
Abstract
Studies have shown that logographemes and radicals, subcharacter units in Chinese characters, are represented in the orthographic lexicon and are functional processing units in the writing of Chinese characters. Nevertheless, there is no consensus regarding how characters should be segmented into logographemes and radicals. This article reports handwriting data for a list of 209 Chinese characters (95 nonphonetic compounds and 114 phonetic compounds) in a copying task. To validate the constituent logographemes and radicals of the target Chinese characters, comparisons among between-radical interstroke intervals (ISIs), between-logographeme ISIs, and within-logographeme ISIs, as well as their interactions with orthographic factors including character frequency, stroke number, and configuration, were conducted using factorial analyses. The results showed that the ISI comparison method is effective in validating the constituent logographemes and radicals in Chinese characters. On the basis of this list of 209 stimuli, another 1,227 Chinese characters that share the same set of radicals with the stimuli were further identified. Their constituent logographemes were deduced accordingly. Altogether, the over 1,000 Chinese characters with validated constituent logographemes will serve as a powerful reference for future psycholinguistic and neurolinguistic research. Future potential applications are discussed.
Similar content being viewed by others


Background
It has long been the goal among psycholinguistic researchers to understand how people write words. By investigating the word writing process, the storage and processes of the orthographic, phonological and semantic information of words in the lexicon can be deciphered. Studies in alphabetic orthographies documented the use of sublexical units such as digraphs (Tainturier & Rapp, 2004), syllables (Caramazza & Miceli, 1990), and morphemes (Schiller, Greenhall, Shelton, & Caramazza, 2001) as functional writing units. Similarly, psycholinguistic studies in nonalphabetic orthographies, such as Chinese, also documented the use of sublexical units as functional writing units, with some cross-linguistic differences (e.g., Law & Leung, 2000).
In the last two decades, sizeable number of experiments were conducted to explore the processing in writing Chinese. By observing the writing errors produced by brain-damaged patients, these studies have advanced our understandings of the lexical processing in writing Chinese, including the hypothesis of structural representations of Chinese graphemes that include characters, radicals and logographemes (Han, Zhang, Shu, & Bi, 2007; Law & Leung, 2000; Law, Yeung, Wong, & Chiu, 2005). However, there is currently no consensus regarding the definition of the constituent radicals and logographemes in Chinese characters among published studies (e.g., Lui, 2012; Xing, 2005). The aim of the present study was to explore the possibility of using handwriting experiments to validate the radical and logographeme boundaries in Chinese characters.
The Chinese writing system is morphosyllabic, where each Chinese character usually corresponds to one syllable and one morpheme (Hoosain, 1992). Basically, each Chinese character is a compilation of strokes organized in a square construction. For example, the character 下 corresponds to the syllable [haa6]Footnote 1 and the morpheme <down> and is constructed by putting the three strokes 一, 丨, and 丶 in a specific pattern. A major group of characters exists in Chinese called phonetic compounds, which are composed by combining semantic radicals that give clues to meanings and phonetic radicals that give clues to sound. For example, the character 枝 [zi1] <twig> contains the semantic radical 木 <wood>, which gives a clue to the character’s meaning, and the phonetic radical 支 [zi1] <support>, which gives a clues to the pronunciation of the character. The role of radicals in character recognition has been reported in plenty of studies (e.g., Feldman & Siok, 1999; Lau, Leung, Liang, & Lo, 2015; Law & Wong, 2005; Zhou & Marslen-Wilson, 1999). In general, higher accuracy and shorter latencies were observed in the processing of regular characters—those that share the same syllables with their phonetic radicals—than of irregular characters.
Radicals also play significant role in Chinese character writing. For example, Law et al. (2005) tested a Chinese dysgraphic patient using tasks of writing-to-dictation and written-naming. They reported that the patient produced errors that involve substitutions, additions and deletions of strokes, phonetic radicals or semantic radicals. They suggested that the results indicate that apart from strokes, phonetic and semantic radicals are involved as functional processing units in the writing process. However, in another study, Law and Leung (2000) reported a Chinese dysgraphic patient produced writing errors that involve substitutions of subradical units called logographemes (stroke patterns in radicals that are spatially separated—e.g., 十 and 又 in the radical 支). In another study, by Han et al. (2007), another stroke patient produced similar errors of logographeme substitutions, deletions, and transpositions. These authors, therefore, concluded that besides radicals and strokes, logographemes are also functional processing units in writing Chinese characters. Since all dysgraphic patients were observed to produce writing errors with all units (strokes, logographemes and radicals), it is in general agreed that orthographic units with different sizes are organized in the orthographic representations at the same level in the mental lexicon (Law et al., 2005) and are all involved in the writing process.
Nevertheless, replicating the results above among normal individuals’ writing is difficult, if not impossible. Current research of Chinese writing relies heavily on observations of errors produced by individuals to infer the functional writing units used by them. Because normal people seldom make errors in their writing, it is not possible to infer the functional writing units that they use. In addition, because normal people seldom make errors in frequently occurring stimuli, it is not possible to identify the functional writing units by asking them to write frequently occurring stimuli. Instead, less frequently occurring stimuli have to be used. However, the use of less frequently occurring stimuli not only limits the generalizability of the results, but might also yield unwanted results, since substitutions of homophonous characters might occur. This makes analysis of the written outcome of the target characters impossible. Finally, even if errors are successfully observed from some participants, it is still unclear whether they came from the normal processing of writing or they only reflected the use of compensatory strategy in fulfilling the writing task requirements.
Using an experimental design, Chen and Cherng (2013) attempted to detect the use of logographemes and radicals in Chinese character writing among normal individuals. They arranged characters with shared first strokes, shared first logographemes, or shared first radicals into three “homogeneous” groups, and characters without shared components into another three “heterogeneous” groups. They observed that in the written version of the form preparation task, using either the homogeneous or the heterogeneous group of stimuli, their participants showed shorter response times when writing characters in the shared-logographeme and shared-radical homogeneous groups than in their corresponding heterogeneous groups. In contrast, comparable response times were observed in the shared-stroke homogeneous group and its corresponding heterogeneous group. Clearly, the results by Chen and Cherng supported the notion that logographemes and radicals, instead of strokes, are the functional writing units in Chinese character writing. Nevertheless, Chen and Cherng also highlighted the issue of operational ambiguity regarding the current definition of logographemes.
Xing (2005) and Xing and Shu (2008) documented a list of “basic components” of Chinese characters. Although the representativeness of the list of over 500 components is supported by the fact that they were identified in primary school Chinese textbooks, the overlapping components within the list were concerned. For example, the items  , ⎅, and 象 are all included in the list as “basic” components of Chinese characters. It is obvious that the former three are subcomponents of the last component, 象. If the component 象 is considered the “basic” component, it seems unreasonable that it can be further broken down into other “basic” components. Such overlapping in the contents is one of the major sources of the operational ambiguity of the definition of logographemes.
, ⎅, and 象 are all included in the list as “basic” components of Chinese characters. It is obvious that the former three are subcomponents of the last component, 象. If the component 象 is considered the “basic” component, it seems unreasonable that it can be further broken down into other “basic” components. Such overlapping in the contents is one of the major sources of the operational ambiguity of the definition of logographemes.
Lui, Leung, Law, and Fung (2010) offered another list of 249 logographemes, also extracted from Chinese characters in primary school Chinese textbooks. The logographemes were identified according to the three major criteria of “(1) spatial separation of components, . . . (2) replaceability of components, . . . and (3) frequency of co-occurrence of components among characters” (p. 10). This list has an advantage over the list given by Xing (2005) and Xing and Shu (2008), that overlapping components were greatly reduced. For example, the item 象 was not in their list, but was broken down into  ,
,  ⎅, and
⎅, and  . One potential problem associated with their list, however, is that the logographemes identified were not validated using empirical writing data. That is, it is unclear whether people actually break down the item 象 into
. One potential problem associated with their list, however, is that the logographemes identified were not validated using empirical writing data. That is, it is unclear whether people actually break down the item 象 into  , ⎅, and 象, as proposed in the list, when they write the item 象. One possible solution would be to obtain writing data to validate the contents in the list.
, ⎅, and 象, as proposed in the list, when they write the item 象. One possible solution would be to obtain writing data to validate the contents in the list.
By obtaining handwriting data from large groups of participants, studies have successfully detected people’s use of orthographic units of various grain sizes in writing (e.g., Kandel, Álvarez, & Vallée, 2006; Kandel, Hérault, Grosjacques, Lambert, & Fayol, 2009). For example, by measuring the interletter intervals (ILIs) in a multimorphemic word-copying task, Kandel et al. (2006) observed that within-morpheme ILIs were shorter than between-morpheme ILIs. They suggested that the results indicated the participants’ use of morphemes as processing units in writing. In another handwriting study using a multisyllabic word-copying task, Kandel et al. (2009) observed that the peak letter stroke durations in participants’ handwriting were located at the syllable boundaries. Similarly, the results were suggested to indicate participants’ use of syllables as the processing units in writing.
Handwriting studies have also been applied in the search for functional processing units in writing Chinese (Chu & Lau, 2017; Lau, Ha, & Law, 2016). Lau et al. (2016) created pseudo-characters by combining semantic and phonetic radicals in their legal positions and instructed school-aged participants to copy the pseudo-characters using a wireless pen in the form of a capacitive stylus on the screen of a tablet. The tablet recorded the durations and positions (coordinates) each time the capacitive stylus touched and left the screen. The interstroke intervals (ISIs) and interstroke distances (ISDs) were calculated accordingly. For example, Fig. 1 illustrates the strokes labeled A to L of the character 結. A0 indicates the starting position of the stroke A, and A1 indicates its ending position; B0 indicates the starting position of the stroke B, and B1 indicates its ending position; and so on. In their study, Lau et al. (2016) compared the ISIs between radicals—for example, between F1 and G0, in the given figure—the ISIs between logographemes—for example, between C1 and D0 or between I1 and J0—and the ISIs within logographemes—for example, between A1 and B0 or between K1 and L0. They reported that ISIs between radicals were significantly longer than the ISIs between logographemes, which were significantly longer than the ISIs within logographemes, after controlling for ISD. They suggested that the longer between-unit ISIs were due to the longer processing time for planning and/or retrieval of the subsequent writing unit(s). In a similar developmental study by Chu and Lau (2017), an identical copying task was used, but pseudo-characters were created by combining either high- or low-frequency radicals according to graphotactic rules. Chu and Lau reported that after controlling for ISD, between-radical ISIs were longer than within-radical ISIs in both the high- and low-frequency conditions. In addition, they also reported that between-radical ISIs in the high-frequency condition were longer than between-radical ISIs in the low-frequency condition, whereas within-radical ISIs were not affected by radical frequency. The significant interaction between radical frequency and ISI location further supported that the longer between-unit ISIs were driven by processing of the orthographic units instead of merely by visual–motor processes. Altogether, the results of these studies confirmed that handwriting studies, originally believed to be reflective only of peripheral processing of writing (Ellis & Young, 1996), are capable of capturing the central processing of writing as well.

Examples of (i) an interstroke interval (ISI) at a logographeme boundary, (ii) an ISI at a radical boundary, and (iii) an ISI within a logographeme.
Therefore, the aim of the present study was to examine the possibility of validating the constituent radicals and logographemes in Chinese characters using handwriting data. The resulting database should be an invaluable tool for future psycholinguistic and neurolinguistic studies.
Method
Stimuli
A total of 211 traditional Chinese characters were chosen. These consisted of 95 nonphonetic compounds (non-PCs) and 116 phonetic compounds (PCs) selected from the Hong Kong Corpus of Chinese Newspapers (HKCCN; Leung & Lau, 2010). The details of the non-PCs and PCs are given in Appendices A and B, respectively. In all, 6,866 different traditional Chinese characters are represented in the HKCCN, which consists of 123,677 news articles published by the eight most popular newspaper publishers in Hong Kong. The 211 target characters were selected because they contain only unambiguous logographeme and radical boundaries—that is, all the logographemes and radicals are nonsuperimposedFootnote 2 in these characters. The following lexical and sublexical variables of the selected characters were also derived from the HKCCN.
Character frequency
The effect of character frequency on Chinese lexical processing has been widely reported. High-frequency characters have usually yielded quicker responses in experimental tasks such as naming (e.g., Lee, Tsai, Su, Tzeng, & Hung, 2005), lexical decision (e.g., Sze, Liow, & Yap, 2014), and writing-to-dictation (e.g., Delattre, Bonin, & Barry, 2006). In the present study, character frequencies were compiled from the HKCCN. There are approximately 7.6 million characters in the HKCCN. The character frequency value of each of the target items refers to the count of appearances of the character per million.
PC versus nonPC
A considerable number of studies have demonstrated the roles of semantic radicals (e.g., Feldman & Siok, 1999) and phonetic radicals (e.g., Zhou & Marslen-Wilson, 2000) in the processing of PCs. In the present study, the characters are categorized as either PCs or non-PCs according to the HKCCN. The HKCCN categorizes characters into PCs or non-PCs on the basis of the Shuowen Jiezi Zhu (Xu, 1963) dictionary, which documents the origins of individual characters.
Configuration
Semantic and phonetic radicals in Chinese characters are usually combined in different spatial arrangements, or configurations. According to Fu (1993), up to ten different configurations have been identified, including horizontal (e.g., 清), vertical (e.g., 完), and semi-enclosed (e.g., 速) configurations. Previous studies have suggested that character configuration plays a significant role in Chinese character recognition (e.g., Yeh & Li, 2002). In this present study, PCs having semantic and phonetic radicals arranged in either horizontal or vertical configurations were selected. Altogether, there were 65 horizontally configured PCs and 43 vertically configured PCs in the target list.
Radical and logographeme boundaries
The radical and logographeme boundaries of the selected PCs in the present study were defined according to the HKCCN. As was stated above, the semantic and phonetic radicals of PCs are coded in the HKCCN according to Xu (1963); therefore, the present radical boundaries were defined accordingly. In the HKCCN, logographemes of characters are coded according to Lui et al. (2010). According to Lui (2012), there is some ambiguity in the process of logographeme identification, particularly when one identified logographeme is superimposed on another logographeme. All the characters selected for the present study do not contain superimposed logographemes, to ensure that they have unambiguous radical and logographeme boundaries.
Stroke numbers
The role of number of strokes in Chinese character recognition is controversial. For example, Leong, Cheng, and Mulcahy (1987) reported that both skilled and less skilled Chinese readers responded more quickly to characters with fewer strokes than to characters with many strokes in speeded naming and lexical decision tasks. On the other hand, in the megastudy by Liu, Shu, and Li (2007), the effect of number of strokes on character naming was not significant. Nevertheless, the factor of number of strokes was included in the present study, to explore its role on Chinese character writing. The selected items were first ranked according to their number of strokes, in ascending order. Items in the upper and lower thirds of this list were identified as characters with many strokes and characters with few strokes, respectively. Among the targets, the numbers of strokes of characters with few strokes ranged from three to eight, and the numbers of strokes of characters with many strokes ranged from 10 to 18.
Table 1 summarizes the mean character frequencies and mean numbers of strokes of each factorial comparison conducted in this study.
Participants
A total of 20 right-handed undergraduate students (gender-balanced, mean age = 22.4 years, SD = 1.8) with normal or corrected-to-normal vision were recruited. All participants were native Cantonese speakers born and received mainstream education in Hong Kong. None of the participants reported to have history of cognitive, learning, or motor problems.
Procedure
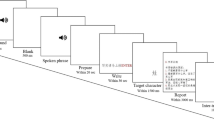
A direct copying task was used. Each participant was instructed to use one tablet and one stylus pen in the copying task. Two preexperimental training trials on using the stylus pen to write on the tablet were conducted, to ensure that the participants knew how to manage the pen and tablet. In each of the randomly ordered experimental trials a target character was displayed, and the participants were required to directly write down the presented character on the tablet screen using the stylus pen. The participants were instructed to write each stroke precisely by avoiding merging successive strokes. The elapsed time and coordinates each time the stylus pen touched or left the tablet screen were recorded accordingly. The duration of the whole experiment was about 15 min.
Measures
The ISI and the corresponding ISD, calculated on the basis of the coordinates where the stylus pen left and retouched the table screen were obtained. The ISIs (and the corresponding ISDs) were then categorized into different boundary types (between-radical, between-logographeme, and within-logographeme ISIs) according to the positions they occurred at in the writing process. Finally, the entire writing process and the final written output was also obtained.
Data analysis
Non-PCs
A 2 (boundary type) × 2 (stroke number) analysis of covariance (ANCOVA) and a 2 (boundary type) × (character frequency) ANCOVA were calculated, using the mean ISI of each item as the dependent variable and mean ISD of each item as the covariate.
PCs
A 3 (boundary type) × 2 (configuration) ANCOVA, a 3 (boundary type) × 2 (stroke number) ANCOVA, and a 3 (boundary type) × 2 (character frequency) ANCOVA were calculated, using the mean ISI of each item as the dependent variable and the mean ISD of each item as the covariate.
Because more within-logographeme data existed than between-logographeme and between-radical data, random sampling was conducted on the within-logographeme data to ensure equal group sizes before conducting the ANCOVA tests. Post-hoc analyses using Bonferroni tests were calculated when any of the main and/or interaction effects were significant.
Results
Two PC items, 菊 and 糜, were excluded from the analysis because over 10% of the participants used stroke sequences that crossed the logographeme boundaries; that is, they wrote 米 using the sequence 十 ➔  ➔
➔  , instead of the
, instead of the  ➔ 木 suggested by Lui et al. (2010). The different stroke sequences observed across participants probably suggest that the participants either (1) do not segment the 米 into logographemes or (2) do not consistently segment the logographemes in 米 in the same way. In the rest of the items, no more than 5% of the participants used stroke sequences that crossed the logographeme boundaries. The data from items with stroke sequences crossing the logographeme boundaries (a total of 0.7%) and ISIs beyond three standard deviations from the mean (a total of 0.9%) were excluded from the analysis.
➔ 木 suggested by Lui et al. (2010). The different stroke sequences observed across participants probably suggest that the participants either (1) do not segment the 米 into logographemes or (2) do not consistently segment the logographemes in 米 in the same way. In the rest of the items, no more than 5% of the participants used stroke sequences that crossed the logographeme boundaries. The data from items with stroke sequences crossing the logographeme boundaries (a total of 0.7%) and ISIs beyond three standard deviations from the mean (a total of 0.9%) were excluded from the analysis.
Non-PCs
Table 2 summarizes the within- and between-logographeme ISIs after controlling for the ISDs of characters with many strokes and characters with few strokes. The ANCOVA results revealed a significant main effect of boundary type [F(1, 133) = 35.51, MSE = .047, p < .0001]Footnote 3 and a significant main effect of stroke number [F(1, 133) = 7.692, MSE = .010, p = .006] after controlling for ISDs. Between-logographeme ISIs were longer than within-logographeme ISIs after controlled for ISDs. The interaction effect between boundary type and stroke number was also significant [F(1, 133) = 9.36, MSE = .012, p = .003]. The results of the post-hoc analysis showed that between-logographeme ISIs among characters with many strokes were significantly longer than the between-logographeme ISIs among characters with few strokes (p = .004). Within-logographeme ISIs were comparable between characters with many and characters with few strokes.
Table 3 summarizes the within- and between-logographeme ISIs after controlling for the ISDs of high- and low-frequency characters. The ANCOVA results revealed a significant main effect of boundary type [F(1, 189) = 57.09, MSE = .072, p < .0001] and a significant main effect of character frequency [F(1, 189) = 23.09, MSE = .029, p < .001] after controlling for ISDs. Between-logographeme ISIs were longer than within-logographeme ISIs, and the ISIs of high-frequency characters were longer than those of low-frequency characters after controlling for ISDs. The interaction effect between boundary type and character frequency was also significant [F(1, 189) = 13.69, MSE = .017, p < .001]. Results of the post-hoc analysis showed that the between-logographeme ISIs among low-frequency characters were significantly longer than those among high-frequency characters (p < .001). Within-logographeme ISIs were comparable between high- and low-frequency characters.
PCs
Configuration
Table 4 summarizes the within-logographeme, between-logographeme, and between-radical ISIs after controlling for the ISDs of horizontally and vertically configured characters. The ANCOVA results revealed a significant main effect of boundary type [F(2, 297) = 69.57, MSE = .069, p < .0001] after controlling for ISDs. Results of the post-hoc analysis showed that between-radical ISIs were longer than between-logographeme ISIs, which in turn were longer than within-logographeme ISIs after controlling for ISDs (p < .001). The main effect of configuration and the interaction between boundary type and configuration were not significant (ps > .1)
Many strokes versus few strokes
Table 5 summarizes the within-logographeme, between-logographeme, and between-radical ISIs after controlling for the ISDs of characters with many and with few strokes. The ANCOVA results revealed a significant main effect of boundary type [F(2, 248) = 78.33, MSE = .058, p < .0001] and a significant main effect of stroke number [F(1, 248) = 10.40, MSE = .007, p = .001] after controlling for ISDs. Results of the post-hoc analysis showed that between-radical ISIs were longer than between-logographeme ISIs, which in turn were longer than within-logographeme ISIs, after controlling for ISDs. In addition, the ISIs of characters with many strokes were longer than the ISIs of characters with few strokes after controlled for ISDs. The interaction effect between boundary type and stroke number was also significant [F(2, 248) = 5.11, MSE = .004, p = .003]. Results of the post-hoc analysis showed that the between-radical and between-logographeme ISIs among characters with many strokes were significantly longer than their counterparts among characters with few strokes (ps = .001 and .003, respectively). Within-logographeme ISIs were comparable between characters with many and characters with few strokes.
High frequency versus low frequency
Table 6 summarizes the within-logographeme, between-logographeme, and between-radical ISIs after controlling for the ISDs of high- and low-frequency characters. The ANCOVA results revealed a significant main effect of boundary type [F(2, 329) = 71.90, MSE = .125, p < .0001] and a significant main effect of character frequency [F(1, 329) = 32.37, MSE = .056, p < .0001] after controlling for ISDs. Results of the post-hoc analysis showed that between-radical ISIs were longer than between-logographeme ISIs, which in turn were longer than within-logographeme ISIs, after controlling for ISDs. In addition, the ISIs of low-frequency characters were longer than the ISIs of high-frequency characters after controlled for ISDs. The interaction effect between boundary type and character frequency was also significant [F(2, 321) = 12.56, MSE = .022, p < .001]. Results of the post-hoc analysis showed that between-radical and between-logographeme ISIs among low-frequency characters were significantly longer than their counterparts among high-frequency characters (ps < .001). Within-logographeme ISIs were comparable between high- and low-frequency characters.
Discussion
The aim of the present study was to verify the possibility of applying the method of comparisons of between-unit and within-unit ISIs to validate the constituent logographemes and radicals in Chinese characters. Participants were invited to copy non-PC and PC characters on an Android tablet, and the handwriting data were obtained accordingly. The results from the non-PC copying showed longer between-logographeme than within-logographeme ISIs after controlling for ISDs. Similarly, the results from the PC copying showed longer between-radical than between- and within-logographeme ISIs, as well as longer between-logographeme than within-logographeme ISIs after controlling for ISDs. The longer between-unit ISIs were attributed to the time required for retrieval and/or planning of the constituents and stroke sequences of the successive writing units (Chu & Lau, 2017; Kandel et al., 2006; Lau et al. 2016). Therefore, the results were consistent with previous reports that people use radicals and logographemes as functional processing units in writing Chinese characters (Han et al., 2007; Law & Leung, 2000; Law et al., 2005).
The nonsignificant main effect of configuration and interaction effect between configuration and boundary type observed in the PC copying indicated that after controlling for ISDs, potential confounding from the longer distance the stylus traveled due to the different configurations of components within the characters can be avoided. It is important to emphasize that the results of the present study do not reject the importance of character configurations in Chinese character writing. Instead, the configurations of Chinese characters in the writing process must be indispensable, or characters with similar components—for example, 易 and 昒—would be confused with each other. However, it is hypothesized that the configurations of characters should be retrieved before the implementation of handwriting processes. Using the examples given, the horizontal and vertical configurations predefine the position of the first stroke and the sizes of the logographemes to be written. Otherwise, the output would be distorted.
Ellis and Young (1996) suggested that the architecture of the writing process can be divided into central and peripheral processing. The central processes involve the orthographic long-term memory, conversion from phonology to orthography, and orthographic short-term memory. On the other hand, peripheral processing involves allograph selections, graphic motor pattern selections, and graphic motor pattern execution. As is illustrated in the above example, to avoid confusions among characters with similar components, the configurations of Chinese characters should be stored in orthographic long-term memory—hence, processed in the central processing of writing. The handwriting production observed in the present study, on the other hand, should more reflect peripheral processing, instead. This explains the nonsignificant main effect of configuration observed.
Another important finding of the present study is the significant effect of number of strokes in Chinese character handwriting. The results showed longer between-unit ISIs among characters with many strokes than among characters with few strokes, in both non-PC and PC copying. On the other hand, within-unit ISIs among characters with many strokes were comparable to within-unit ISIs among characters with few strokes, in both non-PC and PC copying. There are two possible explanations for this observation. First, it may be possible that writing units with more strokes requires a longer retrieval and/or planning time. However, to the author’s knowledge, there is a lack of previous reports to support this explanation. More work on the effect of stroke number in character writing will be needed to warrant this proposition. Alternatively, a more probable explanation is that the longer between-unit ISIs associated with writing units with more strokes are related to the role of the orthographic output buffer (Caramazza, Miceli, Villa, & Romani, 1987; Han et al., 2007) in the writing process. The orthographic output buffer temporarily stores orthographic units output from the orthographic lexicon, while the units are pending motor execution in handwriting (Caramazza et al., 1987). In a French study using words with different syllable length in a copying task, Lambert, Kandel, Fayol, and Espéret (2008) observed that writing latencies were modulated by the number of syllables in words. They suggested that the longer latencies associated with words with more syllables could be attributed to increased demand, due to more processing units temporarily being stored in the orthographic output buffer. Han et al. (2007) suggested that logographemes are the functional units temporarily stored in the orthographic output buffer in the case of Chinese character writing. In the present study, since characters with many strokes also contain more logographemes than characters with fewer strokes (p < .001 for both PCs and non-PCs), it is possible that the increased number of logographemes in characters with many strokes resulted in increased demands on the orthographic output buffer in the task. Hence, longer between-unit ISIs were observed. The comparable within-unit ISIs across different conditions indicated that, once retrieval and/or planning was completed, motor execution within the writing units would not be affected.
Nevertheless, the effect of stroke number on Chinese character processing is controversial. Although some studies reported its significance in Chinese character recognition and attributed it as an indicator of visual complexity (Leong et al., 1987), others reported no significant effect of stroke number on character recognition (e.g., Liu et al., 2007). Su and Samuels (2010) suggested that the discrepancies could be due to different frequency ranges of the stimuli used in different studies. Another possible confounding factor is the age-of-acquisition of the stimuli. As was indicated in the large-scale study by Liu et al., number of strokes of characters correlated significantly with age of acquisition. Characters with fewer strokes tend to be learnt earlier than characters with more strokes, in elementary classrooms in which intensive copying practice were emphasized (Liu et al., 2007). All of these confounding factors make verifying the effect of stroke number on Chinese character processing difficult. Nevertheless, the results obtained in the present study involving character encoding might also indicate that stroke number has a stronger effect on character encoding, as both central and peripheral processing are involved, than character decoding. Future large-scale studies that include more items and other psycholinguistic measures, such as age of acquisition ratings, will be needed to verify this proposal.
Finally, a significant effect of character frequency on Chinese character handwriting was observed in the present study. The results showed longer between-unit ISIs among low-frequency than among high-frequency characters, in both non-PC and PC copying. On the other hand, the within-unit ISIs among high- and low-frequency characters were comparable, again in both non-PC and PC copying. The longer pauses between writing units in the low-frequency than in the high-frequency condition suggest that the time required for retrieval and/or planning of the constituents and their stroke sequences of the low-frequency writing units is longer than that required for high-frequency writing units. Similar orthographic frequency effect on handwriting have been reported before (e.g., Chu & Lau, 2017; Lambert et al., 2008). This finding is also consistent with the notion of a cascaded relationship between the central processing and peripheral processing of writing (e.g., Roux, McKeeff, Grosjacques, Afonso, & Kandel, 2013).
Altogether, the interactions between boundary types and different orthographic factors, including character frequency and complexity, confirmed that the significant results in the ISI comparisons were driven by orthographic processing instead of mere visual motor processing.
The present study has made the first attempt to validate the constituent logographemes and radicals of the target Chinese characters by using handwriting measures. The significant difference between-unit ISIs and within-unit ISIs indicated that people showed a tendency to spend longer pauses between logographemes and between radicals in handwriting. The significant frequency and stroke number effects observed further supported that the longer pauses observed were driven not only by peripheral but also by central processing of Chinese character writing. However, a few methodological and theoretical issues still need to be addressed.
First of all, methodologically, a more stringent and ideal validation process would be to conduct the ISI comparison on each individual item instead of conducting a group analysis, as was done in the present study. However, there would then be a concern about statistical power if individual item analyses were to be conducted. Conducting 209 ANCOVA analyses would mean that, in order to avoid Type I errors, a lot more participants would have to be involved in copying each item, so as to fulfill even the minimal critical value required after the corrections for multiple comparisons. Even if this could be done, however, the chance of making Type II errors by accepting only the minimally critical values of 209 ANCOVA tests would also be increased. Therefore, conducting individual item analyses might not be feasible unless very big data sets are collected. It is suggested that future studies taking advantage of the recent trend toward crowdsourcing research (e.g., Huang, Wang, Yao, & Chan, 2016) should be considered, in order to achieve a more ideal validation of the set of constituent logographemes tested in the present study.
Next, theoretical concerns need to be addressed. In the present study, separate analyses were conducted on PCs and non-PCs. One of the reasons is that it is uncertain whether or not the processes of encoding PCs and non-PCs are identical. Another, yet more important, reason is that defining “radicals” in non-PCs can be difficult. In the present study, the term “radical” has been used specifically to represent only phonetic radicals, which give clues to the sounds of phonetic compound characters, and semantic radicals, which give clues to the meaning of phonetic compound characters. Hence, in the non-PC condition, no between-radical ISIs were identified because, according to definition, phonetic and semantic radicals only exist in PCs. Further studies will be needed to determine whether the processing of PCs and non-PCs are different and whether the processing of semantic and phonetic radicals is different from that of logographemes. If the processing of semantic and phonetic radicals is different from that of logographemes, it will be reasonable to assume that the processing of PCs and non-PCs should be different. Likewise, if the processing of radicals and logographemes is the same, the processing of PCs and non-PCs would be, as well.
Another theoretic issue concerns the definition of logographemes. In the present literature, an “operational ambiguity” (Chen & Cherng, 2013, p. 6) exists in definitions of the terms “bujian,” “stroke clusters,” and “logographemes.” One major confusion caused by the ambiguity is that some logographemes share the same orthographic forms with radicals (e.g., 亻, 扌), and some even share the same orthographic forms with simple characters (e.g., 又, 山). This usually leads to debates such as whether it is necessary to assume a hierarchical organization of characters, radicals, and logographemes in the mental representations, or whether the radical 亻 and the logographeme 亻are stored as separate mental representations. For example, the orthographic unit 目 [muk6] <eyes> in the character 矇 [mung4] <unclear> serves as its semantic radical, which contributes to the meaning of <visually related>. However, the orthographic unit 目 in the character 想 [soeng2] <think>, with the phonetic radical 相 [soeng1] <mutual> and the semantic radical 心 [sam1] <mind-related>, contributes to neither the meaning nor the sound. Whether or not the 目 in 矇 and the 目 in 想 are separate psychological entities in the lexicon remains unclear.
In fact, such ambiguity exists not only in the case of Chinese, but also in some other languages. For example, Henderson (1985) discussed the issue of lack of a clear definition of the word “grapheme” in English, despite its usage in many published studies. No doubt, the approach of defining graphemes as a set of letters that represent phonemes versus the other approach, based on defining graphemes as the minimal functional contrastive unit of a writing system, will result in two different sets of graphemes being defined. As Henderson suggested, using stimuli defined with the former approach might have the potential risk that graphemes and phonemes—and hence, orthographic and phonological effects—would not be easily dissociable in experimental studies. Finding a solution to these issues is not simple. A lot more studies in this field of lexical processing will be needed in order to allow a “better” definition of graphemes.
Potential research application
It is considered that the list of 209 Chinese characters with constituent logographemes validated in the present study using handwriting data could be an invaluable reference for various psycholinguistic and neurolinguistic research. First of all, the contents of this list can be generalized to other Chinese characters sharing the same constituents. For example, in the present study, the constituent logographemes 夂 and  of the target non-PC 冬 [dung1] <winter>, as well as the constituent logographemes幺,
of the target non-PC 冬 [dung1] <winter>, as well as the constituent logographemes幺,  , 刀, and 巴 of the target PC 絕 [zyut6] <absolute>, were validated. Therefore, it can be deduced that the constituent logographemes of the character 終 [zung1] <end>, which share the same semantic radical with the target PC 絕 and contain the non-PC 冬 as a phonetic radical, are 幺,
, 刀, and 巴 of the target PC 絕 [zyut6] <absolute>, were validated. Therefore, it can be deduced that the constituent logographemes of the character 終 [zung1] <end>, which share the same semantic radical with the target PC 絕 and contain the non-PC 冬 as a phonetic radical, are 幺,  , 夂, and
, 夂, and  . Following this construction, a total of 1,227 Chinese characters were identified from the HKCCN. These identified Chinese characters either shared with the PC stimuli the same set of constituent radicals or contained at least one of the present PCs or non-PCs as a radical. The constituent component logographemes of these 1,227 Chinese characters were deduced from the respective PCs and non-PCs in the target list of 209 Chinese characters used in the present study. Together with their corresponding frequencies of occurrence indicated in the HKCCN, the list of 1,227 characters is given in Appendix C. It is expected that the total of 1,436 Chinese characters with validated constituent logographemes in the appendices will become an invaluable resource for future psycholinguistic and neurolinguistic studies in Chinese.
. Following this construction, a total of 1,227 Chinese characters were identified from the HKCCN. These identified Chinese characters either shared with the PC stimuli the same set of constituent radicals or contained at least one of the present PCs or non-PCs as a radical. The constituent component logographemes of these 1,227 Chinese characters were deduced from the respective PCs and non-PCs in the target list of 209 Chinese characters used in the present study. Together with their corresponding frequencies of occurrence indicated in the HKCCN, the list of 1,227 characters is given in Appendix C. It is expected that the total of 1,436 Chinese characters with validated constituent logographemes in the appendices will become an invaluable resource for future psycholinguistic and neurolinguistic studies in Chinese.
For example, although studies have documented the significant role of logographemes in writing Chinese characters, their role in character recognition remains unclear. Chua (2014) reported the logographeme frequency effect on lexical decision of Chinese characters over a small group of participants and a small number of stimuli. Replications of her results, accomplished by selecting more items from the list of Chinese characters in the appendices, will be possible in the future. The results of these studies will help verify the theories proposed to explain lexical processing in Chinese (e.g., Perfetti, Liu, & Tan, 2005; Weekes, Yin, Su, & Chen, 2006).
Another potential direction of studies concerns orthographic development in children. Theories have proposed that over the course of human development, orthographic representations develop from small units to large units (e.g., Ziegler & Goswami, 2005). However, reports from previous studies in Chinese do not seem to support this theory (Lau et al., 2016). One potential reason is the current lack of a reference for the constituent logographemes of characters that has been validated using handwriting data. Using the contents in the appendices, orthographic development in Chinese can be investigated. Consequently, theories of orthographic development can be substantiated.
In short, the list of characters with valid constituent logographemes should allow researchers to investigate the different roles of logographemes in lexical processing in Chinese, which was formerly not possible due to the ambiguity of the definition of logographemes in Chinese characters.
Limitation
One limitation of the present set of constituent logographemes of more than 1,000 characters is that they were all identified from traditional Chinese characters; hence, their direct application to simplified Chinese characters is very difficult, if not impossible. Although orthographic units are shared between simplified and traditional Chinese (e.g., 亻, 刂), it may be suggested that a similar handwriting verification study based on those characters in the list that are shared by both traditional and simplified Chinese should be conducted. This will help to maximize the generalizability of the results of the current study.
Another limitation of the present set of characters with constituent logographemes is that they did not include those with superimposed logographemes proposed by Lui et al. (2010)—for example, 東, 回, and potentially 米. Future studies involving targets with the proposed superimposed logographemes will be needed. Although the present ISI comparisons may not be applicable, due to the difficulties of defining between-unit ISIs in these items, other handwriting measures might be useful in validating the proposed superimposed logographemes—for instance, writing speed within units, assuming that the writing speed of logographemes with identical orthographic forms (e.g., the 木 in 東 and the 木 in 栗) should be comparable.
Conclusion
In summary, the aim of the present study was to investigate whether it is possible to validate a database of characters with definitions of radicals and logographemes using handwriting data. This possibility was confirmed by the significantly longer between-radical than between-logographeme ISIs and significantly longer between-logographeme than within-logographeme ISIs that were observed after controlling for ISD across different conditions. Particularly, the significant effects of radical frequency and stroke number substantiated that the handwriting data obtained reflected not only peripheral but also central processing in Chinese character writing. Future work will be needed to extend the validated list of logographemes from the present study to other characters not in the list. Finally, the contents of the character list, with constituent logographemes and radicals, included with the article should also serve as a useful resource for future psycholinguistic and neurolinguistic studies.
Notes
This present study was conducted in Hong Kong, where traditional Chinese characters and Cantonese were used. In this article, phonetic transcriptions are represented in jyutping, a romanization system developed by the Linguistic Society of Hong Kong.
In the original list proposed by Lui et al. (2010), some of the characters were chunked on the basis of logographemes superimposed on each other—for example, 東 was chunked into 木 and 曰. These characters were not selected in the present study, because the between-unit ISIs can be very ambiguous in these stimuli. More will be discussed about this group of characters in the Discussion.
Altogether, five ANCOVA tests were conducted. Therefore, a more stringent critical value of 0.05/5 = 0.01 will be used as reference for detection of statistical test significance.
References
Caramazza, A., & Miceli, G. (1990). The structure of graphemic representations. Cognition, 37, 243–297. https://doi.org/10.1016/0010-0277(90)90047-N
Caramazza, A., Miceli, G., Villa, G., & Romani, C. (1987). The role of the graphemic buffer in spelling: Evidence from a case of acquired dysgraphia. Cognition, 26, 59–85.
Chen, J.-Y., & Cherng, R.-J. (2013). The proximate unit in Chinese handwritten character production. Frontiers in Psychology, 4, 517. https://doi.org/10.3389/fpsyg.2013.00517
Chu, S. K.-W., & Lau, D. K.-Y. (2017). Logographeme boundedness effect on the choice of writing units of different grain size—A developmental study. Frontiers in Human Neuroscience Conference Abstract: Academy of Aphasia 55th Annual Meeting. https://doi.org/10.3389/conf.fnhum.2017.223.00066
Chua, L.-L. (2014). Logographeme type and token frequency effects during Chinese character recognition: An event-related potential study (Unpublished bachelor’s thesis). University of Hong Kong, Pokfulam, Hong Kong SAR.
Delattre, M., Bonin, P., & Barry, C. (2006). Written spelling to dictation: Sound-to-spelling regularity affect writing latencies and durations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32, 1330–1340.
Ellis, A. W., & Young, A. W. (1996). Human cognitive neuropsychology: A textbook with readings, Hove, UK: Psychology Press.
Feldman, L. B., & Siok, W. W. (1999). Semantic radicals contribute to the visual identification of Chinese characters. Journal of Memory and Language, 40, 559–576.
Fu, Y.-H. (1993). The structure and construction of Chinese characters (in Chinese). In Y. Chen (Ed.), Computational analysis of modern Chinese characters (pp. 108–169). Shanghai, China: Shanghai Educational Press.
Han, Z., Zhang, Y., Shu, H., & Bi, Y. (2007). The orthographic buffer in writing Chinese characters: Evidence from a dysgraphic patient. Cognitive Neuropsychology, 24, 431–450.
Henderson, L. (1985). On the use of the term grapheme.” Language and Cognitive Processes, 1, 135–148.
Hoosain, R. (1992). Psychological reality of the word in Chinese. In H.-C. Chen & O. J. L. Tzeng (Eds.), Language processing in Chinese (pp. 111–130). Amsterdam, The Netherlands: North-Holland.
Huang, C-R., Wang S-C., Yao Y., & Chan, A. (2016). Crowdsourcing, word segmentation, and semantic transparency: A new empirical approach to Chinese linguistics. Paper presented at the 15th International Symposium on Chinese Languages and Linguistics (IsCLL-15), Taiwan, China.
Kandel, S., Álvarez, C. J., & Vallée, N. (2006). Syllables as processing units in handwriting production. Journal of Experimental Psychology: Human Perception and Performance, 32, 18–31. https://doi.org/10.1037/0096-1523.32.1.18
Kandel, S., Hérault, L., Grosjacques, G., Lambert, E., & Fayol, M. (2009). Orthographic vs. phonological syllables in handwriting production. Cognition, 110, 440–444.
Lambert, E., Kandel, S., Fayol, M., & Espéret, E. (2008). The effect of the number of syllables on handwriting production. Reading and Writing, 21, 859–883.
Lau, D. K.-Y., Ha, W. W. T., & Law, A. H. S. (2016). Functional processing units in writing Chinese—A developmental study. Frontiers in Psychology Conference Abstract: 54th Annual Academy of Aphasia Meeting. https://doi.org/10.3389/conf.fpsyg.2016.68.00008
Lau, D. K.-Y., Leung, M. T., Liang, Y., & Lo, C. M. J. (2015). Predicting the naming of regular-, irregular- and non-phonetic compounds in Chinese. Clinical Linguistics and Phonetics, 29, 776–792.
Law, S. P., & Leung, M. T. (2000). Structural representations of characters in Chinese writing: Evidence from a case of acquired dysgraphia. Psychologia, 43, 67–83.
Law, S. P., & Wong, R. (2005) A model-driven treatment of a Cantonese speaking dyslexic patient with impairment to the semantic and nonsemantic pathways. Cognitive Neuropsychology, 22, 95–110.
Law, S. P., Yeung, O., Wong, W., & Chiu, K. M. (2005). Processing of semantic radicals in writing Chinese characters: Data from a Chinese dysgraphic patient. Cognitive Neuropsychology, 22, 885–903.
Lee, C. Y., Tsai, J.-L., Su, E. C.-I., Tzeng, O. J. L., & Hung, D. L. (2005). Consistency, regularity, and frequency effects in naming Chinese characters. Language and Linguistics, 6, 75–107.
Leong, C. K., Cheng, P.-W., & Mulcahy, R. (1987). Automatic processing of morphemic orthography by mature readers. Language and Speech, 30, 181–196.
Leung, M. T., & Lau, D. K. Y. (2010). The Hong Kong Corpus of Chinese Newspapers (Unpublished database). The University of Hong Kong.
Liu, Y., Shu, H., & Li, P. (2007). Word naming and psycholinguistic norms: Chinese. Behavior Research Methods, 39, 192–198. https://doi.org/10.3758/BF03193147
Lui, H.-M. (2012). The processing units of writing Chinese characters: A developmental perspective. Unpublished M. Phil. thesis. The University of Hong Kong.
Lui, H.-M., Leung, M.-T., Law, S.-P., & Fung, R. S.-Y. (2010). A database for investigating the logographeme as a basic unit of writing Chinese. International Journal of Speech-Language Pathology, 12, 8–18.
Perfetti, C. A., Liu, Y., & Tan, L. H. (2005). The lexical constituency model: Some implications of research on Chinese for general theories of reading. Psychological Review, 112, 43–59. https://doi.org/10.1037/0033-295X.112.1.43
Roux, S., McKeeff, T. J., Grosjacques, G., Afonso, O., & Kandel, S. (2013). The interaction between central and peripheral processes in handwriting production. Cognition, 127, 235–241. https://doi.org/10.1016/j.cognition.2012.12.009
Schiller, N. O., Greenhall, J. A., Shelton, J. R., & Caramazza, A. (2001). Serial order effects in spelling errors: Evidence from two dysgraphic patients. Neurocase, 7,1–14.
Su, Y.-F., & Samuel, S. J. (2010). Developmental changes in character-complexity and word-length effects when reading Chinese script. Reading and Writing, 23, 1085–1108. https://doi.org/10.1007/s11145-009-9197-3
Sze, W. P., Rickard Liow, S. J., & Yap, M. J. (2014). The Chinese Lexicon Project: A repository of lexical decision behavioral responses for 2,500 Chinese characters. Behavior Research Methods, 46, 263–273. https://doi.org/10.3758/s13428-013-0355-9
Tainturier, M. J., & Rapp, B. C. (2004). Complex graphemes as functional spelling units: Evidence from acquire dysgraphia. Neurocase, 10, 121–131.
Weekes, B. S., Yin, W., Su, I. F., & Chen, M. J. (2006). The cognitive neuropsychology of reading and writing in Chinese. Language and Linguistics, 7, 595–617.
Xing, H. (2005). A statistic analysis of components of the character entries in the HSK Graded Character List. Chinese Teaching in the World, 72, 49–55.
Xing, H., & Shu, H. (2008). A statistical study on the basic components of Chinese characters in Chinese textbooks for primary schools. Applied Linguistics, 3, 72–80.
Xu, S. (1963). Shuowen jiezi zhu. Beijing, China: Chung Hwa Book Co.
Yeh, S.-L., & Li, J.-L. (2002). Role of structure and component in judgments of visual similarity of Chinese characters. Journal of Experimental Psychology: Human Perception and Performance, 28, 933–947.
Zhou, X., & Marslen-Wilson, W. (1999). The nature of sublexical processing in reading Chinese characters. Journal of Experimental Psychology: Learning, Memory, and Cognition, 25, 819–837. https://doi.org/10.1037/0278-7393.25.4.819
Zhou, X., & Marslen-Wilson, W. (2000). Lexical representations of compound words: Cross-linguistic evidence. Psychologia, 43, 47–66.
Ziegler, J. C., & Goswami, U. (2005). Reading acquisition, developmental dyslexia, and skilled reading across languages: A psycholinguistic grain size theory. Psychological Bulletin, 131, 3–29. https://doi.org/10.1037/0033-2909.131.1.3
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Lau, D.KY. Validation of constituent logographemes and radicals in Chinese characters using handwriting data. Behav Res 52, 305–316 (2020). https://doi.org/10.3758/s13428-019-01227-z
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13428-019-01227-z