
Abstract
Computational accounts of reading aloud largely ignore context when stipulating how processing unfolds. One exception to this state of affairs proposes adjusting the breadth of lexical knowledge in such models in response to differing contexts. Three experiments and corresponding simulations, using Coltheart, Rastle, Perry, Langdon, and Ziegler’s (2001) dual-route cascaded model, are reported. This work investigates a determinant of when a pseudohomophone such as brane is affected by the frequency of the word from which it is derived (e.g., the base word frequency of brain) by examining performance under conditions where it is read aloud faster than a nonword control such as frane. Reynolds and Besner’s (2005a) lexical breadth account makes the novel prediction that when a pseudohomophone advantage is seen, there will also be a base word frequency effect, provided exception words are also present. This prediction was confirmed. Five other accounts of this pattern of results are considered and found wanting. It is concluded that the lexical breadth account provides the most parsimonious account to date of these and related findings.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
How do skilled readers use lexical knowledge when reading words and orthographically novel letter strings? Recent evidence suggests that a complete answer to this question requires a consideration of context. For instance, list context influences (1) how letter-level processing and lexical-level processing communicate with one another (e.g., Besner & O’Malley, 2009; Besner, O’Malley, & Robidoux, 2010; O’Malley & Besner, 2008) and (2) how semantics affects visual word recognition (e.g., Brown, Stolz, & Besner, 2006; Robidoux, Stolz, & Besner, 2010; Ferguson, Robidoux, & Besner, 2009; Stolz & Neely, 1995). Other work examining print-to-sound translation suggests that context also affects (3) how the breadth of lexical knowledge contributes to the generation of a phonological code. According to Reynolds and Besner (2005a), the breadth of the lexical contribution can vary from narrow, where relatively few entries in the mental lexicon are activated, to broad, where many such entries are activated. The present study derives, tests, and confirms a novel prediction of this account for reading aloud.
Reading aloud
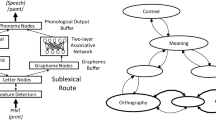
The currently most successful theories of how pronounceable letter strings are read aloud postulate two pathways for translating print into sound (Coltheart, Rastle, Perry, Langdon, & Ziegler, 2001; Perry, Ziegler, & Zorzi, 2007). For instance, in Coltheart and colleagues’ dual-route cascaded (DRC) model, the nonlexical pathway (pathway B in Fig. 1) assembles a phonological code, using grapheme-to-phoneme rules (e.g., ‘th’ → /T/). This pathway generates a correct pronunciation for regular words (e.g., hint) and nonwords (e.g., zint) but regularizes exception words (e.g., pint is read so as to rhyme with hint). The lexical pathway (pathway A in Fig. 1) consists of two layers that participate in interactive activation: the orthographic lexicon contains a representation consisting of a lexical entry (node) for each uniquely spelled word, and the phonological lexicon contains a lexical entry for each unique sounding word the model knows. The lexical route addresses a lexical–phonological code from a lexical orthographic code. This pathway generates a correct pronunciation for regular words (e.g., hint) and exception words (e.g., pint). The lexical pathway does not generate a correct pronunciation for nonwords (e.g., zint), because their spellings are not represented in the orthographic input lexicon. Both routes are always active.

The structural architecture of a dual route model of reading aloud with lexical (pathway A) and non-lexical (pathway B) routes
Interestingly, the role of each process-specific module in computational accounts of skilled reading is currently context independent. Although there is growing evidence that performance varies as a function of context (see the references noted above, see also Reynolds & Besner, 2005a, 2005b, 2008), there has been little attempt to formally implement mechanisms that could alter the impact of process-specific modules in computational accounts of visual word recognition and reading aloud. Consequently, processing in these accounts is “structurally determined” in the sense that the same computations are always performed in the same way on a stimulus (Reynolds & Besner, 2005a, 2005b, 2008; Underwood, 1978). For this reason, it is sometimes argued that computational models of reading meet all of the requirements for “automatic” processing (e.g., McCann, Remington, & Van Selst, 2000).
One account of contextual control over reading aloud that has been implemented in Coltheart and colleagues’ (2001) DRC model is Reynolds and Besner’s (2005a) breadth of lexical activation hypothesis. According to this hypothesis, readers adjust how they use the mental lexicon when reading aloud so as to activate either a narrow spectrum of lexical entries that are orthographically and phonologically similar to the target item or a broad spectrum, so that increasingly dissimilar items in terms of orthography and phonology are activated.
Reading pseudohomophones aloud
Reynolds and Besner (2005a) proposed their lexical breadth account in order to explain the complex pattern of data that has been reported in studies of pseudohomophone reading spanning the last quarter century. Pseudohomophones are nonwords that sound identical to a real word (e.g., brane for brain) but are not spelled exactly like that word. These kinds of items have been used to study how the phonological knowledge that people have acquired about words affects how they read letter strings that they have never seen before. This is accomplished by (1) comparing performance for pseudohomophones (such as brane) with nonword controls (such as frane) and (2) considering when base word frequency of the pseudohomophone affects performance.
Reynolds and Besner (2005a) reviewed this literature and concluded that context affects (1) whether pseudohomophones are read aloud faster or slower than nonword controls (a pseudohomophone advantage vs. a disadvantage) and (2) whether the time to read pseudohomophones aloud is affected by how frequently the base words (e.g., brain) are encountered in print (the presence vs. absence of a base word frequency effect). To date, only three of the four logically possible conjunctions of the pseudohomophone advantage/disadvantage and the presence/absence of a base word frequency effect have been reported (see Table 1).
As can be seen in Table 1, the one outcome that has not been reported to date is the conjunction of a pseudohomophone advantage and a base word frequency effect. The purpose of the present experiments is to test the hypothesis that such a pattern will be seen when pseudohomophones, nonwords, and exception words are read aloud in a single intermixed list context. This hypothesis is derived from Reynolds and Besner’s (2005a) lexical breadth account. We first review this account briefly.
The breadth of lexical activation account
Reynolds and Besner (2005a) proposed that context influences the breadth of lexical knowledge brought to bear when a phonological code is computed, such that the lexical contribution can vary from a narrow scope primarily due to a specific word in the mental lexicon (the base word of a pseudohomophone; e.g., brain for brane) to a broad scope where the lexical contribution is due to many words with similar spellings and sounds. Changes in the breadth of lexical activation arise because unfamiliar contexts and unfamiliar words result in uncertainty about how a phonological code should be generated. In such situations,salient characteristics of the stimuli (e.g., pseudohomophony and lexicality) and the temporal structure of the experiment (e.g., predictive patterns; see Reynolds & Besner, 2005b, 2008) influence how skilled readers generate phonology from print. With respect to pseudohomophones and nonwords, Reynolds and Besner (2005a) argued that skilled readers initially take advantage of the fact that pseudohomophones have a base word by reading with a narrow lexical contribution to reduce uncertainty (e.g., brane → brain). This luxury is not easily afforded for many nonwords, so they are more likely to be read with a broad lexical contribution (trink → brink, drink, think, trick, trunk).
Reynolds and Besner (2005a) reported a series of simulations with Coltheart et al.’s (2001) DRC model. These simulations showed that varying the breadth of the lexical contribution when reading aloud has at least three straightforward consequences.
First, narrowing the lexical scope results in fewer entries becoming activated in the mental lexicon; this, in turn, serves to increase the time to read aloud (see, e.g., Andrews, 1992; McCann & Besner, 1987; Reynolds & Besner, 2002, 2004). Second, as the scope narrows, the effects of individual lexical entry characteristics (e.g., the frequency of the base word) increase because there are fewer lexical entries activated that dilute these effects (less noise in the system). Third, if pseudohomophones and nonwords are read aloud using the same lexical breadth parameters, the pseudohomophones are read aloud faster than the nonwords, because of their identical match in phonological lexical memory that is denied to the nonword controls (e.g., McCann & Besner, 1987). Unlike the base word frequency effect, however, the pseudohomophone advantage arises because the correct phonemes (e.g., for brane) are activated in the phoneme buffer that, in turn, is engaged in interactive activation with the phonological output lexicon, where the lexical entry for the base word exists (i.e., /br1n/).
The consequences of these changes in the breadth of lexical activation for pseudohomophone and nonword reading performance provide the following account of the three cells in Table 1 that have been reported to date.
Blocked presentation
-
1.
When pseudohomophones are read aloud before nonwords in a blocked design (pure lists), they are read with a narrow lexical scope in order to maximize the utility of the lexical entry for the base word. This results in the relatively slow computation of phonology for the pseudohomophones, because few lexical entries are activated. However, it does allow characteristics of the base word to affect performance (i.e., word frequency, because there is less noise [competition from other lexical entries]). In contrast, the nonwords are read aloud with a broad(er) lexical scope because they lack an identical match in the lexicon. The increased lexical activation from the broad lexical scope results in the nonwords being read aloud faster than the pseudohomophones, because the latter items are read with a narrow scope. In summary, the use of a blocked design in which the pseudohomophones are read first yields the conjunction of a base word frequency effect and a pseudohomophone disadvantage (see Table 1).
-
2.
When pseudohomophones are read aloud after nonword controls in a blocked design, the nonwords are read aloud with a broad scope, which influences how subjects subsequently read the pseudohomophones.Footnote 1 The exposure to successful reading of the nonwords, using a broad scope, anchors subjects so that they choose an intermediate lexical breadth scope. This yields the conjunction of a null base word frequency effect and a pseudohomophone disadvantage, because the intermediate scope is broad enough to reduce the impact of other lexical entries but narrow enough to slow the generation of a phonological code, relative to the nonwords.
Mixed presentation
-
3.
When pseudohomophones and nonwords appear in a mixed list, the absence of exact matches in the lexicon for the nonwords leads to both types of items being read aloud using a broad lexical scope. This yields the conjunction of a null base word frequency effect and a pseudohomophone advantage. The pseudohomophone advantage arises because, when pseudohomophones and nonwords are read aloud using the same lexical breadth settings, the presence of an identical match in the phonological lexicon results in substantially greater activation of all of the correct phonemes for the pseudohomophone, yielding faster responses than for nonword controls that do not have such phonological lexical entries. The null base word frequency effect is observed because the broad lexical scope dilutes the impact of individual characteristics of a lexical entry.
Filling the fourth cell: The present experiments
The purpose of the present experiments was to assess the novel prediction that the conjunction of a pseudohomophone advantage and a base word frequency effect will be observed when both pseudohomophones and nonwords are read aloud with a narrow lexical contribution. The base word frequency effect will arise because a narrow lexical scope allows the individual characteristics of lexical entries to affect performance. The pseudohomophone advantage will arise because when pseudohomophones and nonwords are read aloud using the same lexical scope, the benefit of having an identical match in the phonological lexicon will be observed.
Exception words were included in the list context in order to induce subjects to read with a relatively narrow lexical contribution. The logic is that because exception words violate typical spelling-to-sound correspondence rules, accurate reading aloud of an exception word such as yacht relies on activation of the specific orthographic and phonological lexical entries of that particular word (see Coltheart et al., 2001). A narrow lexical contribution is the most beneficial setting to this end. Experiment 1 thus had subjects read aloud exception words, pseudohomophones, and nonwords randomly intermixed in a single block of trials. If this context promotes a narrow lexical contribution, the novel combination of a pseudohomophone advantage and a base word frequency effect should be observed. To anticipate the results, this is exactly what was observed.
Experiment 1
Method
Subjects
Thirty undergraduate students from the University of Waterloo participated in the present experiment for pay. All the subjects reported normal or corrected-to-normal vision and English as their first language. None of the subjects had participated in any other reading experiments.
Stimuli
The stimuli consisted of the 80 pseudohomophones and 80 nonword controls used by McCann and Besner (1987) and a set of 160 exception words. McCann and Besner’s stimuli were used because three different laboratories have reported that, when pseudohomophones and nonwords are randomly intermixed, they produce the conjunction of a pseudohomophone advantage and a null base word frequency effect when read aloud in the absence of any words.
Apparatus
Stimulus presentation was controlled by a Pentium IV 1.8-gHz computer running E-Prime 1.1. Vocal responses were collected using a Plantronics LS1 microphone headset and a voice key assembly. Stimuli were displayed on a 17-in. ADI Micro Scan monitor.
Procedure
A trial began with a fixation marker (+) in the center of the screen for 750 ms, followed by a blank screen for 100 ms. The target letter string was then presented at fixation until a vocal response was made. A blank screen then appeared for 1,000 ms, during which time the experimenter coded the response as correct, incorrect (e.g., extra or deleted phoneme, or lexicalization), or spoiled (e.g., cough, stutter, or voice key failed to activate). Each subject received 16 practice trials, followed by 320 experimental trials. Stimuli were presented in a different randomized order for each subject. All stimuli were presented in black, 16-pt. lowercase letters on a white background, using the Times Roman font. Each letter subtended approximately 0.6° of visual angle. Subjects were told that some of the stimuli consisted of words and fake words and that some of the fake words would sound like words they knew. As part of the visually displayed instructions, they were provided examples of types of stimuli in the experiment. They were also instructed to pronounce each letter string as quickly and accurately as possible.
Results
One participant was excluded from the analyses because of a base word frequency effect for pseudohomophones that was over 5 standard deviations away from the mean. The pseudohomophone supe and its control zupe were also excluded from the analyses, because the pseudohomophone was incorrectly entered into the experiment as tupe.
Trials on which subjects made a pronunciation error (7.7%) or there was a voice key failure (4.8%) were not included in the analysis of the response time (RT) data.
Pseudohomophone advantage
Prior to examining whether a pseudohomophone advantage was present, the RTs for correct responses were subjected to a recursive trimming procedure in which the criterion cut off for outlier removal was established independently for each condition for each subject, by reference to the sample size in that cell (VanSelst & Jolicoeur, 1994). This resulted in the removal of 2.4% of the correct RT data. In order to reduce the impact of subject variability on item estimates, the RT data for each subject were z-scored before item means were calculated.
The mean correct RTs and mean percentage of errors can be seen in Table 2. Pseudohomophones were read aloud 21 ms faster than nonword controls for both subjects, t(28) = 4.4, SE = 6.0, p < .01, and items, t(78) = 4.3, SE = .054, p < .05. There were no significant effects in the error data (ts < 1).
Base word frequency effect
The RTs to correct responses for the pseudohomophones were subjected to a trimming procedure in which the criterion cut-off for outlier removal was defined as residuals larger than 3 standard deviations from the best fit regression line for each subject. This resulted in the removal of 0.7% of the correct RTs. The subject analysis was conducted on the slopes relating base word frequency and RT for each subject. The item waije was excluded from the item analysis because its residual was larger than 3 standard deviations from the best fit regression line. The relationship between base word frequency and RT can be seen in the top panel of Fig. 2. There was a –9.3 ms/log10 base word frequency effect for both subjects, t(28) = 2.9, SE = 3.3, p < .01, and items, r = –.27, t(78) = 2.4, p < .05. There was no effect of base word frequency on errors (ts < 1).

Mean RT (ms) to read aloud pseudohomophones as a function of base word frequency by skilled readers (Top Panel) and cycles to criterion for DRC with a narrow lexical contribution (Bottom Panel)
Discussion
The conjunction of a pseudohomophone advantage and a base word frequency effect was observed for the McCann and Besner (1987) stimuli when mixed with exception words in Experiment 1. These same stimuli have been repeatedly reported to yield a pseudohomophone advantage and a null base word frequency effect when exception words were not included (e.g., Borowsky, Owen, & Masson, 2002; Marmurek & Kwantes, 1996; McCann & Besner, 1987). The outcome of Experiment 1 is therefore consistent with the prediction derived from the breadth of lexical activation account. Namely, given that exception words require a narrow lexical scope to be read aloud, intermixing them with pseudohomophones and nonword controls will result in a narrow lexical contribution being used for all of the items. Under such conditions, a pseudohomophone advantage and a base word frequency effect will be observed.
Experiment 2
In Experiment 2, we sought to broaden the empirical base for the conjunction of a pseudohomophone advantage and a base word frequency effect. In this experiment, a new set of high- and low-frequency pseudohomophones were matched, instead of using the regression approach, as in Experiment 1 and in McCann and Besner (1987). Matching the high- and low-frequency pseudohomophone stimuli reduces the possibility that other variables correlated with base word frequency (e.g., initial phoneme) are driving the observed change in the base word frequency effect across context.
Method
Subjects
Forty undergraduate students from the University of Waterloo participated for pay. All the subjects reported normal or corrected-to-normal vision and English as their first language. None of the subjects had participated in any other reading experiments.
Stimuli
The stimuli consisted of 20 pseudohomophones with high-frequency base words, 20 pseudohomophones with low-frequency base words, 40 nonword controls, and a new set of 80 exception words. The ARC nonword database was used to control for extraneous variables (Rastle, Harrington, & Coltheart, 2002). The high- and low-frequency pseudohomophones and nonword controls were matched on initial letter, onset phoneme, and the number of letters. Stimulus sets were equated on number of orthographic neighbors (the number of words that can be created by changing one letter at a time), number of phonological neighbors (the number of words that can be created by changing one phoneme at a time), number of body neighbors (the number of words that share the same orthographic body), including number of body friends (the number of body neighbors whose body yields the same pronunciation) and number of enemies (the number of body neighbors whose body yields a different pronunciation), as well as type (number of words with) and token (number of times the pattern occurs) of position-specific and position-nonspecific, bigram and trigram frequencies (see Table 3).
Apparatus and procedure
The apparatus and procedure were the same as those in Experiment 1.
Results
Trials on which subjects made a pronunciation error (9.4%) or there was a voice key failure (2.4%) were not included in the analysis of the RT data. The remaining RTs were subjected to a recursive trimming procedure in which the criterion cutoff for outlier removal was established independently for each condition for each subject, by reference to the sample size in that cell (VanSelst & Jolicoeur, 1994). This resulted in the removal of 1.9% of the correct RT data. In order to reduce the impact of subject variability on item estimates, the RT data for each subject were z-scored before calculating item means.
Pseudohomophone advantage
Mean RTs and percentage of errors can be seen in Table 2. Pseudohomophones were read aloud 22 ms faster than the nonwords, t s(39) = 4.6, SE = 4.7, p < .05, and t i(78) = 2.9, SE = .09, p < .05, and 6.8% more accurately than the nonwords, t s(39) = 5.9, SE = 1.2, p < .05, and ti(78) = 3.3, SE = 2.2, p < .05.
Base word frequency effect
As can be seen in Table 2, high-frequency pseudohomophones were read aloud 13 ms faster than low frequency pseudohomophones, t s(39) = 3.0, SE = 4.3, p < .05, and t i(38) = 2.0, SE = .08, p < .06. There was no effect of base word frequency on accuracy, t s(39) < 1, SE = 1.2, and t i(38) < 1, SE = 1.8.
Discussion
The conjunction of a pseudohomophone advantage and a base word frequency effect was again observed, thus replicating the outcome of Experiment 1 with a different stimulus set. This provides further evidence consistent with the claim that when exception words are randomly intermixed with pseudohomophones and nonword controls, skilled readers utilize a narrow lexical parameter setting.
Experiment 3
Unlike the stimuli used in Experiment 1, the conjunction of a pseudohomophone advantage and a null base word frequency effect has not been assessed for the stimuli used in Experiment 2. Given this, the conjunction of a pseudohomophone advantage and a base word frequency effect observed in Experiment 2 cannot be unequivocally attributed to the presence of exception words in the mixed list context. Converging evidence is provided by a demonstration that a pseudohomophone advantage and a null base word frequency effect is observed for these stimuli when they are read aloud in a mixed list context in the absence of exception words.
Method
Subjects
A new set of 40 undergraduate students from the University of Waterloo participated for pay. All the subjects reported normal or corrected-to-normal vision and English as their first language.
Stimuli
The stimuli consisted of the pseudohomophones and nonword controls from Experiment 2. The exception words were removed.
Apparatus and procedure
The apparatus and procedure were the same as those in Experiment 1.
Results
Trials on which subjects made a pronunciation error (7.6%) or there was a voice key failure (5.5%) were not included in the analysis of the RT data. Correct RTs were again subjected to the same recursive trimming procedure as that described for Experiment 2. This resulted in the removal of 2.5% of the correct RT data.
Pseudohomophone advantage
Mean RTs and percentage of errors can be seen in Table 2. Pseudohomophones were read aloud 18 ms faster than the nonwords, t s(39) = 4.6, SE = 3.8, p < .05, and t i(78) = 3.7, SE = .06, p < .05, and were also read 5.2% more accurately than the nonwords, t s(39) = 7.1, SE = .73, p < .05, and t i(78) = 3.4, SE = 1.5, p < .05.
Base word frequency effect
As can be seen in Table 2, there was no effect of base word frequency either on RTs, t s(39) < 1, SE = 4.5, and t i(38) < 1, SE = .07, or on how accurately the pseudohomophones were read aloud, t s(39) = 1.2, SE = 1.1, and t i(38) < 1, SE = 1.4.
Discussion
The conjunction of a pseudohomophone advantage and a null base word frequency effect was observed in Experiment 3, consistent with other reports in the literature (e.g., Herdman, LeFevre, & Greenham, 1996; Marmurek & Kwantes, 1996; McCann & Besner, 1987). This result is consistent with the explanation that a phonological code was generated using a broad lexical contribution, as predicted by the breadth of lexical activation account. Furthermore, it reinforces the conclusion that the conjunction of a advantage and a base word frequency effect observed in Experiment 2 can be attributed to the presence of exception words in the mixed list context.
Simulations
Reynolds and Besner (2005a) simulated the three different conjunctions of a pseudohomophone advantage/disadvantage and the presence/absence of a base word frequency effect that had been reported in the literature. These effects were simulated in the context of Coltheart et al.’s (2001) DRC model by changing the letter-to-word inhibition parameter in response to the stimulus context. A high value of this parameter corresponds to a narrow lexical contribution; a low value corresponds to a broad lexical contribution.
Reading aloud with a narrow lexical contribution
The parameter set used by Reynolds and Besner (2005a) to simulate reading with a narrow lexical scope was intended only to simulate pseudohomophone and nonword reading. Getting the DRC model to accurately simulate both nonword and exception word reading with a single parameter set requires a delicate balance between the two routes. If the lexical route is too strong, lexical capture will occur, and nonwords will be read as words, whereas if the nonlexical route is too strong, exception words will be regularized (e.g., pint read so as to rhyme with hint). We therefore used Coltheart et al.’s (2001) default parameter set (see Table 4) to simulate reading aloud using a narrow lexical scope when both exception words and nonwords were presented in the same context (i.e., Experiments 1 and 2). Indeed, Coltheart et al. explicitly noted that this parameter set does not allow many lexical entries to be activated, and they also noted that this parameter set was developed so that “DRC reads all exception words and all nonwords” (p. 219). Coltheart et al.’s default parameter set is similar to the one used by Reynolds and Besner (2005a), in that letter to word inhibition is high (–.435).
Simulation of Experiment 1
As can be seen in Table 5, DRC read aloud exception words, pseudohomophones, and nonwords from Experiment 1 very accurately when the default parameter set was used. Critically, DRC produced both a pseudohomophone advantage, t(134) = 4.2, SE = 2.9, p < .05, and, as can be seen in the bottom panel of Fig. 2, a base word frequency effect, r = –.39, t(70) = 3.6, SE = 2.2, p < .05.
Simulation of Experiment 2
As can also be seen in Table 5, DRC read aloud the exception words, pseudohomophones, and nonwords from Experiment 2 accurately when Coltheart et al.’s (2001) default parameter set was used. Critically, DRC again produced both a pseudohomophone advantage, t(76) = 3.8, SE = 3.7, p < .05, and a base word frequency effect, t(37) = 3.1, SE = 4.4, p < .05.
Reading aloud with a broad lexical contribution
Reading aloud with a broad lexical contribution was simulated using the same parameter values as those in Reynolds and Besner (2005a). This parameter set increases the breadth of the lexical contribution by reducing inhibitory connections along the lexical route (see Table 4). Coltheart et al. (2001, pp. 224–225) used this same approach to increase the number of neighbors activated by a letter string in order to allow DRC to produce a neighborhood density effect for words. In order to reduce lexical capture in response to the nonwords, the output of the lexical route was also reduced by decreasing the excitatory connections from the phonological output lexicon to the phoneme level for the present simulations (see Table 4).
Simulation of Experiment 3
As can be seen in Table 5, DRC read aloud the pseudohomophones and nonwords from Experiment 3 accurately when the broad lexical activation parameter set was used. Critically, DRC successfully produced a pseudohomophone advantage, t(68) = 4.7, SE = 5.1, p < .001, and a null base word frequency effect, t(33) = 1.2, SE = 5.3.
Exception words
A major assumption of the present work is that the correct reading aloud of an exception word requires a narrow lexical scope. It is therefore important to examine how reading with a broad lexical contribution affects performance for exception words. The expectation is that reading with a broad lexical contribution will negatively affect how quickly and accurately exception words are read aloud. Consistent with this view, only 31% of the exception words from Experiment 1 and 37% of the exception words from Experiment 2 were read aloud correctly with a broad lexical contribution. Furthermore, the exception words that were read aloud correctly took significantly longer to read, as compared with when these same items were read aloud with a narrow lexical contribution: 108 cycles versus 79 cycles, t(48) = 10.4, SE = 2.79, p < .05, for the stimuli from Experiment 1, and 114 cycles versus 78 cycles, t(29) = 9.7, SE = 3.73, p < .05, for the stimuli from Experiment 2.
An alternative interpretation of the reduced performance for the exception words is that the parameter values used to simulate reading with a broad lexical contribution have simply reduced the lexical contribution by reducing the output from the lexical route (i.e., by reducing facilitation from the phonological lexicon to the phoneme level from .14 to .05). Two pieces of evidence are inconsistent with this interpretation. First, despite exception words slowing down, the pseudohomophones and the nonwords sped up. Therefore, reducing the excitation from the phonological lexicon to the phoneme level cannot have resulted in an overall reduction in activation. Second, there was no reduction in the magnitude of the pseudohomophone advantage, an outcome that would be expected if the lexical contribution was reduced.
Summary of the simulation results
The DRC model successfully produced the conjunction of a pseudohomophone advantage and a base word frequency effect when the lexical contribution to performance was narrow and the conjunction of a pseudohomophone advantage and a null base word frequency effect when the lexical contribution to performance was broad. Thus, DRC was able to simulate the outcome of all three of the present experiments by varying the breadth of the lexical contribution to performance in the way dictated by Reynolds and Besner’s (2005a) account.Footnote 2
General discussion
A rich variety of findings have been reported in the literature on reading pseudohomophones aloud. Reynolds and Besner (2005a) provided a detailed review and proposed an account in which skilled readers generate a pronunciation with a contribution from lexical memory that varies from narrow to broad in scope, depending on the context. In the present work, it was hypothesized that exception words encourage skilled readers to adopt a narrow(er) lexical scope, because accurate reading aloud of an exception word relies on activation of the specific orthographic and phonological lexical entries of that particular word. This view predicts that when both pseudohomophones and nonword controls are read with a narrow lexical contribution, (1) pseudohomophones will be read aloud faster than the nonword controls, and (2) the pseudohomophones will produce a base word frequency effect. Both of these predictions were confirmed. This represents a novel and fourth context (see Table 1) that affects how pseudohomophones are read aloud. Any viable account of reading aloud will therefore need to account for these four conjunctions of two binary effects.
As always, it is important to consider possible alternative accounts of the data reported here, as well as previously. Below we discuss five such accounts. All of them are problematic in one way or another.
1. The pathway control hypothesis
The pathway control hypothesis is an alternative account of how reading processes change across context, based on the dual-route framework (Baluch & Besner, 1991; Coltheart & Rastle, 1994; Havelka & Rastle, 2005; Monsell, Patterson, Graham, Hughes, & Milroy, 1992; Rastle & Coltheart, 1999; Reynolds & Besner, 2005b; Reynolds & Besner, 2008; Tabossi & Laghi, 1992; Zevin & Balota, 2000). This account postulates that the relative contribution of a particular pathway for translating print into sound will be emphasized or de-emphasized in response to the type of stimuli being read aloud. In particular, the relative contribution of a pathway will be increased when it is required to read a class of stimuli correctly and decreased when it cannot generate a correct pronunciation for that class of stimuli.
The pathway control hypothesis makes a number of straightforward predictions in the context of computational models, such as Coltheart et al.’s (2001) DRC model and the closely related CDP+ model of Perry et al. (2007). Namely, the nonlexical pathway will be emphasized when nonwords are read aloud, because it is required to generate a correct pronunciation for items not represented in the orthographic and phonological lexicons. Similarly, the lexical pathway will be emphasized when words are being read aloud that violate the nonlexical spelling-to-sound mappings. For instance, the lexical route would be emphasized for exception words in the DRC model, because they do not follow the model’s grapheme–phoneme conversion rules (in the case of the CDP + model, the nonlexical route learns by exposure to print; there are no explicitly specified rules for converting print to sound sublexically).
If changes in pathway control arise because a pathway is required to generate a correct pronunciation, the pathway control hypothesis does not predict differences in pseudohomophone performance when they are read aloud in a pure list, as compared with when mixed with nonword controls. The reason is that both pseudohomophones and nonword controls require the nonlexical route to be read aloud correctly. As a consequence, accommodating the pattern of data observed when pseudohomophones and nonword controls are read aloud under blocked and mixed conditions would require some form of change to one or more of the central assumptions of the pathway control hypothesis.
2. Response time homogenization
Lupker and colleagues (Chateau & Lupker, 2003; Kinoshita & Lupker, 2002, 2003; Lupker, Brown, & Colombo, 1997; Taylor & Lupker, 2001) have proposed that contextual changes in reading performance are best understood in terms of changes outside the reading system. According to their RT homogenization account, skilled readers use a time criterion to determine when they will make an overt response. This time criterion for responding is adjusted on a trial-by-trial basis in response to the relative speed of the previous trial and is influenced by how long it takes, on average, to respond in a particular context (e.g., over a block of trials). Thus, the time criterion is set earlier following a fast trial and later following a slow trial. The consequence of these adjustments is that mixing “fast” and “slow” stimuli in a single block will result in slower responses to the “fast” stimuli and faster responses to the “slow” stimuli. Critically, RT homogenization is not influenced by the nature of the stimuli (e.g., whether the stimulus is a word or a nonword).
Compelling support for the claim that subjects do homogenize their responses at least some of the time has been reported in a number of studies (e.g., Chateau & Lupker, 2003; Kinoshita & Lupker, 2002, 2003; Lupker et al., 1997; Raman, Baluch, & Besner, 2004; Taylor & Lupker, 2001). However, it is unclear how this account can explain the complete pattern of data observed when pseudohomophones are read aloud. Of particular concern is the observation that pseudohomophones are read aloud more slowly than nonword controls in pure lists, but more quickly than nonword controls when the two types of stimuli are mixed together. Homogenization easily explains how the difference between two blocked variables gets smaller when they are mixed together, but not how they reverse.
Kinoshita and Lupker (2002, 2003) have argued that subjects may perform a “lexical check,” in addition to RT homogenization, under conditions where low-frequency exception words are part of the list context. According to this account, the presence of low-frequency exception words results in readers sometimes checking whether the pronunciation they have generated matches a lexical entry. This lexical checking account is unable to explain the changes in pseudohomophone performance across list contexts that do not involve the presentation of low-frequency exception words. It is therefore unclear why lexical checking would be invoked to explain why pseudohomophones are read aloud more quickly than nonword controls in mixed lists and more slowly than nonword controls in pure lists.Footnote 3
3. A response criterion account
Another account that has recently been proposed to explain the pattern of complex findings observed in pseudohomophone reading aloud is that context influences the criterion setting used to make a response (Kwantes & Marmurek, 2007). Accordingly, pseudohomophones in the pure list condition are read aloud with a conservative criterion, whereas the pseudohomophones mixed with nonword controls are read aloud with a more liberal criterion. Reading aloud pseudohomophones with a conservative response criterion results in longer RTs and a base word frequency effect (because the base word has a greater opportunity to affect performance). When pseudohomophones are read aloud with a liberal response criterion, they are read aloud more quickly and do not yield a base word frequency effect (because the base word has insufficient time to yield a unique contribution to performance).
Problematically for this account, simulation data suggest that a simple shift in response criterion is insufficient to account for the pattern of data when pseudohomophones are read aloud. For instance, Reynolds and Besner (2011a) reported simulation work with the DRC model showing that reducing the response criterion as suggested by Kwantes and Marmurek (2007) fails to eliminate the base word frequency effect, unlike what is seen for skilled readers.
Furthermore, if shifting the criterion to be more conservative increases the contribution from lexical variables so as to yield a base word frequency effect, the contribution from other lexical variables should increase as well. Reynolds and Besner (2011a) tested this prediction by conducting simulations examining how changes in the response criterion influence the effect of neighborhood density. The standard finding is that the more words that can be created by changing one letter in a letter string, the faster that string is read aloud (Adelman & Brown, 2007; Andrews, 1992; McCann & Besner, 1987; Mulatti, Reynolds, & Besner, 2006; Peereman & Content, 1995, 1997; Reynolds & Besner, 2004). As was expected, increasing the response criterion in DRC so as to simulate reading aloud pseudohomophones in a pure list context yielded both a larger base word frequency effect and a larger effect of neighborhood density, as compared with lower values used to simulate when pseudohomophones and nonwords are randomly intermixed. However, skilled readers yielded the opposite pattern. In the pure list context, the effect of neighborhood density was smaller, not larger, than in the mixed list context (Grainger, Spinelli, & Ferrand, 2000; Reynolds & Besner, 2011a).
4. The connectionist dual-process (CDP+) model
Perry et al. (2007) also argued that changes in the response criterion explain the context effects observed when pseudohomophones and nonword controls are read aloud. They reported three simulations in the context of their CDP + model, using the McCann and Besner (1987) stimuli (that we used in Experiment 1, here). Across simulations, they used three minimum naming activation criterion values: .64 (low), .67 (default), and .73 (high). The low criterion was used to simulate the conjunction of a pseudohomophone advantage and the absence of the base word frequency effect observed when pseudohomophones and nonword controls are read aloud in a mixed list context (see p. 293). According to their simulations, a pseudohomphone advantage is observed and the base word frequency effect is absent when the low criterion (.64) is used. In contrast, a high criterion was used to simulate the reading aloud of pseudohomophones in a pure block so as to produce the pseudohomophone disadvantage and the presence of a base word frequency effect, as seen with skilled readers. Perry and colleagues reported that their simulations resulted in pseudohomophones taking longer to read aloud that the nonword controls (which were read with the low criterion) and produced a base word frequency effect.
However, subsequent work by Robidoux and Besner (2011) has identified a number of problems with the simulations reported by Perry et al. (2007). For instance, some items were either incorrectly excluded from or included in the analyses. In addition, the frequency values used to assess the base word frequency effect did not correspond with those associated with lexical entries in the model. Here we report new simulations of the items used in Experiment 1, which includes a replication of simulations reported by Perry et al. (2007) using the McCann and Besner (1987) stimuli, and simulations for the stimuli from Experiments 2 and 3.
Simulations with the Experiment 1 stimuli
A number of the McCann and Besner (1987) and exception word stimuli were excluded from all of the simulations (see Appendix A). Additional items were excluded on a simulation-by-simulation basis if they yielded a pronunciation error or were an outlier (following Perry et al., 2007, if the time to generate a pronunciation [in cycles] for an item was 3 standard deviations away from the mean in that cell). The data can be seen in Table 6.
First, it is critical to note that although the base word frequency effect gets smaller as the response criterion in the model gets lower, a base word frequency effect is always observed. This is similar to the pattern reported by Reynolds and Besner (2011a), using Kwantes and Marmurek’s (2007) implementation of this account in DRC. This result suggests that, contrary to Perry et al.’s (2007) claim, the CDP + model does not provide a complete account of the data when pseudohomophones are read aloud. In particular, the model is not, at present, able to produce the conjunction of a pseudohomophone advantage and a null base word frequency effect.
Simulation with the Experiment 2 and 3 stimuli
The same three simulations were run for the stimuli used in Experiments 2 and 3. Once again, a number of the stimuli were excluded from all simulations (see Appendix B). Additional items were excluded on a simulation-by-simulation basis if they yielded a pronunciation error or were outliers (3 standard deviations away from the mean in that cell, following (Perry et al., 2007)).
As can be seen in Table 7, the CDP + model failed to produce either a pseudohomophone advantage or a base word frequency effect for the items used in Experiments 2 and 3. In addition, the CDP + model made a number of peculiar pronunciation errors (e.g., wote as what, goph as go, and thout as that).
With respect to the present experiments, the response criterion account falls short in another way; it offers no principled reason for why exception words would change how pseudohomophones and nonwords are read aloud. As can be seen in Tables 6 and 7, exception words were read aloud accurately irrespective of the response criterion used. Given this, it is unclear why the presence of exception words would lead skilled readers to change their response criterion.
In summary, the response criterion account of context effects implemented in the CPD + model does not provide a compelling account of context effects from studies in which pseudohomophones are read aloud.
5. Parallel distributed processing (PDP) models
Parallel distributed processing (PDP) models are an alternative to the dual-route framework seen in DRC and CDP+. In PDP models, knowledge about orthography and phonology is distributed across a large set of nodes; there is no lexicon and, therefore, no lexical entries. To date, computational versions of these PDP models have been unable to simulate the conjunction of a pseudohomophone advantage and absence of a base word frequency effect, as reported by McCann and Besner (1987). Instead, the most persistent advocates of the PDP approach have claimed that the pseudohomophone advantage is not a truly phonological effect (see the exchange between Seidenberg & McClelland, 1990 and Besner, Twilley, McCann, & Seergobin, 1990; see also Plaut, McClelland, Seidenberg, & Patterson, 1996 vs. Besner, 1999; see also Reynolds & Besner, 2005a). From our perspective, the pseudohomophone advantage/disadvantage, in combination with the presence/absence of a base word frequency effect, represents a rich set of findings that these models must attempt to simulate (see Borowsky & Besner, 2006; Roberts, Rastle, Coltheart, & Besner, 2003 for other difficulties faced by PDP models as currently implemented).
Conclusion
In summary, each of the alternative explanations considered here has a problem dealing with one or more facets of the literature on reading aloud of pseudohomophones and their nonword controls. That said, we do not wish to claim that it is impossible to modify any of these accounts so as to accommodate the data reported here and elsewhere. Rather, it remains to be seen whether this is possible.
What we do claim is that the complex but systematic variation observed in the time to read pseudohomophones aloud across different contexts provides compelling evidence that lexical processing is context dependent. Although this may seem obvious, the field at large, with its emphasis on steady state models, has not yet assimilated this simple but important conclusion. Finally, we submit that Reynolds and Besner (2005a) breadth of lexical activation hypothesis provides a sufficient account of the present results, as well as related findings that have accumulated since 1987. In short, this account explains the results from all four cells in Table 1. To date, no other account provides a clearly viable explanation for these data. We therefore suggest that this is the best account that currently exists.
Notes
A simplifying assumption made by Reynolds and Besner (2005a) was that context does not influence how the nonwords were being read aloud. This allowed them to focus on how performance for the pseudohomophones was changing and to reduce degrees of freedom in the model.
It should be noted that one discrepancy between the human data and the simulations concerns how quickly the exception words were read, as compared with the pseudohomophones. In the data of Experiment 1, the difference in RT between the pseudohomophones and nonwords is larger than the difference in RT between the pseudohomophones and the exception words. The opposite pattern is observed in the simulations. Reynolds and Besner (2005a) described this kind of problem as a scaling issue and noted that there are a number of other instances where DRC does not currently capture the rank ordering of a number of different-sized effects (see Table 2 in Reynolds & Besner, 2004). This important issue will need addressing in future iterations of the model.
Lexical checking also has difficulty explaining other types of context effects. For instance, lexical checking has difficulty explaining the observation of symmetric switch costs when high-frequency exception words and nonwords are read aloud in a predictable AABB sequence (Reynolds & Besner, 2008), as well as the observation of switch costs when regular words and nonwords are read aloud in a predictable sequence (Reynolds & Besner, 2011b).
References
Adelman, J. S., & Brown, G. D. A. (2007). Phonographic neighbors, not orthographic neighbors, determine word naming latencies. Psychonomic Bulletin & Review, 14, 455–459.
Andrews, S. (1992). Frequency and neighborhood effects on lexical access: Lexical similarity or orthographic redundancy? Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 234–254.
Baluch, B., & Besner, D. (1991). Visual word recognition: Evidence for strategic control of lexical and nonlexical routines in oral reading. Journal of Experimental Psychology: Learning, Memory and Cognition, 17, 644–652.
Besner, D. (1999). Basic processes in reading: Multiple routines in localist and connectionist models. In R. M. Klein & P. A. McMullen (Eds.), Converging methods for understanding reading and dyslexia (pp. 413–458). Cambridge: MIT Press.
Besner, D., & O’Malley, S. (2009). Additivity of factor effects in reading tasks is still a challenge for computational models: Reply to Ziegler, Perry, and Zorzi (2009). Journal of Experimental Psychology. Learning, Memory, and Cognition, 1, 312–316.
Besner, D., O’Malley, S., & Robidoux, S. (2010). On the joint effects of stimulus quality, regularity and lexicality when reading aloud: New challenges. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36, 750–764.
Besner, D., Twilley, L., McCann, R. S., & Seergobin, K. (1990). On the association between connectionism and data: Are a few words necessary? Psychological Review, 97, 432–446.
Borowsky, R., & Besner, D. (2006). Parallel distributed processing and lexical-semantic effects in visual word recognition: Are a few stages necessary? Psychological Review, 113, 181–195.
Borowsky, R., Owen, W., & Masson, M. (2002). Diagnostics of phonological lexical processing: Pseudohomophone naming advantages, disadvantages, and base-word frequency effects. Memory & Cognition, 30, 969–986.
Brown, M., Stolz, J. A., & Besner, D. (2006). Dissociative effects of stimulus quality on semantic and morphological contexts in visual word recognition. Canadian Journal of Experimental Psychology, 60, 190–199.
Chateau, D., & Lupker, S. J. (2003). Strategic effects in word naming: Examining the route-emphasis versus time-criterion accounts. Journal of Experimental Psychology: Human Perception and Performance, 29, 139–151.
Coltheart, M., & Rastle, K. (1994). Serial processing in reading aloud: Evidence for dual-route models of reading. Journal of Experimental Psychology: Human Perception and Performance, 20, 1197–1211.
Coltheart, M., Rastle, K., Perry, C., Langdon, R., & Ziegler, J. (2001). DRC: A dual route cascaded model of visual word recognition and reading aloud. Psychological Review, 108, 204–256.
Ferguson, R., Robidoux, S., & Besner, D. (2009). Reading aloud: Evidence for contextual control over lexical activation. Journal of Experimental Psychology. Human Perception and Performance, 35, 499–507.
Grainger, J., Spinelli, E., & Ferrand, L. (2000). Effects of base word frequency and orthographic neighborhood size in pseudohomophone naming. Journal of Memory and Language, 42, 88–102.
Havelka, J., & Rastle, K. (2005). The assembly of phonology from print is serial and subject to strategic control: Evidence from Serbian. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 148–158.
Herdman, C. M., LeFevre, J., & Greenham, S. L. (1996). Base-word frequency and pseudohomophone naming. The Quarterly Journal of Experimental Psychology, 49A, 1044–1061.
Kinoshita, S., & Lupker, S. J. (2002). Effects of filler type in naming: Change in time criterion or attentional control of pathways? Memory and Cognition, 30, 1277–1287.
Kinoshita, S., & Lupker, S. J. (2003). Priming and attentional control of lexical and sublexical pathways in naming: A re-evaluation. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29, 405–415.
Kwantes, P., & Marmurek, H. (2007). Controlling lexical contributions to the reading of pseudohomophones. Psychonomic Bulletin & Review, 14, 373–378.
Lupker, S. J., Brown, P., & Colombo, L. (1997). Strategic control in a naming task: Changing routes or changing deadlines? Journal of Experimental Psychology: Learning Memory, and Cognition, 23, 570–590.
Marmurek, H., & Kwantes, P. (1996). Reading words and wirds: Phonology and lexical access. The Quarterly Journal of Experimental Psychology, 49A, 696–714.
McCann, R. S., & Besner, D. (1987). Reading pseudohomophones: Implications for models of pronunciation assembly and the locus of word frequency effects in naming. Journal of Experimental Psychology. Human Perception and Performance, 13, 14–24.
McCann, R. S., Remington, R. W., & Van Selst, M. (2000). A dual-task investigation of automaticity in visual word recognition.Journal of Experimental Psychology: Human Perception and Performance, 26, 1352–1370.
Monsell, S., Patterson, K. E., Graham, A., Hughes, C. H., & Milroy, R. (1992). Lexical and sublexical translation of spelling to sound: Strategic anticipation of lexical status. Journal of Experimental Psychology: Learning, Memory, and Cognition, 18, 452–467.
Mulatti, C., Reynolds, M., & Besner, D. (2006). Neighborhood effects in reading aloud: New findings and new challenges for computational models. Journal of Experimental Psychology: Human Perception and Performance, 32, 799–810.
O’Malley, S., & Besner, D. (2008). Reading aloud: Qualitative differences in the relation between word frequency and stimulus quality as a function of context. Journal of Experimental Psychology. Learning, Memory, and Cognition, 34, 1400–1411.
Peereman, R., & Content, A. (1995). Neighborhood size effect in naming: Lexical processing or sublexical correspondences? Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 409–421.
Peereman, R., & Content, A. (1997). Orthographic and phonological neighborhoods in naming: Not all neighbors are equally influential in orthographic space. Journal of Memory and Language, 37, 382–410.
Perry, C., Ziegler, J. C., & Zorzi, M. (2007). Nested incremental modeling in the development of computational theories: The CDP+ model of reading aloud. Psychological Review, 114, 273–315.
Plaut, D. C., McClelland, J. L., Seidenberg, M. S., & Patterson, K. (1996). Understanding normal and impaired word reading: Computational principles in quasi-regular domains. Psychological Review, 103, 56–115.
Raman, I., Baluch, B., & Besner, D. (2004). On the control of visual word recognition: Changing routes versus changing deadlines. Memory & Cognition, 32, 489–500.
Rastle, K., & Coltheart, M. (1999). Serial and strategic effects in reading aloud. Journal of Experimental Psychology: Human Perception and Performance, 25, 482–5003.
Rastle, K., Harrington, J., & Coltheart, M. (2002). 358, 534 nonwords: The ARC Nonword Database. Quarterly Journal of Experimental Psychology, 55A, 1339–1362.
Reynolds, M. & Besner, D. (2002). Neighbourhood density effects in reading aloud: New insights from simulations with the DRC model. Canadian Journal of Experimental Psychology, 56, 310–318.
Reynolds, M., & Besner, D. (2004). Neighbourhood density, word frequency, and spelling–sound regularity effects in naming: Similarities and differences between skilled readers and the dual route cascaded computational model. Canadian Journal of Experimental Psychology, 58, 13–29.
Reynolds, M., & Besner, D. (2005a). Basic processes in reading: A critical review of pseudohomophoneeffects in naming and a new computational account. Psychonomic Bulletin & Review, 12, 622–646.
Reynolds, M., & Besner, D. (2005b). Contextual control of lexical and sublexical routines when reading English aloud. Psychonomic Bulletin & Review, 12, 113–118.
Reynolds, M., & Besner, D. (2008). Contextual effects on reading aloud: Evidence for pathway control. Journal of Experimental Psychology. Learning, Memory, and Cognition, 3, 50–64.
Reynolds, M., & Besner, D. (2011a). There goes the neighborhood: Contextual control over the breadth of lexical activation when reading aloud. Quarterly Journal of Experimental Psychology, in press.
Reynolds, M., & Besner, D. (2011b). Reading aloud and the pathway control hypothesis: Evidence for endogenous and exogenous control over lexical and non-lexical pathways. Manuscript submitted for publication.
Roberts, M., Rastle, K., Coltheart, M., & Besner, D. (2003). When parallel processing invisual word recognition is not enough: New evidence from naming. Psychonomic Bulletin & Review, 10, 405–414.
Robidoux, S., & Besner, D. (2011). Reading aloud: Is feedback ever necessary? Psychological Review, (submitted for publication).
Robidoux, S., Stolz, J. A., & Besner, D. (2010). Visual word recognition: Evidence for global and local control over semantic feedback. Journal of Experimental Psychology: Human Perception and Performance, 36, 3, 689–703.
Seidenberg, M. S., & McClelland, J. L. (1990). More words but still no lexicon: Reply to Besner et al. (1990). Psychological Review, 97, 447–452.
Stolz, J. A., & Neely, J. H. (1995). When target degradation does and does not enhance semantic context effects in word recognition. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21, 596–611.
Tabossi, P., & Laghi, L. (1992). Semantic priming in the pronunciation of words in two writing systems: Italian and English. Memory & Cognition, 20, 303–313.
Taylor, T. E., & Lupker, S. J. (2001). Sequential effects in naming: A time-criterion account. Journal of Experimental Psychology: Learning, Memory, & Cognition, 27, 117–138.
Underwood, G. (1978). Concepts in information processing theory. In G. Underwood (Ed.), Strategies of information processing (pp. 1–22). New York: Academic Press.
VanSelst, M., & Jolicoeur, P. (1994). A solution to the effect of sample size on outlier elimination. The Quarterly Journal of Experimental Psychology, 47A, 631–650.
Zevin, J. D., & Balota, D. A. (2000). Priming and attentional control of lexical and sublexical pathways during naming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 121–135.
Author information
Authors and Affiliations
Corresponding author
Additional information
This research was supported by Grants 341586 to M.R. and AO998 to D.B. from the Natural Sciences and Engineering Research Council of Canada. Correspondence to Michael Reynolds (michaelchanreynolds@trentu.ca)
Appendix
Appendix
Rights and permissions
About this article
Cite this article
Reynolds, M., Besner, D. & Coltheart, M. Reading aloud: New evidence for contextual control over the breadth of lexical activation. Mem Cogn 39, 1332–1347 (2011). https://doi.org/10.3758/s13421-011-0095-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13421-011-0095-y