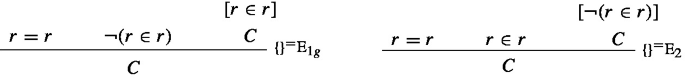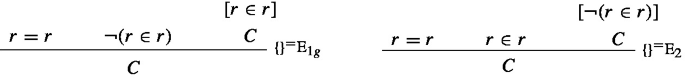Two distinct kinds of cases, going back to Crabbé and Ekman, show that the Tennant-Prawitz criterion for paradoxicality overgenerates, that is, there are derivations which are intuitively non-paradoxical but which fail to normalize. We argue that a solution to “Ekman’s paradox” consists in restricting the set of admissible reduction procedures to those that do not yield a trivial notion of identity of proofs. We then discuss a different kind of solution, due to von Plato, and recently advocated by Tennant, consisting in reformulating natural deduction elimination rules in general (or parallelized) form. Developing intuitions of Ekman we show that the adoption of general rules has the consequence of hiding redundancies within derivations. Once reductions to get rid of the hidden redundancies are devised, it is clear that the adoption of general elimination rules offers no remedy to the overgeneration of the Prawitz-Tennant analysis. In this way, we indirectly provide further support for our own solution to Ekman’s paradox.
In this chapter we discuss two distinct cases in which the Tennant-Prawitz analysis overgenerates, i.e. in which it ascribes paradoxicality to derivations of \(\bot \) that fail to normalize, although they belong to deductive settings of which we know that are too weak to allow for the formulation of paradoxes.
The first case of overgeneration arises in a consistent set theory in which Zermelo’s separation axiom is formulated in rule form:
(the second elimination rule will actually play no role in what follows). We call \(\texttt{NI}^{\mathbin {\supset }\in ^z}\) the system which results by adding these rules to \(\texttt{NI}^{\mathbin {\supset }}\).1
An application of \(\in ^z\)I followed by \(\in ^z\)E constitutes a redundancy that can be eliminated according to the following reduction (we call the formula eliminated a Zermelo-maximal formula occurrence:
What if we now try to reconstruct Russell’s reasoning in this setting? For any set y, we can construct a term denoting the Russell subset of y, i.e. the set of all elements of y which do not belong to themselves, \({r}_y =_{\text {def}} \{x\in y: x\not \in x\}\). Taking now \(\rho _y\) to be \({r}_y \in {r}_y\), an application of \(\in ^z\)E allows one to pass over from \(\rho _y\) to \(\lnot \rho _y\), but in order to pass over from \(\lnot \rho _y\) to \(\rho _y\) using an application of \(\in ^z\)I one needs a further premise, namely \({r}_y\in y\):
Thus, by following Russell’s reasoning in \(\texttt{NI}^{\mathbin {\supset }\in ^z}\) one obtains a derivation of absurdity \(\bot \) in \(\texttt{NI}^{\mathbin {\supset }\in ^z}\) that, contrary to \(\textbf{R}\), depends on an assumption, namely the assumption \({r}_y \in y\) that is needed for the application of \(\in ^z\)I (for visibility the assumption is boxed):
Now assume that existential quantification with its standard rules is available. As y does not occur free in the conclusion nor in any undischarged assumption other than \({r}_y \in y\), by assuming \(\exists y ({r}_y \in y)\) we can obtain by \(\exists E\) a derivation of \(\bot \) from \(\exists y ({r}_y \in y)\) and by \(\supset \)I we can thereby establish \(\lnot \exists y ({r}_y \in y)\), that is that no set contains its own Russell subset:
That no set contains its own Russell subset is a perfectly acceptable conclusion in a consistent set theory like Zermelo’s. It shows in particular that there is no set of all sets, which is something that any set theory based on the separation axiom should be able to prove. However, and here is the problem, the derivation \(\mathbf {R^z}\) of \(\bot \) from \({r}_y \in y\) (and likewise the one of \(\bot \) from \(\exists y ({r}_y \in y)\)) fails to normalize, for the same reason as Russell’s original \(\textbf{R}\). By removing the encircled maximal formula occurrence of \(\lnot \rho _y\), a Zermelo-redundant formula is introduced, and by removing it, one gets back to \(\mathbf {R^z}\). So, on the Prawitz-Tennant analysis the derivation does not represent a real proof, and (as in the case of the derivation of \(\bot \) in naive set theory) no other derivation fares better. That is, on the Prawitz-Tennant analysis, though we have derivations showing that there is no set of all sets in Zermelo set theory based on separation, these derivations are unacceptable as they qualify as paradoxical.2
These facts were first observed by Marcel Crabbé [1] in 1974 at the Logic Colloquium in Kiel (see [2]) and have been largely neglected in the philosophical literature (in particular by Tennant), except for a short reference to them by Sundholm [3]. However, they represent the starting point of modern proof-theoretic investigations of set theory see [4, 5].
2 Ekman’s Paradox
The other kind of overgeneration arises in an even weaker setting: pure propositional logic. Suppose we have derived A by means of a derivation \(\mathscr {D}\). By assuming \(A\mathbin {\mathbin {\supset }} B\), \(\mathscr {D}\) can be extended by \(\mathbin {\supset }\)E to a derivation of conclusion B. By further assuming \(B\mathbin {\supset }A\) one can conclude A, but this had already been established by \(\mathscr {D}\). The two applications of \(\mathbin {\supset }E\) just make one jump back and forth between A and B:
Ekman [6] observed that although the official reductions of \(\texttt{NI}^{\mathbin {\supset }}\) do not allow one to get rid of patterns of this kind, such patterns constitute redundancies which can be easily removed by identifying the top and bottom occurrences of A and removing the two applications of \(\mathbin {\supset }\)E between them. We refer to this conversion as Ekman and we will call an Ekman-maximal formula occurrence the occurrence of B acting as conclusion of the first application of \(\supset \)E and as minor premise of the second application of \(\supset \)E in the schema below3 :
Observe now that \(\lnot A\) follows from \(A\mathbin {\supset }\lnot A\):
By further assuming \(\lnot A\mathbin {\supset }A\), the previous derivation can be extended by \(\mathbin {\supset }\)E to a derivation of A from \(A\mathbin {\supset }\lnot A\) and \(\lnot A\mathbin {\supset }A\):
The two derivations can be joined together by an application of \(\mathbin {\supset }\)E and the result is the following derivation of \(\bot \) from \(A\mathbin {\supset }\lnot A\) and \(\lnot A\mathbin {\supset }A\) (here and below some of the rules labels will be omitted for readability):
The derivation \(\textbf{E}\) is not normal, since the encircled occurrence of \(\lnot A\) is a maximal formula occurrence. By applying \(\mathbin {\supset }\)-Red one introduces a redundancy of the kind observed by Ekman (we encircle in the derivation the Ekman-maximal formula occurrence):
By applying the relevant instance of Ekman:
we get back the derivation \(\textbf{E}\).
Thus, on the natural extension of the set of conversions suggested by Ekman, we have a counterexample to (weak and hence strong) normalization already in \(\texttt{NI}^{\mathbin {\supset }}\):\(\textbf{E}\) is not normal and does not normalize, since its reduction process enters a loop. Given the Prawitz-Tennant’s analysis of paradoxes in term of non-normalizability, the phenomenon observed by Ekman should show that paradoxes already appear at the level of propositional logic.4
In fact, Ekman’s paradox can be taken to show that the logical component of Russell’s paradox can be fully described using propositional logic. The derivations of Russell’s paradox \(\textbf{R}\) and \(\mathbf {R'}\) can be obtained from Ekman’s derivations \(\textbf{E}\) and \(\mathbf {E'}\) by suppressing all occurrences of \(A \supset \lnot A\) and \(\lnot A \supset A\) and by replacing all occurrences of the schematic letter A with \(\rho \): In this way, the applications of \(\supset \)E with major premise \(\lnot A\supset A\) and \(A\supset \lnot A\) become applications of \(\in \)I and \(\in \)E respectively. In other words, the id est inferences involved in the derivation of Russell’s paradox are simulated by applications of \(\supset \)E in \(\textbf{E}\) and \(\mathbf {E'}\), and \(\rho \beta \)—the instance of \(\mathord {\in }\beta \) used to transform \(\mathbf {R'}\) into \(\textbf{R}\)—is simulated by the instance (6.2.1) of Ekman used to transform \(\mathbf {E'}\) into \(\textbf{E}\).
To repeat, the difference between \(\rho \beta \) and the instance of \(\texttt{Ekman}\) triggering Ekmans’s paradox consists only in the fact that the redundancy is in one case generated by id est inferences, whereas in Ekman’s case it is mimicked in propositional logic by applications of modus ponens. The major premises of modus ponens represent the rule applied in id est inferences. As Ekman puts it:
Whatever motivation we have for [\(\mathord {\rho }\beta \)] this motivation also applies to [the instance (6.2.1) of \(\texttt{Ekman}\)] since the two reductions, from an informal point of view, are one and the same, but expressed using two different formal systems.
Given this observation, paradoxical derivations can be analyzed as consisting of an extra-logical construction which is plugged into a portion of purely propositional reasoning. The extra-logical part is constituted by id est inferences which allow one to pass over, for some specific \(\rho \), from \(\lnot \rho \) to \(\rho \) and back. The logical part consists of the derivation E of absurdity \(\bot \) from \(\lnot A \mathbin {\supset }A\) and \(A \mathbin {\supset }\lnot A\), for an unspecific (i.e. for all) A. Ekman’s paradox would thus show that loops are not a feature of the extra-logical part, but of the logical part of paradoxical derivations. The looping feature would not depend on the possibility to move, for a certain \(\rho \), from \(\rho \) to \(\lnot \rho \) and vice versa, but that we can move, for any formula A, from \(\lnot A \mathbin {\supset }A\) and \(A\mathbin {\supset }\lnot A\) to absurdity.
We do not take this to be the right conclusion to be drawn from the phenomenon observed by Ekman. Rather, we take Ekman’s paradox to push the question of when a certain reduction counts as acceptable: Whether a derivation is normal depends on the collection of reductions adopted, and hence Tennant’s criterion requires that one carefully considers what should be taken to be a good reduction. In particular, Ekman’s phenomenon shows that on too loose a notion of reduction, one obtains a too coarse criterion of paradoxicality.
Thus, it is not its logical component that makes Russell’s reasoning paradoxical, but the id est rules encoding naive comprehension. Propositional logic alone is too weak to allow for the formulation of paradoxical expression and thereby there cannot be anything paradoxical about a derivation in \(\texttt{NI}^{\mathbin {\supset }}\).5
3 A Solution to Ekman’s Overgeneration
In almost all presentations of natural deduction, reductions are presented as means to get rid of redundancies within proofs. This is also the background of Tennant’s analysis, who writes:
The reduction procedures for the logical operators are designed to eliminate such unnecessary detours within proofs.
So are other abbreviatory procedures \(\sigma \), which have the general form of ‘shrinking’ to a single occurrence of A, any logically circular segments of branches (within the proof) of the form shown below to the left:
One thereby identifies the top occurrence of A with the bottom occurrence of A, and gets rid of the intervening occurrences of \(B_1, \ldots ,\)\( B_n\), that form the filling of this unwanted sandwich. Logically, one should live by bread alone.(Tennant [7], pp. 199–200)
Given this, Tennant should have nothing to object against the reduction \(\texttt{Ekman}\) as it is a variant of \(\sigma \). However, the understanding of reduction as “abbreviatory procedures” is not the only possible one. We actually claim that this understanding is not appropriate for meaning-theoretical investigations, and take Ekman’s paradox to be a striking phenomenon that points to this fact.
As we detailed in Chap. 2, from a PTS standpoint proofs should be viewed as abstract entities linguistically represented by natural deduction derivations and reduction procedures for derivations can then be viewed as yielding a criterion of identity between proofs.
When one considers conversions besides \(\beta \)-reductions and \(\eta \)-expansions, a minimal requirement for the acceptability of a new conversion should be that of not trivializing identity of proof, in the sense that is should always be possible to exhibit at least one proposition A and two derivations having A as conclusion that belong to two distinct equivalence classes (see, for details, Sect. 2.4). If this requirement is not met, the intensional conception of PTS we advocated in Sect. 2.6 would collapse into a merely extensional picture: for every proposition there would be either a (single) proof or there would be no proof at all. On such an understanding, the notion of reduction is much narrower than the one arising from taking reductions as “abbreviation procedures”. On this narrower conception Ekman’s alleged conversion turns out to be no conversion at all.
As we recalled in Sect. 2.4, it is well-known that any equivalence relation extending \(\beta \eta \)-equivalence trivializes the identity of proofs in \(\texttt{NI}^{\mathbin {\supset }}\). As we will now show, Ekman’s conversion is actually sufficient to trivialize the identity of proofs induced by \(\mathbin {\supset }\beta \) alone.
To begin with, instead of \(\texttt{Ekman}\) we actually consider Ekman’s reduction in the more general form
i.e., we allow for \(A \mathbin {\supset }B\) and \(B \mathbin {\supset }A\) to be obtained by derivations \(\mathscr {D}'\) and \(\mathscr {D}''\). This means that we assume, as it is natural to do, that Ekman’s reduction is closed under substitution of derivations for undischarged assumptions.6
For simplicity of exposition, we reason in the extension \(\texttt{NI}^{\wedge \mathbin {\supset }}\) of \(\texttt{NI}^{\mathbin {\supset }}\). A corresponding, but less well-readable example could be given in \(\texttt{NI}^{\mathbin {\supset }}\) as well. Consider the formulas \(A\wedge A\) and A and the following proofs of their mutual implications7:
Given an arbitrary derivation \(\mathscr {D}\) of \(A \wedge A\), consider the following derivation \(\mathscr {D}'\):
Observe that \(\mathscr {D}'\) reduces both to \(\mathscr {D}\) (with an application of \(\texttt{Ekman}^*\)) and to the following derivation (with two applications of \({\mathbin {\supset }}\beta \)):
If we suppose that \(\mathscr {D}\) ends with an introduction rule, i.e. that the form of \(\mathscr {D}\) is the following (for some arbitrary derivations \(\mathscr {D}_1\) and \(\mathscr {D}_2\) of A):
we thus have that
and
respectively. Therefore the adoption of Ekman’s (starred) reduction implies that the following two derivations
are equivalent with respect to reducibility, i.e. that they represent the same proof. This means that also the following two derivations, which result from the previous ones by extending each of them with an application of \(\wedge \)E\(_2\):
are equivalent with respect to reducibility. If we apply to each of them the reduction \(\wedge \beta _2\), we obtain the two derivations
meaning that \(\mathscr {D}_1\) and \(\mathscr {D}_2\) belong to the same equivalence class induced by \({\mathbin {\supset }}\beta \), \(\wedge \beta _1\), \(\wedge \beta _2\) and \(\texttt{Ekman}^*\). Therefore by using Ekman’s (starred) reduction in addition to the standard reductions, we can show that any two derivations \(\mathscr {D}_1\) and \(\mathscr {D}_2\) of a formula A represent the same proof. As argued above, this is a devastating consequence. If we require that reductions do not trivialize the notion of identity of proofs, Ekman’s transformation does not count as a reduction.
We thus propose to amend Tennant’s paradoxicality criterion by requiring that reductions do not trivialize identity of proofs. In this way the problem posed by Ekman’s result for the Prawitz-Tennant test for paradoxicality is resolved in that Ekman’s derivation E now fails to count as a paradox.8
Ekman’s “paradox” not only teaches us the importance of an appropriate notion of reduction for formulating a proof-theoretic criterion of paradoxicality, but also tells us something about the nature of paradoxical propositions. What triggers a genuine paradox is not simply the assumption that a proposition is interderivable with its own negation, as in Ekman’s derivation. A genuine paradox is a proposition A such that there are proofs from A to \(\lnot A\) and from \(\lnot A\) to A that composed with each other give us the identity proof A (i.e., the formula A considered as proof of A from A), that is a genuine paradox is a proposition which is isomorphic (in the sense of Sect. 2.5) with its own negation.
In conclusion, if one requires that reductions must not trivialize proof identity, there are strong reasons to reject Ekman’s reduction. Unfortunately, there does not seem to be any immediate way of applying this strategy to solve the other kind of overgeneration cases observed by Crabbé. From the perspective of identity of proof, there is a strong asymmetry between the two cases, and the overgeneration cases observed by Crabbé show a particular resilience.
4 Von Plato’s Solution to Ekman
A different kind of solution to the overgeneration phenomenon observed by Ekman was put forward by von Plato [8] and recently reinstated by Tennant [9], who showed how it could be used to overcome also the other kind of overgeneration cases. For Tennant, this alternative solution is preferable not only because it allows one to solve both issues at once, but also because it does not require one to introduce criteria to select what counts as an appropriate reduction. The aim of what follows is a critical discussion of this alternative solution, which shows, at least, that the question of what is to count as an appropriate reduction cannot be evaded so quickly as Tennant apparently supposes.
To clarify our position, we are strongly sympathetic to the Tennant-Prawitz analysis of paradoxes, and we do not take the kind of overgeneration observed by Ekman as being a real threat, provided the criterion for paradoxality is based on a qualified notion of reduction procedure. On the other hand, we do regard the kind of overgeneration observed by Crabbé as problematic (even on our refined formulation of the Prawitz-Tennant criterion) and calling for further investigations.
What we are not at all sympathetic with is the “solution” to both kinds of overgeneration proposed by von Plato and Tennant, which will be shown in the remaining part of the present chapter to be, in fact, no solution at all, being flawed by the same problems of Tennant’s original proposal. The line of argument developed in the remaining part of the chapter is thereby meant as a further—though indirect—reason to adopt our solution to the Ekman kind of overgeneration, and to further investigate the exact nature of the Crabbé kind of overgeneration.
According to von Plato [8] the source of Ekman’s problem9 is the form of the elimination rule for implication, and he suggested that the problem could be solved by replacing \(\mathbin {\supset }\)E with its general version:
We call \(\texttt{NI}^{\mathbin {\supset }}_g\) the system obtained from \(\texttt{NI}^{\mathbin {\supset }}\) by replacing \(\mathbin {\supset }\)E with \(\mathbin {\supset }\)E\(_g\).
Consecutive applications of the introduction and of the general elimination rule for implication also constitute a redundancy that can be eliminated according to the following reduction (we call the formula of the form \(A\supset B\) eliminated by the reduction an \(\supset _g\)-maximal formula occurrence):
In \(\texttt{NI}^{\mathbin {\supset }}_g\) the derivation of Ekman’s paradox can be recast as follows:
The reduction \(\mathbin {\supset }_g\beta \) does not apply to \(\mathbf {E_{g}'}\). Moreover, neither does Ekman (obviously, since \(\mathbf {E_{g}'}\) is formulated with the general elimination rule and not with modus ponens) nor any generalization thereof,
which have the general form of ‘shrinking’ to a single occurrence of A, any logically circular segments of branches (within the proof ) of the form shown below to the left
which Tennant [9] calls subproof compactification. Note that, as Ekman [5] already observed, \(\in \)-Red and \(\in ^z\)-Red are also instances of subproof compactification (and so are the standard reductions for conjunction of Prawitz [10]), though neither \({\supset }\beta \) nor \(\mathord {\supset _g}\beta \) are.
On these grounds, von Plato concludes that
the problem about normal form in Ekman [6] is solved by a derivation using the general \(\supset \)E rule. (von Plato [8], p. 123)
5 Another “Safe Version” of Russell’s Paradox
Independently of Crabbé, Tennant [11, 12] proposed a weakening of naive comprehension, but in the context of a (negative) free logic. By free logic, one means a logic which is free from the assumption that singular terms denote. Using Zermelo’s comprehension one wishes to neutralize Russell’s paradox by recasting Russell’s reasoning as showing that no set contains its Russell subset as element. Similarly, Tennant wishes to recast Russell’s reasoning as showing that Russell’s term lacks a denotation.
That a term t does possess a denotation is expressed by the formula \(\exists !t =_{def} \exists x (t=x)\), and accordingly in (negative) free logic the introduction rule for identity is weakened to the effect that \(t=t\) can be derived only if one has previously shown that t denotes10:
In this setting, Tennant proposes to replace the rules for naive comprehension with rules to introduce and eliminate set terms in the context of identity statements. As our focus here is not a discussion of set-theoretic paradoxes in the context of free logics, but rather of the proof-theoretic analysis of paradoxical derivations, we omit some premises and dischargeable assumptions of the form \(\exists !t\) from Tennant’s rule. In this way it is easier to highlight the analogy with von Plato’s solution to Ekman’s paradox discussed in the previous section. Observe however that each derivation using the rules here discussed should be understood as an abbreviation of a derivation using Tennant’s original rules. The interested reader can easily reconstruct full derivations by adding the (in most cases trivial) subderivations of each of the missing premises of each rule application.
Here is the simplified version of Tennant’s rules:
We call \(\texttt{NI}^{\mathbin {\supset }\in ^=}\) the system that results by adding these rules to \(\texttt{NI}^{\mathbin {\supset }\in }\).11
It is important to observe that in Tennant’s reformulation of the rules of comprehension we have two elimination rules for set terms, and the two elimination rules of Tennant correspond respectively to Prawitz’s \(\in \)I and \(\in \)E rules. By taking s to be \(\{x:A\}\) we have that Tennant’s \(\{\}^=\)E\(_1\) allows one to infer \(t\in \{x:A\}\) from A(t/x) together with the premise \(\{x:A\}=\{x:A\}\), and that \(\{\}^=\)E\(_2\) allows one to infer A(t/x) from \(t\in \{x:A\}\)together with the premise \(\{x:A\}=\{x:A\}\). (The extra premises can be regarded as expressing the requirement that \(\{x:A\}\) is a denoting set term: are remarked above, in contrast to predicate logic in which \(t=t\) is always derivable for any term t, in free logic such premises need to be derived from the assumption \(\exists ! \{x:A\}\).)
Redundancies constituted by consecutive applications of the introduction rule followed immediately by the corresponding elimination rule can be eliminated using the obvious reductions. Moreover, consecutive applications of the two elimination rules give rise to Ekmanesque redundancies of which one can get rid using the following reduction (we call respectively Ekman\(^=\)andEkman\({^=}\)-maximal formula occurrence this transformation and the occurrence of \(t\in s\) in the schematic derivation on the left-hand side):
To reconstruct Russell’s reasoning in this further setting Tennant suggests to choose both t and s to be some variable y and to take A to be the formula \(\lnot (x\in x)\). One thereby obtains the following instances of \(\{\}^=\)E\(_1\), \(\{\}^=\)E\(_2\) (as before we abbreviate Russell’s term \(\{x: \lnot (x\in x)\}\) with r):
By abbreviating \(y\in y\) with \(\upsilon \), we can reason as in Ekman’s derivation \(\textbf{E}\) and thereby construct a derivation of \(\bot \) depending on the assumption \({r}=y\):
As in \(\mathbf {R^z}\), the variable y in \(\mathbf {R^=}\) occurs free neither in the conclusion nor in any undischarged assumption other than \({r}=y\). In the presence of the rules for the existential quantifier, the derivation \(\mathbf {R^=}\) can thus be extended by \(\exists \)E and \(\supset \)I to a closed derivation of \(\lnot \exists x ({r}=x)\) that establishes that r has no denotation.
However, as in Ekman’s \(\textbf{E}\), the encircled occurrence of \(\lnot \upsilon \) is a maximal formula occurrence. The reader can easily check that by getting rid of it using \(\mathbin {\supset }\beta \), an Ekman\(^=\)-redundant formula occurrence is introduced. By getting rid of it using the following instance of Ekman\(^=\):
one gets back to \(\mathbf {R^=}\). As in the previous cases, in spite of its innocuous character the derivation fails to normalize. This overgeneration case seems a perfect blend of the two previously discussed, and Tennant [9] showed how the (purported) solution of von Plato to Ekman’s case can be applied also to this one. Let us replace the elimination rules \(\{\}^=\)E\(_1\) and \(\{\}^=\)E\(_2\) with their general versions (we call the resulting system \(\texttt{NI}^{\mathbin {\supset }\in ^=}_g\)):
Taking as before t and s to be y and A to be \(\lnot (x\in x)\), one thereby obtains the following instances of \(\{\}^=\)E\(_{1g}\), and \(\{\}^=\)E\(_{2g}\) (as before r abbreviates Russell’s term \(\{x: \lnot (x\in x)\}\)):
Using them one can give the following (apparently) redundancy-free derivation of \(\bot \) from \({r}=y\) (as before \(\upsilon \) abbreviates \(y\in y\))12:
An application of \(\exists \)E followed by one of \(\mathbin {\supset }\)I yields a closed normal derivation of \(\lnot \exists x(r=x)\).
6 Ekman on Decomposing Inferences
Although we believe that the Prawitz-Tennant analysis undoubtedly provides the basis for a proof-theoretic clarification of the phenomenon of paradoxes, we do not find the way out of the overgeneration cases proposed by von Plato and Tennant satisfactory.
It is true that in the derivations \(\mathbf {E_g'}\) and \(\mathbf {{R_g^=}'}\) no subproof compactification is possible. However, as we will now show, it is still possible to detect some redundancies which are hidden by the more involved shape of derivations constructed with general elimination rules. By defining procedures to get rid of these hidden redundancies, Ekmanesque loops will crop up again. In the remaining part of the chapter this suggestion will be made precise.
The possibility of reformulating his “paradox” using general elimination rules was clearly envisaged by Ekman in his doctoral thesis, where he introduces the notion of ‘decomposing inference’:
Let \(\Pi \) and A designate the premise deductions and conclusion of a rule R respectively. That is, R is the inference schema:
We obtain the corresponding decomposing inference schema \(R_D\) as follows.
We obtain the premise deductions of the inference schema \(R_D\) by adding one deduction \(\mathscr {E}\) to the premise deductions of the R schema, where \(\mathscr {E}\) designates a deduction in which occurrences of the conclusion A of the R schema, as open assumptions in \(\mathscr {E}\) may be cancelled at the \(R_D\) inference. If, in the R schema, B designates an open assumption in any of the premise deductions \(\Pi \) and B may be cancelled at the R inference, then in the \(R_D\) schema, B also designates an open assumption of the same premise deduction and B may be cancelled at the \(R_D\) inference. (EKman [5], pp. 9–10)
Obviously, in the case of \(\supset \)E, the decomposing inference \(\supset \)E\(_D\) is just the general rule \(\supset \)E\(_g\).13
Ekman [5, p. 10] introduces the notion of a simple deduction corresponding to one with decomposing inferences by giving an informal, though precise description of a procedure for translating derivations with decomposing inferences into derivations with the corresponding “simple” inferences. When restricted to the systems \(\texttt{NI}^{\mathbin {\supset }}\) and \(\texttt{NI}^{\mathbin {\supset }}_g\), Ekman’s translation amounts to the following (the definition is by induction on the number of inference rules applied in a derivation)14:
1.
If \(\mathscr {D}\) is an assumption, then \(\mathscr {D}^s=\mathscr {D}\)
2.
If \(\mathscr {D}\) ends with an application of \(\supset \)E\(_g\), i.e. it is of the following form:
then \(\mathscr {D}^s\) has the following form:
3.
If \(\mathscr {D}\) ends with an application of \(\supset \)I, then \(\mathscr {D}^s\) is obtained by applying \(\supset \)I to the translation \(\mathscr {D}_1^s\) of the immediate subderivation \(\mathscr {D}_1\) of \(\mathscr {D}\).
At this point Ekman writes:
Let \(\mathscr {H}\) and \(\mathscr {H}'\) be a deduction with decomposing inferences and its corresponding simple deduction, respectively. Then indeed, \(\mathscr {H}\) and \(\mathscr {H}'\) both represent the same informal argument. The difference is only a matter of the display of the inferences. Therefore it ought to be the case that \(\mathscr {H}\) is normal if and only if \(\mathscr {H}'\) is normal.
The translation \((\mathbf {E_g'})^{s}\) of von Plato’s derivation \(\mathbf {E_g'}\) into \(\texttt{NI}^{\mathbin {\supset }}\) is indeed \(\textbf{E}'\). It is beyond doubt that the quoted passage hints at the possibility of extending the set of conversions of \(\texttt{NI}^{\mathbin {\supset }}_g\) so that on the extended set of conversions von Plato’s derivation \(\mathbf {E_g'}\) fails to normalize as well.
To this we now turn.
7 Implication-as-Link and General Ekman-Reductions
As a starting point, we recall Schroeder-Heister’s [13] proposal to distinguish between two ways in which the assumption of an implication can be interpreted: Implication-as-rule and implication-as-link. In natural deduction the two interpretations correspond to the two distinct forms that the rule of implication elimination may take (see also [14]).
The adoption of \(\mathbin {\supset }\)E yields the implication-as-rule interpretation. Suppose we have a derivation \(\mathscr {D}\) of conclusion A. By assuming the implication \(A \mathbin {\supset }B\) we can extend \(\mathscr {D}\) as if we had at our disposal a rule R allowing one to pass over from A to B:
On the other hand, the adoption of \(\mathbin {\supset }\)E\(_g\) does not amount to assuming only the rule to pass over from A to B, but rather to assuming also the existence of a link connecting two distinct derivations:
Applications of the rule R correspond—even graphically—to the application of \(\mathbin {\supset }\)E. This is not so in \(\mathbin {\supset }\)E\(_g\), where there is nothing in the structure of the rule which can be said to correspond to the application of the rule to pass from A to B. The transition from A to B remains implicit.
The implicit link in \(\supset \)E\(_g\) between the two subderivations \(\mathscr {D}\) and \(\mathscr {D}'\) is a form of transitivity: if B can be derived by means of \(\mathscr {D}\) from a set of assumptions \(\Gamma \) (among which the rule R that allows one to pass over from A to B), and C can be derived by means of \(\mathscr {D}'\) from some other set of assumptions \(\Delta \) together with (a certain number of copies of) B, then C can be derived from \(\Gamma \) and \(\Delta \) alone.
We wish to defend the claim that the transitivity principle encoded by \(\mathbin {\supset }\)E\(_g\)hides a redundancy in the derivation \(\mathbf {E_g'}\). In fact, Ekman [5] himself refers to decomposing rules as ‘cut-hiding’.
To state this intuition in a more explicit manner we take seriously the idea that in \(\mathbin {\supset }\)E\(_g\) the minor premise A is linked with the assumptions of form B which are discharged by the application of the rule.
Certain configurations of two consecutive applications of \(\mathbin {\supset }\)E\(_g\) may thus be viewed as constituting a redundancy. Consider for instance situations of the following kind:
The formula A which is the conclusion of \(\mathscr {D}\) is linked by \(A\mathbin {\supset }B\) to the discharged occurrence of B marked with m. This in turn is linked by \(B\mathbin {\supset }A\) to the discharged assumptions A marked by n. In other words, the two applications of the general elimination rule make one jump from A to B and back in a quite unnecessary way. This intuition, which is essentially Ekman’s, can be spelled out by defining a new conversion to get rid of redundancies of this kind.
By directly linking together \(\mathscr {D}\) and \(\mathscr {D}'\), both applications of \(\mathbin {\supset }\)E\(_g\) could be eliminated as follows:
However, this is only possible if in the original derivation no other occurrence of B is discharged in \(\mathscr {D}'\) by the application of \(\mathbin {\supset }\)E\(_g\) marked with m.
If such occurrences of B are present, then the lower application of \(\mathbin {\supset }\)E\(_g\) is still needed in order to discharge them. This is perfectly reasonable, since these occurrences of B do not belong to the detour generated by the links of the two applications of \(\mathbin {\supset }\)E\(_g\). We take the following reduction to be what in \(\texttt{NI}^{\mathbin {\supset }}_g\) corresponds to Ekman (the occurrence of B in the leftmost derivation constituting the redundancy is encircled and will be called an \(\texttt{Ekman}_g\)-maximal formula occurrence):
Observe now that von Plato’s \(\mathbf {E_{g}'}\) contains an Ekman\(_g\)-redundant formula occurrence (encircled):
The redundancy can be eliminated using the following instance of Ekman\(_g\):
By applying this instance of Ekman\(_g\) to \(\mathbf {E_{g}'}\) one obtains the following derivation:
The encircled occurrence of \(\lnot A\) is the conclusion of an application of \(\mathbin {\supset }\)I and the major premise of an application of \(\mathbin {\supset }\)E\(_g\) and thus it is an \(\supset _g\)-redundant formula occurrence. By applying \(\mathbin {\supset }_g\beta \) to this derivation, one gets back to \(\mathbf {E_{g}'}\). That is, by enriching the set of conversions with Ekman\(_g\), the process of normalizing the derivations \(\mathbf {E_{g}}\) and \(\mathbf {E_{g}'}\) gets stuck in a loop in the same way as that of the derivations \(\textbf{E}\) and \(\textbf{E}'\). As already observed in Sect. 6.6, \(\mathbf {E'}\) is the image of \(\mathbf {E_{g}'}\) under the translation \(()^s\) from \(\texttt{NI}^{\mathbin {\supset }}_g\) to \(\texttt{NI}^{\mathbin {\supset }}\), and as the reader can easily check the same is true of \(\textbf{E}\) and \(\mathbf {E_{g}}\). It is easy to see that the foregoing line of reasoning can be extended in a straightforward manner to Tennant’s derivation \(\mathbf {R^=_g}\) in \(\texttt{NI}^{\mathbin {\supset }\in ^=}_g\). In particular, the remarks on the cut-hiding nature of \(\supset \)E\(_g\) can be applied to Tennant’s \(\{\}^=\)E\(_1\) and \(\{\}^=\)E\(_2\) as well. Hence, we can define the general version of the Ekman\(^=\)-reduction depicted in Table 6.1 .
The derivation \(\mathbf {{R^=_g}'}\), like \(\mathbf {E_g'}\), contains a hidden redundancy that can be eliminated using Ekman\(^=\). As the reader can check, by applying the reduction one obtains a derivation that, like \(\mathbf {E_g}\), contains an \(\supset _g\)-redundant formula occurrence. By eliminating it using \({\supset _g}\beta \) one gets back to Tennant’s \(\mathbf {{R^=_g}'}\). Moreover, the translation \(()^s\), mapping \(\texttt{NI}^{\mathbin {\supset }}_g\)-derivations onto \(\texttt{NI}^{\mathbin {\supset }}\)-derivations, can be easily extended to a translation \(()^{s^\in }\) mapping \(\texttt{NI}^{\mathbin {\supset }\in ^=}_g\)-derivations onto \(\texttt{NI}^{\mathbin {\supset }\in ^=}\)-derivations. The image of Tennant’s derivation \(\mathbf {{R^=_g}'}\) and of the derivation to which \(\mathbf {{R^=_g}'}\) reduces via Ekman\(_g\) are Tennant’s [11, 12] derivations \(\mathbf {{R^=}'}\) and \(\mathbf {{R^=}}\) respectively.
8 Copy-and-Paste Subproof Compactification
As observed by Tennant, both Ekman and Ekman\(^=\) are instances of the general reduction pattern called by Tennant subproof compactification. Crudely put, the adoption of general elimination rules has the result of chopping up derivations and scattering around their subderivations. As a consequence, it is natural to generalize subproof compactification to a reduction pattern that could be called copy-and-paste subproof compactification: if a derivation \(\mathscr {D}\) contains a subderivation \(\mathscr {D}'\) of A and some assumptions of the form A are discharged in \(\mathscr {D}\), the result of replacing \(\mathscr {D}'\) for the discharged assumptions of A may bring to light hidden possibilities of applying subproof compactification. Although some subderivations may have to be copied in the process, the overall result will be a derivation depending on less assumptions than the original one and containing less (explicit or implicit) redundancies.
Instances of copy-and-paste sub-proof compactification are not just the conversions Ekman\(_g\) and Ekman\(_g^=\), but also all other known reductions, in particular \({\supset }\beta \) (and \({\supset _g}\beta \)), that could be analyzed as consisting of one (respectively two) step(s) of “copy-and-paste”, where the “copy-and-paste” operation could be schematically depicted as follows:
followed by one step of subproof compactification. In the case of \(\supset \)-Red, we would have:
9 General Introduction Rules and Ekman\(_g\)
It may be retorted that, compared to Ekman’s original conversion, the conversion Ekman\(_g\) is much less straightforward, and one may wonder whether in the end, it is not just artificial. We rebut this criticism by observing that Ekman\(_g\) is just as plausible as Ekman. Or at least, that this is the case if one (like von Plato himself) is willing to accept not only general elimination rules but general introduction rules as well.
According to Negri and von Plato [15], not only elimination rules, but also introduction rules can be recast in general form, according to the following idea: “General introduction rules state that if a formula C follows from a formula A, then it already follows from the immediate grounds for A; general elimination rules state that if C follows from the immediate grounds for A, then it already follows from A.” (ibid. 217).15
For example, the Prawitz-Gentzen introduction and elimination rules for conjunction are recast in general form as follows:
Milne [16] argued for the significance of these rules for the inferentialist project of characterizing the meaning of logical constants through the inference rules governing them. In this context he suggested reductions to eliminate consecutive applications of the general introduction and elimination rules for a connective. In the case of conjunction, Milne’s proposal amounts to the following transformation:
However, one cannot exclude that the application of the general introduction rule labeled with \(\langle n\rangle \) discharges some occurrences of \(A\wedge B\) in \(\mathscr {D}'\) as well. Such further occurrences (if any) are not part of the redundancy, and the application of \(\wedge \)I\(_g\) would still be needed to discharge them. The solution consists in revising Milne’s proposed reduction as follows16:
The conversion \(\wedge _G\beta \) certainly has the flavor of Ekman\(_g\). To spell out the analogy between reductions for general introduction-elimination patterns and Ekman\(_g\) in full, we consider the general version of the introduction and elimination rules for naive set theory of Prawitz:
and the reduction \({\in _G}\beta \) associated with \(\in \)I\(_g\) and \(\in \)E\(_g\) (we call \(\in _G\)-redundant formula occurrence the encircled formula occurrence):
By removing all occurrences of \(\lnot A\supset A\) and of \(A\supset \lnot A\) from von Plato’s \(\textbf{E}_g'\) and replacing all occurrences of A with occurrences of \(\rho \), all applications of \(\supset \)E\(_g\) with major premises \(\lnot A\supset A\) and of \(A\supset \lnot A\) in \(\textbf{E}_g'\) are turned into applications of the following instances of \(\in \)I\(_g\) and \(\in \)E\(_g\) respectively:
Thus \(\textbf{E}_g'\) becomes the following derivation of \(\bot \) in the system obtained by extending \(\texttt{NI}^{\mathbin {\supset }}_g\) with \(\in \)I\(_g\) and \(\in \)E\(_g\) (we call it \(\texttt{NI}^{\mathbin {\supset }\in }_G\))17:
The derivation \(\textbf{R}_G'\) in fact contains an \(\in _G\)-redundant formula occurrence (encircled). To eliminate this redundancy we can apply the following instance of \(\in _G\)-Red:
As the reader can check, one thereby introduces a new \(\supset _g\)-redundant formula occurrence. By getting rid of this redundancy using \(\mathord {\supset _g}\beta \) one gets back the derivation \(\textbf{R}_G'\) from which one started.
The relation between the relevant instances of \(\in _G\)-Red and of Ekman\(_g\) is exactly the same as that between the relevant instances of \(\in \)-Red and of Ekman. Thus, as Ekman’s reduction can be seen as encoding Russell’s paradox in \(\texttt{NI}^{\mathbin {\supset }}\), the general Ekman reduction we propose can be seen as encoding the version of Russell’s paradox with general rules in \(\texttt{NI}^{\mathbin {\supset }}_g\).
10 Conclusions and Outlook
The addition of the conversion Ekman to the standard set of reductions for \(\texttt{NI}^{\mathbin {\supset }}\) (consisting of \(\mathbin {\supset }\beta \) alone) results in counterexamples to normalization. These can be viewed as simulations in the propositional setting of the counterexamples to normalization in the extension of \(\texttt{NM}\) with Prawitz’s rules for naive set theory. The “safe” version of Russell’s paradox proposed by Tennant [11, 12] faces the same problem as soon as one considers—besides reductions to get rid of introduction-elimination redundancies—the further reduction Ekman\(^=\).
Replacing standard elimination rules with their general versions does not help. As we have shown, it is possible to define general versions of the Ekmanesque reductions, that can be seen as simulating the reduction for general introduction and elimination rules for naive set theory. Using these reductions, Ekman’s paradox and Tennant’s safe version of Russell’s paradox fail to normalize even when formulated using general elimination rules.
As we pointed out in the first part of the chapter, we take these phenomena to call for a thorough investigation of criteria of acceptability for reduction procedures. In particular, we proposed as a (minimal) criterion that reductions must not trivialize the notion of identity of proof induced by the standard reductions.
On such an understanding of reductions, neither Ekman nor its variants are acceptable, but only reductions to get rid of introduction-elimination patterns. Thus, Ekman’s derivations do not qualify as paradoxical, nor does Tennant’s safe version of Russell’s paradox, independently of whether standard or general rules are adopted.
As remarked, the phenomenon observed by Crabbé is however unaffected by our proposed constraint on reductions, thus showing that further work is required for a thorough analysis of paradoxes along the lines of the Prawitz-Tennant analysis.18
Notes to This Chapter
1.
Since we will make no use of \(\bot \)E in this chapter, we assume to be working in extensions of \(\texttt{NI}^{\mathbin {\supset }}\), rather than of \(\texttt{NI}^{\mathbin {\supset }\bot }\) as we did in the previous chapters, thereby taking \(\bot \) to simply be a distinguished atomic proposition.
2.
Although this is undoubtedly a case of overgeneration for the Prawitz-Tennant analysis of paradoxes, it is worth stressing that, if we judge whether the derivation \(\mathbf {R^z}\) denotes a proof using the notions of validity developed in the previous chapter, we have that although the derivation turns out not to be valid\(^{**}\) according to Definition 5.5 it would qualify as valid\(^*\) according to Definition 5.2. In the present chapter, the issue of validity is left on the background, as the goal is that of sharpening the original Prawitz-Tennant analysis according to which a paradox is a non-normalizing derivation of \(\bot \).
3.
We observe already now that there is a fundamental distinction between Ekman and, say, \(\mathbin {\supset }\beta \) in that the latter is a means of getting rid of an application of an introduction rule followed by an application of the corresponding elimination and it thus an immediate consequence of the harmony governing the two rules. Not so for Ekman, that may thus be seen as lacking a prima facie plausible meaning-theoretical justification. This remark will be fully exploited in Sect. 6.3 below to untrigger the kind of overgeneration discussed in this section.
4.
Observe that the loop is not only a feature of the particular derivations E and E’. Ekman demonstrated that in \(\texttt{NI}^{\mathbin {\supset }}\) there is no derivation of \(\bot \) from \(A \mathbin {\supset }\lnot A\) and \(\lnot A \mathbin {\supset }A\), which is normal with respect to \(\mathord {\mathbin {\supset }}\beta \) and \(\texttt{Ekman}\).
5.
Elia Zardini observes that the derivations \(\textbf{E}\) and \(\mathbf {E'}\) are paradoxical because there are instances of them which are paradoxical. Observe however, that \(\textbf{R}\) and \(\mathbf {R'}\) are not simply instances of \(\textbf{E}\) and \(\mathbf {E'}\), as they do not arise by simply instantiating A with \(\rho \), but moreover by replacing the assumptions \(\lnot A\mathbin {\supset }A\) and \(A\mathbin {\supset }\lnot A\) with genuine inferential steps, and it is to these steps that the source paradoxicality is—in Tennant’s intentions—to be ascribed.
6.
As we show in Note 8 even without this generalization a corresponding counterexample can be given.
7.
A substantially equivalent counterexample in the purely implicational fragment can be obtained using the formulas \(A\mathbin {\supset }(A\mathbin {\supset }B)\) and \(A \mathbin {\supset }B\).
8.
In defense of Ekman, one might argue that he formulates his reduction with \(A\mathbin {\supset }B\) and \(B\mathbin {\supset }A\) in assumption position according to \(\texttt{Ekman}\), whereas to show that his reduction trivializes identity of proofs we considered the generalized form \(\texttt{Ekman}^*\). This generalized form is closed under substitution of derivations for open assumptions. Now it is hard to make sense of a notion of reduction not closed under substitution in this sense. However, the following example demonstrates our trivialization result even without this assumption, on the basis of Ekman’s reduction in the form \(\texttt{Ekman}\). The following derivation (encircled is an Ekman redundant formula):
reduces via \(\texttt{Ekman}\) to the following (in which the applications of \(\mathbin {\supset }\)I without numeral do not discharge anything):
which in turn reduces via two applications of \({\mathbin {\supset }}\beta \) to
On the other hand, by applying first \({\mathbin {\supset }}\beta \) (for four times) and then \(\wedge \beta _1\) (twice) to the first derivation one obtains
In other words, we have that the two derivations
are equivalent with respect to reducibility even when one adopts the restricted form of Ekman’s reduction. Thus the restricted form of Ekman’s reduction is sufficient to trivialize identity of proofs (by the argument given in the main text).
9.
It should be observed that von Plato [8] is not in the least interested in the issue of paradoxes, and regards Ekman’s phenomenon as a problem for normalization in minimal propositional logic.
10.
Similar modifications of the rules of the quantifiers are required as well, see, e.g., Tennant [11, Sect. 7.10]. Note that the qualification “negative” is essential, as in positive free logics \(t=t\) holds also when t is a non-denoting term, see for details.
11.
For the present purposes, no substantial use we will made of the rules for the existential quantifier.
12.
Alternatively, by taking A to be \(\lnot x\in x\) and both u and t to be Russell’s term r, one obtain the following pair of instances of \(\{\}^=\)E\(_{1g}\), and \(\{\}^=\)E\(_{2g}\):
from which one can construct a derivation of \(\bot \) from \(r=r\) having the same form of the derivation \(\mathbf {{R^=_g}'}\). As observed above, in free logic \(r=r\) does not come for free, but it rather has to be derived from \(\exists !r\), i.e. from \(\exists x(r=x)\). By an application of \(\mathbin {\supset }\)I one therefore obtains another closed normal derivation of \(\lnot \exists x(r=x)\). This derivation is discussed in Tennant [17, Sect. 6] albeit in slightly different form. The consequence of applications of \(\{\}^=\)E\(_{1g}\) are atomic formulas, and hence cannot be themselves major premises of an application of an elimination rule. For this reason, the rule need not be put in general elimination form to guarantee that major premises of elimination rules stand proud as required in Core Logic (see Note 16 to Chap. 3). Similar considerations apply to applications of \(\mathbin {\supset }\)E with major premise \(\lnot A\). In spite of the hybrid use of general and standard elimination rules, the considerations to be developed in the remaining part of the chapter apply, mutatis mutandis, to this derivation as well.
13.
The two notions of general rule and decomposing inference do not in general coincide, since according to the schema given by Ekman the decomposing inferences associated with the conjunction elimination rules of Gentzen [18] and Prawitz [10] differ from the (more commonly adopted) single elimination rule considered by Schroeder-Heister [19] following Prawitz [20]:
(\(\wedge \)E\(_{1D}\) and \(\wedge \)E\(_{2D}\) are in fact the elimination rules for conjunction one would obtain by \(\texttt{JR}\)-inversion, see Sect. 3.7.) It is finally worth observing that the notion of decomposing inference is not restricted to elimination rules only. When applied to introduction rules, it yields what Negri and von Plato [15, pp. 213ff.] called general introduction rules. More on this in Sect. 6.9.
14.
Here we are not assuming derivations to be normal, as in Tennant’s Core Logic (see Note 16 to Chap. 3). Hence, the major premises of \(\supset \)E\(_g\) need not be assumptions.
15.
In fact, general introduction rules are nothing but the decomposing inference corresponding to the usual introduction rules according to the pattern proposed by Ekman given in Sect. 6.6.
16.
Kürbis [21] is also aware of the difficulty in Milne’s original reductions. He gives a proof of the normalization theorem for an intuitionistic natural deduction system with general introduction and elimination rules using slightly different reductions than the one here presented.
17.
To obtain a derivation in a system in which all rules are in general form, one should have to add an extra discharged premise in correspondence of the application of \(\supset \)I so to turn it into an application of \(\supset \)I\(_g\):
18.
Further investigation is also needed to clarify the exact relationship between the Prawitz-Tennant analysis of paradoxes based on normalization failure and the solution to paradoxes consisting in restricting the use of the cut rule in sequent calculus, a solution which goes back at least to Hallnäs [22] and that has been recently brought up again by several authors, notably Ripley [23]. Given the close correspondence between normalization in natural deduction and cut elimination in sequent calculus, the solution to paradoxes arising from restricting to normalisable derivations can certainly be seen as anticipating current non-transitive sequent-calculus-based solutions (see also Note 8 to Chap. 5).. The adoption of general elimination rules called for by Tennant brings the two approaches even closer, given that general elimination rules more directly correspond to sequent calculus left rules than standard elimination rules. The results presented in this chapter, however, suggest that the relationship between two two approaches is not as obvious as one may assume. Von Plato’s and Tennant’s derivations correspond to cut-free derivations, and thereby it is prima facie unclear to which sort of transformation on sequent calculus derivations, the reductions we proposed correspond. Moreover whereas in natural deduction we have two kinds of derivations (normalisable and non-normalisable ones) in sequent calculus, by ruling out the cut rule from the outset (as Ripley, but also Tennant in his most recent work, recommend to do) no such distinction is available, and hence the original Tennant-Prawitz criterion for paradoxicality based on looping reduction sequences cannot immediately be reformulated in a cut-free setting. Arguably, by allowing cut as a primitive rule, a distinction analogous to the one available in natural deduction can be formulated in sequent calculus as well (that is, between derivations for which the cut-elimination procedure does or does not enter a loop) and the reductions for general elimination rules can find a counterpart in the sequent calculus setting as well. But a thorough investigation of these issues must be left for another occasion.
Müller, G. H., Oberschelp, A., & Potthoff, K. (eds.). (1975). ISILC-Logic Conference, Proceedings of the International Summer Institute and Logic Colloquium, Kiel 1974 (Vol. 499). Springer.
Schroeder-Heister, P. (2011). Implications-as-rules vs. implications-as-links: An alternative implication-left schema for the sequent calculus. Journal of Philosophical Logic, 40(1), 95–101.
Schroeder-Heister, P. (2014). Generalized elimination inferences, higher-level rules, and the implications-as-rules interpretation of the sequent calculus. In E. H. Haeusler, L. C. Pereira, & V. de Paiva (Eds.), Advances in Natural Deduction. Springer.
Tennant, N. (2024). Frege’s class theory and the logic of sets. In: T. Piecha, & K. Wehmeier (Eds.), Peter Schroeder Heister on Proof-Theoretic Semantics. Springer.
Prawitz, D. (1979). Proofs and the meaning and completeness of the logical constants. In: J. Hintikka, I. Niiniluoto, & E. Saarinen (Eds.), Essays on Mathematical and Philosophical Logic: Proceedings of the Fourth Scandinavian Logic Symposium and the First Soviet-Finnish Logic Conference, Jyväskylä, Finland, June 29-July 6, 1976 (pp. 25–40). Dordrecht: Kluwer. (revised German translation ’Beweise und die Bedeutung und Vollständigkeit der logischen Konstanten, Conceptus, 16, 1982, 31–44).
Kürbis, N. (2021). Normalisation and subformula property for a system of intuitionistic logic with general introduction and elimination rules. Synthese, 199, 14223–14248.
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Tranchini, L. (2024). Two Kinds of Difficulties.
In: Harmony and Paradox. Trends in Logic, vol 62. Springer, Cham. https://doi.org/10.1007/978-3-031-46921-3_6