
Abstract
In recent years, the body of research on artificial intelligence (AI) has grown rapidly. As the European Union strives for excellence in AI development, this study aims to establish the publication achievements in the field among its member states between 2010 and 2019. We applied clustering and principal component analysis (PCA) on a set of bibliometric data concerning research publications on AI obtained from Scopus. The results reveal that while the union’s most populous countries—the United Kingdom, Germany, France, Spain, and Italy—were the most prolific producers of AI publications between 2010 and 2019, the highest impact was noted for publications that originated in the Nordic and Benelux countries, as well as in Austria and Ireland. Analysis confirms that the division between ‘old’ and ‘new’ member states has endured: the nations that joined the EU after 2004 recorded the lowest results in scientific output and impact in the AI field. This study can assist research agencies and researchers in developing a broad grasp of the current state of AI research.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

Keywords
- Artificial intelligence
- Bibliometric analysis
- Bibliometric indicators
- Clustering
- European Union
- Principal component analysis
1 Introduction
The body of research on artificial intelligence (AI) has grown rapidly in application and use. AI is soon likely to become a general purpose technology; this will affect the nature of work and the labour market [1, 2], and inequalities [3], as well as entailing significant economic [4] and societal impacts [5, 6]. Researchers in AI have long recognised the absence of a definitional consensus in the field [7, 8]. Policymakers and AI researchers have adopted different approaches in defining the term: while the former tend to favour human thinking or behaviour, the latter focus on technical problem specification and functionality [9]. A significant degree of conceptual development and controversy exists around the notion of AI; this has produced heated philosophical and ethical debates [10].
AI has garnered much attention in academic research, as well as in geopolitics. Although it is well known that the United States and China are the current leaders, the European Union (EU) harbours its own ambitions in the field [11]. Since 2017 [12], the EU has seen considerable development of the AI-relevant regulatory policies necessary to settle the scene for the technology’s development. According to the EU White Paper on Artificial Intelligence—one component of the digital agenda package adopted by the European Commission in 2020—AI is broadly understood as ‘a collection of technologies that combine data, algorithms and computing power’ [13]. The White Paper asserts that uptake of AI across sectors of the economy can support ‘Europe’s technological sovereignty’. This, in turn, is conditioned by the development of the research and innovation sector. In order to boost research and innovation, the EU must undertake a wide range of interventions: increasing investment for AI, supporting basic and industrial research, creating a network of AI Research Excellence Centres, and delivering AI to companies through Digital Innovation Hubs – as well as establishing testing and experimentation infrastructures for AI. It is also crucial that AI be incorporated into higher education programmes and attract top-tier scholars. Moreover, the EU has obliged its member states to issue national AI development strategies, recognising that AI diffusion pat-terns will benefit from a conducive policy environment. As the EU is considered a global leader in regulation, policy solutions adopted inside the bloc can also influence the direction of AI regulation beyond its borders [12].
Against a backdrop of such plain ambition in the race for AI, this paper aims to address the question: how did European Union member states perform in AI research between 2010 and 2019? Answering this question is central to ascertaining the current state of AI scholarship and revealing insights into the research performed in the last decade. A response will also enable scientists and research agencies to lay plans for the future.
2 Method
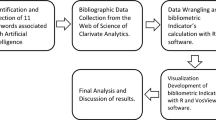
Our approach applies unsupervised machine learning methods to classify EU member states into homogeneous groups based on bibliometric dataFootnote 1. The Scopus database—which, along with Web of Science, is one of the widely used repositories for performing bibliometric analyses [14]—served as the key data source. To retrieve AI-related publications from Scopus, we used English-language AI keywords. The initial list was drafted on the basis of sources listed in the References section. Preparation of the search terms was guided by the assumption that they should identify publications which concern the AI topic in a broad sense, i.e. take into account both technical and social aspects of the term. Next, the list was verified by six independent experts at the Polish National Information Processing Institute – each of whom has extensive hands-on experience of AI. At this stage, words which were not unique to the AI field were excluded. Experts had also the opportunity to present their own propositions of keywords. Then, the candidate keywords were used to search for publications. Of this dataset, a sample of titles and publication keywords was selected to verify the validity of the terms in identifying appropriate publications. After elimination of words which were too ambiguous (e.g. systems theory, deep blue, blackboard system, CAD, finite differences, knowledge acquisition, neural networks, knowledge representation), the final keyword list comprised 276 words related to AI theme.
The publication data was retrieved from Scopus API on 15 April 2020. A publication was included in the dataset if it contained at least one of the 276 keywords in its title or keywords. After limiting our search to English-language articles and conference materials published between 2010 and 2019 by authors affiliated to institutions in EU member states, our dataset was restricted to 175 808 publications. It is noteworthy that each of the scientists could potentially be affiliated to multiple institutions.
Based on the information in the publication dataset, the following set of bibliometric indicators were calculated at national level:
-
(1)
Number of publications (p). This metric measures a member state’s total scientific output. If a publication has more than one author from different countries, we counted one for each country, i.e. full counting method was applied.
-
(2)
Number of citations per publication (cpp). The total number of citations divided by the total number of publications of a given member state. Due to the limitations of Scopus’s API, self-citation publications were not excluded and an open-ended citation window was used. A publication was classified as cited if it scored at least one citation prior to the date the data was collected. As this indicator does not correct for differences in citations collected over time, differences in citation rates for different document types, nor field-specific differences in citation frequencies, the citation indicators described below (MNCS and pp_top) were normalised for publications of similar ages, types, and fields.
-
(3)
Mean normalised citation score (MNCS) [15, 16]. The indicator normalises the citation impact of a given paper with the mean impact of similar papers published in the same field, document type, and publication year. In our analysis, the normalisation for field differences was based on Scopus’s All Science Journal Classification (ASJC) system, which comprises 27 main fields. Each journal in which a publication appeared belongs to one or more subject areas. Since normalised indicators are fundamentally inconsistent when full counting is used [17, 18], our indicators were obtained using an author-level fractional counting method.
-
(4)
Proportion of member states’ scientific output belonging to the 10% most-cited European Union documents (pp_top) [19]. This indicator, which is also known as the excellence indicator, measures the proportion of a member state’s research output that belongs to the top 10% most frequently cited, compared with others of the same field, publication year, and document type. Like MNCS, the normalisation for field differences is based on Scopus’s ASJC. Contrary to mean-based indicators—which are constructed using extremely skewed citation distributions, and can be determined by a low number of frequently-cited documents—the excellence indicator is robust to outliers, as it exclusively considers publications at the high end (e.g. 10%) of the citation distribution. To overcome the difficulty of ties (i.e. publications having the same number of citations), we applied Waltman & Schreiber’s method [20].
-
(5)
Proportion of member states’ documents produced in international collaboration (pp_int). This metric captures the proportion of publications by co-authors who are affiliated to two or more countries.
On the basis of the above, cluster analysis was performed using a k-means algorithm to partition the EU member states into multiple and homogenous groups. Prior to the clustering, the variables were standardised and clustering tendency [21] was assessed using Hopkins statistic [22]. Its value was 0.74, which indicates the presence of significant and meaningful clusters. Due to the nondeterministic nature of k-means, the algorithm was initialised 50 times for different values of k. The value that minimised the objective function, within-cluster variation, was selected for further analysis. To determine the optimal number of clusters, we deployed the elbow method [23] with the support of the silhouette coefficient [24]. The latter was also used to evaluate the fit of individual observations in the classification and quality of clusters, as well as the broader classification.
3 Results
3.1 Clustering
The member states were grouped into three clusters, in accordance with both the elbow method and the silhouette coefficients. For evaluation of the clustering fit of individual observations, a silhouette plot is presented in Fig. 1. It illustrates the silhouette widths sorted in descending order computed for member states, which were grouped into three clusters obtained using the k-means algorithm. Each cluster is presented in a different colour. The grey dotted vertical line depicts the overall average silhouette width for whole classification.

Clusters of EU member states based on bibliometric indicators (1)–(5).
The resulting partition contains the three main clusters:
-
Cluster 1 comprises the five most populous countries in the EU: Germany, Italy, Spain, the United Kingdom, and France. Germany was classified with the greatest certainty, as confirmed by having the widest silhouette (0.55) of the five.
-
Cluster 2 comprises three Nordic countries (Finland, Denmark, and Sweden), the Benelux countries (Belgium, Netherlands and Luxembourg), Ireland, and Austria. This cluster presents the most profound and visible structure (silhouette width = 0.60). Luxembourg was classified with the lowest certainty (silhouette width = 0.48); Finland was classified with the greatest – both within this cluster and among all EU member states (silhouette width = 0.69)
-
Cluster 3 comprises Central and Eastern European countries (Hungary, Poland, Czechia, Croatia, Slovakia, Slovenia, Bulgaria, and Romania), the Baltic states (Estonia, Latvia, and Lithuania) and four Southern European countries (Malta, Greece, Portugal, and Cyprus). Poland, Slovakia, Greece, Portugal, Cyprus, and Estonia were classified with the lowest certainty, which is illustrated by their respective silhouette widths of less than 0.5. As Estonia recorded a silhouette width slightly above zero (0.04), it is considered an intermediate case, that lies between Clusters 2 and 3; determining which assignment is more valid is not unequivocal.
3.2 Principal Component Analysis
Having clustered the EU member states, we used principal component analysis (PCA) to reduce dimensionality among the highly correlated dataset and visualize it using a lower number of dimensions – principal components. Table 1 presents Spearman’s rank correlations coefficients between bibliometric indicators used in clustering and dimensional reduction algorithms. According to Kaiser-Guttman rule, principal components with eigenvalues greater than one should be retained. As a result, two principal components out of five were retained, which accounted for more than 93% of original data’s variability.

A biplot of the bibliometric indicators (variables) and EU member states (observations) on the two principal components.
Figure 2 illustrates a biplot – a graphical representation of principal component scores and principal component loadings. The variables (bibliometric indicators) are plotted as black arrows, their loadings as coordinates, and the coloured circles as the principal component scores for the observations (EU member states). The distance between the variables’ loadings and the plot origin represents the quality of each variable on the factor map. A supplementary categorical variable that represents each observation’s assignment to a given cluster obtained from k-means was added to the plot and is depicted as a colour aesthetic.
The first principal component captures almost 74% of the original data variance and separates member states based primarily on citation impact indicators (cpp, MNCS, and pp_top). They correlate highly and positively not only with the first component, but also with each other, as their principal component loadings lie in close proximity. Although the contribution made to the first component spreads evenly across citation impact indicators, the MNCS—with a contribution of 30% and a very high quality of representation at 0.98—is the variable on which the component places most of its weight. This means that it is the best-suited variable for approximating the scientific impact dimension, and can be considered a ‘consensus’ measure among all citation impact indicators used in the PCA.
The first principal component also correlates positively with the member states’ proportions of international publications (pp_int). According to the Spearman’s rank correlation coefficients reported in Table 1, a moderate, positive relationship exists between citation impact indicators and member states’ degrees of international collaboration; thus, publications of authors affiliated to countries whose scientific output relies heavily on foreign cooperation are characterised by greater impacts.
The member states of Clusters 1 and 2, which are located on the right side of the Y axis, perform well on citation impact indicators; the opposite is true for those positioned on the left (Cluster 3). The fourth quadrant contains member states that scored relatively highly on scientific impact indicators, and had high proportions of international publications in their AI research output. These countries can be found in Cluster 2.
The second principal component retains more than 19% of dataset’s variability and puts weight on the total number of publications (p); approximately 80% of the second component is influenced solely by this metric. The remainder is attributed to the scientific collaboration indicator; this is reflective of the degree of foreign cooperation, with which it correlates negatively. International collaboration has no significant effect on the size of member states’ publication output. This is reflected by the perpendicular placement of their loadings, as illustrated in the biplot. For these reasons, our results differ from the findings of Aksnes et al. [17], who observed a negative correlation between member states’ scientific output and the degree to which they collaborate internationally.
The member states with the largest scientific outputs in AI—are placed above the X axis, leaning towards the first quadrant; conversely, the lowest ranked member states are positioned in the third quadrant. It is noteworthy that while all countries in Cluster 3 generally achieved low scores in impact indicators, those located in the second quadrant had relatively large AI research outputs. One member state within this cluster, Portugal, achieved average scores on all indicators, as it is located near the centre of the biplot.
4 Summary and Conclusions
The primary aim of this study was to construct an overview of the AI publication achievements in the European Union member states between 2010 and 2019. We have presented a clear division of member states into three clusters on the basis of a set of bibliometric indicators that reflect scientific output, impact, and collaboration. Clusters 1 and 2 comprised solely ‘old’ member states, while Cluster 3 mostly comprised ‘new’ ones that joined the EU after 2004 – with the exceptions of Portugal and Greece. The member states of Cluster 1—the United Kingdom, Germany, France, Italy, and Spain—performed strongly in AI research output between 2010 and 2019. These results, however, correlate with the sizes of those member states’ populations. Concerning scientific impact, the member states contained in Cluster 2 achieved the best results – even without having the largest scientific outputs. It should be noted that the citation impact of these countries might also relate to internationalisation. Twelve Central, Eastern, and Southern member states, together with the three Baltic states comprised Cluster 3 – the largest one. Those member states’ achievements in scientific output, impact, and collaboration are far lesser than those of Clusters 1 and 2.
The analysis allows us to draw several conclusions. First, our results confirm that AI research is a field in which the division between ‘old’ and ‘new’ EU member states has endured since the 2004 accession. With evidence that the United Kingdom was the top producer of AI publications between 2010 and 2019, this paper supports the conclusion that the United Kingdom’s exit from the bloc will influence the EU’s future scientific performance in AI considerably [25].
Second, our analysis focuses on EU member states, but their position in the AI research should be viewed in a broader geopolitical context: one that incorporates the AI aspirations of the United States and China. According to Scopus data, between 2010 and 2019, the largest number of AI publications was produced by China, followed by the EU and the United States [26]. While studies have demonstrated clearly that the United States and the EU outperform China in terms of scientific impact (measured by the Field-Weighted Citation Impact, FWCI) [27] and of excellence (measured by the share of AI-related documents in the 10% most cited publications worldwide) [28], China has registered a remarkable increase in both measures in the field of AI; the country’s FWCI rose from 0.6 in 2012 to 0.9 in 2017 – almost reaching the global average [11]. Moreover, China surpassed the EU for the first time in 2016, and the United States in 2020 [29] in its share of global AI journal citations and experienced an increase in scientific excellence between 2006 and 2016 [28]. This signals that China’s position in AI research is likely to continue elevating.
Finally, sources indicate that beyond the three leaders—the United States, China, and the EU—other nations (most notably India) have also made progress in AI [28]. This serves to complicate the picture in which the United States, China, and the EU fully dominate the AI research landscape. While it can be envisaged that the domination of the three leaders will endure, and that there is a basis to compare such large entities due to their scales, questions remain on the extent of their future success, and whether newcomers in AI research can achieve comparably.
Notes
- 1.
We treated the United Kingdom as part of the European Union, as it formally departed the bloc on January 31, 2020.
References
Acemoglu, D., Restrepo, P.: Automation and new tasks: how technology displaces and reinstates labor. J. Econ. Perspect. 33, 3–30 (2019). https://doi.org/10.1257/jep.33.2.3
Lane, M., Saint-Martin, A.: The impact of Artificial Intelligence on the labour market (2021). https://www.oecd-ilibrary.org/content/paper/7c895724-en
Korinek, A., Stiglitz, J.E.: Artificial Intelligence and Its Implications for Income Distribution and Unemployment. National Bureau of Economic Research, Inc. (2017)
Agrawal, A., Gans, J., Goldfarb, A.: Economic Policy for Artificial Intelligence (2018)
Omar, M., Mehmood, A., Choi, G.S., Park, H.W.: Global mapping of artificial intelligence in Google and Google Scholar. Scientometrics 113(3), 1269–1305 (2017). https://doi.org/10.1007/s11192-017-2534-4
Stone, P., Brooks, R., Brynjolfsson, E., Calo, R., Etzioni, O., Hager, G., et al.: Artificial intelligence and life in 2030. Stanford University (2016)
Kaplan, A., Haenlein, M.: Siri, Siri, in my hand: Who’s the fairest in the land? On the interpretations, illustrations, and implications of artificial intelligence. Bus. Horiz. 62, 15–25 (2019). https://doi.org/10.1016/j.bushor.2018.08.004
Russel, S.J., Norvig, P.: Artificial Intelligence. A Modern Approach. Pearson Education (2016)
Krafft, P.M., Young, M., Katell, M., Huang, K., Bugingo, G.: Defining AI in Policy versus Practice. Proc. 2020 AAAIACM Conf. AI Ethics Soc. AIES. (2020)
Stahl, B.C., Antoniou, J., Ryan, M., Macnish, K., Jiya, T.: Organisational responses to the ethical issues of artificial intelligence. AI Soc. 1–15 (2021). https://doi.org/10.1007/s00146-021-01148-6
Castro, D., McLaughlin, M., Chivot, E.: Who Is Winning the AI Race: China, the EU or the United States? Center for Data Innovation (2019)
Andraško, J., Mesarčík, M., Hamuľák, O.: The regulatory intersections between artificial intelligence, data protection and cyber security: challenges and opportunities for the EU legal framework. AI Soc. 36(2), 623–636 (2021). https://doi.org/10.1007/s00146-020-01125-5
European Commission: White Paper on Artificial Intelligence - A European approach to excellence and trust, (2020)
Zhu, J., Liu, W.: A tale of two databases: the use of Web of Science and Scopus in academic papers. Scientometrics 123(1), 321–335 (2020). https://doi.org/10.1007/s11192-020-03387-8
Waltman, L., van Eck, N.J., van Leeuwen, T.N., Visser, M.S., van Raan, A.F.J.: Towards a new crown indicator: an empirical analysis. Scientometrics 87, 467–481 (2011). https://doi.org/10.1007/s11192-011-0354-5
Rehn, C., Wadskog, D., Gornitzki, C., Larsson, A.: Bibliometric Indicators - Definitions and usage at Karolinska Instututet. Karolinska Institutet (2014)
Aksnes, D., Schneider, J., Gunnarsson, M.: Ranking national research systems by citation indicators. A comparative analysis using whole and fractionalised counting methods. J Informetr. 6, 36–43 (2012). https://doi.org/10.1016/j.joi.2011.08.002
Waltman, L., van Eck, N.J.: Field-normalized citation impact indicators and the choice of an appropriate counting method. J. Informetr. 9, 872–894 (2015). https://doi.org/10.1016/j.joi.2015.08.001
Leydesdorff, L., Bornmann, L., Mutz, R., Opthof, T.: Turning the tables on citation analysis one more time: Principles for comparing sets of documents. J. Am. Soc. Inf. Sci. Technol. 62, 1370–1381 (2011). https://doi.org/10.1002/asi.21534
Waltman, L., Schreiber, M.: On the calculation of percentile-based bibliometric indicators. J. Am. Soc. Inf. Sci. Technol. 64, 372–379 (2013). https://doi.org/10.1002/asi.22775
Jain, A.: Data clustering: 50 years beyond K-means. Award Win. Pap. 19th Int. Conf. Pattern Recognit. ICPR. 31, 651–666 (2010). https://doi.org/10.1016/j.patrec.2009.09.011
Lawson, R.G., Jurs, P.C.: New index for clustering tendency and its application to chemical problems. J. Chem. Inf. Comput. Sci. 30, 36–41 (1990). https://doi.org/10.1021/ci00065a010
Syakur, M.A., Khotimah, B.K., Rochman, E.M.S., Satoto, B.D.: Integration K-means clustering method and elbow method for identification of the best customer profile cluster. IOP Conf. Ser. Mater. Sci. Eng. 336, 012017 (2018). https://doi.org/10.1088/1757-899x/336/1/012017
Rousseeuw, P.J.: Silhouettes: a graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 20, 53–65 (1987). https://doi.org/10.1016/0377-0427(87)90125-7
European Commission: Science, Research and Innovation Performance of the EU 2020. A fair, green and digital Europe. Publications Office of the European Union, Luxembourg (2020)
Frankowska, A., Pawlik, B., Feldy, M., Witkowska, E.: Artificial Intelligence and science and higher education sector. Review of strategic documents and scienfitic achievements [PL: Sztuczna inteligencja a sektor nauki i szkolnictwa wyższego. Przegląd dokumentów strategicznych i osiągnięć na świecie]. National Information Processing Institute, Warszawa (2020)
Elsevier: ArtificiaI Intelligence: How knowledge is created, transferred, and used. Trends in China, Europe and the United States (2018)
Correia, A., Reyes, I.: AI research and innovation: Europe paving its own way. Europaen Commission. Directorate-General for Research and Innovation (2020)
Zhang, D., et al.: The AI Index 2021 Annual Report. Human-Centered AI Institute, Stanford University, Stanford, CA, AI Index Steering Committee (2021)
Sources used in the keyword selection:
Association for the Advancement of Artificial Intelligence, AITopics. https://aitopics.org/search
China Institute for Science and Technology Policy at Tsinghua University: China AI Development Report (2018). http://www.sppm.tsinghua.edu.cn/eWebEditor/UploadFile/Executive_susmmary_China_AI_Report_2018.pdf
Corea F.: AI Knowledge Map: How To Classify AI Technologies. https://www.forbes.com/sites/cognitiveworld/2018/08/22/ai-knowledge-map-how-to-classify-ai-technologies/#35a4feaf7773
Glossary of Artificial Intelligence. https://en.wikipedia.org/wiki/Glossary_of_artificial_intelligence
Goodfellow, I., Bengio, Y., Courville, A.: Deep Learning (2018). https://github.com/janishar/mit-deep-learning-book-pdf/blob/master/complete-book-pdf/deeplearningbook.pdf
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Frankowska, A., Pawlik, B. (2022). A Decade of Artificial Intelligence Research in the European Union: A Bibliometric Analysis. In: Biele, C., Kacprzyk, J., Kopeć, W., Owsiński, J.W., Romanowski, A., Sikorski, M. (eds) Digital Interaction and Machine Intelligence. MIDI 2021. Lecture Notes in Networks and Systems, vol 440. Springer, Cham. https://doi.org/10.1007/978-3-031-11432-8_5
Download citation
DOI: https://doi.org/10.1007/978-3-031-11432-8_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11431-1
Online ISBN: 978-3-031-11432-8
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)