
Abstract
Multivariate conditional simulations can be reduced to a set of independent univariate simulations through multivariate Gaussian transformation of the drill hole data to independent Gaussian factors. These simulations are then back transformed to obtain simulated results that exhibit the multivariate relationships observed in the input drill hole data. Several transformation techniques are cited in geostatistical literature for multivariate transformation. However, only two can effectively simulate high dimensional drill hole data with complex non-linear features: Flow Anamorphosis (FA) and Projection Pursuit Multivariate Transformation (PPMT). This paper presents an alternative iterative multivariate Gaussian transformation (IG) along with a multivariate simulation case study of a large Nickel deposit. Our findings show that IG is computationally faster than FA and PPMT which makes the technique more appealing for most practical and time-sensitive applications.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Traditional univariate conditional simulation techniques transform the data to Gaussian space via quantile–quantile transformation [1] where the simulation proceeds and the results back-transformed to input data space via the corresponding back-transformation. Conventional multivariate simulation techniques like Cosimulation [2], PCA [3, 4] and MAF [4] transform each attribute separately using the quantile–quantile approach and the simulation proceeds by assuming the transformed data have multivariate Gaussian distribution. This assumption is not realistic because having marginal Gaussian distributions does not necessarily ensure the transformed data has multivariate Gaussian distribution. This is no longer an issue for truly multivariate techniques like stepwise conditional transformation (SCT) by Leuangthong et al. [5], Projection Pursuit Multivariate Transformation (PPMT) by Barnett et al. [6] and Flow Anamorphosis (FA) by van den Boogaart [7].
SCT workflow is cumbersome and often difficult to apply with increasing number of attributes [8] which has limited its used in practical applications. FA has the ability to handle a large number of attributes but depends on two parameters, both of which require significant fine-tunning to ensure convergence to a multivariate Gaussian distribution. Further to this, in its current form, FA is impractical for large data sets due to the significant computational processing time required for processing the data. Conversely, PPMT’s lower overall processing time and minimal tunning parameters have made the technique more appealing for most practical.
This paper presents a multivariate simulation case study of a large Nickel deposit using an iterative multivariate Gaussian transformation developed by Laparra et al. [9] for image processing. The technique does not require any tunning parameters, nor does it need to search for the most non-Gaussian projection, which is key to PPMT. Furthermore, its direct and back transformations are faster and convergence to a standard multivariate Gaussian distribution is proven. This position IG as a technique that may supplant PPMT and FA for time-sensitive applications.
2 Iterative Multivariate Gaussianisation
IG is simply a sequential application of univariate marginal Gaussianisation using the quantile–quantile approach followed by a rotation using an orthonormal transformation [9]. An important aspect of IG is that the type of rotation is not critical because the algorithm convergence is proven for any orthonormal transformation.
Let \({X}^{\left(0\right)}\) be the multivariate input data and \(\Psi \left({X}^{\left(0\right)}\right)\) the marginal Gaussianisation of each dimension of \({X}^{\left(0\right)}\). Then the iterative process is defined as
where \({R}_{k}\) is a generic rotation matrix for \(\Psi \left({X}^{\left(k\right)}\right)\) [9]. A simple choice is set \({R}_{k}\) to be the matrix of eigenvectors of \(\Psi \left({X}^{\left(k\right)}\right)\). This provides an easily programmable closed-form for the direct and back-transformations. Furthermore, Srivastava’s skewness and kurtosis multivariate normality test [10] can be seamlessly integrated to derive appropriate stopping conditions. As pointed out by Laparra et al. [9], using the eigenvectors also guarantees the algorithm convergence except for the case of a multivariate input data having all its univariate marginal distributions equal to the standard Gaussian distribution. This case can rarely be found in real data sets.
3 Nickel Laterite Case Study
3.1 Overview
This case study presents the validation results for a multivariate conditional simulation utilising IG for a large nickel laterite deposit. The simulation was generated as part of a Drillhole Spacing Analysis (DSA) with the aim of quantitatively assessing the economic cost vs risk at varying sample densities, based on the quality of the grade estimation and potential for misclassification. Due to the correlated nature of the input variables (Ni, Co, MgO, SiO2 and Al2O3), the simulation required a multivariate approach to ensure that the correlations were reproduced and maintained.
The nickel laterite study area is approximately 2 km2 and is informed by 97,682 samples with variable spacing as shown in Fig. 1. For each sample, multielement data is available from which 5 key elements have been analysed, due to their economic interest to the mine operator. A single lithological domain was identified as the target of the study and warranted basic unfolding techniques to minimise variations in mineralisation orientation.

Plan section of the case study area showing all sample locations
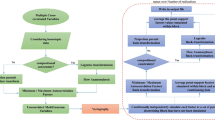
3.2 Workflow
The high-level steps followed to generate the multivariate simulations from the input data for the study area is outlined below.
-
1.
Perform multivariate and compositional exploratory data analysis to confirm variable correlations and validate the composition.
-
2.
Transform coordinates to unfolded space using basic z-only transform for flattening.
-
3.
Perform compositional transformation using an appropriate log-ratio technique In this case, the additive log-ratio (ALR) transformation was used.
-
4.
Perform multivariate normal transformation using IG.
-
5.
Validate statistical properties and spatial decorrelation of independent Gaussian factors.
-
6.
Simulate in Gaussian space using sequential gaussian.
-
7.
Back-transform assays to compositional space, then to raw space.
-
8.
Refold simulations to raw coordinate space.
-
9.
Validate simulation results with input data.
3.3 Multivariate Transformation and Simulation
Multivariate techniques are suitable for element compositions which exhibit correlations and form a composition, or sub-composition. Bivariate analysis of the chosen input variables demonstrated complex non-linear relationships which must be preserved in the simulation results, as shown in Fig. 2.

Hexbin plot showing the input correlation between SiO2 and Al2O3
When the variables under study form a sub-composition, i.e. several variables jointly describe the relative weight with respect to a whole, a form of completing is required to ensure the constant sum constraint, which is the case for the multivariate simulation of Ni, Co, MgO, SiO2 and Al2O3. This is achieved by defining a filler variable which represents all other variables not being considered that make up the remainder of the sample composition. In this case, additive log-ratio (ALR) was selected as the transformation method to be used to unconstraint the sub-composition formed by Ni, Co, MgO, SiO2 and Al2O3. Furthermore, ALR is simple and suited to work with conditional simulations [11].
The IG method was used to further transform the ALR data into equivalent independent factors with multivariate standard Gaussian distribution. IG was chosen because PPMT produced artifacts in the resulting factors regardless of the number of iterations used during the transformation. An example is shown in Fig. 3. The scatterplot between two factors computed using the PPMT transform exhibit linear stripes that do not correspond to the expected scatterplot between independent Gaussian attributes with multivariate Gaussian distribution. Furthermore, IG’s simplicity and reasonably low runtime compared to PPMT and FA were considered major benefits.

Scatterplots between factors for PPMT (left) and IG (right)
Although IG theoretical properties ensure that factors have multivariate standard Gaussian distribution, it is not possible to know in advanced how many iterations are required to achieve convergence. In this study, 60 iterations were used but as shown in Sect. 3.4 much less iterations could have been used. Figure 4 shows all scatterplots between the derived four factors.

Scatterplots between factors derived using the IG transformation. Data is shown in grey along with the confidence ellipses for the 95th (red), 50th (blue) and 15th (green) percentiles according to a standard multivariate Gaussian distribution
The degree of spatial correlation between factors was assessed visually by computing omnidirectional cross variograms for up to 400 m (Fig. 5). The results show that spatial correlation between factors can be considered negligible with an absolute maximum value of 0.14.

Omnidirectional cross variograms between factors derived using the IG approach
Factors were simulated using the Sequential Gaussian Simulation [1]. The simulations informed a 2.5 mN × 2.5 mE × 2 mRL grid of nodes and were considered the point support simulations. Scatterplots were generated for each of the element pairs to ensure that the data correlations were reproduced in the simulation results. Figure 6 demonstrates that the IG technique has successfully maintained the complex non-linear correlations in the input data.

Hexbin plot showing the correlation between SiO2 and Al2O3 for a single, randomly selected realization
Trend plots of the average naïve and de-clustered composites and a single simulation of nickel are presented in Fig. 7. The simulated grades in the trend plots demonstrate minor deviation from the input drillhole data; however, this is primarily influenced by local variability introduced by the simulation process and irregular sample distribution compared to the cell volumes. Globally, the difference amounts to an 8–10% difference; however, majority of simulated cells generally exhibit much lower differences. Visual inspection across the model shows good correlation to immediately surrounding samples and the overall trends of the grades across the deposit.

Trend plot for nickel comparing the naïve (red) and declustered (blue) sample data to a randomly selected simulation (black)
Figure 8 illustrates east–west profiles for three realisations at point support (2.5 mE × 2.5 mN × 2 mRL spacing) of simulated nickel mineralisation, with the conditioning drillhole data, in unfolded space. The simulations show good reproduction of the input data and reflect the mineralization trends and continuity that were evident in the spatial analysis. Additionally, there is good alignment between the simulations with the greatest variability occurring where data is sparser, and the grade data is less continuous.

Northeast-southwest cross-section showing three point support (2.5 m × 2.5 m × 2 m) realisations of nickel mineralisation, with conditioning data, in unfolded space
The conclusions from the validation of the simulations, are:
-
Visual comparison of the simulated grades and the corresponding drillhole grades showed reasonable correlation.
-
A comparison of the global drillhole and simulated domain grades for Ni, Co, SiO2 and Al2O3 shows that the mean grades of the simulations were typically within 5%.
-
Comparison of the variance of the input composite data against the simulations shows that the simulations adequately reproduce the variance of the input data.
-
Analysis of the correlation coefficients between Ni, Co, MgO, SiO2 and Al2O3 for each deposit shows that the correlations of the input composite data are reproduced in the simulated grades. Furthermore, the compositional closure is preserved, as demonstrated in Fig. 6.
-
The input data contains some outlying correlations which the simulations attempt to reproduce and may appear to be artefacts in the scatterplots. These samples are considered to be real and therefore included in the dataset without no top cutting or filtering so that the variability of all aspects of the dataset were reproduced. The number of records which make up these outlying correlations amount to less than 1% of the total dataset.
-
Except for poorly sampled regions, the grade trend plots show a good correlation between simulated and drillhole grades.
The simulations are therefore considered a suitable representation input characteristics observed in the drill hole data.
3.4 Benchmarking
PPMT and IG were compared by analysing the run time as function of increasing number of samples and by testing the rapidness of the convergence to a standard multivariate Gaussian distribution using the Energy test [12]. Flow anamorphosis was not considered during the benchmark due to the long run time required to get the results.
Two run-time tests were conducted to directly compare the total processing time required for each of the IG and PPMT methods. For sample numbers between 10,000 and 50,000 there is a significant time saving when using IG of approximately 90% with an average of 953 samples processed per second compared to PPMT’s 94 samples per second (Fig. 9). Further testing for increasing numbers of samples between 10,000 and 10,000,000 samples indicate that the ratio further increases with greater populations (Fig. 10). In addition, PPMT was unable to complete the ten million sample run in the test environment analysed.

Comparison of total run-time for both IG and PPMT for multiples of 10,000 samples

Comparison of total run-time for both IG and PPMT for log10 sample quantities
Results for the Energy test are shown in Fig. 11. For each iteration, the test was carried out using a 95% confidence level and the resultant P-value reported. The results show that IG requires a fraction of the iterations used by PPMT to converge to a standard multivariate Gaussian distribution.

Comparison of calculated p-value for both IG and PPMT by iteration number
3.5 Artifacts
As with many techniques, a core difficulty is the reproduction of under-represented features and extreme values. An artifact in the data is considered to be where the technique fails to reproduce geological features and relationships in a manner that would be expected in the geological setting. Comparison of IG, PPMT and FA techniques and their ability to minimise artifacts in the presence of extreme values are illustrated in Fig. 12, Fig. 13 and Fig. 14 respectively. Between the three techniques, only FA significantly minimises the effect of extreme values. PPMT provides a few key benefits when compared to the IG results, while retaining some issues with values in regions uninformed by the input data.

Comparison of input data versus backtransformed values for the IG method

Comparison of input data versus backtransformed values for the PPMT method

Comparison of input data versus backtransformed values for the FA method
Comparison of the drillhole data correlations with the simulation results are shown in Fig. 15. These graphs highlight areas where artifacts are most significant due to the values being extreme for the dataset and the compositional transformation ensuring closure. While these features are not typical of a raw geological dataset, the relationships are acceptable within the context of the deposit. In addition, these artifacts are generally pervasive where gaps in the relationships occur and could be improved through additional sampling if they were considered material to the interpretation of the results.

Comparison of input data (left) correlations compared to simulation results (right) for SiO2–Al2O3 (top) and Co–Al2O3 with artifacts highlighted
4 Conclusions
The validation work demonstrates that the simulations generated using compositional and iterative Gaussianisation techniques are valid and accurately represent the input data. In addition to the requirement for a valid technique, many mine production settings require further criteria for long-term uptake of new mathematical techniques and must:
-
1.
Produce results within a timely manner to meet time-sensitive targets for large populations of samples.
-
2.
Be usable in multiple settings, on a range of compositions with a low failure-rate.
-
3.
Be easy to understand and utilise, as well as being openly available for the general resource estimator.
IG meets these criteria as the convergence to a gaussian distribution is always guaranteed, the matrices are always invertible and the technique is fast and simple. These benefits make the technique highly practical for the mining industry where time is precious and datasets exhibit complex relationships.
References
Deutsch, C.V., Journel, A.G.: GSLIB: Geostatistical Software Library and User’s Guide. Oxford University Press, Oxford (1998)
Chiles, J.P., Delfiner, P.: Modeling Spatial Uncertainty, 2nd edn. Wiley, New York (2012)
Bandarian, E., Bloom, L., Mueller, U.: Transformation methods for multivariate geostatistical simulations. In: Proceedings of the IAMG 06 XI-th International Congress for Mathematical Geology (2006)
Rondon, O.: Teaching aid: minimum/maximum autocorrelation factors for joint simulation of attributes. Math. Geosci. 44(4), 469–504 (2012)
Leuangthong, O., Deutsch, C.V.: Stepwise conditional transformation for simulation of multiple variables. Math. Geol. 35, 155–173 (2003)
Barnett, R.M., Manchuk, J.G., Deutsch, C.V.: Projection pursuit multivariate transform. Math. Geosci. 46, 337–360 (2014)
van den Boogaart, K. G., Tolosana-Delgado, R., Mueller, U. (2015). An affine equivariant anamorphosis for compositional data. In: Proceedings of IAMG 2015—17th Annual Conference of the International Association for Mathematical Geosciences, pp. 1302–1311 (2015)
Barnett, R.M., Deutsch, C.: Guide to multivariate modelling with the PPMT. Centre for Computational Geostatistics Guidebook Series, vol. 20 (2015)
Laparra, V., Camps-Valls, G., Malo, J.: Iterative Gaussianization: from ICA to random rotations. IEEE Trans. Neural Netw. Publ. IEEE Neural Netw. Council 22, 537–549 (2011). https://doi.org/10.1109/TNN.2011.2106511
Enomoto, R., Okamoto, N., Seo, T.: Multivariate normality test using Srivastava’s skewness and kurtosis. SUT J. Math. 48(1), 103–115 (2012)
Tolosana-Delgado, R., Mueller, U., Gerald van den Boogart, K.: Geostatistis for compositional data: an overview. Math. Geosci. 51(4), 485–526 (2019)
Szekely. G.J., Rizzo, M.L.: Energy statistics: a class of statistics based on distances. J. Stat. Plan. Infer. 143(8), 1249–1272 (2013)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2023 The Author(s)
About this paper

Cite this paper
Cook, A., Rondon, O., Graindorge, J., Booth, G. (2023). Iterative Gaussianisation for Multivariate Transformation. In: Avalos Sotomayor, S.A., Ortiz, J.M., Srivastava, R.M. (eds) Geostatistics Toronto 2021. GEOSTATS 2021. Springer Proceedings in Earth and Environmental Sciences. Springer, Cham. https://doi.org/10.1007/978-3-031-19845-8_2
Download citation
DOI: https://doi.org/10.1007/978-3-031-19845-8_2
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19844-1
Online ISBN: 978-3-031-19845-8
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)