
Abstract
For this research, we used a dual-task approach to investigate the involvement of working memory in following written instructions. In two experiments, participants read instructions to perform a series of actions on objects and then recalled the instructions either by spoken repetition or performance of the action sequence. Participants engaged in concurrent articulatory suppression, backward-counting, and spatial-tapping tasks during the presentation of the instructions, in order to disrupt the phonological-loop, central-executive, and visuospatial-sketchpad components of working memory, respectively. Recall accuracy was substantially disrupted by all three concurrent tasks, indicating that encoding and retaining verbal instructions depends on multiple components of working memory. The accuracy of recalling the instructions was greater when the actions were performed than when the instructions were repeated, and this advantage was unaffected by the concurrent tasks, suggesting that the benefit of enactment over oral repetition does not cost additional working memory resources.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Performing actions to command requires that a series of operational steps be memorized with the intention to subsequently carry them out, as is common in everyday activities. Many earlier studies have focused on instructions transmitted either verbally (De Renzi & Vignolo, 1962; Engle, Carullo, & Collins, 1991; Gathercole, Durling, Evans, Jeffcock, & Stone, 2008; Kaplan & White, 1980; Kim, Bayles, & Beeson, 2008; Lesser, 1976) or through demonstration (Meltzoff & Prinz, 2002). Although written instructions are commonly encountered in daily life, the cognitive processes underpinning this mode of directing behavior have been less intensively investigated. This form of instruction is the focus of the present research.
The ability to follow instructions is closely related to the capacity to temporarily hold and manipulate information, an ability known as working memory (WM; Brener, 1940; Engle et al., 1991; Gathercole et al., 2008). The link was first noted by Brener, who found correlations between performance accuracy for simple instructions and digit span, a measure of short-term memory. The token test, which involves the execution of a series of actions upon oral commands—for instance, “after picking up the green rectangle, touch the white circle” (De Renzi & Vignolo, 1962)—was also found to be significantly correlated with verbal, visual, and motor aspects of short-term memory (Lesser, 1976; Wold & Reinvang, 1990), though as this test was developed to discriminate subtle oral comprehension difficulties in aphasic patients, grammatical complexity also varied with the length of the instructions.
The ability to successfully encode and act on instructions is particularly important in educational settings, with children with poor WM showing particular difficulty remembering and following classroom-based instruction (Gathercole, Lamont, & Alloway, 2006). In line with this finding, Engle et al. (1991) found positive correlations between WM capacity and children’s ability to manually implement spoken instructions analogous to those often encountered in classrooms. Gathercole et al. (2008) reported similar findings in 5-year-old children using spoken instructions such as “touch the red pencil, then pick up the blue ruler and put it in the black box,” and they also found that children were substantially better at enacting than at verbally repeating such instructions. Gathercole et al. (2008) speculated that this arises from the formation of a motoric or spatial representation linking objects to physical movements. A similar advantage has also been observed in young adults, using written instructions (Koriat, Ben-Zur, & Nussbaum, 1990).
In the present work, we used a dual-task methodology to explore how the multicomponent model of WM (Baddeley, 2000; Baddeley & Hitch, 1974) might contribute to encoding instructions for enactment versus verbal recall in a healthy young adult population. Constructing and storing detailed action plans may be an effortful process, possibly engaging the central executive, a limited-capacity resource responsible for the attentional control of WM (Baddeley, 1996, 2007). This might contribute to several key processes in remembering instructions—for example, dividing attention between reading instructions and monitoring the locations of relevant objects, associating specific movements with objects, and keeping track of task progress (Gathercole & Alloway, 2008). More generally, the construction of a spatial/motoric representation of instruction sequences in the action condition may be attentionally demanding. This is supported by the higher correlations between instruction performance and backward digit recall (which loads on both verbal storage and the central executive) than forward digit recall (depending primarily on verbal storage) that were observed by Gathercole et al. (2008) in 5-year-old children. We therefore predicted that concurrent backward counting, a task widely used to disrupt this component of WM (Allen, Baddeley, & Hitch, 2006; Baddeley, Hitch, & Allen, 2009), would lead to reduced accuracy in general, but also have a relatively larger adverse effect on action than on verbal recall.
The visuospatial-sketchpad component, providing visual and spatial storage and incorporating a spatial maintenance mechanism (Logie, 1995), may also be important. This component may maintain visual codes of written words during reading (Logie, 2003), and spatial/motoric representations of the action sequences (Gathercole et al., 2008). If so, disruption by a complex spatial-tapping activity should particularly impair the performance of instructions. In contrast, when the task simply involves verbal repetition, the storage of a phonological representation of the sentence may be sufficient. According to Baddeley (1986), verbal STM is based on a short-term store (the phonological loop) supplemented by a subvocal rehearsal mechanism that can recode visual information and offset decay. The loop is also involved in integrating information across saccades during reading (Rayner, 1998). It was predicted that disrupting the phonological loop via articulatory suppression (the repetition of irrelevant digits during encoding) should particularly impair the accuracy of verbal recall.
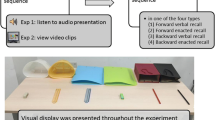
In the present experiments, we investigated how these WM subcomponents may contribute to the recall of instructions. In each of two experiments, participants read a sentence describing a series of action commands involving operations upon different colored objects, such as “push the black pencil and spin the green rubber, then pick up the red pencil and put it into the blue folder and touch the white bag.” At test, participants either performed the instructions on objects placed in front them or recalled the instructions aloud. In Experiment 1, we used the dual-task methodology to examine the contributions of the phonological loop and the central executive during encoding, whereas in Experiment 2 we compared verbal and visuospatial WM.
Experiment 1
Method
Participants
A group of 24 native English speakers 18 to 28 years of age (20 females, four males), all students at the University of York, took part in exchange for course credit or payment.
Materials
The object set consisted of 12 objects, including six smaller items (yellow ruler, blue ruler, white eraser, green eraser, red pencil, and black pencil) and six containers (black box, red box, yellow bag, white bag, blue folder, and green folder). We used five types of movement (touch, pick up . . . put it into, push, and spin). Following pilot work, each instruction contained five action phrases, with each phrase containing a movement, a color, and an object. No repetition of objects was permitted within an instruction sequence, and adjacent objects in the sequence always featured different colors—for instance, “push red box, pick up black pencil, put it into yellow bag, touch red pencil, spin blue ruler.” Three sets of 12 instruction sequences were created, and these were implemented in counterbalanced order for each participant, balanced across each concurrent task condition. Three practice sets containing six trials (two for each condition) were also prepared. Randomly generated three-digit numbers were used for each of the articulatory suppression and backward counting trials.
All objects were placed on a 146-cm (length) × 75-cm (width) × 71-cm (height) desk, with object location varying randomly between trials. A monitor displaying the written instructions was placed behind the objects (see Fig. 1).

Design and procedure
In a 3 × 2 mixed design, concurrent task was a within-subjects variable (baseline vs. articulatory suppression vs. backward counting), and recall type was a between-subjects variable (verbal vs. enactment recall). The order of the concurrent task conditions was counterbalanced between participants.
Each participant carried out the six-trial practice for all conditions, before commencing the test trials. In all conditions, the entire instructional sequence (containing five action segments) was simultaneously presented on screen in Times New Roman font, size 16, for 13 s. Each action segment appeared on a different line, aligned to the screen center. This was followed by a 1-s blank-screen delay and then a beep sound indicating recall. For articulatory suppression, participants first saw a three-digit number (e.g., 358) at screen center (same font type and size as the instructions) for 3 s and began repeating it continuously, at a paced speed of 2 s per cycle, through instruction presentation to the point of recall. The backward counting procedure was similar, except that participants counted in decrements of two.
According to the assigned groups, participants either repeated the instructions back (verbal recall) or performed the actions (enactment recall), with the experimenter recording these responses. At the end of each trial, the experimenter changed the locations of objects randomly on the table while the participants closed their eyes.
Results and discussion
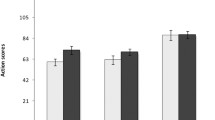
For both the verbal and enactment recall condition, the dependent variable was the mean number of correct actions (including movement, object color, and object identity) per instruction sequence. We defined an action as a “chunk” of elements containing items and movement, with recall being scored as correct only when the combination of movement, color, object, and ordinal position was accurately produced. This response metric had been used by Gathercole et al. (2008) to define span performance on this task. The means and standard errors are illustrated in Fig. 2.

Mean correct recall of actions (with standard errors) as a function of concurrent task and type of recall in Experiment 1. Note that the dependent variable was the mean number of correct actions per instruction sequence
A 3 × 2 (Concurrent Task × Recall Type) analysis of variance (ANOVA) revealed significant main effects of concurrent task, F(2, 44) = 61.017, MSE = 0.271, p < .001, η p 2 = .735, and recall type, F(1, 22) = 12.509, MSE = 0.219, p = .002, η p 2 = .362, with enactment recall being superior to verbal recall. No significant interaction was apparent between concurrent task and recall type, F(2, 44) = 0.014, MSE = 0.271, p = .986, η p 2 = .001. The effects of both articulatory suppression, F(1, 22) = 11.511, MSE = 0.547, p = .003, η p 2 = .344, and backward counting, F(1, 22) = 56.894, MSE = 0.520, p < .001, η p 2 = .721, were found to be significant, but we observed no interactions with recall type: suppression, F(1, 22) < 0.001, MSE = 0.547, p = .998, η p 2 = .001; backward counting, F(1, 22) = 0.021, MSE = 0.520, p = .887, η p 2 = .001.
Therefore, we obtained three principal findings in Experiment 1. First, the disruptive effects of articulatory suppression and backward counting were consistent with the involvement of the phonological loop and central executive components of WM in encoding verbal sequences (Baddeley et al., 2009; Gathercole et al., 2008). Second, the performance of recall by enactment was more accurate than recall by spoken repetition, replicating previous observations of an action advantage (Gathercole et al., 2008; Koriat et al., 1990). Crucially, because the concurrent tasks disrupted verbal and enacted recall equivalently, neither the central executive nor the phonological loop appeared to be the source of the enactment advantage.
Experiment 2
The purpose of Experiment 2 was to explore the involvement of a further component of the Baddeley and Hitch (1974) WM model, the visuospatial sketchpad, in following instructions. A complex spatial-tapping activity adapted from the Corsi-block task (Corsi, 1972; Milner, 1971) was employed as a dual task to disrupt the operation of the visuospatial sketchpad. The original Corsi task involves participants repeating the sequence in which blocks are tapped by the experimenter. In the present experiment, participants were required only to tap three blocks in sequence, to minimize the involvement of executive resources that are required by longer sequences (Vandierendonck, Kemps, Fastame, & Szmalec, 2004). The tapping pattern varied from trial to trial so that it would not become an automatic procedural-memory task. Research has shown that complex tapping configurations involve greater spatial demands than do simple configurations (Busch, Farrell, Lisdahl-Medina, & Krikorian, 2005); hence, the tapping patterns were designed to ensure substantial spatial interference.
An articulatory suppression condition was also included in order to directly compare the contributions of the phonological loop and visuospatial WM. As in Experiment 1, suppression involved retaining and verbally repeating three digits, whereas tapping required maintaining and tapping three locations. Articulation and tapping rates were equated across the two conditions, at 2 s per cycle.
We investigated two hypotheses. First, as spatial coding may contribute to the process of representing instructions in a 3-D task environment, and as Corsi-block tapping is assumed to disrupt this coding, the tapping should also impair subsequent recall of the instructions. The remaining two hypotheses, as in Experiment 1, were that superior recall performance should be observed for enactment than for oral repetition, and that significant articulatory suppression effects would be observed. Although both verbal and visuospatial WM may be important in remembering verbal instructions involving actions in an environment rich in visual and spatial cues, no specific hypotheses were made regarding the relative sizes of their contributions to each response condition.
Method
Participants
A further 36 native English speakers (28 females, eight males, 18 to 32 years of age), all students at the University of York, took part.
Materials
The same sequences of instructions were administered as in Experiment 1. For the practice and concurrent-task trials, 32 three-digit numbers were created, with the numbers for the tapping condition corresponding to three of the nine locations on the Corsi board. No tapping sequences involved three immediately adjacent locations. Thus, a tapping sequence might involve 3–2–8, but not 3–2–4 (see Fig. 1). Half of the digit sets required a clockwise tapping pattern, and the other half required counterclockwise tapping, randomly intermixed.
The arrangement of the objects and the computer screen was equivalent to that in the previous experiment, except that a Corsi-block board (28 × 23 cm), taken from the Block Recall subtest of the Working Memory Test Battery for Children (Pickering & Gathercole, 2001), was fixed under the table and hidden from the view of the participants (see Fig. 1). The numbers on the blocks faced the participants in order to allow rapid identification during the initial tapping phase.
Design and procedure
In a 3 × 2 mixed design, concurrent task was the within-subjects variable (baseline vs. articulatory suppression vs. tapping), and recall type was the between-subjects variable (verbal vs. enactment recall).
Each participant completed three conditions. The procedure was equivalent to that of Experiment 1, with the exception that the to-be-articulated numbers in the suppression conditions were presented for 4 s, to match the preparation time in the tapping conditions.
In the tapping conditions, upon seeing a three-number digit, the participant first located the corresponding tapping blocks on the Corsi-block board and began tapping at the paced rate using a fixed hand configuration (outstretched index finger with the hand shaped into a fist). Participants were allowed to view the blocks during the first round of tapping. After the experimenter ascertained that the correct blocks had been tapped, subsequent tapping continued without viewing throughout the instruction presentation, until the beep sound indicated recall.
Results and discussion
The mean accuracy and standard errors are illustrated in Fig. 3. A 3 × 2 (Concurrent Task × Recall Type) ANOVA revealed significant effects of concurrent task, F(2, 68) = 41.463, MSE = 0.239, p < .001, η p 2 = .549, and recall type, F(1, 34) = 5.176, MSE = 0.268, p = .029, η p 2 = .297, with enactment being superior to verbal recall. We found no significant interaction between concurrent task and recall type, F(2, 68) = 0.230, MSE = 0.239, p = .795, η p 2 = .007. The effects of both articulatory suppression and tapping were significant—F(1, 34) = 22.853, MSE = 0.403, p < .001, η p 2 = .402, and F(1, 34) = 65.113, MSE = 0.607, p < .001, η p 2 = .657, respectively—but neither interacted with recall type: suppression, F(1, 34) = 0.365, MSE = 0.403, p = .550, η p 2 = .011; tapping, F(1, 34) = 0.297, MSE = 0.607, p = .589, η p 2 = .009. A direct comparison of the two concurrent-task conditions indicated significantly better performance after articulatory suppression than after tapping, t(35) = 5.088, p < .001.

Mean correct recall of actions (with standard errors) as a function of concurrent task and type of recall in Experiment 2. Note that the dependent variable was the mean number of correct actions per instruction sequence
As in Experiment 1, the effect of articulatory suppression indicated that remembering written instructions loads on the phonological loop, although the relatively larger effect of tapping suggests a more important role for spatial coding in representing instructions in a 3-D task environment. This reflects the possibility that memorizing locations is an efficient and economic way of encoding information in a rich visual environment, possibly through the use of object locations as temporary markers during the course of sequence encoding (Gathercole et al., 2008), and/or as deictic pointers during retrieval (Spivey, Richardson, & Fitneva, 2004). However, whereas the enactment advantage was replicated in this experiment, the equivalent effects of the concurrent tasks on verbal and enactment recall suggest that this advantage was not attributable to these aspects of WM.
General discussion
Both dual-task experiments provided substantial evidence that the ability to recall instructions presented in written form depends on WM resources. Performance was disrupted by concurrent activities that taxed the central executive and the visuospatial sketchpad, and, to a lesser extent, the phonological loop. These findings substantiate previous evidence that WM is closely related to the ability to encode meaningful verbal sequences, for the purposes of either verbal recall (Baddeley et al., 2009) or instruction implementation (Brener, 1940; Engle et al., 1991; Gathercole et al., 2008; Kim et al., 2008). Thus, participants verbally recode visually presented sequences to draw on phonological storage, and also utilize visual and spatial cues in the environment (e.g., objects and their spatial locations) to facilitate memory performance, with accurate development of these representations requiring central executive support.
Accuracy was consistently higher when participants performed rather than verbally recalled instructions, in line with previous findings (Gathercole et al., 2008; Koriat et al., 1990). This difference emerged despite identical methods of instruction presentation, object arrays, serial recall requirements, and response scoring, and so it cannot be attributed to differences of procedure or scoring metric. Crucially, this enactment advantage in following instructions is not mediated by the central-executive, visuospatial-sketchpad, or phonological-loop components of the Baddeley and Hitch (1974) WM model, as concurrent tasks that are assumed to disrupt the operation of these different components left the advantage intact. This suggests that the benefit of enactment over oral repetition of verbal materials does not require additional WM resources during encoding, and that this effect may be relatively automatic in nature. For example, action words have been shown to activate the premotor and motor areas of the brain in a passive-reading task (Hauk, Johnsrude, & Pulvermüller, 2004). Thus, instructions containing action phrases may prime motor programming for those actions without tapping WM resources. These activated motor schemas would then be exploited during enactment, but perhaps be less useful for verbal recall. Although it is obviously speculative, this possibility is tentatively supported by the more reliable and consistent enactment effect on movement than on color or object (see the Appendix).
Nevertheless, it should be noted that the enactment advantage has been found to be related to WM capacity in young children (Gathercole et al., 2008). Although caution must be maintained when comparing experimental and individual-difference analyses (Logie, 2011), it may be that action planning and implementation follows a developmental trajectory, in that young children have to actively construct such representations in a process that is resource-demanding and reliant on WM (Wojcik, Allen, Brown, & Souchay, 2011). In contrast, in adults, although WM is still important in setting up any form of representation, these can be developed into an action plan for subsequent implementation relatively automatically. These suggestions of course remain speculative, and further research would be required to examine in more detail precisely how encoding for enactment might develop with age.
In summary, the present findings establish that multiple components of WM play significant roles in remembering and performing action sequences presented in written form. Moreover, we found that the benefit of recalling by enactment over oral repetition does not cost additional WM resources, implying that an automatic process is involved. This observation of cognitive effects that are apparently independent of WM is nevertheless valuable, as negative results can often be useful for informing the development of models (Baddeley, 2012). Future study should continue to explore the cognitive and neural mechanisms underlying the enactment advantage. The findings have practical implications for professionals such as teachers and designers, who should consider the memory loads involved in instructions that require sequences of actions, and who should take advantage of the “cost-free” benefit of enactment, at least in young adults.
References
Allen, R. J., Baddeley, A. D., & Hitch, G. J. (2006). Is the binding of visual features in working memory resource-demanding? Journal of Experimental Psychology. General, 135, 298–313. doi:10.1037/0096-3445.135.2.298
Baddeley, A. (1986). Working memory. Oxford, UK: Oxford University Press, Clarendon Press.
Baddeley, A. D. (1996). Exploring the central executive. Quarterly Journal of Experimental Psychology, 49A, 5–28. doi:10.1080/027249896392784
Baddeley, A. D. (2000). The episodic buffer: A new component of working memory? Trends in Cognitive Sciences, 4, 417–423. doi:10.1016/S1364-6613(00)01538-2
Baddeley, A. D. (2007). Working memory, thought, and action. New York, NY: Oxford University Press.
Baddeley, A. (2012). Working memory: Theories, models, and controversies. Annual Review of Psychology, 63, 1–29. doi:10.1146/annurev-psych-120710-100422
Baddeley, A. D., & Hitch, G. J. (1974). Working memory. In G. H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47–89). New York, NY: Academic Press.
Baddeley, A. D., Hitch, G. J., & Allen, R. J. (2009). Working memory and binding in sentence recall. Journal of Memory and Language, 61, 438–456.
Brener, R. (1940). An experimental investigation of memory span. Journal of Experimental Psychology, 26, 467–482.
Busch, R. M., Farrell, K., Lisdahl-Medina, K., & Krikorian, R. (2005). Corsi block-tapping task performance as a function of path configuration. Journal of Clinical and Experimental Neuropsychology, 27, 127–134.
Corsi, P. M. (1972). Human memory and the medial temporal region of the brain. Dissertation Abstracts International, 34(2-B), 819.
De Renzi, E., & Vignolo, L. (1962). The token test: A sensitive test to detect receptive disturbances in aphasics. Brain, 85, 665–678.
Engle, R. W., Carullo, J. J., & Collins, K. W. (1991). Individual differences in working memory for comprehension and following directions. The Journal of Educational Research, 84, 253–262.
Gathercole, S. E., & Alloway, T. P. (2008). Working memory and learning: A guide for teachers. London, UK: Sage.
Gathercole, S. E., Durling, E., Evans, M., Jeffcock, S., & Stone, S. (2008). Working memory abilities and children’s performance in laboratory analogues of classroom activities. Applied Cognitive Psychology, 22, 1019–1037.
Gathercole, S. E., Lamont, E., & Alloway, T. P. (2006). Working memory in the classroom. In S. Pickering (Ed.), Working memory and education (pp. 219–240). London, UK: Academic Press.
Hauk, O., Johnsrude, I., & Pulvermüller, F. (2004). Somatotopic representation of action words in human motor and premotor cortex. Neuron, 41, 301–307. doi:10.1016/S0896-6273(03)00838-9
Kaplan, C., & White, M. (1980). Children’s direction-following behavior in Grades K–5. The Journal of Educational Research, 74, 43–48.
Kim, E. S., Bayles, K. A., & Beeson, P. M. (2008). Instruction processing in young and older adults: Contributions of memory span. Aphasiology, 22, 753–762.
Koriat, A., Ben-Zur, H., & Nussbaum, A. (1990). Encoding information for future action: Memory for to-be-performed tasks versus memory for to-be-recalled tasks. Memory & Cognition, 18, 568–578. doi:10.3758/BF03197099
Lesser, R. (1976). Verbal and non-verbal memory components in the token test. Neuropsychologia, 14, 79–85.
Logie, R. H. (1995). Visuo-spatial working memory. Hove, UK:Lawrence Erlbaum Associates, Ltd.
Logie, R. H. (2003). Spatial and visual working memory: A mental workspace. In D. Irwin & B. H. Ross (Eds.), The psychology of learning and motivation: Advances in research and theory (Vol. 42, pp. 37–78). Amsterdam, The Netherlands: Academic Press.
Logie, R. H. (2011). The functional organization and capacity limits of working memory. Current Directions in Psychological Science, 20, 240–245.
Meltzoff, A. N., & Prinz, W. (2002). The imitative mind. Cambridge, UK: Cambridge University Press.
Milner, B. (1971). Interhemispheric differences in the localization of psychological processes in man. British Medical Bulletin, 27, 272–277.
Pickering, S., & Gathercole, S. E. (2001). Working memory test battery for children. London, UK: Pearson Assessment.
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research. Psychological Bulletin, 124, 372–422. doi:10.1037/0033-2909.124.3.372
Spivey, M., Richardson, D. C., & Fitneva, S. A. (2004). Thinking outside the brain: Spatial indices to visual and linguistic information. In J. M. Henderson & F. Ferreira (Eds.), The interface of language, vision and action: Eye movements and the visual world (pp. 161–189). New York, NY: Psychology press.
Vandierendonck, A., Kemps, E., Fastame, M., & Szmalec, A. (2004). Working memory components of the Corsi blocks task. British Journal of Psychology, 95, 57–79.
Wojcik, D. Z., Allen, R. J., Brown, C., & Souchay, C. (2011). Memory for actions in autism spectrum disorder. Memory, 19, 549–558.
Wold, A. H., & Reinvang, I. (1990). The relation between integration, sequence of information, short-term memory, and token test performance of aphasic subjects. Journal of Communication Disorders, 23, 31–59.
Author note
This work was completed as part of the first author’s PhD thesis at the University of York, and was funded by a Department of Psychology scholarship and an overseas studentship sponsored by the University of York.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
To further investigate the nature of the enactment advantage, its effects on the elements of an action were examined. Each action contained three elements: movement, color, and object. Accuracy was calculated independently for each element, with elements being scored as correct if they were recalled in the appropriate serial position.
Given the different concurrent-task manipulations applied in the two experiments, the enactment effect across different elements was only examined in the baseline condition (note that no significant concurrent task by enactment interactions emerged for any element type, ps > .1). As can be seen from Table 1, in both experiments the enactment advantage was significant for the movement element, marginally nonsignificant for object, and not significant for color.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Yang, T., Gathercole, S.E. & Allen, R.J. Benefit of enactment over oral repetition of verbal instruction does not require additional working memory during encoding. Psychon Bull Rev 21, 186–192 (2014). https://doi.org/10.3758/s13423-013-0471-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13423-013-0471-7