
Abstract
Reports have conflicted about the possible special role of location in visual working memory (WM). One important question is: Do we maintain the locations of objects in WM even when they are irrelevant to the task at hand? Here we used a continuous response scale to study the types of reporting errors that participants make when objects are presented at the same or at different locations in space. When several objects successively shared the same location, participants exhibited a higher tendency to report features of the wrong object in memory; that is, they responded with features that belonged to objects retained in memory but not probed at retrieval. On the other hand, a similar effect was not observed when objects shared a nonspatial feature, such as color. Furthermore, the effect of location on reporting errors was present even when its manipulation was orthogonal to the task at hand. These findings are consistent with the view that binding together different nonspatial features of an object in memory might be mediated through an object’s location. Hence, spatial location may have a privileged role in WM. The relevance of these findings to conceptual models, as well as to neural accounts of visual WM, is discussed.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Numerous studies have shown that spatial location has a unique role in visual perception. For example, when participants are asked to report the location and shape of items specified by their color, correct shape responses are contingent on correct localizations (Nissen, 1985). Another line of studies has shown that participants are more likely to report items that are spatially close to a precued target than to report items that are similar in other dimensions (e.g., color and shape), leading to the conclusion that selective processing of targets specified by different features is accomplished by attending to target location (Snyder, 1972; Tsal & Lavie, 1988, 1993). The special role of spatial location in visual perception and selective attention has been further established using a range of different paradigms (e.g., Johnston & Pashler, 1990; Kwak & Egeth, 1992; Sagi & Julesz, 1985).
Recent research on visual working memory (WM), including other work in this special issue, has focused on the structure of representations within visual WM. A critical question is whether location has a special role in visual WM, as well as in perception and attention? According to one view, objects in memory are maintained in a few independent “slots” (Luck & Vogel, 1997) that can be maintained in an abstract manner, divorced from the way that visual information was originally perceived (Woodman, Vogel, & Luck, 2012). This conclusion suggests that the special role of location might be critical only at the perceptual stage, but not when memory processes are involved.
Woodman et al. (2012) used a change detection task in which a brief sample array of several colored rectangles was followed, after a short delay, by a test array that either was identical to the sample or differed in one of the objects. Scrambling the locations of objects between the sample and test displays did not lead to a significant decrease in performance, leading the authors to conclude that the representations of objects in visual WM are independent of each other and, crucially, are not tightly bound to either absolute or relative locations (Woodman et al., 2012).
However, other studies using very similar approaches have reported impaired change detection performance when the task-irrelevant spatial configuration of objects changed from the sample to the test arrays (Hollingworth, 2007; Hollingworth & Rasmussen, 2010; Jiang, Olson, & Chun, 2000; Olson & Marshuetz, 2005; Treisman & Zhang, 2006), especially following short delays (Logie, Brockmole, & Jaswal, 2011). These results suggest instead that objects in WM might still be organized according to their position, even when location is irrelevant to the task. Indeed, for some authors, location has been considered to have a privileged role in both visual perception and WM, by allowing binding of different nonspatial features that belong to an object located at a specific position in space (Treisman & Gelade, 1980; Treisman & Zhang, 2006; Wheeler & Treisman, 2002).
An alternative view to the “slots” framework regards performance in visual WM tasks as decisions made on noisy signals (Wilken & Ma, 2004). According to this proposal, objects are not represented in an all-or-none, “slot-like” manner, but rather are maintained with variable precision, depending on factors such as the number of objects currently maintained in WM (Bays & Husain, 2008). This alternative view has arisen, in part, with the use of delayed-estimation tasks that use a continuous, analog report scale. Although preceding studies based their conclusions on tasks with strictly discrete reporting alternatives (e.g., “Did the object change or not?”), in continuous-report tasks participants reproduce from memory a specific feature of an object using an analog scale (e.g., Bays, Catalao, & Husain, 2009; Wilken & Ma, 2004; Zhang & Luck, 2008). Each response in such tasks provides much more information on the quality of the underlying memory representation (several bits) than do the traditional binary responses (one bit).
Perhaps more importantly, this technique opens a window on the mechanisms underlying visual WM, by allowing for studying the type of errors that participants exhibit. If errors are spread uniformly across all reporting space, it suggests that participants, in effect, have no access to information to guide their reports when they make erroneous responses (Zhang & Luck, 2008). However, if errors are not random, but are specifically clustered around the target or nontarget objects, this would suggest that some information about previously presented objects can still be accessed, and that this information can systematically influence memory recall (see Bays et al., 2009; Gorgoraptis, Catalao, Bays, & Husain, 2011; Pertzov, Dong, Peich, & Husain, 2012).
Here we used a continuous-report tasks to investigate whether objects in visual WM are indeed organized according to their spatial position, even when location information is irrelevant to the task. We hypothesized that the increased sensitivity as well as the error analysis afforded by this technique might shed new light on the mixed results regarding the role of location that have previously been obtained from change detection tasks (Hollingworth, 2007; Hollingworth & Rasmussen, 2010; Jiang et al., 2000; Logie et al., 2011; Olson & Marshuetz, 2005; Treisman & Zhang, 2006; Woodman et al., 2012). If objects in memory are stored independently of their location (Woodman et al., 2012), it should not matter whether items occupy the same or different locations. If, on the other hand, objects are tied to their locations, they should interfere with each other when they share the same location.
Moreover, investigating the types of errors made can shed important light on the role that location plays in visual WM processes. If location is used to access specific visual features (Nissen, 1985) also at the postperceptual stage, or to bind together the different nonspatial features of an object maintained in WM (Treisman & Zhang, 2006; Wheeler & Treisman, 2002), position-based interference should be associated with a systematic bias to report features belonging to other objects presented at the same location. However, if object features themselves are stored according to their location, then increased level of errors due to location-based interference should be reflected as partial or complete losses of the memory representation, leading to more variable responses around the target item or to random guessing, respectively.
To anticipate our results, we found that memory reports on objects that share the same location are less accurate than those when objects are displayed at different locations, even when object location was irrelevant to the task. Decreased accuracy was not a result of partial or complete information loss, but rather was associated with a systematic increased tendency to report a feature of the wrong object in WM.
Experiment 1
Method
Participants
Eight healthy volunteers (one female, seven male; mean age of 24 years, range = 18–31 years) participated in this study. All of the participants, in all experiments, had normal or corrected-to-normal visual acuity. Informed consent for all experiments was obtained in a manner approved by the local ethics committee.
Stimuli and behavioral procedure
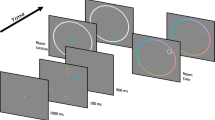
A schematic representation of the task is shown in Fig. 1a.

Memory for orientation with stimuli presented at the same versus different locations. a Participants were presented with a sequence of four bars, each with a different orientation and color. A probe object with the color of one of the objects (in this case, blue) was then presented, and participants adjusted the orientation of the probe to match the orientation of the bar of that color (the target object, in this case the second item in the sequence). b Errors between targets and responses for the two conditions and four serial positions of the target in the sequence. c and d Frequency histograms of responses, aligned with respect to the orientations of targets and nontargets (respectively). Participants systematically reported nontarget orientations significantly more often in the same-location condition. Asterisks denote significance levels of p < .05 for two-tailed t tests: Error bars show SEMs
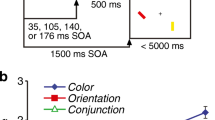
Each trial consisted of a sequence of four colored bars (2º × 0.3º of visual angle) consecutively presented on a gray background, on a 21-in. CRT monitor at a viewing distance of 60 cm. Each bar had a different color and orientation, and all were presented on an invisible circle of 6º radius around fixation. In the same-location condition, one position on the circle was randomly picked and all four stimuli were displayed on that location. In the different-location condition, four different positions were picked, with the constraint of a minimum center-to-center separation of 3º of visual angle.
The sequence of colors in each trial was produced by permutation of a random selection of eight distinguishable colors. Bars within the same sequence differed by at least 10º in orientation, which was otherwise random. Each object was shown for 200 ms, followed by a 300-ms blank screen. Note that this is more than sufficient time for the encoding of each bar (Bays, Gorgoraptis, Wee, Marshall, & Husain, 2011) without the temporal summation of successive items (Holcombe, 2009). At the end of each sequence, a blank screen was presented for 1,000 ms before recall for one of the objects was tested by a probe that was a bar of the same color but with a random orientation, at the center of the screen.
Participants were instructed to rotate the probe, using a response dial (PowerMate USB Multimedia controller, Griffin Technology, USA) to match the remembered orientation of the object of the same color in the sequence—henceforth termed the target. Note that we use the term target here simply to distinguish this object from the other objects in the sequence, or nontargets, that were not probed.
Each participant completed a total of 250–500 valid trials (i.e., that were not disqualified by the online eyetracking process). At least 30 trials were presented for each of the eight combinations of the two conditions (same/different location) and the different serial positions of the target object within the sequence (first to last). All conditions were presented in a random order.
Eye tracking
A video-based tower-mounted eyetracker (Eye Link1000, SR Research) with a sampling rate of 1000 Hz was used for recording eye movements. We used built-in custom programs provided with the eyetracker for calibration and validation purposes (nine points presented in a random sequence). All of the data analyzed in the present article were obtained from recordings with an average Cartesian prediction error of less than 1º during the validation procedures. An online process was used to disqualify trials in which the participants failed to maintain fixation while the fixation cross was presented (all stages except the response). When a fixation was recorded outside of the 1.5º-radius perimeter around the fixation cross, the trial was disqualified and visual feedback was presented to the participant. These trials were not included in the analysis, nor in the total count of trials.
Analysis
For each trial, a measure of the raw errors was obtained by calculating the angular deviation between the orientation reported by the participant and the orientation of the target and nontarget objects in the preceding sequence. These values were averaged separately for the different trial conditions (same/different location) and for the sequential position of the target object. The raw error values around the target and nontarget objects were also divided into bins of 15º, separately for each participant and condition, and presented as normalized histograms. Differences between the two conditions were analyzed with paired two-tailed t tests and repeated measures analyses of variance (ANOVAs) across the participants.
To quantify the contributions of different sources of error to the participants’ performance, we applied a probabilistic mixture model introduced previously by Bays et al. (2009). This model, building on an earlier proposal by Zhang and Luck (2008), attributes errors in the continuous-report task to three sources:
-
1.
A probability on each trial of misreporting one of the other, nontarget orientations in the sequence,
-
2.
A probability of responding with a random orientation, not related to any of the items in the sequence,
-
3.
Gaussian variability in memory for the target orientation.
A graphical representation of these model components is given at the bottom of Fig. 2, and a detailed description of the model can be found in a previous article (Bays, Catalao, & Husain, 2009). Maximum likelihood estimates (Myung, 2003) of the model parameters were obtained separately for each participant and condition using the expectation maximization algorithm (for which MATLAB code available at www.sobell.ion.ucl.ac.uk/pbays/code/JV10/).

Three sources of error and the effect of location in Experiment 1. Participants’ responses in the memory task were decomposed into three separate components; the different types of errors are illustrated by the colored regions in the illustrations at the bottom. Misreports (left) indicate a circular Gaussian distribution centered on each nontarget orientation value. We found a significant increase in reporting nontarget orientations in the same-location relative to the different-location condition. Random guesses (middle) showed a uniform distribution, capturing random responses unrelated to any of the memorized orientations, that was not different between the two conditions. Recall precision (right)—a concentration parameter of the circular Gaussian (von Mises) distributions centered on the orientation value of the target bars—also did not differ between conditions. Higher k corresponds to a narrower, more precise distribution. The model results were obtained separately for the same-/different-location conditions. The asterisk denotes a significant difference between conditions, and error bars denote SEMs across participants
Differences between the model values of the two conditions were analyzed by paired two-tailed t tests.
Results and discussion
Participants were presented with a sequence of randomly oriented colored bars and asked to reproduce from memory the orientation of one of these, the identity of which was specified by its color (Fig. 1a). Angular errors for the different conditions and serial orders of the target are presented in Fig. 1b. A two-way repeated measures ANOVA with Condition (same/different location) and Serial Order of Target (first to last) as factors revealed a significant effect of condition [F(1, 7) = 37.5, p < .001], indicating larger errors in the same-location than in the different-location condition. The main effect of serial order was also significant [F(3, 21) = 5, p = .008], agreeing with the known effects of serial order on this type of task (primacy and recency; Gorgoraptis et al., 2011). The interaction of same/different location with serial order was not significant [F(3, 21) = 0.5, p > .25], indicating a similar effect of location for each serial position of the target (i.e., the item that was probed).
Next, we analyzed the distribution of errors around the target orientation (orientation of the item that was probed; see Fig. 1c) and the nontarget orientations (those of items in the sequence that were not probed; Fig. 1d). The histograms in Fig. 1c and d show the angular “distance” from the target and nontarget items in the sequence. A closer distance to the target means a response that was closer to the true orientation of the probed item. Responses plotted with respect to nontargets are shown such that each nontarget orientation was aligned to 0º.
When objects were presented at the same location, participants’ responses were less than 15º on either side of the target orientation on significantly fewer trials than in the different-location condition [t(7) > 2.7, p < .027]. The same-location condition also had a higher number of trials with very large errors than did the different-location condition [absolute error > 75º: t(7) > 2.6, p < .033]. Thus, the distribution of errors in the same-location condition is less precise with respect to the target orientation.
In addition, the histograms of responses centered on nontarget items (Fig. 1d) reveals that in the same-location condition, participants erroneously reported the orientation of nontarget objects more frequently. When items were presented at the same location, a significantly higher fraction of trials had <15º errors on either side of nontarget items than in the different-location condition [t(7) > 2.8, p < .026]. Thus, the higher level of errors biased toward nontargets in the same-location condition occurred with a corresponding decrease in reporting around the target item.
To further investigate the different sources of error, we applied a mixture model that assumed three potential sources of error: (1) a probability of responding with the remembered orientation of a nontarget bar, termed here a misreporting error; (2) a probability of producing a random response not related to any of the bars presented; and (3) variability in recall of the target orientation (Fig. 2; for further details, see the Method section). This analysis method has been used in previous studies, with both parallel and serial presentation (cf. Bays et al., 2009; Gorgoraptis et al., 2011).
The bottom row of Fig. 2 presents the results of the model analysis. Importantly, the concentration parameter (κ), which is inversely proportional to the width of the underlying distributions, was not statistically different between conditions [Fig. 2, right graph; t(7) = 0.6, p = .6], suggesting that the precisions of the reported features (either target or nontarget) were similar in the two conditions. Consistent with the histogram analysis, in same-location trials participants showed an increased probability to misreport the wrong item in memory [Fig. 2 left graph; t(7) = 3.5, p = .01], but similar likelihoods of responding with a random orientation or guessing [Fig. 2 middle graph; t(7) = 0.4, p = .7].
Both the analysis based on raw errors and the probabilistic model imply that presenting items at the same location in space results in a higher chance of misreporting a nontarget item (i.e., an item held in WM but not probed) instead of the target (probed) item.
To exclude the possibility of temporal summation and iconic trace effects contributing to the results (see the General Discussion below), we ran a control experiment with longer delays between consecutive items (600 instead of 300 ms). The results above were replicated, as is described in the supplemental materials.
These findings demonstrate that when items are encoded into WM with objects presented at the same location, recall is less accurate than if items are presented at different locations. Crucially, this is associated with an increased frequency of misreporting the orientation of the wrong (unprobed) object in memory—even when location is irrelevant to the task. But perhaps a task-irrelevant feature other than location would have a similar effect on recall. Moreover, it might be argued that items presented at different locations would be associated with greater novelty, and thereby attract more attention. In the next experiment, we investigated these issues to examine further whether location is special or, alternatively, whether adding another, nonspatial and task-irrelevant, feature would lead to effects similar to those observed here.
Experiment 2
Method
Participants
Ten healthy volunteers (five female, five male; mean age of 25 years, range = 18–35 years) participated in this study.
Stimuli and behavioral procedure
A schematic representation of the task is shown in Fig. 3a. Whereas in Experiment 1 we probed by color and manipulated the irrelevant feature of location, in Experiment 2 we probed by location and manipulated the irrelevant feature of color. The task was identical to that of Experiment 1, except for the following changes: In all trials, all objects appeared at different locations (so that now there was no difference in the novelty of locations across conditions). In one condition, all items shared the same color, whereas in the other they were of different colors, randomly picked from the subset of seven, excluding white. The probe was white (not matching any of the objects) and appeared at the location of the target object.

Memory for orientation with stimuli of the same or different colors at different locations. a Participants were presented with a sequence of four bars, each with a different orientation and location. A probe object with a neutral color was presented at one of the objects’ locations, and participants adjusted the orientation of the probe to match the orientation of the object at that location (target object—in this case, the second item). b Raw errors for the different conditions and serial positions of the target. (c and d) Frequency histograms of responses, aligned with the target and nontarget orientations (respectively). Error bars denote SEMs across participants
Results and discussion
Participants were presented with a sequence of randomly oriented bars at distinct locations and asked to reproduce from memory the orientation of one bar, specified by location (Fig. 3a). Objects could be presented either with the same color or with distinct colors. The averaged angular raw errors for the different conditions and serial orders of the target are presented in Fig 3b.
A two-way ANOVA (Same/Different Colors × Serial Position) in this experiment no longer revealed a significant main effect of condition [F(1, 9) = 1.7, p = .23]. We again observed a significant main effect of serial position [F(3, 27) = 4.9, p = .007], relating to the known effects of serial position on memory performance (Gorgoraptis et al., 2011), but no interaction [F(3, 27) = 1.7, p = .19]. Importantly, in this experiment, no significant difference was apparent in the distributions of responses centered around the target and the nontargets (see the frequency histograms of responses around the target [Fig. 3c] and nontarget [Fig. 3d] orientations).
Consistent with the analysis above, the mixture-model analysis did not reveal any significant difference between conditions (see Supplemental Fig. S3) for either the misreporting component [t(9) = 1.4, p = .19] or the random-guessing component [t(9) = 0.5, p = .61]. The concentration parameter (κ), which represents the width of the underlying distributions, was also not statistically different between conditions [t(9) = 1.4, p = .18].
When we compare Experiments 1 and 2, it is evident that the experimental manipulation of color affected performance less than the manipulation of location [Manipulation × Experiment interaction: F(1, 16) = 22.6, p < .001]. However, the difference between the two experiments was not constrained only by the task-irrelevant manipulation of color versus location. The method of probing also differed between these two experiments: In Experiment 1, targets were specified by their color, whereas in Experiment 2, the targets were specified by location. We therefore designed a further experiment to test whether the different methods of probing at retrieval might have led to the different results between the experiments.
Experiment 3
Method
Participants
Eight healthy volunteers (four female, four male; mean age of 26 years, range = 22–36 years) participated in this study.
Stimuli and behavioral procedure
A schematic representation of the task is shown in Fig. 4a. The task was identical to the one in Experiment 1, except for the following changes: All objects appeared at different locations, and now also in different colors. However, in one condition the target object was specified by its color, with the probe now being presented at the center of screen. In the other condition, the target was specified by its location (probe color neutral: i.e., white).

Probing by color versus probing by location, for items of different colors presented at different locations. a Participants were presented with a sequence of four bars, each now with a distinct orientation and color. Two kinds of probes were used in a random manner: The probe could appear at the target location with a neutral color (to probe by location) or at a neutral location (the center of the screen) with the object’s color (to probe by color). b Raw errors, in degrees, for the different conditions and serial positions of the target. c and d Frequency histograms of responses, aligned with the target and nontarget orientations (respectively). Error bars denote SEMs across participants
Crucially, participants did not know in advance which type of probe would be used, so they had to remember all features (orientation, color, and location), rather than only two features, as in the former experiments (color–orientation and location–orientation in the first and second experiments, respectively).
Results and discussion
Participants were presented with a sequence of randomly oriented bars at distinct locations and in distinct colors and were asked to reproduce from memory the orientation of one bar, specified by either color or location (Fig. 4a). The angular raw errors for the different conditions and serial orders of the target are presented in Fig 4b. A two-way ANOVA (Probe by Location or Color × Serial Position) revealed no significant main effects of condition [F(1, 7) = 0.8, p = .43], so we found no difference between whether items that were probed by color or location. A significant main effect of serial position emerged [F(3, 21) = 13.4, p < .001], but no interaction [F(3, 21) = 0.24, p = .87].
The similarity in responses between the two probing conditions was also evident in the frequency histogram of responses around the target (Fig. 4c) and nontarget (Fig. 4d) orientations. No significant change was found in any of the bins. These results suggest that the differences in performance found between Experiments 1 and 2 could not be attributed to the different probing methods used in these experiments.
Consistent with the analysis above, the mixture model did not reveal any significant change between conditions (see Supplemental Fig. S3) for either the misreporting component [t(7) = 0.3, p = .75] or the random-guessing component [t(7) = 0.1, p = .9]. The concentration parameter (κ), which represents the width of the underlying distributions, was also not statistically different between conditions [t(7) = 1.0, p = .36].
General discussion
In this study, we examined the manner in which objects are represented in visual WM. The findings suggest that spatial location may indeed have a critical role in maintaining veridical visual memories across time, even when position is irrelevant to the task. When objects shared the same location in space, participants more frequently reported the orientation of a nontarget object (another item held in WM but not probed at retrieval) instead of the target object (Figs. 1 and 2). This finding suggests that presenting objects at different positions helps to distinguish between them in WM, even when location is irrelevant to the task. An analogous manipulation in the color domain did not reveal such an effect. Thus, when objects shared the same color, performance was not significantly different from when the objects’ colors were different (Fig. 3).
Better distinction between items, as indexed by fewer nontarget misreporting errors, might be explained by two different processes. The first possibility is that location has a special role in selecting items from memory, similar to attentional selection in visual perception (Bundesen, 1991; Nissen, 1985; Tsal & Lavie, 1988, 1993). Our third experiment suggests that this might not be the case, because probing by color versus probing by location made no difference to performance, even when the items encoded into WM were distinctively different with respect to both location and color (Fig. 4). But note that even when probed by color, participants might have still used spatial coding to access memory (e.g., “What was the orientation of the bar located at the position of the blue bar?”).
The second, perhaps more parsimonious, explanation for our findings would be consistent with the view that spatial location might have a key role in maintaining integrated objects in visual WM (Wheeler & Treisman, 2002). This might be mediated, at least in part, through binding nonspatial features to an object’s location (Treisman & Zhang, 2006). Thus, features that belong to an item A that shares its location with another object B (a very rare occurrence in real life situations) would be less strongly linked to other features that belong to A.
Both of these conclusions would be inconsistent with the recent claim that items in WM are maintained independent of each other and need not be tightly bound to their perceived locations (Woodman et al., 2012). However, the proposal that items in WM are divorced from their perceived location (Woodman et al., 2012) is based on a null effect: a failure to find position effects on performance in change detection tasks. The inconsistency between our results and those of Woodman et al. might be a result of the greater sensitivity of the continuous-report measure that we used here, relative to change detection tasks.
Another difference between the two investigations is that in the present study, participants reported the orientation of a selected object, whereas in the Woodman et al. (2012) experiment, participants were reporting changes in color. It is possible that trying to remember orientations creates a situation in which the spatial position of the stimuli might still be maintained in memory, despite this being irrelevant to the task, whereas remembering the colors of items might not lead to automatic maintenance of position information. Perhaps consistent with this possibility, a series of recent reports investigating the capacity limits of WM consolidation revealed differences between color and orientation, with two colors being encoded in parallel and two orientations being encoded by a strictly serial process (Becker, Miller, & Liu, 2013; Liu & Becker, 2013).
Regardless of the precise reasons for the discrepancy between studies, our results clearly show that position information can have a critical and privileged role in visual WM, even when location is irrelevant to the task, and that this role involves distinguishing between multiple object representations in WM.
Ruling out possible confounds
One could argue that repeatedly presenting objects at the same location can lead to visual summation that results in higher probability of reporting the features of a nontarget object. However, even the slowest limit on temporal summation of high-level visual processing is less than 250 ms (Holcombe, 2009). Moreover, a study in which the threshold for temporal summation of binding color to orientation of a unified object was investigated showed that this takes only 53 ms (Holcombe & Cavanagh, 2001). With our interstimulus interval of 300 ms, visual temporal summation was therefore unlikely to affect the results. Furthermore, we replicated our results with an interitem interval of 600 ms (see the supplemental materials). Therefore, the temporal parameters that we used here were more than sufficient to rule out any perceptual-fusion account of our results.
Another related concern is the disruption of the iconic trace. According to some estimates, the duration of the iconic trace might exceed the 300- and 600-ms interitem delay intervals (e.g., Cowan, 1988). Thus, participants might have been less accurate, specifically in the same-location conditions, because new items were presented exactly at the same location as the iconic trace lingering from previous items. Backward masking of iconic trace is unlikely to explain our results for three reasons. First, most previous studies have estimated the iconic trace of memory to be shorter than 600 ms (e.g., Coltheart, 1980). Second, the specific disruption of the iconic trace should have no effect on the last item in the sequence, as no additional items were presented subsequently. However, the same-position effect was evident, regardless of the target’s serial position. Finally, disruption of the iconic trace is expected to influence the quality of the orientation information, but our mixture-model analysis showed that the precision of the orientation information was not affected by the location manipulation, only the probability to report the correct item.
The time parameters that we used here do relate to another potential concern. Performance in the same-location condition might be impaired by inhibition of return (IOR; Posner & Cohen, 1984), a response attenuation that develops rapidly at the screen location of a salient, attention-grabbing cue (Klein, 2000; Pertzov, Zohary, & Avidan, 2010). Several reasons make this account unlikely. First, IOR should not influence the first object, but should gradually increase for subsequent items. Instead, we found the effect at all serial positions of the target object (no interaction of condition and serial order). Second, IOR is typically measured in reaction times but not on accuracy measures, as we used here (Terry, Valdes, & Neill, 1994). It certainly has not previously been discussed, as far as we are aware, in the context of the specific type of nontarget misreporting errors described here.
Note that in the same-location condition, participants maintained their attention on the same location in space across the trial, whereas attention had to be shifted to unpredictable locations in the different-location condition. These shifts of attention can potentially degrade encoding and maintenance processes. Note, however, that we found better performance in the different-location conditions. Therefore, any degrading effect of attention shifts should only diminish the highly significant effect that we have found.
Type of spatial code and possible neural accounts
It is important to note that the spatial representation in which the objects are embedded within WM does not have to be the absolute spatial locations of the objects, whether retinotopic or otherwise. A considerable amount of evidence has suggested that the spatial configuration—that is, the global pattern in which the objects are organized relative to each other—might be a critical factor for memory performance (Hollingworth, 2007; Hollingworth & Rasmussen, 2010; Jiang et al., 2000; Zimmer & Lehnert, 2006). Our findings show that the elimination of spatial diversity specifically leads to a higher probability to misreport the feature of the wrong object in memory.
The human visual cortex is divided into many distinct regions, each one specialized in processing of a specific visual aspect of the stimuli. These regions are typically organized in spatial retinotopic maps (Engel, Glover, & Wandell, 1997) in which stimuli that fall at nearby locations on the retina are processed by adjacent neurons in these regions. Previous studies have suggested that visual WM maintenance involves at least some portion of the brain structures related to the initial perceptual-processing stage (Harrison & Tong, 2009; Postle, 2006).
We suggest that activity in such early visual cortices is not likely to mediate the decreased performance that results from displaying items at the same location. This is because the mixture-model analysis suggests that the quality of the underlying orientation representations was not actually affected by the location manipulation, only the probability to report the correct item.
Maintaining items in memory also involves persistent activity in the medial temporal lobe (MTL; e.g., Axmacher et al., 2007), as well as the parietal and frontal cortices (e.g., Curtis, 2006). It has been proposed that these brain regions act as a modality-general storage component of location information (Zimmer, 2008). Previous studies have shown that both parietal (e.g., Friedman-Hill, Robertson, & Treisman, 1995) and MTL (e.g., Olson, Page, Moore, Chatterjee, & Verfaellie, 2006; Pertzov et al., 2013) regions are necessary for correct binding of visual features.
Accordingly, these brain regions have been found to represent space in a topographic manner (Burgess, 2008; Schluppeck, Curtis, Glimcher, & Heeger, 2006; Silver & Kastner, 2009). The fact that WM representations involve neurons (either parietal or MTL) that have some sort of topographical organization of space (not exclusively retinotopic; Pertzov, Avidan, & Zohary, 2011), as well as a role in binding processes, would be in agreement with the prominent role of location in WM that we have found here. Hence, two representations of objects that share the same location may partly rely on the same neural assembly, making the two representations less distinctive, and thereby increasing the probability of reporting a feature belonging to another object in memory.
In conclusion, we have found that when several objects successively shared the same location, rather than different locations, participants exhibited a higher tendency to systematically report features that belong to other objects retained in memory but not probed at retrieval. The effect of location was evident despite being irrelevant to the task, and it appeared to be specific to position information, as irrelevant variation in color had no beneficial effect on performance. Thus, our results support the suggestion that location might be critical not only for perception, but also at the postperceptual stage, when visual information is no longer visible (Astle, Scerif, Kuo, & Nobre, 2009; Fabiani, Ho, Stinard, & Gratton, 2003), and that this role might have to do with binding together different features belonging to the same item in memory (Treisman & Zhang, 2006) or to accessing stored representations. The special role of location might potentially be determined by the topographic organization of the neurons involved in binding or retrieval processes.
References
Astle, D. E., Scerif, G., Kuo, B.-C., & Nobre, A. C. (2009). Spatial selection of features within perceived and remembered objects. Frontiers in Human Neuroscience, 3, 6. doi:10.3389/neuro.09.006.2009
Axmacher, N., Mormann, F., Fernández, G., Cohen, M. X., Elger, C. E., & Fell, J. (2007). Sustained neural activity patterns during working memory in the human medial temporal lobe. Journal of Neuroscience, 27, 7807–7816. doi:10.1523/JNEUROSCI.0962-07.2007
Bays, P. M., Catalao, R. F. G., & Husain, M. (2009). The precision of visual working memory is set by allocation of a shared resource. Journal of Vision, 9(10):7, 1–11. doi:10.1167/9.10.7
Bays, P. M., Gorgoraptis, N., Wee, N., Marshall, L., & Husain, M. (2011). Temporal dynamics of encoding, storage, and reallocation of visual working memory. Journal of Vision, 11(10), 6. doi:10.1167/11.10.6
Bays, P. M., & Husain, M. (2008). Dynamic shifts of limited working memory resources in human vision. Science, 321, 851–854.
Becker, M. W., Miller, J. R., & Liu, T. (2013). A severe capacity limit in the consolidation of orientation information into visual short-term memory. Attention, Perception, & Psychophysics, 75, 415–425. doi:10.3758/s13414-012-0410-0
Bundesen, C. (1991). Visual selection of features and objects: Is location special? A reinterpretation of Nissen’s (1985) findings. Perception & Psychophysics, 50, 87–89.
Burgess, N. (2008). Spatial cognition and the brain. Annals of the New York Academy of Sciences, 1124, 77–97.
Coltheart, M. (1980). Iconic memory and visible persistence. Perception & Psychophysics, 27, 183–228. doi:10.3758/BF03204258
Cowan, N. (1988). Evolving conceptions of memory storage, selective attention, and their mutual constraints within the human information-processing system. Psychological Bulletin, 104, 163–191. doi:10.1037/0033-2909.104.2.163
Curtis, C. E. (2006). Prefrontal and parietal contributions to spatial working memory. Neuroscience, 139, 173–180.
Engel, S. A., Glover, G. H., & Wandell, B. A. (1997). Retinotopic organization in human visual cortex and the spatial precision of functional MRI. Cerebral Cortex, 7, 181–192.
Fabiani, M., Ho, J., Stinard, A., & Gratton, G. (2003). Multiple visual memory phenomena in a memory search task. Psychophysiology, 40, 472–485.
Friedman-Hill, S. R., Robertson, L. C., & Treisman, A. M. (1995). Parietal contributions to visual feature binding: Evidence from a patient with bilateral lesions. Science, 269, 853–855.
Gorgoraptis, N., Catalao, R. F., Bays, P. M., & Husain, M. (2011). Dynamic updating of working memory resources for visual objects. Journal of Neuroscience, 31, 8502–8511. doi:10.1523/JNEUROSCI.0208-11.2011
Harrison, S. A., & Tong, F. (2009). Decoding reveals the contents of visual working memory in early visual areas. Nature, 458, 632–635. doi:10.1038/nature07832
Holcombe, A. O. (2009). Seeing slow and seeing fast: Two limits on perception. Trends in Cognitive Sciences, 13, 216–221. doi:10.1016/j.tics.2009.02.005
Holcombe, A. O., & Cavanagh, P. (2001). Early binding of feature pairs for visual perception. Nature Neuroscience, 4, 127–128.
Hollingworth, A. (2007). Object–position binding in visual memory for natural scenes and object arrays. Journal of Experimental Psychology. Human Perception and Performance, 33, 31–47. doi:10.1037/0096-1523.33.1.31
Hollingworth, A., & Rasmussen, I. P. (2010). Binding objects to locations: The relationship between object files and visual working memory. Journal of Experimental Psychology. Human Perception and Performance, 36, 543–564. doi:10.1037/a0017836
Jiang, Y., Olson, I. R., & Chun, M. M. (2000). Organization of visual short-term memory. Journal of Experimental Psychology: Learning, Memory, and Cognition, 26, 683–702. doi:10.1037/0278-7393.26.3.683
Johnston, J. C., & Pashler, H. (1990). Close binding of identity and location in visual feature perception. Journal of Experimental Psychology. Human Perception and Performance, 16, 843–856.
Klein, R. M. (2000). Inhibition of return. Trends in Cognitive Sciences, 4, 138–147. doi:10.1016/S1364-6613(00)01452-2
Kwak, H., & Egeth, H. (1992). Consequences of allocating attention to locations and to other attributes. Perception & Psychophysics, 51, 455–464.
Liu, T., & Becker, M. W. (2013). Serial consolidation of orientation information into visual short-term memory. Psychological Science, 24, 1044–1050.
Logie, R. H., Brockmole, J. R., & Jaswal, S. (2011). Feature binding in visual short-term memory is unaffected by task-irrelevant changes of location, shape, and color. Memory & Cognition, 39, 24–36. doi:10.3758/s13421-010-0001-z
Luck, S. J., & Vogel, E. K. (1997). The capacity of visual working memory for features and conjunctions. Nature, 390, 279–281.
Myung, I. J. (2003). Tutorial on maximum likelihood estimation. Journal of Mathematical Psychology, 47, 90–100. doi:10.1016/S0022-2496(02)00028-7
Nissen, M. J. (1985). Accessing features and objects: Is location special. In M. I. Posner & O. S. M. Marin (Eds.), Attention and performance XI (pp. 205–219). Hillsdale, NJ: Erlbaum.
Olson, I. R., & Marshuetz, C. (2005). Remembering “what” brings along “where” in visual working memory. Perception & Psychophysics, 67, 185–194. doi:10.3758/BF03206483
Olson, I. R., Page, K., Moore, K. S., Chatterjee, A., & Verfaellie, M. (2006). Working memory for conjunctions relies on the medial temporal lobe. Journal of Neuroscience, 26, 4596–4601. doi:10.1523/JNEUROSCI.1923-05.2006
Pertzov, Y., Avidan, G., & Zohary, E. (2011). Multiple reference frames for saccadic planning in the human parietal cortex. Journal of Neuroscience, 31, 1059–1068.
Pertzov, Y., Dong, M. Y., Peich, M.-C., & Husain, M. (2012). Forgetting what was where: The fragility of object–location binding. PLoS ONE, 7, e48214. doi:10.1371/journal.pone.0048214
Pertzov, Y., Miller, T. D., Gorgoraptis, N., Caine, D., Schott, J. M., Butler, C., & Husain, M. (2013). Binding deficits in memory following medial temporal lobe damage in patients with voltage-gated potassium channel complex antibody-associated limbic encephalitis. Brain, 136, 2474–2485. doi:10.1093/brain/awt129
Pertzov, Y., Zohary, E., & Avidan, G. (2010). Rapid formation of spatiotopic representations as revealed by inhibition of return. Journal of Neuroscience, 30, 8882–8887. doi:10.1523/JNEUROSCI.3986-09.2010
Posner, M. I., & Cohen, Y. (1984). Components of visual orienting. In H. Bouma & D. G. Bouwhuis (Eds.), Attention and performance X: Control of language processes (pp. 531–556). Hillsdale, NJ: Erlbaum.
Postle, B. R. (2006). Working memory as an emergent property of the mind and brain. Neuroscience, 139, 23–38. doi:10.1016/j.neuroscience.2005.06.005
Sagi, D., & Julesz, B. (1985). “Where” and “what” in vision. Science, 228, 1217–1219.
Schluppeck, D., Curtis, C. E., Glimcher, P. W., & Heeger, D. J. (2006). Sustained activity in topographic areas of human posterior parietal cortex during memory-guided saccades. Journal of Neuroscience, 26, 5098–6108.
Silver, M. A., & Kastner, S. (2009). Topographic maps in human frontal and parietal cortex. Trends in Cognitive Sciences, 13, 488–495. doi:10.1016/j.tics.2009.08.005
Snyder, C. R. (1972). Selection, inspection, and naming in visual search. Journal of Experimental Psychology, 92, 428–431. doi:10.1037/h0032268
Terry, K. M., Valdes, L. A., & Neill, W. T. (1994). Does “inhibition of return” occur in discrimination tasks? Perception & Psychophysics, 55, 279–286.
Treisman, A. M., & Gelade, G. (1980). A feature-integration theory of attention. Cognitive Psychology, 12, 97–136. doi:10.1016/0010-0285(80)90005-5
Treisman, A., & Zhang, W. (2006). Location and binding in visual working memory. Memory & Cognition, 34, 1704–1719. doi:10.3758/BF03195932
Tsal, Y., & Lavie, N. (1988). Attending to color and shape: The special role of location in selective visual processing. Perception & Psychophysics, 44, 15–21. doi:10.3758/BF03207469
Tsal, Y., & Lavie, N. (1993). Location dominance in attending to color and shape. Journal of Experimental Psychology. Human Perception and Performance, 19, 131–139. doi:10.1037/0096-1523.19.1.131
Wheeler, M. E., & Treisman, A. M. (2002). Binding in short-term visual memory. Journal of Experimental Psychology. General, 131, 48–64. doi:10.1037/0096-3445.131.1.48
Wilken, P., & Ma, W. J. (2004). A detection theory account of change detection. Journal of Vision, 4(12):11, 1120–1135. doi:10.1167/4.12.11
Woodman, G. F., Vogel, E. K., & Luck, S. J. (2012). Flexibility in visual working memory: Accurate change detection in the face of irrelevant variations in position. Visual Cognition, 20, 1–28. doi:10.1080/13506285.2011.630694
Zhang, W., & Luck, S. J. (2008). Discrete fixed-resolution representations in visual working memory. Nature, 453, 233–235. doi:10.1038/nature06860
Zimmer, H. D. (2008). Visual and spatial working memory: From boxes to networks. Neuroscience and Biobehavioral Reviews, 32, 1373–1395. doi:10.1016/j.neubiorev.2008.05.016
Zimmer, H. D., & Lehnert, G. (2006). The spatial mismatch effect is based on global configuration and not on perceptual records within the visual cache. Psychological Research, 70, 1–12. doi:10.1007/s00426-004-0186-5
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
ESM 1
(DOCX 436 kb)
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution License which permits any use, distribution, and reproduction in any medium, provided the original author(s) and the source are credited.
About this article
Cite this article
Pertzov, Y., Husain, M. The privileged role of location in visual working memory. Atten Percept Psychophys 76, 1914–1924 (2014). https://doi.org/10.3758/s13414-013-0541-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0541-y