
Abstract
Several studies have explored the effects of divided attention on priming, but little is known about the impact of working memory load on implicit visual memory. The aim of this study was to determine whether there are differential effects of working memory load on a visual priming task compared to a recognition task. In the encoding phase, participants were presented with real-object pictures and asked to classify them semantically. At retrieval, 40 studied and 40 new images were presented (partially masked) for 100 ms, and participants had to identify the object. Each trial was immediately followed by a recognition test, in which the unmasked image was shown again, and participants had to indicate whether it had been presented at encoding or not. Regarding working memory load, participants performed a task in which a load was imposed in half of the trials. Twenty-four participants concurrently performed an articulatory suppression task, another group of 24 subjects performed an executive demanding task, and a third group of 24 participants performed a spatial tapping task. Working memory load failed to diminish performance on both priming and recognition tests in the articulatory suppression condition. However, the backward counting and the tapping tasks influenced recognition, rather than priming. The relative pattern of backward counting effects on recognition and priming were then broadly replicated in a follow-up experiment using an adapted priming task (N = 24). Results suggest that a concurrent load has a more robust effect on recognition than on priming, especially when the working memory task is executively demanding.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The distinction between explicit memory, which refers to conscious recollection of prior experiences, and implicit memory, referring to changes in behaviors due to prior experience without conscious recollection (Graf & Schacter, 1985; Roediger, 1990; Schacter, 1987), became a key area of research especially during the 1980s due to the finding that they can be dissociated so that variables that have an effect on explicit tests do not influence, or show an opposite pattern, in implicit tests (Musen & Treisman, 1990; Richardson-Klavehn & Bjork, 1988). The dissociations have been explained from a multiple memory systems’ point of view, which assumes that implicit and explicit memory are supported by distinct memory systems in the brain (see Squire, 2009, for a review). In this sense, research conducted with amnesic patients has shown that brain damage selectively affects the memory system responsible for conscious recollection, such as free recall or recognition tasks, whereas other forms of learning, such as perceptual or motor skills that rely on a different system, are left intact (Tulving, 1985; Weiskrantz, 1987). However, recent evidence favors a single system-model by which explicit (recognition) and implicit memory (repetition priming) are driven by the same memory source (Berry, Henson, & Shanks, 2006; Berry, Kessels, Wester, & Shanks, 2014; Shanks & Berry, 2012). In contrast to these memory systems perspectives, the processing approach suggests that explicit and implicit memory reflect the operation of distinct cognitive procedures required by the tasks (Mandler, 1989; Moscovitch, Goshen-Gottstein, & Vriezen, 1994). The components of processing model (Moscovitch et al., 1994) combines processing and multiple memory systems approaches and suggests that memory is distributed across multiple content-specific subsystems that are processed in specific brain regions. In summary, there are a growing number of studies on the distinction between explicit and implicit memory, and on theoretical speculation concerning processing and memory systems models (Cabeza & Moscovitch, 2013).
The present study focuses on the differential effects of working memory (WM) load on explicit (recognition task) and implicit (visual priming task) memory. Priming refers to the change or facilitation observed in performance (e.g., identification or detection) of an item as a result of prior exposure to the same or a similar item, without making an explicit reference to the studied stimuli. It occurs without deliberate recollection and it can be conceptualized as a form of implicit memory (e.g., Graf & Schacter, 1985; Jacoby & Dallas, 1981). On the other hand, recognition involves discrimination between novel information and previously studied items, and it can be considered an explicit form of memory as it involves conscious awareness (Atkinson & Juola, 1974; Norman & O’Reilly, 2003). Both types of tasks seem to be differentially affected by several variables, for example study duration (Voss & Gonsalves, 2010), levels of processing (LOP; Newell & Andrews, 2004; Richardson-Klavehn & Bjork, 1988), and the generation effect (Jacoby, 1983; Mulligan & Dew, 2009, for a review). Differential patterns of impairment can also be seen in amnesic patients compared with controls (Shimamura, 1993, for a review), and in older adults compared with younger adults (Light & La Voie, 1993, for a review). However, there is also recent evidence showing that some of these manipulations do not affect priming and recognition differently, or if they do, priming is affected in the same way but to a smaller magnitude (e.g., study duration, see Berry, Ward, & Shanks, 2017; amnesia, see Berry et al., 2014; ageing, see Ward, Berry, & Shanks, 2013), which would be consistent with the single-system model (Berry et al., 2006). In this sense, it has been argued that apparent dissociations could in some cases be attributable to methodological issues arising from a lack of reliability within the priming tasks (Buchner & Wippich, 2000).
One manipulation that can have differential effects on priming and recognition and that is more related to the aim of the present study is the division of attention; when attention is diverted away from a target at encoding, recognition is typically impaired relative to a non-divided attention condition (Craik, Govoni, Naveh-Benjamin, & Anderson, 1996; Evans & Baddeley, 2018; Parkin, Reid, & Russo, 1990). However, the effects of dividing attention on priming are less well understood and the evidence is mixed (Mulligan, 1998, 2002, 2003, Mulligan & Peterson, 2008; Rajaram, 2007). Some studies have concluded that dividing attention at encoding impairs performance on conceptual implicit tasks that draw on the semantic associations of studied items (Mulligan, 1998), but not perceptual implicit tests that draw on the physical properties of studied items (Mulligan, 1998; Mulligan & Hartman, 1996; Parkin et al., 1990; Soldan, Mangels, & Cooper, 2008; although this conceptual/perceptual distinction is not that simple and can lead to contrary results; see Mulligan & Peterson, 2008). However, other studies have found that perceptual priming can also be affected by division of attention (Mulligan, 2002), and can be reduced under certain conditions, for instance, the extent to which a concurrent task disrupts encoding of an item depends upon the degree to which processing of a distractor occurs at the same time as processing of to-be-encoded items (Mulligan & Hornstein, 2000; Mulligan, 2003). Differential effects have been found as a function of a range of factors such as the type of priming task, difficulty of the secondary task, explicit contamination, and task modality (see Spataro, Cestari, & Rossi-Arnaud, 2011, for a recent and extensive meta-analysis). Our aim though, was to determine whether selectively loading at encoding the components of WM as described in the multicomponent model (Baddeley, 1986; Baddeley & Hitch, 1974) has differential effects on priming and recognition, and to explore to what extent the findings fit with studies that have reported insensitivity of visual priming to divided attention manipulations. Manipulating WM load using different concurrent tasks enables control of variation in attentional demands, and in the extent to which there is modality overlap between the primary task (i.e., encoding of stimuli for which priming/recognition will be tested) and the secondary task (i.e., a concurrent load). In this sense, only a few studies have directly addressed this issue by selectively loading on WM components.
Performing a concurrent WM task has been shown to either reduce some types of priming such as semantic and negative priming, a decrease that is mostly attributed to strategic processes being disrupted under high load (Conway, Tuholski, Shisler, & Engle, 1999; Sabb, Bilder, Chou, & Bookheimer, 2007; Heyman, Van Rensbergen, Storms, Hutchison, & De Deyne, 2015), or have no effect when other priming tasks such as word stem completion are used (Baqués, Sáiz, & Bowers, 2004). Heyman et al. (2015), explored the effects of WM load on semantic priming in order to assess whether automatic target activation and/or the use of strategies rely on cognitive resources. They used a lexical decision task combined with a visual WM load that had to be held during the main task and found that priming disappeared under a high WM load, suggesting that if cognitive resources are depleted, prospective (and not retrospective) priming is disrupted. Such findings would question accounts of priming that assume automatic activation of target representations. However, a more recent paper by these authors attempted to replicate these findings (Heyman, Goossens, Hutchison, & Storms, 2017) and partly failed to do so when a Bayesian analysis was performed on data from two new experiments. In the replication study there was substantial evidence for priming regardless of load, and it was suggested that the non-automaticity account claimed in the previous study could be ruled out. Conway et al., (1999) examined whether negative priming in a letter-naming task would be affected by varying concurrent verbal (words) or nonverbal (polygons) memory loads (of 0–4 items). These different types of load were implemented to determine whether the underlying processes of negative priming require domain-free resources, or whether they draw on domain-specific processes. They found that priming emerged only when no load was imposed, regardless of the load type condition, and concluded that priming requires general resources. Furthermore, low-span participants failed to show negative priming even under no-load conditions, while high-span participants revealed it at load 0, suggesting that variation in availability of WM resources has differential effects on priming. In a neuroimaging study, Sabb et al., (2007) also found a reduction in semantic priming when a verbal WM load was imposed, which decreased as set size of the load increased, showing that both WM and controlled semantic processing might rely on a single resource. On the other hand, Baqués et al. (2004) found that loading the verbal component of WM at encoding with serial recall of digits caused a disruptive effect on a later explicit task (cued recall of words) while it had no effect on an implicit task (word stem completion). Interestingly, loading the visuospatial component of WM at encoding with a visual recognition task of Japanese characters had no effect on any of the two retrieval tasks.
The results so far are therefore inconsistent, and most of the studies conducted have focused on semantic or controlled priming for verbal material. In this sense, visual long-term memory in general, and visual priming in particular, have received less attention, especially for real-life pictorial items (Evans & Baddeley, 2018; Luck & Hollingworth, 2008). Testing real objects with their surrounding context provide increased ecological validity to the debate about the role of visual priming in learning in real-life. A key novel feature of the present design is that it adopts a multiple component approach to WM as set out by Baddeley and colleagues (Baddeley, 1986, 2012; Baddeley & Hitch, 1974; Baddeley, Hitch, & Allen, 2020). This influential framework identifies separable subcomponents that may contribute to any given task, and which can be indexed by concurrent tasks selected to load on these subcomponents. As such, this approach is useful in providing a clear rationale for the three concurrent tasks designed to disrupt verbal (via an articulatory suppression task), visuospatial processing (a spatial tapping task), and central executive control (counting backwards in twos), as most of the previous studies have not fully considered the different WM components and have focused only on one type of load (e.g., verbal). This approach is also useful in specifying a bidirectional relationship between WM and long-term memory, and whether that changes with the nature of the constituent tasks. Consideration of the effects of a single load type, together with the variety of procedures, materials, and measures of priming that have been employed in previous studies, make it very difficult to draw conclusions from previous work as to which WM components are involved in priming and recognition processes, and to explore whether they are differentially affected as a function of the loaded component. Participants were asked to perform these secondary tasks while encoding a series of real object photographs. In a subsequent response phase, participants performed tasks designed to capture implicit visual priming and explicit recognition. The visual priming test consisted of a picture fragment identification test, which is a commonly used visual priming task (Roediger & Srinivas, 1993) and explicit memory was tested with a Yes/No recognition paradigm. The concurrent task manipulations employed in this study allowed exploration of whether an attentionally demanding modality-independent task (central executive) affects priming and recognition differentially or whether the modality of the secondary task (phonological loop/visuospatial sketchpad) causes a greater disruption in both measures when it overlaps with the primary task (i.e., via visuospatial interference). Results will add evidence to the debate concerning strategic and automatic processes in priming, and how WM processes operating during encoding may influence later long-term memory.
Method
Participants
Seventy-two participants from the Autonomous University of Barcelona (mean age: 19 years, SD = 3.12) took part in the experiment. All reported having normal or corrected-to-normal vision and no deficits in color perception. Participants were randomly assigned to one of the three concurrent task conditions, resulting in three groups of 24 participants each.
Materials
Eighty colored photographs of real objects were used that corresponded to four different categories: 20 vegetables, 20 animals, 20 clothing items, and 20 objects. The images were from Pixabay (2018) database (pixabay.com) and showed different items within their own context (i.e., a pot on a kitchen table). The size was 300 × 225 pixels. Four lists of images were created to ensure several material rotations among participants so that each image was presented in each experimental condition.
Design and procedure
The experiment took place in an individual, sound-proofed cabin. Following ten practice trials (five with load and five without in order to train how to perform the secondary tasks correctly), the encoding phase started in which 40 pictures of real objects were shown for 250 ms each. Participants were asked to semantically categorize them as a vegetable, an animal, a clothing item, or an object by pressing a given key on the arrow section of the keyboard which had the initial on the category on it (participants trained first in order to learn the appropriate keys). During encoding, and following a between-subjects design, a concurrent task that selectively loaded one of three WM components was imposed in half of the trials. There were ten blocks of four trials each, and a load was imposed alternately in five of the blocks (four trials without load followed by four trials with load, and so on).
There were three different concurrent task conditions; articulatory suppression (AS), spatial tapping (ST), and backward counting (BC), designed to load on the phonological loop, visuospatial sketchpad, and central executive aspect of the Baddeley (1986) multicomponent model, respectively (see, e.g., Allen, Hitch, Mate, & Baddeley, 2012; Allen, Havelka, Falcon, Evans, & Darling, 2015). For each block of concurrent task trials, a three-digit number (e.g., “370”) was presented at the beginning of each of the four trials. Within the AS condition, a group of 24 participants performed a concurrent verbal task, which consisted of repeating aloud this three-digit sequence (e.g., “3-7-0-3-7-0…”). A second group performed a spatial tapping task that consisted of tapping a numerical sequence of three digits in the Wechsler Memory Scale (Third Edition) battery’s spatial span subtest (Wechsler, 1997). This is similar to the standard Corsi blocks pad and consists of a board with ten spatially distributed cubes. The board was located on a side table, lower than the keyboard. Participants tapped the three-item numerical sequence on corresponding locations of the Corsi blocks pad, without looking at it. Before starting a block, the participant looked at the pad and started tapping on the correspondent digits locations. Once they were performing well (usually after three to four iterations), they looked at the screen and pressed the space bar with the other hand. They continued watching the screen while tapping and responding to the category judgment question (e.g., Animal, press key 1). Finally, a third group performed a backward counting task (counting backwards in twos). In this condition, participants started counting backwards in decrements of two from the start number (e.g., “370-368-366…”). Before the encoding task started participants were trained to perform the concurrent task alone. Although no specific articulation/tapping rate was imposed through instruction, participants responded at a rate of approximately one three-digit number per 1.5 s, and the experimenter, who was present in the room, monitored that this approximate rate was constant across participants. Each trial (from presentation of the three-digit number, through to pressing SPACE bar for the next trial, as participants could control this interval) lasted approximately 5 s, and each block was composed of four trials; therefore, the switch between load/no-load conditions occurred approximately every 20–30 s.
After encoding, a 10-min distractor phase took place in which demographic information was collected and participants’ color perception was assessed with the Ishihara test (Ishihara, 2004). The test was purely implemented as a distraction task. Finally, the retrieval phase took place. In this phase, 80 images were presented, 40 were new and 40 had appeared at encoding. They were presented for 100 ms each, partially masked by a white stripe that was placed over the image (hiding about 75% of the object), with participants instructed to try to identify and type the name of each item after its presentation (a visual priming task similar to the common picture fragment identification task). Each trial was immediately followed by a recognition test (Yes/No response) in which the whole picture (without the white stripe) was presented again and participants had to decide whether it had appeared at the encoding phase or not by pressing Y or N keys. Figure 1 shows a flow diagram of the procedure.

Flow diagram of the procedure
The resulting design was a mixed 2 (memory load as a within-subjects factor) × 3 (group as a between subjects factor) design.
Results
Outcomes were analyzed with frequentist ANOVA and follow-up tests (where appropriate), and their Bayesian equivalents (using JASP .11.1, JASP Team, 2019). Bayes factor analysis assesses the strength of evidence for the data under the alternative against the null hypothesis and provides a test of equivalence between groups/conditions (Barchard, 2015; Mulder & Wagenmaker, 2016; van Doorn et al., 2019). The most likely model given the data is reported, relative to a null model that includes only random effects of participant. Bayes factors for all main effects and interactions are also reported. If an effect/interaction was included in the most likely model, the BF was calculated by comparing the most likely model to one excluding the effect/interaction of interest. If the effect/interaction was not included in the most likely model, the BF was calculated by comparing the most likely model to this model plus the effect/interaction of interest. BF10 describes the ratio for the likelihood of the data under the alternative hypothesis, relative to the null hypothesis (of no effect/interaction). While Bayes factors should primarily be considered as a continuous scale of evidence, heuristic classifications of BF10 between 3 and 10 can be seen as moderate support for the data under the alternate hypothesis, and over 10 as strong evidence. Conversely, a BF10 of between .10 and .33 can be considered moderate evidence for the data under the null hypothesis (e.g., van Doorn et al., 2019).
Firstly, the proportion of correct identification of visual images presented in the priming task was calculated. Proportion of correctly identified old (images presented before) and new (images not presented before) items is shown in Table 1.
Old items were significantly better identified than new items, showing a general effect of visual priming, both in the condition with concurrent load t(71) = 9.748, p < .001 and in the condition without load t(71) = 9.705, p < .001. Priming was scored by subtracting the proportion of correct identification of new images from the proportion of correct identification of old images. Figure 2 shows the results of proportion of priming.

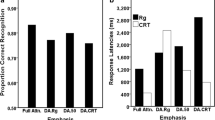
Proportional priming score (and standard error) in visual identification as a function of group and memory load condition in Experiment 1
An analysis of variance with concurrent load (no task vs. task) as a within-subjects factor and group (AS, ST, BC) as a between-subjects factor was carried out on the priming scores. The effects of concurrent load, F(1,69) = .887, MSE = .01, partial η2 = .01, p = .350, BF10 = .27, and group, F(2,69) = .644, MSE = .015, partial η2 = .02, p = .528, BF10 = .22, were not significant. There was also no significant interaction between concurrent load and group, F(2,69) = .225, MSE = .002 partial η2 = .01, p = .799, BF10 = .14. The Bayesian ANOVA indicated that the null model was the best supported and was at least 3.79 times more likely than any other model. These results therefore show that visual priming was not affected by any of the WM manipulations in the experiment.
The mean accuracy for the recognition task was calculated by subtracting the number of false alarms from the hits, and proportion scores were obtained. Proportion of hits and false alarms is shown in Table 2, and Fig. 3 shows the results on the visual recognition task.

Proportion of correct visual recognition (and standard error) as a function of group and memory load condition in Experiment 1
A new ANOVA with concurrent load as a within-subjects factor and group as a between-subjects factor was carried out on the recognition scores. In this case the effect of concurrent load was found to be significant, F(1,69) = 19.674, MSE = .23, partial η2 = .22, p < .001, BF10 = 361, showing better visual recognition in no-task trials. The overall effect of group was not significant, F(2,69) = .444, MSE = .023, partial η2 = .01, p = .643, BF10 = .25. However an interaction effect of memory load by group was also found, F(2,69) = 3.35, MSE = .04, partial η2 =.09, p = .041, BF10 = 1.48. The Bayesian ANOVA indicated that the best supported model contained the effects of load and the load × group interaction. Follow-up tests showed differences in recognition accuracy between no-task and task trials for groups that carried out spatial tapping, t (23) = 4.40, p < .001, d = .90, BF10 = 139,Footnote 1 and backward counting, t (23) = 4.43, p < .001, d = .90, BF10 = 150, but not articulatory suppression, t (23) = .46, p = .653, d = .09, BF10 = .24. Effect sizes (and 95% confidence intervals) for each concurrent task on recognition are illustrated in Fig. 4, displayed alongside those observed on the priming measure.

Effect sizes for each concurrent task in Experiment 1
As a complementary analysis, correlations between priming and recognition scores were computed, but they did not show a significant relationship in any of the three conditions. The correlation index between priming and recognition was r = .060 for the load condition, and r = .202 for the no-load condition. Therefore, for each of the concurrent task conditions, the size of the priming effect exhibited by participants was not related to their performance on the recognition test. Regarding the semantic classification task at encoding, a 2 × 3 ANOVA showed a significant interaction between load × concurrent task on accuracy F(2,69) = 8.055, partial η2 = .19, p = .001, showing that accuracy was significantly lower (p = .001) in backward counting in the load condition (M = .88, SD = .11) compared to the no-load condition (M = .96, SD = .05) and the same pattern was found (p = .04) in articulatory suppression (M = .97, SD = .04 vs. M = .99, SD = .03). A 2 × 3 ANOVA on the reaction times also showed a significant interaction between load × concurrent task F(2,69) = 25.779, partial η2 = .43, p < .001. In this case, reaction times were significantly higher (p < .001) when a load was imposed only in backward counting (M = 1034.13, SD = 441.24 vs. M = 2138.04, SD = 1031.89).
Finally, a reliability analysis (see Table 3) was conducted on recognition and priming measures using split-half correlations, that is, the Pearson correlation of the measures for each half across participants (e.g., Berry et al., 2006; Buchner & Wippich, 2000). Each participant’s data was split into even and odd trials, and proportion of priming and proportion of corrected recognition measures were computed for the trials in each of the halves. Priming showed low reliability, with correlation values of -.16 (AS task), .18 (ST task), and .32 (BC task), all p >.05. Recognition showed numerically higher correlation values of .65, p = .001 (AS task), .36, p = .09 (ST task), and .57, p = .003 (BC task). A directed comparison of the two reliability tests revealed that the reliability of priming and recognition did not differ significantly in the ST task (z-value of 0.59, p = .56) and the BC task (z-value of 1.02, p = .31), but it did differ in the AS task (z-value of 1.99, p = .05).
Experiment 1b
Considering the results obtained in Experiment 1, two different interpretations could be put forward: that recognition of visual images shows a much larger and more reliable impact of WM load compared to priming, or alternatively, that load has a lower impact on priming because it is a measure with low reliability. In order to clarify this, we designed an additional experiment in which 24 participants (mean age: 21.2 years, SD = 3.19) performed a slightly different priming task but using the same materials and procedure as in Experiment 1. This follow-up experiment was limited only to the BC concurrent task as this is the load manipulation that could potentially have a larger impact on performance in both recognition and priming. This larger impact could be expected considering that imposing this load significantly reduced accuracy and increased reaction times, at the encoding phase. Therefore, if backward counting during encoding produces a negative effect in the new priming task that is equivalent in magnitude to that observed in recognition, all prior priming results in Experiment 1 could be explained by a lack of reliability of that task. If not, the explanation in terms of lack of reliability could be rejected.
The main difference between Experiment 1b and Experiment 1 was that in the present case, the identification responses were limited to four alternatives that were shown to participants after each trial (instead of collecting open written identification responses), and therefore reducing variability. For example, after the presentation of a partially masked image of a lion, participants had to choose from the following options: (1) DOG, (2) CAT, (3) LION, or (4) TIGER. They also had the possibility of pressing SPACE if they were not sure about the correct response. This is an alternative-choice paradigm in which items that have been previously presented are expected to facilitate a correct choice, without the participation of explicit memory as no reference is made about the prior phase. Accuracy was the primary dependent variable.
Proportion of correctly identified old and new items is shown in Table 1. A general effect of visual priming was found again, both in the condition with concurrent load t(23) = 6.770, p < .001, d = 1.38 and in the condition without load t(23) = 8.044, p < .001, d = 1.64 (BF10 > 10,000 in each case). Priming was scored by subtracting the proportion of correct identification of new images from the proportion of correct identification of old images. In the task condition the proportion of priming was .15 (SE = .02) and in the no-task condition the proportion of priming was .19 (SE = .02). A mean comparison test showed no significant differences between conditions t(23) = 1.819 , p = .08, d = .38, BF10 = .94,Footnote 2 although the Bayes factor was indeterminate regarding evidence for the null or alternate hypothesis. As in the previous experiment, accuracy for the recognition task was calculated by subtracting the number of false alarms from the hits, and proportion scores were obtained. Proportion of hits and false alarms is shown in Table 2. In the task condition the proportion of correct visual recognition was .48 (SE = .03) and in the no-task condition the proportion of correct visual recognition was .61 (SE = .03), with a mean comparison test indicating a significant difference between conditions t(23) = −4.709 , p < .001, d = .95, BF10 = 250. Overall, results showed that the main effects observed in Experiment 1 were replicated, that is, the load effect was much larger for recognition than for priming, with no clear evidence for a reliable effect on the latter. To further illustrate this, no-task versus task difference scores were calculated for each measure, and directly compared; this indicated a significant difference between the size of the task effects, t(23) = 2.76 , p = .011, d = .56, BF10 = 4.39, with a larger effect on recognition than on priming. Moreover, reliability scores were higher in both measures, with values of .73, p < .001 for the recognition task, and of .49, p = .02 for the priming task (see Table 3). A directed comparison of the two reliability tests revealed that the reliability of priming and recognition did not differ significantly (z-value of 1.27, p = .20).
Regarding the semantic classification task at encoding, mean comparison analyses showed that accuracy was significantly lower, t(23) = 3.385, p = .003, in the load condition (M = .93, SD = .07) compared to the no-load condition (M = .98, SD = .03). Reaction times were significantly higher, t(23) = 11.461, p < .001, when a load was imposed (M = 2637.54, SD = 697.71) compared to the no-load condition (M = 1350.42, SD = 429.63).
Discussion
The aim of the present study was to determine whether selectively imposing a WM load has differential effects on visual priming and recognition of objects and the results of the indicated that, while disrupting concurrent verbal processing via articulatory suppression had no effect on either of the two retrieval tasks, the burden imposed on the central executive and the visuospatial sketchpad components of WM had a much larger effect for recognition than for priming. The evidence for relative insensitivity of priming to encoding-based load manipulations is in line with previous studies on priming and division of attention, which conclude that implicit memory does not require attentional resources during encoding, thus indicating automatic activation (Mulligan, 1998; Mulligan & Hartman, 1996; Parkin et al., 1990; Soldan et al., 2008; Spataro et al., 2011). Moreover, results show that varying modality/processing components has no differential effects either, as none of the components of WM seem to be involved in development of memory representations that serve implicit memory judgments.
The current results contradict previous studies that have reported a decrease for some types of priming when WM load is manipulated (Conway et al., 1999; Engle, Conway, Tuholski, & Shisler, 1995; Heyman et al., 2015; Sabb et al., 2007). Within the domain of negative priming, Engle et al., (1995) found a decrease in letter naming when a load consisting in remembering words was imposed. Conway et al. (1999) went further in exploring whether these findings were due to a domain-specific conflict and employed a verbal (words) and a nonverbal (polygons) load. They found diminished negative priming in both conditions and concluded that it requires domain-free general resources. A decrease in semantic priming has also been reported under verbal (Sabb et al., 2007) and visual loads (Heyman et al., 2015), questioning whether semantic priming is actually automatic and capacity-free. However, the main difference between these previous studies and the present work is the priming task used, as this is the first (to our knowledge) to employ a visual, perceptual priming task using real images under WM load conditions. Similar results have been reported in the verbal domain by Baqués et al. (2004), who failed to find an effect of a verbal and a visual load on a word stem completion task. Although they used words as target stimuli, the priming task also had a perceptual nature. Finally, Mulligan and Hornstein (2000) and Mulligan (2003) has also reported that perceptual priming can be reduced in divided attention conditions with verbal materials when there is a synchronous presentation of study words and distractors or when responses to distractors must be made frequently, irrespective of the interference being cross-modal or intra-modal. In our experiments, the memory load was imposed before the beginning of each trial and it was simultaneous with the presentation of the images but one might argue that they could differ slightly across participants and tasks, making the responses to the non-critical stimuli more infrequent and not perfectly synchronous. This would be consistent with the distractor-selection hypothesis, which predicts that perceptual priming is less likely to be disrupted when responses to non-critical stimuli are required infrequently and the presentation of critical and non-critical stimuli does not occur in synchrony (Mulligan & Hornstein, 2000; Mulligan, 2003; Soldan et al., 2008). However, the concurrent tasks in our study were well trained and monitored to make sure that they did not differ enough to introduce variable impairments in terms of frequency/synchrony, and to rule out any coordination complexity component effect. In any case, those studies are not directly comparable as our aim was not to divide attention per se but to load different WM components, so limited attentional resources were devoted in the intra-modal (ST) and cross-modal (AS) interferences.
It is worth noting that this dissociation in WM load effects was observed even though priming and recognition judgments alternated at the test phase (see also Berry et al., 2014). One possible criticism of the current design might be that this alternation resulted in participants using explicit processing when responding in the priming task as they became aware that some items had been previously presented. However, the fact that the results of the two tasks responded differently to dual-task manipulations allows such a “contamination” account to be ruled out and may indicate such an alternation procedure to be an appropriate methodological approach in future work.
On the other hand, previous studies have found that priming measures can be unreliable, or less reliable than explicit measures such as recognition (Berry et al., 2006; Buchner & Wippich, 2000; Heyman, Bruninx, Hutchison, & Storms, 2018; Meier & Perrig, 2000). Such possible differences in reliability could be a contributory factor in the dissociations between explicit and implicit tasks or the differences in sensitivity to manipulations. However, our split-half correlations indicated that although priming appeared to be unreliable in Experiment 1, it did not differ from recognition reliability for the two WM conditions where dissociations in load effects were observed (i.e., ST and BC). This lack of difference in reliability estimates is consistent with the findings of Buchner and Wippich (2000, Experiment 3). Moreover, it has been argued that reliability tests depend on the list length and that it can be enhanced when more items are used (Buchner & Wippich, 2000; Meier & Perrig, 2000). In our task the number of items was quite limited when split in two halves, and this could be the reason for the low reliability estimates that were obtained. Other factors, such as the selection of the items to divide the sample (odd/even, first/last, or random), can also vary the reliability values obtained within the same test or experiment.
Differential relative impacts of concurrent load on priming and recognition are contrary to what would be predicted by the single-system model (Berry et al., 2006). However, one might instead argue that differences in reliability mean that WM load effects might be similar in both tasks but are obscured in our measure of priming. In order to clarify this, a confirmatory experiment (Experiment 1b) was designed in which only a BC load was imposed, and the responses were limited to four alternatives instead of allowing an open written response. Experiment 1b broadly replicated the main findings in the sense that the concurrent load had a much larger effect on recognition relative to priming, with no clear evidence for a reliable effect on the latter measure. Moreover, the split-half correlation analysis showed high and significant reliability estimates for both measures. While some caution in interpretation should be encouraged given the reliability outcomes of Experiment 1, the priming and recognition tasks did not meaningfully differ in their reliability estimates, and the priming task in Experiment 1b proved to be reliable. Taking this into consideration alongside the much larger and more reliable impacts of load on recognition than on priming in both Experiment 1 and 1b, we would argue that this indicates evidence for a genuine difference in the reliance on WM during encoding for these two subsequent response tasks.
Regarding results from the explicit recognition task, the absence of concurrent articulatory suppression effects has already been reported on a range of visual short-term memory tasks (Luck & Vogel, 1997; Mate, Allen, & Baqués, 2012; Morey & Cowan, 2004; Sense, Morey, Prince, Heathcote, & Morey, 2017), and the present results extend this to visual long-term memory. It could be argued that due to automaticity, verbal rehearsal of syllables or words that are not relevant for the main visual task requires minimal attentional demands. In addition, concurrent load-based reductions in performance may sometimes reflect domain-specific conflict, and there are many examples in the existing literature showing that explicit tasks can be sensitive to a verbal load at encoding when both the main task and the concurrent load require manipulating verbal information (e.g., Cocchini, Logie, Della Sala, MacPherson, & Baddeley, 2002; Thalmann & Oberauer, 2017). On the other hand, the effect of backward counting clearly indicates a role for general executive attentional control in encoding for later explicit episodic long-term memory (see also Evans & Baddeley, 2018). In this sense, Robbins et al. (1996) stated that backward counting not only reflects the importance of verbal coding but that the task is complex enough to impair the phonological loop and the functioning of the central executive. Given that simple articulatory suppression had no effect on performance, these results suggest that general attentional resources are indeed important in encoding for later recognition performance.
Finally, regarding the spatial tapping task, this effect may well reflect domain-specific interference (Cocchini et al., 2002; Thalmann & Oberauer, 2017) during the initial encoding of visual stimuli into long-term memory, caused by the visuospatial processing load induced by this task. It remains possible, however, that the presently observed impact of spatial tapping also at least partly reflects a more general attentional component to this task, thus producing an effect similar in nature to that of backward counting. As argued by Allen et al. (2015), spatial tapping can disrupt a range of visually presented primary tasks, and its use as a visuospatial load manipulation with selective effects on performance is long established (e.g., Farmer, Berman, & Fletcher, 1986; Smyth & Pelky, 1992). Although the effects of this manipulation have previously been dissociated from those of executive load tasks (e.g., Allen, Hitch, & Baddeley, 2009; Kemps, Szmalec, Vandierendonck, & Crevits, 2005), and the executive load imposed by simple spatial tapping may be relatively minimal, such an account cannot be completely ruled out on the basis of the current study. It will be useful for future work to explore the extent to which modality-specific and modality-general effects are apparent during encoding for episodic long-term memory. Differences in both accuracy and reaction times in the semantic classification task at encoding in both experiments also confirm that backward counting is an attentional demanding, more complex task. However, the fact that spatial tapping also had an effect on recognition rules out an alternative explanation that the effect on recognition might be due to disruption of performance on the classification task at encoding, as tapping had no impact on this task, in terms of either accuracy or reaction times.
The broader question that arises is why the two retrieval tasks behave somewhat differently under load conditions. Both tasks must rely on the same memory traces created at encoding. However, WM loads applied at this stage may result in weaker representations due to a limitation in attentional resources, possibly with reduced context/source coding related to episodic memory. This would make an explicit and conscious recognition judgment more difficult but does not affect visual priming to the same extent because this type of information is less relevant for implicit memory. This is consistent with the view that priming effects are not expected to be disrupted by manipulations that might reduce consciousness at encoding, because priming is not subject to conscious inspection (Parkin et al., 1990). Moreover, visual priming is assumed to be mediated by a pre-semantic, perceptual representation system (PRS) that operates independently from explicit memory (Schacter, 1992; Tulving & Schacter, 1990). In this sense, the implicit processing of visual images would not be dependent on semantic properties and, unlike verbal information processing or explicit recognition judgments, would be independent from conscious memory traces related to the functioning of episodic memory, and therefore relatively insensitive to WM loads or to a reduction of attentional resources.
Automaticity in priming effects could be linked to adaptive factors and their central role in implicit learning, because in daily life it is of key importance to be able to process previously encountered visual stimuli faster or more efficiently, and this ability relies on stored perceptual memories. However, other theories state that priming and recognition would rely on the same memory system, but with a distinction in terms of the quantity and quality of associations; explicit memory tasks would require both the activation of (word) nodes and episodes, while priming does not need spatiotemporal cues linked to semantic and episodic memory and therefore is not subject to the strength of the binding between a stimulus and its experimental context (Reder, Park, & Kieffaber, 2009). In a similar vein, priming might be seen as a by-product of memory when the contextual information is lost or damaged, as it refers to whether given perceptual information has been encountered before, and not if a particular item appeared in a specific spatiotemporal context. The relative absence of WM load effects during the learning phase as observed in the present study supports the notion of a contrast between automaticity during encoding for visual priming and the importance of resource availability for later conscious, explicit judgments involved in recognition.
Notes
Bayesian paired-samples t-tests were applied using non-directional alternative hypotheses. However, as directional hypotheses might be considered more appropriate for the effects of WM load, additional Bayesian t-tests were also carried out using this approach (with no task > task as the alternative hypothesis). These analyses produced evidence supporting the same overall patterns of effects (backward counting, BF10 = 299, spatial tapping, BF10 = 279, articulatory suppression, BF10 = .32).
Directional Bayesian paired-samples t-tests were also carried out for each of these comparisons. As with the non-directional analyses, these indicated strong support for an effect of backward counting on recognition, BF10 = 499, and indeterminate evidence for the null versus the alternative hypothesis in terms of the effect on priming, BF10 = 1.80. Finally, based on the outcomes of Experiment 1, the direct comparison of no-task versus task difference scores on recognition versus priming was also analyzed using a directional (effect on recognition > effect on priming) alternative hypothesis, again producing evidence for a larger effect on recognition, BF10 = 8.72.
References
Allen, R. J., Havelka, J., Falcon, T., Evans, S. & Darling, S. (2015). Modality specificity and integration in working memory: Insights from visuospatial bootstrapping. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(3), 820-30. https://doi.org/10.1037/xlm0000058.
Allen, R. J., Hitch, G. J., & Baddeley, A. D. (2009). Cross-modal binding and working memory. Visual Cognition, 17(1-2), 83-102.
Allen, R. J., Hitch, G. J., Mate, J., & Baddeley, A. D. (2012). Feature binding and attention in working memory: A resolution of previous contradictory findings. Quarterly Journal of Experimental Psychology, 65(12), 2369–2383. doi: https://doi.org/10.1080/17470218.2012.687384.
Atkinson, R. C., & Juola, J. F. (1974). Search and decision processes in recognition memory. In D. H. Krantz, R. C. Atkinson, R. D. Luce, & P. Suppes (Eds.), Contemporary developments in mathematical psychology (Vol. 1, pp. 243–293). San Francisco: Freeman.
Baddeley, A. (2012). Working memory: theories, models, and controversies. Annual Review of Psychology, 63, 1-29.
Baddeley, A. D. (1986). Working Memory. Oxford, UK: Oxford University Press
Baddeley, A. D., & Hitch, G. (1974). Working memory. In G.H. Bower (Ed.), The psychology of learning and motivation: Advances in research and theory (Vol. 8, pp. 47–89). New York: Academic Press.
Baddeley, A.D., Hitch, G.J., & Allen, R.J. (2020). A multicomponent model of working memory. In R.H. Logie, V. Camos, & N. Cowan (Eds). Working memory: State-of-the science. Oxford: Oxford University Press.
Baqués, J., Sáiz, D. & Bowers, J. S. (2004). Effects of working memory load on long-term word priming. Memory, 12(3), 301-313. doi:https://doi.org/10.1080/09658210244000469
Barchard, K. A. (2015). Null hypothesis significance testing does not show equivalence. Analysis of Social Issues and Public Policy, 15(1), 418–421. doi: https://doi.org/10.1111/asap.12095
Berry, C. J., Henson, R. N. A. & Shanks, D. R. (2006). On the relationship between repetition priming and recognition memory: Insights from a computational model. Journal of Memory and Language 55, (4) 515–533. doi: https://doi.org/10.1016/j.jml.2006.08.008
Berry, C. J., Kessels, R. P. C., Wester, A. J. & Shanks, D. R. (2014). A single-system model predicts recognition memory and repetition priming in amnesia. The Journal of Neuroscience 34(33): 10963-10974 https://doi.org/10.1523/JNEUROSCI.0764-14.2014.
Berry, C. J., Ward, E. V., & Shanks, D. R. (2017). Does study duration have opposite effects on recognition and repetition priming? Journal of Memory and Language, 97, 154–174. doi: https://doi.org/10.1016/j.jml.2017.07.004
Buchner, A., & Wippich, W. (2000). On the reliability of implicit and explicit memory measures. Cognitive Psychology, 40, 227–259.
Cabeza, R., & Moscovitch, M. (2013). Memory systems, processing modes, and components: Functional neuroimaging evidence. Perspectives on Psychological Science, 8(1) 49-55. doi: https://doi.org/10.1177/1745691612469033
Cocchini, G., Logie, R. H., Della Sala, S., MacPherson, S. E., & Baddeley, A. D. (2002). Concurrent performance of two memory tasks: Evidence for domain-specific working memory systems. Memory & Cognition, 30, 1086–1095.
Conway, A. R. A., Tuholski, S. E., Shisler, R. J., & Engle, R.W. (1999). The effect of memory load on negative priming: An individual differences investigation. Memory & Cognition, 27(6), 1042-1050.
Craik, F. I., Govoni, R., Naveh-Benjamin, M., & Anderson, N. D. (1996). The effects of divided attention on encoding and retrieval processes in human memory. Journal of Experimental Psychology: General, 125(2), 159–80.
Engle, R. W., Conway, A. R. A., Tuholski, S. W., & Shisler, R. J. (1995). Resource account of inhibition. Psychological Science, 6(2),122-125. doi: https://doi.org/10.1111/j.1467-9280.1995.tb00318.x
Evans, K. K., & Baddeley, A. (2018). Intention, attention and long-term memory for visual scenes: It all depends on the scenes. Cognition, 180, 24–37. doi: https://doi.org/10.1016/j.cognition.2018.06.022
Farmer, E. W., Berman, J. V., & Fletcher, Y. L. (1986). Evidence for a visuo-spatial scratch-pad in working memory. The Quarterly Journal of Experimental Psychology Section A, 38(4), 675-688.
Graf, P., & Schacter, D. L. (1985). Implicit and explicit memory for new associations in normal and amnesic subjects. Journal of Experimental Psychology: Learning, Memory, and Cognition, 11(3), 501–518. doi:https://doi.org/10.1037//0278-7393.11.3.501
Heyman, T., Bruninx, A., Hutchison, K. A., & Storms, G. (2018). The (un)reliability of item-level semantic priming effects. Behavior Research Methods. https://doi.org/10.3758/s13428-018-1040-9.
Heyman, T., Goossens, K., Hutchison, K. A., & Storms, G. (2017). Does a working memory load really influence semantic priming? A self-replication attempt. Collabra: Psychology, 3(1), 18. DOI: https://doi.org/10.1525/collabra.96
Heyman, T., Van Rensbergen, B., Storms, G., Hutchison, K. A., & De Deyne, S. (2015). The influence of working memory load on semantic priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(3), 911–920. doi: https://doi.org/10.1037/xlm0000050
Ishihara, T. (2004). Ishihara’s test for colour deficiency. 38 plates edition. Tokyo: Kanehara Trading Inc.
Jacoby, L.L. (1983). Remembering the data: Analysing interactive processes in reading. Journal of Verbal Learning and Verbal Behavior, 22, 485-508. doi: https://doi.org/10.1016/S0022-5371(83)90301-8
Jacoby, L. L., & Dallas, M. (1981). On the relationship between autobiographical memory and perceptual learning. Journal of Experimental Psychology: General, 110(3), 306–340. doi: https://doi.org/10.1037/0096-3445.110.3.306
JASP Team. (2019). JASP (version 0.11.1) [Computer software].
Kemps, E., Szmalec, A., Vandierendonck, A., & Crevits, L. (2005). Visuo-spatial processing in Parkinson's disease: evidence for diminished visuo-spatial sketch pad and central executive resources. Parkinsonism & Related Disorders, 11(3), 181–186. doi: https://doi.org/10.1016/j.parkreldis.2004.10.010
Light, L. L., & La Voie, D. (1993). Direct and indirect measures of memory in old age. In P. Graf & M. E. J. Masson (Eds.), Implicit memory: New directions in cognition, development, and neuropsychology (pp. 207-230). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and their conjunctions. Nature, 390, 279–281. doi: https://doi.org/10.1038/36846
Luck, S. & Hollingworth, A. (2008). Visual memory. New York: Oxford University Press. doi: https://doi.org/10.1093/acprof:oso/9780195305487.001.0001
Mandler, G. (1989). Memory: Conscious and unconscious. In P. R. Solomon, G. R. Goethals, C. M. Kelley, B. R. Stephens (Eds.). Memory: Interdisciplinary approaches. New York: Springer.
Mate, J., Allen, R. J., & Baqués, J. (2012). What you say matters: Exploring visual-verbal interactions in visual working memory. The Quarterly Journal of Experimental Psychology, 65(3), 395–400. doi: https://doi.org/10.1080/17470218.2011.644798
Meier, B., & Perrig, W.J. (2000). Low reliability of perceptual priming: Its impact on experimental and individual difference findings. Quarterly Journal of Experimental Psychology: Human Experimental Psychology, 53A, 211– 233.
Morey, C. C., & Cowan, N. (2004). When visual and verbal memories compete: Evidence of cross-domain limits in working memory. Psychonomic Bulletin & Review, 11(2), 296–301. doi: https://doi.org/10.1037/0278-7393.31.4.703
Moscovitch, M., Goshen-Gottstein, Y., & Vriezen, E. (1994). Memory without conscious recollection: A tutorial review from a neuropsychological perspective. In C. Umilta & M. Moscovitch (Eds.), Attention and performance (Vol. 15, pp. 619–660). Cambridge: MIT Press.
Mulder, J. & Wagenmaker, E. (2016). Editors’ introduction to the special issue “Bayes factors for testing hypotheses in psychological research: Practical relevance and new developments”. Journal of Mathematical Psychology, 72, 1–5. doi: https://doi.org/10.1016/j.jmp.2016.01.002
Mulligan, N. W. (1998). The role of attention during encoding in implicit and explicit memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 24(1), 27–47. doi: https://doi.org/10.1037/0278-7393.24.1.27
Mulligan, N. W. (2002). Attention and perceptual implicit memory: Effects of selective versus divided attention and number of visual objects. Psychological Research, 66, 157–165. doi: https://doi.org/10.1007/s00426-002-0089-2
Mulligan, N. W. (2003). Effects of cross-modal and intramodal division of attention on perceptual implicit memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(2), 262–276. doi: https://doi.org/10.1037/0278-7393.29.2.262
Mulligan, N.W. & Dew, I.T.Z. (2009). Generation and perceptual implicit memory: Different generation tasks produce different effects on perceptual priming. Journal of Experimental Psychology. Learning, Memory, and Cognition, 35, 1522–1538. doi: https://doi.org/10.1037/a0017398.
Mulligan, N. W. & Hartman, M. (1996). Divided attention and indirect memory tests. Memory and Cognition 24, 453–465. doi: https://doi.org/10.3758/BF03200934
Mulligan, N. W., & Hornstein, S. L. (2000). Attention and perceptual priming in the perceptual identification task. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26(3), 626–37. doi: https://doi.org/10.1037//0278-7393.26.3.626
Mulligan, N. W., & Peterson, D. (2008). Attention and implicit memory in the category-verification and lexical decision tasks. Journal of Experimental Psychology: Learning, Memory, and Cognition, 34(3), 662–679. https://doi.org/10.1037/0278-7393.34.3.662
Musen, G., & Treisman, A. (1990). Implicit and explicit memory for visual patterns. Journal of Experimental Psychology: Learning, Memory, and Cognition, 16, 127–137.
Newell, B. R., & Andrews, S. (2004). Levels of processing effects on implicit and explicit memory tasks: Using question position to investigate the lexical-processing hypothesis. Experimental Psychology, 51(2), 132–144. doi: https://doi.org/10.1027/1618-3169.51.2.132
Norman, K. A., & O’Reilly, R. C. (2003). Modeling hippocampal and neocortical contributions to recognition memory: A complementary-learning-systems approach. Psychological Review, 110(4), 611–646. doi: https://doi.org/10.1037/0033-295X.110.4.611
Parkin, A. J., Reid, T. K., & Russo, R. (1990). On the differential nature of implicit and explicit memory. Memory and Cognition, 18, 507–514. doi: https://doi.org/10.3758/BF03198483
Pixabay (2018). Retrieved from https://pixabay.com
Rajaram, S. (2007). Attentional requirements of perceptual implicit memory. In Nairne, J. S. (Ed.) The foundations of remembering: Essays in honor of Henry L. Roediger III. New York: Psychology Press.
Reder, L. M., Park, H., & Kieffaber, P. D. (2009). Memory systems do not divide on consciousness: Reinterpreting memory in terms of activation and binding. Psychological Bulletin, 135(1), 23-49. doi: https://doi.org/10.1037/a0013974
Richardson-Klavehn, A., & Bjork, R. A. (1988). Measures of memory. In M. R. Rosenzweig & L. W. Porter (Eds.), Annual review of psychology. Annual review of psychology (Vol. 39, pp. 475–543). Palo Alto, CA: Annual Reviews.
Robbins, T. W., Anderson, E. J., Barker, D. R., Bradley, A. C., Fearnyhough, C., Henson, R., … Baddeley, A. D. (1996). Working memory in chess. Memory and Cognition, 24(1), 83–93. doi: https://doi.org/10.3758/BF03197274
Roediger, H., & Srinivas, K. (1993) Specificity of operations in perceptual priming. P. Graf, & Masson, M. (Eds.) Implicit memory: New directions in cognition, development and neuropsychology. (pp. 17-48). Hillsdale: Lawrence Erlbaum.
Roediger, H. L. (1990). Implicit memory: Retention without remembering. American Psychologist, 45(9), 1043–1056. doi: https://doi.org/10.1037/0003-066X.45.9.1043
Sabb, F. W., Bilder, R. M., Chou, M., & Bookheimer, S. Y. (2007). Working memory effects on semantic processing: Priming differences in pars orbitalis. NeuroImage, 37, 311–322. doi:https://doi.org/10.1016/j.neuroimage.2007.04.050
Schacter, D. (1987). Implicit memory: History and current status. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13(3), 501–518.
Schacter, D. L. (1992). Priming and multiple memory systems: Perceptual mechanisms of implicit memory. Journal of Cognitive Neuroscience, 4(3), 244-256. doi: https://doi.org/10.1162/jonc.1992.4.3.244
Sense, F., Morey, C. C., Prince, M., Heathcote, A., & Morey, R. D. (2017). Opportunity for verbalization does not improve visual change detection performance: A state-trace analysis. Behavior Research Methods, 49(3), 853-862.
Shanks, D. R., & Berry, C. J. (2012). Are there multiple memory systems? Tests of models of implicit and explicit memory. The Quarterly Journal of Experimental Psychology, 65(8), 1449–1474. doi: https://doi.org/10.1080/17470218.2012.691887
Shimamura, A. P. (1993). Neuropsychological analyses of implicit memory: History, methodology and theoretical interpretations. In P. Graf & M. E. J. Masson (Eds.), Implicit memory: New directions in cognition, development, and neuropsychology (pp. 265-285). Hillsdale, NJ: Lawrence Erlbaum Associates, Inc.
Smyth, M. M., & Pelky, P. L. (1992). Short-term retention of spatial information. British Journal of Psychology, 83(3), 359-374.
Soldan, A., Mangels, J. A. & Cooper, L. (2008). Effects of dividing attention during encoding on perceptual priming of unfamiliar visual objects. Memory, 16(8), 973-895. doi: https://doi.org/10.1080/09658210802360595
Spataro, P., Cestari, V. & Rossi-Arnaud, C. (2011). The relationship between divided attention and implicit memory: A meta-analysis. Acta Psychologica, 136, 329–339. doi: https://doi.org/10.1016/j.actpsy.2010.12.007
Squire, L. R. (2009) Memory and brain systems: 1969–2009. Journal of Neuroscience, 29, 12711–12716. doi: https://doi.org/10.1523/jneurosci.3575-09.2009.
Thalmann, M., & Oberauer, K. (2017). Domain-specific interference between storage and processing in complex span is driven by cognitive and motor operations. The Quarterly Journal of Experimental Psychology, 70(1), 109-126.
Tulving, E. (1985). How many memory systems are there? American Psychologist, 40(4), 385-398. doi: https://doi.org/10.1037/0003-066X.40.4.385
Tulving, E., & Schacter, D. L. (1990). Priming and human memory systems. Science 247, 301–306. doi: https://doi.org/10.1126/science.2296719
van Doorn, J., van den Bergh, D., Bohm, U., Dablander, F., Derks, K., Draws, T., … & Ly, A. (2019). The JASP guidelines for conducting and reporting a Bayesian Analysis.
Voss, J. L., & Gonsalves, B. D. (2010). Time to go our separate ways: Opposite effects of study duration on priming and recognition reveal distinct neural substrates. Frontiers in Human Neuroscience, 4, 227. doi: https://doi.org/10.3389/fnhum.2010.00227
Ward, E. V., Berry, C. J., & Shanks, D. R. (2013). An effect of age on implicit memory that is not due to explicit contamination: Implications for single and multiple-systems theories. Psychology and Aging, 28(2), 429–442. doi: https://doi.org/10.1037/a0031888
Wechsler, D. (1997). Wechsler Adult Intelligence Scale–Third Edition (WAIS–III). San Antonio, TX: The Psychological Corporation.
Weiskrantz, L. (1987). Neuroanatomy of memory and amnesia: A case for multiple memory systems. Human Neurobiology, 6(2), 93–105.
Open practices statement
The data that support the findings of this study are available from the corresponding author upon request.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All authors declare that they have no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards.
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Castellà, J., Pina, R., Baqués, J. et al. Differential effects of working memory load on priming and recognition of real images. Mem Cogn 48, 1460–1471 (2020). https://doi.org/10.3758/s13421-020-01064-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-020-01064-y