
Abstract
Subsumption resolution is an expensive but highly effective simplifying inference for first-order saturation theorem provers. We present a new SAT-based reasoning technique for subsumption resolution, without requiring radical changes to the underlying saturation algorithm. We implemented our work in the theorem prover Vampire, and show that it is noticeably faster than the state of the art.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others
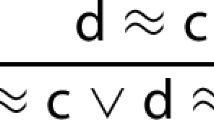


1 Introduction
Saturation-based proof search is a popular approach to first-order theorem proving [6, 14, 18]. In addition to efficient inference systems [1, 8], saturation provers also implement redundancy elimination to reduce the size of the search space. Redundancy elimination deletes clauses from the search space by showing them to be logical consequences of other (smaller) clauses, and therefore redundant. However, checking whether a first-order formula is implied by another first-order formula is undecidable, and so eliminating redundant clauses is in general undecidable too. In practice, saturation systems apply cheaper conditions for redundancy elimination, such as removing equational tautologies by congruence closure or deleting subsumed clauses by establishing multiset inclusion. Recently, SAT solving has been applied to efficiently detect and remove subsumed clauses [10]. We extend SAT-based reasoning in first-order theorem proving to a combination of subsumption and resolution, subsumption resolution [2] (Sect. 4).
Both subsumption and subsumption resolution are NP-complete [4]. To improve efficiency in practice, we (i) encode subsumption resolution as SAT formulas over (match) set constraints (Sect. 5) and (ii) directly integrate CDCL SAT solving for checking subsumption resolution in first-order theorem proving (Sect. 6). We implement our approach in the theorem prover Vampire [6], improving the state-of-the-art in first-order reasoning (Sect. 7).
Related Work. Subsumption and subsumption resolution are some of the most powerful and frequently used redundancy criteria in saturation-based provers. Subsumption resolution is supported as contextual literal cutting in [14], along with efficient approaches for detecting multiset inclusions among clauses [6, 13, 18]. Special cases of unit deletion as a by-product of subsumption tests are also proposed in [16]. Much attention has been given to refinements of term indexing [13, 16] to drastically reduce the set of candidate clauses checked for subsumption. Recently, these approaches have been complemented by SAT solving [10], reducing subsumption checking to SAT. Our work generalises this approach by solving for both subsumption and subsumption resolution via SAT.
SAT solvers have been applied widely to first-order theorem proving, including but not limited to AVATAR [17], instance-based methods [5], heuristic grounding [14], global subsumption [12] and combinations thereof [11], but using SAT solvers for classical subsumption methods is under-explored. To the best of our knowledge, SAT solving for subsumption resolution has so far not been addressed in the landscape of automated reasoning.
2 Illustrative Examples and Main Contributions
Let us illustrate a few challenges of subsumption resolution, which motivate our approach to solving it (Sect. 4). Given a pair of clauses L and M, denoted as (L, M), the problem is to decide whether M can be simplified by L via a special case of logical consequence. In Fig. 1 we show examples where it is not obvious for which pairs \((L_i,M_i)\) subsumption resolution can be applied.

Illustrative examples.
In fact, subsumption resolution can only be applied to \((L_1, M_1)\). Later, we show how our approach determines that \(M_1\) can be shortened in the presence of \(L_1\) (Example 3.1), but also how the remaining pairs cannot apply subsumption resolution (Examples 5.1, 5.2, and 4.1). For example, \((L_4,M_4)\) is filtered by pruning to bypass the SAT routine altogether.
Our Contributions
-
1.
We cast the problem of subsumption resolution over pairs of first-order formulas (L, M) as a SAT problem (Theorem 5.1), ensuring any instance of subsumption resolution is a model of this SAT problem.
-
2.
We tailor encodings of subsumption resolution (Sects. 5.1–5.2) for effective SAT-based subsumption resolution (Algorithm 1).
-
3.
We integrate our approach into the saturation loop, solving for subsumption and subsumption resolution simultaneously (Sect. 6).
-
4.
We implement our work in the theorem prover Vampire and showcase our practical gains in first-order proving (Sect. 7).
3 Preliminaries
We assume familiarity with first-order logic with equality. We include standard Boolean connectives and quantifiers in the language, and the constants \(\top , \bot \) for truth and falsehood. We use x, y, z for first-order variables, c, d, e for constants, f, g for functions, p, q, r for atoms, l, m for literals, and L, M for clauses, all potentially with indices. If L is a clause \(l_1\vee \ldots \vee l_n\), we sometimes consider it as a multiset of its literals \(l_i\), and write |L| for its cardinality (i.e. the number n of literals in L). The empty clause is denoted \(\square \). Free variables are universally quantified. An expression E is a term, atom, literal, clause, or formula.
Substitutions and Matches. A substitution \(\sigma \) is a (partial) mapping from variables to terms. The result of applying a substitution \(\sigma \) to an expression E is denoted \(\sigma (E)\) and is the expression obtained by simultaneously replacing each variable x in E by \(\sigma (x)\). For example, the application of \(\sigma {:}{=}\{ x \mapsto f(c) \}\) to the clause \(L {:}{=}\{ p(x), q(x, y) \}\) yields \(\sigma (L) = \{ p(f(c)), q(f(c), y) \}\). Note that \(\sigma (L)\) is a logical consequence of L.
A matching substitution, in short a match, between literals l and m is a substitution \(\sigma \) such that \(\sigma (l) = m\). For example, the match of p(x) onto p(f(c)) is \(\{x\mapsto f(c)\}\). Two matches are compatible and can be combined in the same substitution iff they do not assign different terms to the same variable. For example, the substitutions \(\{x\mapsto f(c), y\mapsto g(d)\}\) and \(\{x\mapsto f(c), z\mapsto h(e)\}\) are compatible, but \(\{x\mapsto f(c)\}\) and \(\{x\mapsto g(c)\}\) are not.
Saturation and Redundancy. Many first-order systems apply the superposition calculus [1] in a saturation loop [8]. Given an input set F of clauses, saturation iteratively derives logical consequences and adds them to F. By soundness and completeness of superposition, if \(\square \) is derived the system can report unsatisfiability of F; if \(\square \) is not encountered and no further clauses can be derived, the system reports satisfiability of F.
Saturation is more efficient when F is as small as possible. For this reason, saturation-based provers also employ simplifying inferences. Simplifying inferences reduce the number or size of clauses in F. This is formalised using the following notion of redundancy: a ground clause M is redundant in a set of ground clauses F if M is a logical consequence of clauses in F that are strictly smaller than M w.r.t. a fixed simplification ordering \(\succ \). A non-ground clause M is redundant in a set of clauses F if each ground instance of M is redundant in the set of ground instances of F. If M is redundant in F, then M can be removed from F while retaining completeness.
Subsumption. A clause L subsumes a distinct clause M iff there is a substitution \(\sigma \) such that
where \(\subseteq _M\) denotes multiset inclusion. We also say that M is subsumed by L. Note that subsumed clauses are redundant.
Removing subsumed clauses M from the search space F is implemented through a simplifying rule, checking condition (1) over pairs of clauses (L, M) from F. Matches between every literal in L to some literal in M are checked; if a compatible set of matches is found, then M can be removed from F.
Subsumption Resolution. Subsumption resolution aims to remove one redundant literal from a clause. Clauses M and L are said to be the main and side premise of subsumption resolution, respectively, iff there is a substitution \(\sigma \), a set of literals \(L'\subseteq L\) and a literal \(m'\in M\) such that
If so, M can be replaced by \(M\setminus \{m'\}\). Subsumption resolution is hence the rule

We indicate the deletion of a clause M by drawing a line through it (
 ), and we refer to the literal \(m'\) of M as the resolution literal of SR. Intuitively, subsumption resolution is binary resolution followed by subsumption of one of its premises by the conclusion. However, by combining two inferences into one it can be treated as a simplifying inference, which is advantageous from the perspective of proof search dynamics.
), and we refer to the literal \(m'\) of M as the resolution literal of SR. Intuitively, subsumption resolution is binary resolution followed by subsumption of one of its premises by the conclusion. However, by combining two inferences into one it can be treated as a simplifying inference, which is advantageous from the perspective of proof search dynamics.
Example 3.1
Consider \(L_1,M_1\) of Fig. 1. Subsumption resolution is applied by using the substitution \(\sigma {:}{=}\{x_1 \mapsto g(y_1), x_2 \mapsto c, x_3 \mapsto e\}\). Note that \(\sigma (L_1) = p(g(y_1), c) \vee p(f(c), e)\). \(\sigma (L_1)\) and \(M_1\) can be resolved to obtain \(p(g(y_1), c)\). The clause \(p(g(y_1), c)\) subsumes \(M_1\), since it is a sub-multiset of \(M_1\). We have

4 SAT-Based Subsumption Resolution
We describe the main steps of our SAT-based approach for deciding the applicability of subsumption resolution on a pair (L, M) of clauses. The core of our work solves (2) by finding match substitutions between literals in L and M. Our technique is summarised in Algorithm 1.

Pruning. The first step of Algorithm 1 prunes pairs (L, M) of clauses that cannot be simplified by subsumption resolution due to a syntactic restriction over symbols in L and M, viz. whether the set of predicates in L is a subset of the predicates in M. If not, then there is a literal in L that cannot be matched to any literal in M, and hence subsumption resolution cannot be applied.
Example 4.1
The clause pair \((L_4, M_4)\) from Fig. 1 is pruned by Algorithm 1: the set of predicates in \(L_4\) and \(M_4\) are respectively \(\{p, q, r\}\) and \(\{p, q\}\), implying that the literal \(r(x_3)\) of \(L_4\) cannot be matched to any literal in \(M_4\).
Match Set. The match set of Algorithm 1 computes matching substitutions over literals of L and M. The match set \( ms \) consists of a sparse matrix that assigns each literal pair \((l_i, m_j) \in L \times M\) a substitution \(\sigma _{i,j}\) such that \(\sigma _{i,j}(l_i) = m_j\) or \(\sigma _{i,j}(l_i) = \lnot m_j\). In addition, a polarity \(P_{i,j}\) is also assigned to \((l_i, m_j)\), as follows: we set polarity \(P_{i,j} = +\) if \(\sigma _{i,j}(l_i) = m_j\) and \(P_{i,j} = -\) if \(\sigma _{i,j}(l_i) = \lnot m_j\). This matrix is sparse because in general not all literal pairs \((l_i, m_j) \in L \times M\) can be matched. Additionally, it is again possible to prune (L, M) while filling the match set: if a row of the match set is empty, then there is some literal in L that cannot be matched to any literal in M. In this case, subsumption resolution cannot use L to simplify M, so the pair (L, M) is pruned.
SAT Solver. The \( solver \) of Algorithm 1 is the CDCL-based SAT solver introduced previously [10], which supports reasoning over matching substitutions in addition to standard propositional reasoning. This solver also features direct support for AtMostOne constraints. Solver performance was tuned for subsumption, which we retain for subsumption resolution. Each propositional variable v is associated with a substitution \(\sigma _v\), and the solver ensures that all substitutions \(\sigma _v\), for which v is assigned \(\top \) in the current model, are compatible. Conceptually, a global substitution \(\sigma \) satisfying the invariant \(\sigma = \bigcup \{\sigma _v\ |\ v = \top \}\) is kept in the SAT solver. In the following, we will write this binding as \(v\Rightarrow \sigma _v \subseteq \sigma \).
Example 4.2
Suppose propositional variables \(v_1\) and \(v_2\) are associated with substitutions \(\sigma _1 := \{ x \mapsto y \}\) and \(\sigma _2 := \{ x \mapsto z \}\), respectively. As \(\sigma _1\) and \(\sigma _2\) are incompatible, the solver will block assigning \(v_1 = \top \) and \(v_2 = \top \) simultaneously since it would break the above invariant.
Encoding Constraints. Given the match set of (L, M), we formalise the subsumption resolution problem (2) as the conjunction of four constraints over matching substitutions. Our formalisation is given in Theorem 5.1 and is complete in the following sense: subsumption resolution can be applied over (L, M) iff each constraint of Theorem 5.1 is satisfiable. Application of subsumption resolution is tested via satisfiability checking over our constraints from Theorem 5.1. Encodings of our subsumption resolution constraints are given in Sect. 5.
Building the Conclusion. If a model is found for the constraints encoding subsumption resolution, the conclusion \(M \setminus \{m'\}\) of SR is built using the model.
5 Subsumption Resolution and SAT Encodings
As mentioned in Sect. 4, we turn the application of subsumption resolution SR over (L, M) into the satisfiability checking problem of Algorithm 1. We give our formalisation of SR in Theorem 5.1, followed by two encodings to SAT (Sect. 5.1–5.2) and adjustments to subsumption (Sect. 5.3).
Theorem 5.1
(Subsumption Resolution Constraints). Clauses M and L are the main and side premise, respectively, of an instance of the subsumption resolution rule SR iff there exists a substitution \(\sigma \) that satisfies the following four properties:
We relate these constraints to the definition of subsumption resolution (2). The existence property (3) requires a literal \(m_j\) in M such that a literal \(l_i\) of L can be matched to \(\lnot m_j\), ensuring the existence of the resolution literal in SR. Uniqueness (4) asserts that the resolution literal \(m_j\) of SR is unique, required because SR performs only a single resolution step. Completeness (5) requires each literal in L be matched either to the complement of a resolution literal, or to a literal in M. Since each (complementary) literal in L is matched to one (resolution) literal of M, the completeness property ensures that the conclusion of SR subsumes M. Finally, coherence (6) states that all literals in M must be matched by literals in L with uniform polarity. This implies that all literals of L other than the resolution literal are present in the conclusion of SR. We note that these constraints can be used to recreate Example 3.1.
Example 5.1
The clause pair \((L_2, M_2)\) of Fig. 1 does not satisfy the uniqueness property: both the match between \(p(x_1)\) and \(\lnot p(y)\) and the match between \(q(x_2)\) and \(\lnot q(c)\) are negative and so no substitution can satisfy all constraints simultaneously. Therefore, subsumption resolution cannot be applied over \((L_2,M_2)\).
Example 5.2
The clause pair \((L_3,M_3)\) violates the coherence property for all possible \(\sigma \), since a negative map from \(p(x_1)\) to \(\lnot p(y)\) cannot coexist with a positive map from \(\lnot p(x_2)\) to \(\lnot p(y)\). Subsumption resolution cannot be performed over \((L_3,M_3)\).
5.1 Direct SAT Encoding of Subsumption Resolution
We present our encoding of subsumption resolution constraints as a SAT problem, allowing us to use Algorithm 1 for deciding the application of SR. In the sequel we consider the clauses L, M as in Theorem 5.1.
Compatibility. We introduce indexed propositional variables \(b_{i, j}^+\) and \(b_{i, j}^-\) to represent \(\sigma (l_i) = m_j\) and \(\sigma (l_i) = \lnot m_j\) respectively, which we use to track compatible matching substitutions between literals of L and M. More precisely, a propositional variable is created if and only if the corresponding match is possible (i.e., in the formulas below, if no match exist, replace the corresponding propositional variable by \(\bot \)). As it is not possible to have simultaneously a substitution \(\sigma _{i, j}(l_i) = m_j\) and \(\sigma _{i, j}(l_i) = \lnot m_j\), we also write \(b_{i,j}\) to mean either \(b_{i,j}^+\) or \(b_{i,j}^-\) when the polarity of the match is irrelevant. Following Sect. 4, the variables are bound to their substitutions:
SR Constraints. Constraints (3)–(6) of Theorem 5.1 employ bounded quantification over the finite number of literals in L, M. Expanding these quantifiers over their respective domains, we translate them into the following SAT formulas:
SR as SAT Problem. Based on the above, application of subsumption resolution is decided by the satisfiability of (7)\(\wedge \)(8)\(\wedge \)(9)\(\wedge \)(10)\(\wedge \)(11). This SAT formula extended with substitutions represents the result of encodeConstraint() in Algorithm 1 and is used further in Algorithm 3. When this formula is satisfiable, we construct the substitution \(\sigma \) required for SR by
From the model of the SAT solver, we extract the first literal \(b_{i,j}^-\) assigned \(\top \), from which we conclude that the jth literal in M is the resolution literal of SR. As such, application of SR over L and M results in replacing M by \(M \setminus \{m_j\}\).
Remark 5.1
Implicitly, all \(l_i\) literals are mapped to at most one literal \(m_j\). Indeed, if there were several literals \(m_j\) such that \(\sigma (l_i) = m_j\) or \(\sigma (l_i) = \lnot m_j\), then either the respective matches are not compatible (guarded by the compatibility property (7)), there are identical literals in M, or M is a tautology (which is not allowed).
Remark 5.2
While we defined \(b_{i,j}\) to be true if, and only if, \(\sigma _{i, j} \subseteq \sigma \), we only encode the sufficient condition \(b_{i,j} \Rightarrow \sigma _{i,j}\subseteq \sigma \). The completeness property (10) together with Remark 5.1 state that each \(l_i\) must have exactly one match to some \(m_j\) or \(\lnot m_j\). Therefore, if \(\sigma _{i,j}\subseteq \sigma \) then the respective \(b_{i,j}\) must be true and the condition also becomes necessary: \(b_{i,j} \Leftarrow \sigma _{i,j}\subseteq \sigma \).
Example 5.3
Consider the pair \((L_1,M_1)\) of Fig. 1. The match set ms of Algorithm 1 is:
Since \(\sigma _{2,1}\) is incompatible with any substitution, \(b_{2,1} = \bot \) need not be defined. This also allows to disregard SAT clauses that are trivially satisfied. The existence (8) and completeness (10) properties cannot have empty clauses: this is easily detected while filling the match set, and the instance of SR is pruned. Adding falsified literals in these constraints is unnecessary. The uniqueness (9) and coherence (11) properties have only negative polarity literals and therefore there is no need to add clauses containing \(b_{2,1}\). In light of the previous comment, we use variables \(b_{1,1}^+\), \(b_{1,2}^-\) and \(b_{2,2}^-\) and encode SR using the following constraints:
The uniqueness (9) and coherence (11) properties are trivial here because the problem is simple: all \(b_{i,j}^-\) have the same j, and no literal \(m_j\) can be mapped with different polarities. By using SAT solving from Algorithm 1 over the above SAT constraints, we obtain the SAT model \(b_{1,1}^+ \wedge \lnot b_{1,2}^- \wedge b_{2,2}^-\), with \(b_{2,2}^-\) the first literal assigned \(\top \) with negative polarity. The application of SR over \((L_1, M_1)\) yields the conclusion \(M \setminus \{m_2\} = p(g(y_1), c)\), replacing M.
5.2 Indirect SAT Encoding of Subsumption Resolution
SAT-based formulas (9) and (11) may yield many constraints, with worst-case complexity \(O(|L|^2 |M|^2)\). In practice such situations rarely occur, since the match set ms is sparsely populated. Nevertheless, to alleviate this worst-case complexity, we further constrain the approach of Sect. 5.1. We introduce structuring propositional variables \(c_j\) such that \(c_j\) is \(\top \) iff there exists a literal \(l_i\) with \(\sigma (l_i) = \lnot m_j\), which we encode as:
SR as revised SAT problem. While the compatibility property (7) remains unchanged, the SR constrains of Theorem 5.1 are revised as given below.
Similarly to Sect. 5.1, application of subsumption resolution is decided via Algorithm 1 by checking satisfiability of (7)\(\wedge \) (12) \(\wedge \) (13) \(\wedge \) (14) \(\wedge \) (15) \(\wedge \) (16) . Using the above SAT formula as the result of encodeConstraint() in Algorithm 1, the worst-case behaviour is eliminated in exchange for O(|M|) propositional variables, \(c_j\). While the direct encoding of Sect. 5.1 is more efficient on small problems as it requires fewer variables and constraints, the indirect encoding of this section is expected to behave better on larger problems (see Sect. 7).
Remark 5.3
Note that the uniqueness property (14) is handled via AtMostOne constraints, based on the approach of [10]. If a variable \(c_j\) is set to \(\top \), then our SAT solver in Algorithm 1 infers that all other variables \(c_{j'}\) are set to \(\bot \).
Example 5.4
Consider again the clause pair \((L_1, M_1)\) of Fig. 1. Compared to Example 5.3, our revised encoding of SR requires one additional variable \(c_2\), as \(m_2\) in Example 5.3 is used with negative polarity. The revised constraints are:
The SAT solver returns \(b_{1, 1}^+\wedge \lnot b_{1, 2}^-\wedge b_{2, 2}^- \wedge c_2\) as a solution to the above SAT problem, from which the application of SR yields a similar result to that of Example 5.3.
Remark 5.4
We note that our method naturally supports commutative predicates, such as equality. Let \(\simeq \) denote object-level equality. Suppose we have literals \(l_i := a \simeq b\) and \(m_j := c \simeq d\). Two propositional variables with associated matching substitutions \(\sigma _{i,j}\) and \(\sigma '_{i,j}\) are introduced, where \(\sigma _{i,j}\) matches \(a \simeq b\) against \(c \simeq d\) and \(\sigma '_{i,j}\) matches \(a \simeq b\) against \(d \simeq c\). If zero or one matches exist, then the problem behaves exactly like the non-symmetric case. If both matches exist, then \(\sigma _{i,j}\) and \(\sigma _{i,j}'\) must be incompatible: otherwise, c and d would be identical terms and the trivial literal \(m_j\) would have been eliminated. Therefore, our SAT-based encodings for subsumption resolution do not need to be adapted and behave as expected.
5.3 SAT Constraints for Subsumption
In the new framework of Algorithm 1, the formulation suggested by [10] was adjusted to work with subsumption resolution. Algorithm 1 needs very little adaptation for subsumption: the \( encodeConstraint ()\) method uses the encoding below, and the conclusion needs not be built as only the satisfiability of the formulas is relevant. The re-written SAT encoding becomes:
Note that the set of propositional variables used in our SAT-based formulas (17)–(19) encoding subsumption is a subset of the variables used by our SAT-based subsumption resolution constraints.
Pruning for Subsumption. The pruning technique described in Sect. 4 can be adapted into a stronger form for subsumption. In this case, we will check for multi-set inclusion between multi-sets of (predicates, polarity) pairs.
6 SAT-Based Subsumption Resolution in Saturation
In this section we discuss the integration of our SAT-based subsumption resolution approach within saturation-based proof search.
Forward/Backward Simplifications. For the purpose of efficient reasoning, saturation algorithms use two main variants of simplification inferences implementing redundancy. Forward simplifications are applied on a newly generated clause M to check whether M can be simplified by an existing clause L. Backward simplifications use a newly generated clause L to check whether L can simplify existing clauses M. Backward simplification tends to be more expensive.
SAT-Based Subsumption Resolution in Saturation. Since subsumption is a stronger form of simplification, subsumption is checked before subsumption resolution. This means that subsumption resolution is applied only if subsumption fails for all candidate premises. We integrate Algorithm 1 within saturation so that it is used both for subsumption and subsumption resolution.


Algorithms 2–3 display a variation of the integration of our SAT-based approach for checking subsumption resolution during saturation. Since most of the setup of subsumption is also required for subsumption resolution, both simplification rules are set up at the same time. As such, whenever turning to subsumption resolution, the same match set ms from Algorithm 2 can be reused, while also taking advantage of pruning steps performed during subsumption.
We modified the forward simplification algorithm as described in Algorithm 4. In this new setting, checking the same pair (L, M) for subsumption directly followed by subsumption resolution enables us to use Algorithms 2 and 3 efficiently. Algorithm 4 pays the price of checking subsumption resolution even if subsumption may succeed, but in practice inefficiencies in this respect are seen rarely.

Role of Indices. When applying inferences that require terms or literals to unify or match, modern automated first-order theorem provers typically use term indices [9] to consider only viable candidates within the set of clauses. Subsumption and subsumption resolution is no exception. Our testbed system Vampire currently uses a substitution tree to index clauses for matching by their literals (Sect. 7).
7 Implementation and Experiments

We implemented and integrated our SAT-based subsumption resolution approach in the saturation-based first-order theorem prover Vampire [6]Footnote 1.
Versions compared. We use following versions of Vampire in our evaluation:
-
Vampire\(_M\) is the master branch without SAT-based subsumption resolution;
-
Vampire\(_I\) is the SAT-based subsumption resolution with the indirect encoding of Sect. 5.2 and a standard forward simplification algorithm with Algorithm 1 — that is, Algorithm 4 is not used here;
-
Vampire\(^*_I\) uses the indirect encoding with Algorithms 2–4;
-
Vampire\(^*_D\) uses the direct encoding of Sect. 5.1 and Algorithms 2–4.
Experimental Setting. To evaluate our work, we used the examples of the TPTP library (version 8.1.2) [15]. In our evaluation, 24 926 problems were used out of the 25 257 TPTP problems; the remaining problems are not supported by Vampire (e.g., problems with both higher-order operators and polymorphism).
Our experimental evaluation was done on a machine with two 32-core AMD Epyc 7502 CPUs clocked at 2.5 GHz and 1006 GiB of RAM (split into 8 memory nodes of 126 GiB shared by 8 cores). Each benchmark problem was run with the options -sa otter -t 60, meaning that we used the Otter saturation algorithm [7] with a 60-second time-out. We use the Otter strategy because it is the most aggressive in terms of simplification and therefore runs the most subsumption resolutions. We turned off the AVATAR framework (-av off) in order to have full control over SAT-based reasoning in Vampire.
Evaluation Setup. Our evaluation process is summarised in Algorithm 5, incorporating the following notes.
-
The conclusion clause of the subsumption resolution rule SR is not necessarily unique. Therefore, different versions of subsumption resolution, including our work based on direct and indirect SAT encodings, may not return the same conclusion clause of SR. Hence, applying different versions of subsumption resolution over the same clauses may change the saturation process.
-
Saturation with our SAT-based subsumption resolution takes advantage of subsumption checking (see Algorithms 3 and 4). Therefore, only checking subsumption resolution on pairs of clauses is not a fair nor viable comparison, as isolating subsumption checks from subsumption resolution is not what we aimed for (due to efficiency).
-
CPU cache influences results. For example, two consecutive runs of Algorithm 4 may be up to 25% faster on second execution, due to cache effects.
For the reasons above, we decided to measure the run time of a complete execution of Algorithm 4. To prevent the branches to change, an Oracle is used to choose the path to follow. The Oracle is based on our indirect SAT encoding (Vampire\(^*_{I}\)). This way, the same computation graph is used for all evaluated methods. To prevent cache preheating, we run the Oracle after the respective evaluated method. This way the cache is in a normal state for the evaluated method. To measure the run time of Algorithm 4, a Wrapper method was built on top of the Forward Simplify procedure of Algorithm 4. This Wrapper replaces the Forward Simplify loop in Vampire with minimal changes to the code. To empirically verify the correctness of our results, we used the Wrapper to compare the result of the evaluated method with the result of the Oracle.
Experimental Details and Analysis. Fig. 2 lists the cumulative instances solved by the respective Vampire versions, highlighting the strength of forward simplifications for effective saturation.

Cumulative instances of applying subsumption resolution, using the TPTP examples. A point (n, t) on the graph means that n forward simplify loops were executed in less than \(t~\mu s\). The flatter the curve, the faster the Vampire version is.
Remark 7.1
Our experimental summary in Fig. 2 shows that the total number of Forward Simplify loops ran in 60 s. However, the average and standard deviation were computed only on the intersection of the problems solved. That is, only the Forward Simplify loops finished by all the methods are taken into account. Otherwise, if a hard problem is solved in, for instance, 1 000 000 \(\mu s\) by one method, and times out for another, the average for the better would increase a lot, but the weaker method would not be penalised. Table 1 summarises the average solving time of our evaluation.

Average time (\(\mu s\)) spent on the creating and solving SAT-based subsumption resolution constraints.
Comparison of Encodings. We correlated the constraint building and SAT solving time with the length of clauses, using the different encodings of Sects. 5.1–5.2. Figure 3 shows that on larger clauses, the average computation time increases faster for the direct encoding than for the indirect encoding.
Experimental Summary. Our experiments show that Vampire\(^*_I\) yields the most stable approach for SAT-based subsumption resolution (Table 1), especially when it comes on solving large instances (Fig. 3). Our results demonstrate the superiority of SAT-based subsumption resolution used with forward simplifications in saturation (e.g., Vampire\(^*_D\) and Vampire\(^*_I\)), as concluded by Table 2.
8 Conclusion
We advocate SAT solving for improving saturation-based first-order theorem proving. We encode powerful simplification rules, in particular subsumption resolution, as SAT problems, triggering eager and efficient reasoning steps for the purpose of keeping proof search small. Our experiments with Vampire showcase the benefit of SAT-based subsumption. In the future, we aim to further extend simplification rules with SAT solving, in particular focusing on subsumption demodulation for equality reasoning [3].
References
Bachmair, L., Ganzinger, H.: Rewrite-based equational theorem proving with selection and simplification. J. Log. Comput. 4(3), 217–247 (1994)
Bachmair, L., Ganzinger, H.: Resolution theorem proving. In: Handbook of Automated Reasoning, vol. 2, pp. 19–99. Elsevier and MIT Press (2001)
Gleiss, B., Kovács, L., Rath, J.: Subsumption demodulation in First-order theorem proving. In: Peltier, N., Sofronie-Stokkermans, V. (eds.) IJCAR 2020. LNCS (LNAI), vol. 12166, pp. 297–315. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-51074-9_17
Kapur, D., Narendran, P.: NP-Completeness of the set unification and matching problems. In: IJCAR, pp. 489–495 (1986)
Korovin, K.: Inst-Gen – a modular approach to instantiation-based automated reasoning. In: Programming Logics: Essays in Memory of Harald Ganzinger, pp. 239–270 (2013)
Kovács, L., Voronkov, A.: First-Order theorem proving and Vampire. In: CAV, pp. 1–35 (2013)
McCune, W., Wos, L.: Otter– the CADE-13 competition incarnations. J. Autom. Reason. 18, 211–220 (1997)
Nieuwenhuis, R., Rubio, A.: Paramodulation-based theorem proving. In: Handbook of Automated Reasoning, pp. 371–443. Elsevier and MIT Press (2001)
Ramakrishnan, I.V., Sekar, R., Voronkov, a.: Term indexing. In: Robinson, J.A., Voronkov, A. (eds.) Handbook of Automated Reasoning, vol. 2, pp. 1853–1964. Elsevier and MIT Press (2001)
Jakob Rath, Armin Biere, and Laura Kovács. First-Order Subsumption via SAT Solving. In FMCAD, page 160, 2022
Reger, G., Suda, M.: The uses of SAT solvers in vampire. In: Vampire Workshop, pp. 63–69 (2015)
Reger, G., Suda, M.: Global subsumption revisited (Briefly). In: Vampire @ IJCAR, pp. 61–73 (2016)
Schulz, S.: Simple and efficient clause subsumption with feature vector indexing. In: Automated Reasoning and Mathematics - Essays in Memory of William W. McCune, pp. 45–67 (2013)
Schulz, S., Cruanes, S., Vukmirovic, P.: Faster, higher, stronger: E 2.3. In: CADE, pp. 495–507 (2019)
Sutcliffe, G.: The TPTP problem library and associated infrastructure. From CNF to TH0, TPTP v6.4.0. J. Autom. Reason. 59(4), 483–502 (2017)
Tammet, T.: Towards efficient subsumption. In: CADE, pp. 427–441 (1998)
Voronkov, A.: AVATAR: the architecture for First-Order theorem provers. In: CAV, pp. 696–710 (2014)
Weidenbach, C., Dimova, D., Fietzke, A., Kumar, R., Suda, M., Wischnewski, P.: SPASS version 3.5. In: CADE, pp. 140–145 (2009)
Acknowledgements
This work is the result of a research internship hosted at TU Wien and defended at the University of Liège. The authors would like to thank Pascal Fontaine for valuable discussions and comments. We acknowledge funding from the ERC Consolidator Grant ARTIST 101002685 and the FWF SFB project SpyCoDe F8504.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Coutelier, R., Kovács, L., Rawson, M., Rath, J. (2023). SAT-Based Subsumption Resolution. In: Pientka, B., Tinelli, C. (eds) Automated Deduction – CADE 29. CADE 2023. Lecture Notes in Computer Science(), vol 14132. Springer, Cham. https://doi.org/10.1007/978-3-031-38499-8_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-38499-8_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-38498-1
Online ISBN: 978-3-031-38499-8
eBook Packages: Computer ScienceComputer Science (R0)