
Abstract
When two independent means μ1 and μ2 are compared, H0 : μ1 = μ2, H1 : μ1≠μ2, and H2 : μ1 > μ2 are the hypotheses of interest. This paper introduces the R package SSDbain, which can be used to determine the sample size needed to evaluate these hypotheses using the approximate adjusted fractional Bayes factor (AAFBF) implemented in the R package bain. Both the Bayesian t test and the Bayesian Welch’s test are available in this R package. The sample size required will be calculated such that the probability that the Bayes factor is larger than a threshold value is at least η if either the null or alternative hypothesis is true. Using the R package SSDbain and/or the tables provided in this paper, psychological researchers can easily determine the required sample size for their experiments.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
In the Neyman–Pearson approach to hypothesis testing (Gigerenzer, 2004) a null and an alternative hypothesis are compared. Suppose the population means of males and females are denoted by μ1 and μ2. Three hypotheses are relevant: the null hypothesis H0: μ1 = μ2, the two-sided alternative hypothesis H1: μ1≠μ2, and the one-sided alternative hypothesis H2: μ1 > μ2. The null hypothesis H0 is rejected if the observed absolute t-statistic falls inside the critical region, where the critical region is a set of values that are equal to or greater than the critical value t1−α/2,v, where α is the type I error rate, and v is the degree of freedom for a two-sided alternative hypothesis. The null hypothesis H0 is rejected if the observed t-statistic falls inside the critical region, where the critical region is a set of values that are equal to or greater than the critical value t1−α,v for a one-sided alternative hypothesis (Gigerenzer 1993, 2004). Statistical power is the probability of finding an effect when it exists in the population, that is, the probability of rejecting the null hypothesis when the alternative is true. Power analysis for Neyman–Pearson hypothesis testing has been studied for more than 50 years. Cohen (1992, 1988) played a pioneering role in the development of effect sizes and power analysis, and he provided mathematical equations for the relation between effect size, sample size, type I error rate and power. For example, if one aims for a power of 80%, the minimum sample size per group should be 394, 64 and 26 for small (d = 0.2), medium (d = 0.5) and large (d = 0.8) effect sizes, respectively for an independent samples two-sided t test at type I error rate α = .05, where Cohen’s d is the standardized difference between two means. To perform statistical power analyses for various tests, the G⋆Power program was developed by Erdfelder et al., (1996) and Faul et al., (2007) and Mayr et al., (2007). Despite the availability of G⋆Power there is still a lot of underpowered research in the behavioral and social sciences, even though criticism with respect to insufficient power is steadily increasing (Maxwell, 2004; Button et al., 2013; Simonsohn et al., 2014).
Numerous articles have criticized the Neyman–Pearson approach to hypothesis testing in the classical framework (e.g., Cohen (1994), Nickerson (2000), Sellke et al., (2001), Wagenmakers (2007), and Hubbard and Lindsay (2008)). As an alternative, Jeffreys (1961) and Kass and Raftery (1995) introduced the Bayes factor (BF). BF quantifies the relative support in the data for one hypothesis against another, and in addition to that, cannot only provide evidence in favor of the alternative hypothesis, but also provides evidence in favor of the null hypothesis. This approach for Bayesian hypothesis evaluation is increasingly receiving attention from psychological researchers, see for example Van de Schoot et al., (2017) and Vandekerckhove et al., (2018), and Wagenmakers et al., (2016). Nevertheless, researchers, especially psychologists, find it difficult to calculate BF and several software packages for Bayesian hypothesis evaluation have been developed. The most important are the R package BayesFactor (Rouder et al., 2009), that can be found at http://bayesfactorpcl.r-forge.r-project.org/ and the R package bain (Gu et al., 2018) that can be found at https://informative-hypotheses.sites.uu.nl/software/bain/. The latter is the successor of the stand-alone software BIEMS (Mulder et al., 2012) that can be found at https://informative-hypotheses.sites.uu.nl/software/biems/. Both BayesFactor and bain are implemented in JASP (https://jasp-stats.org/). The main difference between approximate adjusted fractional Bayes factor (AAFBF) implemented in bain and the Jeffreys–Zellner–Siow Bayes factor implemented in BayesFactor is the choice of the prior distribution. We focus on the AAFBF (to be elaborated in the next section) in this manuscript because it is available for both the t test and the Welch’s test.
When two independent group means are compared, there exist two specific cases in which variances are either equal or unequal for the two groups, which correspond to t test or Welch’s test. The t test is well known, while Welch’s test is often extremely important and useful as demonstrated by Ruscio and Roche (2012) and Rosopa et al., (2013), and Delacre et al., (2017). In the Neyman–Pearson approach to hypothesis testing, the formulae for calculating the sample size are given by an a priori power analysis for t test and Welch’s test (Cohen, 1992; Faul et al., 2007). There is not yet a solid body of literature regarding sample-size determination (SSD) for Bayesian hypothesis evaluation, but Weiss (1997) and De Santis (2004) and De Santis (2007) give different sample-size determination approaches for testing one mean of the normal distribution with known variance. Kruschke (2013) and Kruschke and Liddell (2018) discuss parameter estimation and use the posterior distribution as a measure of evidence strength, and Schönbrodt and Wagenmakers (2018) and Stefan et al., (2019) introduce Bayes factor design analysis applied to fixed-N and sequential designs. This paper will elaborate on these approaches in the following manners. (1) in addition to the Bayesian t test the Bayesian Welch’s test also will be considered. In practice, Welch’s test is more widely used, which is a necessary improvement in this manuscript; (2) both two-sided and one-sided alternative hypotheses are considered. One-sided alternative hypothesis can effectively reduce the required sample size and it is recommended to be used. This manuscript will provide a comprehensive analysis for both two-sided and one-sided alternative hypotheses; (3) the sample size will be calculated such that the probability that the Bayes factor is larger than a user specified threshold is at least η if either the null hypothesis or the alternative hypothesis is true; (4) we use the dichotomy method to compute the sample size very fast. In the previous publication, the sample size is computed through progressively increase the sample size with one until the threshold value is reached. This method is simple and easily used but with high computation effort, especially for the case when the required sample size is large, e.g., the sample size of 500 will cause several hundreds of iterations, while only 12 iterations are required with our method; (5) the sensitivity of SSD with respect to the specification of the prior will be highlighted. This is very important when Bayes factor is used for the hypothesis testing evaluation, because there exists some uncertainty for the required sample size for different prior distributions.
The outline of this paper is as follows. First, we give a brief introduction of the AAFBF, show how it can be computed, discuss the specification of the prior distribution and sensitivity analyses. Subsequently, sample-size determination is introduced. Thereafter, we will discuss the role of sample-size determination in Bayesian inference. The paper continues with an introduction of the ingredients required for sample-size determination. Then, the algorithm used to determine the sample size will be elaborated. Next, features of SSD are described. Thereafter, three examples are presented that will help psychological researchers to use the R package SSDbain if they plan to compare two independent means using the t test or the Welch’s test. The paper ends with a short conclusion.
Bayes factor
In this paper, the means of two groups, μ1 and μ2, are compared for both Model 1: the within-group variances for group 1 and 2 are equal,
and Model 2: the within-group variances for group 1 and 2 are not equal,
where D1p = 1 for person p = 1,⋯ ,N and 0 otherwise, D2p = 1 for person p = N + 1,⋯ ,2N and 0 otherwise, N denotes the common sample size for group 1 and 2, 𝜖p denotes the error in prediction, σ2 denotes the common within-group variance for group 1 and 2, and \({{\sigma _{1}^{2}}}\) and \({{\sigma _{2}^{2}}}\) denote the different within-group variances for group 1 and 2, respectively.
In this paper, the AAFBF (Gu et al., 2018; Hoijtink et al., 2019) is used to test hypotheses: H0 : μ1 = μ2 against H1: μ1≠μ2Footnote 1 or against H2 : μ1 > μ2. The Bayes factor (BF) quantifies the relative support in the data for a pair of competing hypotheses. Specifically, if BF01 = 5, the support in the data is five times stronger for H0 than for H1; if BF01 = 0.2, the support in the data is five times stronger for H1 than for H0. As was shown in Klugkist et al., (2005) the BF in terms of comparing the constrained hypothesis Hi (i = 0,2) with the hypothesis H1 can be expressed in a simple form:
where ci denotes the complexity of the hypothesis Hi, and fi denotes the fit of the hypothesis Hi. The complexity ci (a hypothesis with smaller complexity provides more precise predictions) of Hi describes how specific Hi is, and the corresponding fit fi (the higher the fit the more a hypothesis is supported by the data) describes how well the data support Hi. The formulae of the fit and complexity are:
where g1 (μ∣y,D1,D2) denotes the posterior distribution, and h1 (μ∣y,D1,D2) the prior distribution of μ under H1. In case of H2, f2 and c2 are the proportions of the posterior distribution g1(⋅) and prior distribution h1(⋅) in agreement with H2, respectively; in case of H1 Eq. 3 reduces to the Savage–Dickey density ratio (Dickey, 1971; Wetzels et al., 2010). The BF for H0 against H2 is:
Actually, g1(⋅) is a normal approximation of the posterior distribution of μ1 and μ2:
when Model 1 is considered; and
when Model 2 is considered, where \(\hat {\mu }_{1}\) and \(\hat {\mu }_{2}\) denote the maximum likelihood estimates of the means of group 1 and group 2, respectively, and \(\hat {\sigma }^{2}\), \(\hat {\sigma }_{1}^{2}\) and \(\hat {\sigma }_{2}^{2}\) denote unbiased estimates of the within-group variances. Due to the normal approximation, the general form of the AAFBF can be used to evaluate hypothesis evaluation in a wide range of statistical models such as structural equation modeling, logistic regression, multivariate regression, AN(C)OVA, etc. Therefore, it is currently the most versatile method for Bayesian hypotheses evaluation.
The prior distribution is based on the fractional Bayes factor approach (O’Hagan, 1995; Mulder, 2014). It is constructed using a fraction of information in the data. As elaborated in Gu et al., (2018) and Hoijtink et al., (2019) the prior distribution is given by:
where b is the fraction of information in the data used to specify the prior distribution, when Model 1 is considered, and
when Model 2 is considered.
The prior distribution is NOT used to represent the prior knowledge about the effect size under H1 or H2. The prior distribution is chosen such that a default Bayesian hypothesis evaluation of H0 vs Hi is obtained, that is, subjective input from the researcher is not needed. This is an advantage of default Bayesian hypothesis evaluation because the vast majority of researchers want to evaluate H0 vs H1 or H0 vs H2 and do not want to evaluate the corresponding prior distributions. The default value of b used for the Bayesian t test and Welch’s test equals \(\frac {1}{2N}\). This choice is inspired by the minimal training sample idea (Berger and Pericchi 1996, 2004), that is, turn a noninformative prior into a proper prior using a small proportion of the information in the data. For our situation this is equivalent to using one half observation from group 1 and one half observation from group 2 is used, which is in total one observation. This makes sense because the focus is on one contrast, that is, μ1 − μ2, which means that one parameter needs to be estimated. This choice is too some extend arbitrary, for example, we could also use 2b (one person is needed to estimate each mean) or 3b (one person for each mean and the half for the residual variance), which still maintains the spirit of the minimal training sample approach. In summary, the goal is to compare H0 with Hi (i = 1,2) by means of Bayes factor, but not comparing the prior distribution of H0 with Hi (i = 1,2) through the Bayes factor. To achieve this, the prior distributions are calibrated such that H0 and Hi can be evaluated without requiring user input. However, there is some uncertainty in the calibrating, hence the AAFBF can be computed using the fractions b, 2b, and 3b, and the required sample sizes can be computed accordingly.
As an illustration, Tables 1 and 2 list the BF for the comparison of H0 with the two-sided alternative H1 and the one-sided alternative H2, respectively, when equal within-groups variances are considered (Model 1). From Table 1, we can see that when H0 is true (e.g., the entry with b), the support in the observed data is 13 times larger for H0 than for H1; when H1 is true, the support in the observed data is 22 (1/0.045) times larger for H1 than for H0. Table 2 shows that the data were nearly 18 times more likely to support H0 when H0 is true; the support in the data is more than 45 (1/0.022) times more likely to support H2 when H2 is true. Therefore, for the same sample size per group, it is much easier to get strong evidence for the one-sided than for the two-sided hypothesis (e.g., compare the corresponding shaded areas of the columns BF01 in Table 1 and BF02 in Table 2, BF20= 1/BF02 is larger than BF10= 1/BF01). The fit is higher for the true hypothesis (e.g., see column f0 in Table 1, f0 = 2.816 when H0 is true is larger than f0 = 0.009 when H1 is true). As can be seen in Tables 1 and 2 (bottom two panels) the BF is sensitive to the choice of the fraction. The complexity c0 becomes larger for H0 if the fraction increases (from 0.209 to 0.295, then to 0.362), while the complexity c2 is not affected by the fraction for H2 (0.5 for any value of fraction). This is because the complexity of a hypothesis specified using only inequality constraints is independent of the fraction, see Mulder (2014) for a proof. The corresponding BF for H0 becomes smaller (e.g., in the column BF01, BF decreases from 13.49 to 9.54, then to 7.79), and the BF for H2 does not change.
Criteria for sample-size determination
For the Neyman–Pearson approach to hypothesis testing power analysis renders an indication of the sample sizes needed to reject the null-hypothesis with a pre-specified probability if it is not true. If the sample sizes are sufficiently large, under-powered studies can be avoided (Maxwell, 2004). A power analysis is conducted prior to a research study, and can be executed if three ingredients, type I error rate, type II error rate, and effect size are given. The main difficulty is getting an a priori educated guess of the true effect size. In practice, often one of two approaches to choose the effect size is used: use an estimate of the effect size based on similar studies in the literature, experts’ opinion or a pilot study (Sakaluk, 2016; Anderson et al., 2017); or, use the smallest effect size that is considered to be relevantly different from zero for the study at hand (Perugini et al., 2014). If the chosen effect size is smaller than the unknown true effect size, the sample sizes will be larger than necessary, which can be costly or unethical, and if the chosen effect size is larger than the unknown true effect size, the sample sizes will be too small and the resulting study will be underpowered.
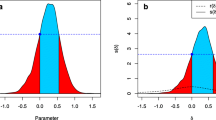
When the Bayes factor is used for hypothesis testing, sample-size determination instead of power analysis is used although the goals are similar. The main ingredients for SSD in a Bayesian framework are explained in Fig. 1. Panel (a) on the left: t test, sample size N = 26 per group, distribution of BF01 when data are repeatedly sampled from a population in which H0 : μ1 = μ2 is true. Panel (b) on the right: t test, sample size N = 104 per group, distribution of BF10 when data are repeatedly sampled from a population in which μ1≠μ2, but with the addition that the effect size has to be chosen (here we use effect size d = 0.5 to simulate data). We face the same problem as for power analysis, namely an unknown true effect size, but as will be elaborated in the next section, the combination of SSD and Bayesian updating can be used to address this problem.

The sampling distribution of BF01 under H0 and BF10 under H1. The vertical dashed line denotes the BFthresh = 3. The grey area visualizes η = 0.80. Note that, as will be illustrated in Table 4 later in this paper, the sample size is the maximum of 26 and 104
Sample size will be determined such that P(BF01 > BFthresh|H0) ≥ η and P(BF10 > BFthresh|H1) ≥ η, that is, the probability that BF01 is larger than a user specified threshold value if H0 is true should be at least η, and the probability that BF10 is larger than the threshold value if H1 is true should be at least η. This is in line with power analysis in Neyman–Pearson approach to hypothesis testing in which the type I error rate α and type II error rate β are given beforehand. In the Bayesian framework, instead of type I error rate and type II error rates, we use the probability that the Bayes factor is larger than BFthresh under the null hypothesis and under the alternative hypothesis. With respect to the choice of BFthresh, two situations can be distinguished. Situation 1: if one wants to explore which hypothesis is more likely to be supported, one can set BFthresh= 1. Situation 2: if one wants to find compelling evidence to support the true hypothesis, one can set BFthresh equal to 3, 5, or 10, depending on the strength of the evidence that is required. With respect to the choice of η it should be noted that 1 − η are, for the null and alternative hypotheses, the Bayesian counterparts of the type I and the type II error rates. In high-stakes research, the probability of an erroneous decision should be small, therefore a larger value of η such as 0.90 should be used. In low-stakes or more exploratory research erroneous decisions may be less costly and smaller values like η = 0.80 could be used.
The role of sample-size determination in Bayesian inference
In the Bayesian framework, updating (Rouder, 2014; Schönbrodt et al., 2017; Schönbrodt and Wagenmakers, 2018) can be seen as an alternative for sample-size determination that does not require specification of the effect size under the alternative hypothesis. Bayesian updating proceeds along the following steps: (i) specify an initial sample size per group and the required support in terms of BF; (ii) collect data with the initial sample size; (iii) compute the BF; (iv) if the support in favor of either H0 or H1 is large enough the study is finished; if the support is not large enough, increase the sample size and return to (iii). Because in the Bayesian framework the goal is not to control the Type I and Type II error rates (the goal is to quantify the support in the data for the hypotheses under consideration) this is a valid procedure.
With the availability of Bayesian updating and sample-size determination, two strategies can be used to obtain sufficient support for the hypotheses under consideration, which will be described in the next two sub-sections: (i) sample-size determination as a pre-experimental phase in case updating is not an option; and, (ii) sample-size determination followed by updating.
Sample-size determination as a pre-experimental phase
If updating can be used, it is an approach that avoids pre-specification of the effect size under the alternative hypothesis and is a worthwhile option to pursue. However, updating cannot always be used or sample-size determination is a required step before updating can be executed. Consider the following situations. Situation 1. The population of interest is small, for instance, persons with a rare disease or cognitive disorder. The control and treatment groups will very likely not be large. Updating is in this situation not an option. However, if, for example, a researcher is interested to detect an effect size of Cohen’s d (for the t test) equal to .8 with a probability η = 0.80 that the Bayes factor is at least 5, the sample size required is 67 per group (see Table 5, which will be discussed after the next two sections). Since such a large sample size cannot be obtained, it is decided not to execute the experiment in this form. Situation 2. Next month a survey will start in which 150, currently single, men and women will be tracked for 21 years. Updating is not an option in such a longitudinal cohort study, but Table 4 shows that 104 persons per group are needed to have a probability of at least η = 0.80 to obtain a Bayes factor larger than 3 if the effect size is Cohen’s d = .5. Since the effect size is expected to be 0.5, the study can be actually conducted because the sample size is 150 persons per group. Situation 3. The researchers have to submit the research plans to the (medical) ethical committee. They want to use updating, but both the researchers and the committee’s members may want an indication of the sample size needed to obtain sufficient support for different effect sizes under the alternative hypothesis. Only with these numbers they can argue that they have sufficient funding and research time to execute the research plan. Sample-size determination can be used to obtain an indication of the sample sizes needed to obtain sufficient support for different effect sizes. These numbers can be included in the researcher’s research proposal for the (medical) ethical committee.
Sample-size determination followed by updating
When sample-size determination is used, however, as will be highlighted using Situations 4 and 5, having to specify the effect size under the alternative hypothesis may have two undesirable consequences. Consider the following situations. Situation 4. If the alternative hypothesis is true, the researchers expect an effect size Cohen’s d = .5. They determine the sample sizes such that an effect size of Cohen’s d (for the t test) equal to .5 with η = 0.80 that the Bayes factor is at least 3 is detected, that is, 104 persons per group. After collecting data, they obtain BF01 = 2.5. This is an undesirable result because they did not achieve the desired support. They can remedy this by updating, that is, increasing the sample size until the Bayes factor is at least 3. The latter is only possible if updating is an option. Situations 1 and 2 are examples of cases where this is not an option. Situation 5. Analogous to Situation 4, but now the researchers find BF01 = 8.3. This is a problem in the sense that they spent more funds and research time than would have been necessary. The researchers plan and are able to collect the data from 104 persons per group. If the research design permits this they can update until they reach the required support (which may be achieved at a sample size smaller than 104 per group), which will save funds and research time. The combination of sample-size determination and updating is the most powerful approach, whenever it is applicable.
Ingredients for sample-size determination
Sample-size determination for the Bayesian t test and the Bayesian Welch’s test is implemented in the function SSDttest of the R package SSDbain available at https://github.com/Qianrao-Fu/SSDbain. In this section, we introduce and discuss the necessary input for sample-size determination with the SSDttest function. In the sections that follow, we will provide the algorithms used for Bayesian SSD, and a discussion of SSD properties using three tables for Cohen’s d equal to .2, .5, and .8, respectively. Furthermore, three examples of the application of SSDttest are presented.
After loading the SSDbain library, the following call is used to determine the sample size per group:
library(SSDbain) SSDttest(type='equal',Population_mean= c(0.5,0),var=NULL,BFthresh=3,eta=0.80, Hypothesis ='two-sided',T=10000)
The following ingredients are used:
-
1.
type, a string that specifies the type of the test. If type='equal', the t test is used; if type='unequal', the Welch’s test is used. The default setting is type='equal'. If one expects (based on prior knowledge or prior evidence) that the two within-group variances are equal, choose the Bayesian t test, otherwise, choose the Bayesian Welch’s test (Ruxton, 2006; Ruscio & Roche, 2012; Delacre et al., 2017).
-
2.
Population_mean, vector of length 2 specifying the population means of the two groups under H1 or H2. The default setting is Population_mean=c(0.5,0) when the effect size is d = 0.5. Note that, if var=NULL and the population mean in group 2 equals 0, the population mean in group 1 is identical to Cohen’s d.
-
3.
var, vector of length 2 giving the two within-group variances. If type='equal', the default is var=c(1,1); if type='unequal', the default is var=c(4/3,2/3). Of course, any values of the variances can be used as input for the argument var.
-
4.
BFthresh, a numeric value that specifies the magnitude of Bayes factor, e.g., 1, 3, 5, 10. The default setting is BFthresh= 3. If one chooses 5, one requires that BF01 is at least 5 if the data comes from a population in which H0 is true, and the BF10 is at least 5 if the data comes from a population in which H1 or H2 is true. The choice for the BFthresh value is subjective meaning that different values may be chosen by different researchers, for different studies and in different fields of science. A large BFthresh value may be chosen in high-stakes research were the degree of support of a hypothesis against another needs to be large. In pharmaceutical research for instance, the chances to have a new drug for cancer to be approved may be larger if there is high support for it increasing life expectancy as compared to an existing drug, especially so when the new drug may have side effects. A lower BFthresh value may be chosen in low-stakes research. An example also comes from pharmaceutical research, where a new headache relief drug and an existing competitor are compared on their onset of action, and side effects are not likely to occur.
-
5.
eta, a numeric value that specifies the probability that the Bayes factor is larger than the BFthresh if either the null hypothesis or the alternative hypothesis is true, e.g., 0.80, 0.90. The default setting is eta= 0.80.
-
6.
Hypothesis, a string that specifies the hypothesis. Hypothesis='two-sided' when the competing hypotheses are H0 : μ1 = μ2, H1 : μ1≠μ2; Hypothesis='one-sided' when the competing hypotheses are H0 : μ1 = μ2, H2 : μ1 > μ2. The default setting is Hypothesis='two-sided'. This argument is used to decide whether a two-sided (labelled H1 earlier in the paper) or a one-sided (labeled H2 earlier in the paper) alternative hypothesis is to be used. For example, one may wish to compare a new drug with an existing drug. If the researcher is not certain if the new drug will be more or less effective than the existing drug, a two-sided alternative hypothesis should be chosen. If the researcher has strong reasons to believe the new drug is more effective than the old one, a one-sided alternative hypothesis should be chosen.
-
7.
T, a positive integer that specifies the number of data sets sampled from the null and alternative populations to determine the required sample size. The default setting is T = 10,000, and the recommended value is at least 10,000. This argument will be elaborated in the next section.
The output results include the sample size required and the corresponding probability that the Bayes factor is larger than the BFthresh when either the null hypothesis or the alternative hypothesis is true:
Using N=xxx and b P(BF0i>BFthresh|H0)=xxx P(BFi0>BFthres}|Hi)=xxx Using N=xxx and 2b P(BF0i>BFthresh|H0)=xxx P(BFi0>BFthresh|Hi)=xxx Using N=xxx and 3b P(BF0i>BFthresh|H0)=xxx P(BFi0>BFthresh|Hi)=xxx
where xxx will be illustrated in the examples that will be given after the next section.
Algorithm used in Bayesian sample-size determination
Figure 2 presents Algorithm 1, which is the basic algorithm used to determine the sample size. The ingredients in the first four Steps have been discussed in the previous section. In Step 5, T = 10,000 data sets are sampled from each of the populations of interest (e.g., H0 vs. H1), starting with a sample size N = 10 per group. In Step 6 the Bayes factor for each data set sampled from each hypothesis is computed. In Step 7, the probabilities P(BFi1 > BFthresh|H0) and P(BFi0 > BFthresh|Hi) are computed. If both are larger than η specified in Step 4, the output presented in the previous section is provided. If one or both are smaller than η, N is increased by 1 per group and the algorithm restarts in Step 5. To be able to account for the sensitivity of the Bayes factor to the specification of the prior distribution, this algorithm is executed using fractions equal to b, 2b, and 3b. The A presents a refinement of Algorithm 1 that reduces the number of iterations in Algorithm 1 to maximally 12.

Algorithm 1: Sample-size determination for the Bayesian t test and Welch’s test
Features of SSD
In this section, features of SSD will be discussed. This will be done using Tables 3, 4 and 5, which were constructed using SSDttest. The tables differ in effect size: Table 3 is for effect size d = 0.2, Table 4 is for effect size d = 0.5, and Table 5 is for effect size d = 0.8. The following features will be discussed: difference between the Bayesian t test and Bayesian Welch’s test, effect of the effect sizes, effect of the fraction b used to construct the prior distribution, and comparison of the two-sided and one-sided alternative hypothesis.
There seems to be little difference between the t test and Welch’s test with respect to the sample size required and the corresponding probability that the Bayes factor is larger than BFthresh if either the null or the alternative hypothesis is true. For example, for BFthresh= 3, two-sided testing, effect size d = 0.5, and η = 0.80 (see Table 4), the sample size is 104 per group, and the probability that the Bayes factor is larger than 3 if H0 is true is 0.92, and the probability that the Bayes factor is larger than 3 if H1 is true is 0.80 for the t test. The sample size is 104 per group, and the probability that the Bayes factor is larger than 3 if H0 is true is 0.92, and the probability that the Bayes factor is larger than 3 if H1 is true is 0.80 for Welch’s test.
As expected, the sample size required decreases as the effect size under Hi increases. For example, for the two-sided t test, BFthresh= 3 and η = 0.80, the sample sizes required for effect sizes 0.2, 0.5, and 0.8 are 769, 104, and 36 per group, respectively. This is because an increase of the effect size makes the alternative more distinguishable from the null hypothesis. However, for some special cases, the sample size required for effect size 0.5 and 0.8 are the same, for example for the two-sided t test, BFthresh= 5 and η = 0.80 if the fraction 2b is used for the prior distribution. The reason is that the sample size required is the maximum of the sample size required if the null hypothesis is true and the sample size required if the alternative hypothesis is true. In cases like the examples given, the maximum sample size is determined by the null hypothesis, which is the same for effect size 0.5 and 0.8.
The sample size required increases with the fraction going from b to 2b, and then to 3b if the null hypothesis is true, while the opposite relation is found if the alternative hypothesis is true. This feature can be explained as follows: according to Equations (9) and (10), as the fraction gets larger, the prior variance decreases, the relative complexity c0 gets larger, thus the Bayes factor under H0 gets smaller. Consequently, the sample size required increases. Conversely, the sample size required when the alternative hypothesis is true decreases. This feature highlights that a sensitivity analysis is important: results depend on the fraction of information used to specify the prior distribution.
As can be seen in Tables 3–5, the required sample sizes for one-sided testing are always smaller than or about equal to the sample sizes required for two-sided testing. Therefore, if a directional hypothesis can be formulated, a one-sided testing is preferred over a two-sided testing.
Practical examples of SSD
In this section, three examples of SSD will be given. The examples use the function SSDttest because it allows researchers to choose Cohen’s d, BFthresh, and η as they desire. As an alternative, researchers can also consult Tables 3, 4 and 5, although there sample sizes are only given for a limited number of values for Cohen’s d, BFthresh and η.
Example 1
Researchers want to conduct an experiment to investigate whether there is a difference in pain intensity as experienced by users of two types of local anesthesia. The researchers would like to detect a medium effect size d = 0.5 with a two-sided t test, when either H0 or H1 with d = 0.5 is true, such that they have a probability of 0.80 that the resulting Bayes factor is larger than 3. The researchers choose BFthresh = 3 because they want to get a compelling evidence for the high-stakes experiment that one of the two types of anesthesia is better able to reduce the pain intensity for users. As elaborated below, the researchers can combine SSD with Bayesian updating to (i) stop sampling before a sample size of N = 104 per group if the true effect size is larger than d = 0.5 used for SSD, or (ii) to continue sampling beyond N = 104 per group if the true effect size is smaller than 0.50. The sample size required to detect d = 0.5 is obtained using the following call to SSDttest:
SSDttest(type='equal',Population_mean= c(0.5,0),var=c(1,1),BFthresh=3,eta=0.80, Hypothesis= 'two-sided',T=10000)
The results are as follows:
Using N=104 and b P(BF01>3|H0)=0.92 P(BF10>3|H1)=0.80
The following can be learned from these results:
The researchers need to collect 104 cases per type of local anesthesia to get a probability of 0.92 that the resulting Bayes factor is larger than 3 when H0 is true, and to get a probability of 0.80 that the resulting Bayes factor is larger than 3 when H1 is true and d = 0.5.
The researchers will execute the Bayesian updating as follows. First, the researchers will start with 25% of the sample size per group, that is, 26 cases per group. If the resulting BF01 or BF10 is larger than 3, the desired support is achieved and updating can be stopped. Otherwise, the researchers can add 26 cases per group and recompute and re-evaluate the Bayes factors. Once the threshold of 3 has been achieved, this process can be stopped, otherwise it can be repeated, also beyond a sample size of 26 cases per group. The SSD executed before these researchers started collecting data is useful because it gives an indication of the sample size that are required to evaluated H0 and H1. Updating ensures that the researchers use their resources optimally.
Example 2
Researchers want to carry out a test to explore whether there is a difference between the yield obtained with a new corn fertilizer and with a current fertilizer. They expect the new fertilizer is more effective than the current one. The researchers want to determine the number of field plots used in a study of the test to detect an effect size d = 0.2 with a one-sided t test. When either H0 or H2 with d = 0.2 is true they want to have a probability of 0.90 that the resulting Bayes factor is larger than 1. The researchers used BFthresh = 1 and η = 0.90 because they want to get a Bayes factor to point to the true hypothesis with a high probability. They are not necessarily interested in strong evidence for the true hypothesis. The sample size required is obtained using the following call to SSDttest:
SSDttest(type='equal',Population_mean=c (0.2,0),var=c(1,1),BFthresh=1,eta=0.90, Hypothesis ='one-sided',T=10000)
The results are as follows:
Using N=676 and b P(BF02>1|H0)=0.99 P(BF20>1|H2)=0.90
The following can be learned from the output:
The researchers need to collect 676 field plots per fertilizer to get a probability of 0.99 that the resulting Bayes factor is larger than 1 if H0 is true, and a probability of 0.90.16 that the resulting Bayes factor is larger than 1 if H2 is true.
Example 3
Researchers wish to compare two weight loss regimens to determine whether there is a difference in the mean weight loss. Past experiments have shown that the standard deviations are different for these two regimens. Researchers want to determine the sample size required to detect the effect size d = 0.5 with a two-sided Welch’s test. When either H0 or H1 is true they want to have a probability of 0.80 that the resulting Bayes factor is larger than 3. They also want to execute a sensitivity analysis and therefore look at the sample sizes required for b, 2b, and 3b. The required sample size is obtained using the following call to SSDttest:
SSDttest(type='unequal',Population_mean=c (0.5,0),var=c(1.33,0.67),BFthresh=3,eta= 0.80, Hypothesis='two-sided',T=10000)
The results are as follows:
Using N=104 and b P(BF01>3|H0)=0.92 P(BF10>3|H1)=0.80 Using N=96 and 2b P(BF01>3|H0)=0.87 P(BF10>3|H1)=0.80 Using N=91 and 3b P(BF01>3|H0)=0.83 P(BF10>3|H1)=0.80
From the results the following can be learned:
The output from SSDttest can be used to perform a sensitivity analysis. As can be seen the required sample sizes for b, 2b and 3b are 104, 96, and 91 per group, respectively. This implies that if the researchers plan to execute a sensitivity analysis they should aim for a sample size of at least 104 per group. The probabilities of supporting H0 and H1 when they are true become more similar with bigger fractions of information. If this is a desirable feature for the researchers, they can use 3b which renders a required sample size of N = 91 per group and η is about equal to 0.80 both when H0 and H1 are true.
Conclusions
The function SSDttest implemented in the R package SSDbain (https://github.com/Qianrao-Fu/SSDbain) has been developed for sample-size determination for two-sided and one-sided hypotheses under a Bayesian t test or Bayesian Welch’s test using the AAFBF as implemented in the R package bain. This function was used to construct sample size tables that are counterparts to the frequently used tables in Cohen (1992). If the tables are not applicable to the situation considered by researchers, the SSDbain package can be used.
With the growing popularity of Bayesian statistics (Van de Schoot et al., 2017), it is important tools for sample-size determination in the Bayesian framework become available. In this manuscript, we developed software to calculate sample sizes within the framework of Bayesian t test and Bayesian Welch’s test hypotheses using time-efficient algorithms. However, the SSDbain package also has its limitation: we focused on the AAFBF, but as was shortly highlighted in the introduction to this paper, there are other Bayes factors researchers may use. Furthermore, we focused on the Bayesian t test and Welch’s test, but in our future research we will extend to other statistical models, such as Bayesian ANOVA, ANCOVA, linear regression, and normal linear multivariate models.
Notes
Note that, H1 is equivalent to the unconstrained hypothesis Hu : μ1, μ2, in the sense that the Bayes factor for a constrained hypothesis versus H1 is the same as versus Hu
References
Anderson, S. F., Kelley, K., & Maxwell, S. E. (2017). Sample-size planning for more accurate statistical power: a method adjusting sample effect sizes for publication bias and uncertainty. Psychological Science, 28 (11), 1547–1562. https://doi.org/10.1177/0956797617723724.
Berger, J. O., & Pericchi, L. R. (1996). The intrinsic Bayes factor for model selection and prediction. Journal of the American Statistical Association, 91(433), 109–122. https://doi.org/10.1080/01621459.1996.10476668.
Berger, J. O., & Pericchi, L. R. (2004). Training samples in objective Bayesian model selection. The Annals of Statistics, 32(3), 841–869. https://doi.org/10.1214/009053604000000229.
Button, K. S., Ioannidis, J. P., Mokrysz, C., Nosek, B. A., Flint, J., Robinson, E. S., & Munafò, M. R. (2013). Power failure: Why small sample size undermines the reliability of neuroscience. Nature Reviews Neuroscience, 14(5), 365. https://doi.org/10.1038/nrn3502.
Cohen, J. (1988) Statistical power analysis for the behavioral sciences, (2nd edn.) Hillsdale: Erlbaum.
Cohen, J. (1992). A power primer. Psychological Bulletin, 112(1), 155–159. https://doi.org/10.1037/0033-2909.112.1.155.
Cohen, J. (1994). The earth is round (p<. 05). American Psychologist, 49(12), 997–1003. https://doi.org/10.1037/0003-066X.49.12.997.
De Santis, F. (2004). Statistical evidence and sample size determination for Bayesian hypothesis testing. Journal of Statistical Planning and Inference, 124(1), 121–144. https://doi.org/10.1016/S0378-3758(03)00198-8.
De Santis, F. (2007). Alternative Bayes factors: Sample size determination and discriminatory power assessment. Test, 16(3), 504–522. https://doi.org/10.1007/s11749-006-0017-7.
Delacre, M., Lakens, D., & Leys, C. (2017). Why psychologists should by default use Welch’s t test instead of Student’s t test. International Review of Social Psychology, 30(1), 92–101. https://doi.org/10.5334/irsp.82.
Dickey, J. M. (1971). The weighted likelihood ratio, linear hypotheses on normal location parameters. The Annals of Mathematical Statistics, 42(1), 204–223. https://doi.org/10.1214/aoms/1177693507.
Erdfelder, E., Faul, F., & Buchner, A. (1996). Gpower: A general power analysis program. Behavior Research Methods. Instruments, & Computers, 28(1), 1–11. https://doi.org/10.3758/BF03203630.
Faul, F., Erdfelder, E., Lang, A. -G., & Buchner, A. (2007). G* power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146.
Gigerenzer, G. (1993). The superego, the ego, and the id in statistical reasoning. A handbook for data analysis in the behavioral sciences: Methodological issues, 311–339. https://doi.org/10.1093/acprof:oso/9780195153729.003.0013.
Gigerenzer, G. (2004). Mindless statistics. The Journal of Socio-Economics, 33(5), 587–606. https://doi.org/10.1016/j.socec.2004.09.033.
Gu, X., Mulder, J., & Hoijtink, H. (2018). Approximated adjusted fractional Bayes factors: a general method for testing informative hypotheses. British Journal of Mathematical and Statistical Psychology, 71(2), 229–261. https://doi.org/10.1111/bmsp.12110.
Hoijtink, H., Gu, X., & Mulder, J. (2019). Bayesian evaluation of informative hypotheses for multiple populations. British Journal of Mathematical and Statistical Psychology, 72(2), 219–243. https://doi.org/10.1111/bmsp.12145.
Hubbard, R., & Lindsay, R. M. (2008). Why p values are not a useful measure of evidence in statistical significance testing. Theory & Psychology, 18(1), 69–88. https://doi.org/10.1177/0959354307086923.
Jeffreys, H. (1961) Theory of probability, (3rd edn.) Oxford: Oxford University Press.
Kass, R. E., & Raftery, A. E. (1995). Bayes factors. Journal of the American Statistical Association, 90(430), 773–795. https://doi.org/10.1080/01621459.1995.10476572.
Klugkist, I., Laudy, O., & Hoijtink, H. (2005). Inequality constrained analysis of variance: A Bayesian approach. Psychological Methods, 10(4), 477. https://doi.org/10.1037/1082-989X.10.4.477.
Kruschke, J. K. (2013). Bayesian estimation supersedes the t test. Journal of Experimental Psychology: General, 142(2), 573. https://doi.org/10.1037/a0029146.
Kruschke, J. K., & Liddell, T. M. (2018). The Bayesian new statistics: Hypothesis testing, estimation, meta-analysis, and power analysis from a Bayesian perspective. Psychonomic Bulletin & Review, 25(1), 178–206. https://doi.org/10.3758/s13423-016-1221-4.
Maxwell, S. E. (2004). The persistence of underpowered studies in psychological research: Causes, consequences, and remedies. Psychological Methods, 9(2), 147–163. https://doi.org/10.1037/1082-989X.9.2.147.
Mayr, S., Erdfelder, E., Buchner, A., & Faul, F. (2007). A short tutorial of gpower. Tutorials in Quantitative Methods for Psychology, 3(2), 51–59. https://doi.org/10.20982/tqmp.03.2.p051.
Mulder, J. (2014). Prior adjusted default Bayes factors for testing (in) equality constrained hypotheses. Computational Statistics & Data Analysis, 71, 448–463. https://doi.org/10.1016/j.csda.2013.07.017.
Mulder, J., Hoijtink, H., De Leeuw, C., & et al. (2012). Biems: a Fortran 90 program for calculating Bayes factors for inequality and equality constrained models. Journal of Statistical Software, 46(2), 1–39. https://doi.org/10.18637/jss.v046.i02.
Nickerson, R. S. (2000). Null hypothesis significance testing: a review of an old and continuing controversy. Psychological Methods, 5(2), 241–301. https://doi.org/10.1037/1082-989X.5.2.241.
O’Hagan, A. (1995). Fractional Bayes factors for model comparison. Journal of the Royal Statistical Society:, Series B (Methodological), 57(1), 99–138. https://doi.org/10.2307/2346088.
Perugini, M., Gallucci, M., & Costantini, G. (2014). Safeguard power as a protection against imprecise power estimates. Perspectives on Psychological Science, 9(3), 319–332. https://doi.org/10.1177/1745691614528519.
Rosopa, P. J., Schaffer, M. M., & Schroeder, A. N. (2013). Managing heteroscedasticity in general linear models. Psychological Methods, 18(3), 335–351. https://doi.org/10.1037/a0032553.
Rouder, J. N. (2014). Optional stopping: No problem for Bayesians. Psychonomic Bulletin & Review, 21(2), 301–308. https://doi.org/10.3758/s13423-014-0595-4.
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16(2), 225–237. https://doi.org/10.3758/PBR.16.2.225.
Ruscio, J., & Roche, B. (2012). Variance heterogeneity in published psychological research. Methodology, 8(1), 1–11. https://doi.org/10.1027/1614-2241/a000034.
Ruxton, G. D. (2006). The unequal variance t test is an underused alternative to Student’s t test and the Mann–Whitney U test. Behavioral Ecology, 17(4), 688–690. https://doi.org/10.1093/beheco/ark016.
Sakaluk, J. K. (2016). Exploring small, confirming big: An alternative system to the new statistics for advancing cumulative and replicable psychological research. Journal of Experimental Social Psychology, 66, 47–54. https://doi.org/10.1016/j.jesp.2017.09.004.
Schönbrodt, F. D., & Wagenmakers, E.-J. (2018). Bayes factor design analysis: Planning for compelling evidence. Psychonomic Bulletin & Review, 25(1), 128–142. https://doi.org/10.3758/s13423-017-1230-y.
Schönbrodt, F. D., Wagenmakers, E.-J., Zehetleitner, M., & Perugini, M. (2017). Sequential hypothesis testing with Bayes factors: Efficiently testing mean differences. Psychological Methods, 22(2), 322–339. https://doi.org/10.1037/met0000061.
Sellke, T., Bayarri, M., & Berger, J. O. (2001). Calibration of ρ values for testing precise null hypotheses. The American Statistician, 55(1), 62–71.
Simonsohn, U., Nelson, L. D., & Simmons, J. P. (2014). P-curve and effect size: Correcting for publication bias using only significant results. Perspectives on Psychological Science, 9(6), 666–681. https://doi.org/10.1177/1745691614553988.
Stefan, A. M., Gronau, Q. F., Schönbrodt, F.D., & Wagenmakers, E.-J. (2019). A tutorial on Bayes factor design analysis using an informed prior. Behavior Research Methods, 2, 1–17. https://doi.org/10.3758/s13428-018-01189-8.
Van de Schoot, R., Winter, S. D., Ryan, O., Zondervan-Zwijnenburg, M., & Depaoli, S. (2017). A systematic review of Bayesian articles in psychology: The last 25 years. Psychological Methods, 22(2), 217–239. https://doi.org/10.1037/met0000100.
Vandekerckhove, J., Rouder, J. N., & Kruschke, J. K. (2018). Editorial: Bayesian methods for advancing psychological science. Psychonomic Bulletin & Review, 25(1), 1–4. https://doi.org/10.3758/s13423-018-1443-8.
Wagenmakers, E. -J. (2007). A practical solution to the pervasive problems of p values. Psychonomic Bulletin & Review, 14(5), 779–804. https://doi.org/10.3758/BF03194105.
Wagenmakers, E. -J., Morey, R. D., & Lee, M. D. (2016). Bayesian benefits for the pragmatic researcher. Current Directions in Psychological Science, 25(3), 169–176. https://doi.org/10.1177/0963721416643289.
Weiss, R. (1997). Bayesian sample size calculations for hypothesis testing. Journal of the Royal Statistical Society: Series D (The Statistician), 46(2), 185–191. https://doi.org/10.1111/1467-9884.00075.
Wetzels, R., Grasman, R. P., & Wagenmakers, E. -J. (2010). An encompassing prior generalization of the Savage–Dickey density ratio. Computational Statistics & Data Analysis, 54(9), 2094–2102. https://doi.org/10.1016/j.csda.2010.03.016.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The first author is supported by the China Scholarship Council. The second author is supported by a fellowship from the Netherlands Institute for Advanced Study in the Humanities and Social Sciences (NIAS-KNAW) and the Consortium on Individual Development (CID) which is funded through the Gravitation program of the Dutch Ministry of Education, Culture, and Science and the Netherlands Organization for Scientific Research (NWO grant number 024.001.003).
Appendix: : Algorithm 2
Appendix: : Algorithm 2
We have described the basic Algorithm 1 used to determine the sample size. In this appendix, a refinement of Algorithm 1 is described that reduces the number of iterations of Algorithm 1 to maximally 12. It is very time consuming to iterate Steps 5-7 many times in Algorithm 1, especially if the alternative hypothesis is one-sided. The number of iterations will be reduced if Step 7 from Algorithm 1 is replaced by Algorithm 2. The basic principle of Algorithm 2 is to gradually adjust the sample size using a dichotomy algorithm until P(BF0i > BFthresh|H0) and P(BFi0 > BFthresh|Hi) (i = 1, 2) hold for sample sizes ranging between \(N_{\min \limits }=10\) and \(N_{\max \limits }=1000\). If it turns out that \(N_{\max \limits }\) is too small, its value will be increased. Using Algorithm 2 the number of iterations will be at most 12 (\(O(\log _{2} (1000-10))+2= 12\)) see https://en.wikipedia.org/wiki/Binary_search_algorithm for a detail.
-
(1)
If both P(BF0i > BFthresh|H0) and P(BFi0 > BFthresh|Hi) (i = 1, 2) are larger than η, set \(N_{\max \limits }=N_{\text {mid}}\); otherwise, set \(N_{\min \limits }=N_{\text {mid}}\), where \(N_{\text {mid}}=(N_{\min \limits }+N_{\max \limits })/2\); and continue with (2).
-
(2)
If \(N_{\text {mid}}=N_{\min \limits }+1\), then N = Nmid, and the algorithm stops and output is provided; otherwise return to Step 5 from Algorithm 1 with N equal to Nmid.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Fu, Q., Hoijtink, H. & Moerbeek, M. Sample-size determination for the Bayesian t test and Welch’s test using the approximate adjusted fractional Bayes factor. Behav Res 53, 139–152 (2021). https://doi.org/10.3758/s13428-020-01408-1
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-020-01408-1