
Abstract
We analyze two approaches to clustering 2D shapes representing cross-sections of rotationally symmetrical objects. These approaches are based on two ways of shape representation - contours and silhouettes - and a number of similarity measures which are based on a combination of Procrustes analysis (PA) and Dynamic Time Warping (DTW) as well as on binary matrix analysis. The comparison of efficiency of the proposed approaches is performed on datasets of archaeological ceramic vessels.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
- Clustering
- Shape analysis
- Procrustes analysis
- Dynamic time warping
- Similarity measures
- Contours
- Binary matrix comparison
- Hamming distance
- Vari distance
- Rogers-Tanimoto distance
- Archaeological ceramic vessels
1 Introduction and Problem Formulation
Clustering methods, which rely on grouping data sets into clusters without imposing the number of clusters in advance [16, 20], are widely used in many applications from natural speech recognition to biology and medicine (e.g. [13]). In order to obtain significant results of clustering, aside from the choice of the specific clustering algorithm, the following issues are of fundamental importance:
-
1.
the choice of suitable data representation,
-
2.
the definition of adequate similarity measure.
The problem of suitable data representation has been recognized in the literature, see e.g. [6]. The choice of data representation for the investigated data set has a considerable impact on the possibility to achieve satisfying results. Studies on the impact of shape representation on clustering architectural plans have been conducted in e.g. [17].
1.1 The Problem
Our contribution is devoted to clustering 2D objects with respect to shape and size. We consider two types of shape representations: contours and silhouettes. For contour representations we use similarity measures based on a combination of DTW [1, 4, 15] and PA [5, 9, 10], as discussed in [12]. For silhouettes representations we use a number of binary distances, e.g. Hamming, Vari, Rogers-Tanimoto [18]) as well as Pattern-difference, Size-difference distance [3].
In the case of contour representation, the overall similarity measures are defined as combinations of size and shape similarity measures as proposed in [12], see Sect. 3, i.e. the clustering is performed simultaneously with respect to size and shape, whereas in the case of silhouette shape representation, we start with the clustering with respect to size, and, within the obtained (size) clusters, the clustering is next performed with respect to shape (Sect. 2).
1.2 Motivation and Contribution
The aim of the present contribution is twofold. First, by using binary matrix representation of the investigated 2D shapes we propose a clustering algorithm based on a number of discrete similarity measures combined with Affinity Propagation algorithm. Secondly, we investigate the impact of the choice of shape representation and similarity measures on the results of clustering of 2D cross-sections of rotationally symmetric 3D objects, by comparing the binary matrix approach with the contour-based approach proposed in [12].
Both approaches, the silhouette-based approach proposed in Sect. 2 and the contour-based approach proposed in [12] and recalled briefly in Sect. 3 can be applied to clustering of general 2D objects. Our motivation comes from digital cultural heritage and is related to clustering of archaeological ceramic vessels with respect to size and shape. Due to technological principles, ceramic vessels are rotationally symmetric, and so the clustering can be limited to their 2D cross sections (see Fig. 1). The papers devoted to this topic are scarce in the literature, e.g. [8, 11, 21].
The experiments are performed on real-life archaeological data representing cross-sections of ceramic vessels. Our entry data are in the form of black and white images of a unified resolution. When clustering archaeological ceramic data one can hardly specify the number of clusters in advance, so we are bound to use algorithms which do not require the number of clusters to be predefined.
The representations and the similarity measures, are discussed in Sect. 2 and Sect. 3. The results of experiments for archaeological ceramic data sets and the discussion are presented in Sect. 4.

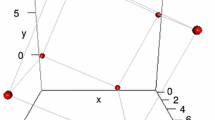
The transformation of a section of rotationally symmetric object into input data.
2 Silhouette-based Approach
2.1 Data Representation
In this approach we represent shapes as matrices of pixels, to be clustered as binary matrices or, in some cases, as binary vectors. Process of preparing input data consists of two steps.
The first step relies on the analysis of the size of original input data. Size analysis is performed by KMeans cluster algorithm. To find the optimal division of the dataset, this algorithm finds clusters consisting of similar-sized objects. In the case of our experimental data, the typical outcome of KMeans algorithm, is one or two subsets-clusters of objects of similar size. This step is performed by an application written in Python 3.6. in order to retain the information about size of the investigated objects, as in the second step we perform normalization, which leads to the loss of size information. This information is recalled in the last step, before the final clustering.
Second step is related to data transformation. We start with transforming every object to the chosen fixed size, which is related to resolution of provided objects. Next step is to create matrix representation of each object. The rows and columns of the matrix represent pixels of objects. Knowing that every image consists of black and white pixels only, the matrix of pixels is created as follows: element (i, j) is given as 1, when the particular pixel is black and 0 when the particular pixel is white. This matrix represent the objects. This step is performed by application written in Python 3.6.
After data preparation, we perform clustering, based on similarity measures dedicated to binary data [3]. In this process we recall the size information (division obtained through KMeans), to be included in the final clustering result. Depending on the number of clusters obtained by KMeans (clustering with respect to size), next step, i.e. clustering with respect to shape is performed independently, i.e. in each cluster separately.
2.2 Similarity Measure
A lot of measures have been proposed for computing the similarity/dissimilarity between two vectors. In the present investigation we are interested only in those dedicated to binary input data. We base our choice on 76 binary similarity and dissimilarity measures recalled in [3]. Our selection of similarity measures for further analysis was focused on the diversity. As a result, five measures were selected for further analysis. Let X, Y - binary matrices in the same sizes. Let \(x_{ij}\in X\), \(y_{ij}\in Y\) be elements located at the same positions in rows and columns of matrices X and Y, respectively. Let \(d_{xy}\) be the number of instances where specific combinations of zero and ones occur: \(d_{00}\), \(d_{11}\), \(d_{01}\), \(d_{10}\). Initially, every \(d_{xy}\) value is set to 0. Next, we update them, i.e. for every pair of elements \(x_{ij}\) and \(y_{ij}\) the following operations are performed:
- (i):
-
\(x_{ij}=0 \wedge y_{ij}=0\Rightarrow d_{00}=d_{00}+1\)
- (ii):
-
\(x_{ij}=1 \wedge y_{ij}=1\Rightarrow d_{11}=d_{11}+1\)
- (iii):
-
\(x_{ij}=0 \wedge y_{ij}=1\Rightarrow d_{01}=d_{01}+1\)
- (iv):
-
\(x_{ij}=1 \wedge y_{ij}=0\Rightarrow d_{10}=d_{10}+1\)
In our clustering analysis we use the following similarity measures/distances:
-
1.
Hamming distance: \(M_{H}(X,Y)=d_{01}+d_{10}\),
-
2.
Vari distance: \(M_{V}(X,Y)=\frac{d_{01}+d_{10}}{4(d_{11}+d_{01}+d_{10}+d_{00})}\),
-
3.
Rogers - Tanimoto dissimilarity coefficient: \(M_{RT}(X,Y)=\frac{2(d_{01}+ d_{10})}{d_{11}+2(d_{01}+d_{10})+d_{00}}\),
-
4.
Pattern - Difference distance: \(M_{PD}(X,Y)=\frac{4d_{01}d_{10}}{(d_{11}+d_{01}+d_{10}+d_{00})^{2}}\),
-
5.
Size - Difference distance: \(M_{SD}(X,Y)=\frac{(d_{01}+d_{10})^{2}}{(d_{11}+d_{01}+d_{10}+d_{00})^{2}}\),
Several characteristic features of the above similarity measures are observed:
- (a):
-
Hamming distance focuses only on information about the difference between objects. It can be successfully applied to Android malware detection ( [19]).
- (b):
-
Vari’s distance and Roger-Tanimoto factors analyse the full spectrum of information on object similarities and differences. It was applied to nature cases e.g. maize genetic coefficients based on microsatellite markers or diversity in olives (see e.g. [2, 18, 22] and the references therein).
- (c):
-
The Pattern-difference and Size-difference distance measures the squares of information;
After calculating the similarity matrix, the effectiveness of each of the similarity measures was evaluated by the clustering method. The clustering is performed by the Affinity Propagation algorithm (see e.g. [7]), which does not require a predefined number of clusters. This is an essential feature of our archaeological application. This part of clustering process is performed by application written in Python 3.6.
Below there are main algorithms used in analysis. Symbols used in algorithms:
-
1.
\(I_n[x_{I_n}, y_{I_n}]\) - original image \(I_n\) with sizes: \(x_{I_n}\) - width, \(y_{I_n}\) - height
-
2.
\(R_n [x_{R_n}, y_{R_n}]\) - resized image \(R_n\) with sizes: \(x_{R_n}\) - width, \(y_{R_n}\) - height
-
3.
\(B_n [x_{B_n}, y_{B_n}]\) - binary matrix \(B_n\) with size: \(x_{B_n}\) - number of columns, \(y_{B_n}\) - number of rows
-
4.
N - number of images
-
5.
D - size difference threshold
-
6.
\(d_{00}\), \(d_{11}\), \(d_{01}\), \(d_{10}\) - number of instances where specific condition is passed as followed (described above)





An important feature of the approach proposed in Algorithm 1-Algorithm 5 is that the clustering analysis is performed sequentially: first with respect to size ( K-Means algorithm), and next with respect to shape (Affinity Propagation algorithm).
3 Contour-based Approach
Below we recall the contour based approach, as proposed in [12]. Contours (boundary discrete curves) are extracted from cross-sections by standard contour extraction techniques and smoothed by Savitzky-Golay filtering. Hence, objects to be clustered, are discrete curves \(\alpha \), i.e. pairs of vectors,
3.1 Composite DTW-PA Similarity Measures
By \(n\ge 2\) we denote the cardinality of the set of contours to be clustered. By i and j, \(i,j=1,...,n\), we denote the i-th and the j-th contour, respectively. We calculate ,,distances” between contours i and j, \(i\ne j\) by using the formulas (2), (3), (4) which measure the degree of similarity between i and j,
where PA(i, j) denotes the Procrustes measure between i and j obtained from Matlab Statistics and Machine Learning Toolbox (for more details see [12]),
where \(DC(i,j)=DTW(i,Z_j)\), DTW measure is calculated in Matlab Signal Processing Toolbox, and \(Z_j\) is the optimal curve obtained from PA(i, j), the measure DC was introduced and analysed in [12],
where \(\gamma ^*(i,j)\) is the optimal scaling factor obtained from the PA(i, j) (see [12] for more details). We put \(pa(i,i)=0, \ dc(i,i)=0, \ \gamma (i,i)=0.\) To ensure comparability of the above defined measures, we use the following normalization formulas for dc and \(\gamma \)
In absence of normalization we put \(ndc(j)=ndc=1\), for all \(j=1,...,n\) or \(n\gamma (j)=n\gamma =1\), for all \(j=1,...,n\).
3.2 Similarity Matrix
Now we recall the similarity measure (5) and the similarity matrix (6), which where defined and investigated in [12]. Let \(\mu , \lambda , \omega \in \mathbb {R}\) be given numbers (weights). The similarity measure (SM) is given as follows:
Depending upon the choice of parameters \(\mu , \lambda , \omega \in \mathbb {R}\) we obtain basic measures \(pa(i,j), dc(i,j), \gamma (i,j)\), combinations of two or three of them, with, or without, normalization. By calculating \(SM_{ij}\) according to (5) for every pair of contours i and j, \(i,j=1,...,n\), we get the similarity matrix
which is symmetric and has zeros on the main diagonal. Different choices of \(\mu ,\lambda ,\omega ,ndc, n\gamma \) lead to different similarity matrices and consequently, to different clustering outcomes. In particular, we obtain
-
1.
weighted Procrustes and scale component matrix
$$\begin{aligned} WPSM=SM(\mu ,0,\omega ,1,1), \end{aligned}$$(7) -
2.
weighted direct composition and scale component matrix where direct composition values are normalized
$$\begin{aligned} WNDCSM=SM(0,\lambda ,\omega ,ndc,1), \end{aligned}$$(8) -
3.
weighted direct composition and scale component matrix, where both direct composition values and scale component values are normalized
$$\begin{aligned} WNDCNSM=SM(0,\lambda ,\omega ,ndc,n\gamma ). \end{aligned}$$(9)
We perform clustering on the basis of the similarity matrix (6) by the standard hierarchical algorithms (Matlab Statistics and Machine Learning Toolbox) and generate the dendrogram. The average linkage is used to measure the distance between clusters.
An important feature of the contour-based approach is that the weights appearing in the definition of the similarity measures (5) allow the simultaneous clustering with respect to size and shape.
4 Discussion of the Results of the Experiment
Below we summarize the clustering results obtained with the help of methods from Sect. 2 and Sect. 3. The experiment has been conducted on seven sets of real-life data compiled from archaeological material. One of the datasets is presented in Fig. 2. It is worth noting that there are no benchmark data sets related to clustering of archaeological ceramics.

Set 1
According to general basic evaluation criteria (e.g. [16]), clustering results are acceptable when the resulting clusters are well defined, i.e. the distances between elements within the cluster are small (intra clusters characteristic), while the distances between clusters are high (extra clusters characteristic). Due to the unlabeled nature of the investigated data our evaluation is expert-based.
The percentage of correctly clustered elements is summarized in Table 1. Average scores have been calculated over all sets for all methods. For readability, best scores for both classes of methods (i.e. contour- and silhouette-based) are marked in bold.
Based on the results, we feel confident to evaluate the performance of both approaches as acceptable, with the average scores for each method between 78.68%–86.63%.
Some correlations between characteristics of the data sets and the results obtained with the two approaches can be established. The situation is interesting for e.g. Sets 1. Here the contour-based approach performs well while the silhouette-based approach seems to be lacking. The opposite is true for Set 2, where the average score for contour-based approach is 85%, while the silhouette-based approach has an average score of 92%. Same is true for Set 4 with scores 86% and 94% respectively. This points to a set of characteristics of the original dataset that have a strong impact on the results obtained. Moreover, with few, set-specific exceptions, the choice of the similarity measure in silhouette-based approach, seem to have little impact on the resulting clusters. What is even more striking, also the applied orders of clustering: sequential (first size, next shape in silhouette-based approach), simultaneous (weighted size and shape in contour-based approach) seem not to influence the clustering results in a decisive way. One should note, however, that the reported computational experiment is based on sets of medium sizes (30–40 elements). Some robustness of the results with to respect sequential versus simultaneous approaches could be implied by the fact that size and shape are the features of completely different natures: the size can easily be quantified, whereas the formal quantified expression of shape is still the topic of current research https://www.dam.brown.edu/people/mumford/vision/shape.html, [14]. The characteristics impacting the results of the considered approaches remain to be investigated and are the subject of ongoing investigation.
5 Conclusion
In conclusion, both, the contour- and the silhouette-based approaches are viable to be applied to the clustering of 2D objects with respect to size and shape. Moreover, to the best of our knowledge, the silhouette-based approach, has not yet been used in archaeological applications. In further research, the problem of computational experiments for large data sets should be addressed.
References
Aronov, B., Har-Peled, S., Knauer, C., Wang, Y., Wenk, C.: Fréchet distance for curves, revisited. In: Azar, Y., Erlebach, T. (eds.) ESA 2006. LNCS, vol. 4168, pp. 52–63. Springer, Heidelberg (2006). https://doi.org/10.1007/11841036_8
Balestre, M., Von Pinho, R., Souza, J., Lima, J.: Comparison of maize similarity and dissimilarity genetic coefficients based on microsatellite markers. Genet. Mol. Res. 7(3), 695–705 (2008)
Choi, S.S.S.: Correlation analysis of binary similarity and dissimilarity measures (2008)
Efrat, A., Fan, Q., Venkatasubramanian, S.: Curve matching, time warping, and light fields: new algorithms for computing similarity between curves. J. Math. Imaging Vision 27(3), 203–216 (2007)
Eguizabal, A., Schreier, P.J., Schmidt, J.: Procrustes registration of two-dimensional statistical shape models without correspondences. CoRR abs/1911.11431 (2019)
Farias, F.C., Bernarda Ludermir, T., Bastos-Filho Ecomp, C.J.A., Rosendo da Silva Oliveira, F.: Analyzing the impact of data representations in classification problems using clustering. In: 2019 International Joint Conference on Neural Networks (IJCNN), pp. 1–6 (2019). https://doi.org/10.1109/IJCNN.2019.8851856
Frey, B.J., Dueck, D.: Clustering by passing messages between data points. Science 315, 2007 (2007)
Gilboa, A., Karasik, A., Sharon, I., Smilansky, U.: Towards computerized typology and classification of ceramics. J. Archaeol. Sci. 31(6), 681–694 (2004)
Goodall, C.: Procrustes methods in the statistical analysis of shape. J. R. Statist. Soc. Ser. B (Methodol.) 53(2), 285–339 (1991)
Hosni, N., Drira, H., Chaieb, F., Amor, B.B.: 3D gait recognition based on functional PCA on Kendall’s shape space. In: 2018 24th International Conference on Pattern Recognition (ICPR), pp. 2130–2135 (2018)
Hristov, V., Agre, G.: A software system for classification of archaeological artefacts represented by 2D plans. Cybern. Inf. Technol. 13(2), 82–96 (2013)
Kaliszewska, A., Syga, M.: A comprehensive study of clustering a class of 2D shapes. arXiv: 2111.06662 (2021)
Leski, J.M., Kotas, M.P.: Linguistically defined clustering of data. Int. J. Appl. Math. Comput. Sci. 28(3), 545–557 (2018)
Mumford, D.: Mathematical theories of shape: do they model perception? In: Proceedings of Conference 1570, Society of Photo-Optical & Instrumentation Engineers (SPIE), pp. 2–10 (1991)
Müller, M.: Information Retrieval for Music and Motion. Springer Science, Heidelberg (2007). https://doi.org/10.1007/978-3-540-74048-3
Owsiński, J.W.: Data Analysis in Bi-partial Perspective: Clustering and Beyond. Studies Computational Intelligence, Springer, Cham (2020). https://doi.org/10.1007/978-3-030-13389-4
Rodrigues, E., Sousa-Rodrigues, D., Teixeira de Sampayo, M., Gaspar, A.R., Gomes, A., Henggeler Antunes, C.: Clustering of architectural floor plans: a comparison of shape representations. Autom. Construct. 80, 48–65 (2017)
Rogers, D.J., Tanimoto, T.T.: A computer program for classifying plants. Science 132(3434), 1115–1118 (1960)
Taheri, R., Ghahramani, M., Javidan, R., Shojafar, M., Pooranian, Z., Conti, M.: Similarity-based android malware detection using hamming distance of static binary features. Future Gener. Comput. Syst. 105, 230–247 (2020)
Wierzchoń, S.T., Kłopotek, M.A.: Algorithms of Cluster Analysis. Institute of Computer Science, Polish Academy of Sciences (2015)
Yan, C., Mumford, D.: Geometric structure estimation of axially symmetric pots from small fragments. In: IASTED International Conference on Signal Processing, Pattern Recognition, and Applications, vol. 2, pp. 92–97 (2002)
Zaher, H., et al.: Morphological and genetic diversity in olive (olea europaea subsp. europaea l.) clones and varieties. Plant Omics J. 4(7), 370–376 (2011)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter's Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter's Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2022 The Author(s)
About this paper

Cite this paper
Baczyńska, P., Kaliszewska, A., Syga, M. (2022). On Two Approaches to Clustering of Cross-Sections of Rotationally Symmetric Objects. In: Biele, C., Kacprzyk, J., Kopeć, W., Owsiński, J.W., Romanowski, A., Sikorski, M. (eds) Digital Interaction and Machine Intelligence. MIDI 2021. Lecture Notes in Networks and Systems, vol 440. Springer, Cham. https://doi.org/10.1007/978-3-031-11432-8_13
Download citation
DOI: https://doi.org/10.1007/978-3-031-11432-8_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-11431-1
Online ISBN: 978-3-031-11432-8
eBook Packages: Intelligent Technologies and RoboticsIntelligent Technologies and Robotics (R0)