
Abstract
Given natural memory limitations, people can generally attend to and remember high-value over low-value information even when cognitive resources are depleted in older age and under divided attention during encoding, representing an important form of cognitive control. In the current study, we examined whether tasks requiring overlapping processing resources may impair the ability to selectively encode information in dual-task conditions. Participants in the divided-attention conditions of Experiment 1 completed auditory tone-distractor tasks that required them to discriminate between tones of different pitches (audio-nonspatial) or auditory channels (audio-spatial), while studying items in different locations in a grid (visual-spatial) differing in reward value. Results indicated that, while reducing overall memory accuracy, neither cross-modal auditory distractor task influenced participants’ ability to selectively encode high-value items relative to a full attention condition, suggesting maintained cognitive control. Participants in Experiment 2 studied the same important visual-spatial information while completing demanding color (visual-nonspatial) or pattern (visual-spatial) discrimination tasks during study. While the cross-modal visual-nonspatial task did not influence memory selectivity, the intra-modal visual-spatial secondary task eliminated participants’ sensitivity to item value. These results add novel evidence of conditions of impaired cognitive control, suggesting that the effectiveness of top-down, selective encoding processes is attenuated when concurrent tasks rely on overlapping processing resources.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The ability to prioritize information in attention and memory is a skill that is crucial to daily life given the wealth of information with which we are constantly inundated. We cannot truly pay attention to and/or remember everything we experience as cognitive resources are limited in nature. Given these natural limitations, it is adaptive to identify a subset of information that is most important on which to focus these limited resources in order to subsequently increase the likelihood of remembering that information at the expense of less important information. For instance, it may be more important to remember where we have placed our wallet or car keys when we return home after a long day at work relative to our pen or coat. This ability to selectively encode and retrieve information as a function of its importance, termed value-directed remembering (VDR), has been extensively studied (e.g., Castel, 2008; Castel et al., 2002) and represents a crucial form of goal-oriented cognitive control, as attentional resources must be distributed in a top-down manner (at least partially) to a particular subset of information in order to maximize goal-related memory ability.
In general, the effect of information importance on memory is robust under a variety of different conditions; maintained prioritization in memory is found in cognitively healthy older adults (Castel et al., 2002; Siegel & Castel, 2018a, 2019), younger adults under dual-task conditions (Middlebrooks et al., 2017; Siegel & Castel, 2018b), individuals with lower working memory capacity (Hayes et al., 2013; Robison & Unsworth, 2017) and even, to some extent, children with and without attention-deficit/hyperactivity disorder (ADHD; Castel, Humphreys, et al., 2011; Castel, Lee, et al., 2011) and older adults with Alzheimer’s disease (Castel et al., 2009; Wong et al., 2019). Further, this prioritization ability has been demonstrated in recognition (Adcock et al., 2006; Elliott et al., 2020; Elliott & Brewer, 2019; Gruber et al., 2016; Gruber & Otten, 2010; Hennessee et al., 2017, 2019; Sandry et al., 2014; Spaniol et al., 2013), cued recall (Griffin et al., 2019; Schwartz et al., 2020; Wolosin et al., 2012), and free-recall memory paradigms (Allen & Ueno, 2018; Atkinson et al., 2018; Castel et al., 2002; Cohen et al., 2017; Nguyen et al., 2019; Stefanidi et al., 2018), as well as with more naturalistic, real-world materials like severe medication interactions (Friedman et al., 2015; Hargis & Castel, 2018), potentially life-threatening allergies (Middlebrooks, McGillivray, et al., 2016), and important faces (DeLozier & Rhodes, 2015; Hargis & Castel, 2017). Behavioral and eye-tracking work suggests that the effect of value on memory is a result of both automatic, bottom-up and strategic, top-down control processes, with value automatically and involuntarily capturing attention (Anderson, 2013; Roper et al., 2014; Sali et al., 2014) and explicitly directing controlled, goal-oriented attention (Ariel & Castel, 2014; for a review, see Chelazzi et al., 2013; Ludwig & Gilchrist, 2002, 2003). Neuroimaging work reveals similar findings demonstrating that neural activity occurs in typical reward-processing regions like the ventral tegmental area (VTA) and the nucleus accumbens (NAcc) as well as frontotemporal regions involved in executive functioning like the left inferior frontal gyrus and left posterior lateral temporal cortex (Adcock et al., 2006; Carter et al., 2009; Cohen et al., 2014, 2016).
Effective cognitive control may be particularly critical for maximizing selectivity in the context of visual-spatial information. The ability to remember the identity and location of items (like the location of your wallet) is a form of visual-spatial memory that relies on the accurate binding of the “what” and “where” features of an item (Chalfonte & Johnson, 1996; Thomas et al., 2012). That is, it is not sufficient to remember what your wallet looks like (visual information) or its potential locations (spatial information), but rather the link between the item and the location (e.g., my wallet is on top of my nightstand). As informed by theories of visual search (e.g., feature integration theory; Treisman & Gelade, 1980; Treisman & Sato, 1990), the binding of object identity and location information into a solitary unit in memory may be more cognitively demanding than memory for single-feature memory (i.e., identity or location) due to the serial and effortful allocation of attention that is required during encoding. To support this notion, much empirical work has shown that the incorporation of individual visual and spatial features into an integrated unit requires attentional resources (e.g., Elsley & Parmentier, 2009; Schoenfeld et al., 2003; Wheeler & Treisman, 2002). As such, selective encoding in the visual-spatial memory domain may be particularly resource intensive, as attention is required to both bind items to locations and differentially study information according to its value.
However, despite the cognitively demanding nature of visual-spatial binding, prior work has indicated that participants can selectively attend to and remember high-value over low-value item-location information, even under dual-task conditions (Siegel & Castel, 2018a, 2018b). In previous work utilizing a visual-spatial VDR task (Siegel & Castel, 2018b), participants were presented with items of differing value within a grid array and were asked to prioritize high-value over low-value items for a later item-relocation test. Half of the participants studied items while completing a concurrent auditory tone discrimination task in which 1-back same/different decisions were made about low and high pitch tones. While overall memory performance was significantly worsened relative to full attention conditions with no secondary encoding task, selectivity was maintained with participants recalling an equivalent proportion of high-value relative to low-value item-locations.
This lack of effect of a secondary task on prioritization ability was also found in a non-associative, verbal memory context (i.e., individual words paired with point values) in which various auditory tone tasks taxed cognitive resources to differing degrees during encoding (Middlebrooks, Kerr, & Castel, 2017). In this study, participants attempted to prioritize words in memory based on point values while engaging in auditory tasks that required attentional and working memory resources to different extents – that is, one group of participants merely indicated whether a tone they just heard was low-pitched or high-pitched (lowest load), a second group indicated whether two tones played during a word’s presentation were the same pitch (medium load), and a final group indicated whether the current tone was the same or a different pitch from the tone immediately preceding it (highest load). Despite the increase in working memory load across these tasks, participants in all three divided-attention conditions were equivalently selective in their memory, suggesting that the degree of working memory load from a secondary task does not impair prioritization ability in the primary task, at least in the context of verbal memory (Middlebrooks, Kerr, & Castel, 2017). Other work, however, has found that selective encoding can be impaired in some circumstances (Elliott & Brewer, 2019), with results indicating that random number generation, but not articulatory suppression (i.e., repeating the same digit), impairs selectivity in a remember/know recognition paradigm. As such, the extent to which dividing attentional resources during encoding impacts value-directed cognitive control processes remains equivocal.
Considered alongside the results from Middlebrooks, Kerr, and Castel (2017), the results of Siegel and Castel (2018b) indicate that participants can maintain memory selectivity in both verbal and visual-spatial recall memory domains and under various levels of cognitive load during encoding. Despite cognitively demanding auditory distractor tasks resulting in lower overall memory performance, participants were still able to selectively study and remember information according to its value, suggesting that efficient cognitive control and strategizing during encoding may be relatively unimpaired by increased cognitive load. At the center of this maintained prioritization is participants’ ability to successfully direct attention to high-value information in order to increase the likelihood of recall. Evidently, tying up some attentional resources does not detract from participants’ ability to direct the remaining resources towards items of their choosing. In other words, these divided attention tasks are not interfering with participants’ selective attention towards the visual-spatial or verbal primary task. The goal of the current study, then, was to determine if there is some form of secondary task that would not only draw resources away from the primary visual-spatial memory task, but also interfere with the ability to direct attention within that primary task. The current study examines whether secondary tasks that draw upon the same attentional resources used in the primary task may result in an impaired ability to direct attention during encoding and thus impair selectivity where secondary tasks have not done so (Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018b).
Understanding the processes guiding dual-task interference is crucial due to our limited attentional capacity (Kinchla, 1992). Pashler (1994) described attention as a non-sharable resource between tasks that instead alternates between concurrent tasks. When viewing attentional resources as occurring sequentially in time (i.e., a single-channel model), a processing bottleneck will arise when two tasks are drawing upon the same processing resources simultaneously. A less discrete view of attentional resources during dual-task situations relies on capacity sharing, where shared attentional resources for both tasks are utilized simultaneously and become less efficient when capacity demands increase for the task at hand (see Pashler & Johnston, 1998, for a further overview of theoretical accounts of attentional limitations and dual-task interference). Navon and Miller (1987) describe dual-task interference in the context of a content-dependent account of attention, where interference occurs between the processes guiding related, competing tasks. Pashler and Johnston (1998) suggest that the content-dependent theory of attention may fit within the single-channel model of attention in that processing operations occurring sequentially (as opposed to simultaneously) would thus prevent against the occurrence of crosstalk between tasks with overlapping information (Pashler, 1994).
Central to the proposed hypotheses in the current study is the idea of modality-specific pools of attention. While a debate existed between the existence of one central, amodal “pool” of attention (Kahneman, 1973; Taylor et al., 1967) and theories suggesting the presence of modality-specific attentional pools (i.e., one pool for visual attention, one for auditory attention, etc.; Navon & Gopher, 1979; Pashler, 1989; Treisman & Davies, 1973; Wickens, 1980, 1984), there has been strong empirical support for the latter (Allport et al., 1972; for empirical work supporting the central, amodal view of attentional resources, cf. Arnell & Jolicoeur, 1999; Duncan et al., 1997; Hein et al., 2006; Martens et al., 2010; McLeod, 1977; Parkes & Coleman, 1990; Rees et al., 2001; Rollins & Hendricks, 1980; Soto-Faraco & Spence, 2002; Van der Burg et al., 2013). There are also important considerations to be made regarding task-dependent processing within and across modalities. Chan and Newell (2008) reveal that information processing occurs differently depending on the type of task and not based on how similar the tasks are to each other. Specifically, the authors show task specificity for inter-modal interference, which is especially pronounced for the processing of spatial location information (Chan & Newell, 2008). In this work, a same/different paradigm was used for both the primary and interference tasks to avoid induced interference from task switching and/or additional demands on attentional resources (Chan & Newell, 2008; Hirst & Kalmar, 1987; Kinsbourne, 1980). However, in the present study, participants are engaged in higher-order cognitive interference during encoding, as the secondary distractor tasks employed here utilize a 1-back same/different judgment during visual encoding, while the primary task is a visual-spatial memory relocation task occurring following the divided-attention task during encoding. Anecdotally, in the real world many people drive a car while listening to the radio with relative ease; however, few can (or should) drive and read a book or text message at the same time without experiencing major difficulties. Multiple resources theory (Wickens, 1980, 1984) would suggest that these two tasks can be completed simultaneously with little impairment in performance on either task because driving relies on visual attention and listening to the radio upon auditory attention. However, when two tasks draw upon the same pool of resources (e.g., reading and driving), this pool is drained more rapidly, and decrements can be observed in one or both of the tasks. Furthermore, a cross-modal “what” versus “where” processing framework would suggest that higher cognitive interference from task switching and/or additional demands on attentional resources may be induced by a secondary non-visual task occurring simultaneously with the visual-spatial task of driving a car.
More recent work has suggested that whether or not a task draws upon the same attentional pool may depend on whether the task involves spatial attention (i.e., attending to a location in space). This work has shown that spatial attentional resources are shared between the sensory modalities of audition and vision (Wahn & König, 2015), and that attentional resources are generally shared for spatial attention tasks, while attentional resources for feature-based tasks tend to be distinct and partially shared for tasks requiring a combination of feature-based and spatial attentional resources (Wahn & König, 2017). Furthermore, visual and spatial working memory may rely on similar but separable processing resources (Logie, 1995; Vergauwe et al., 2009), and that verbal and spatial resources may be functionally and neurocognitively distinct (Polson & Friedman, 1988). As such, attentional allocation across sensory modalities and the extent to which secondary tasks prove detrimental to one’s ability to selectively allocate attention to the primary task may also depend on whether the task requires the use of spatial resources.
The current study sought to clarify the conditions (if any) in which the ability to prioritize in attention and memory, an important form of cognitive control, may be compromised by testing predictions made by multiple resources theory – that is, whether tasks requiring overlapping modality-specific resources may interfere with selective memory for high-value information. While it is important to study how divided attentional resources may influence our ability to remember information in general, it is also important to understand how it influences our ability to selectively attend to and encode important subsets of information in memory. Understanding the limitations of our ability to selectively attend to and encode important information when people are engaged in tasks requiring the same resources has many practical implications. For instance, students who opt to complete two visual tasks simultaneously (e.g., watching television while studying a diagram for an exam) may not remember the important information visually processed from the diagram for a later test relative to a student studying the same visual diagram while engaging in a secondary task that does not share overlapping visual resources (e.g., listening to a podcast). The main goal of the current study, then, was to determine whether cognitive control in the form of selective encoding may be impaired when a secondary task requires the use of overlapping attentional resources, potentially diminishing the extent to which resources could be devoted to the primary memory task.
Experiment 1
As found in previous work (e.g., Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018b), participants are able to maintain selectivity despite increasingly cognitively demanding secondary tasks. However, the secondary tasks utilized in these experiments required only the use of auditory attentional resources with no visual or spatial component present. If attentional resources are indeed modality-specific, then it is of little surprise that these secondary tasks do not hinder participants’ ability to selectively remember high-value information. The goal of Experiment 1 was to determine whether an audio-spatial secondary task would succeed in impairing selectivity during the completion of a visual-spatial primary task. The secondary tasks utilized in the current study were similar in nature to the 1-back discrimination tasks used in prior work (Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018a, 2018b), and they were chosen in order to induce a relatively high working memory load. That is, while we refer to these secondary tasks as dividing attention, the tasks themselves require working memory resources in order to discriminate between a current tone and the one immediately preceding it, which must be held in working memory. As such, for successful performance, attentional resources must be divided between the primary and secondary tasks, which both required attentional and working memory resources to differing extents.
We hypothesized that the addition of a secondary audio-nonspatial task (as used in prior work; Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018b) would reduce memory performance, but result in equivalent selectivity to a full attention control group with no secondary task during encoding. However, we expected that the addition of a secondary audio-spatial task would draw upon the shared attentional resources as the primary visual-spatial task (i.e., spatial attentional resources), consistent with multiple resources theory (Wickens, 1980, 1984), and result in both decreased memory performance and selectivity relative to the control group.
To test these hypotheses, three between-subjects encoding conditions were utilized: a control condition with no secondary distractor task, an audio-nonspatial divided-attention condition, and an audio-spatial divided-attention condition. Participants in each of the three conditions completed eight trials of the visual-spatial selectivity task used in previous work (Siegel & Castel, 2018a, 2018b) in which participants were asked to remember the location of items paired with points values indicating their importance placed in random locations in a grid. During the study phase, the audio-nonspatial and audio-spatial conditions were asked to also complete a secondary auditory distractor task. While participants in the audio-nonspatial condition made 1-back same/different judgments about low-pitched and high-pitched tones during encoding (with no spatial component), participants in the audio-spatial group were required to make same/different judgments about the auditory channel or side on which the tone was played. That is, for these participants the tones during the task were played in either the left channel or the right channel and participants had to judge whether the most recent tone played was in the same channel (e.g., left-left) or a different channel (right-left) to the tone just prior. Thus, being successful on this secondary task required the usage of audio-spatial resources during encoding.
Method
Participants
The participants in Experiment 1 were 72 University of California, Los Angeles (UCLA) undergraduate students (51 females, Mage = 20.08 years, SDage = 2.00, age range: 18–31). The highest level of education reported by participants was 63% some college, 15% associate’s degree, 13% high school graduate, and 10% bachelor’s degree. All participants participated for course credit and reported normal or corrected-to-normal vision.
Our sample size was based on prior work investigating similar research questions (e.g., Allen & Ueno, 2018; Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018b). To determine the post hoc sensitivity of our analyses of variance with the given sample sizes, we used the G*Power program (Faul et al., 2007). When including the relevant parameters (three between-subjects groups and eight within-subjects measures) and a power level of 0.95, the resultant effect size was Cohen’s f = .16, suggesting that this is the smallest effect that we could have reliably detected with the current sample size. Converting this Cohen’s f to eta-squared results in η2 = .024 (Cohen, 1988). In both experiments, all significant findings had effect sizes that surpassed this value, suggesting that our sample size provided adequate power to detect significant differences in the current study.
Materials
Similar to prior work (Siegel & Castel, 2018a, 2018b), the materials in this study consisted of eight unique 5 × 5 grids containing ten items each presented on a computer screen (see Fig. 1 for an example grid). The grids were approximately 15 × 15 cm on the screen (17.06° visual angle) and contained 25 cells, each of which was approximately 3 × 3 cm in size (3.44° visual angle). Within each of ten randomly chosen cells was an item selected from a normed picture database (Snodgrass & Vanderwart, 1980). The items used were 80 black and white line drawings of everyday household items (e.g., a key, a camera, and an iron). On the computer screen, items were approximately 2 × 2 cm in size (2.29° visual angle). To form a grid, ten items were randomly selected from the 80-item pool and randomly placed in the cells of the grid with the constraint that no more than two items be present in any row or column of the grid (to reduce the likelihood of the item arbitrarily forming spatial patterns that may aid memory). Items were then randomly paired with point values ranging from 1 point (lowest value) to 10 points (highest value) indicated by the numerical value placed in the top left portion of each item-containing cell. Each value was used once per grid. This process was repeated to form eight unique grids for each participant. For example, while one participant may have been presented with an iron paired with the 7-point value in the top left cell of the second grid, a different participant could encounter that same item paired with the 4-point value in the bottom right cell of the sixth grid. As such, each participant was presented with a different set of eight completely randomized grids.

An example grid that participants may have been presented with during the study phase. Items were everyday household objects taken from a normed picture database. Information importance was indicated by the numerical value in the top left corner of each item-containing cell. In Experiment 1, items were presented one at a time, with only one item present in the grid at any point during the study phase (sequentially). In Experiment 2, items were presented all at the same time (simultaneously) as shown in the figure
Procedure
Participants were randomly assigned to one of three between-subjects encoding conditions: full attention (FA), audio-nonspatial divided attention (ANS), or audio-spatial divided attention (AS). All participants were instructed that they would be presented with ten items placed within a 5 × 5 grid and would be later tested on that information. Participants were further instructed that each item would be paired with a point value from 1 to 10 indicated by a number in the top left portion of each item-containing cell. The participants were told that their goal was to maximize their point score (a summation of the points associated with correctly remembered information) on each grid. Participants were shown items one at a time, each for 3 s (totaling 30 s for the ten items), which were presented randomly with regard to their location in the grid and their associated point value. Participants were told that after they studied the information within the grid, they would immediately be shown the items underneath a blank grid and be asked to replace each item in its previously presented location by first clicking on the item and then the cell in which they wanted to place it. Participants were also able to drag and drop the item into the cells and could move items around to different cells before submitting their final response. If participants were unsure of an item’s location, they were asked to guess, as they would not be penalized for incorrectly placed items. Participants were given an unlimited duration to complete this testing phase and were required to place all ten items before advancing to the next trial. After participants placed all ten items, they clicked a submit button and were then given feedback on their performance in terms of the items that they correctly placed, the number of points they received (out of 55 possible), and the percentage of points they received. After receiving feedback, participants repeated this procedure with unique grids for seven further study-test cycles (for a total of eight trials).
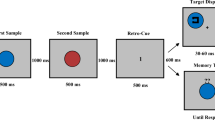
Participants in the divided-attention conditions also completed tone-distractor tasks during the study period (Fig. 2). Participants were instructed that they would hear a series of tones during the study phase. Tones were presented auditorily through headphones worn by the participants throughout the duration of the experiment. In the ANS condition, tones were one of two pitches: low pitch (400 Hz) and high pitch (900 Hz). In the AS condition, all tones were 650 Hz (the average of the low and high pitch frequencies used in the ANS condition) but were either played only in the right auditory channel or the left auditory channel. In both conditions, each tone was played for a duration of 1 s and the order of presentation was random for each participant with the constraint that no pitch (ANS) or side (AS) was played more than three times consecutively. Participants completed a 1-back tone discrimination task such that they were required to determine whether the most current tone they heard was the “same” as or “different” to the tone immediately preceding it. For example, in the ANS condition, a “same” response was required when two consecutive tones were high pitch, while in the AS condition a “same” response was required when two consecutive tones were played in the left channel. The corresponding keys for “same” and “different” were labeled as such on the keyboard (the “[” and “.” keys, respectively).

Schematic representation of the study phase in Experiment 1 for the divided-attention conditions. In the audio-nonspatial condition (left), participants made 1-back same/different judgments on tones of high/low frequency. In the audio-spatial condition (right), participants made 1-back same/different judgments on tones in the left/right channel. In both conditions, participants made a total of ten judgments during the study phase of each trial before advancing to the relocation test
Before each study-test cycle, a blank grid appeared on the screen and the first tone was played. Participants were instructed that they were not required to respond to this first tone. After 3 s, the first item appeared along with the second tone. Participants then had to make their first decision (“same” as or “different” to the first tone). After that, the remaining tones were played in 3-s intervals, totaling 11 tones by the end of the study period (one preceding the presentation of items and ten during item presentation). The tones were played for the first second of each item’s 3-s presentation duration. For both conditions, participants were required to make their tone discrimination response within the 3-s window before the following tone was played. Participants were able to change their response within that 3-s interval and their final response was used in later analyses. To encourage participants to equivalently divide their effort between the two tasks, feedback on tone-distractor task performance (i.e., the number of correct tone decisions out of ten possible) was presented along with the primary grid task feedback after each trial. For the divided-attention conditions, we set an inclusion criterion based on tone-distractor task performance such that, to be included in the study, participants had to (i) have responded to at least 50% of tones and (ii) have tone discrimination accuracy greater than 50% averaged across all eight grids, similar to prior work (Siegel & Castel, 2018b). Participants were excluded from the study if they did not fulfill either (i) or (ii) and data were collected until there were 24 participants in each divided-attention condition that satisfied these criteria. In the ANS condition, a total of 32 participants were collected with eight excluded for not meeting inclusion criteria, and in the AS condition, a total of 42 participants were collected with 18 excluded.Footnote 1
Results
In this task, memory performance was analyzed using a distance to target location (DTL) measure. As the current study utilized grids containing items of differing value, the materials allowed for a unique, fine-grained exploration of memory accuracy. Compared to studies in which memory performance is measured in a binary manner (i.e., an item is either recalled or not recalled), the grids utilized in the current study permitted a more detailed analysis of participants’ memory as a function of value in each encoding condition (i.e., the degree to which an item’s location was correctly recalled). All of the following analyses were also conducted using binary recall (0 = not correctly replaced, 1 = correctly replaced) as the dependent measure, which resulted in a consistent pattern of findings. Given that the DTL measure may represent a more precise measure of memory performance by capturing both verbatim item-location memory and gist-based memory (Siegel & Castel, 2018a, 2018b), we report the following analyses using DTL as the outcome measure.
The DTL measure depicted in Fig. 3 was calculated for each item placed by participants. A DTL score of 0 indicated an item was correctly placed in its previously presented location, while a score of 1 indicated that an item was misplaced by one cell from the target location (either horizontally, vertically, or diagonally), a score of 2 indicated an item was misplaced two cells from the target location, and so on. DTL scores could range from 0 (correctly placed in the target location) to 4 (four cells away from the target cell). While certain locations had a maximum DTL of 3 (e.g., a cell in the center of the grid) and others a maximum of 4 (e.g., a cell in the corner of a grid), these differences were likely evenly distributed across items and trials due to the random placement of items within grids and across trials for each participant. DTL scores were used as the dependent variable in the following analyses. In all such analyses, smaller DTL scores indicate closer placement to the target cell (and more accurate memory performance), while larger DTL scores indicate farther placement from the target cell (and less accurate memory performance).

An example of distance to target location (DTL) scores relative to an item’s correct location. DTL represents the number of “steps” from an incorrectly placed item to the previously presented location. Depending on the target location, the DTL score ranged from 0 (correctly placed in the target location) to 4 (distance of four horizontal, vertical, or diagonal steps from target location). Lighter shades indicate placement closer to the target cell resulting in a small DTL score. Darker shades indicate placement farther from the target cell resulting in a larger DTL score
Given the multifaceted nature of these data, we used a conjunction of statistical analyses to examine memory performance. First, we examined participants’ tone-distractor performance to ensure that participants were adequately attempting the secondary tone task. We next examined overall memory performance between encoding conditions without regard to item value using analyses of variance (ANOVAs) on DTL scores. Then, we examined memory performance as a function of item value, using this measure as a predictor of DTL in a multilevel regression model. As such, this allowed us to appropriately examine differences in overall memory (using analyses of variance) and differences in the effects of value between encoding conditions (using multilevel modeling).
Tone distractor accuracy
To examine how participants in the divided-attention conditions performed on the auditory tone-distractor task between encoding conditions, we conducted an independent-samples t-test on tone-distractor accuracy (i.e., the proportion of tones out of ten to which a correct same/different judgment was made), which indicated no significant difference in accuracy between the ANS condition (M = .78, SD = .08) and the AS condition (M = .80, SD = .13), t(46) = 0.81, p = .42, Cohen’s d = .24. To determine whether performance differed from chance (i.e., 50%), we conducted one-sample t-tests on tone-distractor accuracy within each encoding condition, which indicated that performance was higher than chance in both the ANS condition, t(23) = 16.98, p < .001, Cohen’s d = 3.47, and the AS condition, t(23) = 11.36, p < .001, Cohen’s d = 2.32. These results suggest that participants in both divided-attention conditions were equivalently accurate on the tone-distractor task and that performance was above chance throughout the experiment.
Overall memory accuracy
Memory performance on the visual-spatial grid task was measured using the previously described DTL measure (ranging from 0 to 4) depicted in Fig. 4, with lower values indicating an item was relocated closer to the target location (i.e., better memory performance) and higher values indicating an item was relocated farther form the target location (i.e., worse memory performance). We conducted a between-subjects analysis of variance (ANOVA) examining DTL scores as a function of encoding condition (FA, ANS, AS). In this and all following ANOVAs in the current study, in the case of sphericity violations, Greenhouse-Geisser corrections were used. There was a significant effect of encoding condition, F(2, 69) = 22.85, p < .001, η2 = .40, with Bonferroni-corrected independent-samples t-tests indicating significantly lower DTL scores in the FA condition (M = 0.83, SD = .40) relative to the ANS condition (M = 1.42, SD = .31), t(46) = 6.14, p < .001, Cohen’s d = 1.62, and the AS condition (M = 1.36, SD = .25), t(46) = 5.52, p < .001, Cohen’s d = 1.56. However, there was no significant difference in DTL scores between the ANS and AS conditions, t(46) = 0.62, p > .99, Cohen’s d = 0.21. As such, these results show that participants in the divided-attention conditions had less accurate memory performance compared to participants in the full attention condition, but the type of divided attention (ANS or AS) did not result in different overall memory accuracy.

Distance to target location (DTL) between encoding conditions as a function of item value in Experiment 1. Smaller values indicate placement closer to the target location and larger values indicate placement farther from target location. Error bars represent ±1 standard error of the mean. ANS audio-nonspatial, AS audio-spatial, FA full attention
Memory selectivity
Average DTL scores as a function of item value and encoding condition are depicted in Fig. 4. In order to compare selectivity between conditions, we used multilevel modeling/hierarchical linear modeling (HLM), which has been used in many previous studies investigating memory selectivity (Castel et al., 2013; Middlebrooks & Castel, 2018; Middlebrooks, Kerr, & Castel, 2017; Middlebrooks, McGillivray, et al., 2016; Middlebrooks, Murayama, & Castel, 2016, 2017; Raudenbush & Bryk, 2002; Siegel & Castel, 2018a, 2018b, 2019). We first considered analyzing the data in an ANOVA framework using different value “bins” (i.e., low, high, and medium value) as levels of a categorical predictor. However, the post hoc binning of items may not accurately reflect each individual participant’s valuations of to-be-learned stimuli (e.g., Participant 1 may consider items with values 6–10 to be of “high” value, while Participant 2 with a lower capacity may only consider items with values 8–10 as such). In contrast, HLM treats item value as a continuous variable in a regression framework, allowing for a more precise investigation of the relationship between relocation accuracy and item value. Further, by first clustering data within each participant and then examining possible condition differences, HLM accounts for both within- and between-subject differences in strategy use, the latter of which would not be evident when conducting standard analyses of variance or simple linear regressions. Thus, HLM allows for a more precise analysis of participants’ unique value-based strategies.
In a two-level HLM (level 1 = items; level 2 = participants), DTL scores were modeled as a function of item value. Item value was entered into the model as group-mean centered variables anchored at the mean value of 5.5. The encoding conditions (ANS, AS, FA) were included as dummy-coded level-2 predictors. In this analysis, participants in the ANS condition were treated as the comparison group, while Comparison 1 compared ANS and AS, and Comparison 2 compared ANS and FA. We also conducted the same HLM including serial position as a linear and quadratic predictor and found consistent results of value on memory as the analyses presented below; therefore, we describe the analyses without serial position here for concision (the HLM including serial position is presented in the Online Supplemental Materials (OSM), which indicated typical effects of primacy and recency in all three conditions). Table 1 presents the tested model and estimated regression coefficients in the current study. The HLM indicated that there was a negative effect of item value on DTL scores for the ANS group, β10 = -.03, p = .02. This effect was consistent for the other encoding conditions as indicated by the lack of significance of the comparison coefficients, β11 = -.01, p = .49, β12 = .01, p = .53. As such, for all three encoding conditions, as item value increased, items were relocated closer to the target location and all three encoding conditions were equivalently selective in their memory.
In order to provide direct evidence of a null effect of value on DTL between encoding conditions, we conducted a Bayesian analysis and computed a Bayes factor (BF10) that would provide the relative strength of evidence for the null hypothesis (i.e., no differences between encoding conditions) relative to the alternative hypothesis (for a review of the benefits of Bayesian hypothesis testing in psychological science, see Wagenmakers et al., 2017). Bayesian null hypothesis testing has been used to determine the likelihood of null effects in previous value-directed remembering research (e.g., Middlebrooks, Kerr, & Castel, 2017; Middlebrooks, Murayama, & Castel, 2016; Siegel & Castel, 2018a, 2018b). Comparing Bayes factors within an HLM framework can be difficult (Lorch & Myers, 1990; Murayama et al., 2014), so we conducted a simpler two-step procedure Middlebrooks, Murayama, & Castel, 2016; Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018a, 2018b). First, DTL was regressed on item value within each grid for each participant. Then, we conducted a one-way Bayesian ANOVA on the obtained slopes using default priors. The computed Bayes factor (BF10 = .229) for the main effect of encoding condition indicated that the null hypothesis was 1/.229 = 4.38 times as likely to be true than the alternative hypothesis. This represents “moderate” evidence (Jeffreys, 1961; Lee & Wagenmakers, 2013) that the lack of difference between encoding conditions likely reflects a similar effect of value on memory performance for these groups, rather than a lack of statistical power to detect an existing difference.
Discussion
To summarize the results, there were no differences in performance between the non-spatial and spatial divided-attention conditions. Participants in both conditions had equivalent tone-distractor accuracy and overall DTL magnitudes. Crucially, while participants in both conditions had less accurate performance than those in the control condition, there were no differences in selectivity between participants in the control condition and in the divided-attention conditions, or between those in the divided-attention conditions themselves as evidenced by the multilevel modeling analyses. Given these results, it is clear that the addition of a secondary task during encoding that involved an auditory spatial component did not hinder participants’ ability to prioritize information in visual-spatial memory, contrary to our initial theoretically motivated hypotheses.
Experiment 2
The results of Experiment 1 and previously published work (cf. Elliott & Brewer, 2019; Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018b) demonstrate that selectivity is maintained under conditions of auditory-nonspatial and auditory-spatial divided attention in both verbal and visual-spatial memory domains. However, while the AS condition certainly involved a spatial component (i.e., judging between tones played in left channel vs. right channel), it was not truly sharing the exact same processing resources as the primary task, which requires visual-spatial, not audio-spatial resources. Perhaps, then, selectivity may be impaired when the secondary task is truly intra-modal, sharing the exact same processing resources as the primary task, which as indicated by previous work in the visual search domain may interfere with cognitive control processes (Burnham et al., 2014; Kim et al., 2005; Lin & Yeh, 2014). Experiment 2 sought to determine whether intra-modal divided attention may produce deficits in memory prioritization where cross-modal divided attention did not. It stands to reason that tasks that require the same processing and attentional resources during encoding may draw upon the same attentional pool, limiting the resources that can be devoted to either task and diminishing participants’ ability to selectively study information (cf., Marsh et al., 2009). However, on the other hand, this limitation in resources may only produce deficits in memory accuracy, and not impairments in selectivity similar to prior cross-modal divided attention findings.
As such, Experiment 2 compared how visual-spatial selectivity may be affected in new conditions of cross-modal (e.g., visual-nonspatial) and intra-modal (i.e., visual-spatial) divided attention. Further, as compared to Experiment 1, in which objects were presented sequentially, objects in Experiment 2 were presented simultaneously (i.e., all at the same time) to allow for higher recall and more effective strategy implementation, as indicated by prior work (Ariel et al., 2009; Middlebrooks & Castel, 2018; Schwartz et al., 2020; Siegel & Castel, 2018a, 2018b). In Experiment 1, overall recall accuracy (i.e., the proportion of items correctly replaced in the exact previous location) was relatively low in the divided-attention conditions (MANS = .32, MAS = .34), so this change was made to ensure that any observed differences in selectivity would be due to the nature of the divided attention task and not the difficulty of the presentation format.
Method
Participants
The participants in Experiment 2 were 72 UCLA undergraduate students (50 females, Mage = 20.71 years, SDage = 1.65, age range: 18–28). The highest level of education reported by participants was 64% some college, 18% bachelor’s degree, 10% associate’s degree, and 8% high-school graduate. All participants participated for course credit and reported normal or corrected-to-normal vision. None of the participants had participated in Experiment 1.
Materials and procedure
The primary memory task used in the current experiment was the previously described visual-spatial VDR task used in Experiment 1. Grids contained ten everyday objects placed in randomly selected locations in a 5 × 5 grid. The objects were randomly assigned a point value ranging from 1 to 10 and participants were directed to maximize their point score (a summation of points associated with correctly placed objects). Participants had 18 s to study the grid with objects simultaneously presented for the whole study time. Study time was reduced from Experiment 1 as pilot data indicated that performance was potentially approaching ceiling when given 30 s to study simultaneously presented objects. After studying, participants were given an item-relocation test in which they were asked to replace items in their previously presented locations. They were then given feedback on their total score and completed a total of eight unique study-test cycles. The type of divided attention task during encoding differed between subjects. While we attempted to mirror the auditory 1-back tone-distractor task used in Experiment 1 as closely as possible, some changes were necessary to incorporate visual distractors.
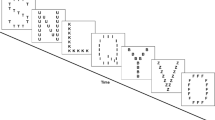
In Experiment 2, participants were randomly assigned to one of three between-subjects conditions: full attention (FA), visual-nonspatial divided attention (VNS), or visual-spatial divided attention (VS; n = 24 per condition). Participants in the FA condition completed the task without any secondary distractor during encoding, studying the objects in locations for 18 s followed by the relocation test. Participants in the VNS condition were required to complete a 1-back color discrimination task while studying the objects in the grid. As depicted in Fig. 5, before presentation of the study grid, a square the exact same dimensions as the to-be-presented grid would appear in the center of the screen. This square was colored, in the red-green-blue (RGB) color format, a shade of grey with the following characteristics (R = 128, G = 128, B = 128). This grey square was presented for 3 s, followed by the study grid with the simultaneously presented objects, which appeared in place of the grey square. Participants studied the objects in their locations for 3 s, after which a second grey square appeared in place of the grid, and participants were required to make their first judgment: is this shade of grey the same or different than the shade of grey that preceded it? For different shades, the color was modified from the previous shade such that it was ± (R = 51, G = 51, B = 51) darker or lighter. Participants were required to make this judgment within the 3 s that the grey square was present on the screen and could change their response within that time frame only with their final response used in later analyses. After the 3 s elapsed, the same study grid would appear with the same objects in the same locations for a duration of 3 s, at which point the third grey square appeared and participants had to make their second judgment: is this shade of grey the same as or different to the second grey square? This process repeated such that participants studied the objects in the grid for a total of 18 s and made a total of six color judgments on the seven presented grey squares (one preceding the presentation of items and six during object presentation). So, the study period was a total of 39 s in length (3 s for the first grey square, 18 s for the following six grey squares, and 18 s for the study grid) alternating between the grey squares and objects in locations. On each trial, there were a total of three correct “same” decisions and three correct “different” decisions in a randomized order. After the sixth and final study grid presentation, a brief visual mask was shown, and the object relocation test began. In both conditions, the corresponding keys for “same” and “different” were labeled as such on the keyboard.

Schematic representation of the study phase in Experiment 2 for the divided-attention conditions. In the visual-nonspatial condition (top), participants made 1-back same/different judgments on shades of grey. In the visual-spatial condition (bottom), participants made 1-back same/different judgments on patterns of filled in cells. In both conditions, participants made a total of six judgments during the study phase of each trial before advancing to the relocation test
The VS condition followed the same general procedure, but with different stimuli alternating with the study grid. In this condition, participants completed the 1-back visual pattern discrimination task shown in Fig. 5. Prior to presentation of the objects, the grid appeared with three randomly selected cells filled in black. Participants viewed this pattern for 3 s at which point it disappeared and the objects immediately appeared in their randomly selected cells for another 3 s. Then, a second pattern of three black squares appeared for 3 s at which point participants were required to make their first same/different judgment: was this pattern of filled in cells the same or different than the previously presented pattern? For different patterns, one of the cells was randomly selected to be offset one cell either vertically, horizontally, or diagonally from its location in the previous pattern, while the other two filled cells remained the same. After making this judgment the objects reappeared for another 3 s followed by the third pattern and second same/different judgment. Again, this process repeated such that participants studied the items in the grid for a total of 18 s and made a total of six pattern judgments on the seven presented patterns (one preceding the presentation of items and six during item presentation) with a total study period of 39 s alternating between the patterns and objects in locations. Similar to the VNS condition, on each trial, there were a total of three correct “same” decisions and three correct “different” decisions in a randomized order. After the sixth and final study grid presentation, a brief visual mask was shown and the object relocation test began. Participants were given feedback on their same/different judgment performance (i.e., the number and proportion out of six to which they correctly responded) along with their object/grid memory performance during the feedback phase in order to encourage equivalent participation in the tasks.
Finally, similar to Experiment 1, we set an inclusion criterion based on the visual distractor tasks in the divided-attention conditions. Participants were excluded from the study if they did not (i) respond on at least 50% of visual distractor judgments or (ii) have visual distractor accuracy greater than 50% across trials. Data were collected until there were 24 participants in each divided-attention condition that satisfied these criteria. In the VNS condition, a total of 37 participants were collected, with 13 excluded for not meeting inclusion criteria, and in the VS condition, a total of 38 participants were collected, with 14 excluded.Footnote 2
Results
The same analytical approach used in Experiment 1 was again applied in Experiment 2. We first analyzed visual distractor accuracy in the divided-attention conditions, then we examined overall visual-spatial grid memory accuracy between encoding conditions, and finally we analyzed memory selectivity between encoding conditions using HLM.
Visual distractor accuracy
To examine how participants in the divided-attention conditions performed on the visual distractor task, we conducted an independent samples t-test on visual distractor accuracy (i.e., the proportion of distractor decisions out of six to which a correct same/different judgment was made) between encoding conditions. There was no effect of encoding condition, t(46) = 1.01, p = .32, Cohen’s d = 0.29, such that distractor accuracy was not significantly different between the VNS (M = .67, SD = .11) and the VS (M = .64, SD = .09) conditions. To determine whether performance differed from chance (i.e., 50%), we conducted one-sample t-tests on visual distractor performance within each encoding condition. These analyses revealed that accuracy was significantly higher than chance in both the VNS, t(23) = 7.69, p < .001, Cohen’s d = 1.57, and the VS conditions, t(23) = 7.86, p < .001, Cohen’s d = 1.61. These results indicate that there was no difference in visual distractor accuracy between encoding conditions and that participants’ performance was above chance.
Overall memory accuracy
Memory performance on the visual-spatial grid task was measured using the DTL measure (ranging from 0 to 4) depicted in Fig. 6. We conducted a between-subjects ANOVA on DTL scores between encoding conditions (FA, VNS, VS). There was a significant effect of encoding condition, F(2, 69) = 8.30, p < .001, η2 = .19, with Bonferroni-corrected independent-samples t-tests indicating that DTL scores were lower in the FA condition (M = 0.54, SD = 0.37) than in the VNS condition (M = 0.88, SD = 0.37), t(46) = 3.29, p = .01, Cohen’s d = 0.92, and the VS condition (M = 0.92, SD = 0.33), t(46) = 3.73, p = .001, Cohen’s d = 1.09. However, there was no significant difference between the VNS and VS conditions, t(46) = 0.44, p > .99, Cohen’s d = 0.13. Overall, memory accuracy was significantly higher in the FA relative to both divided-attention conditions, which did not significantly differ from each other.

Distance to target location (DTL) between encoding conditions as a function of item value in Experiment 2. Smaller values indicate placement closer to the target location and larger values indicate placement farther from target location. Error bars represent ±1 standard error of the mean. VNS visual-nonspatial, VS visual-spatial, FA full attention
Memory selectivity
In a two-level HLM (level 1 = items; level 2 = participants), DTL scores were modeled as a function of item value between encoding conditions. Similar to Experiment 1, item value was entered into the model as group-mean centered variables and the encoding conditions (0 = VNS, 1 = VS, 2 = FA) were included as level-2 predictors. In this analysis, participants in the VNS condition were treated as the comparison group, while Comparison 1 compared VNS and VS, and Comparison 2 compared VNS and FA. Table 1 presents the tested model and estimated regression coefficients in the current study. The HLM indicated that there was a negative effect of item value on DTL scores for the VNS group, β10 = -.04, p < .001, which was not significantly different for the FA condition, β12 = .01, p = .52. However, this was significantly different for the VS group, β11 = .03, p = .03. Rerunning the analysis with VS as the comparison group to calculate the simple slope indicated that value was not a significant predictor of DTL in the VS condition, β = -.01, p = .57. So, this analysis indicates that value was significantly negatively predictive of DTL scores in the VNS and FA conditions, but not the VS condition.
Memory selectivity of high distractor performers
When comparing the difficulties of the auditory and visual distractor tasks, the auditory task was relatively easier to perform than the visual task (M = .79 vs. M = .65 when averaged across both DA conditions, respectively). An alternative explanation of the lack of selectivity in the VS condition could be that the AS task from Experiment 1 only required relatively few resources and hence did not interfere with memory selectivity even though resources were shared. As such, we sought to assess whether participants who had similar performance on the visual-spatial task to the audio-spatial still showed interference in memory selectivity, potentially providing evidence against the notion that distractor difficulty may be driving the observed results.
To examine participants who performed well on the visual distractor task, we conducted a median split on distractor task accuracy within each visual distractor group (VS and VNS) and selected the top half of participants in each group (n = 12 per condition). Naturally, the distractor accuracy averaged across groups increased (M = .73, SD = .06) relative to when all participants’ data were included (M = .65, SD = .10). While this mean was closer to the mean distractor accuracy averaging across audio distractor conditions in Experiment 1 (M = .79, SD = .11), it was still significantly less accurate, t(70) = 2.61, p = .01, d = .65. In an effort to equate distractor accuracy between the experiments, we further trimmed the data to only examine the top tertile (i.e., 33%) of participants in each visual distractor condition (n = 8 per condition). Participants’ visual distractor accuracy in this top tertile (M = .76, SD = .05) was not significantly different to Experiment 1 participants’ audio distractor accuracy, t(62) = 1.19, p = .24, d = .34.
Then, to determine whether participants who had similar performance on the visual-spatial task to the auditory-spatial task still showed interference in memory selectivity, we conducted the same HLM analysis described in the Memory Selectivity section, but with only the top half and top tertile (in separate analyses) of visual distractor performers’ data included for the VS and VNS groups. Given that the patterns of significance were identical across the two models (i.e., either including the top half or the top tertile), we elected to include more participants’ data by describing the former here. The HLM indicated that there was a negative effect of item value on DTL scores for the VNS group, β10 = -.05, p < .001, which was not significantly different for the FA condition, β12 = .02, p = .19. However, this was significantly different for the VS group, β11 = .04, p = .01, and rerunning the analysis with VS as the comparison group to calculate the simple slope indicated that value was not a significant predictor of DTL in the VS condition, β = -.01, p = .38. So, similar to the analyses with the full groups of participants, this HLM considering only the top half of visual distractor performers indicated that value was significantly negatively predictive of DTL scores in the VNS and FA conditions, but, importantly, not in the VS condition. In sum, this analysis shows that even participants who were performing well on the visual-spatial distractor still exhibited impaired memory selectivity, while those high-performing participants on the visual-nonspatial distractor were selective to the same extent as participants in the full attention condition.
Discussion
To summarize the results, participants in both divided-attention conditions had equivalent visual distractor accuracy and overall memory performance and were significantly less accurate on the visual-spatial grid task than those in the FA condition. Crucially, as revealed by the HLM, selectivity was equivalent between the FA and VNS conditions, with participants’ memory accuracy increasing with item value; however, even with equivalent overall memory performance, participants in the VS condition were not at all selective with their memory performance insensitive to item value. This was not merely a result of the combination of the two visual-spatial tasks in the VS condition being more difficult to complete overall, as visual distractor and memory performance was matched with those in the VNS condition – rather, the addition of the VS distractor task influenced the type (not amount) of information remembered. Further, when examining only the top half of performers on the visual distractor tasks in order to equate performance with audio distractor performance in Experiment 1, these top performers in the VS condition were still not selective towards item value, providing evidence against the notion that distractor difficulty may be driving the results. As such, results from Experiment 2 indicate that participants’ ability to prioritize information in visual-spatial memory is impaired when the secondary encoding task shares overlapping processing resources with the primary memory task (i.e., visual-spatial attention and memory resources).
General discussion
The goal of the current study was to determine whether secondary encoding tasks that shared similar processing resources to the primary memory task would result in impairments to goal-directed memory prioritization. Previous work has found that memory capacity is lowered but memory selectivity unaffected in a dual-task paradigm when the secondary encoding distractor task relies on relatively distinct processing resources (cf. Elliott & Brewer, 2019; Middlebrooks, et al. 2017; Siegel & Castel, 2018b). In both Experiment 1 and Experiment 2, secondary encoding distractors reduced memory accuracy relative to full attention conditions. Further, when the distractor attention task did not share the exact same processing resources as the primary visual-spatial memory task (i.e., the audio-nonspatial, audio-spatial, and visual-nonspatial conditions), selectivity was equivalent to full attention conditions demonstrating unaffected memory prioritization ability. The only distractor task that impaired selectivity was the visual-spatial pattern discrimination that resulted in no sensitivity to item value in participants’ memory performance. This result provides the first instance of reduced attentional resources leading to impaired encoding selectivity in cognitively healthy individuals relative to a wealth of prior work showing intact prioritization including in older adults (Castel et al., 2002; Siegel & Castel, 2018a, 2019), younger adults under dual-task conditions (Middlebrooks, Kerr, & Castel, 2017; Siegel & Castel, 2018b), and individuals with lower working memory capacity (Hayes et al., 2013; Robison & Unsworth, 2017). As such, these results suggest that in dual-task conditions when both tasks require the same processing resources, constraints are placed not only on memory capacity, but on cognitive control during encoding with participants less able to engage in selective attentional control processes.
The findings of the current study are consistent with predictions made by Wickens’ (1980, 1984) multiple resources theory. According to multiple resources theory, there are four dimensions in which cognitive tasks can be categorized: processing stages (perception, cognition, action), perceptual modality (visual, auditory), visual channels (focal, ambient), and processing codes (verbal, spatial), all of which have physiological correlates in the brain (Wickens, 2002). In a dual-task setting in which finite resources are split between multiple tasks, more interference will occur when the two tasks both demand resources from the same level of the dimension (e.g., two tasks that require visual perception) relative to when the two tasks require resources from different levels (e.g., one task that requires visual perception and one that requires auditory perception). In the context of the current study, the primary memory task involved the visual modality and both verbal and spatial codes, with participants likely recoding the visual information into verbal form in working memory (e.g., the key in the top left corner of the grid). The secondary distractor tasks in Experiment 1 required auditory-nonspatial (e.g., distinguishing low pitch from high pitch tones) and auditory-spatial (e.g., distinguishing left channel from right channel tones) processing resources resulting in overall primary task performance decrements, but no effect on selective encoding strategies. In Experiment 2, the visual-nonspatial task (e.g., distinguishing between different shades of grey) affected performance similarly.
Contrary to an attentional resource-based approach (Cowan, 1995; Lange, 2005; Neath, 2000), Marsh et al. (2009) argue that a process-oriented approach best explains the adaptive and dynamic nature of selective attention mechanisms and empirically limited memory capacity for competing information streams under divided attention (Hughes & Jones, 2005; Jones & Tremblay, 2000). Such an interference-by-process view suggests that more meaningful, task-extraneous material automatically elicits competing semantic memory processes with those in place for the primary memory task (Hughes & Jones, 2005; Jones & Tremblay, 2000; Klatte et al., 2013; Marsh et al., 2009; Neumann, 1996). Additionally, a process-oriented approach would also oppose a content-based approach (Gathercole & Baddeley, 1993; Neath, 2000), such that streams of information compete as a consequence of the mechanism driving how they are processed and not by what content is being processed (Marsh et al., 2009). In a content-dependent view of attention, dual-task interference occurs between the cognitive processes guiding related, competing tasks (Navon & Miller, 1987). Given that we observed maintained memory selectivity in all tasks of the present study except for the condition where visual-spatial resources were directly shared between both the primary and secondary tasks, it seems plausible that our findings are supported by a content-based account of attention, as crosstalk may be occurring between the two tasks with overlapping information (i.e., visual-spatial primary memory task and visual-spatial secondary memory distractor task; Pashler, 1994). Further, the interference-by-process account and experiments by Marsh et al. (2009) provide support for the drivers of attentional selectivity and impaired memory performance under divided attention, although this process-based view hinges on cases where similar semantic memory processes guide the retrieval of task-relevant and task-irrelevant information, independent of how similar the task-relevant and task-irrelevant information is. However, in the current study, both the primary memory task (visual-spatial grid) and the secondary distractor task (Experiment 1: auditory 1-back tone discrimination, Experiment 2: visual 1-back pattern discrimination) were equally as important for participants to do well on (i.e., achieve high memory performance) as was explicitly stated in the instructions. It is therefore plausible to consider that a process-based account would supersede a content-based view in light of the current study given maintained selectivity and decreased memory performance in dual-task conditions where both tasks do not require the same processing resources.
It must also be noted that presenting auditory tone discrimination tasks as an entirely non-spatial task may not be completely warranted given that prior research has revealed that participants tend to linearly associate visual object location with tone pitch frequency (i.e., high-pitch sounds with high visual object locations/low-pitch sounds with low visual object locations; Spence, 2011). It is therefore possible that the 1-back auditory tone discrimination secondary task within the current study was not entirely non-spatial, as participants may have employed spatial attentional processing resources to engage in this task. Future research should therefore utilize secondary discrimination tasks that are more directly disassociated from the spatial domain.
Only the visual-spatial (i.e., intra-modal) task distinguishing between different spatial patterns in the visually presented array interfered with both memory performance and the ability to selectively allocate attention. It is likely, then, that the combination of the visual modality and the spatial processing code led to these observed cognitive control deficits, as precisely these resources were required to encode information for the primary memory task, whereas either of these dimensions on their own were not sufficient to do so. Evidently, these resources that would otherwise be devoted to engaging in value-based encoding strategies are instead diverted to completion of the secondary task. When resources exactly overlapped between the tasks, this resulted not only in decrements in memory output, but also the effectiveness of top-down attentional control processes that would usually aid in encoding items differentially as a function of their value. As such, while it is well established that memory performance suffers as a consequence of additional cognitive load during encoding (e.g., Castel & Craik, 2003; Craik et al., 1996; Fernandes & Moscovitch, 2000; Naveh-Benjamin et al., 2000), the results from the current study add novel evidence that cognitive control processes can also be negatively affected when tasks share overlapping processing resources.
It is important to reconcile the results of the current study with previous work investigating memory selectivity under divided-attention conditions (Elliott & Brewer, 2019; Hu et al., 2014, 2016; Middlebrooks, Kerr, & Castel, 2017). Firstly, in the non-associative verbal domain, Middlebrooks, Kerr, and Castel (2017) found no effect of a variety of auditory tone tasks on selectivity for individual words of varying value. In this study, the divided attention tasks were all auditory in nature and included tone monitoring (i.e., pressing a key when a tone was played), paired tone discrimination (i.e., pressing a key when a pair of two tones were the same frequency), and 1-back tone discrimination (i.e., determining whether the current tone was the same or different frequency than the prior tone). While the word stimuli were presented visually, they were likely recoded into verbal working memory (Baddeley, 1986). It is evident then that the auditory tone-distractor tasks employed did not interfere with selective verbal encoding, as the two types of stimuli (i.e., asemantic tones at differing pitches and semantically meaningful nouns) may have been sufficiently perceptually distinct to draw upon different processing resources, as suggested by multiple resources theory (Wickens, 2002). As such, the tasks utilized in Middlebrooks, Kerr, and Castel (2017) may essentially be considered similar to “cross-modal” tasks that rely on separate resource pools resulting in negligible effects on selective encoding as seen in Siegel and Castel (2018b) and the audio-nonspatial, audio-spatial, and visual-nonspatial conditions in the current study.
In Elliott and Brewer (2019), results indicated that random number generation, but not articulatory suppression, impaired selectivity in a remember/know recognition paradigm. A follow-up experiment using a tone-monitoring secondary encoding task, similar to Middlebrooks, Kerr, and Castel (2017), also eliminated the effect of value on recognition memory, representing contrasting results with maintained selectivity under divided attention in free recall (Middlebrooks, Kerr, & Castel, 2017) and cued recall (Siegel & Castel, 2018b). These observed differences may be due to the nature of recognition testing, which may be less sensitive to effects of value in the first place, as (i) participants can rely on both recollective and familiarity-based memory (Hennessee et al., 2017), and (ii) recognition is unconstrained by working memory capacity (Unsworth, 2007) or output interference (Roediger & Schmidt, 1980) as is free recall. Thus, with memory less sensitive to value in recognition memory from the outset, interference of a secondary task in memory selectivity may be more likely to emerge from the data.
Other work has shown that cognitively demanding secondary tasks can influence the ability to remember high-value items when using a dichotomous value structure in which participants were asked to prioritize the first or last item presented in a series of items (Hu et al., 2014, 2016). Taxing attentional resources may have a more detrimental effect on high-value information in this type of paradigm, where the value structure is dichotomous – that is, if the single high-value item is not remembered, then participants’ ability to selectively encode high-priority information is considered impaired. In the current study, where the value structure is continuous, the effects of a secondary task during encoding may be more dispersed over a range of values, rather than one high-value item in particular. As such, these apparent differences in the effects of attentional load on memory may be due to the differences in value structure of the tasks, rather than participants’ ability to remember information of differing importance.
Our results add to previous work indicating that some cognitive control processes can be influenced by the availability of processing resources. A substantial body of work has indicated that the ability to filter out and ignore task-irrelevant information, another form of cognitive control, is reduced under conditions of high working memory load (Burnham, 2010; Gil-Gómez de Liaño et al., 2016; Kelley & Lavie, 2011; Konstantinou et al., 2014; Lavie et al., 2004; Lavie & De Fockert, 2005; Rissman et al., 2009; Sabri et al., 2014), especially when task resources overlap (Burnham et al., 2014; Kim et al., 2005; Lin & Yeh, 2014). Perceptual load theory (Lavie, 2005; Lavie & Dalton, 2013; Murphy et al., 2016) accounts for these results by positing that the effectiveness of selective attention is dependent on the demands of the task, such that distractor inhibition may be more likely to fail when cognitive load is high. In particular, our results are highly consistent with Burnham et al. (2014), who found that performance on a visual search task was more susceptible to distractors when participants simultaneously completed separate visual or spatial working memory tasks relative to a verbal working memory task which had no effect on distractor interference. These results suggest less effective attentional control (in the form of distractor rejection) when concurrent tasks required the same resources. The current study extends these predictions to the domain of selective attention and memory encoding in a value-directed remembering context, with concurrent tasks that share processing resources impairing cognitive control.
There are, of course, a few limitations that qualify the possible interpretations from the current experiments. Firstly, it is evident that the auditory distractor tasks in Experiment 1 were less resource intensive than the visual distractor tasks in Experiment 2 given the differences in overall distractor accuracy. Despite analyses showing that participants who performed well on the visual distractor task (i.e., the top half of performers) were still not selective towards value, it is possible that more difficult, resource-consuming audio distractor tasks may also induce selectivity impairments on the primary visual-spatial task. This may especially be the case for a more difficult audio-spatial distractor which would simultaneously utilize spatial attentional resources. The inclusion of a greater frequency of tone discrimination decisions during study or the addition of a third pitch from which to discriminate (e.g., a medium pitch of 650 Hz or central pitch played through both channels) may induce lower distractor accuracy and allow for the evaluation of this alternative explanation. It is important to note though, when considering the addition of more difficult secondary tasks, that approximately one-third of participants in each experiment were excluded due to a failure to meet the a priori inclusion criteria based on secondary task response rate and accuracy. While analyses without exclusion of participants produced the same patterns of results, any increase in difficulty of the secondary task is likely to result in even more exclusions which could cause problems in the interpretation of the results due to the restricted sample. This tradeoff between increasing task difficulty and retaining participants should be carefully considered when determining the nature of secondary tasks and the setting of inclusion criteria in future work. On the other hand, a visual-spatial distractor task that does not superimpose itself on the primary visual task (i.e., use the same grid array) may provide visual less interference and therefore not impair selectivity. That is, what may be driving the lack of prioritization ability in the VS condition may not necessarily be only the type of the secondary task, but the fact that the primary and secondary tasks occupy the same spatial locations. In a sense, these two factors may combine to produce the observed selectivity impairment, but the paradigm used in the current study cannot definitively tease apart their relative contributions. Redesigning the format of the secondary tasks such that they do not overlap in visual space by, for example, shifting the distractor stimuli to locations around rather than inside the grid array would provide evidence towards disentangling these two factors. If in fact selectivity is still disrupted when the secondary visual-spatial task does not share spatial location with the primary visual-spatial task, then it is likely that the type of task (i.e., visual-spatial) rather than the superimposition is what produces deficits in prioritization ability. Lastly, future research investigating the role of a secondary distractor task during both the encoding and the retrieval stages of the visual-spatial memory task could unlock crucial insights regarding higher-order cognitive interference as a result of cross-modal task switching (Kinsbourne, 1980) and attentional resource demands (Hirst & Kalmar, 1987) as participants would be required to encode and retrieve two competing streams of information simultaneously, in parallel.
The ability to prioritize important information in memory using selective attentional control processes is a robust finding that has generally been shown to persist under conditions of increased cognitive load (Middlebrooks et al., 2017; Siegel & Castel, 2018b) and reduced cognitive resources (Castel et al., 2002; Hayes et al., 2013; Robison & Unsworth, 2017; Siegel & Castel, 2018a). The current study provides novel evidence of a reduced ability to selectively remember information in a dual-task paradigm, but only when tasks rely on the same processing resources. These findings are informed by multiple resource theory (Wickens, 1980, 1984) and load theory (Lavie, 2005; Lavie & Dalton, 2013; Murphy et al., 2016), suggesting that the cognitive control processes responsible for selective encoding can be negatively impacted when relevant processing resources are redirected to a secondary task. As such, the current study identifies important constraints on the effectiveness of the cognitive control processes involved in memory for high-value information. Given the natural limitations of memory capacity, examining the conditions under which cognitive load impairs executive functioning is crucial for understanding the adaptivity of memory when resources are taxed by competing task demands. In sum, goal-directed selective memory processes may indeed be vulnerable to interference in some circumstances which should continue to be studied to provide further understanding of the complex relationship between attention, memory, and cognitive control.
Notes
We also conducted all analyses including data from participants who were originally excluded, but did in fact attempt the secondary task as evidenced by greater than 0% tone response rate and 0% accuracy (an additional seven participants in the ANS condition and 16 participants in the AS condition). The inclusion of this additional data produced an identical pattern of findings to those described in the Results section and thus we decided to maintain the a priori inclusion criterion in order to identify participants who were both actually attempting the secondary task and providing an adequate level of accurate responses, as we could be sure that these participants’ attention was truly divided between the two tasks.
Similar to Experimen 1, we also conducted all analyses including originally excluded participants who displayed greater than 0% secondary task response rate and accuracy producing an identical pattern of results to the analyses described below that exclude these participants. As such, we opted to only maintain our a priori inclusion criteria and include only participants who sufficiently engaged with and were successful in the secondary tasks to ensure an adequate division of attention.
References
Adcock, R. A., Thangavel, A., Whitfield-Gabrieli, S., Knutson, B., & Gabrieli, J. D. (2006). Reward-motivated learning: mesolimbic activation precedes memory formation. Neuron, 50, 507-517.
Allen, R. J., & Ueno, T. (2018). Multiple high-reward items can be prioritized in working memory but with greater vulnerability to interference. Attention, Perception, & Psychophysics, 80, 1731-1743.
Allport, D. A., Antonis, B., & Reynolds, P. (1972). On the division of attention: A disproof of the single channel hypothesis. Quarterly Journal of Experimental Psychology, 24, 225-235.
Anderson, B. A. (2013). A value-driven mechanism of attentional selection. Journal of Vision, 13, 7.
Ariel, R., & Castel, A. D. (2014). Eyes wide open: enhanced pupil dilation when selectively studying important information. Experimental Brain Research, 232, 337-344.
Ariel, R., Dunlosky, J., & Bailey, H. (2009). Agenda-based regulation of study-time allocation: When agendas override item-based monitoring. Journal of Experimental Psychology: General, 138, 432-447.
Arnell, K. M., & Jolicoeur, P. (1999). The attentional blink across stimulus modalities: Evidence for central processing limitations. Journal of Experimental Psychology: Human Perception and Performance, 25, 630-648.
Atkinson, A. L., Berry, E. D. J., Waterman, A. H., Baddeley, A. D., Hitch, G. J., & Allen, R. J. (2018). Are there multiple ways to direct attention in working memory? Annals of the New York Academy of Sciences, 1424, 115-126.
Baddeley, A. D. (1986). Working memory. Clsarendon Press.
Burnham, B. R. (2010). Cognitive load modulates attentional capture by color singletons during effortful visual search. Acta Psychologica, 135, 50-58.
Burnham, B. R., Sabia, M., & Langan, C. (2014). Components of working memory and visual selective attention. Journal of Experimental Psychology: Human Perception and Performance, 40, 391.
Carter, R. M., MacInnes, J. J., Huettel, S. A., & Adcock, R. A. (2009). Activation in the VTA and nucleus accumbens increases in anticipation of both gains and losses. Frontiers in Behavioral Neuroscience, 3, 21.
Castel, A. D. (2008). The adaptive and strategic use of memory by older adults: Evaluative processing and value-directed remembering. In A. S. Benjamin & B. H. Ross (Eds.), The psychology of learning and motivation (Vol. 48, pp. 225-270). London: Academic Press.
Castel, A. D., Balota, D. A., & McCabe, D. P. (2009). Memory efficiency and the strategic control of attention at encoding: Impairments of value-directed remembering in Alzheimer’s disease. Neuropsychology, 23, 297-306.
Castel, A. D., Benjamin, A. S., Craik, F. I., & Watkins, M. J. (2002). The effects of aging on selectivity and control in short-term recall. Memory & Cognition, 30, 1078-1085.
Castel, A. D., & Craik, F. I. (2003). The effects of aging and divided attention on memory for item and associative information. Psychology and Aging, 18, 873-885.
Castel, A. D., Humphreys, K. L., Lee, S. S., Galván, A., Balota, D. A., & McCabe, D. P. (2011). The development of memory efficiency and value-directed remembering across the lifespan: A cross-sectional study of memory and selectivity. Developmental Psychology, 47, 1553-1564.
Castel, A. D., Lee, S. S., Humphreys, K. L., & Moore, A. N. (2011). Memory capacity, selective control, and value-directed remembering in children with and without attention-deficit/hyperactivity disorder. Neuropsychology, 25, 15-24.
Castel, A. D., Murayama, K., Friedman, M. C., McGillivray, S., & Link, I. (2013). Selecting valuable information to remember: Age-related differences and similarities in self-regulated learning. Psychology and Aging, 28, 232.
Chalfonte, B. L., & Johnson, M. K. (1996). Feature memory and binding in young and old adults. Memory & Cognition, 24, 403-416,
Chan, J. S., & Newell, F. N. (2008). Behavioral evidence for task-dependent “what” versus “where” processing within and across modalities. Perception & Psychophysics, 70(1), 36-49.
Chelazzi, L., Perlato, A., Santandrea, E., & Della Libera, C. (2013). Rewards teach visual selective attention. Vision Research, 85, 58-72.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences, 2nd ed. Erlbaum.
Cohen, M. S., Rissman, J., Hovhannisyan, M., Castel, A. D., & Knowlton, B. J. (2017). Free recall test experience potentiates strategy-driven effects of value on memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43, 1581-1601.
Cohen, M. S., Rissman, J., Suthana, N. A., Castel, A. D., & Knowlton, B. J. (2014). Value-based modulation of memory encoding involves strategic engagement of fronto-temporal semantic processing regions. Cognitive, Affective, & Behavioral Neuroscience, 14, 578-592.
Cohen, M. S., Rissman, J., Suthana, N. A., Castel, A. D., & Knowlton, B. J. (2016). Effects of aging on value-directed modulation of semantic network activity during verbal learning. NeuroImage, 125, 1046-1062.
Cowan, N. (1995). Attention and memory: An integrated framework. Oxford University Press.
Craik, F. I., Govoni, R., Naveh-Benjamin, M., & Anderson, N. D. (1996). The effects of divided attention on encoding and retrieval processes in human memory. Journal of Experimental Psychology: General, 125, 159-180.
DeLozier, S., & Rhodes, M. G. (2015). The impact of value-directed remembering on the own-race bias. Acta Psychologica, 154, 62-68.
Duncan, J., Martens, S., & Ward, R. (1997). Restricted attentional capacity within but not between sensory modalities. Nature, 387, 808-810.
Elliott, B. L., Blais, C., McClure, S. M., & Brewer, G. A. (2020). Neural correlates underlying the effect of reward value on recognition memory. NeuroImage, 206, 116296.
Elliott, B. L., & Brewer, G. A. (2019). Divided attention selectively impairs value-directed encoding. Collabra: Psychology, 5.
Elsley, J. V., & Parmentier, F. B. (2009). Short article: Is verbal–spatial binding in working memory impaired by a concurrent memory load?. Quarterly Journal of Experimental Psychology, 62, 1696-1705.
Faul, F., Erdfelder, E., Lang, A. G., & Buchner, A. (2007). G* Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39, 175-191.
Fernandes, M. A., & Moscovitch, M. (2000). Divided attention and memory: Evidence of substantial interference effects at retrieval and encoding. Journal of Experimental Psychology: General, 129, 155-176.
Friedman, M. C., McGillivray, S., Murayama, K., & Castel, A. D. (2015). Memory for medication side effects in younger and older adults: The role of subjective and objective importance. Memory & Cognition, 43, 206-215.
Gathercole, S. E., & Baddeley, A. D. (1993). Working memory and language. Psychology Press.
Gil-Gómez de Liaño, B., Stablum, F., & Umiltà, C. (2016). Can concurrent memory load reduce distraction? A replication study and beyond. Journal of Experimental Psychology: General, 145, e1-e12.
Griffin, M. L., Benjamin, A. S., Sahakyan, L., & Stanley, S. E. (2019). A matter of priorities: High working memory enables (slightly) superior value-directed remembering. Journal of Memory and Language, 108, 104032.
Gruber, M. J., & Otten, L. J. (2010). Voluntary control over prestimulus activity related to encoding. Journal of Neuroscience, 30, 9793-9800.
Gruber, M. J., Ritchey, M., Wang, S. F., Doss, M. K., & Ranganath, C. (2016). Post-learning hippocampal dynamics promote preferential retention of rewarding events. Neuron, 89, 1110-1120.
Hargis, M. B., & Castel, A. D. (2017). Younger and older adults’ associative memory for social information: The role of information importance. Psychology and Aging, 32, 325-330.
Hargis, M. B., & Castel, A. D. (2018). Younger and older adults’ associative memory for medication interactions of varying severity. Memory, 26, 1151-1158.
Hayes, M. G., Kelly, A. J., & Smith, A. D. (2013). Working memory and the strategic control of attention in older and younger adults. Journals of Gerontology Series B: Psychological Sciences and Social Sciences, 68, 176-183.
Hein, G., Parr, A., & Duncan, J. (2006). Within-modality and cross-modality attentional blinks in a simple discrimination task. Perception & Psychophysics, 68, 54-61.
Hennessee, J. P., Castel, A. D., & Knowlton, B. J. (2017). Recognizing what matters: Value improves recognition by selectively enhancing recollection. Journal of Memory and Language, 94, 195-205.
Hennessee, J. P., Patterson, T. K., Castel, A. D., & Knowlton, B. J. (2019). Forget me not: Encoding processes in value-directed remembering. Journal of Memory and Language, 106, 29-39.
Hirst, W., & Kalmar, D. (1987). Characterizing attentional resources. Journal of Experimental Psychology: General, 116(1), 68.
Hu, Y., Allen, R. J., Baddeley, A. D., & Hitch, G. J. (2016). Executive control of stimulus-driven and goal-directed attention in visual working memory. Attention, Perception, & Psychophysics, 78, 2164-2175.
Hu, Y., Hitch, G. J., Baddeley, A. D., Zhang, M., & Allen, R. J. (2014). Executive and perceptual attention play different roles in visual working memory: Evidence from suffix and strategy effects. Journal of Experimental Psychology: Human Perception and Performance, 40, 1665-1678.
Hughes, R. W., & Jones, D. M. (2005). The impact of order incongruence between a task-irrelevant auditory sequence and a task-relevant visual sequence. Journal of Experimental Psychology: Human Perception and Performance, 31(2), 316.
Jeffreys, H. (1961). Theory of Probability, (3rd ed.) Oxford University Press.
Jones, D. M., & Tremblay, S. (2000). Interference in memory by process or content? A reply to Neath (2000). Psychonomic Bulletin & Review, 7(3), 550-558.
Kahneman, D. (1973). Attention and effort. (Vol 1063). Prentice-Hall.
Kelley, T. A., & Lavie, N. (2011). Working memory load modulates distractor competition in primary visual cortex. Cerebral Cortex, 21, 659-665.
Kim, S., Kim, M., & Chun, M. M. (2005). Concurrent working memory load can reduce distraction. Proceedings of the National Academy of Sciences, 102, 16524-16529.
Kinchla, R. A. (1992). Attention. Annual Review of Psychology, 43, 711-742.
Kinsbourne, M. (1980). Mapping a behavioral cerebral space. International journal of Neuroscience, 11(1), 45-50.
Klatte, M., Bergström, K., & Lachmann, T. (2013). Does noise affect learning? A short review on noise effects on cognitive performance in children. Frontiers in psychology, 4, 578.
Konstantinou, N., Beal, E., King, J. R., & Lavie, N. (2014). Working memory load and distraction: Dissociable effects of visual maintenance and cognitive control. Attention, Perception, & Psychophysics, 76, 1985-1997.
Lange, E. B. (2005). Disruption of attention by irrelevant stimuli in serial recall. Journal of Memory and Language, 53(4), 513-531.
Lavie, N. (2005). Distracted and confused?: Selective attention under load. TRENDS in Cognitive Sciences, 9, 75-82.
Lavie, N., & Dalton, P. (2013). Load theory of attention and cognitive control. In S. Kastner & A. C. Nobre (Eds.), Handbook of attention (pp. 56 -75). New York, NY: Oxford University Press.
Lavie, N., & De Fockert, J. (2005). The role of working memory in attentional capture. Psychonomic Bulletin & Review, 12, 669-674.
Lavie, N., Hirst, A., De Fockert, J. W., & Viding, E. (2004). Load theory of selective attention and cognitive control. Journal of Experimental Psychology: General, 133, 339-354.
Lee, M. D., & Wagenmakers, E. J. (2013). Bayesian modeling for cognitive science: A practical course. Cambridge University Press.
Lin, S., & Yeh, Y. (2014). Domain-specific control of selective attention. PLoS ONE, 9, e98260.
Logie, R. H. (1995). Visuo-spatial working memory. Erlbaum.
Lorch, R. F., & Myers, J. L. (1990). Regression analyses of repeated measures data in cognitive research. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16(1), 149.
Ludwig, C. J., & Gilchrist, I. D. (2002). Stimulus-driven and goal-driven control over visual selection. Journal of Experimental Psychology: Human Perception and Performance, 28, 902-912.
Ludwig, C. J., & Gilchrist, I. D. (2003). Goal-driven modulation of oculomotor capture. Perception & Psychophysics, 65, 1243-1251.
Marsh, J. E., Hughes, R. W., & Jones, D. M. (2009). Interference by process, not content, determines semantic auditory distraction. Cognition, 110(1), 23-38.
Martens, S., Kandula, M., & Duncan, J. (2010). Restricted attentional capacity within but not between sensory modalities: an individual differences approach. PLoS One, 5, e15280.
McLeod, P. (1977). A dual task response modality effect: Support for multiprocessor models of attention. Quarterly Journal of Experimental Psychology, 29, 651-667.
Middlebrooks, C. D., & Castel, A. D. (2018). Self-regulated learning of important information under sequential and simultaneous encoding conditions. Journal of Experimental Psychology: Learning, Memory, and Cognition, 44, 779-792.
Middlebrooks, C. D., Kerr, T. K., & Castel, A. D. (2017). Selectively distracted: Divided attention and memory for important information. Psychological Science, 28, 1103-1115.
Middlebrooks, C. D., McGillivray, S., Murayama, K., & Castel, A. D. (2016). Memory for allergies and health foods: How younger and older adults strategically remember critical health information. Journals of Gerontology: Psychological Sciences, 71, 389-399.
Middlebrooks, C. D., Murayama, K., & Castel, A. D. (2016). The value in rushing: Memory and selectivity when short on time. Acta Psychologica, 170, 1-9.
Middlebrooks, C. D., Murayama, K., & Castel, A. D. (2017). Test expectancy and memory for important information. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43, 972-985.
Murayama, K., Sakaki, M., Yan, V. X., & Smith, G. M. (2014). Type I error inflation in the traditional by-participant analysis to metamemory accuracy: A generalized mixed-effects model perspective. Journal of Experimental Psychology: Learning Memory, and Cognition, 40(5), 1287.
Murphy, G., Groeger, J. A., & Greene, C. M. (2016). Twenty years of load theory—Where are we now, and where should we go next?. Psychonomic Bulletin & Review, 23, 1316-1340.
Naveh-Benjamin, M., Craik, F. I., Perretta, J. G., & Tonev, S. T. (2000). The effects of divided attention on encoding and retrieval processes: The resiliency of retrieval processes. The Quarterly Journal of Experimental Psychology, Section A, 53, 609-625.
Navon, D., & Gopher, D. (1979). On the economy of the human-processing system. Psychological Review, 86, 214-255.
Navon, D., & Miller, J. (1987). Role of outcome conflict in dual-task interference. Journal of Experimental Psychology: Human Perception and Performance, 13(3), 435.
Neath, I. (2000). Modeling the effects of irrelevant speech on memory. Psychonomic Bulletin & Review, 7(3), 403-423.
Neumann, O. (1996). Theories of attention. In Handbook of perception and action (Vol. 3, pp. 389-446). Academic Press.
Nguyen, L. T., Marini, F., Zacharczuk, L., Llano, D. A., & Mudar, R. A. (2019). Theta and alpha band oscillations during value-directed strategic processing. Behavioural Brain Research, 367, 210-214.
Parkes, A. M., & Coleman, N. (1990). Route guidance systems: A comparison of methods of presenting directional information to the driver. In E. J. Lovesey (Ed.), Contemporary Ergonomics (pp. 480–485). London: Taylor & Francis.
Pashler, H. (1989). Dissociations and dependencies between speed and accuracy: Evidence for a two-component theory of divided attention in simple tasks. Cognitive Psychology, 21, 469-514.
Pashler, H. (1994). Dual-task interference in simple tasks: data and theory. Psychological bulletin, 116(2), 220.
Pashler, H., & Johnston, J. C. (1998). Attentional limitations in dual-task performance. Attention, 155-189.
Polson, M. C., & Friedman, A. (1988). Task-sharing within and between hemispheres: A multiple-resources approach. Human Factors, 30, 633-643.
Raudenbush, S. W., & Bryk, A. S. (2002). Hierarchical linear models: Applications and data analysis methods (2nd ed.). Sage.
Rees, G., Frith, C., & Lavie, N. (2001). Processing of irrelevant visual motion during performance of an auditory attention task. Neuropsychologia, 39, 937-949.
Rissman, J., Gazzaley, A., & D’Esposito, M. (2009). The effect of non-visual working memory load on top-down modulation of visual processing. Neuropsychologia, 47, 1637-1646.
Robison, M. K., & Unsworth, N. (2017). Working memory capacity, strategic allocation of study time, and value-directed remembering. Journal of Memory and Language, 93, 231-244.
Roediger, H. L., & Schmidt, S. R. (1980). Output interference in the recall of categorized and paired-associate lists. Journal of Experimental Psychology: Human Learning and Memory, 6, 91-105.
Rollins, H. A., & Hendricks, R. (1980). Processing of words presented simultaneously to eye and ear. Journal of Experimental Psychology: Human Perception and Performance, 6, 99-109.
Roper, Z. J. J., Vecera, S. P., & Vaidya, J. G. (2014). Value-driven attentional capture in adolescence. Psychological Science, 25, 1987-1993.
Sabri, M., Humphries, C., Verber, M., Liebenthal, E., Binder, J. R., Mangalathu, J., & Desai, A. (2014). Neural effects of cognitive control load on auditory selective attention. Neuropsychologia, 61, 269-279.
Sali, A. W., Anderson, B. A., & Yantis, S. (2014). The role of reward prediction in the control of attention. Journal of Experimental Psychology: Human Perception and Performance, 40, 1654-1664.
Sandry, J., Schwark, J. D., & MacDonald, J. (2014). Flexibility within working memory and the focus of attention for sequential verbal information does not depend on active maintenance. Memory & Cognition, 42, 1130-1142.
Schoenfeld, M. A., Tempelmann, C., Martinez, A., Hopf, J. M., Sattler, C., Heinze, H. J., & Hillyard, S. A. (2003). Dynamics of feature binding during object-selective attention. Proceedings of the National Academy of Sciences, 100, 11806-11811.
Schwartz, S. T., Siegel, A. L. M., & Castel, A. D. (2020). Strategic encoding and enhanced memory for positive value-location associations. Memory & Cognition.
Siegel, A. L. M., & Castel, A. D. (2018a). Memory for important item-location associations in younger and older adults. Psychology and Aging, 33, 30-45.
Siegel, A. L. M., & Castel, A. D. (2018b). The role of attention in remembering important item-location associations. Memory & Cognition, 46, 1248-1262.
Siegel, A. L. M., & Castel, A. D. (2019). Age-related differences in metacognition for memory and selectivity. Memory, 27, 1236-1249.
Snodgrass, J. G., & Vanderwart, M. (1980). A standardized set of 260 pictures: Norms for name agreement, image agreement, familiarity, and visual complexity. Journal of Experimental Psychology: Human Learning and Memory, 6, 174-215.
Soto-Faraco, S., & Spence, C. (2002). Modality-specific auditory and visual temporal processing deficits. The Quarterly Journal of Experimental Psychology: Section A, 55, 23-40.
Spaniol, J., Schain, C., & Bowen, H. J. (2013). Reward-enhanced memory in younger and older adults. Journals of Gerontology, Series B: Psychological Sciences and Social Sciences, 69, 730-740.
Spence, C. (2011). Crossmodal correspondences: A tutorial review. Attention, Perception, & Psychophysics, 73(4), 971-995.
Stefanidi, A., Ellis, D. M., & Brewer, G. A. (2018). Free recall dynamics in value-directed remembering. Journal of Memory and Language, 100, 18-31.
Taylor, M. M., Lindsay, P. H., & Forbes, S. M. (1967). Quantification of shared capacity processing in auditory and visual discrimination. Acta Psychologica, 27, 223-229.
Thomas, A. K., Bonura, B. M., Taylor, H. A., & Brunyé, T. T. (2012). Metacognitive monitoring in visuospatial working memory. Psychology and Aging, 27, 1099-1110.
Treisman, A., & Davies, A. (1973). Divided attention between eye and ear. In S. Kornblum (Ed.), Attention and Performance IV. New York: Academic Press.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97-136.
Treisman, A. M., & Sato, S. (1990). Conjunction search revisited. Journal of Experimental Psychology: Human Perception and Performance, 16, 459-478.
Unsworth, N. (2007). Individual differences in working memory capacity and episodic retrieval: Examining the dynamics of delayed and continuous distractor free recall. Journal of Experimental Psychology: Learning, Memory, and Cognition, 33, 1020-1034.
Van der Burg, E., Nieuwenstein, M. R., Theeuwes, J., & Olivers, C. N. (2013). Irrelevant auditory and visual events induce a visual attentional blink. Experimental Psychology, 60, 80-89.
Vergauwe, E., Barrouillet, P., & Camos, V. (2009). Visual and spatial working memory are not that dissociated after all: A time-based resource-sharing account. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 1012-1028.
Wagenmakers, E. J., Verhagen, J., Ly, A., Matzke, D., Steingroever, H., Rouder, J. N., & Morey, R. D. (2017). The need for Bayesian hypothesis testing in psychological science. Psychological science under scrutiny: Recent challenges and proposed solutions, 123-138.
Wahn, B., & König, P. (2015). Audition and vision share spatial attentional resources, yet attentional load does not disrupt audiovisual integration. Frontiers in Psychology, 6, 1084.
Wahn, B., & König, P. (2017). Is attentional resource allocation across sensory modalities task-dependent?. Advances in Cognitive Psychology, 13, 83-96.
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology: General, 131, 48-64.
Wickens, C. D. (1980). The structure of attentional resources. In R. Nickerson (Ed.), Attention and Performance VIII (pp. 239-257). Lawrence Erlbaum.
Wickens, C. D. (1984). Processing resources in attention. In R. Parasuraman and R. Davies (Eds.), Varieties of Attention (pp. 63-101). New York: Academic Press.
Wickens, C. D. (2002). Multiple resources and performance prediction. Theoretical Issues in Ergonomics Science, 3, 159-177.
Wolosin, S. M., Zeithamova, D., & Preston, A. R. (2012). Reward modulation of hippocampal subfield activation during successful associative encoding and retrieval. Journal of Cognitive Neuroscience, 24, 1532-1547.
Wong, S., Irish, M., Savage, G., Hodges, J. R., Piguet, O., & Hornberger, M. (2019). Strategic value-directed learning and memory in Alzheimer's disease and behavioural-variant frontotemporal dementia. Journal of Neuropsychology, 13, 328-353.
Author Note
This research was supported in part by the National Institutes of Health (National Institute on Aging; Award Number R01 AG044335 to Dr. Alan Castel). The authors would like to thank Mary Hargis, Tyson Kerr, Catherine Middlebrooks, Dillon Murphy, Julia Schorn, Katie Silaj, and Mary Whatley. We appreciate helpful comments from Catherine Middlebrooks on a previous version of the manuscript.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
There are no conflicts of interest to disclose.
Additional information
Open Practices Statement
The data are available upon request from the corresponding author, ALMS, and none of the experiments were preregistered.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
ESM 1
(DOCX 29 kb)
Rights and permissions
About this article

Cite this article
Siegel, A.L.M., Schwartz, S.T. & Castel, A.D. Selective memory disrupted in intra-modal dual-task encoding conditions. Mem Cogn 49, 1453–1472 (2021). https://doi.org/10.3758/s13421-021-01166-1
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-021-01166-1