
Abstract
The perceived offset position of a moving target has been found to be displaced forward, in the direction of motion (Representational Momentum; RM), downward, in the direction of gravity (Representational Gravity; RG), and, recently, further displaced along the horizon implied by the visual context (Representational Horizon; RH). The latter, while still underexplored, offers the prospect to clarify the role of visual contextual cues in spatial orientation and in the perception of dynamic events. As such, the present work sets forth to ascertain the robustness of Representational Horizon across varying types of visual contexts, particularly between interior and exterior scenes, and to clarify to what degree it reflects a perceptual or response phenomenon. To that end, participants were shown targets, moving along one out of several possible trajectories, overlaid on a randomly chosen background depicting either an interior or exterior scene rotated −22.5º, 0º, or 22.5º in relation to the actual vertical. Upon the vanishing of the target, participants were required to indicate its last seen location with a computer mouse. For half the participants, the background vanished with the target while for the remaining it was kept visible until a response was provided. Spatial localisations were subjected to a discrete Fourier decomposition procedure to obtain independent estimates of RM, RG, and RH. Outcomes showed that RH’s direction was biased towards the horizon implied by the visual context, but solely for exterior scenes, and irrespective of its presence or absence during the spatial localisation response, supporting its perceptual/representational nature.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
The transmission of neural impulses, and, hence, information relay, is known to be relatively sluggish, a fact first noticed by von Helmholtz in 1850 (Warren & Warren, 1968). For visual afference, these delays might add up to about 100 milliseconds, between the cells in the retina until the striate cortex, which would impair our abilities to accurately perceive a moving object, let alone prepare and execute appropriate motor actions (see Nijhawan, 2008). The very fact that, ceteris paribus, simply intersecting a moving ball is uneventful in our daily lives and, generally, taken for granted within our behavioural repertoire, suggests that the perception of a dynamic event comprises extrapolation-neural mechanisms which actively compute its future states (Hogendoorn, 2020; Nijhawan, 1994, 2002, 2008). On the other hand, it has been suggested that such extrapolation mechanisms are further fine-tuned by explicitly considering ecologically relevant environmental invariants (Shepard, 1984), such as, prominently, the constant gravitational acceleration on Earth, in the form of an analogous internal model (Angelaki et al., 2004; Grush, 2005; Lacquaniti et al., 2013; McIntyre et al., 2001; Tin & Poon, 2005). Finally, and given that humans, as well as other animals, are themselves moving beings, the perceived direction of gravity has to be continuously updated and is known to depend on an integration of vestibular, somatosensory (idiotropic vector), and visual cues (Barra et al., 2010; Haji-Khamneh & Harris, 2010; Harris et al., 2011; Howard & Templeton, 1973; Jenkin et al., 2011; Kheradmand & Winnick, 2017; MacNeilage et al., 2008; Mittelstaedt, 1986; Oman, 2007; Volkening et al., 2014).
These lines of reasoning have come to intersect in the psychophysical research on spatial mislocalisation phenomena of moving stimuli. In their seminal study, Freyd and Finke (1984) reported that after observers were shown a sequence of images depicting a rectangle undergoing apparent rotation, they were more prone to judge that a static rectangle had the same orientation as the last one in the inducing sequence if it was, actually, further rotated in the direction of implied motion. In the original interpretation, and upon seeing a kinematic stimulus, a contingent visual representation is automatically generated, endowed with dynamic features which analogously represent temporal and physical invariants—Dynamic Representations (Freyd, 1987). When the inducing stimulus is halted, the accompanying dynamic representation keeps unfolding for some time, resulting in a misjudgement of the actual last seen orientation, as if an analogue of momentum was embedded in the visual representation—Representational Momentum (for an early review, see Hubbard, 2005). In accordance, bigger Representational Momentum was found for faster shown motions (Finke et al., 1986; Freyd & Finke, 1985) and for increasing temporal intervals imposed after motion offset, until a maximum at about 300 ms (Freyd & Johnson, 1987). Further research revealed Representational Momentum to be affected by tacit knowledge regarding expected dynamics—for instance, it was found to be increased for kinematic displays depicting an ascending rocket, in comparison with a building (with similar visual features; Reed & Vinson, 1996), and to emerge for static freeze-frame photographs implying motion (e.g., a person jumping from a wall; Freyd, 1983). Similarly, and of relevance, Representational Momentum was also found to be increased for objects moving downward, in the direction of gravity (Bertamini, 1993; Nagai et al., 2002).
Ever since, Representational Momentum has been replicated with varying types of stimuli and different paradigms (Hubbard, 2005, 2015), including, prominently, continuous moving targets and motor spatial localisation responses (Hubbard, 1990, 1995a, b; Hubbard & Bharucha, 1988). In these studies, a simple target (e.g., a square or a circle) is shown moving smoothly along the screen and, after covering a certain distance, disappears. Afterwards, a cursor controllable with a computer mouse or a trackball appears on the centre of the screen, and participants are instructed to position it at the location where the target vanished. With this method, and due to the bidimensionality of the spatial localisation onscreen, it is possible to compute not only the displacement along the target’s trajectory—M-displacement—but also the displacement orthogonal to the target’s trajectory—O-displacement (Hubbard, 1998). For horizontally moving targets, and besides a forward M-displacement, indexing the classical Representational Momentum, a downward O-displacement is also systematically found. Furthermore, for vertically moving targets, O-displacement is usually null, but the forward M-displacement is significantly bigger for descending targets than for ascending ones. Both the downwards O-displacement for horizontally moving targets and the directional asymmetry found for M-displacement with vertically moving targets have been interpreted as an empirical measure of Representational Gravity (Hubbard, 1990, 1995a, 1998, 2020; Hubbard & Bharucha, 1988), a putative mental analogue of gravity. Theoretically, these types of spatial mislocalisation phenomena have been taken as an empirical manifestation of extrapolation perceptual mechanisms (Hubbard, 2005, 2015; Vinson et al., 2017) which reflect internalized ecologically relevant physical invariants, extending the notion of second-order isomorphism paved out by Roger Newland Shepard (1984, 1994), and, recently and particularly in what refers to Representational Gravity, an internal model of gravity (Angelaki et al., 2004; Barra et al., 2010; De Sá Teixeira, 2014; Grush, 2005; Lacquaniti et al., 2013; McIntyre et al., 2001; Tin & Poon, 2005).
Notwithstanding, alternate accounts for Representational Momentum, particularly for smoothly moving targets, reliant upon low-level mechanisms, have been put forth, prominently, by Kerzel (2000, 2006). Briefly, when shown a smoothly moving object, observers typically track it with their eyes, engaging smooth pursuit eye movements which tend to overshoot its offset when it suddenly halts (Mitrani & Dimitrov, 1978; Pola & Wyatt, 1997). This oculomotor feature might arguably explain the forward displacement found in Representational Momentum studies, precluding the need to postulate a role for high-level cognitive-based mechanisms (Kerzel, 2006). In agreement, Representational Momentum for continuously moving targets (but not implied motion stimuli; Kerzel, 2003) has been found to be null, or severely reduced, when smooth pursuit eye movements are prevented (e.g., by requiring observers to fixate a point; De Sá Teixeira et al., 2013; De Sá Teixeira, 2016b; De Sá Teixeira & Oliveira, 2014; Kerzel, 2000; Kerzel et al., 2001), although that reduction does not seem to be the case when participants have to manually point to the perceived offset location (Ashida, 2004; Kerzel & Gegenfurtner, 2003). Concurrently, preventing smooth pursuit eye movements seems to have no discernible effect on Representational Gravity—neither the increased forward M-displacement for descending targets (De Sá Teixeira, 2016b) nor the downward O-displacement for horizontally moving targets (De Sá Teixeira et al., 2013; De Sá Teixeira & Oliveira, 2014) are affected by preventing eye movements or, for that matter, by response modality (De Sá Teixeira et al., 2019a, b). Furthermore, and regardless of the presence or absence of eye movements, Representational Gravity continuously increases as longer temporal intervals are imposed between target offset and spatial localisation response initiation (De Sá Teixeira, 2016a, b; De Sá Teixeira et al., 2013; De Sá Teixeira & Hecht, 2014), in a pattern that further differentiates it from Representational Momentum.
Notice that, depending on the direction of the target’s motion, Representational Momentum and Representational Gravity might be more or less entangled, jointly determining the spatial mislocalisation (for a detailed geometrical derivation of the periodic changes in M-displacement as the orientation of target’s trajectory is varied see De Sá Teixeira, 2016b; see also Hubbard, 1995a, 2005, 2020). Specifically, consider a descending target—in this case, both Representational Momentum and Representational Gravity would lead to an increased M-displacement along the same vector (downwards); for an ascending target, the reverse is the case, with Representational Momentum and Representational Gravity acting in opposite directions and partially cancelling each other out in the measurement of M-displacement; finally, for horizontally moving targets, Representational Momentum alone would determine the magnitude of M-displacement (with Representational Gravity reflecting solely on O-displacement). This logic can be further expanded—consider a target moving diagonally: in this case, M-displacement, in addition to the contribution of Representational Momentum, should be slightly increased or decreased (depending on whether the vertical component of the target’s motion is, respectively, downward or upward) as it would be partially affected by Representational Gravity. Stated differently, Representational Momentum is made manifest by a forward M-displacement, irrespective of target’s motion direction, the magnitude of which is further modulated by Representational Gravity, made manifest by a further displacement along one single direction (downwards). Analytically, the specific contribution of Representational Gravity (and, by extension, its magnitude and direction) can be neatly determined as a periodic component embedded in a set of M-displacements, if and when measured for targets moving along several directions within the frontal-parallel plane, by taking advantage of the Fourier theorem (with target’s motion direction as parameter; for an in depth explanation of the underlying logic and procedure of the Fourier decomposition see Sekuler & Armstrong, 1978).
Using this logic, it was found that the direction of Representational Gravity coincides with whichever direction in which the participants’ feet are pointed, although its time course is reduced as participants’ bodies are further misaligned with the gravito-inertial vector (that is, Representational Gravity becomes a constant and does not increase with time; De Sá Teixeira, 2014; De Sá Teixeira et al., 2017), reflecting the contribution of vestibular processing (De Sá Teixeira et al., 2019a, b). Furthermore, besides Representational Momentum and Representational Gravity, these studies systematically reported one further periodic component, accounting for an increased M-displacement for targets moving horizontally (either rightwards and leftwards). The relevance of this latter harmonic component has only recently been ascertained, though. Freitas and De Sá Teixeira (2021) conducted a study where M-displacement was measured for targets moving along 16 possible directions (leftward, rightward, downward, upward, and varying degrees of diagonal trajectories in between) while overlaid on a background image depicting the interior view of the Harmony module of the International Space Station, which could be either on an upright orientation or tilted leftwards or rightwards by 22.5º. The second harmonic’s orientation was found to be biased towards the horizon implied by the visual context—that is, targets moving along the horizontal line implied by the background scene (irrespective of its misalignment with the actual horizontal) led to increased M-displacements. This trend was further found to be correlated, at an individual level, with measures of subjective visual vertical (SVV) made with the same visual context, strengthening the relevance of visual spatial orientation (Haji-Khamneh & Harris, 2010; Harris et al., 2011; Howard & Templeton, 1973; Jenkin et al., 2010, 2011; MacNeilage et al., 2008; Oman, 2007) for the perception of dynamic events (see also Moscatelli & Lacquaniti, 2011).
In this vein, the present study has as its primary objective to replicate the results of Freitas and De Sá Teixeira (2021), specifically in what refers to the effect of visual context orientation on the second harmonic present in M-displacements—which we coin Representational Horizon—and to extend that finding for a variety of scenes, beyond the one used in that previous study. As a secondary goal, we set forth to ascertain to what degree Representational Horizon is determined by the presence of the visual context during the spatial localisation response or if it only requires that the inducing moving stimuli is shown embedded in it. The former scenario would cast doubts that Representational Horizon reflects the perceptual processing of the dynamic event, while the latter would support that view. Finally, we sought to test the robustness of the effect of the orientation of the visual context on Representational Horizon by using both interior scenes (e.g., bedrooms, living rooms, halls, libraries) and exterior scenes (e.g., rural and urban landscapes, beaches, streets, forests). To that end, we performed a standard spatial localisation task for the offset position of a target that could be shown moving along several directions, overlaid on an upright or tilted (leftward or rightward) visual context, depicting either an interior or exterior scene. For half of the participants, the visual context shown while the target moved remained onscreen until a spatial localisation response was provided; for the remainder of the participants, the visual context was replaced with a blank screen (with the same mean luminance as the visual context) when the target vanished.
Method
Participants
Based on the reported magnitude of the effect of visual context orientation (partial η2 = 0.21, for the coefficient b2) in Freitas and De Sá Teixeira (2021), a power analysis reveals that a minimum sample size of 12 participants would be required. To strengthen the robustness of statistical inference, forty participants (29 females; 11 males) were recruited for the experiment in exchange for partial course credits. Their ages ranged from 18 to 26 years (M = 19.8 years, SD = 1.58) and all had normal or corrected-to-normal vision and no known neurological or vestibular deficits. The experiment was preapproved by the Ethics Committee of the University of Aveiro (Protocol 34-CED/2021).
Stimuli
Eighty free stock images were used as visual context (see Fig. 1), 40 depicting exterior scenes (e.g., beaches, mountains, urban and rural landscapes) and 40 depicting interior scenes (e.g., bedrooms, living rooms, libraries, gymnasiums, halls). These images were chosen to be as varied as possible and rich in visual orientation cues. The selected images were processed as follows: each image was cropped to conform to a 1:1 ratio and its size adjusted to the height of the screen (1,024 pixels); afterward, all images were rendered as black-and-white and their luminance equalised to RGB = (127, 127, 127). The target for the spatial localisation task was a black circle, with a radius of 21 pixels (about 0.7º of visual angle) with a white circumference of 1 pixel.

Image pool used for visual context, separated by interior (top panel) and exterior (bottom panel) scenes
Apparatus, procedure, and design
Participants sat in an office chair, with adjustable height, in front of a computer screen with a refresh rate of 60 Hz and resolution of 1,280 × 1,024 pixels (physical size of 37.5 × 30 cm). Their view of the screen was restricted to a circular central window with a custom-made black cardboard cylinder with a diameter of 30 cm (equal to the height of the screen) and a length of 50 cm (ensuring a fixed distance between the participant’s cyclopean eye and the centre of the screen in addition to occluding any peripheral view of the laboratory setting). Furthermore, participants wore noise-cancelling earmuffs during the experimental task, to minimise distracting noises from the laboratory and/or building. Stimuli presentation, trial randomization, and data collection were programmed in Python using PsychoPy (Peirce, 2007, 2008).
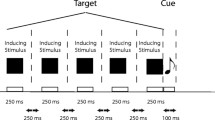
Each trial (see Fig. 2) started with a random sequence of noise frames during 1 second, being immediately replaced with a randomly chosen image (visual context) from one of two image pools (interior or exterior scenes), covering the entire visible section of the screen and either tilted leftward (−22.5º), rightward (22.5º), or in an upright orientation (0º). One second after the onset of the visual context, the target emerged from the visible boundary of the circular window, already in motion toward the centre of the screen at a speed of 616 pixels/s (about 20.4º/s). The target’s motion lasted for 1 second, and it could be shown moving leftward (trajectory orientation of 0º), rightward (180º), upward (90º), downward (270º), or intermediate trajectories between those cardinal orientations (22.5º, 45º, 67.5º, 112.5º, 135º, 157.5º, 202.5º, 225º, 247.5º, 292.5º, 315º, or 337.5º). The target’s starting location was randomly chosen such that its offset fell inside an area of 16 × 16 pixels (about 0.54º × 0.54º) centred 92 pixels beyond the screen’s centre (about 3.1º). Upon the vanishing of the target, the visual context either remained on the screen (for half the participants) or was immediately replaced by a blank grey screen (RGB = [127, 127, 127]; for the remainder of the participants) until a response was given. In both cases, 300 ms later a cursor, given by a black dot with a diameter of 5 pixels with a 1-pixel white contour, appeared on the centre of the screen. The cursor’s location onscreen was controllable with a computer mouse and the participants were instructed, at the beginning of the experiment, to use it to position the cursor in the same location where the target vanished, as precisely as possible and referring to its geometric centre. The spatial location was confirmed by pressing the left mouse button. The next trial started 500 ms after each spatial localisation response.

Trial structures when spatial localisation responses are made with (A) and without (B) the same visual context present during the target’s motion
The experiment thus followed a mixed factorial design given by 3 (visual context orientation: −22.5º, 0º, or 22.5º) × 2 (visual scene: interior or exterior) × 16 (orientation of target trajectory: 0º, 22.5º, 45º, 67.5º, 90º, 112.5º, 135º, 157.5º, 180º, 202.5º, 225º, 247.5º, 270º, 292.5º, 315º, or 337.5º) × 4 (replications) × 2 (response background: blank screen or visual context; between-participants), totalling 384 trials per participant. Before the experiment, the participants performed a few practise trials until the experimenter made sure the task was fully understood. Finally, a brief pause was allowed after half of the experimental trials were completed. The entire experiment, including instructions, debriefing, practise trials, main task, and intermission, lasted about 80 minutes.
Calculations, hypotheses, and statistical analyses
For each trial, the horizontal and vertical difference, in pixels, between the target’s actual offset and the location indicated by the participant was calculated. The obtained values were then used to calculate the orthogonal projection of the participant’s response onto the target’s motion trajectory, to obtain the displacement along motion direction—M-displacement—and such that positive values indicate a displacement forward and negative values a displacement backwards, in relation to motion direction. The individual sets of M-displacements, averaged across replications and for each experimental condition, were subjected to a discrete Fourier decomposition (for a detailed tutorial on this procedure, see Sekuler & Armstrong, 1978; see also De Sá Teixeira, 2014, 2016b; Freitas & De Sá Teixeira, 2021), with target’s motion direction (θ) as parameter, and so as to obtain the individual estimates of a constant c and harmonic coefficients ai (cosine) and bi (sine) up to i = 4, in accordance with:
In Eq. 1, c reflects a constant displacement across all motion directions θ and, as such, is taken as a measure of Representational Momentum (see Fig. 3, first inset line). Coefficients a1 and b1, taken together, reflect an increased displacement towards one preferred direction; in previous studies (De Sá Teixeira, 2016b; Freitas & De Sá Teixeira, 2021), a1 was found to be null and a negative b1 is commonly found, which translates as a greater displacement downward, towards the participants’ feet and, thus, taken as a measure of Representational Gravity (see Fig. 3, second inset line). The coefficient a2 is typically found to be significant, reflecting an increase in forward displacement for horizontally moving targets—Representational Horizon. Importantly, it has been previously reported (Freitas & De Sá Teixeira, 2021) that the orientation of the visual context is accompanied by a modulation of coefficient b2 such that the orientation of Representational Horizon is biased toward the horizon implied by the visual context (see Fig. 3, third inset line). In that same study, coefficients a4 and b4—which together reflect an increased forward displacement along four preferred directions—were also found to be affected by the orientation of the visual context, although this trend is arguably due to the fact that the specific visual context employed depicts a prominent rectangular frame. Given the set of images used as visual context in the present study, we hypothesized that varying orientations of the visual context would reflect solely on the measured b2 coefficients (see Fig. 3, top plots).

Hypothesized effect of visual context orientation on M-displacements, depicted in polar plots. Note. The bottom insets represent the underlying harmonic components for each visual context orientation
To statistically test these hypotheses, estimated individual values of c, coefficients a1–a4 and b1–b4, were subjected to a mixed multivariate analysis of variance (MANOVA), with response context (inducing stimuli or blank screen) as a between-subjects factor and visual context orientation (−22.5º, 0º, and 22.5º) and scene type (interior or exterior scenes) as repeated-measures factors. Whenever the sphericity assumption was violated, degrees of freedom were adjusted with the Greenhouse–Geisser correction.
Results
Prior to the main analyses, mean M-displacement for each target’s motion direction, visual context orientation and scene type were subjected to one-sample t tests to ensure that it differed from 0 and, hence, that forward perceptual displacements were observed. For all conditions, M-displacement was significantly bigger than zero (p < .002 for all tests). Figure 4 depicts polar plots for the mean M-displacements as a function of target’s motion direction (radial lines) and scene type (line parameter) for the varying orientations of the visual context (panel columns) and presence/absence of a visual context during the spatial localisation responses (line parameter). Visual inspection shows that M-displacements were considerably higher when no visual context was shown during the response stage (plots D, E, and F). Also, M-displacements seem to vary with the orientation of the visual context, being somewhat larger for targets moving along the horizon implied by the visual context.

Polar plots of M-displacements as a function of target’s motion direction (θ; radial parameter). Note. Data markers depict empirically observed M-displacements and lines the best fitting models including constant c (RM), coefficients a1 and b1 (RG), and coefficients a2 and b2 (RH). Top insets depict the orientations of visual context
Statistical analyses provided support for visual inspection. Response context significantly affected constant c, F(1, 38) = 19.67, p < .001, partial η2 = 0.341, coefficient a2, F(1, 38) = 10.75, p = .002, partial η2 = 0.221, and coefficient b3, F(1, 39) = 4.393, p = .043, partial η2 = 0.104. Overall, spatial localisation responses made with a blank background led to a considerably higher Representational Momentum (constant c: M = 48.21, SD = 32.33), compared with responses made with a visual context (constant c: M = 15.17, SD = 7.99; see Fig. 5). At the same time, responses made with a blank background led to both a slightly higher a2 coefficient (M = 10.45, SD = 7.92) and a negative b3 coefficient (M = −1.31, SD = 2.32), compared with responses made with a visual context (a2: M = 4.24, SD = 2.97; b3: M = −0.15, SD = 0.86), which, taken together, reflect a larger forward displacement in the former condition for targets moving along the actual horizontal and in a downwards slant. No other main effects were found for the response context.

Mean estimated constant c (Representational Momentum; RM), coefficients a1 and b1 (Representational Gravity; RG), and coefficients a2 and b2 (Representational Horizon; RH). Note. Error bars depict the standard errors of the means. Top insets depict the orientations of visual context
In what refers to the effects of visual context, scene type was found to significantly affect constant c, F(1, 38) = 48.038, p < .001, partial η2 = 0.558, disclosing a bigger Representational Momentum for exterior scenes, and more so for those participants whose responses were made without visual context, as revealed with a significant interaction between scene type and response context, F(1, 38) = 21.401, p < .001, partial η2 = 0.36.
Concurrently, a main effect of orientation of the visual context was found for coefficient b2, F(2, 76) = 3.24, p = .045, partial η2 = 0.079, with only a significant linear contrast, F(1, 38) = 8.571, p = .006, partial η2 = 0.184. The latter is of particular relevance, as it results in a trend where, overall, the second harmonic component, indexing Representational Horizon, tends to follow the horizon implied by the visual context (see Fig. 6, bottom plots). Interestingly, coefficient b2 was also modulated by a significant interaction between visual context orientation and scene type, F(2, 76) = 5.395, p = .006, partial η2 = 0.124, with only a significant linear-linear contrast, F(1, 38) = 9.048, p = .005, partial η2 = 0.192, revealing that Representational Horizon’s conformance to the horizon implied by the visual context was chiefly present for exterior, but not the interior scenes (see Fig. 6, dashed lines in the bottom plots for each panel).

Polar plots of the mean estimated first (coefficients a1 and b1—Representational Gravity; RG) and second (coefficients a2 and b2—Representational Horizon; RH) harmonic components
The orientation of the visual context was also found to interact with the type of scene in determining the magnitude of the constant c, F(1.428, 54.273) = 3.896, p = 0.039, partial η2 = 0.093. This effect reflects a slight tendency for Representational Momentum to be smaller specifically for upright interior visual contexts. The orientation of the visual context also interacted with response context in modulating the coefficient a4, F(2, 76) = 3.762, p = .028, partial η2 = 0.09, in a pattern in which spatial localisation responses made with an upright visual context resulted in a slightly increased forward displacement for targets moving diagonally. Finally, three-way interactions between response context, visual context orientation, and scene type were found for coefficient a1, F(2, 76) = 4.929, p = .01, partial η2 = 0.115, and b3, F(2, 76) = 3.535, p = .034, partial η2 = 0.085. The former reflects a slight tendency for the direction of Representational Gravity to be biased clockwise (downward and leftward), and more so when the visual context was tilted rightward, albeit solely for exterior scenes and when the spatial localisation response was made with the same visual context present during target motion (see Fig. 5). The latter captures slightly increased forward displacements for targets moving at a downward slant for exterior visual contexts and for interior upright scenes. No other main effects or interactions reached statistical significance.
In light of the disclosed differential effect of scene type on the Representational Horizon, an unplanned ad hoc analysis of the image pools was performed, aiming to provide some hints as to which visual features of the exterior scenes, in contrast with interior ones, drive the modulation of Representational Horizon. Arguably, exterior scenes, in general, are more likely to naturally include visible portions of the sky and textured gradients from ground surfaces which, together, strongly and less ambiguously imply a horizon, even if not manifestly shown. Stated differently, we considered the possibility that, by their nature, interior and exterior scenes might present specific visual features regarding horizontally and vertically oriented elements which, in its turn, might play a role in emphasising visual space orientation. To explore this hypothesis, all visual contexts were processed to roughly quantify the presence of such elements (see Fig. 7 for an illustration of the different stages adopted) and to obtain an estimate of the orientation of image elements based upon image gradients.

Illustration of the main stages for the overall estimation of horizontally and vertically oriented gradient image elements in the visual context images: the image gradient is computed (leftmost plates), filtered by orientation (centre plates), and a gradient density map computed (rightmost plates). Note. To facilitate the illustration and improve readability, the gradient images have been enhanced (luminance inversion and contrast adjustment (i.e., darker values correspond to higher gradients) and the density values normalized for each orientation to cover the full range of the colormap
To this end, we computed the image gradients (Burger & Burge, 2016) which yield, at each pixel, the direction of maximum intensity variation along with the rate of that change (a higher gradient magnitude means a more abrupt change). The gradient’s direction was considered to filter only those pixels corresponding to horizontal or vertical variations (corresponding to vertically and horizontally oriented image elements, respectively, e.g., an abrupt luminance change from left to right visually results in a vertical ‘edge’). Finally, the filtered gradient data were processed to compute the amount of gradient per visual context region adopting a 20 × 20 pixels grid. As an overall illustration of the obtained results for each context category and image element orientation, Fig. 8 depicts the mean gradient distribution for horizontally and vertically oriented elements considering all exterior and interior scenes.

Mean gradient distribution for exterior and interior stimuli regarding horizontally (top row) and vertically (bottom row) oriented image elements. (Colour figure online)
To analytically detect differences in mean horizontally and vertically oriented image gradients between exterior and horizontal scenes a mixed MANOVA, given by 20 (scene region columns; repeated measures) × 20 (scene region rows; repeated measures) × 2 (scene type: exterior or interior; between groups).
Considering the context images from left to right, both horizontally, F(4.179, 325.99) = 32.143, p < .001, partial η2 = 0.292, and vertically, F(7.807, 608.934) = 7.484, p < .001, partial η2 = 0.088, oriented image elements were found to vary across scene region columns, in a pattern where both had a more prominent presence near the vertical centre of the visual context. Importantly, neither horizontally, F(4.179, 325.99) = 1.326, p = .259, partial η2 = 0.017, nor vertically, F(7.807, 608.934) < 1, oriented image elements were found to be modulated by the type of scene when considering their variation from left to right (compare vertical histograms, above each plot, for both horizontally and vertically oriented image elements, in Fig. 8).
Similarly, mean gradients corresponding to vertically oriented image elements were also found to be modulated by scene region rows (i.e., observing the context images from top to bottom), F(3.265, 254.707) = 30.513, p < .001, partial η2 = 0.281, without significant interaction with scene type, F(3.265, 254.707) = 2.445, p = .059, partial η2 = 0.03. Overall, for both interior and exterior scene pools, vertically oriented image elements were found to be mostly concentrated near the horizontal central regions. Conversely, and importantly enough, observing the mean gradient distribution from top to bottom (i.e., across region rows) unveils a main effect on horizontally oriented image elements, F(5.052, 394.029) = 17.877, p < .001, partial η2 = 0.186, and a statistically significant interaction with the type of scene, F(5.052, 394.029) = 4.178, p = .001, partial η2 = 0.054. The latter effect reflects the fact that horizontally oriented image elements are concentrated on the bottom half region for exterior scenes but more evenly distributed for interior scenes (see horizontal histograms on the interior sides of the top plots in Fig. 8), likely reflecting a higher predominance of a textured visual ground providing horizontal cues which, when contrasting with a less structured sky, in exterior images might strengthen the implication of a well-defined visual horizon.
Discussion and conclusions
The present experiment aimed to replicate the finding that Representational Horizon, where the spatial localisation of the offset position of a moving target is further displaced beyond what would be expected due to Representational Momentum alone, is biased towards the horizon implied by the visual context (Freitas & De Sá Teixeira, 2021).
In particular, we intended to check for this trend across a wide set of visual contexts, including interior and exterior scenes, as in that previous work only one single visual context was used. The outcomes closely followed our predictions, albeit solely for exterior scenes. This finding was unexpected, for in previous work Freitas and De Sá Teixeira (2021) first reported a tilting of the orientation of Representational Horizon towards the horizon of a visual context using a depiction of an interior scene. However, it should be noticed that the image used as a visual context in that report depicted an empty rectangular frame, with conspicuous horizontal and vertical lines which provided unambiguous visual orientation cues. It can hardly be argued that the set of images employed in the present work, both of interior and exterior spaces, were not rich in visual orientation cues, and it is unlikely that higher-order features, such as the fact that the visual context depicts an open or enclosed space, were responsible for the found difference. However, and by virtue of their very nature, typical exterior scenes might more unambiguously convey a spatial orientation due to the fact that, in such settings, a visually textured ground gradient and a sparsely structured sky are invariably present, besides any other possible elements (e.g., buildings, cars, trees, people), implying a visual horizon line.
Following this reasoning, we set forth to ascertain to what degree the pools of visual contexts employed in our study reflect these natural scene statistics. By quantifying the amount of horizontally and vertically oriented image elements, resorting to image gradients, we found evidence that the former is unequally distributed for exterior but not interior scenes. Specifically, the set of exterior contexts seems to more consistently include a vertical anisotropy, wherein horizontally oriented image elements more likely occur in the bottom half of the scenes, naturally populated by visual surfaces and textured ground. Arguably, this statistical distribution of horizontally oriented image elements results in exterior scenes strongly implying the presence of a horizon line, which, in its turn, might be highly effective in providing a strong spatial orientation cue. Interestingly, this conclusion converges with the finding reported by Hemmerich et al. (2020), where only a simple earth-fixed horizon line was efficient in reducing visually induced motion sickness, supporting the paramount role of that visual feature as a strong cue for spatial orientation. This account opens interesting prospects for future research, where the present experiment might be replicated using as visual context only simple visual features such as a line implying a horizon and/or texture ground gradients (e.g., a chequerboard depicted in perspective).
In any case, the effect of visual context on the orientation of Representational Horizon, in the present study, was shown not to depend on the presence or absence of visual context during the localisation response, revealing that it reflects processes of visual motion representation. However, and unsurprisingly, removing the visual context before the spatial localisation response led to an increase in Representational Momentum, reflecting the fact that participants rely, to some extent, on visual landmarks when providing their spatial localisation judgements (see Gray & Thornton, 2001, for a similar result).
Besides their effect on Representational Horizon, exterior scenes also resulted in a quantifiable increase in Representational Momentum, in comparison with interior scenes. This outcome, in itself, is of particular interest, as it reveals a previously undisclosed trend. To the degree that Representational Momentum reflects the functioning of extrapolating mechanisms for dynamic events (Hubbard, 2005, 2010, 2015, 2019), this effect might reflect tacit knowledge that an enclosed space constrains the trajectory lengths of moving objects—that is, in contrast with an outside setting, where a projectile can move longer and for wider trajectories (given that enough force is imparted to it), an interior space is more likely to be cluttered and any motion is necessarily restricted to the space between the walls (for an effect of explicit barriers, with which the target could collide and bounce back reversing its direction, on the magnitude of Representational Momentum, see Experiment 4 in Hubbard & Bharucha, 1988). Even though somewhat speculative, this account adds to the discussion concerning the degree to which Representational Momentum is sensitive to high-level cognitive expectations (Hubbard, 2006) besides being affected by oculomotor biomechanical constraints (De Sá Teixeira, 2016b; Kerzel, 2000, 2006).
In the present experiment, no particular instruction was given regarding oculomotor behaviour and, thus, it is likely that participants tracked the moving target with their eyes (Churchland & Lisberger, 2002), irrespective of the type of scene used as visual context. Albeit it has been reported that the mere presence of a structured background reduces smooth pursuit eye movements (Collewijn & Tamminga, 1984), it is reasonable to expect no main differences in this regard between our sets of interior and exterior scenes. On the other hand, smooth pursuit eye movements have been shown to be cognitively penetrable, reflecting anticipation of expected trajectories, based on previous experience (Barnes, 2008; Barnes & Collins, 2008; Kowler et al., 2019). Notwithstanding, and since in this study eye movements were not monitored, our explanation remains tentative at this time.
In conclusion, the present study successfully extended the previous finding that the orientation of Representational Horizon, indexed by the second harmonic component underlying the patterns of spatial localisation of a moving target, is biased by visual orientation cues (Freitas & De Sá Teixeira, 2021). Specifically, this biasing was found to be reliably induced by a variety of natural scenes, further emphasising the link between dynamic representations of motion (Freyd, 1987; Hubbard, 2005, 2010, 2015), internal models (De Sá Teixeira & Hecht, 2014; De Sá Teixeira et al., 2013, 2019a, b; Lacquaniti et al., 2013; McIntyre et al., 2001), and spatial orientation (Haji-Khamneh & Harris, 2010; Harris et al., 2011; Howard & Templeton, 1973; Jenkin et al., 2010, 2011; MacNeilage et al., 2008; Mittelstaedt, 1986).
References
Angelaki, D. E., Shaikh, A. G., Green, A. M., & Dickman, J. D. (2004). Neurons compute internal models of the physical laws of motion. Nature, 430(6999), 560–564. https://doi.org/10.1038/nature02754
Ashida, H. (2004). Action-specific extrapolation of target motion in human visual system. Neuropsychologia, 42(11), 1515–1524. https://doi.org/10.1016/j.neuropsychologia.2004.03.003
Barnes, G. R. (2008). Cognitive processes involved in smooth pursuit eye movements. Brain and Cognition, 68(3), 309–326. https://doi.org/10.1016/j.bandc.2008.08.020
Barnes, G. R., & Collins, C. J. S. (2008). Evidence for a link between the extra-retinal component of random-onset pursuit and the anticipatory pursuit of predictable object motion. Journal of Neurophysiology, 100(2), 1135–1146. https://doi.org/10.1152/jn.00060.2008
Barra, J., Marquer, A., Joassin, R., Reymond, C., Metge, L., Chauvineau, V., & Pérennou, D. (2010). Humans use internal models to construct and update a sense of verticality. Brain, 133(12), 3552–3563. https://doi.org/10.1093/brain/awq311
Bertamini, M. (1993). Memory for position and. Memory & Cognition, 21(4), 449–457. https://doi.org/10.3758/BF03197176
Burger, W., & Burge, M. J. (2016). Digital image processing: An algorithmic introduction using Java (2nd ed.). Springer. https://doi.org/10.1007/978-1-4471-6684-9
Churchland, A. K., & Lisberger, S. G. (2002). Gain control in human smooth-pursuit eye movements. Journal of Neurophysiology, 87(6), 2936–2945. https://doi.org/10.1152/jn.2002.87.6.2936
Collewijn, H., & Tamminga, E. P. (1984). Human smooth and saccadic eye movements during voluntary pursuit of different target motions on different backgrounds. The Journal of Physiology, 351(1), 217–250. https://doi.org/10.1113/jphysiol.1984.sp015242
De Sá Teixeira, N. A. (2014). Fourier decomposition of spatial localization errors reveals an idiotropic dominance of an internal model of gravity. Vision Research, 105, 177–188. https://doi.org/10.1016/j.visres.2014.10.024
De Sá Teixeira, N. A. (2016). How fast do objects fall in visual memory? Uncovering the temporal and spatial features of representational gravity. PLOS ONE, 11(2), e0148953. https://doi.org/10.1371/journal.pone.0148953
De Sá Teixeira, N. A. (2016). The visual representations of motion and of gravity are functionally independent: Evidence of a differential effect of smooth pursuit eye movements. Experimental Brain Research, 234(9), 2491–2504. https://doi.org/10.1007/s00221-016-4654-0
De Sá Teixeira, N. A., & Hecht, H. (2014). Can representational trajectory reveal the nature of an internal model of gravity? Attention, Perception, & Psychophysics, 76(4), 1106–1120. https://doi.org/10.3758/s13414-014-0626-2
De Sá Teixeira, N. A., & Oliveira, A. M. (2014). Spatial and foveal biases, not perceived mass or heaviness, explain the effect of target size on representational momentum and representational gravity. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(6), 1664–1679. https://doi.org/10.1037/xlm0000011
De Sá Teixeira, N. A., Hecht, H., & Oliveira, A. M. (2013). The representational dynamics of remembered projectile locations. Journal of Experimental Psychology: Human Perception and Performance, 39(6), 1690–1699. https://doi.org/10.1037/a0031777
De Sá Teixeira, N. A., Hecht, H., Diaz Artiles, A., Seyedmadani, K., Sherwood, D. P., & Young, L. R. (2017). Vestibular stimulation interferes with the dynamics of an internal representation of gravity. Quarterly Journal of Experimental Psychology, 70(11), 2290–2305. https://doi.org/10.1080/17470218.2016.1231828
De Sá Teixeira, N. A., Bosco, G., Delle Monache, S., & Lacquaniti, F. (2019). The role of cortical areas hMT/V5+ and TPJ on the magnitude of representational momentum and representational gravity: A transcranial magnetic stimulation study. Experimental Brain Research, 237(12), 3375–3390. https://doi.org/10.1007/s00221-019-05683-z
De Sá Teixeira, N. A., Kerzel, D., Hecht, H., & Lacquaniti, F. (2019). A novel dissociation between representational momentum and representational gravity through response modality. Psychological Research, 83(6), 1223–1236. https://doi.org/10.1007/s00426-017-0949-4
Finke, R. A., Freyd, J. J., & Shyi, G. C. (1986). Implied velocity and acceleration induce transformations of visual memory. Journal of Experimental Psychology: General, 115(2), 175–188. https://doi.org/10.1037/0096-3445.115.2.175
Freitas, R. R., & De Sá Teixeira, N. A. (2021). Visual space orientation and representational gravity: Contextual orientation visual cues modulate the perceptual extrapolation of motion. Journal of Experimental Psychology: Human Perception and Performance, 47(12), 1647–1658. https://doi.org/10.1037/xhp0000962
Freyd, J. J. (1983). The mental representation of movement when static stimuli are viewed. Perception & Psychophysics, 33(6), 575–581. https://doi.org/10.3758/BF03202940
Freyd, J. J. (1987). Dynamic mental representations. Psychological Review, 94(4), 427–438. https://doi.org/10.1037/0033-295X.94.4.427
Freyd, J. J., & Finke, R. A. (1984). Representational momentum. Journal of Experimental Psychology: Learning, Memory, and Cognition, 10(1), 126–132. https://doi.org/10.1037/0278-7393.10.1.126
Freyd, J. J., & Finke, R. A. (1985). A velocity effect for representational momentum. Bulletin of the Psychonomic Society, 23(6), 443–446. https://doi.org/10.3758/BF03329847
Freyd, J. J., & Johnson, J. Q. (1987). Probing the time course of representational momentum. Journal of Experimental Psychology: Learning, Memory, and Cognition, 13(2), 259–268. https://doi.org/10.1037/0278-7393.13.2.259
Gray, R., & Thornton, I. M. (2001). Exploring the link between time to collision and representational momentum. Perception, 30(8), 1007–1022. https://doi.org/10.1068/p3220
Grush, R. (2005). Internal models and the construction of time: Generalizing from state estimation to trajectory estimation to address temporal features of perception, including temporal illusions. Journal of Neural Engineering, 2(3), S209–S218. https://doi.org/10.1088/1741-2560/2/3/S05
Haji-Khamneh, B., & Harris, L. R. (2010). How different types of scenes affect the subjective visual vertical (SVV) and the perceptual upright (PU). Vision Research, 50(17), 1720–1727. https://doi.org/10.1016/j.visres.2010.05.027
Harris, L. R., Jenkin, M., Dyde, R. T., & Jenkin, H. (2011). Enhancing visual cues to orientation. In F. H. Santos (Ed.), Progress in brain research (19th ed., pp. 133–142). Elsevier. https://doi.org/10.1016/B978-0-444-53752-2.00008-4
Hemmerich, W., Keshavarz, B., & Hecht, H. (2020). Visually induced motion sickness on the horizon. Frontiers in Virtual Reality, 1, 582095. https://doi.org/10.3389/frvir.2020.582095
Hogendoorn, H. (2020). Motion extrapolation in visual processing: Lessons from 25 years of flash-lag debate. The Journal of Neuroscience, 40(30), 5698–5705. https://doi.org/10.1523/JNEUROSCI.0275-20.2020
Howard, I. P., & Templeton, W. B. (1973). Human spatial orientation. Wiley.
Hubbard, T. L. (1990). Cognitive representation of linear motion: Possible direction and gravity effects in judged displacement. Memory & Cognition, 18(3), 299–309. https://doi.org/10.3758/BF03213883
Hubbard, T. L. (1995). Cognitive representation of motion: Evidence for friction and gravity analogues. Journal of Experimental Psychology: Learning, Memory, and Cognition, 21(1), 241–254. https://doi.org/10.1037/0278-7393.21.1.241
Hubbard, T. L. (1995). Environmental invariants in the representation of motion: Implied dynamics and representational momentum, gravity, friction, and centripetal force. Psychonomic Bulletin & Review, 2(3), 322–338. https://doi.org/10.3758/BF03210971
Hubbard, T. L. (1998). Some effects of representational friction, target size, and memory averaging on memory for vertically moving targets. Canadian Journal of Experimental Psychology, 52(1), 44–49. https://doi.org/10.1037/h0087278
Hubbard, T. L. (2005). Representational momentum and related displacements in spatial memory: A review of the findings. Psychonomic Bulletin & Review, 12(5), 822–851. https://doi.org/10.3758/BF03196775
Hubbard, T. L. (2006). Computational theory and cognition in representational momentum and related types of displacement: A reply to Kerzel. Psychonomic Bulletin & Review, 13(1), 174–177. https://doi.org/10.3758/BF03193830
Hubbard, T. L. (2010). Approaches to representational momentum: Theories and models. In R. Nijhawan & B. Khurana (Eds.), Space and time in perception and action (pp. 338–365). Cambridge University Press. https://doi.org/10.1017/CBO9780511750540.020
Hubbard, T. L. (2015). The varieties of momentum-like experience. Psychological Bulletin, 141(6), 1081–1119. https://doi.org/10.1037/bul0000016
Hubbard, T. L. (2019). Spatiotemporal illusions involving perceived motion. In V. Arstila, A. Bardon, S. E. Power, & A. Vatakis (Eds.), The illusions of time (pp. 289–313). Springer International Publishing. https://doi.org/10.1007/978-3-030-22048-8_16
Hubbard, T. L. (2020). Representational gravity: Empirical findings and theoretical implications. Psychonomic Bulletin & Review, 27(1), 36–55. https://doi.org/10.3758/s13423-019-01660-3
Hubbard, T. L., & Bharucha, J. J. (1988). Judged displacement in apparent vertical and horizontal motion. Perception & Psychophysics, 44(3), 211–221. https://doi.org/10.3758/BF03206290
Jenkin, M. R. M., Harris, L. R., & DydeOman, R. T. R. T. (2010). Where’s the floor? Seeing and Perceiving, 23(1), 81–88. https://doi.org/10.1163/187847510X490826
Jenkin, M., Zacher, J., Dyde, R., Harris, L., & Jenkin, H. (2011). Perceptual upright: The relative effectiveness of dynamic and static images under different gravity states. Seeing and Perceiving, 24(1), 53–64. https://doi.org/10.1163/187847511X555292
Kerzel, D. (2000). Eye movements and visible persistence explain the mislocalization of the final position of a moving target. Vision Research, 40(27), 3703–3715. https://doi.org/10.1016/s0042-6989(00)00226-1
Kerzel, D. (2003). Mental extrapolation of target position is strongest with weak motion signals and motor responses. Vision Research, 43(25), 2623–2635. https://doi.org/10.1016/s0042-6989(03)00466-8
Kerzel, D. (2006). Comment and Reply Why eye movements and perceptual factors have to be controlled in studies on “representational momentum”. Psychonomic Bulletin & Review, 13(1), 166–173. https://doi.org/10.3758/BF03193829
Kerzel, D., & Gegenfurtner, K. R. (2003). Neuronal processing delays are compensated in the sensorimotor branch of the visual system. Current Biology, 13(22), 1975–1978. https://doi.org/10.1016/j.cub.2003.10.054
Kerzel, D., Jordan, J. S., & Müsseler, J. (2001). The role of perception in the mislocalization of the final position of a moving target. Journal of Experimental Psychology: Human Perception and Performance, 27(4), 829–840. https://doi.org/10.1037/0096-1523.27.4.829
Kheradmand, A., & Winnick, A. (2017). Perception of upright: Multisensory convergence and the role of temporo-parietal cortex. Frontiers in Neurology, 8, 552. https://doi.org/10.3389/fneur.2017.00552
Kowler, E., Rubinstein, J. F., Santos, E. M., & Wang, J. (2019). Predictive smooth pursuit eye movements. Annual Review of Vision Science, 5(1), 223–246. https://doi.org/10.1146/annurev-vision-091718-014901
Lacquaniti, F., Bosco, G., Indovina, I., La Scaleia, B., Maffei, V., Moscatelli, A., Zago, M. (2013). Visual gravitational motion and the vestibular system in humans. Frontiers in Integrative Neuroscience, 7. https://doi.org/10.3389/fnint.2013.00101
MacNeilage, P. R., Ganesan, N., & Angelaki, D. E. (2008). Computational approaches to spatial orientation: From transfer functions to dynamic Bayesian inference. Journal of Neurophysiology, 100(6), 2981–2996. https://doi.org/10.1152/jn.90677.2008
McIntyre, J., Zago, M., Berthoz, A., & Lacquaniti, F. (2001). Does the brain model Newton’s laws? Nature Neuroscience, 4(7), 693–694. https://doi.org/10.1038/89477
Mitrani, L., & Dimitrov, G. (1978). Pursuit eye movements of a disappearing moving target. Vision Research, 18(5), 537–539. https://doi.org/10.1016/0042-6989(78)90199-2
Mittelstaedt, H. (1986). The subjective vertical as a function of visual and extraretinal cues. Acta Psychologica, 63(1), 63–85. https://doi.org/10.1016/0001-6918(86)90043-0
Moscatelli, A., & Lacquaniti, F. (2011). The weight of time: Gravitational force enhances discrimination of visual motion duration. Journal of Vision, 11(4), 5–5. https://doi.org/10.1167/11.4.5
Nagai, M., Kazai, K., & Yagi, A. (2002). Larger forward memory displacement in the direction of gravity. Visual Cognition, 9(1/2), 28–40. https://doi.org/10.1080/13506280143000304
Nijhawan, R. (1994). Motion extrapolation in catching. Nature, 370(6487), 256–257. https://doi.org/10.1038/370256b0
Nijhawan, R. (2002). Neural delays, visual motion and the flash-lag effect. Trends in Cognitive Sciences, 6(9), 387–393. https://doi.org/10.1016/S1364-6613(02)01963-0
Nijhawan, R. (2008). Visual prediction: Psychophysics and neurophysiology of compensation for time delays. Behavioral and Brain Sciences, 31(2), 179–198. https://doi.org/10.1017/S0140525X08003804
Oman, C. (2007). Spatial orientation and navigation in microgravity. In F. Mast & L. Jäncke (Eds.), Spatial processing in navigation, imagery and perception (pp. 209–247). Springer. https://doi.org/10.1007/978-0-387-71978-8_13
Peirce, J. W. (2007). PsychoPy—Psychophysics software in Python. Journal of Neuroscience Methods, 162(1/2), 8–13. https://doi.org/10.1016/j.jneumeth.2006.11.017
Peirce, J. W. (2008). Generating stimuli for neuroscience using PsychoPy. Frontiers in Neuroinformatics, 2. https://doi.org/10.3389/neuro.11.010.2008
Pola, J., & Wyatt, H. J. (1997). Offset dynamics of human smooth pursuit eye movements: Effects of target presence and subject attention. Vision Research, 37(18), 2579–2595. https://doi.org/10.1016/S0042-6989(97)00058-8
Reed, C. L., & Vinson, N. G. (1996). Conceptual effects on representational momentum. Journal of Experimental Psychology: Human Perception and Performance, 22(4), 839–850. https://doi.org/10.1037/0096-1523.22.4.839
Sekuler, R., & Armstrong, R. (1978). Fourier analysis of polar coordinate data in visual physiology and psychophysics. Behavior Research Methods & Instrumentation, 10(1), 8–14. https://doi.org/10.3758/BF03205080
Shepard, R. N. (1984). Ecological constraints on internal representation: Resonant kinematics of perceiving, imagining, thinking, and dreaming. Psychological Review, 91(4), 417–447. https://doi.org/10.1037/0033-295X.91.4.417
Shepard, R. N. (1994). Perceptual-cognitive universals as reflections of the world. Psychonomic Bulletin & Review, 1(1), 2–28. https://doi.org/10.3758/BF03200759
Tin, C., & Poon, C.-S. (2005). Internal models in sensorimotor integration: Perspectives from adaptive control theory. Journal of Neural Engineering, 2(3), S147–S163. https://doi.org/10.1088/1741-2560/2/3/S01
Vinson, David W., Engelen, J., Zwaan, R. A., Matlock, T., & Dale, R. (2017). Implied motion language can influence visual spatial memory. Memory & Cognition, 45(5), 852–862. https://doi.org/10.3758/s13421-017-0699-y
Volkening, K., Bergmann, J., Keller, I., Wuehr, M., Müller, F., & Jahn, K. (2014). Verticality perception during and after galvanic vestibular stimulation. Neuroscience Letters, 581, 75–79. https://doi.org/10.1016/j.neulet.2014.08.028
Warren, R. M., & Warren, R. P. (1968). Helmholtz on perception: Its physiology and development. John Wiley & Sons.
Acknowledgments
This work was supported with national funds from FCT–Fundação para a Ciência e Tecnologia, I.P., in the context of the project UID/04810/2020, and partially by grant 2022.11875.BD.
Funding
Open access funding provided by FCT|FCCN (b-on).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Open Practices Statement
All data and files used for the experimental task are available (https://doi.org/10.17605/OSF.IO/NTKUZ). The experiment was not preregistered
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
De Sá Teixeira, N.A., Freitas, R.R., Silva, S. et al. Representational horizon and visual space orientation: An investigation into the role of visual contextual cues on spatial mislocalisations. Atten Percept Psychophys 86, 1222–1236 (2024). https://doi.org/10.3758/s13414-023-02783-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-023-02783-5