
Abstract
In this work we propose to use Network Architecture Search (NAS) for controlling the per layer parameters of a Tensor Compression (TC) algorithm using Tucker decomposition in order to optimize a given convolutional neural network for its parameter count and thus inference performance on embedded systems. TC enables a quick generation of the next instance in the NAS process, avoiding the need for a time consuming full training after each step. We show that this approach is more efficient than conventional NAS and can outperform all TC heuristics reported so far. Nevertheless it is still a very time consuming process, finding a good solution in the vast search space of layer-wise TC. We show that, it is possible to reduce the parameter size upto 85% for the cost of 0.1–1% of Top-1 accuracy on our vision processing benchmarks. Further, it is shown that the compressed model occupies just 20% of the original memory size which is required for storing the entire uncompressed model, with an increase in the inference speed of upto 2.5 times without much loss in the performance indicating potential gains for embedded systems.
This publication was created as part of the research project “KI Delta Learning” (project number: 19A19013K) funded by the Federal Ministry for Economic Affairs and Energy (BMWi) on the basis of a decision by the German Bundestag.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Similar content being viewed by others


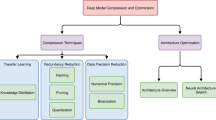
References
Choudhary, T., Mishra, V., Goswami, A., et al.: A comprehensive survey on model compression and acceleration. Artif. Intell. Rev. 53, 5113–5155 (2020). https://doi.org/10.1007/s10462-020-09816-7
Helms, D., Amende, K., Bukhari, S., et al.: Optimizing neural networks for embedded hardware. In: SMACD/PRIME 2021; International Conference on SMACD and 16th Conference on PRIME, pp. 1–6 (2021)
Han, S., Mao, H., Dally, W:J.: Deep compression: compressing deep neural networks with pruning, trained quantization and Huffman coding. Published as a Conference Paper at ICLR (oral) (2016). https://doi.org/10.48550/ARXIV.1510.00149
Zhou, S., et al.: DoReFa-Net: training low bitwidth convolutional neural networks with low bitwidth gradients, CoRR; abs/1606.06160
Uhlich, S., et al.: Mixed precision DNNs: all you need is a good parametrization. arXiv:1905.11452 (2019)
Yang, L., Jin, Q.: FracBits: mixed precision quantization via fractional bit-widths. arXiv:2007.02017 (2020)
Esser, SK., et al.: Learned step size quantization, CoRR. arXiv:1902.08153 (2019)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network (2015). arXiv:1503.02531
Tucker, LR.: Some mathematical notes on three-mode factor analysis. Psychometrika 31, 279–311 (1966). https://doi.org/10.1007/bf02289464
Microsoft NNI (2021). https://nni.readthedocs.io/en/stable/index.html
Kim, Y.-D., Park, E., Yoo, S., et al.: Compression of deep convolutional neural networks for fast and low power mobile applications (2016)
Cao, X., Rabusseau, G.: Tensor regression networks with various low-rank tensor approximations (2018). arXiv:1712.09520v2
Alter, O., Brown, P.O., Botstein, D.: Singular value decomposition for genome-wide expression data processing and modeling. Proc. Nat. Acad. Sci. (2000). https://www.pnas.org/content/97/18/10101
Kim, H., Khan, M.U.K., et al.: Efficient neural network compression. arXiv:1811.12781
Accelerating Deep Neural Networks with Tensor Decompositions. https://jacobgil.github.io/deeplearning/tensor-decompositions-deep-learning
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Advances in Neural Information Processing Systems. 2nd edn. Curran Associates, Inc. (2012). https://dl.acm.org/doi/10.5555/2999134.2999257
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 IFIP International Federation for Information Processing
About this paper

Cite this paper
Thirunavukkarasu, A., Helms, D. (2023). Using Network Architecture Search for Optimizing Tensor Compression. In: Henkler, S., Kreutz, M., Wehrmeister, M.A., Götz, M., Rettberg, A. (eds) Designing Modern Embedded Systems: Software, Hardware, and Applications. IESS 2022. IFIP Advances in Information and Communication Technology, vol 669. Springer, Cham. https://doi.org/10.1007/978-3-031-34214-1_12
Download citation
DOI: https://doi.org/10.1007/978-3-031-34214-1_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-34213-4
Online ISBN: 978-3-031-34214-1
eBook Packages: Computer ScienceComputer Science (R0)