
Abstract
“Dogs” are connected to “cats” in our minds, and “backyard” to “outdoors.” Does the structure of this semantic knowledge differ across people? Network-based approaches are a popular representational scheme for thinking about how relations between different concepts are organized. Recent research uses graph theoretic analyses to examine individual differences in semantic networks for simple concepts and how they relate to other higher-level cognitive processes, such as creativity. However, it remains ambiguous whether individual differences captured via network analyses reflect true differences in measures of the structure of semantic knowledge, or differences in how people strategically approach semantic relatedness tasks. To test this, we examine the reliability of local and global metrics of semantic networks for simple concepts across different semantic relatedness tasks. In four experiments, we find that both weighted and unweighted graph theoretic representations reliably capture individual differences in local measures of semantic networks (e.g., how related pot is to pan versus lion). In contrast, we find that metrics of global structural properties of semantic networks, such as the average clustering coefficient and shortest path length, are less robust across tasks and may not provide reliable individual difference measures of how people represent simple concepts. We discuss the implications of these results and offer recommendations for researchers who seek to apply graph theoretic analyses in the study of individual differences in semantic memory.






Similar content being viewed by others

Data Availability
All data and analytic code are available on the Open Science Framework repository at https://osf.io/26wku/.
Change history
12 December 2023
A Correction to this paper has been published: https://doi.org/10.3758/s13428-023-02317-9
Notes
By proximity scores we mean semantic similarity—where higher values indicate greater similarity between concepts, or semantic distance—where lower values indicate greater similarity between concepts.
We do not make the traditional distinction between associative and semantic relations because their definitions are overlapping, as noted in, e.g., Kumar (2021).
Correlations are expected to be negative in the raw data because the spatial arrangement task measures semantic relatedness in terms of distance, and the rating tasks measure semantic relatedness in terms of similarity.
References
Bagrow, J. P., & Bollt, E. M. (2019). An information-theoretic, all-scales approach to comparing networks. Applied Network Science, 4(1), 1–15.
Barabasi, A. L. (2016). Communities (pp. 321–377). Network Science.
Baronchelli, A., Ferrer-i-Cancho, R., Pastor-Satorras, R., Chater, N., & Christiansen, M. H. (2013). Networks in cognitive science. Trends in cognitive sciences, 17(7), 348–360.
Benedek, M., Kenett, Y. N., Umdasch, K., Anaki, D., Faust, M., & Neubauer, A. C. (2017). How semantic memory structure and intelligence contribute to creative thought: a network science approach. Thinking & Reasoning, 23(2), 158–183.
Benjamin, A. S., Tullis, J. G., & Lee, J. H. (2013). Criterion noise in ratings-based recognition: evidence from the effects of response scale length on recognition accuracy. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39(5), 1601.
Bieth, T., Kenett, Y., Ovando-Tellez, M., Lopez-Persem, A., Lacaux, C., Oudiette, D., & Volle, E. (2021). Dynamic changes in semantic memory structure support successful problem-solving.
Borge-Holthoefer, J., & Arenas, A. (2010). Categorizing words through semantic memory navigation. The European Physical Journal B, 74, 265–270.
Charest, I., Kievit, R. A., Schmitz, T. W., Deca, D., & Kriegeskorte, N. (2014). Unique semantic space in the brain of each beholder predicts perceived similarity. Proceedings of the National Academy of Sciences, 111(40), 14565–14570.
Collins, A. M., & Loftus, E. F. (1975). A spreading-activation theory of semantic processing. Psychological Review, 82(6), 407.
Cosgrove, A. L., Beaty, R. E., Diaz, M. T., & Kenett, Y. N. (2023). Age differences in semantic network structure: Acquiring knowledge shapes semantic memory. Psychology and aging.
Cosgrove, A. L., Kenett, Y. N., Beaty, R. E., & Diaz, M. T. (2021). Quantifying flexibility in thought: The resiliency of semantic networks differs across the lifespan. Cognition, 211, 104631.
De Deyne, S., Navarro, D. J., & Storms, G. (2013). Better explanations of lexical and semantic cognition using networks derived from continued rather than single-word associations. Behavior research methods, 45, 480–498.
DeStefano, I., Vul, E., & Brady, T. F. (2020). Influences of both prior knowledge and recent history on visual working memory. In: Proceedings of the Annual Conference of the Cognitive Science Society.
Domhof, J. W., Jung, K., Eickhoff, S. B., & Popovych, O. V. (2021). Parcellation-induced variation of empirical and simulated brain connectomes at group and subject levels. Network Neuroscience, 5(3), 798–830.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon the identification of a target letter in a nonsearch task. Perception & psychophysics, 16(1), 143–149.
Estes, W. K. (1956). The problem of inference from curves based on group data. Psychological Bulletin, 53(2), 134.
Falmagne, J. C., & Narens, L. (1983). Scales and meaningfulness of quantitative laws. Synthese, 287–325.
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior research methods, 39(2), 175–191.
Goldstone, R. (1994). An efficient method for obtaining similarity data. Behavior Research Methods, Instruments, & Computers, 26(4), 381–386.
Griffiths, T. L., Steyvers, M., & Firl, A. (2007). Google and the mind: Predicting fluency with PageRank. Psychological science, 18(12), 1069–1076.
He, L., Kenett, Y. N., Zhuang, K., Liu, C., Zeng, R., Yan, T., Huo, T., & Qiu, J. (2021). The relation between semantic memory structure, associative abilities, and verbal and figural creativity. Thinking & Reasoning, 27(2), 268–293. https://doi.org/10.1080/13546783.2020.1819415.
Hedge, C., Powell, G., & Sumner, P. (2018). The reliability paradox: Why robust cognitive tasks do not produce reliable individual differences. Behavior research methods, 50, 1166–1186.
Howard, M. W., Shankar, K. H., & Jagadisan, U. K. (2011). Constructing semantic representations from a gradually changing representation of temporal context. Topics in Cognitive Science, 3(1), 48–73.
Jones, M. N., Willits, J., Dennis, S., & Jones, M. (2015). Models of semantic memory. Oxford handbook of mathematical and computational psychology, 232–254.
Kalna, G., & Higham, D. J. (2006). Clustering coefficients for weighted networks. In Symposium on network analysis in natural sciences and engineering (p. 45).
Kellen, D., Davis-Stober, C. P., Dunn, J. C., & Kalish, M. L. (2021). The problem of coordination and the pursuit of structural constraints in psychology. Perspectives on Psychological Science, 16(4), 767–778.
Kemp, C., & Tenenbaum, J. B. (2008). The discovery of structural form. Proceedings of the National Academy of Sciences, 105(31), 10687–10692.
Kenett, Y. N., & Faust, M. (2019). A semantic network cartography of the creative mind. Trends in cognitive sciences, 23(4), 271–274.
Kenett, Y. N., & Hills, T. T. (2022). Editors' introduction to networks of the mind: How can network science elucidate our understanding of cognition? Topics in Cognitive Science, 14(1), 45–53.
Kenett, Y., Anaki, D., & Faust, M. (2014). Investigating the structure of semantic networks in low and high creative persons. Frontiers in Human Neuroscience, 8, 407.
Kenett, Y. N., Levi, E., Anaki, D., & Faust, M. (2017). The semantic distance task: Quantifying semantic distance with semantic network path length. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(9), 1470.
Kenett, Y. N., Ovando-Tellez, M., Benedek, M., & Volle, E. (2019). Building Individual Semantic Networks and Exploring their Relationships with Creativity. Proc Natl Aca Sci, 41.
Kriegeskorte, N., & Mur, M. (2012). Inverse MDS: Inferring dissimilarity structure from multiple item arrangements. Frontiers in Psychology, 3, 245.
Kumar, A. A. (2021). Semantic memory: A review of methods, models, and current challenges. Psychonomic Bulletin & Review, 28, 40–80.
Kumar, A. A., Steyvers, M., & Balota, D. A. (2022). A critical review of network‐based and distributional approaches to semantic memory structure and processes. Topics in Cognitive Science, 14(1), 54–77.
Landauer, T. K., & Dumais, S. T. (1997). A solution to Plato's problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychological Review, 104(2), 211.
Latora, V., Nicosia, V., & Russo, G. (2017). Complex networks: principles, methods and applications. Cambridge University Press.
Liddell, T. M., & Kruschke, J. K. (2018). Analyzing ordinal data with metric models: What could possibly go wrong? Journal of Experimental Social Psychology, 79, 328–348.
Lin, E. L., & Murphy, G. L. (2001). Thematic relations in adults' concepts. Journal of Experimental Psychology: General, 130(1), 3.
Majewska, O., McCarthy, D., van den Bosch, J. J., Kriegeskorte, N., Vulić, I., & Korhonen, A. (2021). Semantic Data Set Construction from Human Clustering and Spatial Arrangement. Computational Linguistics, 47(1), 69–116.
Malmberg, K. J. (2002). On the form of ROCs constructed from confidence ratings. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(2), 380.
Marko, M., & Riečanský, I. (2021). The structure of semantic representation shapes controlled semantic retrieval. Memory, 29(4), 538–546.
Morais, A. S., Olsson, H., & Schooler, L. J. (2013). Mapping the structure of semantic memory. Cognitive Science, 37(1), 125–145.
Nelson, D. L., McEvoy, C. L., & Schreiber, T. A. (2004). The University of South Florida free association, rhyme, and word fragment norms. Behavior Research Methods, Instruments, & Computers, 36(3), 402–407.
Ovando-Tellez, M., Benedek, M., Kenett, Y. N., Hills, T., Bouanane, S., Bernard, M., Belo, J., Bieth, T., & Volle, E. (2022). An investigation of the cognitive and neural correlates of semantic memory search related to creative ability. Communications Biology, 5(1), 604.
Ovando-Tellez, M., Kenett, Y. N., Benedek, M., Bernard, M., Belo, J., Beranger, B., Bieth, T., & Volle, E. (2022). Brain connectivity–based prediction of real-life creativity is mediated by semantic memory structure. Science Advances, 8(5), eabl4294.
Page, L., Brin, S., Motwani, R., & Winograd, T. (1997). PageRank: Bringing order to the web (72nd ed.). Stanford Digital Libraries Working Paper.
Rayner, K., & Frazier, L. (1989). Selection mechanisms in reading lexically ambiguous words. Journal of Experimental Psychology: Learning, Memory, and Cognition, 15(5), 779.
Regenwetter, M., Hsu, Y. F., & Kuklinski, J. H. (2019). Towards meaningful inferences from attitudinal thermometer ratings. Decision, 6(4), 381.
Reilly, J., Finley, A. M., Litovsky, C. P., & Kenett, Y. N. (2023). Bigram semantic distance as an index of continuous semantic flow in natural language: Theory, tools, and applications. Journal of Experimental Psychology: General.
Richie, R., White, B., Bhatia, S., & Hout, M. C. (2020). The spatial arrangement method of measuring similarity can capture high-dimensional semantic structures. Behavior Research Methods, 52(5), 1906–1928.
Roberts, F. S. (1985). Applications of the theory of meaningfulness to psychology. Journal of Mathematical Psychology, 29(3), 311–332.
Rogers, T. T., & McClelland, J. L. (2004). Semantic cognition: A parallel distributed processing approach. MIT press.
Rubinsten, O., Anaki, D., Henik, A., Drori, S., & Faran, Y. (2005). Free association norms in the Hebrew language. Word norms in Hebrew, 17–34.
Schvaneveldt, R. W., Durso, F. T., & Dearholt, D. W. (1989). Network structures in proximity data. In G. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (24th ed., pp. 249–284). Academic Press.
Schvaneveldt, R. (2023). Pathfinder Networks (https://www.mathworks.com/matlabcentral/fileexchange/59378-pathfinder-networks), MATLAB Central File Exchange. Retrieved April 18, 2023.
Siew, C. S., Wulff, D. U., Beckage, N. M., Kenett, Y. N. (2019). Cognitive network science: A review of research on cognition through the lens of network representations, processes, and dynamics. Complexity, 2019.
Simmons, J. P., Nelson, L. D., & Simonsohn, U. (2011). False-positive psychology: undisclosed flexibility in data collection and analysis allows presenting anything as significant. Psychological Science., 22, 1359–1366. https://doi.org/10.1177/0956797611417632
Steyvers, M., & Tenenbaum, J. B. (2005). The large-scale structure of semantic networks: Statistical analyses and a model of semantic growth. Cognitive science, 29(1), 41–78.
Taconnat, L., Baudouin, A., Fay, S., Raz, N., Bouazzaoui, B., El-Hage, W., ... & Ergis, A. M. (2010). Episodic memory and organizational strategy in free recall in unipolar depression: The role of cognitive support and executive functions. Journal of Clinical and Experimental Neuropsychology, 32(7), 719–727.
Tulving, E. (1972). Episodic and Semantic Memory. In E. Tulving & W. Donaldson (Eds.), Organization of memory (pp. 381–403). Academic Press.
Van Fraassen, B. C. (2008). The empirical stance. Yale University Press.
Watts, D. J., & Strogatz, S. H. (1998). Collective dynamics of ‘small-world’ networks. Nature, 393(6684), 440–442.
Wicherts, J. M., Veldkamp, C. L., Augusteijn, H. E., Bakker, M., Van Aert, R., & Van Assen, M. A. (2016). Degrees of freedom in planning, running, analyzing, and reporting psychological studies: A checklist to avoid p-hacking. Frontiers in Psychology, 7, 1832.
Wulff, D. U., De Deyne, S., Aeschbach, S., & Mata, R. (2022). Using network science to understand the aging lexicon: Linking individuals' experience, semantic networks, and cognitive performance. Topics in Cognitive Science, 14(1), 93–110.
Wulff, D. U., Aeschbach, S., De Deyne, S., Mata, R. (2022a). Data from the MySWOW proof-of-concept study: Linking individual semantic networks and cognitive performance. Journal of Open Psychology Data, 10(1).
Zhang, B., & Horvath, S. (2005). A general framework for weighted gene co-expression network analysis. Statistical Applications in Genetics and Molecular Biology, 4(1).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open science statement
All data and analysis code are available at: https://osf.io/26wku/.
This work is not preregistered.
Appendices
Appendices
Appendix 1: Technical description of the adaptive multi-arrangement task and algorithm
The adaptive multi-arrangement task requires participants to arrange items in an arena based on their semantic relatedness. On subsequent trials, the algorithm samples two items for which there is already some evidence. This ensures that dissimilarity matrices are aligned across trials. Once a pair of items is sampled, additional items are sampled if they improve “trial efficiency.” Trial efficiency is the ratio between “utility benefit” and “trial cost.” Trial cost is defined as the additional cost of evaluating a given pair of items and is simply the number of items sampled for a given trial (n) raised to a power X, that is, \({n}^{X}\). We used an exponent of 1.2 under the assumption that the time it takes items is super-linear but sub-quadratic. Trial benefit is the additional utility gained if a given pair of items is included on a trial. In this context, trial benefit is the sum of evidence utility, which is calculated using the exponential saturation function \(1-{e}^{-w*d}\), where \(w\) is the current evidence weight for a given word pair, which is simply the onscreen distance of that item squared. This definition of evidence utility assumes that the dissimilarity signal-to-noise ratio is proportional to the onscreen distances, such that smaller distances have a smaller signal-to-noise ratio. The evidence utility exponent \(d\) was set to 10, which is the default value used by Kriegeskorte and Mur (2012). For this formula, evidence utility is arbitrarily close to 1 as \(w\) approaches .5. For this reason, .5 is used as a criterion for terminating the algorithm; that is, once each item pair has an evidence value of .5, or times out (after 35 minutes), the experiment ends.
Since the algorithm “zooms in” on subclusters of items on different trials, a scaling factor needs to be defined that rescales and combines distances of each arrangement in a way that ignores the on-screen distance for that specific arrangement. This is implemented iteratively. A reference dissimilarity matrix is used to calculate the rescaling factor on each trial. For 20 words, the reference dissimilarity matrix can be seen as a vector of 190 values, and the rescaled matrix is this vector normalized. The values in this vector are the average of the onscreen distances weighted by their evidence utility obtained from previous trials. These values are used to rescale dissimilarity vectors for all item pairs obtained on the current and previous trials. Specifically, after the reference dissimilarity vector is normalized, entries from dissimilarity estimates from all trials are set to equal the values in the normalized reference vector. Then a new reference matrix is calculated using the evidence-weighted average of the rescaled distances. This is repeated iteratively until the root mean square of the deviations between the reference matrix from the previous and current iteration is arbitrarily close to 0.
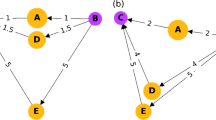
Appendix 2: Example graph representations
Graphs
Each figure below shows binary graphs of two randomly sampled participants and the average data from Experiment 1a (Fig. 7) and 2a (Fig. 8), as well as the similarity adjacency matrices of two different sample participants and average data from Experiment 1a (Fig. 9) and 2a (Fig. 10).

Example graphs from Experiment 1 of two participants (first two upper panels) and graph constructed from average data (lower panel)

Example graphs from Experiment 2 of two participants (first two upper panels) and graph constructed from average data (lower panel)

Heatmaps of adjacency matrices (0=similar, 1=similar) from Experiment 1 of two participants (first two upper panels) and average data (lower panel)

Heatmaps of adjacency matrices (0=similar, 1=similar) from Experiment 2 of two participants (first two upper panels) and average data (lower panel)
Appendix 3: Secondary methodological contribution
Validation of the adaptive multi-arrangement task for detecting individual differences
A secondary methodological contribution of our research is that we are the first to show that the adaptive version of the spatial multi-arrangement task can be used to predict individual differences in semantic processing for words. Previous work by Kriegeskorte and Mur (2012) demonstrated that this task and algorithm can be used to recover the high-dimensional structure of similarity judgments for visual stimuli, and follow-up work by Charest et al. (2014) demonstrated that the task correlates with individual differences in neural representations of visual stimuli, e.g., real-world objects. Furthermore, recent work by Majewska et al. (2021) applied the adaptive spatial multi-arrangement task to a large-scale data set with verb stimuli and demonstrated that it can provide a fine-grained measure of subclasses of semantic concepts, although the authors did not examine its potential to capture individual differences. Finally, Richie et al. (2020) recently demonstrated that a non-adaptive version of the algorithm (Goldstone, 1994), which does not involve “zooming in” on clusters of objects, can be used to recover high-dimensional structures of words. Richie et al. (2020) also found that performance on this task correlates with performance on binary similarity judgment; however, they did not demonstrate that this measure is sensitive to individual differences and did not compare the robustness of different modeling approaches in their capacity to capture such individual differences. In short, our work contributes to a line of research on validating the adaptive version of the spatial multi-arrangement task. While prior work has shown its potential to recover the high-dimensional structure of similarity judgments and its relative efficiency, we show that it can also be used to recover individual differences in similarity judgments for concepts with different modeling approaches.
Appendix 4: Example of experiment instructions
Instructions for spatial multi-arrangement task
In this study you will complete two tasks. This is the first session and this task will take approximately 35–40 minutes to complete. The first part of the experiment is called the Word Arrangement task. It is explained below. The second part of the experiment will be described to you during the second session of the study. The Word Arrangement task requires you to arrange 20 words according to their similarity. Specifically, you will use the mouse to click on a word and drag it into a circular arena. You should use the relative distance between words to indicate how similar you think each words is relative to other words. In other words, similar objects are placed closer together; dissimilar objects are placed far apart. In the current context, the objects are blocks with words inside of them, and the distance from the center of two blocks represents their dissimilarity. If you were to place two blocks such that they completely overlap with one another, that would mean you consider the words to be identical. Consider this example...<Image of example arrangement> You will not be shown all of the 20 words at once, but will be shown subsets of the 20 (up to 10) words on each trial. Often, words will repeat across trials so that we can obtain similarity judgments between all words, and/or get more precise similarity judgements for specific words pairs. Thus, on some trials, you will see many words (up to 10), and on other trials you will see fewer words (as few as 3). It does not matter how many words you see; you should use all of the space available to you in the circle to arrange the words and communicate the dissimilarity between words given to you on a given trial. For instance, if you see 10 words, you should arrange words that are relatively similar to one another closer together, and words that are less similar further apart. As an example, consider the example array below. The words “Dracula,” “vampire,” and “cape” are relatively close to each other because this person considered these words to be more similar to one another than the others. On a different trial, however, the algorithm <b>zooms in</b> on the three words “Dracula,” “vampire,” and “cape.” This allows us to collect more precise measurements of your judgments of similarity. Therefore, if you see fewer (3 words), you should still use ALL of the space in the arena to precisely communicate the relative similarity of those three words. As an example, consider the example array below, which now just has the words “Dracula,” “vampire,” and “cape,” This person considered “Dracula” and “vampire” to be more similar to one another, so they are placed closer together, and are further apart from the word “cape.” Again, it is important to note that even if these words are similar to one another, all of the space in the circle is used to communicate the relative similarity between these three words. Finally, note from this example that it does not matter where on the circle you place words—that is, whether they are on the top, left, right, or bottom of the circle. What matters is the distance between each word, which is a measure of how similar you think those words are to each other. If you need to reset an arrangement, you can right-click the “START OVER” button on the bottom left-hand side of the screen. Once you are ready to advance, you should click the “NEXT TRIAL” button on the bottom right hand side of the screen. The program uses an adaptive algorithm that is based on the precision and consistency with which you make your judgments. Therefore, you will see words repeatedly on different trials. The more you think about your judgments on each trial, the faster the experiment will end. If you arrange words randomly on each trial, the algorithm will not reach criterion, and it will take longer to complete the task. Therefore, you should try to make your arrangements precise and consistent, rather than speeding through. This will ensure that the algorithm reaches criterion faster, and ends this task. Keep in mind that there is no wrong way to arrange the words. This is a method for measuring your subjective judgment of similarity between each of the words, so there is no wrong answer as long as you are not doing the arrangements randomly and follow the instructions given above.
Instructions for relatedness ranking task (100-point slider scale). Note that instructions for the Likert 6-point rating task are identical with the exception that they refer to the 6-point rather than 100-point scale
You are done with the first part of the experiment and ready to start the second part of the experiment. In this part of the task you will be asked to judge similarity between two words in a different way. This part of the experiment will last 20–25 minutes. Specifically, you will be shown a pair of words at a time, and asked to rate how similar you think the two words are on a scale from 1 (maximally different) to 100 (identical). To report on your similarity judgments, you will use a sliding scale with your mouse. Please think about each rating carefully and try to make your ratings as precise as possible using values of the scale that seem to best match your judgment. For instance, I may think that the words “bread” and “baguette” are extremely similar, so I would give them a rating of 90. I may think that “bread” and “butter” are similar, but less similar than baguette, so I would give them a rating of 75. I may think that “bread” and “knife” are somewhat similar, though less similar than “bread” and “butter” so I would give them rating of 60. Similarly, I may think that “bread” and “doctor” are extremely dissimilar, so I would give them a rating of 1. Note that these are just examples to illustrate how different values of the scale relate to different similarity judgments, and you should choose values that seem best to you.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Robinson, M.M., DeStefano, I.C., Vul, E. et al. Local but not global graph theoretic measures of semantic networks generalize across tasks. Behav Res (2023). https://doi.org/10.3758/s13428-023-02271-6
Accepted:
Published:
DOI: https://doi.org/10.3758/s13428-023-02271-6