
Abstract
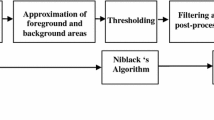
This paper describes a proposed document analysis system that aims at automatic indexing of digitized images of old newspaper microfilms. This is done by extracting news headlines from microfilm images. The headlines are then converted to machine readable text by OCR to serve as indices to the respective news articles. A major challenge to us is the poor image quality of the microfilm as most images are usually inadequately illuminated and considerably dirty. To overcome the problem we propose a new effective method for separating characters from noisy background since conventional threshold selection techniques are inadequate to deal with these kinds of images. A Run Length Smearing Algorithm (RLSA) is then applied to the headline extraction. Experimental results confirm the validity of the approach.
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Hideyuki Negishi etc. “Character Extraction from Noisy Background for an automatic Reference System” ICDAR pp. 143–146, 1999
James L. Fisher, Stuart C. Hinds. etc “A Rule-Based System for Document Image Segmentation” IEEE Trans. Pattern Matching, 567–572,1990
L. O’Gorman “Binarization and multithresholding of Document images using Connectivity” CVGIP: Graphical Model and Image Processing Vol.56, No. 6 November, pp. 494–506, 1994
L.A. Flecher and R. Kasturi,” A robust algorithm for text string separation from mixed text/graphics images” IEEE Trans. Pattern Anal. Machine Intel. Vol. 10 no. 6, pp. 910–918, Nov 1988
L. O’Gorman “Image and document processing techniques for the Right Pages Electronic library system” in Pro.11th Int. Conf. Pattern Recognition(ICPR) Aug 1992, pp. 260–263.
Y. Liu, R. Fenrich, S.N. Srihari, An object attribute thresholding algorithm for document image binarization, International Conference on Document Analysis and Recognition, ICDAR’ 93, Japan, 1993, pp. 278–281.
M.A. Forrester, etc “Evaluation of potential approach to improve digitized image quality at the patent and trademark office” MITRE Corp., McLean, VA, Working Paper WP-87W00277, July 1987.
F.M. Wahl, K.Y. Wong, and R.G. Casey “Block segmentation and text extraction in mixed text / image documents”, Computer vision, Graphics, Image Processing, vol 20, pp. 375–390, 1982.
K.Y. Wong, R.G. Casey, and F.M. Wahl, “Document analysis system”, IBM J.Res.Develop, vol.26, no. 6, pp. 647–656, Nov.1983.
T. Pavlidis: Algorithms for graphics and image processing, Computer Science Press, 1982.
Otsu, N., “A threshold selection Method from Gray-Level Histogram” IEEE Trans. System, Man and Cybernetics, Vol. SMC-9, No. 1, pp. 62–66, Jan 1979
W. Niblack,”An Introduction to Image Processing”, Prentice-Hall, Englewood Cliff, NJ, pp. 115–116,1986.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2002 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Liu, Q.H., Tan, C.L. (2002). Automatic Indexing of Newspaper Microfilm Images. In: Lopresti, D., Hu, J., Kashi, R. (eds) Document Analysis Systems V. DAS 2002. Lecture Notes in Computer Science, vol 2423. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-45869-7_41
Download citation
DOI: https://doi.org/10.1007/3-540-45869-7_41
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-44068-0
Online ISBN: 978-3-540-45869-2
eBook Packages: Springer Book Archive
