
Abstract
To-be-memorized information in verbal working memory (WM) can be presented sequentially, like in oral language, and simultaneously, like in written language. Few studies have addressed the importance and implications for verbal WM processing of these two presentation modes. While sequential presentation may favor discrete, temporal encoding processes, simultaneous presentation may favor spatial encoding processes. We compared immediate serial recall tasks for sequential versus simultaneous word list presentation with a specific focus on serial position curves of recall performance, transposition gradients, and the nature of serial order errors. First, we observed higher recall performance in the simultaneous compared to the sequential conditions, with a particularly large effect at end-of-list items. Moreover, results showed more transposition errors between non-adjacent items for the sequential condition, as well as more omission errors especially for start-of-list items. This observation can be explained in terms of differences in refreshing opportunities for start-of-list items during encoding between conditions. This study shows that the presentation mode of sequential material can have a significant impact on verbal WM performance, with an advantage for simultaneous encoding of sequence information.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
To date, the mechanisms underlying encoding in working memory (WM) have been widely investigated but several questions remain unanswered, and the way memoranda is encoded in WM is still controversial. Tan and Ward (2008) examined to what extent the time available for rehearsal during an immediate serial recall task influences the way memoranda are maintained and structured by the participants. They observed that at fast presentation rates (1 s/word), participants had little time to rehearse and generally used a fixed rehearsal strategy, i.e., they solely rehearsed the most recently presented item (e.g., for ABC, they rehearsed “A” or “AAA” after the presentation of A, then “B” or “BBB” after the presentation of B, and so on). At medium (2.5 s/word) and slow (5 s/word) rates, participants essentially used a cumulative rehearsal strategy (e.g., “ABC ABC ABC”), especially for the early items of the list. Moreover, it was observed that toward the end of the list at serial positions 5 and 6, cumulative rehearsal decreased, and fixed rehearsal increased. These observations suggest that the encoding strategies used in immediate serial recall tasks are strongly dependent on the time available for rehearsal. In a recent study, Barrouillet et al. (2021) suggested that rehearsal is not the only mechanism involved in memory encoding, but that several systems of maintenance (i.e., the phonological loop plus the central attentional system) can come into play during complex memory measures such as maxispan tasks. The combined use of both systems has been shown to allow the maintenance of at least eight items (four items via the phonological loop plus four items via the attentional system). This finding suggests that commonly used simple span measures tend to underestimate the capacity of verbal WM, because they do not force participants to engage multiple maintenance strategies during encoding. Previous studies (Lewandowsky & Oberauer, 2015; Souza & Oberauer, 2018), on the other hand, have questioned the beneficial effect of phonological rehearsal on immediate serial recall. Indeed, in their study, Lewandowsky and Oberauer did not find convincing evidence for a favorable effect of rehearsal on recall performance. This finding has been confirmed by Souza and Oberauer (2018) who observed no significant difference in performance in a condition in which participants were instructed to rehearse memoranda overtly and in an articulatory suppression condition that blocked rehearsal of memoranda. All these studies show that, to date, it is still unclear how sequence material is encoded in WM and what systems support encoding of sequence material in WM. Moreover, when reviewing the literature on serial order encoding, it appears that this mechanism has been extensively studied in the area of memory and perception separately but there has been little integration across areas (Logan, 2021).
In the WM literature, contextual/temporal models of serial order WM consider that information in WM is encoded via dynamic signals that change over time, meaning that each item of a sequence is associated with a different state of the signal (Brown et al., 2000; Burgess & Hitch, 1999, 2006; Hartley et al., 2016; Henson, 1998; Hurlstone et al., 2014). These models are particularly relevant for a sequential encoding mode as adopted in commonly used memory-span tasks and predict a specific transposition gradient, with serial order errors being more likely for temporally close items (i.e., adjacent items) as they will be associated with a more similar contextual/temporal signal. These models are more difficult to apply to a simultaneous presentation mode as frequently used in visual WM studies or in perception tasks. We could, however, predict that according to these models, the entire sequence would be associated with the same contextual/temporal signal and hence coding of serial order information may be less precise, resulting in a flatter transposition gradient reflecting an increase in serial position exchange errors over non-adjacent serial positions. Another type of model that has been proposed involves spatial coding of serial position information (Abrahamse et al., 2014; De Belder et al., 2015; Ginsburg & Gevers, 2015; Guida et al., 2016; van Dijck et al., 2013; van Dijck & Fias, 2011) and may be particularly relevant for simultaneous encoding conditions. Van Dijck and colleagues have proposed the mental whiteboard hypothesis according to which each successive item is associated with a position on a mental horizontal line, organized from left to right (for populations with a left-to-right reading system; Guida et al., 2018), with early items being associated with leftward positions and final items with rightward positions. This implies that the serial position of items is recoded using a permanently available spatial grid enabling the parallel encoding of serial position. This mechanism would be facilitated by a simultaneous list-presentation condition in which items are already organized from left to right. In sum, based on these two hypotheses, a sequential presentation mode may favor discrete, temporal encoding processes, with one item being processed at a time. Moreover, each item may be associated with a distinct temporal signal, resulting in a steeper transposition gradient, while a simultaneous presentation mode may favor spatial encoding processes encouraging parallel processing of all list items and a flatter transposition gradient (Marcer, 1967).
Regarding perception, the question of how sequence material is encoded in memory has been extensively studied in the domain of reading (Grainger, 2018; Pegado & Grainger, 2021; Snell et al., 2017; Snell & Grainger, 2019). While some authors assume that written words of a sentence are processed one by one (i.e., sequentially) from left to right (Reichle et al., 1998, 2009), others suggest that word-order encoding during text reading occurs at least partly in parallel, that is, multiple words being processed simultaneously (McClelland & Mozer, 1986; Mozer, 1983; Snell et al., 2017; Snell & Grainger, 2019). According to the sequential hypothesis, a sequential system prevents the reader from incorrectly encoding the order of words in a sentence (Reichle et al., 1998, 2009). However, recent evidence suggests that word-order information is not encoded as precisely as a serial system predicts (e.g., Mirault et al., 2018). In response to these recent findings, Snell et al. (2018) proposed a model of reading, OB1-reader, in which word order is controlled by the interaction between location-independent activation of words and sentence-level representations in WM. According to this model, “feedback is provided to individual words based on top-down syntactic and semantic expectations” (Snell & Grainger, 2019, p. 6). That is, when readers encounter a determiner at position 1, they may expect a noun at position 2, and so on. Thus, according to these authors, the reader keeps track of the position of words in a sentence by associating word identities with spatiotopic coordinates in WM. This implies that sentence processing takes place in WM by involving several words of the sentence simultaneously and not one word at a time.
Serial order encoding having been examined separately for these two research areas, it remains unclear whether the way serial order information is encoded during perceptual tasks such as reading (where memoranda are commonly presented simultaneously) differs from the way it is encoded during WM tasks such as immediate serial recall (where memoranda are commonly presented one-by-one at the center of the screen). In a recent study, Logan (2021) has examined this question by presenting the participants with a whole report task (measuring perception) and an immediate serial recall task (measuring WM performance). In these tasks, participants were presented with sequences of letters that were displayed for 100ms and 1,000ms respectively. In the whole report task, participants were told to begin typing as soon as the first item appeared at the screen, while they had to wait until the sequence disappeared from the screen to begin typing in the immediate serial recall task. Analyses revealed that serial order in perception and memory are governed by the same underlying mechanism. In that study, sequences were presented simultaneously in both tasks. However, as seen earlier, new information can enter WM either sequentially, when presented auditorily (e.g., as in common WM tasks), or simultaneously, when presented visually (e.g., as in reading). Thus, although it seems that the way information enters WM has major implications on the mechanisms used to structure and maintain the memoranda, few studies have examined this question in a specific manner by directly comparing a sequential versus simultaneous presentation mode. While numerous research studies exist comparing recall performance on sequentially versus simultaneously presented sequences of e.g., colors or objects in visual WM or sequences of faces in long-term memory (Ahmad et al., 2017; Bhatarah et al., 2008; Carretti et al., 2013; Finley et al., 2015; Mammarella et al., 2006; Ricker & Cowan, 2014), little work has been done on the serial order encoding of linguistic material such as written and spoken words or letters. Furthermore, many studies still try to compare performance on WM tasks involving linguistic material but using different presentation modes. However, encoding spoken letters, for example, differs fundamentally from encoding seen letters and the encoding of sequentially presented letters differs fundamentally from encoding simultaneously presented letters (Marcer, 1967). Also, visual material can either be presented sequentially or simultaneously, while auditory material can only be presented sequentially. Yet, when having to encode sequentially presented material there might be far less chance to encode it as a single chunk compared to when all items are presented simultaneously (Marcer, 1967).
Interestingly, one of the few studies comparing sequential versus simultaneous presentation modes (Frick, 1985) has shown that simultaneously presented sequences naturally lead to a visual encoding of memoranda, while sequentially presented material rather leads to an auditory encoding. More precisely, in his study, Frick observed that a sequential presentation increased auditory errors and reduced visual errors, while the opposite was true for the simultaneous condition. Frick (p. 354) explains these findings by suggesting that “a sequential presentation represents the order of the items temporally [like in auditory material (e.g., spoken language)], whereas a simultaneous presentation represents the order of the items spatially [like in visual material (e.g., written language)]”. This assumption is in line with the contextual/temporal and spatial (spatiotopic) models of WM and reading presented earlier. In another study comparing sequential versus simultaneous list presentation (Battacchi et al., 1990), it has been shown that when sequences of visual stimuli are presented sequentially in a fixed location, small recency effects are generally observed. On the contrary, when stimuli are distributed over space, as e.g., in simultaneous list presentations, the observed recency effect is much larger. However, again, findings are controversial, as LeCompte (1992) did not find an enhanced recency effect when stimuli are distributed over space, even though they meticulously followed the method used by Battacchi et al. Moreover, some studies have shown that visual information (e.g., letters or shapes), when presented simultaneously, leads to better recall performance compared to when it is presented sequentially, that is, one item at a time (Crowder, 1966; Dalmaijer et al., 2018; Marcer, 1967). Marcer observed that presenting all stimuli simultaneously encouraged participants to encode the entire sequence as a single chunk, which in turn led to more similar recall performance between positions (i.e., flatter serial position curves) compared to situations in which stimuli are presented sequentially, rather encouraging the encoding of each stimulus as a single chunk and leading to differences in terms of recall performance per position (e.g., primacy and/or recency effects). These findings suggest that the presentation mode not only affects overall recall performance but more specifically the very nature of the encoding and maintenance of serial order information. In sum, the observed advantage for simultaneous presentation has been suggested to involve the spontaneous use of chunking mechanisms facilitated by the left-to-right spatial arrangement of the simultaneous list of items (Crowder, 1966; Dalmaijer et al., 2018; Marcer, 1967).
Given the contradictory findings obtained in prior research, in the present study we aim to bridge the gaps identified in the WM literature by trying to understand whether the encoding of visually presented verbal sequence material in WM is affected by the presentation mode, that is, when memoranda are presented sequentially (like in verbal WM tasks) versus simultaneously (like in perspective tasks such as reading). We further provide a detailed examination of serial recall performance in terms of serial position curves, transposition gradients, input-output position matrix, and transition matrix between consecutive items.
In this study, we compared immediate serial recall performance for sequentially or simultaneously presented lists of words. Based on recent WM models, we hypothesized that the sequential presentation condition should encourage temporal encoding (i.e., one item at a time), resulting in steep transposition gradients with few serial position exchanges over non-adjacent items. We hypothesized that the simultaneous presentation condition should encourage a spatial encoding resulting in flatter transposition gradients. The latter prediction is also supported by recent findings of the reading literature (Grainger, 2018; Grainger et al., 2014; Snell et al., 2017) showing that the default strategy, under limited exposure durations, might be to encode all list items in parallel, leading furthermore to an overall advantage of encoding and maintaining simultaneously presented lists over sequentially presented lists. Indeed, when list items are spatially encoded on a mental line, all list items are available at the same time, allowing each item to be processed several times, hence strengthening its representation in WM.
Method
Participants
We recruited 116 adults via Prolific (www.prolific.ac), a platform for online recruitment of participants in behavioral studies. To determine the number of participants, we used the BFDA (Bayes Factor Design Analysis) package (Schönbrodt, 2016) implemented in R (Version 3.6.1). This analysis showed that if the effect of interest exists, the minimal sample size needed for reaching minimal evidence (BF10 = 3) in favor of the effect in 95% of simulated samples was N = 60. For this sensitivity analysis, we assumed a medium effect size of Cohen’s d = 0.5. Three participants had to be excluded due to non-compliance with task instructions. Data were retained for a total of 113 participants (Mage: 28.15 years, SD: 8.95, range 18–64 years, 47 females, 62 males, four “other”). All participants had to be native French-speakers and their French proficiency was checked using Lextale (Brysbaert, 2013), a receptive vocabulary test. The study was approved by the Comité de Protection des Personnes SUD-EST IV and was performed in accordance with the ethical standards described in the Declaration of Helsinki (1964). All participants gave their written informed consent before their inclusion in the study and received monetary compensation (£8/h).
Materials and procedure
Data collection took place online via the experiment builder LabVanced (Finger et al., 2017).
Lextale
We used the French version of Lextale (Brysbaert, 2013) developed to measure language proficiency in French from very little knowledge to adult native-speaker level proficiency. The test contains words and nonwords selected from the Lexique 3.72 project (New et al., 2004) and the French Lexicon Project (Ferrand et al., 2010). It is composed of 56 French words of varying difficulty and from different lexical frequency levels and 28 nonwords matched for phonological structure. In the present study, words and nonwords were presented in random order. Each (non)word was displayed on the center of the screen and participants had to make a yes/no decision to all items by pressing “O” (for “oui” [yes]) as a response to an existing word and “N” (for “non” [no]) as a response to a nonword. The dependent variable was the proportion of correct responses.
Immediate serial recall task
This task was composed of two lists of 20 sequences, containing each six frequent, monosyllabic, and semantically unrelated nouns (i.e., 120 nouns per list). Two consecutive nouns of a sequence could not start with the same letter. The nouns were selected from the database Lexique 3.83 (New et al., 2004) and were of high lexical frequency (freqlemfilm2 variable; range 26–1,031 per million words). The two lists were matched for lexical frequency (MList1: 160.55, MList2: 157.78, p = .92) from the data base Lexique 3.83 (see Appendix for the word lists). The two lists were counterbalanced across conditions (i.e., if List 1 was presented in the simultaneous condition, List 2 was presented in the sequential condition).
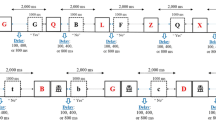
Participants performed two immediate serial recall tasks. In a first condition (see Fig. 1a), the sequential condition, the items composing the sequences were presented one by one on the center of the screen. Each item was presented for a total of 750 ms. In the second condition (see Fig. 1b), the simultaneous condition, items were presented all at the same time, structured from left to right on the screen. Each sequence was presented for a total of 4,500 ms, which corresponds to 6 × 750 ms in order to hold the total time of sequence presentation comparable between conditions. Each sequence was immediately followed by a mask. Participants had to recall each word in its correct serial position by typing it into an answer box centered on the bottom of the screen. Participants had to press “enter” to type the next word of the sequence and to proceed to the next trial. The order of conditions was counterbalanced across participants. For each condition, we calculated a serial order score (number of items recalled in correct serial position) and an item score (number of items recalled regardless of serial position). Moreover, we computed transposition gradients on serial order errors for each participant and each condition by determining the number of negative displacements (items recalled ahead of their correct positions) and positive displacements (items recalled after their correct position). Taking the example of “time god day mom” recalled as “time mom god day”, “time” will result in a displacement score of 0 (no displacement), “mom” will result in a displacement score of -2, “god” will result in a displacement score of +1, and “day” will result in a displacement score of -1. Finally, we conducted detailed analyses on output order by computing an input-output position matrix representing the distribution of items recalled in the different output positions and an item-item transition matrix representing the distribution of transitions of successive pairs of responses. These analyses allowed us to obtain more precise information about the dynamics of serial order encoding and retrieval in both conditions.

a A typical trial for the sequential condition. b A typical trial for the simultaneous condition
The statistical analysis conducted in the present study adopted a Bayesian model comparison approach (Dienes, 2011, 2016; Wagenmakers, 2007; Wagenmakers et al., 2008). This approach directly compares the null hypothesis to the alternative hypothesis (i.e., the effect of interest) and assesses evidence for the null effect and the effect of interest simultaneously (Dienes, 2014). Results are interpreted using the Bayes factor (BF), which reflects the likelihood ratio of two compared models. The BF10 is used to determine the likelihood ratio of the alternative model relative to the null model. We relied on the guidelines proposed by Jeffreys (1961) for interpreting Bayes factors. A BF10 > 3 provides anecdotal evidence, a BF10 > 10 provides strong evidence, and a BF10 > 100 provides decisive evidence for the alternative hypothesis. All the analyses were conducted with the JASP software package (JASP Team, 2021), using default settings for Cauchy prior distribution (Wagenmakers et al., 2018).
Results
Table 1 shows the descriptive statistics of the Lextale and the immediate serial recall task.
We first compared overall recall performance between the sequential and simultaneous conditions by running a 2 (Condition: Sequential vs. Simultaneous) × 6 (Position: 1 to 6) Bayesian repeated-measures ANOVA on the serial order score as dependent variable (see Fig. 2). Results revealed decisive evidence for an effect of Condition (BF10 = 1.06e+23) with better performance for the simultaneous (M = .69, SD = .17) compared to the sequential condition (M = .55, SD = .17), decisive evidence for an effect of Position (BF10 = 4.89e+165), and decisive evidence for an interaction between Condition and Position (BF10 = 1.51e+6). Bayesian paired t-tests showed decisive evidence for an effect of Condition at all positions but with particularly large effects for end-of-list positions as well as position 2 (Position 1: BF10 = 1,120; Position 2: BF10 = 3.65e+22; Position 3: BF10 = 255,485; Position 4: BF10 = 715; Position 5: BF10 = 4.57e+12; Position 6: BF10 = 4.46e+11). Similar results were observed when considering the item score (see Fig. 3). Indeed, a 2 × 6 Bayesian repeated-measures ANOVA on the item score showed decisive evidence for an effect of Condition (BF10 = 3.02e+11) with again better performance for the simultaneous condition (M = .73, SD = .14) compared to the sequential condition (M = .63, SD = .14), decisive evidence for an effect of Position (BF10 = 6.57e+171), and decisive evidence for an interaction between Condition and Position (BF10 = 1.81e+6). Bayesian paired t-tests showed strong evidence for a difference at position 1 (BF10 = 32.95), decisive evidence for a difference at positions 2, 3, 5, and 6 (BF10 = 2.66e+17, BF10 = 201, BF10 = 1.84e+8, and BF10 = 6.54e+10 respectively), and no evidence for a difference at position 4 (BF10 = 0.63). Thus, item recall performance was higher in the simultaneous than in the sequential condition, and for all serial positions except for positions 4 where the effect was absent. In sum, we observed better recall performance for serial order and item recall in the simultaneous compared to the sequential condition and especially for end-of-list items.

Proportions correct per position for the serial order score. Error bars represent 95% confidence intervals

Proportions correct per position for the item score. Error bars represent 95% confidence intervals
Next, we examined the transposition gradients for serial order recall errors as a function of condition by running a 2 (Condition: Sequential vs. Simultaneous) × 11 (Transposition gradients: -5 to 5) Bayesian repeated-measures ANOVA (see Fig. 4). Results revealed no evidence for an effect of Condition (BF10 = 0.09), decisive evidence for an effect of Transposition (BF10 = 3.95e+124), and decisive evidence for an interaction between Condition and Transposition (BF10 = 2.41e+69). Analyses showed decisive evidence for a difference between conditions for displacements of -3, -1, 0, 1, and 3, with more transposition errors in the sequential compared to the simultaneous condition (see Table 2). Again, this interaction reveals more precise serial order encoding for the simultaneous compared to the sequential condition. Interestingly and as already reported earlier, we observed that items that were recalled in the wrong position were recalled close to their correct position in both conditions, but in contrast with our hypothesis, with more transposition errors between distant items (transposition errors of ± 3) in the sequential compared to the simultaneous condition. Thus, contrary to our hypothesis, we did not observe steeper transposition gradients in the sequential compared to the simultaneous condition, as the tendency for transposition errors to cluster around their correct position was more pronounced in the simultaneous condition.

Transposition gradients for each condition
Moreover, we examined how serial order errors are distributed over serial position in both conditions by running a 2 (Condition: Sequential vs. Simultaneous) × 6 (Position: 1 to 6) Bayesian repeated-measures ANOVA on transposition errors (see Fig. 5). In accordance with our previous findings, we again observed decisive evidence for an effect of Condition (BF10 = 1.45e+20), with more transposition errors in the sequential compared to the simultaneous condition, decisive evidence for an effect of Position (BF10 = 1.22e+54), with transposition errors increasing with serial position. We observed decisive evidence for an interaction between Condition and Position (BF10 = 547) with at least two times more transposition errors in the sequential (MPos1 = .011, MPos2 = .055, MPos3 = .090, MPos5 = .153) compared to the simultaneous condition (MPos1 = .004, MPos2 = .016, MPos3 = .038, MPos5 = .076) for all positions apart from positions 4 and 6 (MPos4 = .110, MPos6 = .106 and MPos4 = .062, MPos6 = .066 for the sequential and simultaneous condition, respectively), which are more comparable between conditions. These findings highlight more transposition errors in the sequential compared to the simultaneous condition and more transposition errors at the end of the sequence compared to the start of the sequence, especially in the sequential condition.

Proportion of transposition errors per position for the sequential and the simultaneous condition. Error bars represent 95% confidence intervals
We computed the same analysis for omission errors. A 2 (Condition: Sequential vs. Simultaneous) × 6 (Position: 1 to 6) Bayesian repeated-measures ANOVA on omission errors (see Fig. 6) revealed an effect of Condition (BF10 = 3.32e+8) with more omission errors in the sequential compared to the simultaneous condition, decisive evidence for an effect of Position (BF10 = 4.09e+168), with omission errors increasing with serial position for both conditions, and decisive evidence for an interaction between Condition and Position (BF10 = 7.66e+7). This interaction reveals a particularly large difference for positions 1 and 2 compared to the remaining positions between both conditions with mean proportions of omissions errors being about two times larger for the sequential condition (MPos1 = .031; MPos2 = .055) compared to the simultaneous condition (MPos1 = .013; MPos2 = .027).

Proportion of omission errors per position for the sequential and the simultaneous condition. Error bars represent 95% confidence intervals
Finally, in order to better understand the observed differences between conditions in terms of transposition gradients, we computed an input-output matrix for each condition (see Table 3), tabulating each input position by output position as done by Bhatarah et al. (2008). This table represents the number of items recalled at the different output positions (Howard & Kahana, 1999). In this table, “blank” refers either to an omission or to an intrusion error. As shown in Table 3 as well as in Figs. 7 and 8, typical transposition gradients are observed for all serial positions and both sequential and simultaneous conditions: When an item is recalled at the wrong position, it is most often recalled at the position directly following its expected position (e.g., serial position 1 recalled at serial position 2).

Distribution of words recalled by serial position and output position (OP) for the sequential condition. Note that correct responses (i.e., serial position = output position) are not represented on the graph

Distribution of words recalled by serial position and output position (OP) for the simultaneous condition. Note that correct responses (i.e., serial position = output position) are not represented on the graph
Moreover, we calculated the transitions between consecutive words recalled (see Table 4). From these transitions, the Lag (difference between the serial positions of the successively recalled items, see Howard & Kahana, 1999, and Kahana, 1996, for more information) can be calculated by subtracting the serial position of the word recalled in output position n from the word recalled in output position n-1. Note that positive values of lag correspond to forward recalls and negative values of lag correspond to backward recalls. Large absolute values of lag correspond to the successive recall of items that are widely spaced in the sequence and small absolute values correspond to the successive recall of items that are close together in the to-be-recalled sequence (Kahana, 1996). Our data show a predominance of lag +1 responses, i.e., responses that are output in forward serial order. Crucially, the total number of positive lags was far greater than the total number of negative lags (see Table 4), suggesting that recall was mainly in a forward order in both conditions, (e.g., when the item from a given position was recalled in a wrong position, there was a stronger tendency for this item being recalled after than before an item from an earlier position).
In sum, as expected, our findings showed better recall performance for the simultaneous compared to the sequential condition and this especially for serial order information recall compared to item information recall. More precisely, we observed weaker serial order recall performance especially for end-of-list items in the sequential condition. Moreover, results showed typical transposition gradients for both conditions but, contrary to our hypothesis, with more transpositions between distant positions for the sequential compared to the simultaneous condition. Also, we observed more transposition errors for the last serial positions in both conditions. Furthermore, analyses revealed more omission errors in the sequential compared to the simultaneous condition, especially for the two first positions and with more comparable performance for the last position between conditions. However, even though the presentation mode seems to lead to differences in terms of recall performance as well as in terms of the nature of serial order errors, we observed some similarities regarding the dynamics of encoding and retrieval between both conditions. Indeed, our results revealed that recall proceeded mainly in a forward serial order in both conditions.
Discussion
In the present study, we investigated the influence of two presentation modes (sequential vs. simultaneous) on the way memoranda is structured and maintained in WM. In most WM studies, to-be-recalled sequences are presented sequentially, that is, one item at a time, like in oral language. However, in some WM studies, the material is presented simultaneously, that is, all items at a time, like in written language. Nevertheless, the influence of presentation mode (sequential vs. simultaneous) on recall performance has barely been investigated and it is unclear whether WM performance and the nature of encoding mechanisms differ between sequentially versus simultaneously presented sequences. A few prior studies have observed differences in WM performance between these two presentation modes, but empirical evidence allowing us to understand these differences remains scarce and is sometimes contradictory (Battacchi et al., 1990; Crowder, 1966; Dalmaijer et al., 2018; Frick, 1985; LeCompte, 1992; Marcer, 1967). In the present study, we therefore examined performance in both sequentially and simultaneously presented list material and proposed detailed analyses by comparing serial position curves for recall performance and the nature of recall errors between conditions. Based on recent models of WM encoding (i.e., temporal vs. spatial models), we hypothesized that a sequential presentation mode should encourage a temporal encoding (i.e., one item at a time), which may manifest itself by a steep transposition gradient with more serial position exchanges over adjacent compared to non-adjacent items. On the other hand, we expected a spatial encoding when the material is presented simultaneously, leading to a flatter transposition gradient.
In line with prior studies, our findings revealed higher recall performance in the simultaneous compared to the sequential condition (Crowder, 1966; Dalmaijer et al., 2018; Marcer, 1967), especially for the recall of serial order information compared to item information. Interestingly, the observed difference in performance between conditions was especially observed for end-of-list items. Indeed, recall performance was weaker for end-of-list items in the sequential condition. Our observation of better recall for end-of-list items in the simultaneous compared to the sequential condition is also in line with a previous study in the visual WM domain (Battacchi et al., 1990). That study showed that, when sequences of visual stimuli are presented simultaneously, i.e., when stimuli are distributed over space, a larger recency effect is observed compared to when sequences of visual stimuli are presented sequentially and in fixed locations.
Further analyses showed typical transposition gradients with more serial position exchange errors over adjacent compared to distant serial positions and with more transposition errors at the end of the sequence for both conditions. However, contrary to our temporal and spatial encoding hypotheses assuming steeper transposition gradients for sequentially presented material and flatter transposition gradients for simultaneously presented material, we observed more transposition errors between distant positions for the sequential compared to the simultaneous condition. Moreover, we observed more omission errors for the sequential compared to the simultaneous condition, and this in a particularly more pronounced manner for the two first positions. We suggest that these findings may rather be explained by differences in refreshing opportunities of initial items during encoding. Indeed, when a sequence is presented sequentially, participants can only process one item at a time, which may rapidly lead to forgetting of earlier presented items. Forgetting of start-of-list items may subsequently disrupt accurate encoding of the overall structure of sequence, increasing the likelihood of non-adjacent serial position exchanges. On the contrary, when the memory list is presented simultaneously, all list items are available at any time during encoding, allowing each part of the sequence to be processed several times during encoding, strengthening both item representations and the representation of their serial order within the list. This situation will particularly advantage start-of-list items in the simultaneous condition relative to the sequential condition given that in the latter condition, start-of-list items will be subject to the highest amount of decay/forgetting over the encoding process and hence are the most in need of repeated encoding. This suggests that the encoding strategies used in immediate serial recall tasks are strongly dependent on the time available for refreshing. Moreover, we suggest that the higher recall performance for the simultaneous condition may also be due to the use of a reading-related parallel encoding strategy (Grainger, 2018; Grainger et al., 2014; Snell et al., 2017), in which the reader keeps track of the position of words in a sequence by associating word identities with spatiotopic coordinates in WM. Also, similar to sentence processing, we suggest that the processing of simultaneously presented sequences takes place in WM by involving several items of the sequence simultaneously, and not one item at a time, allowing strengthening of the links between words and encouraging the spontaneous use of chunking mechanisms.
Note that even though we observed differences in performance and serial order error patterns in both conditions, important similarities also characterize both conditions. Indeed, the data indicated that forward serial recall was prevalent in both conditions, meaning that, when items were incorrectly recalled, participants most frequently recalled them after earlier items of the list rather than the reverse (e.g., the sequence 1 2 3 4 5 6, would be recalled as 1 4 5 2 3 6 rather than 1 4 5 3 2 6). These findings are in accordance with the assumption that forward serial recall is a general property of memory, as shown in previous studies of free recall (Bhatarah et al., 2008; Howard & Kahana, 1999; Kahana, 1996) and serial recall (Klein et al., 2005; Nairne, 2002).
Finally, note that in their article Barrouillet et al. (2021) claim that commonly used simple span measures tend to underestimate WM capacity, because participants try to maintain all list items via the phonological loop, which has a limited capacity of about four or five items. Barrouillet et al. suggest that splitting the items into two maintenance systems, that is, the phonological loop and the central attentional system, would allow retaining at least up to eight items (as the capacity of the attentional system is also estimated to more or less four). Indeed, they observed a dramatic increase in spans (from six letters in simple span measures to eight letters with maxispan instruction) when asking participants to maintain the first four items via the phonological loop, while studying (looking at) the following (four) items (via the central attentional system). Based on this, it is likely that processing in the sequential condition in the present study may have been suboptimal and would have benefitted from maxispan instructions. However, the aim of the present study was to examine how simultaneous and sequential encoding conditions impact WM encoding via default cognitive processing strategies, and not via an optimized procedure, which is why we have not used a maxispan procedure in the current experiment. Note also that the design of the current study does not directly tell us whether the observed superiority of the simultaneous presentation is due to opportunity to re-encode items several times or to the presence of additional spatial cues. To tease apart the impact of the two factors, it would be interesting in future work to adopt a design similar to Guitard et al. (2021), in which the items of the sequential condition appear at the same location as in their simultaneous presentation. However, the overall pattern of results is more in line with the hypothesis of a processing and re-encoding advantage in the simultaneous condition than a purely spatial processing hypothesis.
In sum, our study revealed that the presentation mode of a sequence of stimuli can have implications on WM performance and on the way the memoranda are structured and refreshed in WM. Besides these observed differences, we also observed some similarities between both conditions regarding the dynamics of serial order encoding and retrieval. Our findings have important implications for furthering our understanding of maintenance mechanisms of verbal material in WM, and indicate that the way to-be-memorized material is presented in WM tasks should be taken into account when comparing recall performance between tasks or studies.
Data availability
The datasets generated and/or analyzed during the current study are available in the OSF repository: https://osf.io/c7vzs/?view_only=012b21b8ae5944b6b528bb6b3e423208.
References
Abrahamse, E., van Dijck, J.-P., Majerus, S., & Fias, W. (2014). Finding the answer in space : The mental whiteboard hypothesis on serial order in working memory. Frontiers in Human Neuroscience, 8. https://doi.org/10.3389/fnhum.2014.00932
Ahmad, J., Swan, G., Bowman, H., Wyble, B., Nobre, A. C., Shapiro, K. L., & McNab, F. (2017). Competitive interactions affect working memory performance for both simultaneous and sequential stimulus presentation. Scientific Reports, 7(1), 4785. https://doi.org/10.1038/s41598-017-05011-x
Barrouillet, P., Gorin, S., & Camos, V. (2021). Simple spans underestimate verbal working memory capacity. Journal of Experimental Psychology. General, 150(4), 633-665. https://doi.org/10.1037/xge0000957
Battacchi, M. W., Pelamatti, G. M., & Umiltà, C. (1990). Is there a modality effect? Evidence for visual recency and suffix effects. Memory & Cognition, 18(6), 651-658. https://doi.org/10.3758/bf03197107
Bhatarah, P., Ward, G., & Tan, L. (2008). Examining the relationship between free recall and immediate serial recall : The serial nature of recall and the effect of test expectancy. Memory & Cognition, 36(1), 20-34. https://doi.org/10.3758/MC.36.1.20
Brown, G. D., Preece, T., & Hulme, C. (2000). Oscillator-based memory for serial order. Psychological Review, 107(1), 127-181. https://doi.org/10.1037/0033-295x.107.1.127
Brysbaert, M. (2013). LexTALE_FR : A fast, free, and efficient test to measure language proficiency in French. Psychologica Belgica, 53(1), 23-37. https://doi.org/10.5334/pb-53-1-23
Burgess, N., & Hitch, G. J. (1999). Memory for serial order : A network model of the phonological loop and its timing. Psychological Review, 106(3), 551-581. https://doi.org/10.1037/0033-295X.106.3.551
Burgess, N., & Hitch, G. J. (2006). A revised model of short-term memory and long-term learning of verbal sequences. Journal of Memory and Language, 55(4), 627-652. https://doi.org/10.1016/j.jml.2006.08.005
Carretti, B., Lanfranchi, S., & Mammarella, I. C. (2013). Spatial-simultaneous and spatial-sequential working memory in individuals with Down syndrome : The effect of configuration. Research in Developmental Disabilities, 34(1), 669-675. https://doi.org/10.1016/j.ridd.2012.09.011
Crowder, R. G. (1966). Visual presentation of stimuli in immediate memory. Psychonomic Science, 6(10), 449-450. https://doi.org/10.3758/BF03328085
Dalmaijer, E. S., Manohar, S. G., & Husain, M. (2018). Parallel encoding of information into visual short-term memory. BioRxiv, 398990. https://doi.org/10.1101/398990
De Belder, M., Abrahamse, E., Kerckhof, M., Fias, W., & van Dijck, J.-P. (2015). Serial Position Markers in Space : Visuospatial Priming of Serial Order Working Memory Retrieval. PLoS ONE, 10(1). https://doi.org/10.1371/journal.pone.0116469
Dienes, Z. (2011). Bayesian versus orthodox statistics : Which side are you on? Perspectives on Psychological Science, 6(3), 274-290.
Dienes, Z. (2014). Using Bayes to get the most out of non-significant results. Frontiers in Psychology, 5. https://doi.org/10.3389/fpsyg.2014.00781
Dienes, Z. (2016). How Bayes factors change scientific practice. Journal of Mathematical Psychology, 72, 78-89.
Ferrand, L., New, B., Brysbaert, M., Keuleers, E., Bonin, P., Méot, A., Augustinova, M., & Pallier, C. (2010). The French Lexicon Project : Lexical decision data for 38,840 French words and 38,840 pseudowords. Behavior Research Methods, 42(2), 488-496. https://doi.org/10.3758/BRM.42.2.488
Finger, H., Goeke, C., Diekamp, D., Standvoß, K., & König, P. (2017). LabVanced : A unified JavaScript framework for online studies. In International Conference on Computational Social Science (Cologne).
Finley, J. R., Roediger, H. L., Hughes, A. D., Wahlheim, C. N., & Jacoby, L. L. (2015). Simultaneous Versus Sequential Presentation in Testing Recognition Memory for Faces. The American Journal of Psychology, 128(2), 173-195. https://doi.org/10.5406/amerjpsyc.128.2.0173
Frick, R. W. (1985). Testing visual short-term memory : Simultaneous versus sequential presentations. Memory & Cognition, 13(4), 346-356. https://doi.org/10.3758/bf03202502
Ginsburg, V., & Gevers, W. (2015). Spatial coding of ordinal information in short- and long-term memory. Frontiers in Human Neuroscience, 9, 8. https://doi.org/10.3389/fnhum.2015.00008
Grainger, J. (2018). Orthographic processing : A « mid-level » vision of reading: The 44th Sir Frederic Bartlett Lecture. Quarterly Journal of Experimental Psychology (2006), 71(2), 335-359. https://doi.org/10.1080/17470218.2017.1314515
Grainger, J., Mathôt, S., & Vitu, F. (2014). Tests of a model of multi-word reading : Effects of parafoveal flanking letters on foveal word recognition. Acta Psychologica, 146, 35-40. https://doi.org/10.1016/j.actpsy.2013.11.014
Guida, A., Leroux, A., Lavielle-Guida, M., & Noël, Y. (2016). A SPoARC in the Dark : Spatialization in Verbal Immediate Memory. Cognitive Science, 40(8), 2108-2121. https://doi.org/10.1111/cogs.12316
Guida, A., Megreya, A. M., Lavielle-Guida, M., Noël, Y., Mathy, F., van Dijck, J.-P., & Abrahamse, E. (2018). Spatialization in working memory is related to literacy and reading direction : Culture « literarily » directs our thoughts. Cognition, 175, 96-100. https://doi.org/10.1016/j.cognition.2018.02.013
Guitard, D., Saint-Aubin, J., & Cowan, N. (2021). Grouping effects in immediate reconstruction of order and the preconditions for long-term learning. Quarterly Journal of Experimental Psychology, 17470218211030824. https://doi.org/10.1177/17470218211030825
Hartley, T., Hurlstone, M. J., & Hitch, G. J. (2016). Effects of rhythm on memory for spoken sequences : A model and tests of its stimulus-driven mechanism. Cognitive Psychology, 87, 135-178. https://doi.org/10.1016/j.cogpsych.2016.05.001
Henson, R. N. (1998). Short-term memory for serial order : The Start-End Model. Cognitive Psychology, 36(2), 73-137. https://doi.org/10.1006/cogp.1998.0685
Howard, M. W., & Kahana, M. J. (1999). Contextual variability and serial position effects in free recall. Journal of Experimental Psychology. Learning, Memory, and Cognition, 25(4), 923-941. https://doi.org/10.1037//0278-7393.25.4.923
Hurlstone, M. J., Hitch, G. J., & Baddeley, A. D. (2014). Memory for serial order across domains : An overview of the literature and directions for future research. Psychological Bulletin, 140(2), 339-373. https://doi.org/10.1037/a0034221
JASP Team. (2021). JASP (Version 0.16)[Computer software].
Jeffreys, H. (1961). Theory of probability (3 ed.). Oxford University Press.
Kahana, M. J. (1996). Associative retrieval processes in free recall. Memory & Cognition, 24(1), 103-109. https://doi.org/10.3758/bf03197276
Klein, K. A., Addis, K. M., & Kahana, M. J. (2005). A comparative analysis of serial and free recall. Memory & Cognition, 33(5), 833-839. https://doi.org/10.3758/bf03193078
LeCompte, D. C. (1992). In search of a strong visual recency effect. Memory & Cognition, 20(5), 563-572. https://doi.org/10.3758/bf03199588
Lewandowsky, S., & Oberauer, K. (2015). Rehearsal in serial recall : An unworkable solution to the nonexistent problem of decay. Psychological Review, 122(4), 674-699. https://doi.org/10.1037/a0039684
Logan, G. D. (2021). Serial order in perception, memory, and action. Psychological Review, 128(1), 1-44. https://doi.org/10.1037/rev0000253
Mammarella, I. C., Cornoldi, C., Pazzaglia, F., Toso, C., Grimoldi, M., & Vio, C. (2006). Evidence for a double dissociation between spatial-simultaneous and spatial-sequential working memory in visuospatial (nonverbal) learning disabled children. Brain and Cognition, 62(1), 58-67. https://doi.org/10.1016/j.bandc.2006.03.007
Marcer, D. (1967). The effect of presentation method on short-term recall of CCC trigrams. Psychonomic Science, 8(8), 335-336. https://doi.org/10.3758/BF03331689
McClelland, J. L., & Mozer, M. C. (1986). Perceptual interactions in two-word displays : Familiarity and similarity effects. Journal of Experimental Psychology. Human Perception and Performance, 12(1), 18-35. https://doi.org/10.1037//0096-1523.12.1.18
Mirault, J., Snell, J., & Grainger, J. (2018). You That Read Wrong Again ! A Transposed-Word Effect in Grammaticality Judgments. Psychological Science, 29(12), 1922-1929. https://doi.org/10.1177/0956797618806296
Mozer, M. C. (1983). Letter migration in word perception. Journal of Experimental Psychology. Human Perception and Performance, 9(4), 531-546. https://doi.org/10.1037//0096-1523.9.4.531
Nairne, J. S. (2002). Remembering over the short-term : The case against the standard model. Annual Review of Psychology, 53, 53-81. https://doi.org/10.1146/annurev.psych.53.100901.135131
New, B., Pallier, C., Brysbaert, M., & Ferrand, L. (2004). Lexique 2 : A new French lexical database. Behavior Research Methods, Instruments, & Computers: A Journal of the Psychonomic Society, Inc, 36(3), 516-524. https://doi.org/10.3758/bf03195598
Pegado, F., & Grainger, J. (2021). On the noisy spatiotopic encoding of word positions during reading : Evidence from the change-detection task. Psychonomic Bulletin & Review, 28(1), 189-196. https://doi.org/10.3758/s13423-020-01819-3
Reichle, E. D., Pollatsek, A., Fisher, D. L., & Rayner, K. (1998). Toward a model of eye movement control in reading. Psychological Review, 105(1), 125-157. https://doi.org/10.1037/0033-295x.105.1.125
Reichle, E. D., Liversedge, S. P., Pollatsek, A., & Rayner, K. (2009). Encoding multiple words simultaneously in reading is implausible. Trends in Cognitive Sciences, 13(3), 115-119. https://doi.org/10.1016/j.tics.2008.12.002
Ricker, T. J., & Cowan, N. (2014). Differences between Presentation Methods in Working Memory Procedures : A Matter of Working Memory Consolidation. Journal of Experimental Psychology. Learning, Memory, and Cognition, 40(2), 417-428. https://doi.org/10.1037/a0034301
Schönbrodt, F. D. (2016). BFDA: An R package for Bayes Factor Design Analysis, version 0.1. https://www.github.com/nicebread/bfda.
Snell, J., & Grainger, J. (2019). Readers Are Parallel Processors. Trends in Cognitive Sciences, 23(7), 537-546. https://doi.org/10.1016/j.tics.2019.04.006
Snell, J., Meeter, M., & Grainger, J. (2017). Evidence for simultaneous syntactic processing of multiple words during reading. PloS One, 12(3), e0173720. https://doi.org/10.1371/journal.pone.0173720
Snell, J., van Leipsig, S., Grainger, J., & Meeter, M. (2018). OB1-reader : A model of word recognition and eye movements in text reading. Psychological Review, 125(6), 969-984. https://doi.org/10.1037/rev0000119
Souza, A. S., & Oberauer, K. (2018). Does articulatory rehearsal help immediate serial recall? Cognitive Psychology, 107, 1-21. https://doi.org/10.1016/j.cogpsych.2018.09.002
Tan, L., & Ward, G. (2008). Rehearsal in immediate serial recall. Psychonomic Bulletin & Review, 15(3), 535-542. https://doi.org/10.3758/pbr.15.3.535
van Dijck, J.-P., & Fias, W. (2011). A working memory account for spatial-numerical associations. Cognition, 119(1), 114-119. https://doi.org/10.1016/j.cognition.2010.12.013
van Dijck, J.-P., Abrahamse, E. L., Majerus, S., & Fias, W. (2013). Spatial attention interacts with serial-order retrieval from verbal working memory. Psychological Science, 24(9), 1854-1859. https://doi.org/10.1177/0956797613479610
Wagenmakers, E.-J. (2007). A practical solution to the pervasive problems ofp values. Psychonomic Bulletin & Review, 14(5), 779-804.
Wagenmakers, E.-J., Lee, M., Lodewyckx, T., & Iverson, G. J. (2008). Bayesian versus frequentist inference. In Bayesian evaluation of informative hypotheses (p. 181-207). Springer.
Wagenmakers, E.-J., Love, J., Marsman, M., Jamil, T., Ly, A., Verhagen, J., Selker, R., Gronau, Q. F., Dropmann, D., Boutin, B., Meerhoff, F., Knight, P., Raj, A., van Kesteren, E.-J., van Doorn, J., Šmíra, M., Epskamp, S., Etz, A., Matzke, D., … Morey, R. D. (2018). Bayesian inference for psychology. Part II : Example applications with JASP. Psychonomic Bulletin & Review, 25(1), 58-76. https://doi.org/10.3758/s13423-017-1323-7
Acknowledgements
This study was supported by the CHUNKED ANR project (#ANR-17-CE28-0013-02) and the ERC advanced grant (#742141). We would like to thank all participants for their time and effort invested in this study.
Code availability
Not applicable.
Funding
This work was supported by the CHUNKED ANR project (#ANR-17-CE28-0013-02) and the ERC advanced grant (#742141).
Author information
Authors and Affiliations
Contributions
Laura Ordonez Magro conceptualized the design, collected the data, conducted the data analyses, and wrote the paper; Jonathan Mirault helped to conduct the data analyses; Steve Majerus and Jonathan Grainger helped conceptualize the design and write the paper.
Corresponding author
Ethics declarations
Conflicts of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Ethics approval
This study was performed in line with the principles of the Declaration of Helsinki. Approval was granted by the Comité de Protection des Personnes SUD-EST IV.
Consent to participate
All participants gave prior written consent before their inclusion in the study.
Consent for publication
All participants gave written informed consent for publication.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
List1_item | List1_freqfilm2 | List2_item | List2_freqfilm2 |
|---|---|---|---|
cris | 26.79 | bague | 26.14 |
race | 27.09 | souffle | 26.55 |
poil | 27.09 | date | 26.88 |
maire | 27.91 | job | 27.24 |
somme | 28.27 | pause | 27.30 |
star | 28.91 | herbe | 27.64 |
coupe | 29.16 | patte | 28.16 |
caisse | 29.46 | cible | 28.69 |
gorge | 29.78 | corde | 28.89 |
mur | 30.04 | croix | 29.10 |
offre | 30.23 | membre | 29.34 |
sucre | 30.57 | note | 29.40 |
trace | 30.98 | aube | 30.04 |
style | 31.08 | perte | 30.20 |
lac | 31.16 | choc | 30.22 |
geste | 31.41 | mode | 30.79 |
haine | 31.49 | parc | 31.02 |
arbre | 32.40 | soif | 31.28 |
douche | 32.56 | soupe | 31.72 |
note | 33.42 | titre | 32.40 |
gloire | 34.78 | chaise | 32.70 |
ombre | 35.98 | test | 34.87 |
veste | 36.00 | don | 35.47 |
vache | 36.24 | coffre | 35.97 |
gaz | 36.33 | chair | 36.01 |
mine | 36.84 | poche | 36.23 |
champ | 38.05 | source | 37.34 |
doigt | 38.83 | neige | 37.52 |
couple | 41.13 | front | 38.81 |
pluie | 42.91 | taille | 41.32 |
piste | 43.01 | tombe | 41.33 |
code | 43.58 | crise | 43.51 |
risque | 45.98 | prince | 44.83 |
marche | 46.61 | plage | 44.99 |
chasse | 46.80 | ventre | 46.07 |
zone | 46.97 | voie | 47.01 |
ange | 47.90 | bombe | 48.70 |
nord | 50.38 | pont | 50.45 |
goût | 50.51 | bain | 50.52 |
bus | 50.63 | centre | 53.46 |
base | 51.69 | soin | 54.45 |
fil | 51.83 | juge | 56.40 |
reine | 56.26 | glace | 58.09 |
lait | 59.41 | lune | 58.29 |
blague | 60.33 | pain | 62.81 |
preuve | 60.79 | tas | 65.28 |
club | 61.99 | jambe | 67.51 |
gosse | 62.92 | signe | 67.74 |
pote | 65.03 | bière | 68.55 |
art | 65.93 | clé | 68.73 |
flic | 67.53 | bande | 69.10 |
thé | 67.84 | tante | 70.69 |
fleur | 74.56 | joie | 71.07 |
nez | 75.18 | vent | 71.50 |
trou | 75.32 | poste | 72.64 |
bord | 77.06 | ferme | 73.53 |
vin | 80.92 | vol | 74.14 |
forme | 82.61 | garde | 76.76 |
vue | 84.42 | balle | 77.32 |
loi | 87.37 | bruit | 78.94 |
bon | 90.13 | crime | 81.77 |
coin | 93.43 | peau | 83.83 |
scène | 96.66 | dame | 86.50 |
doute | 97.51 | bouche | 87.75 |
rêve | 99.39 | groupe | 90.16 |
dos | 100.34 | carte | 96.11 |
calme | 105.08 | œil | 97.13 |
peuple | 105.65 | sorte | 98.33 |
sac | 105.96 | mer | 99.49 |
lettre | 108.79 | honte | 103.26 |
pièce | 110.66 | pied | 105.51 |
table | 111.44 | camp | 105.92 |
bois | 115.56 | force | 108.29 |
gueule | 118.45 | fric | 108.99 |
plan | 119.54 | fond | 110.07 |
âme | 122.22 | salle | 111.10 |
face | 124.33 | livre | 112.43 |
prix | 126.55 | arme | 114.40 |
rue | 127.35 | sens | 117.57 |
choix | 130.83 | maître | 118.88 |
voix | 130.83 | bout | 121.12 |
fête | 138.03 | oncle | 124.11 |
ciel | 142.22 | faim | 127.49 |
paix | 144.86 | ordre | 132.50 |
bras | 149.26 | compte | 138.88 |
route | 152.83 | cours | 143.05 |
verre | 154.13 | âge | 150.45 |
jeu | 156.79 | lieu | 153.12 |
faute | 163.19 | sœur | 155.22 |
aide | 171.41 | chien | 158.77 |
tour | 175.56 | roi | 166.34 |
lit | 176.10 | mot | 174.83 |
chef | 189.79 | droit | 175.60 |
film | 195.10 | point | 186.70 |
fin | 207.34 | peine | 193.42 |
cause | 213.51 | reste | 203.10 |
genre | 219.66 | guerre | 212.82 |
train | 244.40 | feu | 215.87 |
mec | 252.94 | cœur | 224.98 |
suite | 274.18 | corps | 250.15 |
terre | 276.29 | chambre | 263.93 |
place | 280.54 | truc | 274.94 |
type | 280.62 | ville | 277.98 |
part | 299.31 | cas | 280.59 |
frère | 311.45 | main | 286.62 |
yeux | 315.89 | eau | 290.61 |
mort | 372.07 | sang | 304.30 |
coup | 389.49 | mois | 312.31 |
tête | 453.13 | mal | 318.27 |
fils | 480.15 | chance | 334.02 |
peur | 551.83 | heure | 415.40 |
nuit | 557.56 | air | 473.50 |
gens | 594.29 | nom | 528.17 |
fille | 627.59 | soir | 555.85 |
jour | 635.22 | femme | 806.57 |
mère | 672.00 | père | 879.31 |
homme | 781.11 | peu | 894.78 |
monde | 823.62 | fois | 899.25 |
dieu | 852.91 | vie | 986.59 |
temps | 1031.05 | chose | 1321.79 |
Rights and permissions
About this article

Cite this article
Ordonez Magro, L., Mirault, J., Grainger, J. et al. Sequential versus simultaneous presentation of memoranda in verbal working memory: (How) does it matter?. Mem Cogn 50, 1756–1771 (2022). https://doi.org/10.3758/s13421-022-01284-4
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-022-01284-4