
Abstract
Terriglobus saanensis SP1PR4T is a novel species of the genus Terriglobus. T. saanensis is of ecological interest because it is a representative of the phylum Acidobacteria, which are dominant members of bacterial soil microbiota in Arctic ecosystems. T. saanensis is a cold-adapted acidophile and a versatile heterotroph utilizing a suite of simple sugars and complex polysaccharides. The genome contained an abundance of genes assigned to metabolism and transport of carbohydrates including gene modules encoding for carbohydrate-active enzyme (CAZyme) family involved in breakdown, utilization and biosynthesis of diverse structural and storage polysaccharides. T. saanensis SP1PR4T represents the first member of genus Terriglobus with a completed genome sequence, consisting of a single replicon of 5,095,226 base pairs (bp), 54 RNA genes and 4,279 protein-coding genes. We infer that the physiology and metabolic potential of T. saanensis is adapted to allow for resilience to the nutrient-deficient conditions and fluctuating temperatures of Arctic tundra soils.
Similar content being viewed by others
Introduction
Strain SP1PR4T (= DSM 23119 = ATCC BAA-1853) is the type strain of Terriglobus saanensis. It is second of two validly ascribed species of the genus Terriglobus, with T. roseus first isolated from agricultural soils in 2007 [1]. T. saanensis SP1PR4T was isolated from Arctic tundra soil collected from a wind exposed site of Saana fjeld, north-western Finland (69°01′N, 20°50′E) [2,3]. The species name saanensis (sa.a.nen’ sis. N.L. masc. adj. saanensis) pertains to Mount Saana in Finland.
Acidobacteria are found in diverse soil environments and are widely distributed in Arctic and boreal soils [4–8]. However, relatively little is still known about their metabolic potential and ecological roles in these habitats. Despite a large collection of Acidobacteria 16S rRNA gene sequences in databases that represent diverse phylotypes from various habitats, few have been cultivated and described. Acidobacteria represent 26 phylogenetic subdivisions based on 16S rRNA gene phylogeny [9] of which subdivisions 1, 3, 4 and 6 are most commonly detected in soil environments [10]. The abundance of Acidobacteria has been found to correlate with soil pH [2,10,11] and carbon [1,12,13] with subdivision 1 Acidobacteria being most abundant in slightly acidic soils. The phylogenetic diversity, ubiquity and abundance of this group suggest that they play important ecological roles in soils.
Our previous studies on bacterial community profiling from Arctic alpine tundra soils of northern Finland have shown that Acidobacteria dominate in the acidic tundra heaths [2] and after multiple freeze-thaw cycles [6]. Using selective isolation techniques, including freezing soils at −20°C for 7 days, we have been able to isolate several slow growing and fastidious strains of Acidobacteria. On the basis of phylogenetic, phenotypic and chemotaxonomic data, including 16S rRNA, rpoB gene sequence similarity and DNA-DNA hybridization, strain SP1PR4T was classified as a novel species of the genus Terriglobus [3]. Here, we summarize the physiological features together with the complete genome sequence and annotation of Terriglobus saanensis SP1PR4T.
Classification and features
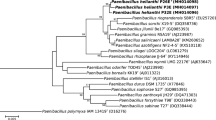
Within the genus Terriglobus, two species are ascribed with validly published names, T. saanensis SP1PR4T [3] isolated from Arctic tundra soils and T. roseus KBS 63T (DSM 18391) isolated from agricultural soils (KBS-LTER site) [1]. Searching the NCBI non-redundant nucleotide database for homology to 16S rRNA gene sequence of T. saanensis SP1PR4T identified 10 cultured and 20 uncultured strains that were unclassified, with ≥97% 16S rRNA sequence identity. Phylogenetic tree based on 16S rRNA gene depicting the position of T. saanensis SP1PR4T relative to the other type strains within the family Acidobacteriaceae is shown in Figure 1. T. saanensis SP1PR4T is distinctly clustered into a separate branch with T. roseus KBS 63T (DQ660892) [1], as its closest described relative (97.1% 16S rRNA sequence identity). Strain SP1PR4T showed ∼95% 16S rRNA gene identity to four strains in the genus Granulicella isolated from tundra soils, namely “G. tundricola” (95.9%), “G. sapmiensis” (95.8%), “G. mallensis” (95.5%) and “G. arctica” (94.9%) [3,15] (Figure 1).

Phylogenetic tree highlighting the position of T. saanensis SP1PR4T relative to the other type strains within the family Acidobacteriaceae. The maximum likelihood tree was inferred from 1,359 aligned positions of the 16S rRNA gene sequences and derived using MEGA version 5 [14]. Bootstrap values (expressed as percentages of 1,000 replicates) of >50 are shown at branch points. Bar: 0.02 substitutions per nucleotide position. The strains (type strain=T) and their corresponding GenBank accession numbers are displayed in parentheses with strain T. saanensis SP1PR4T shown in bold. Bryobacter aggregatus MPL3 (AM162405) was used as outgroup. T. saanensis SP1PR4T and T. roseus KBS 63T (DSM 18391) genome sequences have been revealed.
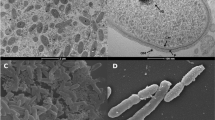
Strain SP1PR4T grows at pH 4.5–7.5 with an optimum at 6.0 and at temperatures of +4 to +30°C with an optimum of +25°C on R2 medium [3]. On R2 agar, strain SP1PR4T forms small, circular, convex colonies with a diameter of approximately 1 mm. The pigment varies from light beige to light pink depending on the age of the culture. Cells of strains SP1PR4T are Gram-negative, non-spore-forming, non-motile aerobic rods with a length of 1.5– 3.0 µm and a diameter of 0.5–0.7 µm. The cell-wall structure in ultrathin sections of electron micrographs of cells of strain SP1PR4T demonstrates numerous outer-membrane vesicles (Table 1, Figure 2).

Electron micrograph of cells of T. saanensis strain SP1PR4T (bar 0.5 µm).
Strain SP1PR4T utilized carbon substrates for growth which include cellobiose, D-fructose, D-galactose, D-glucose, lactose, D-maltose, D-mannose, D-ribose, sucrose, D-trehalose, D-xylose, D-melezitose, D-raffinose and N-acetyl-D-glucosamine. Strain SP1PR4T hydrolyzed polysaccharides such as starch, pectin, laminarin and aesculin but not gelatin, cellulose, xylan, lichenan, sodium alginate, pullulan, chitosan or chitin. Enzyme activities of strain SP1PR4T include chitobiase, catalase, acid and alkaline phosphatase, leucine arylamidase, naphthol-AS-B1-phosphohydrolase, α- and β-galactosidase, α- and β-glucosidase, β-glucuronidase, N-acetyl-β-glucosaminidase, α-mannosidase and α-fucosidase [3,15].
Chemotaxonomy
The major cellular fatty acids in T. saanensis SP1PR4T are iso-C15:0 (39.9%), C16:1 ω7c (28.4%), iso-C13:0 (9.8%) and C16:0 (9.8%). The cellular fatty acid compositions of strain SP1PR4T were relatively similar to that of T. roseus DSM 18391T, with higher relative abundance of iso-C13:0 and a corresponding lower abundance of iso-C15:0 in strain SP1PR4T [3].
Genome sequencing and annotation
Genome project history
Strain SP1PR4T was selected for sequencing in 2009 by the DOE Joint Genome Institute (JGI) community sequencing program. The Quality Draft (QD) assembly and annotation were completed on August 6, 2010. The complete genome was made available on Jan 24, 2011. The genome project is deposited in the Genomes On-Line Database (GOLD) [25] and the complete genome sequence of strain SP1PR4T is deposited in GenBank. Table 2 presents the project information and its association with MIGS version 2.0 [16].
Growth conditions and genomic DNA extraction
Strain SP1PR4T was cultivated in R2 medium as previously described [3]. Genomic DNA (gDNA) of high sequencing quality was isolated using a modified CTAB method and evaluated according to the Quality Control (QC) guidelines provided by the DOE Joint Genome Institute.
Genome sequencing and assembly
The finished genome of T. saanensis SP1PR4T (JGI ID 4088690) was generated at the DOE Joint genome Institute (JGI) using a combination of Illumina [26] and 454 technologies [27]. For this genome, an Illumina GAii shotgun library which generated 23,685,130 reads totaling 916 Mb, a 454 Titanium standard library which generated 409,633 reads and a paired end 454 library with an average insert size of 10.8 kb which generated 180,451 reads totaling 157 Mb of 454 data, were constructed and sequenced. All general aspects of library construction and sequencing performed at the JGI can be found at the JGI website [28]. The 454 Titanium standard data and the 454 paired end data were assembled together with Newbler, version 2.3. Illumina sequencing data was assembled with Velvet, version 0.7.63 [29]. We integrated the 454 Newbler consensus shreds, the Illumina Velvet consensus shreds and the read pairs in the 454 paired end library using parallel phrap, version SPS - 4.24 (High Performance Software, LLC). The software Consed [30,31] was used in the finishing process. Illumina data was used to correct potential base errors and increase consensus quality using the software Polisher developed at JGI (Alla Lapidus, unpublished). Possible mis-assemblies were corrected using gapResolution (Cliff Han, unpublished), Dupfinisher [32], or sequencing cloned bridging PCR fragments with sub-cloning. Gaps between contigs were closed by editing in Consed, by PCR and by Bubble PCR (J-F Cheng, unpublished) primer walks. The final assembly is based on 157 Mb of 454 data which provides an average 39× coverage and 916 Mb of Illumina data which provides an average 180× coverage of the genome.
Genome annotation
Genes were identified using Prodigal [33] as part of the Oak Ridge National Laboratory genome annotation pipeline, followed by a round of manual curation using the JGI GenePRIMP pipeline [34]. The predicted CDSs were translated and used to search the National Center for Biotechnology Information (NCBI) non-redundant database, UniProt, TIGRFam, Pfam, PRIAM, KEGG, (COGs) [35,36], and InterPro. These data sources were combined to assert a product description for each predicted protein. Non-coding genes and miscellaneous features were predicted using tRNAscan-SE [37], RNAMMer [38], Rfam [39], TMHMM [40], and signalP [41]. Additional gene prediction analysis and functional annotation were performed within the Integrated Microbial Genomes Expert Review (IMG-ER) platform [42].
Genome properties
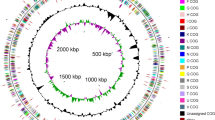
The genome consists of one circular chromosome of 5,095,226 bp in size with a GC content of 57.3% and consists of 54 RNA genes (Figure 3, Table 3). Of the 4,333 predicted genes, 4,279 are protein-coding genes (CDSs) and 99 are pseudogenes. Of the total CDSs, 67% represent COG functional categories and 43% consist of signal peptides. The distribution of genes into COG functional categories is presented in Figure 3 and Table 4.

Graphical representation of circular map of the chromosome of T. saanensis strain SP1PR4T displaying relevant genome features. From outside to center: Genes on forward strand (color by COG categories), genes on reverse strand (color by COG categories), RNA genes (tRNAs green, rRNAs red, other RNAs black), GC content, GC skew.
Discussion
Genome analysis of T. saanensis identified a high abundance of genes assigned to COG functional categories for transport and metabolism carbohydrates (9.5%) and amino acids (7.6%), energy conversion (6.2%), cell envelope biogenesis (9.6%) and transcription (9.2%) [15]. This indicates that the T. saanensis genome encodes for functions involved in transport and utilization of nutrients, mainly carbohydrates and amino acids for energy production and cell biogenesis to maintain cell integrity in cold tundra soils. Further genome analysis revealed an abundance of gene modules for glycoside hydrolases, glycosyl transferases, polysaccharide lyases, carbohydrate esterases, and non-catalytic carbohydrate-binding modules within the carbohydrate-active enzymes (CAZy [43]) family involved in breakdown, utilization and biosynthesis of carbohydrates [15]. T. saanensis hydrolyzed complex carbon polymers, including pectin, laminarin, and starch, and utilized sugars such as cellobiose, D-mannose, D-xylose, D-trehalose and laminarin. This parallels genome predictions for CDSs encoding for enzymes such as pectinases, chitinases, alginate lyases, trehalase and amylases. T. saanensis was unable to hydrolyze carboxymethyl cellulose (CMC) on plate assays and lacked CDSs encoding for cellulases involved in cellulose hydrolysis. However, the T. saanensis genome contained a BcsZ gene encoding for an endocellulase (GH8) as part of a bacterial cellulose synthesis (bcs) operon involved in cellulose biosynthesis in several species. This operon consists of clusters of genes in close proximity to the BcsZ gene which includes a cellulose synthase gene (bcsAB), a cellulose synthase operon protein (bcsC) and a cellulose synthase operon protein (yhj) [15]. In addition, the T. saanensis genome encoded for a large number of gene modules representing glycosyl transferases (GTs) involved in carbohydrate biosynthesis which include cellulose synthase (UDP-forming), α-trehalose phosphate synthase [UDP-forming], starch glucosyl transferase, ceramide β-glucosyltransferase involved in biosynthesis of cellulose, trehalose, starch, hopanoid, and capsular/free exopolysaccharide (EPS) [15]. This suggests that T. saanensis is involved in hydrolysis of lignocellulosic soil organic matter, utilization of stored carbohydrates and biosynthesis of exopolysaccharides. Therefore, we surmise that T. saanensis may be central to carbon cycling processes in Arctic and boreal soil ecosystems.
References
Espinosa E, Marco-Noales E, Gomez D, Lucas-Elio P, Ordax M, Garcias-Bonet N, Duarte CM, Sanchez-Amat A. Taxonomic study of Marinomonas strains isolated from the seagrass Posidonia oceanica, with descriptions of Marinomonas balearica sp. nov. and Marinomonas pollencensis sp. nov. Int J Syst Evol Microbiol 2010; 60:93–98. PubMed http://dx.doi.org/10.1099/ijs.0.008607-0
Lucas-Elío P, Marco-Noales E, Espinosa E, Ordax M, Lopez MM, Garcias-Bonet N, Marba N, Duarte CM, Sanchez-Amat A. Marinomonas alcarazii sp. nov., M. rhizomae sp. nov., M. foliarum sp. nov., M. posidonica sp. nov. and M. aquiplantarum sp. nov., isolated from the microbiota of the seagrass Posidonia oceanica. Int J Syst Evol Microbiol 2011; 61:2191–2196. PubMed http://dx.doi.org/10.1099/ijs.0.027227-0
Arnaud-Haond S, Duarte CM, Díaz-Almela E, Marbà N, Sintes T, Serräo EA. Implications of extreme life span in clonal organisms: millenary clones in meadows of the threatened seagrass Posidonia oceanica. PLoS ONE 2012; 7:e30454. PubMed http://dx.doi.org/10.1371/journal.pone.0030454
Celdran D, Espinosa E, Sanchez-Amat A, Atucha A. Effects of epibiotic bacteria on leaf growth and epiphytes of seagrass Posidonia oceanica Mar Ecol Prog Ser 456: 21–27. http://dx.doi.org/10.3354/meps09672
Tamura K, Dudley J, Nei M, Kumar S. MEGA4: Molecular Evolutionary Genetics Analysis (MEGA) software version 4.0. Mol Biol Evol 2007; 24:1596–1599. PubMed http://dx.doi.org/10.1093/molbev/msm092
Field D, Garrity G, Gray T, Morrison N, Selengut J, Sterk P, Tatusova T, Thomson N, Allen MJ, Angiuoli SV, et al. I, Wilson G, and Wipat A: The minimum information about a genome sequence (MIGS) specification. Nat Biotechnol 2008; 26:541–547. PubMed http://dx.doi.org/10.1038/nbt1360
Woese CR, Kandler O, Wheelis ML. Towards a natural system of organisms: proposal for the domainsArchaea, Bacteria, and Eucarya. Proc Natl Acad Sci USA 1990; 87:4576–4579. PubMed http://dx.doi.org/10.1073/pnas.87.12.4576
Garrity GM, Bell JA, Lilburn T. Phylum XIV. Proteobacteria phyl. nov. In: Garrity GM, Brenner DJ, Krieg NR, Staley JT (eds), Bergey’s Manual of Systematic Bacteriology, Second Edition, Volume 2, Part B, Springer, New York, 2005, p. 1.
Validation of publication of new names and new combinations previously effectively published outside the IJSEM. List no. 106. Int J Syst Evol Microbiol 2005; 55: 2235–2238. http://dx.doi.org/10.1099/ijs.0.64108-0
Garrity GM, Bell JA, Lilburn T. Class III. Gammaproteobacteria class. nov. In: Garrity GM, Brenner DJ, Krieg NR, Staley JT (eds), Bergey’s Manual of Systematic Bacteriology, Second Edition, Volume 2, Part B, Springer, New York, 2005, p. 1.
Garrity GM, Bell JA, Lilburn T. Order VIII. Oceanospirillales ord. nov. In: Garrity GM, Brenner DJ, Krieg NR, Staley JT (eds), Bergey’s Manual of Systematic Bacteriology, Second Edition, Volume 2, Part B, Springer, New York, 2005, p. 270.
Garrity GM, Bell JA, Lilburn T. Family I. Oceanospirillaceae fam. nov. In: Garrity GM, Brenner DJ, Krieg NR, Staley JT (eds), Bergey’s Manual of Systematic Bacteriology, Second Edition, Volume 2, Part B, Springer, New York, 2005, p. 271.
Validation List no. 13. Validation of the publication of new names and new combinations previously effectively published outside the lJSB. Int J Syst Bacteriol 1984; 34:91–92. http://dx.doi.org/10.1099/00207713-34-1-91
van Landschoot A, De Ley J. Intra- and intergeneric similarities of the rRNA cistrons of Alteromonas, Marinomonas, gen. nov. and some other Gram-negative bacteria. J Gen Microbiol 1983; 129:3057–3074.
Espinosa E, Marco-Noales E, Gómez D, Lucas-Elío P, Ordax M, Garcías-Bonet N, Duarte CM, Sanchez-Amat A. Taxonomic study of Marinomonas strains isolated from the seagrass Posidonia oceanica, with descriptions of Marinomonas balearica sp. nov. and Marinomonas pollencensis sp. nov. Int J Syst Evol Microbiol 2010; 60:93–98. PubMed http://dx.doi.org/10.1099/ijs.0.008607-0
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K, Dwight SS, Eppig JT, et al. Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet 2000; 25:25–29. PubMed http://dx.doi.org/10.1038/75556
López-Serrano D, Solano F, Sanchez-Amat A. Identification of an operon involved in tyrosinase activity and melanin synthesis inMarinomonas mediterranea. Gene 2004; 342:179–187. PubMed http://dx.doi.org/10.1016/j.gene.2004.08.003
Sanchez-Amat A, Lucas-Elio P, Fernández E, Garcia-Borrón JC, Solano F. Molecular cloning and functional characterization of a unique multipotent polyphenol oxidase from Marinomonas mediterranea. Biochim Biophys Acta 2001; 1547:104–116. PubMed http://dx.doi.org/10.1016/S0167-4838(01)00174-1
Curson ARJ, Todd JD, Sullivan MJ, Johnston AWB. Catabolism of dimethylsulphoniopropionate: microorganisms, enzymes and genes. Nat Rev Microbiol 2011; 9:849–859. PubMed http://dx.doi.org/10.1038/nrmicro2653
Todd JD, Rogers R, Li YG, Wexler M, Bond PL, Sun L, Curson AR, Malin G, Steinke M, Johnston AWB. Structural and regulatory genes required to make the gas dimethyl sulfide in bacteria. Science 2007; 315:666–669. PubMed http://dx.doi.org/10.1126/science.1135370
Lucas-Elío P, Goodwin L, Woyke T, Pitluck S, Nolan M, Kyrpides N, Detter JC, Copeland A, Teshima H, Bruce D, et al. Complete genome sequence of the melanogenic marine bacterium Marinomonas mediterranea type strain (MMB-1T). Stand Genomic Sci 2012; 6:63–73. PubMed http://dx.doi.org/10.4056/sigs.2545743
Fernández E, Sanchez-Amat A, Solano F. Location and catalytic characteristics of a multipotent bacterial polyphenol oxidase. Pigment Cell Res 1999; 12:331–339. PubMed http://dx.doi.org/10.1111/j.1600-0749.1999.tb00767.x
Bennett S. Solexa Ltd. Pharmacogenomics 2004; 5:433–438. PubMed http://dx.doi.org/10.1517/14622416.5.4.433
Margulies M, Egholm M, Altman WE, Attiya S, Bader JS, Bemben LA, Berka J, Braverman MS, Chen YJ, Chen Z, et al. Genome sequencing in microfabricated high-density picolitre reactors. Nature 2005; 437:376–380. PubMed
DOE Joint Genome Institute. http://www.jgi.doe.gov
Zerbino DR, Birney E. Velvet: algorithms for de novo short read assembly using de Bruijn graphs. Genome Res 2008; 18:821–829. PubMed http://dx.doi.org/10.1101/gr.074492.107
Ewing B, Hillier L, Wendl MC, Green P. Base-calling of automated sequencer traces using phred. I. Accuracy assessment. Genome Res 1998; 8:175–185. PubMed
Ewing B, Green P. Base-calling of automated sequencer traces using phred. II. Error probabilities. Genome Res 1998; 8:186–194. PubMed
Gordon D, Abajian C, Green P. Consed: a graphical tool for sequence finishing. Genome Res 1998; 8:195–202. PubMed
Han C, Chain P. Finishing repeat regions automatically with Dupfinisher. Arabnia, H. R. and Valafar, H. Proceeding of the 2006 International Conference on bioinformatics and computational biology, 141–146. 2006. CSREA Press.
Hyatt D, Chen GL, Locascio PF, Land ML, Larimer FW, Hauser LJ. Prodigal: prokaryotic gene recognition and translation initiation site identification. BMC Bioinformatics 2010; 11:119. PubMed http://dx.doi.org/10.1186/1471-2105-11-119
Pati A, Ivanova NN, Mikhailova N, Ovchinnikova G, Hooper SD, Lykidis A, Kyrpides NC. GenePRIMP: a gene prediction improvement pipeline for prokaryotic genomes. Nat Methods 2010; 7:455–457. PubMed http://dx.doi.org/10.1038/nmeth.1457
Lowe TM, Eddy SR. tRNAscan-SE: a program for improved detection of transfer RNA genes in genomic sequence. Nucleic Acids Res 1997; 25:955–964. PubMed
Lagesen K, Hallin P, Rodland EA, Staerfeldt HH, Rognes T, Ussery DW. RNAmmer: consistent and rapid annotation of ribosomal RNA genes. Nucleic Acids Res 2007; 35:3100–3108. PubMed http://dx.doi.org/10.1093/nar/gkm160
Griffiths-Jones S, Bateman A, Marshall M, Khanna A, Eddy SR. Rfam: an RNA family database. Nucleic Acids Res 2003; 31:439–441. PubMed http://dx.doi.org/10.1093/nar/gkg006
Krogh A, Larsson B, von Heijne G, Sonnhammer EL. Predicting transmembrane protein topology with a hidden Markov model: application to complete genomes. J Mol Biol 2001; 305:567–580. PubMed http://dx.doi.org/10.1006/jmbi.2000.4315
Bendtsen JD, Nielsen H, von Heinje G, Brunak S. Improved prediction of signal peptides: SignalP 3.0. J Mol Biol 2004; 340:783–795. PubMed http://dx.doi.org/10.1016/j.jmb.2004.05.028
Markowitz VM, Mavromatis K, Ivanova NN, Chen IM, Chu K, Kyrpides NC. IMG ER: a system for microbial genome annotation expert review and curation. Bioinformatics 2009; 25:2271–2278. PubMed http://dx.doi.org/10.1093/bioinformatics/btp393
ffrench-Constant RH, Dowling A, Waterfield NR. Insecticidal toxins from Photorhabdus bacteria and their potential use in agriculture. Toxicon 2007; 49:436–451. PubMed http://dx.doi.org/10.1016/j.toxicon.2006.11.019
Waterfield NR, Bowen DJ, Fetherston JD, Perry RD, French-Constant RH. The tc genes of Photorhabdus: a growing family. Trends Microbiol 2001; 9:185–191. PubMed http://dx.doi.org/10.1016/S0966-842X(01)01978-3
Barth H, Aktories K. New insights into the mode of action of the actin ADP-ribosylating virulence factors Salmonella enterica SpvB and Clostridium botulinum C2 toxin. Eur J Cell Biol 2011; 90:944–950. PubMed http://dx.doi.org/10.1016/j.ejcb.2010.11.007
Jackson AP, Thomas GH, Parkhill J, Thomson NR. Evolutionary diversification of an ancient gene family (rhs) through C-terminal displacement. BMC Genomics 2009; 10:584. PubMed http://dx.doi.org/10.1186/1471-2164-10-584
Lin RJ, Capage M, Hill CW. A repetitive DNA sequence, rhs, responsible for duplications within the Escherichia coli K-12 chromosome. J Mol Biol 1984; 177:1–18. PubMed http://dx.doi.org/10.1016/0022-2836(84)90054-8
Poole SJ, Diner EJ, Aoki SK, Braaten BA. t’Kint dR, Low DA, and Hayes CS. Identification of functional toxin/immunity genes linked to contact-dependent growth inhibition (CDI) and rearrangement hotspot (Rhs) systems. PLoS Genet 2011; 7:e1002217. PubMed http://dx.doi.org/10.1371/journal.pgen.1002217
Polz MF, Hunt DE, Preheim SP, Weinreich DM. Patterns and mechanisms of genetic and phenotypic differentiation in marine microbes. Philos Trans R Soc Lond B Biol Sci 2006; 361:2009–2021. PubMed http://dx.doi.org/10.1098/rstb.2006.1928
Lauro FM, McDougald D, Thomas T, Williams TJ, Egan S, Rice S, DeMaere MZ, Ting L, Ertan H, Johnson J, et al. The genomic basis of trophic strategy in marine bacteria. Proc Natl Acad Sci USA 2009; 106:15527–15533. PubMed http://dx.doi.org/10.1073/pnas.0903507106
Acknowledgements
The work conducted by the US Department of Energy Joint Genome Institute is supported by the Office of Science of the US Department of Energy Under Contract No. DE-AC02-05CH11231. This work was funded in part by the Academy of Finland and the New Jersey Agricultural Experiment Station.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
This article is published under an open access license. Please check the 'Copyright Information' section either on this page or in the PDF for details of this license and what re-use is permitted. If your intended use exceeds what is permitted by the license or if you are unable to locate the licence and re-use information, please contact the Rights and Permissions team.
About this article
Cite this article
Rawat, S.R., Männistö, M.K., Starovoytov, V. et al. Complete genome sequence of Terriglobus saanensis type strain SP1PR4T, an Acidobacteria from tundra soil. Stand in Genomic Sci 7, 59–69 (2012). https://doi.org/10.4056/sigs.3036810
Published:
Issue Date:
DOI: https://doi.org/10.4056/sigs.3036810