
Abstract
In the attentional boost effect, participants encode images into memory as they perform an unrelated target-detection task. Later memory is better for images that coincided with a target rather than a distractor. This advantage could reflect a broad processing enhancement triggered by target detection, but it could also reflect inhibitory processes triggered by distractor rejection. To test these possibilities, in four experiments we acquired a baseline measure of image memory when neither a target nor a distractor was presented. Participants memorized faces presented in a continuous series (500- or 100-ms duration). At the same time, participants monitored a stream of squares. Some faces appeared on their own, and others coincided with squares in either a target or a nontarget color. Because the processes associated with both target detection and distractor rejection were minimized when faces appeared on their own, this condition served as a baseline measure of face encoding. The data showed that long-term memory for faces coinciding with a target square was enhanced relative to faces in both the baseline and distractor conditions. We concluded that detecting a behaviorally relevant event boosts memory for concurrently presented images in dual-task situations.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Some events are more important for behavior than others. For example, when waiting for coffee at a cafe, hearing the barista call out one’s own name requires a response, whereas hearing someone else’s name does not. A consequence of variability in the relevance of events is variability in attention over time: Events that require a response demand more attention than those that do not (Duncan, 1980). Because attention is limited in capacity (Kinchla, 1992), increasing attention to one stimulus (such as the goal-relevant item) should reduce the processing of concurrent information. However, recent studies have challenged this conclusion, suggesting that the selection of relevant stimuli in time may enhance, rather than impair, the ability to process concurrently presented stimuli (Lin, Pype, Murray, & Boynton, 2010; Swallow & Jiang, 2010), a phenomenon termed the attentional boost effect.
In the attentional boost effect, participants press a button whenever a prespecified target (e.g., a blue square) appears in a stream of distractors (e.g., squares of different colors). At the same time they memorize a series of briefly presented background images (typically presented at a rate of 500 ms/item). Subsequent long-term memory for images encoded with targets is superior to memory for images encoded with distractors. The term “attentional boost effect” implies that the effect reflects a processing enhancement. Indeed, it has been argued that the selection of behaviorally relevant events in time produces brief, but broad, enhancements in perceptual processing, thereby facilitating the processing of the target and concurrent, but unrelated, background images (Swallow & Jiang, 2012). Consistent with this account, images presented at the same time as an unrelated target are remembered better than images presented before or after the target, ruling out standard attentional-cueing and alerting effects as likely sources (Swallow & Jiang, 2011). However, the attentional boost effect is a relative, rather than an absolute, memory advantage. As a result, it could reflect processes that are triggered either by target detection or by distractor rejection.
Without an appropriate baseline, however, there is no way to disambiguate whether the attentional boost effect reflects enhancements due to target detection or inhibitory processes associated with distractor rejection. Both possibilities are compatible with known attentional mechanisms. Selection enhances the processing of relevant items, allowing them to be more deeply processed and to influence behavior (Driver, 2001). However, distractor rejection can also trigger mechanisms that decrease the likelihood that irrelevant items will influence performance (Moher & Egeth, 2012; Tsal & Makovski, 2006). Indeed, the attention literature is full of data suggesting that attentional selection goes hand in hand with attentional inhibition. In the visual cortex, attending to a location increases activity in brain regions that represent that location, but decreases activity in regions representing nearby locations (Silver, Ress, & Heeger, 2007). Behavioral studies have also suggested that distractors are inhibited, resulting in phenomena such as negative priming (Tipper, 2001), visual marking (Watson & Humphreys, 1997), and distractor devaluation (Raymond, Fenske, & Westoby, 2005).
The observation that long-term memory is better for images presented at the same time as targets than for images presented at the same time as distractors could therefore reflect either of two processes (or some combination thereof): enhancement due to target detection (enhancement hypothesis) or inhibition due to distractor rejection (inhibition hypothesis). Previous studies had attempted to tease apart these possibilities by using memory for items encountered under single-task conditions as the baseline (Lin et al., 2010; Spataro, Mulligan, & Rossi-Arnaud, 2013). However, two issues make it difficult to assume that these data apply to the attentional boost effect in long-term recognition memory. The first is that these experiments tested either source memory (e.g., participants had to indicate whether a particular picture was presented in the most recent trial; Lin et al., 2010) or lexical priming (Spataro et al., 2013). Although it is likely that all of these effects represent similar encoding enhancements, they can engage different memory systems (Johnson, Hashtroudi, & Lindsay, 1993; Tulving & Schacter, 1990). Moreover, unlike recognition memory, source memory for scenes under single-task conditions was near chance (Lin et al., 2010; Swallow & Jiang, 2010). More fundamentally, using single-task encoding as a measure of baseline performance confounds the baseline with changes in task demands (dual- vs. single-task processing). Extraneous factors, such as differences in cognitive load and task engagement, are likely to influence estimates of item memory when no targets or distractors are presented. In the present study, we separated target-induced enhancements from distractor-induced inhibition by obtaining a baseline under dual-task encoding conditions. Baseline trials were randomly intermixed with target and distractor trials to ensure that global task demands and strategies were equated across conditions. The results will be important for understanding how two tasks interact when they are performed at the same time.
Experiment 1: No-square baseline
We modified the standard attentional boost effect paradigm (Swallow & Jiang, 2010, 2012) to include trials on which neither a detection target nor a distractor was presented. Participants memorized a long series of continuously presented faces. In addition, a series of colored squares flanked the faces (Fig. 1a). Participants were asked to encode all of the faces into memory and pressed a button when the colored squares were a prespecified target color. Faces could be presented at the same time as target squares, at the same time as distractor squares, or on their own (no squares). Because neither target nor distractor squares were presented in the no-square trials, face encoding in these trials could not be influenced by either the detection of a target color or the rejection of a distractor color. Trials were randomly intermixed to make the occurrence of no-square trials unpredictable. The no-square trials therefore evaluated image encoding in the context of the target-detection task, while minimizing the processes specific to target detection and distractor rejection.

Task, design, and recognition accuracy in Experiment 1. (a) Five trials comprised a trial series. Trials included a face and, usually, two flanking colored squares. Participants pressed a button when the squares were a target color. In some trial series, the squares were omitted on one trial. Items are not to scale. (b) Recognition accuracy (adjusted for false alarms) for faces presented at each serial position, separately for trial series involving target squares or no squares. Error bars represent ±1 SE of the mean. T/NS, target or no square
If the attentional boost effect reflects a detection-related enhancement, then faces presented with target squares should be remembered better than faces presented with no squares. In contrast, if rejecting distractor squares inhibits the processing of concurrently presented faces, then faces presented with distractor squares should be recognized more poorly than faces presented with no squares.
Method
Participants
Sixteen college students (11 female, five male; 18–33 years old) completed Experiment 1. The data from two additional participants were removed due to poor task performance in the square task. Sample sizes were based on previously reported effect sizes (mean d = 0.88 in Swallow & Jiang, 2010; mean d = 1.06 in Swallow & Jiang, 2012). In all experiments, participants had normal or corrected-to-normal visual acuity. They were compensated with cash or extra course credit. The University of Minnesota IRB approved all procedures.
Equipment
Stimulus presentation was controlled using MATLAB and Psychophysics Toolbox (Brainard, 1997; Pelli, 1997). Stimuli were presented on a 17-in. CRT color monitor (1,024 × 768 pixels, 75 Hz) with an unrestrained viewing distance of approximately 40 cm.
Materials
A set of 300 color images of famous faces was obtained through online searches. Faces subtended 12.5º × 12.5º over a gray background. For each participant, the faces were randomly and evenly assigned to three groups: old faces presented during encoding, foils presented in the memory test, and fillers that jittered trial order during encoding. Forty additional faces were shown during practice.
Procedure
The experiment occurred in two phases. In the dual-task encoding phase, participants performed two tasks simultaneously (Fig. 1a). For the encoding task, a long series of faces appeared at a rate of 500 ms/item (no interstimulus interval). For the detection task, flanking squares (1.0º × 1.0º) that were identical in size and color onset at the same time as the faces. One square appeared on each side of the face (1.0º gap). The squares were shown for 100 ms, followed by a 400-ms interstimulus interval. Although faces were presented on every trial (every 500 ms), the squares were sometimes omitted (see the Design section).
Participants encoded the faces for a later memory test. They also pressed a key as quickly as possible whenever squares in a target color appeared (blue for some participants, and orange for others). Nontarget colors were randomly selected from a set of eight colors that were distinct from the target. The task paused after blocks of 90 trials, to provide a break and feedback on the detection task.
In the second phase, participants completed an old–new recognition test. On each trial, participants viewed a single face and pressed a key to report whether it had been shown in the encoding phase. They then indicated their confidence in their recognition response on a 7-point Likert scale. Because the attentional boost effect was indexed by recognition accuracy in previous studies, our analyses focused on recognition accuracy (though confidence ratings are included in the Appendix).
Design
The dual-task encoding phase consisted of 200 trial series. Trial series contained trials in five serial positions (Fig. 1a). Each series included four distractor trials, in Serial Positions 1, 2, 4, and 5, in which the squares were one of eight distractor colors. The third serial position was either a target trial (in which the squares were the target color) or a no-square trial (in which no squares were presented). These two types of trial series—target series or no-square series—were equally frequent and were randomly intermixed. The beginning and end of each trial series was not apparent to participants, due to their continuous presentation and randomization, and to the inclusion of filler trials between adjacent trial series (see the end of this section). This design yielded ten conditions: five serial positions in two series types.
The 100 old images were randomly and evenly divided across conditions, resulting in ten images per condition. As in previous studies (e.g., Swallow & Jiang, 2010), each face was presented ten times to enhance memory. Each time that a face was presented, it was always in the same condition. Face order was otherwise randomized. Because multiple faces were associated with each condition, the order of faces was unpredictable.
To eliminate temporal predictability of the target squares, trial series were separated by zero to eight filler trials. These consisted of a filler face and flanking squares that were usually one of the distractor colors. However, to encourage continuous engagement in the task, filler trials included targets (filler targets) when two trial series were separated by three or more fillers. Because the number of fillers was random, the numbers of filler targets differed across participants (range: 141–161). Filler faces were not tested in the recognition test.
Results and discussion
Detection task performance
Participants quickly and accurately responded to target squares (M = 96.4%, SE = 0.92; response time M = 396 ms, SE = 9). False alarms (i.e., responses more than 2 s after a target or after a response had already been made to the target) occurred infrequently (M = 2%, SE = 0.33). However, they were three times more likely to follow a distractor trial (M = 3.1%, SE = 0.55) than a no-square trial (M = 0.9%, SE = 0.33), t(15) = 3.45, p = .003, d = 1.19. Thus, distractor squares were more likely to lead to a buttonpress than were no squares. This indicates that participants were more likely to confuse the distractor squares (rather than no squares) with the target squares.
Face recognition
To adjust for response biases, the false recognition rate (incorrectly recognized new faces; overall M = .294, SE = .036) was subtracted from the hit rate (correctly recognized old faces; overall M = .713, SE = .037). Because old and new faces were tested in a random order, all conditions were associated with the same false recognition rate.
If the attentional boost effect reflects inhibition due to distractor rejection, faces presented with distractors should be more poorly recognized than those presented with no squares. However, recognition accuracy for faces in the no-square and distractor trials did not differ significantly, t(15) = 0.34, p = .734. In contrast, if the attentional boost effect reflects an enhancement due to target detection, faces presented with targets should be recognized better than those presented with no squares or with distractors. Consistent with this proposal, faces presented in target trials were recognized better than those presented in no-square, t(15) = 3.24, p = .006, d = 0.9, or distractor, t(15) = 3.62, p = .002, d = 1.0, trials (Fig. 1b).
An analysis of variance (ANOVA) with serial position and series type (no square or target) as variables further supported these conclusions. This analysis showed a significant interaction between series type and serial position, F(4, 60) = 2.75, p = .036, η p 2 = .155, and a main effect of series type, F(1, 15) = 9.34, p = .008, η p 2 = .284. The main effect of serial position was not significant, F(4, 60) = 1.48, p = .219. Post-hoc analyses indicated that the Type × Serial Position interaction was driven by a main effect of serial position for target series, F(4, 60) = 3.95, p = .006 (uncorrected), η p 2 = .208, but not for no-square series, F < 1.
Confidence ratings were also analyzed, but the pattern was inconsistent across experiments (see the Appendix). They were therefore neither consistent nor inconsistent with either the enhancement or inhibition hypotheses. For completeness, these data are reported in the Appendix.
The recognition accuracy data supported the enhancement hypothesis: Faces that coincided with targets were remembered better than faces presented with distractors or on their own. In addition, recognition accuracy for faces presented with distractors was similar to that for faces in the baseline condition.
Experiment 2: Baseline for frequent targets
Because targets were infrequent in Experiment 1 (the target-to-distractor ratio was approximately 1:4), participants may not have continuously engaged in the detection task. If the distractor squares were not continuously monitored, they would not consistently trigger inhibitory processes. In addition, one might worry that the 500-ms presentation rate allowed additional resources to be focused on the faces after a distractor was presented, potentially offsetting inhibition effects that might occur when the distractor was actually on the screen. Thus, the face stimuli may have been presented for too long to observe an effect of distractor-related inhibition. To address these issues, we conducted a second experiment that evaluated whether increasing target frequency reveals an inhibitory effect of distractor squares on face encoding, particularly when the faces are presented for briefer durations.
To address these issues, the targets in Experiment 2 were presented frequently, on half of the trials, to ensure continuous attention to the squares. In addition, face duration was manipulated across participants to examine whether inhibition would be greater for faces that offset at the same time as the distractor squares.
Method
Participants
A group of 32 college students (26 female, six males; 18–42 years old) completed Experiment 2—16 in Experiment 2a and 16 in Experiment 2b. One participant who performed at chance on the recognition memory test (the proportion of correct responses was .494) was replaced. The sample size was greater than that of Experiment 1 due to the manipulation of one factor (face duration) between groups.
Materials
This experiment included 320 famous faces, randomly assigned to be 160 old faces and 160 foils for each participant. We created luminance-matched masks by dividing each face into 1,024 pieces and shuffling the locations of the pieces. An additional 100 faces were shown during practice.
Procedure
Experiment 2 was identical to Experiment 1, except in the following respects (cf. Fig. 1a). Because targets could appear on consecutive trials, stimuli were presented more slowly (1 s/item) to provide adequate time for responses. Each trial consisted of a face (Exp. 2a, 500-ms duration; Exp. 2b, 100-ms duration) and a mask (Exp. 2a, 500-ms duration; Exp. 2b, 900-ms duration) that immediately followed it. Two squares of the same color and size (1º × 1º) appeared to the left and right (1º gap) of the face on most trials (100-ms duration + 900-ms interval). These flanker squares onset at the same time as the face, and both flanker squares were either blue or red. The colors (red or blue) assigned to the target and distractor conditions were counterbalanced across participants. Participants received feedback on their overall speed and accuracy every 80 trials; they performed 100 trials of practice prior to beginning the dual-task encoding phase.
Memory for the faces was tested in an unspeeded two-alternative forced choice recognition test. Two faces, one old and one new, appeared on the left and right sides of the screen on each trial. Participants pressed a left or a right button to choose the old picture and then rated their confidence. Faces were tested in a random order in the forced choice recognition test.
Design
Unlike in Experiment 1, trials were not grouped into trial series, due to the high frequency of target trials. Three conditions were presented in a pseudorandom order: Old faces were presented with either target squares (N = 80), distractor squares (N = 64), or no squares (N = 16). Both the large number of target trials and the small number of no-square trials should have increased task engagement. Each face was presented three times, and always in the same condition, for a total of 480 trials. All faces were shown once before any were repeated.
The target to distractor to no-square trial ratio was 5:4:1. The global trial frequency was faithfully reflected in the local trial statistics: Every ten trials contained five target trials, four distractor trials, and one no-square trial. No-square trials always followed a target or distractor trial. Participants were given a break every 80 trials.
Results and discussion
Detection task
Participants performed the detection task equally well in both duration conditions (Table 1), ts(30) < 1.16, ps > .254. Participants were more than twice as likely to false alarm on distractor trials (M = .035, SE = .005) than on no-square trials (M = .014, SE = .004), F(1, 30) = 42.5, p < .001, η p 2 = .586. This difference did not interact with face duration, F(1, 30) = 1.44, p = .239. As in Experiment 1, participants were more likely to press a button when distractor squares were presented than when no squares were presented; participants thus treated the no-square trials differently than the distractor trials.
Face recognition
Despite the increase in target frequency, the data from Experiment 2 followed the same pattern as those in Experiment 1 (see Fig. 2). Recognition accuracy varied across the three encoding conditions [main effect of encoding condition, F(2, 60) = 6.97, p = .002, η p 2 = .188]. Consistent with target-related enhancement, faces presented in target trials were later better recognized than the faces presented in no-square, t(31) = 3.28, p = .003, d = 0.54, and distractor, t(31) = 4.26, p < .001, d = 0.53, trials. Although the longer face duration facilitated face memory, F(1, 30) = 15.8, p < .001, η p 2 = .344, it did not interact with the effect of targets on later memory, F < 1. Faces presented with distractors were remembered just as well as faces presented in isolation, t(30) = –0.42, p = .675, providing no evidence for the inhibition hypothesis.

Accuracy from the two-alternative forced choice face recognition test in Experiment 2. Error bars represent ±1 SE of the mean.
The data from Experiment 2 confirmed that the attentional boost effect is best characterized as an enhancement due to target detection: Memory for images presented at the same time as a target was enhanced relative to those presented on their own, even when targets were common. Moreover, in two groups of participants, we found no evidence that distractor squares inhibited memory for concurrently presented images, even when the images were briefly presented. Although memory is usually better for rare events (Hunt, 1995), memory for no-square trials was no better than that for target or distractor trials.
Experiment 3: Frequent baseline trials
To ensure constant engagement in the task, the blank trials were relatively rare in Experiments 1 and 2. However, it is possible that participants expected a square to appear on every trial and effectively treated the no-square trials as distractor trials. Alternatively, rare distractors, such as those that appear in an unexpected color, can interfere with face encoding (Swallow & Jiang, 2012). If this were the case, then a difference between the no-square and distractor trials could have been masked by the fact that the no-square trials were rare and could trigger inhibitory processes on their own. Experiment 3 addressed this concern by making the no-square trials as frequent as the distractor-square and target-square trials. If the data from Experiments 1 and 2 were due to either the expectation that a square would be presented on every trial or the novelty of the no-square trials, then increasing the frequency of the no-square trials should reveal differences between the no-square and distractor-square conditions in Experiment 3.
Method
Participants
Sixteen college students (13 female, three male; 18–32 years of age) completed Experiment 3.
Design and procedure
Experiment 3 was identical to Experiment 2b (100-ms face duration, 900-ms mask), with the exception that the target to distractor to no-square trial ratio was changed to 1:1:1. Along with this change, 120 old faces and 120 new faces were now presented. The old faces were divided into 40 faces per condition, with each face presented three times over the course of 360 trials. Each time that a face was presented, it was shown in the same encoding condition (i.e., target square, distractor square, or no square). Trial conditions were randomized, with the contraint that the same encoding condition could occur on no more than four consecutive trials.
Results and discussion
Detection task
Participants responded to most of the target squares (M = .989, SE = .003), to few of the distractor squares (M = .016, SE = .003), and to fewer of the no-square trials (M = .001, SE = .001). False alarm rates were reliably greater for distractor than for no-square trials, t(15) = 4.46, p < .001, d = 1.61. Response times to target squares were comparable to those in the previous experiments (M = 346 ms, SE = 11).
Face recognition
The recognition data replicated those from Experiment 2. As before, an ANOVA indicated that encoding condition reliably influenced recognition memory for the faces, F(2, 30) = 4.46, p = .02, η p 2 = .229. As can be seen from Fig. 3, left panel, recognition memory was best for faces presented at the same time as a target square, but was similarly low for faces presented at the same time as a distractor square or with no square. Follow-up analyses indicated that faces that were presented at the same time as a target square were recognized better than those presented at the same time as a distractor square, t(15) = 2.69, p = .017, d = 0.75. The difference between faces in the target-square and no-square conditions approached significance, t(15) = 2.05, p = .058, d = 0.67. Finally, memory for faces in the distractor-square and no-square conditions did not reliably differ, t(15) = 0.6, p = .56.

Although faces presented on no-square trials occurred as frequently as targets and distractors, we found no evidence that such faces were remembered better than those in the distractor trials in Experiment 3. Most importantly, faces that coincided with target squares were recognized better than those that were presented on their own or with distractor squares. Increasing the frequency of the no-square trials failed to reveal a different pattern of data than those found in Experiments 1 and 2: Detecting a target boosted the encoding of concurrently presented faces, enhancing later memory.
Experiment 4: Covert response
Experiments 1–3 required participants to press a button on a target-square trial, and to make no response on a no-square or distractor-square trial. In this task, the decision to respond to a target was accompanied by an overt motor response. Although previous research has shown that the attentional boost effect occurs even when no motor response is required (Swallow & Jiang, 2011, in press), other data suggest that motor inhibition can reduce long-term memory (Herbert & Sütterlin, 2012) and affective evaluations of stimuli (Raymond et al., 2005). To ensure that the enhancements observed in Experiments 1–3 were not due to the motor response to the targets, participants in Experiment 4 performed a covert counting task.
Method
Participants
Sixteen college students (nine males, seven females; 18–31 years) completed Experiment 4.
Design and procedure
In Experiment 4, we replaced the detection task used in Experiment 3 with a covert counting task (100-ms face duration, 900-ms mask; target to distractor to no-square ratio of 1:1:1). As in Experiment 3, faces were presented at the same time as a target colored square, a distractor colored square, or no square. The colors of the squares (red/blue) that were assigned to the target and distractor conditions were counterbalanced across participants. During encoding, the task paused after 8–12 targets (randomly selected), and participants reported the count. They reported the number of times that they had seen the target color by selecting from one of five options (8–12). After reporting their count, participants immediately received feedback on their accuracy. They were encouraged to take a short break before continuing the task.
For Experiment 4, we used 300 faces that were randomly assigned to be new faces for the recognition test (N = 150) or old faces that appeared with either target squares (N = 50), distractor squares (N = 50), or no squares (N = 50) during encoding. Each old face was presented three times during the encoding task, and always in the same condition.
Results and discussion
Counting task
On average, participants correctly reported the number of target squares a mean of 88.8% of the time (SE = 3.48%). Reported counts deviated from the true number of targets by a mean of 0.11 (SE = 0.37) across all trials.
Face recognition
As is shown in Fig. 3, right panel, recognition accuracy was greater for faces that coincided with target squares than for faces in the other two conditions, producing a significant main effect of encoding condition in a one-way ANOVA, F(2, 30) = 3.61, p = .039, η p 2 = .194. Planned comparisons further indicated that this effect reflected a memory benefit in the target condition relative to the no-square condition, t(15) = 2.51, p = .024, d = 0.48, and the distractor-square condition, t(15) = 2.17, p = .046, d = 0.47. We observed no apparent memory reduction in the distractor condition relative to the no-square condition, t(15) = 0.43, p = .67.
These data confirmed that the attentional boost occurred even when no overt motor response was planned or executed. They also pose a significant challenge to the idea that spillover from motor inhibitory processes could account for the similar levels of performance for faces in the distractor-square and no-square conditions. These data strengthen the conclusion that the attentional boost effect reflects enhancement from target detection, even when no overt motor responses are involved.
Confidence ratings
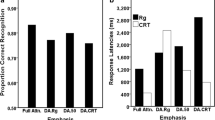
Across experiments, confidence ratings exhibited multiple patterns, with some effects reaching statistical significance in some cases but not in others (see the Appendix). Although confidence ratings and accuracy are often positively correlated in old–new recognition, the relationship between accuracy and confidence is complex, varying across test types and statistical approaches to the data (Roediger, Wixted, & DeSoto, 2012). Even when effects are positively correlated, strong effects in accuracy do not always occur alongside strong effects in confidence (e.g., Busey, Tunnicliff, Loftus, & Loftus, 2000, Exps. 1 and 2). These considerations and the lack of consistency across experiments suggest that our experimental paradigm is unlikely to have produced large, reliable effects on a person’s subjective and retrospective impressions of memory strength.
General discussion
Over the last several years, a growing number of studies have suggested that events that exert high attentional and perceptual demands do not always impair the processing of concurrently presented items (Lin et al., 2010; Makovski, Swallow, & Jiang, 2011; Pascucci & Turatto, 2013; Spataro et al., 2013; Swallow & Jiang, 2010, 2011, 2012, in press). Many of these studies have used a dual-task paradigm that contrasted the effect of events that required a response (targets) with the effect of those that did not (distractors) on memory for concurrently presented images, leaving the studies open to different interpretations: The memory advantage for faces coinciding with targets relative to those that coincided with distractors could have reflected enhancements triggered by target detection, interference from distractor rejection, or both. A resolution to this issue will be critical for understanding what generates the attentional boost effect. Explanations of why rejecting a distractor impairs memory for concurrent images should differ considerably from those that attempt to account for why detecting a target enhances such memory.
Interference in a dual-task paradigm like that used to study the attentional boost effect could originate from several different sources. One is interference from processes that are triggered by the recognition that an item is a target, and therefore requires a response, or the rejection of that item as a distractor, which therefore requires no response. In either case, processes specific to the squares could interfere with the ability to encode or later retrieve the concurrent image (item-specific interference). The second source of interference results from the fact that multiple goals and rule sets need to be actively maintained in memory when two tasks are performed at the same time (task-specific interference). For all trials in these experiments, participants had to maintain the encoding task and the detection task. For the detection task, participants would additionally need to ensure that they were prepared to respond to the target squares when they appeared. Importantly, interference from this last task is absent when encoding under single-task conditions is used as a baseline against which the target and distractor conditions are compared.
To avoid conflating the baseline measure of face encoding with changes in central demands and task specific interference, the baseline used in this study was acquired in a block of trials in which participants performed two tasks at once. In these experiments, faces could appear with target squares, distractor squares, or on their own. Faces that appeared on their own did not include additional items to draw attention away from the image. In addition, because no squares were present, processes that would be triggered by the presence of items that could require a response should not have been triggered. In fact, false alarm rates on no-square trials were markedly lower than those on distractor-square trials. The data indicated that memory for faces presented with unrelated target squares was better than memory for faces presented in isolation. In addition, faces presented on their own were remembered no better than faces presented with distractor squares. Across four experiments, target detection facilitated image memory both when targets were rare and when they were frequent. The advantages were similar for images presented for 100 and 500 ms. In the experiments in which a motor response was made, distractors produced more than twice as many false alarms as did no squares, yet they did not reliably reduce later memory for concurrent images. Thus, detecting targets for one task enhanced the processing and encoding of concurrently presented images.
Although one could claim that any event that does not require a response is treated as a distractor, several considerations argue against this reduction. First, square onsets were a critical cue to the presence of targets in these experiments, increasing the likelihood that distractor squares were attended (Folk, Remington, & Johnston, 1992). Onsets at the locations of the squares were not present on the no-square trials. Second, rare distractors impair memory for concurrent faces (Swallow & Jiang, 2012). If no-square trials were equated with distractors, then they should have interfered more with image encoding when they were rare, and less so when they were frequent. Yet, changing the frequency with which the no-square trials occurred (rarely in Exps. 1 and 2, frequently in Exps. 3 and 4) had little effect on the data. Third, participants were much less likely to press a button in response to a no-square trial than to a distractor square trial. The increased false alarm rate suggests that distractor trials are more similar to the target trials, and hence should have received greater inhibition than no-square trials to prevent unwanted selection (cf. Chun & Potter, 1995; Maki & Mebane, 2006). Finally, one of the main questions posed in this study was whether distractor squares interfere with concurrent image encoding as a result of inhibitory processes that are engaged when a stimulus could lead to an error. Engaging these processes even when no potential target stimuli were present would not only be inefficient, it would also suggest that inhibition is the default response to events. If that were the case, the distinction between baseline performance and inhibition would lose its meaning (Makovski, Jiang, & Swallow, 2013). All of these considerations led us to favor the conclusion that the attentional boost effect reflects enhanced processing of stimuli that coincide with stimuli that require a response.
These experiments were the first to acquire a baseline measure of image memory under dual-task conditions. Previous reports have relied on across-task comparisons to address this issue, often comparing the effects of target detection on dual-task encoding to those on single-task encoding (Lin et al., 2010; Spataro et al., 2013). Importantly, although the conclusions from all of these studies were similar to the present one, they did not address two concerns. The first is that the strategies and task demands may differ too greatly between dual-task and single-task blocks to rely on single-task encoding as a baseline for dual-task encoding. A second concern is that these studies examined the effects of target detection on two specific kinds of memory—source memory and implicit memory—that likely rely on different memory systems than those used in long-term recognition memory (Johnson et al., 1993; Tulving & Schacter, 1990). Indeed, whereas single-task encoding conditions yielded poor source memory in one study (Lin et al., 2010), they enhanced long-term recognition memory in another (Swallow & Jiang, 2010).
Other studies provided post-hoc evidence for the enhancement hypothesis. For example, in Swallow and Jiang (2011), faces were presented simultaneously with squares in some blocks, or preceded or trailed squares by 100 ms on other blocks. Images presented at the same time as targets in simultaneous blocks were remembered better than images presented in the nonsimultaneous blocks. However, because these conditions were blocked, participants may have processed the images in nonsimultaneous blocks differently. Similar concerns may be raised for other reports that have relied on post-hoc comparisons or single- versus dual-task comparisons (Leclercq & Seitz, 2012; Lin et al., 2010; Spataro et al., 2013). Additionally, whereas target items enhance activity in early visual cortex relative to distractor items (Swallow, Makovski, & Jiang, 2012), the effect of these enhancements on later memory has yet to be determined. The experiments presented here represent the strongest, most direct evidence that the attentional boost effect is due to target detection rather than distractor rejection. The baseline condition was obtained from the same participants, under the same task instructions, and when participants could not anticipate which trial types would be shown next.
According to the dual-task interaction model (Swallow & Jiang, 2013), detecting a behaviorally relevant event produces a temporally specific, but modality-independent and spatially broad, enhancement (Swallow et al., 2012). This temporal selection mechanism could be supported by brief increases in activity in the locus coeruleus–norepinephrine system (LC-NE), which increase the responsivity of afferent regions to new input. LC firing rates increase briefly when monkeys detect a target, but do not decrease below baseline when monkeys reject a distractor (Aston-Jones & Cohen, 2005). The behavioral data obtained in the present study strengthen the link between the attentional boost effect and the LC-NE system (though other neurophysiological systems could be involved). Because the LC projects broadly throughout the neocortex, its impact is likely widespread, influencing activity in brain regions that are not involved in target processing.
It is important to note that our data do not imply that distractor processing does not involve inhibition. It is possible that under appropriate task conditions, the target-induced attentional boost effect might be observed alongside distractor-induced attentional suppression. To conclude that distractor rejection does not interfere with concurrent image encoding would require greater sensitivity and statistical methods that would permit such conclusions. What the present set of experiments do suggest, however, is that distractor rejection does not influence secondary task processing as strongly or as consistently as target detection. The attentional boost effect therefore is primarily a processing enhancement due to target detection, rather than a suppression due to distractor inhibition.
This study joins a growing body of evidence that target detection produces broad perceptual enhancements. Detecting an auditory target enhances activity in visual cortical areas (Swallow et al., 2012). Target detection also facilitates the perceptual learning of visual features that coincide with the target (Seitz & Watanabe, 2003) and increases visual perceptual illusions (Pascucci & Turatto, 2013). Thus, not only does target detection enhance memory for the target itself (Makovski et al., 2013), it also boosts memory for concurrent images. Temporal selection of behaviorally relevant events broadly boosts perceptual encoding.
References
Aston-Jones, G., & Cohen, J. D. (2005). An integrative theory of locus coeruleus–norepinephrine function: Adaptive gain and optimal performance. Annual Review of Neuroscience, 28, 403–450. doi:10.1146/annurev.neuro.28.061604.135709
Brainard, D. H. (1997). The Psychophysics Toolbox. Spatial Vision, 10, 433–436. doi:10.1163/156856897X00357
Busey, T. A., Tunnicliff, J., Loftus, G. R., & Loftus, E. F. (2000). Accounts of the confidence–accuracy relation in recognition memory. Psychonomic Bulletin & Review, 7, 26–48. doi:10.3758/BF03210724
Chun, M. M., & Potter, M. C. (1995). A two-stage model for multiple target detection in rapid serial visual presentation. Journal of Experimental Psychology: Human Perception and Performance, 21, 109–127. doi:10.1037/0096-1523.21.1.109
Driver, J. (2001). A selective review of selective attention research from the past century. British Journal of Psychology, 92, 53–78. doi:10.1348/000712601162103
Duncan, J. (1980). The locus of interference in the perception of simultaneous stimuli. Psychological Review, 87, 272–300. doi:10.1037/0033-295X.87.3.272
Folk, C. L., Remington, R. W., & Johnston, J. C. (1992). Involuntary covert orienting is contingent on attentional control settings. Journal of Experimental Psychology: Human Perception and Performance, 18, 1030–1044. doi:10.1037/0096-1523.18.4.1030
Herbert, C., & Sütterlin, S. (2012). Do not respond! Doing the think/no-think and go/no-go tasks concurrently leads to memory impairment of unpleasant items during later recall. Frontiers in Psychology, 3, 269. doi:10.3389/fpsyg.2012.00269
Hunt, R. R. (1995). The subtlety of distinctiveness: What von Restorff really did. Psychonomic Bulletin & Review, 2, 105–112. doi:10.3758/BF03214414
Johnson, M. K., Hashtroudi, S., & Lindsay, D. S. (1993). Source monitoring. Psychological Bulletin, 114, 3–28. doi:10.1037/0033-2909.114.1.3
Kinchla, R. A. (1992). Attention. Annual Review of Psychology, 43, 711–742. doi:10.1146/annurev.ps.43.020192.003431
Leclercq, V., & Seitz, A. R. (2012). Fast task-irrelevant perceptual learning is disrupted by sudden onset of central task elements. Vision Research, 61, 70–76. doi:10.1016/j.visres.2011.07.017
Lin, J. Y., Pype, A. D., Murray, S. O., & Boynton, G. M. (2010). Enhanced memory for scenes presented at behaviorally relevant points in time. PLoS Biology, 8, e1000337. doi:10.1371/journal.pbio.1000337
Maki, W. S., & Mebane, M. W. (2006). Attentional capture triggers an attentional blink. Psychonomic Bulletin & Review, 13, 125–131. doi:10.3758/BF03193823
Makovski, T., Jiang, Y. V., & Swallow, K. M. (2013). How do observer’s responses affect visual long-term memory? Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 1097–1105. doi:10.1037/a0030908
Makovski, T., Swallow, K. M., & Jiang, Y. V. (2011). Attending to unrelated targets boosts short-term memory for color arrays. Neuropsychologia, 49, 1498–1505. doi:10.1016/j.neuropsychologia.2010.11.029
Moher, J., & Egeth, H. E. (2012). The ignoring paradox: Cueing distractor features leads first to selection, then to inhibition of to-be-ignored items. Attention, Perception, & Psychophysics, 74, 1590–1605. doi:10.3758/s13414-012-0358-0
Pascucci, D., & Turatto, M. (2013). Immediate effect of internal reward on visual adaptation. Psychological Science, 24, 1317–1322. doi:10.1177/0956797612469211
Pelli, D. G. (1997). The VideoToolbox software for visual psychophysics: Transforming numbers into movies. Spatial Vision, 10, 437–442. doi:10.1163/156856897X00366
Raymond, J. E., Fenske, M. J., & Westoby, N. (2005). Emotional devaluation of distracting patterns and faces: A consequence of attentional inhibition during visual search? Journal of Experimental Psychology: Human Perception and Performance, 31, 1404–1415. doi:10.1037/0096-1523.31.6.1404
Roediger, H. L., III, Wixted, J. H., & DeSoto, K. A. (2012). The curious complexity between confidence and accuracy in reports from memory. In L. Nadel & W. Sinnott-Armstrong (Eds.), Memory and law (pp. 84–118). Oxford, UK: Oxford University Press.
Seitz, A. R., & Watanabe, T. (2003). Is subliminal learning really passive? Nature, 422, 36. doi:10.1038/422036a
Silver, M. A., Ress, D., & Heeger, D. J. (2007). Neural correlates of sustained spatial attention in human early visual cortex. Journal of Neurophysiology, 97, 229–237. doi:10.1152/jn.00677.2006
Spataro, P., Mulligan, N. W., & Rossi-Arnaud, C. (2013). Divided attention can enhance memory encoding: The attentional boost effect in implicit memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 39, 1223–1231. doi:10.1037/a0030907
Swallow, K. M., & Jiang, Y. V. (2010). The attentional boost effect: Transient increases in attention to one task enhance performance in a second task. Cognition, 115, 118–132. doi:10.1016/j.cognition.2009.12.003
Swallow, K. M., & Jiang, Y. V. (2011). The role of timing in the attentional boost effect. Attention, Perception, & Psychophysics, 73, 389–404. doi:10.3758/s13414-010-0045-y
Swallow, K. M., & Jiang, Y. V. (2012). Goal-relevant events need not be rare to boost memory for concurrent images. Attention, Perception, & Psychophysics, 74, 70–82. doi:10.3758/s13414-011-0227-2
Swallow, K. M., & Jiang, Y. V. (2013). Attentional load and attentional boost: A review of data and theory. Frontiers in Psychology, 4, 274. doi:10.3389/fpsyg.2013.00274
Swallow, K. M., Makovski, T., & Jiang, Y. V. (2012). Selection of events in time enhances activity throughout early visual cortex. Journal of Neurophysiology, 108, 3239–3252. doi:10.1152/jn.00472.2012
Tipper, S. P. (2001). Does negative priming reflect inhibitory mechanisms? A review and integration of conflicting views. Quarterly Journal of Experimental Psychology, 54A, 321–343. doi:10.1080/713755969
Tsal, Y., & Makovski, T. (2006). The attentional white bear phenomenon: The mandatory allocation of attention to expected distractor locations. Journal of Experimental Psychology: Human Perception and Performance, 32, 351–363. doi:10.1037/0096-1523.32.2.351
Tulving, E., & Schacter, D. L. (1990). Priming and human memory systems. Science, 247, 301–306. doi:10.1126/science.2296719
Watson, D. G., & Humphreys, G. W. (1997). Visual marking: Prioritizing selection for new objects by top-down attentional inhibition of old objects. Psychological Review, 104, 90–122. doi:10.1037/0033-295X.104.1.90
Author note
This research was funded in part by the Institute of Marketing and Research of the University of Minnesota. The authors thank Tal Makovski for discussion, and Lily Berrin, Birgit Fink, Mary-Kelly Mulligan, and Tian Saltzman for help with data collection.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix
Rights and permissions
About this article

Cite this article
Swallow, K.M., Jiang, Y.V. The attentional boost effect really is a boost: Evidence from a new baseline. Atten Percept Psychophys 76, 1298–1307 (2014). https://doi.org/10.3758/s13414-014-0677-4
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-014-0677-4