
Abstract
The perception of threatening facial expressions is a critical skill necessary for detecting the emotional states of others and responding appropriately. The anger superiority effect hypothesis suggests that individuals are better at processing and identifying angry faces compared with other nonthreatening facial expressions. In adults, the anger superiority effect is present even after controlling for the bottom-up visual saliency, and when ecologically valid stimuli are used. However, it is as yet unclear whether this effect is present in children. To fill this gap, we tested the anger superiority effect in children ages 6–14 years in a visual search task by using emotional dynamic stimuli and equating the visual salience of target and distractors. The results suggest that in childhood, the angry superiority effect consists of improved accuracy in detecting angry faces, while in adolescence, the ability to discriminate angry faces undergoes further development, enabling faster and more accurate threat detection.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
A famous quote by Marcus Tullius Cicero states: “The face is a picture of the mind with the eyes as its interpreter.” The central message here is that facial expressions play a crucial role in guiding our expectations during social interactions. For instance, when we encounter someone with a happy facial expression, our expectation is typically that they are approachable, friendly, and receptive to social interaction. Conversely, when we encounter someone with an angry facial expression, our expectation is that they are unfriendly and potentially hostile.
From an evolutionary perspective, the ability to accurately detect and interpret facial expressions related to danger or threat holds significant adaptive value, because it allows us to respond appropriately to potential threats. In support of this idea, several studies have demonstrated that, in a visual search task, individuals are better able to detect an angry face among a group of different expressions than a happy face (Dixson et al., 2022; Gong & Smart, 2021; Calvo et al., 2006; Hansen & Hansen, 1988; Horstmann & Bauland, 2006; Li et al., 2022; Öhman et al., 2001; see also Rapuano et al., 2023). This effect, known as Anger Superiority Effect (ASE), highlights the unique ability of angry facial expressions to capture attention and elicit an accurate response.
The ASE has primarily been studied in adults. However, a growing body of research has turned its focus towards children, suggesting that attention biases towards threatening stimuli typically emerge early in development (e.g.,LoBue, 2009; LoBue & DeLoache, 2008; Peltola et al., 2009a, b; Reider et al., 2022).
Indeed, as early as 6–8 months of age, children demonstrate a preference for fearful and angry facial expressions (e.g., Kotsoni et al., 2001; Leppänen et al., 2018; LoBue et al., 2010; Morales et al., 2017; Peltola et al., 2018). Moreover, they exhibit slower disengagement from fearful facial configurations (e.g., Peltola et al., 2008, 2013, 2009a, b) and quicker detection of angry facial expressions compared with positive or neutral stimuli (e.g., LoBue & DeLoache, 2008; Nakagawa & Sukigara, 2012). This bias also extends to nonsocial stimuli. For instance, infants display faster attentional orientation towards snakes and spiders over frogs and caterpillars (LoBue, 2010; LoBue & DeLoache, 2008; LoBue et al., 2017).
Numerous studies have suggested that the ASE can offer valuable insights into the emotional and psychological well-being of children (e.g., Denham et al., 2002; LoBue & Pérez-Edgar, 2014; Pérez-Edgar et al., 2010; Pollak & Sinha, 2002). For instance, LoBue and Pérez-Edgar (2014) showed that children at risk for anxiety displayed an increased bias in detecting angry faces compared with low-shy comparison children. This heightened bias aligns with the findings of Pérez-Edgar et al. (2011), who reported that attention biases towards threats played a pivotal role in mediating the relationship between behaviorally inhibited temperaments and social withdrawal in children.
Conversely, maltreated children have demonstrated a heightened sensitivity to threatening stimuli, as highlighted by studies conducted by Masten et al. (2008), Briggs-Gowan et al. (2015), Swartz et al. (2011), and Pollak (2015). For instance, Pollak and Sinha (2002) found a correlation between exposure to violence or abuse and an increased likelihood of displaying the ASE, suggesting that encounters with violent events could impact their ability to recognize emotions effectively.
One particular aspect that has received meticulous attention in recent literature is the influence of low-level visual features as potential confounding factors in ASE assessments (e.g., Becker & Rheem, 2020). Converging lines of evidence suggest that the empirical results supporting the ASE are often driven by the low-level visual features of the stimulus materials, rather than by the emotion that is being portrayed (Savage et al., 2013). For instance, a number of studies (e.g., Hansen & Hansen, 1988; Horstmann & Bauland, 2006) have revealed that the ASE prevails with the Picture of Facial Affect (Ekman & Friesen, 1976), whereas the opposite effect, that is an advantage for the detection of happy faces over other facial expressions (Happiness Superiority Effect) has been often reported with the Karolinska Directed Emotional Faces (Lundqvist et al., 1998), or with the NimStim database (Tottenham et al., 2009). Horstmann et al. (2012) showed that the ASE can be confounded with the presence of diagnostic features such as the presence/absence of an open mouth with visible teeth. In particular, their research revealed that if a happy face displays teeth and an angry face does not, people are able to locate the happy face more quickly than the angry face. Conversely, if an angry face displays teeth and a happy face does not, people are able to locate the angry face more quickly than the happy face. Other studies investigated the ASE by using drawings of schematic faces (e.g., Calvo et al., 2006). However, this type of stimuli is entirely unrealistic; while they may convey negative emotions, they might not necessarily evoke a sense of threat (Becker et al., 2011). The asymmetries between angry or happy faces, typically observed when using schematic faces, may be more related to the early visual processing of line orientation than to threat detection itself (Kennett & Wallis, 2019). In line with these findings, Ceccarini and Caudek (2013) found that when bottom-up saliency is controlled, static faces do not yield an ASE. However, they did observe a reliable ASE when the same stimulus displays conveyed facial emotions through dynamic information. A possible explanation for these results may reside in the fact that, in natural conditions, emotional expressions can only be transmitted through nonrigid motions resulting from face deformations. Consequently, while static stimuli may elicit a form of processing that does not completely reflect the cognitive mechanisms naturally involved in emotion recognition (Foley et al., 2012), the use of more ecologically valid stimuli could potentially evoke stronger responses compared with static expressions. Supporting this notion, multiple studies have highlighted the significance of dynamic information for both identity and emotion recognition (LaBar et al., 2003; O’Toole et al., 2011; Thornton & Kourtzi, 2002).
While several studies have explored the impact of low-level visual features as potential confounding variables in adult ASE assessments (e.g., Becker & Rheem, 2020), this aspect has received comparatively less attention in children, especially with respect to the utilization of dynamic information. With this in mind, our current study examines the ASE in children ages 6–14 years and introduces two significant procedural modifications compared with prior research: (1) to mitigate the impact of confounding stimulus-driven factors, we designed our stimulus displays based on the guidelines set forth by Becker et al. (2011). (2) To enhance the realism and ecological validity of the stimuli, we employed dynamic facial expressions, adopting the methodology outlined by Ceccarini and Caudek (2013).
Considering that reacting promptly to potential threats offers a distinct evolutionary advantage, we anticipated that children would process angry faces more quickly and/or with greater accuracy than happy facial expressions.
Methods and materials
Participants
A total of 258 participants took part in the study: 85 first-grade students (36 females, Mage = 6.55 years, SD = 0.27), 86 fifth-grade students (41 females, Mage = 10.49 years, SD = 0.29), and 87 ninth-grade students (39 females, Mage = 13.70 years, SD = 0.26). Participants were recruited from four schools in Tuscany, Italy.
We conducted an a priori power analysis using G*Power (Version 3.1.9.7; Faul, et al., 2007) to estimate the necessary sample size. Our approach was informed by prior ASE studies (Ceccarini & Caudek, 2013; Isomura et al., 2014; May et al., 2016). We established an effect size (f) of 0.2 for the mean difference between neutral and angry faces in a visual search task, maintaining a significance criterion of α = 0.05 and power = 0.95. With this effect size, a minimum sample size of n = 45 was determined. Therefore, our sample size provides sufficient power to ensure meaningful and robust testing.
Two 6-year-old children were excluded from the final sample for not completing the task. This study was carried out in accordance with the Declaration of Helsinki and received approval (2015/0008103) from the local ethics committee. Informed written consent was obtained from parents, and oral consent was obtained from children (using age-adequate approaches).
Apparatus
The experiment was controlled by MATLAB R2018a (The MathWorks, Natick, MA) using the Psychophysics Toolbox extensions (Brainard, 1997) on a PC running Windows XP. Stimuli were presented on a 19-in. video monitor operating at 75 Hz with a screen resolution of 1,280 × 1,024 pixels.
Stimuli
The stimuli were created by using the same procedure adopted by Ceccarini and Caudek (2013). For each emotional expression (neutral, happy, angry), we selected from the Radboud Faces Database (RaFD; Langner et al., 2010) 20 facial identities having similar ratings of intensity, clarity, and genuineness. After cropping hair and the background, by using the function PhotoFit SDK of the Facegen software, we generated a three-dimensional (3D) face model for each 200 × 200 pixels image (Fig. 1A). Each face image was then processed with 3D Studio Max, in order to equate illumination intensity and illuminant direction. These images were morphed to obtain a smooth transition between the neutral expression and the full-emotion expression (Caudek, 2013; Caudek & Monni, 2013; Ceccarini & Caudek, 2013; Lorenzino & Caudek, 2015; Lorenzino et al., 2018). The Flash CS5 software was then used to convert frame sequences into videos (Caudek et al., 2015, 2017). For generating dynamic faces with a neutral expression, we used the PhotoFit SDK function of the FaceGen software, which allows a realistic production of the spoken phoneme /W/.

A Example of stimulus generation procedure. The face enclosed in the square frame was selected from the RaFD database and shows a neutral emotional expression. The image was transformed to remove hair and other distinguishing features, and then was morphed to obtain a smooth transition between the neutral expression and the full-emotion expression. B Example of the stimulus display. In both the simulation and the experiment, the face images were more distanced among each other (on average) and their relative positions were pseudorandomly perturbed. C Salience map of the last frame of the stimulus video
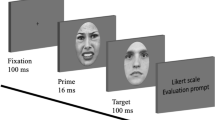
On each trial of the visual search task, participants were shown a stimulus display consisting of nine video clips of human faces showing the unfolding of an angry, happy, or neutral facial expression (Fig. 1B). Each of the nine face video sequences depicted a different facial identity. On each trial, the nine facial identities were randomly chosen from the set of 20 possible RaFD faces.
Within each stimulus display, the nine faces were displayed with a neutral expression for 300 ms, followed by the morphing transition between the neutral face and the final expressive face. The video sequence for a neutral face showed the articulation of the phoneme /W/. The dynamic portion of the stimulus lasted for a total of 533 ms and corresponded to the presentation of the 16 images of the morph continuum, each remaining on the screen for 1/30 s. The last frame of the motion sequence remained on the screen as a static display until the participant’s response. The duration of the temporal unfolding of facial expressions of emotion is in line with previous studies (e.g., Arsalidou et al., 2011; Becker et al., 2012; Horstmann & Ansorge, 2009; Schultz & Pilz, 2009). This procedure has the advantage of allowing a precise control of the timing of the change, without sacrificing the realism of the expressive dynamics (e.g., Becker et al., 2012).
There were three conditions: eight neutral faces and an angry face, eight neutral faces and a happy face, and nine neutral faces. In half of the trials, the target was absent, and in the other half, the target (either an angry or a happy face, with equal probability) was present.
Bottom-up salience analysis
We selected face images having similar low-level visual features across emotional expressions. To achieve this goal, we selected a subset of the RaFD images that provided equivalent levels of bottom-up salience across happy and angry faces according to the computational model of Itti and Koch (2001). The model assumes that the allocation of visual attention is driven by stimulus salience in a bottom-up fashion and analyzes natural images by extracting low-level features such as intensity, color, and orientation at a range of spatial scales. To optimize the detection of local feature differences, these features are converted to center-surround representations; from these representations, separate “conspicuity” maps are created. The conspicuity maps are then combined to form one salience map that is supposed to guide the attentional focus. To check whether our selection procedure obtained its intended purpose, we run the following simulation. In each run of the simulations, we generated a 3 × 3 grid of different face identities, which reproduced the stimulus displays used in the experiment (Fig. 1B). One of these nine face identities was the target (with either an angry or a happy expression) and the remaining eight faces were neutral distractors faces. In each run of the simulation, the target face was positioned in one of the possible slots of the grid, with equal probability; the distractor faces (each with a different facial identity) were randomly assigned to the remaining positions of the grid. Each stimulus display was then processed with the SaliencyToolbox 2.2 (http://www.saliencytoolbox.net) for MATLAB (Walther & Koch, 2006); for the purpose of this study, the standard settings were used. An example of saliency map thus obtained is shown in Fig. 1C. From the saliency map, we measured the total activation within each of the nine regions in which the faces were located and we computed a saliency index as the ratio between the total activation of the target face and the average total activation of the distractors. This process was repeated 504 times for the angry targets and 504 times for the happy targets (by randomly varying the positions of target and distractor faces within the grid), for a total 1,008 repetitions of the simulation. The simulation results indicate that the selected angry and happy faces showed very similar levels of bottom-up salience according to Itti and Koch’s metrics: saliency index difference, 0.01 ± 0.02 SE; 95% credibility interval, [− 0.03 to 0.05].
Amount of image motion
For the twenty selected RaFD face identities, we estimated the amount of image motion generated by the temporal unfolding of a happy or angry facial expression, or for the articulation of the phoneme /W/. The amount of image motion was computed as indicated by Ceccarini and Caudek (2013). We divided the squared I (x, y, t).
greyscale images at the time t1 (first frame of the video sequence) and I2 (last frame of the video sequence) into a grid of smaller 20 × 20 blocks. We summed the values within each block to obtain the reduced images Ir (t1) and Ir (t2). Image motion was then estimated as the sum of all elements of the absolute difference of Ir (t1) and Ir (t2).
Results indicated that, on average, the three facial expressions produced similar amounts of image motion—happy: mean, 0.91 ± 0.193 SE; angry: mean, 0.98, ± 0.231 SE; neutral: mean, 0.88 ± 0.196 SE; F(2, 3) = 1.22, p = 0.3030.
Intensity of emotional expressiveness
The emotional intensity of the 20 selected RaFD faces was evaluated by 94 undergraduate students. Static images of the happy and angry faces were presented for 15 s in random order. Participants were asked to rate the emotional intensity of each face on a scale ranging from 1 (very low intensity) to 4 (very high intensity). We found no evidence that perceived emotional intensity varied across the two facial expressions (happy: mean, 2.98 ± 0.025 SE; sad: mean, 3.01 ± 0.021 SE; z = 0.16, p = .8729).
Procedure
Participants were tested in individual sessions in a quiet room at their school. The experimenter introduced the study as a game. Prior to test trials, participants completed nine practice trials (three with a happy target face, three with an angry target face, and six in the distractor-only condition). Responses to practice trials were excluded from further analyses. If the experimenter judged that the participant understood the task, and if the children also gave their oral consent to continue, the experiment started. Each trial of the visual search task began with the presentation of a central fixation point for 1,000 ms, which was followed by a display containing nine dynamic faces. Participants were asked to indicate with a key-press whether all faces showed the same expression or whether one face showed an expression differing from the others. They were instructed to perform the task as quickly and accurately as possible. Participants received no feedback for correct or incorrect responses. Participants completed the study in a single session lasting approximately 25 minutes, including the breaks between blocks of trials.
Data analysis
Outliers were identified as data points above the third quartile or below the first quartile of 1.5 interquartile ranges, and these were excluded from analysis (Tukey, 1977), resulting in the removal of 1.5% of total trials. Reaction time (RT) distributions, measured in seconds, were analyzed using the ex-Gaussian distributional model (Balota & Yap, 2011). In the ex-Gaussian model, RT distribution is represented as the convolution of two random variables: one normally distributed with mean µ and standard deviation σ, and the other exponential with mean and variance equal to τ.
The ex-Gaussian mean equals µ + τ, and its variance is σ2 + τ 2 (Luce, 1986). Bayesian hierarchical estimation was employed due to its ability to better estimate ex-Gaussian distribution parameters with limited observations compared with maximum likelihood estimation (Rouder et al., 2005).
To estimate participants’ detection ability and response bias, we employed a Bayesian hierarchical extension of the Signal Detection Theory model (SDT; Green & Swets, 1966), which offers advantages over conventional methods (Lee & Wagenmakers, 2014). The posterior distribution of the hierarchical SDT model was estimated via MCMC using the Stan package (Carpenter et al., 2016) within the R statistical language (R Core Team, 2016). Samples were generated from two independent chains, each comprising 50,000 iterations, with 5,000 warm-up iterations. Convergence was assessed using the \(\hat{R}\) statistic (Gelman & Rubin, 1992).
The 95% Bayesian credible intervals (indicating the range within which we can be 95% certain that a parameter’s true value lies given the observed data) were used for statistical inference. In contrast, a frequentist confidence interval reveals that, if the statistical procedure were applied repeatedly to various hypothetical datasets, the confidence interval would encompass the true parameter in 95% of cases. Therefore, the frequentist CI provides insight into the properties of the statistical procedure being employed, but not the parameter’s uncertainty. Conditions were deemed different if their credible intervals did not overlap. We computed the standardized effect size using the δt index (Nalborczyk et al., 2019).
Results
Hierarchical ex-Gaussian fit
Figure 2 shows the posterior distributions of the hierarchical Bayesian estimates of the parameters µ, σ, and τ (all in seconds), for each age group and experimental condition. In terms of RTs, first-grade and fifth-grade students did not show any evidence of prioritization for angry faces (see Table 1). Conversely, ninth-grade students detected angry targets quicker than happy ones.

Hierarchical Bayesian estimates of the parameters µ, σ, and τ (all in seconds) of an ex-Gaussian distribution fitted to the data of each experimental condition for the three age groups
Hierarchical SDT analysis
Table 2 shows the d′ posterior estimates as a function of target type and age groups. Results shows a detection advantage, in all three age groups, for angry target faces over happy target faces. The results are clear enough. But, if one desires to combine a Bayesian “estimation” approach with the frequentist 95% window size for decision making, then it can be noted that the 95% credible intervals of angry and happy target faces do not overlap for first-grade students (the crucial age group), effect size = 0.535, but they do overlap for the two older age groups. To obtain a more precise posterior estimate with a larger sample, we fitted the model again after collapsing the two older age groups. By so doing, we found the following. Angry face targets: µd = 3.02; 95% credible interval, 2.85 to 3.19; happy face targets: µd = 2.64; 95% credible interval, 2.49 to 2.80; effect size = 0.40. We thus conclude that, in terms of detection performance, the ASE is present in both younger and older children. The effect size is in the small-medium range of Cohen’s (1988) effect size benchmarks.
Summary
Hierarchical ex-Gaussian fit indicates angry faces are detected quicker than happy faces only in the older age group. The first-grade and fifth-grade students showed no prioritization for threatening faces. Conversely, detection performance was similar across all age groups. Children were always better at detecting an angry target than a happy target.
General discussion
The primary objective of this study was to explore the ASE across various age groups, encompassing first-grade, fifth-grade, and ninth-grade students. For this purpose, we examined the ASE in young children using dynamic ecologically valid stimuli, and controlling for low-level perceptual confounds. Our results indicate that, during childhood, the ASE manifests as enhanced accuracy in detecting angry faces, while in adolescence, the ASE undergoes additional refinement, leading to both quicker and more precise threat detection. The fact the younger children detect more accurately an angry than a happy target is in line with the previous literature holding that threatening stimuli benefit of an enhanced perceptual encoding from an early age (e.g., LoBue & DeLoache, 2008). However, we found that a quicker detection of angry faces was present only in the older age group (ninth-grade students). A possible explanation for this result may reside in the substantial neurobiological changes occurring during the transition from childhood into adolescence.
Specifically, the development of facial expression recognition constitutes a multifaceted process that involves the maturation of various brain regions, encompassing the occipito-temporal areas responsible for analyzing the holistic perceptual layout of visual facial features. Additionally, an “emotional network,” including the anterior temporal cortex, precuneus, anterior paracingulate cortex, inferior frontal gyrus, amygdala, insula, and the reward system (Duchaine & Yovel, 2015; Gobbini & Haxby, 2007; Haxby et al., 2001; Maffei & Sessa, 2021a, b), contributes to the analysis of facial expressions. During development, this emotional network undergoes noteworthy structural changes (Kanwisher et al., 1997; Thomas et al., 2001) that impact the capacity to process and differentiate facial expressions, particularly those with threatening features (Herba et al., 2006; Herba & Phillips, 2004; Montirosso et al., 2010; Vicari et al., 2000).
Supporting this notion, earlier studies have revealed that children ages 4–8 years exhibit reduced accuracy in recognizing and distinguishing facial expressions in contrast to adolescents and adults (Herba & Phillips, 2004). Only during late childhood do children begin to approach levels of accuracy akin to those of adults in recognizing and discriminating facial expressions (Herba & Phillips, 2004; Herba et al., 2006; Montirosso et al., 2010; Vicari et al., 2000). In light of these findings, the refinement of the ASE during adolescence could be interpreted as an epiphenomenon of the ongoing maturation of the emotional network and the cortical areas related to facial expression discrimination and recognition.
It remains to be explained why some studies have reported a quicker detection for angry faces (e.g., May et al., 2016), while others have reported a faster detection for happy faces (e.g., Leppänen & Hietanen, 2004; Zsido et al., 2021) in children.
One possible explanation for this discrepancy could be linked to the stimuli utilized in prior research. In general, except for a few exceptions (e.g., Ceccarini & Caudek, 2013), investigations into the ASE in children have primarily employed artificial schematic stimuli or static images depicting facial expressions, without adequately considering low-level factors. This might have impacted the visual prominence of distinct facial expressions, potentially introducing a bias that could lead to a faster detection of angry or happy targets. Detecting emotionally charged stimuli is a complex process influenced by both (1) bottom-up factors enhancing visual distinctiveness and (2) top-down attention towards emotional stimuli like angry or happy faces. Demonstrating a “superiority effect” based on emotional content requires showing this advantage persists even when minimizing low-level features. This precisely defines our objective in the present study, and our results indicate that an “anger superiority effect” consistently emerges, even in children.
A distinguishing aspect of our study is the use of dynamic stimuli. Prior research has demonstrated that dynamic facial expressions facilitate improved emotion recognition in comparison to static facial expressions (Frijda, 1953; Harwood et al., 1999; Kozel & Gitter, 1968). Dynamic expressions are rated as more intense than static emotional faces (Biele & Grabowska, 2006) and enable more precise identification. The relevance of dynamic information becomes particularly evident in situations with limited available physical data (Ambadar et al., 2005; Bould et al., 2008) or compromised data (Kätsyri & Sams, 2008; Wallraven et al., 2008). Furthermore, dynamic information is beneficial in clinical contexts. For example, individuals with intellectual disabilities (Harwood et al., 1999), pervasive developmental disorder (Uono et al., 2010), and autism (Back et al., 2007; Gepner et al., 2001) gain advantages from dynamic stimuli, resulting in enhanced recognition of facial expressions. Interestingly, earlier studies have highlighted that perceiving and recognizing static or dynamic facial expressions involve distinct neural pathways (Kilts et al., 2003). In static facial expressions, the perception of anger activates a cortical network encompassing motor, prefrontal, and parietal regions. Conversely, the perception of anger in dynamic facial expressions is linked to heightened right-lateralized activity in the medial, superior, middle, and inferior frontal cortex, as well as the cerebellum. Electromyography studies further support this dissociation, revealing that dynamic expressions tend to evoke more pronounced facial mimic responses and are associated with elevated physiological activation levels (Alves, 2013). Considering the above, utilizing dynamic stimuli facilitates the implementation of a more genuine and ecologically valid task, thereby offering an enhanced opportunity to investigate the ASE (Ceccarini & Caudek, 2013).
Conclusion
The present study provides compelling evidence for the existence of the ASE in children. Specifically, our results confirm that threatening stimuli benefit from an enhanced perceptual encoding from an early age (e.g., LoBue, 2009; LoBue & DeLoache, 2008; Peltola et al., 2009a, b; Reider et al., 2022), substantiating the notion that humans possess a dedicated mechanism for detecting potential threats and directing attentional resources toward them (Öhman & Mineka, 2001). Within this context, the ASE can be interpreted as an adaptive mechanism evolved to prioritize the identification of a potent social warning signal, such as angry faces (Hansen & Hansen, 1988; Horstmann & Bauland, 2006; Öhman et al., 2001).
However, it’s important to acknowledge that this study is not without limitations. Firstly, children were required to discriminate facial expressions with emotional intensity validated in a sample of adult participants. Thus, the emotional intensity of our stimuli might not precisely align with children’s developmental ability to discern facial expressions. Secondly, while our cross-sectional design offers a snapshot of the ASE across different age groups, a longitudinal approach would yield a more comprehensive understanding of the ASE’s developmental trajectory. Lastly, despite employing a validated method to control the bottom-up saliency of our stimuli, other low-level factors could still have impacted our results. Hence, further research is essential to validate and generalize the present findings.
Data Availability
All relevant materials, data and R scripts are available (https://github.com/ccaudek/ase_children).
References
Alves, N. T. (2013). Recognition of static and dynamic facial expressions: A study review. Estudos De Psicologia (Natal), 18, 125–130.
Ambadar, Z., Schooler, J. W., & Cohn, J. F. (2005). Deciphering the enigmatic face: The importance of facial dynamics in interpreting subtle facial expressions. Psychological Science, 16(5), 403–410.
Arsalidou, M., Morris, D., & Taylor, M. J. (2011). Converging evidence for the advantage of dynamic facial expressions. Brain Topography, 24(2), 149–163.
Back, E., Ropar, D., & Mitchell, P. (2007). Do the eyes have it? Inferring mental states from animated faces in autism. Child Development, 78(2), 397–411.
Balota, D. A., & Yap, M. J. (2011). Moving beyond the mean in studies of mental chronometry: The power of response time distributional analyses. Current Directions in Psychological Science, 20(3), 160–166.
Becker, D. V., Anderson, U. S., Mortensen, C. R., Neufeld, S., & Neel, R. (2011). The face in the crowd effect unconfounded: Happy faces, not angry faces, are more efficiently detected in the visual search task. Journal of Experimental Psychology: General, 140, 637–659.
Becker, D. V., Neel, R., Srinivasan, N., Neufeld, S., Kumar, D., & Fouse, S. (2012). The vividness of happiness in dynamic facial displays of emotion. PLoS ONE, 7(1), e26551.
Becker, D. V., & Rheem, H. (2020). Searching for a face in the crowd: Pitfalls and unexplored possibilities. Attention, Perception, & Psychophysics, 82, 626–636.
Biele, C., & Grabowska, A. (2006). Sex differences in perception of emotion intensity in dynamic and static facial expressions. Experimental Brain Research, 171, 1–6.
Bould, E., Morris, N., & Wink, B. (2008). Recognising subtle emotional expressions: The role of facial movements. Cognition and Emotion, 22(8), 1569–1587.
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10(4), 433–436.
Briggs-Gowan, M. J., Pollak, S. D., Grasso, D., Voss, J., Mian, N. D., Zobel, E., & Pine, D. S. (2015). Attention bias and anxiety in young children exposed to family violence. Journal of Child Psychology and Psychiatry, 56(11), 1194–1201.
Calvo, M. G., Avero, P., & Lundqvist, D. (2006). Facilitated detection of angry faces: Initial orienting and processing efficiency. Cognition and Emotion, 20, 785–811.
Carpenter, B., Gelman, A., Homan, M., Lee, D., Goodrich, B., Betancourt, M., … Riddell, A. (2016). Stan: A probabilistic programming language. Journal of Statistical Software, 76(1), 1–32. https://doi.org/10.18637/jss.v076.i01
Caudek, C. (2013). The fidelity of visual memory for faces and non-face objects. Acta Psychologica, 143(1), 40–51.
Caudek, C., Ceccarini, F., & Sica, C. (2015). Posterror speeding after threat-detection failure. Journal of Experimental Psychology: Human Perception and Performance, 41(2), 324–341.
Caudek, C., Ceccarini, F., & Sica, C. (2017). Facial expression movement enhances the measurement of temporal dynamics of attentional bias in the dot-probe task. Behaviour Research and Therapy, 95, 58–70.
Caudek, C., & Monni, A. (2013). Do you remember your sad face? The roles of negative cognitive style and sad mood. Memory, 21, 891–903.
Ceccarini, F., & Caudek, C. (2013). Anger superiority effect: The importance of dynamic emotional facial expressions. Visual Cognition, 21(4), 498–540.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Erlbaum.
Denham, S. A., Caverly, S., Schmidt, M., Blair, K., DeMulder, E., Caal, S., & Mason, T. (2002). Preschool understanding of emotions: Contributions to classroom anger and aggression. Journal of Child Psychology and Psychiatry, 43(7), 901–916.
Dixson, B. J. W., Spiers, T., Miller, P. A., Sidari, M. J., Nelson, N. L., & Craig, B. M. (2022). Facial hair may slow detection of happy facial expressions in the face in the crowd paradigm. Scientific Reports, 12(1), 5911.
Duchaine, B., & Yovel, G. (2015). A revised neural framework for face processing. Annual Review of Vision Science, 1, 393–416.
Ekman, P., & Friesen, W. V. (1976). Measuring facial movement. Environmental Psychology and Nonverbal Behavior, 1, 56–75.
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191.
Foley, E., Rippon, G., Thai, N. J., Longe, O., & Senior, C. (2012). Dynamic facial expressions evoke distinct activation in the face perception network: A connectivity analysis study. Journal of Cognitive Neuroscience, 24, 507–520.
Frijda, N. H. (1953). The understanding of facial expression of emotion. Acta Psychologica, 9, 294–362.
Gelman, A., & Rubin, D. B. (1992). A single series from the Gibbs sampler provides a false sense of security. Bayesian Statistics, 4(1), 625–631.
Gepner, B., Deruelle, C., & Grynfeltt, S. (2001). Motion and emotion: A novel approach to the study of face processing by young autistic children. Journal of Autism and Developmental Disorders, 31, 37–45.
Gobbini, M. I., & Haxby, J. V. (2007). Neural systems for recognition of familiar faces. Neuropsychologia, 45(1), 32–41.
Gong, M., & Smart, L. J. (2021). The anger superiority effect revisited: A visual crowding task. Cognition and Emotion, 35(2), 214–224.
Green, D. M., & Swets, J. A. (1966). Signal detection theory and psychophysics. John Wiley.
Kennett, M. J., & Wallis, G. (2019). The face-in-the-crowd effect: Threat detection versus iso-feature suppression and collinear facilitation. Journal of Vision, 19(7), 6–6.
Hansen, C. H., & Hansen, R. D. (1988). Finding the face in the crowd: an anger superiority effect. Journal of personality and social psychology, 54(6), 917.
Harwood, N. K., Hall, L. J., & Shinkfield, A. J. (1999). Recognition of facial emotional expressions from moving and static displays by individuals with mental retardation. American Journal on Mental Retardation, 104(3), 270–278.
Haxby, J. V., Gobbini, M. I., Furey, M. L., Ishai, A., Schouten, J. L., & Pietrini, P. (2001). Distributed and overlapping representations of faces and objects in ventral temporal cortex. Science, 293(5539), 2425–2430.
Herba, C. M., Landau, S., Russell, T., Ecker, C., & Phillips, M. L. (2006). The development of emotion-processing in children: Effects of age, emotion, and intensity. Journal of Child Psychology and Psychiatry, 47, 1098–1106.
Herba, C., & Phillips, M. (2004). Annotation: Development of facial expression recognition from childhood to adolescence: Behavioural and neurological perspectives. Journal of Child Psychology and Psychiatry, 45(7), 1185–1198.
Horstmann, G., & Ansorge, U. (2009). Visual search for facial expressions of emotions: A comparison of dynamic and static faces. Emotion, 9(1), 29–38.
Horstmann, G., & Bauland, A. (2006). Search asymmetries with real faces: Testing the anger-superiority effect. Emotion, 6, 193–207.
Horstmann, G., Lipp, O. V., & Becker, S. I. (2012). Of toothy grins and angry snarls—Open mouth displays contribute to efficiency gains in search for emotional faces. Journal of Vision, 12(5), 7–7.
Isomura, T., Ogawa, S., Yamada, S., Shibasaki, M., & Masataka, N. (2014). Preliminary evidence that different mechanisms underlie the anger superiority effect in children with and without Autism Spectrum Disorders. Frontiers in Psychology, 5, 461.
Itti, L., & Koch, C. (2001). Computational modelling of visual attention. Nature Reviews Neuroscience, 2(3), 194–203.
Kanwisher, N., McDermott, J., & Chun, M. M. (1997). The fusiform face area: A module in human extrastriate cortex specialized for face perception. Journal of Neuroscience, 17(11), 4302–4311.
Kätsyri, J., & Sams, M. (2008). The effect of dynamics on identifying basic emotions from synthetic and natural faces. International Journal of Human-Computer Studies, 66(4), 233–242.
Kilts, C. D., Egan, G., Gideon, D. A., Ely, T. D., & Hoffman, J. M. (2003). Dissociable neural pathways are involved in the recognition of emotion in static and dynamic facial expressions. NeuroImage, 18(1), 156–168.
Kotsoni, E., de Haan, M., & Johnson, M. H. (2001). Categorical perception of facial expressions by 7-month-old infants. Perception, 30(9), 1115–1125.
Kozel, N. J., & Gitter, G. A. (1968). Perception of emotion: Differences in mode of presentation, sex of perceiver, and race of expressor. CRC Report, 18, 1–61.
LaBar, K. S., Crupain, M. J., Voyvodic, J. T., & McCarthy, G. (2003). Dynamic perception of facial affect and identity in the human brain. Cerebral Cortex, 13(10), 1023–1033.
Langner, O., Dotsch, R., Bijlstra, G., Wigboldus, D. H., Hawk, S. T., & Van Knippenberg, A. D. (2010). Presentation and validation of the Radboud Faces Database. Cognition and Emotion, 24(8), 1377–1388.
Lee, M. D., & Wagenmakers, E. J. (2014). Bayesian cognitive modeling: A practical course. Cambridge University Press.
Leppänen, J. M., & Hietanen, J. K. (2004). Positive facial expressions are recognized faster than negative facial expressions, but why? Psychological Research Psychologische Forschung, 69(1/2), 22–29.
Leppänen, J. M., Cataldo, J. K., Bosquet Enlow, M., & Nelson, C. A. (2018). Early development of attention to threat-related facial expressions. PLoS One, 13(5), e0197424.
Li, X., Lin, Z., Chen, Y., & Gong, M. (2022). Working memory modulates the anger superiority effect in central and peripheral visual fields. Cognition and Emotion, 37(2), 271–283.
LoBue, V. (2009). More than just a face in the crowd: Detection of emotional facial expressions in young children and adults. Developmental Science, 12, 305–313.
LoBue, V. (2010). And along came a spider: An attentional bias for the detection of spiders in young children and adults. Journal of Experimental Child Psychology, 107(1), 59–66.
LoBue, V., Buss, K. A., Taber-Thomas, B. C., & Pérez-Edgar, K. (2017). Developmental differences in infants’ attention to social and nonsocial threats. Infancy, 22(3), 403–415.
LoBue, V., & DeLoache, J. S. (2008). Detecting the snake in the grass: Attention to fear-relevant stimuli by adults and young children. Psychological Science, 19(3), 284–289.
LoBue, V., & Pérez-Edgar, K. (2014). Sensitivity to social and non-social threats in temperamentally shy children at-risk for anxiety. Developmental Science, 17, 239–247.
LoBue, V., Rakison, D. H., & DeLoache, J. S. (2010). Threat perception across the life span: Evidence for multiple converging pathways. Current Directions in Psychological Science, 19(6), 375–379.
Lorenzino, M., Caminati, M., & Caudek, C. (2018). Tolerance to spatial-relational transformations in unfamiliar faces: A further challenge to a configural processing account of identity recognition. Acta Psychologica, 188, 25–38.
Lorenzino, M., & Caudek, C. (2015). Task-irrelevant emotion facilitates face discrimination learning. Vision Research, 108, 56–66.
Luce, R. (1986). Response times: Their role in inferring elementary mental organization (Vol. 3). Oxford University Press.
Lundqvist, D., Flykt, A., & Öhman, A. (1998). Karolinska directed emotional faces. PsycTESTS Dataset, 91, 630.
Maffei, A., & Sessa, P. (2021a). Event-related network changes unfold the dynamics of cortical integration during face processing. Psychophysiology, 58(5), e13786.
Maffei, A., & Sessa, P. (2021b). Time-resolved connectivity reveals the “how” and “when” of brain networks reconfiguration during face processing. NeuroImage: Reports, 1(2), 100022.
Masten, C. L., Guyer, A. E., Hodgdon, H. B., McClure, E. B., Charney, D. S., Ernst, M., & Monk, C. S. (2008). Recognition of facial emotions among maltreated children with high rates of post-traumatic stress disorder. Child Abuse & Neglect, 32(1), 139–153.
May, T., Cornish, K., & Rinehart, N. J. (2016). Exploring factors related to the anger superiority effect in children with autism spectrum disorder. Brain and Cognition, 106, 65–71.
Montirosso, R., Peverelli, M., Frigerio, E., Crespi, M., & Borgatti, R. (2010). The development of dynamic facial expression recognition at different intensities in 4-to 18-year-olds. Social Development, 19(1), 71–92.
Morales, S., Brown, K. M., Taber-Thomas, B. C., LoBue, V., Buss, K. A., & Pérez-Edgar, K. E. (2017). Maternal anxiety predicts attentional bias towards threat in infancy. Emotion, 17(5), 874.
Nakagawa, A., & Sukigara, M. (2012). Difficulty in disengaging from threat and temperamental negative affectivity in early life: A longitudinal study of infants aged 12–36 months. Behavioral and Brain Functions, 8(1), 1–8.
O’Toole, A. J., Phillips, P. J., Weimer, S., Roark, D. A., Ayyad, J., Barwick, R., & Dunlop, J. (2011). Recognizing people from dynamic and static faces and bodies: Dissecting identity with a fusion approach. Vision Research, 51(1), 74–83.
Nalborczyk, L., Batailler, C., Lœvenbruck, H., Vilain, A., & Bürkner, P. C. (2019). An introduction to Bayesian multilevel models using brms: A case study of gender effects on vowel variability in standard Indonesian. Journal of Speech, Language, and Hearing Research, 62(5), 1225–1242.
Öhman, A., Lundqvist, D., & Esteves, F. (2001). The face in the crowd revisited: An anger superiority effect with schematic faces. Journal of Personality and Social Psychology, 80, 381–396.
Öhman, A., & Mineka, S. (2001). Fears, phobias, and preparedness: Toward an evolved module of fear and fear learning. Psychological Review, 108(3), 483.
Peltola, M. J., Hietanen, J. K., Forssman, L., & Leppänen, J. M. (2013). The emergence and stability of the attentional bias to fearful faces in infancy. Infancy, 18, 905–926.
Peltola, M. J., Leppänen, J. M., Mäki, S., & Hietanen, J. K. (2009a). Emergence of enhanced attention to fearful faces between 5 and 7 months of age. Social Cognitive and Affective Neuroscience, 4, 134–142.
Peltola, M. J., Leppänen, J. M., Palokangas, T., & Hietanen, J. K. (2008). Fearful faces modulate looking duration and attention disengagement in 7-month-old infants. Developmental Science, 11, 60–68.
Peltola, M. J., Leppänen, J. M., Vogel-Farley, V. K., Hietanen, J. K., & Nelson, C. A. (2009b). Fearful faces but not fearful eyes alone delay attention disengagement in 7-month-old infants. Emotion, 9(4), 560.
Peltola, M. J., Yrttiaho, S. & Leppänen, J. M. (2018). Infants’ attention bias to faces as an early marker of social development. Developmental Science, 21, e12687.
Pérez-Edgar, K., Bar-Haim, Y., McDermott, J. M., Chronis-Tuscano, A., Pine, D. S., & Fox, N. A. (2010). Attention biases to threat and behavioral inhibition in early childhood shape adolescent social withdrawal. Emotion, 10, 349–357.
Pérez-Edgar, K., Reeb-Sutherland, B. C., McDermott, J. M., White, L. K., Henderson, H. A., Degnan, K. A., Hane, A. A., Pine, D. S., & Fox, N. A. (2011). Attention biases to threat link behavioral inhibition to social withdrawal over time in very young children. Journal of Abnormal Child Psychology, 39, 885–895.
Pollak, S. D. (2015). Multilevel developmental approaches to understanding the effects of child maltreatment: Recent advances and future challenges. Development and Psychopathology, 27, 1387–1397.
Pollak, S. D., & Sinha, P. (2002). Effects of early experience on children’s recognition of facial displays of emotion. Developmental Psychology, 38(5), 784.
Rapuano, M., Iachini, T., & Ruggiero, G. (2023). Interaction with virtual humans and effect of emotional expressions: anger matters! Journal of Clinical Medicine, 12(4), 1339.
R Core Team. (2016). R: A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna. Retrieved on October 11, 2022, from https://www.R-project.org/
Reider, L. B., Bierstedt, L., Burris, J. L., Vallorani, A., Gunther, K. E., Buss, K. A., Pérez-Edgar, K., Field, A., & LoBue, V. (2022). Developmental patterns of affective attention across the first two years of life. Child Development, 93(6), e607–e621.
Rouder, J. N., Lu, J., Speckman, P., Sun, D., & Jiang, Y. (2005). A hierarchical model for estimating response time distributions. Psychonomic Bulletin & Review, 12(2), 195–223.
Savage, R. A., Lipp, O. V., Craig, B. M., Becker, S. I., & Horstmann, G. (2013). In search of the emotional face: Anger versus happiness superiority in visual search. Emotion, 13(4), 758–772.
Schultz, J., & Pilz, K. S. (2009). Natural facial motion enhances cortical responses to faces. Experimental brain research, 194, 465–475.
Swartz, J. R., Graham-Bermann, S. A., Mogg, K., Bradley, B. P., & Monk, C. S. (2011). Attention bias to emotional faces in young children exposed to intimate partner violence. Journal of Child & Adolescent Trauma, 4, 109–122.
Thomas, K. M., Drevets, W. C., Whalen, P. J., Eccard, C. H., Dahl, R. E., Ryan, N. D., & Casey, B. J. (2001). Amygdala response to facial expressions in children and adults. Biological Psychiatry, 49(4), 309–316.
Thornton, I. M., & Kourtzi, Z. (2002). A matching advantage for dynamic human faces. Perception, 31(1), 113–132.
Tottenham, N., Tanaka, J. W., Leon, A. C., McCarry, T., Nurse, M., Hare, T. A., & Nelson, C. (2009). The NimStim set of facial expressions: Judgments from untrained research participants. Psychiatry Research, 168(3), 242–249.
Tukey, J. W. (1977). Exploratory Data Analysis, 2, 131–160.
Uono, S., Sato, W., & Toichi, M. (2010). Brief report: Representational momentum for dynamic facial expressions in pervasive developmental disorder. Journal of Autism and Developmental Disorders, 40, 371–377.
Vicari, S., Reilly, J. S., Pasqualetti, P., Vizzotto, A., & Caltagirone, C. (2000). Recognition of facial expressions of emotions in school-age children: The intersection of perceptual and semantic categories. Acta Paediatrica, 89, 836–845.
Wallraven, C., Breidt, M., Cunningham, D. W., & Bülthoff, H. H. (2008). Evaluating the perceptual realism of animated facial expressions. ACM Transactions on Applied Perception (TAP), 4(4), 1–20.
Walther, D., & Koch, C. (2006). Modeling attention to salient proto-objects. Neural Networks, 19(9), 1395–1407.
Zsido, A. N., Arato, N., Ihasz, V., Basler, J., Matuz-Budai, T., Inhof, O., … Coelho, C. M. (2021). “Finding an Emotional Face” revisited: Differences in own-age bias and the happiness superiority effect in children and young adults. Frontiers in Psychology, 12, 580565.
Funding
Open access funding provided by Università degli Studi di Firenze within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Additional information
Open practices statements
This study was not preregistered.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Ceccarini, F., Colpizzi, I. & Caudek, C. Age-dependent changes in the anger superiority effect: Evidence from a visual search task. Psychon Bull Rev (2024). https://doi.org/10.3758/s13423-023-02401-3
Accepted:
Published:
DOI: https://doi.org/10.3758/s13423-023-02401-3