
Abstract
A controversial issue in the literature on single word reading concerns whether semantic activation from a printed word can be stopped. Several reports have claimed that, even when attention is directed to a single letter in a word, semantic interference persists full blown in the context of variants of Stroop’s paradigm. Incidental word recognition is thus claimed to be unaffected by directed spatial attention and hence to be automatic by this criterion. In contrast, the literature examining the relation between intentional visual word recognition and spatial attention in tasks like lexical decision and reading aloud suggests that spatial attention is a necessary preliminary to lexical/semantic processing of a word. These opposing conclusions raise the question of whether there is a qualitative difference between incidental and intentional visual word recognition when spatial attention is considered. We first consider the methodology from Stroop experiments in which putatively narrowed spatial attention manipulations failed to prevent interference from semantics. We then report a new experiment that better promotes focused spatial attention. The results yield clear evidence that the effect of semantic activation can indeed be sidelined because one or more prior processes were in large measure stopped. We conclude that incidental word recognition is not automatic in the sense of occurring without any kind of attention.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The best-known and most easy to replicate phenomenon in cognitive psychology is, surely, the Stroop effect (Stroop, 1935). This work appears in virtually all introductory psychology and cognitive psychology textbooks, and in numerous chapters and refereed publications (see MacLeod’s 1991 review). Prototypically, readers are slower to identify the color in which a word is printed when that word is incongruent with the color font (e.g., the word “red” appears in green) than when that word is congruent with the color font (e.g., the word “red” appears in red) or when the printed word is not color-related (e.g., the word “toy” appears in red or green). These Stroop effects occur despite the reader being instructed to avoid reading the irrelevant word. Hence, such results are widely claimed to be evidence that it is impossible for readers to avoid reading the word, and therefore widely claimed that such reading should be understood as an automatic process that is unable to be stopped (e.g., Augustinova & Ferrand, 2014; Brown et al., 2002; Burca et al., 2021, among many others refereed publications, and virtually all introductory psychology books and cognitive psychology books).
Despite this being the received view in many quarters, there are various demonstrations that it is possible to reduce or eliminate a Stroop effect by various manipulations (e.g., hypnosis: Raz et al., 2002; relative dimension discriminability: Melara & Mounts, 1993; instructional set: Bauer & Besner, 1997; single letter coloring and spatial cueing: Besner, 2001; Besner et al., 1997; Besner & Stolz, 1999; Manwell et al., 2004; Labuschagne & Besner, 2015). The single letter spatial cuing manipulation is of particular interest in the present context because the results converge with those from the literature on spatial cueing and intentional word recognition, as in lexical decision and reading aloud. The results also converge with the assumptions from the eye movement literature in silent text reading to the effect that the focus of the eyes as they move through the text is closely tied to the distribution of spatial attention (e.g., Miellet et al., 2009).
Spatial attention and visual word recognition
There are a number of experiments in which a brief cue (e.g., a small circle) appears and is followed at a short stimulus onset asynchrony (SOA) by, for example, a single letter either in the location where the cue appeared, or in a different location. When the target letter appears at or spatially close to the cue, this is referred to as a validly cued trial; when the letter appears in a location more distant from the cue, this is referred to as an invalidly cued trial. It is well established that, when the task is letter identification, validly cued trials yield faster response times (RTs) and fewer errors than invalidly cued trials (e.g., Johnston et al., 1995).
Critically, for present purposes, the spatial cueing manipulation has also been extended to lexical decision and reading aloud tasks. Spatial cuing of a target stimulus location again has yielded a main effect: RTs are faster in lexical decision to a single letter string target display when the cue is valid than when it is invalid (e.g., McCann et al., 1992). Importantly, McCann et al. also found that the effects of word frequency (faster RTs to high than to low frequency words) and of lexicality (slower RTs to nonwords than to low frequency words) were additive with the effect of spatial cueing. McCann and colleagues took this additivity to imply that spatial attention was a necessary preliminary to lexical processing. In other words, no processing of the target starts until spatial attention is sufficiently distributed across the target.
Further findings suggest that spatial attention can also be controlled such that it is either broadly distributed or more narrowly focused when reading aloud (e.g., Waechter et al., 2011). When two words were displayed horizontally, each in a different color font, and one color signalled the target throughout the experiment, priming was observed from a semantically related word or a repeated word (displayed in a different case than the target) in the other color. This priming was seen when cue validity was 50%, suggesting that spatial attention was distributed across locations despite favoring the cued location as reflected in an effect of valid vs invalid cuing. In contrast, in experiments in which spatial cueing was 100% valid, there was neither semantic nor repetition priming from a distractor word appearing in the un-cued color font, consistent with the claim that spatial attention was now sufficiently narrowed such that no processing of the distractor took place. Hence, spatial attention is seen as a necessary preliminary to even letter-level processing (Besner et al., 2005; Campbell & White, 2022; Lachter et al., 2004; Waechter et al., 2011).
There also are multiple reports that coloring and spatially cuing a single letter in a color word—as opposed to coloring the entire word—either yields a reduced Stroop effect or, sometimes, eliminates it entirely (e.g., Besner, 2001; Besner et al., 1997; Besner & Stolz, 1999, particularly experiments 3 & 4). These results converge, as noted above, with the conclusion drawn from the results seen in the lexical decision and reading aloud literature when spatial cuing was a factor—that spatial attention is a necessary preliminary to lexical/semantic processing (e.g., Besner et al., 2005; Campbell & White, 2022; Lachter et al., 2004; Waetcher et al., 2011). Figure 1a depicts that spatial attention has its effect very early in processing at the orthographic level.

Two loci for the effect of spatial attention on incidental visual word recognition
The semantic stroop effect
The semantic Stroop effect (e.g., Neely & Kahan, 2001) refers to the situation where words that are associatively/semantically related to colors but are not themselves color words, interfere with color identification. Because the word “sky” is associatively/semantically related to the color blue, it interferes more with the time to identify the color green than does a neutral word like “put.” This effect is little studied in comparison to the standard color-word Stroop effect, and typically is not cited in textbooks, chapters, or articles that discuss various forms of “the” Stroop effect. Nonetheless, there are several reports that single-letter spatial cuing and single-letter coloring fails to reduce this semantic Stroop effect (see the review by Augustinova & Ferrand 2014, with particular reference to Augustinova et al., 2010).Footnote 1 This outcome challenges the claim that the effect of spatial attention in intentional word recognition tasks extends to incidental word recognition processing as seen in a variant of a Stroop task. Indeed, the failure to reduce this semantically based Stroop effect is explicitly taken by Augustinova and Ferrand (2014) as evidence that “visual word recognition” is automatic in the sense of being impervious to spatial attention manipulations.
Critically, if it is true that single-letter coloring and cueing fails to reduce the semantic Stroop effect at all, then this manipulation cannot be exerting its effect(s) prior to the processing of orthography. Instead, the effects of single-letter coloring and spatial cuing in the standard Stroop preparation must occur downstream after orthographic and lexical level processing. According to Augustinova and colleagues, these manipulations reduce response competition but have no effect on semantic level competition between color identification and distractor word identification. This possibility is depicted in Fig. 1b. Manwell et al. (2004) comment on this possibility: A major problem that participants face in many experiments involves discriminating relevant activation from irrelevant activation and trying to prevent crosstalk between these sources. Coloring and cuing a single element provide participants with a cue that helps them select a source of activation to respond to. This makes it easier to discriminate between relevant and irrelevant sources of activation, and hence reduces interference.
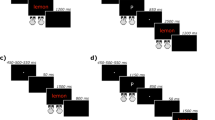
Augustinova and Ferrand’s (2014) conclusion as to the locus of single-letter coloring and spatial cuing effects has, however, been challenged. Labuschagne and Besner (2015) argued that, in Augustinova and colleagues’ experiments, spatial attention was not focused narrowly enough and because of this failed to yield a reduction of the semantic Stroop effect. Labuschagne and Besner therefore conducted an experiment in which the distractor words were associatively related to an incongruent color, but there were spaces between the letters in the word filled by characters from the top of the keyboard, and the un-cued letters appeared in a different color font than the target letter (relatedly, see Besner & Stolz, 1999). Figure 2 shows an example of this kind of display.

Sample stimuli from Labuschagne and Besner (2015); All-Letters-Colored-Cued (left panel) versus a Single-Letter-Colored-Cued (right panel)
Labuschagne and Besner’s (2015) results are shown in Fig. 3 where the semantic Stroop effect is reported as a function of the RT distribution. Figure 3a shows the results when all of the letters in the word are colored and spatially cued. Figure 3b shows the results when only a single letter is colored and cued. These data clearly show that the semantic Stroop effect was eliminated in the single-letter coloring and spatial cueing condition.

Data is from Figs. 2 and 3 in Labuschagne and Besner (2015). The left panel shows the semantic Stroop effect when all letters are colored and cued. The right panel shows the semantic Stroop effect when only a single letter is colored and cued
The results reported by Labuschange and Besner (2015) are in accord with those of Manwell et al. (2004) who also reported the elimination of a semantic Stroop effect in the single letter colored and cued condition, and a blank space appeared between letters. In contrast, Augustinova et al. (2010) reported a full-blown semantic Stroop effect in the face of single letter coloring and cueing. It can be suggested that the conflicting data and conclusions reflect a simple difference in methodological detail rather than necessarily implying anything to do with the distinction between intentional and incidental processing of written language. Further discussion directed at resolving this discrepancy between these two sets of results awaits the consideration of yet other results. This brings us to the report by Burca and colleagues (Burca et al., 2021) because it adds a level of complexity that is addressed first.
Burca and colleagues (Burca et al., 2021) used the paradigm invented by De Houwer (2003) which used his 2:1 response set combined here with single-letter coloring and spatial cueing to further examine the semantic component of the Stroop effect. In this variant, two colors were mapped to one response key and two other colors were mapped to another response key. Burca and colleagues used only color words as incongruent distractors (color associates produce a much smaller effect than color words and hence this would make it more difficult to detect some effects), and compared performance to that observed for neutral words. Critically, distractor color words were associated either with the same response key as the target color or with the other response key. Their logic was that when the distractor word and the target color font are mapped to different keys, responses combine the influences of semantic conflict (despite the absence of a direct semantic manipulation like the use of color associated words) and of response competition. In contrast, when the distractor word is mapped to the same response key as the target color font, there is, by definition, no response competition; the only influence is claimed to be that of semantic conflict in their account.
Burca and colleagues (Burca et al., 2021) obtained a Stroop effect in both response mapping conditions when all letters were colored and spatially cued. Further, the Different response condition yielded a significantly reduced Stroop effect when a single letter was colored and spatially cued, replicating previous results as in Besner (2001; Besner & Stolz, 1999; Besner et al. 1997). When the distractor word was associated with the same response key as the single colored and spatially cued target letter, and hence there was no response competition, there was a small but significant reduction of the Stroop effect using frequentist statistics, but this reduction was associated with a Bayes Factor value which yielded only anecdotal evidence. Burca and colleagues were therefore unable to strongly conclude that semantic level conflict was reduced when the distractor word was mapped to the same response key as the color, but nor do they have any evidence it was eliminated.
The potential importance of the Burca and colleague’s approach
Burca and colleagues exploited the De Houwer paradigm in order to determine whether single letter coloring and cuing reduced or eliminated the pure (semantic) Stroop effect. If it is truly the case that this manipulation fails to eliminate or reduce the Stroop effect with this design, then this is important, because it implies that spatial attention in incidental and intentional word recognition tasks affects performance in a qualitatively different way: Spatial attention matters in intentional word recognition in terms of the uptake of activation, but not incidental word recognition. This seems a strikingly important conclusion. The question we concern ourselves with here is whether it is called for, or not.
A methodological issue
A notable methodological feature that differs between Labuschange and Besner (2015), and Manwell et al. (2004) on the one hand, as compared with Augustinova et al. (2010) and Burca et al. (2021) on the other hand, is that the former studies either have a blank space between letters in all conditions, (relatedly, see Besner, 2001, although this experiment only used color words) or a space between letters filled with a nonletter character. Augustinova et al. (2010) and Burca et al. (2021) have no spaces between letters, nor a nonletter character between letters. Arguably, this spacing in the former cases encourages a more narrowed spatial attentional focus as compared to the latter ones. Given that both Labuschange and Besner (2015) and Manwell et al (2004) reported the elimination of a semantic Stroop effect, whereas Agustinova et al (2010) reported a full-blown semantic Stroop effect, or as in Burca et al. (2021) reported data only suggestive of a reduction in the Stroop effect, we argue that the presence/absence of spacing between letters is an important consideration.
Following Burca et al. (2021), the experiment reported here used color words as incongruent distractors, and we adopt their assumption that their use taps semantic processing. However, this experiment differed from theirs in that all of the irrelevant words had 2 empty letter spaces between letters. The intent of this spacing was to make it easier for spatial attention to be restricted to the target in the single letter colored and cued condition.
Critically, the absence of an interference effect in this condition has theoretical force if and only if there is a Stroop effect when all the letters are colored and spatially cued despite two blank character spaces between letters. That is, in this condition we need to see a Stroop effect, and in similar magnitude to the effect Burca and colleagues report, to rule out the possibility that the two empty spaces per se undermined normal word recognition processing in some unspecified way. It suffices to say that this baseline effect was indeed seen in the present experiment. Moreover, the magnitude of this effect was virtually identical to that seen in Burca et al. (50 ms in our experiment, 51 ms in theirs).
Blocking vs Randomization of cuing conditions
One other procedural difference between Burca and colleagues and the present experiment is that in Burca et al all the conditions were intermixed in a single block of trials whereas here levels of coloring and cueing were blocked. The difference between spatial attention focus across the two conditions should be greater because there is no trial-to-trial task-shift between the two attentional focus conditions (see also Besner, 2001).Footnote 2
Predictions
If spatial coloring and cuing acts as in the account assumed by Augustinova and colleagues (e.g., see Augustinova & Ferrand’s review, 2014, Burca et al. 2021) then the Different response condition should yield a two-way interaction between the Incongruent vs Neutral condition (a Congruency effect) and coloring/cuing level such that there is a smaller Stroop effect in the single letter colored and cued condition than in the all letters colored and cued condition. In contrast, a reduction in the magnitude of the Stroop effect in the Same response condition would be entirely absent since there is only “semantic” competition here, and no response conflict. In short, a main effect of Congruency, but no two-way interaction. These two different patterns (a two-way interaction in the first case, and no interaction in the second case) should therefore yield a three-way interaction.
In contrast, if coloring and cuing a single letter behaves as described in the account by Besner and colleagues (Besner & Stolz, 1999; Besner, 2001; Labuschange & Besner 2015; account 1 in Manwell et al, 2004) then the two-way interaction between Congruency (Incongruent vs Neutral) and coloring/cuing levels seen in the Different response condition should also be seen in the Same response condition. Namely, main effects of Congruency and coloring levels, and an interaction. Given the same pattern of a two-way interaction in Different and Same response conditions, no three-way interaction is expected.
To anticipate the results, we see a main effect of Congruency, a two-way interaction between Congruency and single letter coloring and cuing, no three-way interaction, and the elimination of the semantic Stroop effect in the “same” response condition. The general discussion discusses the theoretical inferences that can be drawn from these results, and relates them more broadly to other paradigms.
Method
Participants
104 University of Waterloo undergraduate students participated in this online experiment in exchange for partial course credit. Expected sample size was based on the sample size reported in Burca et al (2021; N = 88) with more subjects being recruited because, based on our experience, when data collection is online rather than in the laboratory, there is substantial data loss because of responding without enough attention to the request to “go as fast as you can, but try not to make too many errors” (e.g., see Besner & Young, 2022). All participants reported normal or corrected to normal vision and normal color vision. The experiment was approved by the Office of Research Ethics committee (REB #44728) at the University of Waterloo.
Stimuli
The word stimuli consisted of 4 color words (red, blue, green, yellow) and 4 neutral words (kit, jail, table, palace). Neutral words were matched for letter length and word frequency with the color words. Stimuli were presented in lowercase, Consolas font, size 18. Letters in the word were separated by two empty letter spaces. The letters in the words were presented in one of the four color fonts: red (RGB: 255, 0, 0), blue (RGB: 0, 40, 255), green (RGB: 0, 255, 0), or yellow (RGB: 255, 255, 0).
Figure 4 presents examples of the displays used in the experiment. In the All Letters Colored/Spatially Cued condition, all letters were presented in one of the four colors, such that the color was incongruent with the presented color word (e.g., blue presented in green, red, or yellow, but never in blue; See Fig. 4, panel a). This was extended to the neutral words as well, where congruency was associated with the length of the color associates (e.g., jail could be presented in red, green, or yellow but never blue; see Burca et al., 2021). For the single letter colored/spatially cued condition, only a single letter within the word was colored and spatially cued; the rest of the letters appeared in white (RGB: 255, 255, 255; see Fig. 4, panel b).

An example of the stimuli used in the experiment: (a) All-Letters-Colored and Cued condition (b) Single-Letter-Colored and Cued condition
Design
The experiment consisted of a 2 x 2 x 2 within-subject factorial, the factors being Congruency (Incongruent vs Neutral), Coloring/Spatial Cueing (All-Letters- Colored-Cued vs Single-Letter-Colored and Cued), and Target/Distractor response mapping (Same versus Different keys). Following Burca et al. (2021), when the target color and distractor were associated with different response keys, this condition was labelled the Different response mapping; when the target color and distractor word were associated with the same response key, this condition was labelled the Same response mapping. For example, participants were instructed that the ‘L’ key was to be used for the target colors “blue” and “green”, and that the ‘P’ key was to be used for the target colors “yellow” and “red”. If the distractor word table or green was presented in either the target color fonts YELLOW or RED, this would be a DIFFERENT response; if the color carrier words were table or green was presented in the target color BLUE, this would be a SAME response. The different combinations of colors and their associated distractor words or neutral words were counterbalanced across Same and Different response mappings. Thus, the assignment of the color pairs to response keys was counterbalanced into 3 different sets to ensure that each color pair was represented (Counterbalance 1: BLUE/GREEN = L, RED/YELLOW = P; Counterbalance 2: RED/BLUE = L, YELLOW/GREEN = P; Counterbalance 3: RED/GREEN = L, BLUE/YELLOW = P). As noted earlier, letter coloring/cuing was blocked so as to encourage a consistent attentional set across the block. Thus, block presentation was counterbalanced as well. For example, the above color pairings associated with Counterbalance 1 would have the Single-Letter-Colored-Cued condition in the first block of trials followed by the All-Letters-Colored-Cued condition in the second block of trials; whereas Counterbalance 4 would be the reverse block order but same color pair response keys as Counterbalance 1. This led to 6 counterbalances in total. There was a total of 192 experimental trials, with 24 trials per condition.
Procedure
Participants followed a link to the experiment where they read the instructions presented on the screen. They were instructed to respond to the color of the spatially cued letter(s), using the ‘L’ and ‘P’ keys on the keyboard with two fingers of their right hand. They were instructed that each of the keys had two of the colors from the response set associated with them (e.g., if the target colors were BLUE or GREEN, they were to press ‘L’; If the target colors were RED or YELLOW, they were to press ‘P’).
Each block began with a set of 16 practice trials that mimicked the experimental trials, except that the participants received feedback after they made a response on each trial. This feedback was the word ‘CORRECT’ or ‘INCORRECT’ displayed in white (RGB: 255, 255, 255) uppercase, 18point, Consolas font for one second at fixation. This was followed by 96 experimental trials in each block.
At the beginning of each trial, a white fixation marker (‘+’) appeared in the center of the screen on a black background for 500 ms. Next, the spatial cue(s), consisting of 90 mm white vertical lines (‘|’) appeared above and below where the target letter(s) would appear. The end of each cue was approximately 5 mm from each letter.
The onset of the spatial cue was followed 125 ms later by a target. The spatial cue and target remained on the screen until a response was made. After a response, the fixation marker appeared again in the center of the screen, and the participant pressed the spacebar with their left hand to initiate the next trial. Participants were instructed to always rest the fingers of their right hand on the two response keys.
Results
Following Besner and Young (Besner & Young, 2022), participants who committed too many errors (greater than 20% errors in any condition) were first discarded. As in previous work with data collection being online instead of in the laboratory, there were a number of participants who ignored instructions to “go as fast as you can but try not to make too many errors” and simply made many errors. The proportion of participants who behaved this way approximated what Besner and Young (2022) reported in their lexical decision study, also conducted by our laboratory under the auspices of the University of Waterloo. Fifteen participants were discarded for this reason. For the remaining participants, trials on which an error was committed were discarded (3.9 % of trials).
Correct RTs were subjected to outlier removal in which RTs more than 2.5 SD above and below the mean RT per participant, per condition, were removed (Van Selst & Jolicoeur, 1994; Labuschagne & Besner, 2015). This led to the further removal of 3.2% of correct trials. Following error removal and outlier trimming, a grand mean for each participant across all conditions was computed for RT. Participants were removed if their grand mean was more than 3 SD from the mean. This led to 8 additional participants being removed. The final sample consisted of 81 participants.
Mean RTs and percent errors for each condition are shown in Table 1. Below, we report a 2 x 2 x 2 repeated measures ANOVA in which the factors are Congruency (Incongruent vs Neutral), Cuing (all letters colored and cued vs. a single letter colored and cued), and Response Mapping (Different response vs Same response). All analyses and Bayesian statistics reported here used JASP (JASP team, 2023).
To recapitulate the point of the experiment, the central question here is whether the Congruency effect in the Same response condition is reduced or eliminated in the Single-Letter-Colored and Cued condition as compared to the All-Letters-Colored and Cued condition. If the Congruency effect in the Same response condition is reduced or eliminated, this would be inconsistent with Burca and colleagues’ account (i.e., no three-way interaction). In contrast, the Burca et al account predicts a three-way interaction: a Congruency effect that is modulated by color and cueing levels specific to the Different response mapping condition. No such modulation should be seen in the Same response condition; instead, a Stroop effect should be seen here, and not be reduced compared to where all letters were colored and cued.
RT analysis
The RT data are displayed in Table 1. There was a main effect of Congruency in which Incongruent trials were slower than Neutral trials, F (1,80) = 29.78, MSE = 2365.60, p < .001, ηp2 = .271, BF10 = 12318.61, no main effect of Coloring/Cuing, F (1, 80) = .089, MSE =14089, p = .766, ηp2 = .001, BF01 = 432.66 and a main effect of Response Mapping, F(1,80) = 21.34, MSE = 2223.26, p < .001, ηp2 = .211, BF10 = 498.16, such that Different response mapping RTs was slower than Same response mapping RTs. There was an interaction of Congruency with Cuing such that the Congruency effect was smaller in the Single-Letter-Colored and Cued condition than in the All-Letter-Colored-Cued condition, F(1,80) = 10.05 MSE =2853.02, p < .005, ηp2 = .112, BF10 =12766.82 , no Cuing by Response mapping interaction, F (1,80) = .356, MSE =2653.01, p = .552, ηp2 = .004, BF01 =156.35 and an interaction of Response Mapping with Congruency such that Different response mapping, which included both semantic and response conflict, yielded a significantly larger Congruency effect than the Same response mapping, which has only semantic conflict, F(1,80) = 10.86, MSE = 2537.75, p < .005, ηp2 = .120 BF10 = 387.70.
However, the 3-way interaction of Congruency by Cuing by Response Mapping was the critical aspect of the study for evaluating the Burca et al. (2021) account. Contrary to the prediction from this account, the 3-way interaction was not significant, F (1,80) = .873, MSE = 1564.37, p = .353, ηp2 = .011, BF01 = 17.73. That is, the two-way interaction of Congruency x Coloring/Cueing levels was not modulated by Response mapping (Different vs Same). Their account predicts that the three-way interaction should be present because the two-way interaction of Congruency x Coloring/Cueing should be restricted to the Different response condition, which has both semantic and response conflict.
Conventionally speaking, the absence of a three-way interaction precludes any pairwise comparisons. Nonetheless, (at a reviewer’s request) one would like to be assured that the -2 ms Congruency effect in the single letter coloring and cueing condition provides more than anecdotal evidence favoring the null hypothesis. This is indeed the case, t(80) = -.431, p = .668, BF01 = 7.46.
Error analysis
The error data are also shown in Table 1. There was no main effect of Congruency, F(1,80) = .000, MSE = .001, p = 1, ηp2 = .000, BF01 = 8.54, or of Cuing, F(1,80) = .511, MSE = .001, p = .477, ηp2 = .006, BF01 = 7.38, but there was a main effect of Response Mapping where Same response yielded fewer errors than Different response, F(1,80) = 5.43, MSE = .001, p = .022, ηp2 = .064, however the Bayesian analysis revealed an inconclusive BF10 = 1.12. There was no Congruency by Cuing interaction, F(1,80) = 1.45, MSE = .001, p =.233, ηp2 = .018, BF01 = 3.99. There was a significant Congruency by Response Mapping interaction where the congruency effect was larger for Different response mapping than Same response mapping, as it was for RTs, F(1,80) = 6.67, MSE = .001, p = .012, ηp2 = .077, however the Bayes Factor provided inconclusive evidence for the Alternative, BF10 = 1.70. There was no Cuing by Response Mapping interaction, F(1,80) = .000, MSE = .001, p = 1, ηp2 = .000, BF01 = 6.47. The three-way interaction of Congruency by Cuing by Response mapping was not significant, F(1,80) = 2.96, MSE = .001, p = .089, ηp2 = .036, however the Bayesian analysis yielded inconclusive evidence for the null, BF01 = .572. In short, there was nothing in the error data that undermined anything in the RT data.
Discussion
We made two points in the introduction. First, Burca and colleague’s (Burca et al., 2021; Augustinova & Ferrand, 2014; Augustinova et al., 2010) theoretical account to the effect that spatial attention is not a necessary preliminary to incidental visual word recognition (i.e., as in Stroop studies) is unusual in the sense that the literature on intentional visual word recognition has reached a different conclusion—that spatial attention is a necessary preliminary to visual word recognition. If the latter conclusion is correct (indeed there is broad and deep support for this view), and the Burca et al. (2021) experiment proved to be methodologically sound, this would imply that there is indeed a genuine difference between intentional and incidental visual word recognition with regard to the role of spatial attention that researchers in the field have failed to take account of.
Second, we considered the idea that there is at least one central methodological issue that has been overlooked by Burca and colleagues’, as well as by Augustinova et al. (2010), and Augustinova and Ferrand (2014). In particular, Burca and colleagues’ manipulation of single-letter coloring and spatial cueing may have failed to sufficiently narrow spatial attention so as to prevent semantic processing because there were no spaces between letters in the words.
The present results suggest that that this concern about methodological details is warranted. Simply inserting two empty spaces between letters in the distractor word and blocking cueing type is sufficient to eliminate the Congruency effect in the single letter colored/cued, Same response mapping condition of the present experiment. We conclude, therefore, that semantic processing can indeed be derailed in the context of the 2:1 paradigm, just as lexical/semantic processing has been derailed in other variants of the Stroop paradigm (Besner, 2001; Besner et al, 1997; Besner & Stolz, 1999 expts 3 and 4; Labuschange & Besner, 2015; Manwell et al, 2004). That said, it is important to note that the present results (in conjunction with all others considered here) do not show that semantic processing itself is derailed by the present manipulations. A sufficient claim is that these manipulations affect processes that occur prior to semantic processes (such as at the feature and letter levels). If this minimalist assumption is accepted, there is no basis here for supposing that semantic processing itself is directly affected by spatial attention. We take Neely and Kahan (2001) to have made precisely this point.
To the extent that the manipulations used here impairs early level processing (as in feature and letter level analysis) the inference is that visual word recognition uses spatial attention and is therefore not automatic in the sense of forgoing the use of that form of attention. This general claim about the relation between spatial attention and visual word recognition has been made before but has gone largely unattended (e.g., Besner et al., 2016). Stated differently, the conclusion is worth re-iterating: there is no basis at present for rejecting the hypothesis that there is a locus for spatial attention that is early in processing for both intentional and incidental visual word recognition processes. Visual word identification is not automatic, even in this restricted sense.
Notes
Burca et al refer to the reduction of the Stroop effect reported by Besner et al (1997) as involving single letter coloring and spatial cuing. Besner et al did not employ explicit spatial cuing in any of those experiments. The combination of single letter coloring with spatial cuing was first reported by Besner and Stolz (1999).
Besner (2001) blocked coloring levels and spatial cuing, and also had a blank space between letters. The Stroop effect (using color words) was 90 ms in the all cued and all colored condition. The Stroop effect (again using color words) in Condition 3 (80% incongruent trials and 20% congruent trials) where there was a blank space between letters, and all trials consisted of a single letter that was colored and spatially cued yielded a nonsignificant 1 ms Stroop effect.
References
Augustinova, M., & Ferrand, L. (2014). Automaticity of word reading: Evidence from the semantic Stroop paradigm. Current Directions in Psychological Science, 23(5), 343–348. https://doi.org/10.1177/0963721414540169
Augustinova, M., Flaudias, V., & Ferrand, L. (2010). Single-letter coloring and spatial cuing do not eliminate or reduce a semantic contribution to the Stroop effect. Psychonomic Bulletin & Review, 17, 827–833. https://doi.org/10.3758/PBR.17.6.827
Bauer, B., & Besner, D. (1997). Processing in the Stroop task: Mental set as a determinant of performance. Canadian Journal of Experimental Psychology/Revue canadienne de psychologie expérimentale, 51(1), 61–68. https://doi.org/10.1037/1196-1961.51.1.61
Besner, D. (2001). The myth of ballistic processing: Evidence from Stroop’s paradigm. Psychonomic Bulletin & Review, 8(2), 324–330. https://doi.org/10.3758/BF03196168
Besner, D., & Stolz, J. A. (1999). What kind of attention modulates the Stroop effect? Psychonomic Bulletin & Review, 6(1), 99–104. https://doi.org/10.3758/BF03210815
Besner, D., & Young, T. (2022). On the joint effects of stimulus quality and word frequency in lexical decision: Conditions that promote staged versus cascaded processing. Canadian Journal of Experimental Psychology / Revue canadienne de psychologie expérimentale, 76(2), 122–131. https://doi.org/10.1037/cep0000266
Besner, D., Risko, E. F., & Sklair, N. (2005). Spatial attention as a necessary preliminary to early processes in reading. Canadian Journal of Experimental Psychology / Revue canadienne de psychologie expérimentale, 59(2), 99–108. https://doi.org/10.1037/h0087465
Besner, D., Risko, E. F., Stolz, J. A., White, D., Reynolds, M., O’Malley, S., & Robidoux, S. (2016). Varieties of attention: Their roles in visual word identification. Current Directions in Psychological Science, 25(3), 1370–1385. https://doi.org/10.1177/0963721416639351
Besner, D., Stolz, J. A., & Boutilier, C. (1997). The Stroop effect and the myth of automaticity. Psychonomic Bulletin & Review, 4(2), 221–225. https://doi.org/10.3758/BF03209396
Brown, T. L., Gore, C. L., & Carr, T. H. (2002). Visual attention and word recognition in Stroop color naming: Is word recognition “automatic”? Journal of Experimental Psychology: General, 131(2), 220–240. https://doi.org/10.1037/0096-3445.131.2.220
Burca, M., Beaucousin, V., Chausse, P., Ferrand, L., Parris, B. A., & Augustinova, M. (2021). Is there semantic conflict in the Stroop task? Further evidence from a modified two-to-one Stroop paradigm combined with single-letter coloring and cueing. Experimental Psychology, 68(5), 274–283. https://doi.org/10.1027/1618-3169/a000530
Campbell, M. S., & White, A. L. (2022). Capacity limits on multiple word recognition: the case of letter identification. Journal of Vision, 22(14), 3712–3712. https://doi.org/10.1167/jov.22.14.3712
De Houwer, J. (2003). On the role of stimulus-response and stimulus-stimulus compatibility in the Stroop effect. Memory & Cognition, 31(3), 353–359. https://doi.org/10.3758/BF03194393
JASP Team. (2023). JASP (Version 0.18.3) [Computer software]. https://www.jasp-stats.org/
Johnston, J. C., McCann, R. S., & Remington, R. W. (1995). Chronometric evidence for two types of attention. Psychological Science, 6(6), 365–369. https://doi.org/10.1111/j.1467-9280.1995.tb00527.x
Labuschagne, E. M., & Besner, D. (2015). Automaticity revisited: When print doesn’t activate semantics. Frontiers in Psychology, 6, 117. https://doi.org/10.3389/fpsyg.2015.00117
Lachter, J., Forster, K. I., & Ruthruff, E. (2004). Forty-five years after Broadbent (1958): Still no identification without attention. Psychological Review, 111(4), 880–913. https://doi.org/10.1037/0033-295X.111.4.880
MacLeod, C. M. (1991). Half a century of research on the Stroop effect: An integrative review. Psychological Bulletin, 109(2), 163–203. https://doi.org/10.1037/0033-2909.109.2.163
Manwell, L. A., Roberts, M. A., & Besner, D. (2004). Single letter coloring and spatial cuing eliminates a semantic contribution to the Stroop effect. Psychonomic Bulletin & Review, 11(3), 458–462. https://doi.org/10.3758/BF03196595
McCann, R. S., Folk, C. L., & Johnston, J. C. (1992). The role of spatial attention in visual word processing. Journal of Experimental Psychology: Human Perception and Performance, 18(4), 1015–1029. https://doi.org/10.1037/0096-1523.18.4.1015
Melara, R. D., & Mounts, J. R. (1993). Selective attention to Stroop dimensions: Effects of baseline discriminability, response mode, and practice. Memory & Cognition, 21(5), 627–645. https://doi.org/10.3758/BF03197195
Miellet, S., O’Donnell, P. J., & Serono, S. C. (2009). Parafoveal magnification: Visual acuity does not modulate the perceptual span in reading. Psychological Science, 20, 721–728. https://doi.org/10.1111/j.1467-9280.2009.02364
Neely, J. H., & Kahan, T. A. (2001). Is semantic activation automatic? A critical re-evaluation. In H. L. Roediger III., J. S. Nairne, I. Neath, & A. M. Surprenant (Eds.), The nature of remembering: Essays in honor of Robert G. Crowder (pp. 69–93). American Psychological Association. https://doi.org/10.1037/10394-005
Raz, A., Shapiro, T., Fan, J., & Posner, M. I. (2002). Hypnotic suggestion and the modulation of Stroop interference. Archives of General Psychiatry, 59(12), 1155–1161. https://doi.org/10.1001/archpsyc.59.12.1155
Stroop, J. R. (1935). Studies of interference in serial verbal reactions. Journal of Experimental Psychology, 18(6), 643–662. https://doi.org/10.1037/h0054651
Van Selst, M., & Jolicoeur, P. (1994). A solution to the effect of sample size on outlier elimination. The Quarterly Journal of Experimental Psychology, Section A, 47(3), 631–650. https://doi.org/10.1080/14640749408401131
Waechter, S., Besner, D., & Stolz, J. A. (2011). Basic processes in reading: Spatial attention as a necessary preliminary to orthographic and semantic processing. Visual Cognition, 19(2). https://doi.org/10.1080/13506285.2010.51
Funding
This work was supported by the Natural Sciences and Engineering Research Council of Canada (NSERC) Discovery Grant (50503-10030) awarded to Derek Besner.
Author information
Authors and Affiliations
Contributions
Derek Besner: Conceptualization, Funding acquisition, Methodology, Writing – original draft, Writing – review & editing.
Torin Young: Writing – original draft, Writing- review & editing, Validation, Data curation, Software, Project administration, Formal analysis, Investigation, Visualization.
Corresponding author
Ethics declarations
Conflict/Competing interests
Not applicable.
Ethics approval
The experiment was approved by the Office of Research Ethics committee (REB #44728) at the University of Waterloo.
Consent to participate/publish
Informed consent was obtained from all individual participants included in the study. Participants were made aware during the consent process that their data will be published in an aggregate format (mean RTs and mean errors) in a journal. Participants were also were made aware that their anonymized data will be available on the Open Science Framework page associated with the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Availability of data and materials
The data for the experiment are available at https://osf.io/xuq3g/. The experiment was not preregistered. Psychopy program and materials will be made available upon email request to the authors.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Besner, D., Young, T. On the relationship between spatial attention and semantics in the context of a Stroop paradigm. Atten Percept Psychophys (2024). https://doi.org/10.3758/s13414-024-02911-9
Accepted:
Published:
DOI: https://doi.org/10.3758/s13414-024-02911-9