
Abstract
Repeatedly searching through invariant spatial arrangements in visual search displays leads to the buildup of memory about these displays (contextual-cueing effect). In the present study, we investigate (1) whether contextual cueing is influenced by global statistical properties of the task and, if so, (2) whether these properties increase the overall strength (asymptotic level) or the temporal development (speed) of learning. Experiment 1a served as baseline against which we tested the effects of increased or decreased proportions of repeated relative to nonrepeated displays (Experiments 1b and 1c, respectively), thus manipulating the global statistical properties of search environments. Importantly, probability variations were achieved by manipulating the number of nonrepeated (baseline) displays so as to equate the total number of repeated displays across experiments. In Experiment 1d, repeated and nonrepeated displays were presented in longer streaks of trials, thus establishing a stable environment of sequences of repeated displays. Our results showed that the buildup of contextual cueing was expedited in the statistically rich Experiments 1b and 1d, relative to the baseline Experiment 1a. Further, contextual cueing was entirely absent when repeated displays occurred in the minority of trials (Experiment 1c). Together, these findings suggest that contextual cueing is modulated by observers’ assumptions about the reliability of search environments.
Similar content being viewed by others

Natural images contain various statistical regularities (Kersten, Mamassian, & Yuille, 2004). For instance, objects in real life are often positioned at invariant locations (e.g., icons on the desktop of an office computer, a mailbox in a front yard; Palmer, 1975), and the human visual system is able to acquire these regularities from past experience to prioritize where to look and to attend for efficient visual processing of the sensory environment. One such mechanism, which supports the efficient guidance of attention, is contextual cueing (Chun, 2000). Contextual cueing refers to the expedited visual search for targets presented in invariant (“repeated”) distractor configurations. Typically, participants perform a relatively difficult search for a target letter “T” embedded in a set of distractor letters “L.” Unbeknownst to them, half of the trials contain repeated (“old”) displays, while the spatial arrangement of the distractors surrounding the target is compiled anew on each trial in the other half of trials (“new” displays). The typical finding is that reaction times (RTs) are faster to old as compared with new displays. This RT benefit for repeated layouts is referred to as the contextual-cueing effect, which has been shown to remain effective for up to 10 days (van Asselen & Castelo-Branco, 2009; Zellin, von Mühlenen, Müller, & Conci, 2014). Moreover, participants’ ability to discriminate repeated from nonrepeated displays is typically only at chance level. Chun and Jiang (1998) took these findings to suggest that learned spatial target–distractor associations, stored in implicit long-term memory, come to guide search, by “cueing” attention to the target location (Schankin & Schubö, 2009).
The ability to learn and to predict future environmental states is also a central element of current theories of human information processing. At the heart of the so-called predictive-coding models (Friston, 2010; Gold & Shadlen, 2007; Huang & Rao, 2011) is the idea that the brain is essentially an inference machine that actively tries to explain its sensations by reducing surprise, or prediction errors, on the basis of learned information from prior environmental interactions. Thus, in order to behave optimally in a multifaceted and multisensory world, it is important to build up memory representations about the current sensory environment and to use this memory for predicting important objects (events) on future occasions. Applying this idea to the context-based guidance of visual search, statistical knowledge in the form of target–distractor associations stored in memory would correspond to some model of the world (Hohwy, 2015) that the brain can use for predicting important aspects of the scene (such as the location or identity of the critical target object). Critically, predictive-coding models also make assumptions about the relation between sensation and prediction in perceptual experience (i.e., bottom-up and top-down processing, respectively). Specifically, it has been assumed that bottom-up influences vary as a function of the reliability of the sensory environment (Friston, 2010; Hohwy, 2015). A prediction error is likely to act as a learning signal and eventually lead to the buildup (or update) of long-term memory when the environment is itself predictive and contains statistical regularities on many trials. By contrast, prediction errors may be resolved (suppressed) at early stages of the perceptual hierarchy in a “noisy” environment, in which statistical regularities occur only on few trials. Under these conditions, a sensory event, be it a reliable occurrence or unwanted noise, is likely not to affect further (higher order) processing. Note that predictive coding models equate bottom-up sensation with perceptual prediction errors, so that effectively only the prediction error (defined as the mismatch between sensation and expectation) is made available to higher cognitive processes, including learning about repeated search displays. One prediction that follows from this scheme is that the context-based guidance of visual search is modulated by the relative occurrence of repeated (signal) relative to nonrepeated (noise) trials. The present study was designed to examine this idea.
Specifically, we examined whether and how learning of repeated target–distractor arrangements would vary for variable proportions of repeated relative to nonrepeated displays. For instance, according to predictive-coding accounts, one would expect that a large proportion of repeated trials would lead to particularly strong context memory about the repeated displays. In line with this, several studies show that the frequency structure of the visual input can modulate learning in a visual-search task. For instance, Geyer, Müller, and Krummenacher (2008; see also Müller, Geyer, Zehetleitner, & Krummenacher, 2009; Töllner, Müller, & Zehetleitner, 2012) found that the latency of the first eye movement (saccade) on a given search trial was reduced when task-irrelevant distractors were frequent and thus expected (i.e., they were effectively excluded from visual selection). Müller et al. (2009) adopted a paradigm in which the most (bottom-up) salient item was not the target, but rather a distracting nontarget that had to be ignored (see Theeuwes, 1991). In this task variant, behavioral and oculomotor response latencies to the target are typically slower in the presence compared to the absence of the distractor (an effect referred to as distractor interference). Müller and collaborators demonstrated that this effect is sensitive to variation in the proportions of distractor to no-distractor trials. By varying the presentation frequency of distractors occurring in 20%, 50%, or 80% of the trials, they observed a monotonic reduction of distractor interference.
The latter finding is in general agreement with recent neuroscientific studies showing that manipulations of the repetition probability lead to a substantial modulation in the neural processing signatures of incoming sensory stimulation. For instance, Summerfield, Trittschuh, Monti, Mesulam, and Egner (2008; see also Kovács, Kaiser, Kaliukhovich, Vidnyánszky, & Vogels, 2013; Larsson & Smith, 2012) reported a reduction of blood-oxygen-level-dependent (BOLD) activity in the fusiform face area in response to repeated as compared to nonrepeated (face) stimuli, which was particularly pronounced when repetitions were frequent and thus expected. More recently, Summerfield, Wyart, Johnen, and de Gardelle (2011) replicated their original finding using temporally precise electroencephalographic (EEG) measures: they observed enhanced event-related potentials, approximately 300 milliseconds (ms) after stimulus onset at central electrodes, for repeated relative to nonrepeated stimuli when repetitions occurred in the majority of trials (and were thus expected).
Taken together, these findings indicate that (bottom-up driven) visual exploration can be modulated by expectations generated based on the recently experienced frequency distribution patterns in the task environment; that is, recent experiences, including both short-term and long-term memory influences, can act as “primes” to subsequent visual search behavior given sufficient evidence of stimulus repetitions (see Conci, Zellin, & Müller, 2012, for such a view).
Rationale of the present study
The present experiments investigated whether predictive-coding models provide an appropriate account for contextual cueing of visual search, that is, stimulus repetition effects that manifest on a relatively long time scale (of several days; van Asselen & Castelo-Branco, 2009). Although contextual cueing is usually considered to reflect effortless and cognitively impenetrable learning (Chun, 2000), the idea developed above on predictive coding suggests that configural learning is influenced by the reliability of sensory signals, corresponding to observers’ implicit assumptions about the presence versus absence of statistical regularities of the current sensory environment (Friston, 2010). In this view, only highly regular environments will lead to a processing focus on bottom-up perceptual input, thus increasing the detection of a statistical regularity in this display and boosting the learning of associations between the target position and the constant distractor context. In the present study, we tested two such environmental regularities: repetition probability, defined as the proportion of repeated relative to nonrepeated displays (cf. Larsson & Smith, 2012), and repetition volatility, defined as the rate of change of repeated and nonrepeated displays (cf. Summerfield et al., 2011).
A related question concerns the specific way in which environmental regularities influence contextual cueing. For example, if contextual cueing takes into account event probabilities, one would expect the strength of memory-based guidance to be higher in environments with many repeated, as compared with many nonrepeated, displays (regular vs. irregular environments). This may be so because in regular environments, a higher number of repeated displays is detected and subsequently stored in memory—thus increasing the mean contextual-cueing effect. Of note in this regard, several contextual-cueing studies have shown that only very few repeated displays are actually learned (i.e., represented in context memory); in other words, many repeated displays are searched as inefficiently as nonrepeated displays (e.g., Colagiuri & Livesey, 2016; Geyer, Müller, Assumpcao, & Gais, 2013; Johnson, Woodman, Braun, & Luck, 2007; Peterson & Kramer, 2001; Schlagbauer, Müller, Zehetleitner, & Geyer, 2012; Smyth & Shanks, 2008). If regular environments indeed increase the number of displays producing contextual cueing, one would expect an increased overall contextual-cueing effect (averaged across all repeated displays). We refer to this as the “strength” hypothesis. Alternatively, it is possible that regular environments, rather than changing the strength of contextual guidance, do increase the speed with which observers acquire contextual memory representations. This “acceleration” hypothesis would predict that repeated contexts are learned faster in regular as compared with irregular environments; however, once the acquisition is completed (after a learning phase of variable length), context-based search guidance would be comparable in effect magnitude irrespective of the regular or irregular search environment.
In Experiment 1a, observers performed a visual search task in which they encountered repeated and nonrepeated (i.e., randomly generated) display arrangements that were presented in random order across trials within a given block. Thereafter, a recognition test was administered: participants were presented with a display arrangement and had to indicate whether or not they believed having seen this display in the previous search task (two-alternative forced-choice, 2AFC, task; cf. Chun & Jiang, 1998). Each trial of the search task was equally likely to contain a repeated or a nonrepeated arrangement. Thus, Experiment 1a served as baseline against which contextual-cueing effects were compared in the other two experiments, which manipulated environmental regularities. Experiments 1b and 1c tested whether different probabilities of repeated and nonrepeated displays would influence the contextual-cueing effect. Two conditions were used: in Experiment 1b, repeated displays occurred with higher probability than nonrepeated displays: 80% versus 20% (regular condition). These probabilities were reversed in Experiment 1c, presenting only 20% repeated and 80% nonrepeated displays (irregular condition). Importantly, the total number of trials with repeated displays was held constant in all experiments. Thus, variations of the probability with which repeated displays were encountered were achieved by manipulating the number of nonrepeated displays. With this approach, we were able to equate the absolute number of presentations of repeated displays across the regular, irregular, and baseline conditions.
In Experiment 1d, we went on to compare contextual cueing in “stable” versus “volatile” environments. Volatile environments are in essence identical to typical conditions in contextual-cueing experiments: each block of trials presents 50% repeated and 50% nonrepeated displays, with the probability of a repeated or nonrepeated display being the same on a given trial. In the volatile (default) environment, changes from repeated to nonrepeated displays (and vice versa) were frequent, occurring, on average, in 50% of the trials (i.e. about eight times per block of 16 trials; see below for further details). By contrast, in stable environments, each block was composed of two “mini-blocks” (or streaks) of eight repeated and eight nonrepeated displays, respectively (the order of repeated and nonrepeated streaks was counterbalanced across observers). With this manipulation, in stable environments a change from repeated to nonrepeated displays (or vice versa) was rare, occurring in only ~6% of the trials (once per block). One could assume that environmental regularities become evident more strongly under conditions of rare changes, thus increasing the detection of repeated displays as “repeated.” In such a stable environment, contextual cueing should be overall stronger (strength hypothesis) and/or develop earlier (acceleration hypothesis) as compared to the volatile environments.
General method
Participants
The same 13 participants (six male, mean age = 26.8 years; all reporting normal or corrected-to-normal vision) took part in Experiments 1a through 1d. Sample size was determined on the basis of previous studies that investigated perceptual learning of the target in relation to an invariant context of distractor elements, importantly also including Chun’s pioneering work (e.g., Chun & Jiang, 1998, 1999; Chun & Phelps, 1999). These studies (see also Assumpção, Shi, Zang, Müller, & Geyer, 2015; Geringswald, Herbik, Hofmüller, Hoffmann, & Pollmann, 2015; Geyer, Zehetleitner, & Müller, 2010; Zellin, von Mühlenen, Müller, & Conci, 2013, 2014) typically tested between five and 14 participants on the visual search/contextual-cueing task. On the basis of effect size measures provided in these studies (Assumpção et al., 2015; Geringswald et al., 2015; Zellin, von Mühlenen, et al., 2013; Zellin et al., 2014), we determined that our sample size would be appropriate to detect an f(U) effect size of 1.0 with 85% power (partial eta2 = 0.4, groups = 2, number of measurements = 4), given an alpha level of .05 and a nonsphericity correction of 1. To minimize transfer effects, the experiments were performed in individual sessions, which were separated by at least 10 days. Further, the experimental manipulations were administered in two counterbalanced orders: each participant started with Experiment 1a (to obtain an unbiased baseline measure initially), followed by Experiments 1b–c (with Experiments 1b and 1c performed in counterbalanced order across participants), and finally, Experiment 1d. The relative fixed order of experiments was necessary to first establish a baseline contextual-cueing effect in all participants against which the subsequent experimental variations could effectively be compared. Additionally, a within-subjects design was essential for the purpose of the study, as individual differences in the rate of contextual learning (i.e., in the between-subject design) could have obscured potential systematic effects as induced by our environmental manipulations. One participant could not attend further experiments after Experiment 1a (this means that the total number of initially recruited observers was 14, but all analyses reported are based on the 13 observers who completed all experimental parts). All participants provided written informed consent prior to the experiment and received 8 € per hour or course credit for participating in this study. Before the start of each experiment, participants performed one practice block of 24 trials (data not recorded).
Apparatus and stimuli
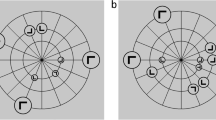
The experimental routine was programmed in Matlab with Psychtoolbox extensions (Brainard, 1997; Pelli, 1997) and was run on a PC under the Windows 7 operating system. Participants were seated in a dimly lit room in front of a 23-inch LCD monitor (ASUS, Taiwan; refresh rate 60 Hz; display resolution: 1920 × 1080 pixels) at a viewing distance of approximately 80 cm (unrestrained). The search displays consisted of 12 dark-gray items (luminance: 1.0 cd/m2; 1 T-shaped target and 11 L-shaped distractors) presented against a black background (0.11 cd/m2). All stimuli extended 0.35° of visual angle in width and height. The items were arranged on four (invisible) concentric circles around the display center (with a radius of 1.74°, 3.48°, 5.22°, and 6.96°, for Circles 1 through 4, respectively). The target was always positioned on the third circle. There were overall 16 possible target locations, eight of which were used for repeated displays with constant distractor layout throughout the experiment (two in each quadrant). The other eight target locations (also two in each quadrant) were used for nonrepeated displays with random distractor arrangements. The “T” target was rotated randomly by 90° to either the left or the right. The 11 remaining items were L-shaped distractors rotated randomly by 0°, 90°, 180°, or 270°.
Trial sequence
A trial started with the presentation of a fixation cross (size: 0.10° luminance: 1.0 cd/m2) for 500 ms, followed by a blank interval of 200 ms before the onset of the search display. Observers were instructed to respond as quickly and accurately as possible to the orientation of the “T” (left vs. right). Each search display stayed on the screen until the observer’s manual choice response was registered. Observers responded to the left/right orientation the “T” target by pressing the left/right arrow button on a computer keyboard with their corresponding index finger. Following an erroneous response, a red minus sign appeared on the screen for 1,000 ms. Each trial was followed by a blank intertrial interval of 1,000 ms.
Design and procedure
In all experiments, the repeated condition was composed of eight randomly arranged target–distractor configurations, generated at the beginning of the experiment. These arrangements were repeatedly presented on randomly selected trials throughout the search task, with the restriction that each repeated display was shown only once per block. Displays in the nonrepeated condition were generated at the beginning of a given trial. In Experiment 1a, repeated arrangements were presented in half of the trials, and nonrepeated arrangements in the other half. Trial order was randomized in each block. To equate target location repetition effects between the two types of displays, the target appeared equally often at each of 16 possible locations throughout the experiment: eight locations were used for repeated displays and the remaining eight for nonrepeated displays. Furthermore, item density was controlled for each display, presenting three search items per quadrant (see Annac, Conci, Müller, & Geyer, 2017). The orientation of the target in a given repeated display was selected at random on each trial, whereas the nontargets were held constant across repetitions (cf. Chun & Jiang, 1998). Figure 1 depicts example search displays for the repeated and nonrepeated conditions. The experiments were divided into 16 blocks each, with a variable number of trials dependent on the number of nonrepeated displays (see below). Participants had the opportunity to take a short break between blocks or continue directly with the next block. To acquire reliable estimates of contextual cueing, we collapsed four consecutive blocks into one epoch for analysis.

Example search displays with repeated and nonrepeated target-distractor configurations (top and bottom panels, respectively)
In Experiment 1a, each block contained 16 trials, yielding a total of 256 trials. In each block, eight trials presented repeated target–distractor arrangements and the other eight trials nonrepeated layouts. Experiment 1a served as baseline against which the effects of the environmental manipulations in Experiment 1b–c and 1d were compared. In Experiment 1b (regular condition), each block contained 10 trials, resulting in a total of 160 trials. Each block consisted of eight repeated and two nonrepeated trials, yielding a ratio of repeated to nonrepeated displays of 80:20. In Experiment 1c (irregular condition), each block contained 40 trials, that is, 640 trials in total. Each block contained eight repeated and 32 nonrepeated displays, with a repeated-display to nonrepeated-display ratio of 20:80. In other words, the crucial difference between Experiments 1b and 1c was the number of nonrepeated displays (32 vs. 512), while the number of repeated displays was constant (always 128). Experiment 1d was similar to Experiment 1a in that half of the trials in a given block contained repeated displays and the other half were nonrepeated displays (the total number of trials was 256 as in Experiment 1a). However, in contrast to Experiment 1a, Experiment 1d introduced “stable” environments where repeated and nonrepeated displays were presented in sequences, or streaks (of eight trials) of repeated and nonrepeated displays. The sequence of repeated and nonrepeated displays was controlled: half of the participants started the experiment with a sequence of repeated displays followed by a sequence of nonrepeated displays (and they continued with this order throughout the experiment), while the other half started with a sequence of nonrepeated displays followed by repeated displays. Note that the order of individual old and new configurations was randomized within the streaks.
Recognition test
At the end of each experiment, observers performed a yes/no recognition test, intended to examine whether they had (any) explicit memory of the repeated configurations (a standard procedure in contextual-cueing experiments; cf. Chun & Jiang, 1998). To this end, eight repeated displays from the search task and eight newly composed displays were shown, and observers were asked to indicate whether or not they had seen a given display previously (by pressing the left or the right mouse key, respectively, without time pressure). The eight repeated and eight nonrepeated displays were presented in random order for four times (i.e., in four separate blocks), yielding a total of 72 recognition trials. Note that the eight nonrepeated displays were also repeated during the four blocks of the recognition test in order to equate display repetitions between repeated and nonrepeated displays. The response was nonspeeded, and no error feedback was provided.
Results
In order to gain a coherent picture of the effects of environmental manipulations on contextual cueing, it was necessary to test for the absence of effects. Since nonsignificant results as such can only be interpreted as absence of evidence, we used Bayes factors which can also be interpreted as evidence of absence given they are sufficiently small (see Dienes, 2013; Rouder, Speckman, Sun, Morey, & Iverson, 2009). Bayes factors allow for an assessment of the degree to which the observed data favor the alternative hypothesis (Jarosz & Wiley, 2014; Jeffreys, 1961). In the present analyses, we used the Bayes factor algorithms implemented in the JASP software (Marsman & Wagenmakers, 2017), with BF10 based on a directional H1 (pre > post) and a Cauchy prior width of 0.707 (default). A Bayes factor of >3 is considered as substantial evidence against the absence of effects, while a factor of <1 is evidence for the null effect. Finally, Bayes factors between 1 and 3 are typically taken as inconclusive evidence and thus neither the null nor the alternative hypothesis is supported.
Individual mean error rates were calculated for each experiment and factor (Epoch × Context) combination. The mean error rate was very low (<1%), and no main effects or interactions were significant (all ps > .1, BF10 < 1).
Next, individual mean RTs were calculated for repeated and nonrepeated contexts separately for each epoch (1–4). Error trials and RTs exceeding the individual’s mean RT by 2.5 standard deviations were excluded from analysis. This outlier criterion led to the removal of <5% of all trials. Greenhouse–Geisser corrected values are reported in case Mauchley’s test of sphericity was significant (p < .05).
Experiment 1a: Baseline
Experiment 1a was performed to acquire a baseline measure of contextual cueing, presenting eight repeated and eight nonrepeated displays per block (ratio: 50:50). Figure 2 shows mean RTs for repeated and nonrepeated contexts as a function of epoch together with the corresponding contextual-cueing effects (RT[nonrepeated] minus RT[repeated]). RTs were subjected to a 2 (context: repeated, nonrepeated) × 4 (epoch: 1–4) repeated-measures ANOVA, which revealed a main effect of context: repeated displays elicited overall shorter RTs compared to nonrepeated displays (see Fig. 2), contextual-cueing effect: 131 ms, F(1, 12) = 17.24, p < .01, ηp2 = 0.590, BF10 > 1841. In addition, the Context × Epoch interaction was significant, F(3, 36) = 7.69, p < .01, ηp2 = 0.391, BF10 = 14.52. As revealed by follow-up analyses, repeated contexts facilitated visual search from Epoch 2 onwards (contextual-cueing effects > 130 ms; all ps < .01, BF10 > 12.00), but not in Epoch 1 (contextual-cueing effect: −1.6 ms), F(1, 12) = 0.001, p > .9, ηp2 = 0.001, BF10 = 0.27.

Mean RTs (in ms) and associated mean standard errors (SEM) for repeated and nonrepeated displays as a function of epoch in the baseline Experiment 1a (50% repeated and 50% nonrepeated displays), and in the regular Experiment 1b (80% repeated, 20% nonrepeated trials), the irregular Experiment 1c (20% repeated, 80% nonrepeated displays), and in the streak Experiment 1d (50% repeated, 50% nonrepeated trials). In Experiments 1a and 1b–c, the type of (repeated vs. nonrepeated) display could randomly switch after each trial. In Experiment 1d, repeated and nonrepeated displays were presented in streaks of eight consecutive trials, with an alternating order of the streaks
This pattern is in line with previous investigations of contextual guidance of visual search, which indicate that context information can serve as a strong cue for the detection (and subsequent processing) of the target in repeated displays, also expressed in expedited guidance of the eyes to the target (e.g., Geyer et al., 2010; Kunar, Flusberg, Horowitz, & Wolfe, 2007; Peterson & Kramer, 2001; Zellin, von Mühlenen, et al., 2013).
Experiment 1b–c: Effects of repetition probability
Experiment 1b–c was designed to examine whether the memory underlying contextual cueing is sensitive to the probability with which repeated displays occur. To carry this out, we kept the total number of repeated displays constant (thus equating the number of to-be-learned displays across different levels of probability) and instead manipulated the number of new displays: either presenting relatively few (Experiment 1b) or relatively many (Experiment 1c) nonrepeated displays together with (a constant number of) repeated displays. In Experiment 1b (henceforth referred to as “regular” condition), there were 32 trials with nonrepeated and 128 trials with repeated displays, leading to a ratio of 20:80 (nonrepeated: repeated displays). In Experiment 1c (“irregular” condition), there were 512 nonrepeated and 128 repeated trials (80:20 ratio). Prior research had shown that contextual cueing is influenced by the frequency with which a given repeated display appears in a given block of trials (with larger contextual-cueing effects for frequently repeated displays; cf. Tseng, Hsu, Tzeng, Hung, & Juan, 2011; Zang, Zinchenko, Jia, Assumpção, & Li, 2018). Given this, investigating the effects of expectations arising from the relative repetitions of repeated and nonrepeated displays on context-based guidance of search would require that the effects of absolute repetitions of individual target–distractor arrangements are equated across the critical learning conditions. For this reason, in Experiments 1b and 1c, we realized variations of the relative occurrence of repeated displays by manipulating the number of nonrepeated displays. According to the strength hypothesis, contextual cueing should be stronger in Experiment 1b (regular condition) and weaker in Experiment 1c (irregular condition), relative to the baseline Experiment 1a. The acceleration hypothesis predicts a faster development of the cueing effect in Experiment 1b, as compared with an intermediate development in the baseline Experiment 1a, and a slow development in Experiment 1c. Of course, these two hypotheses are not mutually exclusive, as it is possible that environmental regularities increase both the onset and asymptotic strength of the cueing effect. Note that a preliminary analysis comparing mean RTs (and standard deviations) of new, baseline, displays in Experiments 1b and 1c revealed no differences between the experiments, F(1, 25) = 1.19, p > .28; Levene’s test F = 0.028, p > .86. This suggests that any differences in contextual-cueing performance between Experiment 1b and 1c are unlikely to be due to differences in observers’ overall response speed.
Experiment 1b: High-repetition probability
In Experiment 1b, nonrepeated displays occurred only rather infrequently (in 32 trials). Given this, in order to achieve a reasonably stable estimate of RTs in the nonrepeated condition, we combined RTs to nonrepeated displays across Experiments 1b and 1c (see, e.g., von Mühlenen & Conci, 2016, for a comparable procedure).
For the RT analysis, we first examined contextual cueing as a function of epoch in Experiment 1b. A 2 (context) × 4 (epoch) repeated-measures ANOVA revealed a main effect of context: repeated displays gave rise to faster RTs relative to nonrepeated displays (contextual-cueing effect: 138 ms). F(1, 12) = 22.24, p < .01, ηp2 = 0.650, BF10 > 1430. The main effect of epoch was also significant: RTs decreased with increasing number of epochs (Epoch 1: 1,154 ms; Epoch 4 = 1,091 ms), F(3, 36) = 7.55, p < .01, ηp2 = 0.386, BF10 = 1.56. Interestingly, the Context × Epoch interaction was not significant, F(3, 36) = 0.565, p > .6, ηp2 = 0.045, BF10 = 0.150: Contextual cueing emerged already in Epoch 1 (cueing effect: 123 ms) and remained strong in all subsequent epochs (cueing effect averaged across Epochs 2–4: 143 ms; ps < .05; see Fig. 2). However, a finer grained analysis comparing the first eight blocks (of the first two epochs) revealed a borderline-significant Block × Context interaction (further considered below).
Next, we compared contextual learning in Experiment 1b with learning in Experiment 1a (baseline condition) by means of a 2 (experiment) × 2 (context) × 4 (epoch) repeated-measures ANOVA. This analysis revealed a main effect of context: repeated displays yielded faster RTs than nonrepeated displays (contextual-cueing effect: 134 ms), F(1, 12) = 50.98, p < .001, ηp2 = 0.809, BF10 > 2954. The main effect of epoch was also significant: RTs became faster with increasing duration of the experiment (Epoch 1 = 1,201 ms; Epoch 4 = 1,144 ms), F(3, 36) = 5.56, p < .01, ηp2 = 0.317, BF10 = 0.09. Finally, and most importantly, the three-way interaction was significant, F(3, 36) = 3.72, p < .05, ηp2 = 0.237, BF10 = 4.18. This interaction reflects the results reported above: Whereas contextual cueing was reliable only from Epoch 2 onwards in the control Experiment 1a (−1.6 ms effect in Epoch 1), cueing was already (almost) fully developed in Epoch 1 in the regular condition in Experiment 1b (123 ms effect in Epoch 1; nonsignificant Context × Epoch interaction), F(3, 36) = 0.565, p > .6, ηp2 = 0.045, BF10 = 0.150. This suggests that, unlike in Experiment 1a, repeated displays facilitated visual search to an equal amount in all epochs when these displays constituted the majority of trials. In other words, a high proportion of repeated displays facilitated the initial buildup of the contextual-cueing effect.
Experiment 1c: Low-repetition probability
In Experiment 1c, repeated displays were presented together with many nonrepeated displays. Under these conditions, there was no evidence for a reliable contextual-cueing effect. A 2 (context) × 4 (epoch) repeated-measures ANOVA revealed no significant main effect or interaction (all ps > 0.1, BF10 < 1; see Fig. 2).
Next, we contrasted the irregular condition (Experiment 1c) with the baseline (Experiment 1a). A 2 (experiment) × 2 (context) × 4 (epoch) repeated-measures ANOVA revealed a significant Experiment × Context interaction, F(1, 12) = 6.69, p < .03, ηp2 = 0.358, BF10 = 6.02: Repeated contexts facilitated visual search for the baseline experiment (cueing effect: 132 ms), but not in the irregular condition (cueing effect: 4 ms; ps > .1, BF10 < 1. In addition, the Experiment × Context × Epoch interaction was significant, F(3, 36) = 3.64, p < .03, ηp2 = 0.233, BF10 = 0.04, owing to the finding (already reported above) that contextual cueing was reliable from Epoch 2 onwards in the Experiment 1a, whereas there was no reliable effect at all in Experiment 1c (no significant main and interaction effects: all ps > .1, BF10 < 1).
Taken together, the results of Experiments 1b and 1c show that increasing the probability of encountering a repeated context facilitates the acquisition of contextual information (Experiment 1b). Conversely, reducing the probability completely eliminates contextual learning. Importantly, these results were obtained despite a constant absolute number of repeated displays across the regular, irregular, and baseline conditions—ruling out that any differences in contextual cueing are attributable to differences in the total number of repeated displays in these conditions. In addition, the difference in cueing performance between the regular and irregular conditions is also unlikely to be due to carryover effects resulting from previous training: Recall that observers initially performed the baseline condition followed by the (counterbalanced) regular or irregular conditions. It is thus possible that initial experience with repeated displays affected contextual cueing in later conditions. However, what is at odds with this proposal is that context cueing was completely opposite in the regular and irregular conditions, despite these conditions being preceded by an identical training schedule (Experiment 1a). Accordingly, the findings from the regular Experiments 1b and irregular Experiment 1c indicate that contextual cueing is highly sensitive to within-experimental factors that pertain to the proportion (or distribution) of repeated and nonrepeated displays.
Next, for Experiment 1d we continued to examine whether a manipulation of the temporal distance within which observers encountered individual repeated displays would exert comparable effects on the context-based guidance of visual search. It should be noted that an inescapable feature of the probability manipulations used in Experiments 1b–c is that they also introduce variations in the intertrial temporal distance of presentations of individual repeated displays. This intertrial spacing is either decreased (10.4 trials; Experiment 1b) or increased (41.8 trials; Experiment 1c) relative to the baseline Experiment 1a (16.7 trials). It might therefore, in principle, be possible that differences in the temporal spacing of individual repeated displays are responsible for differences in contextual-cueing performance. For instance, findings from explicit learning studies show that memory performance is typically better with distributed over massive presentation of studied material (see, e.g., Dempster, 1987). Applying this to (implicit) contextual cueing, it is possible that participants may also learn more with spaced relative to dense presentations of repeated items (e.g., because spaced presentations engage qualitatively different—and deeper—levels of processing; considered further in the General Discussion section). However, more efficient learning of repeated displays may also come with the disadvantage of increasing the interference between individual displays (recall that the repeated condition consists of a set of eight repeated displays) and/or led to greater difficulty in matching a given display to a representation in context memory. This may lead to a situation in which the beneficial effects of item spacing are outperformed by interference from other nonrepeated displays. In a nutshell, then, the temporal spacing account predicts that as the distance between repeated displays increases, learning of repeated displays becomes more efficient. At the same time, however, interference from concurrent displays representations increases, which would effectively decrease contextual-cueing performance. As a consequence, contextual cueing should be relatively constant for conditions of identical spacing of individual repeated displays. An alternative account would predict that the context-based guidance of visual search increases in regular environments whether or not these regularities are confounded by temporal spacing. This idea was tested in Experiment 1d by employing a volatility, instead of a probability, manipulation.
In the new experiment, individual repeated displays were presented across longer sequences of trials (uninterrupted by nonrepeated displays) and followed by another sequence of novel displays (uninterrupted by repeated displays). With this manipulation, the average distance between individual repeated displays was set at 16.7 trials and thus fully comparable to the baseline experiment. However, and in contrast to the baseline experiment, Experiment 1d allowed observers more massed experience of individual repeated displays, uninfluenced by temporal spacing effects.
Experiment 1d: Low volatility
In Experiment 1d, repeated and nonrepeated displays were presented in streaks of trials (cf. Kristjansson, Wang, & Nakayama, 2002), one after the other. A given streak, of eight trials, consisted of only repeated or only nonrepeated displays, and the sequence of streaks of repeated and nonrepeated displays was counterbalanced across observers: They either started with a streak of repeated displays followed by a streak of nonrepeated displays (and continued with this order until the end of the search experiment), or vice versa. Importantly, the number of repeated and nonrepeated displays was equal in Experiment 1d (128 trials each—as in Experiment 1a), and the absolute number of repeated displays was also comparable to all other experiments (Experiments 1a, 1b, and 1c), which allows investigating whether streaks of trials would affect contextual learning without any confounds due to a variable absolute number of trials across experiments. Furthermore, since each block of trials contained the same number of repeated and nonrepeated displays (though these displays were presented in mini-blocks of trials), the temporal distance between individual repeated displays was comparable between Experiment 1d and the “baseline” Experiment 1a. Thus, any variations in contextual cueing between the two experiments are unlikely to result from spacing effects.
RTs were subjected to a 2 (context) × 4 (epoch) repeated-measures ANOVA, which revealed a main effect of context: RTs were faster to repeated relative to nonrepeated displays (contextual-cueing effect: 119 ms), F(1, 12) = 18.53, p < .01, ηp2 = 0.607, BF10 > 1446. The Context × Epoch interaction was nonsignificant, F(3, 36) = 1.91, p > .14, ηp2 = 0.137, BF10 = 0.168, contextual cueing was evident already in Epoch 1 (cueing effect: 91 ms; p < .01, BF10 = 7.76) as well as in all subsequent epochs (cueing effect averaged across Epochs 2–4: 127 ms; ps < .01; BF10 > 30; see Fig. 2).
Given that contextual cueing was reliable already in the first epoch of both Experiments 1b and 1d, we further explored this early onset of the cueing effect by means of a more thorough analysis, comparing reaction times to repeated and nonrepeated displays across individual blocks (of the first epoch). Effectively, we performed a 2 × 2 × 8 repeated-measures ANOVA, with the within-group factors experiment (1b, 1d), context (repeated, nonrepeated), and block (1–8). There was a significant main effect of context, F(1, 12) = 13.96, p = .003, ηp2 = 0.54, in addition to a marginally significant interaction of context and block, F(7, 84) = 1.89, p = .082, ηp2 = 0.14. Follow-up analyses across blocks showed that the main effect of context was significant in all blocks (all ps < .05), except for Blocks 1, t(25) = −0.39, p > .6, and Block 5, t(25) = −1.75, p = .092. There was, however, no interaction of context and experiment, F(1, 12) = 0.36, p = .56, ηp2 = 0.03, as well as no three-way interaction, F(7, 84) = 0.99, p = .447, ηp2 = 0.08. The results of this finer grained analysis suggest that contextual cueing was comparable in terms of temporal development (and overall magnitude) between the “environmentally rich” Experiments 1b and 1d (see Table 1).
In a final analysis, we compared Experiments 1a and 1d in a 2 (experiment) × 2 (context) × 4 (epoch) repeated-measures ANOVA. The results revealed main effects of experiment and context: RTs were overall shorter in Experiment 1d than in Experiment 1a (971 ms vs. 1228 ms), F(1, 12) = 9.82, p < .01, ηp2 = 0.450, BF10 > 16, and the repeated context facilitated search performance overall in both experiments, F(1, 12) = 57.38, p < .001, ηp2 = 0.827, BF10 = 4.82. Of theoretical importance, the Experiment × Context × Epoch interaction turned out to be significant, F(3, 36) = 5.51, p < .01, ηp2 = 0.315, BF10 = 46.15, reflecting the fact that repeated (relative to nonrepeated) displays facilitated search from Epoch 1 onwards in Experiment 1d (Epoch 1 = 91 ms, Epoch 4 = 134 ms), but only from Epoch 2 onwards in Experiment 1a (Epoch 1 = −1.6 ms, Epoch 4 = 139 ms). This pattern suggests that the presentation of repeated and nonrepeated displays in streaks of trials facilitates the initial buildup of contextual cueing, even if temporal distances between individual repeated displays are equated between the critical learning conditions. This finding supports the acceleration hypothesis and further supports the results obtained in Experiment 1b.
Cross-session transfer
Despite of the counterbalanced order in which the experiments were presented, in a final set of analyses, we examined the possibility that cross-experimental variations in contextual cueing nevertheless may reflect differences in the order with which participants performed the individual experiments. Recall that the current study used a within-subject design, which makes it possible that at least parts of the cueing effect transferred across conditions. Although we used relatively large intersession separations (of at least 10 days) and counterbalancing, there remains the possibility that order effects contributed to the observed results. For instance, it is possible that observers’ beliefs about the presence (or absence) of statistical regularities in the current search environment are carried over from one to the other session. This idea is feasible given recent investigations of contextual cueing that showed that the effect can emerge on several consecutive days (e.g., Jiang, Song, & Rigas, 2005; Zellin, von Mühlenen, et al., 2013). However, none of these studies reported increased contextual-cueing scores across subsequent days, as one might expect for the present investigation (e.g., from the baseline Experiment 1a to the regular Experiment 1b). Instead, contextual cueing in the aforementioned studies was either relatively constant (Jiang et al., 2005) or even reduced (Zellin, von Mühlenen, et al., 2013) across subsequent days.
In an attempt to directly address the transfer issue, we reanalyzed RT performance in Experiments 1a–d dependent on the order in which observers experienced the respective environmental manipulations. There were two counterbalanced orders (see Method section): “ascending” (1a➔1b➔1c➔1d) and “descending” (1a➔1c➔1b➔1d). Since all observers started with the baseline Experiment 1a (thus contextual cueing in the baseline could not be affected by a previous experiment), we then performed three separate repeated-measures ANOVAs, for Experiment 1b, 1c, and 1d, in which we included order (ascending, descending) as a variable, besides display type (repeated, nonrepeated) and epoch (1–4). However, none of these ANOVAs revealed a significant effect of order (neither main effects nor interactions; all Fs < 1.87). As a second check, we computed contextual-cueing effects in the “early” Blocks 2–8 of the initial experimental epoch and compared contextual-cueing scores across Experiments 1b–1d, again dependent on whether observers performed these conditions in ascending or descending order. The idea being that any cross-session transfer of environmental expectations should be particularly strong in early blocks and thus up- or down-modulate learning of a new set of repeated displays already in these early blocks. However, variations in contextual cueing due to different orders were only small and nonsignificant (see Table 1). The results of these analyses thus argue against any cross-session transfer of contextual expectations. Instead, variations of contextual cueing seem to arise almost entirely within individual sessions.
Recognition test
As shown by Vadillo, Konstantinidis, and Shanks (2015; see also Smyth & Shanks, 2008), the results of (explicit) recognition tests in contextual cueing crucially depend on the power of the respective tests. While standard tests of recognition in contextual-cueing studies typically fail to find evidence of explicit memory (for review, see Goujon, Didierjean, & Thorpe, 2015), increasing the test power has been argued to be sufficient for revealing above-chance recognition (Smyth & Shanks, 2008). This is supported by a recent meta-analysis by Vadillo et al. (2015), which showed that, even though explicit memory of repeated search displays might go “undetected” in individual studies, the combined evidence indicates above-chance recognition. For this reason, we combined the performance in the current recognition test across all experiments, comparing the hit rates (repeated display correctly judged as repeated in the recognition task) with the corresponding false-alarm rates (nonrepeated display incorrectly judged as repeated in the recognition task) by means of a 2 (type of response: hit, false alarm) × 4 (experiment: 1a, 1b, 1c, 1d) repeated-measures ANOVA. On average, observers correctly recognized repeated displays in 47% of the trials (hit rate), while falsely judging nonrepeated displays as repeated in 42% of trials (false-alarm rate). However, the hit rate was not significantly different from the false alarm rate, F(1, 12) = 2.118, p > .17, ηp2 = 0.150, BF10 = 0.39, and there was also no difference across the three experiments, main effect of experiment: F(3, 36) = 1.228, p > .3, ηp2 = 0.093, BF10 = 0.164; interaction: F(3, 36) = 0.938, p > .4, ηp2 = 0.073, BF10 = 0.062. This suggests that context memory was uninfluenced by explicit knowledge of display repetitions in the present experiments.
General discussion
The present study examined whether environmental regularities can modulate contextual cueing—a form of statistical learning in visual search. In the baseline Experiment 1a, which was a typical contextual-cueing experiment, half of the trials presented repeated displays and the other half nonrepeated displays. Experiment 1b–c then manipulated the display probability, that is, the relative frequency with which repeated target–distractor configurations were presented, while equating the absolute number of repeated displays across experiments. In Experiment 1b, repeated displays occurred in 80% of trials and nonrepeated displays in 20%; these probabilities were reversed in Experiment 1c. Experiment 1d then examined the effects of a second environmental manipulation on context-based learning in visual search, namely, the “volatility” or the rate of change between repeated and nonrepeated displays—by presenting repeated and nonrepeated displays each in longer sequences of eight trials, with alternating sequences of repeated and nonrepeated displays throughout the search experiment. This manipulation also served as a critical test for the effects of interitem spacing on contextual-cueing performance, which may have confounded cueing effects in Experiments 1b–1c.
Environmental regularities and contextual cueing
The main findings were that increasing the probability of repeated relative to nonrepeated displays resulted in an earlier development (onset) of the contextual-cueing effect (Experiment 1b), whereas reducing the probability of repeated relative to nonrepeated displays completely abolished the cueing effect (Experiment 1c), as compared with the baseline Experiment 1a. Moreover, presenting repeated and nonrepeated displays in (separate) streaks of trials expedited the development of contextual cueing, again relative to the baseline condition. The difference in the time course of the cueing effect across the experimental manipulations shows that configural learning is influenced by environmental regularities (or the lack thereof), with regular environments increasing the speed with which observers acquire spatial memory about repeated search displays. On the other hand, the data also show that once a cueing effect has been established, it reaches an asymptotic level—that is, the magnitude of the effect cannot be further improved by statistical regularities (of encountering repeated displays) in the search environment. Thus, “expectations” about the occurrence of invariant displays exert a very specific effect on the context-based guidance of visual search: Configural memory is acquired faster and guidance by repeated contexts manifests in earlier epochs when repeated displays occur on the majority of trials or when they are aggregated into longer sequences of trials. Importantly, these results go beyond earlier demonstrations of the effects of statistical properties of the repeated displays. In particular, Tseng et al. (2011) showed that increasing the frequency of the presentation of repeated displays (e.g., 1, 2, or 3 times per block) results in an increased magnitude of contextual cueing. In line with this, we observed that regular environments have an advantageous effect on the configural learning process. However, unlike Tseng et al. (2011), we found that the asymptotic level of contextual cueing was not influenced by the probability manipulation. Instead, environmental regularities were expressed only in terms of an accelerated development of the contextual-cueing effect.
Furthermore, in the present experiment, we equated the frequency of individual repeated displays (which was again different to the approach taken by Tseng et al., 2011). Thus, in each experiment, the total number of to-be-learned displays was identical and differences in contextual cueing across the experiments can ultimately only be attributed to observers’ expectations about the occurrence of repeated displays. Of note, we conceive these “expectations” as being implicit in nature (similar to other “implicit expectation” effects in visual search; see, e.g., Wolfe, Butcher, Lee, & Hyle, 2003), specifically because observers were unable to explicitly tell apart repeated from nonrepeated displays in the present investigation—even in the case of a regular or structured environment (Experiments 1b and 1d).
We also found that a decrease of the probability of encountering repeated displays substantially reduced the contextual-cueing effect. This finding may imply that the visual system requires a sufficient amount of predictive information for detecting and subsequently learning contextual associations. Previous studies showed that contextual cueing requires some 100–150 trials (four to six repetitions of each individual repeated display) in order to become measurable (Chun & Jiang, 2003; Chun & Turk-Browne, 2008). However, our current findings indicate that it is not simply the absolute number of repetitions of a given repeated display that determines the formation of a stable contextual association, but also the relative amount of evidence provided by the environment, as the number of repeated displays was identical in all experiments of the present study. In other words, our data imply that when repeated displays are rather infrequent, statistical learning may not operate at all. This is consistent with work by Jungé, Scholl, and Chun (2007), who used a training-test design in their experiment. During training, observers completed either 18 blocks of trials with only repeated displays (regular condition) or 18 blocks of trials with only nonrepeated displays (irregular condition), with different groups of observers participating in the two training conditions. In the subsequent test phase (intended for measuring the contextual-cueing effects), both groups received six blocks of trials that contained both repeated and nonrepeating displays. Interestingly, Jungé et al. reported that repeated contexts expedited visual search (relative to nonrepeated contexts) only if participants had encountered the repeated displays initially (regular condition). In the other—irregular—condition, no contextual-cueing effect was evident at all. Jungé et al. took these findings to mean that, in the course of the visual search task, observers develop assumptions about the presence versus absence of contextual regularities. If observers come to the assumption that the current search environment lacks regularities (Jungé et al.’s irregular condition), they “turn off” their learning efforts, even if in the subsequent test phase they are presented with repeated displays on 50% of all trials. The reason for this may be that although contextual memory traces are acquired incidentally (automatically), the retrieval of these traces is an effortful, attention-demanding process (e.g., Annac et al., 2013; Jiang & Leung, 2005). Another explanation might be that configural learning is generally more robust in earlier epochs (sessions), reflecting a kind of primacy effect in statistical learning (Zellin, Conci, von Mühlenen, & Müller, 2013). Whatever the explanation, the results of Jungé et al. (2007) are in line with the present Experiment 1c, showing that expectations about the absence of repeated displays impede, or entirely prevent, the development of contextual-cueing effects.
But probability manipulations inevitably come along with either a decreased (Experiment 1b) or increased (Experiment 1c) temporal spacing of individual repeated displays, relative to the baseline Experiment 1a. Previous studies have repeatedly reported that explicit learning is reliably affected by the temporal distribution of study time (Cepeda, Pashler, Vul, Wixted, & Rohrer, 2006). Specifically, distributed relative to massed presentation of to-be-learned items consistently shows learning benefits that increase proportionally with increased distance between individual presentations (Kornell & Bjork, 2008; for an extensive meta-analysis over 317 experiments, see Cepeda et al., 2006). When the distance between repeated items is relatively small, the first occurrence of the target evokes a mental representation of that object, while a prompt reappearance of the target object reduces its semantic processing. Since semantic priming wears off after a period of time (Kirsner, Smith, Lockhart, King, & Jain, 1984), less semantic priming is expected for the second occurrence of a spaced item and the learning is constrained. However, we believe that spacing effects are unlikely to explain the current results. First, we observed that an increase in the distance of presentations of individual repeated displays results in reduced contextual cueing. While this reduction may be due to increased interference from concurrent contextual-cueing representations—which may beat down the facilitatory effects arising from spaced over dense items, in Experiment 1d we again found an up-modulation of contextual cueing, critically, when interdisplay spacing was identical between the environmental manipulation and the baseline experiment. But in Experiment 1d, repeated and nonrepeated displays were presented in longer streaks of trials, rendering the presence of environmental regularities more salient. This makes an account of (differences in the) temporal spacing of individual search displays unlikely. Instead, it supports a view of contextual cueing according to which context memory takes into account higher order environmental properties, such as the proportion of repeated displays or the rate of change between repeated and nonrepeated displays.
Variations in the number of nonrepeated displays unescapably come along with a variable length of the individual experiments tested here. It is therefore possible that an increased number of trials particularly in the low-probability Experiment 1c (N = 640 trials) resulted in an increased level of fatigue, which could potentially explain why contextual cueing was weakened and even nonsignificant in this experiment. Jiang and Leung (2005; see also Annac et al., 2013) have shown that the expression (i.e., retrieval) of learned context cues requires selective attention. If now assuming that fatigue is accompanied by a reduction of (sustained) attention, this could also reduce the contextual-cueing effect. But we believe that this explanation is rather unlikely. We base this view on prior investigations of spatial context learning that reported strong cueing effects when using, relative to the current Experiment 1c, comparable or even higher numbers of trials (e.g., N = 720 trials in Experiment 1 of Chun & Jiang, 1998). Further, significant contextual cueing was reported in neuroscientific studies that used very high numbers of trials (N > 1,000 trials; e.g., Schankin & Schubö, 2010). Thus, context learning seems to occur even in very long search experiments and thus seems not to be influenced by fatigue or tiredness. In addition, the pattern of results in Experiment 1c is also not compatible with the idea of fatigue in context learning. This experiment revealed no differences in context learning across epochs, which would have been indicative of a possible effect of fatigue on search reaction times/contextual cueing. If fatigue would have been at play in this experiment, then the cueing effect should have been reduced with increasing numbers of trials. However, contrary to this prediction, contextual cueing was absent right from the beginning and did not come to the fore until the end of Experiment 1c (see Fig. 2). This again indicates that factors related to fatigue or tiredness are unlikely to explain the pattern of results in Experiment 1c.
Predictive coding and contextual cueing
Contextual cueing can be interpreted as a form of statistical learning, revealing striking commonalities with current predictive-coding theories (e.g., den Ouden, Kok, & de Lange, 2012, for review). Predictive-coding theories (Friston, 2010) assume that (a) object recognition is largely achieved by taking into account prior object knowledge, and that (b) in order to successfully, that is, statistically optimally, recognize a certain object, the sensory system must represent the variability, or reliability, of (the occurrence/appearance of) this object. For instance, visual object information is more reliable at day than at night, and auditory signals are less ambiguous in a sound-protected environment than in a busy classroom. These differences in the reliability of sensory objects have a large impact on the way prediction error signals are regulated in perceptual inference and learning. In regular environments, a prediction error will receive a high weight in perceptual inference; in other words, in regular environments, the prediction error serves as a strong learning signal. In irregular environments, by contrast, the prediction error has a relatively small weight—thus, less is learned about the sensory environment (in fact, under these conditions, prediction error signals might be effectively suppressed at lower, sensory levels; cf. den Ouden et al., 2012). Applied to the present study, in the “regular” Experiments 1b and 1d, observers will be confident with the current sensory input such that they can attribute meaning (i.e., “signal”) to the input. For this reason, the visual representation of the (invariant) target–distractor relations acts as a strong learning signal for the buildup of contextual memory about this display. When this display is encountered on later occasions, associated configural memory traces are quickly retrieved and come to support visual search. In this scheme, the context-based guidance of visual search may be conceived as an application of the Bayes rule. However, when the current sensory environment contains more “noise” than “signal” trials (i.e., more nonrepeated than repeated displays), less is learned about the repeated displays and visual search may be predominantly driven by the featural properties of the search items. This would correspond to a stimulus-based, rather than memory-based, visual search process in irregular environments.
Conclusion
Current proposals in cognitive neuroscience emphasize predictive coding as a mechanism by which the brain can predict events based on learned statistical environmental regularities. However, less is known about the context factors that modulate statistical learning of sensory environments. Here, we use a visual search paradigm to unravel the mechanisms that determine statistical learning of spatial target-distractor associations (the “contextual-cueing” effect). We show that reaction time gains resulting from learned target–distractor layouts are influenced by the relative proportion of repeated to nonrepeated displays. Importantly, variations in statistical context learning were achieved through manipulations of the number of nonrepeated trials. The results thus go beyond previous findings that showed that absolute frequency with which an event occurs are important determinants in statistical learning. Further, the results are unlikely to be explained by differences in the temporal spacing of repeated search displays. The human perceptual system therefore seems to monitor the level of noise associated with a certain sensory environment, which determines statistical learning of critical task parameters, such as the location of the target in relation to the constant distractor background.
References
Annac, E., Conci, M., Müller, H. J., & Geyer, T. (2017). Local item density modulates adaptation of learned contextual cues. Visual Cognition, 25, 262–277. doi:https://doi.org/10.1080/13506285.2017.1339158
Annac, E., Manginelli, A. A., Pollmann, S., Shi, Z., Müller, H. J., & Geyer, T. (2013). Memory under pressure: Secondary-task effects on contextual cueing of visual search. Journal of Vision, 13(6), 1–15. doi:https://doi.org/10.1167/13.13.6
Assumpção, L., Shi, Z., Zang, X., Müller, H. J., & Geyer, T. (2015). Contextual cueing: Implicit memory of tactile context facilitates tactile search. Attention, Perception, & Psychophysics, 77(4), 1212–22. doi:https://doi.org/10.3758/s13414-015-0848-y
Brainard, D. H. (1997). The psychophysics toolbox. Spatial Vision, 10, 433–436. doi:https://doi.org/10.1163/156856897X00357
Cepeda, N. J., Pashler, H., Vul, E., Wixted, J. T., & Rohrer, D. (2006). Distributed practice in verbal recall tasks: A review and quantitative synthesis. Psychological Bulletin, 132(3), 354–380.
Chun, M. M. (2000). Contextual cueing of visual attention. Trends in Cognitive Sciences, 4(5):170-178. doi:https://doi.org/10.1016/S1364-6613(00)01476-5
Chun, M. M., & Jiang, Y. (1998). Contextual cueing: Implicit learning and memory of visual context guides spatial attention. Cognitive Psychology, 36(1), 28–71. doi:https://doi.org/10.1006/cogp.1998.0681
Chun, M. M., & Jiang, Y. (1999). Top-down attentional guidance based on implicit learning of visual covariation. Psychological Science, 10, 360–365. doi:https://doi.org/10.1111/1467-9280.00168
Chun, M. M., & Jiang, Y. V. (2003). Implicit, long-term spatial contextual memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 29(2), 224–234. doi:https://doi.org/10.1037/0278-7393.29.2.224
Chun, M. M., & Phelps, E. A. (1999). Memory deficits for implicit contextual information in amnesic subjects with hippocampal damage. Nature Neuroscience, 2(9), 844–847. doi: https://doi.org/10.1038/12222
Chun, M. M., & Turk-Browne, N. B. (2008). Associative learning mechanisms in vision. In S. J. Luck & Hollingworth, A. (Eds.), Visual memory (pp. 209–245). Oxford, UK: Oxford University Press. doi:https://doi.org/10.1093/acprof:oso/9780195305487.003.0007
Colagiuri, B., & Livesey, E. J. (2016). Contextual cuing as a form of nonconscious learning: Theoretical and empirical analysis in large and very large samples. Psychonomic Bulletin & Review, 23(6), 1996–2009. doi:https://doi.org/10.3758/s13423-016-1063-0
Conci, M., Zellin, M., & Müller, H. J. (2012). Whatever after next? Adaptive predictions based on short- and long-term memory in visual search. Frontiers in Psychology, 3, 409. doi:https://doi.org/10.3389/fpsyg.2012.00409
Dempster, F. N. (1987). Effects of variable encoding and spaced presentations on vocabulary learning. Journal of Educational Psychology, 79(2), 162–170. doi:https://doi.org/10.1037/0022-0663.79.2.162
den Ouden, H. E., Kok, P., & de Lange, F. P. (2012). How prediction errors shape perception, attention, and motivation. Frontiers in Psychology, 3, 548. doi:https://doi.org/10.3389/fpsyg.2012.00548
Dienes, Z. (2013). How Bayesian statistics are needed to determine whether mental states are unconscious. Behavioural Methods in Consciousness Research, 1–5. doi:https://doi.org/10.1093/acprof:oso/9780199688890.003.0012
Friston, K. (2010). The free-energy principle: A unified brain theory? Nature Reviews. Neuroscience, 11(2), 127–138. doi:https://doi.org/10.1038/nrn2787
Geringswald, F., Herbik, A., Hofmüller, W., Hoffmann, M. B., & Pollmann, S. (2015). Visual memory for objects following foveal vision loss. Journal of Experimental Psychology: Learning, Memory, and Cognition, 41, 1471–1484.
Geyer, T., Müller, H.J., & Krummenacher, J. (2008). Expectancies modulate attentional capture by salient color singletons. Vision Research, 48, 1315–1326.
Geyer, T., Müller, H. J., Assumpcao, L., & Gais, S. (2013). Sleep-effects on implicit and explicit memory in repeated visual search. PLoS ONE, 8(8), e69953. doi:https://doi.org/10.1371/journal.pone.0069953
Geyer, T., Zehetleitner, M., & Müller, H. J. (2010). Contextual cueing of pop-out visual search: When context guides the deployment of attention. Journal of Vision, 10, 20. doi:10.1167/10.5.20
Gold, J. I., & Shadlen, M. N. (2007). The neural basis of decision making. Annual Reviews in Neuroscience, 30, 535–574. doi:https://doi.org/10.1146/annurev.neuro.29.051605.113038
Goujon, A., Didierjean, A., & Thorpe, S. (2015). Investigating implicit statistical learning mechanisms through contextual cueing. Trends in Cognitive Sciences, 19(9), 524–533. doi:https://doi.org/10.1016/j.tics.2015.07.009
Hohwy, J. (2015). The predictive mind. CEUR Workshop Proceedings (Vol. 1542). doi:https://doi.org/10.1017/CBO9781107415324.004
Huang, Y., & Rao, R. P. N. (2011). Predictive coding. Wiley Interdisciplinary Reviews: Cognitive Science, 2(5), 580–593. doi:https://doi.org/10.1002/wcs.142
Jarosz, A. F., & Wiley, J. (2014). What are the odds? A practical guide to computing and reporting Bayes factors. The Journal of Problem Solving, 7, 2–9. doi:https://doi.org/10.7771/1932-6246.1167
Jeffreys, H. (1961). Theory of probability. Oxford, UK: Clarendon Press.
Jiang, Y., & Leung, A. W. (2005). Implicit learning of ignored visual context. Psychonomic Bulletin & Review, 12(1), 100–106. doi:https://doi.org/10.3758/BF03196353
Jiang, Y., Song, J.-H., & Rigas, A. (2005). High-capacity spatial contextual memory. Psychonomic Bulletin & Review, 12(3), 524–529.
Johnson, J. S., Woodman, G. F., Braun, E. L., & Luck, S. J. (2007). Implicit memory influences the allocation of attention in visual cortex. Psychonomic Bulletin & Review, 14(5), 834–839. doi:https://doi.org/10.3758/BF03194108
Jungé, J. A., Scholl, B. J., & Chun, M. M. (2007). How is spatial context learning integrated over signal versus noise? A primacy effect in contextual cueing. Visual Cognition, 15(1), 1–11. doi:https://doi.org/10.1080/13506280600859706
Kersten, D., Mamassian, P., & Yuille, A. (2004). Object perception as Bayesian inference. Annual Review of Psychology, 55, 271–304. doi:https://doi.org/10.1146/annurev.psych.55.090902.142005
Kirsner, K., Smith, M. C., Lockhart, R. S., King, M. L., & Jain, M. (1984). The bilingual lexicon: Language-specific units in an integratednetwork, Journal of Verbal Leaming and Verbal Behavior, 23, 519–539.
Kornell, N., & Bjork, R.A. (2008). Learning concepts and categories: Is spacing the “enemy of induction”? Psychological Science, 19, 585–92.
Kovacs, G., Kaiser, D., Kaliukhovich, D. A., Vidnyanszky, Z. & Vogels, R. (2013). Repetition probability does not affect fMRI repetition suppression for objects. Journal of Neuroscience, 33, 9805–9812
Kristjansson, A., Wang, D. L., & Nakayama, K. (2002). The role of priming in conjunctive visual search. Cognition, 85(1), 37–52. doi:https://doi.org/10.1016/S0010-0277(02)00074-4
Kunar, M. A., Flusberg, S., Horowitz, T. S., & Wolfe, J. M. (2007). Does contextual cuing guide the deployment of attention? Journal of Experimental Psychology: Human Perception and Performance, 33(4), 816–828. doi:https://doi.org/10.1037/0096-1523.33.4.816
Larsson, J., & Smith, A. T. (2012). fMRI repetition suppression: Neuronal adaptation or stimulus expectation? Cerebral Cortex, 22(3), 567–576. doi:https://doi.org/10.1093/cercor/bhr119
Marsman, M., & Wagenmakers, E.-J. (2017). Bayesian benefits with JASP. European Journal of Developmental Psychology, 14(5), 545–555. doi:https://doi.org/10.1080/17405629.2016.1259614
Müller, H.J., Geyer, T., Zehetleitner, M. & Krummenacher, J. (2009). Attentional capture by salient color singleton distractors is modulated by top-down dimensional set. Journal of Experimental Psychology: Human Perception & Performance, 35, 1–16.
Palmer, S. E. (1975). The effects of contextual scenes on the identification of objects. Memory & Cognition, 3(5), 519–526. doi:https://doi.org/10.3758/BF03197524
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10(4), 437–442. doi:https://doi.org/10.1163/156856897X00366
Peterson, M. S., & Kramer, A. F. (2001). Attentional guidance of the eyes by contextual information and abrupt onsets. Perception & Psychophysics, 63(7), 1239–1249. doi:https://doi.org/10.3758/BF03194537
Rouder, J. N., Speckman, P. L., Sun, D., Morey, R. D., & Iverson, G. (2009). Bayesian t tests for accepting and rejecting the null hypothesis. Psychonomic Bulletin & Review, 16(2), 225–237. doi:https://doi.org/10.3758/PBR.16.2.225
Schankin, A., & Schubö, A. (2009). Cognitive processes facilitated by contextual cueing. Evidence from event-related brain potentials. Psychophysiology, 46, 668–679. doi:https://doi.org/10.1111/j.1469-8986.2009.00807.x
Schankin, A., & Schubö, A. (2010). Contextual cueing effects despite of spatially cued target locations. Psychophysiology, 47, 717–727.
Schlagbauer, B., Müller, H. J., Zehetleitner, M., & Geyer, T. (2012). Awareness in contextual cueing of visual search as measured with concurrent access- and phenomenal- consciousness tasks. Journal of Vision, 12(11), 1–12. doi:https://doi.org/10.1167/12.11.25
Smyth, A. C., & Shanks, D. R. (2008). Awareness in contextual cuing with extended and concurrent explicit tests. Memory & Cognition, 36(2), 403–415. doi:https://doi.org/10.3758/MC.36.2.403
Summerfield, C., Trittschuh, E. H., Monti, J. M., Mesulam, M. M., & Egner, T. (2008). Neural repetition suppression reflects fulfilled perceptual expectations. Nature Neuroscience, 11(9), 1004–1006. doi:https://doi.org/10.1038/nn.2163
Summerfield, C., Wyart, V., Johnen, V. M., & de Gardelle, V. (2011). Human scalp electroencephalography reveals that repetition suppression varies with expectation. Frontiers in Human Neuroscience, 5, 67. doi:https://doi.org/10.3389/fnhum.2011.00067
Theeuwes, J. (1991). Cross-dimensional perceptual selectivity. Perception & Psychophysics, 50, 184–193.
Töllner, T., Müller, H. J., & Zehetleitner, M. (2012). Top-down dimensional weight set determines the capture of visual attention: Evidence from the PCN component. Cerebral Cortex, 22(7), 1554-1563.
Tseng, P., Hsu, T. Y., Tzeng, O. J. L., Hung, D. L., & Juan, C. H. (2011). Probabilities in implicit learning. Perception, 40(7), 822–829. doi:https://doi.org/10.1068/p6833
Vadillo, M. A., Konstantinidis, E., & Shanks, D. R. (2015). Underpowered samples, false negatives, and unconscious learning. Psychonomic Bulletin & Review, 23(1), 87–102. doi:https://doi.org/10.3758/s13423-015-0892-6
van Asselen, M., & Castelo-Branco, M. (2009). The role of peripheral vision in implicit contextual cuing. Attention, Perception & Psychophysics, 71(1), 76–81. doi:https://doi.org/10.3758/APP.71.1.76
von Mühlenen, A., & Conci, M. (2016). The role of unique color changes and singletons in attention capture. Attention, Perception, & Psychophysics, 78(7), 1926–1934. doi:https://doi.org/10.3758/s13414-016-1139-y
Wolfe, J. M., Butcher, S. J., Lee, C., & Hyle, M. (2003). Changing your mind: On the contributions of top-down and bottom-up guidance in visual search for feature singletons. Journal of Experimental Psychology: Human Perception and Performance, 29(2), 483–502. doi:https://doi.org/10.1037/0096-1523.29.2.483
Zang, X., Zinchenko, A., Jia, L., Assumpção, L., Li, H. (2018) Global Repetition Influences Contextual Cueing. Frontiers in Psychology 9
Zellin, M., Conci, M., von Mühlenen, A., & Müller, H. J. (2013). Here today, gone tomorrow - Adaptation to change in memory-guided visual search. PLOS ONE, 8(3), e59466. doi:https://doi.org/10.1371/journal.pone.0059466
Zellin, M., von Mühlenen, A., Müller, H. J., & Conci, M. (2013). Statistical learning in the past modulates contextual cueing in the future. Journal of Vision, 13(3),19, 1–14. doi:https://doi.org/10.1167/13.3.19
Zellin, M., von Mühlenen, A., Müller, H. J., & Conci, M. (2014). Long-term adaptation to change in implicit contextual learning. Psychonomic Bulletin & Review, 21, 1073–1079. doi:https://doi.org/10.3758/s13423-013-0568-z
Acknowledgement
This research was supported by a project grant from the German Research Foundation (Deutsche Forschungsgemeinschaft, DFG, Grant GE 1889/4-1) to T. Geyer and M. Conci.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Zinchenko, A., Conci, M., Müller, H.J. et al. Predictive visual search: Role of environmental regularities in the learning of context cues. Atten Percept Psychophys 80, 1096–1109 (2018). https://doi.org/10.3758/s13414-018-1500-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1500-4