
Abstract
DNA is the most elemental level of biodiversity, drives the process of speciation, and underpins other levels of biodiversity, including functional traits, species and ecosystems. Until recently biodiversity indicators have largely overlooked data from the molecular tools that are available for measuring variation at the DNA level. More direct analysis of trends in genetic diversity are now feasible and are ready to be incorporated into biodiversity monitoring. This chapter explores the current state-of-the-art in genetic monitoring, with an emphasis on new molecular tools and the richness of data they provide to supplement existing approaches. We also briefly consider proxy approaches that may be useful for many-species, global scale monitoring cases.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others


Keywords
5.1 Introduction
As the most elemental level of biodiversity, DNA is part of the software on which all life operates. Life has thrived in many different environments over the billions of years, encoding its solutions into DNA—the heredity material. Thanks to this genetic patrimony, many species are equipped with sufficient evolutionary resilience to overcome rapid environmental change (Hughes et al. 2008). Genetic divergence drives the process of speciation. Genetic variation, within and among species, plays an important role in ecosystem structure and function (Whitham et al. 2008). Genetic diversity therefore underpins other levels of biodiversity, including functional traits, species and ecosystems (see Fig. 1.1 in Chap. 1). Life’s capacity to adapt relies on genetic variation, and we should thus value it as a major way of mitigating the ecological degradation threatened by growing human impacts on the Earth system. Genetic variation within species is not only the currency of natural selection, it also underpins animal and plant breeding. As raw material for biotechnology, global genomic biodiversity provides a rich source of ‘parts’ for synthetic biology fuelling the new bio-economy. Molecular solutions discovered over the eons will help humanity address grand societal challenges of the 21st century regarding food, energy, water, and health. For example, crop genetic diversity has a critical role in addressing food and nutrition security, continually increasing yield from crops and livestock (on smaller land space), and instilling resilience to climate change (Dulloo et al. 2014; Hajjar et al. 2008; FAO 2015).
The value of genetic resources includes their capacity to generate ecosystem services, including supporting landscape-level ecosystem resilience (Hajjar et al. 2008; Narloch et al. 2011), maintaining socio-cultural traditions, local identities and traditional knowledge, and allowing plants and animals to undergo natural evolutionary processes, which in turn generate broad genetic variation essential for adaptation to change (Bellon 2009). Genetic variation contributes directly to agriculture by providing a range of valuable traits and genes that are used by modern day breeders for improvement, in particular those species which are closely related to domesticated forms (Hajjar and Hodgkin 2007). Genetic variation also enhances resilience to climate change by providing the traits that are key to the efficiency and adaptability of production systems. It underpins the efforts of local communities and researchers to improve the quality and output of food production (FAO 2015).
This chapter focuses on monitoring of changes in genetic diversity. In that context it is important to ask what is the definition and scope of genetic diversity? The Convention on Biological Diversity (CBD, article 2; www.cbd.int/sp/) defines biodiversity as: ‘the variability among living organisms from all sources. This includes diversity within species, between species and of ecosystems’. For example, the Intergovernmental Platform on Biodiversity and Ecosystem Services (IPBES; Díaz et al. 2015) has defined biodiversity as variation, but also included in the definition ‘changes in abundance and distribution over time and space within and among species, biological communities and ecosystems.’
These and other global efforts highlight the need to clarify the scope and meaning of terms such as ‘variability’ and ‘variation’ particularly when we are concerned with monitoring change over time. Many studies adopt the full range of indices from ecology that have been, or might be, referred to as ‘diversity’ indices, and equate these with ‘biodiversity’ (Faith 2016). McGill et al. (2015) recognised 15 kinds of trends in biodiversity (including genetic diversity), and it is important to consider whether these define the scope of concerns for monitoring within-species genetic diversity. The authors also considered four spatial scales (local, meta-community, biogeographical, and global) and four ‘classes of biodiversity metrics’ (alpha diversity, spatial beta diversity, temporal beta diversity, and abundance). In principle all of these categories could be relevant to genetic variation. However, this expanded notion of biodiversity—which includes change over time, spatial variation and abundance—is a relatively recent development for studies of within-species genetic diversity, which has tended to focus on estimating the number of different genetic units of some kind at a range of possible geographic scales. Homogenisation is also an important kind of genetic change. Other estimates (including many referred to in ecology as diversity indices) can be made, but are not by themselves complete descriptions of biodiversity and do a poor job at representing genetic diversity. Generally, we do not know which genetic units are most crucial to species and ecosystems, and so variability in itself is valued.
This focus on variation helps understand the value of genetic diversity referred to above. Genetic diversity provides ‘option value’—the value that variation has in potentially providing unanticipated benefits for humans in the future and the evolutionary potential of species (Faith 1992). While the relevance and role of genetic diversity was recognised in the Convention on Biological Diversity (CBD), its importance was largely overlooked during the following two decades (Laikre 2010). However, genetic diversity has been given more visibility since the release of the Aichi Biodiversity Targets in 2010, particularly in Target 13: ‘By 2020 the genetic diversity of cultivated plants and farmed and domesticated animals and of wild relatives, including other socio—economically as well as culturally valuable species is maintained and strategies have been developed and implemented for minimizing genetic erosion and safeguarding their genetic diversity.’ This bold and wide-ranging goal poses a major challenge for the scientific community because a globally coordinated approach to monitoring genetic diversity, whether for agricultural species or wildlife, is currently lacking (Hoban et al. 2013; Dulloo et al. 2010). A recent analysis of progress towards the Aichi Biodiversity Targets was unable to adequately assess progress towards Aichi Target 13 due to lack of time series data sources (Tittensor et al. 2014). To discern and compare trends, we need fit-for-purpose genetic monitoring tools that can be easily applied and replicated (Brown 2008; Pinsky and Palumbi 2014). The recently formed Genomic Observatories Network (GOs Network; see Box 5.1) is an example of one concerted, international attempt to respond to these needs. The GOs Network encourages major long-term research sites (e.g., International Long Term Ecological Research network; ILTER), whether in natural or agricultural ecosystems, to integrate genomics into their longitudinal (time-series) studies and to make these data available according to global data standards.
Until now biodiversity indicators have largely overlooked data from the molecular tools that are available for measuring variation at the DNA level, partly due to their limited availability, high expense, and inaccessibility, focusing instead on proxies, such as trends in the number of domestic livestock breeds and their wild relatives (see Tittensor et al. 2014). While such indicators may be useful in capturing higher order biodiversity trends (it is debatable whether number of breeds is an appropriate measure), they do not account for the genetic distinctiveness of the populations they assess; for instance, some breeds are more distinct than others. More direct analysis of trends in genetic diversity using molecular data are now feasible and are ready to be incorporated into biodiversity monitoring. To mobilise molecular genetic information in monitoring programs, standardised estimates of molecular genetic diversity within and among taxa at specific georeferenced points over time need to be implemented to enable spatial (among site) and temporal (within site) genetic variation to be compared. This chapter explores the current state-of-the-art in genetic monitoring, with an emphasis on new molecular tools and the richness of data they provide to supplement existing approaches. We will also briefly consider complementarity proxy approaches that still may be useful for the many-species, global scale monitoring cases.
5.2 Brief Overview of Developments in the Monitoring of Genetic Diversity
During the last 40 years, studies of genetic diversity have been transformed from simple statistical comparisons of allele frequencies of a handful of soluble enzymes (allozymes) for a few individuals within and among populations. It is now possible, and increasingly affordable, to analyse genome-wide sequence variation (thousands to millions of locations across a genome) across many (hundreds to thousands) individuals of any species, even from non-living remains like faeces or feathers. In parallel with the advances in DNA sequencing and related technologies, many sophisticated bioinformatics tools, software architectures and frameworks have been developed, driven by the need to analyse the huge amounts of data that these studies can generate. Some generally accepted standards are also now emerging from the many kinds of data suitable for monitoring of genetic diversity (Table 5.1). For example, DNA ‘barcodes’ (Hebert et al. 2003) allow building a library of sequences of the same gene across many different taxa linked to museum specimens and an authoritative taxonomic identification. Sequencing the barcode gene of any biological sample (including eggs, larvae, or parts of an organism such as legs or leaves) leads to rapid identification if the species has already been catalogued in a reference library (e.g., Barcode of Life Database; Ratnasingham and Hebert 2007).
In addition to species identification and studies of phylogenetic relationships, the variation in DNA sequences also enables refined estimates of genetic diversity at the species level and above (Faith 1992). These can be applied to specific taxa (e.g., an endangered species) and/or places (e.g., a national park or farm) and monitored over time, and these are the units we focus on for genetic monitoring. Within-species genetic diversity estimation has been transformed by the use of various genetic profiling methods since the late 1980s involving the use of DNA sequencing and DNA fragment analysis (Sunnucks 2000) and an ever-expanding range of statistical frameworks in which to analyse the data (Beaumont et al. 2002). Notably we can not only analyse levels of genetic variation but use this information to infer population parameters and demographic trajectories, often from a single point sample. Furthermore, the advent of metagenomics through environmental shotgun sequencing (Tyson et al. 2004; Venter et al. 2004) opened up the microbial world, heralding a new age of biotic exploration documenting what constitutes the overwhelming majority of life in both biomass and variation terms. Some of these advances have not reached the conservation monitoring literature and seemingly went almost unnoticed by the CBD and its associated bodies until recently. This oversight can perhaps be attributed to the astonishing pace of DNA sequencing capacity, increasing at a much faster rate than Moore’s Law since the mid 2000s. Perhaps the explosion in technologies and analytical methods made it difficult to settle on standardised genomics-based approaches for biodiversity monitoring. Of course, attention has also been largely focused on the more established (and visible) levels of biodiversity (e.g., CBD-related efforts on the global taxonomy initiative and the so-called ‘ecosystem approach’).
Ignoring the power and promise of genomics seems increasingly anachronistic. The public is increasingly aware of the benefits the ‘new age of genomics’ offers for personal and public health, and food and energy production (Field and Davies 2015). Genetics is likely to become increasingly important in biodiversity monitoring with rapid molecular assessment of species and ecosystems now feasible using high throughput DNA sequencing in a fraction of the time and cost of previous approaches (Whitham et al. 2008). Simultaneously, with the establishment of the IPBES, the recognition that understanding and maintaining genetic diversity within and among species may be key to ecosystem (and therefore ecosystem service) resilience in the face of climate change and other anthropogenic stressors, has raised the profile of genetic diversity substantially (Sgro et al. 2011; Mace et al. 2012; Pereira et al. 2013) leading to its incorporation into the Aichi Targets.
5.3 Spatio-Temporal Considerations in Genetic Monitoring
While genetic monitoring is a tool that has global relevance for the maintenance of biodiversity, like other monitoring techniques it can be costly and time-consuming. In particular, DNA cannot be read at a distance in contrast to ecosystems (e.g., remote sensing) or species (e.g., visual observation); rather, all genetic analyses require access to biodiversity and its physical sampling (Davies et al. 2012b). Genetic approaches are thus unlikely to be applicable in all cases where monitoring is required and may not be the most cost-effective option in some.
Box 5.1. The Genomic Observatories Network
Genomic Observatories (GOs) are sites where genomic information is collected alongside social-ecological, environmental and/or other biological data, ensuring co-location of observations and much-needed context for such genomic information (Davies et al. 2012a). GOs show commitment to the long-term collection of data, now and into the future, as well as to the depositing of such data in suitable repositories (Field 2011). GOs should be based on a subset of sites of ‘utmost scientific importance’ (Davies et al. 2012b) and be supported by field stations, universities, museums or similar organisations or institutions (Davies et al. 2012a), allowing for long-term observations and thus change detection.
The first published calls for the establishment of a GOs Network (Davies et al. 2012a, b) highlighted the fact that DNA sequences should be part of the data collected to monitor life on earth and that, whilst the costs of collecting and processing such samples remains high, the establishment of GOs could consolidate these monitoring efforts.
By hosting workshops and meetings on the side-lines of various conferences (see www.genomicobservatories.org/ for more information), the efforts in building a community around the GOs Network concept, culminated in the publication of the founding charter of the GOs Network and agreement on the network’s mission as working towards ‘Biocoding the Earth; integrating DNA data into Earth observing systems and eventually building a global Genomic Observatory within the Global Earth Observation System of Systems (GEOSS)’ (Davies et al. 2014; GEO Secretariat n.d.).
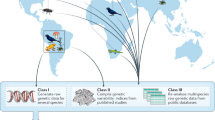
The GOs Network, which is a collaboration between the Group on Earth Observations Biodiversity Observation Network (GEO BON) and the Genomic Standards Consortium (GSC), held its first coordinated action in the form of Ocean Sampling Day (OSD) on 21 June 2014 and repeated it on the same day in 2015 (Field and Davies 2015; Kopf et al. 2015). The effort was joined by a number of GOs Network (marine) sites with the purpose of coordinated, standardised collection and sequencing of seawater throughout the world’s oceans (Field and Davies 2015; see Fig. 5.1).

Map showing registered sites for Ocean Sampling Day, 21 June 2014. Source Kopf et al. (2015)
This emerging network has not only ‘site members’ but recently New Zealand launched its Genomic Observatory project (see http://data.genomicobservatory.cs.auckland.ac.nz/) aimed at the characterisation (environmental and phylogenetically) of terrestrial species in a selected ecosystem, as a first national contribution to the GOs Network (Drummond et al. 2015).
Furthermore, other scientific communities have started work on supporting the efforts of the GOs Network, for example through the creation of the Biological Collections Ontology (BCO), which is to provide the informatics stack for the network (Walls et al. 2014).
A list of the scientific community members involved in the development of the network can be found at http://wiki.gensc.org/index.php?title=GOs_Network_Membership. Parties interested in joining the GOs Network may contact the coordinators of the initiative through their website at http://www.genomicobservatories.org/ and those interested in participating in upcoming OSD events can visit https://www.microb3.eu/osd.
One possibility is that specific sites can act as genetic biodiversity observatories where special efforts are made to document and monitor genetic biodiversity. The GOs Network is promoting just such an approach at the best-studied sites around the world (Davies et al. 2012a, 2014). Apart from the scientific and technical aspects of genetic monitoring, the need to access genetic resources in situ and carry out downstream analyses in laboratories and museums around the globe raises important legal and social concerns that must be addressed at each site. These include compliance with international legal instruments, such as the CBD’s Nagoya protocol on Access and Benefit Sharing (ABS) and CITES, as well as national and/or local regulations and sensitivities, which were often not written with genetic monitoring in mind, but for other reasons like protecting species or preserving sovereignty. Sampling and associated costs appear relatively incompressible (Davies et al. 2012b) and careful thought needs to be given to the spatio-temporal design of genetic monitoring or genetic assessments (defined as multiple or single sampling events, respectively, by Schwartz et al. (2007). A combination of the Global Genome Biodiversity Network (GGBN) and GOs Network, in conjunction with initiatives such as the ILTER (International Long Term Ecosystem Research) network, offers perhaps the best hope for establishing a coordinated global effort to monitor genetic biodiversity.
A wide diversity of molecular approaches can be adopted at any site, or within any ecosystem. The concept of an ecosystem can now be extended to individual organisms, including establishing the diversity of the microbiome within organisms or to the environment using metagenomics (Tringe et al. 2005). Community level diversity (e.g., species richness) might correlate with within-species genetic diversity of ecosystem-defining taxa (Zytynska et al. 2012), however, recent studies attempting to establish whether one diversity estimate might act as a reasonable proxy for the other, have been inconclusive (e.g., Evanno et al. 2009; Struebig et al. 2011; Taberlet et al. 2012). Within-species genetic diversity studies have proliferated during the last 20 years to the point that they are now routinely carried out globally and represent a huge, largely untapped resource for ecosystem evaluation. They have recently begun to be augmented by studies at the genome, epigenome and transcriptome level (Shafer et al. 2015). The domestic animal and plant community has led the way in within-species molecular biodiversity assessment (e.g., Boettcher et al. 2010; Cheng et al. 2011), including making recommendations on common tools for measuring variation in the same species at a global scale. Considering this vast amount of genetic data being generated anyway, another option is to evaluate genetic variation of species expected to have undergone erosion (e.g., due to harvest) and compare this to ‘reference’ or ‘control’ species, those having experienced no impact. This analysis of existing data could give an overall picture of genetic erosion (Hoban, pers comm). Indeed, Pinsky and Palumbi (2014) used this approach for more than 100 species of fish and found identifiable genetic erosion in harvested fish.
Although tools for genetic monitoring are now almost universally available, the statistical approaches needed to compare data, evaluate trends and provide indicators of genetic health are less well developed. This is partly because temporally spaced sampling of the same species at the same site for population genetic evaluation is rare, with the possible exception of commercial species (Hutchinson et al. 2003) where genetic material (e.g., fish fin clips) has been collected since population monitoring began. In the absence of sampling a population over time, analysis of genetic data from a single ‘point sample’ can still provide insights into recent demographic change (Goossens et al. 2006), although different estimators can have wide confidence intervals and provide inconsistent values depending on the methods chosen or model assumptions (Barker 2011). Recently, Hoban et al. (2014) carried out an assessment of temporal indicators of genetic erosion (sensu Aichi Target 13) to assess which metric and sampling would be the most sensitive to detecting short-term declines in genetic diversity. The number of alleles per genetic locus outperformed all other potential indicators (such as heterozygosity) across all scenarios tested. Sampling 50 individuals at as few as two time points with 20 microsatellite (DNA profiling) markers could reliably detect genetic erosion even in cases where 80–90 % of diversity remained. Power increased substantially with more samples or markers, with, for example, 2500 single nucleotide polymorphisms (SNPs) being extremely effective at detecting relatively subtle demographic declines. The latter observation is of particular relevance because since about 2010, biodiversity assessment has routinely used tens of thousands of SNPs (genome scale, or ‘next generation’ sequencing) in domestic animals and plants (e.g., Kijas et al. 2012) and the increased application of genome resequencing (sequencing whole genomes of multiple individuals of the same species) in non-model organisms (e.g., Lamichhaney et al. 2015). These methods can also be used in soil or water (marine, freshwater) samples to analyse ‘environmental DNA’ (eDNA), which includes ancient and modern genetic material from animals and plants as well as microbes (Pedersen et al. 2015; Kelly et al. 2014). Thus global capacity to perform molecular genetic monitoring with very high detail and precision is available and is being deployed in environmental assessment worldwide. Hoban et al. (2014) also concluded that there is ‘high potential for using historic collections in monitoring programs’. They found that statistical power to detect change was significantly improved if samples were available before the onset of decline—so that archived and museum collections clearly could play an important role as part of the monitoring program. Hoban et al. (2014) made another interesting conclusion relevant to the design of monitoring programs ‘many schemes were sufficient, and strict adherence to a particular sampling protocol seems unnecessary’.
5.4 What to Monitor?
While Schwartz et al. (2007) broadly defined genetic monitoring as the tracking of neutral genetic markers through time to estimate demographic and/or population genetic parameters, this Chapter is focused on changes in within-species genetic diversity. This focus is much closer to the studies addressing conservation strategies, at the level of within species genetic diversity. Eizaguirre and Baltazar-Soares (2014) summarised the key challenge: ‘which genetic metrics, temporal sampling protocols, and genetic markers are sufficiently sensitive and robust to be informative on conservation-relevant timescales?’ Dornelas et al. (2013) argued that, for genetic diversity, ‘sources of error are associated with the processes of selection of the genes of interest, amplifying and sequencing genes, and (especially for microbes) determining the boundaries of operational taxonomic units.’ These make sense, however microbial work has largely side-stepped the operational taxonomic units problem by using indices defined at the phylogenetic level (for discussion, see Faith et al. 2009). Unfortunately, these estimators are also the most sensitive to sampling bias (Leberg 2002). Consistent sampling is required to eliminate error or correction for the lowest sample size will often be necessary, resulting in a loss of information and sensitivity (but see Dornelas et al. 2013). Recent advances have provided robust methods that correct for sampling biases in estimates of phylogenetic diversity (e.g., Chao et al. 2015). van Zonneveld et al. (2014) concluded that the number of ‘locally common’ alleles (defined as alleles restricted to a limited area of a species’ distribution, but having high frequencies in these areas) may also be good indicators of overall genetic diversity. The question ‘What to monitor?’ also involves choosing which species or groups of species (including environmental sampling) are of highest priority given the substantial costs of physically sampling biodiversity over time. Target 13 of the CBD cites ‘domesticated plants and animals, their wild relatives, socio-economically important species and culturally valuable species’. We will consider these three categories separately although there is much overlap between them.
5.4.1 Domesticated Species
Domesticated species are relatively easy to define, they are largely found in agri-ecosystems. In such ecosystems, the key commercial crops and livestock must form an integral part of genetic monitoring protocols. We will focus here primarily on crop genetic diversity. To date there is poor knowledge of the distribution of genetic diversity that exists at the global level for all crops. Crop genetic diversity is distributed in space and time and occurs in farmer’s fields, wild habitats, market places and as conserved in ex situ collections such as genebanks and botanic gardens. It is widely believed that crop genetic diversity is being lost in farmers’ fields at an accelerated rate mainly due to the replacement of the heterogeneous (highly diverse) traditional varieties by uniform high-yielding improved varieties, as well as contributing factors that also affect natural ecosystems, such as climate change, habitat change, invasive alien species, overexploitation and pollution (FAO 2010; MA 2005). An additional problem, given the current development of genebank methodologies and management, is that of potential genetic erosion within genebanks, which should be monitored as well (Schoen and Brown 2001).
There is conflicting evidence for the erosion of crop genetic diversity (Dulloo et al. 2010; Bonneuil et al. 2012). There are many examples that have shown the loss of genetic diversity in cultivated plants. One of the classic examples is the study by the Rural Advancement Fund International (RAFI) that compared the number of varieties of different commercial crops known to the U. S. Department of Agriculture in 1903 to the number of varieties of these crops for which seeds existed in the National Seed Storage Laboratory (NSSL) in 1983 (Fowler and Mooney 1990). Considering about 75 different vegetables together, the RAFI study found that approximately 97 % of the varieties on the 1903 lists are now extinct. In China, of almost 10,000 varieties of wheat in use in 1949, only about 1000 remained by the 1970s (Arunachalam 1999). Further evidence for genetic erosion is provided by Hammer et al. (1996), who analysed differences between collecting missions in Albania (1941 and 1993) and in southern Italy (in 1950 and the late 1980s) and claimed high losses in genetic variability—genetic erosion of 72.4 and 72.8 %, respectively.
A major challenge is that there is no consensus on what type of data (genetic or proxy) can effectively be used to monitor genetic diversity at the global level (Dulloo et al. 2010; Pereira et al. 2013; Graudal et al. 2014). Although the molecular tools for measuring genetic diversity are well advanced and the cost becoming more affordable, as mentioned earlier, a major challenge remains to develop simple, inexpensive, and standardised means to monitor genetic diversity at a global scale (Frankham 2010). Up to now, monitoring of crop genetic diversity has focused mainly on existing data and the use of proxy indicators for genetic diversity (Brown 2008; Jarvis et al. 2008; Last et al. 2014). It has also been driven by the FAO’s country-led processes in developing State of the World Reports on plant genetic resources for food and agriculture (FAO 1997, 2010) and in monitoring the implementation of Global Plan of Action for the Conservation and Sustainable Utilization of Plant Genetic Resources for Food and Agriculture (PGRFA). Based on the occurrences and capacity to conserve and use PGRFA, a set of 63 indicators as well as three targets (Conservation of PGRFA, Sustainable use, and institutional and human capacities) for monitoring the status and trends of conservation and use of PGRFA has been developed and adopted (CGRFA 2013). Unfortunately, none of the indicators directly use genetic diversity metrics for assessing status of crop genetic diversity, but proxy indicators for in situ conservation, ex situ conservation, sustainable use and existing capacities are used instead. Further the FAO is developing a composite index based on the 63 indicators for each of the three targets. Brown (2008) discussed many diversity variables and argued that practical ones are based on number of individuals, area occupied in situ, number of accessions and number in gene banks ex situ. He provided a set of 22 genetic indicators for cultivated and wild plants.
At the European level, a pan-European collaborative initiative, Streamlining European Biodiversity Indicators (SEBI) was started in 2005 to provide a workable set of biodiversity indicators for Europe to measure progress towards the target of halting the loss of biodiversity in Europe by 2010 (Biała et al. 2012). The SEBI aim was to build on current monitoring and available data to avoid duplication of efforts and to complement other activities to describe, model and understand biodiversity and the pressures upon it. Within this context, Last et al. (2014) proposed five indicators for the estimation of genetic diversity, by which they meant crop accession or breed diversity at the farm level. These were ‘Crop-Species Richness’, ‘Crop-Cultivar Diversity’, ‘Type of Crop Accessions’, ‘Livestock-Species Richness’ and ‘Breed Diversity’. Additionally, they evaluated the potential role of such indicators for developing strategies to conserve or increase crop cultivars and livestock breeds in agro-ecosystems.
One of the best examples of monitoring crop diversity at the genetic level was by Bonneuil et al. (2012). They carried out a literature review to assess bread wheat diversity, as well as a range of general studies on the assessment of crop genetic diversity (see list in Goffaux et al. 2011), according to the level of genetic diversity they target (varietal or allelic) and in which pool it is measured (ex situ collections, registered varieties, or in situ (on-farm). They showed that most studies assess diversity within registered varieties or genebanks, while only a few considered the diversity actually cultivated. They also argued that the different indices (the number of varieties; the Shannon index, the Simpson index and the Piélou’s hierarchical diversity index) of diversity for in situ (on farm) diversity, account for the richness and evenness of varieties spatial distribution, while Nei’s index accounts for allelic diversity across a pool of varieties. However, there was no study that has combined intra varietal allelic diversity. Bonneuil et al. (2012) therefore developed a composite indicator that integrates richness, evenness and inter-variety allelic diversity as well as within-variety allelic diversity and proposed the H T * index as an integrated indicator for crop diversity on farms. They tested the index on a comprehensive historical dataset of bread wheat varieties dating back to 1878 from a French territory, Eure-et-Loire department. The study revealed that more varieties (the varietal richness factor) can mean less diversity when their genetic structure is more similar (the effect of between-variety genetic diversity), or when more diverse landraces are replaced by many homogeneous lines (the effect of within-variety genetic diversity), or else when one or a few varieties become hegemonic in the landscape (the spatial evenness effect). Furthermore, increased evenness in variety distribution (varietal evenness) can also mean less diversity when varieties are genetically related.
The domestic animal community fully embraced molecular characterisation within and among livestock breeds and species since the early 1990s, thanks to the proactive role of the International Association for Animal Genetics and the FAO, who established and revised guidelines for the use of genetic markers (initially microsatellites; see Hoffmann et al. 2004; Groeneveld et al. 2010). As a result, many studies have used the same marker systems for the more common domestic livestock species. More recently, microsatellites have been largely superceded by medium to high-density Single Nucleotide Polymorphism (SNP) arrays, which provide comprehensive, genome-wide surveys of genetic diversity at an affordable cost (Matukumalli et al. 2009; for a review see Bruford et al. 2015).
5.4.2 Socioeconomically (and Ecologically) Important Species
Socio-economically important species may include those that humans exploit for food, shelter, medicines, fuel and ecotourism income but may also include those that are ecologically important providing other key ecosystem services such as pollination, nutrient cycling and pest regulation (Bailey 2011). The genetics of ‘foundation species’, those that structure their environment, such as trees and corals, could be particularly important as heritable changes in these species could affect entire ecosystems. The field of community genetics (Whitham et al. 2008) has tended to focus on genetic surveys of key indicator species of ecosystems, often including vegetation (Bailey 2011; Zytynska et al. 2012). Indicators or foundation species may be a first priority to monitor. An alternative approach may be to choose representatives from key functional groups within ecosystems, standard practice in microbial community genetics (Nannipieri et al. 2003; He et al. 2007), and routinely applied in animal and plant ecology.
Wild species that are commercially relevant such as marine and freshwater fish, timber trees, crop pests and large predators have seen an explosion in genetic studies during the last three decades, focusing on DNA barcoding for species identification and wildlife forensics (e.g., Minhós et al. 2013), delineation of commercial stocks using population genetics approaches (e.g., Nielsen et al. 2012), genetic assignment of individuals or their products to source population (e.g., Lowe and Cross 2011) and assessing the impacts of anthropogenic barriers such as roads or dams to the movement of individuals (e.g., Keller and Largiader 2003). Such approaches are directly influencing policy and management, enabling law enforcement helping authorities to prioritise their direct interventions and redefine populations for exploitation management.
5.4.3 Monitoring Genetic Diversity in Culturally Valued Species
The definition of culturally valuable species is even more open to interpretation, but could reasonably include locally important domesticated breeds and landraces, wild species of emblematic significance, wild species of medicinal value (e.g., Shivaprakash et al. 2014) and those in immediate danger of extinction that attain cultural significance. The field of conservation genetics has traditionally focused on emblematic and endangered species and local breeds that might be regarded as culturally valuable, however, a wider definition of cultural value may be needed to ensure all elements of this category can be encapsulated in a comprehensive manner (Hoban et al. 2013).
5.5 Proxies for Reporting Changes in Genetic Diversity
Earlier we expressed some caution about the use of simple proxies for within species genetic diversity. The increased capacity to capture genomics information for many species at many places will gradually reduce reliance on proxy approaches. However, interest in human impacts on biodiversity at the level of within-species genetic variation includes not only poorly studied species but also those still unknown to science. Thus, well-designed proxies may still fill a gap in providing broad-brush ‘report cards’ on change in within-species genetic diversity, for many species at broad scales (e.g., globally; see the section on PGRFA above). Hoban et al. (2014) cautioned against some simplistic uses of proxies for genetic diversity change, and this seems particularly relevant when considering a single target species. In contrast, proxies may serve well as a complement to these direct approaches, when a broad brush report card on all species is needed. What sorts of proxies may be useful? Good candidates will build on information that is already widely available through existing monitoring efforts at the species level. For example, information on the range extent, distribution and abundance for many species is available, and this information is often complemented by associated information on key environmental variables.
There are two fundamental geographic scales for such proxies—proxies may be developed within one area, or for a collection of many areas (thus, regional or global). As an example of a localised proxy, Taberlet et al. (2012) assessed how well the estimated species richness of geographic areas corresponded to the area’s average within-species genetic diversity. These proxies were judged as not useful, countering conventional assumptions that patterns in species richness among areas may be informative about genetic diversity. More effective proxies may operate among-areas, and take advantage of changes in species’ range extent and/or occupancy of ‘environmental space’. Such broad-brush approaches can take advantage of, and add value to, the well-developed regional-to-global monitoring systems at the species level (e.g., Map of Life; https://www.mol.org/). One broad-brush approach can assess the loss of genetic diversity, using models that link loss of geographic range for a given species to its loss of genetic diversity. Previous work has largely focussed on comparisons among species to make predictions about their relative levels of genetic diversity. For example, Frankham (1996) showed that genetic variation will be greater in those species with wider ranges. Vellend and Geber (2005) treated species diversity–genetic diversity relationships by looking at correlation coefficients between species diversity and the genetic diversity of a focal species among localities. The key information gap is about how loss of the geographic or environmental range within a given species relates to loss of its genetic diversity. Recently, Mimura et al. (in revision) provided some evidence that patterns of genetic diversity, covering the range of various well-sampled species, provide support for a ‘power curve’ relationship (analogous to the well-known species-area relationship) linking range loss to loss of genetic diversity. They also argued that the exact relationship for a given species may vary in a predictable way according to factors such as the general dispersal ability of the species. This may allow a small number of proxy-models based on power curves to infer genetic diversity losses for a wide range of species.
A closely-related approach can use changes in a species’ coverage of its environmental range or ‘environmental space’ to infer its consequent loss in genetic diversity. When a population of a given species exists in predictable environmental space, changes in area of that space may suggest changes in genetic diversity thus loss of environmental range may correlate with loss of genetic diversity. There is some empirical support for these proxies. Zhang et al. (2013) showed that both geographic and environmental distances are significant correlates of genetic differentiation among locations. Congruence between geographic and environmental distances and genetic distances supports the potential for genetic diversity proxy models that assess loss of coverage of environmental space (Faith 2015).
The challenge to produce global report cards on the loss of within-species genetic diversity is timely. For example, the Planetary Boundaries framework (Rockström et al. 2009) has proposed that loss of global genetic diversity is one of the key variables for understanding whether society is within a ‘safe operating space’ for sustainability. Such assessments could be augmented by monitoring the loss of geographic and/or environmental range, for a representative sample of species. Mimura et al. (in revision) argue that the indicator value for a representative subset of species can provide a general indicator of within-species genetic diversity loss for all species and outline a procedure to derive this subset, based on the available distribution information. They define three steps: (1) For any two species, calculate their ‘dissimilarity’ based on the difference in their locations in geographic (or environmental) space; (2) Use the dissimilarities to derive an arbitrary but pre-chosen k number of clusters of species. For example, k-means clustering algorithms can directly use dissimilarities or genetic data to derive k clusters. Choose a member of each cluster to form the subset of k representative species; (3) For the k species, apply the proxy model to infer loss of genetic diversity based on loss of geographic (or environmental) range extent.
Proxy indicators are a potentially efficient approach to bridging the evidence gap on genetic diversity within species. However, the relationships mentioned above in terms of genetic diversity and ecological space are dependent on various assumptions including demographic history, natural and/or artificial selection signatures and the ability to disperse. Therefore, we would advocate these approaches as primarily extension mechanisms and would not suggest they can replace genetic data nor do they provide the rich information available from the genomes of the planet’s species.
References
Arunachalam, V. (1999). Genetic erosion in plant genetic resources and early warning system: a diagnosis dilating genetic conservation. M. S. Swaminathan Research Foundation, Chennai, India. http://59.160.153.185/library/node/403
Bailey, J. K. (2011). From genes to ecosystems: A genetic basis to ecosystem services. Population Ecology, 53, 47–52.
Barker, J. S. F. (2011). Effective population size of natural populations of Drosophila buzzatti, with a comparative evaluation of nine methods of estimation. Molecular Ecology, 20, 4452–4471.
Beaumont, M. A., Zhang, W., & Balding, D. J. (2002). Approximate Bayesian computation in population genetics. Genetics, 162, 2025–2035.
Bellon, M. R. (2009). Do we need crop landraces for the future? Realizing the global option value of in situ conservation. In A. Kontoleon, U. Pascual, & M. Smale (Eds.), Agrobiodiversity and economic development (pp. 51–59). London and New York: Routledge.
Biała, K., Condé, S., Delbaere, B., Jones-Walters, L., & Torre-Marín, A., (2012). Streamlining European biodiversity indicators 2020: Building a future on lessons learnt from the SEBI 2010 process. EEA Technical Report No. 11/2012. EEA, Copenhagen, Denmark.
Boettcher, P. J., Tixier-Boichard, M., Toro, M. A., Simianer, H., Eding, H., Gandini, G., et al. (2010). Objectives, criteria and methods for using molecular genetic data in priority-setting for conservation of animal genetic resources. Animal Genetics, 41(s1), 64–77.
Bonneuil, C., Goffaux, R., Bonnin, I., Montalent, P., Hamon, C., Balfourier, F., et al. (2012). A new integrative indicator to assess crop genetic diversity. Ecological Indicators, 23, 280–289.
Brown, A. H. D. (2008). Indicators of Genetic Diversity, Genetic Erosion and Genetic Vulnerability for Plant Genetic Resources for Food and Agriculture. Food and Agriculture Organisation of the United Nations, Rome, Italy.
Bruford, M. W., Ginja, C., Hoffmann, I., Joost, S., Orozco-terWengel, P., Alberto, F. J., et al. (2015). Prospects and challenges for the conservation of farm animal genomic resources 2015-2025. Frontiers in Genetics, 6, 314.
CGRFA. (2013). Report of the fourteenth regular session of the Commission on genetic resources for food and agriculture, Rome Italy 15-19 April 2013. CGRFA- 14/13/Report. Food and Agriculture Organisation of the United Nations, Rome, Italy.
Chao, A., Chiu, C. H., Hsieh, T. C., Davis, T., Nipperess, D. A., & Faith, D. P. (2015). Rarefaction and extrapolation of phylogenetic diversity. Methods in Ecology and Evolution, 6, 380–388.
Cheng, F., Liu, S., Wu, J., Fang, L., Sun, S., Liu, B., et al. (2011). BRAD: The genetics and genomics database for brassica plants. BMC Plant Biology, 11, 1.
Davies, N. & Field, D., and the Genomic Observatories Network (2012a). Sequencing data: A genomic network to monitor Earth. Nature 481, 145.
Davies, N., Meyer, C., Gilbert, J. A., Amaral-Zettler, L., Deck, J., Bicak, M., Rocca-Serra, P., et al. (2012b). A call for an international network of genomic observatories (GOs). Gigascience 1, 5.
Davies, N., Field, D., Amaral-Zettler, L., Clark, M., Deck, J., Drummond, A., et al. (2014). The founding charter of the Genomic Observatories Network. GigaScience, 3, 2.
Díaz, S., Demissew, S., Carabias, J., Joly, C., Lonsdale, M., Ash, N., et al. (2015). The IPBES Conceptual Framework—Connecting nature and people. Current Opinion in Environmental Sustainability, 14, 1–16.
Dornelas, M., Magurran, A. E., Buckland, S. T., Chao, A., Chazdon, R. L., Colwell, R. K., et al. (2013). Quantifying temporal change in biodiversity: Challenges and opportunities. Proceedings of the Royal Society of London B: Biological Sciences, 280, 20121931.
Drummond, A. J., Newcomb, R. D., Buckley, T. R., Xie, D., Dopheide, A., Potter, B. C., et al. (2015). Evaluating a multigene environmental DNA approach for biodiversity assessment. GigaScience, 4, 46.
Dulloo, M. E., Hunter, D., & Borelli, T. (2010). Ex situ and in situ conservation of agricultural biodiversity: Major advances and research needs. Notulae Botanicae Horti Agrobotanici Cluj-Napoca, 38, 123–135.
Dulloo, M. E., Hunter, D., & Leaman, D. (2014). Plant diversity in addressing food, nutrition and medicinal needs. In A. Gurib-Fakim (Ed.), Novel plant bioresources: applications in food, medicine and cosmetics (pp. 1–21). Chichester, UK: Wiley.
Eizaguirre, C., & Baltazar-Soares, M. (2014). Evolutionary conservation—Evaluating the adaptive potential of species. Evolutionary Applications, 7, 963–967.
Evanno, G., Castella, E., Antoine, C., Paillat, G., & Goudet, J. (2009). Parallel changes in genetic diversity and species diversity following a natural disturbance. Molecular Ecology, 18, 1137–1144.
Faith, D. P. (1992). Conservation evaluation and phylogenetic diversity. Biological Conservation, 61, 1–10.
Faith, D. P. (2015). Phylogenetic diversity, function trait diversity and extinction: avoiding tipping points and worst-case losses. Philosophical Transactions of the Royal Society of London B: Biological Sciences, 370, 1–10.
Faith, D. P. (2016). A general model for biodiversity and its value. In J. Garson, A. Plutynski, & S. Sarkar (Eds.), The routledge handbook on the philosophy of biodiversity. Routledge.
Faith, D. P., Lozupone, C. A., Nipperess, D., & Knight, R. (2009). The cladistic basis for the phylogenetic diversity (PD) measure links evolutionary features to environmental gradients and supports broad applications of microbial ecology’s “phylogenetic beta diversity” framework. International Journal of Molecular Sciences, 10, 4723–4741.
FAO. (1997). Report on the state of the world’s plant genetic resources. Food and Agriculture Organisation of the United Nations, Rome, Italy.
FAO. (2015). Coping with climate change—The roles of genetic resources for food and agriculture. Food and Agriculture Organisation of the United Nations, Rome, Italy.
FAO. (2010). The second report on the state of the world’s plant genetic resources for food and agriculture. Food and Agriculture Organisation of the United Nations, Rome, Italy.
Field, D. (2011). What is a Genomic Observatory? Retrieved November 7, 2015, from http://genomicobservatories.blogspot.co.za/2011/08/what-is-genomic-observatory.html
Field, D., & Davies, N. (2015). Biocode: The new age of genomics. Oxford, UK: Oxford University Press.
Fowler, C., & Mooney, P. (1990). Shattering food, politics, and the loss of genetic diversity. Tucson, USA: The University of Arizona Press.
Frankham, R. (1996). Relationship of genetic variation to population size in wildlife. Conservation Biology, 10, 1500–1508.
Frankham, R. (2010). Challenges and opportunities of genetic approaches to biological conservation. Biological Conservation, 143, 1919–1927.
GEO Secretariat. (n.d.). GEOSS: access—Connecting users. Retrieved November 7, 2015, from http://www.earthobservations.org/geoss.php
Goffaux, R., Goldringer, I., Bonneuil, C., Montalent, P., & Bonnin, I. (2011). Quels indicateurs pour suivre la diversité génétique des plantes cultivées. Le cas du blé tendre cultivé en France depuis un siècle. Rapport FRB, Série Expertise et synthèse, 44.
Goossens, B., Chikhi, L., Ancrenaz, M., Lackman-Ancrenaz, I., Andau, P., & Bruford, M. W. (2006). Genetic signature of anthropogenic population collapse in orang-utans. PLoS Biology, 4, 285–291.
Graudal, L., Aravanopoulos, F., Bennadji, Z., Changtragoon, S., Fady, B., Kjær, E. D., et al. (2014). Global to local genetic diversity indicators of evolutionary potential in tree species within and outside forests. Forest Ecology and Management, 333, 35–51.
Groeneveld, L. F., Lenstra, J. A., Eding, H., Toro, M. A., Scherf, B., Pilling, D., et al. (2010). Genetic diversity in farm animals—A review. Animal Genetics, 41(s1), 6–31.
Hajjar, R., & Hodgkin, T. (2007). The use of wild relatives in crop improvement: A survey of developments over the last 20 years. Euphytica, 156, 1–13.
Hajjar, R., Jarvis, D. I., & Gemmill-Herren, B. (2008). The utility of crop genetic diversity in maintaining ecosystem services. Agriculture, Ecosystems & Environment, 123, 261–270.
Hammer, K., Knüpffer, H., Xhuveli, L., & Perrino, P. (1996). Estimating genetic erosion in landraces—Two case studies. Genetic Resources and Crop Evolution, 43, 329–336.
He, Z., Gentry, T. J., Schadt, C. W., Wu, L., Liebich, J., Chong, S. C., et al. (2007). GeoChip: A comprehensive microarray for investigating biogeochemical, ecological and environmental processes. The ISME journal, 1, 67–77.
Hebert, P. D., Cywinska, A., & Ball, S. L. (2003). Biological identifications through DNA barcodes. Proceedings of the Royal Society of London B: Biological Sciences, 270, 313–321.
Hoban, S., Arntzen, J. A., Bruford, M. W., Godoy, J. A., Rus Hoelzel, A., Segelbacher, G., et al. (2014). Comparative evaluation of potential indicators and temporal sampling protocols for monitoring genetic erosion. Evolutionary Applications, 7, 984–998.
Hoban, S. M., Hauffe, H. C., Pérez-Espona, S., Arntzen, J. W., Bertorelle, G., Bryja, J., et al. (2013). Bringing genetic diversity to the forefront of conservation policy and management. Conservation Genetics Resources, 5, 593–598.
Hoffmann, I., Marsan, P. A., Barker, J. S. F., Cothran, E. G., Hanotte, O., Lenstra, J. A., Milan, D., et al. (2004). New MoDAD marker sets to be used in diversity studies for the major farm animal species: recommendations of a joint ISAG/FAO working group. In Proceedings of the 29th International Conference on Animal Genetics (Vol. 123), Meiji University, Tokyo, Japan. Food and Agriculture Organisation of the United Nations, Rome, Italy.
Hughes, A. R., Inouye, B. D., Johnson, M. T., Underwood, N., & Vellend, M. (2008). Ecological consequences of genetic diversity. Ecology Letters, 11, 609–623.
Hutchinson, W. F., van Oosterhout, C., Rogers, S. I., & Carvalho, G. R. (2003). Temporal analysis of archived samples indicates marked genetic changes in declining North Sea cod (Gadus morhua). Proceedings of the Royal Society of London B: Biological Sciences, 270, 2125–2132.
Jarvis, D. I., Brown, A. H., Cuong, P. H., Collado-Panduro, L., Latournerie-Moreno, L., Gyawali, S., et al. (2008). A global perspective of the richness and evenness of traditional crop-variety diversity maintained by farming communities. Proceedings of the National Academy of Sciences, 105, 5326–5331.
Keller, I., & Largiader, C. R. (2003). Recent habitat fragmentation caused by major roads leads to reduction of gene flow and loss of genetic variability in ground beetles. Proceedings of the Royal Society of London B: Biological Sciences, 270, 417–423.
Kelly, R. P., Port, J. A., Yamahara, K. M., Martone, R. G., Lowell, N., Thomsen, P. F., et al. (2014). Harnessing DNA to improve environmental management. Science, 344, 1455–1456.
Kijas, J. W., Lenstra, J. A., Hayes, B., Boitard, S., Neto, L. R. P., San Cristobal, M., et al. (2012). Genome-wide analysis of the world’s sheep breeds reveals high levels of historic mixture and strong recent selection. PLoS Biology, 10, e1001258.
Kopf, A., Bicak, M., Kottmann, R., Schnetzer, J., Kostadinov, I., Lehmann, K., Fernandez-Guerra, A., et al. (2015). The ocean sampling day consortium. GigaScience, 4, 1–5. http://doi.org/10.1186/s13742-015-0066-5
Laikre, L. (2010). Genetic diversity is overlooked in international conservation policy implementation. Conservation Genetics, 11, 349–354.
Lamichhaney, S., Berglund, J., Almén, M. S., Maqbool, K., Grabherr, M., Martinez-Barrio, A., et al. (2015). Evolution of Darwin’s finches and their beaks revealed by genome sequencing. Nature, 518, 371–377.
Last, L., Arndorfer, M., Balázs, K., Dennis, P., Dyman, T., Fjellstad, W., et al. (2014). Indicators for the on-farm assessment of crop cultivar and livestock breed diversity: A survey-based participatory approach. Biodiversity Conservation, 23, 3051–3071.
Leberg, P. L. (2002). Estimating allelic richness: Effects of sample size and bottlenecks. Molecular Ecology, 11, 2445–2449.
Lowe, A. J., & Cross, H. B. (2011). Application of DNA methods to timber tracking and origin verification. IWA Journal, 32, 251–262.
MA [Millennium Ecosystem Assessment]. (2005). Ecosystems and human wellbeing: Synthesis. Washington, DC, USA: Island Press.
Mace, G. M., Norris, K., & Fitter, A. H. (2012). Biodiversity and ecosystem services: A multilayered relationship. Trends in Ecology & Evolution, 27, 19–26.
Matukumalli, L. K., Lawley, C. T., Schnabel, R. D., Taylor, J. F., Allan, M. F., Heaton, M. P., et al. (2009). Development and characterization of a high density SNP genotyping assay for cattle. PLoS ONE, 4, e5350.
McGill, B. J., Dornelas, M., Gotelli, N. J., & Magurran, A. E. (2015). Fifteen forms of biodiversity trend in the Anthropocene. Trends in Ecology & Evolution, 30, 104–113.
Minhós, T., Wallace, E., da Silva, M. J. F., Sá, R. M., Carmo, M., Barata, A., et al. (2013). DNA identification of primate bushmeat from urban markets in Guinea-Bissau and its implications for conservation. Biological Conservation, 167, 43–49.
Nannipieri, P., Ascher, J., Ceccherini, M., Landi, L., Pietramellara, G., & Renella, G. (2003). Microbial diversity and soil functions. European Journal of Soil Science, 54, 655–670.
Narloch, U., Pascual, U., & Drucker, A. G. (2011). Cost-effectiveness targeting under multiple conservation goals and equity considerations in the Andes. Environmental Conservation, 38, 417–425.
Nielsen, E. E., Cariani, A., Mac Aoidh, E., Maes, G. E., Milano, I., Ogden, R., et al. (2012). Gene-associated markers provide tools for tackling illegal fishing and false eco-certification. Nature Communications, 3, 851.
Pedersen, M. W., Overballe-Petersen, S., Ermini, L., Der Sarkissian, C., Haile, J., Hellstrom, M., et al. (2015). Ancient and modern environmental DNA. Philosophical Transactions of the Royal Society of London B: Biological Sciences, 370, 20130383.
Pereira, H. M., Ferrier, S., Walters, M., Geller, G. N., Jongman, R. H. G., Scholes, R. J., et al. (2013). Essential biodiversity variables. Science, 339, 277–278.
Pinsky, M. L., & Palumbi, S. R. (2014). Meta-analysis reveals lower genetic diversity in overfished populations. Molecular Ecology, 23, 29–39.
Ratnasingham, S., & Hebert, P. D. (2007). BOLD: The Barcode of Life Data System (http://www.barcodinglife.org). Molecular Ecology Notes 7, 355–364.
Rockström, J., Steffen, W., Noone, K., Persson, Å., Chapin, F. S., Lambin, E. F., et al. (2009). A safe operating space for humanity. Nature, 461, 472–475.
Schoen, D. J., & Brown, A. H. D. (2001). The conservation of wild plant species in seed banks. Biosciences, 51, 960–966.
Schwartz, M. K., Luikart, G., & Waples, R. (2007). Genetic monitoring as a promising tool for conservation and management. Trends in Ecology and Evolution, 22, 25–33.
Sgro, C., Lowe, A. J., & Hoffmann, A. A. (2011). Building evolutionary resilience for conserving biodiversity under climate change. Evolutionary Aspplications, 4, 326–337.
Shafer, A. B. A., Wolf, J. B. W., Alves, P. C., Bergström, L., Bruford, M. W., Brännström, I., et al. (2015). Genomics and the challenging transition into conservation practice. Trends in Ecology and Evolution, 30, 78–87.
Shivaprakash, K. N., Ramesha, B. T., Shaanker, R. U., Dayanandan, S., & Ravikanth, G. (2014). Genetic structure, diversity and long term viability of a medicinal plant, Nothapodytes nimmoniana Graham. (Icacinaceae), in protected and non-protected areas in the Western Ghats biodiversity hotspot. PloS One, 9, e112769.
Struebig, M., Kingston, T., & Petit, E. J. (2011). Parallel declines in species and genetic diversity in tropical forest fragments. Ecology Letters, 14, 582–590.
Sunnucks, P. (2000). Efficient markers for population biology. Trends in Ecology and Evolution, 15, 199–203.
Taberlet, P., Zimmermann, N. E., Englisch, T., Tribsch, A., Holderegger, R., Alvarez, N., et al. (2012). Genetic diversity in widespread species is not congruent with species richness in alpine plant communities. Ecology Letters, 15, 1439–1448.
Tittensor, D. P., Walpole, M., Hill, S. L. L., Boyce, D. G., Britten, G. L., Burgess, N. D., et al. (2014). A mid-term analysis of progress towards international biodiversity targets. Science, 346, 241–244.
Tringe, S. G., Von Mering, C., Kobayashi, A., Salamov, A. A., Chen, K., Chang, H. W., et al. (2005). Comparative metagenomics of microbial communities. Science, 308, 554–557.
Tyson, G. W., Chapman, J., Hugenholtz, P., Allen, E. E., Ram, R. J., Richardson, P. M., et al. (2004). Community structure and metabolism through reconstruction of microbial genomes from the environment. Nature, 428, 37–43.
van Zonneveld, M., Dawson, I., Thomas, E., Scheldeman, X., van Etten, J., Loo, J., et al. (2014). Application of molecular markers in spatial analysis to optimize in situ conservation of plant genetic resources. In R. Tuberosa, A. Graner, & E. Frison (Eds.), Genomics of plant genetic resources (pp. 67–91). Netherlands: Springer.
Vellend, M., & Geber, M. A. (2005). Connections between species diversity and genetic diversity. Ecology Letters, 8, 767–781.
Venter, J. C., Remington, K., Heidelberg, J. F., Halpern, A. L., Rusch, D., Eisen, J. A., et al. (2004). Environmental genome shotgun sequencing of the Sargasso Sea. Science, 304, 66–74.
Walls, R. L., Deck, J., Guralnick, R., Baskauf, S., Beaman, R., Blum, S., et al. (2014). Semantics in support of biodiversity knowledge discovery: an introduction to the biological collections ontology and related ontologies. PLoS One, 9, e89606.
Whitham, T. G., DiFazio, S. P., Schweitzer, J. A., Shuster, S. M., Allan, G. J., Bailey, J. K., et al. (2008). Extending genomics to natural communities and ecosystems. Science, 320, 492–495.
Zhang, Q. X., Shen, Y. K., Shao, R. X., Fang, J., He, Y. Q., Ren, J. X., et al. (2013). Genetic diversity of natural Miscanthus sinensis populations in China revealed by ISSR markers. Biochemical Systematics and Ecology, 48, 248–256.
Zytynska, S. E., Khudr, M. S., Harris, E., & Preziosi, R. F. (2012). Genetic effects of tank-forming bromeliads on the associated invertebrate community in a tropical forest ecosystem. Oecologica, 170, 467–475.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is distributed under the terms of the Creative Commons Attribution-Noncommercial 2.5 License (http://creativecommons.org/licenses/by-nc/2.5/) which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
The images or other third party material in this chapter are included in the work’s Creative Commons license, unless indicated otherwise in the credit line; if such material is not included in the work’s Creative Commons license and the respective action is not permitted by statutory regulation, users will need to obtain permission from the license holder to duplicate, adapt or reproduce the material.
Copyright information
© 2017 The Author(s)
About this chapter
Cite this chapter
Bruford, M.W., Davies, N., Dulloo, M.E., Faith, D.P., Walters, M. (2017). Monitoring Changes in Genetic Diversity. In: Walters, M., Scholes, R. (eds) The GEO Handbook on Biodiversity Observation Networks. Springer, Cham. https://doi.org/10.1007/978-3-319-27288-7_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-27288-7_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-27286-3
Online ISBN: 978-3-319-27288-7
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)