
Abstract
We present a self-supervised approach to training convolutional neural networks for dense depth estimation from monocular endoscopy data without a priori modeling of anatomy or shading. Our method only requires sequential data from monocular endoscopic videos and a multi-view stereo reconstruction method, e.g. structure from motion, that supervises learning in a sparse but accurate manner. Consequently, our method requires neither manual interaction, such as scaling or labeling, nor patient CT in the training and application phases. We demonstrate the performance of our method on sinus endoscopy data from two patients and validate depth prediction quantitatively using corresponding patient CT scans where we found submillimeter residual errors. (Link to the supplementary video: https://camp.lcsr.jhu.edu/miccai-2018-demonstration-videos/)
Russell H. Taylor is a paid consultant to and owns equity in Galen Robotics, Inc. These arrangements have been reviewed and approved by JHU in accordance with its conflict of interest policy.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


1 Introduction
Minimally invasive procedures, such as functional endoscopic sinus surgery, typically employ surgical navigation systems to visualize critical structures that must not be disturbed during surgery. Computer vision-based navigation systems that rely on endoscopic video and do not introduce additional hardware are both easy to integrate into clinical workflow and cost effective. Such systems generally rely on the registration of preoperative data, such as CT scans, to intraoperative endoscopic video data [1]. This registration must be highly accurate in order to guarantee reliable performance of the navigation system. Since the accuracy of feature-based video-CT registration methods is dependent on the quality of reconstructions obtained from endoscopic video, it is critical for these reconstructions to be accurate. Further, in order to solve for the additional degrees of freedom required by deformable registration methods [2], these reconstructions must also be dense. Our method satisfies both of these requirements (Fig. 1).
Several reconstruction methods have been explored in the past. Multi-view stereo methods, such as Structure from Motion (SfM) [1] and Simultaneous Localization and Mapping (SLAM) [3], are able to simultaneously reconstruct 3D structure and estimate camera poses in feature-rich scenes. However, the paucity of features in endoscopic images of anatomy can cause these methods to produce sparse reconstructions, which can lead to inaccurate registrations.
Mahmoud et al. [4] propose a quasi-dense SLAM method for minimally invasive surgery that is able to produce dense reconstructions. However, it requires careful manual parameter tuning. Further, the accuracy of the reconstruction is lower than that required for sinus surgery, where low prediction errors are critical due to the proximity of critical structures such as the brain, eyes, carotid arteries, and optic nerves. Shape from Shading (SfS) based methods explicitly [5, 6] or implicitly [7] model the relationship between appearance and depth. These methods generally require a priori modeling of the lighting conditions and surface reflectance properties. Since the true lighting and reflectance conditions are hard to model, SfS-based methods rely on simplified models that can result in noisy and inaccurate reconstructions, e.g., in the presence of specular reflections.

Visual comparison of reconstructions: the green dots in the endoscopic image (left) are 2D projections of the sparse reconstruction (middle) from a recent SfM-based method [1]. In this example, SfM only yields 67 3D points. Our method (right) produces a dense reconstruction with 125369 3D points, shown here from approximately the same viewpoint as the SfM reconstruction. The higher the resolution of the input image, the greater the number of points our method is able to reconstruct. (Color figure online)
Convolutional neural networks (CNNs) have shown promising results in high-complexity problems including general scene depth estimation [8] which benefits from local and global context information and multi-level representations. However, using CNNs directly in endoscopic videos poses several challenges. First, dense ground truth depth maps are hard to obtain inhibiting the use of fully supervised methods. Hardware solutions, such as depth or stereo cameras, often fail to acquire dense and accurate depth maps from endoscopic scenes because of the non-Lambertian reflectance properties of tissues and paucity of features. Software solutions, such as those discussed above, do not produce reconstructions with the density or accuracy required for our application. More recent CNN-based methods [9] use untextured endoscopy video simulations from CT to train a fully supervised depth estimation network and rely on another trained transcoder network to convert RGB video frames to texture independent frames required for depth prediction. This procedure requires per endoscope photometric calibration and complex registration which may only work well in narrow tube-like structures. It is unclear whether this method will work on in-vivo images since it is only validated on two lung nodule phantoms. Second, endoscopic images do not provide the photo-constancy that is required by unsupervised methods for depth estimation of general scenes [10]. This is because the camera and light source move jointly and, therefore, the appearance of the same anatomy can vary substantially with different camera poses. In addition, texture-scarce regions make it hard to provide valuable information to guide the unsupervised network training even if the appearance was preserved across camera poses.
In this work, we present a self-supervised approach to training deep learning models for dense depth map estimation from monocular endoscopic video data. Our method is designed to leverage improvements in SfM- or SLAM-based methods since our network training exploits reconstructions produced by these methods for self-supervision. Our method also uses the estimated relative camera poses to ensure depth map consistency in the training phase. While this approach requires the intrinsic parameters of the corresponding endoscope, it does not require any manual annotation, scaling, registration, or corresponding CT data.
2 Methods
We introduce a method for dense depth estimation in unlabeled data by leveraging established multi-view stereo reconstruction methods. Although SfM-based methods are only able to produce sparse reconstructions from endoscopic video data, these reconstructions and relative camera poses have been shown to be reliable [1]. Therefore, we use these reconstructions and camera poses to supervise the training of our network using novel loss functions. Doing so enables us to produce reliable dense depth maps from single endoscopic video frames.
2.1 Training Data
Our training data consists of pairs of RGB endoscopic images, 3D reconstructions and coordinate transformations between the image pairs from SfM, and the rectified intrinsic parameters of the endoscope. The training data generation is completely autonomous given the endoscopic and calibration videos and could, in principle, be computed on-the-fly with SLAM-based methods.
For each frame, we compute a sparse depth map to store the 3D reconstructions. By applying perspective geometry, 3D points can be projected onto image planes. Since SfM- or SLAM-based methods do not consider all frames when triangulating one particular 3D point, we only project the 3D points onto associated image planes. \(b_{i,j}=1\) indicates frame j is used to triangulate the 3D point i and \(b_{i,j}=0\) indicates otherwise. \(\left( u_i^{j}, v_i^{j}\right) \) are projected 2D coordinates of the 3D point i in frame j. The sparse depth map \(Y_j^*\) of frame j is

\(z_i^{j}\) is the depth of 3D point i in frame j. Since the reconstruction is sparse, large regions in \(Y_j^*\) will not have valid depth values.
We also compute sparse soft masks to ensure that our network can be trained with these sparse depth maps and mitigate the effect of outliers in the 3D reconstructions. This is achieved by assigning confidence values to valid regions in the image while masking out invalid regions. Valid regions are 2D locations on image planes where 3D points project onto, while the remaining image comprises invalid regions. The sparse soft mask, \(W_j\), of frame j is defined as

\(c_i\) is a weight related to the number of frames used to reconstruct 3D point i and the accumulated parallax of the projected 2D locations of this point in these frames. Intuitively, \(c_i\) is proportional to the number of frames used for triangulation and the accumulated parallax. Greater magnitudes of \(c_i\) reflect greater confidence.
2.2 Network Architecture
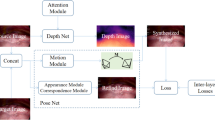
Our overall network architecture (Fig. 2) is a two-branch Siamese network [11] with high modularity. For instance, our single-frame depth estimation architecture can be substituted with any architecture that produces a dense depth map. We introduce two custom layers in this network architecture.

Network architecture: our training network (top) is a self-supervised two-branch Siamese network that uses sparse 3D points and relative camera poses from SfM to estimate dense depth maps from pairs of images and enforce depth consistency, respectively. The soft sparse mask and sparse depth map are represented as a single blue square with dots. During the application phase (bottom), we use the trained weights of the single-frame depth estimation architecture (Fig. 3) to predict a dense depth map that is accurate up to a global scale. (Color figure online)
The Depth Map Scaling Layer scales the predicted dense depth map from the single-frame depth estimation architecture to remain consistent with the scale of the coordinate transformation. It uses the corresponding sparse depth map as the anchor point for scale computation.
The Depth Map Warping Layer warps a scaled dense depth map to the coordinate frame of the other input to the Siamese network using the relative camera pose between the two frames. We implement this layer in a differentiable manner so that the training loss can be backpropagated. These two layers work together to generate data that is used to enforce depth consistency, described in the following section.
2.3 Loss Functions
In the training phase, we use two loss functions that leverage the sparse depth annotations and relative camera poses between frames produced by SfM.
The first loss function, Scale-invariant Weighted Loss, allows the network to train with sparse depth annotations because it uses sparse soft masks as weights to ignore regions in the training data where no depth values are available. Given a sparse depth map, \(Y^*\), a predicted dense depth map, Y, and a sparse soft mask, W, the Scale-invariant Weighted Loss is defined as
\(w_i\) is the value of the sparse soft mask at pixel location i and \(d_i = \log y_i - \log y_i^*\) is the difference between the predicted and ground truth depth at location i [12]. The scale-invariance of this loss function is advantageous given the inherent scale ambiguity of single-frame depth estimation. It makes the network potentially generalizable to different patients, endoscopes, and anatomy because the network simply needs to estimate correct depth ratios without having to estimate the correct global scale. The global scale can vary considerably across different scenarios and is almost impossible for the network to estimate solely from endoscopic frames with no additional a priori information as input. Finally, it makes the automatic training data generation in our method feasible. If the depth estimation network is set up to predict global scale, the results from SfM- or SLAM-based methods must resolve scale ambiguity first. This requires additional steps, e.g. registration to preoperative CT data, to recover the correct global scale. However, registration usually requires manual initialization and, therefore, user interaction. Alternatively, external tracking devices can record data that reflects global scale information but are often not accurate and can change the clinical workflow. With the Scale-invariant Weighted Loss, the automatically generated 3D reconstructions and camera poses are directly usable for network training. This allows our method to use all existing endoscopic videos as training data in a fully automatic manner as long as the intrinsic parameters of the corresponding endoscopes are known.
The second loss function, Depth Consistency Loss, adds spatial constraints among frames in the training phase. By using the Scale-invariant Weighted Loss only, the network does not gain any information from regions where no sparse depth annotations are available and the training is prone to overfitting to the measurement noise or outliers from SfM- or SLAM-based methods. The Depth Consistency Loss helps gain more information and mitigate the overfitting issues. It requires inputs from the Depth Map Scaling Layer and the Depth Map Warping Layer. We denote the predicted depth map of frame k as \(Z_k\) and the warped depth map, warped from its original coordinate frame j to the coordinate frame k, as \(\check{Z}_{k,j}\). Pixels in \(\check{Z}_{k,j}\) and \(Z_k\) at location i are denoted \(\check{z}_i^{k,j}\) and \(z_i^k\), respectively. The Depth Consistency Loss of frame j w. r. t. k is defined as
N is the number of pixels in the region where both maps have valid depths.
The network overall loss is a weighted combination of the two loss functions defined above. Given the predicted dense depth map, Y, and sparse depth map, \(Y^*\), the overall loss for network training with a single pair of training data from frame j and k is defined as
\(\omega \) is used to control how much weight each type of loss function is assigned.
3 Experimental Setup
Our network is trained using an NVIDIA TITAN X GPU with 12 GB memory. We use two sinus endoscopy videos acquired using the same endoscope. Videos were collected from anonymized and consenting patients under an IRB approved protocol. The training data consist of 22 short video subsequences from Patient 1. We use the methods explained above to generate a total of 5040 original image pairs. The image resolution is \(464\times 512\), and we add random Gaussian noise to image data as an augmentation method. We use \(95\%\) of these data for training and \(5\%\) for validation. The learning rate and the weight, \(\omega \), of the loss function are empirically set to \(1.0\mathrm {e}^{-4}\) and \(2.0\mathrm {e}^{-4}\), respectively. For evaluation, we use 6 different scenes from Patient 1 and 3 scenes from Patient 2, each containing 10 test images as input to the network in the application phase. These depth maps are converted to point clouds that were registered [13] to surface models generated from corresponding patient CTs [14]. We use the residual error produced by the registration as our evaluation metric for the dense reconstructions. The single-frame depth estimation architecture we use is an encoder-decoder architecture with symmetric connection skipping (Fig. 3) [15].

Single-frame depth estimation architecture: with the encoder-decoder architecture and symmetric connection skipping mechanism, the network is able to extract global information while preserving details.
4 Results and Discussion
The mean residual error produced by registrations over all reconstructions from Patient 1 is \(0.84 \, ({\pm } 0.10)\) mm and over all reconstructions from Patient 2 is \(0.63 \, ({\pm } 0.19\)) mm. The mean residual error for Patient 1 is larger than that for Patient 2 due to the larger anatomical complexity in the testing scenes of Patient 1. The residual errors for all 9 testing scenes are shown in Fig. 4. Since our method relies on results from SfM or other multi-view stereo reconstruction methods, improvements in these methods will be reflected immediately in our dense reconstructions. However, if these methods are not able to reconstruct any points from training videos or if the reconstructed points and estimated camera poses have large systematic errors, our method will also fail.
We are able to detect and ignore frames where no reconstructions are estimated as well as individual outliers in reconstructions when the number of outliers is small relative to the number of inliers. However, there are cases where all reconstructed points and estimated camera poses are incorrect because of the extreme paucity of features in certain regions of the nasal cavity and sinuses. Currently, we rely on manual checking to ensure that 2D projections of SfM reconstructions are locked onto visual features in order to ignore erroneous reconstructions. However, in the future, we hope to develop an automatic method to detect these failures. Further, with training data from a single patient and evaluation on only two patients, it is unclear whether our method is able to generalize or is overfitting to this particular endoscope. Our current results also do not allow us to know whether or not fine-tuning the network in a patient-specific manner will improve the accuracy of reconstructions for that particular patient. In the future, we hope to acquire a larger dataset in order to investigate this further.
Samples from our current dense reconstruction results are shown in Fig. 5 for qualitative evaluation. There are several challenges in these examples where the traditional SfS methods are likely to fail. For example, shadows appear in the lower middle region of the second sample and the upper right region of the fourth sample. There are also specular reflections from mucus in the first, third and fourth samples. With the capability of extracting local and global context information, our network recognizes these patterns and produces accurate predictions despite their presence. Figure 1 also shows a comparison between a sparse reconstruction obtained using SfM and a dense reconstruction obtained using our method.

Mean residual errors for all testing scenes from Patients 1 and 2.

Examples of dense photometric reconstructions from Patients 1 and 2: each column captures a different region in the nasal cavity and sinuses. The top row shows the color endoscopic images, the middle row shows the corresponding depth images where red maps to high values and blue to low values, and the bottom row shows the photo-realistic 3D reconstructions produced by our method. (Color figure online)
5 Conclusion
In this work, we present an approach for dense depth estimation in monocular endoscopy data that does not require manual annotations for training. Instead, we self-supervise training by computing sparse annotations and enforcing depth prediction consistency across multiple views using relative camera poses from multi-view stereo reconstruction methods like SfM or SLAM. Consequently, our method enables training of depth estimation networks using only endoscopic video, without the need for CT data, manual scaling, or labeling. We show that this approach can achieve submillimeter residual errors on sinus endoscopy data. Since our method can generate training data automatically and directly maps original endoscopic frames to dense depth maps with no a priori modeling of anatomy or shading, more unlabeled data and improvements in SfM- or SLAM-based methods will directly benefit our approach and enable translation to different endoscopes, patients, and anatomy. This makes our method a critical intermediate step towards accurate endoscopic surgical navigation. In the future, we hope to evaluate our method on different endoscopes, patients, and anatomy and compare with other methods. Substituting the single-frame depth estimation architecture with a multi-frame architecture is also a potential future direction to explore.
References
Leonard, S., et al.: Evaluation and stability analysis of video-based navigation system for functional endoscopic sinus surgery on in-vivo clinical data. IEEE Trans. Med. Imaging 62(c), 1–10 (2018). https://doi.org/10.1109/TMI.2018.2833868
Sinha, A., Liu, X., Reiter, A., Ishii, M., Hager, G.D, Taylor, R.H.: Endoscopic navigation in the absence of CT imaging. Med. Image Comput. Comput. Assist. Interv. (2018, in press). https://arxiv.org/abs/1806.03997
Grasa, O.G., Bernal, E., Casado, S., Gil, I., Montiel, J.M.M.: Visual SLAM for handheld monocular endoscope. IEEE Trans. Med. Imaging 33(1), 135–146 (2014). https://doi.org/10.1109/TMI.2013.2282997
Mahmoud, N., Hostettler, A., Collins, T., Soler, L., Doignon, C., Montiel, J.M.M.: SLAM based quasi dense reconstruction for minimally invasive surgery scenes. arXiv:1705.09107 (2017)
Tatematsu, K., Iwahori, Y., Nakamura, T., Fukui, S., Woodham, R.J., Kasugai, K.: Shape from endoscope image based on photometric and geometric constraints. Procedia Comput. Sci. 22, 1285–1293 (2013). https://doi.org/10.1016/j.procs.2013.09.216
Ciuti, G., Visentini-Scarzanella, M., Dore, A., Menciassi, A., Dario, P., Yang, G.Z.: Intra-operative monocular 3D reconstruction for image-guided navigation in active locomotion capsule endoscopy. In: 4th IEEE RAS & EMBS International Conference on Biomedical Robotics and Biomechatronics (BioRob), pp. 768–774 (2012). https://doi.org/10.1109/BioRob.2012.6290771
Reiter, A., Leonard, S., Sinha, A., Ishii, M., Taylor, R.H., Hager, G.D.: Endoscopic-CT: learning-based photometric reconstruction for endoscopic sinus surgery. In: Proceedings of SPIE Medical Imaging 2016: Image Processing, vol. 9784, p. 978418–6 (2016). https://doi.org/10.1117/12.2216296
Laina, I., Rupprecht, C., Belagiannis, V., Tombari, F., Navab, N.: Deeper depth prediction with fully convolutional residual networks. In: Fourth International Conference on 3D Vision (3DV), pp. 239–248 (2016). https://doi.org/10.1109/3DV.2016.32
Visentini-Scarzanella, M., Sugiura, T., Kaneko, T., Koto, S.: Deep monocular 3D reconstruction for assisted navigation in bronchoscopy. Int. J. Comput. Assist. Radiol. Surg. 12(7), 1089–1099 (2017). https://doi.org/10.1007/s11548-017-1609-2
Zhou, T., Brown, M., Snavely, N., Lowe, D.G.: Unsupervised learning of depth and ego-motion from video. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 2, no. 6, pp. 6612–6619 (2017). https://doi.org/10.1109/CVPR.2017.700
Chopra, S., Hadsell, R., LeCun, Y.: Learning a similarity metric discriminatively, with application to face verification. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR), vol. 1, pp. 539–546 (2005). https://doi.org/10.1109/CVPR.2005.202
Eigen, D., Puhrsch, C., Fergus, R.: Depth map prediction from a single image using a multi-scale deep network. In: Proceedings of International Conference on Neural Information Processing Systems, vol. 2, pp. 2366–2374 (2014). http://dl.acm.org/citation.cfm?id=2969033.2969091
Billings, S., Taylor, R.: Generalized iterative most likely oriented-point (G-IMLOP) registration. Int. J. Comput. Assist. Radiol. Surg. 10(8), 1213–1226 (2015). https://doi.org/10.1007/s11548-015-1221-2
Sinha, A., Reiter, A., Leonard, S., Ishii, M., Hager, G.D., Taylor, R.H.: Simultaneous segmentation and correspondence improvement using statistical modes. In: Proceedings of SPIE Medical Imaging 2017: Image Processing, vol. 10133, p. 101331B–8 (2017). https://doi.org/10.1117/12.2253533
Mao, X., Shen, C., Yang, Y.B.: Image restoration using very deep convolutional encoder-decoder networks with symmetric skip connections. In: Proceedings of International Conference on Neural Information Processing Systems, pp. 2802–2810 (2016). https://dl.acm.org/citation.cfm?id=3157412
Acknowledgement
The work reported in this paper was funded in part by NIH R01-EB015530, in part by a research contract from Galen Robotics, and in part by Johns Hopkins University internal funds.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Liu, X. et al. (2018). Self-supervised Learning for Dense Depth Estimation in Monocular Endoscopy. In: Stoyanov, D., et al. OR 2.0 Context-Aware Operating Theaters, Computer Assisted Robotic Endoscopy, Clinical Image-Based Procedures, and Skin Image Analysis. CARE CLIP OR 2.0 ISIC 2018 2018 2018 2018. Lecture Notes in Computer Science(), vol 11041. Springer, Cham. https://doi.org/10.1007/978-3-030-01201-4_15
Download citation
DOI: https://doi.org/10.1007/978-3-030-01201-4_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01200-7
Online ISBN: 978-3-030-01201-4
eBook Packages: Computer ScienceComputer Science (R0)