch zu verstehen...“ bezogen auf die Aufgabe sind ein Indiz für diese Episode, auch wenn zwischendurch vereinzelt explorative Aussagen getätigt werden. Die nicht immer leicht zu identifizierenden Unterschiede zwischen Analysis und Exploration liegen in der Struktur und dem Inhalt. In einer Episode der Analyse arbeiten die Problemlöser eher dicht am Aufgabentext und gehen eher strukturiert vor.
- Exploration: :
-
Jegliche Erkundung, die weder direkt an der Aufgabenstellung orientiert ist wie Analysis, noch einen gezielten Plan verfolgt wie Planning und Implementation, sondern in der nach Lösungsmöglichkeiten gesucht wird. In dieser Phase werden mitunter viele verschiedene Ansätze ausprobiert, das Vorgehen an sich ist aber eher unsicher und nicht wirklich zielgeleitet. Diese Phase kann auch dann kodiert werden, wenn die Aufgabenstellung noch nicht oder nicht ganz verstanden wurde, der Problemlöser aber schon eine (vermeintliche) Idee davon hat, was von ihm verlangt wird und eine grobe Richtung einschlägt. Eine Kodierung mehrerer Explorations-Episoden hintereinander ist hier nicht notwendig, da neue Ideen/Ansätze gesondert kodiert werden.
- Planning: :
-
Die Entwicklung eines Plans, der ein bestimmtes (Zwischen-)Ziel verfolgt. Es genügt hier nicht, lediglich ein Ziel aufzustellen. Es muss auch eine Idee geben, wie dieses Ziel zu erreichen ist. Oft gehören Planning und Implementation zusammen, allerdings muss nicht jeder Plan auch implementiert werden. Wenn Planning und Implementation als getrennte Episoden zu erkennen sind, sollten sie auch entsprechend kodiert werden.
- Implementation: :
-
Die Umsetzung eines Plans. Meistens ist hier schon klar, wie in etwa vorgegangen werden muss. Dennoch muss diese Phase nicht immer geradlinig verlaufen, diese Episode kann z. B. auch beinhalten, dass ein Plan verworfen wird. Gibt es bei der Durchführung noch Unsicherheiten bzw. ist an einigen Stellen noch nicht klar, wie es weiter geht, wird Exploration kodiert. Kleinere Hindernisse, die sich schnell aus dem Weg schaffen lassen, gehören aber zur Implementation. Oft wird ein Plan auch zeitgleich mit der Implementation entwickelt oder die Planung erstreckt sich über einen sehr kurzen Zeitraum oder wird nicht expliziert. In dem Fall werden Planning und Implementation gleichzeitig kodiert.
- Verification: :
-
Hierbei handelt es sich um die Überprüfung des Ergebnisses oder eines Teilergebnisses. Kurze Kontrollen und Evaluationen der Argumentation oder des Rechenwegs zählen nicht hierzu.
- Transition: :
-
Die Übergänge zwischen zwei Episoden. Viele Transitions haben keine zeitliche Ausdehnung, werden also auch nicht extra kodiert. Wenn aber die vorhergehende Episode bereits abgeschlossen ist, die neue aber noch nicht angefangen hat, werden Transitions kodiert. Nicht zu dieser Episode zählen Schweigen (nichts Sichtbares passiert) oder organisatorische Tätigkeiten. So etwas wird als zur vorhergehenden Episode gehörig kodiert. Transitions sind meist geprägt von metakognitiven Aktivitäten (Beurteilung des bisherigen Vorgehens, Entscheidungen über das weitere Vorgehen), da hier bewusste Richtungsentscheidungen getroffen werden. Es kann auch zwischen zwei gleichnamigen Episoden Transitions geben (z. B. Exploration – Transition – Exploration). Hier wird beispielsweise ein Ansatz verworfen, das weitere Vorgehen geplant und dann ein weiterer Ansatz verfolgt.
Grundsätzlich wurde für die einzelnen Episoden eine Mindestlänge von 30 Sekunden gesetzt, da zu kurze Episoden der Übersichtlichkeit schaden könnenFootnote 7. Ausnahmen können die Episoden Reading, Planning und Transition bilden, da diese in der Regel eher kurz sind. Für Reading und Planning wurde eine Mindestlänge von 10 Sekunden gesetzt, für die Transition keine, da ein solcher Übergang sehr schnell gehen kann und die Episode eher durch das Ende der vorherigen und den Beginn der nächsten definiert ist. Die Einteilung der Episoden wurde nicht am Transkript, sondern am Videomaterial vorgenommen, um so einen direkteren Blick auf die Prozesse zu haben. Eine Arbeit am Transkript könnte hier zu sehr ins Detail gehen und den holistischen Blick verstellen. Aus demselben Grund sollte vor der Kodierung der Prozess mindestens einmal in seiner Gänze betrachtet werden.
5.3.2 Arbeit mit dem Skript oder anderen externen Ressourcen
Wie bereits erwähnt, durften die Probanden sämtliche Materialien, die sie selbst mitgebracht haben oder auf die sie mit Hilfe des Internets zugreifen konnten, verwenden. Zusätzlich wurde ihnen der Teil des jeweiligen Skriptes zur Vorlesung zur Verfügung gestellt, der die fachlichen Inhalte der Aufgabe zum Thema hat. Der Umgang mit dem Skript wurde ebenfalls in einem Event-Sampling-Verfahren kodiert. Er bildet eine zu den Schoenfeld-Episoden unabhängige Dimension. Hierbei wurde zwischen gezieltem und explorativem Nachschlagen unterschieden. Ersteres wurde kodiert, wenn deutlich wurde, dass nach einer ganz bestimmten Stelle (z. B. einem Satz oder einer Definition) gesucht wird, letzteres, wenn keine solche Absicht vorlag oder keine erkennbar war. Ein Beispiel für einen Prozess mit Schoenfeld-Episoden und Kodierung der Arbeit mit dem Skript lässt sich Abbildung 5.2 entnehmen. Eine hellere Färbung in der ersten Zeile (Skriptnutzung) zeigt ein gezieltes Nachschlagen an. In den weiteren Zeilen sind die Schoenfeld-Episoden in der Reihenfolge des Kodiermanuals (vgl. Abschnitt 5.3.1). In Anhang E sind alle Prozesse auf diese Weise graphisch dargestellt.

Beispiel für die Darstellung von Episoden
Über die reine Markierung von Nachschlage-Episoden hinaus wurde für jeden Prozess auch kodiert, zu welchem Zweck das Skript und andere Materialien herangezogen wurden. Hierbei wurden folgende Kategorien unterschieden:
- (U0) :
-
Das Skript wird nicht verwendet.
- (U1) :
-
Das Skript wird ausschließlich zur Absicherung der eigenen Gedankengänge herangezogen.
- (U2) :
-
Das Skript wird zusätzlich zur Klärung von Begriffen herangezogen.
- (U3a) :
-
Das Skript wird von Beginn an auch zur Ideenfindung herangezogen.
- (U3b) :
-
Das Skript wird, nachdem eigenständige Ideenfindung nicht erfolgreich war, auch hierzu herangezogen.
Tatsächlich sind diese Antwortmöglichkeiten disjunkt, d. h. keiner der Probanden hat das Skript zu Ideenfindung, aber nicht zur Begriffsklärung verwendet. Mit Absicherung der eigenen Gedankengänge ist gemeint, dass entweder Begriffe und Zusammenhänge nachgeschlagen wurden obwohl deutlich wurde, dass diese auch ohne Hilfe des Skriptes klar waren, oder geäußert wurde, dass bevor eine eigene Idee verfolgt wird zur Sicherheit nachgeschlagen wird, ob man nicht wichtige Zusammenhänge übersehen hat.
5.3.3 Einschätzung der Lösungsqualität
Ähnlich wie die Arbeit mit dem Skript wird auch die Qualität einer Lösung global beschrieben. Hierbei gibt es folgende Kategorien:
- (L0) :
-
Es wurde kein wesentlicher Lösungsfortschritt erzielt.
- (L1) :
-
Die Aufgabe wurde zwar nicht gelöst, aber trotzdem wesentlicher Fortschritt erzielt.
- (L2) :
-
Die Aufgabe wurde mit kleinen Lücken gelöst.
- (L3) :
-
Die Aufgabe wurde vollständig gelöst.
Hier wurde (L0) auch dann vergeben, wenn zwar eine sinnvolle Analyse der Aufgabe stattgefunden hat, darüber hinaus aber kein Fortschritt gemacht wurde. Zu (L1) kann das Erreichen einer Teillösung oder der Beweis eines Spezialfalls zählen, währen bei (L2) nur wenig bis zur Lösung der kompletten Aufgabe fehlt. Die vorgegebenen Antwortmöglichkeiten wurden von einem Modell von Zazkis et al. (2015) übernommen.
5.3.4 Kodierung von Heurismen
Auch der Heurismeneinsatz stellt einen wichtigen Aspekt des Problemlösens dar (vgl. Abschnitt 2.3.2) und wird hier genauer betrachtet. Hierbei wurde das Kodierschema von Rott (2013, im Anhang; vgl. auch Rott, 2018) übernommen und der Situation angepasst. In Abbildung 5.3 und 5.4 ist die überarbeitete Version des Kodiermanuals abgebildet, der sich auch Beispiele für die jeweiligen Kategorien entnehmen lassen. Ausführlichere Beispiele finden sich in Abschnitt 5.5.4.

Das verwendete Kodiermanual zu Heurismen – Seite 1

Das verwendete Kodiermanual zu Heurismen – Seite 2
Bei der Kodierung der Heurismen wurden zunächst alle Tätigkeiten markiert, bei denen es sich um heuristische handeln könnte (im weit gefassten Sinne Pólyas als strategisches Vorgehen, das bei der Problembearbeitung hilfreich sein könnte) und erst im Anschluss wurde versucht, diese einer existierenden Kategorie zuzuordnen. War das nicht möglich, wurden sie zunächst einer Restkategorie zugeordnet, aus der später neue Kategorien gebildet wurden. In wenigen Fällen wurde konsensuell entschieden, dass es sich bei den markierten Tätigkeiten nicht um heuristische handelt (was wiederum handlungsleitend für folgende Kodierungen bzw. Nicht-Kodierungen wurde). Im Gegensatz zur Einteilung der Prozesse in Episoden und der Identifizierung des Nachschlagens wurden Heurismen, wie auch die in den folgenden Abschnitten beschriebenen metakognitiven Aktivitäten, Rückgriffe auf Fachwissen, Fehler und neue Lösungsansätze als Ereignisse kodiert, d. h. anstatt Anfangs- und Endzeitpunkt festzulegen, wurde nur der Zeitpunkt markiert, an dem das jeweilige Ereignis aufgetreten ist.
Die Anpassungen, die im Vergleich zum Rott’schen Manual vorgenommen wurden, seien im Folgenden kurz beschrieben. Einige Kodes wurden zwar bis zum Ende im Kodiermanual belassen, wurden aber nie kodiert und deshalb aus dieser Darstellung aus Gründen der Übersichtlichkeit entfernt. Diese sind: Messen, Extremfall, Suche nach Mustern, Systematisches Probieren, Backtracking und Kombiniertes Vorwärts- und Rückwärtsarbeiten.
Des Weiteren wurden einige Kategorien zusammengefasst, weil eine klare Unterscheidung nicht mit großer Inter-Rater-Übereinstimmung möglich war. Möglicherweise war in Kontext von Rotts Aufgaben, zu denen auch geometrische zählten, diese Unterscheidung einfacher. Die Kategorien informative Figur und operative Figur wurden zur Kategorie Skizze zusammengefasst. Die Kategorie Bezeichnungen einführen wurde unter die Kategorie Hilfselemente gefasst. Das Transformationsprinzip wurde gestrichen, da es sich nicht gut von den verschiedenen Darstellungswechseln (Skizze, Tabelle und Gleichung) unterscheiden ließ.
Außerdem wurden, wie oben beschrieben, einige neue Kategorien hinzugefügt, deren Bedeutung aus dem Kodiermanual deutlich werden sollte: Das Begriffe klären, die imaginäre Figur, die Nutzung aller Voraussetzungen, die Metapher und die Suche nach neuen Ergebnissen, die eng mit der Skriptnutzung zusammenhängt. Interessant ist hier die Nutzung aller Voraussetzungen, denn Kilpatrick, der zur Kodierung von Heurismen die Pólya-Fragen als Grundlage genommen und diese drastisch verkürzt hat, schreibt:
Many of the categories were unoccupied: subjects seemingly did not exhibit behavior even remotely resembling actions suggested by the heuristic questions. For example, no subjects asked themselves aloud whether they were using all of the essential notions of the Problem. (Kilpatrick, 1967, S. 44)
Gerade diese Kategorie, die Kilpatrick exemplarisch als bei seinen Untersuchungen mit Achtklässlern nicht existent erwähnt, scheint im universitären Zusammenhang (aus dem die Pólya-Fragen ebenfalls ursprünglich stammen) wieder an Bedeutung zu gewinnen.
5.3.5 Kodierung von Metakognition
Bei der Kodierung der Metakognition wurde nicht auf ein bestehendes Schema zurückgegriffen. Eines der bekanntesten Kodierschemata zu diesem Aspekt geht auf (Cohors-Fresenborg & Kaune, 2007) zurück, ist aber für unsere Zwecke zu umfangreich und erfordert die Transkription der beobachteten Prozesse. Da in der vorliegenden Arbeit ein holistischer Blick auf die Problembearbeitungsprozesse gerichtet wird, wurde stattdessen entschieden, induktiv ein eigenes Schema aus den betrachteten Prozessen herzuleiten. Hierbei wurde sich an den Grundsätzen der qualitativen Inhaltsanalyse nach Mayring (2020) orientiert: Zunächst wurden an einigen Beispielprozessen Äußerungen identifiziert, die metakognitive Aktivitäten darstellten. Auch hierbei wurden zunächst sehr großzügig alle Aussagen und schriftlichen Aktivitäten markiert, die auf ein Nachdenken über die eigenen Aktivitäten hindeuten könnten. Da sich metakognitive Aktivitäten so nur indirekt identifizieren lassen, können sicherlich nicht alle erfasst werden. Die Aussagen wurden paraphrasiert und auf ein vorher festgelegtes Abstraktionsniveau generalisiert. Anschließend wurden bedeutungsgleiche Paraphrasen gestrichen, so dass eine übersichtliche Liste entstand, aus der durch Bündelung von Aussagen Kategorien gebildet wurden. Das Ergebnis ist als Kodiermanual in Abbildung 5.5 und 5.6 dargestellt. Auch einige der Paraphrasen sind hier beispielhaft aufgeführt. In Abschnitt 5.5.6 werden weitere ausführlichere Beispiele genannt.

Das verwendete Kodiermanual zu Metakognition – Seite 1

Das verwendete Kodiermanual zu Metakognition – Seite 2
Zur weiteren Zusammenfassung der Kategorien gibt es verschiedene Möglichkeiten: Das Kodierschema von Cohors-Fresenborg & Kaune (2007) unterscheidet die drei Hauptkategorien Planung, Monitoring und Reflexion, also grob gesagt etwas in die Zukunft Schauendes, die Gegenwart Beobachtendes und Rückblickendes. Bei der Auswertung der vorliegenden Prozesse hat sich allerdings gezeigt, dass gerade das Monitoring sich in Aussagen (die zeitlich meist nach dem Beobachteten liegen) kaum von einer Reflexion abgrenzen lassen. Folgende Zusammenfassung hat sich allerdings als hilfreich erwiesen: Kontrollprozesse im Sinne von Schoenfeld (1985) sind solche Aktivitäten, die sich auf Richtungsentscheidungen beziehen, also die Frage, ob ein Ansatz weiter verfolgt werden oder verworfen werden soll. Hierunter fallen die Kategorien Voraussicht, bei der eine Idee beurteilt wird, bevor diese umgesetzt wird, Evaluation, bei der während oder nach Durchführung eines Ansatzes dessen Nutzen eingeschätzt wird, und der Regulation des Vorgehens, bei der eine Richtungsentscheidung getroffen wird, ohne dass explizit ein Ansatz beurteilt wird. Auch die Kategorien der Planung im weiteren Sinne können, ähnlich wie bei Cohors-Fresenborg und Kaune (2007) zusammengefasst werden. Hierzu gehören die Zielsetzung, die Planungsaktivität, bei der zusätzlich zur Zielsetzung auch ein Mittel benannt wird, wie dieses Ziel erreicht werden soll und die Klärung der Handlungsoptionen, die eine Art Vorstufe der Planung darstellt, da es hier noch zu keiner Entscheidung kommt. Auch die eben erwähnte Voraussicht stellt eine Art der Planung dar, da der Nutzen eines möglichen Ansatzes eingeschätzt und darauf basierend das weitere Vorgehen geplant wird. Da aus diesem Grund Kontrollprozesse nicht eindeutig von Planung abgegrenzt werden kann, wurden nur die ersteren zu einer Oberkategorie zusammengefasst. Besonders auf diese wird in Abschnitt 5.5.6 stärker eingegangen.
5.3.6 Kodierung von Fachwissen, Fehlern und neuen Lösungsansätzen
Da das verfügbare Vorwissen und die tatsächliche Nutzung dessen einer der wesentlichen Aspekte des Problemlösens ist (vgl. Abschnitt 2.3.1), wurde in den betrachteten Prozessen der Rückgriff auf Fachwissen und das Auftreten von Fehlern, die häufig ein Zeichen mangelnden Fachwissens sind, kodiert. Zusätzlich wurden neue Lösungsansätze und -ideen markiert. Auch hier wurden, ähnlich wie bei Heurismen und Metakognition, zunächst alle Aktivitäten markiert, die unter diese Kategorien fallen könnten, um anschließend gemeinsam zu entscheiden, ob es sich dabei wirklich um solche handelt. Im Folgenden sollen einige Beispiele für diese Kategorien gegeben werden:
Als auftretendes Fachwissen wird unter anderem die Erklärung von Begriffen (z. B. Stetigkeit, Konvergenz oder Beschränktheit) kodiert. Außerdem Zusammenhänge in verschiedenen Formen: Hierzu zählen unter anderem Aussagen aus der Vorlesung (Strenge Monotonie impliziert Injektivität, der Grenzwert einer Folge ist eindeutig bestimmt, Teilfolgen von konvergenten Funktionen konvergieren gegen denselben Grenzwert, Beschränkte Folgen haben mindestens eine konvergente Teilfolge, beschränkte und monotone Folgen sind konvergent, die Grenzwertsätze, der Zwischenwertsatz etc.). Diese werden nicht nur kodiert, wenn sie als Sätze aus dem Skript zitiert werden, sondern immer, wenn deutlich wird, dass diese Zusammenhänge dem Probanden bekannt sind. Zusammenhänge können auch in vorhergehenden Übungen bewiesen worden sein (etwa die Konvergenz einer Folge gegen einen bestimmten Grenzwert) oder im Prozess auftreten, ohne dass eine Quelle dafür deutlich wird (Hierbei handelt es sich häufig um einfache Feststellungen, etwa dass Stetigkeit nicht Monotonie impliziert, der Grenzwert von \(a_{n+1}\) gleich dem Grenzwert von \(a_n\) ist, sofern existent etc.). Auch Verfahren (wie die Anwendung des Quetschlemmas, der rechnerische Umgang mit dem Betrag oder Ähnliches) sowie Konventionen, etwa die Schreibweise der n-ten Wurzel als \((\ldots )^{\frac{1}{n}}\) fallen unter die Kategorie des Vorwissens. Natürlich kann auch hier nur kodiert werden, was sich in irgendeiner Form (mündlich oder schriftlich) äußert. Auf die Kodierung elementarer logischer Zusammenhänge (wie die Tatsache, dass Äquivalenz der Implikation in beide Richtungen entspricht) wurde nach einiger Diskussion hier verzichtet, da sonst viele Routinetätigkeiten mit aufgenommen werden müssten.
Auch bei Fehlern gibt es eine große Bandbreite. Geering (1995) unterscheidet drei Arten von Fehlern: Fertigkeitsfehler, Wissensfehler und Strategiefehler. Bei den Fertigkeitsfehlern handelt es sich um Flüchtigkeitsfehler oder Rechenfehler, wenn etwa ein Student beim Notieren der ersten Glieder einer Folge falsche Werte aufschreibt. Die Wissensfehler umfassen alle oben genannten Formen mangelhaften Fachwissens. In den meisten Fällen handelt es sich um Fehlvorstellungen irgendeiner Art. Hierbei kann es sich um grundlegendes Begriffsverständnis handeln, wenn z. B. nicht genau klar ist, was eine Teilfolge ist oder wie sich eine divergente Folge verhält, oder um Schwierigkeiten mit Zusammenhängen, wenn etwa aus dem Satz von Weierstraß (stetige Funktionen auf einem kompakten Intervall besitzen ein Maximum und ein Minimum) gefolgert wird, dass diese Funktionen nicht streng monoton sein können (weil dem Bearbeiter nicht klar ist, dass dieses Maximum auch am Rand des Intervalls liegen kann). Aber auch die Vermutung von nicht-existenten Zusammenhängen fällt unter dieser Kategorie. So vermutet z. B. ein Student, dass aus der Stetigkeit einer Funktion folgt, dass, wenn zwei Funktionswerte gleich sind, alle Werte dazwischen ebenfalls gleich sein müssen. Auch falsche Schreib- oder Sprechweisen sind in der Regel auf mangelndes Wissen zurückzuführen, wenngleich diese den Lösungserfolg einer isolierten Aufgabe meist nicht beeinflussen. Ebenfalls zu Wissensfehlern zählen Missverständnisse bezüglich der Aufgabenstellung, wenn etwa nicht klar ist, was zu zeigen ist, eine Voraussetzung missverstanden wurde oder beim Versuch eines indirekten Beweises die Negation der Folgerung falsch durchgeführt wird. Als dritte Fehlerart nennt Geering (ebd.) die StrategiefehlerFootnote 8. Hierbei handelt es sich um mangelnde oder falsch eingesetzte kognitive (Heurismen) oder metakognitive Strategien. Da diese Strategien an anderer Stelle ausführlich behandelt werden, wurden solche Fehler nicht gesondert kodiert. Auf eine Unterscheidung von Fertigkeits- und Wissensfehlern wurde bei der Kodierung zunächst ebenfalls verzichtet.
Die neuen Lösungsansätze sind ebenfalls sehr vielfältig. Trotzdem war den Kodierern intuitiv schnell klar, was als neuer Lösungsansatz oder neue Lösungsidee zählt und was nicht. Im Nachhinein betrachtet treten diese in folgenden Zusammenhängen auf: Zum einen in Kombination mit Zielsetzungen („Die Koeffizienten müssten gleich Null sein, damit die Vektoren linear unabhängig sind“Footnote 9 oder „Wenn ich die Monotonie der Folge gezeigt hätte, wäre sie auch konvergent.“). Eine andere Möglichkeit liegt darin, dass sie sich als präformale Ideen bzw. durch das Erkennen von Mustern („L gibt so etwas wie das Wachstum der Folge an.“ oder „Die Summanden müssten alle kleiner gleich Eins sein.“) oder das Aufstellen von Vermutungen („Wenn das konvergent ist, müsste \(L=1\) sein“ oder „Ich nehme mal an, dass der Grenzwert nur von \(a_N\) abhängt“) äußern. Auch um die Nennung möglicher Werkzeuge oder Methoden kann unter diese Kategorie fallen. Mit Werkzeugen sind an dieser Stelle zum einen Zusammenhänge (Sätze) und Verfahren aus der Vorlesung gemeint (Intervallschachtelung, Quetschlemma, Zwischenwertsatz, Dreiecksungleichung, Folgenstetigkeit etc.), zum anderen aber auch typische Tätigkeiten, wie das Addieren mehrerer Gleichungen oder die Abschätzung einer Folge. Letztere sind häufig noch weniger konkret und geben nur eine Ahnung wieder („Ich glaube, ich müsste nur das m clever wählen...“ oder „Vielleicht kann ich hier ja einen Faktor ausklammern.“). Methoden hingegen sind allgemeinere Vorgehensweisen, wie das Führen eines indirekten Beweises, die Zerlegung der Aufgabe in mehrere Teile oder ein Beweis durch Induktion. Auch diese müssen in Bezug auf die Aufgabe erst noch konkretisiert werden. Gerade bei den Lösungsansätzen zeigen sich große Überschneidungen zu den anderen betrachteten Dimensionen. So treten bestimmte Ideen häufig im Zusammenhang mit Heurismen auf. Eine Überschneidung, bei der die Unterscheidung nicht offensichtlich (allerdings auch nicht zwingend notwendig) ist, soll im folgenden Abschnitt exemplarisch betrachtet werden.
Planung, metakognitive Planungsaktivitäten, Zielsetzung und Lösungsansätze
Größere Gemeinsamkeiten gibt es zwischen der Schoenfeld-Episode Planning, den metakognitiven Aktivitäten der Zielsetzung bzw. Planungsaktivitäten (PA) sowie Ideen und Lösungsansätzen. Während die drei erstgenannten fast immer mit neuen Ideen bzw. Lösungsansätzen einhergehen, sollte klar sein, dass umgekehrt nicht jede Idee auch zu einem Planvollen Vorgehen (weder im Sinne von Schoenfeld, noch als metakognitive Aktivität) führen oder ein bestimmtes Ziel verfolgen muss. Bevor Planning und PA gegenübergestellt werden, soll zunächst auf die Unterschiede zwischen Zielsetzung und PA eingegangen werden:
Wie dem Kodiermanual (Abbildung 5.5) zu entnehmen ist, beschränkt sich die Planungsaktivität im Gegensatz zur Zielsetzung nicht darauf, zu benennen, wo es hingehen soll. Zusätzlich wird hierbei noch ein möglicher Weg dorthin angegeben. Ob dieser Weg tatsächlich zum Ziel führt, ist zunächst unerheblich. Als Beispiel sei hier Niklas Bearbeitung der Aufgabe zur konstanten Funktion (vgl. Abschnitt 5.2.2) genannt. Er sagt: „Jetzt würde ich probieren das irgendwie über das Delta zu nem Widerspruch zu bringen (25:55).“ Es wird also ein Ziel (Widerspruch) und auch der Weg (Delta) benannt. Das Wort „irgendwie“ im obigen Zitat gibt bereits einen Hinweis darauf, dass Niklas noch nicht weiß, wie genau dieser Weg aussehen könnte.
Hierin besteht ein wesentlicher Unterschied zur Planning-Episode. Hier muss der Weg zu einem gewissen Grad vorgezeichnet sein, so dass dieser bei einer möglichen Implementation ohne größere Hindernisse beschritten werden kann. Darüber hinaus muss dem Problembearbeiter klar sein, was die Erreichung des Ziels für den weiteren Problemlöseverlauf bringt. Ein Beispiel für eine solche Episode gibt es bei Andreas’ Bearbeitung der Aufgabe zur linearen Unabhängigkeit (vgl. Anhang D). Um die lineare Unabhängigkeit zu zeigen, stellt er zunächst fest (10:02), dass bei einer Linearkombination „die Vorfaktoren gleich Null sein“ müssen (Zielsetzung). Um dies zu erreichen, fasst er den Plan: „Ich pack die erstmal alle zusammen (10:13 – Planning).“ Aus dem weiteren Vorgehen wird außerdem deutlich, dass er diesen Plan (abgesehen von kleinen Schwierigkeiten beim Rechnen) zielstrebig umsetzen kann und mit dem Ergebnis auch etwas anfangen kann. Hier wurde deswegen eine Planning-Episode kodiert. In Abschnitt 5.5.2 wird insbesondere auf diese Episoden ausführlicher eingegangen.
5.3.7 Leitfragen
Anders als etwa die Lösungsqualität oder die Skriptnutzung ist die Qualität des Heurismeneinsatzes und der metakognitiven Aktivitäten nicht so eindeutig operationalisierbar. Da quantitativ messbare Werte hier aber wenig hilfreiche Aussagen zulassen, wurden diese beiden Dimensionen in Form von Leitfragen betrachtet. Hierbei wurde sich den Arbeiten von Nowińska (2016) orientiert. Sie hat gezeigt, dass nach intensiver Beschäftigung mit videographierten Prozessen, zu der auch die detaillierte Kodierung von Einzelereignissen zählt, eine Einschätzung von Prozessen anhand von Leitfragen mit vorher festgelegten Antwortmöglichkeiten mit großer Übereinstimmung zwischen verschiedenen Ratern möglich ist, wenn diese vertraut mit den Prozessen sind. Die Beantwortung dieser Fragen ermöglicht einen schnellen Überblick über die wesentlichen Punkte des Problemlöseprozesses. Die folgenden Leitfragen wurden von Nowińska (ebd.) übernommen. Zu deren Beantwortung wurden alle vorher beschriebenen Kodierungen und eine erneute Betrachtung der Prozesse herangezogen.
Heurismeneinsatz
Zu welchem Grad wurden Heurismen verwendet?
- (H0) :
-
Heurismen werden wenig bis gar nicht verwendet.
- (H1) :
-
Heurismen werden in erwartbarer Qualität verwendet.
- (H2) :
-
Heurismen werden erstaunlich gut verwendet.
Wenngleich vor allem die Antwortmöglichkeit (H2) zunächst recht unklar definiert scheint, gab es beim Beantworten dieser Frage wenig Zweifel, welche Antwort gewählt werden soll, da bereits eine große Erfahrung mit den betrachteten Prozessen vorhanden war, so dass auf Vergleichswerte zurückgegriffen werden konnte. Dies deckt sich mit den Erfahrungen von Nowińska (2016). Die erwartbare Qualität bedeutet in diesem Zusammenhang, dass naheliegende Heurismen ohne größere Schwierigkeiten verwendet wurden. Unter erstaunlich guter Verwendung ist solches Vorgehen zu verstehen, das aus Sicht des Beobachters bemerkenswert über dieses Erwartbare hinausgeht. Wenngleich die Anzahl der verwendeten Heurismen sicherlich Einfluss auf diese Frage hat, ist die Beantwortung grundsätzlich eher von qualitativen Eindrücken abhängig.
Metakognitive Aktivitäten
Zu welchem Grad treten metakognitive Aktivitäten auf?
- (M0) :
-
Metakognitive Aktivitäten treten wenig bis gar nicht auf.
- (M1) :
-
Metakognitive Aktivitäten werden in erwartbarer Qualität durchgeführt.
- (M2) :
-
Metakognitive Aktivitäten werden erstaunlich gut durchgeführt.
In derselben Form wie bei den Heurismen werden hier qualitative Überlegungen herangezogen, um den Grad der metakognitiven Aktivitäten eines Prozesses global einzuschätzen.
5.4 Training der Kodierer
Wenngleich die Kodierung von Schoenfeld-Episoden auf der einen und von Ereignissen wie Heurismeneinsatz, Metakognition, Fehlern etc. auf der anderen Seite sich in wesentlichen Punkten von einander unterscheidet, basiert das Training der Kodierer in beiden Fällen auf denselben Ideen und wird deswegen im Folgenden zusammengefasst:
An der Auswertung der Daten waren zwei Kodierer beteiligt (TS und LH). Bei den Kodierungen wurde wie folgt vorgegangen: Als erstes wurden Beschreibungen von Schoenfeld-Episoden (vgl. Rott, 2013 und Schoenfeld, 1985) sowie das Kodiermanual zu Heurismen von Rott (2013) gemeinsam gesichtet und dabei aufkommende Fragen beantwortet. Zur Klärung von Restunsicherheiten stand, wie beim kompletten Kodierungsprozess, Rott als Experte zur Verfügung.
Dann wurde zunächst ein Prozess gemeinsam unter den genannten Gesichtspunkten kodiert. Auch metakognitive Aktivitäten, verwendetes Vorwissen, Fehler und Lösungsansätze wurden identifiziert. Gerade in diesem ersten Prozess wurde sich viel Zeit gelassen, d. h. es wurde zunächst der Prozess betrachtet, ohne zu kodieren. Dann wurden mehrere Durchläufe vorgenommen, jeweils mit Fokus auf einer der genannten Dimensionen. Hier wurden erstmal nur Episodengrenzen gesetzt bzw. Ereignisse markiert. Erst im Anschluss wurde gemeinsam diskutiert, wie die Episoden eingeordnet und die Heurismen kategorisiert werden sollen. Erste Kategoriebildung der metakognitiven Aktivitäten wurde vorgenommen.
Dann haben die Kodierer drei Prozesse unabhängig von einander bearbeitet. Die Ergebnisse wurden abgeglichen und konsensuell validiert, d. h. Unterschiede wurden diskutiert, bis ein Konsens gefunden wurde. Hierbei wurde nicht nur die Zuordnung zu den Kategorien, sondern auch die Zeitpunkte, zu denen Episodenwechsel oder andere Ereignisse kodiert wurden, abgeglichen. In Anlehnung an das Vorgehen bei Rott (ebd.) wurde hierbei eine Abweichung von bis zu fünf Sekunden zugelassen. Bei schwer zu klärenden Fragen wurde wieder auf die Expertise von Rott zurückgegriffen. Wichtige Ergebnisse dieser Diskussion wurden in das Kodiermanual aufgenommen. Die Kategoriebildung zur Metakognition wurde gemeinsam weiter ausgeschärft. Dem folgte ein weiterer Zyklus mit denselben Aktivitäten.
Anschließend war eine akzeptable Übereinstimmung der Kodierer erreicht. In der Regel wurden über 60 % der Zeitpunkte gleich gesetzt und über 70 % der Kategorisierungen gleich vorgenommen. Das ist nicht überragend, aber bei der konsensuellen Validierung wurde in allen Fällen eine schnelle Einigung gefunden. Bei den Kategorien zur Metakognition wurden ausschließlich Werte oberhalb von 85 % erreicht. Dies lässt sich dadurch erklären, dass hier die Kategorien gemeinsam erstellt wurden und man sich nicht an ein fremdes System gewöhnen musste (gerade die Schoenfeld-Episoden sind anfangs nicht leicht zugänglich).
Das Training galt damit als abgeschlossen. Mit zwei Ausnahmen wurden in der Folge alle hier behandelten Prozesse von beiden Kodierern unabhängig bearbeitet und anschließend konsensuell validiert.
Die Beantwortung der Leitfragen konnte aus organisatorischen Gründen nur noch von Kodierer TS vorgenommen werden. Da diese sich aber auf die vorherige Kategorisierung stützt und hierbei kaum Zweifel auftraten, scheint ein notwendiges Maß an Objektivität gegeben zu sein (vgl. Nowińska, 2016).
5.5 Ergebnisse der qualitativen Erhebung
In diesem Abschnitt werden die Ergebnisse der verschiedenen Auswertungen beschrieben und zusammengebracht. Zu Beginn (Abschnitt 5.5.1) steht ein Beispielprozess, der ausführlich zusammengefasst und analysiert wird. Abschnitt 5.5.2 beschäftigt sich mit den Schoenfeld-Episoden und Wild Goose Chases. In Abschnitt 5.5.3 wird die Skriptnutzung der Probanden untersucht. Ein genauerer Blick auf den Heurismeneinsatz wird in 5.5.4 gerichtet, gefolgt von einer Betrachtung des Vorwissens und der Entstehung von Ideen (Abschnitt 5.5.5) Anschließend (Abschnitt 5.5.6) werden die metakognitiven Aktivitäten untersucht. Den Abschluss bilden mögliche Auswirkungen der Interventionsmaßnahme (Abschnitt 5.5.7).
Ein Überblick über die untersuchten Problembearbeitungsprozesse wird in Tabelle 5.1 gegeben. In der ersten Spalte steht der Name des Probanden und eine Zahl, die angibt, ob es sich um einen Prozess am Anfang (1) oder im Semester (2) handelt. Die zweite Spalte gibt den Kurznamen der bearbeiteten Aufgabe an. Dahinter steht, ob der Proband zur Interventions- (IG) oder zur Kontrollgruppe (KG) gehört. Die nächsten beiden Spalten geben die (vgl. Abschnitt 5.3.3) und die Art des Umgangs mit dem Skript an (vgl. Abschnitt 5.3.2). Dahinter steht die Reihenfolge der Schoenfeld-Episoden (vgl. Abschnitt 5.3.1), wobei solche Prozesse, in denen Planungs- und Implementationsepisoden vorgekommen sind, fett gedruckt sind. Die letzten fünf Spalten geben den Grad des Heurismeneinsatzes (vgl. Abschnitt 5.3.7), die Anzahl der kodierten Heurismeneinsätze (Abschnitt 5.3.4), den Grad der metakognitiven Aktivitäten (Abschnitt 5.3.7), die Anzahl der kodierten metakognitiven Aktivitäten (Abschnitt 5.3.5) und die Anzahl der Lösungsansätze (Abschnitt 5.3.6) an.
Bevor auf einzelne Aspekte der Tabelle eingegangen wird, ein paar Vorbemerkungen zur Auswertung. Es handelt sich um eine qualitative Auswertung. Mit 13 Prozessen können keine quantitativen Aussagen getroffen werden. Hinzu kommt, dass fast alle betrachteten Aspekte davon abhängen, wie viel und auf welche Art der Proband gesprochen hat. Aktivitäten können nur kodiert werden, wenn sie erkannt werden. Gerade im Bereich der Metakognition geschieht vieles unausgesprochen. Auch Ideen wurden nur kodiert, wenn sie deutlich wurden. Vor allem in Bezug auf die letzten fünf Spalten können Prozesse daher nur sinnvoll mit einander verglichen werden, wenn sie vom selben Probanden durchgeführt wurden. Selbst dann müssen diese Vergleiche mit äußerster Sorgfalt geschehen, da sich, wie bereits erwähnt, die Aufgaben stark voneinander unterscheiden. Darüber hinaus können die in der viertletzten, vorletzten und letzten Spalte angegebenen Anzahlen nur eine ganz grobe Orientierung geben. Eine hohe Anzahl bedeutet nicht unbedingt ein gutes Vorgehen. Wenn etwa die erste Idee zum Ziel führt, sind keine weiteren nötig. Auch wurde bereits angesprochen, dass Problembearbeiter mit einer hohen geistigen Beweglichkeit ohne Heurismeneinsatz auskommen (Abschnitt 2.4.5). Abgesehen von den genannten Einschränkungen ist ein Vergleich von Interventions- und Kontrollgruppe ohnehin wenig sinnvoll, da unterschiedlichen Persönlichkeitsmerkmale der Probanden bereits bei der ersten Messung für große Unterschiede sorgen.
Eine Übersicht über die verwendeten Heurismen und metakognitive Aktivitäten wird später (in Abschnitt 5.5.4 bzw. 5.5.6) noch gegeben.
5.5.1 Ausführliche Betrachtung eines Bearbeitungsprozesses
Bevor im Detail auf die verschiedenen Aspekte eingegangen wird, soll ein Prozess beispielhaft zusammengefasst werden. Es handelt sich hierbei um Niklas Bearbeitung der Aufgabe zur n-ten Wurzel (vgl. Anhang D). Hierbei wurden alle Aspekte, also Schoenfeld-Episoden (vgl. Abbildung 5.7), Heurismeneinsatz, metakognitive Aktivitäten, Rückgriffe auf Vorwissen, Fehler sowie Lösungsideen benannt und kursiv markiert. Nach der Beschreibung einer Episode (mit Ausnahme der ersten) folgt jeweils ein Abschnitt mit Interpretationen und Kommentaren.

Episodenkodierung Niklas (n-te Wurzel)
- Reading (00:00–00:13) :
-
Niklas liest die Aufgabe stumm.
- Analysis (00:13–10:24) :
-
Zunächst (00:13) stellt Niklas fest, dass die FolgeFootnote 10 monoton steigend ist. Bei 01:18 formuliert er die gegebene Gleichung in eine andere Schreibweise (als n-te Wurzel) um (vgl. Abbildung 5.8 oben). Anschließend schlägt er gezielt im Skript nach, um zu kontrollieren, ob diese Schreibweise korrekt ist (02:30–03:10). Dann (03:15) notiert er eine weitere, fehlerhafte, Schreibweise (vgl. Abbildung 5.8 unten) und verkündet die Hoffnung (03:52), dass eine der beiden Schreibweisen richtig ist und ihn zum Ziel führt. Hierauf folgt eine zeitlang Schweigen, wobei er zweimal (06:01–06:55) und (07:32–08:05) im Skript blättert. Bei 08:10 entscheidet er sich, Spezialfälle für n zu betrachten und schreibt zunächst den Term (in korrekter Schreibweise) für \(n=3\) auf. Nachdem er wieder etwas im Skript geblättert hat (09:48–10:24) fragt er nach einem Skriptausschnitt aus einem anderen Kapitel, das ihm nicht vorlag, in dem bewiesen wird, dass es zu jeder reellen Zahl r eine ganze Zahl z gibt, so dass \(z \le r \le z+1\) ist. Während der Interviewer diese Stelle sucht, streicht er den Term für \(n=3\) durch und notiert stattdessen den Spezialfall \(n=2\) (11:40). Der Interviewer gibt ihm einen Laptop mit der geforderten Skriptstelle, die sich Niklas anschaut (12:16–12:46). Hierbei stellt er mit dem Kommentar „Ich wusste, im Beweis steht da was Ähnliches drin“ fest, dass seine zweite Schreibweise falsch war (Kontrolle). Dann vergewissert er sich nochmal beim Interviewer, dass die andere Schreibweise richtig ist (12:51).
Abbildung 5.8 
Niklas Schreibweisen der n-ten Wurzel
Bis hierhin bestehen Niklas Aktivitäten nur darin, die Aufgabe zu verstehen. Das Nachschlagen im Skript dient seinen Aussagen zufolge vermutlich hauptsächlich dazu, zu kontrollieren, welche Schreibweise der n-ten Wurzel korrekt ist. Interessant ist hierbei, dass er sich erinnert, etwas Ähnliches in einem Beweis im Skript gesehen zu haben (Da es hier aber nur um eine Schreibweise und keinen Ansatz handelt, wurde nicht das Analgoieprinzip kodiert). Darüber hinaus betrachtet er zwei Spezialfälle für n, ohne aber konkret an diesen zu arbeiten. Dies folgt in der nächsten Episode.
- Exploration (10:25–26:24) :
-
Niklas plant (10:25), einen Faktor aus der Summe auszuklammern, mit dem Ziel „etwas aus der Wurzel herauszuziehen“(Planungsaktivität). Er weiß aber noch nicht, welcher Faktor das sein kann. Nach einiger Zeit (17:56) kommt ihm die Idee, \(a_1^n\) auszuklammern, was er direkt am Spezialfall \(n=2\) durchführt (Abbildung 5.9 oben). Anschließend erinnert er sich, dass die n-te Wurzel einer Konstanten gegen 1 konvergiert (Rückführungsprinzip), benennt aber die Schwierigkeit, dass er sich noch nicht sicher ist, „wie das ist, wenn man als Exponenten unter der Wurzel auch noch jeweils ein n stehen hat (19:36).“ Im nächsten Schritt (20:11) zieht er \(a_1\) schriftlich aus der Wurzel heraus (Abbildung 5.9). Schließlich stellt er durch Nutzen aller Voraussetzungen (21:49) fest, dass durch die Monotonie der Folge die einzelnen Summanden unter der Wurzel „größer Eins“ sind. Zum Ende der Episode fasst er seine bisherigen Ergebnisse zusammen (24:42).
Abbildung 5.9 
Herausziehen von \(a_1\)
Erwähnenswert ist, dass an dieser Stelle keine Planning-Episode kodiert wurde. Stattdessen wird zu Beginn der Episode eine Planungsaktivität kodiert. Wie auf S. 108 f. beschrieben wurde, müsste für eine Planning-Episode dem Probanden die grobe Umsetzung klar sein. Da Niklas aber weder zu wissen scheint, welcher Faktor ausgeklammert werden soll, noch, wie ihn das Ergebnis weiterbringt, ist das nicht gegeben. Global gesehen bleibt es zunächst also bei einem Erkunden des Problemraumes durch Manipulation des Terms. Da er aber ein Ziel (etwas aus der Wurzel herausziehen) und auch einen möglichen Weg benennt (einen Faktor ausklammern), liegt eine Planungsaktivität vor. Bei (17:56) kommt es nicht zu einer weiteren Planung, es wird aber eine Idee benannt, wie der bisherige Plan konkret umzusetzen ist. Des Weiteren ist zum Ende der Episode interessant, dass Niklas (noch) nicht in der Lage ist, die Erkenntnis, dass die einzelnen Summanden größer gleich Eins sind, umzukehren und \(a_k\) statt \(a_1\) herauszuziehen, was dazu führen würde, dass die Summanden allesamt kleiner gleich Eins wären (dazu später mehr). Bemerkenswert ist auch, dass er nach anfänglichen Klärungen in der Analysis-Episode im gesamten Prozess nicht mehr auf seine Unterlagen zurückgreift. Alle Ideen entstehen aus dem Kopf und werden nicht durch externe Ressourcen angeregt.
- Transition (26:24–26:35) :
-
Niklas sagt: „Ich probiere einfach mal einen anderen Ansatz aus“ (Regulation).
Wie bereits im letzten Absatz beschrieben, wäre es möglicherweise sinnvoll gewesen, den alten Ansatz weiter zu verfolgen.
Abbildung 5.10 
Multiplikationen der Eins
- Exploration (26:35–42:40) :
-
Niklas nächste Idee liegt darin, den Term mit einer 1 zu multiplizieren (28:31). Hierzu schreibt er verschiedene Möglichkeiten auf (Abbildung 5.10). Schließlich sagt er „Ich glaube, ich habe eine Antwort, aber ich denke nicht, dass die richtig ist (33:16 – Evaluation).“ Er wiederholt seine schriftlichen Überlegungen mündlich und folgert dass, da \(\frac{1}{n}\) (im Exponenten) gegen Null geht, die gesamte Folge gegen 1 konvergieren muss (35:19 – Fehler). Auf Niklas entsprechende Frage, ob das stimmen kann, antwortet der InterviewerFootnote 11, dass dem nicht so ist, weil der Ausdruck unter der Wurzel gegen unendlich geht. Schließlich (38:41) kommt Niklas die Idee, den letzten Summanden \(a_k\) auszuklammern (vgl. Abbildung 5.11), weil dann die einzelnen Summanden und damit auch ihre n-ten Potenzen kleiner gleich Eins sind. Hieraus folgert er (42:13), dass auch die Zahl unter der Wurzel kleiner als k sein muss.
In diesem Fall führte die Regulation des Vorgehens zunächst weiter vom Ziel weg, bevor die ursprüngliche Idee wieder aufgenommen wird, diesmal mit dem größten Summanden. An dieser Stelle hätte mit Hilfe der Grenzwertsätze (wenn der Ausdruck unter der n-ten Wurzel konvergiert, dann kann mit dem Grenzwert weitergerechnet werden) oder der Überlegung, dass die n-te Wurzel einer beschränkten Folge gegen Eins konvergiert, bereits das Ergebnis erreicht werden können. Trotzdem ermöglichen die bisherigen Überlegungen die folgende Episode.
Abbildung 5.11 
Herausziehen von \(a_k\)
- Planning (42:40–44:43) :
-
Nun kommt Niklas auf die Idee, das Quetschlemma (vgl. S. 89) zu verwenden (Rückführungsprinzip), hierbei soll nach oben so abgeschätzt werden, dass alle Summanden dem größten (\(a_k\)) entsprechen. Er sagt außerdem, dass ihm eine Abschätzung nach unten noch nicht klar ist (43:27 – Einschätzen des Fortschritts), bemerkt aber: „Dann würde nach dem Quetschlemma auch diese Folge konvergieren“ (Voraussicht).
Hier wird ein klares Ziel formuliert (das Nutzen des Quetschlemmas) und auch der globale Grund dieses Ziels ist klar (die Konvergenz der Folge). Außerdem ist, zumindest für die obere Abschätzung, der Weg zu diesem Ziel vorgezeichnet. Es kann also Planning kodiert werden. Voraussetzung für die Entstehung dieses Plans ist die Kenntnis des Quetschlemmas.
- Exploration (44:43–46:07) :
-
Bevor es zur Umsetzung des Plans kommt, erkundet Niklas noch die nach oben abgeschätzte Folge. Er ist etwas unsicher, was ihren Grenzwert angeht, weil es ihm „nicht plausibel“ erscheint (intuitives Verständnis), dass sie gegen \(a_k\) konvergiert.
Der Plan wird nicht sofort umgesetzt, weil es Zweifel an der Richtigkeit der bisherigen Überlegungen gibt. Das Zögern ist aber nur von kurzer Dauer.
- Implementation (46:07–51:41) :
-
Nun lässt Niklas für die Abschätzung nach unten alle Summanden außer dem kleinsten weg (46:07), mit der Erklärung, dass sie alle größer gleich Null sind (Abbildung 5.12 oben). Der Grenzwert dieser Folge ist \(a_1\). Außerdem berechnet er den Limes der bereits ausgewählten größeren Folge (Abbildung 5.12 unten – 48:22). Er hält fest, dass der gesuchte Grenzwert sich zwischen \(a_1\) und \(a_k\) befindet (Einschätzen des Lösungsfortschritts) und evaluiert sein Vorgehen mit den Worten: „Das ist schonmal ein guter Ansatz, das ist besser als nichts (51:26).“
Abbildung 5.12 
Abschätzungen der Folge nach unten und oben
Zusätzlich zur Umsetzung des Plans zur Abschätzung nach oben findet Niklas hier eine, bei der Planung noch nicht bekannte, Abschätzung nach unten, die zwar noch nicht zum Ziel führt, zumindest aber das Ergebnis einschränkt. Was er nicht sieht, ist, dass mit einem ähnlichen Vorgehen (nämlich dem Weglassen aller Summanden außer dem größten) bereits am Ziel wäre. Die Idee kommt ihm auch im weiteren Verlauf nicht, so dass die Aufgabe schließlich abgegrochen wird.
- Exploration (51:41–60:09) :
-
In dieser letzten Exploration werden verschiedene Ideen angedacht und mehr oder weniger verfolgt. So bringt Niklas an (52:48), dass jede Teilfolge einer konvergenten Folge gegen denselben Grenzwert konvergiert (Fachwissen), verfolgt diese Idee mit dem Kommentar „Ich weiß nicht, ob mich das weiterbringt (53:03)“(Voraussicht) aber nicht weiter. Dann (55:09) kommt ihm die Idee „dasselbe Spiel“ wie bei der Abschätzung nach oben auch bei der Abschätzung nach unten durchzuführen, nämlich jeden Summanden nach unten durch \(a_1^n\) abzuschätzen (Ähnliche Aufgabe), sagt dann (55:32) aber: „Das brauche ich ja gar nicht machen“, weil da, ähnlich wie oben, der Grenzwert \(a_1\) herauskommen wird (Voraussicht). Anschließend äußert er Verunsicherung, weil \(a_k\) größer gleich den anderen Summanden ist (55:39 – Benennen von Schwierigkeiten). Seine nächste Idee (56:25) ist, unter der Wurzel eine Folge aus dem Mittelwert von \(k \cdot a_1^n\) und \(k \cdot a_k^n\) zu bilden. Nachdem er eine solche Folge niedergeschrieben hat, stellt er fest, dass ihn auch das nicht weiterbringt (57:50 – Evaluation). Als Ziel äußert er: „Ich muss die Folge weiter eingrenzen (58:10).“ Die nächste Aussage (58:17) ist etwas schwierig zu interpretieren und wird deswegen wörtlich wiedergegeben: „Das blöde ist, dass ich jetzt nicht z. B. die Hälfte der Anzahl der Folgenglieder von \(a_k\) nehmen kann, weil ich nicht definitiv sagen kann, dass die immer noch größer ist als die Folge, welche nur aus \(a_1\) besteht, weil wenn theoretisch jeder Wert gleich dem Nachfolger ist, wäre das sozusagen ne falsche Behauptung. Daher muss ich bei der Anzahl von meinen Folgengliedern gleich bleiben. Ich kann nur verändern, welche Folgenglieder ich nehme.“ Etwas später (59:06) sagt er, dass er die folgende Idee für unwahrscheinlich hält, weil sie sehr aufwändig ist und sehr lange dauern würde (Voraussicht): Er beschreibt ein Verfahren, bei dem zunächst alle Summanden gleich \(a_k^n\) abgeschätzt werden und nach und nach einzelne Summanden, beginnend beim ersten wieder durch den ursprünglichen Summanden (in dem Fall durch \(a_1^n\)) ersetzt werden. Bei 60:09 fragt er den Interviewer nach einem Tipp, woraufhin dieser immer stärker in den Prozess eingreift, da er der Meinung war, dass die neuen Ideen weiter vom Ziel wegführen und der Bearbeitungsprozess nach über einer Stunde zu einem für Niklas befriedigenden Abschluss geführt werden sollte. Die Beschreibung des Prozesses endet deswegen hier.
Die in dieser letzten Exploration entstehenden Ideen sind weniger zielführend als das, was vorher im Prozess passiert. Teilweise ist auch kaum nachvollziehbar, worauf genau Niklas hinaus will. Man hat das Gefühl, er hätte sein Pulver verschossen und klammert sich gegen Ende des Prozesses an Strohhalme. Allerdings zeigt er gute Voraussicht bei der Einschätzung dieser Ideen. Erstaunlich ist nach wie vor, dass er nicht auf die Idee kommt, alle bis auf den letzten Summanden wegzulassen, zumal er das Prinzip einer ähnlichen Aufgabe ja bei 55:09 anwendet und dies nur noch für den Ansatz in 46:07 machen müsste.





5.5.2 Schoenfeld-Episoden
Ein Punkt, der gleich ins Auge fällt, weil er am Anfang der Prozesse steht, dem aber deswegen nicht zu viel Bedeutung zugemessen werden sollte, ist der, dass alle Prozesse entweder mit Reading oder mit Analysis beginnen. Der einzige Unterschied ist, dass bei letzteren Prozessen die Aufgabe nicht erst komplett gelesen wird, sondern bereits beim Lesen analysiert bzw. systematisiert wird.
So schreibt beispielsweise Jan bei seiner Bearbeitung der Rangaufgabe Schritt für Schritt die einzelnen Teile der Aufgabenstellung mit eigenen Formulierungen nieder (vgl. Abb. 5.13).

Jans Zusammenfassung der Aufgabenstellung
Dass hierbei bereits eine Analysetätigkeit erfolgt, lässt sich daran festmachen, dass er die Aufgabe nicht wörtlich abschreibt (Die genaue Formulierung dieser Aufgabe 5 findet sich zum Vergleich in Anhang D), sondern paraphrasiert, bevor er weiterliest, falsche Indizes korrigiert, vor allem aber daran, dass er die Matrizen A, \(A_1\) und \(A_2\) konkret aufschreibt, bevor er sich der Behauptung (der eigentlichen Rangungleichung) zuwendet.
Auch Julia gibt bei Ihrer ersten Bearbeitung (Grenzwert L) die Aufgabe direkt mit eigenen Worten wieder. Wenngleich sie keine eigenen Formulierungen aufschreibt, wird durch die Paraphrasierung deutlich, dass sie bereits in die Analyse eingestiegen ist.
Da Aufgaben im universitären Kontext in der Regel keine redundanten Informationen geben, kann dieses Vorgehen durchaus sinnvoll sein und sogar als ein Zeichen strukturierten Vorgehens gesehen werdenFootnote 12. Bei Aufgaben im schulischen Kontext (z. B. Sachaufgaben) ist es im Gegensatz dazu in der Regel aber ratsam, zunächst die Aufgabe komplett zu lesen, um wichtige von unwichtigen Informationen trennen.
Welche weiteren Informationen kann man aus den Episoden herauslesen? Ein Verhalten, das Schoenfeld bei seinen Betrachtungen von Problembearbeitungsprozessen hervorhebt, bezeichnet er als Wild Goose Chase. Hiermit meint er solche Prozesse, in denen „[...] students picked a solution direction, and then pursued that approach until they ran out of time“ (Schoenfeld, 1992, S. 195). Es wird also eine Richtung eingeschlagen, die dann ohne wesentliche metakognitive Steuerung beibehalten wird. Im Hinblick auf die Episoden benennt er diejenigen Prozesse als Wild Goose Chases, die nur die Episoden Reading und Exploration enthalten. Rott ordnet dieser Kategorie auch solche Prozesse zu, die zusätzlich Analysis enthalten und merkt an, dass auch in den von Schoenfeld als Beispiel für Wild Goose Chases genannten Prozessen eigentlich eine kurze Analyse kodiert werden müsste (Rott, 2013, S. 302). Mit anderen Worten: Alle Prozesse, die weder Planung und Implementation, noch Verifikation enthalten, gelten als Wild Goose Chases.
Bei den in der vorliegenden Arbeit betrachteten Prozessen ist allerdings das von Schoenfeld beschriebene Verhalten so nicht aufgetaucht: Meistens wurden im Prozess mehrere Ansätze durchdacht. Bei erfolglosen Bearbeitungen war nicht das Problem, dass ein Ansatz zu lange verfolgt wurde, sondern dass gar nicht erst einer gefunden wurde. Hierfür kann es mehrere Gründe geben. Zum einen sind die hier betrachteten Aufgaben stärker begrifflich als rechnerisch geprägt. Es gibt also wenig bis keine Möglichkeiten, sich im Berechnen wenig hilfreicher Werte zu verlierenFootnote 13. Zum anderen waren die Prozesse, die Schoenfeld (1992) beobachtet hat, durch die Aufnahmetechnik zeitlich auf etwa 20 Minuten beschränkt. Da dies bei unseren Prozessen nicht der Fall war, konnte die Zeit auch nicht ablaufen. Die Bearbeitungen wurden erst dann von den Studierenden selbst beendet, wenn sie keine Ideen bzw. keine Energie mehr hatten. So war die Möglichkeit, mehrere Ansätze durchzuspielen stärker gegeben. Auf Momente, in denen eine besser metakognitive Steuerung Zeit erspart hätte, wird in Abschnitt 5.5.6 genauer eingegangen.
Trotzdem scheinen die Prozesse, die Planung und Implementation enthalten, eine Sonderstellung einzunehmen. Es ergibt sich die
- Frage 1: :
-
Wie wirkt sich das Vorhandensein der Episoden Planning und implementation auf die Lösungsqualität der Bearbeitung aus?
Ein Blick auf die Übersichtstabelle lässt einen positiven Effekt vermuten, haben doch, mit einer Ausnahme (Jan 1), diese Prozesse mindestens Lösungsqualität 2 und alle anderen eine geringere. An dieser Stelle ist allerdings Vorsicht geboten. Ein Zitat aus dem Kodiermanual besagt zur Episode Implementation (vgl. Abschnitt 5.3.1): „Gibt es bei der Durchführung noch Unsicherheiten bzw. ist an einigen Stellen noch nicht klar, wie es weiter geht, wird Exploration kodiert“. Das kann bedeuten, dass bei erfolglosen Bearbeitungen (niedrige Lösungsqualität) eher Exploration kodiert wird, auch wenn ein Back vorhanden ist und umgekehrt bei erfolgreichen, bei denen zumindest ein Teil ohne Unsicherheiten abgelaufen ist, eher Planning und Implementation. Genau das zeigt sich auch beim einzigen Prozesses, der Planung, aber keine Implementation enthält (Manuel 1).
Zur qualitativen Beantwortung dieser Frage wird im Folgenden genauer auf die entsprechenden Stellen (teils durch ausführliche Analysen, teils durch Zusammenfassungen) in ausgewählten Prozessen, beginnend mit Jans Bearbeitung der Aufgabe zur Rangungleichung (siehe Anhang D) geschaut. Dieser Prozess nimmt insofern eine Sonderstellung ein, dass er der einzige ist, bei dem direkt auf die Analyse eine Planung folgt, was darauf hindeutet, dass der Proband von vornherein eine Idee hat, wie die Aufgabe zu lösen ist.
- Planning (04:25–05:12) :
-
Jan sagt (04:25): „Entweder: Wenn ich jetzt hier (zeigt auf die Matrix A – vgl. Abbildung 5.13) n unabhängige Zeilen und Spalten habe und angenommen die beiden (zeigt auf zwei Zeilen der Matrix A) wären linear abhängig, dann wären sie hier (zeigt auf die Matrizen \(A_1\) und \(A_2\)) in unterschiedlichen Matrizen und würden sich dementsprechend aufaddieren, so dass das hier (zeigt auf die rechte Seite der Rangungleichung) mehr wäre.“ Dann (04:50) spricht er noch den Spezialfall an, dass alle Zeilen der Matrix A linear unabhängig sind, woraus folgt, dass die Matrizen \(A_1\) und \(A_2\) ebenfalls nur aus linear unabhängigen Zeilen bestehen.
Voraussetzung (Fachwissen) für Jans Vorgehen ist die Vorstellung des Rangs einer Matrix als Anzahl ihrer linear unabhängigen Zeilen (bzw. Spalten). Wenngleich seine mündlichen Äußerungen formal nicht perfekt sind (zwei linear abhängige Zeilen in A müssen sich nicht in jedem Fall auf \(A_1\) und \(A_2\) aufteilen) lassen sie doch erkennen, dass eine informelle Grundidee zur Lösung der Aufgabe vorhanden ist. Zwar ist an dieser Stelle noch nicht klar, ob ein Plan zur formalen Umsetzung dieser Idee vorhanden ist, dies wird aber in der folgenden Episode deutlich.
- Implementation (05:12–09:13) :
-
Jan betrachtet zunächst (05:12) den Spezialfall, dass alle Zeilen linear unabhängig sind. Hierzu schreibt er seine Überlegungen auf (Abbildung 5.14).Bei 08:40 äußert er, dass er ein „Problem bei den Spalten“ hat, welches er aber nicht in Worte fassen kann und auf das er nicht weiter eingeht.
Das Problem mit den Spalten, das Jan anspricht, liegt vermutlich darin, dass wenn A mehr Spalten als Zeilen hat, die Überlegungen nicht funktionieren. In dem Fall könnten aber nicht alle Zeilen linear unabhängig sein, womit er sich nicht mehr im Spezialfall befände. Mit dieser Überlegung hätte Jan es sich etwas einfacher machen können. Trotz kleiner Unsicherheiten (die Anzahl der Zeilen von \(A_2\) muss \(m-r\) sein), gelingt die Umsetzung des Plans für den Spezialfall aber befriedigend.
- Exploation (09:13–11:11) :
-
Jan stellt fest (09:13), dass er jetzt nur noch untersuchen muss, was passiert, wenn A „nicht vollen Rang besitzt.“ Hierzu schaut er ins Skript (09:54–10:30), was ihn daran erinnert (10:19), dass sich der Rang einer Matrix nicht durch Anwenden des Gauss-Verfahrens verändert. Diese Erkenntnis kommentiert er aber mit „Das bringt mir aber nicht viel (10:35 – Voraussicht).“
Es wird deutlich, dass Jan hier noch keinen genauen Plan verfolgt, was sich auch darin zeigt, dass er zur weiteren Ideenfindung auf das Skript zurückgreift.

Jans Überlegungen zum vollen Rang
In der folgenden Implementation (11:11–12:50) geht er wieder auf den vorher betrachteten Spezialfall zurück, wobei er sein bisheriges Vorgehen noch etwas sauberer mündlich zusammenfasst. Später im Prozess kommt er in einer weiteren Planning-Phase (15:45–16:12) auf seine ursprüngliche Idee zurück, dass sich linear abhängige Zeilen in A auf \(A_1\) und \(A_2\) aufteilen können. Es gelingt ihm leider nur teilweise, diesen Plan umzusetzen. Am Ende der Implementation (16:12–20:14) steht zumindest die Aussage „Jede linear unabhängige Zeile in A muss zwangsläufig linear unabhängig in \(A_1\) bzw. \(A_2\) sein.“ Der Rest des Prozesses (bis 32:01) hat wieder explorativen Charakter, wobei es Jan nicht gelingt, die bisherigen Erkenntnisse auf die Rangungleichung zu übertragen. Man hat gesehen, dass hier von vornherein ein Plan vorlag (informell hat Jan direkt sehr gut verstanden, warum die Aussage gilt). So konnte zumindest ein Spezialfall bewiesen werden und auch zum Beweis der allgemeinen Aussage hat nicht viel gefehlt.
Dass informelles Verständnis der Aufgabe nicht unbedingt dafür ausreicht, dass Planning kodiert wird (und dass ein wesentlicher Lösungsfortschritt erzielt wird), zeigt Julias Bearbeitung der Aufgabe zur Monotonie (Siehe Anhang D). Nachdem sie sich ein Koordinatensystem aufgezeichnet hat, sagt sie: „Jeder Wert auf meiner y-Achse wird nur einmal getroffen, weil’s ja injektiv ist und dann kann ich auch dazwischen keinen Graphen haben, der irgendwie so hin- und hertanzt (11:13)“ und zeichnet einen nicht-monotonen stetigen Graphen ein. Außerdem äußert sie die Vermutung, dass „das irgendwie mit dem Zwischenwertsatz zu zeigen sein wird (11:36).“ Da sie aber keine Idee hat, wie genau der ZWS hier angewendet werden kann, wurde hier zwar eine metakognitive Planungsaktivität kodiert, nicht aber die Episode Planning. Bei (12:01) benennt sie noch die Schwierigkeit, dass der ZWS nur für kompakte Intervalle gilt, während in der Aufgabe von einem beliebigen Intervall die Rede ist. Später (14:12) merkt sie an, dass alle in der Aufgabe vorkommenden Begriffe auch im ZWS und dessen Beweis vorkommen, was ihre Vermutung stärkt, dass dieser herangezogen werden muss. Nach einiger Zeit, in der sie keine Fortschritte gemacht hat, sagt sie, dass sie die Aufgabe nicht lösen kann (16:19), obwohl sie sieht, „dass das hier (zeigt auf den ZWS im Skript) alles drin steckt und ich sehe, dass ich mich damit der Aufgabe nähern könnte, aber keine Idee, wie ich das mathematisch aufschreiben muss. Ich hab auch noch nichtmals ne Idee, wie ich mir graphisch den Beweis überlegen soll.“ Etwas später (18:54) bricht sie die Bearbeitung ab. Hier wurde das Grundprinzip der Aufgabe zwar verstanden, aber kein Plan gefunden, diese formal oder graphisch zu beweisen, weswegen keine Planning-Episode kodiert wurde.
Ein Beispiel, bei dem Planung und Implementation, zumindest zu einem Teilziel geführt hat, wurde weiter oben bereits betrachtet (113 ff.). Niklas hat hier mit Hilfe von Abschätzungen und dem Quetschlemma ein Intervall gefunden, in dem sich der Grenzwert befinden muss. Eine kleine Korrektur der Abschätzung hätte bereits zur Lösung geführt.
Bei einer weiteren Bearbeitung von Jan, diesmal zur Fixpunkt-Aufgabe (siehe Anhang D), zeigt sich, dass Planning und Implementation nicht zwingend zielführend sein muss, in diesem Fall, weil bereits der Plan fehlerhaft ist. Jan „wählt“ (15:40) für den gesuchten Fixpunkt \(m:=f^{-n}(m)\) und zeigt in der Folge, dass dann, wie gefordert \(f^n(m)=m\) ist. Hierbei geht er sehr planvoll vor und zeigt sogar, dass die bijektiven Funktionen mit der Verknüpfung eine Gruppe sind. Nachdem er damit fertig ist, glaubt er die Aufgabe gelöst zu haben. Leider liegt hier aber ein Zirkelschluss vor, denn ein m, für das \(m=f^{-n}(m)\) ist, gibt es nur (genau) dann, wenn \(f^n(m)=m\) ist. Das ist aber gerade zu zeigen.
Die Bearbeitung der Aufgabe zum Grenzwert von Quotient und Wurzel (siehe Abschnitt 5.2.3) von Manuel stellt ein Beispiel dafür, dass einer Planning-Phase nicht zwingend eine Implementation folgen muss. Nachdem er vermeintlich gezeigt hat, dass \(L=1\) sein muss (das gilt nur, wenn die Folge \(a_n\) konvergiert), fasst er folgenden Plan:
- Planning (33:09–33:45) :
-
Er sagt: „Wenn ich grad bewiesen habe, dass \(L=1\) ist, muss ich doch einfach nur zeigen, dass – egal was für ne Folge – davon die n-te Wurzel, dass das auch gegen 1 konvergiert (33:09)“ und „Ich zeig das erstmal für ne beliebige Zahl: n-te Wurzel von c (33:27).“
Anschließend schreibt er sauber auf, was er zeigen möchte, evaluiert den Ansatz dann aber mit den Worten „Das [die n-te Wurzel von c] konvergiert nicht gegen 1, das konvergiert gegen 0“ und verwirft diesen.
Zusammenfassend kann bezüglich der Frage 1 gesagt werden, dass bei den von uns analysierten Prozessen die Existenz einer Planning-Episode dann zum Erreichen eines Teilziels geführt hat, wenn der Plan (a) nicht fehlerhaft war und (b) auch tatsächlich implementiert wurde. Andererseits haben Prozesse ohne Planning allesamt niedrige Lösungsqualität (L0 oder L1). Wie aber bereits weiter oben angemerkt wurde, könnte dieses Ergebnis mit der Tendenz zusammenhängen, erfolgreiche Aktivitäten eher als geplant zu kodieren als erfolglose.
Außerdem fällt bei Betrachtung der Prozesse auf, dass eine lang andauernde Analysis-Episode ein Hinweis darauf sein könnte, dass der jeweilige Bearbeiter Verständnisschwierigkeiten aufgrund mangelnden Vorwissens haben könnte. Dem wird in Abschnitt 5.5.5 weiter nachgegangen.
Interessant ist auch, dass keiner der Prozesse mit Planung und Implementation von vornherein das Skript zur Ideenfindung verwendet hat (U3a). Hierauf wird in Abschnitt 5.5.3 eingegangen.
Zuletzt sei erwähnt, dass bei keiner der Bearbeitungen eine Episode der Verification kodiert wurde. Es ist durchaus denkbar, dass das Setting der Interviews darauf Einfluss hatte. Da der Interviewer im Raum saß und den Probanden klar war, dass nach der Bearbeitung noch über die Aufgabe gesprochen wurde, sahen sie möglicherweise keine Notwendigkeit, das Ergebnis noch zu verifizieren.
5.5.3 Umgang mit dem Skript
- Frage 2: :
-
Welchen Einfluss hat der Umgang mit dem Skript auf die Bearbeitungsqualität des Prozesses?
Wie bereits erwähnt, scheint planvolles Vorgehen mit Ideenfindung ohne Hilfe des Skriptes einherzugehen. Außerdem sieht man, dass diejenigen Probanden, die sich von Anfang an sehr stark am Skript orientieren (U3a), nur eine Lösungsqualität von 0 oder 1 erreichen. Nun wird es wahrscheinlich nicht so sein, dass man diesen Studierenden nur das Skript wegnehmen muss, damit sie erfolgreicher werden. Es scheint aber so zu sein, dass Probanden, die sich so gut mit den fachlichen Zusammenhängen des Problems auskennen, dass sie nicht oder nur wenig auf das Skript zurückgreifen müssen, zielführendere Prozesse durchlaufen.
Aufgrund der geringen Zahl der betrachteten Prozesse, lässt sich keine quantitative Aussage treffen. Es ist allerdings möglich, die Ideen, die mit Hilfe des Skriptes entstanden sind, genauer zu betrachten und deren Nutzen einzuschätzen. In Abschnitt 5.5.5 werden außerdem die Ideen, die entscheidend zur erfolgreichen Problembearbeitung beigetragen haben, unter die Lupe genommen. Ohne zu viel vorwegnehmen zu wollen, kann an dieser Stelle bereits gesagt werden, dass keine davon aus Arbeit mit dem Skript oder anderen externen Ressourcen entstanden ist.
Die Interpretation der Arbeit mit dem Skript hat sich in der Praxis als schwierig erwiesen, da die Probanden trotz lauten Denkens die betrachteten Ausschnitte meistens nicht vorlesen. Dadurch ist nicht immer ganz klar, welche Stelle der aufgeschlagenen Seite sie sich gerade anschauen. Daher werden im Folgenden nur wenige Beispiele betrachtet, bei denen bestimmte Schlagworte aus dem Skript genannt wurden, wohlwissend, dass es sich hierbei bereits um Stellen handelt, die die Probanden aus verschiedensten Gründen bereits für erwähnenswert hielten. Es wurde also durchaus eine Vorauswahl getroffen.
Zunächst gibt es zwei Beispiele, bei denen Skriptausschnitte möglicherweise für Verwirrung bzw. eine falsche Vorstellung eines Begriffes gesorgt haben.
Zum einen stößt Patrick bei seiner Bearbeitung der Aufgabe zur Umkehrung der Grenzwertsätze (siehe Anhang D) direkt zu Beginn (02:08) auf den Begriff der bestimmten DivergenzFootnote 14. Im weiteren Verlauf äußert er immer wieder, dass eine divergente Folge gegen unendlich läuft. Besonders deutlich wird, dass er sich auf das Skript bezieht, als er sagt: „Jetzt weiß ich aus der Divergenz, dass \(x_n > c\) sein muss, um divergent zu sein (16:57).“ Den Fall der unbestimmten Divergenz hat er offenbar zu diesem Zeitpunkt (und wahrscheinlich auch zu allen anderen) nicht auf dem Schirm.
Während sich Patricks Überlegungen ungewollt auf einen Spezialfall konzentrieren, führt bei Jonas (Aufgabe Quetschlemma – vgl. Abschnitt 5.2.1) eine Fehlinterpretation zu falschen Vorstellungen, die den Problembearbeitungsprozess massiv behindern. Auch er liest zu Beginn (02:06) eine Definition („Eine Folge \(\{x_n\}n \subset \mathrm{{I\!R}}\) nennen wir konvergent gegen \(\alpha \in \mathrm{{I\!R}}\), wenn \(\{x_n - \alpha \}_n\) eine Nullfolge ist“). Später im Prozess (19:57) schreibt er auf: „\(a_n, b_n, c_n\) Nullfolgen.“ Hier wurde offenbar die richtige (wenngleich etwas ungewöhnlich formulierte) Information aus dem Skript falsch verstanden.
Weder Jonas noch Patrick konnten Lösungsfortschritt erzielen, was sicherlich nicht nur an ihrem Umgang mit dem Skript lag. Es zeigt sich jedoch, dass gerade Studierende, die bereits unsicher (und deswegen vielleicht auf die Hilfe des Skriptes angewiesen) sind, auch Schwierigkeiten haben, Informationen aus dem Skript sinnvoll einzuordnen und zu verwerten.
Weitere Begriffe, die bei vielen Prozessen zur Konvergenz aus dem Skript heraus genannt werden, aber bei der Bearbeitung der entsprechenden Aufgaben (Umkehrung der Grenzwertsätze, Quetschlemma, n-te Wurzel und Grenzwert von Quotient und Wurzel), zumindest bei üblichen Lösungswegen, keine Hilfe sind, sind die Teilfolge und die Intervallschachtelung. In den meisten Fällen werden diese Begriffe nur benannt und eine wirkliche Arbeit mit diesen Ideen ist nicht zu erkennen. Ob das daran liegt, dass metakognitive Kontrollentscheidungen (vgl. Abschnitt 5.5.6) getroffen wurden oder ob die Probanden einfach keinen Weg gefunden haben, hiermit umzugehen, ist meist nicht ersichtlich. Für die zweite Variante würde die eben aufgestellte These, dass Studierende, die viel mit dem Skript arbeiten eher unsicher im Umgang mit den Begriffen, Zusammenhängen und Verfahren sind. Exemplarisch soll im Folgenden ein Ausschnitt aus einer Exploration-Episode von Manuel wiedergegeben werden, der die Aufgabe zum Grenzwert von Quotient und Wurzel (vgl. Abschnitt 5.2.3) bearbeitet und hierbei auf das Skript zurückgreift. Der gesamte Prozess dauert 45:37 Minuten, hiervon arbeitet Manuel knapp ein Drittel (13:23 Minuten) mit dem Skript (vgl. Abbildung 5.15).

Episoden Manuel
Bevor er das erste Mal zum Skript greift (07:52), hat Manuel sich ohne große Fortschritte auf die Untersuchung der Quotientenfolge konzentriert und scheint hier auch fortfahren zu wollen. Nach kurzem Lesen verweist er (08:19) auf eine Stelle im Skript (eine Folgerung aus den Grenzwertsätzen, die besagt: „Es gelte \(a_n \rightarrow a\) und \(b_n \rightarrow b\) bei \(n \rightarrow \infty \) mit \(b \ne 0\). Dann gibt es ein \(n_0 \in \mathrm{{I\!N}}\) sodass \(b_n \ne 0\) für alle \(n \ge n_0\) ; ferner konvergiert die Folge \(\left( \frac{a_n}{b_n}\right) _{n \ge n_0}\) gegen \(\frac{a}{b}\)“ und folgert daraus (08:46): „Dann wäre \(L=\frac{\lim (a_{n+1})}{\lim (a_n)}\)“ und fügt hinzu: „Theoretisch sollte \(a_{n+1}=a_n\) sein – ja, zumindest der Grenzwert sollte derselbe sein (08:55)“ (beides gilt nur, wenn \(a_n\) konvergiert). Wenig später (09:32) stellt Manuel fest: „Wenn ich beweisen kann, dass die dieselben sind, ergibt sich für L, dass es gleich 1 ist.“ Sein Ziel ist also zunächst, zu zeigen, dass „der Limes von \(a_{n+1}\) [...] der gleiche ist von Limes \(a_n\) (10:11).“ Nach weiterem stummen Blättern im Skript sagt er: „Vielleicht könnte ich ja \(a_{n+1}\) als konvergente TeilfolgeFootnote 15 von \(a_n\) aufschreiben (11:42)“ und etwas später: „Dann müsste ich jetzt, glaube ich, Intervallschachtelung machen (12:04).“ Etwas weiter unten im Skript wird der Auswahlsatz, der besagt, dass jede beschränkte Folge eine konvergente Teilfolge besitzt, mit Hilfe des Intervallhalbierungsverfahrens, bei dem ein durch die Beschränkung der Folge vorgegebenenes Intervall immer wieder halbiert wird, wobei in mindestens einer Hälfte unendlich viele Folgenglieder liegen müssen, bewiesen. Diesen schaut er sich ab (12:26) laut eigener Aussage etwas ausführlicher an. Bei (13:09) äußert er noch Bedenken (Voraussicht): „Intervallschachtelung – Ich weiß nicht, ob ich das für so ne allgemeine Folge machen kann. Ich muss ja immer das Intervall nehmen, was unendlich viele Punkte in sich hat“, sagt aber schließlich (13:36): „Ich glaube, ich kann das machen.“ Bei (14:04) löst er sich vom Skript und überlegt, wie er das Startintervall wählen soll. Schließlich (14:36) schreibt er, dass er \(I_1=[0;\frac{L}{\lim (a_{n+1})}]\) wählt und blättert anschließend (14:46) wieder im Skript, bis er sagt: „Das muss ich, glaub ich, gar nicht machen. Ich glaube, das gilt einfach, dass \(a_{n+1}=a_n\) ist – also zumindest, dass sie gegen denselben Grenzwert konvergieren (15:13)“ und seine Versuche, dies zu beweisen, abbricht.
Hier sieht man zunächst, dass Manuel nach Betrachten der Grenzwertsätze fälschlicherweise vermutet, dass \(L=1\) sein muss. Ob er hierbei direkt vom Skript auf diese falsche Fährte gebracht wurde, ist fraglich, da er bereits vor dem hier wiedergegebenen Abschnitt die Grenzwertsätze erwähnt. Etwas später bringt ihn das Skript auf die Idee, \(a_{n+1}\) als Teilfolge von \(a_n\) zu betrachten. Je nach Definition des Begriffes kann das möglich sein. So wie die Definition im Skript steht (vgl. Fußnote), ginge es tatsächlich mit Hilfe der Zuordnung \(p \rightarrow p-1\). Daraus würde direkt folgen, dass die Folgen (falls vorhanden) denselben Grenzwert haben müssen. Diese Zuordnung sucht Manuel aber nicht, weil er (vermutlich durch den folgenden Beweis des Auswahlsatzes) auf die Idee gebracht wird, eine Intervallschachtelung anzuwenden. Zwar zweifelt er bei (13:09) kurz daran (ob sein Zögern darauf zurückzuführen ist, dass eine Intervallschachtelung nur bei beschränkten Folgen sinnvoll ist oder ob er nur nicht weiß, wie er eine solche umsetzen soll, wird nicht klar), versucht aber noch einige Zeit, sein Zwischenziel auf diese Weise zu erreichen. Diese Versuche bricht er aber nach einiger Zeit ab. Hier sieht man, wie das Skript Ideen evozieren kann, die kaum oder nur mit großem Aufwand zu realisieren sind (man könnte sicherlich beweisen, dass \([0;\frac{L}{\lim (a_{n+1})}+\varepsilon ]\) für ein geeignetes \(\varepsilon \) unendlich viele Folgenglieder von \(a_n\) enthält) und dabei Zeit und kognitive Kapazitäten beanspruchen. Manuels Ziel, zu zeigen, dass \(a_n\) und \(a_{n+1}\), wenn sie konvergieren, denselben Grenzwert haben, lässt sich vergleichsweise schnell über die Definition der Konvergenz zeigen.
Auch Julia arbeitet bei derselben Aufgabe (vgl. Abschnitt 5.2.3) recht lange mit dem Skript (20:18 von insgesamt 40:44 Minuten). Diese Arbeit soll im Folgenden kurz zusammengefasst werden (vgl. auch 5.16): In der ersten Hälfte der Bearbeitung geht sie das Kapitel zur Konvergenz im Skript Schritt für Schritt (von 01:29 bis 03:56, 05:45 bis 07:21 und von 08:04 bis 10:39) durch. Unter anderem stößt sie auf die Grenzwertsätze (02:16), die sie zu der Fehlannahme (oder wohlwollend betrachtet zum Spezialfall) führen, dass \(L=1\) ist. Hierbei entdeckt sie (09:11) in einem Beweis aus dem Skript (im Gegensatz zu Manuel) auch die Bemerkung, dass „mit \(a_n \rightarrow a\) auch \(a_{n+1} \rightarrow a\) bei \(n \rightarrow \infty \) gilt.“ Später zieht sie auch das Internet zu Rate (30:19 bis 32:20), wobei hier nicht klar wird, was genau sie sich anschaut (einer vorherigen Bemerkung zufolge, sucht sie vermutlich nach hilfreichen Beispielen von Folgen). Von 33:39 bis zum Ende arbeitet sie wieder mit dem Skript. Hierbei kommt sie auf die Idee: „Es geht um die Monotonie der Konvergenz (34:05)“ und schlägt anschließend (!) die Stelle im Skript auf, an der der Satz zur Monotonen Konvergenz (monotone und beschränkte Folgen sind konvergent) und dessen Beweis steht. Fast bis zum Ende des Prozesses beschäftigt sie sich mit dem Begriff der Monotonie (sowie der Beschränktheit), zunächst mit Hilfe des Skriptes, dann (ca. ab 37:00) mit Hilfe des Internets. Als Abschlussbemerkung (40:29) sagt sie „Das Prinzip der Intervallschachtelung habe ich ja noch nicht so richtig nachgearbeitet, aber ich würde jetzt versuchen, darüber irgendwie weiterzukommen.“

Episoden Julia
Es zeigen sich hier ähnliche Tendenzen, wie bei Manuel. Vor allem im letzten Teil (ab 33:39) verfolgt Julia eine Idee, die (zumindest mit einfachen Mitteln) nicht zielführend sein kann. Zwar ist auch hier die Idee nicht völlig abwegigFootnote 16, letztlich aber wenig hilfreich. Trotzdem wird sie gut sechs Minuten verfolgt, ohne sie einer kritischen Prüfung zu unterziehen. Interessant ist hier die Frage, wie Julia auf diese Idee gekommen ist, da sie erst nach deren Äußerung auf die entsprechende Stelle im Skript zurückgreift. Da sie aber sehr gezielt diese Seite aufschlägt, ist zu vermuten, dass sie sich daran aus dem ersten Durcharbeiten des Skriptes erinnert (sie hat auch bei (07:07) den entspechenden Satz erwähnt). Das würde bedeuten, dass auch hier das Skript die Ideenfindung stark beeinflusst hat, auch in dem Fall eher negativ.
Bei Ihrer zweiten Aufgabenbearbeitung (Aufgabe Monotonie – vgl. Anhang D) zeigt Julia schon geschickteren Umgang mit dem Skript. Die Teile des Prozesses, in denen hiermit gearbeitet wird, sollen als Beispiel komplett wiedergegeben werden. Insgesamt wird das Skript in 07:43 von 18:54 Minuten verwendet.
Nachdem Julia eine Kurzform der Definition der Stetigkeit aufgeschrieben hat (5.17 oben), kommt das Skript zum ersten Mal von (03:25) bis (06:56) zum Einsatz. Relativ schnell (04:00) fällt Julia die Definition einer monotonen Funktion auf, die sie auch, paraphrasiert, auf den Aufgabenzettel überträgt und markiert, indem sie einen Kasten darum zieht (5.17 unten). Das dauert bis (05:58). Bei (06:04) sagt sie: „Stetigkeit habe ich ja eigentlich schon aufgeschrieben“, während sie weiter im Skript blättert (und nicht auf einer Seite ist, in der Stetigkeit definiert oder charakterisiert wird). Bei (06:24) paraphrasiert sie den Satz von Weierstraß: „Weierstraß sagt, dass wenn das Intervall kompakt wäre und stetig, dann habe ich mindestens ein Minimum oder Maximum, dann wäre es ja nicht monoton.“ In dieser Aussage sieht sie einen Widerspruch zur Aufgabenstellung, über den sie in der Folge (im Wesentlichen ohne Verwendung des Skripts) nachdenkt. Hierbei hinterfragt sie ihre Vorstellung von Monotonie („Was bedeutet denn Monotonie (07:58)?“) und artikuliert (08:23), dass ein Gipfel dafür sorgen würde, dass die Funktion nicht monoton istFootnote 17. Schließlich (08:33) entscheidet sie mit den Worten „Naja, ich geh jetzt mal weiter“, diesen scheinbaren Widerspruch nicht genauer zu untersuchen und blättert wieder im Skript. Bei (08:44) zeigt sie auf die Definition der Stetigkeit und sagt: „Das habe ich schon aufgeschrieben.“ Leise nennt sie Schlagwörter, die markieren, an welcher Stelle im Skript sie sich befindet (hierbei geht sie offenbar das Unterkapitel Funktionen und Stetigkeit der Reihe nach durch): „Alternative Definition von Stetigkeit (08:56)“ (gemeint ist Stetigkeit im \(\mathrm{{I\!R}}^m\)), „Beispiele (09:01)“ (stetiger und unstetiger Funktionen), „Folgenkriterium (09:05)“, bevor sie sich wieder vom Skript abwendet (09:22). In den folgenden Minuten wird deutlich, dass Julia (mit Hilfe einer Skizze) die Aufgabe informell verstanden hat (vgl. S. 125). Sie Äußert sogar einen Plan: „Und wenn ich dass hier so aufmale, dann denke ich, dass das irgendwie mit dem Zwischenwertsatz zu zeigen sein wird (11:36).“ Diesen versucht sie nun (ab 11:45) wieder mit Hilfe des Skriptes zu verfolgen und schlägt den Zwischenwertsatz (11:59) auf. Bei (12:01) sagt sie: „Wobei der Zwischenwertsatz nur definiert ist für kompakte Intervalle und hier ist ja mein Intervall beliebig.“ Nach einem weiteren kurzen Blick ins Skript (vermutlich in den Beweis des Zwischenwertsatzes), wendet sie sich wieder davon ab (12:39). Unter anderem sagt sie: „Ich sehe jedenfalls, dass ich all diese Begriffe in der Definition und dem Beweis für den Zwischenwertsatz auch finde und dass das deshalb damit irgendwie wahrscheinlich zu beweisen sein wird (14:27).“ Ab (15:48) geht sie weiter den Beweis des Satzes bis (16:19) durch (hierbei fällt auch wieder der Begriff des Intervallschachtelungsprinzips (15:05)). An dieser Stelle ist sie kurz davor, die Bearbeitung abzubrechen, überlegt aber (zunächst wieder ohne Skript), ob sie zumindest einen „graphischen (16:42)“ finden kann. Zum Abschluss (17:41 bis 18:40) blättert sie noch etwas im Skript, bevor sie die Bearbeitung abbricht.

Julias Niederschrift der wichtigen Definitionen
Wenngleich Julia hier zu keinem fertigen Beweis kommt, so zeigt sie doch ein gezielteres Arbeiten mit dem Skript als noch bei ihrer ersten Bearbeitung. Ebenso wird (möglicherweise damit zusammenhängend) zumindest informelles Verständnis erreicht. In welchen Punkten unterscheidet sich diese Bearbeitung von anderen, die viel mit dem Skript arbeiten? Zunächst einmal wird hier nicht mehr, wie vorher, das Skript von Anfang bis Ende durchgearbeitet, sondern gezielt Stellen herausgesucht, die hilfreich sein könnten. So ist die Definition einer streng monotonen Folge das Erste, was herausgegriffen wird. Die Stetigkeit wurde vorher schon ohne Hilfe des Skripts aufgeschrieben, weswegen diese Stelle nicht weiter gesucht wird. In der Folge wird zwar der (für diese Aufgabe wenig hilfreiche) Satz von Weierstraß über einen Zeitraum von etwa zwei Minuten aufgegriffen, danach wird aber bewusst davon Abstand genommen. Hier zeigt sich gute metakognitive Kontrolle des Vorgehens. In der Folge werden (etwa eine Minute lang) verschiedene Skriptstellen genannt, die ebenfalls bei dieser Aufgabe keine große Hilfe sind, allesamt aber nur überflogen. Auch das könnte ein Zeichen guter Kontrolle sein. Die nächste Beschäftigung mit dem Skript folgt aus einem klaren Plan (den Zwischenwertsatz anzuwenden) und ist damit sehr zielgerichtet. Grundsätzlich ist die Idee auch völlig richtig, Julia begründet sogar, warum sie diese weiter verfolgt (weil alle Begriffe der Aufgabe im Zwischenwertsatz vorkommen). Leider scheitert sie aber an der Umsetzung, was zum einen daran liegt, dass die Aufgabenstellung ein beliebiges Intervall vorgibt, der Zwischenwertsatz aber nur für kompakte Intervalle gilt (was die Aufgabe etwas schwieriger macht), möglicherweise aber auch daran, dass sie sich etwas zu sehr auf den Beweis des Zwischenwertsatzes konzentriert und weniger auf dessen Anwendung.
Zwar wurden hier nur wenige Prozesse betrachtet, die Erkenntnisse, die sich durch deren Analyse in Bezug auf Frage 2 gewonnen werden konnten, lassen sich wie folgt zusammenfassen: Grundsätzlich haben Studierende, die Ideen ohne Hilfe des Skriptes generieren, haben größere Aussichten auf eine erfolgreiche Problembearbeitung als solche, die auf das Skript angewiesen sind. Arbeit mit dem Skript kann zu ablenkenden, teilweise sogar abwegigen Ideen führen. Werden diese Ideen aber einer guten metakognitiven Kontrolle unterzogen, sind Studierende durchaus in der Lage, sich nicht zu sehr auf diese Ablenkungen einzulassenFootnote 18. Bei gezielter Verwendung, wie bei Julias zweitem Prozess zu beobachten war, kann das Skript aber ein starker Verbündeter werden. Insgesamt scheint ein gutes Vorwissen (vgl. Abschnitt 5.5.5) zu einer reflektierten Skriptnutzung beitragen zu können.
5.5.4 Heurismeneinsatz
Tabelle 5.2 gibt einen Überblick darüber, in welchen Prozessen welche Heurismen eingesetzt wurden. Hier steht jede Spalte für einen Heurismus mit der im Kodiermanual auf S. 100 verwendeten Abkürzung. Die imaginäre Figur wurde in dieser Tabelle mit der Skizze zusammengefasst.
- Frage 3: :
-
Ist Heurismeneinsatz aufgabenabhängig?
Die Theorie zu Heurismen (vgl. Abschnitt 2.3.2) sowie die bisherigen Untersuchungen von Problembearbeitungsprozessen (z. B. von Rott (2013) und Schoenfeld (1985)) weisen darauf hin, dass dem so ist. An dieser Stelle soll also bestätigt werden, dass diese Aussage auch im hier betrachteten Kontext zutrifft.
Exemplarisch soll dies an der Aufgabe n-te Wurzel (vgl. Anhang D) gezeigt werden, die von Niklas (vgl. Abschnitt 5.5.1) und Malik bearbeitet wurde. Beide betrachten zunächst einen Spezialfall des zu betrachtenden Terms. Interessanterweise ist bei den beiden Probanden die Variable, die festgelegt wird unterschiedlich. Während Niklas (08:12) das zweite Folgenglied betrachtet (also \(n=2\) setzt), reduziert Malik die Anzahl der Summanden unter der Wurzel zunächst auf drei (02:26), dann auf zwei (06:05 – er setzt also \(N=3\) bzw. \(N=2\))Footnote 19. Beide versuchen offenbar, den Term durch einsetzen von Beispielwerten greifbarer zu machen. Hierbei zeigt sich Maliks Wahl als hilfreicher, denn er kommt durch das betrachtete Beispiel schnell auf die (korrekte) Vermutung, dass ein kleiner Summand für \(n \rightarrow \infty \) „unrelevant wird (03:52)“ und damit \(a_N\) der Grenzwert der Folge sein muss. Er beweist diese Vermutung in der Folge zunächst für den Spezialfall und versuchtFootnote 20 diesen dann mittels des Induktionsprinzips zu verallgemeinern. Auch dieser Heurismus ist naheliegend und von der Aufgabe evoziert. Niklas hingegen geht, nachdem er eine zeitlang mit dem Spezialfall gearbeitet hat, in seinen schriftlichen Aufzeichnungen kommentarlos wieder vom Spezialfall \(n=2\) auf ein allgemeines n zurück (ca. bei 20:00). Auch das Nutzen aller Voraussetzungen spielt eine wichtige Rolle. Beide Probanden gehen erst im Laufe der Prozesse darauf ein, dass \(0 \le a_1 \le \ldots \le a_N\) ist, Malik mit den Worten: „Mir fällt grad auf, [\(\ldots \)] dass ich noch gar nicht verwendet hab, dass \(a_N\) größer als \(a_1\) sein muss, also wird das auf jeden Fall eine Rolle spielen (12:16)“ und Niklas, um daraus zu folgern, dass die Quotienten \(\frac{a_k}{a_1}\) größer gleich (21:49) bzw. später, dass die Quotienten \(\frac{a_k}{a_N}\) kleiner gleich Eins sind (39:04). Es ist klar, dass ohne diese Voraussetzung die Behauptung nicht zutrifft und damit zwingend darauf zurückgegriffen werden muss. Im weiteren Verlauf versuchen beide das Quetschlemma anzuwenden (Rückführungsprinzip), wobei Niklas damit nur zu einem Teilerfolg gelangt (vgl. Abschnitt 5.5.1), weil ihm eine geeignete Abschätzung nach unten fehlt. Diese Vorgehensweise ist die mit Abstand ökonomischste, um die Aufgabe zu lösen. Wie man an Maliks Bearbeitung sieht, gibt es zwar auch andere Lösungswege, die aber deutlich aufwändiger sind. Er selbst kommentiert zum Abschluss (49:08) seinen Prozess mit den Worten: „Ich hab etwa gerade ne Stunde gerechnet und hab die Lösung in zehn Minuten komplett neu berechnet.“ An diesen Bearbeitungen sieht man, dass das Betrachten eines Spezialfalls, das Nutzen aller Voraussetzungen und die Rückführung auf das Quetschlemma naheliegende, ja fast notwendige Heurismen sind. Tabelle 5.2 lässt sich entnehmen, dass es noch mehr Heurismen gibt, die von beiden Bearbeitern verwendet wurde, allerdings lässt sich hier kein Zusammenhang mit den Erfordernissen der Aufgabe erkennen. Das Verfahren von ähnlichen Aufgaben etwa wird an zwei völlig unterschiedlichen Stellen verwendet (Niklas überträgt sein Vorgehen von der Abschätzung nach oben auf die nach unten, während Malik bei der Manipulation eines Bruchterms durch die größte Folge kürzt, was auf einem vorherigen Übungszettel bereits gemacht wurde).
Andersherum ist der Tabelle 5.2 zu entnehmen, dass es auch Aufgaben gibt, für die sich bestimmte Heurismen nicht anbieten. Eine qualitative Betrachtung von Ereignissen, die nicht auftreten, ist kaum zu liefern, allerdings lässt sich deren Fehlen theoretisch erklären. So wird beispielsweise die Begriffsklärung bei den Aufgaben, in denen im Wesentlichen Terme manipuliert werden (lin. Unabhg., n-te Wurzel und Grenzwert L), nicht genutzt. Bei all diesen Aufgaben kommt es weniger auf den exakten als auf einen geschickten rechnerischen Umgang mit den grundlegenden Begriffen an. Zwar müssen die Bearbeiter grundsätzlich verstanden haben, was lineare Unabhängigkeit bzw. Folgenkonvergenz bedeutet, der Hauptteil der Aufgaben besteht aber darin, eine Gleichung aufzustellen und zu zeigen, dass die Koeffizienten gleich Null sein müssen (bei der linearen Unabhängigkeit) bzw. einen Term durch geschickte Abschätzungen und Umformulierungen so zu manipulieren, dass der Grenzwert gefunden und bewiesen wird (bei den beiden anderen genannten Aufgaben). Hierbei sind weniger Begriffe als Zusammenhänge (wie etwa das Quetschlemma) hilfreich. Ist ein grundlegendes Begriffsverständnis allerdings nicht vorhanden, wäre sicherlich eine Klärung notwendig. Das scheint aber bei den Probanden nicht der Fall gewesen zu sein. Bei denselben Aufgaben wurde (mit Ausnahme der Bearbeitung von Manuel, der sich als Beispiel für eine konvergente Folge die Funktion \(e^{\frac{1}{x}}\) visualisiert) auch keine Skizze angefertigt. Das scheint ebenfalls mit der formalen Struktur der Aufgaben zusammenzuhängen. Zwar sind hier grundsätzlich Skizzen denkbar (etwa um sich lineare Unabhängigkeit oder das Quetschlemma vor Augen zu führen), bei der Manipulation der Terme aber ebenfalls nicht naheliegend. Ein weiteres Beispiel ist das Anfertigen einer Tabelle, das nur von Jan in Form einer Matrix Rangungleichung und von Manuel als Auflistung der ersten Glieder einer Folge Grenzwert von Quotient und Wurzel durchgeführt wurde.
Da, wie bereits in Abschnitt 5.3.4 beschrieben, Kilpatrick (1967) bei seiner, an die Liste von Pólya (1945) angelehnten Kodierung, unter anderen die Pólya Frage Did you use all the data? im Nachhinein aus dem Kodiermanual gestrichen hat, weil ein entsprechendes Verhalten niemals aufgetreten ist, wird der hiermit in engem Zusammenhang stehende Heurismus Nutzen aller Voraussetzungen im Folgenden etwas genauer betrachtet. Im universitären Zusammenhang scheint dieser sehr wohl eine große Bedeutung zu haben. Aufgabe für Aufgabe (abgesehen von der Aufgabe zur n-ten Wurzel, die zu Beginn des Abschnittes bereits behandelt wurde) soll deswegen sein Auftreten und sein möglicher Nutzen untersucht werden (wenn nicht anders aufgeführt, finden sich die Aufgaben in Anhang D):
Die Behauptung der Aufgabe zur Umkehrung der Grenzwertsätze (Wenn \(\{x_n\}_n\) divergent und \(\{y_n\}_n\) konvergent ist, dann ist \(\{x_ny_n\}_n\) divergent), die zu beweisen oder widerlegen ist, lässt sich nicht in zwei Voraussetzungen aufteilen, da die Folgerung (\(\{x_ny_n\}_n\) ist divergent) beide Elemente aus der Voraussetzung enthält. Es ist deswegen nur schwerlich denkbar, diese von einander zu trennen. Außerdem ist die vorangestellte Voraussetzung, dass es sich bei \(\{x_n\}_n\) und \(\{y_n\}_n\) um Folgen handelt, implizit bereits in der Voraussetzung der Divergenz bzw. Konvergenz enthalten und kann, so dass diese nicht losgelöst davon betrachtet werden können. Sich bewusst zu machen, dass alle Voraussetzungen genutzt werden müssen, ist bei dieser Aufgabe also nicht notwendig.
Die Aufgabe zum Fixpunkt lässt sich allerdings gut in zwei Voraussetzungen aufteilen: Zum einen ist f eine Abbildung einer (nichtleeren) Menge M auf sich selbst, zum anderen ist M endlich. Hieraus folgt, dass es ein \(n<0\) gibt, so dass \(f^n\) (mindestens) einen Fixpunkt hat. Die Bearbeitung von Jan scheitert daran, dass er die zweite Voraussetzung (M ist endlich) gar nicht verwendet. Ein Beweis ist ohne diese Voraussetzung nicht möglich. Es ist also zwingend notwendig, dass man sich bei der Bearbeitung bewusst ist, dass man alle Voraussetzungen verwenden muss.
Wenngleich die Aufgabe zur Rangungleichung relativ komplex aussieht, hat sie im Grunde genommen nur eine Voraussetzung: Wenn eine Matrix (deren Koeffizienten genauer spezifiziert werden) in zwei Teile geteilt wird, so gilt die Rangungleichung. Auch hier kann dieser Heurismus also nicht sinnvoll zum Tragen kommen.
Bei der Aufgabe zur Linearen Unabhängigkeit gibt es (zusätzlich dazu, dass man sich in einem K-Vektorraum befindet) gleich mehrere Voraussetzungen. Erstens sind die Vektoren \(v_1,\ldots ,v_n\) linear unabhängig und zweitens ist \(v:=\sum _{i=1}^n a_i v_i\). Die dritte Voraussetzung steckt in der Äquivalenzbehauptung (genau dann, wenn \(v_1-v,\ldots ,v_n-v\) linear unabhängig sind, ist \(\sum _{i=1}^n a_i \ne 1\)). Bei einer typischen Aufgabenbearbeitung wird allerdings recht schnell eine Gleichung aufgestellt (etwa \(\sum _{j=1}^n \lambda _j(v_j-v)=0\)), in die v (also die zweite Bedingung) eingesetzt wird. Weiterhin wäre typisch, die Gleichung so umzustellen, dass die \(v_j\) von einander isoliert sind (um die erste Bedingung zu verwenden). Alle Koeffizienten davor müssen dann gleich Null sein, was entweder dann der Fall ist, wenn die \(v_j-v\) linear unabhängig sind oder \(\sum _{i=1}^n a_i = 1\) ist. Obwohl es hier gleich drei Voraussetzungen gibt, werden diese bei einer typischen Bearbeitung (so auch bei Andreas) direkt zu Beginn Schritt für Schritt eingesetzt. Dieses Vorgehen ist bei Aufgaben zur linearen Unabhängigkeit so üblich, dass die meisten Bearbeiter sich nicht extra bewusst machen müssen, dass wirklich alle Voraussetzungen genutzt werden sollten.
Beim Quetschlemma (vgl. Abschnitt 5.2.1) haben die beiden erfolglosen Bearbeiter (Jonas und Tim) diesen Heurismus nicht angewandt. Wie wir später (Abschnitt 5.5.5) sehen werden, ist das aber nicht der einzige Grund für ihr Scheitern. Es ist bei dieser Aufgabe auch durchaus denkbar, dass alle Voraussetzungen gemeinsam gedacht werden (\(b_n\) liegt zwischen \(a_n\) und \(c_n\), die beide gegen denselben Grenzwert c konvergieren. Die sehr schöne Bearbeitung dieser Aufgabe von Malik wird in 5.5.5 genauer betrachtet. Hier soll bereits erwähnt werden, dass die Voraussetzungen nicht etwa in die Ungleichung \(a_n \le b_n \le c_n\) auf der einen und die Konvergenz von \(a_n\) und \(c_n\) gegen c auf der anderen Seite, sondern in \(a_n \le b_n\) und \(a_n \rightarrow c\) auf der einen sowie \(b_n \le c_n\) und \(c_n \rightarrow c\) auf der anderen aufgeteilt wurde.
Die Aufgabe zur konstanten Funktion hat die Voraussetzungen, dass zum einen f eine stetige (reelle) Funktion ist und zum anderen \(f(x)=f(x^2)\) für alle x gilt. Zwar würde eine typische Bearbeitung recht schnell die Stetigkeit (in Form von Folgenstetigkeit) mit der gegebenen Gleichung verbinden (und von da an mit einer Gleichung, die beide Voraussetzungen enthält, weiterarbeiten), dass dies aber nicht selbstverständlich ist, zeigt Niklas Bearbeitung. Trotzdem scheint es bei dieser Aufgabe wenig sinnvoll zu sein, die beiden Voraussetzungen getrennt von einander zu betrachten. Die Stetigkeit alleine wird sicherlich nicht zur Behauptung, dass f konstant ist führen. Nur mit der Gleichung zu arbeiten, ist eher denkbar, zumindest in der betrachteten Bearbeitung von Niklas enthalten ausnahmslos alle Ansätze aber auch die Stetigkeit. Zumindest in diesem Prozess war der Heurismus Nutzen aller Voraussetzungen also auch nicht explizit notwendig.
Die Aufgabe zum Grenzwert von Quotient und Wurzel hat nur eine Voraussetzung, nämlich dass der Quotient gegen L konvergiert. Dass es sich bei \(a_n\) um eine Folge handelt und der Nenner nie Null ist, ist implizit darin enthalten.
Die Aufgabe zur Monotonie enthält wieder zwei essenzielle Voraussetzungen: Eine stetige und injektive Funktion ist streng monoton. Keine der beiden kann weggelassen werden. Auch hier ist nicht vorstellbar, nur mit der Stetigkeit zu arbeiten. Julia macht sich bei (09:29) bewusst, dass sie noch nicht beide Voraussetzungen nutzt, indem sie sich fragt: „Wofür ist das wichtig, dass die stetig und injektiv ist?“ wobei sie das und betont. Auch hier wid also der Heurismus eingesetzt.
Die Frage 3 lässt sich also auch im Kontext der Studieneingangsphase eindeutig beantworten: Der Einsatz bestimmter Heurismen ist abhängig vom zu bearbeitenden Problem. Außerdem wird die Erfahrung aus den ersten Phasen der Intervention verstärkt, dass es sich lohnt, heuristische Hilfsmittel zu unterrichten (vgl. Abschnitte 2.4.5 sowie 4.4). Im Einzelnen handelt es sich hierbei um die Begriffsklärung, das Anfertigen einer Skizze oder einer Tabelle, das Aufstellen einer Gleichung oder das Betrachten eines SpezialfallsFootnote 21. Bei all diesen Heurismen fällt die Entscheidung, ob deren Einsatz notwendig, hilfreich oder keines von beiden ist, vergleichsweise leicht, es ist also eher selten der Fall, dass Problembearbeiter sich von ihnen ablenken bzw. auf Abwege bringen lassen. Dass diese trotzdem einer metakognitive Kontrolle bedürfen zeigt die Bearbeitung der Aufgabe zur n-ten Wurzel von Malik (vgl. auch Abschnitt 5.5.5). Ihm hilft der betrachtete Spezialfall zunächst sehr dabei, eine Vermutung für den Grenzwert zu generieren, anschließend versteift Malik sich aber zu sehr darauf, diesen zu beweisen, anstatt nach anderen Möglichkeiten zu suchen. In diesem Beispiel wurde der Spezialfall auch über die Analysis-Phase hinaus verwendet, so dass er nicht mehr als heuristisches Hilfsmittel anzusehen ist.
Nachdem die Aufgabenabhängigkeit von Heurismen bestätigt wurde, stellt sich noch die
- Frage 4: :
-
Ist Heurismeneinsatz vom Problembearbeiter abhängig?
Auch diese Frage wird von der Theorie (vgl. Abschnitt 2.3.2) bejaht. Betrachtet man Tabelle 5.2, scheinen aufgabenübergreifend auf den ersten Blick Heurismen wie die Einführung von Hilfselementen oder Systematisierungshilfen sowie das Nutzen von Metaphern abhängig vom Bearbeiter zu sein. Daher soll im Folgenden auf diese Heurismen bei den Studierenden, von denen zwei Prozesse untersucht wurden (Jan, Malik, Niklas und Julia), ein kurzer Blick geworfen werden. Wirkliche Vorlieben lassen sich aufgrund der geringen Datenbasis (nur vier Probanden mit jeweils zwei Bearbeitungen) nicht herleiten. Bei den eingesetzten Hilfselementen handelt es sich in der Regel um Variablen, die neu eingeführt werden, entweder um längere Terme übersichtlich zusammenzufassen oder um mit einem bisher nicht bezeichneten Element leichter arbeiten zu können. Auch hier ist naheliegend, dass dieser Heurismus eher bei Aufgaben mit längeren Rechnungen angewandt wird. So bezeichnet beispielsweise Malik bei der Aufgabe zur n-ten Wurzel den vermuteten Grenzwert des Ausdrucks unter der Wurzel mit \(x^n\). Bei seiner Bearbeitung der Quetschlemma-Aufgabe führt er keine neue Bezeichnung ein. Die Systematisierungshilfen können Markierungen, meist in Form von Umrandungen, wichtiger Stellen in den eigenen Bearbeitungen sein, häufig treten sie aber auch in Form von Pfeilen auf, die Zusammenhänge zwischen verschiedenen Stellen in der Niederschrift der Gedanken sein. Beide Heurismen können dabei helfen, die eigenen Gedanken zu strukturieren. Exemplarisch seien die Bearbeitungen von Jan genannt: Er verwendet bei beiden Aufgaben neue Bezeichnungen, bei der Fixpunkt-Aufgabe werden Potenzen von f, die zwischen 0 und n liegen mit a bezeichnet, bei der Aufgabe zur Rangungleichung werden die Ränge der Teilmatrizen mit a bzw. b bezeichnet, die Zeilen der Matrix A (als Vektoren) mit \(Z_i\). Auch Systematisierungshilfen werden in beiden Bearbeitungen verwendet, allerdings in unterschiedlicher Form. Bei der Fixpunkt-Aufgabe wird ein Zwischenergebnis, das er im weiteren Verlauf auch weiter nutzen möchte, und später auch sein Ziel (\(m \rightarrow f^1(m)\)) umrandet, bei der Aufgabe zur Rangungleichung werden Verbindungen in Form von Pfeilen zwischen der Matrix A und den Teilmatrizen, in die diese aufgespalten wird, sowie zwischen Teilergebnissen, die mit einander verbunden werden sollen, gezogen. Zwar lässt sich, auch aufgrund der Unterschiedlichkeit der Systematisierungshilfen, kein eindeutiges Muster festmachen, eine Tendenz, seine Aufzeichnungen zu systematisieren scheint aber im Vergleich zu anderen Bearbeitern erkennbar zu sein. Möglicherweise hängt diese auch damit zusammen, dass er insgesamt relativ viel aufschreibt und dabei den Überblick behalten möchte. Für genauere Aussagen müsste man sich, wie bereits erwähnt, insgesamt mehr verschiedene Aufgabenbearbeitungen anschauen. Metaphern wurden insgesamt recht wenig verwendet, weswegen eine Aussage zu Vorlieben noch schwerer fällt. Ohnehin ist nicht ganz klar, ob es sich hierbei wirklich um einen Heurismus handelt, der dem Problembearbeiter bei der Lösung helfen soll, oder ob Metaphern eher dem lauten Denken geschuldet sind, also aus der Pflicht, die Gedanken auszudrücken, resultieren. Beispielsweise redet Jan davon, dass die Matrix bei der Rangungleichung „durchgeschnitten“ wird, Niklas redet bei der Aufgabe zur konstanten Funktion im Zusammenhang der Stetigkeit von einer „Delta-Kugel“ für die Delta-Umgebung eines Punktes (ein in Mathematikerkreisen nicht unüblicher Sprachgebrauch, so dass nicht einmal klar ist, ob es sich wirklich um eine Metapher handelt) und Julia spricht bei der Aufgabe zur Montonie von einem Graphen, der „hin- und hertanzt“, also nicht monoton ist. Insgesamt bedarf die Beantwortung von Frage 4 also der Betrachtung weiterer Prozesse.
Inwiefern Heurismeneinsatz zum Lösungserfolg beiträgt, wird im folgenden Abschnitt, der die Ideengenerierung in den Blick nimmt, genauer betrachtet. Dass sowohl Prozesse mit geringem Heurismeneinsatz (Andreas und Niklas 1), als auch solche mit hohem Heurismeneinsatz (Malik 1 und 2) zu guten Lösungen führen können, ist bereits der Tabelle 5.1 zu entnehmen.
5.5.5 Ideengenerierung und Bedeutung des Vorwissens
In diesem Abschnitt, der besonders interessante Erkenntnisse liefert, werden Erfolgs- und Misserfolgsfaktoren der Prozesse genauer unter die Lupe genommen. Hierbei soll zum einen (sofern das den Prozessen zu entnehmen ist) untersucht werden, wie vor allem die hilfreichen Ideen generiert wurden. Es wird beschrieben, welche Tätigkeiten und Gedanken diesen Ideen vorangegangen sind und versucht, diese Aktivitäten zu interpretieren. Hierbei spielt das Vorwissen bereits eine entscheidende Rolle. Des Weiteren wird vor allem darauf geachtet, wie mangelndes Vorwissen eine erfolgreiche Aufgabenbearbeitung verhindern oder zumindest erschweren kann. Auch andere Faktoren, die zum Teil in den vorherigen Kapiteln bereits angesprochen wurden, werden ebenfalls wiederholend zusammengefasst. Zunächst wird also geschaut auf die folgende
- Frage 5: :
-
Welche Faktoren führen zu Ideen, die bei der Problembearbeitung hilfreich sind?
Zur Beantwortung dieser Frage werden im Folgenden die Prozesse betrachtet, die zumindest einen Teilerfolg erzielt haben und analysiert, welche Ideen sich dabei als hilfreich erwiesen haben. Wenn nicht anders erwähnt, finden sich die Aufgaben in Anhang D.
Bei Jans Bearbeitung der Aufgabe zur Rangungleichung wird bereits zu Beginn (04:25) die Idee generiert, dass die lineare Unabhängigkeit von Zeilen der Matrix A beim Aufteilen auf die zwei Teilmatrizen \(A_1\) und \(A_2\) erhalten bleibt, während das für linear abhängige Zeilen nicht der Fall sein muss (vgl. die ausführliche Beschreibung der Schoenfeld-Episoden in Abschnitt 5.5.2). Wenn diese Idee gut formalisiert wird, ist das bereits die Lösung der Aufgabe. In diesem Fall ist die Idee direkt nach einer ausführlichen Analyse der Aufgabe entstanden. Jan hat sich zunächst aus den Angaben der Aufgabe die Matrix A in Tabellenform aufgeschrieben (02:00) und anschließend (03:20) zwischen der r-ten und \(r+1\)-ten Zeile einen Strich gezogen (Systematisierungshilfe – vgl. Abbildung 5.13 links). Danach (03:40) hat er daneben die resultierenden Matrizen \(A_1\) und \(A_2\) ebenfalls in Tabellenform notiert (vgl. Abbildung 5.13 rechts). Bereits dieser Darstellungswechsel scheint ihm genügt zu haben, diese wichtige Idee zu generieren. In der Folge gelingt es ihm leider nur den Spezialfall, dass A vollen Rang hat, zu beweisen. Zwar kommt ihm noch die (richtige) Idee, dies durch Widerspruch zu zeigen, was man als Rückwärtsarbeiten interpretieren könnte, wo genau diese Idee herkommt, ist der Bearbeitung nicht zu entnehmen, er sagt aber: „Für ‚gleich‘ habe ich’s jetzt gezeigt [...], wenn ich jetzt das andersrum zeigen möchte, dass es quasi kleiner sein muss [...], ich könnte ja mal annehmen, dass der Rang von A größer sein kann [...] (18:09).“ Die Folgerung, dass es dann in den Matrizen \(A_1\) und \(A_2\) mehr unabhängige Zeilen geben muss als in A, findet er leider nicht mehr. In diesem Beispiel wurde also die wichtigste Idee bereits durch die Analysis der Aufgabe kreiert.

Andreas’ Überlegungen zur linearen Unabhängigkeit
Auch Andreas kommt bei seiner Bearbeitung der Aufgabe zur linearen Unabhängigkeit relativ früh (bei 06:39) auf die Idee, eine Linearkombination der Vektoren \(v_i-v\) zu bilden, deren Koeffizienten nach Voraussetzung gleich Null sein müssen (vgl. Abbildung 5.18 unten nach der horizontalen Linie). Zusätzlich zur Analysis-Phase (00:00–01:06), in der er im Wesentlichen die Aufgabe mit eigenen Formulierungen aufgeschrieben hat, wurden in einer ersten Exploration noch die Vektoren \(v_i-v\) systematisch mit einer Gleichung umgeformt (siehe Abbildung 5.18 oben). Möglicherweise war bereits vor dem Aufstellen dieser Gleichungen die Idee vorhanden, eine Linearkombination aufzustellen, da es sich hierbei um ein Standardverfahren zur linearen Unabhängigkeit handelt, sie wurde aber erst im Anschluss geäußert. Des Weiteren sagt er hierzu: „Die Vermutung liegt ja nahe, dass wir irgendwas haben mit ‚Eins minus‘ und dann addieren wir die einzelnen \(a_i\)-s auf (09:25)“ wodurch die Bedingung, dass diese Summe nicht gleich Eins sein darf, erfüllt ist. Es folgt eine lange Umformung, bei der ihm ein Fehler unterläuft (18:10). Dieser Fehler ist auf einen falschen Umgang mit der Doppelsumme zurückzuführen. Andreas nimmt an, dass \(\sum \limits _{i=1}^n \lambda _i \sum \limits _{j=1}^n a_j v_j = \sum \limits _{i=1}^n \lambda _i a_i v_i\) ist (vgl. Abbildung 5.19). Diese Umformung macht die Aufgabe im Endeffekt leichter, so dass kein korrekter Beweis erreicht wird. Derselbe Fehler unterläuft ihm erneut beim Beweis der Rückrichtung (24:13). Auch bei dieser Bearbeitung wird eine wichtige Idee im Zusammenhang mit dem systematischen Aufschreiben der gegebenen Voraussetzungen generiert.

Fehler bei der Umformung
Obwohl Julia am Beweis der Aufgabe zur Monotonie scheitert, erreicht sie immerhin ein informelles Verständnis der Aufgabe. Auch hier ist dies ein Ergebnis einer Analysis-Episode. Nachdem Julia sich in der ersten Analysis-Phase (00:31–06:23) die Definitionen der wichtigsten Begriffe (Stetigkeit, Injektivität und Monotonie) vergegenwärtigt hat, kehrt sie nach einer zunächst erfolglosen Exploration-Phase (06:23–09:28) zur Analysis (09:28–11:35) zurück. Hier wiederholt sie nochmal die Definition der Injektivität und fertigt eine Skizze an (10:54), woraufhin ihr klar wird: „Jeder Wert auf meiner y-Achse wird nur einmal getroffen, weil’s ja injektiv ist und dann kann ich auch dazwischen keinen Graphen haben, der irgendwie so hin- und hertanzt (11:08).“ Auch die folgende Idee (11:35), dass der Beweis mit dem Zwischenwertsatz zu führen ist wird vermutlich mit Hilfe der Skizze generiert.

Spezialfall \(N=2\)
Maliks Bearbeitung zur Quetschlemma-Aufgabe wird weiter unten im Kontrast zu einem weniger erfolgreichen Prozess von Jonas ausführlich beschrieben. Bei seiner Bearbeitung der Aufgabe zur n-ten Wurzel führt, wie bereits in Abschnitt 5.5.4 beschrieben, das Betrachten eines Spezialfalls (02:26 – \(N=2\) bzw. \(N=3\)) zu der Vermutung, dass der Grenzwert der Folge \(a_N\) sein muss (03:52). Man muss allerdings erwähnen, dass Malik schon vorher (01:49) sagt: „Entweder müsste die Lösung so sein, dass alle außer das Größte unrelevant sind oder alle as sind relevant.“ Die Idee, dass der Grenzwert nur von \(a_N\) abhängt, steht also vor Betrachten des Spezialfalls schon im Raum, eine Vermutung, was genau der Grenzwert ist, allerdings noch nicht. Es folgt eine lange Phase (09:22–28:21), in der Malik sich dem Beweis des Spezialfalls \(N=2\) widmet, auf die aber im Detail nicht eingegangen werden soll, da es sich um langwierige TermmanipulationenFootnote 22 handelt, bei denen in den meisten Fällen auch nicht klar ist, wie Malik auf die Idee gekommen ist, so vorzugehen. Nachdem er den Spezialfall erfolgreich (mit kleinen Schönheitsfehlern) bewiesen hat, stellt er fest, dass er hierbei verwendet hat, dass \(a_1<a_2\) ist (und damit \((\frac{a_1}{a_2})\) eine Nullfolge ist), nach Voraussetzung aber auch \(a_1=a_2\) sein könnte (29:07). Wenig später (30:08) fällt ihm ein (Vorwissen), dass \(\root k \of {2}\) gegen 1 konvergiert, so dass auch bei Gleichheit der Grenzwert \(a_2\) wäre (vgl. Abbildung 5.20). Anschließend versucht er (31:05–44:56) erfolglos den Spezialfall zu verallgemeinern. Ein vielversprechender Ansatz ist das Induktionsprinzip, also die Idee, Schritt für Schritt einen Summanden hinzuzufügen, der jeweils kleiner als \(a_N\) ist, wodurch sich der Grenzwert nicht verändern dürfte. Bei (44:56) kommt ihm eine weitere Idee: „Ich hab jetzt überlegt: Würde sich was ändern, wenn wir einfach alle Werte gleich \(a_N\) setzen? Das ist ja der größte Wert, den wir rausbekommen. [...] Und dass der kleinste Wert, also sozusagen, der kann ja nicht kleiner sein als nur \(a_N\) zu haben und damit hätten wir eigentlich hier schon die Lösung.“ Wie auch seine folgenden Ausführungen und Rechnungen (vgl. Abbildung 5.21) bestätigen, möchte Malik also das Quetschlemma anwenden. Nach knapp fünf Minuten (49:20) hat er die Aufgabe gelöst. Diese Idee erscheint auf den ersten Blick recht unvermittelt und man fragt sich, warum sie an dieser Stelle kommt. Auf der anderen Seite bekommt man den Eindruck, dass ein Großteil (die 19 Minuten, die zum Beweis des Spezialfalls aufgewendet wurden sowie die fast 14 Minuten erfolgloser Versuche zu dessen Verallgemeinerung) des etwa 50-minütigen Prozesses unnötig waren. Auch Malik sieht das ähnlich: „Ich hab etwa gerade ne Stunde gerechnet und hab die Lösung in zehn Minuten komplett neu berechnet (49:08).“ Ganz so ist es sicherlich nicht. Es ist davon auszugehen, dass die lange Beschäftigung mit der Aufgabe den Einfall, das Quetschlemma anzuwenden, vorbereitet hat. Zumindest die in Abbildung 5.20 dargestellte Gleichung für \(a_1=a_2\) wird Einfluss auf die Abschätzung nach oben (bei der alle \(a_i\) gleich sind) gehabt haben. Zusammenfassend haben die Vermutung (die nach Beweis des Spezialfalls sehr stark war), dass \(a_N\) der Grenzwert sein muss, die Vergewisserung, dass dies auch bei Gleichheit der Summanden gilt (begründet auf das Vorwissen, dass die n-te Wurzel einer Konstanten gegen Eins konvergiert) und die gute Kenntnis des Quetschlemmas zu dieser entscheidenden Idee beigetragen. Sicherlich hätten metakognitive Kontrollstrategien (vgl. 5.5.6) den Prozess an der ein oder anderen Stelle abkürzen können.

Implementation der Idee, das Quetschlemma anzuwenden
Die Bearbeitung derselben Aufgabe (n-te Wurzel) von Niklas wurde in Abschnitt 5.5.1 bereits ausführlich dargestellt. Da er vergleichsweise wenig redet, ist bei ihm schwer zu erkennen, welche Überlegungen seinen Ideen vorangehen. Eine wichtige Idee äußert er bei (38:41): Hier klammert er den größten Summanden aus, was ihn zur Abschätzung nach oben führt (vgl. Abbildung 5.11). Diese Idee wurde durch den vorherigen Versuch des Ausklammerns des kleinsten Summanden (20:11 – vgl. Abbildung 5.9) und die Idee, dass die Ungleichung aus der Voraussetzung genutzt werden muss (21:49) vorbereitet. Die Abschätzung führt dann zur Idee, das Quetschlemma anzuwenden (42:40). Auch hier helfen also Vorüberlegungen, die zunächst nicht zum Ziel geführt haben, neue Ideen zu generieren. Auch der Heurismus Nutzen aller Voraussetzungen war sehr hilfreich.
Zur Beantwortung von Frage 5 lässt sich sagen: Es gibt einige Prozesse, bei denen gute Ideen während einer oder im Anschluss an eine Analysis-Phase, in Verbindung mit entsprechenden heuristischen Hilfsmitteln (Anfertigen einer Tabelle oder Skizze, Betrachten eines Spezialfalls etc.) entstanden sind. Auch andere Heurismen, wie das Nutzen aller Voraussetzungen oder das RückführungsprinzipFootnote 23 liefern wichtige Ideen. Bei letzterem ist klar, dass ein gewisses Vorwissen vorhanden sein muss, aber auch in den anderen Fällen ist dies meist Voraussetzung (oder entsprechendes Wissen muss während des Prozesses erarbeitet werden). Wichtige Vorstellungen zu den grundlegenden Begriffen (Rang, lineare Unabhängigkeit, Stetigkeit, Injektivität, Monotonie, Konvergenz) und Werkzeugen (Quetschlemma, Zwischenwertsatz, Verfahren zum Beweis linearer Unabhängigkeit, Rechenregeln etc.) scheinen notwendig zu sein.
Während man bei erfolgreichen Bearbeitungen Gefahr läuft, Vorwissen als selbstverständlich hinzunehmen, zeigt sich bei weniger erfolgreichen, dass der Mangel hieran die Prozesse sehr erschweren oder gar komplett stören kann. Hieraus ergibt sich die
- Frage 6: :
-
Welchen Einfluss hat Vorwissen bzw. der Mangel daran auf den Bearbeitungserfolg beim Problemlösen?
Auch diese Aussage steht im Einklang mit der Theorie, schließlich ist Vorwissen (bzw. Ressources) einer der vier Einflussfaktoren auf das Problemlösen nach Schoenfeld (1985). Allerdings wurde dieser Aspekt bei vielen empirischen Untersuchungen bewusst ausgeblendet, um sich auf die anderen Faktoren fokussieren zu können. Umso interessanter ist es, in unserem Kontext mit authentischen Übungsaufgaben, den Einfluss des Vorwissens genauer zu betrachten. Exemplarisch werden zunächst drei Bearbeitungen der Quetschlemma-Aufgabe (vgl. Abschnitt 5.2.1) betrachtet, beginnend mit dem wenig erfolgreichen Prozess von Tim.

Episoden Tim (Quetschlemma)
Ein Hinweis darauf, dass Tim starke begriffliche Schwierigkeiten hat, wird bereits durch die Episodenkodes gegeben (vgl. Abbildung 5.22): Zum einen wird ein Großteil der Bearbeitungszeit (knapp 33 von 49 Minuten) mit Analysis zugebracht, zum anderen wird mehr als 36 Minuten mit dem Skript gearbeitet. Dieser Eindruck verstärkt sich noch, wenn man sich den Prozess genauer anschaut. Im Folgenden werden ausgewählte Fehler, die bezeichnend sind für das mangelnde Verständnis herausgearbeitet. Nachdem er einige Zeit stumm im Skript geblättert hat, fertigt Tim eine Skizze (09:29) an (vgl Abbildung 5.23). Hierzu sagt er: „Den Grenzwert für a setzen wir links hin, den Grenzwert für c setzen wir ganz rechts hin und in der Mitte ist dann eben der Grenzwert für b, der dazwischen liegt.“ Später im Prozess sagt er in diesem Zusammenhang: „Ich stelle mir das so vor: Es ist ja so, dass wir drei Werte haben. Da auf dem Zahlenstrahl positiv und minus Unendlich ist, muss man eben überlegen, wie diese Werte – vor allem wenn sie Grenzwerte haben, das heißt, dass sie nur in einem bestimmten Bereich gelten – diesen Zahlenstrahl der reellen Zahlen abdecken. Für mich würde das heißen, dass zum Beispiel der erste Wert a links bis c geht und bis minus Unendlich, dann eben die Lücke kommt, die b erfüllt, dann eben rechts – b ist ja beschränkt [...], durch den Wert c, [der] auf der rechten Seite von c bis positiv Unendlich geht. Dass eben a und c diese Bereiche abdecken ist schon durch die Aufgabe gegeben. [...] Die Frage, die ich beantworten [muss], ob b auch dagegen konvergiert. Jetzt müsste ich eben nur zeigen, dass es dazwischen liegt, dass es keine Überschneidungen gibt. (37:31).“ Ein anderer Ausschnitt aus seiner Niederschrift (34:37) ist in Abbildung 5.24 zu sehen.

Tims Skizze zur Quetschlemma-Aufgabe
Die beiden Ausschnitte sowie das Zitat offenbaren einige fachliche Mängel. Zum einen geht Tim davon aus, dass \(a_n\) und \(c_n\) Nullfolgen sind (bzw. schreibt zumindest eine entsprechende Ungleichung auf). Wäre dies das einzige Problem, dann hätte er zumindest noch diesen Spezialfall (c=0) beweisen können. Es zeigen sich aber weitere grundlegende Missverständnisse zum Grenzwertbegriff im Allgemeinen und zur Aufgabe im Speziellen. Abgesehen davon, dass er von „Werten“ statt von „Folgen“ spricht und sprachlich nicht zwischen c und \(c_n\) unterscheidet, geht er davon aus, dass die drei Folgen die reellen Zahlen disjunkt abdecken. Das kann schon deswegen nicht stimmen, weil konvergente Folgen beschränkt sind. Außerdem gilt die Ungleichung \(a_n \le b_n \le c_n\) nur punktweise, es kann also sehr wohl Elemente aus \(a_n\) geben, die größer sind als Elemente aus \(b_n\) oder \(c_n\). Dann kommt der Wert c zweimal in der Skizze vor, es wird also nicht beachtet, dass \(a_n\) und \(c_n\) gegen denselben Grenzwert konvergieren. Auch die Vorstellung, dass die Folgen durch ihren Limes beschränkt sind, trifft in der Regel nicht zu. Schließlich stimmt auch die Aussage, dass zu zeigen ist, dass \(b_n\) zwischen \(a_n\) und \(c_n\) liegt, nicht, denn das ist ja bereits die Voraussetzung. Es zeigen sich also erhebliche Fehlvorstellungen und so ist es nicht verwunderlich, dass Tim keinen einzigen Ansatz findet. Auch der Heurismeneinsatz, wie das Anfertigen einer sinnvollen Skizze wird dadurch unmöglich gemacht.

Weiterer Ausschnitt aus Tims Mitschrift

Episoden Jonas (Quetschlemma)

Jonas’ Skizze zur Quetschlemma-Aufgabe
Ähnlich sieht es bei Jonas aus. Auch hier lässt bereits die Episodenkodierung auf große Schwierigkeiten schließen (vgl. Abbildung 5.25). Die Analysis-Phase nimmt mit knapp der Hälfte der Zeit (etwa 20 von 44 Minuten) einen ungewöhnlich hohen Anteil an und es wird 19 Minuten mit dem Skript gearbeitet. Zur Nachvollziehbarkeit der Verständnisprobleme seien ausgewählte Fehler im Folgenden unkommentiert dargestellt: Auch er fertigt eine fragwürdige Skizze (06:37) an (vgl. Abbildung 5.26). Dann (16:10) schreibt er auf: „\(a_n \le b_n \le c_n \le c\)“ und schließlich (19:57) notiert er: „\(a_n\), \(b_n\), \(c_n\) Nullfolgen.“ Auch Jonas scheint so massive Verständnisprobleme zu haben, dass er keine Ideen hat und auch im Heurismeneinsatz stark eingeschränkt ist.

Episoden Malik (Quetschlemma)
Zu Maliks Bearbeitung derselben Aufgabe zeichnen bereits die Episodenkodierungen ein ganz anderes Bild: Von über 45 Minuten werden nur eine Minute und vierzig Sekunden für die Analysis aufgewendet (vgl. Abbildung 5.27). Bis auf eine kurze Phase (23:11–24:37) wird auch nicht mit dem Skript gearbeitet. Beides deutet auf Sicherheit im Umgang mit den Begriffen hin. Dennoch stößt Malik auf einige Schwierigkeiten, die im Folgenden beschrieben werden:

Konvergenz der Folgen \(a_n\) und \(c_n\)
- Analysis (00:22–02:09) :
-
Zunächst stellt er sich den Sachverhalt mit Hilfe einer imaginären Figur vor: „Wenn \(a_n\) [und] \(c_n\) gegen den gemeinsamen Grenzwert c konvergieren, jetzt versuche ich mir das ein bisschen zu visualisieren, das heißt ja, dass zwischen \(a_n\) und \(c_n\) sozusagen kein Abstand mehr herrscht und dann muss auch, jetzt nur von der logischen Sicht, auch \(b_n\) gegen c konvergieren, weil das ja zwischen \(a_n\) und \(c_n\) ist und dass vom Abstand her ja zwischen \(a_n\) und \(c_n\) kein Abstand herrschen kann (00:35)“. Anschließend notiert er die Konvergenz von \(a_n\) und \(c_n\) in Formelgestalt (vgl. Abbildung 5.28). Wenngleich Malik keine Skizze anfertigt, scheint er sich die wesentlichen Zusammenhänge visualisiert zu haben und notiert diese auch formal.
- Exploration (02:09–35:47) :
-
Nach einer kurzen Überlegung (03:39), die er nicht weiter verwendet (er stellt die gegebene Gleichung zu \(a_n-b_n \le 0\) und \(b_n-c_n \le 0\) um), geht er wieder zu seiner imaginären Figur zurück: „Jetzt versuche ich gerade erstmal wieder, weil bei meiner ersten Vorstellung war das ja relativ klar, zu überlegen, ob [...] ich das irgendwie aus dieser graphischen Vorstellung leichter ins Mathematische übersetzen könnte (04:24).“ Etwas später deutet er eine Idee an: „Wenn jetzt \(c_n - c\) immer kleiner als Epsilon ist, dann ist ja auch \(b_n - c\) kleiner als Epsilon und dasselbe gilt dann mit dem \(a_n\)-Bereich (05:20).“ Er erkennt allerdings, dass es hier ein Problem mit dem Betrag gibt, entschließt sich, dieses aber zunächst zu ignorieren: „Da ich eine Idee hatte ohne Betrag, versuch ich es erstmal ohne Betrag und überlege dann, wie man das mit dem Betrag machen könnte (06:05).“ Nach weiteren Überlegungen (Malik notiert sein Ziel, dass \(|b_n-c|<\varepsilon \) für alle \(\varepsilon \) sein muss und schreibt die Gleichung \(|a_n|-|c|<c\)Footnote 24 auf, die er im weiteren Verlauf ebenfalls nicht mehr verwendet), geht er erneut auf die visuelle Vorstellung zurück: „Ich hab mir das wieder versucht graphisch vorzustellen und bin auf den Schluss gekommen, dass wir einmal nur zeigen müssen, dass es ja größer ist und einmal zeigen müssen, dass es kleiner ist (09:52).“ Anschließend (10:40–12:49) notiert er eine Abschätzung nach oben (vgl. Abbildung 5.29 – die mittlere Zeile wurde sofort nach dem Notieren durchgestrichen).
Abbildung 5.29 
Abschätzung nach oben
Dies stellt bereits nach knapp 13 Minuten die Hälfte des Beweises dar. In der Folge werden aber einige Schwierigkeiten mit dem Betragsbegriff deutlich, so dass die zweite Hälfte (es muss noch gezeigt werden, dass auch \(c-b_n< \varepsilon \) ist) sehr viel mehr Zeit und Energie in Anspruch nimmt. Zwar ist Malik, wie eben gesehen, sich dessen bewusst, dass \(|x| > x\) ist, die Fallunterscheidung, dass |x| entweder gleich x oder gleich \(-x\) ist (Abbildung 5.30 zeigt die entsprechende Stelle aus dem während der Bearbeitung vorliegenden Skript), kommt ihm aber nicht in den Sinn.
Abbildung 5.30 
Skriptausschnitt zum Betrag
Nun sucht Malik zunächst mehr als 20 Minuten vergeblich nach einer Möglichkeit, den zweiten Teil der Aufgabe zu beweisen. Im Folgenden sollen die wesentlichen Ideen nur kurz skizziert werden. Einen guten Eindruck in Maliks Überlegungen gibt seine Niederschrift ab diesem Zeitpunkt, die in Abbildungen 5.31–5.36 vollständig abgebildet ist.
Abbildung 5.31 
Maliks Notizen zum Quetschlemma (Teil 1)
Abbildung 5.32 
Maliks Notizen zum Quetschlemma (Teil 2)
Abbildung 5.33 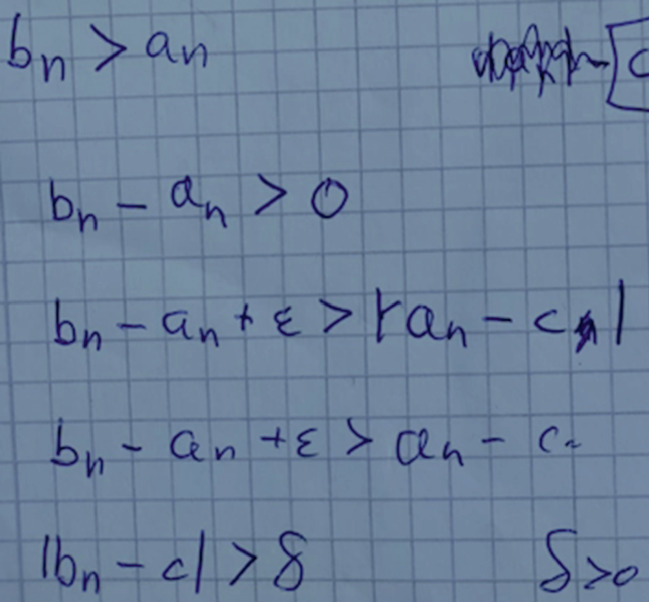
Maliks Notizen zum Quetschlemma (Teil 3)
Abbildung 5.34 
Maliks Notizen zum Quetschlemma (Teil 4)
Zunächst (12:59) fasst er zusammen: „Wir wissen ja jetzt, es ist \(b_n - c\) kleiner als \(\varepsilon \), wir wissen nur nicht, dass der Betrag kleiner ist.“ Ein (erfolgloser) Ansatz ist anschließend (14:58), zu zeigen, dass \(b_n-c \ge 0\) (vgl. Abbildung 5.31) ist (dann wäre dieser Ausdruck gleich seinem Betrag). Das muss aber nicht so sein. Ab (18:33) fasst er noch einmal zusammen, was er bereits gezeigt hat und was gegeben ist (vgl Abbildung 5.32 und 5.33 oben). Ein weiterer Ansatz, der nicht zum Ziel führt (ab 21:23), ist der, die beiden gegebenen Ungleichungen (\(b_n-a_n \ge 0\) und \(|a_n-c| < \varepsilon \)) durch Addition mit einander zu verknüpfen (vgl. Abbildung 5.33). Nach einem kurzen Blick ins Skript (23:11–24:30), kommt Malik auf die Idee, einen Beweis durch Widerspruch zu führen (24:50)Footnote 25, also zunächst anzunehmen, dass es ein \(\delta \) gibt, so dass \(|b_n-c| > \delta \) ist (vgl. Abbildung 5.34). Bei (25:48) sagt er: „Jetzt überleg ich, ob das graphisch auch Sinn macht vielleicht, ob ich wirklich nur so viel wissen kann mit der Aussage. Also das sind ja zwei Teilaussagen, die wir eigentlich haben: \(b_n\) kleiner gleich \(c_n\) und \(a_n\) kleiner gleich \(b_n\) und zum einen gehe ich, weil die Aufgabe das sagt, davon aus, dass ich beides brauche und zum anderen kann ich mir das gut graphisch vorstellen, dass ich beides brauche und überlege, ob ich wirklich auch alle Informationen sozusagen mit dem \(b_n\) kleiner gleich \(c_n\), die ich daraus bekommen kann, ob ich das schon hab.“ Aus dieser Aussage wird zum Ersten deutlich, dass Malik nach wie vor auf visuelle Vorstellungen zurückgreift, zum Zweiten verweist er darauf, dass er alle Voraussetzungen nutzen muss und zum Dritten teilt er die Aufgabe in zwei Teilaufgaben auf. In der Folge vergewissert er sich, dass er die Informationen zu \(c_n\) bereits ausgeschöpft hat. „Das heißt, dass ich [...] mich auf diese Teilaussage gar nicht mehr konzentriere und überlege, was kann ich jetzt nochmal wirklich aus \(a_n\) ist kleiner gleich \(b_n\) rausholen (26:58)?“ Bereits vorher hat er nur die Informationen zu \(a_n\) verwendet (wie aus der Niederschrift deutlich wird), hinterfragt und bestätigt dieses Vorgehen hier aber noch einmal. Wenig später sagt Malik: „Diese Aussage \(|b_n - c|\) größer als \(\delta \) können wir eigentlich mit der Aussage \(|a_n - c|\)Footnote 26 ist kleiner als \(\varepsilon \) widerlegen. Das kann ich mir jetzt gerade wieder vorstellen, aber ich überlege gerade auch noch mal, wie das mathematisch aussehen muss (29:11).“ Auch hier nutzt er weiterhin eine visuelle Vorstellung. Der Ansatz des indirekten Beweises scheint ihm gedanklich ebenfalls zu helfen, wenngleich er diesen formal nicht weiter verwendet. Er präzisiert seine Idee weiter: „Wir haben im Prinzip ja schon fast gezeigt, dass \(b_n\) maximal so groß ist, wie c, bzw. \(c + \varepsilon \). Jetzt müssen wir eigentlich nur beweisen, dass es mindestens so groß ist, wie \(c - \varepsilon \) und das können wir ja [...] damit, dass ja \(a_n\) gegen c konvertiert (sic) (30:04).“ Malik betont noch einmal: „Ich weiß auf jeden Fall, dass ich ja die Aussage brauche \(a_n - c < \varepsilon \). Das macht für mich einfach auch von der Vorstellung Sinn. Das heißt, ich muss auch auf jeden Fall mit dieser Aussage im mathematischen Bereich arbeiten (31:12).“ Anschließend (31:28) notiert er erneut, was er zeigen möchte (\(|b_n-c|< \varepsilon \)) und aus der „Vorstellung, ohne das mathematisch zu haben (32:36)“, dass \(c- \varepsilon < a_n\) ist (vgl. Abbildung 5.35). Es folgt ein Versuch, dies formal zu beweisen, der zunächst aber auch nicht zum Ziel führt (33:41 – vgl. Abbildung 5.36 links). Das fällt ihm aber recht schnell auf (Evaluation): „Jetzt haben wir genau die falsche Seite (34:41)“ (Denn es wurde gezeigt, dass \(c+\varepsilon >a_n\) ist).
- Planning (35:47–36:57) :
-
Schließlich fasst Malik doch den Plan, das Negative des Terms im Betrag zu betrachten: „Wenn \(a_n - c\) kleiner als \(\varepsilon \) ist, der Betrag davon, dann ist ja auch der Betrag des Negativen davon kleiner als \(\varepsilon \) (35:47).“ Er erklärt noch, wie er auf diese Idee gekommen ist: „Ich habe gesehen, dass am Ende irgendwie das Vorzeichen sich geändert hat. [...] Also ich hab hier \(c + \varepsilon > a_n\). Hab gesehen, dass ich einmal \(+\varepsilon \) hab statt \(-\varepsilon \) und die anderen beiden haben halt nicht verdrehtes Vorzeichen und ich hab größer gleich statt kleiner gleich, wodurch ich halt gemerkt habe, dass ich zum Teil ein Minus brauche, also zum Teil die Vorzeichen ändern muss und zum Teil nicht, und deswegen habe ich mir schon gedacht, dass es irgendwie im Betrag liegen muss (36:19).“







Maliks Notizen zum Quetschlemma (Teil 5)
In der folgenden Implementation (36:57–37:52) wird dieser Plan recht schnell in die Tat umgesetzt (vgl. Abbildung 5.36 Mitte oben). Es folgt eine weitere Exploration-Phase, in der noch recht lange (37:52–46:25) braucht, um die beiden bewiesenen Aussagen, die er zu Beginn dieser Phase (38:12) notiert (vgl. Abbildung 5.35 unten), in die gesuchte Betragsungleichung zu überführen. Auch hier hätte ein gefestigteres Verständnis des oben angesprochenen Aspektes des Betragsbegriffs (dass \(|b_n - c| < \varepsilon \) äquivalent ist zu \(b_n - c< \varepsilon \wedge c - b_n < \varepsilon \)) den Vorgang deutlich abkürzen können.
Zusammenfassend ergibt die Betrachtung dieses Problemlöseprozesses Folgendes: Malik hat noch nicht alle Aspekte des Betragsbegriffes verinnerlicht, was die Bearbeitung der Aufgabe erschwert. Dennoch gelingt es ihm nach einiger Zeit, diese Schwierigkeiten zu überwinden und die Aufgabe zu lösen. Hierbei haben ihm ein gutes Verständnis des zugrunde liegenden Grenzwertbegriffes (Vorwissen), geschickter Heurismeneinsatz (imaginäre Figur, Nutzen aller Voraussetzungen, Zerlegung in Teilaufgaben etc.) sowie eine gute metakognitive Steuerung durch Zielsetzung (Was ist noch zu zeigen?) und Evaluation der gewählten Ansätze geholfen. Es ist also durchaus möglich, gewisse Lücken während des Problembearbeitungsprozesses zu schließen. Häufig ist es sogar erwünscht, dass durch die Aufgabenbearbeitung neue Inhalte oder Aspekte eines Begriffs erschlossen werden. Vermutlich wird Malik durch diesen Prozess einen tieferen Einblick in den Betragsbegriff bekommen haben, als wenn er den oben zitierten Skriptausschnitt (vgl. Abbildung 5.30) auswendig gelernt hätte.

Maliks Notizen zum Quetschlemma (Teil 6)
Im Folgenden werden exemplarisch einige Verständnisprobleme der anderen Bearbeitungen aufgeführt, die ebenfalls den Erfolg verhindern.
Patrick (Umkehrung der Grenzwertsätze) hat Schwierigkeiten mit dem Konvergenzbegriff. So sagt er: „Konvergent ist, wenn [die Folge] gegen einen Wert konvergiert, also größer als Null definitiv (11:48).“ Natürlich wäre auch eine Nullfolge oder eine Folge, die gegen einen negativen Grenzwert geht, konvergent. Noch größere Probleme ergeben sich aber mit dem Divergenzbegriff. Bei (11:24) sagt er: „Wenn eine der Folgen divergiert, dann geht die gegen Null. Nee moment, divergent, geht die gegen Null oder geht die gegen unendlich?“ Ersteres ist schlicht falsch und auch die Vorstellung, dass divergente Folgen gegen Unendlich (oder minus Unendlich) gehen, stimmt nicht immer. Auch alternierende Folgen können divergent sein. Mit diesem Wissen könnte man leicht ein Gegenbeispiel zu der Behauptung finden (etwa \(x_n=\frac{1}{n}\) und \(y_n=(-1)^n\)). Seine Schwierigkeiten mit dem Begriff zeigen sich auch darin, dass er mehrfach (bei 03:09 und bei 14:09) nach einem Beispiel für divergente Folgen sucht und keines findet, obwohl das Skript mehrere BeispieleFootnote 27 liefert.
Niklas hat bei der Bearbeitung der Aufgabe zur konstanten Funktion (vgl. Abschnitt 5.2.2) einige Schwierigkeiten mit dem Stetigkeitsbegriff, die sich in folgenden Aussagen offenbaren: „[Aus der Definition der Stetigkeit] folgt ja, es muss ein \(\delta >0\) existieren mit der Eigenschaft, dass der Betrag von \(f(x)-f(x_0)\) quasi gleich Null ist für alle x, die in diesem Intervall liegen (24:08)“ und „Die Funktionswerte, wenn ich mir die jetzt auf der y-Achse vorstelle [...], können sich nicht weiter von einander entfernen, wenn die Werte auf der x-Achse sich auch näher kommen.“ Zwar ließe sich diese Aufgabe mit Hilfe des Folgenstetigkeitskonzepts auch trotz dieser Fehlvorstellungen lösen, ein alternativer Ansatz ohne dieses Konzept wird aber auch hier verhindert.
Bei den Prozessen zum Grenzwert von Quotient und Wurzel (vgl. Abschnitt 5.2.3) ist beiden Bearbeitern der in einer vorherigen Übung bewiesene Zusammenhang, dass für jede Konstante k gilt \(\lim \limits _{n \rightarrow \infty } \root n \of {k}=1\), ohne den die Aufgabe kaum zu lösen ist, nicht bekannt. Zwar ist grundsätzlich denkbar, dass diese Aussage selbst hergeleitet wird, was aber den Aufwand noch um einiges erhöhen würde. Erschwerend kommt in diesem Fall hinzu, dass der Zusammenhang nicht im Skript, sondern in alten Übungen zu finden ist, sonst hätte Julia, die gut mit dem Skript arbeitet, diesen evtl. gefunden.
Auch prozedurale Mängel führen zu unvollständigen Bearbeitungen, wie das weiter oben in diesem Abschnitt bereits behandelte Beispiel von Andreas’ Umgang mit Doppelsummen zeigt. Dieser Fehler hat allerdings nicht zu völligem Misserfolg geführt.
Zusammenfassend lässt sich in Bezug auf Frage 6 sagen, dass gerade Schwierigkeiten auf begrifflicher Ebene die Prozesse (und auch den Einsatz von Heurismen) erheblich erschweren können. Bei Malik haben wir allerdings gesehen, dass solche Schwierigkeiten durch guten Heurismeneinsatz und Metakognition auch überwunden werden können. Auch fehlendes Zusammenhangs- oder prozedurales Wissen kann zu Schwächen in der Bearbeitung führen.
5.5.6 Metakognitive Aktivitäten
Wie die Heurismen wurden auch die metakognitiven Aktivitäten in einer Tabelle 5.3 dargestellt. Außerdem wurde hier noch der durch die Leitfragen (vgl. Abschnitt 5.3.7) bestimmte Grad der Metakognition aufgeführt. Da Tim während seiner Bearbeitung so wenig gesprochen hat, dass kaum metakognitive Aktivitäten zu erkennen waren, wurde sein Prozess zur besseren Übersicht an das Ende der Tabelle verschoben. Dasselbe gilt, in etwas schwächerem Maße, auch für Jonas.
Lässt man diese beiden Bearbeitungen außen vor, fällt auf, dass ein Großteil der Kategorien in fast jedem Prozess vorkommt. Dies könnte ein Hinweis darauf sein, dass insgesamt im beobachteten Kontext die Metakognition auf einem hohen Niveau ist (was angesichts des Alters der Probanden im Vergleich etwa zu Schülern durchaus plausibel wäre). Da das Kategoriensystem allerdings eigens für diese Arbeit entwickelt wurde und es somit keine Vergleichsmöglichkeiten zu anderen Kontexten gibt, könnte es auch bedeuten, dass die Wahl der Kategorien zu grob ist (davon abgesehen, dass die Betrachtung von nur elf Prozessen ohnehin nur eine Orientierung und keine verallgemeinerbaren Aussagen zulässt). Auch trägt die Dauer der Prozesse, die mit bis zu einer Stunde deutlich höher ist als andere bekannte Beobachtungen von Problembearbeitungen, möglicherweise dazu bei, dass viele verschiedene Aktivitäten auftreten. Trotzdem (oder gerade deshalb) ist es interessant, die Lücken in dieser Tabelle genauer unter die Lupe zu nehmen.
In jedem Prozess tritt entweder Zielsetzung oder Planungsaktivität auf. Wie bereits beschrieben (vgl. S. 108 f.), unterscheiden sich diese beiden Kategorien nur darin, dass bei letzterer noch ein grober Plan genannt wird, wie das gesetzte Ziel zu erreichen ist. Zielsetzung ist also in Planungsaktivität enthalten. Deswegen macht es auch keinen großen Unterschied, dass bei Niklas’ zweitem Prozess nur letztere, erstere aber nicht vorkommt. Es stellt sich aber die
- Frage 7: :
-
Inwiefern wirken sich Planungsaktivitäten auf die Bearbeitungsqualität aus?
Betrachtet man nur die Zahlen, so sind sowohl bei Prozessen mit Planungsaktivität als auch bei solchen ohne alle Grade der Metakognition von M0 bis M2 vertreten. Bei der Lösungsqualität sieht es ähnlich aus, wobei nur Malik, der in beiden Prozessen Planungsaktivitäten durchführt, die beste Lösungsqualität L3 erreicht, was auch auf individuelle Faktoren zurückzuführen sein könnte. Hieraus lassen sich also kaum Vermutungen ableiten. Um einen besseren Eindruck von Planungsaktivitäten zu bekommen, wird im Folgenden aus jedem Prozess, der eine solche enthält, ein Beispiel betrachtet.
Malik sagt bei der Bearbeitung der Quetschlemma-Aufgabe (vgl. Abschnitt 5.2.1), dass er eine „Idee hatte ohne Betrag“, weswegen er plant, die Behauptung zunächst ohne Betrag zu beweisen, um anschließend zu überlegen, „wie man das mit dem Betrag machen könnte (06:04).“ Gemeint ist, in diesem Zusammenhang, zunächst zu zeigen, dass \(b_n - c < \varepsilon \) ist. Dies ist das gewählte Zwischenziel. Der Weg hierhin wird zwar nicht explizit benannt, es wird aber aus der weiteren Bearbeitung deutlich, dass die Idee für den Studenten ziemlich klar war. In diesem Fall wurde das benannte Ziel mit den geplanten Mitteln erreicht (bei 12:38) und hat wesentlich zur Lösung der Aufgabe beigetragen.
Bei der Bearbeitung der Aufgabe zur n-ten Wurzel (vgl. Anhang D) sagt Malik: „Jetzt überlege ich, wie das bei \(2^n + 3^n\) aussieht, wenn man da die n-te Wurzel zieht (03:54).“ Außerdem sagt er in diesem Zusammenhang, dass er dies tut, um mehr über den gesuchten Grenzwert zu erfahren, unter anderem, um seine Vermutung zu bestätigen, dass dieser nur von \(a_N\) abhängt. Es wird also ein klares Ziel benannt und als Weg ein Spezialfall gewählt. Diese Planung führt dazu, dass als Grenzwert \(a_N\) vermutet wird, was Malik letztlich auch beweisen kann.
Bei derselben Aufgabe fasst Niklas den Plan: „Ich überlege halt gerade, ob ich eine Möglichkeit finde, unter der KlammerFootnote 28 irgendetwas auszuklammern, damit ich halt ein Produkt unter der Klammer habe, wodurch ich dann die Möglichkeit habe, etwas aus der Wurzel herauszuziehen (15:15).“ Das Ziel ist also, einen Faktor aus der Wurzel herausziehen zu können, was durch ausklammern mit Hilfe des Distributivgesetzes geschehen soll. Zwar ist an dieser Stelle noch nicht klar, welcher Faktor das sein soll, aber auch diese Idee trägt wesentlich zur Lösung des Problems bei.
Dass eine Planungsaktivität aber nicht zum Ziel führen muss, zeigen die nächsten beiden Beispiele. Bei der Aufgabe Konstante Funktion sagt Niklas: „Jetzt würde ich probieren, das halt irgendwie über das Delta zu nem Widerspruch zu bringen (25:55).“ Das Ziel (Widerspruch) soll also mit Hilfe des Deltas aus der Stetigkeitsdefinition erreicht werden. Julia nennt während ihres Prozesses zur Monotonie (siehe Anhang D) mehrfach den Zwischenwertsatz als Mittel zur Erreichung des (nicht explizit genannten) Ziels, die Monotonie der Funktion zu zeigen (was kein Zwischenziel, sondern Gesamtziel der Aufgabe ist). So sagt sie beispielsweise: „[...], dann denke ich, dass das das irgendwie mit dem Zwischenwertsatz zu zeigen sein wird (11:36).“ Sowohl bei Niklas als auch bei Julia wird bei diesen Plänen kein Fortschritt erzielt. Beide Probanden haben zwar Mittel zur Erreichung ihrer Ziele benannt, sie scheinen aber, im Gegensatz zu den vorher genannten Beispielen keine genauere Vorstellung davon zu haben, wie diese Mittel eingesetzt werden sollen, was schon an der Verwendung des Wortes „irgendwie“ in beiden Zitaten deutlich wird. Während bei Niklas der Plan zumindest nicht der üblichen Lösung dieser Aufgabe entspricht, wäre Julias Idee bei konsequenter Umsetzung tatsächlich zielführend. In beiden Fällen hat mangelndes Fachwissen die Umsetzung der Pläne verhindert.
In Bezug auf Frage 7 zeigt sich also, dass Planungsaktivitäten wichtige Elemente von Problemlöseprozessen sein können. Ob sie wirklich weiterhelfen, ist aber stark von der Situation abhängig. Neben dem Fachwissen scheint es besonders darauf anzukommen, wie konkret der Plan bereits im Kopf des Probanden vorhanden ist. Dieser Faktor ist von außen nur schwer zu erfassen. Allerdings konnten bei den oben genannten Beispielen die genauen Formulierungen bereits Hinweise darauf geben.
Es folgt eine kurze Untersuchung weiterer Beobachtungen zu metakognitiven Aktivitäten, die auch nach genauerer Betrachtung weniger wichtig zu sein scheinen. Diesen Aktivitäten wird deswegen keine eigene Fragestellung gewidmet.
Die metakognitive Aktivität der Zielsetzung kann ähnliche Funktionen erfüllen, auch wenn hier die Mittel zur Erreichung nicht direkt benannt werden. Es ist auch möglich, dass zunächst ein Ziel genannt wird und erst später eine Idee zu dessen Erreichung auftritt. In den Abschnitten zu Schoenfeld-Episoden (5.5.2) und Ideengenerierung (5.5.5) wurde beschrieben, wie sich Planung auf den Lösungserfolg auswirkt und welche Aktivitäten zur Generierung von Ideen beigetragen haben.
Bei Julias Bearbeitung der Aufgabe zur Monotonie wurde (wie auch bei Jonas und Tim) weder Einschätzen des Lösungsfortschritts noch Evaluation kodiert. Beide Aktivitäten sind rückblickend auf die bisherigen Tätigkeiten. Da bei den drei genannten Prozessen kein Ansatz durchgeführt und damit auch kein Lösungsfortschritt, der über die mehr oder weniger erfolgreiche Analyse der Aufgabe hinausgeht, erzielt wurde, waren diese metakognitiven Aktivitäten gar nicht möglich.
Die Einschätzung der eigenen Fähigkeiten wurde von den metakognitiven Aktivitäten am seltensten durchgeführt. Hierbei haben die Probanden fast ausschließlich negative Aussagen über sich selbst getätigt: Patrick, der insgesamt große Verständnisschwierigkeiten hat, tätigt mehrfach Aussagen wie: „Mir fällt auf, dass mir da doch ein bisschen die Kenntnis fehlt (10:20)“ (ohne genauer zu spezifizieren, worauf sich diese Kenntnis bezieht) oder „Da vertue ich mich öfter mal mit (11:38)“ (in Bezug auf die Definition der Divergenz). Auch die Aussagen von Manuel („Ich stehe ein bisschen gerade auf dem Schlauch (18:59)“) und Julia („Ich glaub, das ist zu kompliziert für meinen kleinen Kopf (25:54)“) kommentieren nur grundsätzliche Schwierigkeiten, ohne diese genauer zu spezifizieren und sind daher für die Bearbeitung des jeweiligen Problems wenig hilfreich. Alle diese Aussagen fanden nach mindestens 10 Minuten der Beschäftigung der Aufgabe statt und stehen dementsprechend nicht als Einschätzung der (individuellen) Aufgabenschwierigkeit am Anfang der Prozesse. Ein positiver Einfluss auf den Bearbeitungsprozess ist damit höchst unwahrscheinlich. Zwar geben solche Aussagen einen Hinweis auf Schwierigkeiten bei der Bearbeitung und hängen daher mit dem Lösungserfolg zusammen, auf die Qualität der metakognitiven Aktivitäten geben sie aber kaum einen Hinweis. In allen drei Fällen wurden aber Schwierigkeiten konkreter benannt, woran sich eine grundsätzlich positive Reflexion der Bearbeitung erkennen lässt.
Auch bei Äußerungen zum intuitiven Verständnis konnten keine Vor- oder Nachteile für die Problembearbeitung ausgemacht werden. Die Tabelle suggeriert einen Zusammenhang mit der Regulation des Vorgehens, aber auch hierfür konnten keine Bestätigungen oder mögliche inhaltliche Begründungen gefunden werden.
Wie bereits in Abschnitt 5.3.5 beschrieben, lassen sich die Aktivitäten Voraussicht, Evaluation und Regulation zu Kontrollstrategien im Sinne von Schoenfeld (1985) zusammenfassen, also solchen Strategien, die direkt mit Richtungsentscheidungen zusammenhängen. Wie die folgenden Beispiele zeigen werden, wurde eine Regulation (also eine Entscheidung, das Vorgehen zu verändern) häufig in einem Atemzug mit einer Beurteilung eine Ansatzes in Form von Voraussicht (a priori) oder Evaluation (a posteriori) durchgeführt. In solchen Fällen wurde Regulation nicht gesondert kodiert. Das Fehlen dieser Aktivität hat also (ähnlich wie bei der Zielsetzung) keinen wesentlichen Einfluss auf die Bearbeitung der Aufgaben, sofern die entsprechenden Aktivitäten durchgeführt wurden.
Im Zusammenhang mit Kontrollstrategien spricht Schoenfeld auch die Wild-Goose-Chase-Prozesse (vgl. Abschnitt 5.5.2) an. In solchen Prozessen schlagen die Bearbeiter einen Weg ein und behalten diesen für längere Zeit bei, ohne diese Wahl mit Hilfe von Kontrollstrategien weiter zu hinterfragen (Schoenfeld, 1985, S. 192). Ein solches Verhalten war, wie bereits erwähnt, bei den betrachteten Prozessen kaum zu beobachten. Meist hatten die Probanden eher Schwierigkeiten damit, überhaupt einen Lösungsansatz zu finden, den es sich (aus ihrer Sicht) lohnte, weiter zu verfolgen. Das hängt sicherlich auch mit der Wahl der Aufgaben zusammen, da hier (mit wenigen Ausnahmen), im Gegensatz zu den Problemen von Schoenfeld, aber auch vergleichbaren Untersuchungen aus dem Schulkontext, weniger konkrete Berechnungen als konzeptionelles Verständnis und logisches Schließen im Mittelpunkt stehen. Allerdings könnte das seltene Auftreten solcher Wild Goose Chases auch als Zeichen guter Metakognition (oder Kontrolle im Sinne Schoenfelds) gesehen werden.
Ob bestimmte Kontrollstrategien wirklich verhindert haben, dass sich ein Proband zu lange mit einem Ansatz beschäftigt, lässt sich schwer sagen, da es höchst spekulativ ist, was passiert wäre, hätte die entsprechende Beurteilung des Ansatzes nicht stattgefunden. Im Folgenden sollen zunächst verschiedene Spielarten dieser Strategien benannt werden, bevor einige Stellen betrachtet werden, bei denen sich Studierende längere Zeit einem gewählten Ansatz gewidmet haben.
Die wesentlichen Kontrollstrategien sind die Voraussicht und die Evaluation. Beide lassen sich noch weiter unterteilen in die positive und die negative Einschätzung eines Ansatzes. So bedeutet etwa negative Voraussicht, dass ein Ansatz a priori als wenig hilfreich eingeschätzt (und dem entsprechend meistens auch nicht weiter verfolgt) wird. Die Paraphrase „Das hilft mir nicht weiterFootnote 29“ ist typisch für diese Strategie. Ansätze werden hierbei, im Gegensatz zur Evaluation bereits sehr früh beurteilt. Interessant ist, dass diese Strategie häufig im Zusammenhang mit Aussagen aus dem Skript auftritt und eher selten im Bezug auf eigene Ideen. Ein Grund dafür liegt möglicherweise darin, dass eigene Ideen, sofern sie bereits sehr früh als wenig hilfreich eingeschätzt werden, gar nicht erst geäußert werden und deshalb auch keine explizite Einschätzung getätigt wird. Einige Ausnahmen gibt es allerdings: Malik etwa sagt, ohne das Skript zu benutzen bei seinen rechnerischen Manipulation zur Aufgabe n-te Wurzel: „Bernoulli-Ungleichung wird mir jetzt nicht weiterhelfen, vermutlich (20:03).“ Ein weiteres Beispiel wäre Niklas, der bei der Aufgabe Konstante Funktion die Idee hat eine Skizze anzufertigen, diese aber mit den Worten „Ich glaube, das führt zu ner Sackgasse (12:33)“ wieder verwirft. Auch Manuel beurteilt eine eigene Idee (bei der Aufgabe Grenzwert von Quotient und Wurzel diese beiden Grenzwerte \(\lim \frac{a_{n+1}}{a_n}\) und \(\lim \root n \of {a_n}\) gleichzusetzen) mit den Worten „Kann ich mir, ehrlich gesagt, nicht vorstellen (19:36)“ Einige Male wird auch der Aufwand als Grund genannt, einen Ansatz nicht durchzuführen. Zitate wie „Das wäre zu mühselig, das jetzt alles mit der Hand auszurechnen (Andreas – 16:34),“ „Halte ich für unwahrscheinlich, weil die [Idee] sehr lange dauern würde (Niklas, n-te Wurzel – 59:06)“ und „Das sieht eigentlich auch sehr aufwändig aus (Malik, n-te Wurzel – 22:49)“ sind vermutlich weniger ein Ausdruck von Faulheit als vom Vertrauen darin, dass eine sinnvoll gestellte Aufgabe keine solch langwierigen Berechnungen erfordert. Insgesamt bleiben Begründungen, warum ein Ansatz als nicht hilfreich eingestuft wird, eher aus. Auf der anderen Seite steht die positive Voraussicht, bei der bereits vor seiner Durchführung ein Ansatz als hilfreich eingeschätzt wird. Hier ist es allerdings so, dass der direkte Bezug zum Skript („Satz 4.2 hilft mir, gehe ich von aus (Patrick – 06:08)“ oder „Das heißt, dass ich diese Idee und Definition von Intervallschachtelung und Häufungspunkt irgendwie brauchen werde (Julia, Grenzwert von Quotient und Wurzel – 19:01)“) eher die Ausnahme bildet. Vielmehr werden eigene Ideen mit Aussagen wie „Mit der Überlegung müsste das funktionieren (Jan, Rangungleichung – 05:45)“ beurteilt. Häufig geschehen diese Einschätzungen bereits in einem Atemzug mit der Benennung der Idee, etwa: „Ich glaub, wenn ich [die] n-te Wurzel ziehe, hätten wir’s bewiesen (Malik, n-te Wurzel – 15:40)“ oder „Wenn ich das hier so aufschreibe, dann denke ich, dass das irgendwie mit dem Zwischenwertsatz zu zeigen sein wird (Julia, Monotonie – 11:49).“ Auch bei der positiven Voraussicht werden selten Begründungen geliefert, warum eine Idee als hilfreich eingeschätzt wird. Außer den beiden bisher genannten Formen der Voraussicht gibt es noch eine dritte, bei der die Probanden sich selbst nach der Nützlichkeit einer Idee fragen, aber keine Antwort geben: „Ist die Monotonie in dem Fall überhaupt wichtig (Julia, Grenzwert von Quotient und Wurzel – 07:26)?“ oder „Ich weiß nicht, ob mich das weiterbringt (Niklas, n-te Wurzel – 53:03).“ In den wenigen Prozessen, in denen eine solche Aussage auftritt, wurden die entsprechenden Ansätze nicht weiter verfolgt, es ist also eine gewisse Nähe zur negativen Voraussicht zu vermuten, wenngleich die Einschätzung nicht explizit vorgenommen wird.
Im Gegensatz zur Voraussicht geschieht eine Evaluation erst, nachdem ein Ansatz zumindest ein wenig verfolgt wurde. Die hierbei getätigten Einschätzungen beruhen möglicherweise zum Teil auf den Erfahrungen, die dabei gemacht wurden. Bei diesen Evaluationen entscheidet sich, ob der gewählte Weg beibehalten oder abgeändert wird. Hier kann verhindert werden, dass man sich in einen nicht-zielführenden Ansatz verbeißt. Eine Richtungsänderung kann unter anderem durch eine negative Evaluation, also die Einschätzung, dass dieser Ansatz nicht weiterhilft, herbeigeführt werden. Typisch hierfür ist etwa Jans Aussage (Aufgabe: Fixpunkt): „Ich glaub, dieser Ansatz, den ich jetzt gerade habe, der verläuft irgendwie gefühlt im Nichts (19:38).“ Anders als die Aussagen zur Voraussicht präzisieren die zur Evaluation aber häufiger, warum die entsprechenden Ansätze als nicht hilfreich eingestuft werden. Beispiele hierfür sind: „Ach nein, das ist ja ein Kreisschluss (Jan, Rangungleichung – 20:15),“ „Jetzt haben wir genau die falsche Seite (Malik, Quetschlemma – 34:31),“ „Aber dann haben wir nicht bewiesen, dass wir hinzuaddieren können (Malik, n-te Wurzel – 42:45)“ und „Damit hab ich einfach nur die Aufgabenstellung nochmal... (Niklas, konstante Funktion – 18:36)“. Auf die Zusammenhänge dieser Zitate wird weiter unten genauer eingegangen. Interessanterweise kommt eine positive Evaluation fast gar nicht vor. Eine solche Selbstbestätigung, auf dem richtigen Weg zu sein, ist zwar implizit in der Tatsache, dass ein Ansatz weiterverfolgt wird, enthalten, explizit geäußert wird sie allerdings äußerst selten. Im Hinblick auf die von Schoenfeld (1985) benannte Gefahr, dass mangelnde metakognitive Steuerung zum verharren auf einem nicht-zielführenden Weg führen kann, wären solche expliziten Begründungen interessant zu beobachten gewesen. Tatsächlich war positive Evaluation nur an zwei Stellen zu beobachten. Zum einen bleibt Malik (Aufgabe: Quetschlemma) an seinem Anfangs gewählten Ansatz dran (die Ungleichung \(b_n \le c_n\) zu verwenden, um zu zeigen, dass \(b_n-c < \varepsilon \) ist), „weil das vom Gefühl her mir zeigt, dass ich auf dem richtigen Weg bin (06:52).“ Leider wird nicht deutlich, was genau zu diesem Gefühl führt. Der Autor vermutet, dass dieses Gefühl von der mehrfach erwähnten graphischen Vorstellung des mathematischen Sachverhalts gespeist wird (vgl. Abschnitt 5.5.5). Zum anderen sagt Niklas, nachdem der Interviewer (da gegen Ende des Prozesses die Ideen immer weniger zielführend wurden) eingegriffen und darauf hingewiesen hat, dass den jüngsten Überlegungen ein Denkfehler zugrunde lag, „Ich glaube, dass ich damit trotzdem evtl. weiterkommeFootnote 30 (41:19).“ Hier hat also eine Perturbation von außen dazu geführt, dass der beschrittene Weg nochmal genauer hinterfragt wird, was zur expliziten positiven Evaluation geführt hat. Insgesamt bleibt es aber bei diesen beiden Beispielen. Auch bei der Evaluation gibt es neben der positiven und der negativen auch eine unbestimmte Variante. So sagt etwa Andreas nach Abschluss einer längeren Rechnung: „Ist nur die Frage, ob mir das jetzt wirklich weiterhilft (09:35).“ Niklas (Aufgabe: konstante Funktion) fährt nach seiner Aussage „Ich bin mir da aber jetzt gerade nicht sicher [...], ob ich da überhaupt den richtigen Ansatz habe (26:06)“ mit genau diesem Ansatz fort, worin sich diese Variante klar von der negativen Evaluation unterscheidet, die immer zu einer Regulation des Vorgehens geführt hat.
Eine Regulation kann auch auftreten, ohne dass ein Ansatz oder Lösungsweg explizit hinterfragt wird: „Ich probiere einfach mal einen anderen Ansatz aus (Niklas, n-te Wurzel – 26:24)“ oder „Nö, ich mach jetzt mal weiter (Julia, Monotonie – 08:33).“ Ob der vorhergehende Ansatz dabei als nicht hilfreich eingeschätzt wurde oder der jeweilige Bearbeiter hier schlicht nicht weiterkam, lässt sich hieraus nicht erkennen. Darüber hinaus kam es nicht selten vor, dass eingeschlagene Wege kommentarlos abgebrochen wurde. Das ist ein starker Hinweis darauf, dass hier metakognitive Aktivitäten abliefen, die von außen, trotz lautem Denkens, nicht zu erkennen waren.
Die Klärung der Handlungsoptionen, die nur bei Patrick kodiert wurde, kann man bei entsprechender Betrachtungsweise als Aufzählung möglicher Ansätze bezeichnen. Solche Aufzählungen sind auch bei anderen Probanden vorgekommen, allerdings wurde hier in der Regel zu jedem dieser Ansätze eine kurze Einschätzung (Voraussicht) abgegeben. Hierzu schien Patrick nicht in der Lage gewesen zu sein, als er sagt: „Ob ich das explizit an dem machen kann oder ob ich mir da jetzt ein Beispiel für konstruieren müsste, das ist dann wieder die nächste Frage (02:34).“
- Frage 8: :
-
Welchen Einfluss haben Kontrollstrategien auf die Problembearbeitungsprozesse?
Im Folgenden werden also einige Prozesse hinsichtlich der Kontrollstrategien genauer unter die Lupe genommen. Hierbei wird auf eine Betrachtung der Analysis-Phasen verzichtet, da die hier durchgeführten Aktivitäten sich in der Regel als notwendig erweisen (zumindest war dies bei den betrachteten Prozessen der Fall) und deswegen keiner größeren metakognitiven Kontrolle bedürfen. Der Fokus der folgenden Absätze liegt auf Phasen, in denen sich die Probanden längere Zeit (ab circa 3 Minuten) einer Idee widmen.
Zunächst soll Andreas’ Bearbeitung der Aufgabe zur linearen Unabhängigkeit (vgl. Abschnitt 5.5.5 und Anhang D) betrachtet werden. Diese Aufgabe ist ein Beispiel dafür, wie längere Rechenoperationen, in denen man sich leicht verirren kann, auch in der universitären Fachmathematik eine wichtige Rolle spielen können (bei den meisten hier betrachteten Aufgaben war dies nicht der Fall). Andreas bildet, nachdem er sich in der Analysis-Phase die Gestalt der Vektoren \(v_i-v\) vor Augen geführt hat, aus diesen zunächst eine Linearkombination (07:09–09:11). Auf seine folgenden Umformungen vorausblickend sagt er: „Die Vermutung liegt ja nahe, dass wir irgendwas haben mit ‚Eins minus‘ und dann addieren wir die einzelnen \(a_i\)’s auf (09:25).“ Ein solches Ergebnis würde sehr gut zu der Eigenschaft aus der Aufgabenstellung, dass \(\sum \limits _{i=1}^n a_i \ne 1\) ist, passen. Nach einer längeren Rechnung hat er die aufgestellte Gleichung korrekt umgeformt, das Ergebnis sieht aber aufgrund der Pünktchenschreibweise relativ unübersichtlich aus (vgl. Abbildung 5.37). Er evaluiert dieses Zwischenergebnis mit „Ist nur die Frage, ob mir das jetzt wirklich weiterhilft (15:36)“ und bricht diese Rechnung wenig später, zugunsten eines erneuten Versuchs in Summenschreibweise mit den Worten „Das wäre zu mühselig, das jetzt alles mit der Hand auszurechnen (16:24)“ ab. Bei der folgenden Umformung unterläuft ihm der in Abschnitt 5.5.5 bereits genannte Fehler (vgl. Abbildung 5.19), dass \(\sum \limits _{i=1}^n \lambda _i \sum \limits _{j=1}^n a_j v_j = \sum \limits _{i=1}^n \lambda _i a_i v_i\) ist. Bei (18:00) beendet er seine Rechnung, im Glauben die Hinrichtung bewiesen zu haben. Beim Beweis der Rückrichtung führt er interessanterweise dieselbe Rechnung nochmal durch (20:49–25:04) und macht auch denselben Fehler.

Ergebnis der Umformung in Pünktchenschreibweise
In diesem Prozess hat es wenig Kontrollprozesse gegeben, allerdings wäre der eingeschlagene Weg zum einen richtig gewesen, hätte es den Umformungsfehler nicht gegeben, zum anderen war dieser typisch für Aufgaben zur linearen Unabhängigkeit, so dass kein Grund zum Zweifel an der Wahl des Weges vorlag. Interessant ist, dass die Richtungsentscheidung nicht mit der langwierigen und unübersichtlichen Pünktchenschreibweise fortzufahren, möglicherweise zu diesem Fehler geführt hat. Zumindest hätte ein Vergleich des Zwischenergebnisses mit den späteren Ergebnissen zu einem Konflikt führen können.
Als Nächstes wird ein Blick auf Jans Bearbeitung der Fixpunkt-Aufgabe geworfen (vgl. Anhang D). Nach der Analyse der Aufgabe sucht der Proband zunächst nach Ideen. Als Erstes (04:10) betrachtet er den Fall, dass \(n=1\) ist, stellt aber bald fest: „[Damit] komme ich nicht weiter,“ da \(f^1(m)\) nicht gleich m sein muss. Dann macht er sich nochmal klar, dass \(f \circ f=f^2\) ist. Auch hier kommentiert er: „Das bringt mich jetzt aber auch noch nicht so viel weiter (06:32).“ Zwar ist diese Information zum Bearbeiten der Aufgabe zwingend notwendig, sie scheint ihn aber noch nicht zu einem Lösungsansatz zu führen. Wenig später (07:11) sagt er: „Ich weiß aber nichts Genaueres über die Menge M.“ Das ist deswegen besonders interessant, weil die Endlichkeit von M entscheidend für die Richtigkeit der zu beweisenden Aussage ist. Hier wird also deutlich, dass diese Eigenschaft von Jan übersehen oder als nicht wichtig eingestuft wurdeFootnote 31. Es scheint sich hierbei also weniger um eine Richtungsentscheidung als um eine fachliche Fehleinschätzung zu handeln (es wurde ja nicht bewusst entschieden, die Endlichkeit der Menge zu vernachlässigen). Stattdessen beginnt Jan ab (07:44) mit der Umkehrabbildung zu arbeiten (die Existenz einer solchen ist nicht unbedingt gegeben). Zwar evaluiert er diese Idee nach etwa fünf Minuten (12:30) mit den Worten „Ich glaub, dieser Ansatz, der verläuft gefühlt irgendwie im Nichts“, ändert aber die Richtung seiner Überlegungen nicht (möglicherweise aus Mangel an alternativen Ideen). Sein Weg führt ihn zunächst (13:36) dazu, \(m=f^{-1}(m)\) zu „wählenFootnote 32“, woraus sich \(\text {Id}(m)=f^1(m)\) ergibt. Da aber \(m=f^n(m)\) zu zeigen ist, gibt er sich damit nicht zufriedenFootnote 33. Bei (15:40) „wählt“ er also \(m=f^{-n}(m)\). Um die Korrektheit seiner Umformungen stützen zu können, beweist Jan (etwa 17:00 bis 20:00), dass es sich bei Abbildungen mit der Hintereinanderausführung als Verknüpfung um eine Gruppe handeltFootnote 34. Anschließend zeigt er durch Rechenumformungen (ab 20:11), dass \(f^m(f^{-m}(m))=\text {Id}(m)\) ist. Ab (20:56) beschäftigt er sich noch weiter damit, zu zeigen, dass \(\text {Id}(m)=m\) ist. Zuletzt (23:55) schreibt Jan noch seinen Antwortsatz auf und bei (25:09) endet der Prozess.
Von den betrachteten Prozessen kann dieser am ehesten als Wild Goose Chase bezeichnet werden: Von (07:44) bis (25:09) beschäftigt Jan sich mit einem Ansatz, der nicht zu einer korrekten Lösung der Aufgabe führt. Zwar schätzt er diesen selber bei (12:30) als „im Nichts“ verlaufend ein, diese Evaluation führt ihn aber nicht zu einer Richtungsänderung. Am Ende des Prozesses ist Jan davon überzeugt, die Aufgabe richtig gelöst zu haben, was auch erklärt, warum er so lange auf dem gewählten Pfad geblieben ist. Im Gegensatz zu Andreas, der sich grundsätzlich auf dem richtigen Weg befand, bei dem aber ein Rechenfehler zum Scheitern geführt hat, führte Jans Ansatz komplett in eine falsche Richtung. Hierbei spielten zwei Fehleinschätzungen eine Rolle: Zum einen existiert eine Umkehrabbildung nur bei bijektiven (oder zumindest injektiven) Funktionen, zum anderen wurde eine zielführende Möglichkeit (das Ausnutzen der Endlichkeit von M) nicht erkannt. Jans Ergebnis stellt sich außerdem bei genauerer Betrachtung als Zirkelschluss heraus.
Die zweite Aufgabe, die Jan bearbeitet, ist die zur Rangungleichung (vgl. Anhang D und Abschnitt 5.5.2). Nachdem er sich in der Analysis-Phase die Gestalt der Matrizen genauer vor Augen geführt hat, betrachtet er zunächst (04:09–09:13) den Spezialfall, dass alle Zeilen der Matrix A linear unabhängig voneinander sind, die Matrix also vollen Rang hat. Diesen Spezialfall kann er recht schnell argumentativ belegenFootnote 35 und es werden auch keine Zweifel an diesem Ansatz geäußert. Das weitere Vorgehen ist nicht mehr so zielstrebig. Im Skript findet Jan die Information, dass sich Zeilen- und Spalten-Rang bei Durchführung des Gauss-Verfahrens nicht ändern, was er aber mit den Worten „Das bringt grad nicht viel (10:35)“ zunächst abtutFootnote 36. Jan verbringt noch etwas Zeit (11:12–12:09) damit, den oben genannten Spezialfall zu konkretisieren, etwa indem er den Rängen der Matrizen Variablen zuordnet. Ab (13:12) überlegt er dann, was passiert, wenn (mindestens) eine Zeile linear abhängig istFootnote 37. Bei (15:14) kommt ihm die Idee (zu erkennen an einem lauten „Ah!“), dass sich zwei linear abhängige Zeilen in A auf \(A_1\) und \(A_2\) aufteilen. Diese beurteilt er mit der Voraussicht: „Das müsste funktionieren“. Es wird im kompletten Prozess nicht erkennbar, ob Jan klar ist, dass sich solche Zeilen aufteilen können, aber nicht müssen. Wie diese Idee formal umzusetzen ist, wird Jan während des gesamten Prozesses nicht klar. Zunächst versucht er, die lineare Abhängigkeit in Formeln darzustellen (16:17). Diesen Versuch bricht er aber wenig später mit den Worten „Ich weiß nicht genau, wie man das aufschreiben müsste (17:14)“ ab. Anschließend (18:24) versucht er sich an einem Beweis durch Widerspruch, indem er zunächst annimmt, dass \(\text {Rang}(A)>\text {Rang}(A_1)+\text {Rang}(A_2)\) ist. Die folgenden Überlegungen (19:01–19:50) sind schwierig zu interpretieren und werden deswegen wörtlich wiedergegeben: „Hier (zeigt auf die rechte Seite der Ungleichung) müssen Zeilen dazugekommen sein. Jede linear unabhängige Zeile in A muss zwangsläufig linear unabhängig in \(A_1\) bzw. \(A_2\) sein. Wenn der Rang von A größer wäre als der Rang [von] \(A_1\) plus der Rang von \(A_2\), das würde implizieren, dass das eben nicht so ist.“ Geht man davon aus, dass mit den Zeilen, die auf der rechten Seite der Ungleichung dazugekommen sind, linear abhängige Zeilen (die in A linear unabhängig waren) gemeint sind, so stecken in diesen Aussagen bereits alle wesentlichen Elemente für einen Widerspruchsbeweis drin. Dennoch bricht Jan diese Überlegung mit dem Kommentar „Ach nein, das ist ja ein Kreisschluss (20:15)“ ab. Das ist vor allem vor dem Hintergrund, dass in Jans erstem Prozess (s. o.) ein Kreisschluss zum falschen Ergebnis geführt hat, interessant. Möglicherweise ist er (zumindest in der Situation vor demselben Interviewer und der Kamera) hierfür besonders sensibel geworden. Die Idee des Widerspruchsbeweises wird etwas später (21:47) komplett abgebrochen. Bis zum Ende des Prozesses (32:21) versucht Jan, ohne Erfolg und ohne dass er Kontrollüberlegungen äußert, die Behauptung direkt zu beweisen. Insgesamt werden hier mehr Regulationsstrategien angewandt als bei Jans erstem Prozess, allerdings wird auch eine anscheinend zielführende Überlegung aufgrund einer Fehleinschätzung abgebrochen.
Die Bearbeitung der Aufgabe zur n-ten Wurzel von Niklas wurde bereits in Abschnitt 5.5.1 ausführlich beschrieben. An dieser Stelle soll eine kurze Zusammenfassung im Hinblick auf die Kontrollstrategien gegeben werden. Die erste Idee, die Niklas verfolgt (ab 13:24), ist die, etwas aus der Wurzel auszuklammern. Zunächst ist ihm noch nicht klar, was das sein kann. Diese Idee wird bis (26:24) nicht explizit hinterfragt. Insgesamt haben Evaluationen nur stattgefunden, wenn es hier erwähnt wird. Bei (17:56) konkretisiert er, dass er \(a_1^n\) ausklammern möchte und erkennt später (21:49), dass dann für die dadurch entstehenden Summanden \(\frac{a_n}{a_1} \ge 1\) gelten mussFootnote 38. Bei (26:24) entscheidet sich Niklas für eine Regulation: „Ich probiere einfach mal einen anderen Ansatz aus“, auch hier ohne den Ansatz des Ausklammerns explizit zu evaluieren. Die nächste Idee ist, die Folge durch Multiplikation mit Eins zu manipulieren (etwa 28::30 bis 35:30 – vgl. Abbildung 5.10). Bei (38:41) kehrt er wieder zu der Idee des Ausklammerns zurück, diesmal mit dem Faktor \(a_k^n\). Das führt ihn schließlich zur Idee, das Quetschlemma anzuwenden (42:40). Als Abschätzung nach oben gibt er direkt an, dass alle Summanden dem größten (also \(a_k\)) entsprechen. Eine Abschätzung nach unten zu finden fällt ihm allerdings schwer. Zunächst fällt ihm ein, dass Teilfolgen einer konvergenten Folge gegen denselben Grenzwert konvergieren (52:50). Hierzu sagt er allerdings schnell: „Ich weiß nicht, ob mich das weiterbringt (53:03).“ Dann versucht er eine änhliche Idee, wie bei der Abschätzung nach oben (55:11), nämlich alle Summanden gleich dem kleinsten (\(a_1\)) zu setzen. Er zeigt Voraussicht, indem er sagt: „Das brauche ich nicht mehr zu machenFootnote 39, weil das ähnlich ablaufen wird (55:32).“ Außerdem stellt er fest, dass ihm das noch kein Ergebnis, immerhin aber ein Intervall, in dem dieses liegen muss, liefert (Denn die Abschätzung nach unten führt zum Grenzwert \(a_1\), die nach oben zu \(a_k\)). Die nächsten beiden Ideen werden nun explizit evaluiert: Zunächst (56:25) überlegt er, eine Folge aus Mittelwerten zu bilden, was er mit „Das bringt mich gerade nicht so weiter (57:50)“ kommentiert. Dann hat er die Idee, die Summanden paarweise zusammenzufassen. Hierzu sagt er: „Halte ich für unwahrscheinlich, weil die sehr lange dauern würde (59:06).“ Insgesamt gibt es in diesem Prozess eher wenig explizit geäußerte Einschätzungen der Ansätze. Bei (26:24) wird ein vielversprechender Ansatz (das Ausklammern) zunächst verworfen, der aber bei (38:41) wieder aufgegriffen wird.
Auch bei Niklas’ zweiter Bearbeitung sind explizite Äußerungen über mögliche Ansätze eher selten. Bereits in der Analysis-Phase wird der Versuch, eine Skizze zu zeichnen mit den Worten „Ich glaub, das führt zu ner Sackgasse (12:33)“ abgebrochen. Aus dem Kontext wird klar, dass die Ursache hierfür eine Fehlvorstellung zu Funktionen war, denn Niklas hat nach eigener Aussage Schwierigkeiten damit, dass jedem x-Wert zwei y-Werte zugeordnet werdenFootnote 40. Die erste Idee (13:05), die Niklas dann äußert, ist die Folgenstetigkeit zu nutzen. Konkretisiert wird diese erst vier Minuten später (17:05). Hier erklärt Niklas, dass wenn eine Folge \(x_k\) gegen \(x_0\) konvergiert, nicht nur \(f(x_k) \rightarrow f(x_0)\), sondern auch \(f(x_0) \rightarrow f(x_0^2)\) gelten muss. Etwas später stellt er aber fest: „Damit hab ich einfach nur die Aufgabenstellung nochmal [...] (18:36)“Footnote 41. Eine Idee, die er im Folgenden etwas länger verfolgt (ca. 23:00 bis 29:00), lässt sich wie folgt zusammenfassen: Da \(|f(x)-f(x^2)|=0\) ist, muss für alle \(x_0\) im Intervall \((x;x^2)\) gelten, dass \(|f(x)-f(x_0)|<\varepsilon \) ist. Diese Fehlvorstellung wiederholt Niklas später in ähnlicher Form (27:52) nochmal, indem er behauptet, dass die Abstände in y-Richtung sich nicht vergrößern können, wenn die Abstände in x-Richtung kleiner werden. In den sechs Minuten, in denen er diesen Ansatz verfolgt, sagt er zwar einmal „Ich bin mir da aber jetzt gerade nicht sicher [...], ob ich da überhaupt den richtigen Ansatz habe (26:06)“, fährt aber trotzdem auf diesem Weg fort. Die nächste Idee, ist mit einem Mittelwert zu arbeiten (35:03): Wenn \(x_0\) in einer \(\delta \)-Umgebung um x liegt, dann muss das auch für den Mittelwert von den beiden gelten. Auch dieser Weg ist nicht zielführend, da aus diesen Überlegungen zu den x-Werten keinerlei Folgerungen für die y-Werte abzuleiten sind. Als seine ersten Überlegungen fehlschlagen, sagt er: „Ich glaube, dass ich damit trotzdem eventuell weiterkomme (41:19).“ Wenig später (42:47) bricht er die Bearbeitung ab. Ein Großteil der in diesem Prozess gefällten Richtungsentscheidungen kann man zumindest als fragwürdig einschätzen. Dass der Versuch einer Skizze erfolglos abgebrochen wird ist vielleicht noch nicht einmal eine Entscheidung, sondern resultiert eher aus Unvermögen. Als nächstes wird der objektiv sinnvolle Weg über Folgenstetigkeit abgebrochen, weil eine Teilüberlegung sich im Kreis dreht. Die weiteren Überlegungen basieren allesamt auf Fehlvorstellungen zur Stetigkeit, werden aber recht lange verfolgt und zum Teil auch als zielführend eingeschätzt. Hier sieht man, dass erfolgreiche Metakognition sehr eng mit gutem Vorwissen verknüpft sein kann.
Betrachtet man die Übersicht (Abbildung 5.3), fällt auf, dass in Maliks Bearbeitung der Quetschlemma-Aufgabe keine Voraussicht aufgetreten ist. In Abschnitt 5.5.5 wurde dieser Prozess bereits ausführlich beschrieben, die folgenden Betrachtungen konzentrieren auf die Anwendung von Kontrollstrategien. Nachdem sich Malik in der Analysis-Phase ein graphische Vorstellung von der Situation gemacht hat, ist seine erste Idee, die Voraussetzung \(b_n \le c_n\) zu verwenden (05:14). Er präzisiert sogar, dass \(b_n-c \le c_n-c < \varepsilon \) ist, stört sich aber noch daran, dass in dieser Ungleichungskette kein Betrag vorkommt. Trotzdem entscheidet er sich (Evaluation) dazu, diese Idee weiter zu verfolgen „weil das vom Gefühl her mir zeigt, dass ich auf dem richtigen Weg bin (06:52).“ Schriftlich umgesetzt wird diese, bis dahin nur mündlich formulierte Idee etwas später (etwa von 10:30 bis 13:00), so dass damit bereits bewiesen ist, dass \(b_n-c < \varepsilon \) ist (ohne genauere Präzisierung, für welche n diese Ungleichung gilt). Ab (14:16) beginnt Malik, die Voraussetzung \(b_n \ge a_n\) zu nutzen. Zunächst folgert er daraus, dass \(b_n \ge c\) ist (was nicht stimmen muss). Hieraus würde folgen, dass \(|b_n - c|=b_n - c\) ist. Bei (17:01) stellt Malik aber fest: „\(b_n - c\) ist auch gar nicht größer gleich Null, das muss gar nicht der Fall sein.“ Aufgrund dieser Evaluation bricht er die Überlegungen in diese Richtung ab. Die nächste Idee, die Malik verfolgt, ist, die Ungleichungen \(a_n \le b_n\) und \(|a_n-c| < \varepsilon \) zu addieren (vgl. Abbildung 5.33). Diese wird etwas später kommentarlos abgebrochen und bei (23:04) sucht Malik im Skript nach weiteren Ideen. Ohne dass eine Verbindung zu dem, was er im Skript gelesen hat, zu erkennen ist, benennt Malik bei etwa (25:00) die Idee eines Beweises durch Widerspruch, indem er schreibt: \(|b_n - c| > \delta \). Diese Idee wird aber im weiteren Verlauf nicht weiter kommentiert oder aufgegriffen. Seitdem er bei Minute 13 gezeigt hat, dass \(b_n - c < \varepsilon \) ist, hat Malik die Ungleichung \(b_n \le c_n\) nicht mehr verwendet. Dieses Vorgehen evaluiert er mit den Worten: „Das ist tatsächlich auch vermutlich alles, was ich aus dieser Teilaussage \(b_n \le c_n\) bekommen kann (26:41).“ Nach dieser (korrekten) Einschätzung konzentriert er sich weiterhin auf die Voraussetzung \(a_n \le b_n\). Etwa bei Minute 30 verdeutlich er nochmal, dass er \(b_n < c - \varepsilon \) zeigen möchte. Bei (32:52) sagt er, dass er hierfür zeigen muss, dass \(c - \varepsilon < a_n\) ist, was er sich graphisch bereits verdeutlicht hat. Der nächste Versuch einer Umformung der Ungleichung \(|a_n - c| < \varepsilon \) (33:41) führt ihn auf \(c + \varepsilon > a_n\) (vgl. Abbildung 5.36 links). Hierzu stellt er schnell fest: „Jetzt haben wir genau die falsche Seite (34:41).“ Wenig später kommt er aber auf die Idee, den „Betrag des Negativen“ zu betrachten (vgl. Abbildung 5.36 Mitte oben), was schließlich (etwa bei Minute 38) zu der gesuchten Aussage führt. Den Rest des Prozesses (immerhin noch bis 46:25) benötigt Malik, um die beiden Teilaussagen zu der zu zeigenden Behauptung zusammenzufassen. Die gewählte Richtung, mit den bewiesenen Ungleichungen und dem Betrag zu arbeiten (vgl. Abbildung 5.36 unten) wird nicht mehr hinterfragt, ist aber auch eine sinnvolle Möglichkeit.
In diesem Prozess gibt es relativ wenige explizite Beurteilungen des Vorgehens (nur die hier erwähnten). Allerdings ist die Qualität dieser wenigen Aussagen sehr hoch: Bereits zu Beginn (06:52) äußert Malik die Einschätzung, dass er sich auf dem richtigen Weg befindet. Ein falscher Ansatz (14:16) wird nach recht kurzer Zeit (17:01) als solcher erkannt. Etwa in der Mitte des Prozesses (26:41) wird evaluiert, dass das bisherige Vorgehen gut war und ein kleiner Umweg bei einer Rechnung (33:41) wird erkannt (34:41) und es werden daraus richtige Konsequenzen gezogen (35:47). Auch nicht explizit erwähnte Richtungsentscheidungen sind gut, denn es werden ungünstige Lösungsversuche schnell abgebrochen. Interessant ist auch, dass Malik hier an keiner Stelle explizit eine Voraussicht erwähnt. Vor dem Hintergrund, dass seine Kontrollstrategien von guter Qualität sind, lässt sich das dadurch erklären, dass Malik sich seiner Sache von Beginn an durch die graphische Vorstellung sehr sicher war, so dass ihm, ähnlich wie bei der positiven Evaluation aller Probanden, eine Bestärkung nicht notwendig erschien.
Auch Maliks Bearbeitung der Aufgabe (vgl. Abschnitt 5.5.5) zur n-ten Wurzel soll hier im Hinblick auf Kontrolle betrachtet werden. Nach einer kurzen Analysis-Phase beginnt Malik mit der Betrachtung von Spezialfällen (02:26). Bevor er hierzu konkret etwas aufschreibt, erinnert er sich daran, dass \(\root n \of {c}\) für konstante c gegen 1 konvergiert, trifft dazu aber die Voraussicht: „Das hilft uns eigentlich auch nicht weiter (03:33).“ Später zeigt sich, dass diese Einschätzung nicht ganz richtig ist, zu diesem Zeitpunkt in der Bearbeitung ist diese Information allerdings tatsächlich noch nicht hilfreich. Malik betrachtet nun die konkrete Folge \(\root n \of {1^n+2^n+3^n}\) und vermutet bald, dass der erste Summand für große n nicht mehr ins Gewicht fällt, weil er immer gleich 1 ist. Daraufhin (04:42) stellt er sich die Frage, ob das auch für den zweiten Summanden \(2^n\) gilt und möchte dementsprechend zeigen, dass \(\root n \of {2^n+3^n} \rightarrow 3\) gilt. In Voraussicht auf diesen Ansatz sagt er: „Das müsste vermutlich dann auch für beliebige Zahlen gelten (05:06).“ Um seine Vermutung zu unterstützen, rechnet er im Kopf Beispielwerte für \(n=2\) aus, plant dasselbe für \(n=3\), bricht diese Rechnung aber mit den Worten „Rechne ich nicht aus (06:55)“ ab, möglicherweise, weil die exakte Rechnung im Kopf recht aufwändig ist. Von (09:22) bis (28:21) widmet Malik sich dem Beweis des Spezialfalls \(N=2\). Es soll hier nicht jede Rechnung im einzelnen dokumentiert werden, der grundlegende Ansatz besteht darin \(x^n := a_1^n + a_N^n\) zu setzen und diese Gleichung umzuformen, mit dem Ziel, zu zeigen, dass sich \(x^n\) für große n an \(a_N^n\) annähertFootnote 42. Eine der ersten Ideen besteht darin, beide Seiten durch \(a_1^n\) zu dividieren, so dass die Gleichung \((\frac{a_N}{a_1})^n = (\frac{x}{a_1})^n - 1\) herauskommt. An dieser Stelle sei angemerkt, dass es geschickter gewesen wäre, hier durch \(a_N^n\) zu dividieren, denn hätte in der Gleichung \((\frac{a_1}{a_N})^n = (\frac{x}{a_N})^n-1\) auf der linkens Seite eine Nullfolge gestanden und es wäre deutlich leichter gewesen, die Behauptung zu zeigen. Dies wurde von Malik leider nicht erkannt. Insgesamt wurden bei den Berechnungen kaum Evaluationen vorgenommen. Nach einiger Zeit ist Malik auf folgende Gleichung gekommen:
An dieser Stelle sagt er: „Vielleicht denke ich einfach in die falsche Richtung (21:07).“ Dies ist die einzige Stelle in den fast 20 Minuten, die sich Malik mit dem Beweis des Spezialfalls beschäftigt, an der er kurz das reine Rechnen unterbricht. Bei (22:49) überlegt er zu zeigen, dass es sich um eine monotone und beschränkte Folge handelt, nimmt davon aber mit den Worten „Das sieht eigentlich auch sehr aufwändig aus (23:46)“ Abstand und kehrt wieder zu seinen vorherigen Überlegungen zurück. Diese beiden Aussagen bleiben die einzigen Einschätzungen von Ansätzen in diesem Zeitraum. Tatsächlich gelingt es Malik, die kompliziert anmutende Gleichung so umzuformen, dass am Ende (28:21) die gesuchte Behauptung gezeigt wird. Anschließend (29:07 bis 30:58)) betrachtet er noch den Fall, dass \(a_1=a_N\) ist (vgl. Abbildung 5.20). Es folgen einige Ansätze, das Ergbenis zu verallgemeinern: Malik überlegt, den Limes unter die Wurzel zu bringen (33:09), induktiv immer einen Summanden hinzuzufügen (34:18 bis 37:10), die vorherigen Rechnungen mit drei Summanden zu wiederholen (39:53 – wird nicht verfolgt), bei den Rechnungen erreichte Zwischenergebnisse zu verwenden (41:08) und mit N Summanden zu beginnen und induktiv immer einen zu eliminieren (43:27). Hiervon wird nur die erste explizit bewertet, mit den Worten „Nee, das macht auch gar keinen Sinn (33:48)“, trotzdem aber auch nur die zweite eine Zeitlang verfolgt. Schließlich (44:56) kommt Malik auf die Idee, die Folge nach oben abzuschätzen, indem er alle Summanden gleich \(a_N\) setzt. Das führt ihn schließlich dazu, das Quetschlemma anzuwenden, mit dessen Hilfe er die Aufgabe bis (49:20) gelöst hat (vgl Abbildung 5.21).
In diesem Prozess kann man die längste fragwürdige Phase von fast 20 Minuten beobachten. Während dieser Zeit werden nur zwei explizite Aussagen zu Kontrollprozessen getätigt. Auch der anschließende Versuch der Verallgemeinerung hat fast 15 Minuten gedauert und beinhaltet nur eine solche Aussage. Zwar lässt sich darüber diskutieren, ob und wie stark diese lange Rechnung zu der Idee, das Quetschlemma anzuwenden, beigetragen hat, dennoch lässt sich beobachten, dass sehr viel Zeit aufgewendet wird, ohne dass die Richtungsentscheidung wesentlich hinterfragt wird. Am Ende des Prozesses stellt Malik dasselbe fest: „Ich hab etwa gerade ne Stunde gerechnet und hab die Lösung in zehn Minuten komplett neu berechnet (49:08).“ Dass dies der einzige Prozess ist, in dem derartig viel Zeit in eine fragwürdige Richtung gearbeitet wird, lässt sich möglicherweise mit der Gestalt der Aufgabe erklären, da diese, im Gegensatz zu den meisten anderen Aufgaben, überhaupt erst lange Termmanipulationen zulässt.
Zur Beantwortung von Frage 8: Im Gegensatz zu Schoenfeld (1985), der (zumindest bei untrainierten Probanden) recht häufig beobachtet, dass diese eine Richtung wählen und diese über eine lange Zeit verfolgen, ohne diese Entscheidung zu hinterfragen (Wild Goose Chases), kommen bei der vorliegenden Arbeit vergleichsweise häufig Kontrollstrategien zum Einsatz. Insgesamt hat es aber nur drei Prozesse gegeben, in denen über einen längeren Zeitraum ein Ansatz verfolgt wurde, der nicht oder nicht ganz zum Ziel geführt hat: Maliks Bearbeitung der Aufgabe zur n-ten Wurzel ist der Prozess, der am ehesten von kritischerem Hinterfragen profitiert hätte. Nicht nur wird viel Zeit (fast 20 Minuten) auf einen rechnerischen Beweis des Spezialfalls aufgewendet, dessen Nutzen diesen langen Zeitaufwand wahrscheinlich nicht rechtfertigt, auch innerhalb dieses Ansatzes werden ungünstige Richtungsentscheidungen nicht hinterfragt oder rückgängig gemacht. Dennoch gelingt es Malik letztlich, das Problem zu lösen. Andreas’ Ansatz dauert zwar lange und führt nicht zu einem korrekten Ergebnis, das liegt aber an einem Rechenfehler. Grundsätzlich ist die eingeschlagene Richtung durchaus sinnvoll. Auch Jan hat bei der Fixpunkt-Aufgabe einen falschen Weg gewählt, der von der falschen Voraussetzung, es gäbe ein \(m:=f^{-n}(m)\) ausgeht. Zwar benennt er zwischendurch Zweifel an seinem Ansatz, führt diesen dennoch weiter fort. Da er seinen Fehler aufgrund mangelndem Fachwissens nicht erkennt, hat er auch nicht die Möglichkeit, den Ansatz richtig einzuschätzen, denn ohne diesen Fehler ist er tatsächlich zielführend. Auch die Feststellung, dass es zur Menge M keine Informationen gibt (die letztlich das korrekte Lösen der Aufgabe unmöglich macht), kann als fachliche Fehleinschätzung angesehen werden. Vorwissen und das Treffen von Richtungsentscheidungen können also eng mit einander verknüpft sein. Das zeigt sich zum Teil auch bei solchen Entscheidungen, die zum Abbruch eines guten Weges geführt haben: Jan diagnostiziert bei dem Versuch, zur Rangungleichung einen indirekten Beweis zu führen, einen Kreisschluss, der nicht nachzuvollziehen ist, Andreas bricht die für ihn vertraute Berechnung in Pünktchenschreibweise ab, obwohl diese korrekt ist und es gelingt ihm nicht, die Diskrepanz zur falschen Berechnung in Summenschreibweise zu erkennen und Niklas verwirft bei der Aufgabe zur konstanten Funktion den Ansatz über Folgenstetigkeit, weil eine Teilidee nicht funktioniert. Dies sind nur einige Beispiele, die zeigen, dass Regulation auch in die falsche Richtung führen kann. Insgesamt scheint die Verbesserung dieser Entscheidungen ein wichtiges Ziel von Problemlösetraining zu sein. Wie gesagt, scheint dieser Faktor ebenfalls stark mit dem Vorwissen zusammenzuhängen.
5.5.7 Mögliche Auswirkungen der Interventionsmaßnahme
- Frage 9: :
-
Welche Auswirkungen hat die Interventionsmaßnahme auf die Problembearbeitungsprozesse der Teilnehmer?
Zur Beantwortung dieser Frage werden keine neuen Untersuchungen angestellt. Lediglich die bisherigen Betrachtungen werden aus diesem Blickwinkel zusammengefasst. Hierzu werden die Bearbeitungen von Malik, Julia und Jan mit einander verglichen. Grundsätzlich konnten Veränderungen beobachtet werden, allerdings müssen diese nicht auf die Maßnahme zurückzuführen sein, da die Probanden sich über ein Semester hinweg mit einigen Problemen auseinander gesetzt haben. Eine positive Entwicklung kann also verschiedene Gründe haben. Dennoch lassen sich einige Veränderungen erkennen, die, um es mit Schoenfelds Worten zu sagen, als Existenzbeweis dienen können. D. h. es gibt Veränderungen, diese müssen aber zum einen nicht bei jedem Probanden auftreten, zum anderen nicht zwingend auf die Maßnahme zurückzuführen sein. Da sich die Aufgaben stark von einander unterscheiden, kann auch das ein wichtiger Faktor sein.
In Bezug auf Heurismeneinsatz wurden keine wesentlichen Unterschiede zwischen dem ersten und dem zweiten Messzeitpunkt erkannt. Eine solche Änderung war, wie bereits in Abschnitt 2.4.5 beschrieben, auch nicht zu erwarten, da kurzfristige Heurismentrainings kaum Erfolge bringen.
Bei Jan lässt sich allerdings eine starke Verbesserung der metakognitiven Aktivitäten erkennen (vgl. S. 170 f.). Nicht nur haben sich diese quantitativ mehr als verdoppelt (von 19 auf 45, bei einer Zeitsteigerung von nur knapp acht Minuten von etwa 26 auf 34Footnote 43), was für sich genommen nicht bedeuten muss, auch die Qualität hat sich erhöht: Wurde beim ersten Prozess noch ein Weg eingeschlagen, der nicht zu einem richtigen Ergebnis führt, und dieser nur einmal hinterfragt und trotzdem weiter verfolgt, wird der zweite deutlich besser gesteuert. Zwar wird hier ein vielversprechender Ansatz verworfen, aber insgesamt kommt es zu vielen guten Einschätzungen, die auch mit einer Teillösung des Problems belohnt werden.
Auch bei Julia ist die grundsätzliche Steuerung ihrer Aktivitäten deutlich besser geworden (auch wenn es quantitativ relativ zur Zeit nur eine leichte Veränderung von 24 Aktivitäten in 41 Minuten zu 13 Aktivitäten in 18 Minuten). Dies zeigt sich vor allem in der Arbeit mit dem Skript (vgl. S. 131), die beim zweiten Mal zum einen sehr viel zielstrebiger ist (es wird nicht mehr das Skript Seite für Seite durchgegangen), zum anderen werden hier die vom Skript aufgeschnappten Begriffe besser in Bezug auf ihre Nützlichkeit eingeschätzt, was letztlich sogar zu der richtigen Vermutung führt, dass der Zwischenwertsatz das richtige Werkzeug sein muss, die aber leider nicht umgesetzt werden kann.
Bei Malik sieht die Sache nicht so eindeutig aus. Wie auf Seite 176 f. beschrieben, ist bereits bei seiner ersten Bearbeitung die Qualität der Kontrollstrategien sehr hoch. Allerdings kommt hier noch keine explizite Voraussicht vor und rein quantitativ hat sich die Zahl der metakognitiven Aktivitäten von 28 deutlich auf 67 (mit 47 bzw. 50 Minuten in fast derselben Zeit) erhöht. Auf der anderen Seite ist dies der Prozess, bei dem die meiste Zeit (fast 20 Minuten) für einen Ansatz aufgewendet wird, der zwar einen Spezialfall beweist, dessen Nützlichkeit aber (wahrscheinlich) in keinem guten Verhältnis zum Aufwand steht. Kurz gesagt: Es zeigen sich beim zweiten Durchgang zwar mehr und auch vielfältigere Aktivitäten als beim ersten Mal, die Qualität scheint aber eine geringere zu sein.
Es wurde also gezeigt, dass es Probanden gibt, bei denen sich die metakognitiven Aktivitäten nach Durchführung der Intervention verbessert haben, bei Malik war aber, was die Qualität angeht, eher das Gegenteil der Fall. Der einzige Proband aus der Kontrollgruppe, von dem zwei Prozessen untersucht wurden (Niklas) hat sich bezüglich der metakognitiven Aktivitäten eher verschlechtert.
5.6 Zusammenfassung
In diesem Abschnitt wurden die qualitativen Auswertungen des bei aufgabenbasierten Interviews gesammelten Videomaterials dargestellt. Es wurden insgesamt 13 Problembearbeitungsprozesse von neun verschiedenen Studienanfängern betrachtet. Hierbei wurden drei der vier Aspekte des Problemlösens nach Schoenfeld (1985) betrachtet: Die Rolle des Vorwissens (oder Ressources, Abschnitt 5.3.6 und 5.5.5), der Einsatz von Heurismen (Abschnitt 5.3.4 und 5.5.4) und metakognitive Aktivitäten (Abschnitt 5.3.5 und 5.5.6). Die Qualität der beiden letztgenannten wurde auch in Form von Leitfragen eingeschätzt (Abschnitt 5.3.7 bzw. 5.3.7). Der vierte Aspekt, die Beliefs, wurde hier nicht untersucht, da er zwar Einfluss auf die Prozesse hat, sich aber hierin nicht unmittelbar beobachten lässt. Darüber hinaus wurden Schoenfeld-Episoden (ebd.) betrachtet (Abschnitt 5.3.1 und 5.5.2). Hierbei haben sich insbesondere die Episoden des Planning und der Implementation als interessant herausgestellt. Zusätzlich wurde die Nutzung externer Ressourcen (im Wesentlichen handelt es sich hierbei um Arbeit mit dem Skript) untersucht (Abschnitt 5.3.2 und 5.5.3). Außerdem wurde mit Hilfe der gesammelten Materialien untersucht, welche Aktivitäten hilfreichen Ideen vorausgegangen sind (Abschnitt 5.5.5).
Ziel dieses Abschnittes ist die Beantwortung der
- Forschungsfrage 2: :
-
Wie laufen Problembearbeitungsprozesse bei Studienanfängern der Mathematik an authentischen Übungsaufgaben ab und welchen Einfluss hat dabei die Teilnahme an der Fördermaßnahme?
Diese Forschungsfrage wurde im Verlauf der BetrachtungenFootnote 44 in neun Teilfragen unterteilt, die sich in den entsprechende Unterabschnitten von Abschnitt 5.3 wiederfinden und im Folgenden referenziert werden.
Die bemerkenswerteste Erkenntnis aus den Untersuchungen ist die enorme Bedeutung des Vorwissens bei der Bearbeitung von Problemen in der Studieneingangsphase. Sicherlich ist nicht überraschend, dass dieses eine Rolle spielt (schließlich ist es einer der von Schoenfeld genannten Aspekte), bei der Betrachtung der Prozesse hat genau das sich aber als der entscheidende Faktor herausgestellt. Das ist besonders interessant, da die meisten Untersuchungen zum Problemlösen die Hürde des Vorwissens aus nachvollziehbaren Gründen möglichst gering halten.
Frage 6 hat gezeigt, dass mangelndes Vorwissen das Problemlösen erheblich erschweren oder eine erfolgreiche Bearbeitung komplett verhindern kann. Acht der betrachteten 13 Prozesse wurden durch fachliche Mängel behindert, teilweise in dem Maße, dass guter Heurismeneinsatz unmöglich gemacht wurde. In diesem Zusammenhang stellt sich die Frage, inwiefern Lernen durch Problemlösen (vgl. etwa Holzäpfel, Lacher, Leuders und Rott (2018)) stattfinden kann, wenn zum Problemlösen erst bestimmtes Vorwissen aufgebaut werden muss. Malik zeigt, dass es durchaus möglich ist, sich während des Problemlösens neues Wissen zu erarbeiten. Möglicherweise müssen Probleme und Vorwissen auch stärker auf einander abgestimmt werden.
Darüber hinaus stellt sich bei Beantwortung der Frage 5 heraus, dass für die Generierung hilfreicher Ideen grundlegendes Begriffswissen meist notwendige Voraussetzung ist. Darüber hinaus sind die Gründe für entstehende Ideen vielschichtig und oft auch nicht erkennbar. Allerdings hat sich eine systematische Analysis (Schoenfeld, 1985) bzw. gutes Understanding the Problem (Pólya, 1945) als wichtige Grundlage für die Ideenfindung erwiesen, weswegen den heuristischen Hilfsmittel großer Nutzen zukommt.
Bei der Skriptnutzung (Frage 2) hat sich gezeigt, dass die Probanden, die weniger auf externe Ressourcen zurückgreifen, bessere Erfolgsaussichten haben. Ein möglicher Grund liegt darin, dass diese Studierenden bereits eine gute mentale Repräsentation (Vorwissen) der fachlichen Inhalte haben, so dass sie nicht auf das Skript angewiesen sind und sich entsprechend leichter tun. Auch können Schlagwörter aus dem Skript leicht auf eine falsche Fährte führen, insbesondere, wenn die Bearbeiter ohnehin schon unsicher sind. Hier, wie bei jeder Richtungsentscheidung, kann eine gute metakognitive Kontrolle helfen.
Auch auf metakognitive Aktivitäten hat das Vorwissen Einfluss, wie Frage 8 zeigt. Die Studierenden setzen erstaunlich viele Kontrollstrategien ein, das heißt sie hinterfragen ihre Richtungsentscheidungen (im Gegensatz etwa zu Schoenfelds Probanden) regelmäßig. Nicht-zielführende Aktivitäten dauern selten länger als ein paar Minuten an: Bei zwei Probanden (Andreas und Jan) haben fachliche Fehler dazu geführt, dass jeweils ein länger verfolgter Ansatz nicht zur korrekten Lösung geführt, bei Malik wurde zu viel Zeit für die aufwändige Berechnung eines Spezialfalls aufgewendet, letztlich aber trotzdem das Ziel erreicht. Anderseits gab es ein paar Situationen, in denen das Vorgehen kontrolliert, also ein Ansatz hinterfragt wurde, dann aber die ungünstige Entscheidung getroffen wurde, eine zielführende Idee zu verwerfen. Auch diese Entscheidungen sind letztlich auf fachliche Fehleinschätzungen, also mangelndes Vorwissen zurückzuführen.
Planung wurde auf zwei verschiedene Arten betrachtet: Zum Einen in Form der Schoenfeld-Episoden Planning und Implementation (Frage 1), zum Anderen als metakognitive Planungsaktivität (Frage 7). Beide haben sich in gewisser Weise als vorteilhaft für den Problemlöseprozess erwiesen. Die Bearbeitungen, die Planning und Implementation enthalten, haben insgesamt höhere Lösungsqualitäten erreicht. Wie bereits diskutiert, ist dieses Ergebnis aber mit Vorsicht zu genießen, da die Art der Kodierung (sprich: ob Planning kodiert wird, möglicherweise von späteren (Teil-)Erfolgen beeinflusst wird. Beim Auftreten von Planungsaktivitäten hängt der Nutzen im Wesentlichen davon ab, wie konkret der Plan (möglicherweise auch nach außen hin unsichtbar) in den Gedanken des Probanden ist.
In Bezug auf den Heurismeneinsatz haben sich bisherige Erkenntnisse bestätigt: Zum Einen sind viele Heurismen stark aufgabenabhängig (Frage 3), wobei hier zu betonen ist, dass sich heuristische Hilfsmittel für sehr viele Aufgaben eignen oder, wenn das nicht der Fall ist, sich die Frage, ob ein solches Hilfsmittel sinnvoll ist, meist eindeutig verneinen lässt. Wie bereits erwähnt (Frage 5) sind es gerade diese Heurismen, die Ideengenerierung vorbereiten. Zum Anderen ist Heurismeneinsatz aber auch vom Bearbeiter abhängig. Bei den hier betrachteten Prozessen sind persönliche Vorlieben vor allem aber nicht ausschließlich beim Einsatz von Hilfselementen und Systematisierungshilfen aufgefallen.
Frage 9 beschäftigt sich mit den Effekten der Interventionsmaßnahme. Insgesamt scheint diese, wie viele kurzfristige Heurismentrainings (vgl. Abschnitt 2.4.5), keine Auswirkungen auf die Qualität des Heurismeneinsatzes zu haben. Allerdings zeigen sich bei zwei der drei betrachteten Fälle aus der Kontrollgruppe Verbesserungen bezüglich der Metakognition. Der dritte Fall war der erfolgreichste Problembearbeiter und hat auch im zweiten Prozess, trotz etwas schwächerer Metakognition, die Aufgabe vollständig gelöst. Vor allem das Beispiel von Jan kann als Existenzbeweis für Fortschritte während der Maßnahme gesehen werden. Ob diese Fortschritte auch ohne die Maßnahme gemacht worden wären, lässt sich allerdings nicht sagen.
Insgesamt konnte in einzelnen Prozessen der positive Einfluss von Heurismen und Metakognition bzw. Schwachstellen durch das Fehlen derselbigen ausgemacht werden. Besonders auffällig ist aber die überwältigende Bedeutung des Vorwissens das im authentischen Setting der gängigen universitären Übungspraxis nicht nur für sich genommen von großer Wichtigkeit ist, sondern auch die anderen Aspekte (Heurismeneinsatz und metakognitive Aktivitäten) mitbestimmt. Dieses Ergebnis passt zu den Erkenntnissen von Chi et al. (1989), die gezeigt haben, dass Experten in einem Gebiet stärker im Problemlösen sind, vor allem weil sie in der Lage sind, wichtige von unwichtigen Informationen zu unterscheiden.
Notes
- 1.
Eine Studentin sagte „Normalerweise würde ich mich jetzt duschen und mir die Haare föhnen. Dann fällt mir meistens was Gutes ein“.
- 2.
Zwar schreibt Schoenfeld an keiner Stelle explizit, dass er sich an Pólya orientiert hat, bei einem Vergleich seiner Episodentypen mit den Pólya-Phasen wird der Einfluss aber deutlich (vgl. hierzu auch Rott, 2013).
- 3.
Eine präzise Definition wird von Schoenfeld nicht gegeben, allerdings scheint nach dem Studium der einzelnen Episodentypen recht klar zu sein, was hier gemeint ist. Eine Diskussion der Problematik findet sich ebenfalls bei Rott (2013).
- 4.
Rott vermutet, dass diese Episodentypen bei Schoenfeld nicht notwendig waren, da dieser zum einen mit erwachsenen Probanden gearbeitet hat und zum anderen der Interviewer bei den Prozessen mit im Raum war. Dass bei den in der vorliegenden Arbeit betrachteten Prozessen ebendiese Bedingungen ebenfalls gegeben waren und auch hier diese Episodentypen als unnötig empfunden wurden, bestärkt Rotts Vermutung.
- 5.
wenn es beispielsweise einen Druckfehler in der Aufgabenstellung gegeben hat oder der Stift eines Probanden ersetzt werden musste, weil er nicht mehr schrieb
- 6.
Im Gegensatz zu den weiter unten abgedruckten Manualen zur Kodierung von Heurismen bzw. metakognitiven Aktivitäten sind hier keine Beispiele angegeben, da diese hier nicht prägnant zusammengefasst werden können. Den Kodierern wurden aber zu Beginn des Trainings mehrere Beispiele vorgeführt.
- 7.
Bereits Schoenfeld warnt davor, Episoden zu feinkörnig zu kodieren, die Festlegung der Mindestlänge wurde aber von Rott (2013) übernommen.
- 8.
Die Braunschweiger Arbeitsgruppe um Frank Heinrich hat sich intensiv mit Strategiefehlern beim Problemlösen beschäftigt. Betrachte hierzu etwa die Dissertationen von Heinrich (2004) oder Fritz (2020)
- 9.
Die in diesem Abschnitt in Anführungszeichen gesetzten Aussagen sind keine Zitate, sondern aus dem Gedächtnis gerufene Paraphrasen
- 10.
Genau genommen handelt es sich hierbei nicht um eine Folge, sondern um endlich viele (N) Zahlen. Hier und im Folgenden wird aber diese Formulierung, die Niklas durchweg verwendet, übernommen.
- 11.
Eigentlich sollte der Interviewer nicht eingreifen, aber in dieser Situation hat er sich dafür entschieden, wohl auch, weil andere Probanden in ähnlichen Situationen die Bearbeitung abgebrochen haben, in der Überzeugung, eine Antwort gefunden zu haben.
- 12.
Man könnte hier positive Auswirkungen auf die Lösungsqualität oder Verbindungen zum Grad der metakognitiven Aktivitäten (da letztere auch mit Strukturierung der eigenen Bearbeitung zu tun haben) vermuten. Anhand der beiden betrachteten Prozesse lassen sich allerdings keine Aussagen treffen.
- 13.
Zum Teil geschieht das in Maliks Bearbeitung der Quetschlemma-Aufgabe, auf die in Abschnitt 5.5.5 genauer eingegangen wird. Er kommt aber durch einen Wechsel des Ansatzes schließlich doch recht schnell zum Ziel. Auch Jan beschäftigt sich bei seiner Bearbeitung der Aufgabe zur konstanten Funktion sehr lange mit einem nicht-zielführenden Ansatz. Dieser Prozess liegt noch am nächsten an einer Wild Goose Chase (und das, obwohl er Planung und Implementation enthält! – Vgl. hierzu Abschnitt 5.5.6). Grundsätzlich denkbar ist eine lange Rechnung auch bei der Aufgabe zur linearen Unabhängigkeit, die Andreas bearbeitet.
- 14.
Die Stelle im Skript lautet wörtlich: „Eine Folge \(\{x_n\}_n \subset \mathrm{{I\!R}}\) heißt bestimmt divergent gegen \(+\infty \) (bzw. gegen \(-\infty \)), wenn zu jedem \(c \in \mathrm{{I\!R}}\) ein \(N \in \mathrm{{I\!R}}\) existiert, so dass \(x_n > c\) (bzw. \(x_n < c\)) für alle \(n \ge N\).“
- 15.
Auf der Seite, die er gerade aufgeschlagen hat, steht die Definition einer Teilfolge: „Eine Folge \((b_p)_{p \in \mathrm{{I\!N}}}\) heißt „Teilfolge“ der Folge \((a_n)_{p \in \mathrm{{I\!N}}}\), falls es eine Zuordnung \(p \rightarrow n_p \in \mathrm{{I\!N}}\), wobei \(p \in \mathrm{{I\!N}}\), gibt, mit \(n_1< n_2< \cdots< n_p< n-{p+1} < \cdots \), sodass \(b_p:=a_{n_p}\) für alle \(p \in \mathrm{{I\!N}}\) gilt.“
- 16.
Durch die Konvergenz des Quotienten gegen L könnte man auf die Idee kommen, dass \(a_n\) monoton (steigend oder fallend) ist. Dass dies nicht stimmt, zeigt das Gegenbeispiel \(a_n=(-1)^n\).
- 17.
Diese Einschätzung ist völlig richtig. Was Julia übersieht, ist, dass das Maximum (oder Minimum), das von einer Funktion auf einem kompakten Intervall laut Weierstraß immer angenommen wird, auch am Rand des Intervalls liegen kann.
- 18.
Genau genommen gilt dies für alle abwegigen Ideen, hier aber ganz besonders.
- 19.
Maliks Aufgabenstellung weicht in der Schreibweise leicht von der in Anhang D dargestellten ab: Die Variablen k und n sind bei ihm vertauscht, d. h. n ist der Laufindex der Summe und k gibt das k-te Folgenglied an. Zur besseren Übersicht wird die Notation hier (auch in Zitaten) angepasst, so dass dieselbe wie bei Niklas vorliegt.
- 20.
Diesen Versuch, der wahrscheinlich auch erfolgreich gewesen wäre, bricht er ab, weil ihm eine (vermutlich) schnellere Möglichkeit, nämlich das Anwenden des Quetschlemmas, einfällt, die er weiter verfolgt.
- 21.
Wie bereits bemerkt, handelt es sich hierbei nicht um ein heuristisches Hilfsmittel im engeren Sinne, da Spezialfälle nicht nur in der Analysis-Phase zur Anwendung kommen.
- 22.
Die eleganteste Methode, die sich auch leicht auf beliebige N übertragen ließe, wäre, aus der Summe unter der Wurzel \(a_N\) auszuklammern. Auf diese Idee kommt Malik aber nicht.
- 23.
Sicherlich sind das nicht die einzigen hilfreichen Heurismen. Diese sind aber bei den wenigen betrachteten Prozessen aufgefallen.
- 24.
gemeint ist auf der rechten Seite sicherlich \(\varepsilon \).
- 25.
Obwohl diese Idee direkt auf die Skriptnutzung folgt, ist nicht zu erkennen, dass der Blick ins Skript zur ihrer Generierung beigetragen hat. Malik schaut sich die Grenzwertsätze an, die weder direkt etwas mit dieser Idee zu tun haben, noch durch Widerspruch bewiesen werden.
- 26.
Die Betragsstriche spricht Malik nicht mit, er zeigt aber auf die entsprechenden Ungleichungen in seiner Niederschrift.
- 27.
So stehen etwa direkt nach der bereits in Abschnitt 5.5.3 erwähnten Definition der bestimmten Divergenz, die Patrick sogar vorliest, die Beispiele „Die Folge \(\{n\}_n\) divergiert bestimmt gegen \(+\infty \)“ und „Die Folge \(\{(-1)^n\}_n\) ist divergent aber nicht bestimmt divergent“.
- 28.
gemeint ist hier sicherlich die Wurzel
- 29.
Meist im Sinne von „Das wird/würde mir nicht weiterhelfen“ gemeint, aber im Präsens Indikativ formuliert, weswegen für eine Unterscheidung von Voraussicht und Evaluation der Wortlaut meist nicht ausreicht und der Kontext zwingend mitbetrachtet werden muss.
- 30.
Nach reiflicher Prüfung ist der Autor zu dem Schluss gekommen, dass die Einschätzung des Interviewers korrekt war und dieser Ansatz wirklich nicht hilfreich war.
- 31.
Bei vielen Aufgaben stehen zu Beginn Informationen, die den Gültigkeitsbereich einer Aussage bestimmen, darüber hinaus aber wenig bis keine Relevanz für den Beweis haben. Beispiele hierfür sind „Sei \(x \in \mathrm{{I\!R}}\)“, „Sei V ein K-Vektorraum“ oder eben „Sei M eine Menge“
- 32.
Dieser Ansatz führt letztlich zu einem Zirkelschluss, da man nicht einfach davon ausgehen kann, dass es ein m mit dieser Eigenschaft gibt.
- 33.
Da die Aufgabe nur zu zeigen verlangt, dass es ein n gibt, für das diese Gleichung gilt, würde dieses Ergebnis mit \(n=1\) schon genügen, wäre es kein Zirkelschluss
- 34.
dass dies nur für bijektive Abbildungen gilt, wird nicht beachtet, die Existenz von Umkehrfunktionen vorausgesetzt, ist der Beweis aber korrekt
- 35.
Da alle Zeilen linear unabhängig sind, wird dies auch so bleiben, wenn diese Zeilen in zwei Teilmatrizen aufgeteilt werden.
- 36.
Mit dieser Information ist das Problem aber durchaus leichter anzupacken, etwa dadurch, dass sich nach Durchführung des Gauss-Verfahrens die linear abhängigen Zeilen als Nullzeilen am unteren Ende der Matrizen wiederfinden oder dadurch, dass, wenn zuerst das Gauss-Verfahren bei \(A_1\) und \(A_2\) durchgeführt wird, Zeilen in \(A_1\) mit Zeilen in \(A_2\) übereinstimmen können, was bedeuten würde, dass der Rang von A kleiner wäre als die Summe der Ränge von \(A_1\) und \(A_2\).
- 37.
Natürlich braucht es mindestens zwei Zeilen für eine lineare Abhängigkeit, wenn es sich nicht gerade um eine Nullzeile handelt. Hier und im Folgenden wird die Sprechweise des Studenten übernommen, der während des Prozesses durchgehend den Eindruck macht, als wüsste er um die Verkürzung dieser Darstellung.
- 38.
Eine Wahl, bei der die Summanden kleiner 1 wären, etwa wenn der größte Summand \(a_k\) ausgeklammert würde, wäre zielführender.
- 39.
gemeint ist vermutlich „auszurechnen“.
- 40.
Dem ist ja nicht so, allerdings hat jeder y-Wert, der geroffen wird, mindestens zwei Urbilder (nämlich x und \(x^2\)).
- 41.
Denn hieraus folgt nur, dass \(f(x_0)=f(x_0^2)\) ist
- 42.
Streng genommen muss man hier aufpassen, da durchaus beide Folgen gegen unendlich gehen können. Letztlich zeigt Malik eher, dass \((\frac{x}{a_N})^n\) gegen 1 konvergiert.
- 43.
Die hier angegebenen Zahlen können nur eine grobe Orientierung geben. Obwohl ein Vergleich zweier Prozesse derselben Person sich eher rechtfertigen lässt, als der Verglich verschiedener Personen, können die verschiedenen Aufgaben unterschiedliche Anforderungen an die reine Menge der Aktivitäten liefern. Trotzdem sollen die Zahlen hier nicht verschwiegen werden.
- 44.
nicht a priori, da der ganzheitliche Blick nicht verstellt werden sollte
Author information
Authors and Affiliations
Corresponding author
5.1 Elektronische Zusatzmaterial
Rights and permissions
Open Access Dieses Kapitel wird unter der Creative Commons Namensnennung 4.0 International Lizenz (http://creativecommons.org/licenses/by/4.0/deed.de) veröffentlicht, welche die Nutzung, Vervielfältigung, Bearbeitung, Verbreitung und Wiedergabe in jeglichem Medium und Format erlaubt, sofern Sie den/die ursprünglichen Autor(en) und die Quelle ordnungsgemäß nennen, einen Link zur Creative Commons Lizenz beifügen und angeben, ob Änderungen vorgenommen wurden.
Die in diesem Kapitel enthaltenen Bilder und sonstiges Drittmaterial unterliegen ebenfalls der genannten Creative Commons Lizenz, sofern sich aus der Abbildungslegende nichts anderes ergibt. Sofern das betreffende Material nicht unter der genannten Creative Commons Lizenz steht und die betreffende Handlung nicht nach gesetzlichen Vorschriften erlaubt ist, ist für die oben aufgeführten Weiterverwendungen des Materials die Einwilligung des jeweiligen Rechteinhabers einzuholen.
Copyright information
© 2023 Der/die Autor(en)
About this chapter

Cite this chapter
Stenzel, T. (2023). Aufgabenbasierte Interviews. In: Mathematisches Problemlösen in der Studieneingangsphase . Essener Beiträge zur Mathematikdidaktik. Springer Spektrum, Wiesbaden. https://doi.org/10.1007/978-3-658-39052-5_5
Download citation
DOI: https://doi.org/10.1007/978-3-658-39052-5_5
Published:
Publisher Name: Springer Spektrum, Wiesbaden
Print ISBN: 978-3-658-39051-8
Online ISBN: 978-3-658-39052-5
eBook Packages: Life Science and Basic Disciplines (German Language)