
Abstract
Actions can be investigated by using sequential priming tasks, in which participants respond to prime and probe targets (sometimes accompanied by distractors). Facilitation and interference from prime to probe are measured by repeating, changing, or partially repeating features or responses between prime and probe. According to the action control literature, feature–feature or feature–response bindings are universal and apply for all actions. The attentional orienting literature, however, suggests that if the task is to detect stimuli, such binding effects may be absent. In two experiments, we compared performance in a discrimination task and a detection task with the exact same perceptual setup of prime–probe sequences. For the discrimination task, we replicated the typical feature–response binding pattern. Crucially, we did not observe any binding effects for the detection task, which can be explained by task-specific processes or fast response execution. These results reveal an important boundary of current binding models in action control.
Similar content being viewed by others

Detecting and discriminating stimuli are two fundamental processes for successfully interacting with the environment. Both abilities can be easily investigated in an experimental setting, in which participants respond to serially presented stimuli with key presses. In the most simplistic basic design with sequentially appearing single stimuli, discrimination tasks demand that participants discriminate each stimulus’ identity (e.g., color or shape) with a key press, whereas detection tasks demand that participants just make a key press to the onset of each stimulus, irrespective of its identity. In both tasks, the participant has an intention. That is, in both cases, there is goal-directed behavior (i.e., an intent to detect or classify the stimulus). According to the action control literature, this intent is the crucial aspect that defines an action—that is, only intentional movements constitute an action (see, e.g., Frings et al., in press; Hommel, 2004; Prinz, 1998). In other words, a simple body movement becomes an action if this body movement is done with the intent to achieve a certain goal (Frings et al., in press). Action control models typically consider all intentional actionsFootnote 1 their explanandum. Thus, there is no theoretical reason to assume—from an action control perspective—that the underlying action processes contributing to detection and discrimination performance should differ because both involve an intentional key press in response to the stimulus. In this article, we evaluate this assumption by comparing performance in a stimulus detection task against performance in a stimulus discrimination task.
In action control research, several processes (like, e.g., feature integration and episodic retrieval; see, e.g., Hommel, 2010) have been investigated, assuming that these contribute to actions. Accordingly, paradigms have been developed to assess specific consequences of actions—for example, in task switching (Kiesel et al., 2010), negative priming (Frings, Schneider, & Fox, 2015), stimulus–response binding (Frings, Rothermund, & Wentura, 2007; Hommel, 1998), and conflict (Gratton, Coles, & Donchin, 1992) tasks. A common assumption across these tasks and several action control theories is that the response to a stimulus is integrated with the stimulus’ features (e.g., color, shape, location) to form a common representation (e.g., an event file; Hommel, 2004). The integration process is often labeled feature binding and describes the coupling of stimulus features to responses (Hilchey, Rajsic, Huffman, & Pratt, 2017; Hommel, 2004), and to other stimulus features (Hommel, 2004; Treisman & Gelade, 1980), even if the latter are task irrelevant (Frings et al., 2007). According to the theory of event coding (Hommel, 1998, 2004), upon repetition of a stimulus’ property or response, the information recently associated with it is likewise retrieved (see also Denkinger & Koutstaal, 2009; Frings et al., 2007). If there is a partial mismatch between the retrieved information and the response or stimulus property, that must be processed, interference occurs, thereby increasing response times and error rates. Similarly, the instance theory of automatization (Logan, 1988, 2002), the parallel episodic processing (PEP) model (Schmidt, De Houwer, & Rothermund, 2016), as well as the binding and retrieval in action control (BRAC) model (Frings et al., in press) assume that repeating a stimulus or response retrieves information bound to it.
From an action control perspective, feature–response binding mechanisms are more flexible and ubiquitous than previously assumed and are at work in paradigms in which they are not intentionally investigated, as in many priming tasks (Henson, Eckstein, Waszak, Frings, & Horner, 2014; see also Frings et al., in press). Although it is argued that binding effects are influenced by the importance of certain features (or feature dimensions) for a task (in the sense of “intentional weighting”; Memelink & Hommel, 2013) and that task relevance of and attention to certain features plays a role in observing binding effects (e.g., Hommel, Memelink, Zmigrod, & Colzato, 2014; Singh, Moeller, Koch, & Frings, 2018), it is assumed that binding processes may potentially be at work in every task. Though rare, restrictions to this ubiquity of binding effects have been reported; for example, Hommel (2007) found that location gets bound only if it is somehow task relevant (e.g., as a relevant feature or a spatial response). Generally, however, “binding” explanations exist for many classic experimental tasks that involve a sequential design such as negative priming (e.g., Rothermund, Wentura, & De Houwer, 2005), task switching (e.g., Koch, Frings, & Schuch, 2018), the Gratton effect (e.g., Davelaar & Stevens, 2009), action planning tasks (e.g., Kunde, Hoffmann, & Zellmann, 2002), and so on.
Yet looking at the attentional orienting literature, one can actually come to a contrary conclusion. Although focusing on the phenomenon of inhibition of return (IOR)—that is, relatively slow responses to previously attended relative to unattended locations (Klein, 2000), IOR and binding paradigms can be very similar procedurally (Hommel, 1998) in that the stimulus location is random (Posner & Cohen, 1984; Posner, Rafal, Choate, & Vaughan, 1985), the response to it can be varied (e.g., Welsh & Pratt, 2006; Wilson, Castel, & Pratt, 2006) and the stimulus’s identity can randomly repeat or change (e.g., Fox & de Fockert, 2001; Pratt, Hillis, & Gold, 2001). For example, Kwak and Egeth (1992, Experiments 1, 2, and 4) investigated the effects of randomly repeating a target’s color or location in a detection task, where participants had to indicate the onset of a single stimulus with a single key press. They found slower reaction times if the target location repeated, but neither an effect of repeating the target color nor an interaction between target color and location repetition, as would have been predicted by action control theories. Yet Terry, Valdes, and Neill (1994) noticed that when stimuli were sequentially identified instead of detected, interactions between target response and location repetition emerged. Repeating versus switching the target location led to faster responses when the response repeated, and to slower responses when the response switched (see also, Hilchey et al., 2017; Klein, Wang, Dukewich, He, & Hu, 2015, for additional interactions between response and location repetition).
Based on a review of the classic IOR literature with detection and localization responses, Huffman, Hilchey, and Pratt (2018) argued that binding effects must only occur when the task requires target identity processing in order to make the correct response. This is not the case for detection tasks, in which one can react to the mere onset of a stimulus irrespective of its identity. With such thoughts in mind, Hilchey, Rajsic, Huffman, Klein, and Pratt (2018) investigated binding and IOR effects by combining a manual discrimination task with a saccadic localization task in the same experiment with prime–probe sequences. That is, participants looked at each target prior to identifying it with a key-press response. Assuming that the binding processes are spurred on by the need to process target identity information, the authors hypothesized that key-press identification responses would show evidence of binding processes due to the discriminatory judgement needed to form the correct response, whereas saccadic localization responses would not (see also the “discrimination response hypothesis”; Hilchey, Leber, & Pratt, 2018). As predicted, eye movements were slowest when the target location repeated irrespective of its identity (color or shape), consistent with IOR, whereas the target location repetition effects for manual discrimination responses were dramatically modified by whether the target identity and response repeated, in a manner consistent with the theory of event coding. The authors concluded that this inhibited reorienting observed for eye movements is an ubiquitous consequence of prior (oculomotor) activation; yet this effect can be obscured entirely by binding effects in the manual response system when target identity information (e.g., shape) has to be processed for forming the manual response. The findings appear to elucidate an important boundary on action control theories by showing that binding effects are confined mainly to discrimination judgments.
A similar discrepancy between detection and discrimination performance can be found in the visual search literature.Footnote 2 In visual search odd-one-out tasks, participants have to signal (i.e., to detect) the presence of a target among multiple distractors (e.g., Found & Müller, 1996; Müller, Heller, & Ziegler, 1995); in such tasks, the target pops out by being different from the other distractors in one dimension (or redundantly in more dimensions; see, e.g., Krummenacher, Müller, & Heller, 2002), for example, a diagonal bar among vertical bars or a red bar among grey bars. By repeating the target-defining dimension of the previous trial(s), participants respond faster; according to the dimensional weighting account (Found & Müller, 1996; Müller et al., 1995), this is due to the cognitive system preattentively assigning more “weight” to the target-defining dimension, therefore allowing faster responding, if the target-defining dimension repeats (see also Müller & Krummenacher, 2006). Crucially, this pattern can only partially be observed in compound search tasks (e.g., Pollmann, Weidner, Müller, Maertens, & von Cramon, 2006; Töllner, Gramann, Müller, Kiss, & Eimer, 2008; Zehetleitner, Rangelov, & Müller, 2012). In these tasks, participants search for a target popping out among distractors as in an odd-one-out task, but additionally, the target contains a response-defining feature—for example, in Töllner et al. (2008), participants had to search for a target that could pop out in one of two dimensions—a square (shape) or a red circle (color)—in an array of multiple blue distractor circles. The target (and all distractors) contained stripes of either vertical or horizontal orientation, which had to be discriminated using two keys (for a similar design, see, e.g., Zehetleitner et al., 2012, Experiment 1a). In such tasks, in which a response-defining feature follows target selection, reaction time benefits occur, when the target-defining dimension (in this example, shape or color) and response-defining feature (horizontal or vertical orientation) fully repeat; however, if the target-defining dimension repeats, but the response-defining feature changes, responses are slowed down (e.g., Töllner et al., 2008; Zehetleitner et al., 2012). Zehetleitner et al. (2012) could show, that these partial repetition costs specifically arise at the postselective, that is, response-defining stage, which is also supported by neurophysiological data (Pollmann et al., 2006; Töllner et al., 2008). Although not focusing on binding processes, these results suggest that a postselective target discrimination is crucial for observing partial repetition costs, which cannot be observed in simple detection (odd-one-out) tasks in visual search.
The present study
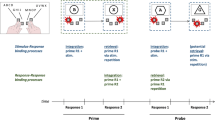
In our study, the task was to detect or discriminate the color of a stimulus. Crucially, both tasks were visually identical, as the stimulus could appear in two different colors and at two different locations. On the one hand, action control theories would predict binding effects to emerge from such a detection task because signaling the detection of a stimulus via key press is clearly an intentional movement and hence by definition an action. However, it is unclear which components of a stimulus and its response exactly would be bound, because several predictions are justified by the action control literature (see below). A binding-is-task-independent account originating from the action control literature would actually allow for the prediction of three types of bindings here (Hommel, 2004): (1) feature–feature binding between color and location, (2) feature–response binding between response and location, and (3) feature–response binding between response and color. In all cases, if one aspect of the bound representation repeats but another does not, there should be a relative cost attributable to interference between some aspect of the current target and the prior event representation.
On the other hand, attentional orienting research would predict the absence of a binding effect for the detection task because it is not necessary to process the target’s identity information to form the response (Hilchey, Rajsic, et al., 2018; Huffman et al., 2018). A binding-is-task-specific account, as suggested by the attentional orienting literature, would expect no binding effect for the detection task but a binding effect for the discrimination task (Hilchey, Rajsic, et al., 2018; Huffman et al., 2018).
All predictions for the detection task are shown in Fig. 1Footnote 3 and can be compared with the color discrimination task. This discrimination task should show typical binding effects (e.g., Hilchey et al., 2017; Hommel, 2004)—that is, we expect to observe an interaction for color/response x location.

Predictions with hypothetical data. A task-independent binding model allows for three predictions based on feature–feature or feature–response binding for the detection task. A task-dependent binding model predicts binding effects in the discrimination task but no such effects in the detection task (see text). Note that in the discrimination task, color and response are confounded and that either one or both could cause the binding effect
We conducted two experiments, each comprising a detection and a discrimination task that only differed in their instructions. The discrimination task should show a typical binding effect, whereas the detection task might or might not be affected by binding.
Experiment 1
Participants completed two tasks—a discrimination task and a detection task—with the same prime–probe sequences. Except for the response mapping to the target stimuli, the experimental setup was identical. In the discrimination task, participants had to discriminate the color of the target stimuli, regardless of their locations. In the detection task, participants had to respond to each stimulus, regardless of its color and location. For both tasks, participants were told to fixate on a cross and to use their peripheral vision to process primes and probes.
Method
Participants
Sample-size estimation was based on Frings et al. (2007); binding effects are usually stable and strong with a medium to high effect size (Cohen’s d between .4 and 1). In the current study, the binding effect is computed as the interaction between color and location relation. For finding this effect, we decided to run the experiment with N = 30 participants, based on a power of 1 − β = .96 with an assumed α = .05 (one-tailed) and expected effect size dz = 0.64 (G*Power, Version 3.1.9.2; Faul, Erdfelder, Lang, & Buchner, 2007). This should yield enough power for reliably detecting any binding effects. Thirty students of the University of Trier participated for course credit and gave written informed consent. Data of one participant was excluded due to high error rates in both tasks (the participant was far out when compared with the sample). This resulted in a sample size of 29 participants (21 women, eight men, Mage = 21.79, SDage= 2.97, age range: 19–33 years).
Apparatus and materials
Stimuli were displayed on a screen (refresh rate: 60 Hz) with a display resolution of 1,680 × 1,050 pixels, spanning a field of 44.45° × 28.63° of visual angle, and a black background (luminanceFootnote 4: 0.21 cd/m2). A chin rest was positioned at approximately 58 cm in front of the screen. A white fixation cross (luminance: 244 cd/m2) measuring 0.40° in visual angle in diameter was presented at the left half of the screen (x-axis: 640 px, y-axis: central). Target stimuli were red (RGB: 224, 32, 64; luminance: 44.1 cd/m2) and blue (RGB: 64, 64, 192; luminance: 20.2 cd/m2) dots, 0.69° in visual angle (25 px) in diameter, presented at the right half of the screen (x-axis: 1,040 px). For catch trials, there was no visible prime or probe target. For stimuli, position on the y-axis was dependent on the trial condition, with top position being 3.06° of visual angle (y-axis = 414 px) above and bottom position being 3.06° of visual angle (y-axis = 636 px) below midline. All in all, fixation cross and stimuli were 11.13° of visual angle (400 px) apart on the x-axis, resulting in an approximately 31° angle between target stimuli from the fixation cross. The diagonal distance between fixation cross, and a target stimulus was approximately 11.52° of visual angle, and the two positions where a target could appear were approximately 6.12° of visual angle (center to center) apart. Participants had to respond on a QWERTZ keyboard.
Design
The experiment used a 2 (task: discrimination vs. detection) × 2 (color relation: repeated vs. changed) × 2 (location relation: repeated vs. changed) design. All variables were varied within subjects. Binding effects were computed as the interaction of color relation × location relation.
Procedure
The order of tasks was balanced across participants: Half of the participants started with the detection task, whereas the other half started with the discrimination task. The order alternated with every new participant. Every task started with the instructions on the screen, followed by a practice block and the experimental block.
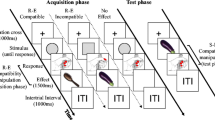
Every trial consisted of a prime–probe-sequence (see Fig. 2). The prime was the first stimulus and the response to it, and the probe was the second stimulus and the response to it, in the sequence. A trial started with the fixation cross that was shown throughout a whole prime–probe sequence. Participants were instructed to fixate the cross throughout the trial. The first screen showed the fixation cross in isolation with a variable duration of 500–750 ms (i.e., 30–45 frames per second). Afterwards, a prime stimulus accompanied the fixation cross for 100 ms. Participants were allowed to respond with target onset and up to 1,000 ms after target offset. In the discrimination task, participants had to respond by pressing “f” (with the left index finger) to a blue stimulus, and by pressing “j” (with the right index finger) to a red stimulus. In the detection task, participants had to respond to any stimulus by pressing the space bar with their right index finger. For catch trials, in which an isolated fixation cross appeared for a whole prime–probe sequence, no key press was allowed.Footnote 5 If a participant responded incorrectly, or failed to press any key although the participant had to, an error message appeared on-screen for 1,500 ms. After a correct response—that is, a key press for target trials and no response for catch trials (or an error message), the screen showed the fixation cross in isolation again for 500 ms. This was followed by the presentation of the probe stimulus, to which either a detection or discrimination response was made. After the probe response, the screen turned blank for 500 ms (i.e., the fixation cross disappeared), ending the prime–probe sequence.

Example trial of a prime–probe sequence as used in both experiments (stimuli are not drawn to scale). This example depicts a trial in which color repeats while location changes. Prime and probe targets could be red or blue
Location and color of the stimulus were orthogonally varied. Thus, color could repeat or change from prime to probe independently of stimulus location. In the discrimination task, participants responded to the color. In the detection task, participants just pressed one key to the appearance of every stimulus.
Each task started with 19 practice trials, followed by 285 experimental trials. The experimental trials consisted of 60 trials for each condition and 45 catch trials. Trials were presented in random order. Trial conditions were color repetition with location repetition (CRLR), color repetition with location change (CRLC), color change with location repetition (CCLR), and color change with location change (CCLC).
Note that stimulus selection was sequential, and independent of trial condition. This means that color and location was dependent on the previous color and location selection, although conditions were randomly drawn. In turn, specific combinations of location and color were unbalanced, with slightly different proportions for each participant in each of the four conditions. Otherwise, the trial conditions were unaffected by this. Most importantly, probe color and location was unforeseeable.
After the 95th trial and the 190th experimental trial, there was a short break, which participants terminated by their own choice.
Results
Reaction times
Trials were only included, if both prime response and probe response were correct. Only probe reaction times that were above 50 ms or below 1.5 interquartile range above the third quartile of a participant’s distribution (Tukey, 1977) were included in the analysis.Footnote 6 Due to these constraints, 9.20% of probe trials were discarded.
For reaction times, we performed a 2 (task: discrimination vs. detection) × 2 (color relation: repeated vs. changed) × 2 (location relation: repeated vs. changed) repeated-measures ANOVA. There was a main effect of task, F(1, 28) = 415.67, p < .001, \( {\upeta}_p^2 \) = .94, in that participants were faster in the detection task (243 ms), compared with the discrimination task (412 ms). There was no main effect of color relation, F(1, 28) = 2.36, p = .136, \( {\upeta}_p^2 \)= .08, but a main effect of location relation, F(1, 28) = 26.56, p < .001, \( {\upeta}_p^2 \)= .49. Participants were faster when location changed (321 ms), compared with when location repeated (334 ms). There was a significant interaction between task and color relation, F(1, 28) = 4.68, p = .039, \( {\upeta}_p^2 \)= .14: in the discrimination task, participants were faster for color-response repetitions (408 ms) than changes (415 ms). This pattern could not be found in the detection task (color repetition: 244 ms; color change: 243 ms). The interaction between task and location relation was not significant, F(1, 28) = 3.24, p = .083, \( {\upeta}_p^2 \)= .10. There was a significant interaction between color and location relation, F(1, 28) = 147.09, p < .001, \( {\upeta}_p^2 \)= .84, depicting a binding effect: Trials with color repetition–location repetition (CRLR: 324 ms) and color change–location change (CCLC: 313 ms) had faster reaction times, compared with trials with color repetition–location change (CRLC: 328 ms) and color change–location repetition (CCLR: 345 ms). Importantly, the three-way interaction amongst task, color relation, and location relation was significant, F(1, 28) = 156.11, p < .001, \( {\upeta}_p^2 \)= .85, in that a feature–response binding effect was found for the discrimination task, but not for the detection task. To highlight this three-way interaction, we ran separate repeated-measures ANOVAs for both tasks. For the discrimination task, the main effect for color relation was significant, F(1, 28) = 4.21, p = .050, \( {\upeta}_p^2 \)= .13, with a benefit for color repetition (408 ms) compared with color change (415 ms). Additionally, the main effect for location relation was significant, F(1, 28) = 14.15, p = .001, \( {\upeta}_p^2 \)= .34, with participants being faster in location change (407 ms) compared with location repetition trials (417 ms). The interaction between color and location relation was significant, F(1, 28) = 255.77, p < .001, \( {\upeta}_p^2 \)= .90, depicting a binding effect (CRLR: 395 ms; CRLC: 421 ms; CCLR: 439 ms; CCLC: 392 ms). For the detection task, there was no main effect of color relation, F(1, 28) = 0.34, p = .564, \( {\upeta}_p^2 \)= .01, but a main effect of location relation, F(1, 28) = 21.05, p < .001, \( {\upeta}_p^2 \)= .43. The latter showed a benefit for location change (235 ms) over location repetition (252 ms)—that is, inhibition of return. Crucially, the interaction was not significant, F(1, 28) = 0.19, p = .670, \( {\upeta}_p^2 \)= .01. The relationships between color and location relation separated for each task are depicted in Fig. 3 (left panel).

Means and standard errors of reaction times (left panel) and error rates (right panel) of the discrimination and detection task of Experiment 1. The results confirm the task-dependent binding model (see Fig. 1), in that they show binding effects for the discrimination task, but not for the detection task. Note, however, that error rates overall for the detection task were low
Error rates
Probe accuracy was only included, if prime accuracy was correct (i.e., error rate is the amount of incorrect responses to correct responses given after the prime response was correct). For the discrimination task, these errors could be due to a false key press or a miss. For the detection task, a false response could only be a miss. Due to this constraint, 3.53% of probe trials were excluded from the analysis.
As with the reaction times, we performed a 2 (task: discrimination vs. detection) × 2 (color relation: repeated vs. changed) × 2 (location relation: repeated vs. changed) repeated-measures ANOVA on error rates of probe responses. There was a main effect of task, F(1, 28) = 75.62, p < .001, \( {\upeta}_p^2 \)= .73, in that participants made fewer errors in the detection task (1.21%), compared with the discrimination task (6.72%). There was no main effect of color relation, F(1, 28) = 0.80, p = .379, \( {\upeta}_p^2 \)= .03, and no main effect of location relation, F(1, 28) = 1.99, p = .169, \( {\upeta}_p^2 \) = .07. There were no interactions between task and color relation, F(1, 28) = 1.28, p = .268, \( {\upeta}_p^2 \)= .04, or task and location relation, F(1, 28) = 0.05, p = .827, \( {\upeta}_p^2 \)< .01. There was a significant interaction between color and location relation, F(1, 28) = 95.14, p < .001, \( {\upeta}_p^2 \)= .77: Participants made fewer errors in color repetition-location repetition trials (CRLR: 1.76%) and color change-location change trials (CCLC: 1.65%), compared with color repetition-location change trials (CRLC: 5.81%) and color change-location repetition trials (CCLR: 6.64%). Importantly, the three-way interaction amongst task, color relation and location relation was significant, F(1, 28) = 77.49, p < .001, \( {\upeta}_p^2 \)= .74, in that a feature–response binding effect for error rates was found for the discrimination task, but not for the detection task. A separate repeated-measures ANOVA for the discrimination task revealed neither a main of color relation, F(1, 28) = 1.12, p = .299, \( {\upeta}_p^2 \)= .04, nor a main effect of location relation, F(1, 28) = 0.53, p = .473, \( {\upeta}_p^2 \)= .02, but a significant interaction between color and location relation, F(1, 28) = 92.82, p < .001, \( {\upeta}_p^2 \)= .77, depicting a binding effect (CRLR: 1.90%; CRLC: 10.74%; CCLR: 11.94%; CCLC: 2.31%). In the detection task neither the main effects of color relation, F(1, 28) = 0.10, p = .758, \( {\upeta}_p^2 \)< .01, and location relation, F(1, 28) = 1.57, p = .221, \( {\upeta}_p^2 \)= .05, nor the interaction, F(1, 28) = 0.49, p = .490, \( {\upeta}_p^2 \)= .02, were significant. Note however, that participants barely made errors in the detection task. See Fig. 3 (right panel) for error rates.
Discussion
Using the same experimental setup, we compared sequencing effects between discrimination and detection tasks. In accordance with previous literature, the discrimination task yielded a strong feature–response binding effect. Crucially, we found no evidence for a feature–binding effect in the detection task. The observed pattern (see Fig. 3) favors the task-dependent binding model (Fig. 1). This finding clearly supports the view (Huffman et al., 2018), that binding effects in action control are not as general as previously thought. However, we decided to replicate the results for two reasons. First, in the second experiment, the setup was the same, except that the selection of stimuli (position and color of each stimulus) was chosen randomly (not sequentially, as in Experiment 1), leading to a fully balanced design. Second, although the main result is the significant three-way interaction, this interaction hinges, to some degree, on the nonsignificant interaction in the detection task. For these reasons, we thought it prudent to replicate Experiment 1.
Experiment 2
Method
Participants
Thirty students of the University of Trier participated in the experiment, receiving either course credit or 6 € for participation. All participants gave written informed consent. Due to a labelling error, data of the discrimination task of one participant was overwritten; the participant’s detection task data was therefore excluded from the analysis. This resulted in a sample size of 29 participants (23 women, five men, one missing,Footnote 7Mage = 23.52, SDage = 2.95, age range: 20–31 years).
Apparatus, materials, design, and procedure
We used the same apparatus, materials, design, and procedure as in Experiment 1, except for the stimulus selection. In the second experiment, stimulus selection (i.e., color or location) was pseudorandom. This led to a fully balanced design: color (red and blue) and location (top and bottom) were equally balanced across trials, conditions, and participants.
Results
Reaction times
We used the same inclusion and cutoff criteria as in Experiment 1.Footnote 8 Due to these constraints, 10.95% of probe trials were discarded.
For reaction times we performed a 2 (task: discrimination vs. detection) × 2 (color relation: repeated vs. changed) × 2 (location relation: repeated vs. changed) repeated-measures ANOVA. The main effects of task, F(1, 28) = 377.65, p < .001, \( {\upeta}_p^2 \)= .93 (detection task: 237 ms; discrimination task: 395 ms), and location relation, F(1, 28) = 20.94, p < .001, \( {\upeta}_p^2 \)= .43 (location repetition: 321 ms; location change: 312 ms) were significant. Additionally, the main effect of color relation was significant, F(1, 28) = 11.23, p = .002, \( {\upeta}_p^2 \)= .29, in that participants were faster when color repeated (312 ms), compared with when color changed (321 ms). There was a significant interaction between task and color relation, F(1, 28) = 24.09, p < .001, \( {\upeta}_p^2 \)= .46: in the discrimination task, participants were faster for color-response repeats (385 ms) than switches (406 ms). In the detection task, this pattern was slightly reversed (color repetition: 239 ms; color change: 235 ms). Again, the interaction of task and location relation was not significant, F(1, 28) = 0.24, p = .631, \( {\upeta}_p^2 \)= .01. There was a significant interaction between color and location relation, F(1, 28) = 166.84, p < .001, \( {\upeta}_p^2 \)= .86, depicting a feature-binding effect as in the first experiment (CRLR: 307 ms; CRLC: 317 ms; CCLR: 334 ms; CCLC: 307 ms).
Critically, we replicated the three-way interaction amongst task, color relation and location relation, F(1, 28) = 191.24, p < .001, \( {\upeta}_p^2 \)= .87, in that a feature-binding effect was found in the discrimination task, but not in the detection task. Separate repeated-measures ANOVAs revealed a main effect for color relation, F(1, 28) = 19.34, p < .001, \( {\upeta}_p^2 \)= .41, with a benefit for color repetition (385 ms) over change (406 ms), and a main effect for location relation, F(1, 28) = 11.51, p = .002, \( {\upeta}_p^2 \)= .29, with a benefit for location change (391 ms) over repetition (399 ms) in the discrimination task. Here, the interaction between color and location relation was significant, F(1, 28) = 223.03, p < .001, \( {\upeta}_p^2 \)= .89, again depicting a binding effect (CRLR: 370 ms; CRLC: 399 ms; CCLR: 429 ms; CCLC: 383 ms). In the detection task, the main effect of color relation, F(1, 28) = 4.82, p = .037, \( {\upeta}_p^2 \)= .15, with a benefit for color change (235 ms) over repetition (239 ms), and the main effect for location relation, F(1, 28) = 14.17, p = .001, \( {\upeta}_p^2 \)= .34, with a benefit for location change (232 ms) over repetition (242 ms), were significant. Of importance, the interaction between color relation and location relation was not significant, F(1, 28) = 0.79, p = .383, \( {\upeta}_p^2 \)= .03. The interaction of color relation and location relation separated for each type of task is depicted in Fig. 4 (left panel).

Means and standard errors of reaction times (left panel) and error rates (right panel) of the discrimination and detection task of Experiment 2. The results again confirm the task-dependent binding model, in that they show binding effects only for the discrimination task (see Fig. 1). As in Experiment 1, error rates overall for the detection task were low
Error rates
Probe accuracy was only included in the analysis if prime accuracy was correct, as reported for Experiment 1. Due to this constraint, 5.41% of probe trials were excluded from the analysis.
We performed a 2 (task: discrimination vs. detection) × 2 (color relation: repeated vs. changed) × 2 (location relation: repeated vs. changed) repeated-measures ANOVA on error rates of probe responses. There was a main effect of task, F(1, 28) = 32.92, p < .001, \( {\upeta}_p^2 \)= .54 (detection task: 1.53%; discrimination task: 6.65%), a main effect of color relation, F(1, 28) = 9.81, p = .004, \( {\upeta}_p^2 \)= .26 (color repetition: 3.32%; color change: 4.85%), and a main effect of location relation, F(1, 28) = 5.19, p = .031, \( {\upeta}_p^2 \)= .16 (location repetition: 4.53%; location change: 3.65%). There was an interaction between task and color relation, F(1, 28) = 7.02, p = .013, \( {\upeta}_p^2 \)= .20: for the discrimination task, participants made less errors in color repetition trials (5.23%) compared with color change trials (8.06%). This pattern was similar in the detection task, but not as strong: In color repetition trials (1.41%) participants made slightly fewer errors compared with color change trials (1.64%). There was no interaction between task and location relation, F(1, 28) = 1.29, p = .265, \( {\upeta}_p^2 \)= .04. Again, there was a significant interaction between color and location relation, F(1, 28) = 36.05, p < .001, \( {\upeta}_p^2 \)= .56, as in Experiment 1 (CRLR: 1.84%; CRLC: 4.80%; CCLR: 7.21%; CCLC: 2.50%). The three-way interaction amongst task, color relation, and location relation was significant, F(1, 28) = 35.89, p < .001, \( {\upeta}_p^2 \)= .56, therefore replicating Experiment 1. In the discrimination task, the main effect of color relation was significant, F(1, 28) = 9.01, p = .006, \( {\upeta}_p^2 \)= .24, with fewer errors in color repetition trials (5.23%) compared with color change trials (8.06%). The main effect of location relation was not significant, F(1, 28) = 3.71, p = .064, \( {\upeta}_p^2 \)= .12. Again, the interaction between color relation and location relation was significant, F(1, 28) = 37.39, p < .001, \( {\upeta}_p^2 \)= .57 (CRLR: 2.04%; CRLC: 8.42%; CCLR: 12.50%; CCLC: 3.62%). In the detection task, neither the main effects for color relation, F(1, 28) = 0.76, p = .390, \( {\upeta}_p^2 \)= .03, and location relation, F(1, 28) = 2.95, p = .097, \( {\upeta}_p^2 \)= .10, nor the interaction was significant, F(1, 28) = 0.03, p = .866, \( {\upeta}_p^2 \)< .01. Again, participants barely made errors in the detection task. See Fig. 4 (right panel) for error rates.
Discussion
In the second experiment, we clearly replicated the results of Experiment 1. We found no evidence for feature binding effects in the detection task. Again, the observed data pattern (see Fig. 4) supports the task-dependent binding model (Fig. 1).
One might wonder whether the difference between detection and discrimination tasks observed in both our experiments might also be due to a difference in the response mapping (two-forced-choice task vs. one-forced-choice task). Note however, that this is covered by the second and third prediction of our task-independent binding model (i.e., binding caused by an interaction of response and location relation or response and color relation): In the detection task, participants were instructed to always respond with their right index finger to the onset of a stimulus; due to this, a response in the detection task can always be seen as a response repetition. If binding effects would have factored into the detection task performance, we would have seen a main effect of color relation or location relation (which favors repetition over change; see Fig. 1). Therefore we argue that the difference in response mappings should not affect our general findings of the absence of a binding effect of any kind. If binding effects would be ubiquitous, they should occur in a detection task in which participants respond with their right hand.
General discussion
We investigated if feature binding approaches as discussed in action control research are task dependent. In particular, participants performed a discrimination task and a detection task with the same experimental setup, except for the stimulus processing requirements: In the discrimination task, participants had to discriminate prime and probe color, whereas in the detection task, participants had to detect prime and probe, irrespective of color. For the discrimination task, we replicated a feature–response binding effect for reaction times and error rates, which included the retrieval of task-irrelevant information (Frings et al., 2007). Importantly, reaction times in the detection task showed no such binding pattern. The same holds true for error rates, although the number of correct trials was close to ceiling. In fact, we can reject all three possible predictions of a task-independent binding model of action control theories. This means that in detection tasks neither bindings between stimulus features nor between stimulus and response features affected performance. Instead, there is simply an IOR effect (Kwak & Egeth, 1992; Maylor & Hockey, 1985). These results were replicated in a second experiment. They reveal an important boundary on the assumed ubiquity of binding effects: in contrast to what most current approaches assume, binding effects cannot be observed for all actions but are task-dependent.
Yet binding effects emerge due to two likely independent processes—namely, the integration (or binding) process and retrieval of previous episodes (Frings et al., in press; Laub, Frings, & Moeller, 2018). Concerning the integration process, given that participants were dramatically faster and barely made errors in the detection task compared with the discrimination task, it might be that from the specific perceptual processes necessary to perform the task as there was no requirement to process target color information to form the response (Hilchey, Rajsic, et al., 2018; Huffman et al., 2018) integration simply did not take place (and hence nothing could be retrieved later on). Additionally, Hommel (2007) found that bindings for locations only occur, if that domain is task-relevant as stimulus location or response location. In our detection task, the response was non-spatial (single key press, compared with a spatial left/right response set in the discrimination task) and simply signaled the detection of an appearing stimulus. Thus, it can be argued that location, response, and color features are not processed strongly enough for integrating these features.
Our results are also in line with the discrepancy between detection and discrimination performance in visual search. SimilarFootnote 9 to odd-one-out tasks used in visual search (Found & Müller, 1996; Müller et al., 1995), in both our tasks a target pops out from its surroundings (i.e., it appears in the periphery from a black background with a fixation cross). The target-defining dimension stays the same, only its features change (a red or blue dot at one of two positions). For the detection task, the popping-out target already allows for a response (see, e.g., Krummenacher, Müller, Zehetleitner, & Geyer, 2009; Müller & Krummenacher, 2006; Müller, Reimann, & Krummenacher, 2003); participants might be even unaware of the stimulus feature while giving the response (see Müller, Krummenacher, & Heller, 2004). For the discrimination task, the selected target has to be further processed (i.e., the response-defining feature, color, has to be processed to form a response); as in compound tasks, this allows partial repetition costs to arise (see Zehetleitner et al., 2012). Note that this interpretation highlights a functional difference between target search/identification and (discriminatory) response generation: Not having to postselectively process a target to form a response might cause the absence of a binding effect in our detection task. In comparison, an action control point of view (e.g., Hommel, 2004) might assume that stimulus features and the given response should be integrated and upon repetition be retrieved—without assuming different stages of feature processing (note, however, the influence of attention regarding certain features; see, e.g., Hommel et al., 2014; Singh et al., 2018). Consequently, action control theories assume that partial repetition costs arise due to interference caused by retrieval of the previous event. However, the visual search literature (e.g., Krummenacher et al., 2009; Müller & Krummenacher, 2006; Töllner et al., 2008) attributes this interference to unmet response expectancies (see Kingstone, 1992), even if target dimensions and response features are uncorrelated: If the target-defining dimension repeats, the cognitive system assumes to give the prior response—but if the response-defining feature changes, this mismatch causes interference. If, on the other hand, the target-defining dimension changes, a response change is also assumed by the cognitive system, leading to benefits if the response defining feature changes (but interference if it repeats). Again, this would only apply for our discriminatory task, in which a target has to be further processed after identification to form a response.
An alternative explanation for the absence of binding effects in the detection task concerns the retrieval part, as in the probe the response might be computed before any retrieval operation has had a chance to alter the probe response. According to the “horserace” account (e.g., Frings & Moeller, 2012), two competing mechanisms start with target onset—namely, retrieval processes versus target response generation (see Neill, 1997). With probe onset in the detection task, the easily computed probe response is simply so fast and “wins” the horserace before any retrieval of previous episodes can impact on response generation. Therefore, we cannot confirm the absence of retrieval or binding processes with our current experiments. However, we can rule out that they have an influence on detection performance given the specific time frame.
Note that both the visual search (e.g., Krummenacher et al., 2009; Zehetleitner et al., 2012) and attentional orienting literature (Huffman et al., 2018) allow for a task-dependent explanation that highlights a functional difference between detection and discrimination performance (i.e., no postselective discrimination stage or no need to process target identity in the detection task, respectively). This theoretical difference can be seen as task immanent and might therefore be invulnerable to the mentioned alternative explanation of limited time being the factor why no binding effects occurred (Frings & Moeller, 2012).
Another aspect is whether binding effects are confined to specific effectors. In fact, looking at the results of Hilchey, Rajsic, and colleagues (2018), one might presume that the fact that no binding effects (but IOR) emerged in their saccadic task was effector specific. However, here, we found exactly the same pattern in a hand-performed detection task—no binding effects emerged, but IOR did. Thus, it seems that either the processes needed to compute the response or the speed of response execution diminish binding effects in detection tasks —irrespective of the particular effector.
Conclusion
Using the same experimental setup with different stimulus processing requirements, we found that feature–feature or feature–response binding effects could only be observed when a discrimination response was needed. Detection responses showed no evidence of binding. This data pattern is in accordance with findings from the attentional orienting literature (see Huffman et al., 2018) and shows similarities to findings from the visual search literature (e.g., Krummenacher et al., 2009). Converging on these findings, we show a new and theoretically important boundary for human action control approaches: Detection performance is unaffected by feature–feature or feature–response binding effects.
Open practices statement
Data for both experiments is available under https://dx.doi.org/10.23668/psycharchives.2630. Code for both experiments is available under http://dx.doi.org/10.23668/psycharchives.2631. None of the experiments were preregistered.
Notes
Particularly simple actions are focused on, though most approaches would argue that this is due to the used laboratory tasks; for a coarse-grained differentiation contrast, fast and retrieval-based actions versus deliberate, very controlled actions such as, for example, pressing a button versus buying a car.
We would like to thank Hermann Müller for pointing this out and suggesting literature.
Inhibition of return could influence binding effects and vice versa—that is, we could add more model predictions that (additively) combine both effects. However, our research question is completely covered by four predictions.
All luminance values were measured directly on a computer screen (LG monitor 22MB65PM; brightness: 100, contrast: 70, sharpness: 5; gamma: 1, color temp RGB: 50, 50, 50) using a luminance meter (Mavo-Monitor USB, Measuring Instrument for Luminance; Gossen, Nürnberg, Germany). Not all testing sessions took place at this type of computer screen, therefore slight variations in luminance might have occurred. Note that the luminance measurements are average values of several measurements and are therefore approximations.
Catch trials were used to avoid participants pressing keys in foreseeable intervals, especially in the detection task. Note that catch trials lasted a whole prime–probe sequence, and were, due to this, mostly a catch for prime responses. Catch trials were excluded from all analyses.
Effects were stable using different cutoff criteria. We performed additional analyses by including only reaction times above 50 ms or 100 ms and those that were below 1.5, or 3 interquartile range above the third quartile of a participant’s distribution.
One participant reported a different gender for both tasks (potentially a typing error); as our experimental data are anonymously saved, the gender cannot be specified. However, both tasks were executed directly in sequence, and all other given information (age, etc.) match.
Effects were stable using different cutoff criteria, which were the same as reported in the footnote for Experiment 1.
When participants in visual search experiments signal the detection (e.g., Found & Müller, 1996) or discriminate a feature (e.g., Töllner et al., 2008) of a target popping out, the setup is usually more complex than the tasks reported here, as it often involves multiple distractors, as well as target-defining dimension repetitions or changes (for compound tasks without distractors, see, e.g., Zehetleitner et al., 2012; Experiment 1b and 2). While it might be unjustified to fully equate these tasks, some parallels can be made (see main text).
References
Davelaar, E. J., & Stevens, J. (2009). Sequential dependencies in the Eriksen flanker task: A direct comparison of two competing accounts. Psychonomic Bulletin & Review, 16(1), 121–126. doi:https://doi.org/10.3758/PBR.16.1.121
Denkinger, B., & Koutstaal, W. (2009). Perceive-decide-act, perceive-decide-act: How abstract is repetition-related decision learning? Journal of Experimental Psychology: Learning, Memory, and Cognition, 35(3), 742–756. doi:https://doi.org/10.1037/a0015263
Faul, F., Erdfelder, E., Lang, A. G., Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39, 175–191.
Found, A., & Müller, H. J. (1996). Searching for unknown feature targets on more than one dimension: Investigating a “dimension-weighting” account. Perception & Psychophysics, 58(1), 88–101. doi:https://doi.org/10.3758/BF03205479
Fox, E., & de Fockert, J.-W. (2001). Inhibitory effects of repeating color and shape: Inhibition of return or repetition blindness? Journal of Experimental Psychology: Human Perception and Performance, 27(4), 798–812. doi:https://doi.org/10.1037/0096-1523.27.4.798
Frings, C., Koch, I., Rothermund, K., Dignath, D., Giesen, C., Hommel, B., . . . Philipp, A. (in press). Merkmalsintegration und Abruf als wichtige Prozesse der Handlungssteuerung – eine Paradigmen-übergreifende Perspektive [Feature integration and retrieval as important processes of action control—A paradigm-overlapping perspective]. Psychologische Rundschau.
Frings, C., & Moeller, B. (2012). The horserace between distractors and targets: Retrieval-based probe responding depends on distractor-target asynchrony. Journal of Cognitive Psychology, 24(5), 582–590. doi:https://doi.org/10.1080/20445911.2012.666852
Frings, C., Rothermund, K., & Wentura, D. (2007). Distractor repetitions retrieve previous responses to targets. The Quarterly Journal of Experimental Psychology, 60(10), 1367–1377. doi:https://doi.org/10.1080/17470210600955645
Frings, C., Schneider, K. K., & Fox, E. (2015). The negative priming paradigm: An update and implications for selective attention. Psychonomic Bulletin & Review, 22(6), 1577–1597. doi:https://doi.org/10.3758/s13423-015-0841-4
Gratton, G., Coles, M. G. H., & Donchin, E. (1992). Optimizing the use of information: Strategic control of activation of responses. Journal of Experimental Psychology: General, 121(4), 480–506. doi:https://doi.org/10.1037/0096-3445.121.4.480
Henson, R. N., Eckstein, D., Waszak, F., Frings, C., & Horner, J. (2014). Stimulus–response bindings in priming. Trends in Cognitive Sciences, 18(7), 376–384. doi:https://doi.org/10.1016/j.tics.2014.03.004
Hilchey, M. D., Leber, A. B., & Pratt, J. (2018). Testing the role of response repetition in spatial priming in visual search. Attention, Perception, & Psychophysics, 80(6), 1362–1374. doi:https://doi.org/10.3758/s13414-018-1550-7
Hilchey, M. D., Rajsic, J., Huffman, G., Klein, R. M., & Pratt, J. (2018). Dissociating orienting biases from integration effects with eye movements. Psychological Science, 29(3), 328–339. doi:https://doi.org/10.1177/0956797617734021
Hilchey, M. D., Rajsic, J., Huffman, G., & Pratt, J. (2017). Intervening response events between identification targets do not always turn repetition benefits into repetition costs. Attention, Perception, & Psychophysics, 79(3), 807–819. doi:https://doi.org/10.3758/s13414-016-1262-9
Hommel, B. (1998). Event files: Evidence for automatic integration of stimulus–response episodes. Visual Cognition, 5, 183–216. doi:https://doi.org/10.1080/713756773
Hommel, B. (2004). Event files: Feature binding in and across perception and action. Trends in Cognitive Sciences, 8(11), 494–500. doi:https://doi.org/10.1016/j.tics.2004.08.007
Hommel, B. (2007). Feature integration across perception and action: Event files affect response choice. Psychological Research, 71(1), 42–63. doi:https://doi.org/10.1007/s00426-005-0035-1
Hommel, B. (2010). Grounding attention in action control: The intentional control of selection. In B. Bruya (Ed.), Effortless attention: A new perspective in the cognitive science of attention and action (pp. 121–140). Cambridge, MA: MIT Press.
Hommel, B., Memelink, J., Zmigrod, S., & Colzato, L. S. (2014). Attentional control of the creation and retrieval of stimulus–response bindings. Psychological Research, 78(4), 530–538. doi:https://doi.org/10.1007/s00426-013-0503-y
Huffman, G., Hilchey, M. D., & Pratt, J. (2018). Feature integration in basic detection and localization tasks: Insights from the attentional orienting literature. Attention, Perception, & Psychophysics, 80(6), 1333–1341. doi:https://doi.org/10.3758/s13414-018-1535-6
Kiesel, A., Steinhauser, M., Wendt, M., Falkenstein, M., Jost, K., Philipp, A. M., & Koch, I. (2010). Control and interference in task switching—A review. Psychological Bulletin, 136(5), 849–874. doi:https://doi.org/10.1037/a0019842
Kingstone, A. (1992). Combining expectancies. The Quarterly Journal of Experimental Psychology, 44(1), 69–104. doi:https://doi.org/10.1080/14640749208401284
Klein, R. M. (2000). Inhibition of return. Trends in Cognitive Sciences, 4(4), 138–147. doi:https://doi.org/10.1016/S1364-6613(00)01452-2
Klein, R. M., Wang, Y., Dukewich, K. R., He, S., & Hu, K. (2015). On the costs and benefits of repeating a nonspatial feature in an exogenous spatial cuing paradigm. Attention, Perception, & Psychophysics, 77, 2293–2304. doi:https://doi.org/10.3758/s13414-015-0941-2
Koch, I., Frings, C., & Schuch, S. (2018). Explaining response-repetition effects in task-switching: Evidence from switching cue modality suggests episodic binding and response inhibition. Psychological Research, 82(3), 570–579. doi:https://doi.org/10.1007/s00426-017-0847-9
Krummenacher, J., Müller, H. J., & Heller, D. (2002). Visual search for dimensionally redundant pop-out targets: Parallel-coactive processing of dimensions is location specific. Journal of Experimental Psychology: Human Perception and Performance, 28(6), 1303–1322. doi:https://doi.org/10.1037//0096-1523.28.6.1303
Krummenacher, J., Müller, H. J., Zehetleitner, M., & Geyer, T. (2009). Dimension- and space-based intertrial effects in visual pop-out search: Modulation by task demands for focal-attentional processing. Psychological Research, 73, 186-197. doi:https://doi.org/10.1007/s00426-008-0206-y
Kunde, W., Hoffmann, J., & Zellmann, P. (2002). The impact of anticipated action effects on action planning. Acta Psychologica, 109(2), 137–155. doi:https://doi.org/10.1016/S0001-6918(01)00053-1
Kwak, H.-W., & Egeth, H. (1992). Consequences of allocating attention to locations and to other attributes. Perception & Psychophysics, 51(5), 455–464. doi:https://doi.org/10.3758/BF03211641
Laub, R., Frings, C., & Moeller, B. (2018). Dissecting stimulus-response binding effects: Grouping by color separately impacts integration and retrieval processes. Attention, Perception, & Psychophysics, 80(6), 1474–1488. doi:https://doi.org/10.3758/s13414-018-1526-7
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95(4), 492–527. doi:https://doi.org/10.1037/0033-295X.95.4.492
Logan, G. D. (2002). An instance theory of attention and memory. Psychological Review, 109(2), 376–400. doi:https://doi.org/10.1037/0033-295X.109.2.376
Maylor, E. A., & Hockey, R. (1985). Inhibitory component of externally controlled covert orienting in visual space. Journal of Experimental Psychology: Human Perception and Performance, 11(6), 777–787. doi:https://doi.org/10.1037/0096-1523.11.6.777
Memelink, J., & Hommel, B. (2013). Intentional weighting: A basic principle in cognitive control. Psychological Research, 77(3), 249–259. doi:https://doi.org/10.1007/s00426-012-0435-y
Müller, H. J., Heller, D., & Ziegler, J. (1995). Visual search for singleton feature targets within and across feature dimensions. Perception & Psychophysics, 57(1), 1–17. doi:https://doi.org/10.3758/BF03211845
Müller, H. J., & Krummenacher, J. (2006). Locus of dimension weighting: Preattentive or postselective? Visual Cognition, 14(4/8), 490–513. doi:https://doi.org/10.1080/13506280500194154
Müller, H. J., Krummenacher, J., & Heller, D. (2004). Dimension-specific intertrial facilitation in visual search for pop-out targets: Evidence for a top-down modulable visual short-term memory effect. Visual Cognition, 11(5), 577–602. doi:https://doi.org/10.1080/13506280344000419
Müller, H. J., Reimann, B., & Krummenacher, J. (2003). Visual search for singleton feature targets across dimensions: Stimulus- and expectancy-driven effects in dimensional weighting. Journal of Experimental Psychology: Human Perception and Performance, 29(5), 1021–1035. doi:https://doi.org/10.1037/0096-1523.29.5.1021
Neill, W. T. (1997). Episodic retrieval in negative priming and repetition priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23(6), 1291–1305. doi: https://doi.org/10.1037/0278-7393.23.6.1291
Pollmann, S., Weidner, R., Müller, H. J., Maertens, M., & von Cramon, D. Y. (2006). Selective and interactive neural correlates of visual dimension changes and response changes. NeuroImage, 30, 254–265. doi:https://doi.org/10.1016/j.neuroimage.2005.09.013
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. Attention and Performance X: Control of Language Processes, 32, 531–556.
Posner, M. I., Rafal, R. D., Choate, L. S., & Vaughan, J. (1985). Inhibition of return: Neural basis and function. Cognitive Neuropsychology, 2(3), 211–228. doi:https://doi.org/10.1080/02643298508252866
Pratt, J., Hillis, J., & Gold, J. M. (2001). The effect of physical characteristics of cues and targets on facilitation and inhibition. Psychonomic Bulletin & Review, 8(3), 489–495. doi:https://doi.org/10.3758/BF03196183
Prinz, W. (1998). Die Reaktion als Willenshandlung [Responses considered as voluntary actions]. Psychologische Rundschau, 49(1), 10–20.
Rothermund, K., Wentura, D., & De Houwer, J. (2005). Retrieval of incidental stimulus–response associations as a source of negative priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31(3), 482–495. doi:https://doi.org/10.1037/0278-7393.31.3.482
Schmidt, J. R., De Houwer, J., & Rothermund, K. (2016). The parallel episodic processing (PEP) model 2.0: A single computational model of stimulus-response binding, contingency learning, power curves, and mixing costs. Cognitive Psychology, 91, 82–108. doi:https://doi.org/10.1016/j.cogpsych.2016.10.004
Singh, T., Moeller, B., Koch, I., & Frings, C. (2018). May I have your attention please: Binding of attended but response-irrelevant features. Attention, Perception, & Psychophysics, 80(5), 1143–1156. doi:https://doi.org/10.3758/s13414-018-1498-7
Terry, K. M., Valdes, L. A., & Neill, T. (1994). Does “inhibition of return” occur in discrimination tasks? Perception & Psychophysics, 55(3), 279–286. doi:https://doi.org/10.3758/BF03207599
Töllner, T., Gramann, K., Müller, H. J., Kiss, M., & Eimer, M. (2008). Electrophysiological markers of visual dimension changes and response changes. Journal of Experimental Psychology: Human Perception and Performance, 34(3), 531–542. doi:https://doi.org/10.1037/0096-1523.34.3.531
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi: https://doi.org/10.1016/0010-0285(80)90005-5
Tukey, J. (1977). Exploratory data analysis. Reading, MA: Addison-Wesley.
Welsh, T. N., & Pratt, J. (2006). Inhibition of return in cue-target and target-target tasks. Experimental Brain Research, 174(1), 167–175. doi:https://doi.org/10.1007/s00221-006-0433-7
Wilson, D. E., Castel, A. D., & Pratt, J. (2006). Long-term inhibition of return for spatial location: Evidence for a memory retrieval account. The Quarterly Journal of Experimental Psychology, 59(12), 2135–2147. doi:https://doi.org/10.1080/17470210500481569
Zehetleitner, M., Rangelov, D., & Müller, H. J. (2012). Partial repetition cost persist in nonsearch compound tasks: Evidence for multiple-weighting-systems hypothesis. Attention, Perception, & Psychophysics, 74(5), 879–890. doi:https://doi.org/10.3758/s13414-012-0287-y
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Statement of significance
Human action control is often explained by integration and retrieval of stimulus–response episodes, which typically result in so-called binding effects. In this article, we challenge the assumed ubiquity of such binding effects by defining an important threshold, showing that in detection tasks binding effects do not emerge.
Rights and permissions
About this article

Cite this article
Schöpper, LM., Hilchey, M.D., Lappe, M. et al. Detection versus discrimination: The limits of binding accounts in action control. Atten Percept Psychophys 82, 2085–2097 (2020). https://doi.org/10.3758/s13414-019-01911-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-019-01911-4