
Abstract
Searching for a target is faster in a repeated context compared to a new context, possibly because the learned contextual information guides visual attention to the target location (attentional guidance). Previous studies showed that switching the target location following learning, or having the target appear in one of multiple possible locations during learning, fails to produce search facilitation in repeated contexts. In this study, we re-examined whether the learning of an association between a distractor configuration context and a target is limited to one-to-one context-target associations. Visual search response times were facilitated even when a repeated context was associated with one of four possible target locations, provided the target locations were also shared by other repeated distractor contexts. These results suggest that contextual cueing may involve mechanisms other than attentional guidance by one-to-one context-target associations.
Similar content being viewed by others


Introduction
Although visual scenes are typically complex, there are often regularities embedded in scenes. The ability to extract such regularities is a key property of our cognitive system (Reber, 1967; Turk-Browne, Jungé, & Scholl, 2005). One such type of regularity is the spatial layout of objects in the environment. Extensive research has demonstrated that humans are able to learn to utilize repetitions in spatial layout (Goujon, Didierjean, & Thorpe, 2015; Reber, 1989). One example of this type of visual learning is the contextual cueing effect (CCE; Chun & Jiang, 1998). CCE occurs when visual search performance is improved by the repeated pairing across trials of a search target and a particular spatial configuration of distractors.
The contextual cueing effect (CCE)
In the seminal study of Chun and Jiang (1998), participants were required to search for a target letter T among rotated distractor letter Ls, and then to press one of two keys based on whether the target letter T was rotated 90° clockwise or counterclockwise from upright. Within each block, the target location and distractor context were always different between trials. Unknown to participants, for half of the trials, the distractor contexts and target locations were repeated across blocks. For the other half of the trials, the distractor contexts were always novel, appearing only once in the experiment. The results showed that reaction time (RT) became faster across blocks for the trials with repeated distractor contexts relative to the trials with novel distractor contexts. Chun and Jiang (1998) proposed that observers learned an association between distractor contexts and target location, and that this learned association guided observers’ search for the target, resulting in the CCE. Interestingly, in a follow-up recognition test, participants could not recognize repeated distractor configurations from novel distractor configurations. This recognition result suggests that the CCE was actually based on implicit spatial learning, although the implicit nature of contextual learning is in debate (Kroell, Schlagbauer, Zinchenko, Müller, & Geyer, 2019; Vadillo, Konstantinidis, & Shanks, 2016).
Mechanisms producing the CCE
Many prior studies support the view that the mechanism underlying the CCE is attentional guidance (Chun, 2000; Chun & Jiang, 1998; Jiang, Song, & Rigas, 2005; Jiang & Wagner, 2004; Zellin, Conci, von Mühlenen, & Müller, 2011). For example, Chun and Jiang (1998) found smaller slopes in the RT × set size function for repeated distractor contexts than for novel distractor contexts. However, not all studies support the attendance guidance interpretation of the CCE. For example, Kunar et al. (2007) failed to find a significant slope difference for repeated and novel contexts. They also observed a CCE in an easy pop-out search task in which attentional guidance should play little role, and they found the CCE to be sensitive to the introduction of response selection demands. As a result, they argued against the attentional guidance view, and proposed instead that response selection mechanisms determine the CCE.
Yet other studies have suggested that both attentional guidance and response selection contribute to the CCE (Schankin, Hagemann, & Schubö, 2011; Schankin & Schubö, 2010; Sewell et al., 2018; Zhao et al., 2012). Zhao et al. (2012) used behavioral and eye movement measures to examine mechanisms underlying the CCE. Slope and intercept measures showed that both attentional guidance and response selection could play a role in the CCE. Eye-movement measures were consistent with this interpretation. The search phase was shorter for repeated distractor contexts than for novel distractor contexts, indicating that attentional guidance contributed to the CCE, and the process that followed search but preceded the response was also shorter for repeated than novel contexts, indicating that response selection could also contribute to the CCE. In line with these results, Schankin et al. (2011, 2010) reported a CCE that was reflected in a late positive evoked-response potential (ERP) component typically linked to response-related processes. Finally, Sewell et al. (2018) reported a diffusion model analysis of RTs that indicated both the speed of search and response level factors contribute to the CCE.
Multiple target locations in contextual learning
The CCE implies that participants can learn the association between a target location and a particular distractor configuration, but can participants learn the association between a distractor configuration and more than one target location? Chun and Jiang (1998, Experiment 6) first investigated contextual cueing with one repeated distractor context paired with two possible target locations; that is, although there was only one target on each trial, that target appeared in either of two possible target locations for a particular repeated distractor context across learning blocks. The results revealed a modest CCE. Zellin et al. (2011) confirmed that the CCE is reduced for two target locations relative to just one target location paired with a repeated distractor context, and no CCE was observed for three target locations paired with a single repeated distractor context. Furthermore, they found that when the CCE is observed for multiple targets, there is one “dominant” target location that is learned, and the overall CCE effect appears to be a blend of performance for trials in which a CCE occurs and trials in which a CCE does not occur. These findings suggest that a single distractor context may only cue one target well, which is consistent with the notion that attentional guidance contributes to the CCE. In a more recent study, Beesley, Vadillo, Pearson, and Shanks (2015) showed that there was little CCE observed when each repeated context was paired four possible target locations.
Effect of target relocation on the CCE
In addition to varying the number of target locations associated with a given repeated context during learning, a target relocation paradigm has been used to examine the nature of the association between the target and distractor array. In this case, following learning of a constant association between a single target and a particular distractor configuration, the target is relocated to a different position. The question here is whether contextual learning of the distractor configuration can still benefit search following a relocation of the target. Clearly, if learning of an association between a particular target location and a consistent distractor configuration provides the attentional guidance responsible for the CCE, then the CCE should not occur with target relocation.
Manginelli and Pollmann (2009) examined this issue with a conventional learning phase in which a single target was associated with a repeated distractor context, followed by a target relocation phase in which the target was relocated to a location that had been empty during the learning phase. The results showed that target relocation eliminated the CCE. This behavioral evidence for the learning of target-context association was further supported by evidence showing that eye movements during the relocation phase included saccades to the previous learned but no-longer relevant target location. Presumably, the learned association guided attention to the original target location, resulting in a slowing of RTs for the repeated distractor contexts with relocated targets. In addition, Makovski and Jiang (2010) showed that the CCE decreases with increasing distance between the original target location and the relocated target. Moreover, the RT benefit for the repeated distractor contexts turned into an RT cost when the repeated context target switched with a distractor location. Zellin, Conci, Mühlenen, and Müller (2013) found that following CCE disappearance with target relocation, an adapted CCE effect to the relocated target did not emerge even after extensive training. Zellin et al. (2014) later confirmed that such effects upon target relocation involve learning that is slow and effortful, requiring three days of training and more than 80 distractor context repetitions. It has since been shown that frontopolar cortex (FPC) could play an important role in updating of spatial target-distractor context contingencies after target relocation in learned spatial arrays (Zinchenko, Conci, Taylor, Müller, & Geyer, 2018 ).
Together, these results support the idea that attentional guidance causes the CCE. According to this view, attentional guidance is produced by a learned association between a target and a repeated distractor context, which facilitates performance for repeated distractor contexts relative to novel distractor contexts. Target relocation
undermines the CCE effect because the learned association between target and distractor contexts guides visual attention to the originally learned target location, or to the area spatially adjacent to this location (Manginelli & Pollmann, 2009). When targets are relocated far away from this original location, the learned association between target and distractor contexts becomes a misleading cue and can even reverse the effect of repeated contexts from a benefit to a cost.
However, a recent study by Zellin, Mühlenen, Müller, and Conci (2013) reported a finding that is difficult to reconcile with a strict interpretation of the attentional guidance view. The key manipulation in their study was that target relocation was achieved by switching targets between different repeated contexts. The procedure had three phases: learning, exchange, and return. In the learning phase, participants learned an association between a target and distractor context as in a typical CCE paradigm. In the exchange phase, the target locations of two repeated contexts switched. In the return phase, the target locations reverted back to their original pairings with the distractor contexts from the learning phase. The results showed that the CCE in the exchange and return phases were largely equivalent to the CCE produced in the learning phase. This result demonstrates that target relocation does not always impair the CCE, in particular if the target is relocated to a location that previously served as a target location for another repeated distractor context.
Current study
If attentional guidance from learned one-to-one target-distractor context associations is the only mechanism underlying the CCE, then the CCE ought to be smaller when a distractor context is paired with multiple possible target locations than when it is paired with one target location. The rationale for this prediction is that when a distractor context is possibly associated with more than one location during learning, attentional guidance does not unambiguously lead visual attention to the location of the target. Instead, on some trials a cost will be incurred when the distractor context cues attention to a wrong location. This search cost will increase with increases in the number of possible target locations.
In the present study, we re-examined this issue using a modified multiple-targets contextual cueing paradigm. Our method was inspired by the study of Zellin et al., (2013), in which the CCE was little affected with relocation of the target associated with one distractor context to the target location associated another distractor context. We applied this method of manipulation of target location during learning to examine the CCE in five experiments with different numbers of possible target locations associated with a given repeated distractor context.
Experiment 1 used the conventional CCE paradigm, with each repeated distractor context paired with only one possible target location (abbreviated as 1C-1T). Performance in this experiment served as a control against which the results from Experiments 2–4 were compared. In Experiment 2, we examined the CCE using a procedure in which every two particular repeated distractor contexts switched their targets randomly across blocks (abbreviated as 2C-2T). In Experiment 3, targets of every four repeated distractor contexts switched randomly across blocks (abbreviated as 4C-4T). In Experiment 4, targets of 12 repeated distractor contexts switched across blocks (abbreviated as 12C-12T). Experiment 5 combined the methods of Experiments 1 (1C-1T) and 3 (4C-4T) in a within-subject design. In all experiments, there was only one target on each search trial; however, with the exception of Experiment 1 and one condition in Experiment 5, the target on repeated distractor trials was located in one of multiple possible locations. Although the target location was not the same in every block, these trials are still labeled “repeated” because the distractor configurations were identical across blocks.
Although our method was inspired by that of Zellin et al., (2013), the purpose of implementing the manipulation was different. Zellin et al., (2013) examined the influence of switching targets between repeated distractor contexts after learning. The learning phase itself in their study did not involve multiple target-context associations. Rather, the learning phase involved a one-to-one target-context association and then a following exchange phase introduced switched one-to-one target-context associations. In contrast, in our study participants encountered constantly changing target-context associations in the learning phase. Thus, in our study, we examined the possibility of learning involving association of one invariant distractor context with two, four, or 12 possible targets, with those targets switching constantly across blocks during the learning phase.
Experiment 1: One context – one target (1C-1T)
Experiment 1 was conducted to replicate the typical contextual cueing paradigm, and the results served as a baseline for comparison to subsequent experiments. Critically, each repeated distractor context was associated with one specific target location. We hypothesized that a robust CCE should be observed in this experiment.
Method
Participants
To determine the appropriate sample size, we calculated the effect size for the contextual cueing effect of the 1C-1T condition in the study by Zellin etal (2011). Their t-test comparing repeated and novel contexts resulted in t(15) = -2.86, from which we calculated the effect size dz = t/√n = -0.715. This effect size was used to calculate a minimum sample size of 19 participants for the present experiments (assuming pha = 0.05 and 1− β = 0.90, calculated with G-power; Faul et al., 2009). Consequently, in all of our experiments we tested at least 20 participants. The exact number of participants differed slightly across experiments because of unpredictability in the number of participants who signed up to participate but did not show up for the experimental session.
In this experiment, 20 university students (four males) whose age ranged from 19 to 24 years (mean = 20.1 years) took part for course credit. All participants had normal or corrected-to-normal vision, and none had previously participated in any similar laboratory visual search tasks.
Apparatus and stimuli
The procedure and data collection were controlled by Experiment Builder, and carried out on an HP (Pavilion 23) computer. The stimuli were displayed on a 23-in. monitor, with a resolution of 1,024 × 768 and a refresh rate of 60 Hz. The viewing distance was about 57 cm.
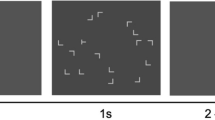
The search displays contained one T-shaped target that was rotated 90° from upright either clockwise or counter-clockwise, and 11 L-shaped distractors that were rotated a random 0°, 90°, 180°, and 270° from upright. Each item was positioned within a 2.25° × 2.25° cell of an invisible 6 × 8 grid that measured a total of approximately 14° × 18°. The location of search items within each cell was jittered randomly within a range of ±0.1°, horizontally or vertically, to avoid collinearities between stimuli. Both the horizontal and vertical size of each stimulus were about 0.7°.The 6 × 8 grid was divided into four invisible quadrants, and each quadrant contained three search items placed in three randomly selected cells within the quadrant. The background color of the search display was gray, and all search items were displayed in black on the gray background.
Procedure
Each trial began with a fixation marker presented for a random duration between 400 ms and 600 ms. The search array was then displayed and remained on the screen until a response was made or 10 s had elapsed. Participants were required to search for the target letter T among 11 rotated distractor letter Ls, and to identify whether the target T was rotated to the left or right from upright, as quickly and accurately as possible. If the target T was rotated to the left, participants were asked to press the F key on the keyboard, whereas if the target T was rotated to the right, participants were asked to press the J key. The search display was followed by a feedback display for 500 ms. If participants made an incorrect response, an auditory beep occurred and the word “wrong” was presented. If participants made a correct response the word “correct” was presented. If no response was made within 10 s, the message “no response” was displayed. Following this feedback, the next trial proceeded automatically.
The experiment followed a 2 (Context: repeated, novel) × 32 (block: 1-32) within-subject repeated measures design. The repeated distractor contexts were repeated across blocks, while the novel distractor contexts appeared only once throughout the experiment. The learning session included 32 blocks. Each block contained 12 repeated distractor contexts and 12 novel distractor contexts. For repeated contexts, although the locations of all search items were repeated, the orientations of each distractor item were randomized on a trial-by-trial basis (rather than repeated across blocks).Footnote 1
To rule out target location probability as the source of the CCE, 24 distinct target locations were selected, with 12 target locations assigned to repeated distractor contexts and the other 12 target locations assigned to novel distractor contexts. The eccentricities of the two sets of targets were comparable, with an average of 5.88° and 5.89° for repeated and novel contexts, respectively. Moreover, the 12 repeated contexts were determined before the experiment (rather than randomly generated for each participant). There was a total of four sets of 12 repeated contexts (and 12 repeated target locations). Each participant was randomly assigned to be tested with one of those four sets of repeated contexts and target locations. Most important, the exact same four sets of contexts/targets were used in all experiments in this study. The only difference across experiment was the manner in which the targets and contexts were paired.
Before starting the experimental session, participants completed a practice block of 24 trials that were not repeated in the subsequent experimental session. Participants were given a 10-s break following each block in the experimental session. Overall, the experimental session consisted of 32 blocks of 24 trials each, for a total of 768 trials.
Recognition task
A recognition task followed the visual search task. A total of 24 search displays were tested; 12 were the “repeated” search displays used in the search phase and 12 were completely new displays that had not been presented previously in the search phase. Participants were required to judge whether they had seen each of the search displays in the prior search phase of the experiment. Participants pressed either the Y or N key on the keyboard to indicate “yes” or “no,” respectively.
Results and discussion
Data from the 32 blocks were collapsed into eight epochs, with four blocks in each epoch. Accuracy in the visual search task was high (98.6%), and repeated-measures ANOVAs of error rates with factors Context (repeated, novel) and Epoch (1–8) revealed no significant main effects or interactions in any of the experiments (all ps > 0.1). As a result, analyses of error rates for this and subsequent experiments are not discussed further.
Mean RTs were computed for each condition, separately for each participant, after excluding trials in which the RT was less than 200 ms or exceeded the mean RT for that condition by two standard deviations. These two criteria were applied to all experiments in the present study, and resulted in exclusion from analysis of 5.75% of the trials in the present experiment. Mean RTs were submitted to a 2 × 8 repeated-measures ANOVA with the factors Context (novel, repeated) and Epoch (1–8). Means of the mean RTs, collapsed across participants, are displayed in Fig. 1A.

Mean reaction times (RTs) for repeated and novel contexts as a function of epoch in Experiments 1 (see panel A – 1C-1T in repeated scenes), 2 (see panel B - 2C-2T), 3 (see panel C – 4C-4T), and 4 (see panel D – 12C-12T), respectively. Error bars represent standard errors corrected to remove between-subject variability in overall performance (Morey, 2008)
The analysis revealed significant main effects of both Context, F(1, 19) = 17.12, p < .01, \( {\eta}_p^2 \) = .47, and Epoch, F(7, 133) = 59.72, p < .01, \( {\eta}_p^2 \) = .76. Responses were faster for repeated than novel contexts, and increased in speed across epochs. The interaction between Context and Epoch was also significant, F(7, 133) = 2.93, p < .01, \( {\eta}_p^2 \) = .13. As is clear in Fig. 1A, the difference between repeated and novel contexts emerged across epochs, a hallmark of the CCE. The CCE (mean RT for novel contexts minus mean RT for repeated distractor contexts) was 105 ms in the final two epochs.
In the recognition task, the data from two participants were excluded from analysis as these participants pressed the same button throughout the task. Hit and false-alarm rates from the remaining participants were submitted to a paired sample t-test. This analysis revealed a non-significant difference between the hit rate (.551) and the false-alarm rate (.555), t(17) = 0.069, p = .94. This result indicates that participants could not explicitly discriminate repeated contexts from novel contexts. The recognition results of subsequent experiments were quite similar and in line with those of previous studies (Chun & Jiang, 1998), and as such are not discussed further in this article.
Taken together, Experiment 1 constitutes a successful replication of the CCE. When each repeated distractor context was paired with a single target location, responses for repeated trials were faster than for novel trials, and this effect emerged across epochs. Moreover, the results of the recognition test indicate that implicit learning for the repeated contexts underlies this CCE.
Experiment 2: Two contexts – two targets (2C-2T)
In Experiment 2, we examined whether the CCE can occur when one repeated distractor context is paired with either of two possible target locations. Importantly, the two targets were associated with a single repeated distractor context by switching the target locations of two repeated distractor contexts across blocks. In other words, the target location of one specific repeated distractor context in one block served as the target location for another repeated distractor context in another block. In this manner, the two targets of the two repeated distractor contexts switched their respective target locations randomly across blocks. An implication of this method is that each repeated distractor context was paired with two possible target locations and yet no additional target locations were needed beyond the number used for the one-to-one mapping in Experiment 1.
Method
Participants
Twenty-six volunteers (five males) ranging in age from 18 to 25 years (mean = 19.7 years) participated in this experiment.
Design
All details of the design were identical to Experiment 1, except that each repeated distractor context was paired with one of two possible target locations. Specifically, as shown in Table 1 and Fig. 2, in contrast to the design in Experiment 1, the 12 repeated contexts were divided into six context pairs, and then the two target locations of these pairs switched between blocks. The nature of the target location switch between repeated distractor contexts equally often involved a left-right, up-down, or diagonal switch in target location when considered with respect to the four quadrants of the search display.

Left: Examples of two repeated scenes in Experiment 1. Context A paired with Target a in all blocks and Context B paired with Target b in all blocks. Right: Examples of two repeated scenes in Experiment 2. Context A paired with Ta and Context B paired with Tb in block 1, but Context A paired with Tb and Context B paired with Ta in another block. Thus, the targets for Context A and Context B switched across blocks
Results
The same outlier procedure as in Experiment 1 was applied, resulting in the exclusion of 5.59% of RTs from further analysis. The resulting mean RTs were submitted to a 2 × 8 repeated-measures ANOVA with the factors Context (repeated, novel) and Epoch (1–8). Means of the mean RTs, collapsed across participants, are displayed in Fig. 1B.
The main effect of Context was significant, F(1, 25) = 10.68, p < .01, \( {\eta}_p^2 \) = .30, as was the main effect of Epoch, F(7, 175) = 41.49, p < .001, \( {\eta}_p^2 \) = .62. As in Experiment 1, responses were faster for repeated than novel contexts, and increased in speed across the eight epochs (see Fig. 1B), with a CCE of 69 ms in the last two epochs. However, the interaction between Context and Epoch was not significant, F(7, 175) = 1.39, p > .05.
To provide a more sensitive analysis of the learning that occurred across the experimental session, we conducted an analysis that compared specifically Epoch 1 to Epoch 8 (see also Chun & Jiang, 1998; Chua & Chun, 2003). A repeated-measures ANOVA with the factors Context (repeated, novel) and Epoch (1, 8) revealed significant main effects of Context, F(1, 25) = 49.66, p < .001, \( {\eta}_p^2 \) = .67, and Epoch, F(1, 25) = 38.79, p < .001, \( {\eta}_p^2 \) = .61, and a significant interaction between Context and Epoch, F(1, 25) = 29.64, p < .001, \( {\eta}_p^2 \) = .54. As is clear in Fig. 1B, the null effect of Context in epoch 1 contrasts sharply with the Context effect in epoch 8, which together demonstrate the presence of a robust CCE in this experiment.
Experiment 3: Four contexts – four targets (4C-4T)
In Experiment 3, we examined whether a CCE would occur if each repeated distractor context was associated with four target locations that switched randomly across blocks.
Method
Participants
Twenty-six new volunteers (four males) ranging in age from 18 to 27 years (mean = 21.3 years) participated in this experiment.
Design and procedure
The design of Experiment 3 was identical to Experiment 2 except for the following details. In Experiment 3, each repeated context was paired with four possible target locations in a manner similar to Experiment 2. Specifically, the 12 repeated contexts were divided into three groups of four, and within each group the four target locations were assigned to each of the four repeated distractor contexts for an equal number of blocks. In other words, for each group of four repeated distractor contexts, the four target locations rotated among the four repeated distractor contexts across blocks. The four target locations that were associated to a particular repeated distractor context appeared in each of the four quadrants of the display with equal probability.
Results and discussion
The same outlier procedure as in previous experiments was applied, resulting in exclusion of 5.50% of the RTs from further analysis. The resulting mean RTs were submitted to a repeated measures ANOVA with the factors Context (repeated, novel) and Epoch (1–8). Means of the mean RTs, collapsed across participants, are displayed in Fig. 1C.
The analysis revealed significant main effects of Context, F(1, 25) = 14.42, p < .01, \( {\eta}_p^2 \) = .37, and Epoch, F(7, 175) = 65.40, p < .001, \( {\eta}_p^2 \) = .72, with faster responses for repeated than novel contexts, and increasing speed of responses across the eight epochs, with a CCE of 68 ms in the last two epochs. Most importantly, the interaction between Context and Epoch also reached significance, F(7, 175) = 2.39, p < .05, \( {\eta}_p^2 \) = .09. As is clear in Fig. 1C, the effect of Context emerged with increasing experience across the eight epochs, indicating the presence of a CCE.
Experiment 4: Twelve contexts – 12 targets (12C-12T)
In Experiment 4, we examined whether the CCE would occur when all twelve repeated contexts switched target locations across blocks in the manner described in previous experiments. In particular, each of the twelve repeated distractor contexts was paired randomly with each of the twelve repeated target locations across blocks.
Method
Participants
Thirty-three new volunteers (seven males) ranging in age from 18 to 26 years (mean = 20.2 years) participated in this experiment.
Design and procedure
All details were the same as in Experiment 3, except that each of the 12 repeated distractor contexts was paired randomly across blocks with the full set 12 target locations. That is, the repeated distractor contexts now shared the same set of target locations.
Results and discussion
The same outlier procedure as in prior experiments resulted in exclusion of 5.49% of the RTs from further analysis. The resulting mean RTs were submitted to a repeated measures ANOVA with the factors Context (repeated, novel) and Epoch (1–8). Means of the mean RTs, collapsed across participants, are displayed in Fig. 1D.
The analysis revealed a significant main effect of Epoch, F(7, 224) = 85.52, p < .001, \( {\eta}_p^2 \) = .73. As in prior experiments, the speed of responses increased steadily across the eight epochs (see Fig. 1D). However, neither the main effect of Context, F(1, 32) = .22, p = 0.64, nor the interaction between Context and Epoch were significant, F(7, 224) = 0.53, p = 0.81, with a CCE of 27 ms in the last two epochs. A repeated-measures ANOVA that examined just the first and last epochs, and that treated Context (repeated, novel) and Epoch (1, 8) as repeated measures, also revealed that the interaction between Context and Epoch was not significant. These results indicate that there was little evidence for a CCE when all 12 targets switched randomly among the repeated distractor contexts across blocks, and suggest that some amount of predictive information for the target is critical to produce the learning of contextual associations that underlies the CCE (Zinchenko, Conci, Müller, & Geyer, 2018). Importantly, it is not simply the absolute number of repetitions of a given repeated distractor context, but also the opportunity for relative association involving a repeated distractor context and target, that determines the contextual association that underlies the CCE. The frequent change and sharing of target positions across the repeated distractor contexts in the 12C-12T condition reduced the overall predictability of target location, which resulted in the absence of a CCE in the 12C-12T condition.
Experiment 5: Within-subject design comparing 1C-1T and 4C-4T
The results of Experiments 1–4 can be compared only informally, as participants belonged to different experimental groups. As such, although we were struck by the similarity of results between Experiments 1 and 3, with a robust CCE observed in both experiments, we were interested in directly comparing results across the 1C-1T and 4C-4T conditions in a better designed experiment. Here we manipulated this factor within-subjects. If the results observed in Experiments 1 and 3 are robust to this change in design, then we should observe a CCE effect in both the 1C-1T and 4C-4T conditions in Experiment 5.
Method
Participants
Twenty-one participants (six males) ranging in age from 18 to 24 years (mean = 19.9 years) participated in this experiment.
Design and procedure
All details were identical to Experiment 1 with the exception of the following. We used a 3 (Contexts: 1C-1T, 4C-4T, novel) × 8 (Epochs: 1–8) within-subjects design. In each block, there were eight trials for each of three distractor context conditions: 1C-1T, 4C-4T, and novel. There were 32 learning blocks, and data for each of eight sets of four blocks were collapsed into epochs.
Results and discussion
The same outlier procedure used in prior experiments resulted in exclusion of 5.79% of trials from further analysis. The resulting mean RTs were submitted to a repeated measures ANOVA with Context (1C-1T, 4C-4T, novel) and Epoch (1–8) as factors. Means of the mean RTs, collapsed across participants, are displayed in Fig. 3.

The results revealed a significant main effect of Context, F(2, 40) = 11.52, p < .001, \( {\eta}_p^2 \) = .37, and a significant main effect of Epoch, F(7,140) = 32.61, p < .001, \( {\eta}_p^2 \) = .62. The interaction between context and epoch was not significant, F(14, 280) = 1.44, p > .05. Post hoc tests showed that there was a significant difference between the 1C-1T condition and the novel condition, t(20) = 3.87, Cohen’s d = 0.85, pbonf = .003, and a significant difference between the 4C-4T condition and the novel condition, t(20) = 3.84, Cohen’s d = 0.84, pbonf = .003. However, there was no significant difference between the 1C-1T and 4C-4T conditions, t(20) = -1.29, Cohen’s d = -0.28, pbonf = .64. The Bayes factor was 4.04, suggesting that the pattern of results was four times more likely to occur under H0 (i.e., there was no difference in the magnitude of the CCE between 1C-1T and 4C-4T) than under H1 (i.e., there was a difference in the magnitude of CCE between 1C-1T and 4C-4T). The CCEs for the 1C-1T and 4C-4T conditions were 84 ms and 61 ms, respectively, in the last two epochs.
A repeated-measures ANOVA that focused on just the first and last epochs, and that treated Context and Epoch as within-participant factors, was also conducted. The interaction between Context and Epoch approached significance, F(2, 40) = 2.88, p = .068, generally supporting the view that a CCE occurred in this experiment. A follow-up analysis that included only the 1C-1T and 4C-4T conditions revealed a non-significant interaction, F(7, 140) = 1.56, p = .151. In other words, there was again little evidence that the CCE differed for these two conditions.
All told, the results generally replicated those of Experiments 1 and 3. Remarkably, there was no evidence that the CCE differed for the 1C-1T and 4C-4T repeated distractor contexts.
Magnitude of CCE across experiments
We also compared the magnitude of the CCE at the end of learning across the five experiments described above. Again, following Chun and Jiang (1998), the CCE was defined as the mean RT for novel contexts minus the mean RT for repeated distractor contexts for the last two epochs. As shown in Fig. 4A, results from the first four experiments indicated that the largest CCE (105 ms) was in 1C-1T condition, whereas the CCE was comparable in the 2C-2T and 4C-4T conditions (69 ms and 68 ms, respectively). Similarly, results from the within-subject experiment (Experiment 5) indicated that the CCE (84 ms) was largest in the 1C-1T condition, and only slightly smaller in the 4C-4T condition (61 ms).

(A) The contextual cueing effect (defined as the mean reaction time (RT) difference between novel and repeated distractor contexts for the last two epochs) in Experiments 1 (1C-1T in repeated scenes), 2 (2C-2T), 3 (4C-4T), 4 (12C-12T), and 5 (1C-1T and 4C-4T). (B) Comparison of the average contextual cueing effect between Blocks 2–4 in the 1C-1T condition and Epochs 2–4 in the 4C-4T condition across experiments/conditions (both with the same accumulated amount of exposure for a particular context-target association). Error bars reflect the within-subjects SEM. Here we compared contextual learning for the same amount of exposure for each context-target pairing. We did not include results for the first block for the 1C-1C condition and the first epoch for the 4C-4T condition because a learning effect can only be seen starting at the second occurrence of particular context-target associations.
A one-way ANOVA was conducted to compare the CCE across the first four experiments. The results showed that there was a significant effect, F(3, 101) = 2.82, p < .05, \( {\eta}_p^2 \) = .07. Post hoc tests showed that there was a significant difference between Experiment 1 (1C-1T) and Experiment 4 (12C-12T), pbnof = .028. There were no other significant differences between experiments. In addition, a paired t-test comparing the two conditions in the within-subject experiment (Experiment 5) showed a non-significant difference between the CCE in the 1C-1T and 4C-4T conditions, t(20) = 1.71, p > .05, Cohen’s d = 0.37.
Finally, when one context is paired with more than one possible target location across blocks, participants would have had many fewer exposures to a particular context-target association than in the 1C-1T condition. For example, participants would need four times of number of epochs to offer comparable opportunities to learn a specific one-to-one context-target association in the 4C-4T condition than in 1C-1T condition. Fig. 4B shows the CCE during the earlier phases of learning for the same amount of accumulated exposure to a given association across Experiments 1 and 3 (left two bars) and in Experiment 5 (right two bars). The CCE was generally larger for experiments/conditions with multiple possible targets compared to that for one target. Paired-sample t tests showed that the CCE was significantly larger for the 4C-4T conditions (Epochs 2–4) than for the corresponding 1C-1T condition (Blocks 2–4) in the within-subject design of Experiment 5, t(20) = -2.81, p = .005, Cohen’s d = -0.61, although the corresponding difference did not reach significance for the between-subject design (Experiments 3 vs 1), t(44) = -1.28, p = .10, Cohen’s d = -0.38. We address the implications of these results further in the General discussion.
General discussion
In this study, we examined whether the CCE would occur when one repeated distractor context was associated with multiple possible target locations. Although the largest CCE was obtained in Experiment 1 in which each repeated context was associated with one specific target location, the CCE was also evident (although smaller in magnitude) when one context was associated with two possible target locations. Surprisingly, we also found a CCE when each repeated context was associated with four possible target locations. Importantly, the CCE found in the 4C-4T condition was comparable to that in the 2C-2T condition. Moreover, in addition to Experiments 1–4 in which the number of targets associated to repeated distractor contexts was manipulated between experiments, Experiment 5 used a within-subject design to compare 1C-1T and 4C-4T conditions. The results of Experiment 5 generally replicated those from the corresponding between-subject experiments, suggesting that the pattern of effects found across Experiments 1 and 3 is a robust one.
Interpretation of the CCE in multiple context-target association tasks
Previous studies (Chun & Jiang, 1998; Zellin et al., 2011) had examined whether the CCE can occur when one context is paired with two possible targets. Chun and Jiang (1998) found a modest CCE in the last epoch (~40 ms). Zellin et al. (2011) also found a small CCE (36 ms), but mainly due to a learned association between each repeated distractor context and one particular target. However, in both of these studies, each repeated distractor context was associated with two unique target locations that were not shared with any other repeated context. Thus, the total number of target locations across all repeated contexts was twice the number of repeated contexts overall.
In the present study, multiple associations between repeated distractor contexts and target locations were created without increasing the total number of target locations. This aim was achieved by dividing the 12 repeated distractor contexts into six groups of two (2C-2T), three groups of four (4C-4T), or one group of 12 (12C-12T), and then randomly switching target locations between the repeated distractor contexts within those groups. As a result, the total number of target locations for repeated distractor contexts in the 2C-2T, 4C-4T, and 12C-12T conditions was 12, just as it was in the 1C-1T condition. This method of increasing the number of associations between repeated distractor contexts and targets without increasing the total number of target locations is a unique property of our designs, and very likely contributed to the significant CCEs found in the 2C-2T and 4C-4T conditions.
In addition to controlling the total number of targets across the entire set of repeated distractor contexts, the “reuse” of target locations between repeated distractor contexts may have played an important role in the results of the present study. As a fixed set of target locations was consistently paired with a fixed set of repeated distractor contexts, these repeated pairings did provide a basis for statistical learning that could, in principle, facilitate visual search; repeated distractor contexts did offer predictive information about likely target locations. Note that targets on novel context trials were not paired with repeated distractor contexts. Thus, our experimental design rules out target location probability alone as the cause of the multiple target CCEs that were observed. A target that is consistently paired with novel distractor contexts is missing the consistent pairing between context and target necessary for associative learning. Therefore, the CCEs observed here must in some way be related to multiple targets being associated with a consistent set of repeated distractor contexts, which in turn facilitated search relative to a comparable set of targets on novel context trials that lacked such an association. This type of contextual learning is somewhat different than that usually described in studies of contextual cueing, but could nonetheless contribute to the CCE (Zellin et al., 2013).
The results of Experiments 2, 3, and 5 of the present study demonstrate that participants learned the association between multiple repeated distractor contexts and multiple target locations despite being exposed to the pairing of just one repeated context and one target on any given trial. We propose that this learning effect is unlikely to have occurred by learning that involved the specific relation between one repeated distractor context and a single target location. Such a relation would be difficult to learn, as it would be consistently subject to interference from exposure to the same context paired with other target locations, or the same target paired with other contexts. Learning of a one-to-one relation would also be of limited use as, for any particular trial, a repeated distractor context does not predict which of two or more targets will appear. For these reasons, we propose that our results are inconsistent with the notion that participants learned the association between one context and one specific target location. Indeed, for the same amount of accumulated exposure across experiments, the CCE was significantly larger for experiments/conditions with multiple possible targets compared to that for one target (see Fig. 4B). A caveat is that this result would also have occurred if learning was simply slower in early blocks than later blocks of the experimental session irrespective of the particular distractor-target configuration condition. Slower learning early in the experimental session would bias selectively against learning effects in the 1C-1T condition in this type of contrast. Future studies could address this issue by independently varying exposure to the multiple target-contexts and exposure to the single target-context associations.
At the same time, we must acknowledge that the learning of multiple context-target associations likely requires more exposure than the one-to-one context-target associations typically measured in studies of the CCE. For example, in the 12C-12T condition of Experiment 4, each context-target pair was displayed fewer than three times on average across the whole experiment, and indeed there was little evidence of a CCE. In the 4C-4T condition of Experiment 3, each context-target pair was displayed eight times in total, and although it is remarkable that a CCE effect was observed, this effect did appear to be somewhat smaller than that observed in the 1C-1T condition of Experiment 1. In summary, we cannot be certain whether insufficient exposure to particular context-target associations, or difficulty in learning a complex mapping that involves multiple contexts and multiple targets, lies at the root of the effects reported here. Future research that examines whether a CCE could be obtained if the number of blocks for the 12C-12T condition were increased substantially would usefully address this issue.
Dominant – minor target analysis
Although a CCE in overall mean RT was observed for multiple context-target associations in several conditions in the present study, it is in theory possible that not all target-context associations were learned equally. Zellin et al. (2011) found a modest CCE when two target locations were paired with one repeated context and, more importantly, there was one “dominant” target location that was learned, and one “minor” target that was not learned. The overall CCE (averaging over all scenes) appeared to be a combined effect from trials in which a CCE occurred and trials in which a CCE did not occur. Their findings suggest that a single distractor context may only cue one target well, which is consistent with the notion that attentional guidance contributes to the CCE.
We performed similar analysis for our 2C-2T conditions. The 12 targets in the repeated scenes were partitioned into six pairs of targets, with each pair corresponding to the two contexts that shared two targets (e.g., targets a and b, both paired with context A and context B). For each participant, averaged RTs in the last two epochs were calculated separately for the two targets in each pair. The difference between this RT value and mean RT value for the novel scenes would be the magnitude of CCE (RT for novel scenes minus RT for repeated scenes) for a given target. Indeed, similar to what Zellin et al. (2011) observed, there was a “dominant” target with a mean CCE of 241.2 (SE=26.4) ms and a “minor” target with a smaller (in fact, negative) mean CCE of -114.1 (SE=29.7) ms. However, careful examination of those targets showed that “dominant” and “minor” target differed in target eccentricity. We found that the eccentricity of the dominant targets (mean of 5.92°) was significantly smaller than the eccentricity of the minor targets (mean of 8.69°). We also found that there was a high positive correlation (r = 0.88, p < .001) between target eccentricity and participants’ RT.
To correct for the effect of eccentricity, for each of the target pairs in the 2C-2T condition, we identified the corresponding targets (that exactly matched in eccentricity) in the 1C-1T condition. The mean CCE values in the 1C-1T condition for the targets corresponding to the “dominant” and “minor” targets in the 2C-2T condition were 288.3 (SE = 24.9) ms and -78.5 (SE = 25.4) ms, respectively. For each participant, the CCE in the 2C-2T condition for a given target was subtracted from the CCE value (averaged across participants) for the corresponding target in 1C-1T condition. These CCE difference scores for “dominant” (with mean of 47.0 ms) and “minor” targets (with mean of 35.6 ms) were compared with a t-test. There was no significant difference in CCE difference score between “dominant” and “minor” targets, t(25) = 0.70, p > 0.05, Bayes factor = 0.26. Therefore, the “dominant” versus “minor” difference found in Zellin et al. (2011) does not seems to apply to the results in our study. The learning of the two targets in a pair was likely comparable.
Implications of our results for the mechanisms of CCE
Our proposed statistical learning of multiple target locations as a result of exposure to pairing of those target locations with multiple repeated distractor contexts differs substantially from the conventional notion of attentional guidance, the most widely accepted mechanism to explain the CCE. Attentional guidance requires a one-to-one association between a context and a target location, and the learning of this association then guides attention definitively towards the target. Many studies in the literature support the notion that the learned associations between repeated distractor context and target location guides visual attention, and that this type of attentional guidance is the mechanism underlying contextual cueing (Chun & Jiang, 1998; Jiang & Wagner, 2004; Makovski & Jiang, 2010; Tseng & Li, 2004).
In our study, we found a CCE for repeated contexts that were associated with two targets (Experiment 2: 2C-2T) and with four targets (Experiment 3: 4C-4T). Importantly, the CCE effects found in these two experiments were comparable. For any given trial in both of these experiments, the target location that would be paired with a repeated distractor context was not predictable. Consequently, a one-to-one attentional guidance process would have a 50% chance of misguiding attention in the 2C-2T condition, and a 75% chance of misguiding attention in the 4C-4T condition. If attentional guidance were the only mechanism underlying the CCE, then the CCE ought to be smaller in the 4C-4T condition than in the 2C-2T condition, which was not the case. Therefore, attentional guidance cannot possibly be the only mechanism underlying the CCE in our study.
Although attentional guidance in the conventional sense (one-to-one context-target associations) may not be the mechanism underlying the CCE in our study, it may be that repeated distractor contexts can facilitate search by guiding attention to a small number of “hot” spots. Although the exact target location was not predictable, it would still have been beneficial to predict a small number of possible target locations. Although eye movements can only be executed in one direction, preparation for an eye movement could involve a preferred status for multiple locations, just as covert attention can focus on more than one location (Müller, Malinowski, Gruber, & Hillyard, 2003). According to this view, the occurrence of a CCE in the 4C-4T condition could reflect a preferred status for four different target locations in early stages of visual-cortical processing. One can think of this type of contextually based prediction as an extension of the “attentional guidance” mechanism discussed in the contextual cueing literature.
Alternatively, search times for repeated context items in the present study may have been facilitated by decision or response selection processes that occur after the eyes move to a target location. In our earlier work on the CCE that focused on RT × set size functions and eye movement indicators, we found that the intercept of the set size function was lower for repeated compared to novel contexts, suggesting that response selection processes contribute to the CCE (Zhao et al., 2012). Other studies have also pointed out the contribution of response selection to the CCE (Kunar et al., 2007; Schankin et al., 2011; Schankin & Schubö, 2010). In the current study, it is conceivable that response selection processes were responsible for the CCE in the 2C-2T and 4C-4T experiments.
Beesley et al. (2015) suggested that learning about repeated distractor contexts irrespective of target location may contribute to the CCE. In our study, repeated distractor contexts appeared in consecutive blocks, whereas target locations associated with these repeated distractor contexts often did not repeat in consecutive blocks (in the 2C-2T, 4C-4T, 12C-12T conditions). As a result, the targets might have stood out as “unusual” items thus attracting attention. However, the results from the 12C-12T condition (Experiment 4) suggest that the contribution of repeated distractor contexts alone to the CCE in the present study was limited, as the same repeated distractor contexts that produced a reliable CCE in Experiments 1, 2, and 3, produced little CCE at all in Experiment 4.
Interestingly, to isolate the effect of repeated distractor contexts, Experiment 1 of Beesley et al. (2015) implemented a pre-exposure phase where the distractor contexts were repeated but target locations were only occasionally repeated. Their pre-exposure phase happened to involve essentially the same design as that in our Experiment 3 (4C-4T). In their study, each repeated context was also paired with one of four possible target locations. However, their design differed from ours in two respects. They implemented only four repeated contexts (and an equal number of novel contexts) whereas we implemented 12 repeated contexts (three sets of four). In total their pre-exposure phase contained 20 exposures for each repeated context (five blocks of 32 trials) whereas ours contained 32 exposures (32 blocks of 24 trials) for each repeated distractor context. They concluded that no CCE was found in their pre-exposure phase. The difference in results between our two studies could be caused by the different amount of exposure for the repeated contexts. In our 4C-4T condition, the learning became more evident starting in Epoch 4 (16 exposures for each repeated context).
It is also important to point out that mechanisms of contextual learning may not be fixed and instead may vary as a function of task context. We have concluded that attentional guidance (in the sense of one-to-one repeated context-target associations) may not be the only mechanism responsible for the CCE. At the same time, there may be task contexts in which attentional guidance is indeed the predominant mechanism underlying the CCE. The visual system requires a sufficient amount of predictive information to detect and subsequently learn contextual associations (Zinchenko et al., 2018), and the mechanism responsible for the CCE could depend on the nature of the regularities embodied in the environment. For example, when one repeated context is constantly paired with one fixed target location, attentional guidance might play the main role in contributing to the CCE. However, when repeated contexts are paired with multiple possible target locations in the manner of the present study, the contribution of one-to-one context-target attentional guidance to the CCE could decrease. Future studies would benefit from further study of this multiple-process view of the CCE.
Conclusion
Although the CCE is typically measured by pairing each of a set of repeated distractor contexts with one particular target, we found that the CCE can also be obtained when repeated distractor contexts are associated with as many as four possible target locations, provided the target locations are also shared by other repeated contexts. The current study suggests that contextual cueing could involve mechanisms other than the conventional “one-to-one” context-target attentional guidance implicated in many prior studies of the CCE.
Notes
Previous studies revealed that repeated binding of identity and location can facilitate contextual learning (Brockmole, Castelhano, & Henderson, 2006; Rosenbaum and Jiang, 2013; Makovski, 2016, 2017). To avoid learning of a regularity between unique distractor orientation and specific target location, distractor orientation was randomized on a trial-by-trial basis for the multiple presentations of repeated distractor contexts.
References
Beesley, T., Vadillo, M. A., Pearson, D., & Shanks, D. R. (2015). Pre-exposure of repeated search configurations facilitates subsequent contextual cuing of visual search. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41(2), 348–362. https://doi.org/10.1037/xlm0000033
Brockmole, J. R., Castelhano, M. S., & Henderson, J. M. (2006). Contextual cueing in naturalistic scenes: Global and local contexts. Journal of Experimental Psychology: Learning, Memory, and Cognition, 32(4), 699.
Chua, K.-P. & Chun, M. (2003). Implicit scene learning is viewpoint dependent. Perception & Psychophysics, 65, 72–80. https://doi.org//10.3758/BF03194784.
Chun, M. M. (2000). Contextual cueing of visual attention. Trends in Cognitive Sciences, 4(5), 170–178. https://doi.org/10.1016/S1364-6613(00)01476-5
Chun, M. M., & Jiang, Y. (1998). Contextual Cueing: Implicit Learning and Memory of Visual Context Guides Spatial Attention. Cognitive Psychology, 36(1), 28–71. https://doi.org/10.1006/cogp.1998.0681
Faul, F., Erdfelder, E., Buchner, A., & Lang, A.-G. (2009). Statistical power analyses using G*Power 3.1: Tests for correlation and regression analyses. Behavior Research Methods, 41(4), 1149–1160. https://doi.org/10.3758/BRM.41.4.1149
Goujon, A., Didierjean, A., & Thorpe, S. (2015). Investigating implicit statistical learning mechanisms through contextual cueing. Trends in Cognitive Sciences, 19(9), 524–533. https://doi.org/10.1016/j.tics.2015.07.009
Jiang, Y., & Wagner, L. C. (2004). What is learned in spatial contextual cuing— configuration or individual locations? Perception & Psychophysics, 66(3), 454–463. https://doi.org/10.3758/BF03194893
Jiang, Y., Song, J.-H., & Rigas, A. (2005). High-capacity spatial contextual memory. Psychonomic Bulletin & Review, 12(3), 524–529. https://doi.org/10.3758/BF03193799
Kroell, L. M., Schlagbauer, B., Zinchenko, A., Müller, H. J., & Geyer, T. (2019). Behavioural evidence for a single memory system in contextual cueing. Visual Cognition, 27(5–8), 551–562. https://doi.org/10.1080/13506285.2019.1648347
Kunar, M. A., Flusberg, S., Horowitz, T. S., & Wolfe, J. M. (2007). Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology: Human Perception and Performance, 33(4), 816–828. https://doi.org/10.1037/0096-1523.33.4.816
Makovski, T. (2016). What is the context of contextual cueing? Psychonomic Bulletin & Review, 23, 1982–1988.https://doi.org/10.3758/s13423-016-1058-x.
Makovski, T. (2017). Learning “What” and “Where” in Visual Search: Learning “what” and “where” Japanese Psychological Research, 59(2), 133–143. https://doi.org/10.1111/jpr.12146
Makovski, T., & Jiang, Y. V. (2010). Contextual cost: When a visual-search target is not where it should be. Quarterly Journal of Experimental Psychology (2006), 63(2), 216–225. https://doi.org/10.1080/17470210903281590
Manginelli, A. A., & Pollmann, S. (2009). Misleading contextual cues: how do they affect visual search? Psychological Research, 73(2), 212–221. https://doi.org/10.1007/s00426-008-0211-1
Morey, R. D. (2008). Confidence Intervals from Normalized Data: A correction to Cousineau (2005). Tutorials in Quantitative Methods for Psychology, 4(2), 61–64. https://doi.org/10.20982/tqmp.04.2.p061
Müller, M. M., Malinowski, P., Gruber, T., & Hillyard, S. A. (2003). Sustained division of the attentional spotlight. [published correction appears in Nature. 2003 Dec 4;426(6966):584]. Nature, 424(6946), 309-312. https://doi.org/10.1038/nature01812
Reber, A. S. (1967). Implicit learning of artificial grammars. Journal of Verbal Learning and Verbal Behavior, 6(6), 855–863. https://doi.org/10.1016/S0022-5371(67)80149-X
Reber, A. S. (1989). Implicit learning and tacit knowledge. Journal of Experimental Psychology: General, 118(3), 219–235. https://doi.org/10.1037/0096-3445.118.3.219
Rosenbaum, G. M., & Jiang, Y. V. (2013). Interaction between scene-based and array-based contextual cueing. Attention, Perception, & Psychophysics, 75(5), 888–899. https://doi.org/10.3758/s13414-013-0446-9
Schankin, A., & Schubö, A. (2010). Contextual cueing effects despite spatially cued target locations. Psychophysiology. https://doi.org/10.1111/j.1469-8986.2010.00979.x
Schankin, A., Hagemann, D., & Schubö, A. (2011). Is contextual cueing more than the guidance of visual–spatial attention? Biological Psychology, 87(1), 58–65. https://doi.org/10.1016/j.biopsycho.2011.02.003
Sewell, D. K., Colagiuri, B., & Livesey, E. J. (2018). Response time modeling reveals multiple contextual cuing mechanisms. Psychonomic Bulletin & Review, 25(5), 1644–1665. https://doi.org/10.3758/s13423-017-1364-y
Tseng, Y.-C., & Li, C.-S. R. (2004). Oculomotor correlates of context-guided learning in visual search. Perception & Psychophysics, 66(8), 1363–1378. https://doi.org/10.3758/BF03195004
Turk-Browne, N. B., Jungé, J. A., & Scholl, B. J. (2005). The Automaticity of Visual Statistical Learning. Journal of Experimental Psychology: General, 134(4), 552–564. https://doi.org/10.1037/0096-3445.134.4.552
Vadillo, M. A., Konstantinidis, E., & Shanks, D. R. (2016). Underpowered samples, false negatives, and unconscious learning. Psychonomic Bulletin & Review, 23(1), 87–102. https://doi.org/10.3758/s13423-015-0892-6
Zellin, M., Conci, M., von Mühlenen, A., & Müller, H. J. (2011). Two (or three) is one too many: testing the flexibility of contextual cueing with multiple target locations. Attention, Perception, & Psychophysics, 73(7), 2065–2076. https://doi.org/10.3758/s13414-011-0175-x
Zellin, M., Conci, M., Mühlenen, A. von, & Müller, H. J. (2013). Here Today, Gone Tomorrow – Adaptation to Change in Memory-Guided Visual Search. PLOS ONE, 8(3), e59466. https://doi.org/10.1371/journal.pone.0059466
Zellin, M., Mühlenen, A. von, Müller, H. J., & Conci, M. (2013). Statistical learning in the past modulates contextual cueing in the future. Journal of Vision, 13(3), 19–19. https://doi.org/10.1167/13.3.19
Zellin, M., von Mühlenen, A., Müller, H. J., & Conci, M. (2014). Long-term adaptation to change in implicit contextual learning. Psychonomic Bulletin & Review, 21(4), 1073–1079. https://doi.org/10.3758/s13423-013-0568-z
Zhao, G., Liu, Q., Jiao, J., Zhou, P., Li, H., & Sun, H. (2012). Dual-state modulation of the contextual cueing effect: Evidence from eye movement recordings. Journal of Vision, 12(6), 11–11. https://doi.org/10.1167/12.6.11
Zinchenko, A., Conci, M., Müller, H. J., & Geyer, T. (2018). Predictive visual search: Role of environmental regularities in the learning of context cues. Attention, Perception, & Psychophysics, 80(5), 1096–1109. https://doi.org/10.3758/s13414-018-1500-4
Zinchenko, A., Conci, M., Taylor, P. C. J., Müller, H. J., & Geyer, T. (2018). Taking Attention out of Context: Frontopolar Transcranial Magnetic Stimulation Abolishes the Formation of New Context Memories in Visual Search. Journal of Cognitive Neuroscience, 1–11. https://doi.org/10.1162/jocn_a_01358
Acknowledgements
We thank Drs. David Shore and Shiyi Li for helpful discussion during the course of the study. We are also grateful for the reviewers’ insightful comments.
Open practice statement
The study was not pre-registered. Data and material will be made available upon request.
Funding
This research was supported by grant from Natural Sciences and Engineering Research Council of Canada (NSERC).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interests
The authors declare that there is no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Wang, C., Bai, X., Hui, Y. et al. Learning of association between a context and multiple possible target locations in a contextual cueing paradigm. Atten Percept Psychophys 82, 3374–3386 (2020). https://doi.org/10.3758/s13414-020-02090-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-020-02090-3