
Abstract
Observing others performing an action can lead to false memories of self-performance – the observation-inflation effect. The action simulation hypothesis proposes that an action simulation caused by people’s observation of an action is the key reason for this effect. Previous studies have inconsistent views of this hypothesis. In the present study, we re-examined the role of action simulation and discussed the key aspects of the mental processes associated with it. We examined the hypotheses that (a) the magnitude of the observation-inflation effect would decrease as the action simulation was impeded and (b) the magnitude of the observation-inflation effect would not be significantly different in conditions in which participants watched either a part of a video or a full video. The results are consistent with the hypotheses. This study provides strong evidence that action simulation influences the generation of observation-inflation effects and that the process is continuous and can refer to further action information.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
False memory is a common memory distortion phenomenon that occurs in daily life. For example, people often forget whether they have taken their daily medications (Park & Kidder, 1996), which leads to many cases in which people either do not take their daily medications or take them again by mistake (Lindner et al., 2014). As another example, in cooperative activities, children not only overestimate their own contribution to the team (Rogoff, 1990; Vygotsky, 1978), but also mistake others’ behaviors for their own. Thus, these children do not correctly understand their own and others’ contributions to the team and may even have a negative bias against their peers, which is not conducive to future cooperative learning (Sommerville & Hammond, 2007).
False memory especially easily occurs in action events. That is, action-related memory is prone to disturbances by other factors and the production of bias. For example, imagining an action can make an individual firmly believe in later memory that he or she performed the action, which is called the imagination-inflation effect (Goff & Roediger, 1998; Thomas et al., 2003). This phenomenon caused researchers to speculate that action observation could produce a similar effect. Lindner et al. (2010) first examined this problem. The authors proposed the three-phase paradigm of observation inflation based on the three-phase paradigm of imagination inflation. In Phase 1, the participants were asked to perform or read some action phrases (such as “squeeze the sponge” or “clean the blackboard”). In Phase 2, the participants were asked to watch the actor perform some action phrases (such as “clean the blackboard”). In Phase 3, the participants were asked to participate in a source memory test to determine whether the action phrases they presented were performed/read in the first phase. The results showed that it was easy for the participants to mistake the actions they had observed in Phase 2 (cleaned the blackboard) for the actions they had performed in Phase 1. That is, only observing an action can cause the observer to mistakenly remember that he or she performed the action. This other-self confusion in action memory is called the observation-inflation effect.
The discovery of the observation-inflation effect has aroused the interest of researchers, and they have begun to explain its mechanism from different theoretical perspectives. First, from the perspective of source monitoring, Lindner et al. (2010) believe that the reason individuals confuse their own actions and the actions of others may be due to their lax source-monitoring of memory. However, the results of Lindner et al. (2010) showed that false memory did not decrease even when participants were reminded of the source-monitoring memory or the existence of an observation-inflation effect before the test. Furthermore, researchers have endeavored to explain the observation-inflation effect from the perspective of perceptual similarity. The overlap of perceptual features between action imagination/observation and action performance – such as the appearance characteristics of an action object (lambinen et al., 2003), an action mode (Thomas et al., 2003), and sound (Lindner et al., 2016) – causes the individual to mistake the imagined/observed action for an action that he or she has performed. To test this inference, the authors conducted a special treatment on an action video that the participants watched in the study. In this video, the perceptual information (such as color, texture, and sound) was removed, and only the action information was retained. The results showed that the observation-inflation effect still occurred, and it did not decrease compared with the observation-inflation effect under the standard video condition. This finding indicates that the overlap of perceptual features is not the key to the observation-inflation effect and demonstrates that action information may play an important role in the observation-inflation effect.
Therefore, we cannot fully explain the generation of the observation-inflation effect from the perspectives of either monitoring or the perceptual overlap of input information. The main reason that the effect cannot fully be explained is that the empirical research from these two theoretical perspectives only allows participants to process the received information on the surface and does not reach the level of confusing one’s own actions with those of others. The observation-inflation effect involves deep processing, information integration, and a high degree of self-involvement (Lindner et al., 2016). However, its causes require further deduction. A number of studies have shown that, as they observe actions, individuals unconsciously simulate the observed body movements (Bach & Tipper, 2007; Vannuscorps et al., 2015), thus replicating the mental and physical states of others (Gallese & Goldman, 1998; Hari & Kujala, 2009). Moreover, the individual’s mental simulation of the observed action causes the motor system to produce alternative activation. That is, when an individual observes another person’s action, he or she activates the same motor system as when he or she performs the action himself or herself (Wilson & Knoblich, 2005; Zentgraf et al., 2011). This kind of alternative activation is believed to narrow the distance between the self and others (Decety & Sommerville, 2003; Uddin et al., 2007), resulting in an individual’s feeling of “I did” on the observed action in hindsight. Therefore, the action simulation caused by the action observation may play an important role in the observation-inflation effect.
Lindner et al. (2016) manipulated action simulation variables for the first time to study the generation of the observation-inflation effect. Specifically, the authors created two conditions in the action observation stage (the second stage): a congruent and an incongruent condition. Under the congruent condition, the participants were asked to perform the same actions as the actors in the video (e.g., the actors performed the action of wearing a watch, and the participants simulated the action of wearing a watch). Under the incongruent condition, the participants were asked to perform different actions (e.g., the actor was performing the action of pouring water, and the participants kept their hands away or close to each other) when watching the video to prevent them from performing action simulation. The results show that the observation-inflation effect decreased after the action simulation was impeded, which indicates that action simulation is the key reason for the observation-inflation effect. However, Lange et al. (2017) used the same method to prevent the participants from performing action simulations but came to the opposite conclusion. That study showed that even if the participants were prevented from performing the simulation, they would still recall the actions performed by their partners as their own, and the occurrence of false memory did not decrease.
Furthermore, results conflict concerning whether action simulation plays an important role in the observation-inflation effect. Lindner et al. (2016) and Lange et al. (2017) adopted different methods. Lange et al. (2017) divided the experiment into two stages: observation and test (without encoding of the action phrase stage). In the observation stage, the participants were not required to watch the video of the actor performing the action, but experimental partners were required to face each other and take turns performing the actions necessary to form the shapes of the presented letters, numbers, or symbols using their body parts. In the test stage, the participants were randomly presented with all the stimulus materials presented in the observation stage and were asked to perform the actions they had performed previously. In the observation stage, when the participants thought about their own actions, they inevitably imagined the action (including the mode and tracking of the action), which could easily lead to an imagination-inflation effect. Therefore, when the participants’ experimental partners performed the imagined actions, even if performing the secondary motor task during the observation process could prevent participants from performing action simulation and reduce the false memory caused by observation, it could not reduce the false memory induced by imagination. In the test phase, the participants might still recall other people’s actions as ones they performed themselves, and the false memory would not decrease. Because the participants and their partners had to use their body parts to show the shape of the letters, each person performed three different actions. Participants think of many ways to complete the task, so the participants and their partners might think of the same ways. Therefore, Lange et al. tried to reduce the source confusion caused by non-motion traces by limiting language coding but ignored the influence of imagination, an additional variable, on the experimental results.
In addition, the study by Lindner et al. (2016) has certain defects and deficiencies in the method of manipulating the action simulation. Specifically, the participants continuously performed the observed actions under the congruent conditions, which would increase their cues indicating self-performance actions. These cues would make it easier for the participants to regard the observed actions as self-performing ones, which would increase the observation-inflation effect. Therefore, compared with the congruent conditions, the observation-inflation effect under incongruent conditions is smaller. The smaller effect is not due to the decrease in the observation-inflation effect after action simulation is prevented, but because the participants performed the same action as the observed one, which increases the observation-inflation effect under the congruent conditions. This outcome creates a false impression that the observation-inflation effect is smaller under the incongruent conditions. That is, Lindner et al. (2016) failed to completely separate the action simulation components.
In summary, the inference that preventing action simulation can reduce the observation-inflation effect and the hypothesis of action simulation both need to be retested. More importantly, previous research has not explored the processing characteristics of action simulation in the observation-inflation effect. Therefore, this study further explores the role and processing characteristics of action simulation in the observation-inflation effect through two experiments and tests the hypothesis of action simulation.
Experiment 1: The role of movement simulation in the observation-inflation effect
In view of the defects in Lindner’s research, it is impossible to show that action simulation is the key to producing the observation-inflation effect by comparing the magnitude of the decreased effect under incongruent and congruent conditions. Therefore, in Experiment 1, a baseline condition was added in Stage 2: the participants only watched the video and did not perform the action, and the observation influence under the three conditions (i.e., participants only observed and did not perform the action, participants observed the action and performed a congruent action, participants observed the action and performed an incongruent action) was compared to test the role of action simulation in the observation-inflation effect. The hypothesis was that the observation-inflation effect would be reduced when the participants performed actions incongruent with those of the actors.
Methods
Participants
Thirty-five students (Mage = 21.3 years, SD = 2.2; three males, 32 females) were randomly recruited from a university for a reward, none of whom had participated in a similar experiment. All participants signed an informed consent form and had normal or corrected-to-normal vision. Given an α-level of .05, this sample size allowed for a high power (1-β≈.83) to detect an interaction of medium size (f = .25) between the two independent variables (for the within-subjects factor, r was set to .30).
Design
We employed a 2 (encoding mode of action phrase: performed vs. read) × 4 (whether the action phrase was observed and the matching mode of the observed and performed actions: only observation vs. observation with the same action vs. observation with different action vs. no observation) within-participants design. The proportion of the performed responses served as the dependent variable (the proportion of false “performed” responses for action statements presented but not performed in Phase 1 and actions watched in Phase 2). Regarding the conditions, only observation means that the participants only watched the video, observation with the same action means that the participants performed the same action as the actors when watching the video, observation with different action means that the participants performed different actions when watching the video, and no observation means that the actions were not presented in the video.
Materials
First, referring to the experimental materials used in Lindner et al. (2016), 120 action phrases were selected in this study. None of phrases involved the same operation mode, and each object appeared only once. This design avoids inducing participants’ memory in the recognition test. Because the details of the action may affect the degree of the simulation, to increase the consistency of the material, the video was recorded by the same actor. In addition, before recording the video, the actors practiced the task many times to ensure that the range of each action was congruent. Then, according to the selected action phrases, the corresponding action videos were recorded in advance, and each video was presented to participants for 10 s. To avoid interference, the video showed only the actor’s torso, arms, and hands.
Procedure
The experiment was conducted in a separate room. First, the participants were instructed to sit in front of a computer. Then, after ensuring that the participants understood the instructions, the experiment began. The experiment was completed in three phases.
Phase 1 (coding phase)
Participants read or perform action phrases. In the experiment, the computer screen first presented a fixation “+” (500 ms) and then presented a performance or reading instruction (700 ms), such as “please read: shake the bottle; please perform the action: shake the bottle.” The participants were asked to pretend to perform or to read each action phrase once and were asked to carefully follow the instructions. Each fixation “+” was followed by an instruction. All participants were randomly presented with 80 action phrases, 40 of which had to be read and 40 of which had to be performed. The encoding form (performed vs. read) was also randomly assigned.
Phase 2 (observation phase)
The participants observed that the actors in the video performed some of the actions they had performed in Phase 1 as well as some actions the participants had not performed. At the end of Phase 1, the participants were instructed to complete a 5-min mathematical task and then enter Phase 2. First, a fixation “+” (500 ms) was presented on the computer screen, and then the action phrase and the corresponding action video were presented. The participants were asked to read the action phrase once before watching the video. Under the same conditions, the participants were presented with ten action phrases that had been read and ten action phrases that had been performed in Phase 1. After each trial, the participants were instructed to perform the same actions as the actors within 10 s, and each action was performed an average of three times. Under incongruent conditions, the participants were presented with ten action phrases that had been read and performed in Phase 1. After each trial, within 10 s, the participants were instructed to perform different actions to those that the actors performed while watching the video. This was done to prevent participants from simulating the observed actions when they saw them. For example, the action in the video was stretching a rubber band – that is, the hands were far away from or close to each other, but the participants were required to rotate their hands around each other. Each action was performed an average of three times. The instructions for guiding consistent and inconsistent actions were the same, except that the subjects were required to perform the same actions as the actor under consistent conditions and performed different actions from the actor under inconsistent conditions. Under standard conditions, the participants were presented with ten action phrases that had been read and performed in Phase 1, and they only needed to watch the video without doing any actions. Under the three conditions, each action video was presented after the corresponding action phrase. After the experiment, each participant was asked not to discuss any content with other participants.
Phase 3 (test phase)
A source memory (recognition) test was conducted 2 weeks later. Included in the test were 120 action phrases, and 40 new action phrases were added as distractors in addition to the 80 phrases to which the participants had been exposed. The participants were asked to indicate whether each action phrase had been performed, read, or not presented in Phase 1.
Results
The descriptive statistics of the “performed” response are shown in Table 1. When the participants’ false “performed” responses to the action phrases read in Phase 1/observed in Phase 2 were significantly higher than those read in Phase 1/not observed in Phase 2, the observation-inflation effect occurred. See Figs. 1 and 2 for the size of the observation-inflation effect under each condition (the proportion of the “performed” responses under the read-only observation condition, read observation with the same action and read observation with a different action minus the proportion of the “performed” responses under the condition of reading without observation).

Screenshot of action observation phase in Experiment 1

The observation-inflation effect (M ± SE) was observed under various conditions. Read (phase 1) – only observation (phase 2) condition, read (phase 1) – observation with the same action (phase 2) condition, and read (phase 1) – observation with the same action (phase 2) condition, respectively, minus the percentage of reading without observing condition. **p < 0.01
The data were analyzed by a 2 (encoding mode of the action phrase: performed vs. read) × 4 (whether the action phrase is observed or not and the matching mode of action and performance: only observation vs. observation with the same action vs. observation with a different action vs. no observation) repeated-measures analysis of variance (ANOVA). The main effect of the encoding mode was significant (F(1, 34) = 136.37, p <.001, η2 = .80), and the percentage of “performed” responses under the performance encoding condition (M ± SD = 0.50 ± .02) was significantly higher than that under the reading encoding condition (M ± SD = 0.26 ± .02). The main effect of observation was significant (F(3, 102) = 84.02, η2 = 0.71, p < .001) and the percentages of “performed” responses under the observation-only (M ± SD = 0.52 ± .03), observation with the same action (M ± SD = .53 ± .02), and observation with different action conditions (M ± SD = .30 ± .02) were significantly higher than that under the no-observation condition (M ± SD = .18 ± .02). Moreover, the percentage of “performed” responses under the observation-only condition was the same as that under the observation with the same action condition, which was greater than that under the observation with different action condition. Additionally, the interaction between the coding mode and the observation condition was significant (F(3, 102) =11.27, p<.001, η2 = 0.25). A simple effect analysis showed that the percentage of “performed” responses under the observation-only condition (M ± SD = .57 ± .04), the percentage of “performed” responses under the observing the same action condition (M ± SD = .69 ± .03), and the percentage of “performed” responses under the observing different actions condition (M ± SD = .46 ± .04) were significantly higher than those under the no-observation condition (M ± SD = .28 ± .03; t(34) = 7.39, p < . 001 and t(34) = 10.21, p < . 001, respectively). Under the reading coding condition, the percentage of “performed” responses under the observation-only (M ± SD = .47± .03), observation with the same action (M ± SD = .36 ± .03), and observation with different action conditions (M ± SD = .14 ± .02) were significantly higher than those under the no-observation condition (M ± SD = .08 ± .02; t(34) = 12.35, p<.001, t(34) = 9.52, p < .001 and t(34) =2.62, p = .01, respectively). There was no significant difference in the percentage of “performed” responses between the observation condition alone and the observation with the same action condition (t(34) =1.98, p = .07). However, the percentage of “performed” responses under these two conditions was significantly higher than that under the no-observation condition, (t(34) = 2.25, p = .047 and t (34) =10.61, p < .001, respectively). In addition, we used Bayesian statistics to further analyze the difference between the observations without action performance and those with congruent action performance and found that BF10 = .13, indicating that moderate evidence supports no significant difference between the two conditions.
Discussion
Experiment 1 supplemented the baseline level, but the results remain congruent with those of Lindner et al. (2016). Preventing individuals from performing an action simulation can significantly reduce the occurrence of the observation-inflation effect, indicating that action simulation plays an important role in the production of the observation-inflation effect. Specifically, under the standard, congruent, and incongruent conditions, the observation-inflation effect was significant. The results show that regardless of the condition, action observation can induce false memory, a finding that is congruent with previous research conclusions (Lindner & Davidson, 2014; Lindner et al., 2010; Lindner et al., 2012; Schain et al., 2012; Lindner & Echterhoff, 2015; Lindner et al., 2016; Pfister et al., 2017). Compared with the baseline and congruent conditions, the false executive response caused by action observation under incongruent conditions is significantly reduced, which indicates that performing secondary motor tasks during action observation can impede action simulation, which is congruent with previous research conclusions (Mulligan et al., 2016). However, the observation-inflation effect under the condition of observation without execution was similar to that under the condition of observation with congruent execution, and the difference was not significant. This result indicates that there may be no difference in the degree of action simulation between the two conditions. In addition, a decrease in the observation-inflation effect is observed when action simulation is impeded, which further indicates the important role of action simulation in the production of the observation-inflation effect. Hence, this study verified the action simulation hypothesis. Moreover, action simulation is not the same as conceptual action representation. For example, the fMRI results showed somatotopic organization within the contralateral premotor and primary motor cortex during the reading task of action words and motor execution. However, no clear somatotopic organization of action was observed in the given regions of interest within the contralateral hemisphere, although observation of these movements activated these areas significantly (Lorey et al., 2013).
Experiment 2: Processing characteristics of action simulation
Experiment 1 verified the previous results by improving the experimental conditions and confirmed that action simulation plays an important role in the observation-inflation effect. Experiment 2 further investigates the processing characteristics of the action simulation observation-inflation effect on the basis of Experiment 1. According to mental model theory, when an individual is observing an action, the observation not only simulates the action in real time but also automatically simulates follow-up actions (Johnson-Laird, 2006). For example, even if only part of the action is presented to the observer (pick up the water bottle), the next action (drinking water) can be automatically simulated through the process of action simulation. In the subsequent memory test, participants mistakenly thought they had observed the action of drinking water (Ianì et al., 2018). Therefore, we conclude that in the process of action observation, individuals may not need to observe all the action information to realize the action simulation of the observed actions, thus promoting the production of the observation-inflation effect.
In the past, the videos presented to the participants in the study of the observation-inflation effect were complete (Lindner & Davidson, 2014; Lindner et al., 2010; Lindner et al., 2012; Lindner & Echterhoff, 2015; Lindner et al., 2016; Pfister et al., 2017). Participants could watch the videos to simulate the action completely, but in daily life, observing only part of an action can lead to false memory. This fact further shows that simulating part of the action information can produce an observation-inflation effect. Therefore, Experiment 2 further explored the processing properties of action simulation by manipulating the integrity of the action video being viewed as participants were shown a partial video (only part of the video was played; for instance, for the action of drinking water, only the action of picking up the water cup was shown) and a complete video (the full segment of the video was shown). It was assumed that the observation-inflation effect of partial video would be equal to that of complete video.
Methods
Participants
Twenty-six students (Mage = 20.19 years, SD = 2.48; two males, 24 females) were randomly recruited from a university for a reward, none of whom had participated in a similar experiment. We used GPower 3.1 for the analysis. Given an α-level of .05, this sample size allowed for a high power (1–β ≈ .95) to detect an interaction of medium size (f = .38) between the two independent variables (for the within-subjects factor). All participants signed an informed consent form and had normal or corrected-to-normal vision.
Design
We employed a 2 (encoding method of action phrase: performed vs. read) × 3 (observing method of action phrase: observation of partial video vs. observation of complete video vs. no observation) within-participants design. The proportion of performance responses served as the dependent variable (the proportion of false “performed” responses for action statements presented but not performed in Phase 1 and watched in Phase 2). Regarding the conditions, observation of a partial video meant that only part of the actions watched by the participants were played, observation of a complete video meant that the actions watched by the participants were played completely, and no observation meant that the actions were not presented in the video.
Materials
According to the experimental materials of Lindner et al. (2016), 90 action phrases were selected. The other details are the same as those in Experiment 1. Under the partial video condition, the action was only shown for 7 s (the completion rate of each action that the actor performed in the video was approximately 30%, as shown in Fig. 3 in which the actor stops as soon as he pulls the zipper). Then, the video displays the final frame for 3 s (giving the participants time to simulate the action). Afterward, the next action is presented; under the complete video condition, the action is played completely (10 s).

Experiment 2 action observation phase
Procedure
The experimental procedure is similar to that of Experiment 1, but the difference is that in Phase 2, only parts of ten action videos were played, and the complete videos were shown for another ten action videos. The other procedural details are the same as in Experiment 1. After the source memory test, the participants were asked to evaluate the familiarity of the action process of the action phrases presented in Experiment 2 (levels 1–7), in which 1 means that participants were the most unfamiliar with the process of the action performed, 2 means that participants were very unfamiliar with the process of the action performed, 3 means that participants were unfamiliar with the process of the action performed, 4 means that participants were generally familiar with the process of the action performed, 5 means that participants were familiar with the process of the action performed, 6 means that participants were very familiar with the process of the action performed, and 7 means that participants were the most familiar with the process of the action performed. No significant difference was found between partial (M ± SD = 6.23±.64) and complete videos (M ± SD = 5.93±.75) (t (19) = 1.37, p = .19).
Results
The descriptive statistics of the “performed” responses are shown in Table 2. See Figs. 3 and 4 for the magnitude of the observed inflation effect under each condition (the percentage of the “performed” response under the conditions of read-only observation, read observation with the same action, and read observation with a different action minus the proportion of the “performed” response under the condition of reading without observation).

The observation-inflation effect (M ± SE) was observed under various conditions. The percentage of “performed” responses under the condition of read (phase 1) – observation of partial video (phase 2) and the percentage of “performed” responses under the condition of read (phase 1) – observation of complete video (phase 2) minus the percentage of “performed” responses under the condition of read (phase 1) – no observation (phase 2)
The data were analyzed by a 2 (action phrase encoding: performed vs. read) × 3 (observing method of action phrase: observation of a partial video vs. observation of a complete video vs. no observation) repeated-measures ANOVA. The results showed that the main effect of encoding was significant (F(1, 25) = 82.64, p < 0.001, η2 = .77). The percentage of “performed” responses under performance encoding (M ± SD = .50 ± .03) was significantly higher than that under reading encoding (M ± SD = .25 ± .03). The main effect of the observation condition was significant (F(2, 50) = 61.44, p<.001, η2 = .71). The percentages of “performed” responses under the partial (M ± SD = .42 ± .04) and complete observation conditions (M ± SD = .51 ± .03) were significantly higher than that under the no-observation condition (M ± SD = .19 ± .02). The interaction between the coding mode and the observation condition was significant (F(2, 50) = 3.56, p = .036, η2 = .12). A simple effect analysis showed that under the performance encoding condition, the percentages of “performed” responses under the partial (M ± SD = .53 ± .05) and complete observation conditions (M ± SD = .67 ± .04) was significantly higher than that under the no-observation condition (M ± SD = .29 ± .03) (t(25) =5.02, p < . 001 and t(25) =9.91, p < . 001, respectively). Under the reading coding condition, the percentages of “performed” responses under the partial (M ± SD = .32 ± .04) and complete observation conditions (M ± SD = .34 ± .04) were significantly higher than that under the no-observation condition (M ± SD = .08 ± .03) (t(25) =7.16, p < . 001 and t(25) =8.21, p < . 001, respectively). In addition, there was no significant difference in the percentage of “performed” responses between the partial and the complete observation conditions (t(25) =.92, p = .36). Furthermore, we used Bayesian statistics to analyze the data, and the results showed that BF10 = .18. Moderate evidence supports no difference between full and partial video presentation conditions.
Discussion
The results of Experiment 2 show that the observation-inflation effect is significant under the conditions of partial and complete video observation, and the magnitude of the effect is the same. These findings show that watching either the whole video or part of it can induce the participants’ false memory and cause them to mistakenly identify the observed action as self-performed. Only showing part of the action video to the participants could lead to the observation-inflation effect and cause them to erroneously consider the observed action as self-performed. This result shows that an individual needs only to observe part of the action information to automatically simulate the observed action and subsequently produce the observation-inflation effect. The research confirmed our inference: individuals do not need to observe all the action information; they can achieve action simulation and instigate the observation-inflation effect. Current research cannot fully explain whether participants simulate complete actions based on partial or related actions. However, according to the experimental materials we use (mostly in daily life), because the participants are more familiar with them, further complete actions are easier to infer. Therefore, the results of Experiment 2 are more likely to depend on seeing part of the action (requiring completion) rather than seeing associated actions. However, this conclusion needs to be verified through further research, such as brain-imaging research.
This result can support and explain the interesting phenomena observed by previous researchers. For example, Ianì et al. (2018) once asked participants to observe photos of an actor’s action and found that the participants mistakenly thought that the actor had performed the next action in the process of recall. For another example, Gerrie et al. (2006) also asked the participants to watch a sandwich-making movie and found that they recalled the actor’s intentional missing action in the production process. This result is very similar to those observed in this study. We refer to this information because the motion simulation complements further motion information.
General discussion
In real life, individuals observe the behavior of others through various channels, and the generation of an observation-inflation effect has a considerable negative impact on people’s productivity and life. This study has a certain theoretical and practical significance for understanding the mechanism of the observation-inflation effect and reducing the occurrence of false memory. To improve the experimental method, the study examined the role of action simulation in the production of the observation-inflation effect, verified the hypothesis of action simulation, and confirmed that action simulation plays an important role in the production of the observation-inflation effect. Individuals need to rely on only a small amount of action information to complete the automatic simulation of the observed action, which leads to the confusion of one’s own actions with those of others, resulting in an observation-inflation effect.
Action simulation plays an important role in the observation-inflation effect
This study confirmed that action simulation plays an important role in the observation-inflation effect. Based on previous studies, we analyze the underlying reasons from the following three aspects. First, action simulation may activate the action coding involved in the observer’s own performance of the observed action, including the internal cues of self-performance (Wilson & Knoblich, 2005; Zentgraf et al., 2011). After a period of time, when the individual is no longer able to immediately distinguish the subject of the action, the feeling of “I seem to have done” succumbs to a feeling of “I have done,” thus attributing the observed action errors to his or her own performance.
Furthermore, action simulation may be an internal process in which an individual creates an interaction between him- or herself and others in the process of an action observation (e.g., Zentgraf et al., 2011). This process integrates the action representation generated by action observation into the cue of a self-performed action. Through this cue integration, the action representation generated by action observation and that generated by actual operation share the cue of a self-performed action (Anderson, 1981; Lindner et al., 2016). When the action simulation is blocked, so is the relationship between the action representation generated by action observation and the cue of self-performed action (Casile & Giese, 2006; Lindner et al., 2016; Marcello et al., 2012; Zimmermann et al., 2013).
In addition, some studies have pointed out that the observation of an action can cause individuals to simulate the observed events, causing the brain process of observing an action to be the same as that occurring during the action performance (Bauer & Johnson-Laird, 1993; Johnson-Laird, 2006). Several studies based on the theory of reactivation (see Sakai, 2003) have shown that the same cortical regions are activated during action coding and extraction (Heil et al., 1999; Leynes & Bink, 2002; Masumoto et al., 2006; Lindner et al., 2016). Therefore, if the perception of the observed action information automatically activates the individual’s motor system and causes the individual to simulate the observed action, creating a feeling of self-performed action, then the individual’s motor system is also activated when recalling the action. Then, in the extraction phase, the reactivation of the motor system causes the observer to confuse the action subject and mistakenly judge the observed action as a self-performed one. The reactivation degree of the motor system decreases when the participants are prevented from performing the action simulation in the action observation stage. Therefore, in the source memory test, the confusion between the self and others is reduced to decrease the observation-inflation effect. The results obtained under the “observation with different action” condition might be ascribed to attentional rather than purely motor processes. However, Lindner et al. (2016) discussed the influence of the attentional process on the experimental results. They found no significant difference in attention distribution under the consistent and inconsistent conditions.
In summary, the results of this study show that the simulation of actions affects the cognitive process of individuals. The generation of the observation-inflation effect may be closely related to this embodied cognitive process. We speculate that the simulation caused by the observation of the action may be performed offline. Indeed, several studies suggest that the perception of an action automatically triggers its simulation and that simulation may also work offline. A study by Cook and Tanenhaus (2009), for example, showed that speakers’ co-speech gestures while explaining a problem-solving task affected listeners’ behaviors when solving the problem on a computer (later in time, i.e., offline). There is even evidence that speakers’ gestures activate listeners’ motor systems (i.e., automatic simulation; Ping et al., 2014, b). Similar to the above research, our results support the idea that observation or perception can automatically trigger action simulations and that simulations work offline. This kind of action simulation of offline work can influence the memory of the individual after a period of time, and this fact is interpreted as support for embodied cognitive processes.
In the field of embodied cognition, “embodiment” is defined as the effect body or parts of the body (movement, position) can have on cognition (Dijkstra & Post, 2015). Obviously, an individual's erroneous cognition due to observing an action (e.g., thinking that he has performed the action) should also be discussed from the perspective of this theory. In contrast to earlier theories on cognition that consider processing and storage of incoming information to take place in an abstract, symbolic manner, embodied cognition theories focus on the body as being central to shaping the mind (Wilson, 2002). Specifically, cognitive processes are presumed to depend on the sensory-motor system in the brain that reactivates earlier experiences, a process called sensory-motor simulation (Barsalou, 1999a, b). When such an experience is retrieved, neural states are re-enacted from the systems that were relevant for the original experience, such as action and perception systems (Dijkstra & Zwaan, 2014). In other words, memories can profitably be seen as mental simulations consisting of the reactivation of sensorimotor patterns originally associated with events at encoding rather than amodal mental representations (Ianì, 2019). One reason for this view is that cognition is strongly influenced by the body (Glenberg, Witt, & Metcalfe, 2013). For example, the perceptual symbol system proposed by Barsalou implies a perceptual memory system. Through this system, the associated areas of the brain capture the bottom-up activation patterns that occur in the sensorimotor area and then initiate an opposite top-down process (Barsalou et al., 2008). Thus, memory traces are better understood in terms of sensorimotor encoding: they store information on the neural states underpinning perceptions of our environment, our body, and our movements. According to this point of view, memory stores the neural state information of our environment, body, and action perception. Since they are only neural patterns, memory traces are dynamic, that is, plastic, and will inevitably be modified by subsequent encodings. Therefore, what is retrieved in the future will not exactly match all the details of the original encoding, which causes false memory.
Memory traces are multimodal, so their reactivation through mental simulation implies multimodal reactivation. Memories are not abstract items neatly stored in our brains simply because they emerge from proximal sensory projections that include sensorimotor elements in their representations (Harnad, 1990). Memory trace activation, at least partly, enacts neural systems typically associated with perceptual systems (Barsalou, 1999a, b). Several studies have shown that when individuals retrieve action-related information, sensorimotor areas will also be activated (Nyberg, 2002; Nyberg et al., 2001; Persson & Nyberg, 2000). This finding means that experiencing an event in the recognition phase and mentally reconstructing it at recall share the same brain modality-specific activation patterns. This activation mode is similar to the actual execution of a certain action, suggesting that a “covert” simulation of action occurs, which recruits neural structures similar to those involved in the actual action execution (Buccino et al., 2001) and may seriously interfere with the subjects’ correct judgment of the memory source. This rationale is consistent with Cabalo et al. (2020). They found that observational behavior plays a key role in implanting false memories. Specifically, they believe that this phenomenon may be related to the nature of actions, and in particular actions on objects, which may also produce lasting false memories because of the involved sensory/motor activation. Moreover, recent theoretical perspectives on memory mechanisms have emphasized the key role played by body movements in memory functions, implying that memory traces capture and reflect all the components of past experiences (Versace et al., 2014). This finding also provides a possible explanation for the effect of observational inflation: after an individual observes the actions of others and conducts a covert mental simulation of the actions (the actions usually appear in daily life), he or she will be affected by past experience when recalling it. The influence of past experience confuses the exact source of memory. This possibility will be examined in future study. In addition, future research can consider a motor condition, such as the motor areas of the legs, by asking participants to move their legs. Some studies have shown that different motor effectors have an impact on recall performance (Ianì & Bucciarelli, 2018; Ping et al., 2004).
Only part of the action information needs to be simulated to initiate the observation-inflation effect
This study found that the participants needed to observe only part of the action information to experience an observation-inflation effect. They could perform the action simulation, become confused about whether a memory was of their own or other people’s actions, and mistakenly think that they had performed the action that was performed by another person. This result may be closely related to the activation of action representation. Action representation refers to the internal presentation of action information in the brain, which plays a central role in behavioral control and organization (BlaSing et al., 2009). Action observation directly matches action performance. For example, when observing “dance” movements, participants do not need to recognize the observed movement events as dance before the related regions in the brain are activated so the participants can perform these movements. Instead, participants directly share the representation of the movements (De Vignemont & Haggard, 2008). The sharing of action representation is the core of the relationship between two action subjects (Gallese, 2003) and plays a role in action simulation (Iacoboni et al., 1999). Studies have found that action representation occurs because observing an action activates the corresponding action representation internally that the brain can simulate regarding the observed action sequence (Calvo-Merino et al., 2005). Therefore, in this study, the observation of part of the action information may trigger the corresponding action representation of the observer. Furthermore, the activation of the action representation causes the participants to automatically simulate the complete information of the observed action, resulting in the observation-inflation effect.
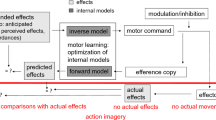
This study provides evidence to support the mental model theory. According to the mental model theory, the deep understanding of a certain state is a process of constructing a mental model through high-level mental activities, through which individuals can understand and infer the development of events (Johnson-Laird, 2006). The model is not static but is a dynamic and temporal process. According to this theory, the mental stimuli of actions induce the same understanding and perception of actions as their performance. Action simulation can be regarded as a real-time internal model for the individual perception of human action. Even when the action is blocked or disappears, the internal model can still play a role in ensuring the continuity of the observed action (Parkinson et al., 2011; Sparenberg et al., 2012). For example, when we see a friend running in the forest, he or she temporarily disappears from our sight due to the occlusion of the trees, but our perception of his or her movement is not interrupted, and we can still track his or her movement trajectory (Parkinson et al., 2012). Moreover, the empirical results on this topic may better enable us to understand the results of Experiment 2. Urgesi et al. (2006) found that the mere observation of static snapshots of hands suggesting a pincer grip action induced an increase in corticospinal excitability compared with the observation of resting, relaxed hands or hands suggesting a completed action. However, the observation is of a nonbiological entity, and although the image includes implicit movement, the reactivity of the test muscle exhibits no change. Therefore, the author believes that the human visual system is highly adapted to perceiving actual movement and to extrapolating dynamic information from static pictures of creatures captured in the middle of actions. Similarly, Aglioti et al. (2008) found that the corticospinal excitability of elite experts increased as they observed actions belonging to their domain of expertise. Furthermore, the authors found that players (such as professional basketball players) could better predict the behavior of other players, resulting in the earlier and more accurate prediction of the free shot outcome at a basket observed on a video compared to people who had no direct motor experience with basketball. This finding shows that, although the neural systems underlying the matching of observed and executed actions may be acquired early, specific learning processes may shape them (Aglioti et al., 2008). In our experiments, the selected experimental materials were the most common action types in daily life. Therefore, individuals can easily predict a complete action result based on the observed action details. A recent behavioral study also showed that action observation triggers by default a mental simulation of action unfolding in time (Ianì et al., 2021). The author assumed that the simulation was embodied, studied it and found that the subject’s posture interfered with the forward simulation. However, we did not manipulate body posture as a variable in our research, and future research can examine its influence on movement-related false memories.
In summary, we found that observing some actions can induce a false memory of the next action. The mental stimuli of actions induce the same understanding and perception of actions as the performance of physical actions, which may be the reason the internal model can guarantee the persistence of the observed actions. Therefore, the present findings enrich mental model theory.
Conclusion
-
(1)
Action simulation plays an important role in the observation-inflation effect.
-
(2)
Individual action simulation is a continuous process of construction that enables further improvement in understanding and reasoning actions.
References
Aglioti, S. M., Cesari, P., Romani, M., & Urgesi, C. (2008). Action anticipation and motor resonance in elite basketball players. Nature Neuroscience, 11(9), 1109-1116. https://doi.org/10.1038/nn.2182
Anderson, N. H. (1981). Information integration theory. Academic Press. https://doi.org/10.1007/978-94-007-0753-5_102013
Barsalou, L. W. (1999a). Perceptual symbol systems. Behavioral and Brain Sciences, 22, 577–660.
Barsalou, L. W. (1999b). Perceptual symbol systems. Behavioral Brain Sciences, 22(3), 577–660.
Barsalou, L. W., Santos, A., Simmons, W. K. , & Wilson, C. D. (2008). Language and simulation in conceptual processing. In M. De Vega, A. M. Glemberg, & A. Graesser (Eds.). Symbols, embodiment, and meaning (pp. 245–283). Oxford University Press.
Bauer, M. I., & Johnson-Laird, P. N. (1993). How diagrams can improve reasoning. Psychological Science, 4, 372–378. https://doi.org/10.2307/40062565
BlaSing, B., Tenenbaum, G., & Schack, T. (2009). The cognitive structure of movements in classical dance. Psychology of Sport and Exercise, 10(3), 350−360. https://doi.org/10.1016/j.psychsport.2008.10.001
Buccino, G., Binkofski, F., Fadiga, L., Fogassi, L., Gallese, V., Seitz, R. J., … Freund, H. J. (2001). Action observation activates premotor and parietal areas in somatotopic manner: An fMRI study. European Journal of Neuroscience, 13(2), 400–404. https://doi.org/10.1111/j.1460-9568.2001.01385.x
Cabalo, D. G., Ianì, F. Bilge, A. R., & Mazzoni, G. (2020). Memory distortions: when suggestions cannot be easily ignored. Applied Cognitive Psychology, 34(1). 210-215. https://doi.org/10.1002/acp.3597
Calvo-Merino, B., Grezes, J., Glaser, D. E., Passingham, R. E., & Haggard, P. (2005). Action observation and acquired motor skills: an fMRI study with expert dancers. Cerebral Cortex, 15, 1243–1249. https://doi.org/10.1093/cercor/bhi007
Casile, A., & Giese, M. A. (2006). Nonvisual motor training influences biological motion perception. Current Biology, 16(1), 69–74. https://doi.org/10.1016/j.cub.2005.10.071
Cook, S. W., & Tanenhaus, M. K. (2009). Embodied communication: speakers’ gestures affect listeners’ actions. Cognition, 113(1), 98-104. https://doi.org/10.1016/j.cognition.2009.06.006
De Vignemont, F., & Haggard, P. (2008). Action observation and execution: what is shared? Social Neuroscience, 3(3–4), 421–433. https://doi.org/10.1080/17470910802045109
Decety, J., & Sommerville, J. A. (2003). Shared representations between self and other: a social cognitive neuroscience view. Trends in Cognitive ences, 7(12), 527–533. https://doi.org/10.1016/j.tics.2003.10.004
Dijkstra, K., & Post, L. (2015). Mechanisms of embodiment. Frontiers in Psychology, 6, 1525-1534. https://doi.org/10.3389/fpsyg.2015.01525
Dijkstra, K., & Zwaan, R. A. (2014). “Memory and action” In: The Routledge Handbook of Embodied Cognition, ed L. A. Shapiro. Taylor and Francis Books, 296–305.
Gallese, V. (2003). The manifold nature of interpersonal relations: The quest for a common mechanism. In C. Frith & D. Wolpert (Eds.), The neuroscience of social interaction. Oxford University Press. https://doi.org/10.1098/rstb.2002.1234
Gerrie, M. P., Belcher, L. E., & Garry, M. (2006). “Mind the gap”: false memories for missing aspects of an event. Applied Cognitive Psychology, 20, 689–696. https://doi.org/10.1002/acp.1221
Glenberg, A. M., Witt, J. K., & Metcalfe, J. (2013). From the revolution to embodiment: 25 years of cognitive psychology. Perspectives on Psychological Science, 8, 573–585. https://doi.org/10.1177/1745691613498098
Goff, L. M., & Roediger, H. L. (1998). Imagination inflation for action events: repeated imaginings lead to illusory recollections. Memory & Cognition, 26(1), 20–33. https://doi.org/10.3758/BF03211367
Harnad, S. (1990). The symbol grounding problem. Physica D: Nonlinear Phenomena, 42,335–346.
Heil, M., Rolke, B., Engelkamp, J., Rosler, F., Ozcan, M., & Hennighausen, E. (1999). Event-related brain potentials during recognition of ordinary and bizarre action phrases following verbal and subject-performed encoding conditions. European Journal of Cognitive Psychology, 11(2), 261–280. https://doi.org/10.1080/713752313
Iacoboni, M., Woods, R. P., Brass, M., Bekkering, H., Mazziotta, J. C., & Rizzolatti, G. (1999). Cortical mechanisms of human imitation. Science, 286, 2526–2528. https://doi.org/10.1126/science.286.5449.2526
Ianì, F. (2019). Embodied memories: reviewing the role of the body in memory processes. Psychonomic. Bulletin & Review, 26(6), 1747-1766. https://doi.org/10.3758/s13423-019-01674-x
Ianì, F. & Bucciarelli, M. (2018). Relevance of the listener’s motor system in recalling phrases enacted by the speaker, Memory, 26(8), 1084-1092. https://doi.org/10.1080/09658211.2018.1433214
Ianì, F., Mazzoni, G., & Bucciarelli, M. (2018). The role of kinematic mental simulation in creating false memories. Journal of Cognitive Psychology, 30, 292–306. https://doi.org/10.1080/20445911.2018.1426588
F Ianì, Limata, T., Mazzoni, G., & Bucciarelli, M. (2021). Observer's body posture affects processing of other humans' actions. Quarterly Journal of Experimental Psychology 2006. https://doi.org/10.1177/17470218211003518
Johnson-Laird, P. N. (2006). How we reason. Oxford University Press. https://doi.org/10.1093/acprof:oso/9780199551330.001.0001
Lampinen, J. M., Odegard, T. N., & Bullington, J. L. (2003). Qualities of memories for performed and imagined actions. Applied Cognitive Psychology, 17(8), 881–893. https://doi.org/10.1002/acp.916
Lange, N., Hollins, T. J., & Patric, B. (2017). Testing the motor simulation account of source errors for actions in recall. Frontiers in Psychology, 8, 1686−1705. https://doi.org/10.3389/fpsyg.2017.01686
Leynes, P. A., & Bink, M. L. (2002). Did i do that? an erp study of memory for performed and planned actions. International Journal of Psychophysiology Official Journal of the International Organization of Psychophysiology, 45(3), 197–210. https://doi.org/10.1016/S0167-8760(02)00012-0
Lindner, I., & Davidson, P. S. R. (2014). False action memories in older adults: relationship with executive functions? Neuropsychology Development & Cognition, 21(5), 560–576. https://doi.org/10.1080/13825585.2013.839026
Lindner, I., & Henkel, L. A.. (2015). Confusing what you heard with what you did: false action-memories from auditory cues. Psychonomic Bulletin & Review, 22(6), 1791–1797. https://doi.org/10.3758/s13423-015-0837-0
Lindner, I., Echterhoff, G., Davidson, P. S., & Brand, M. (2010). Observation inflation: Your actions become mine. Psychological Science, 21(9), 1291–1299. https://doi.org/10.1177/0956797610379860
Lindner, I., Schain Cécile, Kopietz René, & Gerald, E. (2012). When do we confuse self and other in action memory? reduced false memories of self-performance after observing actions by an out-group vs. in-group actor. Frontiers in Psychology, 3, 467–453.
Lindner, I., C Schain., & Echterhoff, G. (2016). Other-self confusions in action memory: the role of motor processes. Cognition, 149, 67–76. https://doi.org/10.1016/j.cognition.2016.01.003
Lorey, B., Naumann, T. , Pilgramm, S., Petermann, C., Bischoff, M., & Zentgraf, K., et al. (2013). How equivalent are the action execution, imagery, and observation of intransitive movements? revisiting the concept of somatotopy during action simulation. Brain & Cognition, 81(1), 139-150. https://doi.org/10.1016/j.bandc.2012.09.011
Masumoto, K., Yamaguchi, M., Sutani, K., Tsuneto, S., Fujita, A., & Tonoike, M. (2006). Reactivation of physical motor information in the memory of action events. Brain Research, 1101(1), 102–109. https://doi.org/10.3389/fpsyg.2012.00467
Nyberg, L. (2002). Levels of processing: A view from functional brain imaging. Memory, 10(5-6),345–348. https://doi.org/10.1080/09658210244000171
Nyberg, L., Petersson, K. M., Nilsson, L. G., Sandblom, J., Åberg, C., & Ingvar, M. (2001). Reactivation of motor brain areas during explicit memory for actions. NeuroImage, 14(2),521–528. https://doi.org/10.1006/nimg.2001.0801
Park, D. C., & Kidder, D. P. (1996). Prospective memory and medication adherence. In M. Brandimonte, G. O. Einstein, & M. A. McDaniel (Eds.), Prospective memory: Theory and applications (pp. 369–390). Erlbaum.
Parkinson, J., Springer, A., & Prinz, W. (2011). Can you see me in the snow? Action simulation aids the detection of visually degraded human motion. Quarterly Journal of Experimental Psychology, 64(8), 1463–1472. https://doi.org/10.1080/17470218.2011.594895
Parkinson, J., Springer, A., & Prinz, W. (2012). Before, during and after you disappear: aspects of timing and dynamic updating of the real-time action simulation of human motions. Psychological Research, 76(4), 421–433. https://doi.org/10.1007/s00426-012-0422-3
Persson, J., & Nyberg, L. (2000). Conjunction analysis of cortical activations common to encoding and retrieval. Microscopy Research and Technique, 51,39–44. https://doi.org/10.1002/1097-0029(20001001)51:13.0.CO;2-Q
Pfister, R., Schwarz, K. A., Wirth, R. , & Lindner, I. (2017). My command, my act: observation inflation in face-to-face interactions. Advances in Cognitive Psychology, 13(2), 166–176. https://doi.org/10.5709/acp-0216-8
Ping, R. M., Goldin-Meadow, S., & Beilock, S. L. (2014). Understanding gesture: is the listener's motor system involved? Journal of Experimental Psychology: General, 143(1), 195-204. https://doi.org/10.1037/a0032246
Rogoff, B. (1990). Apprenticeships in thinking: Cognitive development in social context. Oxford University Press. https://doi.org/10.1126/science.249.4969.684
Sakai, K. (2003). Reactivation of memory: Role of medial temporal lobe and prefrontal cortex. Reviews in the Neurosciences, 14, 241–252. https://doi.org/10.1515/REVNEURO.2003.14.3.241
Sommerville, J. A., & Hammond, A. J. (2007). Treating another’s actions as one‘s own: Children’s memory of and learning from joint activity. Developmental Psychology, 43(4), 1003–1018. https://doi.org/10.1037/0012-1649.43.4.1003
Sparenberg, P., Springer, A., & Prinz, W. (2012). Predicting others' actions: evidence for a constant time delay in action simulation. Psychological Research, 76(1), 41–49. https://doi.org/10.1007/s00426-011-0321-z
Thomas, A. K., Bulevich, J. B., & Loftus, E. F. (2003). Exploring the role of repetition and sensory elaboration in the imagination inflation effect. Memory & Cognition, 31(4), 630–640. https://doi.org/10.3758/BF03196103
Uddin, L. Q., Iacoboni, M., Lange, C., & Keenan, J. P. (2007). The self and social cognition: the role of cortical midline structures and mirror neurons. Trends in Cognitive ences, 11(4), 153–157. https://doi.org/10.1016/j.tics.2007.01.001
Urgesi, C., Moro, V., Candidi, M., & Aglioti, S. M. (2006). Mapping implied body actions in the human motor system. The Journal of Neuroscience: The Official Journal of the Society for Neuroscience, 26(30), 7942-7949. https://doi.org/10.1523/JNEUROSCI.1289-06.2006
Versace, R., Vallet, G. T., Riou, B., Lesourd, M., Labeye, É., & Brunel, L. (2014). Act-In: An integrated view of memory mechanisms. Journal of Cognitive Psychology, 26(3), 280–306. https://doi.org/10.1080/20445911.2014.892113
Vygotsky, L. S. (1978). Mind in society: The development of higher psychological processes. Harvard University Press. https://doi.org/10.2307/1421493
Wilson, M. (2002). Six views of embodied cognition. Psychonomic Bulletin Review, 9(4), 625–636. https://doi.org/10.3758/BF03196322
Wilson, M., & Knoblich, G. (2005). The case for motor involvement in perceiving conspecifics. Psychological Bulletin, 131(3), 460-473. https://doi.org/10.1037/0033-2909.131.3.460
Zentgraf, K., Munzert, J., Bischoff, M., & Newman-Norlund, R. D. (2011). Simulation during observation of human actions – theories, empirical studies, applications. Vision Research, 51(8), 827–835. https://doi.org/10.1016/j.visres.2011.01.007
Zimmermann, M., Toni, I., & Lange, F. P. D. (2013). Body posture modulates action perception. Journal of Neuroscience the Official Journal of the Society for Neuroscience, 33(14), 5930–5938. https://doi.org/10.1523/JNEUROSCI.5570-12.2013
Funding
This work was supported by the MOE Layout Foundation of Humanities and Social Sciences (18YJA190016).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
None
Additional information
Open Practices Statements
The data and materials for all experiments are available at the Open Science Framework at https://osf.io/q8nhs, and none of the experiments were preregistered.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
ESM 1
(DOCX 16 kb)
Rights and permissions
About this article

Cite this article
Wang, L., Chen, Y. & Yue, Y. Is motor activity the key to the observation-inflation effect? The role of action simulation. Mem Cogn 50, 1048–1060 (2022). https://doi.org/10.3758/s13421-021-01259-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-021-01259-x