
Abstract
Manufacturers today are increasingly connected as part of a smart and connected community. This transformation offers great potential to deepen their collaborations through resource and knowledge sharing. While the benefits of artificial intelligence (AI) have been increasingly demonstrated for data-driven modeling, data privacy has remained a major concern. Consequently, information embedded in data collected by individual manufacturers is typically siloed within the bounds of the data owners and thus under-utilized. This paper describes an approach to tackling this challenge by federated learning, where each data owner contributes to the creation of a global data model by computing a local update of relevant model parameters based on its own data. The local updates are then aggregated by a central server to train a global model. Since only the model parameters instead of the data are shared across the various data owners, data-privacy is preserved. Evaluation using sensor data for machine condition monitoring has shown that the global model produced by federated learning is more accurate and robust than the local models established by each of the single data owners. The result demonstrates the benefit of secure information sharing for individual manufacturers, especially Small and Mid-Sized Manufacturers (SMMs), for improved sustainable operation.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Smart and connected technologies, such as multimodal sensing, Internet of Things (IoT), and artificial intelligence (AI), have demonstrated potential in transforming the landscape of manufacturing toward improved productivity and the overall well-being of the community in which manufacturers reside [1]. However, for many Small and Mid-Sized Manufacturers (SMMs), digital transformation presents a significant challenge due to the general lack of resources to support technology adoption. These factors negatively impact SMMs in their competitiveness for digitalization as the future of manufacturing calls for, reducing their resilience to machine performance fluctuation and supply chain disruptions, and affecting the pipeline for workforce training, talent development and retention, which are critical to the sustainability of the community [2, 3]. The Covid-19 pandemic has further underscored the vulnerability of a technologically ill-equipped community in today’s rapidly changing economy [4].
As data is increasingly considered one of the most important resources that a manufacturer can possess [5], one major concern in digital transformation for many SMMs is the lack of sufficient, quality data to build AI models for rational, data-driven decision-making. With the advancement of communication technologies such as IoT, researchers have begun to explore the feasibility of aggregating data from multiple data owners to jointly build AI models that overcomes the data limitation problem that each individual SMM is facing [6]. Compared to the traditional approach that relies on data from a single SMM, such a collaborative, data-sourcing approach is expected to overcome data quality issues that typically arise in siloed data scenarios, such as data imbalance and low data quantity, by utilizing the complementary information from multiple SMMs [7, 8]. The results are reduced production interruption for data collection, improved resource utilization, and more accurate and robust AI models to support the sustained growth of the SMMs in the community.
A major hurdle towards data-oriented collaboration is the concerns about data-privacy, as traditionally, proprietary data collected from individual data owners will need to be shared in a central server for data aggregation-enhanced model building. To overcome such concerns, techniques for transfer learning [9] and data synthesis [10] have been developed. Transfer learning first builds a model in a source domain (e.g., a SMM with high-quality data), before fine-tuning it using data from a target domain (e.g., another SMM) for adaptation and refinement [11]. It has been successfully implemented in applications such as human action recognition in human-robot collaboration (HRC) [12, 13] and machine condition monitoring [14, 15]. In comparison, data synthesis aims to learn data distribution and synthesize new data samples to increase data quantity and reduce imbalance. Recent development of generative adversarial network (GAN) has improved data synthesis capability by using a pair competing networks, one for improving synthesis quality and the other for distinguishing real data from synthetic data [10]. The two ultimately reach an equilibrium point for high-fidelity data synthesis. The effectiveness of GAN has been demonstrated for machine condition monitoring [16,17,18].
Despite the progress, both methods have their limitations. For example, a data model can be SMM-specific and not suited for deployment to different SMMs without substantial modification that still does not guarantee successful model transfer [9]. As a result, when the number of SMMs becomes large, this method becomes computationally inefficient. In addition, training of GAN requires that the available data samples have the same distribution as the underlying data distribution, which is difficult to guarantee if the data quantity is small [18].
To address this problem, federated learning [19] is investigated in this paper. In federated learning, each SMM contributes to the construction of a global data model by computing a local update of relevant model parameters using its own data. The local updates from multiple SMMs are then aggregated by a central server for the training of the global model. Since only the updated parameters of the global model instead of the data themselves are shared during the model update process, data privacy is preserved. In addition, as information from all the participating SMMs is utilized during the model training process, the global model is SMM-independent. Furthermore, federated learning does not impose restrictions on quantity, level of imbalance, or the distribution characteristic of the data being utilized, it is well-suited for real-world scenarios where none of these restrictions can be assumed. Recently, research on federated learning for machine condition monitoring has been reported [20,21,22]. However, these studies focused on a relatively small number of participating data owners (\(\le \) 10). In addition, since each of the data owners has full control of its data, it is possible that the data from a data owner may not participate during the iteration process of federated learning in realistic settings (e.g., due to scheduling conflict), leading to partial participation. Such partial participation has not been investigated in these prior efforts [20,21,22].
This paper aims to fill this research gap, and is organized as follows: Sect. 2 presents the theoretical background of federated learning. In Sect. 3, evaluation of the developed algorithm using publicly available experimental datasets is described. The results are discussed in Sect. 4, and conclusions are drawn in Sect. 5.
2 Theoretical Background
The key idea of federated learning is to solve an optimization problem [19]:
In Eq. (1), \(F\left({\varvec{w}}\right)\) is the loss function of the global model with model parameters \({\varvec{w}}\) (e.g., network weights), N is the total number of participating data owners, \({p}_{k}\) is the weights assigned to the kth data owner such that \({p}_{k}\ge 0\) and \(\sum_{k=1}^{N}{p}_{k}=1\). Without prior knowledge regarding the data from each data owner (as is usually the case with federated learning), \({p}_{k}\) is empirically set to 1/N. \({F}_{k}(\cdot )\) is the local loss function.
Assume the number of training data from the kth SMM is \({n}_{k}\): \({x}_{k,1}\), \({x}_{k,2}\), …, \({x}_{k,{n}_{k}}\), the local loss function \({F}_{k}(\cdot )\) is defined as:
In Eq. (2), \(l({\varvec{w}};{x}_{k,i})\) is the loss induced by the global model parameters \({\varvec{w}}\) and local data sample \({x}_{k,i}\). The specific formulation of \(l(\cdot )\) is application-dependent (e.g., mean squared error for prediction or cross-entropy for classification). In order to minimize Eq. (1), the gradient of each \({F}_{k}\left({\varvec{w}}\right)\) with respect to \({\varvec{w}}\) is first computed, which indicates the direction of minimizing \({F}_{k}\left({\varvec{w}}\right)\). Then, \({\varvec{w}}\) is adjusted in this direction to obtain the new \({F}_{k}\left({\varvec{w}}\right)\). These two steps constitute an iteration in federated learning.
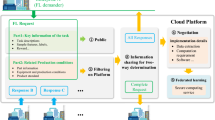
Figure 1 details one such iteration: the jth iteration. The central server first publishes the latest model parameters \({{\varvec{w}}}_{j}\) to all the data owners, which compute their own contributions to the global model update as:
where \(\eta \) is the learning rate and \(\nabla {F}_{k}\) is the gradient of \({F}_{k}\left({\varvec{w}}\right)\). Then, the central server aggregates the contributions from each data owner, \({{\varvec{w}}}_{j+1}^{1}\), \({{\varvec{w}}}_{j+1}^{2}\), …, \({{\varvec{w}}}_{j+1}^{N}\) to obtain the new global model parameters \({{\varvec{w}}}_{j+1}\).

Training iteration in federated learning
In federated learning, each data owner has full control of its own data. Realistically, only a subset S out of the total N owners may be available to participate at each iteration and S can vary from iteration to iteration. Therefore, the aggregation is expressed as:
where \(\left|{S}_{j}\right|\) is the size of \({S}_{j}\). The expectation of the federated learning loss function in Eq. (1), \(F(\cdot )\), has shown to be bounded [19], which provides the theoretical support for federated learning as a learning method that is convergent by nature.
3 Algorithm Evaluation
The effectiveness of the developed federated learning algorithm for machine condition monitoring is evaluated using bearing dataset at Case Western Reserve University (CWRU) [23]. In this dataset, single point faults were seeded to the drive-end bearing (Fig. 2) at the inner or outer race of the bearing, as in the rolling ball. Vibration signals were sampled at 12 kHz, with the bearing rotating speed being 1750 rpm. Signals corresponding to the three fault types were evaluated and compared with signals collected from a healthy, normal bearing, which serves as a reference base.
To evaluate the federated learning algorithm, the dataset is first split into non-overlapping sequences with each containing 800 vibration data points. In total, there are 7,500 sequences in the dataset. The sequences are then allocated into 50 sets to simulate 50 participating data owners (e.g., SMMs), with each set containing a different number of data sequences to simulate varying data quantity from the different SMMs. The data in each set is not restricted to any specific distribution characteristic during the allocation, allowing its level of imbalance to vary from one data owner to another. Each set is then further split into a training set and a testing set with a split ratio of 70% to 30%.

During each iteration of the federated learning process, the number of participating data owners can vary depending on whether each of them grants the access to its data. To simulate such a scenario, a random number n between 41 and 50 is first generated in each iteration, then n data owners are randomly selected from total of 50 based on a uniform distribution, corresponding to a \(\ge \)80% participation rate at each iteration.
The global model of federated learning investigated in this study is based on a 1D convolutional neural network (1D-CNN). This network structure is selected due to its demonstrated capability [26] of extracting multi-level features from sequential data (such as bearing vibration signal) and associating the features to variables of interest (i.e., bearing fault types). The 1D-CNN network structure is determined using a parameter search and is shown in Fig. 3. The learning rate is set to 0.01, the optimizer is stochastic gradient descent (SGD), and batch size is set to 16. Federated learning is carried out using an Nvidia P100 GPU with 16 GB RAM on Google Colaboratory.

1D-CNN structure for federated learning
4 Results and Discussion
For evaluation of the global model obtained through federated learning, its performance is compared with that of another two scenarios:
Centralized: data from all the owners are merged into a single dataset to carry out 1D-CNN training and evaluation. It should be noted this scenario is not feasible in realistic settings and only serves the purpose of evaluating the diagnosis accuracy (in %) and convergence behavior (in number of iterations) of federated learning as compared to an ideal scenario.
Siloed: individual data model is established for each data owner using its own training and testing data. The purpose is to evaluate improvement in diagnosis accuracy (in %) and robustness (in accuracy standard deviation among SMMs) enabled by the global model of federated learning as compared to the model built using siloed data.
First, the training and testing curves associated with federated learning and centralized scenario are plotted in Fig. 4. Federated learning has shown to arrive at about the same level of accuracy as the centralized scenario (99% training accuracy and 96% testing accuracy), indicating that the global model obtained is as effective as the model created using centralized strategy. It is also noted that centralized strategy converges faster (~50 iterations vs. ~ 400 iterations for federated learning), indicating that weights update in federated learning is suboptimal. This can be attributed to the fact that both the local gradient computation and the non-participating data owners at each iteration can induce bias into weights update, which is then propagated over the entire iteration process and causes slow convergence. Since individual iteration in federated learning can take longer to complete as compared to the centralized scenario due to the additional communication delay with different data owners, the negative impact of slow convergence can be exacerbated. Future research will investigate methods to accelerate model convergence, which is currently an open research topic per the literature [19].

Training and testing curves: centralized vs. federated scenarios
The performance of federated learning is then compared to the siloed learning scenario. Model accuracy evaluated on testing dataset from each SMM is plotted as histogram in Fig. 5(a) and associated confusion matrices are shown in Fig. 5(b). It is seen that model accuracy in diagnosis of bearing fault types under the siloed scenario ranges from 35% to 84% with a mean accuracy of only 60%. By contrast, using federated learning, not only the mean accuracy has increased from 60% to 95%, which represents a 58% improvement, the performance variation is also reduced, as reflected by the standard deviation of the diagnosis accuracy (from 12% in siloed scenario to 3% in federated learning, a reduction of 75%). These results demonstrated the global model is both more accurate and more robust as compared to learning from siloed data.

Siloed vs. federated: (a) histogram of fault diagnosis accuracy for SMMs; (b) confusion matrix of fault diagnosis. N: normal; I: inner race fault; B: ball fault; O: outer race fault
5 Conclusions
To enhance sustainability and resilience of manufacturers toward building smart and connected communities through cross-manufacturer collaboration, a federated learning approach has been investigated for improved resource and knowledge sharing while preserving data-privacy. The method is characterized by local model update and global parameter aggregation to arrive at a global model for all participating manufacturers. Using bearing condition monitoring as a representative application, the global model obtained through federated learning has shown a 58% improvement in fault diagnosis accuracy while reducing performance variation by 75% as compared to learning from siloed data, thereby demonstrating an effective solution to a common problem where insufficient or small data constrains the development of high-quality model at individual manufacturer’s site. By arriving at a global diagnosis accuracy comparable to the one that would have been achieved using centralized strategy (96%), federated learning has shown to satisfactorily meet the performance expectation for cross-manufacturer collaboration. One limitation of the presented method is that it requires homogeneous sensor data type from each participating manufacturer as input to the model. Future research will relax this requirement to accommodate different types of sensor data to facilitate broader acceptance of the federated learning method in real-world settings. In addition, future research will also investigate model convergence for increased computational efficiency in data intensive applications.
References
Monostori, L., et al.: Cyber-physical systems in manufacturing. CIRP Ann. 65(2), 621–641 (2016)
Váncza, J., et al.: Cooperative and responsive manufacturing enterprises. CIRP Ann. 60(2), 797–820 (2011)
Lanza, G., et al.: Global production networks: design and operation. CIRP Ann. 68(2), 823–841 (2019)
Gupta, D., Bhatt, S., Gupta, M., Tosun, A.S.: Future smart connected communities to fight covid-19 outbreak. Internet of Things 13, 100342 (2021)
Gao, R., Wang, L., Helu, M., Teti, R.: Big data analytics for smart factories of the future. CIRP Ann. 69(2), 668–692 (2020)
Bechtsis, D., Tsolakis, N., Iakovou, E., Vlachos, D.: Data-driven secure, resilient and sustainable supply chains: gaps, opportunities, and a new generalised data sharing and data monetisation framework. Int. J. Prod. Res. 1–21 (2021)
Zhang, J., Gao, R.: Deep learning-driven data curation and model interpretation for smart manufacturing. Chinese J. Mech. Eng. 34(1), 1–21 (2021)
Sabbagh, R., Gawlik, B., Sreenivasan, S.V., Stothert, A., Majstorovic, V., Djurdjanovic, D.: Big data curation for analytics within the cyber-physical manufacturing metrology model (CPM3). Procedia CIRP 93, 491–495 (2020)
Yan, R., Shen, F., Sun, C., Chen, X.: Knowledge transfer for rotary machine fault diagnosis. IEEE Sens. J. 20(15), 8374–8393 (2019)
Kusiak, A.: Convolutional and generative adversarial neural networks in manufacturing. Int. J. Prod. Res. 58(5), 1594–1604 (2020)
Li, S., Zheng, P.: transfer learning for smart manufacturing: a stepwise survey. IFAC-PapersOnLine 53(5), 37–42 (2020)
Wang, P., Liu, H., Wang, L., Gao, R.: Deep learning-based human motion recognition for context-aware human-robot collaboration. CIRP Ann. 67(1), 17–20 (2018)
Xiong, Q., Zhang, J., Wang, P., Liu, D., Gao, R.: Transferable two-stream CNN for human action recognition. J. Manuf. Syst. 56, 605–614 (2020)
Wang, P., Gao, R.: Transfer learning for enhanced machine fault diagnosis in manufacturing. CIRP Ann. 69(1), 413–416 (2020)
Guo, L., Lei, Y., Xing, S., Yan, T., Li, N.: Deep convolutional transfer learning network: a new method for intelligent fault diagnosis of machines with unlabeled data. IEEE Trans. Industr. Electron. 66(9), 7316–7325 (2018)
Lee, Y.O., Jo, J., Hwang, J.: Application of deep neural network and generative adversarial network to industrial maintenance: a case study of induction motor fault detection. In: IEEE International Conference on Big Data (Big Data), pp. 3248–3253 (2017)
Shao, S., Wang, P., Yan, R.: Generative adversarial networks for data augmentation in machine fault diagnosis. Comput. Ind. 106, 85–93 (2019)
Wang, Z., Wang, J., Wang, Y.: An intelligent diagnosis scheme based on generative adversarial learning deep neural networks and its application to planetary gearbox fault pattern recognition. Neurocomputing 310, 213–222 (2018)
Li, X., Huang, K., Yang, W., Wang, S., Zhang, Z.: On the convergence of FedAvg on non-IID data. In: International Conference on Learning Representations (2019)
Geng, D., He, H., Lan, X., Liu, C.: Bearing fault diagnosis based on improved federated learning algorithm. Computing 104(1), 1–19 (2021). https://doi.org/10.1007/s00607-021-01019-4
Zhang, W., Li, X., Ma, H., Luo, Z., Li, X.: Federated learning for machinery fault diagnosis with dynamic validation. Knowl.-Based Syst. 213, 106679 (2021)
Chen, J., Li, J., Huang, R., Yue, K., Chen, Z., Li, W.: federated learning for bearing fault diagnosis with dynamic weighted averaging. In: International Conference on Sensing, Measurement & Data Analytics in the era of Artificial Intelligence, pp. 1–6 (2021)
Bearing Data Center, engineering.case.edu/bearingdatacenter
Industrial quick search. www.iqsdirectory.com/articles/dynamometers.html
AC motor exploded view. https://www.acmotorkitpicture.blogspot.com/ac-motor-exploded-view.html
Eren, L., Ince, T., Kiranyaz, S.: A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN. J. Signal Process. Syst. 91(2), 179–189 (2019)
Acknowledgement
The authors acknowledge support for this research by the National Science Foundation under award CNS-2125460.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Zhang, J., Cooper, C., Gao, R.X. (2023). Federated Learning for Privacy-Preserving Collaboration in Smart Manufacturing. In: Kohl, H., Seliger, G., Dietrich, F. (eds) Manufacturing Driving Circular Economy. GCSM 2022. Lecture Notes in Mechanical Engineering. Springer, Cham. https://doi.org/10.1007/978-3-031-28839-5_94
Download citation
DOI: https://doi.org/10.1007/978-3-031-28839-5_94
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-28838-8
Online ISBN: 978-3-031-28839-5
eBook Packages: EngineeringEngineering (R0)