
Abstract
The loss of peripheral vision impairs spatial learning and navigation. However, the mechanisms underlying these impairments remain poorly understood. One advantage of having peripheral vision is that objects in an environment are easily detected and readily foveated via eye movements. The present study examined this potential benefit of peripheral vision by investigating whether competent performance in spatial learning requires effective eye movements. In Experiment 1, participants learned room-sized spatial layouts with or without restriction on direct eye movements to objects. Eye movements were restricted by having participants view the objects through small apertures in front of their eyes. Results showed that impeding effective eye movements made subsequent retrieval of spatial memory slower and less accurate. The small apertures also occluded much of the environmental surroundings, but the importance of this kind of occlusion was ruled out in Experiment 2 by showing that participants exhibited intact learning of the same spatial layouts when luminescent objects were viewed in an otherwise dark room. Together, these findings suggest that one of the roles of peripheral vision in spatial learning is to guide eye movements, highlighting the importance of spatial information derived from eye movements for learning environmental layouts.
Similar content being viewed by others

It has been well documented that the integrity of peripheral vision is crucial for competent performance in environmental learning (Dolezal, 1982; Marron & Bailey, 1982; Pelli, 1987). For example, patients with ocular diseases that cause a visual field loss in peripheral vision (e.g., glaucoma and retinitis pigmentosa) tend to learn large-scale spatial layouts less accurately than do normally sighted individuals (Fortenbaugh, Hicks, & Turano, 2008; Turano & Schuchard, 1991). Similarly, when peripheral vision in visually intact people is removed by physically restricting the field of view (FOV) to about 10° of central vision (FOV sizes are reported as diameters in this article), they form more distorted memories of room-sized spatial layouts, as compared with when they have a wide FOV during the initial viewing (Alfano & Michel, 1990; Fortenbaugh, Hicks, Hao, & Turano, 2007). Importantly, these impairments are not simply accounted for by failure in finding to-be-learned objects or by occlusion of spatial cues in the environment due to the narrowing of the FOV (Fortenbaugh et al., 2007). In addition, it is likely that the degree of FOV restriction used in the aforementioned studies does not interfere with accurate perception of egocentric distance and direction of each object under otherwise natural viewing conditions (Wu, Ooi, & He, 2004). Rather, viewing the environment without peripheral vision seems to impede the encoding, maintenance, or retrieval of memories for spatial relations among objects.
The foregoing studies showed that peripheral vision plays a role in visual learning of an environmental layout. This is an important finding, given that it was not entirely clear whether peripheral visual field loss was actually related to abnormal spatial learning observed in ophthalmological patients (Turano, 1991; Turano & Schuchard, 1991). However, because the primary purpose of the previous studies was to empirically confirm that, without intact peripheral vision, spatial learning can be impaired, they were not necessarily designed to distinguish possible different effects of the lack of peripheral vision on spatial learning. Gaining a clearer understanding of peripheral vision’s role stands to improve spatial-learning techniques that may be used by the patients with ocular diseases, presenting a pressing need for further research on this issue. Accordingly, we conducted the present study to elucidate the unique contribution that peripheral vision makes to visual spatial learning.
It is important to note that as an observer learns a spatial layout for possible use in navigation or other spatial behaviors, a variety of processes could be engaged: (1) perceiving each object location, (2) perceiving spatial relations among objects (when more than one object is visible), (3) binding together object locations that are not visible at the same time, (4) maintaining memory traces over time, (5) retrieving spatial memory when necessary, and (6) mentally manipulating spatial information retrieved from memory (e.g., aligning the remembered spatial layout with one drawn on a map). Although previous work has suggested that perception of a single object location relative to the observer is not significantly changed by the size of the FOV (Creem-Regehr, Willemsen, Gooch, & Thompson, 2005; Knapp & Loomis, 2004; Wu et al., 2004), it remains unknown how peripheral vision exerts its influence on other processes. It is possible that spatial information available through peripheral vision is vital for only a subset of these processes, and therefore, an attempt should be made to reveal which processes are impacted by the removal of peripheral vision. A full evaluation of this issue is beyond the scope of the present study. Our approach here was to focus on a specific form of spatial information derivable from peripheral vision, examining its impact on memory of a spatial layout when initial encoding of each object location was equated across various viewing conditions.
A unique property of spatial learning enabled by peripheral vision is that it helps an observer quickly detect new objects in an environment and foveate them efficiently. Peripheral vision permits the observer to simultaneously perceive a wide area of the environment, and when an object appears in the visual periphery, eye movements (with accompanying head movements) readily bring it to the fovea for further processing and precise localization (Henderson & Hollingworth, 1998). It has been shown that moving the eyes between objects enhances the perceived depth relationships between them, as compared with when the observer holds fixation constant on an individual object (Enright, 1991; Foley & Richards, 1972). This suggests that eye movements provide additional information about object locations over and above retinal and extra-retinal information obtainable while each object is fixated. It is conceivable that vestibular and proprioceptive self-motion signals associated with eye and head movements constitute a major source of this additional information and that the observer can derive information about the spatial relation between the origin and destination of an eye movement by integrating these signals over time. On this view, the observer obtains information about spatial relations among locations through effective eye movements, and this improves the memory representation of the larger environmental layout.
On the other hand, when only a narrow area can be viewed at any given time due to the lack of peripheral vision, an observer must perform elaborate scans of an environment to find objects. Consequently, scan paths tend to become circuitous, and these complex scan paths could conceivably be much less useful for learning a spatial layout than more direct scan paths made possible by peripheral vision. It is likely that the observer can localize the origin and destination of complex scan paths, because this can be done independently of the specific shape of the scan path (even when the FOV is restricted; Creem-Regehr et al., 2005; Knapp & Loomis, 2004; Wu et al., 2004). However, extracting the spatial relation between the origin and destination becomes more computationally challenging as the complexity of the scan path increases, because eye and head movement signals must be integrated throughout the scan path. Any errors in sensing and integrating these self-motion signals when searching for objects would increase systematic and variable error of the estimated spatial relationship between locations. This could make information about spatial relations among objects harder to acquire during initial viewing of the environment, potentially leaving the observer only with information about a set of individual object locations that are not well connected with each other.
Taken together, a reasonable hypothesis regarding the role of peripheral vision in spatial learning is that peripheral vision facilitates learning of a spatial layout by guiding eye movements directly to objects in an environment. We tested this hypothesis in Experiment 1 of the present study by asking participants to learn object locations in a room while they were not able to make effective eye movements. This was achieved by having participants view the objects through small apertures located in front of their eyes. If efficiency of eye movements is one of the essential properties peripheral vision provides to visual spatial learning, memory performance should be degraded under this condition.
Because effective eye movements were prevented in Experiment 1 by physically narrowing participants’ FOV, they were able to view very little of environmental surroundings at any given time. As a consequence, effects of eye movements and those of visible surroundings were confounded. Importantly, this could be more than just an experimental artifact; it is possible that being able to view the surroundings, not the capability of making effective eye movements, is the true source of the benefit of peripheral vision to spatial learning. Thus, we conducted Experiment 2, in which participants learned the locations of phosphorescent objects in the dark (i.e., in the absence of visible surroundings) with no FOV restriction. If the lack of visible surroundings made a greater impact on spatial-learning performance than did the inability to make effective eye movements, participants should be impaired at learning object locations in the dark, despite the fact that they were able to foveate the objects via direct eye movements.
Experiment 1
As was mentioned previously, we asked participants to learn object locations by viewing them through small apertures located in front of their eyes. Because this restriction forced the participants to keep their eyes more or less stationary (otherwise, they would not be able to acquire useful information about object locations; details are shown in the Method section below), it allowed us to test the prediction that impeding effective eye movements would impair learning of a spatial layout. If being able to move the eyes directly to an object is indeed crucial for spatial learning, this manipulation should result in worse spatial memory, as compared with when objects are reachable via direct eye movements during learning.
Method
Participants
Twelve students (6 of them male and 6 female, 19–24 years of age) at the George Washington University volunteered for the experiment in return for partial credit in psychology courses. In this and the next experiment, all participants reported normal or corrected-to-normal vision and had never been in the room where the spatial layouts were learned.
Materials
Two layouts of six objects each were constructed (see Fig. 1 for an example). The objects were common, visually distinct, and similar in size (approximately 15 cm in length, width, and height), had monosyllabic names, and shared no primary semantic associations. The layouts were presented within a circular enclosure (3.75-m diameter) formed by a black cylindrical curtain. Distances to each object from a fixed vantage point ranged from 1.46 to 3.29 m (see Fig. 1). The objects were placed on the floor, which was covered with a plain gray carpet. The room was well lit throughout the experiment.

One of the spatial layouts learned by participants. Arrows indicate orientations used in the judgment of relative direction task, with 0° corresponding to the orientation experienced during learning
While participants were viewing objects, their vision was restricted by goggles that had an opening only on the front surface. In one condition, two black opaque plates, each of which had a circular aperture of 2-mm diameter, covered the front opening of the goggles. One aperture was in front of each eye. Given this configuration, the participants had to keep their eyes pointed toward the apertures to clearly view the environment; although they were free to make eye movements, doing so would provide vision only in small areas of the peripheral retina at greatly reduced resolution. Thus, virtually no eye movements could be used to foveate objects in this condition. The distance between the eye surface and the aperture was approximately 3.8 cm, restricting the FOV in each eye to approximately 3° of visual angle. Before starting the experiment, the aperture locations were adjusted individually for each participant in the following manner: The participants put on the goggles without the black plates and binocularly fixated on a square mark on the wall (approximately 2 × 2 cm) that was 2.5 m away and at their eye height. Without moving the head and eyes, one of the black plates was attached to the goggles covering the right half of the front opening, and the participants moved the aperture in front of their right eye so that the fixation mark came into the center of the aperture. Then the same was repeated for the left eye, using the other black plate, so that the participants had a converging binocular FOV. After the aperture locations were fixed, it was confirmed that the participants were able to view the fixation mark when either aperture was closed. This resulted in a horizontal FOV of 3°–5°, most or all of which was binocular. (If the visual field of each eye overlapped perfectly, the horizontal FOV would be 3°. However, the adjustment procedure described above often did not achieve complete binocular overlap, making the horizontal FOV slightly larger than 3°.) This FOV allowed the participants to binocularly view all objects in their entirety (confirmed by postexperiment interviews).
In the other condition, the entire front opening of the goggles, which measured about 13.2 cm horizontally and 5.6 cm vertically, was opened by removing the black plates. This provided a large FOV (approximately 107° × 86° for the two eyes), allowing participants to make eye movements to effectively fixate on an object. We asked them to wear the goggles in this condition, instead of removing FOV restriction entirely, in order to avoid a possible confound that performance could be changed merely by wearing the goggles (i.e., irrespective of the presence or absence of effective eye movements).
Design and procedure
Each participant learned two different layouts, one with the small FOV and one with the large FOV. The small FOV condition always preceded the large FOV condition so that the participants would not have prior experience in seeing the environment with the large FOV. Participants were randomly divided into two groups on the basis of which of the two layouts was used in the small FOV condition, with the constraint that each group had three men and three women. The participants were run individually.
Learning phase
Participants were instructed to memorize the layout of six objects for a later memory test and also were told that those objects would be placed directly on the floor (Wu et al., 2004). The participants were asked to don the goggles before entering a room in which the cylindrical curtain was set up. At this point, the goggles served as a blindfold by closing the opening completely. The participants were then led to a position within the circular enclosure from which they viewed the objects. An arrow labeled as 0° in Fig. 1 indicates this position. The participants were required to stand still at this position throughout the learning phase. While being taken to the viewing position, the participants were guided along a circuitous path and disoriented with respect to the surrounding environment. This disorientation procedure discouraged the participants from using the larger environmental structure as a reference when learning object locations within the cylindrical curtain.
In both conditions, objects were presented sequentially in random order. Once the first object was placed at its location, the material covering the opening of the goggles was removed, and participants were asked to view the object for 5 s. Because, in the small FOV condition, the participants had to scan the floor inside the cylindrical curtain until they found the presented object, they were given 5 s of viewing time after they located the object (judged by the termination of head movement and final head direction). Thus, actual time spent for viewing the objects was the same across conditions. Then the participants were instructed to close their eyes, and an experimenter replaced the just-viewed object with a new object in a new location. Subsequently, the participants were asked to open their eyes and view the second object in the same manner. This procedure was repeated until all objects were viewed.
Objects were presented singly and sequentially so that small and large FOV conditions were equated in terms of the number of visible objects (i.e., only one object could be viewed at a time in the small FOV condition, even if all objects were presented simultaneously). This manipulation prevented participants from directly perceiving interobject spatial relations, which are normally available in peripheral vision (i.e., multiple objects are usually visible within a FOV). In addition, sequential presentation of objects did not allow participants to quickly revisit previously viewed objects, which would have been possible in simultaneous presentation. In spite of these possible disadvantages, sequential presentation most likely exerted minimal influence on subsequent memory performance in the present study, since it has been shown that object locations and their configurations are learned equivalently by viewing them sequentially or simultaneously (Yamamoto & Shelton, 2009b).
After viewing all objects once, participants were asked to point to and name the objects with their eyes closed. This study–test sequence was repeated until the participants accurately and fluently pointed to all object locations twice in a row. Accuracy and fluency were determined by visual inspection of the participants’ pointing performance.Footnote 1 The number of repetitions needed to achieve this accurate and fluent pointing in each condition was recorded. When the criterion was met, the front opening of the goggles was closed again, and the participants were disoriented as they were taken out of the room. This disorientation procedure prevented the participants from forming new associations between the learned object locations and any landmarks in the environment as they walked out of the room (e.g., the shoe was the closest to the door), thus increasing the likelihood that spatial information acquired inside the cylindrical curtain was the only information used for later retrieval of memory for the spatial layout.
It is worth emphasizing that participants were free to make head movements while viewing an object. It was not only necessary for finding objects in the small FOV condition, but also critical for ensuring that the participants were able to accurately perceive each object location. Previous research suggested that object locations in the range of egocentric distance used in the present experiment are accurately perceived despite FOV restriction, as long as head movements are allowed (Creem-Regehr et al., 2005; Knapp & Loomis, 2004; Wu et al., 2004). Although it is possible that, in the small FOV condition, the apertures of 2-mm diameter weakened monocular distance cues by increasing the depth of focus, angular direction, angular declination, and ground–surface cues remained available as strong cues for localizing the objects (Wu et al., 2004).
Test phase
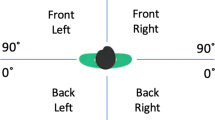
After learning each layout, participants moved to another room in a different floor of the same building to perform judgments of relative direction (JRDs) about the just-learned spatial layout. We used the JRD task as a memory test because it requires mental manipulation of spatial relations among objects and, therefore, is suitable for testing memory of the spatial layout, as opposed to that of each individual object location. On each trial, the participants were asked to imagine standing at one object and facing another object and then to point to a third object (e.g., “Imagine you are at the hat facing the jar. Point to the shoe”). The first two objects constituted an imagined heading. The third was a target to which the participants were to point. Each layout yielded 16 imagined headings, two instances in each of eight orientations differing by 45°. These orientations were labeled counterclockwise from 0° to 315° in 45° steps, with 0° corresponding to the orientation experienced by the participants (e.g., the hat–jar heading used in the example above gave one instance of the 90º orientation; see Fig. 1). Target objects were chosen so that their directions were varied systematically; the egocentric space defined by each imagined heading was divided into four 90°-wide regions, each of which was centered on the front–back or left–right axis, and imagined headings at each orientation had approximately equal instances of target directions in each of these four regions (see Fig. 2).

Schematic diagram showing the definition of target directions in the judgment of relative direction task. The egocentric space was divided into four 90º-wide regions (front, right, left, and back) with respect to a given imagined heading. For example, when participants imagined standing at the hat and facing the jar, and then pointed to the shoe from this imagined position, the target (“shoe”) was in the right (see Fig. 1 for locations of these objects). Note that these target directions were defined relative to the imagined heading, not the participants’ position and orientation in the room during the learning phase
Trials were presented on a computer screen by using custom-written software for the JRD task (Shelton & McNamara, 1997). After receiving instructions about the task and how to use the computer program, participants performed five practice trials that were composed of buildings on the George Washington University campus. On each trial, sentences giving an imagined heading and a target were displayed with a circle and a line that was movable with a mouse (Fig. 3). The participants positioned the line so that it pointed to the target with respect to the particular imagined heading. They then clicked the mouse to make a response. The participants received immediate feedback on their performance after each practice trial. If an incorrect pointing response was made, the experimenter gave another detailed explanation about how to perform the task and demonstrated the correct response. Once the practice session was successfully completed, an actual test session consisting of 64 trials began. These trials were presented in random order. No feedback was given on test trials.

Example of a display of the judgment of relative direction task, which was originally developed by Shelton and McNamara (1997). The sentences gave two objects that specified an imagined heading (“hat” and “jar”) and a target object (“shoe”) that was to be pointed to. The 12 o’clock position of the circle represented the imagined heading. One end of the line was fixed at the center of the circle. Participants moved the line with a mouse so that it pointed to the target relative to the imagined heading. In the figure, the line is approximately in the correct position for this given trial (see Fig. 1 for object locations)
The dependent variables were absolute angular error and response latency in JRDs. Absolute angular error was the angular distance between pointed direction and actual target direction. Response latency was defined as time elapsed between the presentation of a JRD stimulus screen and participants’ response indicated by the mouse click. The participants were instructed to perform the task as accurately as possible, with minimum time required.
Data from the learning phase (i.e., the number of repetitions participants needed to reach criterion) and those from the test phase (i.e., absolute angular error and response latency) were analyzed separately by analyses of variance (ANOVAs) with appropriate factors specified below. F-tests were corrected for nonsphericity by using Greenhouse–Geisser ε when appropriate. The α level of .05 was used. Effects of two layouts were also examined by including an additional between-subjects factor in ANOVAs, but it only had a few minor main effects and interactions. Thus, data were collapsed over two layouts. There were no gender effects in any of the analyses.
Results
Learning
Small and large FOV conditions did not differ in the amount of learning required to reach the criterion. The mean number of repetitions required to meet the criterion (M) and a corresponding standard error of the mean (SEM) were as follows: M = 2.33, SEM = 0.18 (small FOV), and M = 2.17, SEM = 0.11 (large FOV). These data were subjected to an ANOVA with participants’ gender (male or female) as a between-subjects factor and FOV size (small or large) as a within-subjects factor. No significant effects were yielded from this ANOVA (Fs < 2.5, ps > .14, η 2p s < .20, for the main effect of FOV size and the interaction between gender and FOV size), supporting the observation that participants needed the equivalent amount of viewing in the two conditions to learn object locations to criterion.
Judgment of relative direction
Absolute angular error and response latency in JRDs were analyzed separately by ANOVAs with gender (male or female) as a between-subjects factor and FOV size (small or large), orientation (0°–315° with 45° intervals), and target direction (front, right, left, or back) as within-subjects factors.
Absolute angular error
Mean absolute angular error is plotted in Fig. 4a as a function of FOV size and orientation. As is illustrated in this figure, JRDs in the small FOV condition were significantly less accurate than those in the large FOV condition, F(1, 10) = 8.11, p = .017, η 2p = .45. Figure 4a also shows that in both conditions, JRDs were most accurately performed when imagined headings were aligned with the learned orientation (0°). This indicates that spatial memories formed in this experiment exhibited orientation dependence, a hallmark of spatial memory for a room-sized environment (Shelton & McNamara, 2001; Yamamoto & Shelton, 2009a). This observation was supported statistically by the main effect of orientation, F(7, 70) = 5.56, p = .011, η 2p = .36, and the planned contrast comparing JRD performance for the 0° orientation with that for other orientations (45°–315°), F(1, 11) = 28.02, p < .001, η 2p = .72.

Mean absolute angular error (a) and response latency (b) in judgments of relative direction in Experiment 1 as a function of field of view size and orientation. Error bars represent ±1 standard error of the mean
In addition to the major findings above, target direction also yielded some effects in the ANOVA. Table 1 shows mean absolute angular error as a function of target direction and FOV size. Overall, as in previous studies (e.g., Shelton & McNamara, 1997), pointing to the front was more accurate than pointing to the sides (both left and right), which was more accurate than pointing to the back (see the bottom row of Table 1). This accuracy difference was statistically reliable, as shown by the main effect of target direction, F(3, 30) = 18.31, p < .001, η 2p = .65. Moreover, the interaction between target direction and FOV size was significant, F(3, 30) = 3.34, p = .044, η 2p = .25. Table 1 suggests that this interaction was caused by the somewhat intensified effect of target direction in the small FOV condition, as compared with that in the large FOV condition. In line with this observation, simple main-effect tests of target direction at each FOV condition (corrected by Scheffé’s method for post hoc testing) indicated that the effect of target direction was enhanced in the small FOV condition, F(1, 40) = 17.38, p = .004, η 2p = .30 (small FOV), and F(1, 40) = 3.61, p = .33, η 2p = .083 (large FOV).
Response latency
Figure 4b shows mean response latency in JRDs as a function of FOV size and orientation, suggesting that response latency varied in an equivalent way to absolute angular error. Most notably, JRDs consistently took longer in the small FOV condition than in the large FOV condition, as indicated by the main effect of FOV size, F(1, 10) = 8.22, p = .017, η 2p = .45. As in the analysis of absolute angular error, the ANOVA for response latency yielded significant main effects of orientation and target direction as well, F(7, 70) = 5.48, p = .002, η 2p = .35, and F(3, 30) = 8.17, p = .001, η 2p = .45, respectively. Mean response latency and a corresponding standard error of the mean for each target direction were as follows: M = 17.71 s, SEM = 0.67 s (front); M = 20.43 s, SEM = 0.64 s (right); M = 20.13 s, SEM = 0.63 s (left); and M = 21.64 s, SEM = 0.75 s (back). The only difference between effects shown by absolute angular error and those shown by response latency was that, in the analysis of response latency, the interaction between target direction and FOV size was not significant, F(3, 30) = 0.61, p = .50, η 2p = .057.
Discussion
Results from the present experiment showed that preventing effective eye movements significantly impairs spatial-learning performance. Although the amount of learning required to reach criterion was not different between small and large FOV conditions, JRDs following the small FOV condition were consistently less accurate and slower than those following the large FOV condition. These findings are consistent with the notion that the role of peripheral vision in visual spatial learning is to guide eye movements that directly reach objects in an environment.
It is important to note that participants had the same amount of time (5 s) to view a presented object in both conditions. Nevertheless, the small FOV condition showed worsened JRD performance, as compared with the large FOV condition. Given that a critical difference between the conditions was that an extended and inefficient search of the object was necessary only in the small FOV condition, the differentiated JRD performance suggests that how objects are found in an environment has a large influence on the quality of subsequent spatial representations in memory. That is, much of the spatial information critical for learning a spatial layout may be obtained while objects are being searched, not while they are being fixated (i.e., not by consolidating spatial information available from a fixation, such as gaze direction and head position).
It is also important that absolute angular error and response latency showed the same pattern in the present experiment. This is especially informative because it supports the view that the decreased accuracy of JRDs in the small FOV condition was not a mere consequence of distorted space perception during the learning phase due to FOV restriction. That is, if inaccurate encoding was the only source of worsened accuracy in JRDs, there would be no logical ground to assume that the (incorrectly) remembered spatial layout should also differ in other qualities, such as strength of association among objects, durability and accessibility of memory traces, and flexibility of spatial representations (unless perceptual distortion made the remembered spatial layout radically different from the presented layout, which was not likely the case; Creem-Regehr et al., 2005; Knapp & Loomis, 2004; Wu et al., 2004). Therefore, only absolute angular error, not response latency, should increase when possible perceptual distortion entirely accounts for the decrement of memory performance in the small FOV condition. The longer response latency in the small FOV condition argues against this possibility, suggesting that participants indeed had greater difficulty in constructing, maintaining, retrieving, or manipulating mental representations of interobject spatial relations in the small FOV condition.
It should also be noted that although the FOV restriction utilized in the present experiment was primarily intended for impeding effective eye movements, it likely disrupted normal patterns of head movements as well.Footnote 2 It has been shown that head movements tend not to occur when targets are within 20º from a current fixation, because those targets can easily be fixated by eye movements only (Guitton & Volle, 1987; Schons & Wickens, 1993). This suggests that in the small FOV condition, participants had to use small head movements that they normally do not make to acquire an object. As compared with large-amplitude movements that can point the head from one object to the next with precision and accuracy, these small head movements were presumably less efficient in providing information about interobject spatial relations. Therefore, they should be considered as one of the potential sources of difficulty in spatial learning associated with having a small FOV.
The role of effective eye movements in spatial learning was also discussed by Fortenbaugh et al. (2007). In their Experiment 3, participants whose FOV was reduced to 10° or 40° of central vision learned six object locations in a room-sized immersive virtual-reality environment either by viewing them from a fixed position or by walking to each object location from the same position. Subsequently, they were deprived of any visual input and were asked to walk to each object location from the same viewing/starting position as that used in the learning phase. Fortenbaugh et al. (2007) found that the overall accuracy of this walking response was not modulated by the degree of FOV restriction, even though the narrower FOV would have been more disruptive to object viewing via eye movements. On the basis of this finding, Fortenbaugh et al. (2007) argued that impaired spatial learning following the loss of peripheral vision was likely explained by other factors than disruptions in eye movements. Although this appears to contradict the present finding and its interpretation, it should be pointed out that knowledge of individual egocentric object locations was sufficient to perform the memory task used by Fortenbaugh et al. (2007), because it only required participants to walk to each object location separately from the position that was experienced during the learning phase. Given that perception of egocentric object locations is presumably unaffected by FOV restriction under otherwise natural viewing conditions (Creem-Regehr et al., 2005; Knapp & Loomis, 2004; Wu et al., 2004), it was reasonable to find comparable performance in Fortenbaugh et al.’s (2007) memory task irrespective of the size of FOV. Thus, albeit contradictory on the surface, findings from the present experiment and those from Fortenbaugh et al. (2007) are reconcilable. The present findings built upon the results from Fortenbaugh et al. (2007) and showed that constructing mental representations of the overall spatial layout entails more than just encoding a set of individual egocentric object locations. That is, even after learning each object location to the same criterion, participants in the present experiment performed JRDs with increased error and response latency in the small FOV condition. Present findings suggest that eye movements play a role in binding the egocentric object locations into the representation of the entire spatial layout in memory.
The FOV size interacted with target direction in the analysis of absolute angular error such that target direction had a larger effect when participants’ FOV was more restricted. As is shown in Table 1, JRDs were comparably accurate in small and large FOV conditions when target objects were in front, but the difference between the two conditions was larger when target objects were to the sides and in back. This interaction did not appear in response latency, and therefore, caution should be used when interpreting it. Nevertheless, this interaction might suggest that viewing objects with narrow-scope vision allowed the participants to effectively retrieve multiple object locations from memory only when those objects were relatively close to each other in space. That is, once an imagined heading was established for a given JRD trial, target objects in front were located accurately, irrespective of FOV restriction, because those front targets were close enough to the object that the participant imagined facing; however, locating target objects became increasingly erroneous under FOV restriction as those objects went further away from the facing object. This pattern of results seems to suggest that learning a spatial layout with a reduced FOV might also narrow the FOV of the mind’s eye when conjuring up a memory of the spatial layout (Farah, Soso, & Dasheiff, 1992). This interpretation needs to remain tentative, as was mentioned above, but it provides an interesting hypothesis for future research.
Experiment 2
The primary objective of Experiment 2 was to examine whether the lack of visible environmental surroundings, not the deficiency of effective eye movements, caused memory impairments in the small FOV condition of Experiment 1. To this end, we had each participant learn the same spatial layouts under two viewing conditions, one in which objects glowed faintly and were seen in an otherwise darkened room (i.e., in the total absence of visible environmental surroundings) and one in which the room was well lit. Unlike in Experiment 1, participants’ FOV was not restricted at all. Therefore, they were able to detect a presented object in peripheral vision and bring it to the fovea via direct eye movements. If the unavailability of visual surroundings was a major factor in Experiment 1, learning the spatial layout in the dark should have detrimental effects on subsequent JRD performance, even in the presence of effective eye movements. On the other hand, if the inability to view the surroundings was not critical for the worsened memory performance under FOV restriction in Experiment 1, dark and lit conditions should yield equivalent JRDs in the present experiment, given that effective eye movements were possible in both conditions.
Method
Participants
Twelve students (6 of them male and 6 female, 18–23 years of age) at the George Washington University volunteered for the experiment in return for partial credit in psychology courses.
Materials, design, and procedure
Experiment 2 was conducted in the same manner as in Experiment 1, with the following changes: (1) No restriction was imposed on participants’ FOV; (2) the room was completely darkened throughout the learning phase in the dark condition; and (3) objects were coated with phosphorescent paint so that they glowed in the dark. The phosphorescent glow was sufficient to allow the participants to visually recognize a presented object, but it was too faint to make visible anything else in the room. Experimenters used a small flashlight when they were in need of lighting, but only while the participants’ eyes were closed. Postexperiment interviews confirmed that the participants did not see anything but the presented objects in the room. Absolute motion parallax, monocular and binocular parallax, and angular declination were all available to specify the absolute distances to objects (i.e., head movement was unconstrained during object viewing, all objects were placed directly on the floor, and the participants were informed of this in advance); previous work suggested that objects are localized without significant perceptual distortion under these conditions (Ooi, Wu, & He, 2001; Philbeck & Loomis, 1997). In the lit condition, on the other hand, the room was well lit all the time. Hence, the floor, the room ceiling, and the circular enclosure were also visible to the participants when they viewed each object. The dark condition always preceded the lit condition so that the participants would not be exposed to visual information about the environment prior to the dark condition.
Results
Learning
Dark and lit conditions did not differ in the amount of learning required to reach the criterion. The mean number of repetitions required to meet the criterion (M) and a corresponding standard error of the mean (SEM) were as follows: M = 2.33, SEM = 0.14 (dark), and M = 2.42, SEM = 0.14 (lit). These data were subjected to an ANOVA with participants’ gender (male or female) as a between-subjects factor and lighting (dark or lit) as a within-subjects factor. No significant effects were yielded from this ANOVA (Fs < 0.30, ps > .59, η 2p s < .030, for the main effect of lighting and the interaction between gender and lighting), supporting the observation that participants needed the equivalent amount of viewing in the two lighting conditions to learn object locations to criterion.
Judgment of relative direction
Absolute angular error and response latency in JRDs were analyzed separately by ANOVAs with gender (male or female) as a between-subjects factor and lighting (dark or lit), orientation (0°–315° with 45° intervals), and target direction (front, right, left, or back) as within-subjects factors.
Absolute angular error
Figure 5a depicts mean absolute angular error as a function of lighting and orientation, showing that although the lit condition consistently yielded slightly more accurate performance than the dark condition, data from these two conditions resembled each other. Consistent with this observation, the main effect of lighting as well as the interaction between lighting and orientation were not significant, F(1, 10) = 1.08, p = .32, η 2p = .097, and F(7, 70) = 0.29, p = .88, η 2p = .028, respectively. All other interactions involving lighting were also nonsignificant, Fs < 2.14, ps > .14, η 2p s < .17. Figure 5a also showed that JRDs were more accurately performed when imagined headings were aligned with the learned orientation (0°), indicating that participants formed orientation-dependent spatial memories. This observation was also supported statistically by the main effect of orientation, F(7, 70) = 2.93, p = .046, η 2p = .23, and the planned contrast comparing memory performance for the 0° orientation and that for other orientations (45°–315°), F(1, 11) = 6.90, p = .024, η 2p = .39.

Mean absolute angular error (a) and response latency (b) in judgments of relative direction in Experiment 2 as a function of lighting and orientation. Error bars represent ± 1 standard error of the mean
In addition to the major findings above, the ANOVA also yielded a significant main effect of target direction, F(3, 30) = 4.03, p = .038, η 2p = .29. Mean absolute angular error (M) and a corresponding standard error of the mean (SEM) for each target direction were as follows: M = 27.57°, SEM = 1.88° (front); M = 31.99°, SEM = 1.81° (right); M = 32.08°, SEM = 1.72° (left); and M = 37.79°, SEM = 2.21° (back). As in previous studies (e.g., Shelton & McNamara, 1997) and Experiment 1, accuracy in pointing to front targets was higher than that in pointing to side targets (both left and right), which was still higher than that in pointing to back targets. No interactions including target direction were significant, Fs < 2.14, ps > .14, η 2p s < .18. Because the effect of target direction was evenly distributed across all conditions (i.e., four target directions were used approximately in equal frequency at each orientation), it did not alter the conclusions regarding the effects of lighting and orientation.
Response latency
Mean response latency in JRDs is plotted in Fig. 5b as a function of lighting and orientation, showing that response latency exhibited the same general pattern as absolute angular error. Importantly, JRDs following the dark condition did not take longer than those following the lit condition; the main effect of lighting was not significant, F(1, 10) = 0.15, p = .71, η 2p = .014. The only effect that reached statistical significance was the main effect of orientation, F(7, 70) = 3.57, p = .035, η 2p = .26. The main effect of target direction was marginally significant, F(3, 30) = 2.72, p = .073, η 2p = .21.
Discussion
The present experiment compared spatial learning in the dark with that in a well-lit environment to examine whether the lack of visible surroundings while objects were viewed could cause a significant disadvantage to the learning of a room-sized spatial layout. Three major findings converged to indicate that dark and lit conditions yielded almost identical learning and memory performance: First, the same amount of viewing was required to learn object locations to criterion in each condition. Second, JRDs following dark and lit conditions yielded equivalent absolute angular error. Third, response latency in JRDs was also comparable in both conditions. These results demonstrate that effectiveness of visual spatial learning was hardly modulated by the presence of visible surroundings in the present paradigm, confirming that disadvantage of the small FOV in Experiment 1 did not stem from the scarcity of visual information about surroundings. Rather, given that participants had an unrestricted FOV in the present experiment, intact performance in the dark condition suggests that having a large FOV itself was important because it enabled participants to readily detect objects and fixate them via direct eye movements. This provides further support for the hypothesis that a major role of peripheral vision in spatial learning is to guide eye movements.
Additionally, given that the condition that yielded superior performance in Experiment 1 (i.e., the large FOV condition) was always conducted second, it was possible that participants did the JRD task better in the large FOV condition simply by benefiting from performing it a second time. However, equivalent performance in dark and lit conditions indicates that there was little effect of practice on JRDs. Given that Experiments 1 and 2 were conducted in the identical procedure, except for lighting and FOV manipulations, the same amount of practice effects on JRDs (if any) should have been present in both experiments. Thus, it is reasonable to conclude that the practice effects made only a minimal contribution, at best, to findings observed in the present study, and no alterations are required in conclusions regarding the effects of FOV restriction discussed in the previous experiment.
Because the present experiment did not reject the null hypothesis regarding the effect of lighting, it is worth discussing the statistical power of this experiment. Experiments 1 and 2 tested the same number of participants in the identical experimental design, and therefore, FOV size in Experiment 1 and lighting in Experiment 2 were equivalent in terms of their statistical power. Nevertheless, the effect of FOV size was significant in Experiment 1, whereas the effect of lighting was not found in Experiment 2. This suggests that lighting had only a negligible effect, as compared with the effect of FOV size. In fact, effect sizes for the lighting variable (η 2p = .097 and .014 for absolute angular error and response latency, respectively) were much smaller than those for the FOV variable (η 2p = .45 for both absolute angular error and response latency).
General discussion
The present study was conducted to gain insights into how peripheral vision contributes to learning of a spatial layout. It was hypothesized that an important function of peripheral vision is to enable an observer to effectively detect and foveate objects in an environment via eye movements. In Experiment 1, this hypothesis was tested by asking participants to learn a room-sized spatial layout while wearing a FOV-restricting device that prevented direct eye movements to objects. Results showed that retrieval of memory for the spatial layout became more erroneous and time-consuming when it was learned without effective eye movements, suggesting that some spatial information is extracted from eye movement patterns and utilized for building, maintaining, retrieving, or manipulating mental representations of interobject spatial relations. In Experiment 2, potential effects of visual information about surroundings of the spatial layout on subsequent JRDs were examined to rule out the possibility that impairment in spatial learning under FOV restriction was due to the lack of visible environmental surroundings, not the prevention of effective eye movements. Neither absolute angular error nor response latency in JRDs varied according to whether the spatial layout was learned in the dark (i.e., in the complete absence of visible surroundings) or under the light, indicating that the deficiency of visible environmental surroundings was not a major cause of the performance decrement observed in Experiment 1. Together, findings from these two experiments suggest that importance of peripheral vision for spatial learning stems from its role in guiding eye movements.
The present study utilized a head-based FOV restriction to prevent effective eye movements (i.e., apertures in the FOV-restricting goggles were stationary relative to participants’ head). By contrast, other studies (e.g., Fortenbaugh et al., 2007) employed an eye-based FOV restriction in such a way that only a certain area around participants’ gaze was made visible. Often, this technique requires that an experiment be conducted in a virtual-reality environment so that the availability of visual information can be manipulated according to gaze directions. On the other hand, the head-based method can be used reliably in a real environment, as was demonstrated by the present study. This is a significant methodological advantage, given that it is still unknown whether space perception in virtual-reality environments is truly equivalent to that in real environments (Creem-Regehr et al., 2005; Knapp & Loomis, 2004; Thompson et al., 2004; Willemsen, Gooch, Thompson, & Creem-Regehr, 2008). Nevertheless, the merit of the eye-based FOV restriction is still large because it enables more naturalistic simulation of the effects of visual field loss, as well as direct measurements of eye and head movements. Replicating the present study with the eye-based FOV restriction would provide further insights into the roles of eye and head movements in spatial learning. For example, by tracking eye and head positions during object viewing, it may be possible to more clearly separate effects of eye movements and those of head movements on spatial learning.
In the present study, there was always just one object at a time in the environment. In addition, the environment contained few or no landmarks; even when the room was viewed under the light with no FOV restriction, neither the cylindrical curtain nor the plain carpet provided useful cues for spatial learning. Although these manipulations were effective in isolating the role of peripheral vision in eye movement guidance, they also precluded the present study from investigating other possible advantages of seeing objects and surroundings in the visual periphery without eye movements. Thus, further research is needed to understand how visual spatial learning can be enhanced by other kinds of information obtainable through peripheral vision.
It has been well documented that the spatial abilities of patients who have lost a portion of their visual field are generally impaired (Fortenbaugh et al., 2008; Haymes, Guest, Heyes, & Johnston, 1996; Marron & Bailey, 1982; Szlyk et al., 1997; Turano, Geruschat, & Stahl, 1998). It has also been reported, however, that there are large individual differences among these patients in their spatial competence, demonstrating that while some patients suffer from substantial impairment, others can perform spatial tasks as well as normally sighted observers (Turano, 1991; Turano & Schuchard, 1991). Given the strong evidence from the present and previous studies (Alfano & Michel, 1990; Dolezal, 1982; Fortenbaugh et al., 2007; Pelli, 1987) that vision losses in the periphery are detrimental to spatial learning, it is likely that even the spatially competent patients experience adverse effects of their limited FOV. Thus, the fact that they can achieve good performance suggests that they are using some unidentified compensatory mechanisms. The present findings provide initial clues to understanding the compensatory mechanisms, suggesting that alleviating the need for elaborate scans of an environment is a key to improving the memory of a room-sized spatial layout. It is an important challenge for future research to reveal further details of the compensatory mechanisms and make them available to all visual field loss patients.
It is also noteworthy that visual field loss is not the only cause of eye movement deficits. This indicates that the present findings have broader clinical implications. It has been shown that impairment in visually guided reflexive saccades (i.e., stimulus-driven eye movements) is present following brain damage to various cortical and subcortical areas, including the frontal eye field (Rivaud, Müri, Gaymard, Vermersch, & Pierrot-Deseilligny, 1994), posterior parietal cortex (Pierrot-Deseilligny, Rivaud, Gaymard, & Agid, 1991; Pierrot-Deseilligny, Rivaud, Penet, & Rigolet, 1987), and superior colliculus (Pierrot-Deseilligny, Rosa, Masmoudi, Rivaud, & Gaymard, 1991; Sereno, Briand, Amador, & Szapiel, 2006). Neurodegenerative disorders of the basal ganglia (i.e., Huntington’s and Parkinson’s diseases), as well as dementia with Lewy bodies, also impair reflexive eye movements (Mosimann et al., 2005; Peltsch, Hoffman, Armstrong, Pari, & Munoz, 2008; Rascol et al., 1989; Vidailhet et al., 1994). Interestingly, these lesions and disorders are often accompanied by increased difficulty in spatial learning (e.g., Brandt, Shpritz, Munro, Marsh, & Rosenblatt, 2005; Collin, Cowey, Latto, & Marzi, 1982; Galloway et al., 1992; Giraudo, Gayraud, & Habib, 1997; Stark, 1996). The present findings lead to a conjecture that this increased difficulty is attributable in part to the disruption of effective eye movements, suggesting that the theoretical framework put forth by the present study has the potential to provide a coherent explanation for impaired abilities of spatial learning under a variety of conditions.
Notes
Validity of this procedure has been confirmed by previous studies in which participants acquired reliable memories of spatial layouts after meeting the same learning criterion (e.g., Yamamoto & Shelton, 2009b). In addition, the first author conducted extensive pilot testing in which participants’ pointing performance was more precisely measured by having them point to objects with a laser pointer. More stringent criteria were used for terminating the learning phase (e.g., a pointed location had to fall within the radius of 30 cm centered in each object), but these procedures and the one employed in the present study resulted in similar JRD performance. It was also observed that the use of stringent criteria could lead participants to rely more on their pointing performance than their visual experience of an environment for learning locations of objects. If this had occurred in the present study, it would have been a significant confound. On the basis of these considerations, the more relaxed criterion was utilized in the present study.
The authors thank one of the reviewers for pointing out this issue and suggesting references.
References
Alfano, P. L., & Michel, G. F. (1990). Restricting the field of view: Perceptual and performance effects. Perceptual and Motor Skills, 70, 35–45. doi:10.2466/PMS.70.1.35-45
Brandt, J., Shpritz, B., Munro, C. A., Marsh, L., & Rosenblatt, A. (2005). Differential impairment of spatial location memory in Huntington’s disease. Journal of Neurology, Neurosurgery & Psychiatry, 76, 1516–1519. doi:10.1136/jnnp. 2004.059253
Collin, N. G., Cowey, A., Latto, R., & Marzi, C. (1982). The role of frontal eye-fields and superior colliculi in visual search and non-visual search in rhesus monkeys. Behavioural Brain Research, 4, 177–193. doi:10.1016/0166-4328(82)90071-7
Creem-Regehr, S. H., Willemsen, P., Gooch, A. A., & Thompson, W. B. (2005). The influence of restricted viewing conditions on egocentric distance perception: Implications for real and virtual indoor environments. Perception, 34, 191–204. doi:10.1068/p5144
Dolezal, H. (1982). Living in a world transformed: Perceptual and performatory adaptation to visual distortion. New York: Academic Press.
Enright, J. T. (1991). Exploring the third dimension with eye movements: Better than stereopsis. Vision Research, 31, 1549–1562. doi:10.1016/0042-6989(91)90132-O
Farah, M. J., Soso, M. J., & Dasheiff, R. M. (1992). Visual angle of the mind’s eye before and after unilateral occipital lobectomy. Journal of Experimental Psychology. Human Perception and Performance, 18, 241–246. doi:10.1037/0096-1523.18.1.241
Foley, J. M., & Richards, W. (1972). Effects of voluntary eye movement and convergence on the binocular appreciation of depth. Perception & Psychophysics, 11, 423–427. doi:10.3758/BF03206284
Fortenbaugh, F. C., Hicks, J. C., Hao, L., & Turano, K. A. (2007). Losing sight of the bigger picture: Peripheral field loss compresses representations of space. Vision Research, 47, 2506–2520. doi:10.1016/j.visres.2007.06.012
Fortenbaugh, F. C., Hicks, J. C., & Turano, K. A. (2008). The effect of peripheral visual field loss on representations of space: Evidence for distortion and adaptation. Investigative Ophthalmology & Visual Science, 49, 2765–2772. doi:10.1167/iovs.07-1021
Galloway, P. H., Shagal, A., McKeith, I. G., Lloyd, S., Cook, J. H., Ferrier, I. N., & Edwardson, J. A. (1992). Visual pattern recognition memory and learning deficits in senile dementias of Alzheimer and Lewy body types. Dementia, 3, 101–107. doi:10.1159/000107002
Giraudo, M.-D., Gayraud, D., & Habib, M. (1997). Visuospatial ability of parkinsonians and elderly adults in location memory tasks. Brain and Cognition, 34, 259–273. doi:10.1006/brcg.1997.0898
Guitton, D., & Volle, M. (1987). Gaze control in humans: Eye-head coordination during orienting movements to targets within and beyond the oculomotor range. Journal of Neurophysiology, 58, 427–459.
Haymes, S., Guest, D., Heyes, A., & Johnston, A. (1996). Mobility of people with retinitis pigmentosa as a function of vision and psychological variables. Optometry and Vision Science, 73, 621–637.
Henderson, J. M., & Hollingworth, A. (1998). Eye movements during scene viewing: An overview. In G. Underwood (Ed.), Eye guidance in reading and scene perception (pp. 269–293). Oxford, England: Elsevier.
Knapp, J. M., & Loomis, J. M. (2004). Limited field of view of head-mounted displays is not the cause of distance underestimation in virtual environments. Presence: Teleoperators and Virtual Environments, 13, 572–577. doi:10.1162/1054746042545238
Marron, J. A., & Bailey, I. L. (1982). Visual factors and orientation-mobility performance. American Journal of Optometry and Physiological Optics, 59, 413–426.
Mosimann, U. P., Müri, R. M., Burn, D. J., Felblinger, J., O’Brien, J. T., & McKeith, I. G. (2005). Saccadic eye movement changes in Parkinson’s disease dementia and dementia with Lewy bodies. Brain, 128, 1267–1276. doi:10.1093/brain/awh484
Ooi, T. L., Wu, B., & He, Z. J. (2001). Distance determined by the angular declination below the horizon. Nature, 414, 197–200. doi:10.1038/35102562
Pelli, D. G. (1987). The visual requirements of mobility. In G. C. Woo (Ed.), Low vision: Principles and applications (pp. 134–146). New York: Springer-Verlag.
Peltsch, A., Hoffman, A., Armstrong, I., Pari, G., & Munoz, D. P. (2008). Saccadic impairments in Huntington’s disease. Experimental Brain Research, 186, 457–469. doi:10.1007/s00221-007-1248-x
Philbeck, J. W., & Loomis, J. M. (1997). Comparison of two indicators of perceived egocentric distance under full-cue and reduced-cue conditions. Journal of Experimental Psychology. Human Perception and Performance, 23, 72–85. doi:10.1037/0096-1523.23.1.72
Pierrot-Deseilligny, C. H., Rivaud, S., Gaymard, B., & Agid, Y. (1991a). Cortical control of reflexive visually-guided saccades. Brain, 114, 1473–1485. doi:10.1093/brain/114.3.1473
Pierrot-Deseilligny, C., Rivaud, S., Penet, C., & Rigolet, M.-H. (1987). Latencies of visually guided saccades in unilateral hemispheric cerebral lesions. Annals of Neurology, 21, 138–148. doi:10.1002/ana.410210206
Pierrot-Deseilligny, C., Rosa, A., Masmoudi, K., Rivaud, S., & Gaymard, B. (1991b). Saccade deficits after a unilateral lesion affecting the superior colliculus. Journal of Neurology, Neurosurgery & Psychiatry, 54, 1106–1109. doi:10.1136/jnnp. 54.12.1106
Rascol, O., Clanet, M., Montastruc, J. L., Simonetta, M., Soulier-Esteve, M. J., Doyon, B., & Rascol, A. (1989). Abnormal ocular movements in Parkinson’s disease. Brain, 112, 1193–1214. doi:10.1093/brain/112.5.1193
Rivaud, S., Müri, R. M., Gaymard, B., Vermersch, A. I., & Pierrot-Deseilligny, C. (1994). Eye movement disorders after frontal eye field lesions in humans. Experimental Brain Research, 102, 110–120. doi:10.1007/BF00232443
Schons, V., & Wickens, C. D. (1993). Visual separation and information access in aircraft display layout (Report No. ARL-93-7/NASA-A3I-93-1). Retrieved from University of Illinois at Urbana-Champaign, Institute of Aviation website: http://www.humanfactors.illinois.edu/Reports&PapersPDFs/TechReport/93-07.pdf
Sereno, A. B., Briand, K. A., Amador, S. C., & Szapiel, S. V. (2006). Disruption of reflexive attention and eye movements in an individual with a collicular lesion. Journal of Clinical and Experimental Neuropsychology, 28, 145–166. doi:10.1080/13803390590929298
Shelton, A. L., & McNamara, T. P. (1997). Multiple views of spatial memory. Psychonomic Bulletin & Review, 4, 102–106. doi:10.3758/BF03210780
Shelton, A. L., & McNamara, T. P. (2001). Systems of spatial reference in human memory. Cognitive Psychology, 43, 274–310. doi:10.1006/cogp. 2001.0758
Stark, M. (1996). Impairment of an egocentric map of locations: Implications for perception and action. Cognitive Neuropsychology, 13, 481–524. doi:10.1080/026432996381908
Szlyk, J. P., Fishman, G. A., Alexander, K. R., Revelins, B. I., Derlacki, D. J., & Anderson, R. J. (1997). Relationship between difficulty in performing daily activities and clinical measures of visual function in patients with retinitis pigmentosa. Archives of Ophthalmology, 115, 53–59.
Thompson, W. B., Willemsen, P., Gooch, A. A., Creem-Regehr, S. H., Loomis, J. M., & Beall, A. C. (2004). Does the quality of the computer graphics matter when judging distances in visually immersive environments? Presence: Teleoperators and Virtual Environments, 13, 560–571. doi:10.1162/1054746042545292
Turano, K. (1991). Bisection judgments in patients with retinitis pigmentosa. Clinical Vision Sciences, 6, 119–130.
Turano, K. A., Geruschat, D. R., & Stahl, J. W. (1998). Mental effort required for walking: Effects of retinitis pigmentosa. Optometry and Vision Science, 75, 879–886.
Turano, K., & Schuchard, R. A. (1991). Space perception in observers with visual field loss. Clinical Vision Sciences, 6, 289–299.
Vidailhet, M., Rivaud, S., Gouider-Khouja, N., Pillon, B., Bonnet, A.-M., Gaymard, B., Agid, Y., & Pierrot-Deseilligny, C. (1994). Eye movements in parkinsonian syndromes. Annals of Neurology, 35, 420–426. doi:10.1002/ana.410350408
Willemsen, P., Gooch, A. A., Thompson, W. B., & Creem-Regehr, S. H. (2008). Effects of stereo viewing conditions on distance perception in virtual environments. Presence: Teleoperators and Virtual Environments, 17, 91–101. doi:10.1162/pres.17.1.91
Wu, B., Ooi, T. L., & He, Z. J. (2004). Perceiving distance accurately by a directional process of integrating ground information. Nature, 428, 73–77. doi:10.1038/nature02350
Yamamoto, N., & Shelton, A. L. (2009a). Orientation dependence of spatial memory acquired from auditory experience. Psychonomic Bulletin & Review, 16, 301–305. doi:10.3758/PBR.16.2.301
Yamamoto, N., & Shelton, A. L. (2009b). Sequential versus simultaneous viewing of an environment: Effects of focal attention to individual object locations on visual spatial learning. Visual Cognition, 17, 457–483. doi:10.1080/1350628070165364
Author Note
The authors thank Daniel Gajewski and Kinnari Atit for assistance with data collection.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Yamamoto, N., Philbeck, J.W. Peripheral vision benefits spatial learning by guiding eye movements. Mem Cogn 41, 109–121 (2013). https://doi.org/10.3758/s13421-012-0240-2
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-012-0240-2