
Abstract
Four experiments explore the generalizability of two different types of bias in visual comparison. The first type is a spatial congruency bias, in which two target stimuli are more likely to be classified as matching (‘same’) if they appear successively at the same location. The second type is an analytic bias, which varies depending on the overall similarity of the displays and the need to select specific parts from each object. Both types of bias had previously been demonstrated in comparisons based on shape and other visual features. The current tasks move beyond feature comparisons, requiring the comparison of the local positions of visual elements (dots or letters) that appear within each pattern. Given the privileged role of location in visual representations and attentional selection, it is important to test how visual comparisons of location differ from comparisons of shape and other features. The spatial congruency bias is replicated in the comparison of local positions and, as in previous experiments, its strength diminishes when the displays being compared are less similar to one another. Also, as demonstrated previously with letter comparisons, there is an analytic bias shifting responses toward ‘different’ when the displays being compared are less similar to one another. Responses are also shifted more toward ‘same’ in location comparisons relative to feature comparisons. The general pattern of results suggests that as more attentional selection is required in a comparison task, there is a stronger overall bias to respond ‘different’.
Similar content being viewed by others

Introduction
The visual information we are exposed to at any one moment is too extensive and complex for our limited capacity system to process fully. Therefore, an important adaptation to maximise the effectiveness of behaviour is to adjust the scope of visual processing so that it is sufficient but no more detailed than necessary for the task at hand. To assist with this, our visual system utilises processing heuristics that enable behavioural output to be based on ‘best-guesses’. One task in which such a heuristic is likely to be useful is the comparison of objects in our field of view.
Several studies have shown that location information is a key component of visual processing that affects visual comparisons. When participants make same-different object judgements concerning two sequential stimulus displays presented briefly at either the same location or different locations, the task-irrelevant location information biases responses (e.g., Boduroglu & Shah, 2009; Cave & Chen, 2017; Golomb, Kupitz, & Thiemann, 2014), resulting in the stimuli at the same location being more likely to be judged the same than those at different locations. This difference in bias is termed the spatial congruency bias (SCB) (Golomb et al., 2014).
The SCB shows that the location of stimuli can affect responses even when the task is designed to make location irrelevant. This is just one of many examples of location’s unusual and important role in visual perception. Location is central to many theories of attention (e.g., Broadbent, 1982; Cave, 1999; Downing & Pinker, 1985; Eriksen & St. James, 1986; Kubovy, 1981; Lamy & Tsal, 2001; Posner, Snyder, & Davdison, 1980; Treisman, 1988; Treisman & Gelade, 1980; Wolfe, 1994). In some of these theories, location serves as a foundational basis for some types of attentional selection, which sets it apart from other visual properties such as colour, orientation and shape that serve as basic features in object representations. A number of studies have shown that location is encoded regardless of its relevance to the visual task at hand (e.g., Cave & Pashler, 1995; Cave & Zimmerman, 1997; Cepeda, Cave, Bichot, & Kim, 1998; Chen, 2009; Kim & Cave, 1995; Treisman, 1988; Tsal & Lavie, 1993). Thus, it is not a complete surprise that location is also linked to response bias in object-feature comparisons even when it is task-irrelevant.
So far, the SCB has been investigated by manipulating location in same-different judgement tasks using stimuli such as shapes (e.g., Boduroglu & Shah, 2009; Finlayson & Golomb, 2016; Golomb et al., 2014; Shafer-Skelton, Kupitz, & Golomb, 2017), faces (e.g., Paradiso, Shafer-Skelton, Martinez, & Golomb, 2016; Shafer-Skelton et al., 2017), gabor patches (e.g., Shafer-Skelton et al., 2017), letters (e.g., Cave & Chen, 2017), and random dot stereograms (Finlayson & Golomb, 2017). Key findings to date suggest that the SCB is a perceptual effect rather than a response effect, as the magnitude of the bias scales with perceptual similarity (e.g., Cave & Chen, 2017; Golomb et al., 2014; Paradiso et al., 2016) but not with changes in response code (e.g., Cave & Chen, 2017). Furthermore, the SCB is related to the privileged status of location information, as location influences identity or shape judgements but not vice versa (e.g., Golomb et al., 2014). Interestingly, the privileged status of location appears to apply only to 2D location, but not to 3D location. Finlayson and Golomb (2017) used the spatial congruency paradigm to investigate the effect of 2D location on depth-from-disparity/3D judgements and vice versa. The results show that 2D location biases 3D judgements but not the other way round. Based on these findings, the authors suggest that position-in-depth may be processed similarly to an object feature rather than to 2D location. Taken together, the available evidence is consistent with the proposal that the SCB indexes the operation of a mechanism specific to object-feature comparisons, with location playing a binding role (Golomb et al., 2014).
The SCB is a relative effect that measures the difference in bias between displays having the same location and displays having different locations. There is a second type of bias, one that may be independent of the SCB. This bias, the analytic bias (Cave & Chen, 2017), varies according to the demands of the comparison task. In two experiments, Cave and Chen asked participants to judge whether the middle letter of a string of three letters, which were presented at either the same location or different locations, was the same or different in sequential displays. When the flanking distractors stayed the same on sequential displays for the majority of trials, there was a negligible analytic bias (AB). When the distractors changed on most of the trials, there was a bias to respond ‘different’. Cave and Chen proposed that this pattern of data is likely caused by the different processing strategies used in completing the tasks. When distractors are dissimilar, an analytic processing strategy is needed so that attention can be focused on the target. As the filtering of the attentional system is imperfect (B. A. Eriksen & Eriksen, 1974; C. W. Eriksen & Hoffman, 1972), the representations of the distractors are likely to interfere with the representation of the target, resulting in the tendency to respond ‘different’. In contrast, when distractors are the same on most of the trials, the two sets of stimuli can be compared by using a holistic processing strategy with no distractor interference, allowing a relatively broad attentional zoom, and reducing the tendency to respond ‘different’. The exact nature of the AB and the mechanisms underlying it are still unclear, but from what we currently know, the most straightforward way of defining the AB seems to be in relative terms, similar to the definition of the SCB. Thus, for the purposes of this study, the AB is defined as the difference in bias between an analytic task and a corresponding holistic task.
Cave and Chen (2017) also noted that location may play a different role in the two types of processing required in their two tasks. Compared to the holistic task, location is more important in the analytic task, because in their experiments the target was defined by its location relative to the other stimuli in the display and focal attention was needed to perceive the target in an analytic task.
In most previous studies on the SCB, the task was to compare object features such as colour, shape or size. Given the uniqueness of location in visual and attentional tasks in general and in visual comparisons specifically, the new experiments reported here focus on response bias in location judgement. Using a novel experimental paradigm, we manipulate the overall similarity (high vs. low) and the locations of the target displays (same vs. different), and compare the effects of these manipulations on location judgements with their effects on object feature judgements. This allows us to investigate the nature of the SCB and AB, their potential independence, and the mechanisms that may underpin them.
Overview of the present study
The present study investigated how location and display similarity affect response biases in comparison tasks, and how those effects differ between location judgements and identity/shape judgements. In four experiments, participants saw two sequentially presented displays. Each display contained three stimuli within a 3 × 3 grid, with one stimulus in each row. The task was to make judgements about the stimulus in the second row. Depending on the experiment, the stimulus displays to be compared were either highly similar or very different, and participants judged whether the target stimulus in the second display was in the same position within the grid (a location comparison task) and/or was the same letter (a shape comparison task) as the target in the first display. In Experiments 1 and 2, we examined whether an SCB could be found in a location task and whether the AB would be modulated by display similarity. In Experiments 3 and 4 we investigated the effect of task type on response biases. Taken together, these experiments allowed us to examine whether the SCB is a general phenomenon that applies to both location and shape comparisons, and whether and how these two types of comparisons are influenced by display similarity.
Experiment 1
Experiment 1 investigated the SCB in a location task, while also producing bias measurements for a later comparison to assess the AB. Participants saw two highly similar target displays presented sequentially, each containing three identical dots within a 3 × 3 grid, with one dot in each row. The task was to determine whether the dot in the second (middle) row occupied the same position in the row across the two displays. Of particular interest was whether the pattern of data in this location task would be similar to the pattern of data in the letter comparison task in Cave and Chen (2017, Experiment 6b).
Method
Participants
Twenty undergraduate students (17 females) between the ages of 18 and 50 years (M = 25.6 years, SD = 10.6 years) from the University of Canterbury took part in the experiment in return for course credit. The sample size was chosen based on Experiment 6b in Cave and Chen (2017), in which the effect size for the SCB was d = 1.24. A power analysis with G*Power 3.1 (Faul, Erdfelder, Buchner, & Lang, 2009) for a two-tailed test with α = .05 and 95% power gave a recommended sample size of 11. Thus, a sample size of 20 was deemed sufficient. To facilitate cross-experiment comparisons, we used the same sample size in all the experiments reported here.
Apparatus and stimuli
Testing was carried out on a PC with a 50 cm (width) × 30 cm (height) monitor. E-Prime 2.0 was used to generate stimuli and collect responses. Participants were tested individually in two dimly lit rooms at a viewing distance of approximately 60 cm.
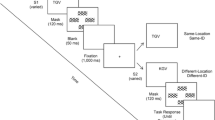
All stimuli were presented against a white background. Each trial consisted of the sequential presentation of two displays (S1 and S2). Each display contained a 3 × 3 grid with one stimulus in each row. S1 and S2 were both preceded by a central fixation and followed by a blank screen, then a mask, then a second blank screen (see Fig. 1).

Examples of trials from Experiment 1. On each trial, two sequential 3 × 3 grids, S1 and S2, each containing three identical dots, were presented briefly at either the same global location or at different global locations. The global location of the 3 × 3 grid was task-irrelevant. Within the 3 × 3 grid there was always one dot in each row. The task was to judge whether the dot in the second row was in the same local position or a different local position in S1 and S2. The dot in the second row was in the same local position in 50% of the trials and equally likely to be in either of the two remaining positions in 50% of the trials. The local positions of the distractor dots in the first and third rows was identical in S1 and S2 on 5/6 of the trials, encouraging participants to use a holistic processing strategy
The fixation was a black cross that subtended 0.48o. The grid for S1 and S2 subtended 3.34o in width and height and was outlined in light grey. Stimuli were three solid black dots, one in each row, that each subtended 0.67o in diameter. In S1, for each row of the 3 × 3 grid the local position of the dot was randomly selected, with each position (left, middle, or right) being equally likely. In S2, the local position of the dot in the second row (the target) was identical to S1 (local-same) on half the trials and different to S1 (local-different) on the other half of the trials. On local-different trials the target dot was equally likely to be in either of the two remaining positions in the row. The local positions of the dots in the first and third rows (the distractors) were identical in S1 and S2 for 5/6 of the trials, and on 1/6 of the trials the local positions were different, with each dot equally likely to be in either of the two remaining positions in its row. Because the local position of the distractor dots was the same in S1 and S2 on the majority of trials, participants could perform the task using a holistic processing strategy, comparing the global configuration of the sequential displays.
In addition, S1 and S2 could each be presented in one of two locations centred 3.34o to the left or to the right of fixation. The location of S1 was randomly selected, with both locations being equally likely. S2 was presented in the same global location as S1 (global-same trials) on half the local-same trials and half the local-different trials. S2 was presented in the corresponding location on the other side of fixation (global-different trials) on the remaining trials.
The mask consisted of two 3 × 3 grids, one centred 3.34o to the left of fixation and one centred 3.34o to the right of fixation. Hence, the mask covered both global locations at which S1 and S2 could be presented. The grid was outlined in grey with a solid black dot in each cell. The dots used in the mask were identical to the dots used in the target displays.
Design and procedure
The experiment used a 2 × 2 within-subjects design, with grid location (global-same vs. global-different) and dot position (local-same vs. local-different) as the key manipulations.
Each trial began with a fixation (500 ms) followed immediately by a brief presentation of S1, whose duration varied across trials based on performance (see details below). The offset of S1 would trigger a blank screen (17 ms), followed by the mask (120 ms), and then a second blank screen (50 ms). A second fixation (1,000 ms) was immediately followed by S2, with the same duration as S1 in that trial. As with S1, the offset of S2 would trigger a blank screen (17 ms), followed by the mask (120 ms), and then a final blank screen that remained until a response was made. The intertrial stimulus interval was 500 ms.
S1 and S2 were initially presented for 116 ms and performance was assessed every 48 trials. An accuracy rate of between 70% and 75% resulted in the presentation duration remaining at 116 ms. Otherwise, if accuracy was above 75% the duration was reduced by 33 ms, and if accuracy was below 70% it was increased by 33 ms. The minimum and maximum presentation durations were 50 ms and 216 ms, respectively.
The task was to judge whether the dot in the second row was in the same local position in S1 and S2. Instructions emphasised that this was a location comparison task, and participants were to respond ‘same’ if the target dot was in the same local position (i.e., the same cell) within the second row in S1 and S2, and they were to respond ‘different’ if it was in a different local position in the row. Participants used the index finger and middle finger of their right hand to press one of two labelled keys on a computer key board (the ‘4’ key if the dot was in the same position and the ‘5’ key if the dot was in a different position). They were instructed to keep their eyes fixed at the fixation throughout the duration of a trial. Eye movements were not monitored during the experiment.
The experiment began with two blocks of 12 practice trials, followed by four blocks of 96 experimental trials. Participants were encouraged to take a short break between blocks. The experiment took approximately 40 min.
Results and discussion
As in previous research (e.g., Cave & Chen, 2017; Golomb et al., 2014), we used signal detection theory (Macmillan & Creelman, 2005) in the data analyses,Footnote 1 and the results reported here include all the trials (i.e., the 5/6 trials in which the distractor dots were at the same positions in S1 and S2 and the 1/6 trials in which these dots were at different positions between S1 and S2).Footnote 2 First, we calculated the ‘hit’ and ‘false-alarm’ rate for each participant and for each grid location (global-same and global-different). If the target dot was in the same position in S1 and S2 and the participant correctly made a ‘same’ response, this was recorded as a hit. If the target dot was in a different position and the participant incorrectly made a ‘same’ response, this was recorded as a false alarm. Using these data, the response bias (c) and sensitivity (d’) were calculated for each participant and for each grid location as follows:
Table 1 shows the mean proportion of ‘hits’ and ‘false alarms’, and Fig. 2 shows the mean response biases. A negative value indicates a bias to make ‘same’ responses and a positive value indicates a bias to make ‘different’ responses. A paired t-test showed a significant difference between the global-same condition (c = -0.392) and the global-different condition (c = -0.015), t(19) = -7.02, p < .001, d = 1.569, indicating a robust SCB. Additional one-sample t-tests against zero further revealed a significant bias for ‘same’ responses when the displays were at the same global location, t(19) = -6.08, p < .001, d = 1.356, but not when the displays were at different locations, t(19) < 1, ns.

Response bias in the location task of Experiment 1 as a function of global location. Error bars show the standard error of the mean. Negative values indicate a bias to respond ‘same’
To examine the AB, we computed the average bias across the combined global-same and global-different trials. A single sample t-test against zero revealed a significant negative bias (c = -0.204), t(19) = -4.51, p < .001, d = 1.010, indicating an overall tendency to respond ‘same’. This value will be compared against the bias in Experiment 2 in order to assess the level of analytic bias.
To examine the effect of location on stimulus sensitivity, we conducted a paired t-test on the d’ data. The result revealed no difference in sensitivity between the global-same trials (d’ = 1.05) and the global-different trials (d’ = 1.15), t(19) = -1.41, p = .176, d = 0.314. This result indicates that location had little effect on discrimination sensitivity for local position. Table 2 shows the d’ results as a function of global location and task for all four experiments.
The magnitude of the SCB in Experiment 1 is similar to that in Cave and Chen (2017, Experiment 6b), in which the task was to compare the shape of the second letter of a three-letter string between S1 and S2 and the distractors were the same on the majority of trials. In both experiments, participants could use a holistic processing strategy, and a robust SCB was found despite differences in task (shape vs. location comparison) and stimulus type (letters vs. dots). These results indicate that the SCB is unlikely to reflect a mechanism that underlies only object-feature comparisons. Instead, it may be a mechanism that underlies visual comparisons in general.
Interestingly, there was also a noticeable shift in the ‘same’ response in the present experiment compared with the experiment in Cave and Chen (2017, Experiment 6b). This is indicated by a clear negative bias (a bias to respond ‘same’) in Experiment 1 (c = -0.20) but not in Cave and Chen (c = -0.03). This difference in results may have something to do with the difficulty of the task. A cross experiment comparison of the d’ data indicated better performance in Cave and Chen (d’ = 1.64) than in Experiment 1 (d’ = 1.10), p = .01. Previous research has shown that location affects object perception when the task is difficult, but not when it is easy (Golomb et al., 2014, Experiment 3). With regard to the present experiment, it seems plausible that participants were more likely to perceive two stimulus displays as being the same when the sensory representations of the displays were relatively poor, resulting in a negative bias. Alternatively, the difference in the bias between the two experiments may be due to the type of task, with a location task being more likely to lead to a ‘same’ response. Before we speculate on possible reasons for this, it would be prudent for us to establish that the change in the bias was indeed due to the type of task.
Although there was no effect of location on sensitivity (i.e., d’), this is not unusual. Previous research shows that the effect of location on discrimination sensitivity in shape judgement tasks is inconsistent, with some reporting increased d’ when the target objects share the same global location compared with when they do not (e.g., Cave & Chen, 2017, Experiments 1–5; Golomb et al., 2014, Experiments 2, 5, and 6; Finlayson & Golomb, 2016), and others reporting no difference as a function of location (e.g., Cave & Chen, 2017, Experiment 7; Golomb et al., 2014, Experiments 1 and 3). It is unclear what factors would affect d’, and further studies are needed to identify them.
Is it possible that participants might utilise a pattern matching strategy to perform the task in Experiment 1, thereby turning a location task into a pattern matching one, at least on some of the trials? Because of the high number of trials in which the locations of the distractor dots were identical, it is plausible that some participants might group the three dots, treat them as a single spatial configuration, and use the overall shape of the configuration to determine whether the location of the target was the same or different. Although this holistic strategy would not work on every trial, it could work on most trials. To address this issue and to examine the effect of display similarity/processing strategies on response biases, we changed the locations of the distractor stimuli between S1 and S2 in Experiment 2 so that they were never the same. This was to make it difficult for participants to utilise the holistic processing strategy, and to encourage them to attend only to the target in the second row of the grid in each display.
Experiment 2
In Experiment 1 the positions of the distractor dots in the first and third rows were the same for S1 and S2 on most of the trials, and this should encourage participants to use a holistic processing strategy. In Experiment 2, we changed the positions of the distractor dots between S1 and S2 on every trial so that they were never the same. This methodological change was to encourage participants to adopt an analytic approach in target encoding by attending to just the middle row, and to prevent them from using the shape of the configuration to perform the task. The goal of the experiment was to determine whether reducing display similarity would still elicit an SCB in a location task, and whether the bias for all conditions combined in Experiment 2 would shift to a tendency to respond ‘different’ as in Cave and Chen (2017, Experiment 6a).
Method
The method for Experiment 2 was the same as for Experiment 1 except that from S1 to S2 the distractor dots always changed local position, and were equally likely to be in either of the two remaining positions within their rows. As before, the local positions of the three dots in S1 were randomly selected and were equally likely to be in any of the three positions in each row.
The experiment again used a 2 × 2 within-subjects design, with grid location (global-same vs. global-different) and dot position (local-same vs. local-different) as the key manipulations. Twenty new participants (17 females) ranging in age from 18 to 42 years (M = 21.1 years, SD = 5.6 years) from the same participant pool took part in exchange for course credit.
Results and discussion
Response data were analysed in the same manner as in Experiment 1. Table 3 shows the mean proportion of ‘hits’ and ‘false alarms’ and Fig. 3 shows the mean response biases. A paired t-test found a significant difference between the global-same (c = -0.078) and global-different (c = 0.095) trials, t(19) = -4.936, p < .001, d = 1.104, indicating an SCB. However, single sample t-tests showed no reliable difference from zero when the displays were at the same global location, t(19) = -1.00, p = .32, d = 0.223, or at different global locations, t(19) =1.33, p = .20, d = 0.300.

As with Experiment 1, the global-same and global-different conditions were combined, and a single-sample t-test compared the bias against zero. The result was not significant (c = 0.008), t(19) = 0.11, p = .91, d = 0.025. A paired t-test on the sensitivity data also revealed no significant difference between the global-same condition (d’ = 1.25) and the global-different condition (d’ = 1.38), t(19) = -1.50, p = .150, d = 0.34, a result similar to that found in Experiment 1.
To measure the effect of display similarity on bias, we conducted a mixed 2 × 2 ANOVA with experiment (Experiment 1 vs. Experiment 2) as a between-subjects factor and grid location (global-same vs. global-different) as a within-subjects factor. All the effects were reliable. For the sake of brevity, we report only the effects related to experiment. There was a main effect of experiment, F(1,38) = 6.16, MSE = .15, p = 0.018, ηp2 = .14. We take this significant difference in bias between Experiment 1 (c = -0.204) and Experiment 2 (c = 0.008) as a demonstration of analytic bias. This result indicates that our manipulation of processing strategy was successful. Reducing the similarity between S1 and S2 changed participants’ processing strategy from ‘holistic’ to ‘analytic’ and eliminated the bias to respond ‘same’. There was also an interaction between experiment and grid location, F(1,38) = 10.13, MSE = .02, p = 0.003, ηp2 = .21, with a larger SCB in Experiment 1 (-0.377) than in Experiment 2 (-0.173), indicating that reducing display similarity weakened the effect of location.
Is it possible that the difference in the AB between Experiments 1 and 2 arises from the adjustments in the exposure time, which were designed to keep the difficulty level similar between the holistic and analytic conditions? To determine whether this might be the case, we computed the display duration for each participant in the two experiments and performed a t-test for independent means. No significant difference in display duration was found between Experiment 1 (134 ms) and Experiment 2 (121 ms), t(38) = 0.98, p = 0.33, d = .31, suggesting that the difference in the AB between the two experiments could not be attributed to display duration.Footnote 3
The replication of a clear SCB in Experiment 2 provides additional support for the conclusion that the SCB results from the operation of a general visual comparison mechanism rather than a mechanism specific to object-feature comparisons. The strategy of grouping the three dots and using the shape of the configuration to perform the task, which might work for Experiment 1, would not work in Experiment 2. As the local positions of the two distractor stimuli always changed, the task could only be performed adequately by filtering out the distractor locations and comparing the locations of the targets. Hence, the finding of the SCB in Experiment 2 provides converging evidence that the global location of a configuration not only affects the perception of features such as shape, colour, and facial expression (e.g., Boduroglu & Shah, 2009; Cave & Chen, 2017; Finlayson & Golomb, 2016; Golomb et al., 2014; Paradiso et.al., 2016; Shafer-Skelton et.al., 2017), but also the perception of the local positions of individual parts. Furthermore, the weakening of the SCB in a task designed to induce a narrow focus of visual attention replicates previous findings (e.g., Cave & Chen, 2017), suggesting that the visual comparison process that produces the SCB is sensitive to attention. We will discuss this in the General discussion.
It is worth noting that no significant bias to respond ‘different’ was found in Experiment 2, and this differed from the result in Cave and Chen (2017, Experiment 6a), who reported a robust ‘different’ bias in a letter comparison task (c = 0.34). A cross-experiment analysis on the d’ data of the two experiments revealed no difference (p = .44), ruling out the possibility that task difficulty was the primary cause for the elimination of the positive bias in Experiment 2. It is notable that this result mirrors the finding in Experiment 1, which showed an increase in the ‘same’ response (i.e., a decrease in the ‘different’ response) when its bias was compared with the bias of Experiment 6b in Cave and Chen. Taken together, the results of Experiments 1 and 2 in the present study indicate that whereas the type of task (shape vs. location) does not influence the magnitude of the SCB, the location task used here produces less of a bias to respond ‘different’ and more of a bias to respond ‘same’ relative to a shape comparison task. In other words, the move from a shape task to a location task produces a bias shift similar to the AB that arises in the move from an analytic task to a holistic task. In the next two experiments, we investigated the effect of task type on bias generally and on the SCB directly by requiring participants to perform both a shape and a location task in a within-subjects design.
Experiment 3
In Experiment 3, we varied the grid locations of the target displays, as in the previous experiments, in both a shape and a location comparison task. By incorporating the same manipulation of the grid location (i.e., global-same vs. global-different) into both the shape and location tasks, we were able to examine the effect of global location on visual comparison as a function of task in a within-subjects design. To enable a direct comparison between the two tasks, and also a comparison with Cave and Chen (2017, Experiments 6a & 6b), we used letter stimuli in both tasks. As in Experiment 1, the two target displays were highly similar. Of particular interest was whether participants would show a similar pattern of data in the two tasks.
Method
Participants
Twenty new participants (ten female) ranging in age from 18 to 32 years (M = 19.9 years, SD = 3.3 years) from the same participant pool took part in exchange for course credit.
Apparatus and stimuli
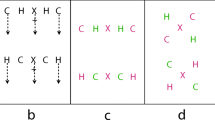
The apparatus and stimuli were the same as those in Experiment 1 except for the following differences. First, the grid from Experiments 1 and 2 was used in these displays, but each of the three dots within the grid was replaced with one of six capitalised block style letters – L, F, E, H, U and P. Thus, there were three letters in S1, and three letters in S2, with one letter in each row (see Fig. 4a). The letters were presented in black and subtended 0.48o in width and 0.67o height. Second, each participant completed separate blocks of trials with two different tasks: a location comparison task as in Experiments 1 and 2, and an additional shape comparison task. For the location task, a different letter was randomly chosen for each row in S1, and the same three letters were used in S2. All the other aspects of the methods were the same as those in Experiment 1.

For the shape task, three different letters were randomly chosen in S1, one for each row, and each of the six letters was equally likely to be selected. The local position of the letters in all three rows was randomly chosen in S1 and each letter was equally likely to be in any of the three positions. The same three positions were used in S2. As in S1, the three letters in S2 were always different from one another. On half the trials (shape-same), S1 and S2 had the same letter in the second row (the target letter). On the other half the trials (shape-different), these two letters were different. The distractor letters in the first and third rows were the same in S2 as in S1 on 5/6 of the trials. On the rest of the trials, the two sets of letters were different; on these trials each distractor letter was equally likely to be any of the remaining letters. In both the shape-same and shape-different conditions, a distractor letter could never be the same as the target letter on a given trial.
Finally, a different mask display was used. It again consisted of two 3 × 3 grids outlined in light grey, one centred 3.34o to the left of fixation and one centred 3.34o to the right of fixation, covering both locations at which S1 and S2 could be presented. However, instead of each cell containing a single black dot, each cell contained a block style figure 8 (see Fig. 4b), consisting of all possible horizontal and vertical lines from the six letters.
Design and procedure
The experiment used a 2 × 2 × 2 within-subjects design, with task (location vs. shape), grid location (global-same vs. global-different), and, depending on the task, target position or letter shape (local-same vs. local-different, or shape-same vs. shape-different) as the key manipulations.
The procedure was the same as for Experiment 1 except for the following differences. Instead of a single task, each participant completed two tasks in separate blocks, and the order of the blocks was counterbalanced across participants. In one block the task was to judge whether the target letter was in the same local position in S1 and S2; in the other block it was to judge whether the target letter was the same letter in S1 and S2. Participants used the index finger and the middle finger of their right hand to press one of two labelled keys on a computer key board (the ‘4’ key for a ‘same’ response and the ‘5’ key for a ‘different’ response). The same keys were used in both tasks.
The experiment began with two blocks of practice trials, one for the shape task and one for the location task. Each practice block consisted of two sets of eight trials to allow participants to ask questions between sets. The order of the shape and location practice blocks varied across participants, and for each participant they were in the same order as the experimental blocks that would follow them. The experiment proper consisted of two blocks of 288 trials. Participants were encouraged to take a short break after every 96 trials. After the completion of a block, they were informed of the change in task for the next block. The experiment took approximately 50 min.
Results and discussion
Response data were analysed in the same manner as in Experiment 1. Table 4 shows the mean proportion of ‘hits’ and ‘false alarms’ and Fig. 5 shows the mean response biases. A preliminary 2 × 2 × 2 mixed ANOVA on the bias data with order (location first vs. shape first) as a between-subjects factor, and task (location vs. shape) and grid location (global-same vs. global-different) as within-subjects factors, indicated no main effect of order or interactions involving order. Thus, the data were pooled across order.

Response bias in the location and shape tasks of Experiment 3 as a function of global location. Error bars are the standard error of the mean
A 2 × 2 repeated-measures ANOVA on the bias data showed a main effect of task, F(1,19) = 9.58, MSE = .07, p = 0.006, ηp2 = .34, indicating that bias was more negative in the location task (c = -0.272) than the shape task (c = -0.095). As expected, a significant SCB was found, F(1,19) = 37.54, MSE = .09, p < 0.001, ηp2 = .66. While there was a strong negative bias on the global-same trials (c = -0.394), the bias was negligible on the global-different trials (c = 0.027). Task and location did not interact, F(1,19) < 1, ns, indicating a comparable SCB in both the location and the shape tasks. These results show that while task type had no influence on the magnitude of SCB, it did influence the bias level generally. The location task biased responses more toward a ‘same’ response than the shape task.
A similar ANOVA on the sensitivity data (d’) found no main effects or interactions. These results indicate no change in discrimination sensitivity regardless of the task or the location of S2 relative to that of S1.
The goal of Experiment 3 was to directly compare the level of bias between the two tasks, as well as the effect on the SCB. A strong SCB was found in both tasks, and the magnitude was comparable across tasks. These results provide additional evidence for the robustness of the SCB and they demonstrate, once again, that the SCB is not sensitive to differences in tasks.
When the global-same and global-different trials are grouped together, the bias differed between the location and shape task. In the location task the bias was again significantly negative, indicating a robust bias to respond ‘same’. However, in the shape task, the bias was much smaller, resulting in a non-significant trend for a ‘same’ response. These results are consistent with the notion that the differences in bias between the present study and the experiments in Chen and Cave (2017) were caused primarily by the type of task, with the location comparison task having a greater tendency to induce the ‘same’ response than a shape task.
Experiment 4
In Experiment 3, we found that bias differed between the shape and location tasks, but the effect of global location on bias did not. In Experiment 4, we repeated the tasks from Experiment 3 but made the displays dissimilar in both tasks. The goal was to determine whether reduced similarity would still result in a comparable SCB in both tasks, and whether the AB would again be modulated by task.
Method
The method was the same as that in Experiment 3 except for the following differences. As with Experiment 2, the displays were made dissimilar by changing the task relevant property of the distractor letters between S1 and S2 on all trials. Specifically, in the location task, the local positions of the distractor letters were always different between S1 and S2, and the positions were randomly selected and equally likely to be either of the two remaining positions in the row. In the shape task, the distractor letters were always different letters between S1 and S2, and the letters were randomly selected and equally likely to be any of the remaining letters.
The experiment again used a 2 × 2 × 2 within-subjects design, with task (location vs. shape), grid location (global-same vs. global-different), and, depending on the task, target position or letter shape (local-same vs. local-different, or shape-same vs. shape-different) as the key manipulations. Twenty new participants (15 female) ranging in age from 18 to 51 years (M = 23.9 years, SD = 10.0 years) from the same participant pool took part in exchange for course credit.
Results and discussion
Response data were analysed in the same manner as in Experiment 1. Table 5 shows the mean proportion of ‘hits’ and ‘false alarms’ and Fig. 6 shows the mean response biases. A preliminary 2 × 2 × 2 mixed ANOVA on the bias data with order (location first vs. shape first) as a between-subjects factor, and task (location vs. shape) and grid location (global-same vs. global-different) as within-subjects factors again indicated no main effect of order or interactions involving order. Thus, the data were pooled across order.

A 2 × 2 repeated-measures ANOVA on the bias data once again showed a main effect of task, F(1,19) = 13.19, MSE = .12, p = 0.002, ηp2 = .41, with a negligible bias in the location task (c = -0.064) but a substantial bias for the ‘different’ response in the shape task (c = 0.222). A significant SCB was also found, F(1,19) = 25.75, MSE = .02, p < 0.001, ηp2 = .58. While there was little bias when S1 and S2 were at the same location (c = 0.001), there was a positive bias when they were at different locations (c = 0.157). There was no interaction between task and location, F(1,19) < 1, ns, indicating a comparable SCB in both the location and the shape tasks.
A 2 × 2 repeated-measures ANOVA on the sensitivity data (d’) revealed a main effect of location, F(1,19) = 7.22, MSE = .15, p = 0.015, ηp2 = .28. Sensitivity was higher in the global-different (d’ = 1.392) than the global-same (d’ = 1.157) trials, indicating higher discrimination sensitivity when the grids did not share the same global location. This was the first time that location was found to influence discrimination sensitivity in this series of experiments. Interestingly, the direction of the effect is not what would be expected based on previous findings (e.g., Cave & Chen, 2017; Finlayson & Golomb, 2016; Golomb et al., 2014). We have no explanations for this result. No other effects were significant.
The goals of Experiment 4 were to determine whether the SCB would remain comparable between the two tasks when the displays were dissimilar, and whether the magnitude of bias would again vary as a function of task. The answers to both questions were affirmative. The SCB was again robust and its magnitude was comparable in both tasks, and bias again differed between tasks. Specifically, in the shape task, bias was significantly positive, indicating a bias towards responding ‘different’, and this result is very similar to the finding of Cave and Chen (2017, Experiment 6a). In contrast, in the location task, bias did not differ from zero, replicating the finding in Experiment 2. This pattern further supports the idea that relative to a shape task, a location task shifts bias in the direction of the ‘same’ response.
As a manipulation check, we again conducted a mixed 2 × 2 × 2 ANOVA with experiment (Experiment 3 vs. Experiment 4) as a between-subjects factor, and task (location vs. shape) and grid location (global-same vs. global-different) as within-subjects factors. Again, for the sake of brevity, we only report the results related to experiment. A main effect of experiment was found, F(1,38) = 8.43, MSE = .33, p < 0.006, ηp2 = .18, indicating a bias to respond ‘same’ when the displays were highly similar in Experiment 3 (c = -0.184) but not when they were dissimilar in Experiment 4 (c = 0.079). In addition, experiment and location interacted, F(1,38) = 12.36, MSE = .06, p = 0.001, ηp2 = .25, indicating a larger SCB in Experiment 3 (-0.421) than in Experiment 4 (-0.156). There was no two-way interaction between experiment and task (p = 0.28). These results confirm the pattern found from Experiment 1 to Experiment 2. Reducing the similarity between S1 and S2 reduced the magnitude of the SCB and shifted bias generally in a positive direction (i.e., a greater tendency to make the ‘different’ response). This general shift is the analytic bias seen in the comparison between Experiments 1 and 2, and also in Cave and Chen (2017).
To be prudent, we again examined the display duration as a function of task (location vs. shape) and experiment (Experiment 3 vs. Experiment 4) to determine whether the change in the AB might have something to do with display duration. The answer was negative. This is evidenced by the results of a mixed ANOVA, which showed no significant main effects or interaction, F(1, 38) < 1, ns, for all the three effects.
General discussion
The aim of this study was twofold: to investigate the effects of shared location and display similarity on response biases in a location task, and to determine whether these effects differ from the effects in a shape task. The two types of bias exhibited in these experiments will be considered separately below.
The spatial congruency bias
The results reported here generalise the SCB to a new paradigm and to a novel location task. Although the global location at which the displays are presented is irrelevant to the correct response, and has the potential to impair performance, it still influences responses. As far as we are aware, this is the first time that the SCB has been found in the judgement of two-dimensional locations.
Consistent with previous research (e.g., Cave & Chen, 2017), our results showed that the SCB was sensitive to display similarity, with the effect of location weakened when the degree of similarity between displays was reduced. Our results also showed that the magnitude of the SCB did not differ between a location and a shape comparison task, and there was no interaction between task type and display similarity. Recently, Golomb et al. (2014, , Experiment 4) reported that while location induced response biases in an identity task, identity (shape) did not lead to response biases in a location task. This asymmetry led to the proposal, which was one of two proposals considered plausible by the researchers, that the SCB may reflect the operation of a feature binding mechanism, with location acting as an anchor point for the binding when object comparisons are made. In the current study, we extended previous research by examining the effect of (global) location in a (local) position task and by using a within-subjects design to directly compare the magnitude of the SCB between a location and a shape task. The SCB was found in both tasks. Furthermore, the magnitude of the bias was comparable regardless of the task and of the stimuli (dots or letters). Given this demonstration that the SCB is robust whether or not the task relevant dimension is an object feature, it seems unlikely that the SCB is driven by a mechanism specific to object-feature comparisons. Instead, it is likely to be driven by a mechanism for visual comparisons more generally. This fits with Golomb et al.’s alternative proposal that the SCB reflects the privileged status of location more generally, outside its potential role in binding features to objects.
However, the effect of location is not immune to changes in overall similarity between the two target displays. In line with previous research (e.g., Cave & Chen, 2017, Experiments 6a & 6b; Golomb et al., 2014, Experiment 3), the current results show that reducing display similarity weakens the influence of location, reducing the magnitude of the SCB. Increasing the differences in displays should induce a more analytic processing strategy. The need for attentional selection of the relevant portion of the target object is likely to reduce the influence of task-irrelevant properties, including the global location of displays. Hence, the strong response bias toward a ‘same’ response for shared locations is reduced. Alternatively, the SCB may reflect the degree to which S1 and S2 are represented as the same object. When S1 and S2 share a location, this could increase the likelihood that both stimuli originate from the same object, which in turn increases the likelihood that they are judged to be identical. However, differences in the irrelevant parts (rows 1 and 3) between S1 and S2 may decrease the likelihood that they are encoded as coming from the same object, lowering the SCB.
The analytic bias
Unlike the SCB, the AB is affected by display similarity: as S1 and S2 decreased in similarity, the AB became more positive (or less negative), indicating an increase in making the ‘different’ response. This result can be explained in terms of an attentional zoom account proposed by Cave and Chen (2017). According to the account, attention can select high-level configurations or low-level details depending on the requirement of the tasks (LaBerge, 1983). In some visual comparison tasks, each of the two stimulus displays can be treated as a unified configuration to be compared against the other configuration. These tasks can be performed by using a holistic processing strategy with a broad attentional zoom. In other comparison tasks, individual components in a configuration must be compared to their corresponding parts in the other configuration. These tasks require an analytic processing strategy with a relatively narrow attentional zoom. In Experiments 1 and 3, the distractors between S1 and S2 were the same on most of the trials. This made it possible to use a holistic processing strategy with a relatively broad attentional zoom to perform the task, resulting in an overall bias for the ‘same’ response. In contrast, in Experiments 2 and 4, the distractors differed in the task relevant feature on every trial. For attention to be focused on the target, an analytic processing strategy with a narrow attentional zoom was needed. As the filtering of the attentional system is imperfect (B. A. Eriksen & Eriksen, 1974; C. W. Eriksen & Hoffman, 1972), the representations of the distractors are likely to interfere with the representation of the target, resulting in a shift in the bias in the direction of the ‘different’ response.
Visual similarity in general may have also played a role in the change in bias between Experiments 1 and 2, and between Experiments 3 and 4.Footnote 4 It is possible that the influence of display similarity on the AB reflects some sort of a priming effect. In Experiments 1 and 3, repeated exposure to similar displays within an experiment could evoke a general sense of ‘sameness’, making participants more likely to respond ‘same’. In Experiments 2 and 4, repeated exposure to dissimilar displays could elicit a general sense of ‘differentness’, priming a ‘different’ response.
There may also be a third factor that contributes to the AB. This factor is related to visual similarity mentioned above, but occurs during the decision stage. When the sensory representation of the target is poor, perhaps because of insufficient attention or the brief presentation of the target displays, participants may be unduly influenced by the distractors, resulting in a tendency to make the ‘same’ response when the distractors in S1 and S2 are the same. Likewise, when the distractors in S1 and S2 are different, the bias shifts in the direction of the ‘different’ response.
Differences in bias between tasks
In addition to display similarity, the bias is influenced by task type. In Experiment 3, the bias was strongly negative (a bias to respond ‘same’) in the location task but not significantly different from zero in the shape task. In Experiment 4, the bias was strongly positive (a bias to respond ‘different’) in the shape task but negligible in the location task. This shift in bias between shape and location tasks may be explained as a relative change in bias related to the AB, with the location task shifting bias more in the ‘same’ direction and the shape task shifting it in the ‘different’ direction. A holistic comparison may be generally more feasible in the location task, because it depends more on the overall configuration of the stimulus elements, while the shape task requires a more analytic selection of target features in order to detect the more subtle shape differences.
However, the differences in bias across tasks may also be the combined results of the nature of the task and the specific methodology we used in the experiments. In Experiment 3, the distractors were the same in S1 and S2 on most of the trials. As we discussed in Experiment 1, this methodological feature allowed participants to have two pieces of information to make judgements in the location task: the position change of the targets, and the change in the shape of the configuration formed by grouping the three stimuli in a display. This differs from the shape task, in which the only way to perform the task was to determine whether the target in S1 changed shape in S2. These differences could lead to a stronger priming effect and/or a broader attentional zoom in the location task compared with the shape task. In both cases, the bias to respond ‘same’ would be larger in the location task than in the shape task, a result found in Experiment 3.
In Experiment 4, the distractors were different between S1 and S2 on every trial. To filter out the distractors, participants would need to use an analytic processing strategy with a narrow attentional zoom in both the location and the shape task. However, there is an important difference between attention to location and attention to an object feature such as shape, colour or orientation. Previous research has shown that while attention to the location of a stimulus does not necessarily lead to the encoding of an object feature of the attended stimulus, the opposite is true when attention is paid to an object feature of a stimulus (Bloem & van de Heijden, 1995; Cave & Pashler, 1995; Cave & Zimmerman, 1997; Cepeda et al., 1998; Chen, 2005, 2009; Johnston & Pashler, 1990; Kim & Cave, 1995). It is likely that this processing asymmetry between location and object features, in this case an object’s shape, together with the letter stimuli we used in the experiment, led to more processing of the distractors in the shape task than in the location task. Reading is an automatic process for most people. Attending the target letter in the shape task would activate not only the representation of the target but also the representations of the distractors through spreading activation. In contrast, the representations of the letters were less likely to be activated in the location task, even though the stimuli also consisted of letters. This is because attention to a target’s location is unlikely to lead to the encoding of the target’s shape (Chen, 2005). As the distractors were processed more in the shape task than in the location task, the bias was more positive (a bias to make the ‘different’ response) in the shape task than in the location task.
Theoretical implications
Location as a privileged feature
These experiments demonstrate just how broadly the SCB applies to different types of comparisons. This demonstration adds to the large body of experimental evidence that location features in visual displays have an influence on behavioural measures regardless of their relevance to the task. This influence can be measured in terms of reaction time or accuracy advantages for shared locations over non-shared locations (e.g., Cave & Pashler, 1995; Chen, 2009; Tsal & Lavie, 1988, 1993), or in terms of a bias towards a ‘same’ response when spatial location or configuration is shared compared with when it is not shared (e.g., Boduroglu & Shah, 2009; Cave & Chen, 2017; Finlayson & Golomb, 2016, 2017; Golomb et al., 2014; Paradiso et al., 2016; Shafer-Skelton et al., 2017). By the same token, variation in other visual features, such as colour and shape, does not appear to have an effect on subsequent processing when it is not relevant to the task (e.g., Cave & Pashler, 1995; Chen, 2009; Etiam, Yeshurun, & Hassan, 2013; Golomb et al., 2014; but see Chen, 2005, and Egeth, 1966, for evidence that task-irrelevant visual features influence response time (RT)).
The privileged nature of location has also been demonstrated in the number of items that we can consciously access at a given moment in time. Huang and colleagues (Huang & Pashler, 2007; Huang, Treisman, & Pashler, 2007) showed that when two colour patches were displayed either sequentially or simultaneously and the task was to judge the colour of a probe target, accuracy was lower in the simultaneous trials compared with the sequential ones, suggesting that our visual system may be limited in accessing only one feature value at a time (cf: Mance, Becker, & Liu, 2012). However, similar impairment in performance in the simultaneous condition was not observed when the same stimuli were used but the task was to judge the location of a probe target. These results led the researchers to conclude that except for location, which is known to have a special status in visual perception, we have conscious access to only one feature value at a time.
Other evidence supporting the special status of location in visual perception came from several recent studies that tested participants’ memory for an attended stimulus feature when questions about that feature were unexpected. Chen and Wyble (2015b, 2016) demonstrated that participants often failed to remember a perceived object feature such as colour or shape when it was not a target attribute to report. This phenomenon, which the researchers referred to as attribute amnesia (Chen & Wyble, 2015a), did not occur in memory for location. In two experiments, Chen and Wyble (2016) showed their participants displays that consisted of a letter and three digits, and the four stimuli differed in colour, identity and location. The task was to report the identity of the letter. After some trials, the participants were unexpectedly asked to identify both the location and colour of the letter. While the memory for colour was substantially impaired when the colour question was a surprise rather than when it was expected, the memory for location did not differ between the two types of trials. Similar asymmetry in memory performance has also been found between location and identity when colour was the expected task (Chen & Wyble, 2015b). These results are in line with the notion that the representation of an object’s location is involuntary (Cave & Pashler, 1995; Chen, 2005, 2009; Tsal & Lavie, 1988, 1993).
As spatial location information is an inherent property of all visual displays (i.e., if an object is visually accessible, there must be a ‘where’ as well as a ‘what’), and it has long been understood that the processing of visual information proceeds in a spatially defined manner (e.g., Gross & Graziano, 1995), it is not surprising that location can influence the speed of visual judgement (e.g., Cave & Pashler, 1995; Cave & Zimmerman, 1997; Cepeda et al., 1998; Chen, 2009; Kim & Cave, 1995; Treisman, 1988; Tsal & Lavie, 1993), memory performance (e.g., Chen & Wyble, 2015b, 2016), and also the visual judgement itself (e.g., Boduroglu & Shah, 2009; Cave & Chen, 2017; Finlayson & Golomb, 2016, 2017; Golomb et al., 2014; Paradiso et al., 2016; Shafer-Skelton et al., 2017). After all, it is a difficult problem to interpret the continuous flow of visual information, which is interrupted constantly by occlusion and saccades. That problem can be simplified somewhat by assuming that sequential stimuli appearing at the same location are more likely to be different views of the same object compared with those that appear at different locations. The results of the current study fit with this assumption, providing additional evidence that location is privileged in visual processing.
It is also likely that the privileged status of location information arises in part from its ecological value (e.g., Golomb et al., 2014). To be adaptive, behaviour should maximize benefits while minimising costs. Thus, on the one hand we might expect that the visual system would fully process the information that is relevant to the current task, while filtering out irrelevant information. On the other hand, the visual system might also maintain a degree of access to potentially useful visual information, regardless of immediate task relevance, in case a visual stimulus requires further disambiguation. Location information would be one of those features that it might be useful to encode irrespective of its immediate relevance. Evidence from the field of robotics demonstrates the ecological value of spatial information. Experiments using models that incorporate retinotopic and spatiotopic processing of visual information show that sharing the same global location and/or the same body posture, although irrelevant to the task, enhances the learning of object names compared with changing location and/or body posture (e.g., Cangelosi & Schlesinger, 2018; Samuelson, Smith, Perry, & Spencer, 2011).
Overlap measure/evidence accumulation
The number of differences between displays influences the speed and/or accuracy of processing in same-different judgement tasks (e.g., Eriksen, O’Hara, & Eriksen, 1982; Krueger, 1973, 1979; Robbins & Bourne, 1983). ‘Same’ responses are generally faster than ‘different’ responses (e.g., Bamber, 1969; Egeth, 1966; Nickerson, 1967). Also, for ‘different’ responses there is an inverse relationship between RT and the number of differences (e.g., Eriksen et al., 1982; Krueger, 1973, 1979; Robbins & Bourne, 1983). These findings have been incorporated into a number of single and dual-process models of visual comparisons (see Farell, 1985, and Ratcliff, 1985, for reviews). A common proposal in these models is that the effect of overall similarity on RT and accuracy is the result of a mechanism that determines the ‘best’ response on the basis of an overlap measure (e.g., Bamber, 1969; Eriksen et al., 1982; Krueger, 1978, 1979; Nickerson, 1969; Ratcliff, 1985). Further, evidence suggests that this mechanism is sensitive to the task relevancy of different visual features (e.g., Farell, 1985).
Although such models have generally focused on reaction time and accuracy measures, it has also been noted that when there are few differences, there is a tendency towards a ‘same’ response and when there are many differences there is a tendency towards a ‘different’ response (e.g., Krueger, 1978, 1979; Nickerson, 1967; Ratcliff, 1985). It is possible that such a mechanism could be involved in the manifestation of the SCB and AB, with a default assumption of ‘same’ when there are no obvious differences and a default assumption of ‘different’ when there are no obvious similarities. In between those two extremes, the strength of the default assumption is likely to correspond to the degree of sameness or differentness between the displays.
The idea of an overlap measure is similar to the concept of ‘evidence accumulation’ discussed by Golomb et al. (2014). This was ruled out as an explanation for the SCB, with a key piece of evidence coming from a comparison of the results from two experiments. Decreasing the number of similarities between compared displays nullified the effect of location on identity judgements (Golomb et al.’s Experiment 3), while increasing the number of similarities, through adding ‘sameness’ on additional task-irrelevant object feature dimensions, did not have an additive effect on the SCB (Golomb et al.’s Experiment 6). However, it is worth noting that information processing does not necessarily result in perfect internal representations. Instead, the representations are often noisy. Such noisy representations are more likely to include a few differences when two displays are identical, than render two different displays as the same (e.g., Krueger, 1978). Due to this internal noise, and the sensitivity of the overlap measure to task relevancy (e.g., Farell, 1985), increasing ‘sameness’ on additional task-irrelevant visual features may not serve to increase the magnitude of the SCB.
Conclusions and future directions
The results reported here suggest that the SCB results from the operation of a general visual processing mechanism, and that the privileged status of location compared with other visual features plays a key role in the manifestation of the SCB. When a judgement has to be made on the basis of a ‘best-guess’, the privileged nature of location information leads to a default assumption; when similar objects appear at the same location, the default is to judge them as ‘same’ and when dissimilar objects appear at different locations the default is to judge them as ‘different’. However, these default assumptions are adjusted as a result of lack of similarity at shared locations and similarity at different locations. It remains to be seen what factors determine the extent of these adjustments and what the boundary conditions of the SCB are. In the current study, the objects only varied on one of two dimensions (i.e., either shape or local position), and in both tasks the task-irrelevant feature of all objects always remained the same. Perhaps variation on additional features and/or reducing display similarity by also changing task-irrelevant features of the objects would allow the boundary conditions to be ascertained.
The results pertaining to the AB and the relative difference in bias between the shape and location tasks suggest that, among other things, the extent of attentional zoom, visual similarity, and the asymmetry in attentional selection between location and object features may all have contributed to the magnitude and direction of the bias. In the present study, it is unclear whether each plays a necessary and/or sufficient role and whether and how they might interact. To understand these questions, future research involving direct manipulation of each of these factors is needed.Footnote 5
Open practices statement
None of the data or materials for the experiments reported here has been made available online, and none of the experiments was preregistered. Data or materials for the experiments can be made available to interested parties on request.
Notes
For completeness, response time (RT) and accuracy data are included in the Appendices for all experiments reported here.
The pattern of the data was the same when only those trials in which the distractor dots were at the same positions in S1 and S2 were included in the analyses. This applies to the results of both Experiments 1 and 3.
We also checked whether there were differences in task difficulty between Experiments 1 and 2 that might contribute to the observed change in the AB between the two experiments. Two ANOVAs were performed, one on the d’ data and the other on the median RTs. No main effects of experiment or interactions involving experiment were found. Similar analyses were also performed on the d’ and median RT data in Experiments 3 and 4. Again, there were neither main effects of experiments nor interactions involving experiment.
We thank Julie Golomb for suggesting visual similarity as a possible factor for the change in the AB between Experiments 1 and 2, and between Experiments 3 and 4.
We thank Julie Golomb for suggesting direct manipulation of attentional zoom.
References
Bamber, D. (1969). Reaction times and error rates for "same"-"different" judgements of multidimensional stimuli. Perception & Psychophysics, 6, 169-174.
Bloem, W., & van der Heijden, H. A. C. (1995). Complete dependence of color identification upon color localization in a single-item task. Acta Psychologica, 89, 101-120.
Boduroglu, A., & Shah, P. (2009). Effects of spatial configurations on visual change detection: An account of bias changes. Memory & Cognition, 37, 1120-1131.
Broadbent, D. E. (1982). Task combination and selective intake of information. Acta Psychologica, 50, 253-290.
Cangelosi, A., & Schlesinger, M. (2018). From babies to robots: the contribution of developmental robotics to developmental psychology. Child Development Perspectives, 12, 183-188.
Cave, K. R. (1999). The FeatureGate model of visual selection. Psychological Research, 62, 182-194.
Cave, K. R., & Chen, Z. (2017). Two kinds of bias in visual comparison illustrate the role of location and holistic/analytic processing differences. Attention, Perception, & Psychophysics, 79, 2354-2375.
Cave, K. R., & Pashler, H. (1995). Visual selection mediated by location: Selecting successive visual objects. Perception & Psychophysics, 57, 421-432.
Cave, K. R., & Zimmerman, J. J. (1997). Flexibility in spatial attention before and after practice. Psychological Science, 8, 399-403.
Cepeda, N. J., Cave, K. R., Bichot, N. P., & Kim, M.-S. (1998). Spatial selection via feature-driven inhibition of distractor locations. Perception & Psychophysics, 60, 727-746.
Chen, H., & Wyble, B. (2015a). Amnesia for object attributes: Failure to report attended information that had just reached conscious awareness. Psychological Science, 26, 203-210.
Chen, H., & Wyble, B. (2015b). The location but not the attributes of visual cues are automatically encoded into working memory. Vision Research, 107, 76-85.
Chen, H., & Wyble, B. (2016). Attribute amnesia reflects a lack of memory consolidation for attended information. Journal of Experimental Psychology: Human Perception and Performance, 42, 225-234.
Chen, Z. (2005). Selective attention and the perception of an attended nontarget object. Journal of Experimental Psychology: Human Perception and Performance, 31, 1493-1509.
Chen, Z. (2009). Not all features are created equal: Processing asymmetries between location and object features. Vision Research, 49, 1481-1491.
Downing, C. J., & Pinker, S. (1985). The spatial structure of visual attention. In M. I. Posner & O. S. M. Marin (Eds.), Attention and performance XI: Mechanisms of attention (pp. 171-187). Hillsdale, NJ: Lawrence Erlbaum.
Egeth, H. E. (1966). Parallel versus serial processes in multidimensional stimulus discrimination. Perception & Psychophysics, 1, 245-252.
Eitam, B., Yeshurun, Y., & Hassan, K. (2013). Blinded by irrelevance: Pure irrelevance induced ‘blindness’. Journal of Experimental Psychology: Human Perception and Performance, 39, 611-615.
Eriksen, B. A., & Eriksen, C. W. (1974). Effects of noise letters upon the identification of a target letter in a nonsearch task. Perception & Psychophysics, 16, 143-149.
Eriksen, C. W., & Hoffman, J. E. (1972). Temporal and spatial characteristics of selective encoding from visual displays. Perception & Psychophysics, 12, 201-204.
Eriksen, C. W., O’Hara, W. P., & Eriksen, B. (1982). Response competition effects in same-different judgements. Perception & Psychophysics, 32, 261-270.
Eriksen, C. W., & St. James, J. D. (1986). Visual attention within and around the field of focal attention. Perception & Psychophysics, 40, 225-250.
Farell, B. (1985). "Same"–"different" judgements: A review of current controversies in perceptual comparisons. Psychological Bulletin, 98, 419-456.
Faul, F., Erdfelder, E., Buchner, A., & Lang, A. G. (2009). Statistical power analyses using G* Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41, 1149-1160.
Finlayson, N. J., & Golomb, J. D. (2016). Feature-location binding in 3D: Feature judgements are biased by 2D location but not position-in-depth. Vision Research, 127, 49-56.
Finlayson, N. J., & Golomb, J. D. (2017). 2D location biases depth-from-disparity judgements but not vice versa. Visual Cognition, 25, 841-852.
Golomb, J. D., Kupitz, C. N., & Thiemann, C. T. (2014). The influence of object location on identity: A ‘spatial congruency bias’. Journal of Experimental Psychology: General, 143, 2262-2278.
Gross, C. G., & Graziano, M. S. (1995). Multiple representations of space in the brain. The Neuroscientist, 1, 43-50.
Huang, L., & Pashler, H. (2007). A boolean map theory of viual attention. Psychologlical Review, 114, 599-631.
Huang, L., Treisman, A., & Pashler, H. (2007). Characterizing the limits of human visual awareness. Science, 317, 823-825.
Johnston, J. C., & Pashler, H. (1990). Close binding of identity and location in visual feature perception. Journal of Experimental Psychology: Human Perception and Performance, 16, 843-856.
Kim, M.-S., & Cave, K. R. (1995). Spatial attention in visual search for features and feature conjunctions. Psychological Science, 6, 376-380.
Krueger, L. E. (1973). Effect of irrelevant surrounding material on speed of same-different judgement of two adjacent letters. Journal of Experimental Psychology, 98, 252-259.
Krueger, L. E. (1978). A theory of perceptual matching. Psychological Review, 85, 278-304.
Krueger, L. E. (1979). A model of unidimensional perceptual matching. Journal of Experimental Psychology: Human Perception and Performance, 5, 277-288.
Kubovy, M. (1981). Concurrent-pitch segregation and the theory of indispensable attributes. In M. Kubovy & J. R. Pomerantz (Eds.). Perceptual organization (pp. 55-98). Hillsdale, NJ: Lawrence Erlbaum Associates Inc.
LaBerge, D. (1983). Spatial extent of attention to letters and words. Journal of Experimental Psychology: Human Perception and Performance, 9, 371-379.
Lamy, D., & Tsal, Y. (2001). On the status of location in visual attention. European Journal of Cognitive Psychology, 13, 305-342.
Macmillan, N. A., & Creelman, C. D. (2005). Detection theory: A user’s guide. Mahwah: Erlbaum.
Mance, I., Becker, M. W., & Liu, T. (2012). Parallel consolidation of simple features into visual short-term memory. Journal of Experimental Psychology: Human Perception and Performance, 38, 429-438.
Nickerson, R. S. (1967). "Same"-"Different" response times with multi-attribute stimulus differences. Perceptual and Motor Skills, 24, 543-554.
Nickerson, R. S. (1969). "Same"-"Different" response times: A model and a preliminary test. Acta Psychologica, 30, 257-275.
Paradiso, M., Shafer-Skelton, A., Martinez, A., & Golomb, J. (2016). Object-location binding: Does spatial location influence high-level judgements of face images? Journal of Vision, 16, 409-409.
Posner, M. I., Snyder, C. R. R., & Davidson, B. J. (1980). Attention and the detection of signals. Journal of Experimental Psychology: General, 109, 160-174.
Ratcliff, R. (1985). Theoretical interpretations of the speed and accuracy of positive and negative responses. Psychological Review, 92, 212.
Robbins, D. W., & Bourne, L. E. (1983). Effects of stimulus similarity on perceptual and conceptual comparisons. Perception & Psychophysics, 33, 479-486.
Samuelson, L. K., Smith, L. B., Perry, L. K., & Spencer, J. P. (2011). Grounding word learning in space. PLOS ONE, 6, e28095.
Shafer-Skelton, A., Kupitz, C. N., & Golomb, J. D. (2017). Object-location binding across a saccade: A retinotopic spatial congruency bias. Attention, Perception, & Psychophysics, 79, 765-781.
Treisman, A. (1988). Features and objects: The fourteenth Bartlett memorial lecture. Quarterly Journal of Experimental Psychology, 40A, 201-237.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97-136.
Tsal, Y., & Lavie, N. (1988). Attending to color and shape: The special role of location in selective visual processing. Perception & Psychophysics, 44, 15-21.
Tsal, Y., & Lavie, N. (1993). Location dominance in attending to color and shape. Journal of Experimental Psychology: Human Perception and Performance, 19, 131-139.
Wolfe, J. M. (1994). Guided Search 2.0: A revised model of visual search. Psychonomic Bulletin & Review, 1, 202-238.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendix 1
Appendix 2
Appendix 3
Appendix 4
Rights and permissions
About this article

Cite this article
Humphries, A., Chen, Z. & Cave, K.R. Both feature comparisons and location comparisons are subject to bias. Atten Percept Psychophys 83, 1581–1599 (2021). https://doi.org/10.3758/s13414-020-02148-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-020-02148-2