
Abstract
Yantis and Jonides (1984) and Jonides and Yantis (1988) reported robust involuntary attentional capture by sudden-onsets, the origin of which has been debated. Prominent accounts have highlighted aspects that include the “new object” status of a sudden-onset (Yantis & Hillstrom, 1994) and the substantial luminance changes accompanying their appearance (Gellatly, Cole & Blurton, 1999; Franconeri, Hollingworth & Simons, 2005), including relative differences in the amount of sensory change between target and nontarget items (Pinto, Olivers & Theeuwes, 2008). In this research we dissociate the amount of sensory change accompanying sudden onsets from the extent to which they appear as newly created objects in search displays. We attempted to determine the relative contribution of local sensory changes and display configuration to attentional capture by sudden-onsets. We showed that the display configuration of old objects modulates the impact of capture caused by sudden-onsets.
Similar content being viewed by others

Jonides and Yantis’s (Jonides, 1981; Yantis & Jonides, 1984; Jonides & Yantis, 1988) seminal contribution to the field of attentional capture showed that task-irrelevant but suddenly appearing or “sudden-onset” stimuli took attentional priority in a visual search task. Their design made use of “placeholder” figure 8 s, which appeared before a search array and transformed (by subtle removal of line segments as in digital watches) into “no-onset” items as the search array appeared. As a contrast to these no-onsets, the sudden-onset item would appear in a location previously unoccupied by a placeholder and was found to capture attention strongly. Yantis and Jonides also ensured that the sudden-onset was a target on only 1/n trials (where n is the set size) and thus unrelated to a concurrent search task. Given that there were no consequent benefits to attend to sudden-onsets, nor costs to ignore them, the extent to which they captured attention was attributed to a purely bottom-up or exogenous process.
Since those early findings, there has been a debate to determine just why sudden-onsets possess such a remarkable ability to capture attention. Although more recent work has shown that colour-singletons and some forms of luminance and colour-changes can capture attention (Theeuwes, 1992; Turatto & Galfano, 2001; Enns, Austen, DiLollo, Rauschenberger, & Yantis, 2001; Spehar & Owens, 2012), it is fair to say that attentional capture by sudden-onsets remains uniquely robust and distinctive (Folk & Remington, 2015). Researchers no longer deliberate over whether it occurs, just about the mechanisms that mediate the superiority of sudden onsets in prioritizing attentional allocation.
Yantis and Hillstrom (1994) proposed that, unlike many other features of stimuli, the sudden-onset is unique in that it represents the appearance of a new perceptual object. The establishment of a new “object file” (after Kahneman, Treisman, & Gibbs, 1992) to acknowledge the appearance of the sudden-onset was argued to cause an attentional interrupt, which prioritizes the sudden-onset. This interpretation has since been referred to as the “new-object” account of attentional capture by sudden-onsets, and although influential, the high-level nature of such an account has attracted a considerable amount of criticism (Theeuwes, 1995). Nevertheless, Yantis and Hillstrom were able to show that even when luminance change was controlled, for example, by defining new objects as a texture, or stereoscopically, attentional capture does occur. However, Gellatly, Cole, and Blurton (1999) pointed out that the more the luminance change was controlled, less capture seemed to occur, suggesting that luminance change might be sufficient to account for attentional capture by sudden onsets, and the new-object account was simply unnecessary.
Although it is a challenge to introduce new objects suddenly without causing any local luminance changes, several researchers have achieved this. Rauschenberger and Yantis’s (2001) technique utilized Kanizsa subjective figures, where circular placeholders became three-quarter circles or half circles, not only providing objects of search at a local level, but entirely illusory objects could be made to appear at a global level without any concomitant perceptual change. Surprisingly, the appearance of a central subjective square slowed reaction times in the local level search, presumably because attention was captured not just by the square but at a more global level of processing (Rauschenberger & Yantis). Similarly, Kimchi, Yeshurun, and Cohen-Savransky (2007) found that attention can be captured by the perceptual organisation of local elements into task-irrelevant objects (Kimchi, Yeshurun, Spehar & Pirkner, 2015).
Franconeri, Hollingworth, and Simons (2005) also created a method of introducing new objects without any concomitant luminance changes but found the opposite: that the appearance of a new-object is in no way sufficient for attentional capture. Their study used a moving ring of considerable thickness, which would either expand or contract across the placeholders array. The search array would be left in the wake of this “annulus” and could then contain a new-object. Because this new-object failed to capture attention, it implied that new-object status was not behind sudden-onset capture. A more recent study by Hollingworth, Simons, and Franconeri (2010) also attempted to obscure the luminance transient, this time with intervals or masks between the placeholders and search arrays; again attentional capture by new-objects was eliminated. Whereas both of these methods eliminated unique luminance changes, they also eliminated the abruptness or suddenness of the appearance of the new object. In many change blindness studies (Simons & Rensink, 2005), a great number of new-objects can appear without participants even noticing, as long as the objects’ appearance is obscured by a mask or blank.
Chua (2009) further accounted for Franconeri et al.’s (2005) findings by arguing that participants simply failed to recognise the new-object as a new-object. When a transient is masked or other elements move, the new-object becomes hard to detect let alone able to capture attention. Chua (2009) manipulated the ease with which participants could encode the placeholders’ locations, that is, to remember where the old objects had been, by reducing as much as possible the load on visual short term memory. When regular geometric placeholders configurations were used, and these placeholders were in a fixed location for any given set-size, attentional capture by new objects was evident, even when their sudden appearance was masked by an opaque annulus. A later study by Chua (2011) further increased the likelihood of participants actually attending to the placeholders. Unlike in Franconeri et al.’s (2005) study where the placeholders were motionless while the annulus moved, Chua (2011) kept the annulus stationary and moved the placeholders through it. Motion is a powerful exogenous tracking cue, so with the moving placeholders, attention was most likely placed on them, such that when a new object appeared it was noticed as new and captured attention. These findings strongly suggest that the perceived newness of an object and its ability to capture attention depends on a more complex configural relationship with other elements in the display.
Rather than trying to eliminate change altogether, Cole, Kentridge, and Heywood (2004) teased out the role of new objects, by directly comparing the appearance of new objects to changes to old objects. Their paradigm involved participants indicating if they noticed a change to one of two complex images, and while this was not a strict test of capture per se, Cole et al. found a strong attentional preference for images containing a new object rather than a change to an old item. Another technique attempting to control for change involved a display wide flicker to all old objects at the same time a new object appeared (Cole & Kuhn, 2009). Despite this large global change, attentional priority was still given to the new objects.
Certainly, when all elements are static, sudden-appearance may herald a new object; however, if all items in a search display move except one, the unchanging item can guide involuntary attentional allocation. Pinto, Olivers, and Theeuwes (2008) presented search displays where all items changed dynamically (by moving or blinking) except one. That unchanging item captured attention, even when irrelevant to the task. Citing search asymmetries (Treisman & Gormican, 1988, cited by Pinto et al.) such that search slopes for blinking items surrounded by static items are much shallower than for static items surrounded by blinking items, Pinto et al. acknowledged that dynamic features may still make a separate contributions to attentional capture.
In the current study, we independently manipulate display configuration and the nature of dynamic transients associated with new objects to further assess the new object hypothesis (Yantis & Hillstrom, 1994) and its account of attentional capture by sudden-onsets. Franconeri et al.’s (2005) innovation in obscuring local changes in the new object is taken as inspiration, but our methodology does allow for suddenness. Chua’s (2009, 2011) findings demonstrating the role of display configuration encouraged us to create placeholder displays of varying regularity. Like Pinto et al. (2008) we hope to show that, while a powerful factor, a local transient is not necessary for attentional capture, and we also expect that the configurational relation to the other elements in the display will influence the perceived salience of new objects. If a new-object captures attention in the absence of a transient, is it being perceived as new because it was absent from visual short-term memory or because of its relationship to the other elements in the display? Chua (2011) used regular square or triangular placeholders arrays and argued that this resulted in better encoding into visual short-term memory (VSTM) of the placeholders as old. However regularly arranged old objects also ensure the new object is disrupting the good form and grouping of that arrangement. We manipulated and directly compared both the regular configuration of old objects and the extent to which new objects do and do not disrupt the good form of those search displays.
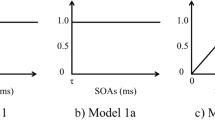
Figure 1a–d illustrates four different display configurations used in this study to explore these issues. We use a “square” condition as this is one of the most typical placeholder configurations used in the classic studies of Yantis (Fig. 1a). With such a regular array, a sudden-onset is appearing amongst readily encoded old objects and can be easily differentiated as a new object. However, its appearance is also breaking the simplicity and symmetry of the placeholder array by appearing within a side of the square. In this study, we included two additional highly regular arrays to distinguish between the ease by which old objects can be readily encoded from the role of perceptual organisation between old and new items in the display. In both of these new conditions, the placeholders are presented in an easy to encode configuration, but in the “congruous” condition (Fig. 1c) the new object appears within or at the end of that configuration, preserving its form for the most part. However in the “incongruous” condition (Fig. 1d), the new object appears above or below the placeholder configuration, breaking its overall perceptual organisation entirely. If the “newness” of an object arises merely as a result of old objects being readily encoded (Chua, 2011), we should not find a difference, but if the location at which a new object appears is also important, greater capture should arise when a new object breaks the good form of the configuration. As a control we also include “random” configurations (Fig. 1b), which load memory by being different and irregular on every trial and ensure that there is no regular form to disrupt.

a–d. Configurations used and the types of new object investigated. Note that the dashed grid is only presented to show the nature of the apparent motion and was not visible in the study. Only movements in one direction are shown but all possible directions were used in 1a and 1b, and left/right and up/down directions were used in 1c and 1d respectively. In each search array shown the new-object is always the letter P. In the Unique Transient condition the line segments were subtlety removed from the figure 8 placeholders to form the no-onsets, and the new-object appeared in a previously blank location as both a new-object and luminance change. In the Non-unique Transient condition all items appeared in new locations*, so there were five luminance changes, but only one was intended to be perceived as a new-object (P). In the Unique non-transient condition, all items except one appear in new locations (as old-object sudden-onsets), but the one new-object (P) appears in a location previously occupied by a placeholder. (*In the Congruous non-unique transient condition only, the new object did have to appear at the end as all other places had been previously occupied by placeholders)
We also meet the methodological challenge of creating a suddenly appearing new object in the absence of a unique and localized luminance change, by changing the entire array. Yantis and Jonides (1996) developed a unique method which involved the entire placeholders array moving across the screen in 15 frames, transforming into the search array only in the final frame. While the aim of their experiment was to make a more general point about visual quality and masking in attentional capture (Gibson, 1996a, b), our own methodology is inspired by their approach. When entire displays move, new objects are no longer uniquely defined by associated local transients but by their relation to “old” items. In the current study, the movement could be characterised as apparent motion, as it is achieved in a single frame, and the distance is short, usually just two widths of the stimuli themselves, such that placeholders and search arrays “overlap” and in some sense the stimuli apparently “move into the gaps” from the earlier display. Despite the simplicity of this method, it is worth emphasising that the result is a strong perception of the display as a whole moving together, and not a percept of four individual items disappearing and reappearing.
As illustrated in Fig. 1a–d, we used three different types of new object stimuli that differ with respect to their association with luminance transients. Where the search stimuli all appear in the same location as placeholders, except for the new object which is a sudden-onset, we refer to this as the “Unique-transient” condition (Fig. 1a–d, top panel on the right), because the new object is the only display element that has a large (sudden-onset) transient associated with it. These trials, across different display configuration types, are identical to those in the classic research of Yantis (Yantis & Jonides, 1984). In the newly devised "Non-unique transient" condition, all search items suddenly appear in locations previously unoccupied by placeholders, so the new object is just one of many other transients appearing at the same time (Fig. 1a–d, middle panel on the right). The third and final condition, the “Unique non-transient” condition, is made possible by having the relative motion of the placeholders and search arrays arranged such that placeholder items move to a new location but the new object appears in one of the locations previously occupied by a placeholder (Fig. 1a–d, bottom panel on the right). This arrangement results in a paradoxical situation where the new object is the only item in the final display that is not accompanied by an abrupt transient. In fact, a new object in this condition is the only item appearing in a location that is "forward" masked by one of the placeholder items. Clearly, if new-object status contributes significantly to attentional capture by sudden-onsets, as has been tentatively shown in the past (Yantis & Hillstrom, 1994), and capture effects do not derive entirely from transients, even these new objects appearing without an accompanying transient should capture attention.
Thus, we investigated the role of configuration in attentional capture and hypothesise that it will play a role in capture in so far as the definition of new objects is affected by it. All configurations contain the same number of elements to assist in encoding (Chua, 2009, 2011), but the new objects appearing in each are differentially emphasised. If new object status plays a role we therefore expect the strongest attentional capture in conditions which emphasise the appearance of the new object stimulus (incongruous and square conditions), and the weakest capture in conditions where a new object is either obscured by irregularity or does not break the good form of the display (congruous and random conditions). Additionally, by defining these new objects both with and without transients, we hypothesise that if new objects capture attention by virtue of their new object status alone, transients should not be necessary. The concurrent manipulation of display configuration and the extent to which new objects are associated with sensory transients also allows us to hypothesise how these factors might interact. If it is the case that sudden-onsets capture attention mainly as a result of the overwhelming and abrupt sensory change that accompanies their appearance, we would not expect the magnitude with which they capture attention to be affected at all by the configuration of old objects surrounding them. However, if display configuration does have an impact on how readily old objects are encoded and this interacts with attentional capture, then the extent to which such capture is truly stimulus driven is called into question.
Method
Participants
Participants were 361 psychology undergraduates from the University of Sydney who participated in the study in return for course credit. Recruiting this large sample enabled us to reduce the number of trials per participant (240) to minimise any practice or “set” effects caused by our method and displays.
Design
All factors were within subjects, such that all participants completed trials in all conditions of the study: 2 (New object associated with target or distractor) x 3 (Unique transient, Non-unique transient, or Unique non-transient) x 4 (Configuration of Search Array: Random, Square, Congruous, Incongruous). Each of the four configuration conditions were in separate blocks, all other factors were manipulated within blocks.
Stimuli
The black used had a mean luminance of 0.7 cd/m2, and the white 88.0 cd/m2. Individual targets were 1.5-cm high and 0.9-cm wide on a screen approximately 65-cm away from the subjects’ eyes. Each individual target thus subtended a visual angle of 1.32 x 0.79 degrees. The square display as a whole was 6 cm x 5.2 cm resulting in a visual angle of 5.29 x 4.58 degrees (random display was approximately 10.6 x 8.2). The experiment was run on iMac machines with 19-inch screens running at a resolution of 1024 x 768. The software used was Inquisit 2.0 running on Windows 98.
In every condition there was a 900-ms interstimulus interval, followed by the appropriate placeholders display for 1000 ms, followed directly by the search array which stayed on screen until a response was made. Because there was no gap at all between placeholders and search arrays, nor any halfway animations, the changes resulted in a strong perception of apparent motion in the relevant conditions, such that all four of the “old object” placeholders were seen to move abruptly in a common direction at the same moment their letter identities were revealed by the removal of line segments. In all search arrays, a fifth stimulus, not associated with any old object, also appeared abruptly, and was intended to be perceived as a new object and will be referred to as such (the letter P in Fig. 1a–d).
The nature of the new object is what distinguishes our three transient conditions. The unique transient conditions involved no apparent motion by old objects, such that the new object also was the only (sudden-onset) transient in the display (as with most prior studies). The non-unique transient conditions occurred when all items were sudden-onsets, including the one which was differentiated as “new” by virtue of the fact there was no corresponding placeholder that had apparently moved into its location. Finally in the unique non-transient condition, all items except the newly appearing object were sudden-onset, as the new object appeared in a location previously occupied by a placeholder. Note that no condition had a fixation cross given the variety of movement conditions and configurations used.
There were four configuration conditions, which dictated both the form of the placeholder old objects, and the possible locations a new object might appear. They are shown in Fig. 1a–d. In the square configuration, four placeholders appeared as if they were corners on a square, and when the search array appeared those four placeholders became letters by the removal of line segments. The fifth new object stimulus appeared in the middle of the gap on one of the four sides of the square. In the random configuration, the four placeholders were spread out on a 6-high x 9-wide grid (Fig. 1b), and the new object could appear anywhere on this grid. Unlike all other displays, the random placeholders and search arrays subtended approximately twice the visual angle because the size of individual elements was kept constant. In both the congruous configuration and the incongruous configuration the four old object placeholders appeared in a horizontal row with gaps in between each. However, in the congruous configuration, the new object appeared either in one of the three gaps in the row or at the end (non-unique transient condition only) of the row of old objects, whereas in the incongruous configuration the new object appeared above or below one of the middle two old objects. While apparent motion could take place up, down, left, or right in the square and random conditions, in the congruous condition, motion was restricted to left or right, and in the incongruous configuration movement was restricted to up or down because of the manner in which new objects had to be masked in the unique non-transient conditions.
Procedure
Participants completed 12 practice trials and then one block each of each configuration condition in a random order. The task was to search for and identify either an E or H, one of which was present in each display, and respond by keyboard key press (the z or ? keys to keep respondents’ hands apart). A loud sound was made each time an error was made, and an error message appeared on screen (400 ms) to encourage accurate responses. Each block consisted of 60 trials, resulting in 240 trials in total. To ensure that the new-object was not actively attended to, it provided no benefit to search, and was only randomly associated with the target, resulting in one-fifth (12) new object target trials and four-fifths (48) new object distractor trials per block, presented in a random order.
Results
Error rates in all conditions were <0.4 % and were not analysed. Raw reaction time means are presented in Table 1. Considered across all conditions, response times were significantly faster when sudden-onsets were associated with targets compared with distractors, F(1, 360) = 252.487, p < 0.001, η p 2 = 0.412.
Compared with the Random Configuration RTs, RTs in the Square condition were significantly faster overall, F(1, 360) = 17.862, p < 0.001, η p 2 = 0.047; RTs in the congruous condition were no different overall F(1, 360) = 0.253, p = 0.615, η p 2 = 0.001; and RTs in the incongruous condition were significantly faster overall F(1, 360) = 36.844, p < 0.000, η p 2 = 0.093. RTs in the Incongruous conditions were fastest overall when compared to the square Condition, F(1, 360) = 5.660, p = 0.018, η p 2 = 0.015.
Compared with the Unique Transient condition, RTs in the Non-Unique transient condition were significantly slower overall F(1, 360) = 23.561, p < 0.000, η p 2 = 0.061; as were RTs in the Unique non-transient condition overall F(1, 360) = 21.733, p < 0.000, η p 2 = 0.057.
The “magnitude of attentional capture” was obtained by subtracting RTs to new object targets away from RTs to old object targets (when the new object was a distractor), and if capture has occurred this is a positive number such that responses are faster when the target is associated with a new object. The average magnitude of capture with 95 % CIs across different conditions is shown in Fig. 2.

The magnitude of attentional capture for each condition in milliseconds. Reaction times when a distractor was a new object minus reaction times when a target was a new object. A positive value implies the new object has been located faster and captured attention. Error bars are 95 % confidence intervals
Assessed with paired t tests, attentional capture was obtained in all but three conditions (see Table 1 for all p values). For the incongruous configuration, when new objects were non-unique transients, the magnitude of attentional capture was not significant (t(1, 360) = 1.158, p = 0.247). In the congruous configuration, the magnitude of attentional capture was significant in both the non-unique transient and unique non-transient conditions (ps < 0.001) but in the unexpected direction. Namely, reaction times were actually slower when the new object was associated with a target (refer to the negative bars in Fig. 2).
Magnitude of attentional capture ANOVA
A 4 x 3 repeated measures ANOVA was next conducted on the magnitude of attentional capture with these two factors: configuration (random, square, congruous, incongruous), and new object type (unique transient, non-unique transient, unique non-transient).
Main effects
As Fig. 2 shows, there was a significant main effect of configuration of displays on magnitude of capture, F(1, 360) = 82.93, p < 0.001, η p 2 = 0.187. Using the “random” configuration as the control/comparison, capture magnitude was significantly stronger when there was a square configuration of stimuli F(1, 360) = 41.359, p < 0.001, significantly weaker in the congruous condition F(1, 360) = 103.482, p < 0.001, and marginally weaker in the incongruous condition F(1, 360) = 4.543, p = 0.034. There also was a significant main effect of new object type on the magnitude of attentional capture, F(1, 360) = 69.067, p < 0.001, η p 2 = 0.161. Attentional capture was strongest overall for unique transients compared with non-unique transients F(1, 360) = 72.239, p < 0.001, η p 2 = 0.161. Attentional capture was marginally weaker for unique non-transients compared with non-unique transients, F(1, 360) = 4.248, p = 0.040.
Interaction effects
Overall, there was a significant interaction between configuration and the transient status of new objects (F(1, 360) = 10.908, p < 0.001, η p 2 = 0.029). When random condition was considered as a baseline, the post-hoc comparisons revealed the following pattern:
-
Random vs. Square Interactions. The magnitude of capture was far greater for unique transients than non-unique transients in the square configuration (first two bars of Fig. 2), whereas this difference was much less pronounced in the random configuration, F(1, 360) = 9.441, p = 0.002. When comparing the non-unique transient and unique non-transient conditions, there is a similar reduction in difference when comparing the square and random configurations but this was not significant, F(1, 360) = 1.546, p = 0.215.
-
Random vs. Congruous Interactions. The pattern of results found in the congruous condition was clearly very different to that found in the random condition, so interactions were significant both when comparing capture magnitude of unique transients to non-unique transients, F(1, 360) = 15.655, p < 0.001, and non-unique transients to the unique non-transient condition, F(1, 360) = 6.118, p = 0.014.
-
Random vs Incongruous interactions. Because capture was not found in the non-unique transient condition for the incongruous configuration, compared with the random condition, capture magnitude was significantly greater in both the unique transient, (F(1, 360) = 5.392, p = 0.021 and unique non-transient F(1, 360) = 19.919, p < 0.001 conditions.
Discussion
We attempted to disentangle several factors that may have contributed to the success of the classic attentional paradigms of Yantis and Jonides (Yantis & Jonides, 1984; Jonides & Yantis, 1988). The work of Franconeri and others (Franconeri et al., 2005; Pinto et al., 2008) inspired us to consider the role of transients in attentional capture, and the work of Chua (2009, 2011) inspired us to consider the role of display configuration. We further considered whether a new object would break the “good form” of a regular display. The general pattern of results regarding the role of transients was that when new objects were unique sudden-onset transients the magnitude of capture was strongest, followed by when they were not unique transients, or not transients at all. The general pattern of results for display configuration was that the square configuration produced the strongest capture, followed by the random and incongruous configurations, with capture mostly eliminated in the congruous condition. While it is obvious that both sensory transients and display configuration factors contribute to attentional capture, several surprising interactions lead us to conclude that these contributions are neither additive nor straightforward.
Our method attempted to separate the contributions of new object status and luminance change to attentional capture, and attentional capture was found in almost all conditions. When new objects were “non-unique transients,” they were sudden-onsets but competed for attention with four other sudden-onsets, and yet in the square and random conditions they were given attentional priority. When new objects were not associated with any kind of transient (“unique non-transient”), and competed for attention with four sudden-onsets, they were given attentional priority in all but the congruous condition. This seems the clearest evidence yet that new object status plays a role in attentional capture, but there are some important limitations on such a conclusion. First, the magnitude of the contribution of new object status to attentional priority observed is only of the order of 20 ms, or 20 % of the magnitude of the effect for unique sudden-onset transients. Earlier studies that tried to partition the contribution of new objects similarly found reliable but small effects (Yantis & Hillstrom, 1994; Rauschenberger & Yantis, 2001). Consider though that these new objects in the unique non-transient condition were the only items masked by placeholders and that they received attentional priority ahead of four, old-object, sudden-onsets, and the finding of capture at all is more impressive. A second caveat we must highlight about this result arises from the fact that as well as being the only new objects, these unique non-transient new objects were also items which were uniquely stationary. Pinto et al. (2008) found that items which were unique in their lack of movement also captured attention, so it remains possible that participants’ attention was guided by the stationary nature of our unique non-transient new objects rather than their new object status. What makes an entirely “uniquely stationary” explanation unlikely however is that the nature of this guidance did not act in isolation of display configuration. For example in the congruous condition, the uniquely stationary item (the new object in the unique non-transient condition) not only did not capture attention, it was hard to see. Indeed, the many interactions between our luminance change manipulations and display configurations suggest that any endeavour to extract “new object” as an independent feature may have been misguided.
The intended role of the congruous and incongruous conditions was to explore the idea that, even if displays are regular and set-size is small, and thus easy to encode in VSTM (Chua, 2009, 2011), a new object defined by breaking the good form of a display is likely to capture attention more than a new object slotting into an established form, in this case a single row of four stimuli. In the congruous condition, the new object that “slotted in” to the row of stimuli or appeared at it ends, was found more slowly than old objects in all but the unique transient condition. It could be that these stimuli were simply not perceived as new objects. Could they have been obscured by lateral masking (Wertheim, Hooge, Krikke, & Johnson, 2006), because they only appeared flanked by two old objects in all but one condition? This seems unlikely, because by sheer necessity in the non-unique transient condition the new object had to appear on the end of the row, yet this did not result in any less inhibition. It is possible that the display as a whole was perceived as compressing or moving in a particular direction. If that is what occurred and the congruous condition essentially masked the new object status of the new stimuli, then what impact would a unique transient sudden-onset have if it appeared as an appendage or addition to a single line object? In the congruous condition unique transient sudden-onsets did capture attention, once more highlighting the salience of dynamic stimuli, but it most interesting to note that the capture obtained was of the weakest magnitude in the study (95 % confidence interval [CI]: 10-31 ms) for unique sudden-onsets. If the congruous condition removed or minimised the new object status of the new stimuli, perhaps this is why capture was reduced too. We suggest that configuration plays a critical role both the definition of a new object, and processes previously assumed to be entirely stimulus-driven.
Consider the unexpected interaction when comparing the square and random configurations. The extent to which a unique, sudden-onset transient captured attention in the square condition was far greater than that found in the random configuration compared with the magnitudes obtained for the non-unique transient conditions. That first bar in Fig. 2 is the replication of most early attentional capture methods, that is: unique transients appearing in a regular display; and this is the effect which has long been considered most stimulus driven and presumably originating from low level features of individual stimuli. Yet this interaction suggests mere arrangement of other stimuli appears to be important. Certainly, the visual angle subtended by the random displays was larger for practical reasons, but capture magnitude in the non-unique transient condition did not drop off to the same degree when stimuli were arranged irregularly. We did hypothesise that configuration would play a role in capture, based on Chua’s (2009) conclusion that new objects do capture attention if old objects are more easily encoded in regular arrays, but we would have expected that factor to have a greater impact in the non-unique transient conditions where apparent motion added a tracking task to the load on visual short term memory. That configuration had an increased impact on the condition we would most expect to be stimulus-driven, suggests form, grouping, and the way those lead to new object status have a more fundamental influence on the process.
However, findings from the incongruous condition do not necessarily support an account solely based on new object status. In the incongruous condition the new object was intended to disrupt the order of the display to a greater extent than in the congruous condition, by appearing isolated above or below the line. Arguably the new-object in the incongruous condition stood out more than any other condition, and we expected this condition to produce the greatest capture magnitudes in all cases. However, capture was only evident in the unique transient and unique non-transient conditions, and was absent in the non-unique transient condition. We think that this is because the non-unique transient condition required that the new object appear in a previously unoccupied location, necessitating that it appear above the line when the movement was up and below the line when the movement was down, always placing it two vertical positions from the starting placeholders, a consistently greater distance than any other condition. Nevertheless in the unique transient condition, which was unaffected by such confounds and which involved the unique sudden-onset transient breaking the good form of the placeholder array, attentional capture also was subdued, at least when compared to the random and square configurations. The regularity of the good form the new object broke, may explain the faster overall reaction times in the incongruous condition, as once participants’ attention was captured by an object which was not the target, they were then required to search through a neatly arranged row of letters directly above or below the location of capture, but this overall benefit was marginal. The incongruous condition was specifically designed to highlight new object status more than any other, yet even when associated with a unique sudden-onset attentional capture was just a fraction of that observed in other conditions, especially the square condition.
To explain the overwhelmingly greater capture observed in the square condition, any new object explanation seems insufficient. If we were limited to comparing just the square and random conditions, we might conclude regularity alone plays a significant role; however, the subdued capture by a unique sudden-onset in the highly regular congruous and incongruous conditions rule this out as the only factor. One possibility for the pre-eminence of capture in the square configuration is that because the square configuration is defined by corners, the sides are somehow preactivated in attention as possible locations for new object appearance; in the square configuration the new object is not so much breaking the form of the structure but completing it. This idea that capture is strongest when stimuli appear in gaps “suggested” by the stimuli could be considered almost top-down in origin, or at the very least guided by processes operating at a relatively high level, yet such influences do interact with the effect of sudden-onsets. To use the more recent conception of Awh, Belopolsky, and Theeuwes (2012), the configuration of search displays may contribute to a participant’s “priority map,” setting up expectations which are combined with factors associated with physical salience and only together determine attentional priority. Interpretations such as these, necessary in the light of the current results, suggest that attentional capture does not arise merely as the result of local transients or the local appearance of objects, but instead emerges from a map of priorities and expectations informed from many sources. The constancy of search and display configurations within each individual study in the field of attentional capture has long obscured this understanding.
The current study was designed to find out why sudden-onsets capture attention. We wanted to test the new object hypothesis (Yantis & Hillstrom, 1994) and factors related to the memory and perception of new objects such as configuration, and of course we anticipated a large contribution to capture by unique luminance transients. What we found is that, while partitioning off capture effects caused by abruptly appearing new objects remains as challenging as ever, the real story of attentional capture by sudden-onsets is that where they appear within a configuration of old objects and the shape of that configuration matters, even when sudden-onsets are the only unique luminance change in the display. Inspired by Chua’s (2009, 2011) investigations into the role of memory and regularity, we anticipated the contributions by luminance change and configuration might be neat and additive, but that is not what we found. Instead, it seems as if the location in which a new item appears, or is anticipated to appear, relative to old items, determines the attentional priority it receives. Most interestingly, we found that a regular pattern of placeholders “completed” by a new item (i.e., within the side of a square), and not necessarily perceived as a new object, produced the strongest attentional capture. It may not be correct to ask any longer about the relative role of transients and new object status in capture, perhaps instead we should be asking which configurations prime an observer to be sensitive to each.
In an attempt to unravel the secrets of Yantis and Jonides’s (1984, Jonides & Yantis, 1988) early demonstrations of capture by sudden-onsets, we have in fact arrived only where they began, with evidence that the regular configurations they chose and the possible locations of sudden-onset appearance were all conspiring together to produce robust attentional capture. In fact, Steve Yantis did not accidentally create his regular figure 8 placeholder’s displays and by pure luck light up the study of attentional capture in the 1980s. To arrive at arguably the strongest possible attentional capture, John Jonides and he worked through several designs for the placeholders before arriving at the optimal configuration (Jonides J, personal communication, April 4, 2016). It is a testament to the skill of the experimenters who pioneered this research, that decades later, the conjunctions of the classic attentional capture research (Yantis & Jonides, 1984; Jonides & Yantis, 1988) are still being uncovered.
References
Awh, E., Belopolsky, A., & Theeuwes, J. (2012). Top-down versus bottom-up attentional control: A failed theoretical dichotomy. Trends in cognitive science, 16, 437–443.
Chua, F. (2009). A new object captures attention – but only when you know it’s new. Attention, Perception, & Psychophysics, 71, 699–711.
Chua, F. (2011). A new object captures attention – but only when you know which objects are old. Attention, Perception, & Psychophysics, 73, 797–808.
Cole, G., Kentridge, R., & Heywood, C. (2004). Visual salience in the change detection paradigm: The special role of object onset. Journal of Experimental Psychology: Human Perception and Performance, 30, 464–477.
Cole, C., & Kuhn, G. (2009). Attentional capture by object appearance and disappearance. The Quarterly Journal of Experimental Psychology, 63, 147–159.
Enns, J. T., Austen, E. L., DiLollo, V., Rauschenberger, R., & Yantis, S. (2001). New objects dominate luminance transients in setting attentional priority. Journal of Experimental Psychology: Human Perception & Performance, 27(6), 1287–1302.
Folk, C. L., & Remington, R. W. (2015). Unexpected abrupt onsets can override a top-down set for color. Journal of Experimental Psychology: Human Perception & Performance, 41, 1153–1165.
Franconeri, S. L., Hollingworth, A., & Simons, D. J. (2005). Do new object capture attention? Psychological Science, 16, 275–281.
Gellatly, A., Cole, G., & Blurton, A. (1999). Do equiluminant objects onsets capture visual attention? Journal of Experimental Psychology: Human Perception & Performance, 25, 1609–1624.
Gibson, B. S. (1996a). Visual quality and attentional capture: A challenge to the special role of abrupt onsets. Journal of Experimental Psychology: Human Perception and Performance, 22, 1496–1504.
Gibson, B. S. (1996b). The masking account of attentional capture: A reply to Yantis and Jonides (1996). Journal of Experimental Psychology: Human Perception and Performance, 22, 1514–1520.
Hollingworth, A., Simons, D. J., & Franconeri, S. L. (2010). New objects do not capture attention without a sensory transient. Attention, Perception & Psychophysics, 72(5), 1298–1310.
Inquisit 2.0 [Computer software]. (2006). Seattle, WA: Millisecond Software.
Jonides, J. (1981). Voluntary versus automatic control over the mind’s eye’s movement. In J. Long & A. Baddeley (Eds.), Attention and performance IX (pp. 187–203). Hillsdale: Erlbaum.
Jonides, J., & Yantis, S. (1988). Uniqueness of abrupt visual onset in capturing visual attention. Perception & Psychophysics, 43, 346–354.
Kahneman, D., Treisman, A., & Gibbs, B. J. (1992). The reviewing of object files: Object-specific integration of information. Cognitive Psychology, 24, 175–219.
Kimchi, R., Yeshurun, Y., Spehar, B., & Pirkner, Y. (2015). Perceptual organization, visual attention, and objecthood. Vision Research.
Kimchi, R., Yeshurun, Y., & Cohen-Savransky, A. (2007). Automatic, stimulus-driven attentional capture by objecthood. Psychonomic Bulletin and Review, 14, 166–172.
Pinto, Y., Olivers, C., & Theeuwes, J. (2008). Static items are automatically prioritized in a dynamic environment. Visual Cognition, 16, 916–932.
Rauschenberger, R., & Yantis, S. (2001). Attentional capture by globally defined objects. Perception & Psychophysics, 63(7), 1250–1261.
Simons, D. J., & Rensink, R. A. (2005). Change blindness: Past, present, and future. Trends in Cognitive Sciences, 9, 16–20.
Spehar, B., & Owens, C. (2012). When do luminance changes capture attention? Attention, Perception and Psychophysics, 74, 674–690.
Theeuwes, J. (1992). Perceptual selectivity for color and form. Perception & Psychophysics, 51, 599–606.
Theeuwes, J. (1995). Abrupt luminance change pops out; abrupt colour change does not. Perception & Psychophysics, 57, 637–644.
Turatto, M., & Galfano, G. (2001). Attentional capture by color without any relevant attentional set. Perception & Psychophysics, 63, 286–297.
Wertheim, A., Hooge, I., Krikke, K., & Johnson, A. (2006). How important is lateral masking in visual search? Experimental Brain Research, 170, 387–402.
Yantis, S., & Hillstrom, A. P. (1994). Stimulus-driven attentional capture: Evidence from equiluminant visual objects. Journal of Experimental Psychology: Human Perception and Performance, 20(1), 95–107.
Yantis, S., & Jonides, J. (1984). Abrupt visual onsets and selective attention: Evidence from visual search. Journal of Experimental Psychology: Human Perception & Performance, 10, 601–621.
Yantis, S., & Jonides, J. (1996). Attentional capture by abrupt onsets: New perceptual objects or visual masking? Journal of Experimental Psychology: Human Perception & Performance, 22(6), 1505–1513.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Owens, C., Spehar, B. Do sudden onsets need to be perceived as new objects to capture attention? The interplay between sensory transients and display configuration. Atten Percept Psychophys 78, 1916–1925 (2016). https://doi.org/10.3758/s13414-016-1183-7
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-016-1183-7