
Abstract
In this paper, we propose a way to transform traditional Q&As into conversational Q&As for an efficient information retrieval in special knowledge. Special knowledge involves difficult words. It requires users to raise a series of questions and get the answers to them to pinpoint the desired information. And, conversational Q&A is appropriate than the traditional Q&A because it allows a user to narrow down searches in a solution space. To transform a given set of Q&As to conversational Q&A system for special knowledge search, we first explore not only the present traditional Q&A systems and conversational Q&A systems for general knowledge search, but also those for special knowledge search. From this, we induce an appropriate search process in conversational Q&A systems for special knowledge. Secondly, we build an ontology with the help of machine learning to support the navigation in special knowledge. Finally, we give a way to evaluate performance after embedding the ontology on our search process of conversational Q&A. We apply this procedure to the case of Korean simplified taxation in a Korean Q&A system, Naver Jisik-In Q&A. We found that searching through Jisik-In Q&A with ontology has better usability than using Jisik-In Q&A only. Therefore, this study aims to improve the usability of special knowledge search, lower the threshold of special knowledge, and develop special knowledge as general as common knowledge using conversational Q&A based on ontology. However, as the number of user experimented is limited and the classifier for the extracted words from existing Q&A system should be reviewed by tax expert, so the future work is demanded.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
People retrieve necessary information by sending a specific query term or phrase that becomes a starting point to a search engine to fetch the relevant documents that may contain necessary information. However, it is difficult for users to pick the most relevant query term or phrase to the necessary information that users want [1]. On the other hand, a Q&A system where users can participate in raising questions and answering to the questions collectively, narrows down the search scope but has the same problem as the other search engines still. The problem is that the users must send a search term or phrase to the system and get the relevant answers iteratively until users discover necessary information. Even worse, if the search term or phrase is somewhat irrelevant, the users have to perform many iterations of sending possible queries to search engines. When the desired information involves special knowledge rather than general knowledge, the number of iterations tends to get larger, facing unfamiliar words which we cannot imagine. Additionally, Q&A systems are unable to let users narrow down the possible answers iteratively and it results in low satisfaction, low accurate answers, and long time to get a satisfactory answer. To improve user experience on having satisfactory answers to a question in expert domain, it is necessary to have an alternative way to search the desired information, which can simplify the search process, and get the correct answer using easy words.
One alternative is a conversational Q&A system that allows users to nail down solution search space along with a series of queries. Conversational system is a service that can communicate with computer or artificial intelligence in natural language and has an interactive structure the system can ask user first, which is not only user can ask, like chatbot. Since conversational system like chatbot to date have mainly focused on conversations that have been set up during development, conversations with the system are limited [2]. Conversational Q & A is where user can ask questions and get answers in the form of words or phrases in conversation. In particular, as the scope of information retrieval is limited in conversational Q&A system, they may not get the answer easily if they do not enter keywords that chatbots or other conversational system can understand.
In order to overcome the difficulty of this information retrieval and limitations of existing conversational system and Q&A system, we propose conversational Q&A system through chatbot in this study.
Our case is Jisik-In which is Q&A system in Naver which is the largest portal site in Korea and has a search engine. The service that makes Naver become a national portal site is Q&A service called Naver Jisik-In, and up to now, there are 320 million responses on Naver Jisik-In. Jisik-In takes the form of a community forum where the user asks and answers the. To construct the conversational Q&A in this study, we extract, analyze, and classify information and articles in Jisik-In to create an ontology that shows what the user is asking about a particular topic and which words to use for the question.
In this study, we show how to transform expert Q&A system to a chatbot system in case of a simplified taxation in Korea. The simplified taxation was designed to reduce the hassle of tax payment by considering that small businesses do not have the capability for tax affairs or to hire tax experts. Otherwise approximately 35,000 questions about simplified taxation have come up on the dominant expert Q&A system, Jisik-In. In other words, although it has tried to provide convenience by allowing the small business to handle tax tasks itself, there are situations in which it is unavoidable to suffer another inconvenience for this convenience. So, it can be expected that if the required information can be conveniently and easily delivered to small businesses to carry out their own tax affairs, they can reduce the cost and mental burden of taxation of small businesses. Therefore, we aim to design a query response system using a ontology based chatbot for the purpose of improving usability to obtain desired information easily and conveniently in the field of specialization.
2 Literature Review
2.1 Information Search Behavior
First, we need to know what information retrieval procedures users have to search for information. The Information Search Process (ISP) is a structured activity that extracts knowledge and information that enables users to solve problems they may have [3]. From the user’s point of view, the information retrieval process is said to be able to integrate with the user’s situation to improve the efficiency of solving the problem [4]. To summarize, the search process is a procedure in which users get information efficiently to solve their problems.
Information Search Behavior (ISB) is a set of behaviors that users take to find information, and there are very diverse patterns, but only a few of them are suggested to be used [5]. It is also thought of as a search strategy, which is the act of finding clues about information to find the information that the user wants. And this search behavior in the domain knowledge is different from search behavior in general knowledge [6]. However, rather than being based on the information search behavior of users, the search engines that conduct such information search are more like those that organize information according to keywords, number of views, and so on. Therefore, it is necessary to identify what information people are searching for and what they are most interested in, and to optimize the information search behavior of users based on this information.
2.2 Ontology
Chatbot is a chatting program that makes you feel like you are talking to people and is actively used in areas such as customer service and entertaining service. It also serves as a kind of search engine, the most common way being a keyword-based or optional interactive chatbot that is specialized to expert information. Chatbot is a substitute for a search engine that can shorten searching time and acquire accurate and specific information while simplifying search behaviors in order to look for desired information in the sea of massive information. But owing to the feature of rule-based, chatbot has limitations including knowledge representation, information retrieval and dialogue capabilities which is that it gives to user what it knows only [7].
Ontology is a way to make people understand and read easily with well-defined meanings [8]. Thus, rather than simply being entered programmatically, the language itself is information that people can understand and read. Chatbots are designed to allow people to communicate with artificial intelligence in a natural language. Many chatbots are designed on the basis of ontology, because, to communicate with people, they need to be expressed and typed in the language of the people, which can increase the efficiency of organizing conversations. Recently, it has been proposed to convert unstructured data into an ontology, and a chatbot based on it. It seems to be able to complement the limitations of existing rule-based chatbots. Especially we focused on the conversations about special knowledge.
Ontology in AI community is often regarded as specification of conceptualization [13, 14]. And it is based on the understanding of people about the specification and conceptualization of a specific concept, word or phrase, so that the exact meaning can be derived, and ontology exists for this [15]. In other words, it is necessary to distinguish concepts that are used for special knowledge or terminology depending on how people understand specific concepts in common, and it is the ontology that can connect special knowledge to concepts that people commonly understand. In addition, semantically composed Q&A system could have flexible search environment [26]. Therefore, we propose that conversational Q&A is designed to be based on an ontology that can understand people’s common expertise.
2.3 Evaluation for Searching Through Ontology
There have been many evaluations of information search procedures through chatbots or search engines. One study proceeds usability evaluation for Dave and four other chatbots in linguistics. Another study suggests ways to improve the user experience and satisfaction, then to personalize the user by chatbot [27, 28]. In addition, other study suggests a tailored usability theory to evaluate the decision model of ontology [29]. But there has been no evaluation of information retrieval based on ontologies before. Since the ontology can be developed as an interactive Q&A system, it is necessary to continuously evaluate the ontology itself and apply feedback derived from the user to develop it. In this study, ontology will be used for user evaluation because it can affect information retrieval behavior to optimize user information search procedure.
3 Methods
In this study, we first review search behaviors of Q&A based on the present search engines and conversational Q&A based on chat bots in both general and special knowledge. Through a systematic review on the relevant literature and services, we categorized the type of search behavior according to search engine and conversational Q&A for common knowledge and special knowledge. Then, we induce the search behavior that necessary for conversational Q&A on special knowledge. And then, we introduce a method of human and machine collaboration to transform the present Q&A into conversational Q&A on special knowledge. In this method, we build an ontology of special knowledge using accumulated human knowledge and automated relation extraction. We use the traditional category system of the special knowledge as well as an automated semantic relation extraction from the words building the special knowledge based on word2vec. And then, a coder draws a skeleton of an ontology using the traditional category system and adds flesh to the skeleton by mapping important words related semantically to the words in the skeleton. In this study, we apply our method to a popular Korean Q&A system, Naver Jisik-In. We add the ontology to the induced conversational Q&A process to make user search specific parts of special knowledge efficiently and effectively. Lastly, we evaluate our conversational Q&A with an experiment that gives users two search options and compares usability between the two options. The two options are searching special knowledge through Jisik-In only and Jisik-In with the ontology.
3.1 Types of Information Search Behavior
One study examined the time and behavioral moves involving finding knowledge using online methods [5]. In other study, they compared information seeking behavior between experts and non-experts. As a result, there was no difference between general topics and general search engines, but not in professional areas [9]. And commonly, the factors that determine the user’s search engine are the reputation of the search engine, the effectiveness, the familiarity with the search engine, or the usability of the interface [22].
In this study, user behavior for information retrieval will be divided into four types. The criteria for classification are divided into the search engine and the conversational Q&A regarding to interface, and also divided into common knowledge and special knowledge regarding to domain of knowledge. Special knowledge is regarded as expert knowledge, which is information about a specific topic that is not universally known to many people [16]. Therefore, expert interpretation or opinion is needed, and this special knowledge is obtained through training, skills, and research [17, 18]. Common knowledge could be regarded as public knowledge and derived from a kind of social consensus. In addition, it is a fundamental concept used in everyday interactions between people [19].
Here, the search engine includes a portal site and a web search, and in particular, a Q & A system belonging to a portal site Naver is also classified as a search engine. Conversational refers to the interaction of a conversation that helps people talking to them, talking like them through text or voice [20]. The role of the conversation here lies in clarifying what the user wants, to help the user [21]. Conversational Q & A refers to ontology-based chatbots proposed in this study.
Type A is a type that searches general knowledge through existing search engine, and searches again to retrieve appropriate terms or add terms. That is a typical narrowing search. It is the most common type of ISB using common search engine (Google, Naver). However, since this method varies from time to time, it would not be guaranteed that finding the same information will yield the same result. One study has suggested that hierarchical term decomposition is considered necessary in search behavior [10]. In other words, it refers to a method of predicting a desired keyword through an upper and lower relationship between terms, and type A may be included to this. One study suggests that user who commonly use yahoo and keyword search, took less time to finish specific task in conducting known-item searches than in unknown-item searches [23]. Simply, imagine googling ‘awesome house’, comparing to search ‘what to write on the contract paper of house’.
Type B is a type of finding special knowledge through a common search engine. One study suggests that finding special knowledge seems to influence finding the appropriate words for people [11]. Therefore, to search for special knowledge, you need to be able to pick out the search words that will produce relevant results for your special knowledge. However, there are also some ironies that need to know jargon to search for special knowledge. For instance, when medical students were looking for data on microbiology, they added concepts and gradually narrowed down the concept to continue specifying the concept [6]. Also, in the most common pattern, M.A students often find information in a way that broadens or specifies the dimension [24]. Following above, academic searching such as looking for appropriate literature in specific domain could be one of type B examples. Or finding a legislation which could be applied to specific case, using search engine of public web of judicial authority would be type B, either.
Type C is a type that finds general knowledge through Q&A chatbot. Nowadays, it mainly focuses on chatbots that provide information on a specific topic. However, as it is about a specific topic, the information that can be found through chatbot is limited, so if you enter the routine term in this way, it could be possible that you will not find the information you want. As the example of type C, SuperAgent which is customer service chatbot of Amazon.com provides product information, customer Q&A [25]. Through Chatbot of SkyScanner, user can do ticket search which is the key features such searching the cheapest ticket.
Type D is a conversational Q & A chatbot based on ontology proposed in this study. It is a type that deals with professional knowledge. Through Naver Jisik-In Q&A system, we propose an ontology composed of extracted words from the most frequently asked questions and answers, then an interactive Q & A based on them. According to this process, conversational Q&A could satisfy what people would ask most about specific knowledge. There are some examples of conversational Q&A system in expert domain. For instance, TEBot has selective type of Q&A system about Big Data, and the questions are like ‘How do we compare Kafka to Flume’ or ‘How do we compare RDBMS to NoSQL Databases’. Law Soup’s chatbot has Q&A system about law and the question we can ask could be ‘What laws protect free speech?’. ‘Do I have rights to content I create and put on the internet?’.
3.2 Ontology Based on Q&A
The search strategy for retrieving and getting information depends on the search method and the search target. In this chapter, we search in the Q&A system from search engine and conversational Q&A system as general knowledge and special knowledge. We can see what processes users take to search and take action, then organize search strategies with search behaviors. Also, in selecting the retrieved information, it is possible to know what information is taken and what information is excluded by users.
We use Naver Jisik-In Q & A system to find out what users want to know about specific special knowledge and what questions they frequently ask. When users post articles on Naver Jisik-In Q & A system, they explain their situation and ask the answerer for the correct answer. Therefore, the situations are different but the same answer is often posted for different questions. That is, there are frequently asked questions by users, and the way to present them to users in the order of frequently asked questions can shorten the user’s search behavior.
-
1.
Data Crawling. In this study, the purpose of the ontology is to create a Q&A chatbot for special knowledge, so first we had to find out what people are curious about a particular keyword. Therefore, we crawled 10,000 questions and answers with keyword of simple taxation from Naver Jisik and segment them into corpus. Then, remove the stopwords among the collected morphemes and words.
-
2.
Extracting Keywords. Then, we extract the top 500 words that appear frequently among the collected corpuses. The purpose of this is to present the question to the user by the important keyword. Also, in order to investigate the connectivity between words, 10 words closest to each of the extracted 500 words were extracted by using Word2Vec. By using Word2vec, it is possible to estimate the distance to all the words related to a specific word in multidimensional rather than to gradually approach the limited words associated with the one-way cognitive and thought processes of human, so the multiple words can be extracted at once. In other words, through associative methods that go beyond human cognitive and thought processes, we derive more relevant words before humans do. As a result, it can play a role of artificial intelligence that progresses the most basic human association process endlessly and multi-dimensionally, but achieves more results faster than humans.
-
3.
Connecting Keyword. Then, create a keyword map that categorizes ranges that have been sorted under the tax law. The centralized vocabularies are included in the upper category. And link the tax terms extracted from the tax law with the vocabulary corresponding to the upper category. This creates a kind of small network. In Fig. 1(p.4), the vocabulary in the bold box belongs to the upper category in the tax law, and the contents in the box with the thin line are the main words extracted from the contents of the tax laws regulations and the above process. Here, the main words belong to the most frequently used words, or vocabularies that simultaneously satisfy both the vocabulary words and tax law terms.
Fig. 1. 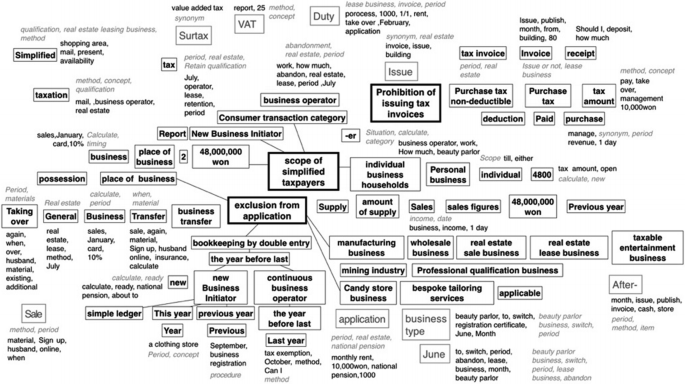
Ontology
-
4.
Categorizing corpus. Once again in this category network, the extracted top 500 terms and the words associated with each term are placed. By determining where each term belongs to on the map, terms would be categorized and sorted to each range. So the map shows the link and status of adjacency between the words.
-
5.
Identifying corpus. On this step, the word or corpus which are outside the box in Fig. 1 were classified into ‘what’, ‘how’, ‘when’, ‘situation’, ‘conception’, ‘type of business’, ‘analogue’. These words identify what other words mean in the context of questions and answers. For example, ‘what’ covers what the user is trying to find or say about including ‘conversion’, ‘abandonment’, and ‘bill’. ‘How’ indicates the method of the subject in the information that the user wants to know including ‘how’, ‘calculation’, ‘imposement rate’, and ‘method’. ‘When’ suggests whether the time is contained in the information that the user desire, including ‘time’, ‘when’ and ‘period’. ‘analogue’ matches words that have a similar meaning to the suggested word including ‘revenue – income’, ‘supply price – sales’. It should be noted here that most of the users do not use revenue and income separately. ‘Type of business’ is the type of industry in which the user is engaged or the assumption of the type of industry the user might be engaged in according to the information desired, including ‘real estate business’ and ‘hairstyling’. ‘Concept’ is the type of information the user wants to ask, such as ‘application scope’, ‘issue or not’ and ‘whether’.

3.3 Evaluation Simulation
Also, for evaluating the usability of conversational Q&A system, it is needed to compare the usability evaluation of the searching special knowledge through Jisik-In only and Jisik-In with the ontology to numerically show the change in the usability actually felt by the users. There are seven indicators in the honeycomb model of Peter Mobile that can be used for usability test [12]. As shown in Table 1, the indicators of honeycomb model are ‘useful’, ‘usable’, ‘desirable’, ‘findable’, ‘accessible’, ‘credible’, and ‘valuable’. ‘Useful’ asks whether to be faster than existing the searching method, ‘usable’ asks whether to be easy to search for information you want, ‘desirable’ asks to be willing to use the searching method, ‘findable’ asks whether to be able to find the desired function, ‘accessible’ asks whether there is many ways to use such the searching method, ‘credible’ asks whether to trust the search interface and ‘valuable’ asks to be satisfied with the searching method. It is necessary to investigate later whether ontology - based chatbots are more efficient than traditional chatbots and provide empirical value to humans.
4 Result
This study investigates the search behavior of ontology based chatbots comparing with the existing search methods such as search engines and existing chatbots. In chatbot which is based on the ontology below, when a user inputs a routine term, professional vocabularies would be suggested which are related to the routine term input first, and when the user selects a professional vocabulary. In summary, when a user enters a routine term, professional vocabularies would be suggested which are related to the routine term input first, and when the user selects a professional vocabulary, secondarily, the selected term is automatically completed. Then questions including the selected terminology are suggested so user can pick one which he/she looks for. We are showing the difference between types of search behavior using search engine and conversational Q&A for common knowledge and special knowledge. Following user’s search behavior, we identify and organize what actions the user takes to initiate until ending the search.
4.1 Comparison of ISB According to Types
Type A (search engine for common knowledge) and B (search engine for special knowledge).
First, user asks questions and finds the keywords associated with him. Assuming that the word user input is a common term, it is necessary to switch to terminology. Therefore, the search engine is used to look for the keyword to convert it into a legal tax term. You can browse through the search for the appropriate terminology, and use multiple search engines in the process. After obtaining the appropriate terminology, the user input the terminology to search through search engine. Again, we filter and narrow down the information we want to obtain and find the answer we want. In summary, type A follows steps of putting routine word, searching and looking up and down to get common knowledge user wants and type B follows steps of putting routine word, searching for analogue or synonym, converting to terminology, putting as terminology and looking up and down to find special knowledge.
In this process, of course, there may be differences according to the field of knowledge or people, but it is more complicated, time consuming, and it is not easy to obtain the information that you want, even if in the case of the general and common procedure for searching routine knowledge. In other words, productivity and efficiency of search behavior is relatively low. This research suggests chatbot as an alternative to solve the inefficiency of this search behavior.
Type C (conversational Q&A for common knowledge) and Type D (conversational Q&A for special knowledge).
In general, the most common search behavior of conversational Q&A can be divided into two types. The first method is a system that can receive an immediate answer by inputting a common term or general sentence. The other is a system to select the category according to the question to be found and to input the appropriate vocabulary to get the answer. In summary, type C follows steps of putting routine word or sentence and looking up and down or, choosing categories, putting routine word and looking up and down to get the information user wants. However, Q&A chatbots so far have not been able to get the answers if the keywords are not included in the dialogs set by the developers of chatbots, or they have questions to ask for chatbots to understand.
Special knowledge conversational chatbot should go through the search behavior in the chatbot with the general knowledge. The search behavior of chatbots for special knowledge search can also be divided into two ways. First, when the user enters a routine term, the user selects an appropriate vocabulary from among the jargon related to the proposed routine term, searches and selects the questions listed in the order frequently asked by the Jisik-In including the terminology. The second is to list the terminology which the user already knows or sentences containing these terms, and if the questions from Jisik-In, including vocabularies input, are presented in order of frequency, the user selects the appropriate questions and obtains immediate answers. In summary, type D follows steps of putting routine word, looking up and down, selecting terminology and looking up and down again or, putting terminology and looking up and down to get special knowledge user wants.
Type B (search engine for special knowledge) and Type D (conversational Q&A for special knowledge).
Let us consider the case where the user searches for special knowledge using routine terms only, then compare the case of searching in Jisik-In only and the case of searching in Jisik-In with the presented ontology. If you look at the procedure for retrieving terminology from Jisik-In, you will take a look at the synonyms from searched common terms for the conversion to specialized knowledge after searching. It is possible to divide into 2cases also. The case of finding the proper terminology and the case of failing finding the proper terminology. In the case of finding the terminology, the user searches the terminology again and searches the results retrieved in the terminology. If you could not find it, may use the category settings to narrow down the questions you are looking for and then repeat the process of browsing the results. When Jisik-In is used with an ontology, the terminology associated with the term is presented in order of frequency, and when the terminology is selected, the related questions are presented in order of frequency. The user first looks up frequently searched questions and searches for appropriate information. In summary, user follows steps in order of search behavior of putting routine word, searching for analogue or synonym, converting to terminology, inputting as terminology and looking up and down or putting routine word, searching for synonym, failing to convert to terminology, narrowing down using categories and looking up and down to get special knowledge through Jisik-In only. Also, user who uses Jisik-In with ontology to get special knowledge follows steps of putting routine word, selecting terminology among suggested and looking up and down.
4.2 Ontology of a Part of Simplified Taxation
Overall, Fig. 1 associates keywords belonging to the upper category, such as the scope of simple taxpayer, the scope of simple taxation, and the exemption of simplified taxation, then arranges the corpuses or words associated with the keyword along with the information type. The light-colored vocabulary in the pale thin-line box was inserted into the category network in consideration of its importance, rather than belonging to one category (in one bold or thin box) on the category network. In addition to this ontology, we have also put together all concepts corresponding to simplified taxation in a keyword map. The more detailed the keywords related to simple taxation (the less common legal terms are used), the fewer keywords users have written down on the ontology.
4.3 A Simulation for Evaluation
To evaluate the ontology that has undergone this transformation process, experiments are conducted on 3 subjects. Given the same task, we can compare and evaluate when using Jisik-In combined with ontology and when using only Jisik-In. A simple experiment and user interview was conducted to find special knowledge, using Naver Jisik-In only and Naver Jisik-In with ontology. The usability test was a comparison between the four ISB types described above using 7criterias suggested. Most of the users answered searching through Naver Jisik-In with ontology was more useful, usable, desirable and credible. Especially, some of them told that slight difference between words and selecting word before searching special knowledge always bother them searching in the existing search engines, but, Jisik-In with ontology could solve the problems. and had no trouble finding special knowledge. In addition, it seems that the difficulty of selecting terms was reduced and the desired results come out more often because the routine terms could be viewed in order of frequency to convert to related jargon terms.
5 Conclusion
In this paper, we propose conversational Q&A, which is based on ontology about specialized knowledge domain that can convert the existing Q&A system into chatbot. And we suggest it would shorten the search behavior and re-evaluate the efficiency of information retrieval. Especially conversational Q & A based on ontology is shown to be able to reduce the steps of ISB, which made it more useful, usable, desirable and desirable. It also appears that the difficulty of choosing terms is reduced, and the accuracy is improved because it is easier to search in appropriate terms. We can see the effect that ontology can have on the conversational Q&A system, and the necessity is suggested.
One of the important reasons why ontology based chatbot should be actively utilized in the field of special knowledge lies in the divergence between common term and terminology. Chatbots can solve users’ questions through conversations, and conversations are interactive rather than one-sided communication. In other words, the user can inquire about the questions that he/she is curious about and can obtain results with high accuracy. If it is difficult to select the appropriate words to search for special knowledge, the user can ask the user what he/she wants by suggesting similar terminology related to the inputted common term, and then it can make a dialogue that lists and presents questions in order. Therefore, it simplifies the complex search behavior in special knowledge search and enables users to find out what they are interested in through active intervention. These chatbots should be based on the ontology and can be optimized by applying the Q & A system that users have raised their own questions.
5.1 Future Work
However, this study suggests only the specialized Q&A chatbot concept, and there is a limitation in identifying classifier for mapping on the category network. It is necessary to ask for expert about the category of the terms or make specific classifier for simplified taxation. Also, it is necessary to ask usability to much more users to quantize. We show the transformation process to conversational Q&A system, so the number of attendants for usability test is not enough to rationalize the efficiency. It could be next step for this study and would make conversational system more useful.
References
Peterson, R.A., Merino, M.C.: Consumer information search behavior and the internet. Psychol. Mark. 20(2), 99–121 (2003)
Radziwill, N.M., Benton, M.C.: Evaluating quality of chatbots and intelligent conversational agents (2017)
Kuhlthau, C.C.: Inside the search process: information seeking from the user’s perspective. J. Am. Soc. Inf. Sci. 42(5), 361–371 (1991)
James, R.: Libraries in the mind: how can we see users’ perceptions of Iibraries? J. Librariansh. 15(1), 19–28 (1983)
Kiestra, M.D., Stokmans, M.J.W., Kamphuis, J.: End-users searching the online catalogue: the influence of domain and system knowledge on search patterns. Electron. Libr. 12(6), 335–343 (1994)
Wildemuth, B.M.: The effects of domain knowledge on search tactic formulation. J. Am. Soc. Inform. Sci. Technol. 55(3), 246–258 (2004)
Al-Zubaide, H., Issa, A.A.: Ontbot: ontology based chatbot. In: International Symposium on Innovations in Information and Communications Technology, pp. 7–12. IEEE, November 2011
Augello, A., Pilato, G., Vassallo, G., Gaglio, S.: Chatbots as interface to ontologies. In: Gaglio, S., Lo Re, G. (eds.) Advances onto the Internet of Things, pp. 285–299. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-03992-3_20
Carmel, E., Crawford, S., Chen, H.: Browsing in hypertext: a cognitive study. IEEE Trans. Syst. Man Cybern. 22(5), 865–884 (1992)
Bhavnani, S.K., Bates, M.J.: Separating the knowledge layers: cognitive analysis of search knowledge through hierarchical goal decompositions. In: ASIST 2002: Proceedings of the 65th ASIST Annual Meeting, Philadelphia, 18–21 November 2002, vol. 39, pp. 204–213 (2002)
Vakkari, P.: Subject knowledge, source of terms, and term selection in query expansion: an analytic study. In: Crestani, F., Girolami, M., van Rijsbergen, C.J. (eds.) ECIR 2002. LNCS, vol. 2291, pp. 110–123. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45886-7_8
User Experience Design. https://semanticstudios.com/user_experience_design/. Accessed 29 Mar 2019
Gruber, Thomas R.: A translation approach to portable ontology specifications. Knowl. Acquis. 5, 199–220 (1993)
Gruber, T.R.: Toward principles for the design of ontologies used for knowledge sharing? Int. J. Hum. Comput. Stud. 43(5–6), 907–928 (1995)
Giaretta, P., Guarino, N.: Ontologies and knowledge bases towards a terminological clarification. Towards Very Large Knowl. Bases Knowl. Build. Knowl. Sharing 25, 32 (1995)
Martin, T.G., et al.: Eliciting expert knowledge in conservation science. Conserv. Biol. 26(1), 29–38 (2012)
Armstrong, J.S.: Combining forecasts. In: Armstrong, J.S. (ed.) Principles of Forecasting, pp. 417–439. Springer, Boston (2001). https://doi.org/10.1007/978-0-306-47630-3_19
Burgman, M., et al.: Redefining expertise and improving ecological judgment. Conserv. Lett. 4, 81–87 (2011)
Halpern, J.Y., Moses, Y.: Knowledge and common knowledge in a distributed environment. J. ACM (JACM) 37(3), 549–587 (1990)
Radlinski, F., Craswell, N.: A theoretical framework for conversational search. In: Proceedings of the 2017 Conference on Conference Human Information Interaction and Retrieval, pp. 117–126, March 2017
Nordlie, R.: “User revealment” – a comparison of initial queries and ensuing question development in online searching and in human reference interactions. In: Proceedings of the ACM SIGIR International Conference on Research and Development in Information Retrieval (SIGIR), pp. 11–18 (1999)
Pew Internet and American Life Project. Search Engine Users (2005). Accessed 19 Apr 2019
Hsieh-Yee, I.: Research on web search behavior. Libr. Inf. Sci. Res. 23(2), 167–185 (2001)
Heinström, J.: Broad exploration or precise specificity: two basic information seeking patterns among students. J. Am. Soc. Inform. Sci. Technol. 57(11), 1440–1450 (2006)
Cui, L., Huang, S., Wei, F., Tan, C., Duan, C., Zhou, M.: Superagent: a customer service chatbot for e-commerce websites. In: Proceedings of ACL 2017, System Demonstrations, pp. 97–102 (2017)
Uren, V., Lei, Y., Lopez, V., Liu, H., Motta, E., Giordanino, M.: The usability of semantic search tools: a review. Knowl. Eng. Rev. 22(4), 361–377 (2007)
Coniam, D.: The linguistic accuracy of chatbots: usability from an ESL perspective. Text Talk 34(5), 545–567 (2014)
Duijst, D.: Can we improve the user experience of chatbots with personalisation. Doctoral dissertation, M.Sc thesis, University of Amsterdam (2017)
Casellas, N.: Ontology evaluation through usability measures. In: Meersman, R., Herrero, P., Dillon, T. (eds.) OTM 2009. LNCS, vol. 5872, pp. 594–603. Springer, Heidelberg (2009). https://doi.org/10.1007/978-3-642-05290-3_73
Acknowledgement
This work has been conducted with the support of the “Design Engineering Postgraduate Schools (N0001436)” program, a R&D project initiated by the Ministry of Trade, Industry and Energy of the Republic of Korea.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Switzerland AG
About this paper

Cite this paper
Jang, J., Lee, K. (2019). Transforming a Specialized Q&A System to a Chatbot System: A Case of a Simplified Taxation in Korea. In: Stephanidis, C., Antona, M. (eds) HCI International 2019 – Late Breaking Posters. HCII 2019. Communications in Computer and Information Science, vol 1088. Springer, Cham. https://doi.org/10.1007/978-3-030-30712-7_38
Download citation
DOI: https://doi.org/10.1007/978-3-030-30712-7_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-30711-0
Online ISBN: 978-3-030-30712-7
eBook Packages: Computer ScienceComputer Science (R0)