
Abstract
The feature codes of stimuli and responses can be integrated, and if a stimulus is repeated it can retrieve the previously integrated response. Furthermore, even irrelevant features can be integrated and, upon repetition, retrieve the response. Yet the role of attention in feature integration and retrieval is not clearly understood. Some theories assume a central role of attention (e.g., Logan, 1988; Treisman & Gelade, 1980), but other studies have shown no influence of attention on feature binding (e.g., Hommel, 2005). In the present experiments the effect of attention on the integration of two different response-irrelevant features of the same stimulus was examined. In two experiments, participants responded to the color (response feature) of word stimuli, while two irrelevant features of the words (word type and valence) were systematically varied. Participants’ attention was directed to either one or the other of the response-irrelevant features by asking participants to report that feature at the end of the trial. Feature–response binding effects in the color task were observed to be stronger for the attended response-irrelevant feature. These results indicate that feature binding is not only very flexible but also sensitive to the distribution of attention. It is also automatic, in the sense that as long as attention is available, feature binding occurs irrespective of the task-specific demands.
Similar content being viewed by others

Human action planning and execution is a central aspect of everyday life. Understanding action control at the micro level (e.g., at the level of feature integration and response selection) has been a goal of cognitive psychology right from the beginning (e.g., Ach, 1910; James, 1890). In the last two decades, researchers have agreed on the idea that responding entails the integration of stimulus and response features into short-lived episodic compounds (e.g., Hommel 1998; Hommel, Müsseler, Aschersleben, & Prinz, 2001; Logan, 1988). These stimulus–response bindings enable retrieval of the response if a stimulus is repeated. According to the theory of event coding (Hommel, 2004; Hommel et al., 2001), the feature codes of the stimulus and the response are integrated into event files, which are feature compounds much like the object files of perception research (see Kahneman, Treisman, & Gibbs, 1992), with the difference that response features are included. Should any of the feature codes be repeated, the entire event file is retrieved, resulting in response facilitation if all the features, including the response, are repeated, and response interference if some of the stimulus or response features change.
Interestingly, not only the stimulus features we respond to can be integrated with the response; rather, even irrelevant features, and even entire irrelevant stimuli that occur simultaneously or in close temporal contiguity with the target stimulus, are integrated with the response—a finding labeled distractor–response binding (Frings, Rothermund, & Wentura, 2007). The stimulus–response retrieval model (Rothermund, Wentura, & De Houwer, 2005) postulates retrieval of the previously executed (and stored) response upon repetition of the distractor. This retrieval, however, has different effects on responding, depending on whether the response remains the same or changes. If a distractor is repeated, it retrieves the integrated response and thus facilitates responding in the case of a repeated response, since the retrieved response matches the response that is to be executed. However, distractor repetition hinders responding if the required response has changed, since the retrieved response does not match the response that must be executed. The distractor–response binding effect has been shown to exist for a number of different types of distractors in the visual, auditory, and tactile modalities (e.g., Frings, et al., 2007; Mayr & Buchner, 2006; Moeller & Frings, 2011; Rothermund et al., 2005); furthermore, it has been shown to exist within as well as across modalities (Frings, Moeller, & Rothermund, 2013).
The interplay between attention and binding
However, the role of attention in producing feature–response binding effects is still not clear. On the one hand, attention is assumed to be necessary for the integration process (e.g., Logan, 1988; Treisman & Gelade, 1980). According to the feature integration theory of attention (Treisman & Gelade, 1980), stimulus features are encoded separately and are later integrated together—a process that requires attention (Treisman & Gelade, 1980). The authors thus likened attention to a “‘glue’ which integrates the initially separable features into unitary objects” (Treisman & Gelade, 1980, p. 98). Another integration theory, the instance theory of automatization (Logan, 1988), is based on the assumption that “encoding into memory is an obligatory, unavoidable consequence of attention” (Logan, 1988, p. 493). This suggests that attended stimuli are inevitably encoded and upon repetition retrieve their previous instance—in short, attention seems to be necessary to producing the effects of instance retrieval. In line with this, spatial attention has been shown to be necessary for feature integration (van Dam & Hommel, 2010) and the integration of distractor stimuli (Moeller & Frings, 2015). For example, Moeller and Frings (2015) observed integration in a dual-task setting if both tasks were presented in the same spatial location, whereas presenting the tasks in two separate locations hindered integration between the distractor stimuli and responses. Moreover, additional stimuli that are relevant due to a second task can also be integrated with responses in a choice reaction task (Moeller & Frings, 2014a). Together, this evidence suggests that additional stimuli can become integrated in a given event file, as long as the stimuli receive sufficient attention.
However, regarding different task-irrelevant features of an individual stimulus, it is still unclear whether these are automatically integrated to similar degrees, or whether attentional allocation also influences bindings within a single stimulus. Hommel (1998, 2004) suggested that only features that are relevant to the task or that are salient are likely to be integrated. In his experiments he observed stronger binding effects for the feature that was relevant to the response than for those features that were not relevant to the response. Binding effects were observed for task-irrelevant features, as well, but such effects were strongest for the response-relevant feature. Hence, Hommel and colleagues suggested that although integration is an automatic process, there is an “attentional-weighting” system through which the features that are more relevant are more likely to retrieve an integrated response (Hommel, 2004; Hommel, Memelink, Zmigrod, & Colzato, 2014; Memelink & Hommel, 2013). Memelink and Hommel referred to this weighting of relevant features as “intentional weighting.” They argued that weighting in the perceptual domain may be referred to as “attentional weighting,” since it affects attentional processes; however, they further argued that such a weighting system also affects action selection in a similar manner, and thus they used the term “intentional weighting” to allow for summing up the weighting processes of both perception and action selection.
There is tentative evidence for intentional weighting of stimulus features from priming studies. Priming effects can be explained by episodic retrieval (e.g., Denkinger & Koutstaal, 2009; Horner & Henson, 2009, 2011). It has been suggested that, when a stimulus is responded to, an S–R episode (Waszak, Hommel, & Allport, 2003) or an event file (Hommel et al., 2001) is created, in which the stimulus and response information is stored. If the stimulus is repeated, it retrieves the response information with which it was integrated, thus resulting in shorter reaction times (RTs) to a repeated stimulus. Such binding effects have also been observed in task-switching contexts (e.g., Koch & Allport, 2006; Koch, Prinz, & Allport, 2005). These bindings do not have to be object-specific; rather, they can be of a conceptual or semantic nature, as well (e.g., Denkinger & Koutstaal, 2009; Henson, Eckstein, Waszak, Frings, & Horner, 2014). Interestingly, Spruyt, De Houwer, and Hermans (2009) found that when a stimulus had two semantic features—one affective and one nonaffective semantic feature—priming effects were found only for that feature to which attention had been directed via a second task. Attention was directed to either an affective or a semantic feature by requiring participants to classify the words on one of the two feature dimensions on either 25% or 75% of the trials (i.e., either an affective semantic classification [positive–negative] or a nonaffective semantic classification [animal–object]). In the remaining trials, the authors observed significant priming effects only if attention was directed to the respective feature. The authors took this as evidence that feature-specific allocation of attention determined the extent to which that feature was processed, and accordingly might reduce the extent to which other features might get processed. Thus, features that receive attention (due to an additional task) are likely to be processed to a greater extent, and might thus reduce the amount of processing for other features.
On the basis of these assumptions, one might also expect to find larger binding effects for attended than for unattended task-irrelevant features. Such a pattern might be seen as analogous to the phenomenon of overshadowing, as observed in such forms of associative learning as classical conditioning. Overshadowing refers to the observation that, when more than one stimulus is present, the more salient of them may decrease or prevent conditioning to the less salient stimulus (Mackintosh, 1975). Due to the attentional manipulation in the present experiments, one of the stimulus features was made more salient, and stronger retrieval effects were expected for this feature.
On the other hand, experiments by Hommel and Colzato (2004) seem to indicate that increased attention does not necessarily lead to increased integration. To increase attention, the participants in an instructed-attention condition were asked to report a feature of the stimulus (at random) after the trial. Even though participants generally had longer RTs in the attended condition, suggesting that the attention manipulation had taken effect, the integration of the reported features was not significantly strengthened due to the additional attention. Thus, although it has been shown that increased attention leads to increased processing of a particular feature (Spruyt et al., 2009), attention has not been shown to influence the integration of task-irrelevant features (Hommel & Colzato, 2004). It should be noted, though, that attention was not drawn to one specific feature, and other features could have been ignored in the study by Hommel and Colzato (2004). Rather, the authors aimed to increase attention generally for all features. Therefore, this study does not reveal information about varying degrees of integration concerning the differently attended features in one stimulus.
Taken together, although some theories suggest that attention is a requirement for integration (e.g., Logan, 1988; Treisman & Gelade, 1980), others suggest that other factors, such as task relevance or salience, can modulate integration (Hommel, 1998; Memelink & Hommel, 2013). Evidence has been found for spatial attention as a prerequisite (Moeller & Frings, 2014b, 2015; van Dam & Hommel, 2010); however, evidence has also been found for the modulation of integration by task relevance and/or salience, given spatial attention (Hommel, 1998; Hommel & Colzato, 2009). Therefore, it would appear that integration does not necessarily follow from attention. Spatial attention toward an object does not ensure integration of all the response-irrelevant features (especially when more than one feature is present), and integration might still be influenced by factors such as task relevance or salience (Hommel, 1998, 2004), long-term learning (Moeller & Frings, 2014b, 2017), or some kind of weighting mechanism (Memelink & Hommel, 2013). In turn, a lack of attentional allocation does not necessarily imply that no integration will occur.
The present study
In the present experiments, the effect of feature-based attention on the binding of responses with irrelevant features was examined. The relevant and irrelevant features all belonged to the same stimulus, and were thus always in the same spatial location, ensuring that all of them were spatially attended. However, feature-based attention toward the response-irrelevant features was manipulated; depending upon the condition, one of two features was attended, while the other was not. Participants responded to the color of a word. Each word had three features: one task-relevant feature—color (yellow vs. green)—and two features—an affective feature (valence: positive vs. negative) and a lexical feature (word type: adjective vs. substantive)—that were irrelevant to the color task. The three particular stimulus features used—color, word type, and valence—were selected because each of these features is processed relatively automatically. Color as a feature can be processed automatically and without focused attention (e.g., Treisman, 1988). Lexical features can be activated relatively automatically, due to the automaticity of reading and language encoding (e.g., Pickering & Braningan, 1998; Roelofs, 1992), and valence as a feature can also be processed relatively automatically, as has been evidenced by studies on affective priming (e.g., Fazio, Sanbonmatsu, Powell, & Kardes, 1986). Only color was relevant to the (RT) task and therefore was always attended. Depending on the experimental condition, one of the other two features was relevant to a second task (and, hence, probably attended), but still it was irrelevant to the color classification task. We expected to observe stronger binding effects for the response-irrelevant but attended features (i.e., the feature irrelevant to the speeded RT task, but relevant to the second task).
In particular, in one condition the lexical feature was attended to, and in the other condition the affective feature was attended to. This was achieved by asking the participants to report either the lexical or the affective feature of the word (depending on the condition) at the end of some of the trials. Please note that these features were still irrelevant to the color classification task that was used to measure binding effects. In each of the conditions, all three features of the word (color and the affective and lexical features) were orthogonally varied, thus allowing us to compute the binding effect for each of the response-irrelevant features in both conditions. If the intentional-weighting mechanism also influences the integration of response-irrelevant features, we expected to see stronger binding effects for the attended than for the nonattended irrelevant feature. More concretely, we would expect to find a significant three-way Response Relation × Valence Relation × Second Task interactions, which would suggest differing Response Relation × Valence Relation interactions depending upon whether or not valence was relevant to the second task. Similarly, we also expected to find a significant three-way Response Relation × Word Type Relation × Second Task interaction, which would suggest differing Response Relation × Word Type Relation interactions depending upon whether or not word type was relevant to the second task. To quantify the strength of the bindings, the distractor–response binding effects for each of the two features was calculated when they were relevant to the second task and when they were not. Here we would expect the strength of the binding effects to be significantly different, depending on whether or not that feature was relevant to the second task. That is, we would expect the distractor–response binding effect for valence to be stronger in the condition in which valence was relevant to the second task than in the condition in which valence was not relevant to the second task. Similarly, we would expect stronger distractor–response binding effects for word type in the condition in which word type was relevant to the second task than in the condition in which it was not relevant.
Experiment 1
Method
Participants
Sixty students (47 female, 13 male) from the University of Trier participated for partial course credit. The 60 participants were randomly assigned to one of two experimental groups. The median age was 22 years (range 18–33). All participants reported normal or corrected-to-normal vision. The sample size was calculated according to previous distractor-based binding effects, which typically lead to middle to large sized effects (Cohen’s d between 0.4 and 1). Thus we planned to run N = 30 participants in each group, leading to a power of 1–β = .96 (assuming an alpha = .05) (GPower 3.1.9.2, Faul, Erdfelder, Lang, & Buchner, 2007).
Design
The experiment was constructed according to a mixed design, with three within-subjects variables—namely, response relation (repetition vs. change), word type relation (repetition vs. change), and valence relation (repetition vs. change)—and one between-subjects variable—namely, second task (word type relevant vs. valence relevant).
Materials
The experiment was run using the E-Prime Software, Version 2.0. The stimuli were 48 German words, taken from the Berlin Affective Word List (Võ et al., 2009), that were either positive or negative in valence and either adjectives or nouns; that is, each of the 48 words had both features (see Table 2). Table 1 contains mean ratings for the lexical characteristics of the two valence groups. The words were presented centrally on a black background in 12-point Courier New font, subtending a visual angle of 0.38° in height and 1.24° to 4.39° in width. The words were presented in either green (RGB Values: 144, 255, 0) or yellow (RGB Values: 228, 225, 0). The viewing distance was approximately 60 cm (Table 2).
Procedure
The participants were tested individually in soundproof chambers. The experimental instructions were presented on screen and summarized by the experimenter. The participants were asked to place their right-hand index finger on the “J” key and their left-hand index finger on the “F” key. The participants were to respond to the color of the words. Half of the participants responded to the yellow color with a right-hand keypress and the green color with a left-hand keypress, and the other half of the participants received the opposite mapping. One half of the participants were encouraged to attend to the valence of the words, and the other half were encouraged to attend to the word type. This was achieved by means of yes/no questions about either the word type or the valence of the words presented in that trial; these questions appeared at the end of 75% of the trials. Each trial started with a fixation cross for 1,000 ms. Participants were instructed to fixate the cross as the stimuli would appear at that position. Then followed the prime, which stayed on screen until a response was made. A blank screen then followed for 500 ms, after which the probe was presented and stayed on screen until a response was made. Depending on the group, on 75% of the trials the participants were asked to report either the word type or the valence of the prime and probe words in the current trial. The questions were yes/no questions and had to be responded to with the “4” and “6” keys on the number pad. Once participants had answered the questions, they could start the next trial by pressing the space bar. The trial sequence is depicted in Fig. 1. It must be noted that no word was ever repeated from the prime to the probe. Before starting the test block, the participants worked through a practice block of 32 randomly selected trials. In the practice trials, the participants received feedback on all trials. In the test block, consisting of 256 trials, the participants received feedback only when they responded incorrectly. Within each condition the response relation, word type relation, and valence relation were manipulated. In response repetition (RR) trials, the same color (green or yellow) was repeated from the prime to the probe, and in response change (RC) trials the color was changed from the prime to the probe. Similarly, in word type repetition (WR) trials the word type (either adjective or noun) was repeated from the prime to the probe, and in word type change (WC) trials it was changed from the prime to the probe. In valence repetition (VR) trials the valence was repeated, and in valence change trials (VC) it was changed between the prime and the probe.

Trial sequence—the screens after the broken line appeared on only 75% (Exps. 1 and 2b) or 33.3% (Exp. 2a) of the trials. Depending on the condition, participants had to report either the valence or the word type of the prime word in response to Question 1, and the valence or the word type of the probe word in response to Question 2. The first question always pertained to the prime (in this example, “Was the first word positive?”); participants responded with a “yes” or “no” response to whether the prime word was positive (or negative) or an adjective (or noun). The second question always pertained to the probe (in this example, “Was the second word positive?”); participants responded with a “yes” or “no” response to whether the probe word was positive (or negative) or an adjective (or noun). After the two questions, participants were asked to press the space bar to continue (“Weiter mit der Leertaste”).
Results
Only trials with correct responses to both the prime and the probe were included in the analysis. Trials that had RTs that were either shorter than 200 ms or longer than 1.5 interquartile ranges above the third quartile of the RT distribution of the participant were not included in the analysis (Tukey, 1977). This resulted in a total of 10.5% of the data being excluded from the RT analysis. Table 3 shows the mean RTs and error rates.
Probe RTs were analyzed in a 2 (response relation) × 2 (word type relation) × 2 (valence relation) × 2 (second task) mixed model multivariate analysis of variance (MANOVA), with second task as the between-subjects factor and Pillai’s trace as the criterion. A significant main effect of response relation was observed, F(1, 58) = 135.02, p < .001, ƞp2 = .70, suggesting faster responses when the same response was to be repeated (M = 574 ms, SD = 198 ms) than when the response had to be changed (M = 627 ms, SD = 198 ms). Significant main effects of word type relation, F(1, 58) = 5.44, p = .023, ƞp2 = .09, and valence relation, F(1, 58) = 4.22, p = .044, ƞp2 = .07, suggested faster responses in general when the word type was repeated (M = 598 ms, SD = 195 ms) than when it changed (M = 603 ms, SD = 200 ms), and faster responses when the valence was repeated (M = 597 ms, SD = 191 ms) than when it changed (M = 604 ms, SD = 205 ms). However the main effect of valence was further modulated by the second task, F(1, 58) = 4.80, p = .033, ƞp2 = .08, suggesting that responses were faster when valence was repeated, but only when valence, not word type, was relevant in the second task. The interaction of response relation and valence relation (which signifies the overall distractor–response binding effect for valence, independent of the second task) was also significant, F(1, 58) = 6.17, p = .016, ƞp2 = .10, suggesting that when both the response and valence were repeated the responses were faster than when only one of these features was repeated. The significant main effect of word type relation was not further modulated by either second task, F(1, 58) = 1.05, p = .310, ƞp2 = .02, or response relation, F(1, 58) = 1.44, p = .235, ƞp2 = .02. The three-way interactions of Response Relation × Valence Relation × Second Task, F(1, 58) = 2.79, p = .100, ƞp2 = .05, and Response Relation × Word Type Relation × Second Task, F(1, 58) = 1.44, p = .235, ƞp2 = .02, were not significant.
Error rates
The same analyses were run for the error rates. A significant interaction of response relation and word type relation, F(1, 58) = 13.08, p = .001, ƞp2 = .18, was observed, which was further modulated by second task, resulting in a significant three-way Response Relation × Word Type Relation × Second Task interaction, F(1, 58) = 11.39, p = .001, ƞp2 = .16, suggesting that when word type was relevant in the second task the binding between response and word type was stronger than when word type was not relevant to the second task. The important three-way Response Relation × Valence Relation × Second Task interaction was also significant, F(1, 58) = 6.72, p = .012, ƞp2 = .10, suggesting that, similar to word type, when valence was relevant to the second task, the binding of response and valence was stronger than when valence was not relevant. Thus, the predicted three-way interactions, although absent in the RT analysis, were observed in the analysis of error rates.
Distractor–response binding effects
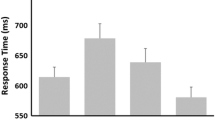
The distractor–response binding (DRB) effects were calculated for RTs and error rates using the following formulas: (RRVC – RRVR) – (RCVC – RCVR), for the valence binding effect, and (RRWC – RRWR) – (RCWC – RCWR), for the word type binding effect. The DRB effects were calculated individually for both distractors in both second-task conditions—that is, for the condition in which the distractor was relevant as well as the condition in which it was not relevant (Fig. 2). There was no significant difference in the DRB effects on RTs for word type when word type was the relevant feature (19 ms) and when it was not the relevant feature (– 1 ms), t(58) = – 1.27, p = .208, nor in the DRB effects for valence when valence was the relevant feature (54 ms) versus when it was not the relevant feature (10 ms), t(58) = 1.67, p = .100. For error rates, however, we did find a significant difference between the DRB effects of word type when word type was the relevant feature (4.4% errors) versus when it was not the relevant feature (0.19% errors), t(58) = – 3.38, p = .001, and between the DRB effects for valence when valence was the relevant feature (2.69% errors) versus when it was not the relevant feature (– 0.68% errors), t(58) = 2.57, p = .013, indicating larger effects for each of the attended features. Thus, the predicted differences in the strength of binding effects that depended upon the second task were observed in the error rates. However, although the difference was not statistically significant for RTs, the pattern of the binding effects was very similar to that for error rates (Fig. 2).

Discussion
The aim of Experiment 1 was to test whether attending to one response-irrelevant feature of a stimulus would result in stronger binding effects for that feature. The participants were encouraged to attend to one of two irrelevant stimulus features, and the binding effects were measured for both the irrelevant attended feature and the irrelevant nonattended feature. The DRB effects in the error data were significantly stronger in the condition in which the features received more attention than in the condition in which the features did not receive attention; that is, the DRB effect for word type was stronger in the condition in which word type received attention than in the condition in which it did not receive attention, and the DRB effect for valence was stronger in the condition in which valence received attention than in the condition in which it did not receive attention. This pattern was also observed in the RT data, even if only at a descriptive level. Together, the results of Experiment 1 indicate that, if more than one response-irrelevant feature is present, the feature that is attended will be integrated with the response to a greater extent (i.e., stronger binding effects). It can be argued that when participants were encouraged to attend to one of the features by asking them to report that feature, the weights for that dimension were set higher than for the other dimension. However, attending to a particular feature does not exclude the possibility of feature–response binding for the unattended feature; attention merely makes it more likely that feature–response binding will be stronger for the attended than for the unattended feature. In Experiment 1, attention to one or the other feature was treated as a between-subjects factor. That is, participants did not need to shift attention between features during the experiment. In such a rather stable attentional situation, differences in attention to response-irrelevant stimuli apparently influence integration. In the following experiment, we aimed to examine the flexibility of this intentional weighting. Therefore, attention to the response-irrelevant features was treated as a within-subjects factor.
Experiment 2
The aim of Experiment 2 was to examine the effect of our attentional manipulation in situations that would require more flexible attentional shifts. Attention to one or the other irrelevant feature was varied within subjects, either in two separate blocks (Exp. 2A) or in a trial-by-trial manner (Exp. 2B). As in Experiment 1, we expected to find significant three-way interactions of Response Relation × Valence Relation × Second Task and Response Relation × Word Type Relation × Second Task. However, we also predicted that if the internal system of intentional weighting is flexible and can respond very quickly to changes in attentional requirements, the three-way interactions of Response Relation × Valence Relation (or Word Type Relation) × Second Task (in which either valence or word type was relevant) would not be further modulated by the manner in which attention was varied (either in two blocks or trial by trial). If, however, this system is not flexible enough to respond to faster changes (as in the trial-by-trial variation), we would expect the three-way interactions to be further modulated by the manner in which attention was varied. Specifically, we would expect to see the significant three-way interactions in the blocked condition but not in the trial-by-trial condition.Footnote 1 As in Experiment 1, the distractor–response binding effects were again computed both for the condition in which the feature was relevant to the second task and for the condition in which it was not. Again, we predicted stronger binding effects when the feature was relevant to the second task than when it was not relevant to the second task.
Method
Participants
Sixty-two participants (47 female, 15 male) from the University of Trier participated for partial course credit (32 in Exp. 2A and 30 in Exp. 2B). The median age of the participants was 21 years (range 18–31). The age data were not logged for one participant due to a technical error, but the data of this participant nonetheless have been included. Two participants (Exp. 2B) were excluded from the analysis due to interruptions in the experiment. All participants reported normal or corrected-to-normal vision.
Design
The experimental design included four within-subjects factors—namely, response relation (repetition vs. change), word type relation (repetition vs. change), valence relation (repetition vs. change), and second task (word type relevant vs. valence relevant)—and one between-subjects factor—attentional manipulation type (block-wise or trial by trial).
Materials and procedure
The materials and procedure were the same as in Experiment 1, except for the following changes: In Experiment 2A, attention was manipulated in a blocked manner, and in Experiment 2B it was manipulated trial by trial by presenting a cue before each trial. In Experiment 2A, the participants were asked to report the feature after 33.3% of the trials, and in Experiment 2B they did so after 75% of the trials.
Results
Reaction times
Only trials with correct responses to both the prime and the probe were included in the analysis. Trials that had RTs that were either shorter than 200 ms or longer than 1.5 interquartile ranges above the third quartile of the RT distribution of the participant were not included in the analysis (Tukey, 1977). This resulted in a total of 11.45% (Exp. 2A) and 10.5% (Exp. 2B) of the data being excluded from the RT analyses. Table 4 shows the mean RTs and error rates.
Probe RTs were analyzed in a 2 (response relation) × 2 (word type relation) × 2 (valence relation) × 2 (second task) × 2 (attentional manipulation type) MANOVA, with Pillai’s trace as the criterion. A significant main effect of response relation was observed, F(1, 58) = 113.03, p < .001, ƞp2 = .66, suggesting faster RTs when the response was repeated (M = 566 ms, SD = 118 ms) than when the response was changed (M = 621 ms, SD = 128 ms). The main effect of word type relation was marginally significant, F(1, 58) = 2.87, p = .096, ƞp2 = .05, suggesting faster RTs when the word type was repeated (M = 591 ms, SD = 121 ms) than when the word type was changed (M = 595 ms, SD = 124 ms). The three way interaction is the second task × response relation × valence relation intraction, i.e. the valence-response integration which is modulated by second task, F(1, 58) = 3.91, p = .053, ƞp2 = .06, suggesting that the integration of valence and response was stronger when valence was relevant to the second task than when it was not relevant to the second task. The Response Relation × Word Type Relation interaction was marginally significant, F(1, 58) = 3.22, p = .078, ƞp2 = .05. No other effects were significant, Fs < 2.5, ps > .152. Thus, in RTs the predicted three-way interaction was (marginally) significant only for valence, but not for word type.
Error rates
The same analysis was conducted for the error rates. The interaction of response relation and valence relation was significant, F(1, 58) = 10.82, p = .002, ƞp2 = .16, suggesting that participants were overall more accurate when both the valence and response were repeated. This interaction was further modulated by attentional manipulation type, F(1, 58) = 4.95, p = .030, ƞp2 = .08, suggesting that responses were more accurate when both the response and valence were repeated, but only for the blocked attentional manipulation type. The Second Task × Response Relation × Valence Relation interaction was not significant, F(1, 58) = 2.53, p = .117, ƞp2 = .04, and was not modulated by attentional manipulation type, F(1, 58) = 0.13, p = .719, ƞp2 = .00. Similarly, for word type the Response Relation × Word Type Relation interaction was significant, F(1, 58) = 23.58, p < .001, ƞp2 = .29, suggesting more accurate responses if both response and word type were repeated. This interaction was further modulated by attentional manipulation type, F(1, 58) = 4.66, p = .035, ƞp2 = .07, in that the effect was stronger for the blocked attentional manipulation type. The crucial three-way Second Task × Response Relation × Word Type Relation interaction was significant, F(1, 58) = 10.84, p = .002, ƞp2 = .16. This interaction was not further modulated by attentional manipulation type, F(1, 58) = 1.97, p = .166, ƞp2 = .03. Thus, in the error rates, the predicted three-way interaction was significant only for word type.
Distractor–response binding effects
As in Experiment 1, the DRB effects were calculated for both valence and word type in both conditions (Fig. 2). The DRB effects were analyzed in a mixed-model ANOVA with one within-subjects factor (DRB effect: for the relevant feature vs. the irrelevant feature) and one between-subjects factor (attentional manipulation type: block-wise vs. trial by trial). In RTs, the DRB effect for valence was significantly different when valence was the relevant feature (20 ms) as compared to when valence was not the relevant feature (– 3 ms), F(1, 58) = 4.00, p = .050, ƞp2 = .06. The DRB effects for word type when word type was the relevant feature (14 ms) versus when it was not the relevant feature (1 ms) did not differ significantly, F(1, 58) = 1.54, p = .219, ƞp2 = .03. For error rates, the DRB effect for valence when valence was the relevant feature (2.57% errors) was marginally different (but would have been significantly different in one-tailed testing) from when valence was not the relevant feature (1.00% errors), F(1, 58) = 2.76, p = .102, ƞp2 = .05. For word type, the difference was significant when word type was the relevant feature (3.65% errors) as compared to when it was not the relevant feature (0.55% errors), F(1, 58) = 11.09, p = .002, ƞp2 = .16. Thus, the predicted difference in the strength of the binding effects of valence when valence was relevant to the second task was observed both in the RTs and (marginally) in the error rates. The predicted difference in the word type binding effects was significant only in the error rates; however, although the difference was not statistically significant, the pattern in the RTs was similar to that found in error rates.
Discussion
The pattern of results in Experiment 2 was identical to that observed in Experiment 1, thus providing further evidence of stronger binding effects for the attended than for the unattended feature. This was the case even when the attentional shifts occurred within subjects, and even when the attentional shifts occurred relatively quickly (in this case, on a trial-by-trial basisFootnote 2). The DRB effects for both irrelevant features were significantly stronger when the features were relevant to the second task than when they were not relevant to the second task. For valence, this significant difference was evident in the RTs and (marginally) in the error rates, and for word type it was found only in the error rates.
General discussion
The aim of the present experiments was to test whether attention modulates binding effects of response-irrelevant features. To investigate this question, we compared binding effects of response-irrelevant features that received attention due to a second task and response-irrelevant features that did not receive attention due to a second task. Our results show that irrelevant features produce binding effects but that attention modulates binding effects of response-irrelevant features.
In the present experiments the stimuli had three features, of which two were irrelevant to the RT task (namely, valence and word type). Significantly stronger binding effects were found for the feature that was attended (in this case, because we asked the participants to report the feature at the end of a proportion of trials) as compared to the other (unattended) feature. This pattern was replicated in a blocked design as well as in a trial-by-trial design. Although the present results provide evidence for a modulation of feature–response binding by attention—that is, attended features are likely to get integrated more strongly with the response than are unattended features—even unattended features might be integrated with the response (e.g., Moeller & Frings, 2015; van Dam & Hommel, 2010). Thus, attention might simply allow for more/stronger binding of the attended feature than of the unattended feature—which may still be integrated, albeit to a lesser extent.
It might be argued that because all features share the same spatial location, they are all likely to be integrated with the response. As we mentioned above, even unattended features may be integrated with the response (e.g., Moeller, Frings, & Pfister, 2016), and spatial location has been shown to modulate integration (e.g., Moeller & Frings, 2015; van Dam & Hommel, 2010). However, this is not always the case, especially not when there is more than one irrelevant feature. For instance, Hommel (1998, Exp. 1; Hommel & Colzato, 2009) found evidence of feature–response integration for only one of the two irrelevant features of the same stimulus. Thus, although spatial location is beneficial to integration, it does not necessarily imply integration. Furthermore, the present results suggest that feature-based attention can modulate binding effects even for features that are already spatially attended.
The present results are in accordance with other studies that have examined the influence of attention on feature binding and retrieval. For instance, Spruyt et al. (2009) found priming effects only for the feature that was attended to. In that study the authors found affective priming effects only when the participants affectively classified the words and not when the semantic classification task was done. Similarly, significant semantic priming was only observed when the participants carried out the semantic classification task. Thus significant priming effects were only observed when the feature received enough attention. However, in that study, the relevant feature was response relevant. The participants had to make either a semantic or affective classification, instead of pronouncing the word, on a certain number of trials. Thus, by virtue of the task, attention was directed to the affective/semantic feature of the stimulus on the classification trials. In the present experiments, however, the valence and word type were always irrelevant to the RT task, they only had to be reported at the end of the trial (75% or 33.3% of the trials) but that response was not a speeded response task. The affective and semantic features never had to be processed in order to make a response in the RT task. Thus the present results suggest that when a feature is attended, even when it is irrelevant to the response, it still influences responding.
The present results are also in accordance with integration theories, which suggest that attention influences what gets integrated. For instance, the feature integration theory of attention (Treisman & Gelade, 1980) argued that attention is necessary for feature integration, the instance theory of automatization (Logan, 1988) argued that encoding stimuli into memory was a consequence of attention directed toward it, suggesting that attention was necessary for a stimulus to be encoded into memory.
However, the results may be seen to be in conflict with the results of other studies that found no effect of attention on integration and retrieval. For instance, Hommel and Colzato (2004) found that asking participants to report one of the three stimulus features at the end of a trial did not increase the strength of the integration and retrieval for the reported feature. This difference, however, might be due to differences in procedure. In the study by Hommel and Colzato (2004), participants were asked to report one of three features at random. In the present Experiment 1, however, the participants consistently reported either one or the other feature. In Experiment 2 of the present study, either participants reported one feature consistently in one block or they were asked to report one feature or the other on a trial-by-trial basis. Thus, the trial-by-trial condition was more similar to the procedure used in the Hommel and Colzato (2004) study; however, there was still one important difference: In the trial-by-trial condition of the present study, a cue appeared before the beginning of each trial and indicated the feature toward which attention should be directed. Thus, in the present study attention was specifically directed toward one or the other feature, rather than attention being generally increased to the stimulus as a whole.
Notably, we found such integration even for a relatively salient feature (in this case, valence), with the response benefiting significantly from receiving attention. We do not, however, dispute the fact that valence and word type might have been activated automatically. Indeed, the significant main effects of valence (although further modulated by second task) and word type in Experiment 1 and the significant main effect of word type in Experiment 2 do suggest that these features might have been activated to some extent. However, their integration with the response was stronger when attention was (explicitly) allocated to them. According to Spruyt et al. (2009), the allocation of feature-specific attention determines the extent to which stimulus features are processed, and not whether or not they are processed at all. When applied to the present results, this would mean that the feature that received attention was processed to a higher level than the other feature. Thus, even though the other feature may have been processed, this was not enough to ensure that it was integrated with and retrieved the response. Such a pattern was observed in the results. In the condition in which attention was directed toward word type, we observed larger binding effects for word type than in the condition in which attention was not directed toward word type. The result pattern for valence was similar. One process that might result in such a feature-specific allocation of attention is intentional weighting (Memelink & Hommel, 2013). The mechanism of intentional weighting serves to weight feature codes on the basis of the intent of the actor. Thus, features that are considered necessary or task-relevant will be weighted more heavily, and will thereby become more salient and receive more attention. The present results suggest that the intentional weighting system is quite flexible and is able to cope with attentional shifts within a stimulus and in a short span of time. In Experiment 2, the attentional manipulation type (whether attention was directed to one feature or the other in a blocked manner or in a trial by trial manner) did not seem to have an effect on integration, since the three-way interactions were not modulated further by the factor of attentional manipulation type. This suggests that when attention is directed to one feature consistently over a specific period of time, as well as when attention shifts from one feature to another very quickly, the system of intentional weighting still functions efficiently, allowing for stronger integration of and retrieval due to the feature that is more relevant to the actor’s goal intentions. Furthermore, intentional weighting applies even to response-irrelevant features. Most interestingly, it does not matter whether a feature is relevant to the task at hand or to a different task. As long as a feature is attended at all, it seems to be weighted more heavily and integrated with any current response.
However, another approach, which is similar to intentional weighting, is that of attentional control sets (e.g., Hommel, 2005). This idea suggests that attentional sets are created on the basis of task goals. These sets contain features or stimuli that are relevant, and that will then be processed or attended in an automatic fashion (e.g., Folk, Remington, & Johnston, 1992). Mast and Frings (2014) showed that this idea could also be extended to distractors, and if there is an overlap between distractor features and task set, then even distractors can capture attention. Analogous to the intentional-weighting idea, then, one would argue that both color and the feature that is currently relevant to the second task would be included in the task set (i.e., would have their weights set higher), and only those features that are included in the set would be processed automatically. However, as we mentioned previously, we cannot discount that both irrelevant features were activated to a certain extent in all conditions.
The present data are also, to a certain extent, in accordance with the idea of specific task representations (Dreisbach & Haider, 2009). Dreisbach and Haider proposed that specific task representations allow attention to be focused only on the response-discriminating features, and thus shield against processing any other information that might interfere with carrying out the task. In this way, only those features that are included in the representation of the task set are processed. Such an approach could principally explain the stronger binding effects for the irrelevant feature that was relevant to the second task in the present study. This would also, however, indicate that task sets do not discriminate between tasks, since here two different tasks had to be performed by the participants, and hence the features relevant to the second task were processed and could bind with the responses to the first task.
The present result pattern is also reminiscent of the phenomenon of overshadowing, as observed in forms of associative learning such as classical conditioning. Overshadowing is observed when, if more than one stimulus is present, the more salient stimulus will reduce or prevent conditioning to the less salient stimulus (Mackintosh, 1975). In the present experiments, attention was directed to one of the two response-irrelevant stimulus features, thereby increasing the salience of that feature. The result pattern conforms to the observations of overshadowing in associative learning, in which binding effects are stronger for the feature toward which attention is directed. This finding might be seen as a further similarity between such short-term distractor–response bindings and learning forms such as classical conditioning (see Giesen & Rothermund, 2014). The present findings, which might be considered analogous to overshadowing, could be seen as evidence of further similarity between such short-term binding effects and long-term forms of learning (see also Moeller & Frings, 2017).
At first sight, it might seem surprising that the valence feature was integrated with and retrieved responses just as the nonaffective feature word type did. In affective priming studies, an RT advantage is usually observed if the prime is of the same valence as the target or if the valence remains the same on two consecutive trials. This is the case even if valence is completely irrelevant to the task. Valence has thus been considered a feature that is processed automatically, and affective priming is thus considered to occur unconditionally, irrespective even of its relevance (e.g., Fazio et al., 1986; Hermans, De Houwer, & Eelen, 1994). Such binding has even been observed to bypass the bottleneck in the psychological refractory period paradigm (Fischer & Schubert, 2008). Furthermore, evidence for automatic processing of valence in the DRB paradigm has also been observed (Giesen & Rothermund, 2011). In the present study, however, valence was only integrated with the response and retrieved the response more strongly when it received sufficient attention. Thus, it would appear that the inherent salience of valence is not enough for it to get integrated with and retrieve responses. When valence is an irrelevant feature, its integration with and later retrieval of the response is stronger when attention is intentionally directed toward it, so that it functions like any other feature. Indeed other studies have shown that valence processing might not be as unconditional as has been assumed (e.g., Klauer & Musch, 2001, Exp. 3; Spruyt et al., 2009; Spruyt, Hermans, De Houwer, & Eelen, 2002). In tasks in which valence was not relevant, no evidence for affective priming has been found (e.g., De Houwer, Hermans, Rothermund, & Wentura, 2002; Hermans, Van den Broeck, & Eelen, 1998).
In conclusion, the results of the present experiments suggest that attention plays a role in binding response-irrelevant stimulus features. This is the case even within a single stimulus to which spatial attention is given. Response-irrelevant features that are allocated more attention due to an additional task are more likely to be integrated (or are likely to be integrated more strongly) with responses, and thus to retrieve them if repeated, than are features that are not allocated attention.
Notes
As we report below, Experiment 2 was in fact run in two slightly different versions that we have presented here as Experiments 2A and 2B. In one version, the participants’ attention was manipulated in a blocked manner and they had to report the relevant feature on 33.3% of the trials, and in the other version their attention was manipulated in a trial-by-trial manner and they reported the relevant feature on 75% of the trials. Furthermore, five words were changed in Experiment 2B, due to their similarity to other words. These changes are noted in Table 1b. All analyses reported below were run with attentional manipulation type as a further independent variable.
A control analysis of possible carryover effects in Experiment 2B was conducted by means of a 2 (cue relation) × 2 (response relation) × 2 (valence relation) × 2 (word type relation) MANOVA. Neither the Cue Relation × Response Relation × Valence Relation interaction, F(1, 29) = 0.37, p = .548, ƞp2 = .013, nor the Cue Relation × Response Relation × Word Type Relation interaction, F(1, 29) = 0.67, p = .419, ƞp2 = .023, was significant, suggesting no significant carryover effects. A similar analysis for Experiment 2A, to examine carryover effects from one block to the next, was not possible due to the design of that experiment, which did not allow for a separation of trials into separate bins (and thus for an analysis of, e.g., the first 25% of trials, to investigate possible carryover effects).
References
Ach, N. (1910). Über den Willensakt und das Temperament. Philosophical Review, 19, 556–667.
De Houwer, J., Hermans, D., Rothermund, K., & Wentura, D. (2002). Affective priming of semantic categorization responses. Cognition and Emotion, 16, 643–666. doi:https://doi.org/10.1080/02699930143000419
Denkinger, B., & Koutstaal, W. (2009). Perceive-decide-act, perceive-decide-act: How abstract is repetition-related decision learning? Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 742–756.
Dreisbach, G., & Haider, H. (2009). How task representations guide attention: Further evidence for the shielding function of task sets. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 477–486. doi:https://doi.org/10.1037/a0014647
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39, 175–191. doi:https://doi.org/10.3758/BF03193146
Fazio, R. H., Sanbonmatsu, D. M., Powell, M. C., & Kardes, F. R. (1986). On the automatic activation of attitudes. Journal of Personality and Social Psychology, 50, 229–238. doi:https://doi.org/10.1037/0022-3514.50.2.229
Fischer, R., & Schubert, T. (2008). Valence processing bypassing the response selection bottleneck? Evidence from the psychological refractory period paradigm. Experimental Psychology, 55, 203–211.
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 18, 1030–1044. doi:https://doi.org/10.1037/0096-1523.18.4.1030
Frings, C., Moeller, B., & Rothermund, K. (2013). Retrieval of event files can be conceptually mediated. Attention, Perception, & Psychophysics, 75, 700–709. doi:https://doi.org/10.3758/s13414-013-0431-3
Frings, C., Rothermund, K., & Wentura, D. (2007). Distractor repetitions retrieve previous responses to targets. Quarterly Journal of Experimental Psychology, 60, 1367–1377. doi:https://doi.org/10.1080/17470210600955645
Giesen, C., & Rothermund, K. (2011). Affective matching moderates S–R binding. Cognition and Emotion, 25, 342–350.
Giesen, C., & Rothermund, K. (2014). Distractor repetitions retrieve previous responses and previous targets: Experimental dissociations of distractor–response and distractor– target bindings. Journal of Experimental Psychology: Learning, Memory, and Cognition, 40(3), 645–659
Henson, R. N., Eckstein, D., Waszak, F., Frings, C., & Horner, A. J. (2014). Stimulus–response bindings in priming. Trends in Cognitive Sciences, 18, 376–384.
Hermans, D., Houwer, J. D., & Eelen, P. (1994). The affective priming effect: Automatic activation of evaluative information in memory. Cognition and Emotion, 8, 515–533.
Hermans, D., Van den Broeck, A., & Eelen, P. (1998). Affective priming using a color-naming task: A test of an affective–motivational account of affective priming effects. Zeitschrift für Experimentelle Psychologie, 45, 136–148.
Hommel, B. (1998). Event files: Evidence for automatic integration of stimulus–response episodes. Visual Cognition, 5, 183–216. doi:https://doi.org/10.1080/713756773
Hommel, B. (2004). Event files: Feature binding in and across perception and action. Trends in Cognitive Sciences, 8, 494–500. doi:https://doi.org/10.1016/j.tics.2004.08.007
Hommel, B. (2005). How much attention does an event file need? Journal of Experimental Psychology: Human Perception and Performance, 31, 1067–1082. doi:https://doi.org/10.1037/0096-1523.31.5.1067
Hommel, B., & Colzato, L. (2004). Visual attention and the temporal dynamics of feature integration. Visual Cognition, 11, 483–521.
Hommel, B., & Colzato, L. S. (2009). When an object is more than a binding of its features: Evidence for two mechanisms of visual feature integration. Visual Cognition, 17, 120–140. doi:https://doi.org/10.1037/a0013821
Hommel, B., Memelink, J., Zmigrod, S., & Colzato, L. S. (2014). Attentional control of the creation and retrieval of stimulus–response bindings. Psychological Research, 78, 520–538.
Hommel, B., Müsseler, J., Aschersleben, G., & Prinz, W. (2001). The Theory of Event Coding (TEC): A framework for perception and action planning. Behavioral and Brain Sciences, 24, 849–878, disc. 878–937. doi:https://doi.org/10.1017/S0140525X01000103
Horner, A. J., & Henson, R. N. (2009). Bindings between stimuli and multiple response codes dominate long-lag repetition priming in speeded classification tasks. Journal of Experimental Psychology: Learning, Memory, and Cognition, 35, 757–779.
Horner, A. J., & Henson, R. N. (2011). Stimulus–response bindings code both abstract and specific representations of stimuli: Evidence from a classification priming design that reverses multiple levels of response representation. Memory & Cognition, 39, 1457–1471. doi:https://doi.org/10.3758/s13421-011-0118-8
James, W. (1890). The consciousness of self. In The principles of psychology (chap. 8). New York, NY: Holt and company.
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: Object-specific integration of information. Cognitive Psychology, 24, 175–219. doi:https://doi.org/10.1016/0010-0285(92)90007-O
Klauer, K. C., & Musch, J. (2001). Does sunshine prime loyal? Affective priming in the naming task. The Quarterly Journal of Experimental Psychology, 54, 727–751.
Koch, I., & Allport, A. (2006). Cue-based preparation and stimulus-based priming of tasks in task switching. Memory & Cognition, 34, 433–444. doi:https://doi.org/10.3758/BF03193420
Koch I., Prinz, W., & Allport, A. (2005). Involuntary retrieval in alphabet–arithmetic tasks: Task-mixing and task-switching costs. Psychological Research, 69, 252–261.
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95, 492–527. doi:https://doi.org/10.1037/0033-295X.95.4.492
Mackintosh, N. J. (1975). A theory of attention: Variations in the associability of stimuli with reinforcement. Psychological Review, 82, 276–298. doi:https://doi.org/10.1037/h0076778
Mast, F., & Frings, C. (2014). The impact of the irrelevant: The task environment modulates the impact of irrelevant features in response selection. Journal of Experimental Psychology: Human Perception and Performance, 40, 2198–2213. doi:https://doi.org/10.1037/a0038182
Mayr, S., & Buchner, A. (2006). Evidence for episodic retrieval of inadequate prime responses in auditory negative priming. Journal of Experimental Psychology: Human Perception and Performance, 32, 932–943. doi:https://doi.org/10.1037/0096-1523.32.4.932
Memelink, J., & Hommel, B. (2013). Intentional weighting: A basic principle in cognitive control. Psychological Research, 77, 249–259.
Moeller, B., & Frings, C. (2011). Remember the touch: Tactile distractors retrieve previous responses to targets. Experimental Brain Research, 214, 121–130. doi:https://doi.org/10.1007/s00221-011-2814-9
Moeller, B., & Frings, C. (2014a). Attention meets binding: Only attended distractors are used for the retrieval of event files. Attention, Perception, & Psychophysics, 76, 959–978. doi:https://doi.org/10.3758/s13414-014-0648-9
Moeller, B., & Frings, C. (2014b). Long term response–stimulus associations can influence distractor–response bindings. Advances in Cognitive Psychology, 10, 68–80
Moeller, B., & Frings, C. (2015). Distractor–response bindings in dual task scenarios. Visual Cognition, 23, 516–531.
Moeller, B., & Frings, C. (2017). Overlearned responses hinder S–R binding. Journal of Experimental Psychology: Human Perception and Performance, 43, 1–5. doi:https://doi.org/10.1037/xhp0000341
Moeller, B., Frings, C., & Pfister, R. (2016). The structure of distractor–response bindings: Conditions for configural and elemental integration. Journal of Experimental Psychology: Human Perception and Performance, 42, 464–479.
Pickering, M. J., & Branigan, H. P. (1998). The representation of verbs: Evidence from syntactic priming in language production. Journal of Memory and Language, 39, 633–651.
Roelofs, A. (1992). A spreading-activation theory of lemma retrieval in speaking. Cognition, 42, 107–142. doi:https://doi.org/10.1016/0010-0277(92)90041-F
Rothermund, K., Wentura, D., & De Houwer, J. (2005). Retrieval of incidental stimulus–response associations as a source of negative priming. Journal of Experimental Psychology: Learning, Memory, and Cognition, 31, 482–495. doi:https://doi.org/10.1037/0278-7393.31.3.482
Spruyt, A., De Houwer, J., & Hermans, D. (2009). Modulation of automatic semantic priming by feature-specific attention allocation. Journal of Memory and Language, 61, 37–54.
Spruyt, A., Hermans, D., De Houwer, J., & Eelen, P. (2002). On the nature of the affective priming effect: Affective priming of naming responses. Social Cognition, 20, 227–256.
Treisman, A. (1988). Features and objects: The Fourteenth Bartlett Memorial Lecture. Quarterly Journal of Experimental Psychology 40, 201–237. doi:https://doi.org/10.1080/02724988843000104
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:https://doi.org/10.1016/0010-0285(80)90005-5
Tukey, J. W. (1977). Exploratory data analysis. Reading: Addison-Wesley.
van Dam, W. O., & Hommel, B. (2010). How object-specific are object files? Evidence for integration by location. Journal of Experimental Psychology: Human Perception and Performance, 36, 1184–1192.
Võ, M. L., Conrad, M., Kuchinke, L., Urton, K., Hofmann, M. J., & Jacobs, A. M. (2009). The Berlin affective word list reloaded (BAWL-R). Behavior Research Methods, 41, 534–538. doi:https://doi.org/10.3758/BRM.41.2.534
Waszak, F., Hommel, B., & Allport, A. (2003). Task-switching and long-term priming: Role of episodic stimulus–task bindings in task-shift costs. Cognitive Psychology, 46, 361–413. doi:https://doi.org/10.1016/S0010-0285(02)00520-0
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Singh, T., Moeller, B., Koch, I. et al. May I have your attention please: Binding of attended but response-irrelevant features. Atten Percept Psychophys 80, 1143–1156 (2018). https://doi.org/10.3758/s13414-018-1498-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-018-1498-7