
Abstract
During feature-positive operant discriminations, a conditional cue, X, signals whether responses made during a second stimulus, A, are reinforced. Few studies have examined how landmarks, which can be trained to control the spatial distribution of responses during search tasks, might operate under conditional control. We trained college students to search for a target hidden on a computer monitor. Participants learned that responses to a hidden target location signaled by a landmark (e.g., A) would be reinforced only if the landmark was preceded by a colored background display (e.g., X). In Experiment 1, participants received feature-positive training (+←YB/ XA→+/A−/B−) with the hidden target to the right of A and to left of B. Responding during nonreinforced transfer test trials (XB−/YA−) indicated conditional control by the colored background, and spatial accuracy indicated a greater weighting of spatial information provided by the landmark than by the conditional cue. In Experiments 2a and 2b, the location of the target relative to landmark A was conditional on the colored background (+←YA/ XA→+/ ZB→+/ +←C /A−/B−). At test, conditional control and a greater weighting for the landmark’s spatial information were again found, but we also report evidence for spatial interference by the conditional stimulus. Overall, we found that hierarchical accounts best explain the observed differences in response magnitude, whereas spatial accuracy was best explained via spatial learning models that emphasize the reliability, stability, and proximity of landmarks to a target.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Skinner (1938) defined a discriminative stimulus as a cue that comes to control the occurrence of an instrumental response. Discriminative stimuli allow organisms to adjust their responding to match environmental contingencies, such as learning whether their responses will pay off. Landmarks are discriminative stimuli that control not only whether (typically measured as the magnitude of responding), but also where responses occur. During conditional discriminations, a second stimulus (the conditional cue) signals the contingency between a discriminative stimulus (landmark) and a reinforced response (see Swartzentruber, 1995, for a review). After considerable research, we know spatial information plays a critical role in many types of learning (e.g., cue competition and causation) and is intimately involved in memory (e.g., working memory subsystems, long-term memory encoding and retrieval, and embodied cognition). Consequently, there is great value in gaining a better understanding of the information value (e.g., causal, spatial, and temporal) of stimuli within conditional discriminations.
During one form of conditional discrimination, a serial feature-positive procedure, two trial types are used: feature-positive (X→A+) and feature-absent (A−). During feature-positive trials, X always precedes the onset of A, and responses are reinforced during or immediately following the presentation of A. Responses to A on feature-absent trials are never reinforced. The X→A+/A− training is meant to establish that A’s validity as a signal for reinforcement is conditional on the presentation of X. Baeyens, Vansteenwegen, Hermans, Vervliet, and Eelen (2001), for example, trained college students that shots fired at invading Martians were successful only if the discriminative stimulus (A, an enemy’s laser shield) was preceded by a feature stimulus (X, a computer image). Participants learned to emit more blaster shots at an invading pack of Martians during A when it was preceded by X (X→A) than on trials when A was presented alone (A−). Since most prior work on feature-positive discriminations has been completed with nonhuman animals, the results of Baeyens et al. (2005; Baeyens et al., 2001) support the cross-species relevance of feature-positive discriminations in guiding instrumental responding.
An unanswered question regarding feature-positive discriminations persists: To what extent is the relationship of A and the reinforced response conditional on X? One measure of X’s conditional properties requires training with a second feature-positive stimulus pair (e.g., Y→B+), followed by test trials of the novel configuration X→B. This transfer test measures the transmission of control from a trained compound to a novel compound (e.g., Bonardi, 1996, Experiment 2). The general finding is that during transfer tests, conditional cues behave differently from simple excitatory cues and that effective transfer depends on two factors; the first is the perceptual quality of the stimuli, and the second is their training history. Concerning the former, Bonardi found that responding to B was enhanced when paired with X (XB) to the extent that the organism generalized between the original (A) and transfer targets (B). Bonardi concluded that a conditional stimulus (e.g., A) modulates a specific discriminative stimulus (e.g., X), and transfer to other discriminative stimuli is limited to the generalization that occurs between the two compounds, XA and YB. Concerning training history, Bonardi argued that previous training of YB in a feature-positive relationship enhances generalization between YB and XA—thereby enhancing responding to B when paired with X. Alternatively, others have argued that X’s ability to control responding to B is determined by the prior role of B as an ambiguous cue (Swartzentruber, 1995; but see Schmajuk, Lamoureux, & Holland, 1998). A cue can be ambiguous as a result of partial reinforcement, extinction, or previous training in a feature-positive relationship. Baeyens et al. (2001) conducted transfer tests with humans with a trained feature paired with a discriminative stimulus made ambiguous via each of the aforementioned methods. When X and A were sequentially trained (X→A+), transfer was observed only when X was paired with a cue that had previously been trained in a feature-positive relationship. These findings validate the use of a discriminative stimulus previously trained in a conditional discrimination for transfer testing and demonstrate the value of transfer tests in evaluating the conditional properties of a cue. Very little research has examined which, if not all, of these predictions readily apply to different types of predictive information a cue can provide, such as when and where the reinforced response must occur.
While there has been no direct examination of transfer of conditional control as a function of training history in the spatial domain, Molet, Gambet, Bugallo, and Miller (2012) used a conditional task to examine contextual control of spatial responding. Young adults were trained in a 3-D virtual environment to locate treasure within an area of response locations. In the first phase, participants learned the spatial relationship between two stimuli (A and B), which differed across two contexts (X and Y). Although the stimuli shifted position across trials, the spatial relationships remained constant in each context. In phase 2, participants learned the relationship between A (with B absent) and a hidden treasure located in one of the response locations. At test, participants were given trials with B alone in either context X or Y. This test evaluated whether the context would selectively retrieve the original spatial relationship between A and B, which would guide the participants to respond at different locations depending on the context in which B was presented. Participants predominately searched at the location relative to B, in each context, that was consistent with the A–B spatial relationship learned in that context (see Molet, Urcelay, Miguez, & Miller, 2010, for a similar demonstration in the temporal domain with rats). In sum, this experiment demonstrated a clear role for spatial information in one form of conditional discrimination.
The aim of our study was to develop a feature-positive landmark procedure and test additional properties of conditional control in the spatial domain. We adapted a previously reported task that required animals to search a linear array of eight response locations and find a hidden goal, hereafter referred to as a target (see Fig. 1; e.g., Leising, Garlick, & Blaisdell, 2011; Leising, Wolf, Hall, & Ruprecht, 2014). College undergraduates were prompted to search for treasure using two cues: a conditional cue, X, and a landmark, A. For the purposes of the present experiment, we define the target as the response location at which responses were reinforced (i.e., presentation of the treasure). When X preceded A, responses to the target were followed by a reinforcer. The present setup differed from previous investigations on feature-positive training in two important ways: 1) Landmark A provided some spatial information about the target but moved across the array of potential response locations (but see Bueno & Holland, 2008, for a procedure with rats that alternated two reinforcer locations without the use of landmarks) and 2) the contingency between the conditional cues and landmarks on transfer tests was always the same, but on some trials, conditional cues and landmarks provided varying amounts of conflicting spatial information about the location of the target (see Fig. 2). One can easily imagine how conditional cues might modulate the informational value of landmarks (e.g., If your car clock says 3:00 pm, then you turn left at the highway intersection to get home; if your car clock says 5:00 pm, then you turn right at the intersection to avoid traffic and get home faster). The central objective of the present work, therefore, was to use transfer tests to determine the role of conditional cues and landmarks in controlling two dimensions of search behavior, the magnitude of responding and spatial accuracy. We define spatial accuracy as a measure of spatial control in relation to the landmark, measured as a higher proportion of responses at the target location (in comparison with the other seven response locations).

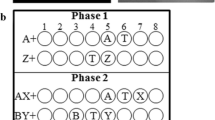
Participants aimed the response apparatus (blaster) at the screen and were able to see their targeting radical on the monitor. The relative location of the target is illustrated in two trials (←XA and YB→) within Experiment 1. During XA and YB trials, only blasts to the location labeled “T” were followed by treasure

Procedure for Experiment 1, Experiment 2a, and Experiment 2b. During training (left column), the dark black arrows indicate the direction that the target was located in relation to the landmark. During test, the dark black arrows indicate where the target had been trained in relation to the landmark, whereass the colored arrows (matching the color of the background) represent the direction of the target indicated by the conditional cue. Treasure chests represent the opportunity for reinforcement for responses to the target; no treasure was presented at test. Trials on which responses to the target were followed by treasure are indicted by a (+); trials on which responses to the target were nonreinforced are marked by a (−)
Humans undoubtedly weigh the relative contribution of multiple spatial cues to orient and plan a successful search, perhaps by some form of adaptive combination (e.g, Byrne & Crawford, 2010; Ratliff & Newcombe, 2008) or in a Bayesian fashion (e.g., Battaglia, Jacobs, & Aslin, 2003; Cheng, Shettleworth, Huttenlocher, & Rieser, 2007). Recently, Byrne and Crawford (2010) described how participants might employ a maximum likelihood estimator during two-dimensional tasks to weight two separate landmarks when planning a reaching response. Within the spatial literature, it is widely understood that spatial accuracy is a function of a landmark’s 1) proximity, 2) stability, and 3) reliability, in relation to the target. First, we define proximity as a pure measure of distance between a landmark and a target. When stimuli are displaced relative to one another, for instance, the location at which a participant searches is often a weighted average of the distance and direction of each landmark, relative to one another (e.g., Cheng 1989; Ratliff & Newcombe, 2008). Humans, moreover, weight proximal and distal landmarks separately: Proximal landmarks are weighted more heavily than distal landmarks when guiding, for instance, human reaching movements during two-dimensional search tasks (e.g., Byrne & Crawford, 2010). Second, we define stability as the variance of a landmark’s vector (distance and direction) to the target across trials. Accuracy during the presentation of any one landmark, for instance, varies as a function of whether the distance and direction of the landmark was more or less stable across trials. More stable landmarks elicit less variable responding when tested in isolation and, in addition, are weighed more than less stable landmarks during situations involving multiple cues. (e.g., Biegler & Morris, 1993). Finally, we define reliability as the probability that reward will occur in the presence of a landmark, irrespective of its distance or direction. This dimension is inherently nonspatial and reflects the contingencies encountered during training. To summarize the present experiments within a spatial framework, we were testing whether a diffuse conditional cue, high in reliability (trials with conditional cues had a high contingency with reward) but low in stability (across trials, the distance and direction of the background to the target was unstable), could control responding to a landmark that was low in reliability (the landmarks themselves had a low contingency with reward) but high in stability (the landmarks maintained a highly consistent distance and direction to the target location).
Previous research on conditional discriminations from a hierarchical learning perspective (e.g., occasion setting) suggests that a conditional cue modulates responding to a specific discriminative stimulus, but the properties (e.g., proximity and reliability) of the discriminative stimulus determine the magnitude of responding. Research from a hierarchical perspective also indicates that the magnitude of responding on transfer tests should be less than that on the training trials—a matter of the generalization between the switched targets. In our task, however, generalization could differentially affect magnitude (total responses) and spatial accuracy. For example, a high amount of perceptual similarity between landmarks signaling the target in different directions would lead to a high response magnitude but inaccurate responding.
Spatial learning models may be better suited to predict spatial accuracy during transfer tests (e.g., Ratliffe & Newcombe, 2008; Battaglia et al., 2003; Biegler & Morris, 1993; Bryne & Crawford, 2010; Cheng et al., 2007; Miller & Shettleworth, 2007; Ratliff & Newcombe, 2008). The conditional cue in our task was a diffuse cue low in stability but high in reliability, whereas the landmark was high in stability but low in reliability. If the influence of each cue on spatial behavior in our task was based on the proximity, reliability, and stability of each cue present during target and reward acquisition (see Miller & Shettleworth, 2007), then these spatial learning models would predict that responding will always be strongly biased in the direction of the target indicated by the most proximal and stable cue, the landmark.
General predictions
We predicted that on transfer trials, the conditional cues will control whether or not the response occurs in the presence of the landmark (i.e., occasion setting) but, when responding does occur, it will be the landmark present on that trial that will determine its location. In other words, the hierarchical account best predicts differences in magnitude, which should be differentially sensitive to novel configurations during transfer testing (e.g., novel landmark, novel background, etc.), whereas spatial accuracy (highly controlled by what participants encoded from the landmark) is best predicted via spatial learning models that describe the various contributions of multiple landmarks to spatial behavior. Additionally, because each landmark relationship to the target was contingent on the preceding conditional cue, we hypothesized that there would be little to no responding during transfer test trials in which (1) no conditional cue was present (landmark-alone trials, A−), (2) no landmark from training was present (novel-landmark, XC−), or (3) no conditional cue from training was present (novel-background, ZA−).
Experiment 1
During conditional discriminations, a stimulus (the conditional cue) signals the contingency between a discriminative stimulus (landmark) and a reinforced response location (target). In Experiment 1, college students were trained on two feature-positive discriminations, XA+ and YB+, in addition to two landmark-alone trials, A− and B−, during which no treasure was available (top left of Fig. 2). Following asymptotic training, participants received tests that fell into six categories: (1) previously trained (2) incongruent (3) novel background, (4) novel landmark, (5) landmark alone, and (6) background alone (top right of Fig. 2). To clarify, if the conditional cue indicated one direction and the landmark the opposite direction in relation to itself, it was referred to as an incongruent test. In contrast, if the conditional cue and landmark indicated the target in the same direction, we termed these congruent tests. The major aim of Experiment 1 was to reveal evidence of feature-positive discriminations in humans (higher responding to XA+ than to A−) within a spatial-search task.
An additional aim was to examine what effect various types of transfer tests would have on the magnitude and spatial accuracy of responding in the presence of a landmark. We expected the strongest general responding (i.e., magnitude) and spatial control (i.e., accuracy) during previously trained trials (XA, YB), followed by incongruent (XB, YA), novel-background (ZA, ZB) and finally novel-landmark (XC, YC) trials. We hypothesized that the landmark’s close spatial proximity and high stability to the target, relative to the conditional stimulus, would lead to more disruption on test trials when the landmark was replaced with a novel stimulus than on test trials with a novel conditional cue. This prediction is also consistent with Bonardi’s 1996) findings that transfer depends on generalization between A and B (the landmarks). In sum, these predictions are consistent with previous research on feature-positive discriminations, but with the added predictions regarding spatial accuracy at test.
Method
Participants
A total of 20 undergraduate psychology students (10 females, 10 males, 18–24 years of age) at Texas Christian University (TCU) participated as a partial fulfillment of course requirements. None of the students had any previous experience with the blaster preparation, and all were uninformed as to the purpose of the experiment. Participants were trained and tested individually; the experiment’s duration was 60 min. All research was conducted in accordance with TCU’s Human Participant Ethics Committee and an approved IRB protocol.
Apparatus and stimuli
A Hewlett Packard Touchsmart computer was used to display stimuli; the computer monitor dimensions were 48.26 cm (l) × 30.48 cm (w). “Light Guns” by ArcadeGuns® (right side of Fig. 1) functioned as a distal mouse using a motion sensor bar mounted above the monitor.
Response locations consisted of a linear series of eight squares that were 4.8 cm in length/width. The row of response locations was located 16 cm from the bottom of the monitor, and each box was equally spaced apart by 6 cm (center to center). In order to increase the response cost of incorrect responses, participants were given an ammunition bar that shrunk with every response. The length of the bar was designed to match the shots needed for an average participant but would simply refill if the ammunition was exhausted. The ammunition bar was removed during all tests (see below). Visual stimuli during the task fell into three major categories: response locations, conditional cues, and landmarks.
The conditional cues were colored backgrounds that surrounded the response locations and filled the remainder of the display (see Supplementary Material). The background colors used were solid red, blue, and cyan (RGB values: 156, 207, 213). In the absence of an active conditional cue, the background appeared black. During feature-positive training, one of six possible response locations (i.e., locations 2–6) served as a landmark (hereafter referred to as the landmark). If a response location was selected to be a landmark, it was replaced with an image of a 4.8-cm (l/w) green (thin vertical white stripes), yellow (thick horizontal stripes), or pink (thick diagonal strips) box. Assignment of color to landmarks and the conditional backgrounds was fully counterbalanced across participants. On any given trial, one location among response locations 2–7 served as a landmark, whereas one of locations 3–6 served as the target.
Procedure
Positioning
The participants were seated in a chair 1.8 m across from the monitor. The top row of Fig. 1 shows the experimental apparatus. Participants were instructed to sit comfortably in the chair and aim the blaster at the screen, with their elbows comfortably rested on the arms of the chair. The participants maintained this basic position throughout the experiment.
Pretraining
Participants were then allowed to explore and take shots into the eight response locations. A shot to one of the eight response locations revealed a treasure chest in the lower portion of the screen. The participants then had to successfully locate two more hidden treasures, this time by firing 2–4 times into the same box, before being advanced to training. The participants were read the following instructions by an experimenter:
From time to time this row of boxes will appear. The boxes can be fired upon and shots to the boxes will only count when you press the trigger while the crosshair is inside the box. When the boxes are available, it also means one of them is hiding a hidden treasure. Your task is to find the box which reveals the hidden treasure. Take this opportunity to explore the screen and locate the hidden treasure. Keep in mind that on some trials you will only have to shoot the box once to reveal the treasure, but other trials may require several shots to the correct box to reveal the treasure.
Training
The top left of Fig. 2 shows the four types of training trials in Experiment 1. On XA+ trials, X was presented (i.e., color of the display changed to the selected conditional cue), but the onset of landmark A was delayed by a variable time (5–10 s), relative to the onset of X; both stimuli coterminated 20 s after the onset of X. A 3-s intertrial interval (ITI) was utilized throughout training. Landmark A was positioned one response location to the right of the reinforced target location; blasts to the target during A were reinforced until offset. BY+ trials were conducted in a similar manner, with the exception that landmark B was positioned one location to the left of the reinforced target location. A shot to the target on feature-positive trials (XA+, YB+) produced a treasure chest graphic in the center of the monitor, 2 cm (bottom border) from the bottom. When the treasure appeared, the cursor momentarily disappeared, and blasts were not recorded. The treasure presentation lasted 2 s. Essential to the spatial component of the search task, the placement of a landmark within the response locations varied from one trial to the next (see Supplementary Material). Thus, there was an unstable relationship between the location of a landmark and the conditional cue, as well as between the conditional cue (colored background) and the target, but the spatial relationship between the landmark and target remained stable across all trials (Fig. 1).Prior to training, participants were read the following instructions:
During the warm up, the background of the screen was black, but on future scenarios you’ll notice different colored walls, or perhaps, different filled patterns on the boxes themselves (experimenter points to the boxes). This is very important! During the next task there will also be scenarios when finding a treasure is NOT possible. First, explore with many shots, to identify when and if there is hidden treasure during a given scenario, and when there is not. You’ll know when a new scenario begins when the screen goes blank and things change again. The duration of the experiment will be dependent on how well you do. At some point a label will come up that tells you to come get the experimenter.
To advance to testing, all participants were required to complete three blocks of eight feature-positive discrimination trials with 80 % accuracy or higher (measured as a discrimination ratio of XA to A and YB to B). Moreover, each subsequent block required a higher response requirement: Block 1 implemented a continuous reinforcement schedule, with every blast to the target being rewarded with treasure; Block 2 implemented a random ratio 2 (RR-2) schedule, with every blast to the target having a 50 % chance of being rewarded; Block 3 implemented an RR-4 schedule, with every blast to the target having a 25 % chance of being rewarded. After the participants achieved an 80 % accuracy or higher on the RR-4 schedule (participants repeated any failed block over again, up to 9 times), they received a message alerting them to get the experimenter and were advanced to test. All participants in Experiment 1 met the criterion for testing.
Test
Participants then received two shuffled blocks of 12 nonreinforced trials: A, B, XA, YB, XB, YA, ZA, ZB, XC, YC, X, and Y; the order was counterbalanced across participants. The duration of ITIs and background/ landmark onsets were identical to training. Prior to testing, participants were read the following instructions:
On scenarios after this signal, you should still do your best to find the box that previously hid the treasure, but no treasure will be shown (though we are still keeping track). This is because we don’t want you to know whether you chose correctly or not, we just want to know which landmark you think is hiding the treasure. Though we are not giving you feedback, you’re accuracy is still being recorded and we will let you know how you did very soon. Now, find as much treasure as possible!
Results
Response magnitude
Categories
The magnitude of responding was calculated by summing all responses detected within the eight response locations for each trial type and averaging across the 20 students. When comparing response magnitude, each separate test was collapsed within six functional categories: previously trained (XA and YB), incongruent (XB and YA), novel background (ZA and ZB), novel landmark (XC and YC), landmark absent (A and B), and background alone (X and Y). Mean comparisons were obtained via t-tests; when appropriate, effect size was reported via Cohen’s d (e.g., Rosenthal & Rosnow, 1991). Prior to collapsing, magnitude did not differ between any tests within the same category, all ts < 1.73, ps > .05.
Between category analysis
Figure 3 displays the mean number of responses for each test. A repeated measures analysis of variance (ANOVA) with category (previously trained, incongruent, novel background, novel landmark, landmark alone, and background alone) as the repeated measure conducted on magnitude revealed a significant main effect of category, F(5, 95) = 30.6, p < .001, η 2 = .51. Post hoc analysis (Tukey’s HSD) compared each category with each other. As is illustrated in Fig. 3, participants responded more during the previously trained tests than during all other tests, including incongruent, p < .01, indicating a limited transfer of responding. Additionally, transfer was specific, such that responding during the incongruent tests was greater than during the background-alone tests, p < .01, novel-landmark, and landmark-alone tests, p < .01. Novel-background tests, moreover, elicited higher responding than did landmark-alone tests, p < .05, whereas novel-landmark tests did not, p > .05. There was no significant difference between novel-background and novel-landmark tests, p > .05.

The y-axis displays the mean total blasts (across all of the eight response locations) during each trial. Only blasts made in the presence of the landmark were recorded for feature-positive and all transfer trials that presented a background and landmark. Error bars represent standard errors of the means
Spatial accuracy
Categories
Since we expected the amount of blasts taken to differ across participants, the proportion of blasts to each location (i.e., blasts to a location/total blasts to all response locations) served as the dependent variable for spatial accuracy. The mean spatial accuracy data were collapsed into the same six categories as before. Again, no groups within the same category differed, all ts < 1.02, all ps > .05, ds < 0.46. Four of the six categories are illustrated in Fig. 4; because landmark-alone and background-alone tests elicited little to no responding (see Fig. 3), they are not illustrated. Across all experiments, less than 2 % of participant’s blasts occurred at any other location than those immediately to the left or right of the landmark. Consequently, while we tracked blasts at all eight locations (including the landmark itself, if presented), we conducted analysis primarily on these two locations (to the left and right of the landmark).

The y-axis displays the mean proportion of blasts at two locations during testing. Responses to the location where the hidden target was expected on the basis of training (in relation to the landmark) are illustrated by the dark gray bars, whereas responses to the location on the opposite side of landmark are illustrated by the white bars. Previously trained (XA, YB), incongruent (XB, YA), novel-background (ZA, ZB), and novel-landmark (XC, YC) tests are presented (collapsed within category). Landmark-alone and background-alone tests are not illustrated, due to lack of responding. Error bars represent standard errors of the means
As Fig. 4 illustrates, across the majority of the tests, a significant majority of blasts were made to the target (all other response locations were well below or equal to chance and did not differ across or within categories). Paired t-tests revealed that a higher proportion of blasts were taken at the target, as compared with the opposite, location during previously trained, t(19) = 4.7, p < .001, d = 2.15, incongruent, t(19) = 3.35, p < .01, d = 1.53, and novel-background, t (19) = 3.04, p < .01, d = 1.39, tests. Responding did not differ between the target and opposite locations during the novel-landmark or landmark-alone tests, all ts = 1.09, ps > .28, ds < 0.5 .
Between-category analysis
We compared the proportion of shots taken to the target between all six categories. A repeated measures ANOVA (category: previously trained, incongruent, novel background, novel landmark, target alone, background alone) conducted on the proportion of blasts to the target revealed a main effect of category, F(3, 57) = 19.7, p < .001, η 2 = .51. Post hoc analysis revealed that previously trained, incongruent, and novel-background tests, which did not differ (with the exception of previously trained vs. novel background, ps < .01), elicited a higher proportion of blasts to the target than did novel-landmark, background-alone, and landmark-alone tests, all ps < .01, which themselves did not differ, p > .05.
Discussion
Experiment 1 illustrates the successful training of a feature-positive discrimination (XA+/A−) during a spatial-search task with landmarks. To summarize, all 20 students were able to learn the basic feature-positive discrimination (e.g., greater responding to XA than to A alone at test), a finding consistent with recent work (Baeyens et al., 2005; Baeyens et al., 2001) using a nonspatial, feature-positive discrimination task with humans. Consistent with other reports on the transfer of control by a conditional cue (i.e., a feature in the associative literature) in a conditional discrimination with nonhuman animals, we found transfer performance on novel trials to be limited and selective (Bonardi, 1996), limited because students responded considerably less during incongruent tests than during previously trained tests, yet selective, because a novel, unfamiliar landmark (C, which had no prior training history) elicited less responding than did the previously trained and incongruent tests, both of which featured previously trained cues. A second interest was spatial accuracy. Tests showed that students appeared to encode spatial information about the landmark and the target, as evidenced by tight spatial control of responding across all tests, excluding those with a novel landmark (Fig. 4), background alone, or landmark alone (not illustrated).
The decrement in magnitude between the previously trained and incongruent trials could be due to interference due to the background and landmark indicating conflicting information (we tested this notion in Experiments 2a and 2b) or generalization decrement, which is a reduction in responding due to a perceptual failure to recognize the landmark during the incongruent transfer trial as the same landmark from training (see Pearce, 1987, 1994). Because the incongruent tests were novel configurations and spatially incongruent, it was not possible to determine whether the novelty of the transfer tests themselves (i.e., generalization decrement) or the spatial incongruence of the conditional cue and landmark was driving the reduction in response magnitude. This issue will be addressed by Experiments 2a and 2b. While interference or generalization decrement appeared to have a marked effect on magnitude (incongruent tests; Fig. 3), no difference in spatial accuracy was found.
The absence of an affect on spatial accuracy could be interpreted two ways: 1) Conditional cues (X and Y) were facilitating (i.e., acting like a gate) spatial information about A and the target, rather than independently exerting control over search accuracy (a hallmark of more general occasion setting phenomena), and/or 2) at the onset of a spatially incongruent test, conditional cues X and Y were weighted considerably less than landmarks A and B, due to their ambiguous reliability to the target (recall that X and Y were diffuse backgrounds). Our results indicate that both mechanisms are acting in concert with one another. All transfer trials indicated a reduction in general responding, with the most acute reductions occurring when the most spatially relevant component of the task, A, was replaced by a novel landmark, C. These results support the notion that the conditional cues (X and Y) were ungating the spatial information that A provided about the target, rather than independently exerting their own control over spatial behavior during incongruent tests. With respect to cue weighting, previous literature shows that when human participants are required to respond on the basis of two or more landmarks, the relative influence of these landmarks, at least in part, is determined by their respective proximity, stability, and reliability to the target (e.g., Battaglia et al., 2003; Ernst & Banks, 2002; Knill, 2007; Knill & Saunders, 2003; Van der Kamp, Savelsbergh, & Smeets, 1997; Vaziri, Diedrichsen, & Shadmehr, 2006). These findings fit well with our observation that spatial accuracy remained high and in the direction of the landmark on incongruent tests. Moreover, the complete lack of responding during landmark-alone tests (A− and B−) is indicative of hierarchical stimulus control, because if the participants were utilizing the reliability/stability of landmarks alone, they would respond on these trials.
A third result of interest was that spatial control by the conditional cue dropped most when a novel landmark, C, was tested, as compared with tests with a novel background, Z. It could have been the case that the identity of A and B were ignored during training but simply served as anchor points from which to respond when preceded by X or Y, an account purely based on discrimination of the conditional cues; however, if this were true, then on trials with a novel landmark, C, participants would have simply responded in the direction indicated by the conditional cue. Instead, we found a large disruption in performance on these trials. Rather, it appears that when deciding where to blast, participants, not surprisingly, learned about the landmarks from training in addition to the diffuse conditional cues, X and Y.
In sum, students in Experiment 1 readily encoded spatial information regarding the landmark and target, and this information was ungated by the preceding presentation of a conditional cue. In particular, hierarchical accounts best explain the observed differences in response magnitude, whereas the participants’ spatial accuracy is best explained via spatial learning models that predict the various contributions of multiple landmarks. In Experiment 2, we investigated whether past training of stimuli affects transfer and whether the disruption of transfer is the result of spatial incongruence or generalization decrement.
Experiment 2a and Experiment 2b
The aim of Experiments 2a and 2b was twofold. First, we aimed to directly test whether a landmark needed to previously participate in a feature-positive discrimination to elicit strong, spatially accurate responding during a transfer test. Previous research showed transfer to be, in part, dependent on the training history of the candidate landmark (Swartzentruber, 1995). To this end, we added training trials of C+, a landmark positioned to the left of a reinforced target location but with no background preceding it. Since trials of C+ were never preceded by a conditional cue, landmark C did not participate in conditional discrimination training. Consequently, we would predict, on the basis of the occasion setting literature, that conditional cues would transfer considerably less facilitation of responding to C during transfer trials (e.g., Davidson & Rescorla, 1986; Holland, 1986a, b, 1989; Wilson & Pearce, 1989, 1990). A key procedural difference between this study, however, and most previous studies was that we did not extinguish C prior to test (see Swartzentruber, 1995). We were interested in whether response magnitude and spatial control by C would be affected if the conditional cue and the landmark were both at full excitatory strength during novel pairings. Any decrement that occurred in Experiment 2a could be the result of generalization decrement or spatial incongruence, whereas Experiment 2b isolated the contribution of generalization decrement in the absence of spatial incongruence.
A second aim of Experiment 2a and Experiment 2b was to investigate whether spatial congruency, or the degree of agreement, between the target predicted by the conditional cue and the landmark during a transfer test would affect the degree of transfer during trials of landmarks with previous feature-positive training. Additionally, an important difference between Experiment 1 and Experiments 2a and 2b was that we trained participants that the conditional cue itself could disambiguate the spatial relation between a single landmark and two separate target locations (left vs. right; see trials ←XA and YA→ in Fig. 2). Consistent with Experiment 2, the colored background was again high in reliability and low in stability. In contrast to Experiment 1, landmark A was also low in stability, as well as reliability. Critically, what was unique about these experiments was that the conditional cue provided information regarding where to respond, relative to the landmark, not the actual location in space. According to recent spatial learning models for humans (e.g., Byrne & Crawford, 2010), allocentric information derived from relatively unstable landmarks is weighed less than that derived from relatively stable landmarks. Therefore, in the present experiments, conditional cues X and Y might be weighted more than conditional cue Z, when participants made decisions on where to respond during transfer trials. In summary, while spatial learning models (e.g., reliability) are able to predict the landmarks’ superior control over responding at test in many transfer trials, it would be more difficult, to predict how participants would successfully solve an ←XA, YA→ discrimination purely by paying attention to the reliability/stability/proximity of A—since it was, in fact, very unreliable and unstable, requiring a reliable cue, X or Y, to disambiguate the spatial relationship. We further investigated conditional control of a landmark in Experiments 2a and 2b.
Summary and hypothesis
In Experiment 1, novel combinations of the conditional cue and the landmark had a marked effect on the general magnitude of responding (Fig. 3) but did not cause a significant drop in spatial accuracy (Fig. 4); however, this empirical observation suggests the need for an additional comparison. Across two experiments, we tested spatially incongruent (Experiment 2a) and congruent (Experiment 2b) transfer trials. On the basis of Experiment 1, we did not expect spatial incongruence to have a marked affect on spatial accuracy, but if the direction indicated by the conditional cue (e.g., go right) conflicted (i.e., was incongruent) with the information indicated by the landmark (e.g., go left), we expected less general responding, in comparison with nonconflicting (congruent) transfer trials or previously trained trials. Moreover, on the basis of previous literature (Swartzentruber, 1995), we hypothesized, within each experiment, that the training history of C would lead to decreased general responding and spatial accuracy on tests with C (e.g., YC and XC), as compared with tests featuring a landmark that had participated in conditional discrimination training (e.g., XB or YB).
Method
Participants
For Experiment 2a and Experiment 2b, 24 and 28 undergraduate psychology students, respectively, participated for partial fulfillment of course requirements. It was found that 8 students in Experiment 2a and 12 students in Experiment 2b never reached the behavioral criterion (80 % accuracy for two consecutive blocks during OS training), which resulted in a total number of 16 participants (8 male, 8 female) for each experiment (ages, 19 to 24). None of them had any previous experience with the blaster preparation, and they were all uninformed as to the purpose of the experiment. All research was conducted in accordance with TCU’s Human Participant Ethics Committee and an approved IRB protocol.
Apparatus and stimuli
The apparatus and stimuli used in Experiment 2a and Experiment 2b were the same as those used in Experiment 1.
Procedure
The pretraining and position procedures in Experiment 2a and Experiment 2b did not differ from those in Experiment 1.
Training
Figure 2 (bottom left) shows the training trials notated for direction. The two experiments were conducted at different time points and with different participants; therefore, we report them separately. In Experiment 2a and Experiment 2b, participants were required to complete at least two 12-trial blocks of the training trials (XA+, ZB+, YA+, C+, A−, nd B−), with 80 % accuracy before advancing to test. As was mentioned earlier, 20 students failed to complete the behavioral criterion across both experiments; thus, their test data were excluded from analysis. On XA+, YA+ and ZB+ trials, the color of the display changed to the selected conditional cue (blue, red, or cyan backgrounds), and the onset of A or B, respectively, was delayed by a variable time (5–10 s); both stimuli coterminated 20 s after the onset of X, Y, or Z, respectively. The ITI during training and test did not differ from that in Experiment 1. Landmarks A and B were positioned one location to the right of the reinforced target location when paired with X and Z, respectively, but A was to the left of the target when paired with Y. Blasts to locations during A and B, when paired with a colored background, were reinforced until offset. Lastly, during C+ trials, C was presented one location to the left of the target and was not preceded by a conditional stimulus (i.e., the background was black, resembling the ITI or landmark-alone trials; see Fig. 1). Blasts to response locations during C were also reinforced until offset.
Participants were advanced to testing identical to Experiment 1, with the exception that participants had to also respond to the target at least once during 100 % of the trials for at least three blocks during C. Across both experiments, 32 participants were able to complete the training requirements in less than 50 min and were advanced to test, whereas 20 participants did not make criterion/ran out of time. All other details were the same as in Experiment 1.
Test
In Experiment 2a, participants received two pseudorandom blocks of eight nonreinforced trials: A, B, XA, YA, ZB, C, XC, and YB. In Experiment 2b, participants received two pseudorandom blocks of eight nonreinforced trials: A, B, XA, YA, ZB, C, YC, and XB. All procedural details were identical to the test during Experiment 1. Since the experiments were conducted separately, the data were analyzed separately for each experiment.
Results
Response magnitude
Categories
Figure 5 displays the magnitude of responding during Experiment 2a and Experiment 2b . The magnitude of responding was calculated as in Experiment 1.Within each experiment, tests were collapsed within three categories. For Experiment 2a, the categories were previously trained (XA, YA, ZB, and C), incongruent (XC and YB), and landmark alone (A and B). For Experiment 2b, the categories were previously trained, congruent (XB and YC), and landmark alone. Within either experiment, no tests within the same category (e.g. incongruent) significantly differed, all ts < 1.51, ps > .05.

The y-axis displays the mean total blasts (collapsed across all of the eight response locations, averaged across participants) during each trial. During previously trained and incongruent (Experiment 2a)/congruent (Experiment 2b) trials, only blasts made during the time the landmark was present were recorded. Error bars represent standard errors of the means
Between-category analysis
In Experiment 2a, responding during the spatially incongruent tests was less than that during the training trials but greater than that durng the landmark-alone tests. A repeated measures ANOVA conducted on magnitude, with category (previously trained, spatially incongruent, landmark alone) as the repeated measure, revealed a significant main effect of category, F(2, 30) = 53.4, p < .001, η 2 = .78. Post hoc analysis (Tukey’s HSD) revealed that previously trained tests differed from all other trial types, ps < .001; additionally, responding on incongruent tests was greater than that on landmark-alone tests, p < .01.
Figure 5 (right side) indicates that responding during the congruent trials appeared similar to that for the previously trained trials, but greater than that for the landmark-alone trials. This was confirmed by a repeated measures ANOVA conducted on magnitude, with category (previously trained, spatially congruent, landmark alone) as the repeated measure, revealing a significant main effect of category F(2, 30) = 87.1, p < .001, η 2 = .78. Post hoc analysis (Tukey’s HSD) revealed that previously trained and congruent tests differed from the landmark alone tests, ps < .01, but themselves, did not differ, p > .05.
Training history
As was reported earlier, the two transfer trials were collapsed in each experiment, meaning that XC and YB did not elicit significantly different amounts of general responding in Experiment 2a, nor did XB and YC in Experiment 2b, meaning that the training history of C did not have a marked effect on general responding at test.
Spatial congruence of conditional cue and landmark
The critical difference between experiments was the presentation of spatially incongruent versus congruent tests. An independent t-test comparing average blasts during incongruent trials (XC, YB; left side of Fig. 5) and congruent trials, (XB, YC; right side of Fig. 5) revealed that students emitted more overall responses during spatially congruent trials (M = 42.9, SD =12.4) than during spatially incongruent trials, (M =20.3, SD =17.5 ), t(30) =4.20, p < .001, d = 1.5.
Spatial accuracy
Categories
Identical to the analysis of magnitude, the data were collapsed into the same three categories: previously trained, incongruent/congruent, and landmark alone. Two of the categories are illustrated in Fig. 6; because landmark alone elicited little to no general responding (Fig. 5), it was not illustrated. Again, no groups within the same category differed, all ts < 1.25, all ps > .05; thus, responding was collapsed across trials.

The y-axis displays the mean proportion of blasts at two locations during testing. Responses to the location where the hidden target was expected on the basis of training (in relation to the landmark) are illustrated by the dark gray bars, whereas responses to the location on the opposite side of landmark are illustrated by the white bars. Previously trained (XA, YB), incongruent (XC, YB; Experiment 2a), and congruent (XB, YC; Experiment 2b) tests are presented (collapsed within category, averaged across participants). Landmark-alone tests were not illustrated, due to lack of responding. Error bars represent standard errors of the means
As Fig. 6 illustrates, across the majority of the tests, a significant majority of blasts were made to the target (all other response locations were well below or equal to chance responding and did not differ across or within categories). In Experiment 2a, paired t-tests revealed that a higher proportion of blasts were taken at the target, as compared with the opposite, location during previously trained, t(15) = 5.1, p < .001, d = 2.6, and incongruent, t(15) = 3.70, p < .01, d = 1.9, tests. In Experiment 2b, participants emitted a higher proportion of blasts to the target location, as compared with the opposite location, during previously trained, t(15) = 7.4, p < .001, d = 3.8, and congruent, t(15) = 3.85, p < .01, d = 1.9, tests.
Between-category analysis
We sought to compare the proportion of blasts taken to the target between previously trained and congruent/incongruent tests. In Experiment 2a, a paired-samples t-test compared responding to the target during previously trained tests and incongruent tests and revealed a nonsignificant difference, t(15) = 1.6, p > .05, d = 0.82. In Experiment 2b, a similar test comparing previously trained and congruent tests also revealed a nonsignificant difference, t(15) = 0.4, p > .05, d = 0.21.
Training history
As is implied from the collapsing of categories above, XC and YB did not elicit a difference in the amount of blasts to the target in Experiment 2a, nor did XB and YC in Experiment 2b.
Spatial congruence of conditional cue and landmark
A crucial difference between experiments was the presentation of spatially incongruent versus congruent tests. An independent t-test comparing the proportion of blasts to the target on spatially incongruent trials, (XC, YB) versus spatially congruent trials, (XB, YC) revealed a nonsignificant difference between the two groups of students in spatial accuracy during the spatially congruent and incongruent tests, t(30) = .87, p > .05, d = 0.31.
Discussion
As in Experiment 1, participants in Experiments 2a and 2b learned a variety of feature-positive discriminations and were able to encode spatial information within these discriminations. The absence of similarity in training history did not disrupt performance. Participants learned when and where to respond to C and treated it similarly to the other landmarks when combined with a conditional cue. With all of the landmarks, when they were preceded by a spatially incongruent conditional cue (colored background) (X), general responding was reduced, but spatial accuracy was unaffected. When a spatially congruent conditional cue preceded the landmark, neither general responding nor accuracy was disrupted. The role of incongruence was also supported by the between-group difference in responding between incongruent and congruent tests; however, the participants in each experiment differed, so this comparison should be made with caution. The significance of these finding is that generalization decrement, which should have occurred to the same degree on novel-congruent and novel-incongruent transfer trials, cannot alone explain the disruption in general responding during the incongruent tests of both Experiment 1 and Experiment 2a.
Conflicting spatial information by the conditional cue and landmark did not result in any reduction in spatial accuracy during transfer tests in the present paradigm, but rather, induces a general reduction in magnitude. We suggest, in the present search paradigm, that magnitude of responding can be interpreted as confidence (i.e., excitatory strength), whereas spatial control reflects spatial information specific to each landmark and target, ungated by the conditional cue. Spatial conflict reduces confidence to respond, it appears, but blasts that do occur are quite accurate in relation to the landmark (also true of the findings of Experiment 1). Because X presumably predicted one response (e.g., go left) that is incompatible with the landmark (e.g., go right), confidence on these trials dropped in comparison with congruent trials (see Holland, 1989, for a similar interpretation).
The failure to find that transfer tests with C and B did not differ when presented in a novel configuration with a conditional cue is inconsistent with some findings in the literature; however, given the present methodology, it is not surprising. Previous studies in the literature extinguish C prior to testing in a novel configuration with a conditional stimulus (e.g., Davidson & Rescorla, 1986; Holland, 1986a, b, 1989; Wilson & Pearce, 1989, 1990). As was mentioned earlier, we did not extinguish C, because we were interested in how the conditional cue would influence the spatial location of responding and magnitude if the conditional cue and the landmark were both at full excitatory strength. It was an interesting prediction that the conditional cues might come to control where the participant responded in the presence of B, but not C, due to previous training of B with Z. However, it is not surprising that pairing C with a novel conditional cue did not disrupt the excitatory strength of C or spatial accuracy.
General discussion
The present experiments aimed to add a spatial component to a conditional learning task by training undergraduates to make feature-positive conditional discriminations involving stimuli that functioned as landmarks. During conditional discriminations, a stimulus (the conditional cue) signals the contingency between a discriminative stimulus (landmark) and a reinforced response. In all three experiments, participants successfully learned the feature-positive discriminations, responding during feature-positive trials more than during landmark-alone trials. In Experiment 1, transfer tests pitted conditional cues and landmarks that signaled different information regarding the direction of the goal, relative to the landmark, and revealed that responding was limited (i.e., response magnitude was greater during previously trained tests than during incongruent tests) and specific (i.e., incongruent was higher than novel landmark). Analysis of spatial control revealed that transfer was not limited (i.e., proportion of responses at the target during previously trained and incongruent were equal) but was specific (i.e., incongruent higher than novel landmark). In Experiment 2a, training history did not influence transfer. With the exception of a nonsignificant effect of training history, the hierarchical account (i.e., occasion setting) best explains the magnitude of responding observed, which was differentially sensitive to novel configurations during transfer testing (e.g., novel landmark, incongruent vs. congruent, etc.), whereas spatial accuracy (highly controlled by what participants encoded from the landmark) is best explained via models that emphasize the reliability, stability, and proximity of landmarks to a target.
Response magnitude (i.e., confidence) was disrupted on spatially incongruent tests; however, this difference disappeared on spatially congruent tests when the conditional cue and landmark predicted the target in the same direction (Experiment 2b). This suggests that the reductions in general responding (magnitude) were due to interference (spatial and/or response competition) and not generalization decrement (e.g., caused by novel configurations of the stimuli), because the combinations of stimuli were equally novel on spatially incongruent and congruent transfer tests but disrupted performance to different degrees. Interpreting why this had no effect on spatial accuracy is best accomplished by models that describe the relative weighting of individual landmarks in guiding the direction of responding depending on three factors: their 1) reliability, 2) stability, and 3) proximity. Consider the two feature-positive trials from Experiment 2a and Experiment 2b, ←XA and YA→. Spatial accuracy was maintained on both XB and YB transfer test trials, irrespective of whether the conditional cue was incongruent (e.g., Y) or spatially congruent (e.g., X) with the landmark. It is interesting that participants successfully learned the two discriminations, ←XA and YA→, but during transfer tests, there was no evidence that participants ever weighted their searches according to where a conditional cue indicated the target would be in relation to the landmark. Rather, it was the case that information from the proximal landmark (B) weighed heaviest on the direction participants responded to during testing, even when the landmark during training was unstable, requiring a conditional cue to disambiguate it.
Although this finding may not be surprising to those from a spatial learning perspective, keep in mind that whether or not the participant responded in the presence of the landmarks was almost entirely dependent on the presence of the conditional cue (see Figs. 2 and 4). Most of the spatial literature discusses integration versus competition among landmarks (Cheng, 1989; Cheng et al., 2007; see Leising & Blaisdell, 2009, for a review), but this study represents the most comprehensive investigation into the conditional control of a landmark. Conditional control has largely been studied from an associative learning (e.g., occasion setting) and cognitive (e.g., emergent relations and memory modeling) perspective. There was one single case of complete transfer (complete, meaning responding equated to responding during previously trained trials) in the present paradigm, when the conditional cue and landmark were spatially congruent (Experiment 2b); elsewhere, the findings are entirely consistent with the extant literature on associative occasion setting, which suggests that transfer is limited and specific (see Holland, 1986a, for an example within the timing literature).
The present spatial-search paradigm was easily adapted, with mostly mechanical modifications, for pigeons (Leising et al., 2014). A task adapted for two species offers a unique opportunity for direct, comparative analysis. Pigeons completed analogues of Experiment 1, Experiment 2a, and Experiment 2b, by pecking a touchscreen for presentations of mixed grain, rather than treasure. In regard to search accuracy, humans behaved much like pigeons, predominately responding to the direction signaled by the landmark. Two interesting distinctions between species, however, are worth mentioning. Figure 7 displays (a) the proportion of responses to the target by 20 students in Experiment 1and 5 pigeons in Leising et al. (2014) during previously trained and incongruent trials, and (b) the distribution of responses across the array for 16 students in Experiment 2b versus another set of 5 pigeons during the two trials pitting the effects of training history, YB versus XC. Regarding Experiment 1, pigeons responded with considerably less accuracy to the target signaled by the landmark on incongruent trials (e.g., YB; top left panel of Fig. 7), whereas humans blasted quite accurately (bottom left panel of Fig. 7). Regarding Experiment 2a, the training history of C had no effect on spatial accuracy in humans, but it did for pigeons (see top and bottom right panels of Fig. 7).

The proportion of responses is shown during the previously trained (YB) and incongruent (YA) trials for pigeons (a) and humans (b). The proportion of responses during a previously trained YB in Experiment 2a is shown for pigeons (c) and humans (d), as well as during tests of a compound featuring a landmark that did not receive conditional discrimination training (e and f). T represents where along the array the landmark indicated the target should be; OPP, indicates the opposite side of the landmark. Error bars represent standard errors of the means
These results, among others, suggest that conditional cues X and Y may serve more of a relational role for humans than for pigeons. Pigeons, for instance, tend to learn to solve a task on the basis of item-specific information (e.g., a specific feature) at the expense of relational information (the relationship between features; Wright, 1997), whereas humans tend to use various mechanisms to solve novel compounds (see Shanks, 2010, for a review). However, previous research has also shown that relational mechanisms can be encouraged in a conditional task by enhancing the salience of the landmark and inserting a gap between the conditional cues and landmark. It remains to be seen whether these manipulations would encourage more relational responding in pigeons in our task.
For both species, it is possible that the discriminations are being solved via a configural method (e.g., Pearce, 1987, 1994). Any reduction in responding at test, according to configural theories, would be a result of how generalizable, for example, the configuration XA is to XB. It is not clear, however, why general responding would be reduced at test, and not spatial accuracy, according to the configural account. Additionally, it is difficult for configural theories to explain how spatial congruence would influence perceptual similarity without concession of the formation of elemental and configural associations. More recent configural (e.g., Honey & Watt, 1998; Kutlu & Schmajuk, 2012) and hierarchical (e.g., Bonardi, Bartle, & Jennings, 2012) theories make so many of the same predictions that there is little room for empirical evidence to distinguish between them. In occasion setting, however, it is interesting to note that, “many of the conditions which support hierarchical learning are contradictory to the conditions that support configural learning” (Miller & Oberling, 1998, p. 7). Specifically, differences in temporal priority and the salience of the conditional cue and the targeted stimulus can encourage or discourage the use of hierarchical versus configural strategies (see Schmajuk et al., 1998, for details). A recent model by Kutlu and Schmajuk proposes that animals will try to solve discriminations via a configural method first, before relying on more complex methods. The inclusion of spatial or temporal information in conditional discrimination and occasion setting tasks may prove fruitful for pursing the distinction.
A concern is that the conditional cue may have never really provided any spatial information on its own. Participants universally responded toward the direction previously indicated by the landmark, and not the conditional cue on transfer trials, in spite of the role of the conditional stimulus in disambiguating the landmark. The most informative trials are the ←XA, YA→ trials during training and the novel configuration conditional cue–landmark transfer trials. Participants in Experiments 2a and 2b would have encountered great difficulty solving the ←XA, YA→ discriminations by attending only to A. We suggest that each conditional cue disambiguated the functional value of the upcoming landmark (X-A-left, Y-A-right), which is consistent with the associative perspective on occasion setting. However, it is also possible that these spatial discriminations could have been solved by simply detecting perceptual differences (i.e., A differs perceptually, when placed presented in compound with X vs. presented with Y). The hierarchical account predicts that generalization between landmarks is crucial for transfer, and functional similarity (←XA and ←ZB) can enhance that generalization, whereas the configural or perceptual account places a greater relative emphasis on the configuration of the conditional cue (colored background) and target and does not make the same prediction regarding generalization on the basis of the target alone.Transfer tests with the novel background and target indicate more disruption in the presence of a novel target, which better fits a hierarchical account. Furthermore, tests with incongruent versus congruent conditional and landmark cues presented similar perceptual changes to each landmark (B following X is just as different as B following Y), but greater responding was observed on congruent trials; which is consistent with greater generalization between landmarks with a history of functional equivalence.
A final concern worth mentioning is that differences in spatial control may be the result of the physical properties of each cue, and not the contingencies. It is surely the case that the physical properties of the two types of cues (diffuse vs. discrete, static vs. dynamic, etc.) influenced learning, but Experiment 2 suggests that the contingencies are crucial and the nonspatial conditional cue can influence where the participants searched in the presence of the landmark with the right contingencies. It is also true that physically diffuse cues (e.g., mountains) can provide important spatial information. Manipulations of the physical properties of each stimulus could alter how the conditional cue and landmark interact to control behavior, but that was not the objective of the present work. The importance of the present work, therefore, is less centered on the relative weighting of multiple signals (across all experiments; we cannot consider colored background as a true landmark, and at minimum, it is an extremely uninformative one) during a conditional discrimination. Rather, the impact lies in our evaluation of whether all or just some of a landmarks ability to guide the intensity and accuracy of behavior falls under conditional control of (i.e., be ungated by) another cue (the background). Our aim was to illustrate the nature of alterations in landmark-based searching by presenting manipulations known in the associative domain to alter more general responding during feature-positive discriminations (e.g., transfer tests). We believe that much can be learned by further studies linking both associative and spatial frameworks. In reality, when humans search and navigate, they use multiple strategies, and all cues can relay some amount of spatial information, depending on their proximity, stability, and reliability in relation to the target.
Small-scale spatial search tasks have become an increasingly valuable tool with which to investigate stimulus control (Cook, Katz, & Blaisdell, 2012; Leising & Blaisdell, 2009; Leising, Garlick & Blaisdell, 2011; Leising, Sawa, & Blaisdell, 2012; Leising et al., 2014; Sawa, Leising, & Blaisdell, 2005). We have thus far demonstrated several similarities between simple feature-positive conditional discriminations in the spatial domain and more conventional settings. The dichotomy between species, moreover, highlights how important comparative studies of cognition are to understanding the mechanisms of spatial memory. Skinner’s original conception of stimulus control is continually evolving and expanding in application; it is imperative, therefore, that we discover precisely what role conditional stimuli play as we search for food and evade threats.
References
Baeyens, F., Vansteenwegen, D., Beckers, T., Hermans, D., Kerkhof, I., & De Ceulaer, A. (2005). Extinction and renewal of Pavlovian modulation in human sequential feature positive discrimination learning. Learning & Memory, 12, 178–192.
Baeyens, F., Vansteenwegen, D., Hermans, D., Vervliet, B., & Eelen, P. (2001). Sequential and simultaneous Feature positive discriminations: Occasion setting and configural learning in human Pavlovian conditioning. Journal of Experimental Psychology: Animal Behavior Processes, 27, 279–295.
Battaglia, P. W., Jacobs, R. A., & Aslin, R. N. (2003). Bayesian integration of visual and auditory signals for spatial localization. Journal of the Optical Society of American: A. Optics Image Science, and Vision, 20, 1391–1397.
Biegler, R., & Morris, R. G. (1993). Landmark stability is a prerequisite for spatial but not discrimination learning. Nature, 361, 631–633.
Bueno, J. L. O., & Holland, P. C. (2008). Occasion setting in Pavlovian ambiguous landmark discriminations. Behavioural Processes, 79, 132–147.
Bonardi, C. (1996). Transfer of occasion setting: The role of generalization decrement. Animal Learning & Behavior, 24(3), 277–289.
Bonardi, C., Bartle, C., & Jennings, D. (2012). US specificity of occasion setting: Hierarchical or configural learning? Behavioural Processes, 90, 311–322.
Byrne, P. A., & Crawford, J. D. (2010). Cue reliability and landmark stability heuristic determine relative weighting between egocentric and allocentric visual information in memory-guided reach. Journal of Neuropsychology, 103, 3054–3069.
Cheng, K. (1989). The vector sum model of pigeon landmark use. Journal of Experimental Psychology: Animal Behavior Processes, 15, 366–375.
Cheng, K., Shettleworth, S. J., Huttenlocher, J., & Rieser, J. J. (2007). Bayesian integration ofspatial information. Psychological Bulletin, 133, 625–637.
Cook, R. G., Katz, J. S., & Blaisdell, A. P. (2012). Temporal properties of visual search in pigeon landmark localization. Journal of Experimental Psychology: Animal Behavior Processes, 38, 209–216.
Davidson, T. L., & Rescorla, R. A. (1986). Transfer of facilitation in the rat. Animal Learning & Behavior, 14, 380–386.
Ernst, M. O., & Banks, M. S. (2002). Humans integrate visual and haptic information in a statistically optimal fashion. Nature, 415, 429–433.
Holland, P. C. (1986a). Temporal determinants of occasion setting in feature-positive discriminations. Animal Learning & Behavior, 14, 111–120.
Holland, P. C. (1986b). Transfer after serial feature positive discrimination training. Learning and Motivation, 17, 243–268.
Holland, P. C. (1989). Acquisition and transfer of conditional discrimination performance. Journal of Experimental Psychology: Animal Behavior Processes, 15, 154–165.
Honey, R. C., & Watt, A. (1998). Acquired relational equivalence: Implications for the nature of associative structures. Journal of Experimental Psychology: Animal Behavior Processes, 24, 325–334.
Knill, D. C. (2007). Learning Bayesian priors for depth perception. Journal of Vision, 7, 1–20.
Knill, D. C., & Saunders, J. A. (2003). Do humans optimally integrate stereo and texture information for judgments of surface slant? Vision Research, 43, 2539–2558.
Kutlu, M. G., & Schmajuk, N. A. (2012). Solving Pavlov’s puzzle: Attentional, associative, and flexible configural mechanisms in classical conditioning. Learning & Behavior, 40, 269–291.
Leising, K. J., & Blaisdell, A. P. (2009). Associative basis of landmark learning and integration in vertebrates. Comparative Cognition & Behavior Reviews, 4, 80–102.
Leising, K. J., Garlick, D., & Blaisdell, A. P. (2011). Overshadowing by proximity with pigeons in an automated open-field and touchscreen. Journal of Experimental Psychology: Animal Behavior, 37(4), 488–494.
Leising, K. J., Sawa, K., & Blaisdell, A. P. (2012). Factors that influence negative summation in a spatial-search task with pigeons. Behavioural Processes, 90, 357–363.
Leising, K. J., Hall, J., Wolf, J. E., & Ruprecht, C. M. (2014). Feature-positive discriminations during a spatial-search task with pigeons. Manuscript submitted for publication.
Miller, R. R., & Oberling, P. (1998). Analogies between occasion setting and Pavlovian conditioning. In N. A. Schmajuk & P. C. Holland (Eds.), Occasion setting: Associative learning and cognition in animals (pp. 3–35). Washington, DC: APA.
Miller, N. Y., & Shettleworth, S. J. (2007). Learning about environmental geometry: An associative model. Journal of Experimental Psychology: Animal Behavior Processes, 33(3), 191–212.
Molet, M., Gambet, B., Bugallo, M., & Miller, R. R. (2012). Spatial integration under contextual control in a virtual environment. Learning and Motivation, 43, 1–7.
Molet, M., Urcelay, G. P., Miguez, G., & Miller, R. R. (2010). Using context to resolve temporal ambiguity. Journal of Experimental Psychology: Animal Behavior Processes, 36, 126–136.
Pearce, J. M. (1987). A model for stimulus generalization in Pavlovian conditioning. Psychological Review, 94, 61–73.
Pearce, J. M. (1994). Similarity and discrimination: A selective review and a connectionist model. Psychological Review, 101, 587–607.
Ratliff, K. R., & Newcombe, N. S. (2008). Reorienting when cues conflict: Evidence for an adaptive combination view. Psychological Science, 19, 1301–1307.
Rosenthal, R., & Rosnow, R. L. (1991). Essentials of behavioral research: Methods and data analysis (2nd ed.). New York: McGraw Hill.
Sawa, K., Leising, K. J., & Blaisdell, A. P. (2005). Sensory preconditioning in spatial learning using a touch screen task in pigeons. Journal of Experimental Psychology: Animal Behavior Processes, 31, 368–375.
Schmajuk, N. A., Lamoureux, J. A., & Holland, P. C. (1998). Occasion setting: A neural network approach. Psychological Review, 105, 3–32.
Shanks, D. R. (2010). Learning: From association to cognition. Annual Review of Psychology, 61, 273–301.
Skinner, B. F. (1938). The behavior of organisms: An experimental analysis. New York: Appleton-Century.
Swartzentruber, D. (1995). Modulatory mechanisms in Pavlovian conditioning. Animal Learning & Behavior, 23, 123–143.
Van der Kamp, J., Savelsbergh, G., & Smeets, J. (1997). Multiple information sources in interceptive timing. Human Movement Science, 16, 787–821.
Vaziri, S., Diedrichsen, J., & Shadmehr, R. (2006). Why does the brain predict sensory consequences of oculomotor commands? Optimal integration of the predicted and the actual sensory feedback. Journal of Neuroscience, 26, 4188–4197.
Wilson, P. N., & Pearce, J. M. (1989). A role for stimulus generalization in conditional discrimination learning. Quarterly Journal of Experimental Psychology, 41b, 243–273.
Wilson, P. N., & Pearce, J. M. (1990). Selective transfer of responding in conditional discriminations. Quarterly Journal of Experimental Psychology, 42b, 41–58.
Wright, A. A. (1997). Concept learning and learning strategies. Psychological Science, 8(2), 19–23.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Ruprecht, C.M., Wolf, J.E., Quintana, N.I. et al. Feature-positive discriminations during a spatial-search task with humans. Learn Behav 42, 215–230 (2014). https://doi.org/10.3758/s13420-014-0140-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13420-014-0140-3