
Abstract
Stimulus and response features are linked together into an event file when a response is made towards a stimulus. If some or all linked features repeat, the whole event file (including the previous response) is retrieved, thereby affecting current performance (as measured in so-called binding effects). Applying the figure-ground segmentation principle to such action control experiments, previous research showed that only stimulus features that have a figure-like character led to binding effects, while features in the background did not. Against the background of recent theorizing, integration and retrieval are discussed as separate processes that independently contribute to binding effects (BRAC framework). Thus, previous research did not specify whether figure-ground manipulations exert their modulating influence on integration and/or retrieval. We tested this in three experiments. Participants worked through a sequential distractor-response binding (DRB) task, allowing measurement of binding effects between responses and distractor (color) features. Importantly, we manipulated whether the distractor color was presented as a background feature or as a figure feature. In contrast to previous experiments, we applied this manipulation only to prime displays (Experiment 1), only to probe display (Experiment 2), or varied the figure-ground manipulation orthogonally for primes and probes (Experiment 3). Together the results of all three experiments suggest that figure-ground segmentation affects DRB effects on top of encoding specificity, and that especially the retrieval process is affected by this manipulation.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The execution of the simplest action might seem all too trivial to us but, in fact, several processes contribute to even simple actions. Often summarized under the term action control, these sets of mechanisms allow humans to intentionally interact with their environment. One of these mechanisms is the binding of stimulus and response features (S-R binding).
The core assumption of S-R binding approaches in action control is that when responding to a stimulus, features of both response and stimulus are integrated into a short-lived episodic memory trace, called the event file, which comprises binary interconnections between features (Hommel, 2004). The Theory of Event Coding (TEC; Hommel et al., 2001) assumes that this is made possible through a common representational format (common coding assumption; Prinz, 1997), coding perceptual and motor information in the same code format. The assumed benefit of this integration process is the creation of a coherent representation of an action and its goal (action plan) that is protected against interference from other bindings (Stoet & Hommel, 1999).
Importantly, repeating some or all features in an event file leads to the retrieval of the whole event file from the previous episode, which improves or hampers performance. The retrieved event file might then influence current behavior and leads to performance costs or benefits. Costs and benefits are together referred to as S-R binding effects.Footnote 1 The duality of integration and retrieval is captured by the Binding and Retrieval in Action Control framework (BRAC; Frings et al., 2020) that conceptualizes both processes as independent from each other and assumes that they can be further modulated by top-down (e.g., task instruction; Memelink & Hommel, 2013; Mocke et al., 2020) or bottom-up (e.g., salience; Schmalbrock et al., 2021) modulators individually.
Interestingly, it is assumed that S-R binding is not only a ubiquitous and automatic process, because it occurs almost inevitably (e.g., Hommel, 2005, 2009, 2019; Logan, 1988, 2002; but see Schöpper et al., 2020, for a limitation to this), but also that it incorporates a broad context because task-irrelevant stimuli are also integrated and can retrieve a previous event file (Frings et al., 2007). If S-R binding is indeed as broad as the literature claims, this would imply that not only irrelevant stimuli might be incorporated into an event file but also any irrelevant information like the background of an episode (Hommel, 2004). The present study investigates this relationship between action control and figure-ground segmentation.
Figure-ground segmentation
Figure-ground segmentation is one of several Gestalt principles, a set of principles that are applied to incoming information (Wagemans et al., 2012, for a review). These kinds of principles guide how different aspects of incoming information are combined to form a coherent perception of objects that initially only exist as independent features. The basic idea is that through a defined set of principles that are applied to incoming information a relationship between basic features is imposed so that a coherent perception of an object can emerge (Vecera, 2000; Wischnewski et al., 2010). These principles can impose, for example, which elements of the scene “belong together” (grouping principles; Wertheimer, 1923), how to deal with occlusion of an otherwise coherent contour (contour integration; e.g., Elder et al., 2003), and what constitutes a background and what a figure in front of this background (figure-ground segmentation; e.g., Rubin, 1915).
What is perceived as background and what as the figure is determined by several external visual and internal cues that can be roughly grouped into two categories (see Wagemans et al., 2012, for a review): image-based principles like convexity or symmetry (Kanizsa & Gerbino, 1976), top-bottom symmetry (Hulleman & Humphreys, 2004), or lower region (Vecera et al., 2002), and non-image based influences like past experience (Peterson & Enns, 2005). These principles have been integrated into several modeling approaches that produce solid classifications of figure and ground (e.g., Domijan & Setić, 2008; Wischnewski et al., 2010). However, although we know much about how figure-ground segmentation emerges in the visual domain, we know less about how segmentation affects action control processes that use this visual information to produce an action that is contingent on the visual input.
Action control and figure-ground segmentation
However, evidence from the figure-ground literature underlines that our cognitive system treads the background differently than a figure. For example, memory for background contours is substantially worse than for figure contours (Driver & Baylis, 1996) or discrimination accuracy for stimuli increases when presented on figures compared to backgrounds (Wong & Weisstein, 1982). Other research underlines that this processing disadvantage for background features probably emerges because the background receives considerably less attention than foreground figures (Mazza et al., 2005; Turatto et al., 2002). In these previous studies on the role of attention in figure-ground segmentation, a change detection task was used, where participants barely reported background changes when instructions were to report any change (compared to good figure change detection). Only when participants were instructed to solely focus on background changes did detection performance rise to foreground levels. They interpreted the fact that they had to specifically tell participants to focus on the background as evidence that attention had to be actively directed towards the background and that the “default mode” was to focus attention on figural features.
From an S-R binding perspective, these findings are rather intriguing. Previous studies showed that attention is a strong modulator of S-R binding (Moeller & Frings, 2014; Singh et al., 2018). Essentially, these previous studies found that attention to stimuli increased the S-R binding effect, while the absence of attention may even lead to the absence of binding. Take, for example, a study by Singh et al. (2018). They varied on which of two irrelevant (for the main task color discrimination) word dimensions participants focused on. Before a trial started, participants were informed which of two dimensions they needed to report after the trial. Intriguingly, S-R binding only emerged for the word feature that participants focused on due to the second task. Different from the literature on the automaticity of S-R binding, these two findings seem to suggest that S-R binding of background features should not be possible or should be at least greatly reduced.
This relationship between irrelevant background information and S-R binding effects has previously been investigated by Frings and Rothermund (2017). They presented participants with a distractor-response binding task (DRB; Frings et al., 2007). DRB is a sequential priming paradigm where participants are required to make an identity judgment towards a target stimulus in two consecutive displays – the prime and the probe display. Importantly, the target stimulus is presented alongside one or more distractor stimuli or features that repeat or change between prime and probe while the response to the target can also change or repeat.Footnote 2 Repetition of the distractor can then retrieve the previous event file and with it the previous response, resulting in performance benefits when all features repeat but interference when only some but not all features repeat. Note that DRB effects are just another form of S-R binding effects where a distractor is the stimulus that is integrated with the response and upon repetition retrieves the previous response. Hence, we refer to the effects observed with the DRB paradigm as DRB effects.
In the study by Frings and Rothermund (2017), the irrelevant distractor was color. In one block, the distractor color was always presented as the background, while in the other block it was always presented as the figure in front of the background. Their results showed that color-response binding effects only occurred when the distractor color was a figure before the background, while DRB effects were absent when the distractor color was presented as the background.
Yet, the figure-ground manipulation was always applied to both the prime (where integration is assumed to play the major role) and the probe (where retrieval is assumed to play the major role for the occurrence of binding effects) displays. Since the BRAC framework (Frings et al., 2020) emphasizes that integration and retrieval are two independent processes, the previous manipulation makes it impossible to pinpoint whether one or both processes are actually affected by their figure-ground manipulation. Therefore, it is the goal of the present study to differentiate if and how this type of manipulation separately affects integration and retrieval.
The present study
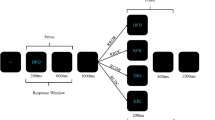
We adapted the DRB paradigm used by Frings and Rothermund (2017) so that the figure-ground manipulation was applied only to the prime (integration) or the probe (retrieval). We used the same figure-ground manipulation as the previous study by making the distractor an irrelevant color. To achieve segmentation, we presented this distractor color as either background or as a foreground figure. However, since we were interested in the influence of this segmentation manipulation on only integration and only retrieval, we applied it to only the prime (Experiment 1) or probe display (Experiment 2), respectively. We achieved this by presenting the distractor color as always part of the target stimulus in the display that was not subject to the present manipulation. For example, when applying the manipulation to only the integration, we present the distractor color as background or figure in the prime (the target would be an achromatic black shape) while the distractor color is always presented as part of the target in the probe (see Fig. 1). The same logic also applies to Experiment 2, except that we switched the figure-ground manipulation from prime to probe.

Exemplary experimental flow for the two prime layer configurations “figure” and “background.” (a) Figure layer configuration with response repetition and color repetition. (b) Background layer configuration with response repetition and color repetition. Responses were made towards the shape identity (triangle vs. square). Layer and probe target color (green vs. blue) was used as distractor. Color and stimuli are not drawn to scale
The figure-ground manipulation may play an important part in Experiment 1 (integration manipulation), because the cognitive system may divert attention only to foreground information. Since attention seems to be necessary for S-R binding effects (Moeller & Frings, 2014; Singh et al., 2018), this would mean that background features do not become integrated into the event file. Repeating or changing distractor colors in the probe would then have no consequences because there would be no distractor color in the event file that could be retrieved (and with them the whole event file).
The figure-ground manipulation may also play an important part in Experiment 2 (retrieval manipulation) because the retrieval process is strongly modulated by varying attention to features (Ihrke et al., 2011). If the processing of color distractors is diminished (or even extinguished) by our manipulation, this would have the consequence that even if distractor colors are part of the event file, they would not be retrieved due to the distractor features not being processed properly in the probe.
If integration or retrieval is affected by our manipulation, we should observe this through a significant interaction between response relation, color relation, and layer (background or figure) in Experiment 1 and/or Experiment 2 in reaction times (RTs) and/or error rates.
Experiment 1: Figure-ground segmentation at the prime
Method
Participants
Thirty students (data of one participant was lost due to technical error and replaced with a new participant) of Trier University (24 female; 29 right-handed) with a median age of 24.5 years (range 20–36 years) participated. All participants were tested for normal or corrected-to-normal vision. They gave written consent and received credits or payment of 10€ for their 1.15 h of service. This study was carried out according to the ethical standards defined by Trier University. The sample size was calculated according to previous studies investigating S-R binding effects, which typically led to medium-sized effects (f = 0.40). Thus, we planned to run N = 30 participants, leading to a power of 1 − β = 0.85 (assuming an alpha = 0.05; GPower 3.1.9.2; Faul et al., 2007), to observe the basic DRB effect without pinpointing the size of the assumed interaction. This would be the same sample size as the previous study that investigated this form of manipulation (Frings & Rothermund, 2017).
Design
For Experiment 1, three within-participant factors were varied: response relation (response repetition vs. response change), color relation (color repetition vs. color change), and layer (figure vs. background).
Apparatus and stimuli
Stimuli were presented on a 22-in. display monitor (60-Hz refresh rate, 1,680 × 1,050 pixels resolution) at a distance of approximately 50 cm. Before testing, the monitor was warmed up for at least 5 min to ensure temporal stability of luminance and color (Poth & Horstmann, 2017). A HP KU-0316 keyboard was used for response executions (QWERTZ layout). The experiment was programmed and run in Psychopy (Peirce et al., 2019; Version 03.01.2020).
Two distinct displays were presented (see Fig. 1): prime and probe display. In the prime display the target was either a triangle or a square (height: 0.8° × width: 0.8°) presented in dark grey (RGB255: 64, 64, 64; 46 cd/m2 ±1). The target was presented within a colored box (height: 1.95° × width: 1.95°, linewidth: 0.01°) or in front of a colored background. Background and box were colored either blue (RGB255: 128, 128, 192; 45 cd/m2 ±1) or green (RGB255: 51, 146, 51; 44 cd/m2 ±1), changing from trial to trial at random. In the probe display, a singular target was presented in either blue or green – repeating the prime color or changing to the unused color. When no colored prime background was presented (i.e., in the figure condition), a light grey tone (RGB255: 134, 134, 134; 41 cd/m2 ±1) background was presented instead.
Procedure
Participants were tested individually in a soundproof chamber. Instructions were presented on the screen. Participants were instructed to place their left index finger on the left arrow key and their right index finger on the right arrow key.Footnote 3 It was emphasized that responses were to be made as fast as possible while maintaining high accuracy. A training with 20 trials was completed before the experimental block – participants received performance feedback after both prime and probe training trials. After the training finished participants only received feedback when they made an erroneous response. Additionally, participants were informed about their performance in the frequent breaks. They received feedback about the number of correct responses in the last 32 trials and their overall mean RT.
The task consisted of two consecutive responses. In both prime and probe participants had to classify the identity of the presented shape. If the shape was a triangle, they responded with the left arrow key; if the shape was a square, they responded with a right arrow key press.
The experiment consisted of 480 trials with a break after each 32-trial block. A single trial consisted of the following chain of events: A trial began with a fixation mark (+) presented at the screen center for 1,000 ms, followed by the prime. The prime display was presented for 200 ms with a response window of 1,000 ms, beginning with display onset. The prime always ended with the end of the response window (independent of the response) and was immediately followed by the probe display. The probe display was, again, presented for 200 ms with a 1,000-ms response window. Each trial was separated from the next by a blank screen for 1,500 ms.
The three factors response relation, color relation, and layer were varied orthogonally. In response repetition trials, the same response required in the prime was required in the probe. Vice versa, in response change trials a different response was required in prime and probe. In color repetition trials, the prime color was again presented in the probe. In color change trials, the prime color was different from the probe color. In figure layer trials, the prime target was presented in a small box colored in the distractor color. In background layer trials, no box was present and the whole background was presented in the distractor color.
Results
Data processing and analysis were done with R (R Core Team, 2019; version 3.6.1). The package ‘dplyr’ (Wickham et al., 2019) was used for data processing and aggregation. Experimental conditions were compared using a repeated-measures analysis of variance (ANOVA) with type-III sums of square, using the ‘ezAnova’-function from the package ‘ez’ (Lawrence, 2016). We report three effect sizes for ANOVAs: ηP2 and ηG2 (Bakeman, 2005). The distractor-response binding effect is computed as the color repetition benefit in response repetition trials minus the color repetition interference in response change trials ([RRCC-RRCR]-[RCCC-RCCR]). This is another form of representing the two-way interaction between response relation and distractor relation. Note that the square root of the F-value (i.e., the t-value) for the critical three-way interaction as well as the p-value is equal to the t-value and p-value for the t-test comparing the DRB effects in both conditions. DRB effects were compared using post hoc t-tests complemented by Bayesian t-tests (Rouder et al., 2009), the Bayes factor (BF01) of which quantifies the evidence in favor of the null hypothesis relative to the evidence in favor of the alternative hypothesis. Bayes factors were computed using the package ‘BayesFactor’ (Morey & Rouder, 2018).
Data processing
Only RTs longer than 200 ms and shorter than 1.5 interquartile ranges over the third quartile of each person’s RT distribution were analyzed (see Tukey, 1977). Only probe RTs in trials with correct answers in both prime and probe were considered. According to these constraints, 11% of all trials were discarded. See Appendix Fig. 6 for a full plot of the RTs and error rates in each condition, and Appendix Figs. 7 and 8 for a plot of individual DRB effects.
Reaction times
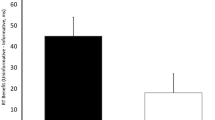
A 2 (response relation: repetition vs. change) × 2 (color relation: repetition vs. change) × 2 (layer: figure vs. background) repeated-measures ANOVA on probe RTs yielded a significant two-way interaction between response relation and color relation, F(1, 29) = 66.50, p < .001, ηG2 < .01, ηP2 = .70, indicating a significant DRB. Intriguingly, this interaction was further modulated by layer, resulting in a significant three-way interaction, F(1, 29) = 7.88, p = .008, ηG2 <.01, ηP2 = .21, suggesting that the DRB effect depends on the layer the prime distractor color was presented in. This effect is further supplemented when Bayes factors are considered: A paired t-test underlined that the DRB effect for the figure layer condition (M = 18 ms, SD = 13) was significantly different from the background layer condition (M = 5 ms, SD = 18), two-sided t(29) = 2.81, p = .008, dz = 0.86, BF01 = 0.20 (see Fig. 2a). Post hoc analysis evidenced that the DRB effects were significantly different from zero for the figure layer condition (two-sided t(29) = 7.23, p < .001, dz = 1.32, BF01 < 0.01) but not for the background layer conditions (two-sided t(29) = 1.94, p = .062, dz = 0.36, BF01 = 0.99).

Average distractor-response binding (DRB) effects as a function of display layer for (a) Experiment 1, manipulation in prime, and (b) Experiment 2, manipulation in probe. Note: Error bars indicate within-participants error of the mean (Morey, 2008). See Appendix Figs. 7 and 8 for a plot of the individual binding effects
Additionally, several main and interaction effects were observed. A main effect for response relation was observed, F(1, 29) = 8.52, p = .007, ηG2 = .01, ηP2 = .23. Participants responded faster in response repetition trials (M = 384 ms, SD = 46) compared to response change trials (M = 398 ms, SD = 52). A main effect for layer was observed, F(1, 29) = 26.05, p < .001, ηG2 < .01, ηP2 = .47. Participants responded faster when the prime distractor color was presented in the background layer (M = 388 ms, SD = 50) compared to when the prime distractor color was presented in the figure layer (M = 394 ms, SD = 49). An interaction between response relation and layer emerged, F(1, 29) = 4.85, p = .036, ηG2 < .01, ηP2 = .14, where participants responded fastest in response repetition × background layer trials (M = 380 ms, SD = 46), somewhat slower in response repetition × figure layer trials (M = 389 ms, SD = 46), even slower in response change × background layer trials (M = 396 ms, SD = 52), and slowest in response change × figure layer trials (M = 400 ms, SD = 52). The main effect for color relation did not reach significance, F(1, 29) = 0.14, p = .709, ηG2 < .01, ηP2 < .01. The interaction between color relation and layer also did not reach significance, F(1, 29) = 2.65, p = .114, ηG2 <.01, ηP2 = .08.
Error rates
For the same analysis on probe error rates, only trials with correct prime responses but incorrect probe responses were considered (i.e., 4.40% of all trials were relevant error trials). The repeated-measures ANOVA on error rates yielded a significant interaction for response relation and color relation, F(1, 29) = 14.21, p < .001, ηG2 = .03, ηP2 = .32, again, indicating a DRB effect. This interaction was not further modulated by the layer the prime color was presented in, F(1, 29) = 2.42, p = .130, ηG2 < .01, ηP2 = .33. A paired t-test underlined that the DRB effect for the figure layer condition (M = 4 %, SD = 5) was not significantly different from the back layer condition (M = 2 %, SD = 5), two-sided t(29) = 1.56, p = .131, dz = 0.40, BF01 = 1.75. Post hoc analysis evidenced that the DRB effect was significantly different from zero for the figure layer condition (two-sided t(29) = 3.73, p < .001, dz = 0.68, BF01 = 0.26) but not for the background layer conditions (two-sided t(29) = 1.63, p = .115, dz = 0.30, BF01 = 1.59).
Additionally, a main effect for layer emerged, F(1, 29) = 10.91, p = .002, ηG2 = .04, ηP2 = .27. No further main effect or interaction reached significance, all Fs < 3.20 and ps > .130.
Experiment 2: Figure-ground segmentation at the probe
Method
Participants
Thirty new participants (one participant was excluded due to an excessive error rate above 25% of all trials, i.e., higher than the outlier criterion) of Trier University (24 female; 25 right-handed) with a median age of 23 years (range 18–32 years) were recruited for this experiment, following the same sample size calculation as the first experiment.
Design
For Experiment 2, three within-participant factors were varied: response relation (response repetition vs. response change), color relation (color repetition vs. color change), and layer (figure vs. background).
Apparatus and stimuli
Stimuli and apparatus were identical to the first experiment.
Procedure
The procedure of Experiment 2 was nearly identical to the procedure of Experiment 1. However, now the probe distractor color could be presented as figure or background, and the prime stimulus was presented in the distractor color (see Fig. 3).

Exemplary experimental flow for the two probe layer configurations “figure” and “background.” (a) Figure layer configuration with response repetition and color repetition. (b) Background layer configuration with response change and color repetition. Responses were made towards the shape identity (triangle vs. square). Layer and prime target color (green vs. blue) were used as distractor. Color and stimuli are not drawn to scale
Results
Data processing
Only RTs longer than 200 ms and shorter than 1.5 interquartile ranges over the third quartile of each person’s RT distribution were analyzed (see Tukey, 1977). Only probe RTs in trials with correct answers in both prime and probe were considered. According to these constraints, 12% of all trials were discarded. See Appendix Fig. 6 for a full plot of the RTs and error rates in each condition, and Appendix Figs. 7 and 8 for a plot of individual DRB effects.
Reaction times
A 2 (response relation: repetition vs. change) × 2 (color relation: repetition vs. change) × 2 (layer: figure vs. background) repeated-measures ANOVA on probe RTs yielded a significant two-way interaction between response relation and color relation, F(1, 28) = 14.27, p < .001, ηG2 <.01, ηP2 = .34, indicating a significant DRB. Intriguingly, this interaction was further modulated by layer, resulting in a significant three-way interaction, F(1, 28) = 13.35, p = .001, ηG2 <.01, ηP2 = .32, suggesting that the DRB effect depends on the layer the probe distractor color was presented in. This effect is further supplemented when Bayes factors are considered: A paired t-test underlined that the DRB effect for the figure layer condition (M = 15.24 ms, SD = 15.98) was significantly different from the back layer condition (M = 2.73 ms, SD = 15.26), two-sided t(28) = 3.65, p = .001, dz = 0.84, BF01 = 0.03 (see Fig. 2b). Post hoc analysis evidenced that the DRB effect were significantly different from zero for the figure layer condition (two-sided t(28) = 5.04, p < .001, dz = 0.94, BF01 < 0.01) but not for the background layer conditions (two-sided t(28) = 0.74, p = .468, dz = 0.14, BF01 = 3.95).
Additionally, several main and interaction effects were observed. A main effect for layer emerged, F(1, 28) = 67.07, p < .001, ηG2 = .02, ηP2 = .71. Participants were faster when the distractor color was presented as the background (M = 396 ms, SD = 45) compared to the figure (M = 411 ms, SD = 42). Further, an interaction effect between response relation and layer emerged, F(1, 28) = 33.03, p < .001, ηG2 <.01, ηP2 = .54. Participants were fastest when the response repeated and the distractor was presented in the background (M = 391 ms, SD = 41), they were somewhat slower when the response changed and the distractor was presented in the background (M = 402 ms, SD = 49), they were even slower when the response changed and the distractor was presented as the figure (M = 409 ms, SD = 43), and were slowest when the response repeated and the distractor was presented as the figure (M = 413 ms, SD = 42).
Error rates
For the same analysis on probe error rates, only trials with correct prime responses but incorrect probe responses were considered (i.e., 5.24% of all trials were relevant error trials). The repeated-measures ANOVA on error rates yielded a significant interaction for response relation and color relation, F(1, 28) = 18.86, p < .001, ηG2 = .04, ηP2 = .38, again indicating a DRB effect. This interaction was not further modulated by the layer the probe color was presented in, F(1, 28) = 1.23, p = .277, ηG2 < .01, ηP2 = .04. A paired t-test underlined that the DRB effect for the figure layer condition (M = 4 %, SD = 7) was not significantly different from the back layer condition (M = 3 %, SD = 5), two-sided t(28) = 1.11, p = .277, dz = 0.27, BF01 = 2.90. Post hoc analysis evidenced that the DRB effect was significantly different from zero for the figure layer condition (two-sided t(28) = 3.24, p = .003, dz = 0.60, BF01 = 0.08) and for the background layer conditions (two-sided t(28) = 3.07, p = .005, dz = 0.57, BF01 = 0.12).
Additionally, a main effect for layer emerged, F(1, 28) = 61.49, p < .001, ηG2 = .20, ηP2 = .69. Participants made less errors when the distractor color was presented as the background (M = 2.71%, SD = 3.08) compared to when the distractor was presented as the figure (M = 7.00%, SD = 5.91). An additional main effect for response relation also emerged, F(1, 28) = 8.06, p = .008, ηG2 = .05, ηP2 = .22. Participants made the least errors when the response changed (M = 3.08%, SD =3.70) compared to when it repeated (M = 5.90%, SD = 6.15). An interaction between response relation and layer was observed, F(1, 28) = 18.86, p < .001, ηG2 = .07, ηP2 = .40. Participants made the least errors when the response repeated and the distractor color was presented as background (M = 2.60%, SD = 3.20), made only marginally more errors when the response changed and the distractor color was presented as background (M = 2.82%, SD = 3.00), made substantially more errors when the response changed and the distractor color was presented as the figure (M = 4.80%, SD = 4.08), and made most errors when the response repeated and the distractor color was presented as figure (M = 9.20%, SD = 6.62).
No further main effect or interaction reached significance, all Fs < 1.49 and ps > .231.
Discussion
Experiments 1 and 2 suggest that background color features are neither integrated into an event file nor do they retrieve event files. This may underline not only the importance of distinguishing between integration and retrieval processes for the DRB effect but also may highlight that background features are indeed less prioritized for integration and retrieval processes than figure features.
However, for Experiments 1 and 2 it could be argued that there always is a mismatch between the prime layer and probe layerFootnote 4 when DRB effects were diminished. That is, in the display that was not manipulated the distractor color was always presented as part of the target and was therefore always part of the figure. Thus, if the color feature was presented in the background in the manipulated display, the layers were mismatched. For example, if the color feature was presented in the background in Experiment 1 (prime only manipulation), it was always presented as the figure in the probe. An alternative interpretation of the data in Experiments 1 and 2 could therefore be not that background features are less integrated/retrieve less but rather that a layer mismatch leads to reduced DRB effects (possibly due to encoding specificity; Laub & Frings, 2020). To exclude this possibility, we orthogonally varied background layer in prime and probe.
For this new experiment, the encoding-specificity account would predict that instead of an effect of figure versus background, the DRB effects should order along the match versus mismatch that the figure-ground manipulation induces. That is, it would predict larger DRB effects in the two matching conditions (figure × figure and background × background) compared to the two mismatching conditions (figure × background and background × figure) but no difference between the two matching conditions – as only the mismatch would reduce DRB effects.
Experiment 3: Figure-ground segmentation at prime and probe
Participants
Sixty-four new participants of Trier University participated online. One participant was excluded due to not complying with the instructions (i.e., they did not respond in any trial). The final sample size consisted of 63 participants (51 female; 55 right-handed) with a median age of 21 years (range 18–35 years). In the absence of any previous study that investigated this kind of manipulation in this type of paradigm, we chose to double the sample size of the previous experiments (N = 60) plus four additional participants in case of drop-out due to the online setting, resulting in a planned sample of 64 participants.
Design
For Experiment 3, four within-participant factors were varied: response relation (response repetition vs. response change), color relation (color repetition vs. color change), prime layer (figure vs. background), and probe layer (figure vs. background).
Apparatus and stimuli
Stimuli and apparatus were identical to Experiments 1 and 2 with the following expectations. The experiment was run online and, therefore, was run on the local computer of each participant. Further, the letters D, F, J, and K were used as targets (each with a font size of 40 pixels).
Procedure
Participants were recruited via the recruitment platform Sona (Sona Systems; sona-systems.com) and were then redirected to the online experiment platform Pavlovia (pavlovia.org) where they consented to participate via the online form. Instructions were presented on the screen. Participants were instructed to place their left index finger on the left arrow key and their right index finger on the right arrow key. If the target letter was an F or a D they responded with a left keypress, if the target was a J or a K they responded with a right keypress. It was emphasized that responses were to be made as fast as possible while maintaining high accuracy. A training period with 16 trials was completed before the experimental block – participants received performance feedback after both prime and probe training trials. After the training finished participants only received feedback when they made an erroneous response. Additionally, participants were informed about their performance in the frequent breaks. They received feedback about the number of correct responses in the last 32 trials.
The experimental block consisted of 480 trials with a break after each 32-trial block. A single trial consisted of the following chain of events: A trial began with a fixation mark (+) presented at the screen center for 1,000 ms, followed by the prime. The prime display was presented for 1,000 ms or until a response was registered. After the prime ended, a black screen was presented for 500 ms. Then the probe display was presented for up to 2,000 ms or until a response was registered. Each trial was separated from the next by a blank screen for 1,500 ms.
The four factors response relation, color relation, prime layer, and probe layer were varied orthogonally. In response repetition trials, the same response required in the prime was also required in the probe. Vice versa, in response change trials a different response was required in prime and probe. In color repetition trials, the prime color was again presented in the probe. In color change trials, the prime color was different from the probe color. In prime figure layer trials, the prime target was presented in a small box colored in the distractor color. In prime background layer trials, no box was present and the whole background was presented in the distractor color. In probe figure layer trials, the probe target was presented in a small box colored in the distractor color. In probe background layer trials, no box was present and the whole background was presented in the distractor color.
Results
Data processing
Adhering to the same constraints as in Experiments 1 and 2, 22% of all trials were discarded.
Reaction times
A 2 (response relation: repetition vs. change) × 2 (color relation: repetition vs. change) × 2 (prime layer: figure vs. background) × 2 (probe layer: figure vs. background) repeated-measures ANOVA on probe RTs yielded a significant two-way interaction between response relation and color relation, F(1, 62) = 40.80, p < .001, ηG2 < .01, ηP2 = .40, indicating the basic DRB effect. Further, a three-way interaction between response relation, color relation, and probe layer emerged, F(1, 62) = 4.61, p = .036, ηG2 < .01, ηP2 = .07. A post hoc t-test revealed that the DRB effect for the probe background layer (M = 11 ms, SD = 28) was significantly smaller than for the probe figure layer (M = 20 ms, SD = 23), t(62) = 2.15, p = .036, dz = 0.27, BF01 = 0.88. DRB effects for probe background trials were significantly different from zero, t(62) = 3.25, p = .002, dz = 0.41, BF01 = 0.07, as were DRB effects for probe figure trials, t(62) = 6.99, p < .001, dz = 0.88, BF01 < 0.01. The three-way interaction between response relation, color relation, and prime layer was not significant, F(1, 62) = 0.95, p = .333, ηG2 < .01, ηP2 = .02. DRB effects for the prime background layer (M = 14 ms, SD = 27) were not significantly different from DRB effects for the prime figure layer (M = 18 ms, SD = 25), t(62) = 0.97, p = .333, dz = 0.12, BF01 = 4.40. Interestingly, a four-way interaction between response relation, color relation, prime layer, and probe layer emerged, F(1,62) = 5.60, p = .021, ηG2 < .01, ηP2 = .08 (see Appendix Figs. 7 and 8 for a plot of individual DRB effects). Specifically, DRB effects in the prime background layer with probe background layer condition (M = 14 ms, SD = 39) were significantly smaller than DRB effects in the prime figure layer with probe figure layer condition (M = 27 ms, SD = 38), t(62) = 0.97, p = .333, dz = 0.12, BF01 = 4.40. Intriguingly, the DRB effect in the prime background layer with probe background layer condition was not significantly different from the prime figure layer with probe background condition (M = 8 ms, SD = 32), t(62) = 1.04, p = .302, dz = 0.07, BF01 = 4.33, nor from the prime background layer with probe figure layer condition (M = 13 ms, SD = 30), t(62) = 0.11, p = .913, dz < 0.01, BF01 = 7.20 (see Fig. 4; please find all other comparisons in the Online Supplementary Material (OSM)).

Average reaction time distractor-response binding (DRB) effects for Experiment 3. The two upper panels show the isolated effect of (a) only manipulating the prime and (b) only manipulating the probe. Panel (c) shows the interaction between prime and probe manipulation. Note that even when the color distractor is presented in the background in the prime and the probe, the DRB effects for this condition are still smaller than for the condition where the color distractor is presented as the figure in the prime and the probe. Error bars indicate within-participants error of the mean (Morey, 2008)
Error rates
For the same analysis on error rates, 7% of all trials were relevant. This analysis yielded a significant two-way interaction between response relation and color relation, F(62) = 17.83, p < .001, ηG2 = .01, ηP2 = .22, indicating the basic DRB effect. Further, neither the three-way interaction between response relation, color relation, and probe layer, F(62) = 0.19, p = .659, ηG2 < .01, ηP2 < .01, nor the three-way interaction between response relation, color relation, and prime layer, F(62) = 0.25, p = .602, ηG2 < .01, ηP2 < .01, reached significance. Interestingly, the four-way interaction between response relation, color relation, prime layer, and probe layer reached significance, F(62) = 6.28, p = .015, ηG2 < .01, ηP2 = .09 (see Fig. 5). See the OSM for a full analysis of the DRB effects.

Average error rate distractor-response binding (DRB) effects for Experiment 3. The two upper panels show the isolated effect of (a) only manipulating the prime and (b) only manipulating the probe. Panel (c) shows the interaction between prime and probe manipulation. Error bars indicate within-participants error of the mean (Morey, 2008)
Discussion
Experiment 3 further investigated an alternative explanation for the results presented in Experiments 1 and 2. That is, a mismatch between the prime and probe layer could also explain these findings based on the encoding specificity of the different displays. Therefore, in Experiment 3, the prime and probe layer were manipulated simultaneously, which could either produce a match between prime and probe layer or a mismatch between prime and probe layer.
First, if you just compare the conditions of Experiment 1 or Experiment 2 in Experiment 3, you see that we exactly replicated the previous results. Experiment 3 showed that, as in Experiments 1 and 2, a mismatch between prime and probe layer resulted in reduced DRB effects compared to the figure x figure condition.
As discussed above, these results coud be re-interpreted in terms of encoding specificity – a mismatch per se resulted in reduced DRB effects and not the figure-ground manipulation. However, a pure encoding specificity-based account would also assume that the matching background × background condition would also lead to strong DRB effects, which is not the case in Experiment 3. RT DRB effects in the background × background condition were significantly smaller than in the figure × figure condition and further did not differ from the DRB effects in the mismatching conditions. This suggests that the figure-ground manipulation has an effect on top of the encoding specificity. That is, DRB effects for background color distractors are reduced – even if prime and probe layer match. This indicates that although a mismatch between the prime and probe layer produces a reduced DRB effect, background colors are additionally less processed than figure colors. Encoding specificity can thus partially explain the results observed in Experiments 1 and 2 but figure-ground segmentation worked on top of the effect of encoding specificity.
We further looked at the isolated effect our manipulation had on prime and probe (i.e., the three-way interaction between response relation, color relation, and prime/probe layer). Here we only observed an effect of the figure-ground manipulation on the probe but not on the prime. Together with the four-way interaction, this indicates that especially retrieval is affected by the figure-ground manipulation.
General discussion
In the present study, we investigated whether integration and/or retrieval in the DRB task is modulated by a figure-ground segmentation manipulation. A previous study showed that background color features did not lead to DRB effects in general. Yet, against the background of recent theorizing (Frings et al., 2020), we suggested that the two processes that contribute to DRB effects, integration and retrieval, might be affected independently by figure-ground segmentation manipulation.
In Experiments 1 and 2, we introduced a figure-ground manipulation to the DRB paradigm that only affected either prime (integration) or probe (retrieval). A distractor color was shown either as the whole background (background condition) or as its own figure in front of a background (figure condition). Overall, we found significant DRB as evidenced by the significant interaction between distractor and response relation. More importantly, we found that this DRB effect is further modulated by figure-ground segmentation as has been shown in previous studies (Frings & Rothermund, 2017). This was evidenced by the significant interaction between response relation, distractor relation, and display layer, as well as the Bayes factors favoring the alternative hypothesis. This effect pattern was observed in both experiments, however, note that we observed this pattern only in the RTs.
In Experiment 3, we investigated a possible alternative explanation in terms of encoding specifity for the results of Experiments 1 and 2. That is, a possible mismatch between the prime and probe layer may have caused reduced DRB effects in the background conditions of Experiments 1 and 2 because the distractor color was always presented as the figure in the not-manipulated display. However, although Experiment 3 revealed that encoding specificity affected the DRB effects, encoding specificity cannot fully account for the pattern we observed in the RT DRB effects.
Together Experiments 1–3 reveal a complex influence of figure-ground segmentation on DRB effects but also on integration and retrieval separately. First, the results reveal that encoding specificity can already emerge by just presenting a color dimension in different layers of scene. Thus, encoding specificity has to be considered for manipulations targeting prime and probe separately as even a slight mismatch (like features being presented in different layers of a scene) might affect the DRB effect. It is also noteworthy that figure-ground segmenatation can affect processing via encoding specifity. Second, in Experiments 1 and 2 we found reduced DRB effects for the background condition. That we found reduced DRB effects in the background × background condition suggests that the findings in the first two experiments cannot solely be attributed to encoding specificity. Thus, they can, albeit carefully, be interpreted as evidence that background features are indeed less likely integrated into an event file and are less likely to retrieve from an event file. However, in Experiment 3 we only found a significant effect of our figure-ground manipulation on the probe but not on the prime. This might suggest that especially retrieval is affected by the figure-ground segmentation manipulation. This would be well in line with previous findings in the literature that suggest that retrieval responds much stronger to manipulation than integration (Hommel et al., 2014; Ihrke et al., 2011).
In a sense, it could be argued that the figure-ground segmentation mechanism works as a gateway mechanism in action control, reducing the amount of irrelevant information that can interfere with the processes resulting in DRB effects. Arguing from a more outside-the-lab perspective, this intuitively makes sense. A unicolored background rarely contributes important information to our everyday actions. Since processing capacity is limited (Bundesen, 1990; Cowan, 2001), it makes sense to consider possible highly irrelevant information less for the competition of stimuli for the limited processing resources (Desimone & Duncan, 1995) and thus giving more important information a chance of processing. One caveat of many action control paradigms and surely the typical DRB paradigm is their very simple and easy to process displays; that is, oftentimes only one or two stimuli (e.g., two letters) are presented so that any kind of selection process may be irrelevant for these kinds of tasks. Thus, previous research might have underestimated the impact of selection processes like figure-ground segmentation. These processes may be much more important for action control in real-world scenarios that are much richer in information than in a laboratory setting.
Still, this consideration might not be generalized to all gestalt principles. At least for color grouping, it was also shown in the laboratory that integration and retrieval are modulated differently (Laub et al., 2018). Here, color-grouped prime distractor-target units led to stronger integration, but ungrouped probe distractor-target units led to stronger retrieval. Yet, it is important to emphasize that figure-ground segmentation and perceptual grouping contribute quite differently to our perception and have been observed to contribute to perception at different levels of processing (figure-ground segmentation as early as V1; e.g., Lamme, 1995, vs. grouping after binocular depth perception; e.g., Rock & Brosgole, 1964; although grouping may occur at different levels of perception; see Wagemans et al., 2012). While figure-ground segmentation may keep irrelevant information out of the cognitive system, grouping determines what belongs together – a process that does not require keeping information out of processing. Thus, it makes sense that both processes lead to different modulations of DRB effects because one hinders attentional deployment to specific features, while the other suggests what belongs together, a process that requires processing and attentional deployment to the features.
In conclusion, the present study extends previous findings by showing that our figure-ground segmentation possibly affected integration and retrieval processes separately. However, it was also revealed that encoding specificity plays an important role in this context. In the context of the figure-ground segmentation literature and the action control literature, the present study highlights the importance of attention for both processes and suggests that the cognitive bias for the foreground reduces the interference from irrelevant background information – not only in perception but also in action.
Data availability
The data that support the findings of this study (https://doi.org/10.23668/psycharchives.5619), and the scripts for data processing and analysis (https://doi.org/10.23668/psycharchives.4715) are openly available at “PsychArchives”. None of the experiments were preregistered.
Notes
Note that we use the term binding effect for the whole effect pattern that integration and retrieval contribute to (i.e., costs and benefits). This differs from some other studies that also used binding instead of integration or that used binding/integration interchangeably. We do this to avoid confusion between the formatting process of an event file (integration) and observed behavioral effects (S-R binding effect) that include the contribution of retrieval.
Distractor identity (color relation) and required response (response relation) can both independently repeat or change from prime to probe display. This leads to the four conditions: response repetition with color repetition (RRCR), response repetition with color change (RRCC), response change with color repetition (RCCR), and response change with color change (RCCC). Usually, full repetition trials (RRCR) lead to fastest reaction times (RTs) because the previous event file is retrieved, including the previous response, which can then be reused without having to compute a new response. Partial repetition (RCCR or RRCC) trials often lead to slower RTs because the repeating features retrieve the previous event file, which conflicts with the demands of the present episode – this conflict has to be resolved before response execution. Full chance trials (RCCC) elicit neither facilitation nor interference because no feature repeats that excludes the possibility for retrieval.
Please note that this 1:1 mapping does not allow us to disentangle the response relation from the target identity relation. However, previous findings (Frings et al., 2007, Exp. 2) showed that the target relation cannot fully account for the crucial interaction between response and distractor relation.
We thank an anonymous reviewer for pointing this out and suggesting the paradigm used in Experiment 3.
References
Allen, M., Poggiali, D., Whitaker, K., Marshall, T. R., & Kievit, R. A. (2019). Raincloud plots: a multi-platform tool for robust data visualization. Wellcome open research, 4. https://doi.org/10.12688/wellcomeopenres.15191.1
Bakeman, R. (2005). Recommended effect size statistics for repeated measures designs. Behavior Research Methods, 37(3), 379–384. https://doi.org/10.3758/BF03192707
Bundesen, C. (1990). A theory of visual attention. Psychological Review, 97(4), 523–547. https://doi.org/10.1037/0033-295x.97.4.523
Cowan, N. (2001). The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behavioral and Brain Sciences, 24(1), 87–114; discussion 114-85. https://doi.org/10.1017/s0140525x01003922
Desimone, R., & Duncan, J. (1995). Neural mechanisms of selective visual attention. Annual Review of Neuroscience, 18, 193–222. https://doi.org/10.1146/annurev.ne.18.030195.001205
Domijan, D., & Setić, M. (2008). A feedback model of figure-ground assignment. Journal of Vision, 8(7), 10.1–27. https://doi.org/10.1167/8.7.10
Driver, J., & Baylis, G. C. (1996). Edge-assignment and figure-ground segmentation in short-term visual matching. Cognitive Psychology, 31(3), 248–306. https://doi.org/10.1006/cogp.1996.0018
Elder, J. H., Krupnik, A., & Johnston, L. A. (2003). Contour grouping with prior models. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(6), 661–674. https://doi.org/10.1109/tpami.2003.1201818
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
Frings, C., & Rothermund, K. (2017). How perception guides action: Figure-ground segmentation modulates integration of context features into S-R episodes. Journal of Experimental Psychology: Learning, Memory, and Cognition, 43(11), 1720–1729. https://doi.org/10.1037/xlm0000403
Frings, C., Rothermund, K., & Wentura, D. (2007). Distractor repetitions retrieve previous responses to targets. Quarterly Journal of Experimental Psychology (2006), 60(10), 1367–1377. https://doi.org/10.1080/17470210600955645
Frings, C., Hommel, B., Koch, I., Rothermund, K., Dignath, D., Giesen, C., Kiesel, A., Kunde, W., Mayr, S., Moeller, B., Möller, M., Pfister, R., & Philipp, A. (2020). Binding and Retrieval in Action Control (BRAC). Trends in Cognitive Sciences, 24(5), 375–387. https://doi.org/10.1016/j.tics.2020.02.004
Hommel, B. (2004). Event files: Feature binding in and across perception and action. Trends in Cognitive Sciences, 8(11), 494–500. https://doi.org/10.1016/j.tics.2004.08.007
Hommel, B. (2005). How much attention does an event file need? Journal of Experimental Psychology. Human Perception and Performance, 31(5), 1067–1082. https://doi.org/10.1037/0096-1523.31.5.1067
Hommel, B. (2009). Action control according to TEC (theory of event coding). Psychological Research, 73(4), 512–526. https://doi.org/10.1007/s00426-009-0234-2
Hommel, B. (2019). Theory of Event Coding (TEC) V2.0: Representing and controlling perception and action. Attention, Perception, & Psychophysics, 81(7), 2139–2154. https://doi.org/10.3758/s13414-019-01779-4
Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). The Theory of Event Coding (TEC): A framework for perception and action planning. Behavioral and Brain Sciences, 24(5), 849–878; discussion 878-937. https://doi.org/10.1017/s0140525x01000103
Hommel, B., Memelink, J., Zmigrod, S., & Colzato, L. S. (2014). Attentional control of the creation and retrieval of stimulus-response bindings. Psychological Research PRPF, 78(4), 520–538. https://doi.org/10.1007/s00426-013-0503-y
Hulleman, J., & Humphreys, G. W. (2004). Is there an assignment of top and bottom during symmetry perception? Perception, 33(5), 615–620. https://doi.org/10.1068/p5092
Ihrke, M., Behrendt, J., Schrobsdorff, H., Michael Herrmann, J., & Hasselhorn, M. (2011). Response-retrieval and negative priming. Experimental Psychology, 58(2), 154–161. https://doi.org/10.1027/1618-3169/a000081
Kanizsa, G., & Gerbino, W. (1976). Convexity and symmetry in figure-ground organization. Henle M, Editor. Art and ArtefactsVision and Artifact. https://ci.nii.ac.jp/naid/10015536416/
Lamme, V. A. (1995). The neurophysiology of figure-ground segregation in primary visual cortex. Journal of Neuroscience, 15(2), 1605–1615. https://doi.org/10.1523/JNEUROSCI.15-02-01605.1995
Laub, R., & Frings, C. (2020). Distractor-based retrieval in action control: The influence of encoding specificity. Psychological Research, 84(3), 765–773. https://doi.org/10.1007/s00426-018-1082-8
Laub, R., Frings, C., & Moeller, B. (2018). Dissecting stimulus-response binding effects: Grouping by color separately impacts integration and retrieval processes. Attention, Perception, & Psychophysics, 80(6), 1474–1488. https://doi.org/10.3758/s13414-018-1526-7
Lawrence, M. A. (2016). ez: Easy analysis and visualization of factorial experiments. R Package Version 4.4-0. https://cran.r-project.org/web/packages/ez/index.html
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95(4), 492–527. https://doi.org/10.1037/0033-295X.95.4.492
Logan, G. D. (2002). An instance theory of attention and memory. Psychological Review, 109(2), 376–400. https://doi.org/10.1037/0033-295x.109.2.376
Mazza, V., Turatto, M., & Umilta, C. (2005). Foreground-background segmentation and attention: A change blindness study. Psychologische Forschung, 69(3), 201–210. https://doi.org/10.1007/s00426-004-0174-9
McGill, R., Tukey, J. W., & Larsen, W. A. (1978). Variations of box plots. The American Statistician, 32(1), 12–16. https://doi.org/10.1080/00031305.1978.10479236
Memelink, J., & Hommel, B. (2013). Intentional weighting: A basic principle in cognitive control. Psychological Research, 77(3), 249–259. https://doi.org/10.1007/s00426-012-0435-y
Mocke, V., Weller, L., Frings, C., Rothermund, K., & Kunde, W. (2020). Task relevance determines binding of effect features in action planning. Attention, Perception, & Psychophysics, 82(8), 3811–3831. https://doi.org/10.3758/s13414-020-02123-x
Moeller, B., & Frings, C. (2014). Attention meets binding: Only attended distractors are used for the retrieval of event files. Attention, Perception, & Psychophysics, 76(4), 959–978. https://doi.org/10.3758/s13414-014-0648-9
Morey, R. D. (2008). Confidence intervals from normalized data: A correction to Cousineau (2005). Tutorials in Quantitative Methods for Psychology, 4(2), 61–64. https://doi.org/10.20982/tqmp.04.2.p06
Morey, R. D., & Rouder, J. N. (2018). BayesFactor: Computation of Bayes factors for common designs. R Package Version 0.9.12-. https://cran.r-project.org/web/packages/BayesFactor/index.html
Peirce, J., Gray, J. R., Simpson, S., MacAskill, M., Höchenberger, R., Sogo, H., Kastman, E., & Lindeløv, J. K. (2019). Psychopy2: Experiments in behavior made easy. Behavior Research Methods, 51(1), 195–203. https://doi.org/10.3758/s13428-018-01193-y
Peterson, M. A., & Enns, J. T. (2005). The edge complex: Implicit memory for figure assignment in shape perception. Perception & Psychophysics, 67(4), 727–740. https://doi.org/10.3758/bf03193528
Poth, C. H., & Horstmann, G. (2017). Assessing the monitor warm-up time required before a psychological experiment can begin. The Quantitative Methods for Psychology, 13(3), 166–173. https://doi.org/10.20982/tqmp.13.3.p166
Prinz, W. (1997). Perception and Action Planning. European Journal of Cognitive Psychology, 9(2), 129–154. https://doi.org/10.1080/713752551
R Core Team. (2019). A language and environment for statistical computing (p. 2012). R Foundation for Statistical Computing.
Rock, I., & Brosgole, L. (1964). Grouping BASED ON PHENOMENAL PROXIMITY Grouping based on phenomenal proximity. Journal of Experimental Psychology, 67(6), 531–538. https://doi.org/10.1037/h0046557
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16(2), 225–237. https://doi.org/10.3758/PBR.16.2.225
Rubin, E. (1915). Visuell wahrgenommene Figuren.
Schmalbrock, P., Laub, R., & Frings, C. (2021). Integrating Salience and Action - Increased Integration Strength through Salience. Visual Cognition, advanced online publication. https://doi.org/10.1080/13506285.2020.1871455
Schöpper, L.-M., Hilchey, M. D., Lappe, M., & Frings, C. (2020). Detection versus discrimination: The limits of binding accounts in action control. Attention, Perception, & Psychophysics, 82(4), 2085–2097. https://doi.org/10.3758/s13414-019-01911-4
Singh, T., Moeller, B., Koch, I., & Frings, C. (2018). May I have your attention please: Binding of attended but response-irrelevant features. Attention, Perception, & Psychophysics, 80(5), 1143–1156. https://doi.org/10.3758/s13414-018-1498-7
Stoet, G., & Hommel, B. (1999). Action planning and the temporal binding of response codes. Journal of Experimental Psychology: Human Perception and Performance, 25(6), 1625–1640. https://doi.org/10.1037/0096-1523.25.6.1625
Tukey, J. W. (1977). Exploratory data analysis. Addison-Wesley.
Turatto, M., Angrilli, A., Mazza, V., Umilta, C., & Driver, J. (2002). Looking without seeing the background change: electrophysiological correlates of change detection versus change blindness. Cognition, 84(1), B1–B10. https://doi.org/10.1016/s0010-0277(02)00016-1
Vecera, S. P. (2000). Toward a Biased Competition Account of Object-Based Segregation and Attention. Brain and Mind, 1(3), 353–384. https://doi.org/10.1023/A:1011565623996
Vecera, S. P., Vogel, E. K., & Woodman, G. F. (2002). Lower region: A new cue for figure-ground assignment. Journal of Experimental Psychology: General, 131(2), 194–205. https://doi.org/10.1037/0096-3445.131.2.194
Wagemans, J., Elder, J. H., Kubovy, M., Palmer, S. E., Peterson, M. A., Singh, M., & von der Heydt, R. (2012). A century of Gestalt psychology in visual perception: I. Perceptual grouping and figure-ground organization. Psychological Bulletin, 138(6), 1172–1217. https://doi.org/10.1037/a0029333
Wertheimer, M. (1923). Untersuchungen zur Lehre von der Gestalt. Advance online publication. https://doi.org/10.1007/bf00410385
Wickham, H., François, R., Henry, L., & Müller, K. (2019). dplyr: A grammar of data manipulation. R Package Version 0.8.3. https://cran.r-project.org/package=dplyr
Wischnewski, M., Belardinelli, A., Schneider, W. X., & Steil, J. J. (2010). Where to Look Next? Combining Static and Dynamic Proto-objects in a TVA-based Model of Visual Attention. Cognitive Computation, 2(4), 326–343. https://doi.org/10.1007/s12559-010-9080-1
Wong, E., & Weisstein, N. (1982). A new perceptual context-superiority effect: Line segments are more visible against a figure than against a ground. Science, 218(4572), 587–589. https://doi.org/10.1126/science.7123261
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The research reported in this article was supported by the Deutsche Forschungsgemeinschaft (FR2133/14-1).
Conflict of interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Statement of Significance
Previous research showed that humans do not use background information for action control mechanisms, measured in so-called distractor-response binding (DRB) effects. However, two processes contribute to these DRB effects, integration and retrieval. We show that both processes neglect background information but that encoding specificity has to be accounted for in this context.
Supplementary Information
ESM 1
(DOCX 78 kb)
Appendices
Appendix 1
Mean performance in Experiment 1 (prime manipulation) and 2 (probe manipulation)
Plots show the average Probe RTs and Probe Error rates for Experiment 1 and Experiment 2 as a function of response relation (repetition vs. change), color relation (repetition vs. change), and layer.

Appendix 2
Individual reaction time binding effects for Experiment 1 and Experiment 2
Plots show the individual reaction time (RT) binding effects for each participant as a function of layer. Plots for (a) prime manipulation and (b) probe manipulation.

Raincloud plots (Allen et al., 2019) for individual binding effects as function of (a) prime layer (Exp. 1) and (b) probe layer (Exp. 2). The horizontal line in each boxplots represents the median of the distribution. Upper and lower whiskers extend to the largest / smallest value above / below the respective hinge but at most 1.5 times the interquartile range above and below the second and first quartiles (McGill et al., 1978)

Raincloud plots (Allen et al., 2019) for individual binding effects as function of prime layer and probe layer for Experiment 3. The vertical line in each boxplots represents the median of the distribution. Upper and lower whiskers extend to the largest/smallest value above/below the respective hinge but at most 1.5 times the interquartile range above and below the second and first quartiles (McGill et al., 1978)
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Schmalbrock, P., Frings, C. A mighty tool not only in perception: Figure-ground mechanisms control binding and retrieval alike. Atten Percept Psychophys 84, 2255–2270 (2022). https://doi.org/10.3758/s13414-022-02511-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-022-02511-5