
Abstract
We examined how differences in attention influence how expert and novice basketball players encode into memory the specific structural information contained within patterns of play from their sport. Our participants were primed during a typical recall task to focus attention on either attacking or defending player formations before being asked to recall the attended or unattended portion of the pattern. Adherence to the instructional set was confirmed through an analysis of gaze distributions. Recall performance was superior for the experts relative to the novices across both the attended and unattended attacking and defensive pattern structures. Expert recall of attacker positions was unchanged with and without attention, whereas recall accuracy for the positions of defenders diminished without attention, as did the novices’ recall of both attack and defense formations. The findings suggest that experienced performers are better than novices at encoding the elements from a complex and dynamic pattern in the absence of focused attention, with this advantage being especially evident in relation to the recall of attacking structure. Some revision of long-term memory theories of expertise will be necessary to accommodate these findings.
Similar content being viewed by others
Observers of a visual image are often surprisingly unaware of changes to the features within the image, even though they may be looking directly at the area of change (Simons & Levin, 1997). For example, O’Regan, Deubel, Clark, and Rensink (2000) showed that up to 40 % of the time, observers viewing static images showing typical, everyday scenes failed to notice relatively large modifications to the colors or the positions of objects within the displays, despite the fact that eye movement recordings indicated that they had fixated on or near the location of the change. Similar results have emerged in other change detection tasks (see Rensink, 2002) for simple schematic images (French, 1953; Pashler, 1988) and dynamic scenes showing everyday environments (Levin & Simons, 1997; Wallis & Bülthoff, 2000).
One of the key variables that appears to moderate the ability to detect change is the orienting of attention (Rensink, O’Regan, & Clark, 1997; Simons, 2000; Simons & Levin, 1997). When observers are instructed or cued to focus their attention on critical display features, change detection improves markedly (Aginsky & Tarr, 2000; Levin & Simons, 1997; Simons & Levin, 1997). However, evidence suggests that appropriate orienting of attention alone may not always be sufficient to guarantee change detection (Levin & Simons, 1997; Simons & Levin, 1997). After viewing a short segment of a motion picture in which the main actor was replaced by an entirely different actor during a change in camera angles, 67 % of observers failed to notice, even though the actors were easily distinguishable (Levin & Simons, 1997). The visual system appears to lack the capacity to encode all of the details present within an image, and therefore it has been proposed that the system only retains an abstract representation of the basic gist of the scene, rather than specific visual details (O’Regan et al., 2000; Rensink, 2000; Rensink, O’Regan, & Clark, 2000; Simons, 2000; Simons & Levin, 1997). Provided that the gist remains the same, observers are unlikely to notice the finer details unless they effortfully attend to them (Simons, 2000; Simons & Levin, 1997). Rather than attempting to encode the minutiae of visual details, the visual system simply encodes those features of direct relevance, thereby maintaining a more stable visual representation of the world (Simons & Levin, 1997). Due to the constraints imposed on working memory, only the pertinent and contextually important properties of a scene appear to be processed without the need for attention; the remaining details within an image are only processed when they attract focused attention, but the capacity to allocate such attention is likely limited (Aginsky & Tarr, 2000).
Another key variable that appears to moderate the ability of the visual system to accurately encode information from a visual display is domain-specific experience (Furley, Memmert, & Heller, 2010; Werner & Thies, 2000). Werner and Thies found that American football experts were better than novices at detecting changes to details in images derived from their domain of expertise, provided that the changes occurred to areas of the display that were important for the interpretation of the scene (e.g., a change of the location of a player). Changes to irrelevant features (e.g., changing the orientation of a shadow cast by a player) were equally poorly detected by both experts and novices (Werner & Thies, 2000). Other research has shown that experts possess a remarkable capacity to extract information from a complex pattern amidst interfering, and often demanding, experimental conditions (e.g., Charness; 1976; Garland & Barry, 1991–1992; Memmert, 2006). For example, when instructed to pay careful attention to a particular defensive player in a basketball video, but to simultaneously attempt to identify potential scoring options, basketball players were significantly more likely to identify an obviously open teammate than were novices (Furley et al., 2010). These results highlight the attentional capacity of experts and their ability to preferentially direct attentional resources toward task-relevant stimuli (see Memmert, 2009, for a review).
The structural and relational information from the elements (i.e., the component parts) in a pattern are critical factors underpinning the ability of expert performers to extract meaning from the pattern (Allard, Graham, & Paarsalu, 1980; Williams, Hodges, North, & Barton, 2006). The importance of pattern structure to expert perception was first demonstrated in studies employing the recall paradigm, in which participants were required to reconstruct the locations of elements from a briefly presented domain-specific stimulus pattern (e.g., Chase & Simon, 1973; de Groot, 1965). In such tasks, expert superiority prevails for structured patterns that are typical of the experts’ domain, but performance (and any expert advantage) diminishes significantly when the patterns show less structured, more random arrangements of elements (Abernethy, Neal, & Koning, 1994; Allard et al., 1980; Chase & Simon, 1973). However, while the importance of the overall pattern structure is well established, further research will be required in order to determine the significance of more specific structures within the pattern itself (Gorman, Abernethy, & Farrow, 2012; Gorman, Abernethy, & Farrow, in press; Williams et al., 2006; Williams & Ward, 2003). Several studies have examined the relative importance of large clusters of elements, such as the attacking and defensive structures, but the findings have been remarkably inconsistent (see, e.g., Abernethy, Baker, & Côté, 2005; Allard et al., 1980; Farrow, McCrae, Gross, & Abernethy, 2010; Williams, Davids, Burwitz, & Williams, 1993). That is, while the expert advantage in recall performance often exists for both the attacking and defending patterns, the general trend across participants has been inconsistent, with some studies showing superior recall of the attacking pattern structures, while on other occasions, the defensive pattern has been recalled with greater accuracy (see Abernethy et al., 2005; Allard et al., 1980; Farrow et al., 2010; Williams et al., 1993). The incongruities in the results are likely due to a number of factors, such as variations in methodological approaches and differences in the sports from which the patterns were derived, but there is nevertheless a clear need to resolve this ambiguity by further examining the specific elements that determine the underlying nature of a complex pattern (Gorman et al., 2012, in press; Williams et al., 2006; Williams & Ward, 2003.
Theoretical explanations for the perceptual–cognitive attributes of experts typically derive from two predominant theories: the template theory of Gobet and Simon (1996) and the long-term working memory theory of Ericsson and Kintsch (1995). In short, the template theory proposes that through practice, experts acquire the capability to recall pattern elements by using elaborate structures in long-term memory called templates (Gobet, 1998; Gobet & Simon, 1996). The templates contain information on the configuration of an extensive array of typical pattern structures that can be accessed for memory-based tasks or used to store additional pattern information for later use (Gobet, 1998; Gobet & Simon, 1996; Weber & Brewer, 2003). The long-term working memory theory, as the name suggests, proposes that expert performers have acquired a greater capacity to hold information in working memory by means of retrieval structures that allow information to be stored in and accessed from long-term memory (Ericsson & Kintsch, 1995; Gobet, 1998; Weber & Brewer, 2003).
The key differences between the two theories are primarily related to differences in the nature of the phenomena that they were designed to explain (Ericsson & Kintsch, 2000). The template theory was initially intended as an explanation for expert chess performance, whereas the long-term working memory theory was aimed at a much broader array of situations involving expert memory, such as mental calculation and medical diagnosis (Ericsson & Kintsch, 1995, 2000; Gobet, 2000). Despite continuing debate concerning their conceptual differences (Ericsson & Kintsch, 2000; Gobet, 2000), the two theories also share a number of commonalities (Gobet, 1998): Both rely on complex knowledge structures stored in long-term memory that are capable of rapidly encoding and retrieving vast amounts of domain-specific information (Ericsson & Kintsch, 1995; Gobet, 1998; Gobet & Simon, 1996). It is believed that through extensive practice in a particular domain, experts acquire detailed knowledge representations that can be accessed during recall or recognition tasks when appropriate cues are present in the pattern structure (Ericsson & Kintsch, 1995; Gobet, 1998; Gobet & Simon, 1996). However, when the structural information is inconsistent with the experts’ memory representations, such as when viewing an unstructured pattern, the expert advantage diminishes accordingly (Ericsson & Kintsch, 1995; Gobet, 1998; Gobet & Simon, 1996). The two theories therefore explain how experts are consistently able to outperform lesser-skilled individuals on demanding memory-based tasks for structured patterns (Ericsson & Kintsch, 1995; Gobet, 1998; Gobet & Simon, 1996).
Weber and Brewer (2003) reported that both the template and long-term working memory theories of expertise assert that the expert memory advantage will also be influenced by attentional focus: Specifically, when attention is directed away from the critical structural information, experts will be unable to extract meaning from the pattern, thereby eliminating any expert recall advantage (Weber & Brewer 2003). Weber and Brewer provided empirical support for this notion, showing that the recall performance of expert field hockey players deteriorated when attentional resources were directed toward structurally irrelevant features in an audio recording of a hockey action sequence, as compared to when attention was directed toward more structurally salient elements. Similar results were reported by Lane and Robertson (1979) for chess experts. These studies, however, have been limited to the use of either static visual images derived from chess patterns (i.e., Lane & Robertson, 1979) or a reliance on auditory information to simulate the pattern structures of an environment that would typically comprise visually rich hockey action sequences (i.e., Weber & Brewer, 2003; see also Gorman, Abernethy, & Farrow, 2011). Moreover, the influence of attentional focus on the encoding of specific elements of the structural information (attack and defense) from a complex and dynamic pattern of play has yet to be fully explored.
The purpose of the present study was to examine how experts and novices encode key elements of domain-specific patterns into memory when attention is directed either toward or away from these elements of interest. Expert and novice participants were primed during a typical recall task to focus attention on either the attacking or defensive structures of basketball patterns before being asked to recall the unattended portion of the pattern. On the basis of the memory-based theories of Gobet and Simon (1996) and Ericsson and Kintsch (1995), it was predicted that the experts would demonstrate an overall recall advantage over the novices when attention was directed toward contextually relevant pattern elements, but that the recall performance of both skill groups would decline significantly in the unattended conditions (see also Weber & Brewer, 2003). However, given that the experts are able to utilize long-term memory structures to rapidly encode a broader array of the elements within a pattern (Ericsson & Kintsch, 1995; Gobet & Simon, 1996), it was also predicted that the experts’ recall performance for the unattended structures would be superior to that of the novices (Furley et al., 2010; Memmert, 2006). We further predicted that the superiority of the experts in recalling the attended and unattended pattern elements would persist across both the attacking and defensive structures and would be equally evident for both of these elements when recalling the overall pattern (see also Abernethy et al., 2005; Allard et al., 1980; Farrow et al., 2010; Williams et al., 1993).
Method
Participants
A group of 17 expert male basketball players and 17 novices were recruited for the experiment. The experts (mean age = 18.35 years, SD = 1.87) were current or former junior players who had competed at a regional, state, or international level, with an average of 10.32 years (SD = 3.36) of playing experience. Participants in the novice group (mean age = 22.29 years, SD = 3.42) reported either limited basketball playing experience in lower-level recreational or social competitions or no experience whatsoever (mean experience = 0.90 years, SD = 1.51). The study received institutional ethical clearance, and informed written consent was provided by the participants.
Materials
The test stimuli were extracted from the same video footage that was described by Gorman et al. (2011, 2012, in press). The images showed a typical five-on-five basketball game between two skilled male basketball teams, filmed from an elevated stand located at the midline of the court. This viewing perspective provided a broad view of the entire playing area and helped to facilitate digitizing of attacking and defensive patterns for the recall task. The level of structure contained within the test images was rated by three expert coaches using a 10-point Likert-type scale (Gorman et al., 2012, in press; North & Williams, 2008; North, Williams, Hodges, Ward, & Ericsson, 2009; Williams et al., 2006). Each coach had more than 40 years of coaching experience, and all had been involved in coaching national or international teams. The attacking and defensive patterns were rated separately to ensure that both were suitably representative of organized game play. The two scores were averaged to provide an overall score for the level of structure contained within the test clips. In order for a given clip to be used for testing, the consensus of the ratings from the coaches needed to be 7 or above to ensure that the test clips were accurate representations of the patterns of play that occur in an elite-level basketball game (Gorman et al., 2012, in press; North & Williams, 2008; North et al., 2009; Williams et al., 2006). Each video clip was 7 s in duration, and all clips were displayed using a custom-built computer program (AIS React).
The visual search behaviors of participants were recorded using a head-mounted eyetracking system (Applied Science Laboratories, Mobile Eye Mark II, Bedford, MA). The system used an eye camera to identify the gaze position of the participant and superimposed this location as a crosshair onto an image of the visual display recorded by a scene camera capturing at 25 Hz (see also Panchuk & Vickers, 2009). The resultant video recording was then subjected to a frame-by-frame analysis by coding both the location of the crosshair and the amount of time (in milliseconds) that the crosshair remained fixated on a given location (e.g., North et al., 2009). These data were then used as a manipulation check to ensure that participants adhered to the experimental protocols.
Procedure
Participants completed the test while seated at a desk in front of a computer monitor (47.5 cm wide × 30 cm tall). The eyetracking system was fitted and then calibrated using a nine-point reference grid. Calibration was checked and adjusted as required at the start and end of each test block. Using a procedure similar to that described by Gorman et al. (2012, in press), each test clip was displayed for its full duration before the players in the image were removed from view, leaving only the blank basketball court on screen. Participants were required to reproduce the final locations of the players as they had appeared at the completion of the playing sequence by dragging Xs (icons indicating the locations of defenders) and/or Os (icons indicating the locations of attackers) onto the image using a computer mouse (the AIS React computer program was used for this purpose). The aim was to position each pattern icon so that the center was aligned between the heels of the player at the location where he had last stood on the court.
The test clips were arranged into three separate test blocks, and these were counterbalanced across the experimental groups. Two practice trials were provided at the beginning of each test block to familiarize participants with the nature of the experimental conditions. In the entire-recall test block, participants were asked to recall the locations of all ten players (five attackers and five defenders) from 12 test clips. Separate scores were calculated for the recall of attacking and defensive player locations. This condition replicated the traditional recall tasks used in previous research and was included to ensure that the recall test was one that showed expertise effects typical of those reported previously in the literature (e.g., Abernethy et al., 2005; Allard et al., 1980).
In the attack-only recall test block, only the attacking players were required to be recalled from the same images (n = 12) that were used in the entire-recall test block. These trials provided a measure of recall performance when attention was primarily directed toward the attacking pattern of play (i.e., attended attack recall). The trials were also designed to prime participants to focus their attention on the attacking structure before commencing an additional and final trial in the series (i.e., Trial 13). Immediately after this final trial in the series disappeared from view, participants were asked to recall only the locations of the defensive players from the image. This provided a measure of the participants’ skill in recalling the unattended elements of the pattern, which in this instance comprised the defensive pattern elements (i.e., unattended defense recall) (for similar methods, see also Furley et al., 2010; Memmert & Furley, 2007; Weber & Brewer, 2003).
The defense-only recall test block was similar to the attack-only recall test, except that only the defensive player locations were required to be recalled (i.e., attended defense recall) from the same images (n = 12) that were used in the other test blocks. Immediately after the final trial in the series (i.e., Trial 13) disappeared from view, participants were asked to recall the locations of the attacking players. This provided a measure of the participants’ skill in recalling the attacking pattern elements when attention was primarily directed toward the defensive structure (i.e., unattended attack recall). The clip used in the final trial of the defense-only recall test block was identical to that used as the final trial in the attack-only recall condition. This clip was also a duplicate of the pattern that had been used as the fourth test trial in each of the three test blocks (the remaining 11 clips were placed in random order within each of the blocks). This test clip was held constant to provide a comparator pattern so as (a) to allow the attended and unattended recall of attacking and defensive pattern structures to be compared across an identical trial and (b) to compare the recall performance of the two skill groups for that same trial in the entire-recall test, to ensure that the clip itself provided a representative stimulus pattern.
Data analysis
Pattern recall data
Recall performance was measured using similar methods as that employed by Gorman et al. (2012, in press). The same custom-built computer program (AIS React) used during testing was also used to score the recall error of participants by applying a least squares approach. The program calculated all combinations of distances between the five coordinates entered by the participant for a given attacking or defending pattern, and the five coordinates of the actual player locations for the given pattern. This essentially created a 5 × 5 matrix with every possible combination of distances between entered and actual coordinates with the attacking and defending patterns analysed separately. Distances were calculated using the formula \( \sqrt{{{{{\left( {{x_1}-{x_2}} \right)}}^2}+{{{\left( {{y_1}-{y_2}} \right)}}^2}}} \). The smallest combination of distances between the actual and entered coordinates was then determined for the five players comprising the particular pattern, and these values were averaged to provide a single score for recall error for the trial. The error scores across all trials in a given experimental condition were averaged to provide an overall score for attack and another score for defense, with smaller scores being indicative of less error. This method basically compared the entered and actual icons so as to find the best possible match between the two patterns, and therefore provided scores for recalling the overall pattern structure, rather than using a binary scoring system (e.g., Abernethy et al., 1994; Allard et al., 1980) in which player locations were considered in isolation from the remaining elements comprising the pattern (Gorman et al., 2012). This distinction may be particularly pertinent in a pattern containing several interrelated elements. Test trials in which participants had inadvertently added or omitted pattern elements were not included in the statistical analyses (eight trials were excluded, which were confined to the entire-recall test).
The entire-recall data were analyzed using a two-way (Skill × Element) analysis of variance (ANOVA) with repeated measures on the last factor. The between-group factor was Skill (expert, novice), and the within-group factor was Element (attack, defense). The attack-only and defense-only recall data were analyzed using a three-way (Skill × Element × Condition) ANOVA with repeated measures on the last two factors. The between-group factor was Skill (expert, novice) and the within-group factors were Element (attack, defense) and Condition (attended, unattended). To ensure that the clip used in the unattended trials was representative of the domain, the results from this single trial for the entire-recall test were compared across skill levels using an independent t test. In addition, the results from this particular trial for the attended and unattended attack and defense conditions were directly compared, to ensure that any differences in recall performance that existed within this single trial were similar to those that existed in the original three-way interaction (which included all 12 of the attended clips). The same three-way (Skill × Element × Condition) ANOVA that was employed in the original analyses was used for this purpose. The level of significance for all analyses was set at p < .05. Only those results that were specifically related to the hypotheses are reported in the Results section.
Eye movement data
A post hoc frame-by-frame analysis was conducted on the video recordings of the eye movement data for 11 experts and nine novices. A consistent subset of eight test clips (from the full set of 12 used in testing) was analyzed in each of the three experimental conditions, in addition to the two unattended trials from the attack-only and defense-only test blocks (i.e., Trial 13). The clips that consistently differentiated recall performance for the two skill levels across all three conditions were selected for analysis. The data were analyzed by calculating the percentages of time (in milliseconds) that participants spent fixating upon (a) attacking players, (b) defending players, (c) open space, or (d) any other location that could not be placed into the aforementioned categories (for a similar approach, see North et al., 2009). A fixation was defined as a stationary gaze at the same feature or location for a minimum duration of 120 ms, which was the equivalent of three frames (North et al., 2009; Williams, Davids, Burwitz, & Williams, 1994). An intraclass correlation analysis (see Thomas & Nelson, 2001) conducted on a subset of the trials (N = 16) for the percent fixation data indicated a high level of intrarater reliability (R = .95).
To assess the level of compliance with the instructional sets, one-sample t tests were used to compare the percentage of viewing time that each skill group spent fixating the attacking and defensive pattern elements in the attack-only and defense-only recall conditions, respectively, with the time spent fixating the other features within the scenes. Similarly, to examine whether the two groups continued to focus their attention on the requested pattern elements during the critical unattended trials, the percentage of time spent fixating the attacking/defensive pattern elements in the preceding attended trials was compared to the time spent viewing the attacking/defensive elements, respectively, in the unattended trial. To investigate differences in visual search behaviors between the experts and novices, multivariate analyses of variance (MANOVAs) were conducted on the percentage viewing time data for the attack-only and defense-only recall conditions, as well as across the two unattended conditions. The fixation locations (attackers, defenders, and space) were the dependent variables, and skill level was the independent variable (the “other” location was removed due to insufficient data for this category). These comparisons were important to identify the source of any skill-related differences exhibited in recall performance for particular display features. For example, in the case of the experts’ recall performance on the unattended trials being superior to that of the novices, it was necessary to determine whether this was due to a genuine expertise effect related to an enhanced capability to extract pattern information in the absence of focused attention or, alternatively, whether it was primarily the result of proportionally more time (as shown by longer fixation periods) being spent viewing the unattended pattern elements.
Results
Recall data
Entire recall
The two-way (Skill × Element) repeated measures ANOVA on the entire-recall data revealed a significant main effect of skill, F(1, 32) = 17.93, p < .001, η p 2 = .36, due to the recall error of the experts being less than that of the novices. This confirmed that the recall test was indeed able to distinguish between the two skill groups, and therefore provided a representative task for examining expert performance in pattern perception. A significant Skill × Element interaction, F(1, 32) = 16.71, p < .001, η p 2 = .34, showed that the source of the expert superiority was confined to the recall of the attacking structure, t(32) = −4.78, p < .001, r = .65. We found no significant skill-related differences for recall of the defensive patterns, t(32) = −0.29, p = .78, r = .05, although both the experts, t(16) = −4.72, p < .001, r = .76, and novices, t(16) = −8.63, p < .001, r = .91, recalled the defensive patterns with less error than the attacking patterns (see Fig. 1). Analysis of the fourth trial in the entire-recall test (the same clip used in the two unattended trials) showed a significant expertise effect, with the experts (M = .057) outperforming the novices (M = .074), t(32) = −3.52, p = .001, r = .53. This confirmed that the clip selected for the presentation of the unattended trials provided a stimulus pattern that was representative of others within the domain (e.g., Abernethy et al., 2005).

Pattern recall error for the entire-recall condition for the two skill groups across attacking and defensive pattern elements. Error bars show standard errors
Attack-only and defense-only recall
Results from the three-way (Skill × Element × Condition) repeated measures ANOVA showed a significant main effect of condition, F(1, 32) = 101.29, p < .001, η p 2 = .76, with recall error being less in the attended condition (M = .058) than in the unattended condition (M = .080). A significant Skill × Condition, F(1, 32) = 24.90, p < .001, η p 2 = .44, interaction was also observed. The recall error of the experts (mean attended = .054, mean unattended = .065) was significantly less than that of the novices (mean attended = .061, mean unattended = .094) in both the attended, t(32) = −3.18, p = .003, r = .49, and unattended, t(23.96) = −6.70, p < .001, r = .81, conditions. Both the experts, t(16) = 6.91, p < .001, r = .87, and the novices, t(16) = 8.10, p < .001, r = .90, exhibited a significant increase in recall error when attempting to recall the unattended portion of the pattern, but the increase for the experts (M = .011) was significantly less than that experienced by the novices (M = .033), t(20.89) = −4.99, p < .001, r = .74.
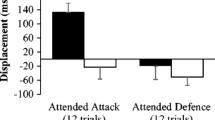
Follow-up analyses for a significant Skill × Element × Condition interaction (see Fig. 2), F(1, 32) = 6.17, p = .02, η p 2 = .16, showed that in the attended condition, the experts’ recall error was less than that of the novices for both the attacking, t(32) = −3.05, p = .005, r = .47, and defensive pattern elements, t(32) = −2.04, p = .049, r = .34. For the unattended condition, the experts once again displayed significantly less error than did the novices when recalling both the attacking, t(32) = −5.37, p < .001, r = .69, and defensive structures, t(32) = −3.24, p = .003, r = .50. The experts’ recall error of the attended defensive patterns was less than their error for the unattended defensive patterns, t(16) = −5.65, p < .001, r = .82, but there were no differences in the experts’ recall of the attended and unattended attacking patterns, t(16) = −1.58, p = .13, r = .37. The recall error of the novices was lower for the attended patterns than for the unattended patterns for both the attacking, t(16) = −5.92, p < .001, r = .83, and the defensive, t(16) = −6.68, p < .001, r = .86, elements. The extent of the expert–novice difference in recall performance increased from the attended to the unattended conditions, being most pronounced in the unattended attack condition. A similar pattern of results existed when the attended and unattended trials were compared across identical clips, with a significant main effect of condition (p < .001) and a significant Skill × Condition interaction (p < .001).

Pattern recall error for the attended and unattended recall conditions for the two skill groups across attacking and defensive pattern elements. Error bars show standard errors
Eye movement data
The one-sample t tests showed that each skill group spent a greater percentage of time fixating the attacking and defending pattern elements in the attack-only and defense-only conditions, respectively, as compared to the percentage of time spent viewing the other features within the display (ps < .05). Importantly, the results also showed that the amounts of time spent fixating the attackers and defenders in the attack-only and defense-only trials, respectively, were no different from the times spent fixating those same pattern elements in the unattended trials (ps > .05). These results suggest that participants complied with the experimental protocols (see Figs. 3 and 4), directing gaze primarily to the attackers in the attack-only trials and to the defenders in the defense-only trials.

Percentages of time (in milliseconds) that participants spent fixating different features within the stimulus patterns for the attack-only recall condition. The percentage of time spent fixating the attacking players in the unattended defense trial is also shown. Error bars show standard errors

Percentages of time (in milliseconds) that participants spent fixating different features within the stimulus patterns for the defense-only recall condition. The percentage of time spent fixating the defending players in the unattended attack trial is also shown. Error bars show standard errors
The results from the MANOVAs revealed no significant skill-related differences for the percentages of time that participants spent fixating the different categories of display features (attackers, defenders, and space) in the attack-only, F(3, 16) = 0.51, p = .68, η p 2 = .09, and defense-only, F(3, 16) = 1.18, p = .35, η p 2 = .18, conditions, as well as in the unattended attack, F(3, 16) = 1.00, p = .42, η p 2 = .16, and unattended defense, F(3, 16) = 0.17, p = .92, η p 2 = .03, trials. These findings suggest that the visual search behaviors, at least in terms of percent viewing time, were largely consistent for experts and novices, and furthermore that any differences in recall performance between the skill groups were likely to be the result of perceptual–cognitive capabilities, rather than differences in visual search strategies.
Discussion
This study was designed to investigate how experts and novices encode into memory the specific pattern structures (attack and defense) that exist in a complex and dynamic team sport when attention is directed either toward or away from these elements of interest. The attentional focus of expert and novice basketball players was manipulated by asking participants to recall either the attacking or the defensive structures of a typical basketball pattern of play (attended conditions), before being requested to recall the unattended portion of the pattern (unattended conditions). It was predicted that the experts would be superior to the novices in both the attended and unattended conditions but that recall performance for both groups would decline in the unattended condition (see also Weber & Brewer, 2003). It was further predicted that the experts would recall the attacking and defensive pattern structures with significantly less error than would the novices in each of the experimental conditions (see also Abernethy et al., 2005; Allard et al., 1980; Farrow et al., 2010; Williams et al., 1993).
As expected, the recall performance of both skill groups declined in the unattended condition when attention was diverted away from the pattern of interest. This finding is consistent with previous research demonstrating that memory performance for both skilled and unskilled performers is significantly impaired when attentional resources are directed away from the structural and functional information contained within a domain-specific pattern (Goldin, 1978; Lane & Robertson, 1979; Weber & Brewer, 2003). It also supports similar work showing that instructions emphasizing specific features within the display can have a marked effect on the type of information that is extracted by the observer (Aginsky & Tarr, 2000; Levin & Simons, 1997) and may impair the capacity to detect items outside the attentional focus (Memmert & Furley, 2007). However, while both skill groups were unable to recall the unattended pattern with the same level of proficiency as in the attended condition, the magnitude of the decline for the experts was significantly less than that exhibited by the novices. In addition, the overall recall of the unattended patterns was significantly better for the experts than for the novices, indicating that the experts were better able to monitor the locations of pattern elements that were external to the focus of attention. These findings suggest that when an expert team-sport performer encodes a structured pattern from their domain, all of the elements within the pattern are included in the memory representation, including those that receive limited attentional resources. However, given that the experts recalled the attended patterns with consistently less error than the unattended patterns, it seems that the relative strength of the encoding is dependent on the extent of the attentional focus: Focused attention appears to augment the strength of the experts’ memory representation (see also Goldin, 1978; Lane & Robertson, 1979; Weber & Brewer, 2003).
The findings are also consistent with the assertions of the template theory (Gobet & Simon, 1996) and the long-term working memory theory (Ericsson & Kintsch, 1995), which both predict a reduction in expert memory performance if attention is diverted away from the structure inherent within the pattern (Weber & Brewer, 2003). However, the theories further claim that under such circumstances, the magnitude of the gap between experts and novices will also decline (Weber & Brewer, 2003). Previous research using patterns from chess (Lane & Robertson, 1979) and field hockey (Weber & Brewer, 2003) has reported empirical support for this prediction, but the results of the present study appear to provide contradictory evidence, showing that the experts were able to maintain their superiority over the novices by more accurately recalling pattern information in the absence of focused attention. Indeed, the magnitude of the expert advantage is more pronounced on the unattended trials than on the attended ones (see Fig. 2). The reason for the discrepancy in the findings between the present study and those preceding it is likely to be related to differences in the experimental manipulations. Previous studies have used tasks in which participants were prevented from focusing on the structure in the entire pattern (e.g., Lane & Robertson, 1979; Weber & Brewer, 2003), whereas in the present study, attentional focus was directed toward either the attacking or the defensive structures, allowing participants to continue to extract some structural information from the display. The results therefore suggest that although the expert memory advantage declines when fewer attentional resources are directed toward specific structural information (see also Lane & Robertson, 1979; Weber & Brewer, 2003), the expert’s superiority over lesser-skilled individuals on the unattended pattern elements will persist, provided that at least some of the key structural details are able to be extracted.
The source of the experts’ advantage was closely linked to the recall of the attacking player locations, with the experts outperforming the novices on the attacking structures in the entire-recall, attended recall, and unattended recall conditions (see also Abernethy et al., 2005; Gorman et al., in press). Moreover, the experts maintained their recall performance for the attacking elements in the absence of direct attention, with the results revealing no significant differences between the experts’ recall of the attended and unattended attacking structures. These findings not only provide evidence in support of the importance of the attacking structure in a complex team-sport pattern (Abernethy et al., 2005; Farrow et al., 2010; Gorman et al., in press; Helsen & Starkes, 1999), but they also suggest that experts are able to accurately encode the locations of the attacking players without the direct allocation of attentional resources. As predicted, the experts were superior to the novices when recalling the attended and unattended defensive structures, but no significant skill-related differences emerged for this element in the entire-recall condition. It seems that, irrespective of the attentional focus, experts are able to recall either the attacking or defensive structures of a team-sport pattern better than are lesser-skilled individuals, but when the task requires the combined recall of both pattern structures, the expert advantage is isolated to the recall of the attacking pattern elements (see also Abernethy et al., 2005; Gorman et al., in press). Given that the primary objective of the attacking team is to achieve a successful shot attempt, the typical attacking structure, at least in comparison to a typical defensive formation, tends to be highly adaptable and relatively unpredictable in nature (Moore & White, 1980; Williams et al., 1993; Wooden, 1988). It is therefore possible that recalling the attacking pattern requires extensive experience in the domain before the requisite memory representations are acquired, although incongruities in the extant literature (see Abernethy et al., 2005; Allard et al., 1980; Farrow et al., 2010; Williams et al., 1993) suggest that additional evidence will be required before the attacking structure can be unequivocally shown to be the primary source of the expert advantage (Gorman et al., in press; see also Williams et al., 2006).
Importantly, analysis of the visual search data revealed that participants strictly adhered to the instructional sets by allocating attentional resources toward the assigned pattern structures. This suggests that the nature of the expert advantage was primarily related to the experts’ enhanced perceptual–cognitive skills, rather than to differences in the orientation of gaze. The superiority of the experts in the attended, unattended, and entire recall conditions demonstrates the capability of expert performers to utilise perceptual-cognitive resources to encode and retrieve critical pattern information, often amidst demanding and interruptive tasks that hamper their ability to devote complete attention towards specific pattern elements (e.g., Charness, 1976; Furley et al., 2010; Garland & Barry, 1991-1992; Memmert, 2006). In this regard, the results are consistent with extant literature that has extolled the expert advantage in similar memory-based tasks from other domains (e.g., Abernethy et al., 1994; Chase & Simon, 1973; Gilhooly, Wood, Kinnear, & Green, 1988). From an applied perspective, the results suggest that instructional emphases from practitioners that direct the attention, especially of learners, toward specific elements within the display may have the concurrent effect of reducing the ability of the observer to extract information from other important display features (see also Memmert, 2006; Memmert & Furley, 2007). From a theoretical perspective, the present study supports long-term memory theories by showing that attentional focus can moderate the extent to which specific structural information is extracted from a domain-specific pattern (Ericsson & Kintsch, 1995; Gobet & Simon, 1996; Weber & Brewer, 2003). However, the results also suggest the need for a slight revision to existing theories in order to account for the experts’ superiority over the novices in the unattended conditions. In light of this, it is perhaps best to conclude that directing attention away from certain structural elements appears to diminish the strength of the memory representation in both experts and novices, but the extent of the decline is likely to be significantly less pronounced in experts, provided that at least some of the critical pattern information is able to be extracted (see also Furley et al., 2010; Memmert, 2006; Weber & Brewer, 2003). Further research in a similarly dynamic and time-constrained environment may be required to further support this claim.
Additional research may also be required in order to determine the extent to which the expert advantage in pattern recall is facilitated by probabilistic knowledge. Given the experts’ experience in the domain and their understanding of the typical pattern structures, it is possible that recall of the locations of the players in an attended pattern may be used as a form of guidance to help place any unattended players in the most logical and/or likely positions. However, the lack of significant differences between the experts’ recall of the attended and unattended attacking structures in the present study suggests that probabilistic information may play a relatively minor role. That is, since the visual search data showed that the experts focused their attention on the attacking players in the attended attack condition, but focused attention on the defenders in the unattended attack condition, both as instructed, it seems unlikely that the two scores would be so closely matched (and not significantly different) if probabilistic information alone had been used to place the unattended players. Similarly, evidence suggests that expert team-sport performers tend to use an anticipatory process when encoding an evolving pattern structure by intuitively predicting the likely subsequent movements of the players within the image (Didierjean & Marmèche, 2005; Gorman et al., 2011, 2012, in press). It is therefore possible that the experts in the present study encoded the patterns as they were likely to be configured at a later point in the playing sequence, not as they were actually shown (Didierjean & Marmèche, 2005; Gorman et al., 2011, 2012, in press). If this was indeed the case, the failure to account for the experts’ prospective encoding may have meant that the extent of the expert advantage in the recall tasks was considerably greater than we reported in the results (Gorman et al., 2012, in press). The tendency of experts to employ both probabilistic and anticipatory information has been reported previously (Abernethy, Gill, Parks, & Packer, 2001; Didierjean & Marmèche, 2005; Gorman et al., 2011, 2012, in press), but the extent to which these capabilities extend to the reconstruction of pattern elements that are external to the focus of attention has not been extensively explored in the literature (but, for examples using simplified images and novice participants, see Hayes & Freyd, 1995, 2002). A closer examination of the influence of anticipatory memory encodings for complex and dynamic displays under varying levels of attentional focus represents an interesting pathway for future investigations.
References
Abernethy, B., Baker, J., & Côté, J. (2005). Transfer of pattern recall skills may contribute to the development of sport expertise. Applied Cognitive Psychology, 19, 705–718.
Abernethy, B., Gill, D. P., Parks, S. L., & Packer, S. T. (2001). Expertise and the perception of kinematic and situational probability information. Perception, 30, 233–252.
Abernethy, B., Neal, R. J., & Koning, P. (1994). Visual–perceptual and cognitive differences between expert, intermediate, and novice snooker players. Applied Cognitive Psychology, 8, 185–211.
Aginsky, V., & Tarr, M. J. (2000). How are different properties of a scene encoded in visual memory? Visual Cognition, 7, 147–162.
Allard, F., Graham, S., & Paarsalu, M. E. (1980). Perception in sport: Basketball. Journal of Sport Psychology, 2, 14–21.
Charness, N. (1976). Memory for chess positions: Resistance to interference. Journal of Experimental Psychology: Human Learning and Memory, 2, 641–653.
Chase, W. G., & Simon, H. A. (1973). Perception in chess. Cognitive Psychology, 4, 55–81.
de Groot, A. D. (1965). Thought and choice in chess. The Hague, The Netherlands: Mouton.
Didierjean, A., & Marmèche, E. (2005). Anticipatory representation of anticipatory basketball scenes by novice and expert players. Visual Cognition, 12, 265–283.
Ericsson, K. A., & Kintsch, W. (1995). Long-term working memory. Psychological Review, 102, 211–245. doi:10.1037/0033-295X.102.2.211
Ericsson, K. A., & Kintsch, W. (2000). Shortcomings of generic retrieval structures with slots of the type that Gobet (1993) proposed and modelled. British Journal of Psychology, 91, 571–590.
Farrow, D., McCrae, J., Gross, J., & Abernethy, B. (2010). Revisiting the relationship between pattern recall and anticipatory skill. International Journal of Sport Psychology, 41, 91–106.
French, R. S. (1953). The discrimination of dot patterns as a function of number and average separation of dots. Journal of Experimental Psychology, 46, 1–9.
Furley, P., Memmert, D., & Heller, C. (2010). The dark side of visual awareness in sport: Inattentional blindness in a real-world basketball task. Attention, Perception, & Psychophysics, 72, 1327–1337. doi:10.3758/APP.72.5.1327
Garland, D. J., & Barry, J. R. (1991–1992). Effects of interpolated processing on experts’ recall of schematic information. Current Psychology: Research and Reviews, 10, 273–280.
Gilhooly, K. J., Wood, M., Kinnear, P. R., & Green, C. (1988). Skill in map reading and memory for maps. Quarterly Journal of Experimental Psychology, 40A, 87–107.
Gobet, F. (1998). Expert memory: A comparison of four theories. Cognition, 66, 115–152.
Gobet, F. (2000). Some shortcomings of long-term working memory. British Journal of Psychology, 91, 551–570.
Gobet, F., & Simon, H. A. (1996). Templates in chess memory: A mechanism for recalling several boards. Cognitive Psychology, 31, 1–40.
Goldin, S. E. (1978). Effects of orienting tasks on recognition of chess positions. The American Journal of Psychology, 91, 659–671.
Gorman, A. D., Abernethy, B., & Farrow, D. (2011). Investigating the anticipatory nature of pattern perception in sport. Memory & Cognition, 39, 894–901. doi:10.3758/s13421-010-0067-7
Gorman, A. D., Abernethy, B., & Farrow, D. (2012). Classical pattern recall tests and the prospective nature of expert performance. Quarterly Journal of Experimental Psychology, 65, 1151–1160. doi:10.1080/17470218.2011.644306
Gorman, A. D., Abernethy, B., & Farrow, D. (in press). Is the relationship between pattern recall and decision-making influenced by anticipatory recall? The Quarterly Journal of Experimental Psychology. doi:10.1080/17470218.2013.777083
Hayes, A., & Freyd, J. J. (1995, November). Attention and representational momentum. Paper presented at the 36th Annual Meeting of the Psychonomic Society, Los Angeles, CA.
Hayes, A. E., & Freyd, J. J. (2002). Representational momentum when attention is divided. Visual Cognition, 9, 8–27.
Helsen, W. F., & Starkes, J. L. (1999). A multidimensional approach to skilled perception and performance in sport. Applied Cognitive Psychology, 13, 1–27.
Lane, D. M., & Robertson, L. (1979). The generality of the levels of processing hypothesis: An application for memory to chess positions. Memory & Cognition, 7, 253–256.
Levin, D. T., & Simons, D. J. (1997). Failure to detect change to attended objects in motion pictures. Psychonomic Bulletin & Review, 4, 501–506.
Memmert, D. (2006). The effects of eye movements, age, and expertise on inattentional blindness. Consciousness and Cognition, 15, 620–627.
Memmert, D. (2009). Pay attention! A review of visual attentional expertise in sport. International Review of Sport and Exercise Psychology, 2, 119–138.
Memmert, D., & Furley, P. (2007). “I spy with my little eye!”: Breadth of attention, inattentional blindness, and tactical decision making in team sports. Journal of Sport & Exercise Psychology, 29, 365–381.
Moore, B. J., & White, J. O. (1980). Basketball: Theory and practice. Dubuque, IA: William C. Brown.
North, J. S., & Williams, A. M. (2008). Identifying the critical time period for information extraction when recognizing sequences of play. Research Quarterly for Exercise and Sport, 79, 268–273.
North, J. S., Williams, A. M., Hodges, N., Ward, P., & Ericsson, K. A. (2009). Perceiving patterns in dynamic action sequences: Investigating the processes underpinning stimulus recognition and anticipation skill. Applied Cognitive Psychology, 23, 878–894.
O’Regan, J. K., Deubel, H., Clark, J. J., & Rensink, R. A. (2000). Picture changes during blinks: Looking without seeing and seeing without looking. Visual Cognition, 7, 191–211.
Panchuk, D., & Vickers, J. N. (2009). Using spatial occlusion to explore the control strategies used in rapid interceptive actions: Predictive or prospective control? Journal of Sports Sciences, 27, 1249–1260.
Pashler, H. (1988). Familiarity and visual change detection. Perception & Psychophysics, 44, 369–378. doi:10.3758/BF03210419
Rensink, R. A. (2000). Visual search for change: A probe into the nature of attentional processing. Visual Cognition, 7, 345–376.
Rensink, R. A. (2002). Change detection. Annual Review of Psychology, 53, 245–277. doi:10.1146/annurev.psych.53.100901.135125
Rensink, R. A., O’Regan, J. K., & Clark, J. J. (1997). To see or not to see: The need for attention to perceive changes in scenes. Psychological Science, 8, 368–373. doi:10.1111/j.1467-9280.1997.tb00427.x
Rensink, R. A., O’Regan, J. K., & Clark, J. J. (2000). On the failure to detect changes in scenes across brief interruptions. Visual Cognition, 7, 127–145.
Simons, D. J. (2000). Current approaches to change blindness. Visual Cognition, 7, 1–15.
Simons, D. J., & Levin, D. T. (1997). Change blindness. Trends in Cognitive Sciences, 7, 261–267.
Thomas, J. R., & Nelson, J. K. (2001). Research methods in physical activity (4th ed.). Champaign, IL: Human Kinetics.
Wallis, G., & Bülthoff, H. H. (2000). What’s scene and not seen: Influences of movement and task upon what we see. Visual Cognition, 7, 175–190.
Weber, N., & Brewer, N. (2003). Expert memory: The interaction of stimulus structure, attention, and expertise. Applied Cognitive Psychology, 17, 295–308.
Werner, S., & Thies, B. (2000). Is “change blindness” attenuated by domain-specific expertise? An expert–novices comparison of change detection in football images. Visual Cognition, 7, 163–173. doi:10.1080/135062800394748
Williams, M., Davids, K., Burwitz, L., & Williams, J. (1993). Cognitive knowledge and soccer performance. Perceptual and Motor Skills, 76, 579–593. doi:10.2466/pms.1993.76.2.579
Williams, A. M., Davids, K., Burwitz, L., & Williams, J. G. (1994). Visual search strategies in experienced and inexperienced soccer players. Research Quarterly for Exercise and Sport, 65, 127–135.
Williams, A. M., Hodges, N. J., North, J. S., & Barton, G. (2006). Perceiving patterns of play in dynamic sport tasks: Investigating the essential information underlying skilled performance. Perception, 35, 317–332. doi:10.1068/p5310
Williams, A. M., & Ward, P. (2003). Perceptual expertise: Development in sport. In J. L. Starkes & K. A. Ericsson (Eds.), Expert performance in sports: Advances in research on sport expertise (pp. 219–249). Champaign, IL: Human Kinetics.
Wooden, J. R. (1988). Practical modern basketball (3rd ed.). New York, NY: Macmillan.
Author Note
We thank the Australian Institute of Sport, Colin Mackintosh, and Chris Barnes for their assistance, as well as the coaches and participants involved in the research. This paper was presented as a poster at the North American Society for the Psychology of Sport and Physical Activity. Please see: Gorman, A. D., Abernethy, B., & Farrow, D. (2012). The influence of attentional focus on expert pattern perception in sport [Abstract]. Journal of Sport & Exercise Psychology, 34, S84-S85.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Gorman, A.D., Abernethy, B. & Farrow, D. The expert advantage in dynamic pattern recall persists across both attended and unattended display elements. Atten Percept Psychophys 75, 835–844 (2013). https://doi.org/10.3758/s13414-013-0423-3
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-013-0423-3