
Abstract
People recall and recognize animate words better than inanimate words, perhaps because memory systems were shaped by evolution to prioritize memory for predators, people, and food sources. Attentional paradigms show an animacy advantage that suggests that the animacy advantage in memory stems from a prioritization of animate items when allocating attentional resources during encoding. According to the attentional prioritization hypothesis, the animacy effect should be even larger when attention is divided during encoding. Alternatively, the animacy effect could be due to more controlled processing during encoding, and so should be reduced when attention is divided during encoding. We tested the attentional prioritization hypothesis and the controlled processing hypothesis by manipulating attention during encoding in free recall (Experiment 1) and recognition (Experiment 2) but failed to find interactions between word type and attentional load in either free recall or recognition, contrary to the predictions from both hypotheses. We then tested whether the semantic representations of animate and inanimate items differ in terms of number of semantic features, using existing recall data from an item-level megastudy by Lau, Goh, and Yap (Quarterly Journal of Experimental Psychology, 71 (10), 2207–2222, 2018). Animate items have more semantic features, which partially mediated the relationship between animacy status and recall.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The evolutionary approach to memory considers the human memory system in terms of how evolution may have shaped the way that the system functions, and proposes that memory is tuned toward fitness-relevant information. Fitness-relevant information is information that would be crucial to a species’ ability to reproduce, and includes a wide variety of factors such as those relating to mate selection (Sandry et al., 2013), fear, threats, social status (Sandry et al., 2013), and survival (Nairne & Pandeirada, 2008). When people encode information in the frame of a fitness-relevant context, memory is benefitted relative to other encoding strategies (Nairne et al., 2007; Nairne et al., 2009; Nairne & Pandeirada, 2008; Weinstein et al., 2008). A memory advantage in favor of fitness-relevant information has been seen in studies examining disgust (Chapman et al., 2013; Charash & McKay, 2002; Croucher et al., 2011; Fernandes et al., 2017), spatial memory (New, Krasnow, et al., 2007b), basic survival (Nairne & Pandeirada, 2008; Sandry et al., 2013), and animacy (Madan, 2020; Nairne et al., 2013; VanArsdall, 2016).
From an evolutionary perspective, the animacy effect – the observation that animate items such as “dog” and “man” are better remembered than inanimate items such as “box” and “flute” (Nairne et al., 2013) – can be interpreted in terms of the relevance of animate items for the survival of early humans. Surviving in an ancestral environment required one to find food, avoid predators, form alliances, and reproduce. In most cases, animate items are more likely to be relevant to these goals than inanimate items because animate items can be a food source, a threat, or a potential friend or mate. Nairne et al. (2013) asked participants to study a list of words, half of which referred to animate items and half of which referred to inanimate items. On a subsequent recall test, more animate items were recalled than inanimate items, despite being equated with inanimate items on many other dimensions, such as concreteness, imageability, and number of letters. The animacy effect extends to cued recall (VanArsdall et al., 2014; but see Popp & Serra, 2016), and to recognition of nonwords newly learned to be animate versus inanimate (e.g., “FRAV” paired with “speaks French” during learning vs. “JOTE” paired with “made of wood”; VanArsdall et al., 2013).
While it is hypothesized that animate items are more easily remembered because evolutionary forces shaped memory to be particularly attuned to fitness-relevant information, the proximal cause of the animacy effect remains unknown. Nairne et al. (2013) proposed two hypotheses to explain the animacy effect in memory: First, animate stimuli might be remembered well because they are prioritized for attention, and second, animate stimuli might be remembered well because their representations have more features or attributes than inanimate stimuli, and that difference in representations supports richer encodings. Possible causes such as differences in imageability (Gelin et al., 2019), category strength (VanArsdall et al., 2017), arousal (Popp & Serra, 2018), and perceived threat (Leding, 2019) have also been explored, but have not proven to be proximal predictors of the animacy effect in memory. The attention hypothesis fits with the fact that animate items are detected more quickly and more accurately in paradigms such as attentional blink (Guerrero & Calvillo, 2016), inattentional blindness, (Calvillo & Jackson, 2013), and change detection (Altman et al., 2016; New, Cosmides, & Tooby, 2007a). Additionally, animate items slow color naming in the Stroop task compared to inanimate items (Bugaiska et al., 2019). Based on the animacy effect observed in the attention literature, New et al. (2007a) proposed the animate monitoring hypothesis, which posits that animate items are prioritized when distributing attention.
If animate items are prioritized for attention during encoding, there would likely be a subsequent memory benefit, and we refer to this as the attentional prioritization hypothesis. Attention plays an integral role during the encoding of memories (Baddeley et al., 1984; Craik et al., 1996; Fisk & Schneider, 1984), and divided attention during encoding produces dramatic reductions in recall. However, the consequences of divided attention during encoding on subsequent recognition memory are more complex. Dual process theories of recognition memory (for a review, see Yonelinas, 2002) propose that items can be recognized by assessing their familiarity or items can be recognized by recollecting details of the study event. Divided attention during encoding disrupts later recollection of details of an event, but has minimal effects on later familiarity (Jennings & Jacoby, 1993).
If differential attention to animate versus inanimate items mediates the animacy effect in memory, then the animacy effect should be particularly robust under divided attention conditions because the animate stimuli should receive more attention than the inanimate stimuli. Our argument parallels the logic used to test whether prioritized attention is one basis for enhanced memory for emotional material under immediate testing conditions (Talmi & McGarry, 2012). The memory advantage for emotional versus neutral stimuli is larger when attention is divided during encoding compared to full attention (Kensinger & Corkin, 2004; Kern et al., 2005; Maddox et al., 2012) because divided attention reduces memory for neutral stimuli more than emotional stimuli.
A contrasting hypothesis with respect to the effects of divided attention during encoding is that the memory benefit for animate relative to inanimate items occurs because of attention-demanding controlled processes, such as greater elaboration of animate than inanimate items. The controlled processing hypothesis is supported by Meinhardt et al. (2020), who found that animate words elicit more thoughts than inanimate words. They presented participants with a list of animate and inanimate words and, for each word, asked participants to write down whatever thoughts came to mind, with no time limit. Participants in both studies provided more thoughts when presented with animate words as compared to inanimate words. Further, the number of thoughts generated partially mediated the animacy effect in recall. Though correlational, these results suggest that animate items can elicit more elaborative thoughts, and that the additional elaboration could partially account for the recall advantage.
Also in accord with the controlled processing hypothesis, Bonin et al. (2013) found that the animacy effect in word recognition is specific to recollection, using a recognition “remember/know” paradigm. In that paradigm, for each item that is recognized as old, participants indicate if they “remember” details of the prior presentation, or whether they simply “know” that the item was studied before. Bugaiska et al. (2016) also found that the animacy effect in recognition arises from an animacy advantage in “remember” judgments, with no effect on the probability of “know” judgments. The localization of the animacy effect to recognition judgments that are judged to be “remembered” in Bonin et al. (2013) and Bugaiska et al. (2016) suggests that the animacy effect in recognition results from greater recollection, which as noted above is disrupted more by divided attention during encoding than is familiarity (Jennings & Jacoby, 1993). According to the controlled processing hypothesis, divided attention during encoding would be more detrimental for animate than inanimate items, leading to a reduced animacy advantage.
Divided attention has been used as a tool to test whether attention is the proximal cause of the animacy effect on memory; however, the findings are mixed. Bonin et al. (2015) tested the effect of a cognitive load (a string of five or seven characters) given to participants prior to categorizing an item as animate or inanimate, followed by a report of the cognitive load. Animate items were recalled better than inanimate, and cognitive load reduced memory, but there was no interaction between load and animacy, as would be predicted by the attentional prioritization hypothesis (larger animacy effect under cognitive load) or by the controlled processing hypothesis (smaller animacy effect under cognitive load). One issue might be that cognitive pre-loads can be stored phonologically and then retrieved after the relatively short 2-s visual presentation of the subsequent word. Hitch and Baddeley (1976) found little effect of cognitive pre-load on a reasoning task, but did find an effect of a concurrent task on the reasoning task, so divided attention during encoding of animate and inanimate items using a concurrent task may yield different results. However, it is important to note that cognitive load reduced recall for both animate and inanimate items in Bonin et al. (2015).
Leding (2019) used concurrent digit monitoring to divide attention during encoding of animate and inanimate words, and tested free recall across three successive attempts. Animate and inanimate words were further subdivided into threatening and non-threatening. In contrast to Bonin et al. (2015), Leding did find a significant interaction between animacy and attention, but did not discuss the implications of the result. The pattern of the means suggests that the source of the interaction lies in a somewhat smaller animacy effect following divided attention, which accords with the controlled processing hypothesis, although the interaction could be the result of near-floor effects for inanimate words following divided attention.
The aim of the current studies was to examine how dividing attention during encoding affects the animacy effect in both a free-recall paradigm and in a “remember/know” recognition paradigm. We predicted interactions between the word type (animate vs. inanimate words) and encoding condition (full vs. divided attention). Following the attentional prioritization hypothesis, we predicted that the animacy effect would be larger under divided attention compared to full attention, as attentional prioritization will have a more pronounced effect on recall as attention becomes limited. Following the controlled processing hypothesis, we predicted that the animacy effect would be smaller under divided compared to full attention conditions, as the attentional resources necessary to facilitate enhanced recollection for animate items may not be available to participants in the divided attention condition, thus eliminating or reducing the animacy advantage. The present studies also incorporate Bayesian statistics in the interpretation of the results, allowing for the quantification of evidence in favor of the null hypothesis of no interaction (Wagenmakers et al., 2017).
To preview the results of Experiments 1 and 2 testing the two attentional hypotheses, we found evidence for the null hypothesis of no interaction between words that were animate versus inanimate and the manipulation of attention during encoding in the free recall Experiment 1, using Bayesian statistics. We could not reject the null hypothesis of no interaction between words that were animate versus inanimate and the manipulation of attention during encoding the recognition “remember” judgments in Experiment 2. Therefore, in a final project, we turned to Nairne et al.’s (2013) second hypothesis, that the semantic representation of animate and inanimate items differ in that animate items have richer semantic representations that afford better encoding than inanimate items.
Experiment 1
The purpose of Experiment 1 was to examine the effects of dividing attention on the animacy effect in a free-recall task. We predicted an interaction between word type (animate vs. inanimate words) and attention condition at encoding (full vs. divided attention) that could take one of two different forms: If animate items are prioritized for attention (as predicted by the attentional prioritization hypothesis), we predicted a larger animacy effect following encoding under conditions of divided attention, whereas if animate items engender more controlled processing (as predicted by the controlled processing hypothesis), we predicted a smaller animacy effect following encoding under conditions of divided attention.
Method
Participants
A power analysis conducted using G*Power 3.0 software revealed that a sample size of 80 would be required to detect the predicted interaction between word type and attention, based on Cohen’s f = .20 with an expected correlation among repeated measures of 0.50. We tested more participants in case of exclusion due to failure to follow instructions, and because more signed up to participate in the final week of testing. A total of 106 undergraduate students at Florida State University participated for partial course credit; however, six participants who failed to follow instructions were removed from the analyses. The sample was evenly divided between the full versus divided attention at encoding conditions.
Stimuli and design
A two (word type: animate vs. inanimate) × two (attention: divided attention vs. full attention) mixed design was used to examine the interaction between word type and attention, and to identify any main effects. Word type was manipulated within subjects, and attention was manipulated between subjects.
A total of 20 words (10 animate and 10 inanimate) were drawn from the materials used by VanArsdall et al. (2017) and from the MRC Psycholinguistic Database version 2 (Wilson, 1988), such that the animate word list and the inanimate word list did not differ on mean number of letters, concreteness ratings, imageability ratings, familiarity ratings, and Kucera-Francis written frequency ratings (MRC Psycholinguistic Database version 2; Wilson, 1988; see Table 1). Animate words included items such as “dog,” “engineer,” and “uncle,” and inanimate words included items such as “branch,” “stove,” and “journal.” To reduce recency and primacy effects, two filler words were added to both ends of the word list (see Experiment 2 for a full description of the filler words). All participants studied the same set of 24 words.
Half of the participants in Experiment 1 were asked to simultaneously perform a divided attention task during encoding. For the divided attention task, participants engaged in a concurrent listening task, in which they listened to a recording of a string of digits being read at a rate of one digit every 1.5 s. Participants responded by tapping the desk with their left hand each time they heard two odd digits in a row (Anderson et al., 2010; Jennings & Jacoby, 1993; Rabinowitz et al., 1982), and the experimenter recorded the digit-monitoring performance. The divided attention task was piloted as in Sahakyan and Malmberg (2018) to ensure that attention was manipulated without producing floor effects.
Procedure
Participants were alternately assigned to either the full attention condition or the divided attention condition. During encoding, participants studied 24 words for 5 s each, followed by a 500-ms blank screen. E-prime software was used to present the items to the participant. Word presentation order was random with the constraint that the animate and inanimate words were divided equally across both halves of the presented list, and that the four filler words served as the first two and last two words in the list. Participants studied the word list for three presentations with a different random order of words in the list during each presentation, to avoid floor effects as in prior studies of divided attention during encoding and recall (Naveh-Benjamin & Brubaker, 2019). Recall was only assessed after the third presentation of the list. For the participants in the divided attention condition who completed the digit-monitoring task concurrently during encoding, a new digit list recording was played for each word list presentation, and the three recordings were given in a random order for each participant.
Following each presentation of the word list, participants were given a filler arithmetic task in which they were asked to complete simple mathematical equations (e.g., “2 + 5”) for 1 min, and were told to solve as many equations as possible while still maintaining accuracy. At test, participants were asked to freely recall as many words as possible from the list they had studied, and to tell the researcher when they finished recall. Participants recalled words aloud, while the experimenter typed the recalled words which appeared on the computer screen during recall. Participants were allowed to self-terminate recall (Dougherty et al., 2014), with a mean recall time of 1 min 22 s (SD = 47 s).
Results and discussion
Secondary task performance
For each participant, average concurrent monitoring-task performance was determined by averaging the proportion of two-odd-digit sequences that had been correctly identified by the participant for each presentation of the list. One participant was dropped from this analysis due to missing data for the divided attention task performance. Mean proportion of correctly detected odd-digit pairs across the three presentations was 0.90 (SD = 0.11), 0.90 (SD = 0.09), and 0.92 (SD = 0.08). It should be noted that Bonin et al. (2015) found that task performance on a secondary memory-load task was worse when the memory-load task coincided with the presentation of an animate item compared to when it coincided with the presentation of an inanimate item. However, due to the design of the present experiment, we are unable to address this possibility.
Main effects and interaction
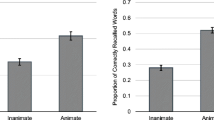
A mixed model ANOVA assessed the effects of word type (animate vs. inanimate) and attention (full attention vs. divided attention) on word recall (see Fig. 1). A significant main effect was found for word type, F (1, 98) = 38.63, p < .001, MSE = 0.016, ηp2 = .28, such that animate items were better recalled than inanimate items (M = 0.43 and M = 0.32, respectively). A significant main effect was also found for attention, F (1, 98) = 97.98, p < .001, MSE = 0.051, ηp2 = 0.50, such that participants in the full attention condition had better recall performance than did participants in the divided attention condition (M = 0.54 and M = 0.22, respectively). The interaction of word type and attention was not significant, F (1, 98) = 0.38, p = 0.539, MSE = 0.016, ηp2 = .004. Planned follow-up comparisons revealed an animacy advantage in both the full attention condition, t (49) = 4.16, p < .001, Cohen’s d = 0.589, and the divided attention condition, t (49) = 4.90, p < .001, Cohen’s d = 0.693.

Means and standard error for free recall in Experiment 1
Bayesian results
A mixed-model Bayesian ANOVA was conducted to further explore the word type by attention interaction term using the repeated-measures ANOVA Bayesian analysis function in JASP (JASP Team, 2020). Priors were set such that P(M) = 0.500 for both the alternative hypothesis (that the interaction between word type and attention condition is significant) and the null hypothesis (that the interaction between word type and attention condition is not significant). The main effects for both word type and attention were included in the null model leaving only the interaction term in the alternative hypothesis model, thus creating a Bayes term that was specific to the alternative hypothesis that the interaction of word type and attention would be significant above and beyond the main effects of both factors. The Bayes factor favored the null, B01 = 4.04, meaning that the observed data are 4.04 times more likely to occur under the null hypothesis than under the alternate hypothesis. Therefore, the Bayesian analysis supports neither of the two hypotheses, suggesting that neither attentional prioritization of animate items nor more controlled processing of animate items is the proximal cause of the animacy effect Fig. 2.

Means and standard error for recognition in Experiment 2 in terms of Pr values
Given the null results in Experiment 1, it is worth noting that both hypotheses may be true: Attention may be prioritized to animate items even under conditions of divided attention, followed by more elaborative processing of animate items when attentional conditions allow. However, the current null result would imply that the two mechanisms, attentional prioritization and controlled elaborative processing, have comparable effects and so offset each other quite precisely. We discuss this further in the General discussion.
Experiment 2
As a further test of the attentional prioritization hypothesis and the controlled processing hypothesis, Experiment 2 examined the effect of divided attention during encoding on the animacy advantage in a “remember/know” recognition paradigm. Both Bonin et al. (2013) and Bugaiska et al. (2016) found that the animacy effect occurs in “remember” judgments, rather than “know” judgments. “Remember” judgments are thought to be due to controlled processing, which is particularly dependent on attention-demanding processes (i.e., elaboration). According to the controlled processing hypothesis, we predicted that the animacy effect in the “remember” judgments would be smaller following divided attention at encoding. In contrast, according to the prioritization hypothesis, we predicted that animate items would be more likely to draw attention than inanimate items, particularly when attention is divided at encoding, producing a larger animacy effect in the “remember” judgments compared to the full attention condition. We did not predict an interaction in the “know” judgments, as familiarity has been found to be resilient against divided attention manipulations (Craik et al., 1996; Gardiner & Parkin, 1990; Mangels et al., 2001).
If the null word type by attention interaction term from Experiment 1 is reflective of the true role that attention plays in the animacy effect, that is, attention is not the proximal cause, then the interaction term should also fail to reach significance in Experiment 2. Instead divided attention should reduce recall for animate items and inanimate items equally.
Method
Participants
A power analysis conducted using G*Power 3.0 software revealed that a sample size of 80 would be required to detect the predicted interaction between word type and attention, based on Cohen’s f = .20 with an expected correlation among repeated measures of 0.50. We again tested more in case of exclusion due to failure to follow instructions, and because more signed up to participate in the final week of testing. Ninety-one undergraduate students participated for partial class credit and were recruited through an online experiment sign-up system. Four participants were dropped from the analysis due to failure to follow instructions, leaving a total of 87 participants divided between the two conditions (full attention condition n = 45, divided attention condition n = 42).
Stimuli
Forty-two words (21 animate and 21 inanimate) were drawn from the materials used by VanArsdall et al. (2017), and an additional 38 words (19 animate and 19 inanimate) were drawn from the MRC Psycholinguistic Database version 2, for a total of 40 animate and 40 inanimate words. Animate and inanimate words were equated on mean number of letters, concreteness ratings, imageability ratings, familiarity ratings, and Kucera-Francis written frequency ratings (see Table 2).
To reduce the likelihood of a ceiling effect on the recognition test, we increased the study list length by adding 40 filler words from the MRC Psycholinguistic Database version 2 (Wilson, 1988). Filler words were not analyzed (but see Appendix A for hit and false alarm rates). Filler words were defined as words that were neither animate nor inanimate such as “Sweet,” “Wage,” and “Express,” and were selected based on coding by four undergraduate experimenters who categorized 570 words for animacy status (animate, inanimate, neither, or unsure [body parts, proper nouns, etc.]). Only words rated “neither” with perfect agreement from all four coders were used as fillers.
The 120 words (40 animate, 40 inanimate, and 40 fillers) were divided into two lists of 60 words, with each list containing 20 animate words, 20 inanimate words, and 20 filler words. For each participant, one of the word lists was used for the encoding phase, and the second list functioned as foils during the “remember/know” recognition test. The list presented during the encoding phase was counterbalanced across participants within both the full attention condition and the divided attention condition.
Design and procedure
Experiment 2 featured a two by two mixed design with word type (animate vs. inanimate) manipulated within-subjects and attention (full vs. divided) manipulated between subjects.
Participants were told that they would see a list of words shown one at a time, and would need to read each word out loud while learning the items for a later memory test. Participants in the divided attention condition were also given instructions for the digit-monitoring task. During encoding, 60 words (20 animate, 20 inanimate, and 20 fillers) were presented randomly, with the constraints that the first two items and the last two items in the list were always filler words to serve as a buffer from primacy and recency effects, and that the remaining items were evenly distributed throughout each quarter of the experiment, similar to the method used by Nairne et al. (2013). The study list was presented once using E-prime software, with each word presented in the center of the screen for 5 s, followed by a 500-ms blank screen. All participants heard the same digit string in the divided attention task. Both the divided attention digit task and the post-encoding arithmetic task were identical to Experiment 1.
After the arithmetic task, participants were tested using a “remember/know” recognition task in which participants made binary choices about the status of each word presented to them (old or new, and Type A or Type B memory [for “old” judgments]). The instructions defining Type A and Type B memory judgments were taken from McCabe and Geraci (2009 , Experiment 2, included here in Appendix B), and have been found to reduce participant confusion over the difference between “remember” and “know” judgments (see also Umanath & Coane, 2020). All 120 words (60 old words and 60 new foils) were presented one at a time in the center of the computer screen. For each word, participants had to first indicate whether the word was old or new, and for words they considered old they were asked to decide if their memory of the word was a “Type A” memory or a “Type B” memory. They were instructed to respond “Type A memory” (typically called a “remember” judgment) if they could recollect some specific aspect of seeing the word on the initial list, and to respond “Type B memory” (typically called a “know” judgment) if they thought they had seen the word before but could not recall any specific details. To ensure proper distinction between the two memory types, participants had to defend their memory type choice to the researcher by either describing the nature of the recollected details or by explaining that the word only felt familiar. The recognition test was self-paced, and all old/new and Type A/Type B decisions were entered into the computer by the experimenter.
Results and discussion
“Remember,” “Know,” Pr, and Br value calculations
Hit and false alarm rates were calculated for each of the three recognition classifications (overall recognition, “remember” judgments, and “know” judgments) such that separate values were calculated for animate and inanimate words (see Appendix C). Hits were instances where the participant correctly responded “old” to an item that was studied during the encoding phase, and false alarms were instances where a participant responded “old” to an item that was not studied during the encoding phase. “Remember” judgments were instances where a participant said an item was “old,” and identified their supporting recall for that claim as a “Type A” judgment (which corresponds to a “remember” judgment), meaning that they were able to recall specific details about that item from when it was encoded. “Know” judgments were instances where a participant said an item was “old,” and identified their supporting recall for that claim as a “Type B” judgment (which corresponds to a “know” judgment), meaning that they felt the item was familiar but could not recall any details from when the item was encoded.
Pr values were calculated following the recommendations of Snodgrass and Corwin (1988). Pr values stem from the two-high threshold model (Yonelinas, 2002), and the basic equation for Pr values is as follows:
where false alarms is defined as the number of new items incorrectly recognized, “remembered,” or “known” dependent upon the present calculation. To avoid undefined values when the hit rate is 1.0 or where the false alarm rate is 0.0, one adds 0.5 to the raw number of hits in that given cell and 1.0 to the number of total items presented in that cell.
Br is the bias measure associated with Pr values, defined as a measure of the likelihood of reporting an item as being “old” when one is uncertain about the true nature of the item. The following equation, taken from Snodgrass and Corwin (1988), was used to calculate Br values:
Again, false alarms is defined as the number of new items incorrectly recognized, “remembered,” or “known” dependent upon the present calculation. A Br value of 0.5 indicates a neutral response bias, a value above 0.5 indicates a liberal response bias (i.e. a tendency to accept an item as “old” in situations of uncertainty), and a value below 0.5 indicates a conservative bias (i.e., a tendency to reject an item as “old” in situations of uncertainty).
Secondary task performance
As in Experiment 1, performance on the concurrent monitoring task was defined as the number of correctly identified odd-digit pairs out of the total number of odd-digit pairs presented to the participant. Mean performance on the concurrent monitoring task during encoding in Experiment 2 was 0.90 (SD = 0.09).
“Remember” judgments
The results reported here, both for the “remember” judgments and the “know” judgments, are based on the calculated Pr values (see Fig. 2); however, there is controversy over the best method of analyzing recognition data. To avoid misinterpreting our data, we conducted all analyses reported here using other measurement models as well, namely, d’ and A’ (Starns et al., 2019). The same pattern of results replicated across all three methods of analysis.
A mixed model ANOVA on the Pr values from the “remember” judgments revealed a significant effect for word type, F (1, 85) = 40.99, p < 0.001, MSE = 0.006, ηp2 = 0.325, such that animate items led to more recollection than inanimate items (M = 0.24 and M = 0.16 respectively), and a significant effect of condition, F (1, 85) = 13.21, p < 0.001, MSE = 0.052, ηp2 = 0.134, such that the full attention condition led to more “remember” judgments than did divided attention (M = 0.26 and M = 0.13 respectively). However, the attention condition during encoding did not differentially affect “remember” judgments for animate versus inanimate words, F (1, 85) = 1.89, p = 0.17, MSE = 0.006, ηp2 = 0.022. Follow-up paired t-tests found an animacy effect in both the full attention condition, t (44) = 5.40, p < 0.001, Cohen’s d = 0.804, and the divided attention condition, t (41) = 3.65, p < 0.001, Cohen’s d = 0.563.
“Know” judgments
Following Bonin et al. (2013) and Bugaiska et al. (2016), we did not expect to find an animacy effect in the “know” judgments, nor did we expect to find an effect of divided attention on the “know” judgments (Craik et al., 1996; Gardiner & Parkin, 1990; Mangels et al., 2001). A final mixed model ANOVA on the Pr values for “know” judgments revealed no significant main effect for animate versus inanimate words (M = 0.23 and M = 0.26 respectively), F (1, 85) = 2.99, p = 0.087, MSE = 0.012, ηp2 = 0.034, no main effect of full versus divided attention (M = 0.27 and M = 0.21, respectively), F (1, 85) = 1.75, p = 0.189, MSE = 0.086, ηp2 = 0.020, and no interaction, F (1, 85) = 0.86, p = 0.357, MSE = 0.012, ηp2 = 0.010.
Bayesian results
A mixed model Bayesian ANOVA was conducted to further explore the word type by attention interaction term on “remember” judgments using the repeated-measures ANOVA Bayesian analysis function in JASP (JASP Team, 2020). Priors were set such that P(M) = 0.500 for both the alternative hypothesis (that the interaction between word type and attention condition is significant) and the null hypothesis (that the interaction between word type and attention condition is not significant). The main effects for both word type and attention were included in the null model leaving only the interaction term in the alternative hypothesis model, thus creating a Bayes term that was specific to the alternative hypothesis that the interaction of word type and attention would be significant above and beyond the main effects of both factors. A Bayes factor of B01 = 2.34 was obtained, meaning that the observed data are 2.34 times more likely to occur under the null hypothesis than under the alternate hypothesis. As in Experiment 1, the Bayes factor failed to support the alternative hypothesis, thus failing to support the idea that attention is the proximal cause of the animacy effect, and the evidence for the null hypothesis of no interaction of attention condition during encoding and the size of the animacy effect is considered at the level of “anecdotal.”
Response biases
Response bias was examined using Br values, the bias measure associated with Pr values. Mixed model ANOVAs assessed the effect of item type and attention condition on the Br measure of response bias (see Table 3 for means and standard deviations). There were no significant results for either the main effect for attention, nor for the interaction term in any of the analyses (see Table 4 for all ANOVA results), and there were no bias differences for animate versus inanimate words in the “remember” judgments, F (1,85) = 0.34, p = 0.563, MSE = 0.002, ηp2 = 0.004. There was a bias difference for animate versus inanimate words in the “know” judgments, F (1, 85) = 23.82, p < 0.001, MSE = 0.008, ηp2 = 0.219, such that participants were more conservative in their “know” judgments for animate items compared to inanimate items, which fits with possible use of a distinctiveness heuristic for animate versus inanimate words (Schacter & Wiseman, 2006).
Following an account of distinctiveness put forth by Gallo et al. (2008), an increase in distinctiveness for animate items should also lead to significantly fewer false alarms to animate items compared to inanimate items. A mixed model ANOVA assessed the effects of animacy and condition on false alarm rates in the know judgments, where false alarm rate was defined as the proportion of foils for which a participate incorrectly responded “old.” As predicted by Gallo et al.’s account, there was a significant main effect of animacy, F (1,85) = 13.33, p < 0.001, MSE = 0.005, ηp2 = 0.136, where the false alarm rate for animate items was lower than that for inanimate items (M = 0.12 and M = 0.15, respectively). There was no significant main effect for condition, F (1,85) = 0.15, p = 0.705, MSE = 0.036, ηp2 = 0.002, with full attention and divided attention conditions leading to similar false alarm rates (M = 0.13 and M = 0.14 respectively), nor was the interaction significant, F (1,85) = 0.92, p = 0.339, MSE = 0.005, ηp2 = 0.011. We expand upon the idea of distinctiveness in the General discussion.
The results from Experiment 2 are consistent with results from Experiment 1 and from Bonin et al. (2015). The animacy effect in “remember” judgments was not increased by divided attention, as the attentional prioritization hypothesis would predict, nor was it decreased by divided attention, as the controlled processing hypothesis would predict. Therefore, Experiment 2 does not support the hypothesis that attention is the cause of the animacy effect in a memory paradigm.
Project 3: Richness of semantic representations of animate and inanimate concepts
Experiments 1 and 2 did not provide support for attentional prioritization or controlled processing as a basis for the animacy advantage in recall or recognition memory. In our third project, we asked whether a difference in the richness of semantic representations between animate and inanimate words partially mediates the advantage animate words hold in recall.
Nairne et al. (2013) proposed that differences in semantic representational dimensions between animate and inanimate stimuli might be responsible for better memory for animate stimuli (Cree & McRae, 2003; Ralph et al., 2017). Semantic representations differ on multiple dimensions, including number of senses, the number of meanings with which a word is associated, emotional valence and arousal, imageability, and body-object interactions. So far, such representational differences as a basis for the animacy effect in memory are elusive. Bonin et al. (2013) tested whether animate words are more likely to be rated as giving rise to sensory experiences than inanimate words, but found no difference. Gelin et al. (2019) tested whether animate words are more likely to spontaneously give rise to visual images than inanimate words. Results were mixed: Although instructions to generate mental images eliminated the free-recall advantage for animate words by improving recall of inanimate words, in accord with a difference in spontaneous imagery, a visual cognitive load did not differentially impair recall of animate words. Gelin et al. (2019) also tested whether animate words are more likely to activate motoric representations than inanimate words, but ratings of body-object interactions were higher for inanimate words. Popp and Serra (2018) and Meinhardt et al. (2018) ruled out differences in emotional valence and arousal.
An important metric of the richness of semantic representations is the number of semantic features (NoF) that participants list for a target word in feature norming studies (McRae et al., 2005). Semantic features have been used in models of concepts, semantic memory, language processing, and memory (Hintzman, 1986; Shiffrin & Steyvers, 1997). To aid model development and testing, semantic feature norms have been generated by presenting participants sets of concept names and asking them to list the features they think are important for each concept (McRae et al., 2005). The results are compiled with the number of participants who listed each feature and indices of feature informativeness, such as the distinctiveness of features. For example, the resulting feature list for moose includes is large, has antlers, has legs, lives in woods, is hunted by people, and the feature list for knife includes has a handle, has a blade, is shiny, made of metal, is sharp, and used for cutting.
Number of features is positively associated with recall and recognition memory (Hargreaves et al., 2012; Lau et al., 2018), such that words selected from the McRae et al. norms that have higher numbers of features are more likely to be recalled and recognized than words with lower numbers of features. Words with a higher number of features may afford richer encoding, and in fact mathematical models of memory such as MINERVA-2 (Hintzman, 1988) and REM (Shiffrin & Steyvers, 1997) conceptualize encoding as the probabilistic recording of values of features into a vector of features. Hintzman (1988) modeled levels of processing effects by allocating a larger portion of each 25-feature item vector to conceptual features (15) compared to shallow features (10). In REM, as more features are stored during study of a word, the memory representation becomes more differentiated from other memories, which makes them more distinguishable at retrieval (Kilic et al., 2017). In a REM simulation of the effects of varying the length of the feature vector, Montenegro et al. (2014) found that longer feature vectors produced a higher recognition hit rate and lower false alarm rates. If animate words have a higher number of features, which would map onto a longer vector length in REM, it could help to explain why animate items are better remembered.
To explore the hypothesis that animate and inanimate words refer to concepts differing in semantic features, we compared the NoF of animate and inanimate words from Experiment 2, using the McRae et al. semantic feature norms. Only five of our animate words and nine of the inanimate words appeared in the norms; nonetheless, in that set, animate words had higher NoF (M = 19.8, SD = 2.78) than inanimate words (M = 12.7, SD = 1.73), t (12) = 5.99, p < .001, Cohen’s d = 3.34. We also compared NoF in the combined word lists from VanArsdall et al. (2017). Of the 14 animate words and 18 inanimate words that were indexed in the McRae et al. norms, animate words were higher on NoF (M= 17.8, SD = 3.66) than inanimate words (M = 14.4, SD = 3.11), t (30) = 2.79, p = .009, Cohen’s d = .994.
As a virtual test of whether the animacy effect is at least partially mediated by differences in the number of features of animate and inanimate words, we analyzed the free-recall data from an item-level megastudy by Lau et al. (2018) that used a large subset of the words from McRae et al.’s feature norm list that had corresponding values for a number of lexical and semantic variables. Participants studied lists of 19 words, presented for 1.5 s per word, and then freely recalled each list. We coded words in Lau et al. as animate versus inanimate, and then performed an item-level analysis to determine if the animacy effect in free recall is at least partially mediated by number of features of animate versus inanimate words.
Methods and results
The 541 words in the McRae et al. (2005) norms were coded for animacy by three trained undergraduate coders. The coders were given a description of the difference between animate and inanimate items, and were told to code all body parts, buildings, plants, and other ambiguous words (e.g., accident, blue, etc.) as being ambiguous with respect to animacy, as we were primarily concerned with words that were clearly animate or inanimate. Words were classified as animate or inanimate when all three raters agreed, with 126 words classified as animate and 232 words as inanimate. Number of semantic features per word was higher for animate words (M = 15.00, SD = 3.81) compared to inanimate words (M = 12.69, SD = 3.32), t (356) = 5.96, p < .001, Cohen’s d = 0.659.
Semantic features as a predictor of free recall
To examine whether a difference in number of features could help to explain the animacy effect, we used item-level recall data from Lau et al. (2018), provided to us by the corresponding author. The dataset from Lau et al. (2018) contained the Number of Feature norms provided in McRae et al. (2005), several other semantic variables including concreteness, imageability, familiarity, and Kucera-Francis word frequency, and a measure of the rate of free recall for each item across 120 participants tested by Lau et al. Words in the McRae et al. norms without all semantic measures had been dropped by Lau et al. We entered our codes from our animacy ratings, resulting in 102 animate words and 204 inanimate words. The animacy effect on free recall was present in the data from Lau et al., t (304) = 4.95, p < .001, Cohen’s d = 0.600, with animate words (M = 0.48, SD = 0.087) producing higher rates of free recall than inanimate words (M = 0.43, SD = 0.075). Importantly, animate words had more semantic features (M = 13.06, SD = 3.34) than inanimate words (M = 11.75, SD = 3.19), t (304) = 3.34, p < .001, Cohen’s d = 0.404.
To explore the potential for a mediation of the effect of animacy on recall via number of semantic features, we conducted a mediation analysis in the Mediation package in R (Tingley et al., 2014) using the bootstrapping method with 5,000 samples. Average rate of free recall served as the dependent variable, animacy status served as the main predictor, and number of semantic features served as the mediator variable. Concreteness, imageability, familiarity, Kucera-Francis written frequency ratings, and the lexical variable number of letters were included in the model as covariates. Missing values were excluded listwise, resulting in 11 words being dropped from the Lau et al. dataset due to missing concreteness ratings. The total effect demonstrated that animacy is a predictor of free recall, b = 0.437, p < 0.001, CI95 [0.024, 0.06], and the average direct effect demonstrated that animacy remains a significant predictor of recall in the mediation model, b = 0.030, p = 0.008, CI95 [0.008, 0.05]. Of critical importance, however, the proportion of the effect of animacy on free recall mediated by number of semantic features was also significant, b = 0.320, p < 0.001, CI95 [0.128, 0.70], suggesting partial mediation, as approximately one-third of the variance in free recall accounted for by animacy was mediated by the number of semantic features, above and beyond any effects of concreteness, imageability, familiarity, Kucera-Francis written frequency ratings, or number of letters.
Taken together, these results have several implications. First, there appears to be a significant difference in number of semantic features between animate and inanimate words, with animate words having significantly more associated semantic features according to the McRae et al. norms. Number of features also varied between animate and inanimate words in our second experiment and in the words used by VanArsdall et al. for words that appear in the McRae et al. norms. Second, the relationship between animacy and free recall in the Lau et al. item-level dataset was partially mediated by number of semantic features. Results thus point to a difference in richness of semantic representation of animate and inanimate words as contributor to the animacy effect in free recall. We discuss how that translates into better memory in the General discussion.
General discussion
Experiments 1 and 2 were designed to explore whether attention is the proximal cause of the animacy effect in memory by testing two hypotheses: The attentional prioritization hypothesis and the controlled processing hypothesis. The attentional prioritization hypothesis, following the animate monitoring hypothesis from New et al. (2007a), suggested that differential attention is given to animate items compared to inanimate items, thus allowing for better encoding and retrieval of animate items. We predicted that dividing attention at encoding would create a more pronounced animacy effect, as the animate items should continue to receive sufficient attention for encoding to take place even if attentional resources were limited. The contrasting controlled processing hypothesis built upon the finding that the animacy effect in recognition memory is found in the “remember” judgments rather than in the “know” judgments. “Remember” judgments are thought to be a measurement of recollection, a mental process that requires controlled attention at encoding. Following this theory, our alternative prediction was that dividing attention during encoding would hinder the participants’ ability to recollect the animate items, thus reducing or eliminating the animacy advantage. Both of the described hypotheses led us to predict that attention condition and word type would interact. However, we found no interactions, and the Bayes factor supported the null hypothesis of no interaction in recall.
Considering the lack of evidence for the attentional hypotheses, we turned next to a hypothesis originally proposed by Nairne et al. (2013) that there are differences in semantic representations between animate and inanimate words, such as differences in the richness of the representations that allow for better encoding of animate words. We indexed richness of representations using the McRae et al. norms for number of features in the concepts referred to by a given word. We found that animate words do have higher numbers of features than inanimate words, and so using data from Lau et al. (2018), we tested whether the animacy advantage in free recall is at least partially mediated by number of features. Number of features partially mediated the animacy advantage in free recall. We will discuss the attentional hypotheses and the richness of representations hypotheses in turn.
Attention as a basis for animacy effect in memory
The attentional prioritization hypothesis was explored by Bonin et al. (2015) and Leding (2019), with mixed results. Full versus divided attention during encoding did not differentially affect animate versus inanimate words in Bonin et al. (2015), whereas for Leding (2019), divided attention during encoding had a greater effect on animate words, although the interpretation of the latter was compromised by floor effects for inanimate words. The present experiments addressed these concerns by using a less difficult version of the digit-monitoring task, and found evidence in favor of a null effect of the interaction of attention condition and animate versus inanimate words in word recall, and no interaction in recognition accompanied by “remember” judgments.
It is possible that attention is prioritized for animate items, even under conditions of divided attention, and also that more controlled, elaborative processing occurs for animate items when attentional conditions allow, as in the thought listing results of Meinhardt et al. (2020). As noted earlier, these two mechanisms would need to be of comparable sizes to lead to offsetting effects of dividing attention, with attentional prioritization increasing encoding of animate items relative to inanimate items during divided attention to the same degree that the relative advantage of elaborative processing for animate items is reduced from full to divided attention conditions. Future research would need to separate the two processes of attention-demanding elaborative encoding and attentional prioritization to see if such offsetting is occurring.
Alternatively, perhaps the advantage for animate items revealed on the thought generation task of Meinhardt et al. occurs rapidly and automatically upon item presentation, followed by slower generation of subsequent thoughts at the same rate for animate and inanimate items. Although divided attention could be reducing elaboration across the rest of the encoding interval, it may be that the animacy effect is driven by initial thoughts that are most strongly associated to the word or most strongly a part of the semantic representation, and so retrieved with little effort upon reading the word.
The lack of an interaction between animacy status and attention condition at encoding parallels a puzzling lack of interaction between several encoding manipulations related to elaborative processing and attention at encoding, including deep versus shallow processing (Craik & Kester, 2000), and intentional versus incidental encoding (Naveh-Benjamin et al., 2007; Naveh-Benjamin et al., 2014; Naveh-Benjamin & Brubaker, 2019). For example, Naveh-Benjamin and Brubaker (2019) found intentional encoding led to greater benefits for recall than did an incidental encoding cover story that the experiments were interested in participants physiologically response to the words, but the size of the benefit was equal under conditions of full versus divided attention at encoding with the Bayes factor supporting a null interaction term. Further, when subjects were sorted by their retrospectively reported encoding strategies, there was no interaction of attention condition with whether participants reported using elaborative strategies rather than shallow or no encoding strategy. Naveh-Benjamin and Brubaker proposed that the incidental versus intentional encoding manipulation produces differences in memory through an automatic process, and the drop in memory with divided attention is produced by disruption of initial registration of items. Similarly, the lack of an interaction between the size of the animacy effect and full versus divided attention may indicate that the animacy advantage is due to automatic access to richer semantic representation, rather than controlled elaborations. Future studies using concurrent strategy reports during encoding could directly measure elaborations to see if they occur at a different rate during study of animate versus inanimate items, and how divided attention affects elaborations. In contrast, the animacy effect may originate from a greater probability of automatic activation of associated semantic or episodic details from prior personal experiences for the animate compared to inanimate words.
Finally, a more taxing manipulation of divided attention during encoding could reveal an interaction of word type and attention condition. In a test of the basis for another adaptive memory phenomenon, Kroneisen et al. (2016) manipulated attentional load while participants encoded words for either their relevance for a survival scenario or their relevance for a control scenario of moving abroad and found that a higher working memory load (a 2-back vs. a 1-back tone-monitoring task) was key to the elimination of the survival processing advantage. Although these findings from the survival processing literature suggest that a dual-task with a higher cognitive load could differentially affect encoding of animate versus inanimate word, they conflict with the null result of Bonin et al. (2015), where a high cognitive load did not differentially affect animate and inanimate items. Additionally, it is important to note that Gelin et al. (2017) argue that the survival processing advantage and animacy advantage are two separate effects with different underlying mechanisms, so the effects of divided attention on the two processes could diverge.
Animate concepts are more richly represented
We found that animate concepts are more richly represented than inanimate concepts as indexed by number of semantic features, and number of semantic features partially mediates the animacy effect in free recall. How does a larger number of features translate into better recall and better recognition? We know of only two studies that have investigated the effects of number of semantic features on memory: Hargreaves et al. (2012), and Lau et al. (2018). Hargreaves et al. suggested that higher NoF words could afford “enriched” encoding, and found a recall advantage for words with a high versus low number of features across three intentional learning experiments. At a test of whether the better encoding of high NoF was due to intentional elaboration, they ran a fourth experiment where encoding was an incidental byproduct of lexical decisions. They argued that the high NoF advantage found in that experiment reflected “a more extensive activation of the semantic system” (Hargreaves et al., p.7). The size of the recall advantage in terms of proportion of words recalled was consistent across the three intentional encoding experiments that would afford more elaboration given a 2-s presentation rate and a 3-s intertrial interval, compared to the fourth experiment that used incidental encoding following lexical decisions that were made in under 700 ms. The recall advantage of large numbers of features appears to occur at the stage of initial processing of the word due to the activation of the richer representation. If that proves true in future studies, then even reading a word under conditions of divided attention might be enough to create a memory advantage for words with more features, including animate words.
Hargreaves et al. (2012) also suggested that concepts with higher numbers of features would produce enhanced memory by creating more distinctive memories, which is similar to interpretations of feature encoding in differentiation models such as REM, which assumes that each feature is encoded probabilistically and independently. Lau et al. (2018) speculated that high NoF words have more features that could be used as potential retrieval cues, and that high NoF words also have a higher likelihood of at least one of the features being distinctive, which would improve memory for high NoF words. We suggest that at least part of the animacy effect in recall is a result of memories of animate words that are more distinctive because more features are encoded.
Distinctive encoding has been conceptualized as storing more unique features for each item, and has long been used to understand why deep, meaningful processing of the myriad conceptual variations among word meanings produces better memory than shallow processing that encodes a limited number of surface features. Gallo et al. (2008) showed that additional benefits of distinctiveness occur at test by allowing people to lower the likelihood of a false alarm on a recognition test, if testing conditions informed them what type of processing had been done on the to-be-tested items. When participants knew they were being tested on deeply processed items, they could reject new foils as unstudied because of the absence of distinctive recollections. If memories for animate items are more distinctive than memories for inanimate items, then people could use such a distinctiveness heuristic to reject new animate items, which accords with our finding in Experiment 2 that people used a higher criterion for “know” judgments for animate compared to inanimate words. A difference in distinctiveness between animate and inanimate memories could be driving both the response bias and the discriminability advantage in recognition.
Finally, although our mediation analysis in our last project found that a third of the variance in the animacy effect in recall in the Lau et al. (2018) data set is accounted for by animate items having more features, there is still variance unaccounted for. One caveat is that feature norms provide an approximation for semantic richness, rather than a direct readout of the features in the representation (McRae et al., 2005). For example, only features that were reported by at least five of the 30 respondents for each concept word in McRae et al. were used in the norms, and idiosyncratic features that were dropped might also vary between animate and inanimate concepts. It may be fruitful to look to existing models of memory for other factors that characterize variations in features and conceptual representations that could contribute to the animacy effect in memory.
Summary
We tested whether differential attention to animate versus inanimate words during encoding is the proximal cause of the animacy effect in memory, as predicted by both the attentional prioritization hypothesis and by the controlled processing hypothesis. Bayesian analyses failed to support either hypothesis, suggesting that attention is not the proximal cause of the animacy effect, in that divided attention during encoding neither increased nor decreased the animacy effect compared to full attention. We then turned to a test of whether animate items are semantically richer than inanimate items, as indexed by norms of number of features. Using data from Lau et al.’s (2018) item-level metanalysis, we found that approximately one-third of the variance in recall due to animacy is mediated by measures of numbers of features, with concepts referred to by animate words have a higher numbers of features than concepts referred to by inanimate words. However, that leaves much variance in the animacy effect still to be explained. Given that animacy is one of the strongest predictors of recall, understanding its proximal cause remains a key challenge for memory researchers.
References
Altman, M. N., Khislavsky, A. L., Coverdale, M. E., & Gilger, J. W. (2016). Adaptive attention:How preference for animacy impacts change detection. Evolution and Human Behavior, 37(4), 303-314. https://doi.org/10.1016/j.evolhumbehav.2016.01.006
Anderson, B. A., Jacoby, L. L., Thomas, R. C., & Balota, D. A. (2010). The effects of age and divided attention on spontaneous recognition. Memory & Cognition, 39(4), 725-735. https://doi.org/10.3758/s13421-010-0046-z
Baddeley, A., Lewis, V., Eldridge, M., & Thomson, N. (1984). Attention and retrieval from long-term memory. Journal of Experimental Psychology: General,113(4), 518-540. https://doi.org/10.1037/0096-3445.113.4.518
Bonin, P., Gelin, M., & Bugaiska, A. (2013). Animates are better remembered than inanimates: Further evidence from word and picture stimuli. Memory & Cognition,42(3), 370-382. https://doi.org/10.3758/s13421-013-0368-8
Bonin, P., Gelin, M., Laroche, B., Méot, A., & Bugaiska, A. (2015). The “how” of animacy effects in episodic memory. Experimental Psychology, 62(6), 371–384. https://doi.org/10.1027/1618-3169/a000308
Bugaiska, A., Grégoire, L., Camblats, A.-M., Gelin, M., Méot, A., & Bonin, P. (2019). Animacy and attentional processes: Evidence from the Stroop task. Quarterly Journal of Experimental Psychology, 72(4), 882–889. https://doi.org/10.1177/1747021818771514
Bugaiska, A., Méot, A., & Bonin, P. (2016). Do healthy elders, like young adults, remember animates better than inanimates? An adaptive view. Experimental Aging Research,42(5), 447-459. https://doi.org/10.1080/0361073x.2016.1224631
Calvillo, D. P., & Jackson, R. E. (2013). Animacy, perceptual load, and inattentional blindness Psychonomic Bulletin & Review,21(3), 670-675. https://doi.org/10.3758/s13423-013-0543-8
Chapman, H. A., Johannes, K., Poppenk, J. L., Moscovitch, M., & Anderson, A. K. (2013). Evidence for the differential salience of disgust and fear in episodic memory. Journal of Experimental Psychology: General, 142(4), 1100–1112. https://doi.org/10.1037/a0030503
Charash, M., & Mckay, D. (2002). Attention bias for disgust. Journal of Anxiety Disorders,16(5), 529-541. https://doi.org/10.1016/s0887-6185(02)00171-8
Craik, F. I., Govoni, R., Naveh-Benjamin, M., & Anderson, N. D. (1996). The effects of divided attention on encoding and retrieval processes in human memory. Journal of Experimental Psychology: General,125(2), 159-80. https://doi.org/10.1037//0096-3445.125.2.159
Craik, F. I. M., & Kester, J. D. (2000). Divided attention and memory: Impairment of processing or consolidation? In E. Tulving (Ed.), Memory, consciousness, and the brain: The Tallinn Conference (p. 38–51). Psychology Press.
Cree, G. S., & Mcrae, K. (2003). Analyzing the factors underlying the structure and computation of the meaning of chipmunk, cherry, chisel, cheese, and cello (and many other such concrete nouns). Journal of Experimental Psychology: General, 132(2), 163–201. https://doi.org/10.1037/0096-3445.132.2.163
Croucher, C. J., Calder, A. J., Ramponi, C., Barnard, P. J., & Murphy, F. C. (2011). Disgust Enhances the Recollection of Negative Emotional Images. PLoS ONE, 6(11), e26571. https://doi.org/10.1371/journal.pone.0026571
Dougherty, M. R., Harbison, J. I., & Davelaar, E. J. (2014). Optional stopping and the termination of memory retrieval. Current Directions in Psychological Science, 23, 332-337. https://doi.org/10.1177/096372141454017
Fernandes, N. L., Pandeirada, J. N. S., Soares, S. C., & Nairne, J. S. (2017). Adaptive memory: The mnemonic value of contamination. Evolution and Human Behavior, 38(4), 451-460. https://doi.org/10.1016/j.evolhumbehav.2017.04.003
Fisk, A. D., & Schneider, W. (1984). Memory as a function of attention, level of processing, and automatization. Journal of Experimental Psychology: Learning, Memory, and Cognition,10(2), 181-197. https://doi.org/10.1037/0278-7393.10.2.181
Gallo, D. A., Meadow, N. G., Johnson, E. L., & Foster, K. T. (2008). Deep levels of processing elicit a distinctiveness heuristic: Evidence from the criterial recollection task. Journal of Memory and Language, 58(4), 1095–1111. https://doi.org/10.1016/j.jml.2007.12.001
Gardiner, J. M., & Parkin, A. J. (1990). Attention and recollective experience in recognition memory. Memory & Cognition,18(6), 579-583. https://doi.org/10.3758/bf03197100
Gelin, M., Bugaiska, A., Méot, A., & Bonin, P. (2017). Are animacy effects in episodic memory independent of encoding instructions? Memory, 25(1), 2–18. https://doi.org/10.1080/09658211.2015.1117643
Gelin, M., Bugaiska, A., Méot, A., Vinter, A., & Bonin, P. (2019). Animacy effects in episodic memory: Do imagery processes really play a role? Memory,1-15. https://doi.org/10.1080/09658211.2018.1498108
Guerrero, G., & Calvillo, D. P. (2016). Animacy increases second target reporting in a rapid serial visual presentation task. Psychonomic Bulletin & Review,23(6), 1832-1838. https://doi.org/10.3758/s13423-016-1040-7
Hargreaves, I. S., Pexman, P. M. Johnson, J. C., & Zdrazilova, L. (2012). Richer concepts are better remembered: Number of features effects in free recall. Frontiers in Human Neuroscience, 6, 73. https://doi.org/10.3389/fnhum.2012.00073.
Hintzman, D. L. (1986). “Schema abstraction” in a multiple-trace memory model. Psychological Review, 93(4), 411–428. https://doi.org/10.1037/0033-295x.93.4.411
Hintzman, D. L. (1988). Judgments of frequency and recognition memory in a multiple-trace memory model. Psychological Review, 95, 528-551.
Hitch, G. J., & Baddeley, A. D. (1976). Verbal reasoning and working memory. Quarterly Journal of Experimental Psychology, 28(4), 603–621. https://doi.org/10.1080/14640747608400587
JASP Team (2020). JASP (Version 0.13.1)[Computer software].
Jennings, J. M., & Jacoby, L. L. (1993). Automatic versus intentional uses of memory: Aging, attention, and control. Psychology and Aging,8(2), 283-293. https://doi.org/10.1037/0882-7974.8.2.283
Kensinger, E. A., & Corkin, S. (2004). Two routes to emotional memory: Distinct neural processes for valence and arousal. Proceedings of the National Academy of Sciences, 101(9), 3310–3315. https://doi.org/10.1073/pnas.0306408101
Kern, R. P., Libkuman, T. M., Otani, H., & Holmes, K. (2005). Emotional Stimuli, Divided Attention, and Memory. Emotion, 5(4), 408–417. https://doi.org/10.1037/1528-3542.5.4.408
Kilic, A., Criss, A. L., Malmberg, K. J., & Shiffrin, R.M. (2017). Models that allow us to perceive the world more accurately also allow us to remember past events more accurately via differentiation. Cognitive Psychology, 82, 65-86. https://doi.org/10.1016/j.cogpsych.2016.11.005
Kroneisen, M., Rummel, J., & Erdfelder, E. (2016). What kind of processing is survival processing? Memory & Cognition, 44(8), 1228–1243. https://doi.org/10.3758/s13421-016-0634-7
Lau, M. C., Goh, W. D., & Yap, M. J. (2018). An item-level analysis of lexical-semantic effects in free recall and recognition memory using the megastudy approach. Quarterly Journal of Experimental Psychology, 71(10), 2207–2222. https://doi.org/10.1177/1747021817739834
Leding, J. K. (2019). Adaptive memory: Animacy, threat, and attention in free recall. Memory & Cognition, 47(3), 383–394. https://doi.org/10.3758/s13421-018-0873-x
Madan, C. R. (2020). Exploring word memorability: How well do different word properties explain item free-recall probability? Psychonomic Bulletin & Review. https://doi.org/10.3758/s13423-020-01820-w
Maddox, G. B., Naveh-Benjamin, M., Old, S., & Kilb, A. (2012). The role of attention in the associative binding of emotionally arousing words. Psychonomic Bulletin & Review, 19: 1128-1134. https://doi.org/10.3758/s13423-012-0315-x
Mangels, J. A., Picton, T. W., & Craik, F. I. (2001). Attention and successful episodic encoding: An event-related potential study. Cognitive Brain Research,11(1), 77-95. https://doi.org/10.1016/s0926-6410(00)00066-5
Meinhardt, M. J., Bell, R., Buchner, A., & Röer, J. P. (2018). Adaptive memory: Is the animacy effect on memory due to emotional arousal? Psychonomic Bulletin and Review, 25, 1399-1404.
Meinhardt, M. J., Bell, R., Buchner, A., & Röer, J. P. (2020). Adaptive memory: Is the animacy effect on memory due to richness of encoding? Journal of Experimental Psychology: Learning, Memory, and Cognition, 46(3), 416-426. https://doi.org/10.1037/xlm0000733
McCabe, D. P., & Geraci, L. D. (2009). The influence of instructions and terminology on the accuracy of remember–know judgments. Consciousness and Cognition,18(2), 401-413. https://doi.org/10.1016/j.concog.2009.02.010
McRae, K., Cree, G. S., Seidenberg, M. S., & McNorgan, C. (2005). Semantic feature production norms for a large set of living and nonliving things. Behavior Research Methods, 37(4), 547–559. https://doi.org/10.3758/bf03192726
Montenegro, M., Myung, J., I., & Pitt, M. A. (2014). Analytical expressions for the REM model of recognition memory. Journal of Mathematical Psychology, 60: 23-28. https://doi.org/10.1016/j.jmp.2014.05.003
Nairne, J. S., Thompson, S. R., & Pandeirada, J. N. S. (2007). Adaptive memory: Survival processing enhances retention. Journal of Experimental Psychology: Learning, Memory, and Cognition,33(2), 263-273. https://doi.org/10.1037/0278-7393.33.2.263
Nairne, J. S., & Pandeirada, J. N. S. (2008). Adaptive memory: Is survival processing special? Journal of Memory and Language, 59, 377-385. https://doi.org/10.1037/e527342012-271
Nairne, J. S., Pandeirada, J. N. S., Gregory, K. J., & Arsdall, J. E. (2009). Adaptive memory Fitness relevance and the hunter-gatherer mind. Psychological Science,20(6), 740-746. https://doi.org/10.1111/j.1467-9280.2009.02356.x
Nairne, J. S., VanArsdall, J. E., Pandeirada, J. N. S., Cogdill, M., & Lebreton, J. M. (2013). Adaptive memory: The mnemonic value of animacy. Psychological Science,24(10), 2099-2105. https://doi.org/10.1177/0956797613480803
Naveh-Benjamin, M. & Brubaker, M. S. (2019). Are the effects of divided attention on memory encoding processes due the disruption of deep-level elaborative processes? Evidence from cued- and free-recall tasks. Journal of Memory and Language, 106, 108-117.
Naveh-Benjamin, M., Guez, J., Hara, Y., Brubaker, M.S., & Lowenschuss-Erlich, I. (2014). The effects of divided attention on encoding processes under incidental and intentional learning instructions: Underlying mechanism? The Quarterly Journal Experimental Psychology, 67, 1682-1696.
Naveh-Benjamin, M., Guez, J., & Sorek, S. (2007). The effects of divided attention on encoding processes in memory: Mapping the locus of interference. Canadian Journal of Experimental Psychology, 61, 1-12.
New, J., Cosmides, L., & Tooby, J. (2007a). Category-specific attention for animals reflects ancestral priorities, not expertise. Proceedings of the National Academy of Sciences,104(42), 16598-16603. https://doi.org/10.1073/pnas.0703913104
New, J., Krasnow, M. M., Truxaw, D., & Gaulin, S. J. (2007b). Spatial adaptations for plant foraging: Women excel and calories count. Proceedings of the Royal Society B: Biological Sciences,274(1626), 2679-2684. https://doi.org/10.1098/rspb.2007.0826
Popp, E. Y., & Serra, M. J. (2016). Adaptive memory: Animacy enhances free recall but impairs cued recall. Journal of Experimental Psychology: Learning, Memory, and Cognition, 42(2), 186–201. https://doi.org/10.1037/xlm0000174
Popp, E. Y, & Serra, M. J. (2018). The animacy advantage for free-recall performance is not attributable to greater mental arousal. Memory, 26. 89-95.
Rabinowitz, J. C., Craik, F. I. M., & Ackerman, B. P. (1982). A processing resource account of age differences in recall. Canadian Journal of Psychology/Revue Canadienne de Psychologie, 36(2), 325–344. https://doi.org/10.1037/h0080643
Ralph, M.A.L., Jefferies, E, Patterson, K., & Rogers, T. T. (2017). The neural and computational bases of semantic cognition. Nature Reviews Neuroscience, 18, 42-55.
Sahakyan, L., & Malmberg, K. J. (2018). Divided attention during encoding causes separate memory traces to be encoded for repeated events. Journal of Memory and Language,101, 153-161. https://doi.org/10.1016/j.jml.2018.04.004
Sandry, J., Trafimow, D., Marks, M. J., & Rice, S. (2013). Adaptive memory: Evaluating alternative forms of fitness-relevant processing in the survival processing paradigm. PLoS ONE,8(4), 1-12. https://doi.org/10.1371/journal.pone.0060868
Schacter, D. L., & Wiseman, A.L. (2006). Reducing memory errors: The distinctiveness heuristic. In Reed R. Hunt, and J. Worthen (Eds). Distinctiveness and memory. New York, Oxford University Press; pp. 89-107.
Shiffrin, R. M., & Steyvers, M. (1997). A model for recognition memory: REM—retrieving effectively from memory. Psychonomic Bulletin & Review, 4(2), 145–166. https://doi.org/10.3758/bf03209391
Snodgrass, J. G., & Corwin, J. (1988). Pragmatics of measuring recognition memory: Applications to dementia and amnesia. Journal of Experimental Psychology: General, 117(1), 34–50. https://doi.org/10.1037/0096-3445.117.1.34
Starns, J. J., Cataldo, A.M., Rotello, C. M., Annis, J., Aschenbrennner, A., Broder, A., Cox, G., Criss, A., Crul, R.A., Dobbins, I.G., Dunn, J., Enam, T., Evans, N. J., Farrell, S., Fraundorf, S. H., Gronlund, S. D., Heathcote, A., Heck, D. W., Hicks, … Wilson, J. (2019). Assessing theoretical conclusions with blinded inference to investigate a potential inference crisis. Advances in Methods and Practices in Psychological Science, 2 (4), 335-349.
Talmi, D., & McGarry, L. M. (2012). Accounting for immediate emotional memory enhancement. Journal of Memory and Language, 66(1), 93–108. https://doi.org/10.1016/j.jml.2011.07.009
Tingley, D., Yamamoto, T., Hirose, K., Keele, L., Imai, K. (2014). Mediation: R Package for Causal Mediation Analysis. Journal of Statistical Software, 59(5), 1-38. URL http://www.jstatsoft.org/v59/i05/.
Umanath, S., & Coane, J. H. (2020). Face Validity of Remembering and Knowing: Empirical Consensus and Disagreement Between Participants and Researchers. Perspectives on Psychological Science, 174569162091767. https://doi.org/10.1177/1745691620917672
VanArsdall, J. E., "Exploring animacy as a mnemonic dimension" (2016). Open Access Dissertations. 873. https://docs.lib.purdue.edu/open_access_dissertations/873
VanArsdall, J. E., Nairne, J. S., Pandeirada, J. N. S., & Blunt, J. R. (2013). Adaptive Memory. Experimental Psychology, 60(3), 172–178. https://doi.org/10.1027/1618-3169/a000186
VanArsdall, J. E., Nairne, J. S., Pandeirada, J. N. S., & Cogdill, M. (2014). Adaptive memory: Animacy effects persist in paired-associate learning. Memory,23(5), 657-663. https://doi.org/10.1080/09658211.2014.916304
VanArsdall, J. E., Nairne, J. S., Pandeirada, J. N. S., & Cogdill, M. (2017). A categorical recall strategy does not explain animacy effects in episodic memory. Quarterly Journal of Experimental Psychology,70(4), 761-771. https://doi.org/10.1080/17470218.2016.1159707
Wagenmakers, E., Marsman, M., Jamil, T., Ly, A., Verhagen, J., Love, J., Selker, R., Gronau, Q. F., Smira, M., Eskamp, S., Rouder, D., & Morey, R. D. (2017). Bayesian inference for psychology. Part I: Theoretical advantages and practical ramifications. Psychonomic Bulletin & Review,25(1), 35-57. https://doi.org/10.3758/s13423-017-1343-3
Weinstein, Y., Bugg, J. M., & Roediger, H. L. (2008). Can the survival recall advantage be explained by basic memory processes? Memory & Cognition,36 (5), 913-919. https://doi.org/10.3758/mc.36.5.913
Wilson, M. (1988). MRC psycholinguistic database: Machine-usable dictionary, version 2.00. Behavior Research Methods, Instruments, & Computers, 20(1), 6–10. https://doi.org/10.3758/bf03202594
Yonelinas, A. P. (2002). The nature of recollection and familiarity: A review of 30 years of research. Journal of Memory and Language,46(3), 441-517. https://doi.org/10.1006/jmla.2002.286
Author information
Authors and Affiliations
Corresponding author
Additional information
Open Practices Statement
The data for the experiments reported here are available at https://osf.io/uvbdc/?view_only=8966213f2a3a4d47a4630618c26cd957. The materials for the experiments reported here are available upon request, and none of the experiments were preregistered.
Author Note
A special thank you to Mabel Lau for sharing her item-level data, and to Deena Alani, Fabienne Alexandre, Elyse Bressler, Noel Crawford, Caitlin McCann, and Maria Szymonowicz for their assistance testing participants.
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix A
Appendix B
Instructions for Recognition Paradigm in Experiment 2.
Type A response—When you see a word on the test, it may bring to mind the exact thought you had from when you first studied the word at the start of the experiment. If you can recall the exact thought you had from when you studied the word earlier, it is a Type A response. Often when people give a Type A response it is because they can recall a personal association that came to mind when they first saw the word, or some other details about when they studied the word. For example, imagine you had studied the word BOOK earlier in the experiment. Imagine also that when you studied the word BOOK that you thought of the title of a book you have recently been reading. If you then saw the word BOOK on the test, and you recalled that when you were studying it you had thought about the title of the book you have been reading, then you would give a Type A response for the word BOOK. There are other details you may recall about studying a word that would lead you to give a Type A response, such as a feeling you had when you saw the word, or a mental image that came to mind while you were studying the word. You may also be able to recall that you associated the word with another word that you studied, or you may recall what the word looked like on the screen. If you can be sure you studied the word because you can recollect specific details about when you studied it, say it is a Type A response. If you decide it is a Type A response, you must give the details of your memory.
Type B response—If you see a word on the test and you believe it was presented but you cannot recall any specific association that you made when you studied it, say it is a Type B response. In other words, a Type B response means you “just know” you studied the word, even though you cannot recall any details from when you studied it.
Appendix C
Rights and permissions
About this article

Cite this article
Rawlinson, H.C., Kelley, C.M. In search of the proximal cause of the animacy effect on memory: Attentional resource allocation and semantic representations. Mem Cogn 49, 1137–1152 (2021). https://doi.org/10.3758/s13421-021-01154-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-021-01154-5